
Effective Transfer Learning with Label-Based Discriminative Feature Learning



Abstract
:1. Introduction
2. Background
3. Related Work
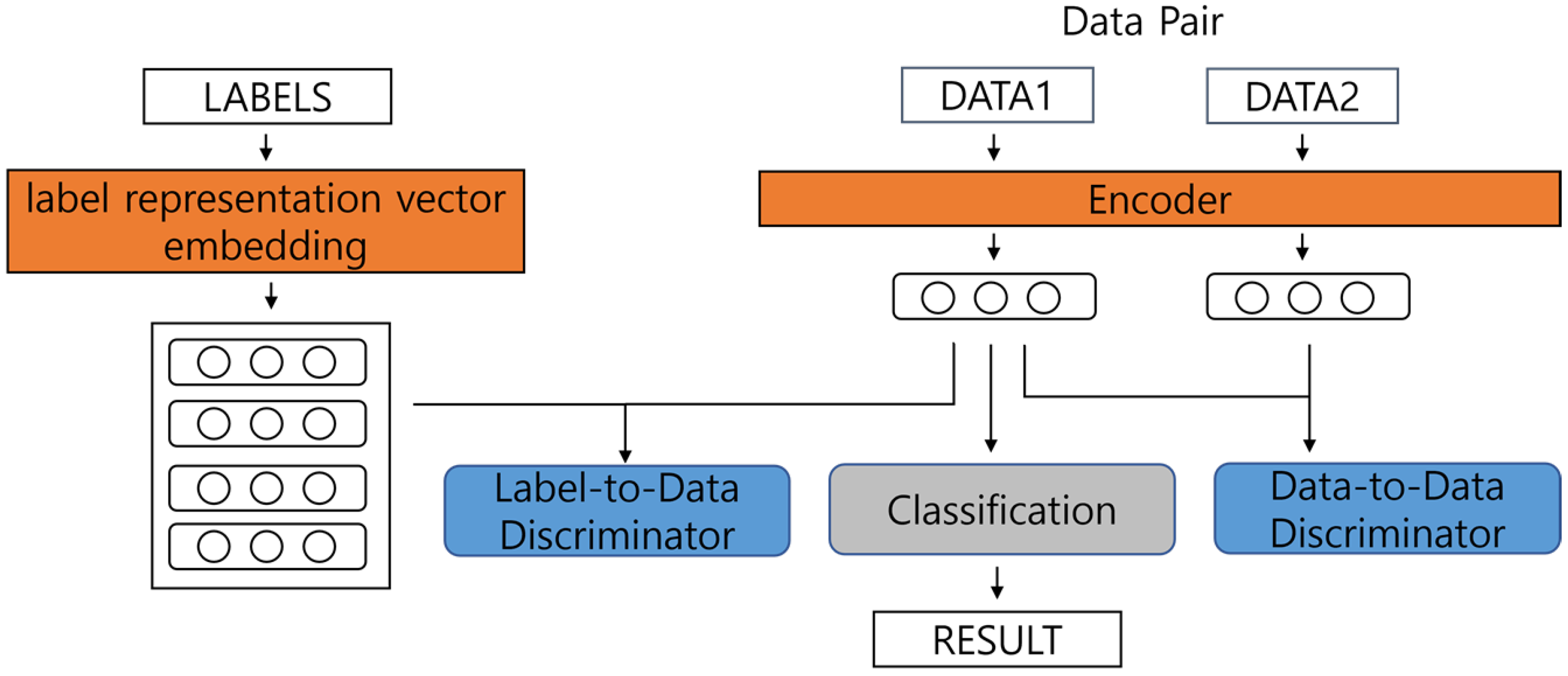
4. Proposed Method
4.1. Main Process
4.2. Data-to-Data Discriminate Process
4.3. Problems in Sections Data-to-Data Discriminate Process
4.4. Label-to-Data Discriminate Process
5. Experiment
5.1. Dataset
- MR—Sentiment is classified into positive or negative sentiment polarities of movie reviews [16].
- R8—Text of Reuters newswire documents is classified into eight categories [17].
- 20news—The 20 newsgroups dataset comprises approximately 18,000 newsgroups posts on 20 topics [18].
- SST-2—Binary sentiment classification of movie reviews is applied [16].
- SST-5—Multi-class sentiment classification of movie reviews is used. The labels are positive, somewhat positive, neutral, somewhat negative, and negative [16].
5.2. Experiment Setup
5.3. Experiment Result
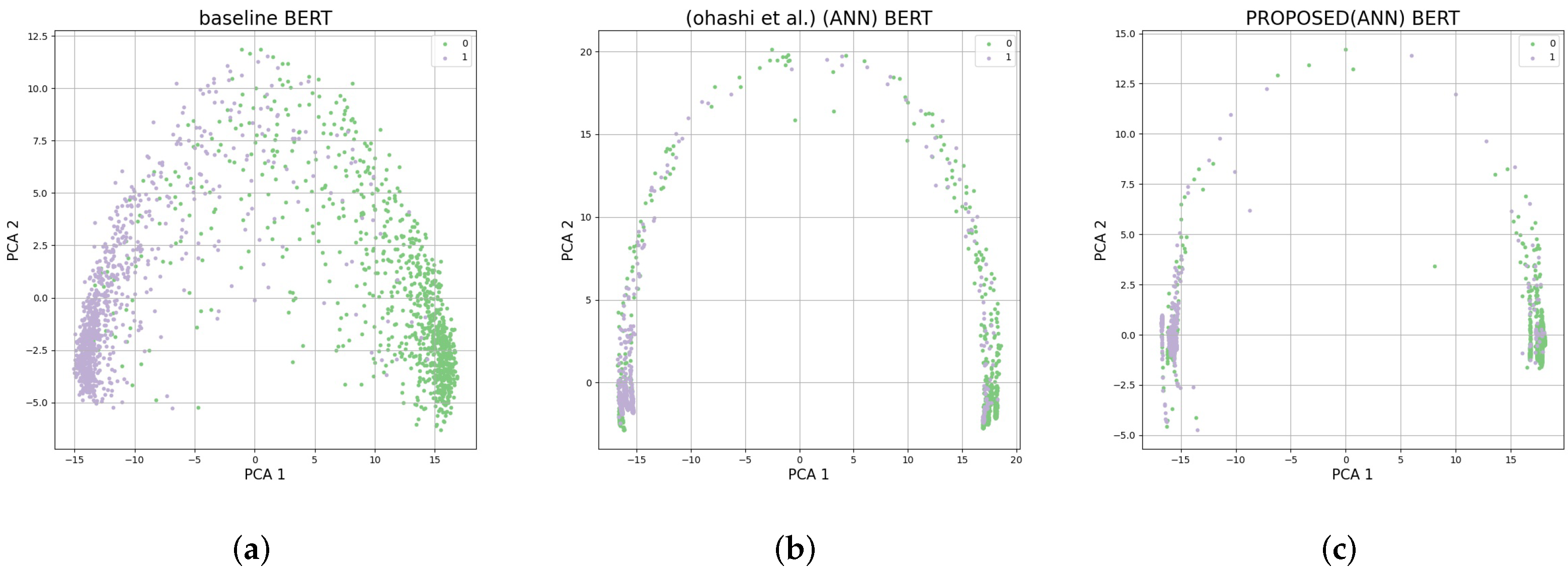
5.4. Analysis of Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; pp. 137–142. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DIALOGPT: Large-Scale Generative Pretraining for Conversational Response Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5–10 July 2020; pp. 270–278. [Google Scholar] [CrossRef]
- Gu, X.; Yoo, K.M.; Ha, J.W. DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances. arXiv 2021, arXiv:2012.01775. [Google Scholar]
- Ram, O.; Kirstain, Y.; Berant, J.; Globerson, A.; Levy, O. Few-Shot Question Answering by Pretraining Span Selection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3066–3079. [Google Scholar] [CrossRef]
- Ohashi, S.; Takayama, J.; Kajiwara, T.; Chu, C.; Arase, Y. Text classification with negative supervision. In Proceedings of the Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 351–357.
- Conneau, A.; Kiela, D. SentEval: An Evaluation Toolkit for Universal Sentence Representations. arXiv 2018, arXiv:1803.05449. [Google Scholar]
- Debole, F.; Sebastiani, F. An analysis of the relative hardness of Reuters-21578 subsets. J. Am. Soc. Inf. Sci. Technol. 2005, 56, 584–596. [Google Scholar] [CrossRef] [Green Version]
- Lang, K. Newsweeder: Learning to filter netnews. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 331–339. [Google Scholar]



{kind=link}
{kind=link}
| Dataset | Number of Training Data | Number of Validation Data | Number of Test Data | Avg. Vocab | Max. Vocab | |
|---|---|---|---|---|---|---|
| MR | 2 | 6398 | 2132 | 2132 | 22 | 6 |
| R8 | 8 | 5485 | - | 2189 | 103 | 965 |
| 20news | 2 | 6532 | - | 2568 | 110 | 1040 |
| SST-2 | 2 | 67,349 | 872 | 1821 | 11 | 57 |
| SST-5 | 5 | 8544 | 1101 | 2210 | 19 | 56 |
| Hyperparameter | Value |
|---|---|
| Sample size (batch size) | 256 |
| Max vocab length | 50 |
| Max vocab length (R8, 20news) | 100 |
| Epoch | 30 |
| Learning rate | 2 × 10 |
| Optimizer | Adam |
| m | −0.75 |
| 0.5 | |
| 0.5 |
| Model | MR | Test | R8 | 20news | SST-2 | Test | SST-5 | Test | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Validation | Validation | Validation | |||||||||
| Baseline | 83.9 | 85.4 | 97.6 | 68.7 | 91.6 | 92.9 | 50.0 | 52.2 | |||
| [15] (AM) | 84.1 | 85.1 | 97.7 | 67.7 | 91.6 | 93.2 | 48.5 | 49.8 | |||
| [15] (ANN) | 84.2 | 85.0 | 97.6 | 68.6 | 91.8 | 92.7 | 50.0 | 51.9 | |||
| Proposed (AM) | 84.6 | 85.9 | 97.8 | 68.4 | 91.6 | 92.7 | 50.8 | 51.4 | |||
| Proposed (ANN) | 84.7 | 85.6 | 97.8 | 68.9 | 91.9 | 93.2 | 50.7 | 52.4 | |||
| Model | MR | Test | R8 | 20news | SST-2 | Test | SST-5 | Test | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Validation | Validation | Validation | |||||||||
| Baseline | 90.0 | 89.8 | 97.6 | 66.9 | 94.9 | 95.2 | 54.1 | 57.2 | |||
| [15] (AM) | 90.0 | 89.4 | 97.6 | 67.5 | 93.9 | 94.5 | 53.7 | 57.5 | |||
| [15] (ANN) | 90.3 | 89.0 | 97.7 | 67.7 | 94.9 | 95.4 | 52.4 | 54.9 | |||
| Proposed (AM) | 89.7 | 89.6 | 97.7 | 67.3 | 94.8 | 95.2 | 53.1 | 57.6 | |||
| Proposed (ANN) | 90.2 | 90.1 | 97.8 | 67.6 | 95.1 | 95.5 | 54.1 | 57.7 | |||
| Model | MR | Test | R8 | 20news | SST-2 | Test | SST-5 | Test | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Validation | Validation | Validation | |||||||||
| Baseline | 86.4 | 88.4 | 97.7 | 68.2 | 93.3 | 95.2 | 52.8 | 55.2 | |||
| [15] (AM) | 86.3 | 88.5 | 97.6 | 67.8 | 93.3 | 95.5 | 52.4 | 55.2 | |||
| [15] (ANN) | 86.8 | 87.6 | 97.5 | 68.1 | 93.3 | 95.4 | 52.9 | 56.0 | |||
| Proposed (AM) | 88.0 | 88.6 | 97.9 | 68.2 | 94.3 | 95.1 | 53.7 | 56.1 | |||
| Proposed (ANN) | 88.0 | 88.4 | 97.8 | 68.4 | 94.0 | 95.6 | 54.5 | 56.3 | |||
| Criteria | Propose | MR | Test | R8 | 20news | SST-2 | Test | SST-5 | Test | Avg | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Model | Val | Val | Val | |||||||||
| Baseline | AM | 0.08 | 0.19 | 9.5e-06 | 0.43 | 0.23 | 0.24 | 0.16 | 0.35 | 0.21 | |||
| Baseline | ANN | 0.18 | 0.10 | 0.01 | 0.01 | 0.14 | 0.29 | 0.03 | 0.01 | 0.05 | |||
| [15] (AM) | AM | 0.02 | 0.15 | 0.004 | 0.16 | 0.03 | 0.01 | 0.01 | 0.08 | 0.10 | |||
| [15] (ANN) | ANN | 0.07 | 0.004 | 0.02 | 0.09 | 0.09 | 0.08 | 0.001 | 0.08 | 0.04 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, G.; Kang, S. Effective Transfer Learning with Label-Based Discriminative Feature Learning. Sensors 2022, 22, 2025. https://doi.org/10.3390/s22052025
Kim G, Kang S. Effective Transfer Learning with Label-Based Discriminative Feature Learning. Sensors. 2022; 22(5):2025. https://doi.org/10.3390/s22052025
Chicago/Turabian StyleKim, Gyunyeop, and Sangwoo Kang. 2022. "Effective Transfer Learning with Label-Based Discriminative Feature Learning" Sensors 22, no. 5: 2025. https://doi.org/10.3390/s22052025