1. Introduction
Morphological biometrics, based on quantitative measures of the human body [
1,
2], as well as behavioural biometrics, based on the patterns of actions performed by a subject, have proved to be helpful for e-security and e-health [
3]. This research focuses on behavioural biometrics. We analyse the online activities performed during certain specific drawing and handwriting tasks performed by the subjects [
4]. For monitoring health conditions, behavioural biometrics, especially online handwriting/drawing, has proved to be more useful in indicating states of mental disorders and diseases, such as dementia, than other popular morphological biometrics traits, such as fingerprint and iris recognition [
3,
4]. Also, behavioural biometrics is a minimally invasive methodology because it is based on tasks that are part of routine functional activities.
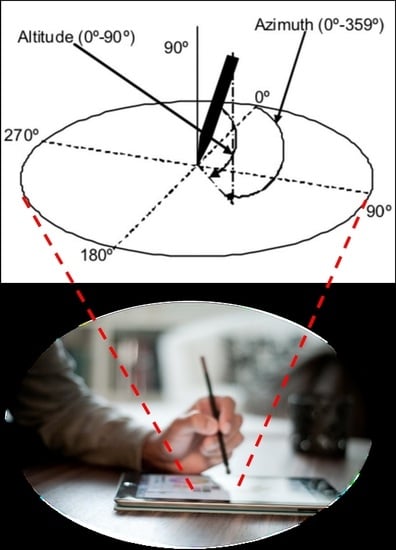
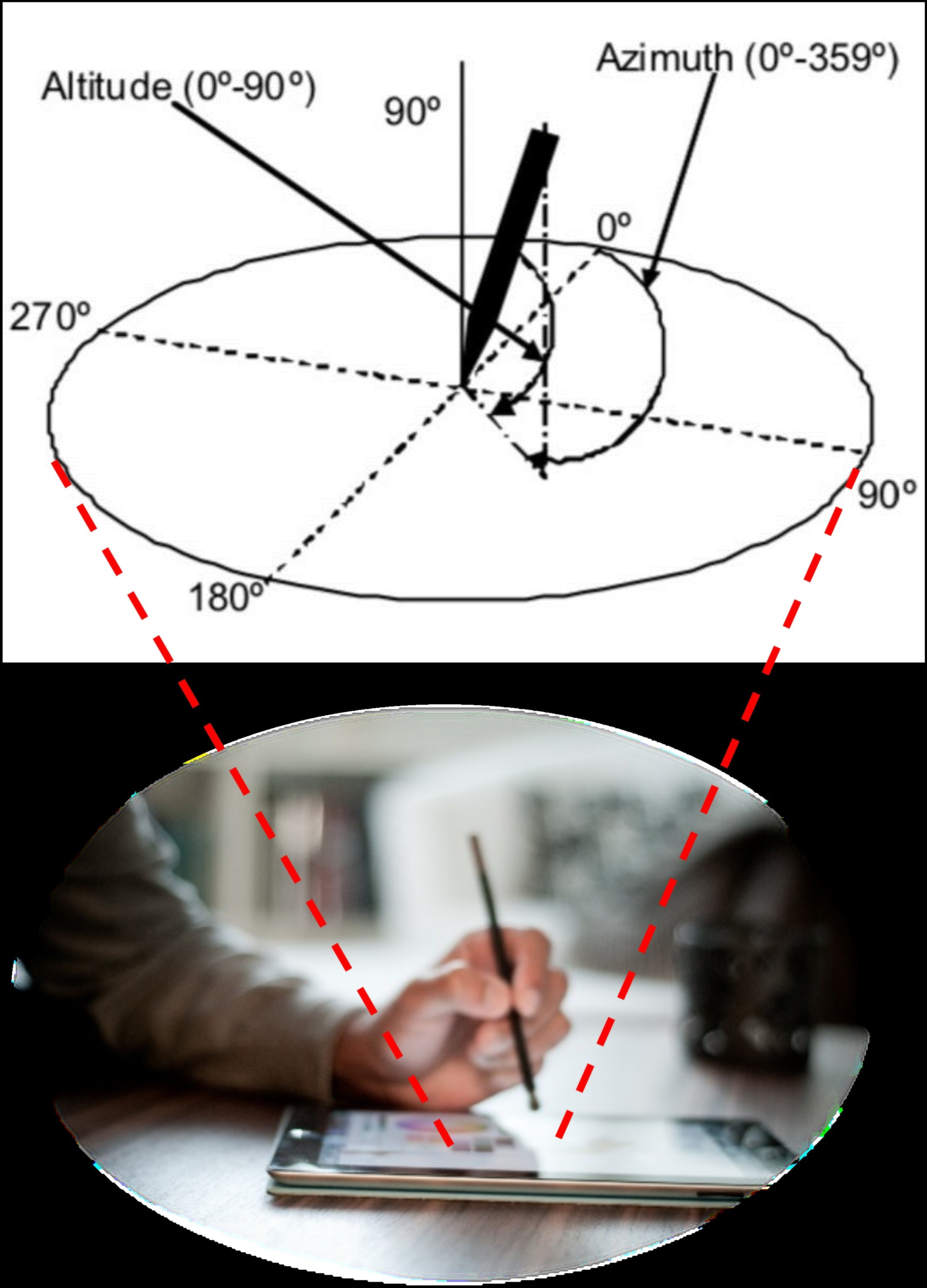
Figure 1 represents the tablet application that captures the sensor data of the tablet and the pen when the user handwrites or draws on the tablet.
Treatment of mental illnesses is a health priority because they significantly impact human well-being and are among the major causes of inabilities in populations worldwide. Indeed, depression, stress and anxiety are the most prevalent negative moods in the world, and stress is often present as a comorbidity. It is estimated that the number of people affected by depression (resp. anxiety) is 4.4% (resp. 3.6%) of the global population [
5], and these numbers are rapidly increasing because of the global spread of the coronavirus disease 2019. The manifestation of such disorders is commonly accompanied by the deterioration of social behaviour mainly because of the inability to express one’s emotions and decode others’ moods [
6]. Unfortunately, these diseases do not have a definitive treatment, and treatments can last for the entire lifetime with a consistent impact on the quality of life of patients and on the health costs of public administrations. Therefore, it is imperative to detect early indicators of mental disorders to provide timely treatment so that they do not become chronic and difficult to treat. Identifying early indicators hence enables early implementation and effective interventions, which reduces public health care costs [
7]. These indicators include changes in a person’s voice, facial expressions and body postures as well as changes in behaviours and functional abilities, such as handwriting and drawing [
8].
We focus on negative moods (depression, stress and anxiety) because they last for long periods and a negative state of mind (mood) deteriorates the quality of life of patients. Depression is a mood disorder that causes energy and interest to disappear, and instils a persistent feeling of sadness, which results in high energy consumption by the brain; this can lead to various emotional and physical problems. Clinical depression can be serious; in fact, when depression is left untreated, it can lead to suicide [
9].
Anxiety is a cognitive-affective response characterised by feelings of tension and worry regarding a potentially negative outcome that the individual perceives as highly probable and imminent [
10]. Anxiety signs and symptoms include nervous sweating, increased heart rate and hyperventilation [
9]. It impacts the activities of the patients because this state causes tiredness [
11].
Stress is a natural reaction to the pressure that the body undergoes when faced with complicated or dangerous life situations [
12]. In general, stress is a normal human response and is part of life, but it becomes a mood disorder when it is experienced frequently and interferes with the ability to perform daily activities. Moreover, when facing stressful situations, the body releases large amounts of several hormones, which can damage the body (causing diabetes and cardiovascular diseases) and cognitive processes [
13].
The use of behavioural biometrics, especially, in particular, the online analysis of the activity of a subject performing a handwriting or drawing task enables the characterisation of mood states, especially, depression, anxiety and stress [
14]. The use of technological tools (e.g., smartphones, tablets and touch screens) and the multiple interactions among subjects on social media, public administration or health platforms provide access to a large amount of data; this is helpful for discovering or evaluating important features of the subject’s condition.
The characterisation of mood detection through behavioural biometrics, in particular, by the online analysis of handwriting and drawings is a novel and promising research field. Unfortunately, to the best of our knowledge, there are few studies and very few datasets that can be used as a benchmark for potential applications.
This research is based on a study published by Likforman-Sulem et al. [
15]; they proposed a methodology to use online handwriting/drawing data to discriminate depressed, stressed and anxious patients from a healthy control group. Their work shows the use of various features to discriminate among negative moods (depression, anxiety and stress) with significant accuracy, sensitivity and specificity by using random forest classification. These features are based on several factors: the duration for which the pen is used on the sheet or near it (in the air), the total time to complete a specific handwriting/drawing task and other features based on the number of strokes performed during a task and/or the pressure applied by the pen on the paper,
In this research, we have improved upon the classification accuracies as compared with our previous research [
15] by using principal component analysis (PCA) and modified fast correlation–based filtering (mFCBF) strategies. However, we had to compromise on the explainability of the results. It was not possible to translate the principal components (PCs) into specific sets of kinematic, temporal and pressure variables for any given handwriting task. Clinicians who tried to apply these findings to their clinical settings could not perform a manual handwriting analysis even though we had provided a list of explainable features in Table II of [
15]. This can be done easily for an automatic machine system that classifies moods by using online handwritten tasks.
In this research, we test our system using the EMOTHAW database. This database uses the same software and hardware that we had already used when detecting Parkinson’s disease. The main difference is that the EMOTHAW database uses other handwriting/drawing patterns to detect mood states. Therefore, we can use the same features to characterise the user’s data.
In our work on Parkinson’s disease detection [
16], we found it useful to add kinematic and statistical features; therefore, the first contribution of this work is to add these features to the user’s features that we used in [
17]. The second contribution of this work is the use of a PCA–mFCBF pipeline; in fact, it is probably the most important contribution. In this paradigm, the features are orthogonalised using PCA. Then, the PCs are selected using mFCBF [
17]. The third contribution of this work is the use of the automated machine learning (AutoML) approach. We proposed to use AutoML because we had successfully used it in our research on Parkinson’s disease. These three contributions allow for achieving a level of accuracy in the results that highly outperformed state of the art results in mood detection [
16].
The last contribution of this research is assessing the detection of three mood states and allowing a high level of precision to the clinical psychologists. This was possible because we achieved 100% accuracy when detecting two mood states.
Section 2 reviews the theory of PCA, which is one of the key concepts used in this work.
Section 3 describes the EMOTHAW dataset, which is used in this research to test our methodology. This section also contains information about the distribution of scores for two and three mood states and the explanation of the overlapping of mood states.
Section 4 describes the data captured from the tablet and pen.
Section 5 describes the temporal, kinematic, statistical, spectral-domain and cepstral-domain features. This section also includes the augmentation method used in this work to synthetically increase the training dataset.
Section 6 describes the feature selection (FS) methodology, which includes the PCA [
18,
19,
20,
21], mFCBF [
17] and the new proposed PCA–mFCBF pipeline.
Section 7 describes the hyperparameters of the front end.
Section 8 defines the machine learning (ML) modelling to maximise the accuracy detection task.
Section 9 reviews the AutoML concepts and AutoML H2O platform used in this work.
Section 10 describes the experiments conducted and their results. Finally, in
Section 11, we state our remarks and conclusion.
2. Principal Component Analysis (PCA)
PCA is useful when multi-colinear vectors are present. PCA can be used to reduce the dimensions and variances of the vectors and to denoise them.
Given the set of possible correlated feature vectors
, PCA applies an orthogonal transformation to obtain a set of linearly uncorrelated observations: the PCs. This is achieved by projecting the original features into a reduced PCA space using the eigenvectors, which are the PCs of the covariance matrix. The number of principal components obtained by applying PCA is less than or equal to the minimum values between the number of observations
and the number of features [
18,
19,
20,
21]. The resulting projected features are a linear combination of the original features, which capture most of the feature variances. In this transformation, the first component explains the maximum variance in the features, and each subsequent PC explains less of the variance. Most of the useful PCs are dictated by the rank of the matrix.
The variance–covariance matrix is defined as follows:
is real symmetric matrix; therefore, the above expression can be decomposed as
where
represents the PCs and is an orthogonal matrix whose columns are eigenvectors of
, and
is a diagonal matrix whose entries are the eigenvalues of
[
22].
Then, the projected features can be expressed as follows:
The PCA transformation corresponds to multiplying the original features
by the transformation matrix
In other words,
can be viewed as a linear regression, that is, each element in
can be predicted with a linear combination of the original feature vector
weighted for a vector in the matrix
is a diagonal matrix that is defined as follows:
Now, substituting for
we obtain
Substituting
, we obtain
Finally, we obtain
which is a diagonal matrix; this implies that all PCs are uncorrelated with one another. For example,
Figure 2 shows the sepal length and sepal width features before and after applying PCA for the well-known Iris dataset [
23]. We can see that the first PC variance PC1 is greatly reduced after applying PCA.
6. Feature Selection
It is important to select the right features because data models also learn irrelevant information, which degrades their performance. There are multiple methods to select features. In this research, we test the accuracy performance measures of PCA, mFCBF and the PCA–mFCBF pipeline.
6.1. Principal Component Analysis (PCA)
PCA is an orthogonal transformation of the features; it rotates the dimensional axis to maximise variability. PCA returns coefficients in order of importance—the first coefficient has the highest variance representation in the entire set. The higher the selected PC, the higher the representability of the variance of the set of features.
Let us represent the PCA function on the feature vector
and mood
as follows:
The maximum number of
calculated by PCA is equal to the number of observations (in this case, it is equal to the number of users). The selected PCs
of the entire features
is represented as follows:
As stated earlier, although PCA helps minimise features to improve model accuracy, it has a negative effect on the model’s explainability, which is a drawback.
6.2. Modified Fast Correlation-Based Filtering (mFCBF)
The system front-end calculates many features from a limited number of time signals captured from the tablet’s sensor. Beside this correlation, certain features contribute more towards creating an accurate model; mFCBF selects the features that, even when they are correlated, mostly contribute to the increase in model accuracy.
FCBF selection is based on two steps [
16]. In the first step, the selected features are those whose correlation with the output are higher than the correlation with the threshold value. The second step takes the features of the first step and selects the features with a correlation less than the threshold value. Algorithm 1 shows the pseudocode of our modified version of the function mFCBF [
17]. This modified version differs from the original version in step 5, where the selected feature has high correlation with the output. The mFCBF algorithm receives a data frame and the thresholds
and
as inputs. Here,
is used to set the lower correlation threshold of each of the selected features and the output; the practical value of this parameter should be greater than 0.2. Also,
is used to set the higher correlation value between the features; the practical value of this parameter should be less than 0.2. By sweeping
and
for a range of values, we can find the right features that maximise the performance of the ML method. This operation for the features
and mood
is expressed as follows:
for
.
Note that , where one dimension represents the number of users, and the other dimension represents the number of selected features.
| Algorithm 1. The mFCBF algorithm receives the users’ feature matrix (), minimum correlation threshold () and the maximum correlation threshold () and returns the selected set of features. |
1: Function mFCBF (,, )
2: Calculate corr ()
3: Select columns whose correlation with the output is >
4: Calculate corr ()
5: Select columns whose correlation with the input is < and with the highest correlation with the output.
6: Return ()
7: End function |
6.3. PCA-mFCBF Pipeline
In
Section 6.1 and
Section 6.2, we selected features using PCA or mFCBF, respectively. In this section, we propose to pipeline them by first applying PCA and then applying mFCBF. The PCA step returns all the PCA coefficients. Then, the selection step is performed using mFCBF. The intra-feature variability is already minimised; therefore, this step selects the PC which has a higher correlation with the output.
This PCA–mFCBF pipeline for the features
and mood
is defined as follows:
In
Section 10, we will prove that orthogonalising before selection with mFCBF is a good strategy to greatly increase the accuracy.
Again, the purpose of mFCBF in this pipeline is to select the PCs’ that contribute the most to increasing the model accuracy. Although it is beneficial to orthogonalise features using PCA to improve the model’s accuracy, a potential drawback of PCA is its adverse effect on the model’s explainability.
9. AutoML
AutoML, also known as augmented ML, is a methodology that aims to automate the data science pipeline for classification and regression. The AutoML pipeline includes data pre-processing (cleaning, imputing and quality checking), feature engineering (transformation and selection), model selection, evaluation and hyper-parameter optimisation.
There are different platforms for implementing AutoML; each platform has a different maturation and state of evolution for continuous improvement. Recently, certain AutoML systems have started to support more focused tasks, such as time-series forecasting. A few of the well-known automated machine platforms are H2O [
28,
29], PyCaret [
30,
31], auto-sklearn [
32,
33], the tree-based pipeline optimisation tool (TPOT) [
34,
35,
36] and MLBox [
37].
H2O includes automatic training and tuning of many models within a user-specified time limit. Stacked ensembles are automatically trained on collections of individual models to produce highly predictive ensemble models.
PyCaret is an end-to-end ML and model management tool that speeds up the experiment cycle exponentially and increases productivity.
The auto-sklearn architecture is an AutoML toolkit and a drop-in replacement for the scikit-learn estimator; it includes algorithm selection and hyper-parameter tuning. It uses Bayesian optimisation, meta-learning and ensemble construction.
TPOT uses genetic programming to determine the best performing ML pipelines, and it is built on top of scikit-learn [
38]. It supports feature pre-processing, feature construction and selection, model selection and hyper-parameter optimisation.
MLBox supports fast reading, distributed data processing, FS, leak detection, cleaning, formatting, accurate hyper-parameter optimisation in high-dimensional space and ML algorithms, such as deep learning, stacking, light gradient boosting machine and XGBoost. An important feature is that it includes prediction with the interpretation of models.
AutoML packages are not perfect, and there are packages with different levels of automation. For example, feature engineering is a task in this pipeline for which AutoML has some features, but a lot more work is required to develop and automate this task, especially for sensor data analysis.
AutoML H2O
For data modelling, we used AutoML H2O [
28,
29], which is a platform that can be used for automating the ML workflow. The automation includes the training and tuning of many models within a user-specified time limit. It also includes hyper-parameter optimisation, which uses a Bayesian approach.
Table 6 shows a few of these models, such as variations of trees, random forests, Naïve Bayes, linear models, additive models, deep learning and support vector machines (SVMs). In addition, H2O also includes a model that is an ensemble of all models and is a model for each family of methods. The ensembled models are mostly the ones with better accuracy results.
10. Experiments and Results
H2O [
28,
29] is an AutoML package intended to automate the ML pipeline starting from data manipulation to ML parameter optimisation.
Table 7 shows the configuration setting that we used for H2O. In this configuration, we limited the maximum expected training time to 200 s to avoid a long processing time. The number of models was set to 15 as a trade-off between the accuracy performance and processing time. We excluded the gradient boosting machine (GBM) modelling because its database did not converge with our database. The number of folds was set to two because when this was increased, the accuracy of the results did not improve, but the process time did. Finally, the stop metric was set to log loss because this was a classification task.
LPO was used for testing. PLO is a variation of leave-one-out; however, instead of leaving one element out, the data model in LPO was tested with a percentage of the registers in the database, and we trained with the rest. In our experiments, we repeated this training–testing cycle until we circulated all the possibilities, and we averaged the accuracy values of all tests. In our experiments, we always left out 10%.
Augmentation was controlled by the percentage of augmentation and the amplitude of the Gaussian random noise applied to the original signal. In this research, we first augmented the data such that all the mood states had the same number of observations. Then, we augmented all the mood states by 80% using the Gaussian noise with 0 and 1 as the mean and variance values, respectively. The Gaussian random noise amplitude was multiplied by 0.2.
Table 8 shows the accuracy results for the binary detection moods for the temporal feature
, for the ML models
and the moods
. In this table, we can observe that the accuracy results with AutoML are much higher than the results obtained using SVM [
16]. This can be explained because AutoML simultaneously evaluates more than 15 classification algorithms.
Table 9 shows the accuracy results for the features
for the ML models
and for the moods
. The second and third columns show the accuracy results obtained when PCA is used as the FS method. We can see that accuracy results with AutoML are much higher than the results obtained with SVM.
The fourth and fifth columns of
Table 9 show the accuracy results obtained when mFCBF is used as the FS method. Clearly, the accuracy results with AutoML are much higher than the results obtained with SVM. Also, the accuracy results obtained when using mFCBF as the FS method (in the fourth and fifth columns) are much higher than the accuracy results obtained with PCA (in the second and third columns).
Finally, sixth and seventh columns of
Table 9 show the accuracy results when the PCA–mFCBF pipeline is applied as the FS method. The accuracy results with AutoML are much higher than the results obtained with SVM. Also, the accuracy results when using the PCA–mFCBF pipeline as the FS method (in the sixth and seventh columns) are much higher than the accuracy results obtained using PCA (in the second and third columns) or mFCBF (in the fourth and fifth columns).
Figure 8 shows the selected feature for each task after applying the PCA–mFCBF pipeline. These features are a mixture of the original PCs and are not necessarily the first ones, which are normally selected when PCA is used for FS. This mixture of PCs is because the first step in mFCBF selects the PCs which have a high correlation with the output. Then, the PCs with low correlation are selected.
Table 10 shows the accuracy for the features
for the ML model
and for the moods
. The second and third columns are the accuracy results when PCA is used as the FS method. The accuracy results with AutoML, when concatenating the kinematic and statistical features, improved 1.75%, 4.38% and 7.9%, for depression, anxiety and stress, respectively. We can see that the accuracy results are higher when the kinematic and statistical features are concatenated.
The fourth and fifth columns of
Table 10 show the accuracy results when mFCBF is used as the FS method. The accuracy results with AutoML, when concatenating the kinematic and statistical features, improved 4.38%, 7.02% and 14.04% for depression, anxiety and stress, respectively. Again, the accuracy of the results is higher when the kinematic and statistical features are concatenated. The accuracy of the results when using mFCBF as the FS method (in the fourth and fifth columns) is much higher than the accuracy of the results that are obtained with PCA (in the second and third columns).
The sixth and seventh columns of
Table 10 show the accuracy of the results when the PCA–mFCBF pipeline is used as the FS method. The accuracy results with AutoML, when concatenating the kinematic and statistical features, improved 3.5%, 7.89% and 11.41% for depression, anxiety and stress, respectively.
Clearly, the accuracy of the results when using the PCA–mFCBF pipeline as the FS method (in the sixth and seventh columns) is much higher than the accuracy of the results obtained when using PCA (in the second and third columns) or mFCBF (in the fourth and fifth columns).
Table 11 shows the accuracy of the results for the trinary classification for the features
for the ML model
and for the moods
. The second columns is the accuracy of the results when PCA is used as the FS method. The accuracy of the results is higher for the PCA–mFCBF pipeline; the second-best accuracy is obtained with mFCBF; and the third-best accuracy is obtained when using PCA. The accuracy is the worst when no selection feature is used. Therefore, the behavioural biometrics with the trinary classification is identical to the behavioural biometrics with the binary classification.
11. Conclusions
In this study, we propose the merging of the temporal, kinematic, statistical, spectral- and cepstral-domain features to detect the mood state. We found that adding the kinematic and statistical features improved the results.
We also proposed to use PCA–mFCBF for FS. PCA is used for orthogonalising features before applying mFCBF to select the features. When using the PCA–mFCBF pipeline, we found that the experimental results were substantially superior to the results obtained when only PCA or mFCBF was used.
The best performance was obtained when adding the kinematic and statistical features pipelined with PCA–mFCBF. The second-best performance was that of the AutoML H2O platform for data modelling. This makes sense because AutoML H2O [
28,
29] includes the Bayesian hyper-parameter optimisation and model assessment.
The experiment results proved that this pipeline strategy for FS and PCA–mFCBF substantially increases the accuracy results and even reaches 100% in the binary classification of our task.
We also classified data into three categories and developed a few experiments using all the described features. Then, we used PCA–FCBF as the FS method and modelled using the AutoML H2O platform. The accuracy results for trinary detection were 82.45%, 72.8% and 74.56% for depression, anxiety and stress, respectively. Also, we found that the results for the trinary detection were not as impressive as the results obtained for binary detection.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}