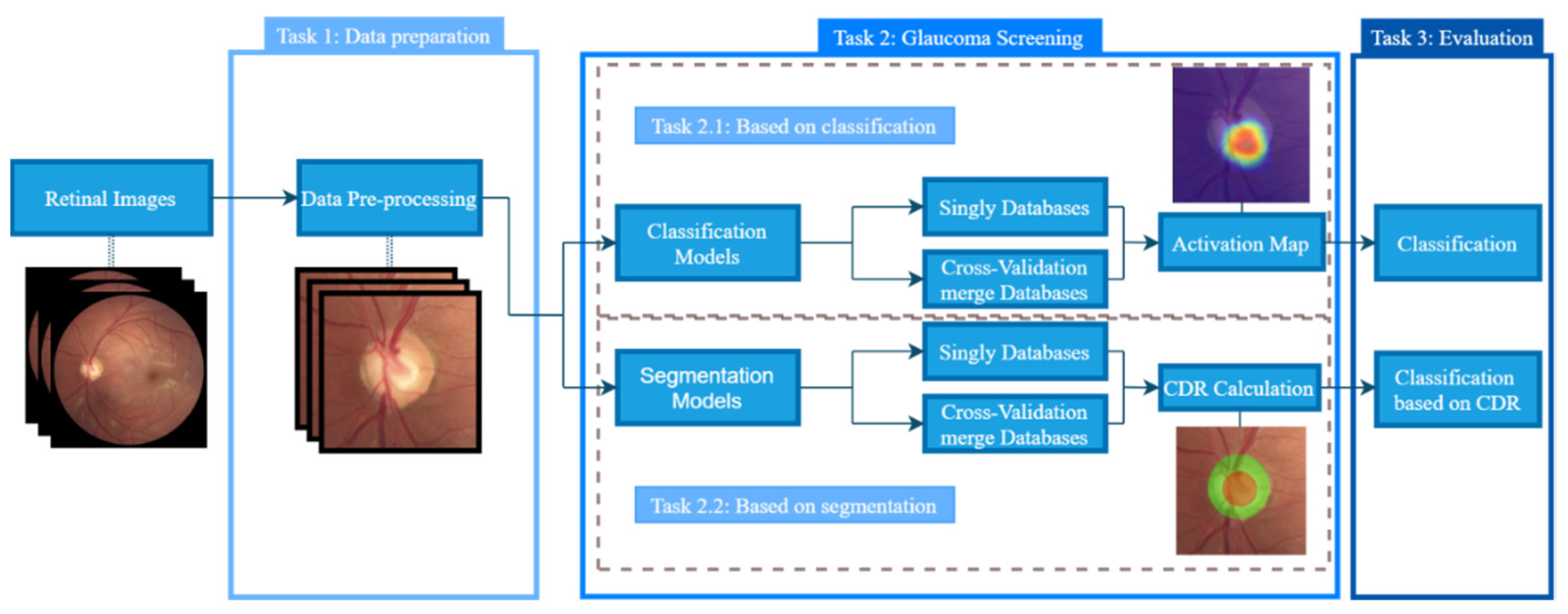
The OD and cup were segmented by two different CNNs, and then the different CDRs were calculated; glaucoma was then classified based on the CDR model. This requires the reference (Ref) masks of each database with annotations of the segmentation made by clinicians, and these were available in the databases selected for this work. Finally, the segmentation and glaucoma screening were compared with the reference masks using the same criteria of the glaucoma classification based on CDR values. To perform the segmentation, two different models, S1 and S2, were used. First, the OD segmentation results are presented, followed by the cup segmentation results, and finally, the glaucoma classification based on the CDR calculation with segmentation masks is provided.
4.2.1. OD Segmentation
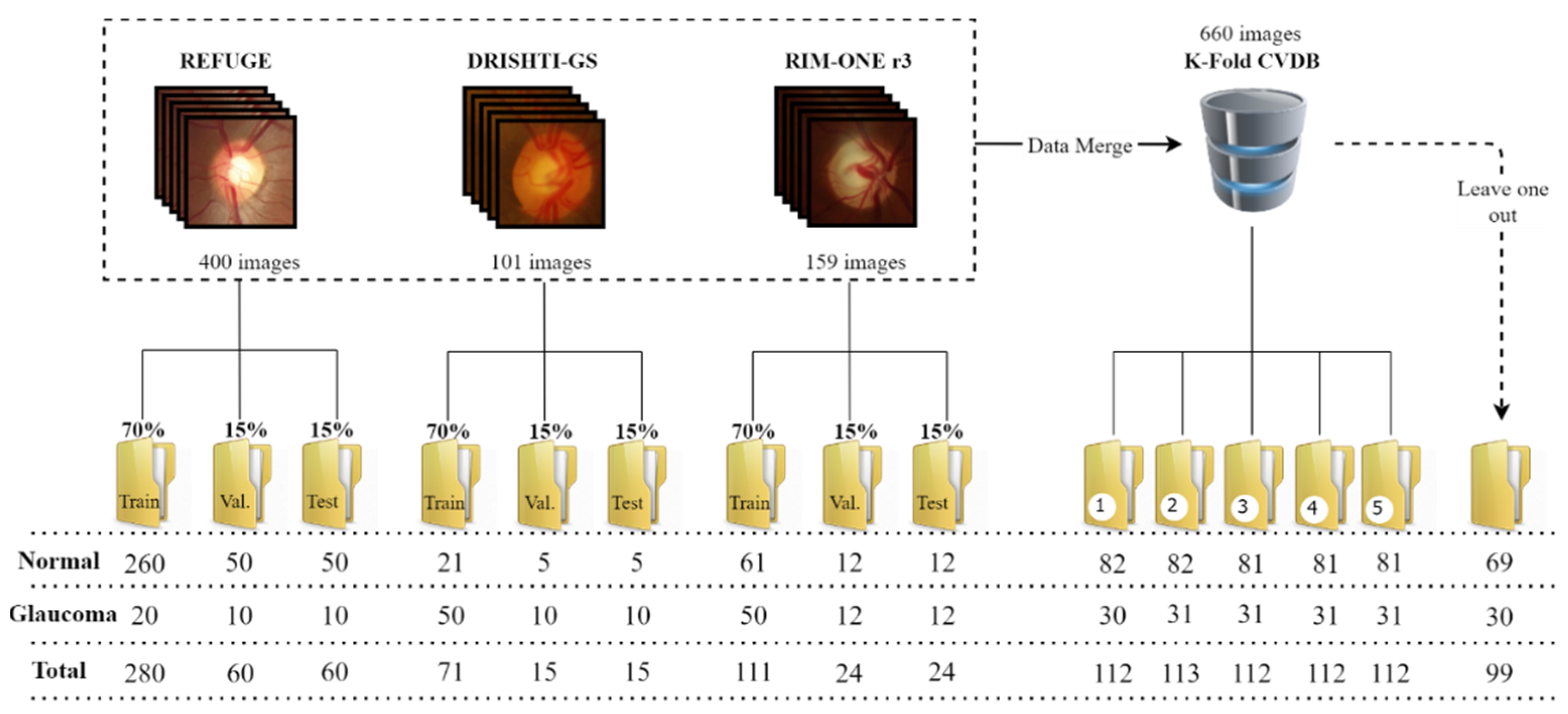
The procedure in the segmentation methods is the same as the one presented for the classification approach, with the segmentation in each database performed separately and with the K-Fold CVDB. For the K-fold CV, the means of IoU and Dice of the five folds in each model were obtained. The final mask is the intersection/agreement of at least four masks of the five iterations of each model to compute the final CDRs. The results for OD segmentation are presented in
Table 5.
At first view, the results in every dataset segmentation are very similar to every compared state-of-the-art method, with a slight but non-significant difference that does not change the outcome of the CDR calculation. This can be explained by the fact that the segmentation of OD is an easy task because of the visible contrast and outline of the OD and the retina, which facilitate identification and segmentation by the neural network. The K-fold CV showed decreases in the IoU and Dice in both models compared to the other results since they represent the mean of five iterations in each model. This can affect the final results, with divergence in the agreement of OD segmentation. However, this difference was not significant enough to jeopardise the CDR calculation, at least in most of the samples. The two models had similar results, with a slightly better performance for S1. After OD segmentation, the procedure was repeated but with different CNN models, this time training the model to segment the cup.
4.2.2. Cup Segmentation
For cup segmentation, the same models were used, but this time, the network was trained to localise and segment the excavation region inside the OD. Contrary to the previous task, cup segmentation is much harder since there is not a high contrast between the exaction zone and the OD (at least not as high as the contrast between the OD and the retina). The results from the two models are presented in
Table 6 with the same structure as the one presented for OD segmentation.
Overall, the results achieved the same baseline as the state-of-the-art methods. When directly compared on the RIM-ONE database, the S1 model had better results than S2 and had better Dice than Al-Bander [
14], and IoU and Dice were only worse compared to Yu’s [
17] work. With DRISHTI-GS, the two models had better IoU and Dice than Al-Bander [
14] and a slight difference in IoU and Dice compared to the remaining works, with an overall better performance observed for the S1 model. In the REFUGE database, the results from our models and Qin’s [
16] work are very similar, with a minor difference in the Dice, and as observed in the segmentation of the other databases, the S1 model had better results as well.
In the K-fold CV, both models had a major decrease in performance compared to the other works and the performance of the same models using each database separately. As in the previous verification, the S1 model continued to produce better results. Compared to OD segmentation, the IoU and Dice were much lower, which is a consequence of these coefficients being too sensitive to small errors when the segmented object is small and not sensitive enough to large errors when the segmented object is larger.
The results of OD and cup segmentation were used to calculate the CDRs to use as an indicator of glaucoma presence. Reference segmentation by clinicians was used as the ground truth but is not an absolute truth since the segmentation process can be subjective, and the results can differ between clinicians. Thus, the segmentation predicted by the CNNs can sometimes cause the misclassification of the images but can be considered another opinion, especially in cup segmentation since the perimeter of the cup is not as delimitated and visible as the OD. After the segmentation of the OD and cup, the CDRs were calculated to obtain the glaucoma classification.
4.2.3. Glaucoma Screening Based on Estimated CDR
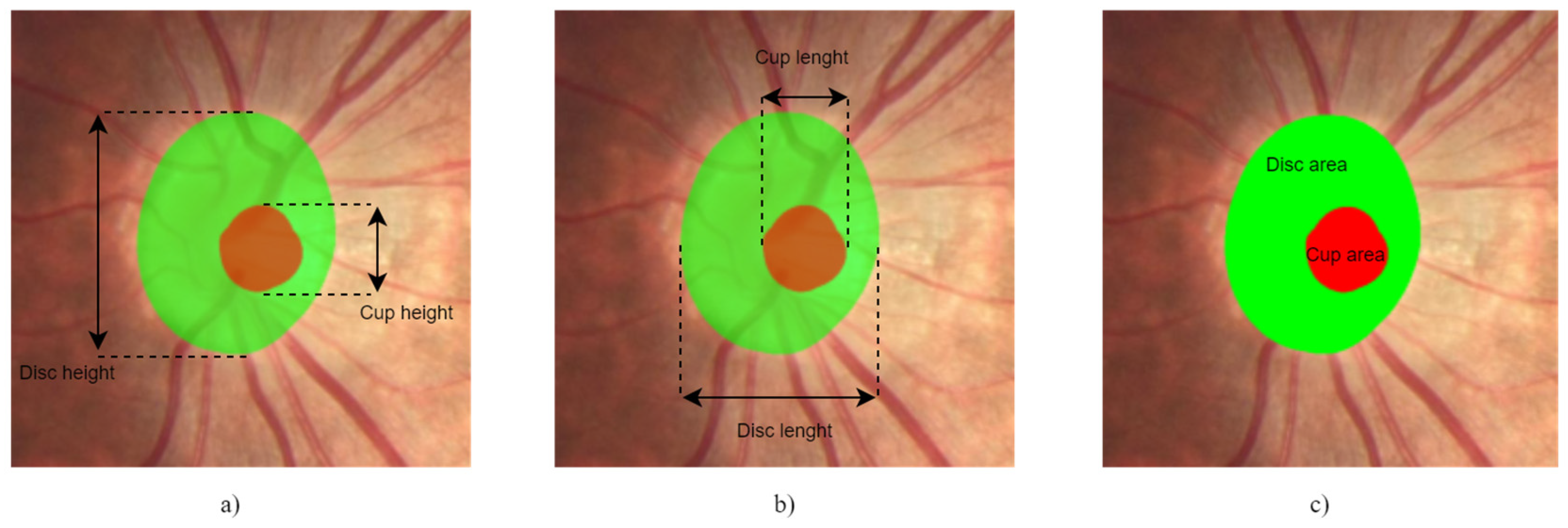
The segmentation masks of the OD and cup of both models were computed and used to calculate the ratio between them. In this work, all CDRs were calculated, including the vertical and horizontal CDRs and the ratio between the areas of the OD and cup. For the VCDR and HCDR, the criteria used were CDR < 0.5 for normal and CDR ≥ 0.5 for glaucomatous, and the ACDR was normal if <0.3 and glaucomatous if ≥0.3, as described in Diaz’s work [
21]. The same criteria were used for the Ref masks to allow a direct comparison between the results of our models and the segmentation performed by ophthalmologists to gauge the reliability of segmentation by the S1 and S2 models. The results are expressed in
Table 7.
The results for both models were similar to the results using the Ref masks, which indicates that they produced similar segmentation results or at least provided similar CDRs. Overall, the results from CDRs based on the Ref masks were better than the results from the two models, but the difference between the models’ classification and the classification in the Ref masks, in a lot of cases, was not significant.
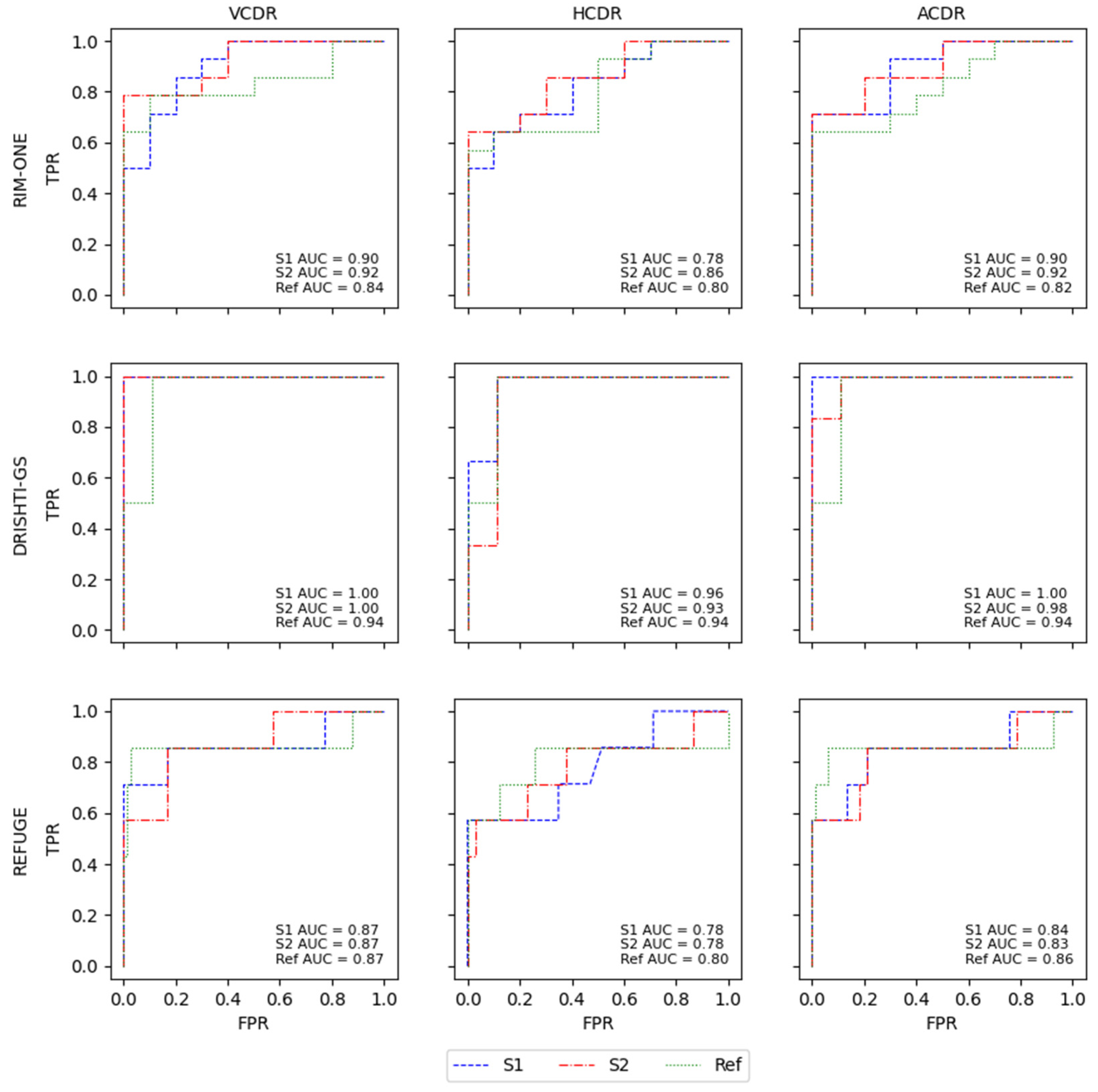
With RIM-ONE, the Ref had a better F1-score for the VCDR and HCDR, but the difference in the F1-scores between the two models was very small. S2 achieved better sensitivity and specificity, but this difference was also small, which may indicate that the masks were very close to each other or had similar forms that led to the computation of similar CDR values. DRISHTI-GS and the K-Fold CVDB were the two datasets with the worst results for both models in comparison with the Ref results, showing a greater difference, but the AUC indicated that the difference was not that large. The results from REFUGE were better for the S2 model compared to S1 and Ref for sensitivity, specificity and F1-score, but in all models and the Ref, the values were very low, which may suggest that, in this case, the CDRs are not a sufficient indicator to produce a classification of glaucoma or normal; thus, for a better decision, complementary information is needed to support the final call. All of the ROC curves from the different databases for all CDRs of the models and Ref masks are presented in
Figure 7.
Of all CDRs, the VCDR and ACDR had the best results. The HCDR was the worst result in the two models and the Ref, and the model with the overall best results was S2. This is also shown in the ROC curves, with the models and the Ref having very similar results in all AUCs for the glaucoma classification based on the different CDRs. The difference between the AUCs of the models and the Ref was not significant and was generally very small, with the Ref showing slightly better performance than the S2 model. This can reinforce the notion that the masks originating from the S1 and S2 models are very close to the Ref masks or compute similar CDRs that lead to a similar glaucoma classification based on CDRs. In the work by Diaz [
21], the model obtained specificity of 0.81 and sensitivity of 0.87, and Al-Bander [
14] achieved an AUC of 0.74 using the VCDR and 0.78 using the HCDR. The majority of our results surpass the results of the state-of-the-art glaucoma classification methods based on CDRs.
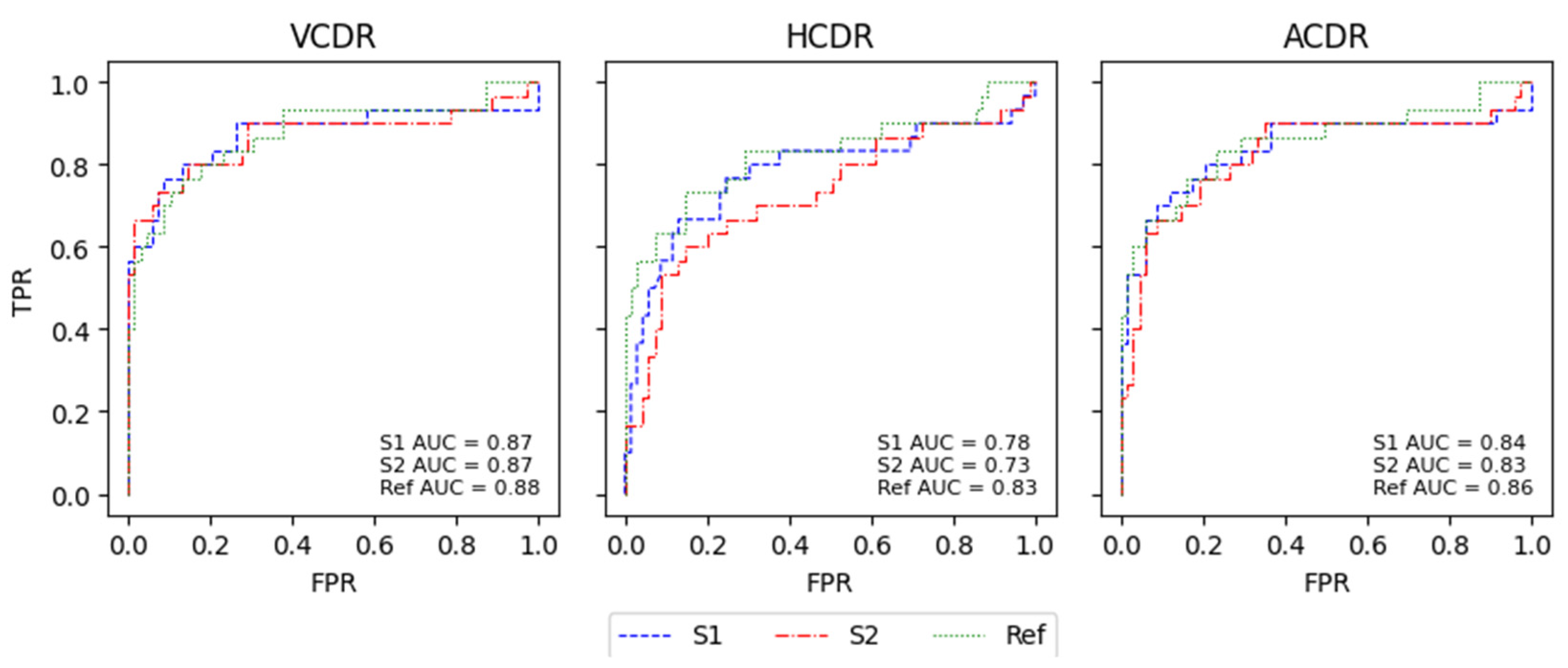
For the K-fold CV, the results of the ROC curves for both models were very similar to those of the Ref and had close AUC values, except for the HCDR. As mentioned previously, the HCDR was the CDR that differed the most, as can be seen in
Figure 8.
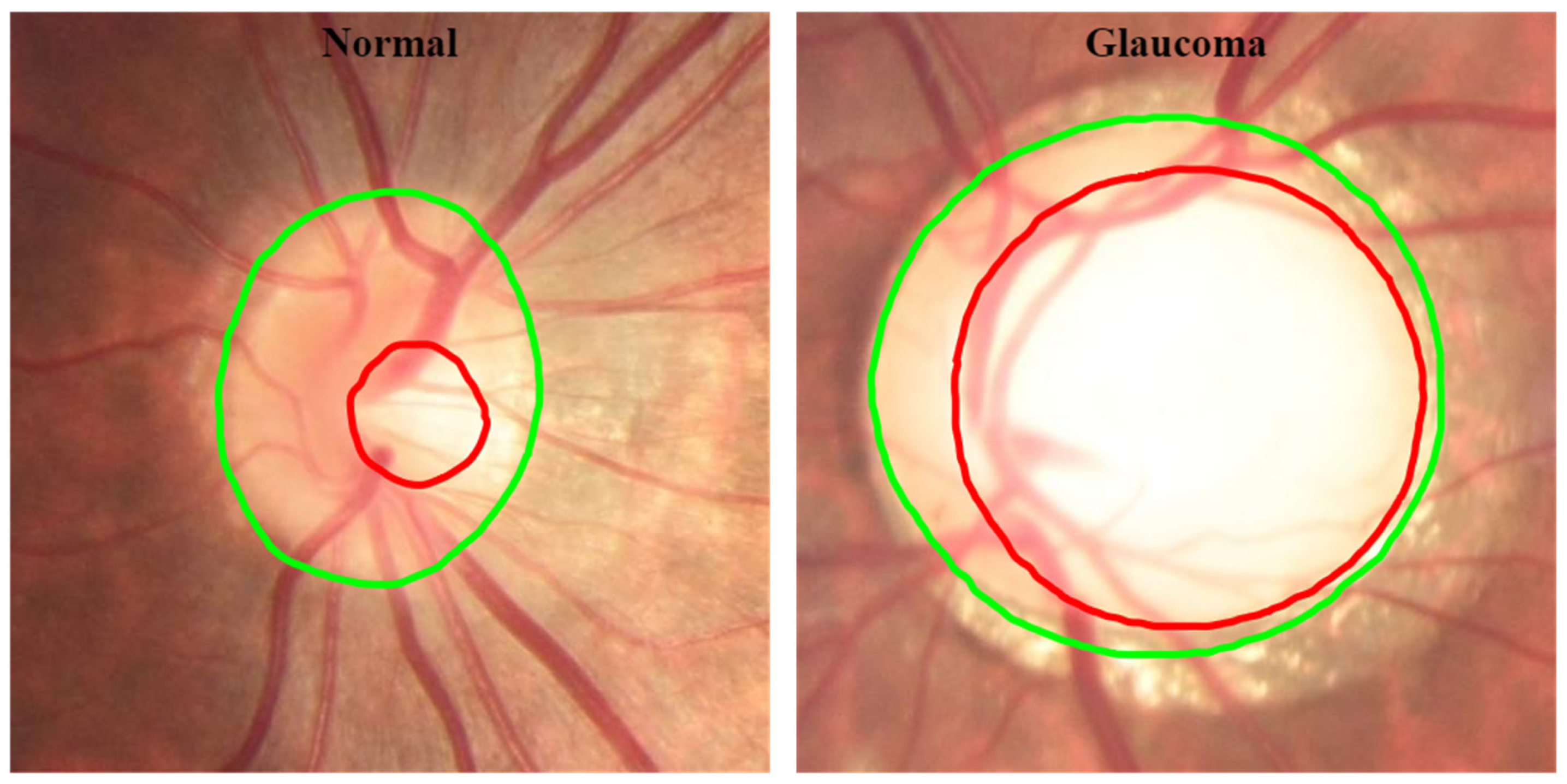
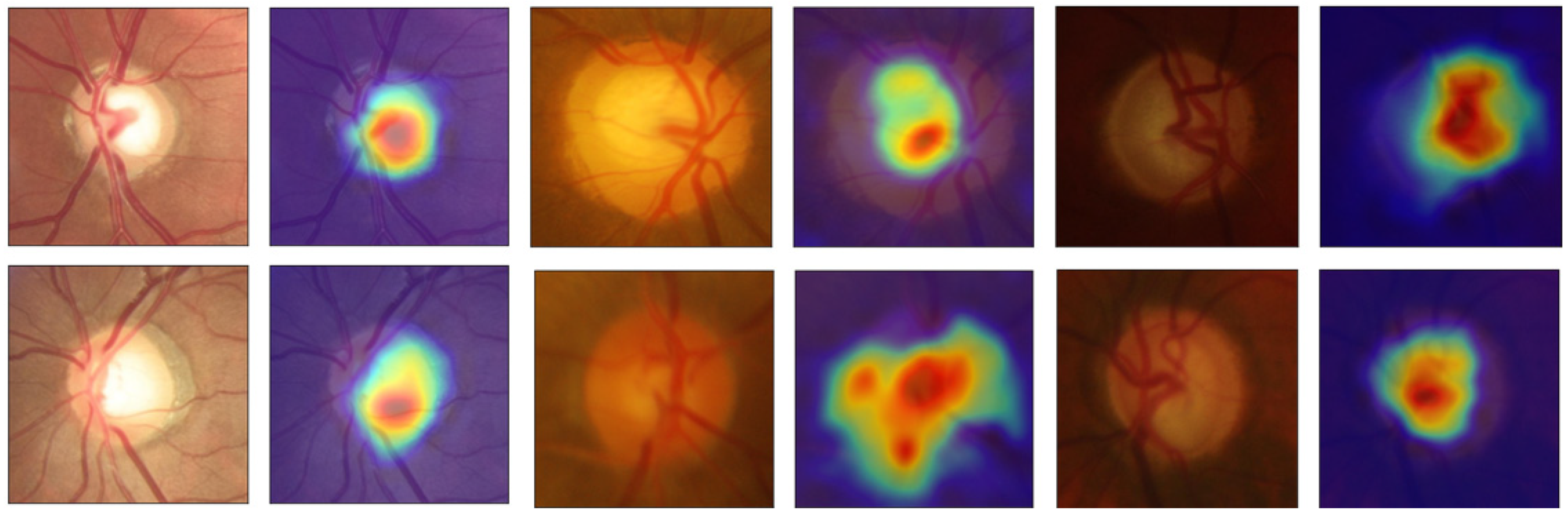
For visual comparison, in the following images, the masks and outlines of both models are drawn in red, and those of the Ref masks are drawn in green. The intersection between the masks predicted by the models and the Ref masks is indicated by the combination of green and red (true positive). The green area represents a false negative since there is no intersection between the masks, and the red area represents a false positive since the model’s prediction does not correspond to the same result as the Ref mask.
In
Figure 9, the CDRs values for higher Dice cases are extremely close to the Ref CDR values. In the K-fold, the resulting masks are the intersection of at least four agreements in the model of the different folds. The predicted masks of the OD and cup are very close to the Ref masks, reflecting high IoU and Dice values. In the lower Dice cases, the CDRs significantly differ compared to Ref CDRs, but despite this, there is complete agreement in the final decision for the classification based on CDRs since all apply the same threshold values, although they differ more than the higher Dice cases.
The two models used achieved state-of-the-art results for the segmentation, and the outcome was similar to the glaucoma classification based on the CDR with the Ref masks, indicating that these types of models can mitigate these labour-intensive and subjective tasks, that is, the segmentation of the OD and cup, providing a more consistent final result. To complement the CDR indicator, additional examination must be performed to make the final diagnosis of the patient using, for example, IOP values, anamnesis data and medical records. Another problem is the thin margin in the threshold CDRs, potentially resulting in an arbitrary classification; to resolve this obstacle, more diagnosis classes can be added based on CDRs, such as a suspicious case of glaucoma in the samples for which the CDR value barely passes or reaches the threshold.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}