
Navigating an Automated Driving Vehicle via the Early Fusion of Multi-Modality



Abstract
:1. Introduction
2. Related Work
3. Methodology
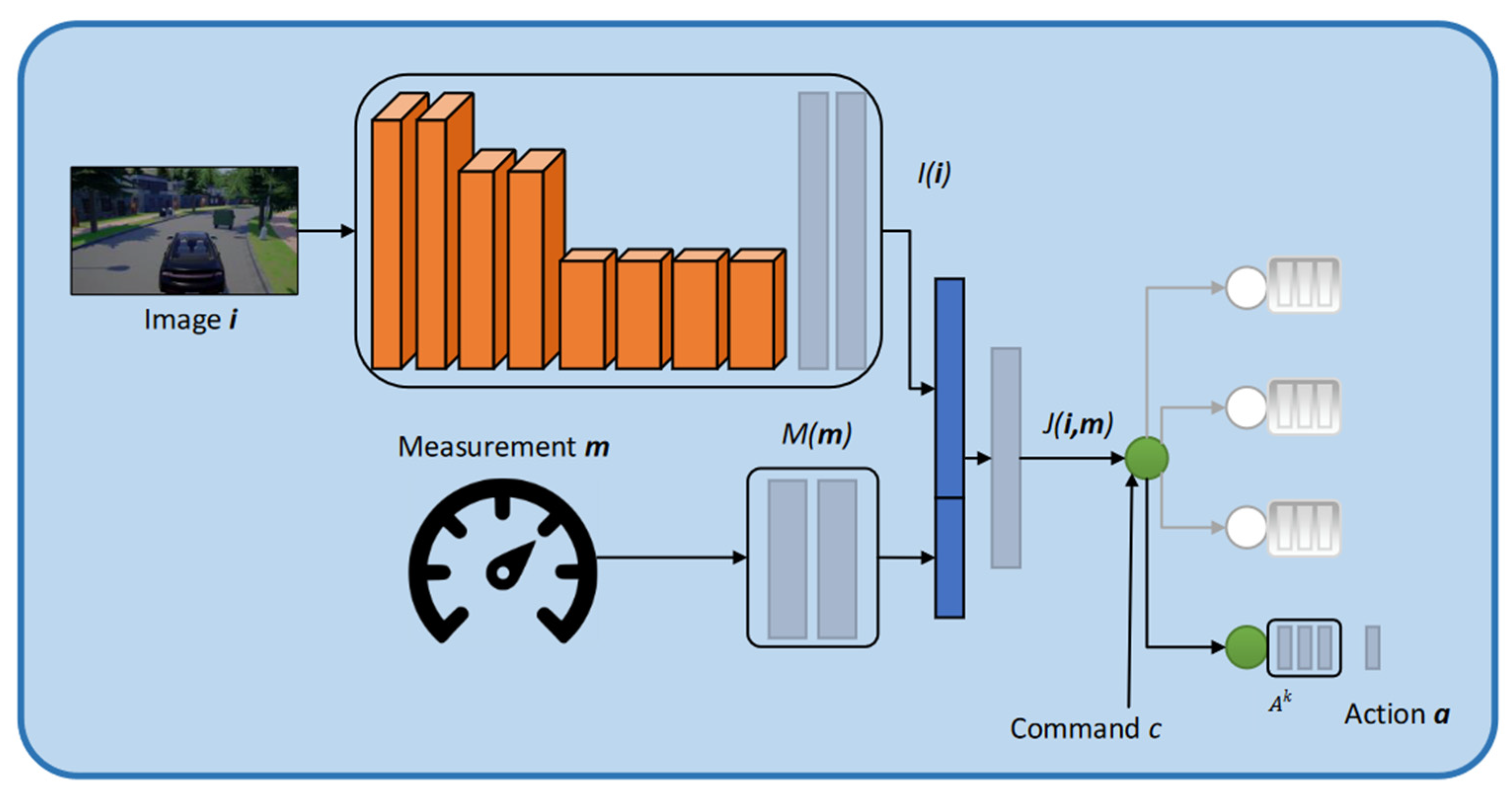
3.1. Basic Conditional Imitation Learning Network Architecture
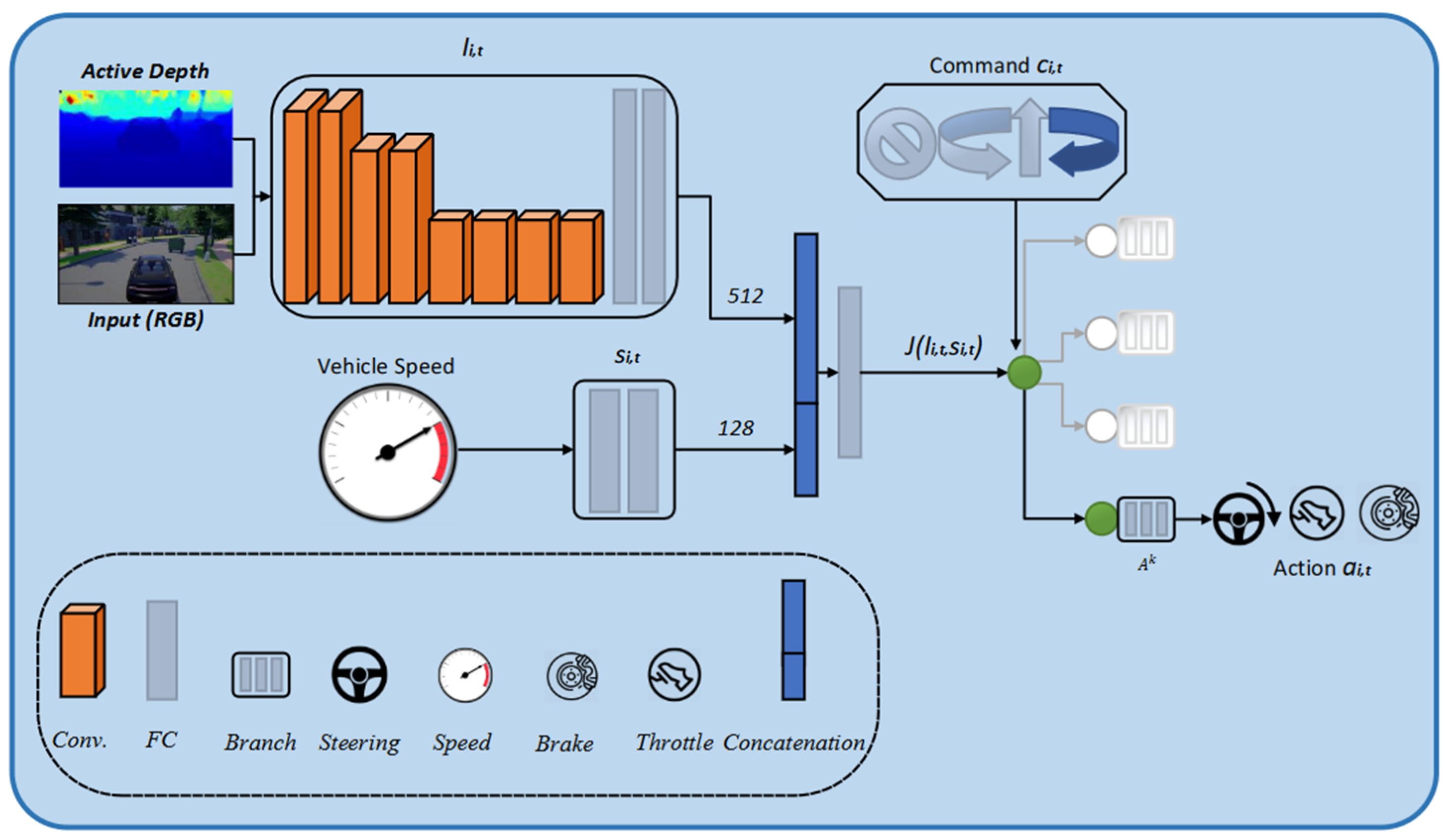
3.2. Early Fusion Multi-Model Network Architecture
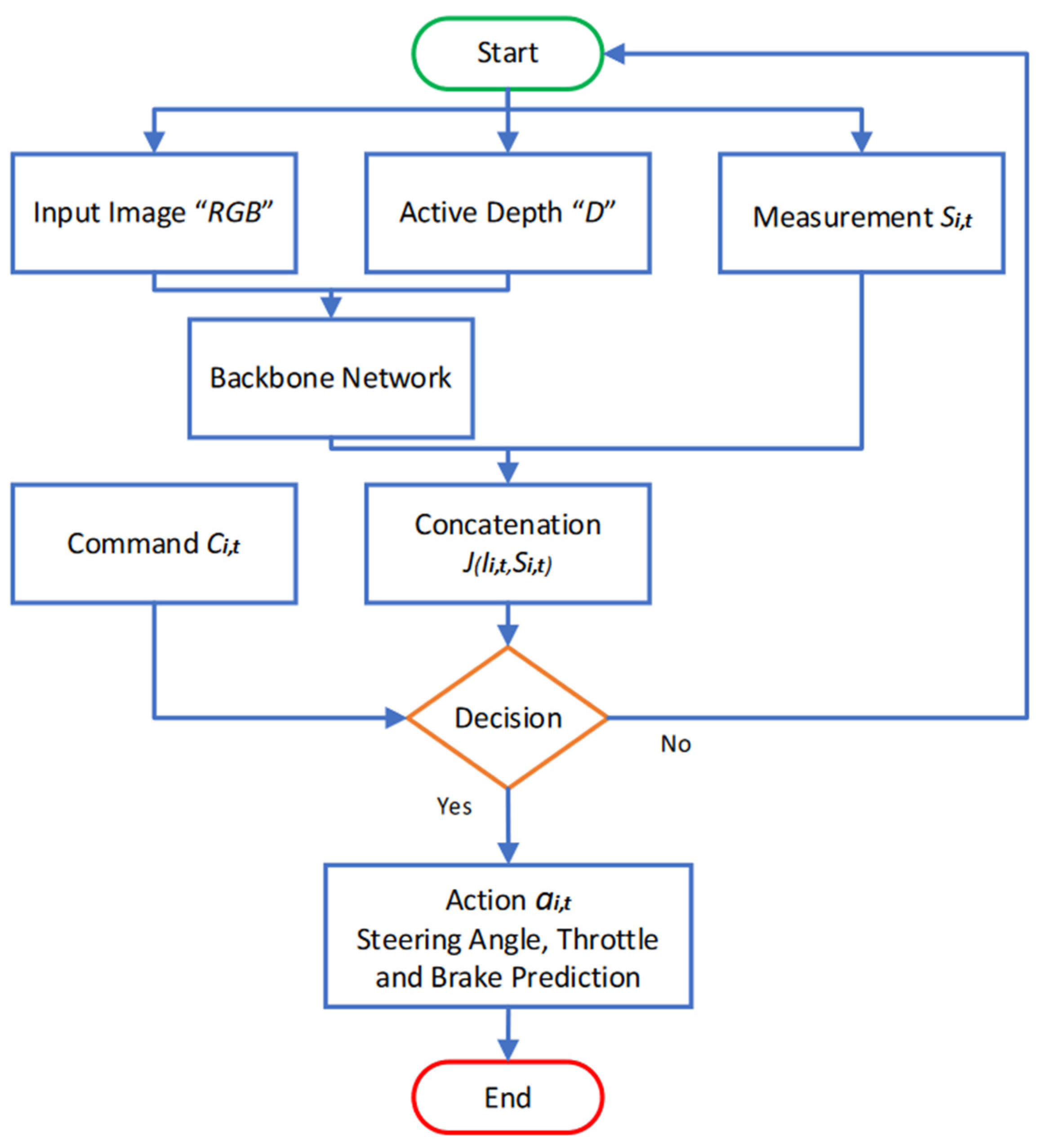
3.3. A Pipeline of the Early Fusion of the Multi-Model Network
4. Experiments
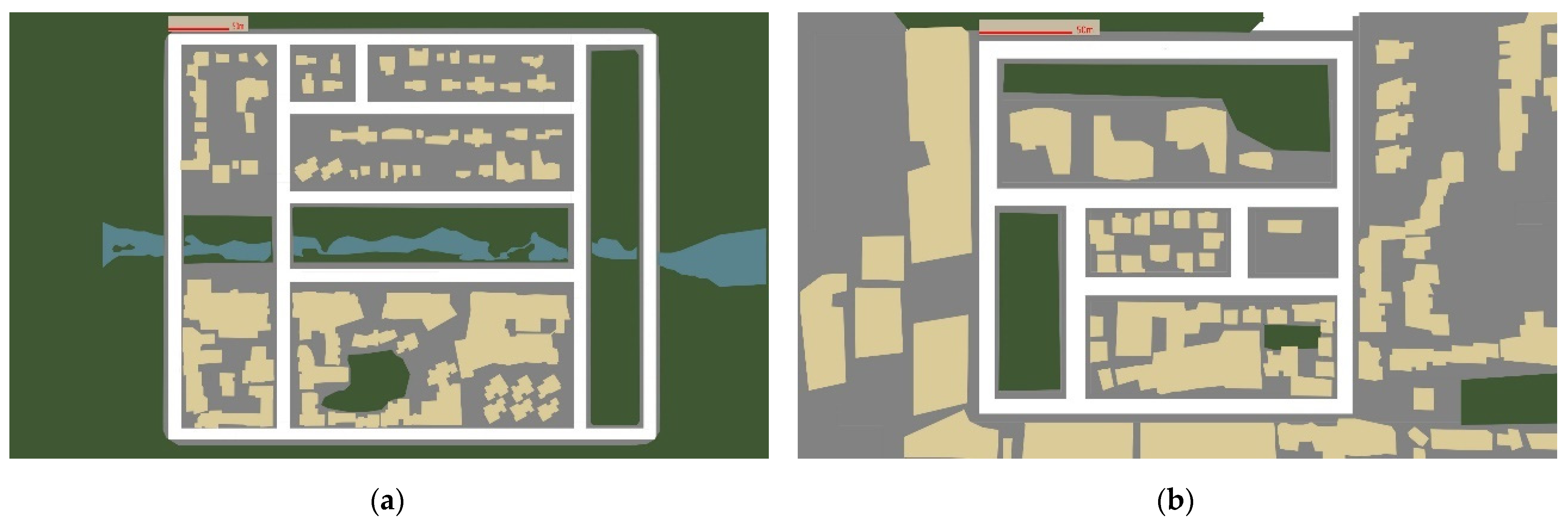
4.1. CARLA Simulator
4.2. Data Collection
- The center front camera and the two side cameras at left and right. The only camera utilized for autonomous driving is the one in the center. In a self-driving vehicle, the images from the side cameras are solely used during training to mimic the driving error recovery graph [25]. The collection includes 2.5 million RGB pictures with a resolution of 800 × 600 pixels and relevant ground truth. The RGB input image is cropped to eliminate the sky and extremely near region, then scaled to provide a channel resolution of 200 × 88 pixels in our early fusion model. Data augmentation is essential for good generalization in our initial experiments. During network training, we conduct augmentation online. We add a random subset of transformations of random sampling magnitudes to each image to be presented to the network. Changes in brightness, contrast, lighting and Gaussian noise are all part of the transformation. Gaussian blur, salt and pepper noise, and area dropout are some of the effects available. Geometric improvements, such as translation and rotation, are not performed, since the control command is not invariant to these transformations.
- We develop an upper bound driver using perfect semantic segmentation in this work. In order to develop this upper bound, the twelve semantic classes of CARLA are mapped to five, which we consider sufficient. We keep the original road surfaces, vehicles and pedestrians, while lane markings and sidewalks are given the status of ‘lane limits’ (Towns 1 and 2 only have roads with one go and one return lane, separated by continuous double lines), and the remaining seven classes are given the status of ‘other’.
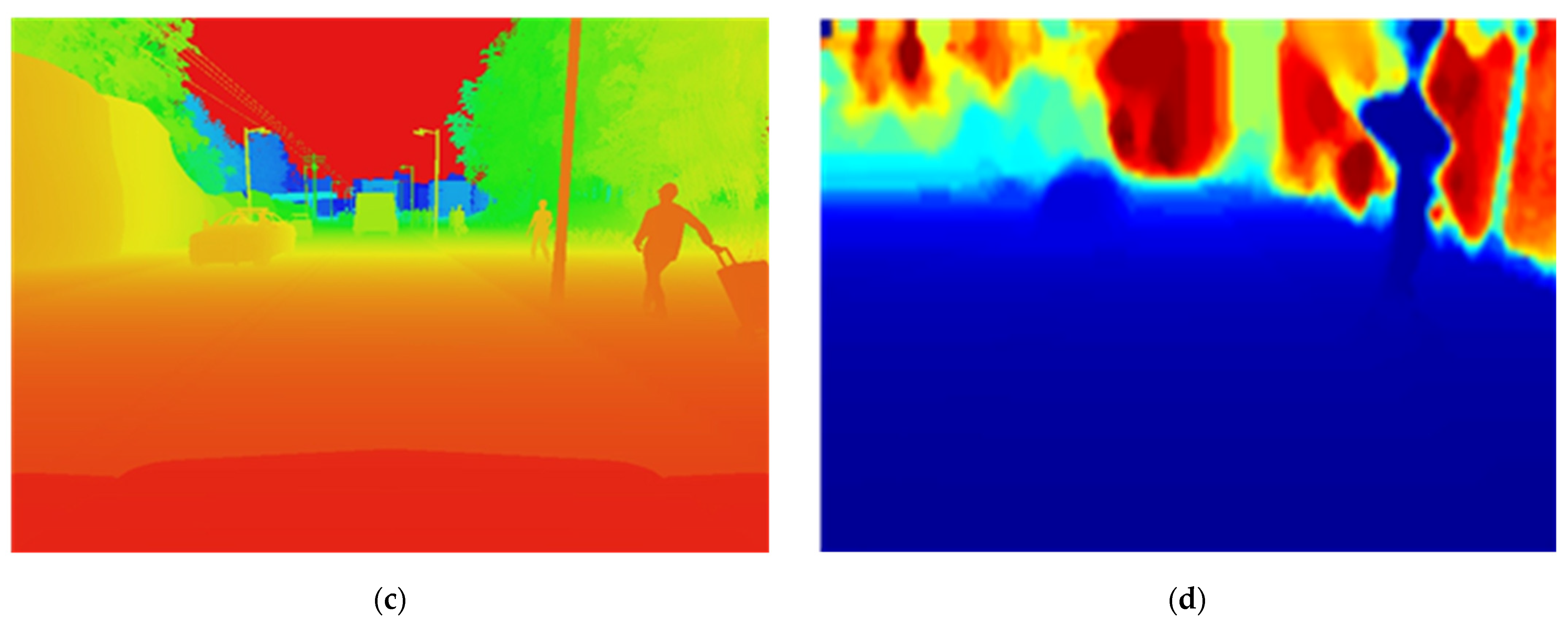
- Premebida et al. [75] obtained depth data from the LiDAR point cloud, and we think RGB images include dense depth data. The CARLA depth of ground truth comes straight from the Z-buffer used for displaying the simulation, and it is extremely accurate. The depth value is 24-bit encoded and spans from 0 to 1000 m, implying a depth precision of around 1/20 mm. An active sensor range coverage and depth accuracy significantly exceed a passive sensor. The use of depth data has been post-processed to make it more realistic. The Velodyne information from the KITTI dataset [76] provides a realistic sensor reference. First, we reduce the depth value only to examine pixels inside the 1100-m range, i.e., pixels with outside values in the depth image. On the other hand, this range does not contain any depth information. Second, we re-quantify the depth value within 4cm of the original. Third, we fix the pixels that have no data. Finally, we apply a median filter to prevent establishing precise depth boundaries between objects. New depth images are utilized during training and testing. Figure 5 shows an example of a CARLA depth image and the equivalent post-processed version.
4.3. Training
5. Experiment Results
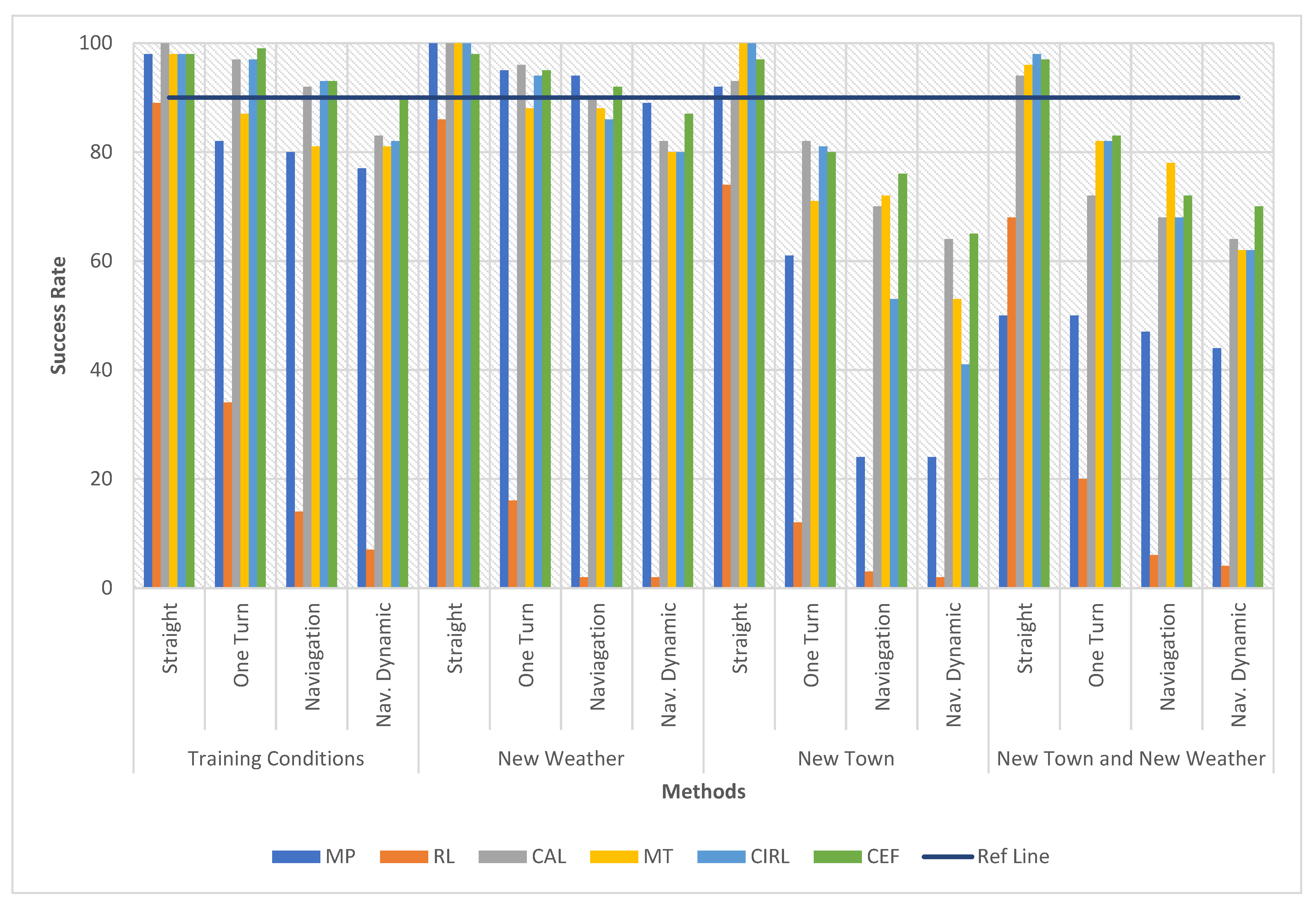
5.1. Success Rate Comparison with Previous Methods
- ➢
- Training conditions: driving (i.e., running the episodes) in the same conditions as the training set (Town 1, four weather conditions).
- ➢
- New Town: driving under the four weather conditions of the training set but in Town 2.
- ➢
- New Weather: driving in Town 1 but not seen at training time under the two weather conditions.
- ➢
- New Town and Weather: driving in conditions not included in the training set (Town 2, two weather conditions).
5.2. Performance of Single & Multi-Models
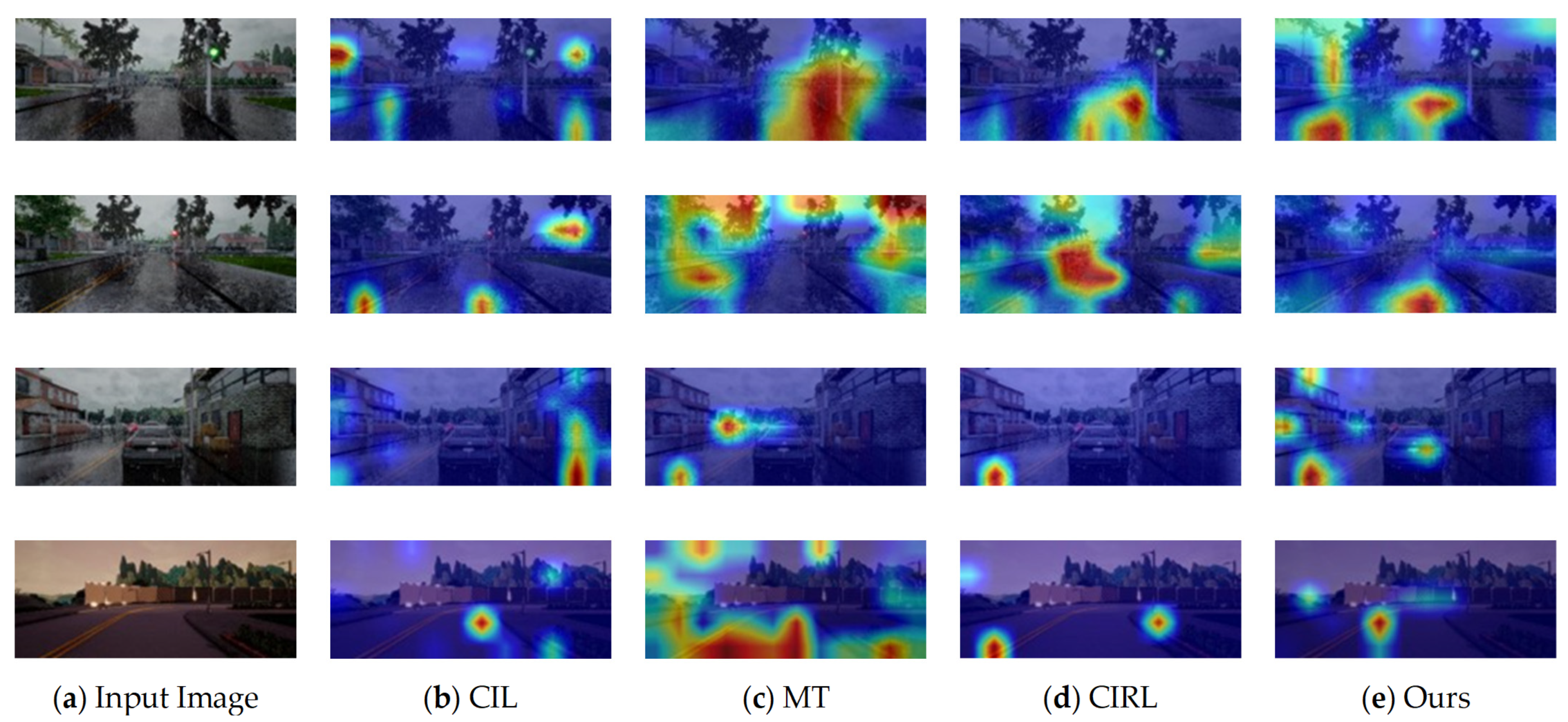
5.3. Grad-CAM Visualizations
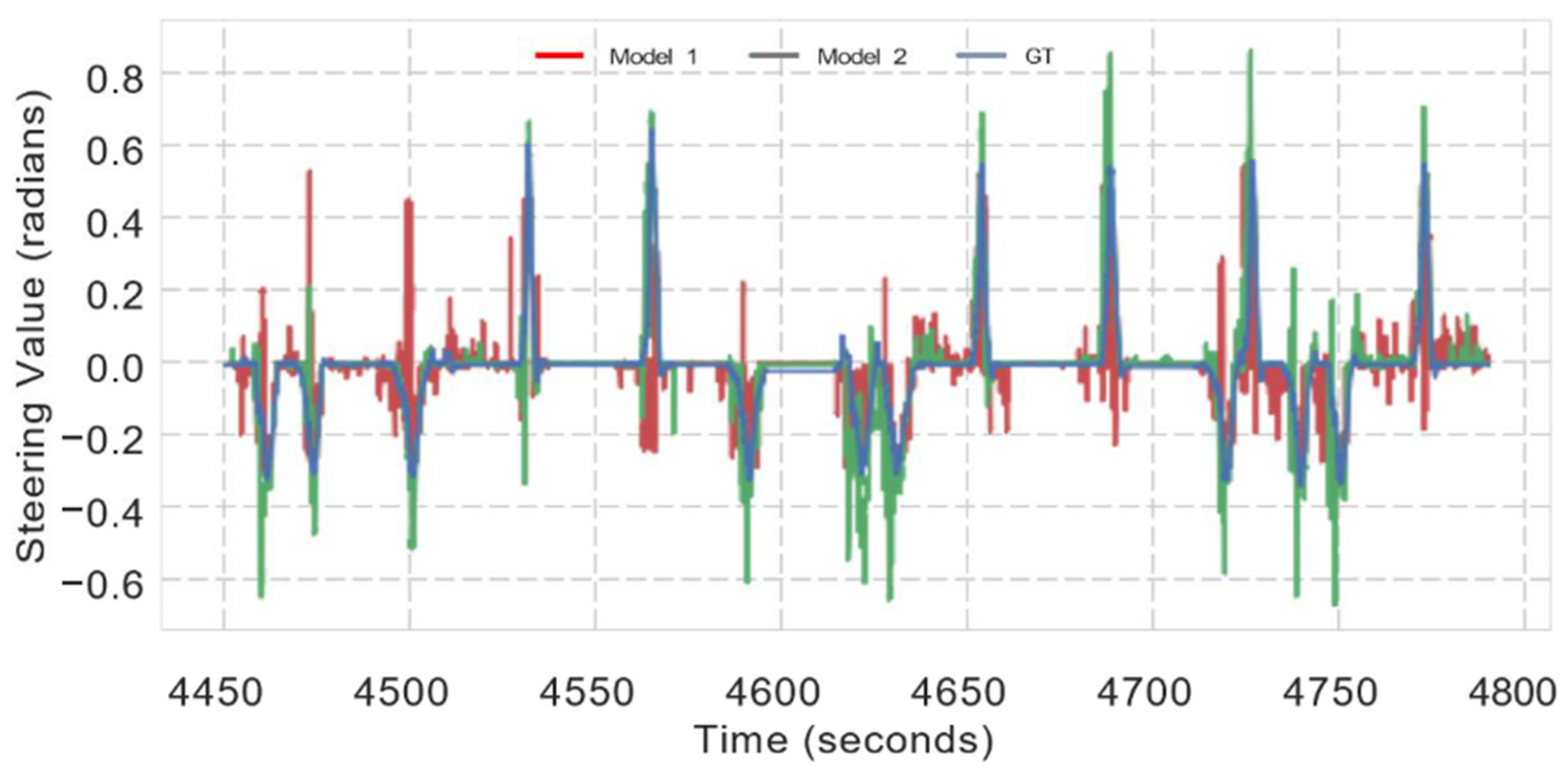
5.4. Prediction of Steering Wheel Angle
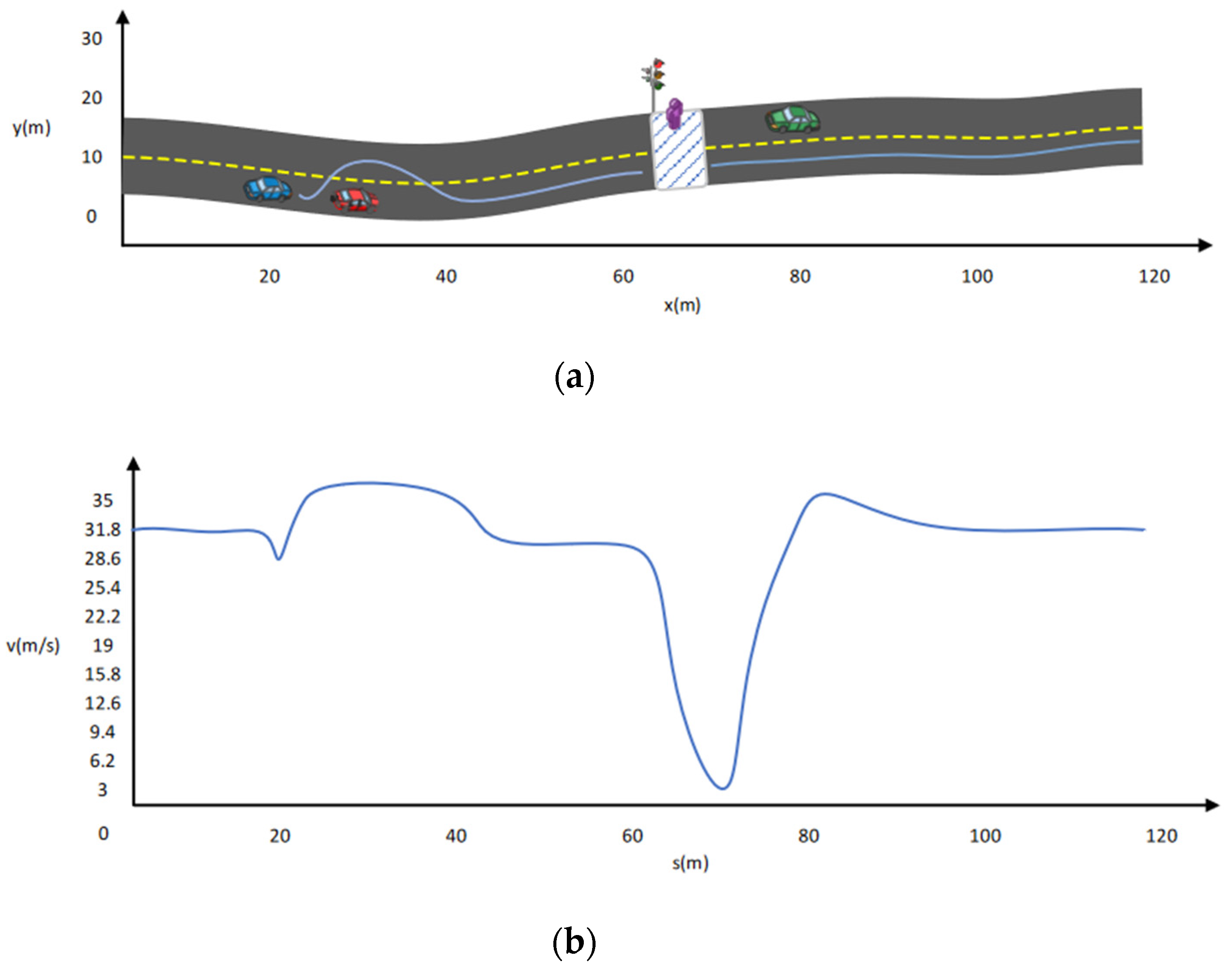
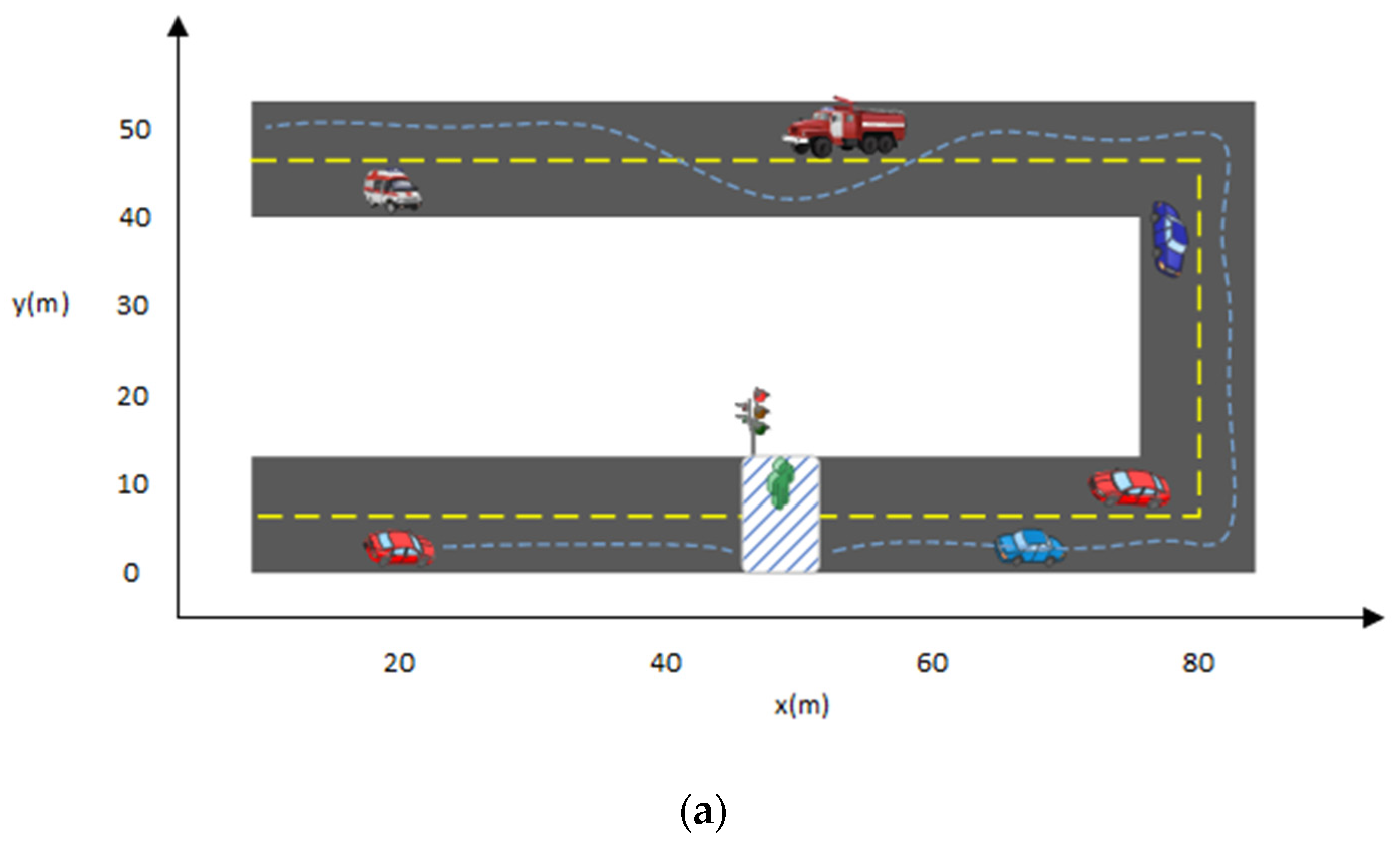
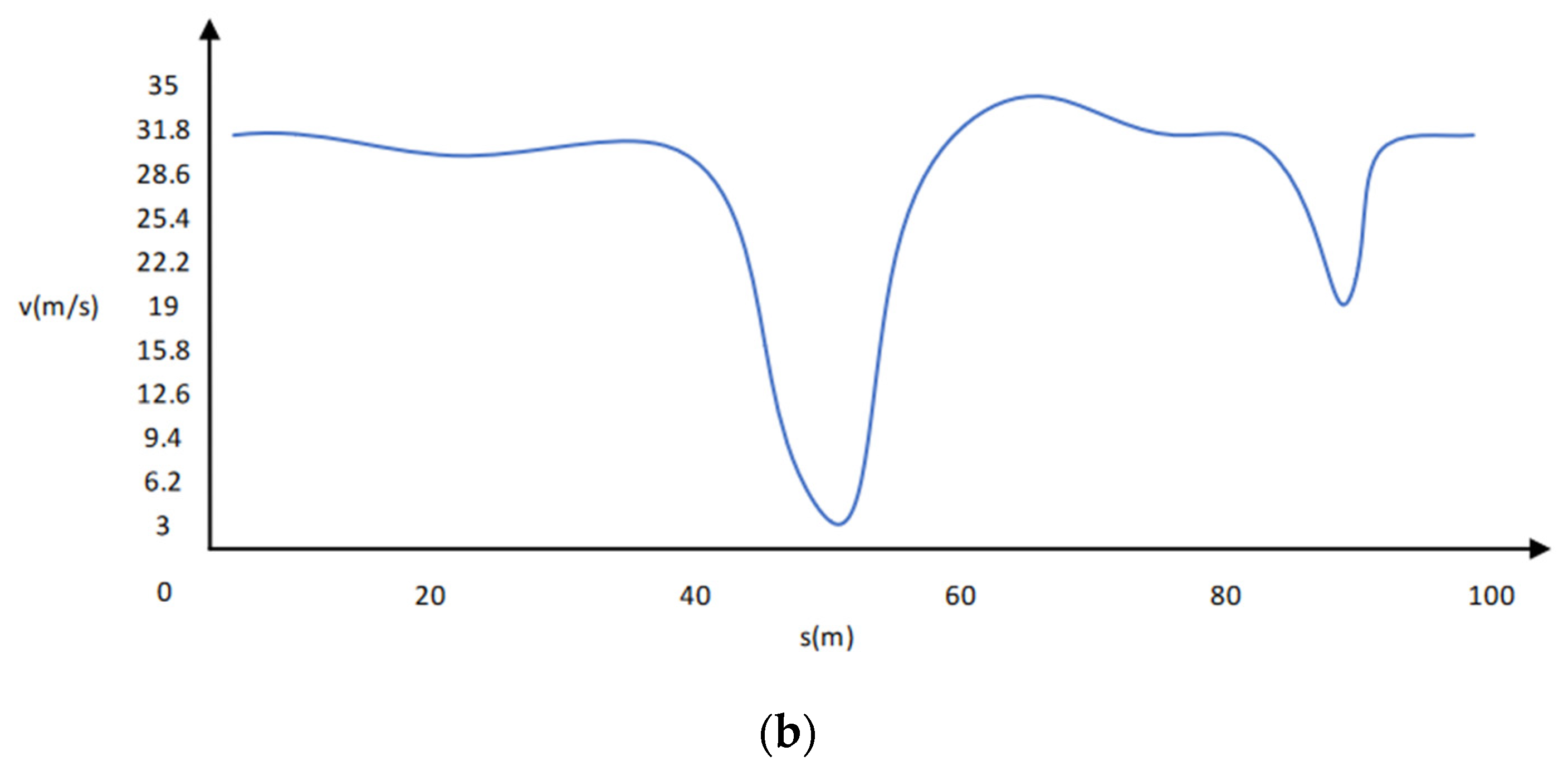
5.5. Path Planning
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Garcia-Bedoya, O.; Hirota, S.; Ferreira, J.V. Control system design for an automatic emergency braking system in a sedan vehicle. In Proceedings of the 2019 2nd Latin American Conference on Intelligent Transportation Systems (ITS LATAM), Bogota, Colombia, 19–20 March 2019. [Google Scholar]
- Perrier, M.J.R.; Louw, T.L.; Carsten, O. User-centred design evaluation of symbols for adaptive cruise control (ACC) and lane-keeping assistance (LKA). Cogn. Technol. Work 2021, 23, 685–703. [Google Scholar] [CrossRef]
- Haris, M.; Hou, J. Obstacle Detection and Safely Navigate the Autonomous Vehicle from Unexpected Obstacles on the Driving Lane. Sensors 2020, 20, 4719. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Hashemi, E.; Khajepour, A. Integrated Crash Avoidance and Mitigation Algorithm for Autonomous Vehicles. IEEE Trans. Ind. Inform. 2021, 17, 7246–7255. [Google Scholar] [CrossRef]
- Hrovat, D.; Hubbard, M. Optimum Vehicle Suspensions Minimizing RMS Rattlespace, Sprung-Mass Acceleration and Jerk. J. Dyn. Syst. Meas. Control 1981, 103, 228–236. [Google Scholar] [CrossRef]
- Huang, Q.; Wang, H. Fundamental Study of Jerk: Evaluation of Shift Quality and Ride Comfort; SAE Technical Paper; State Key Laboratory of Automotive Safety and Energy Tsinghua University: Beijing, China, 2004. [Google Scholar]
- Lv, Q.; Sun, X.; Chen, C.; Dong, J.; Zhou, H. Parallel Complement Network for Real-Time Semantic Segmentation of Road Scenes. IEEE Trans. Intell. Transp. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Hamian, M.H.; Beikmohammadi, A.; Ahmadi, A.; Nasersharif, B. Semantic Segmentation of Autonomous Driving Images by the combination of Deep Learning and Classical Segmentation. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021. [Google Scholar]
- Zhou, K.; Zhan, Y.; Fu, D. Learning Region-Based Attention Network for Traffic Sign Recognition. Sensors 2021, 21, 686. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Luo, W.; Urtasun, R. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7652–7660. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Haris, M.; Glowacz, A. Road object detection: A comparative study of deep learning-based algorithms. Electronics 2021, 10, 1932. [Google Scholar] [CrossRef]
- Haris, M.; Glowacz, A. Lane Line Detection Based on Object Feature Distillation. Electronics 2021, 10, 1102. [Google Scholar] [CrossRef]
- Haris, M.; Hou, J.; Wang, X. Multi-scale spatial convolution algorithm for lane line detection and lane offset estimation in complex road conditions. Signal Process. Image Commun. 2021, 99, 116413. [Google Scholar] [CrossRef]
- Haris, M.; Hou, J.; Wang, X. Lane Lines Detection under Complex Environment by Fusion of Detection and Prediction Models. Transp. Res. Rec. 2021, 03611981211051334. [Google Scholar] [CrossRef]
- Haris, M.; Hou, J.; Wang, X. Lane line detection and departure estimation in a complex environment by using an asymmetric kernel convolution algorithm. Vis. Comput. 2022, 1–20. [Google Scholar] [CrossRef]
- Gurram, A.; Urfalioglu, O.; Halfaoui, I.; Bouzaraa, F.; López, A.M. Monocular depth estimation by learning from heterogeneous datasets. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; IEEE: Suzhou, China, 2018; pp. 2176–2181. [Google Scholar]
- Gan, Y.; Xu, X.; Sun, W.; Lin, L. Monocular depth estimation with affinity, vertical pooling, and label enhancement. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 224–239. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2002–2011. [Google Scholar]
- Shin, Y.-S.; Park, Y.S.; Kim, A. Direct visual slam using sparse depth for camera-lidar system. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; IEEE: Brisbane, QLD, Australia, 2018; pp. 5144–5151. [Google Scholar]
- Qiu, K.; Ai, Y.; Tian, B.; Wang, B.; Cao, D. Siamese-ResNet: Implementing loop closure detection based on Siamese network. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; IEEE: Suzhou, China, 2018; pp. 716–721. [Google Scholar]
- Yin, H.; Tang, L.; Ding, X.; Wang, Y.; Xiong, R. Locnet: Global localization in 3d point clouds for mobile vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; IEEE: Suzhou, China, 2018; pp. 728–733. [Google Scholar]
- Pomerleau, D.A. Alvinn: An Autonomous Land Vehicle in a Neural Network. Available online: https://proceedings.neurips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf (accessed on 28 December 2021).
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Muller, U.; Ben, J.; Cosatto, E.; Flepp, B.; Cun, Y.L. Off-Road Obstacle Avoidance Through End-to-End Learning. Available online: https://proceedings.neurips.cc/paper/2005/file/fdf1bc5669e8ff5ba45d02fded729feb-Paper.pdf (accessed on 28 December 2021).
- Codevilla, F.; Miiller, M.; Lopez, A.; Koltun, V.; Dosovitskiy, A. End-to-End Driving Via Conditional Imitation Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; IEEE: Brisbane, QLD, Australia, 2018; pp. 4693–4700. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2174–2182. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; Volume 1, pp. 431–440. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Eraqi, H.M.; Moustafa, M.N.; Honer, J. End-to-end deep learning for steering autonomous vehicles considering temporal dependencies. arXiv 2017, arXiv:1710.03804. [Google Scholar]
- Hou, Y.; Hornauer, S.; Zipser, K. Fast recurrent fully convolutional networks for direct perception in autonomous driving. arXiv 2017, arXiv:1711.06459. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Wang, Q.; Chen, L.; Tian, W. End-to-end driving simulation via angle branched network. arXiv 2018, arXiv:1805.07545. [Google Scholar]
- Liang, X.; Wang, T.; Yang, L.; Xing, E. Cirl: Controllable imitative reinforcement learning for vision-based self-driving. In Proceedings of the The European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 584–599. [Google Scholar]
- Li, Z.; Motoyoshi, T.; Sasaki, K.; Ogata, T.; Sugano, S. Rethinking self-driving: Multi-task knowledge for better generalization and accident explanation ability. arXiv 2018, arXiv:1809.11100. [Google Scholar]
- Sauer, A.; Savinov, N.; Geiger, A. Conditional affordance learning for driving in urban environments. In Proceedings of the Conference on Robot Learning, PMLR, Zürich, Switzerland, 29–31 October 2018; pp. 237–252. [Google Scholar]
- Müller, M.; Dosovitskiy, A.; Ghanem, B.; Koltun, V. Driving policy transfer via modularity and abstraction. arXiv 2018, arXiv:1804.09364. [Google Scholar]
- Rhinehart, N.; McAllister, R.; Levine, S. Deep imitative models for flexible inference, planning, and control. arXiv 2018, arXiv:1810.06544. [Google Scholar]
- Thrun, S.; Montemerlo, M.; Dahlkamp, H.; Stavens, D.; Aron, A.; Diebel, J.; Fong, P.; Gale, J.; Halpenny, M.; Hoffmann, G.; et al. Stanley: The robot that won the DARPA Grand Challenge. J. Field Robot. 2006, 23, 661–692. [Google Scholar] [CrossRef]
- Ziegler, J.; Bender, P.; Schreiber, M.; Lategahn, H.; Strauss, T.; Stiller, C.; Dang, T.; Franke, U.; Appenrodt, N.; Keller, C.G.; et al. Making Bertha Drive—An Autonomous Journey on a Historic Route. IEEE Intell. Transp. Syst. Mag. 2014, 6, 8–20. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.-Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar]
- Güney, F.; Geiger, A. Deep discrete flow. In Proceedings of the Asian Conference on Computer Vision, Hyderabad, India, 13–16 January 2006; Springer: Berlin/Heidelberg, Germany, 2016; pp. 207–224. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Rob. Res. 2016, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Geiger, A.; Urtasun, R. Understanding high-level semantics by modeling traffic patterns. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3056–3063. [Google Scholar]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3D Traffic Scene Understanding From Movable Platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1012–1025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and Decision-Making for Autonomous Vehicles. Annu. Rev. Control Robot. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Bojarski, M.; Yeres, P.; Choromanska, A.; Choromanski, K.; Firner, B.; Jackel, L.; Muller, U. Explaining how a deep neural network trained with end-to-end learning steers a car. arXiv 2017, arXiv:1704.07911. [Google Scholar]
- Hubschneider, C.; Bauer, A.; Weber, M.; Zöllner, J.M. Adding navigation to the equation: Turning decisions for end-to-end vehicle control. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; IEEE: Yokohama, Japan, 2017; pp. 1–8. [Google Scholar]
- Amini, A.; Rosman, G.; Karaman, S.; Rus, D. Variational end-to-end navigation and localization. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Montreal, QC, Canada, 2019; pp. 8958–8964. [Google Scholar]
- Barto, A.G.; Mahadevan, S. Recent Advances in Hierarchical Reinforcement Learning. Discret. Event Dyn. Syst. 2003, 13, 41–77. [Google Scholar] [CrossRef]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef] [Green Version]
- Konidaris, G.; Kuindersma, S.; Grupen, R.; Barto, A. Robot learning from demonstration by constructing skill trees. Int. J. Robot. Res. 2011, 31, 360–375. [Google Scholar] [CrossRef]
- Kulkarni, T.D.; Narasimhan, K.R.; Saeedi, A.; Tenenbaum, J.B. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. arXiv 2016, arXiv:1604.06057. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Pastor, P.; Hoffmann, H.; Asfour, T.; Schaal, S. Learning and generalization of motor skills by learning from demonstration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; IEEE: Kobe, Japan, 2009; pp. 763–768. [Google Scholar]
- Da Silva, B.; Konidaris, G.; Barto, A. Learning parameterized skills. arXiv 2012, arXiv:1206.6398. [Google Scholar]
- Deisenroth, M.P.; Englert, P.; Peters, J.; Fox, D. Multi-task policy search for robotics. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Hong Kong, China, 2014; pp. 3876–3881. [Google Scholar]
- Kober, J.; Wilhelm, A.; Oztop, E.; Peters, J. Reinforcement learning to adjust parametrized motor primitives to new situations. Auton. Robot. 2012, 33, 361–379. [Google Scholar] [CrossRef]
- Schaul, T.; Horgan, D.; Gregor, K.; Silver, D. Universal value function approximators. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1312–1320. [Google Scholar]
- Dosovitskiy, A.; Koltun, V. Learning to act by predicting the future. arXiv 2016, arXiv:1611.01779. [Google Scholar]
- Javdani, S.; Srinivasa, S.S.; Bagnell, J.A. Shared autonomy via hindsight optimization. Robot. Sci. Syst. 2015. [Google Scholar] [CrossRef]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deep Driving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Al-Qizwini, M.; Barjasteh, I.; Al-Qassab, H.; Radha, H. Deep learning algorithm for autonomous driving using googlenet. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Redondo Beach, CA, USA, 11–14 June 2017; IEEE: Los Angeles, CA, USA, 2017; pp. 89–96. [Google Scholar]
- Huang, J.; Tanev, I.; Shimohara, K. Evolving a general electronic stability program for car simulated in TORCS. In Proceedings of the 2015 IEEE Conference on Computational Intelligence and Games (CIG), Tainan, Taiwan, 31 August 2015–1 September 2015; IEEE: Tainan, Taiwan, 2015; pp. 446–453. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 102–118. [Google Scholar]
- Ebrahimi, S.; Rohrbach, A.; Darrell, T. Gradient-free policy architecture search and adaptation. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 505–514. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cuDNN: Efficient Primitives for Deep Learning. arXiv 2014, arXiv:1410.0759. [Google Scholar]
- Wymann, B.; Espié, E.; Guionneau, C.; Dimitrakakis, C.; Coulom, R.; Sumner, A. Torcs, the Open Racing Car Simulator. 2000. Available online: http//torcs.sourceforge.net (accessed on 6 March 2021).
- Codevilla, F.; López, A.M.; Koltun, V.; Dosovitskiy, A. On Offline Evaluation of Vision-Based Driving Models. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 236–251. [Google Scholar]
- Premebida, C.; Carreira, J.; Batista, J.; Nunes, U. Pedestrian detection combining RGB and dense LIDAR data. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; IEEE: Chicago, IL, USA, 2014; pp. 4112–4117. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the KITTI vision benchmark suite. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multi-task learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | Layer | Output Shape |
|---|---|---|---|
| Input Image | Input Speed | 1 | |
| Conv2d_1 | FC | 128 | |
| Conv2d_2 | |||
| Conv2d_3 | |||
| Conv2d_4 | |||
| Conv2d_5 | |||
| Conv2d_6 | |||
| Conv2d_7 | FC | 128 | |
| Conv2d_8 | |||
| Flatten | 8192 | ||
| FC | 512 | ||
| FC | 256 | ||
| FC | 256 | ||
| FC | 256 | Total 4 branches for all 4 commands | |
| FC | 256 | ||
| Output | 1 | ||
| Model | Abbreviation | Manuscript |
|---|---|---|
| Modular Perception | MP | [33] |
| Reinforcement Learning | RL | [33] |
| Controllable Imitative Reinforcement Learning | CIRL | [35] |
| Multi-Task Learning | MT | [36] |
| Conditional Affordance Learning | CAL | [37] |
| Active | Estimated | Active | Estimated | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task | SS | RGB | D | EF | D | EF | SS | RGB | D | EF | D | EF |
| Training Conditions | New Town | |||||||||||
| Straight | 98.0 | 96.3 | 98.7 | 98.3 | 92.3 | 97.3 | 100 | 84.0 | 94.3 | 96.3 | 78.3 | 71.6 |
| One Turn | 100.0 | 95.0 | 92.0 | 99.0 | 84.6 | 96.3 | 96.6 | 68.0 | 74.3 | 79.0 | 46.3 | 47.0 |
| Navigation | 96.0 | 89.0 | 89.3 | 92.6 | 75.3 | 94.3 | 96.0 | 59.6 | 85.3 | 90.0 | 45.6 | 46.6 |
| Nav. Dynamic | 92.0 | 84.0 | 82.6 | 89.3 | 71.0 | 90.6 | 99.3 | 54.3 | 70.3 | 84.3 | 44.3 | 46.6 |
| New Weather | New Town and Weather | |||||||||||
| Straight | 100.0 | 84.0 | 99.3 | 96.0 | 92.0 | 84.6 | 100 | 84.6 | 97.3 | 97.3 | 78.0 | 89.3 |
| One Turn | 100.0 | 76.6 | 94.6 | 94.6 | 93.3 | 80.6 | 96.0 | 66.6 | 72.7 | 82.7 | 62.6 | 64.0 |
| Navigation | 95.3 | 72.6 | 89.3 | 91.3 | 73.3 | 80.6 | 96.0 | 57.3 | 84.0 | 92.7 | 55.3 | 60.7 |
| Nav. Dynamic | 92.6 | 68.6 | 90.0 | 86.0 | 76.6 | 77.3 | 98.0 | 46.7 | 68.3 | 94.0 | 54.0 | 49.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haris, M.; Glowacz, A. Navigating an Automated Driving Vehicle via the Early Fusion of Multi-Modality. Sensors 2022, 22, 1425. https://doi.org/10.3390/s22041425
Haris M, Glowacz A. Navigating an Automated Driving Vehicle via the Early Fusion of Multi-Modality. Sensors. 2022; 22(4):1425. https://doi.org/10.3390/s22041425
Chicago/Turabian StyleHaris, Malik, and Adam Glowacz. 2022. "Navigating an Automated Driving Vehicle via the Early Fusion of Multi-Modality" Sensors 22, no. 4: 1425. https://doi.org/10.3390/s22041425