


An Ensemble Learning Aided Computer Vision Method with Advanced Color Enhancement for Corroded Bolt Detection in Tunnels

Abstract
:1. Introduction
- 1.
- We optimized the MSRCR color enhancement algorithm based on auto-matched dynamic filters and regularization to avoid blurring the image when brightening the dark areas.
- 2.
- We put forward ensemble learning with its fusion strategy combining models with different parameters to improve precision accuracy.
- 3.
- The experiments are conducted on actual data collected from a practical railway tunnel. We disclosed our labeled dataset, the first public corroded lining bolt dataset using a professional tunnel scanner.
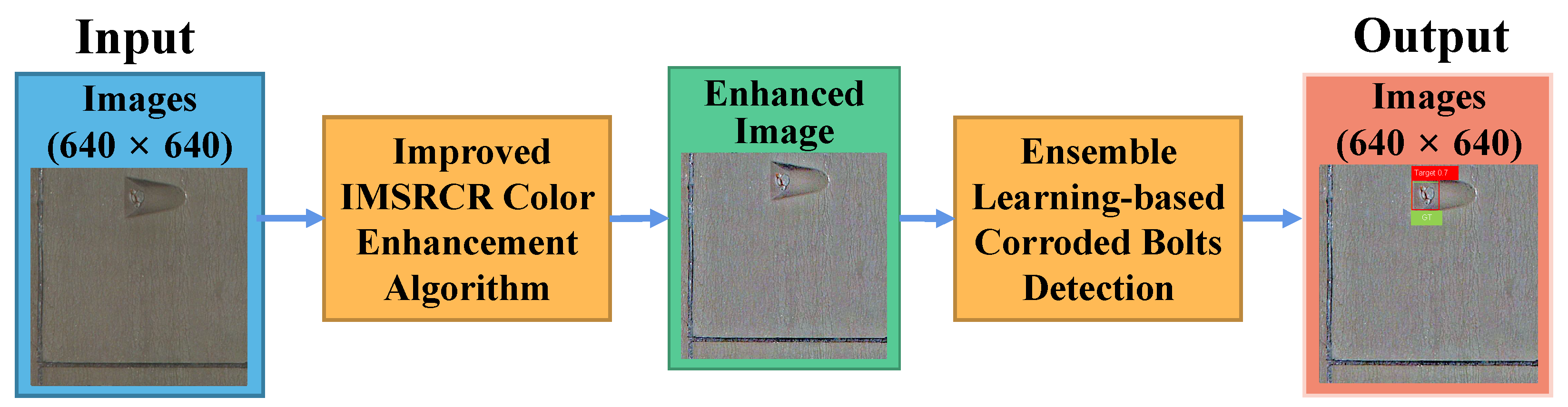
2. Methodology
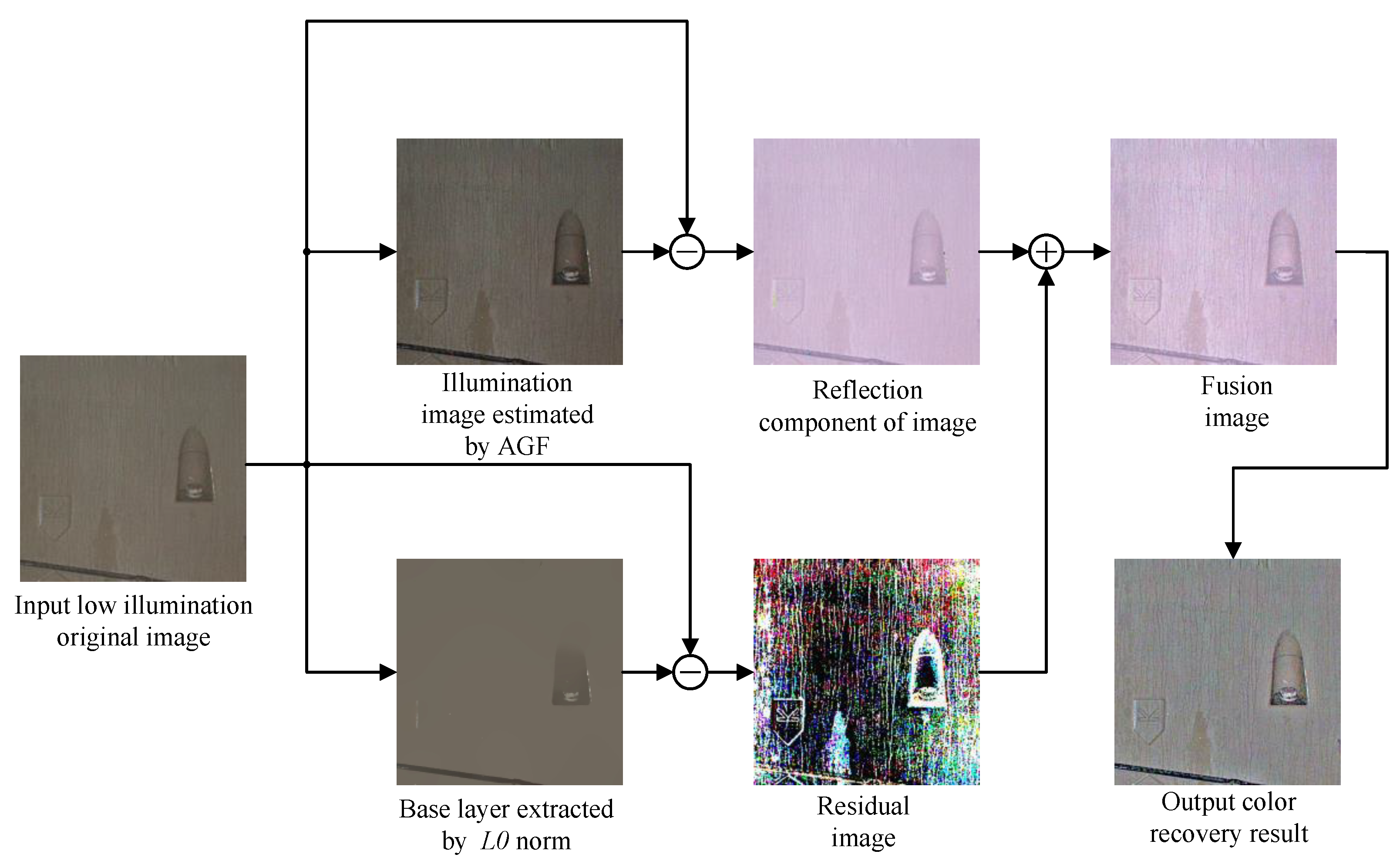
2.1. The Improved IMSRCR Color Enhancement Algorithm
2.1.1. Illumination Estimation
2.1.2. Residual Fusion
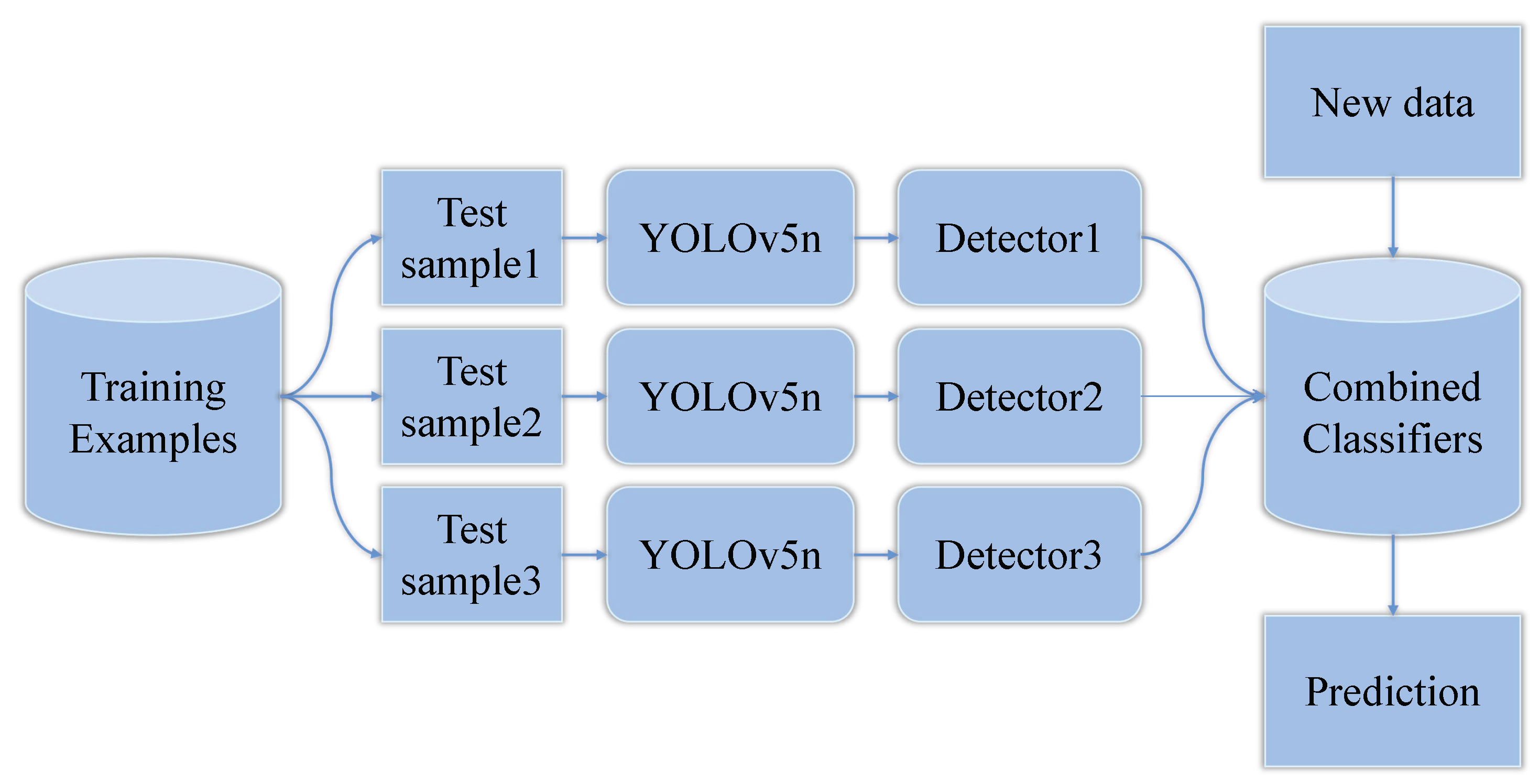
2.2. Ensemble Learning-Based Corroded Bolts Detection
2.2.1. Ensemble Learning Method
2.2.2. Fusion Strategy in Ensemble Learning
3. Experiment
3.1. Data Acquisition System and Dataset
3.2. Experiment Settings
3.3. Evaluation Metrics
3.4. Performance Comparisons
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, X.; Cao, Y.; Sun, Y.; Tang, T. Railway Automatic Switch Stationary Contacts Wear Detection Under Few-Shot Occasions. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14893–14907. [Google Scholar] [CrossRef]
- Hu, X.; Cao, Y.; Tang, T.; Sun, Y. Data-driven technology of fault diagnosis in railway point machines: Review and challenges. Transp. Saf. Environ. 2022, 4, tdac036. [Google Scholar] [CrossRef]
- Wen, T.; Xie, G.; Cao, Y.; Cai, B. A DNN-Based Channel Model for Network Planning in Train Control Systems. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2392–2399. [Google Scholar] [CrossRef]
- Nikravesh, S.M.Y.; Goudarzi, M. A review paper on looseness detection methods in bolted structures. Lat. Am. J. Solids Struct. 2017, 14, 2153–2176. [Google Scholar] [CrossRef] [Green Version]
- Reddy, M.S.B.; Ponnamma, D.; Sadasivuni, K.K.; Aich, S.; Kailasa, S.; Parangusan, H.; Ibrahim, M.; Eldeib, S.; Shehata, O.; Ismail, M.; et al. Sensors in advancing the capabilities of corrosion detection: A review. Sens. Actuators A Phys. 2021, 332, 113086. [Google Scholar] [CrossRef]
- Xu, Y.; Li, D.; Xie, Q.; Wu, Q.; Wang, J. Automatic defect detection and segmentation of tunnel surface using modified Mask R-CNN. Measurement 2021, 178, 109316. [Google Scholar] [CrossRef]
- Fan, Z.; Song, Z.; Xu, J.; Wang, Z.; Wu, K.; Liu, H.; He, J. Object Level Depth Reconstruction for Category Level 6D Object Pose Estimation From Monocular RGB Image. arXiv 2022, arXiv:2204.01586. [Google Scholar] [CrossRef]
- Fan, Z.; Liu, H.; He, J.; Jiang, S.; Du, X. PointFPN: A Frustum-based Feature Pyramid Network for 3D Object Detection. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1129–1136. [Google Scholar] [CrossRef]
- Zhang, X.; Sheng, Z.; Shen, H.L. FocusNet: Classifying better by focusing on confusing classes. Pattern Recognit. 2022, 129, 108709. [Google Scholar] [CrossRef]
- Cao, S.Y.; Hu, J.; Sheng, Z.; Shen, H.L. Iterative Deep Homography Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 1879–1888. [Google Scholar] [CrossRef]
- Chang, S.; Zhang, R.; Ji, K.; Huang, S.; Feng, Z. A Hierarchical Classification Head based Convolutional Gated Deep Neural Network for Automatic Modulation Classification. IEEE Trans. Wirel. Commun. 2022, 21, 8713–8728. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Ta, Q.B.; Huynh, T.C.; Pham, Q.Q.; Kim, J.T. Corroded Bolt Identification Using Mask Region-Based Deep Learning Trained on Synthesized Data. Sensors 2022, 22, 3340. [Google Scholar] [CrossRef] [PubMed]
- Suh, G.; Cha, Y.J. Deep faster R-CNN-based automated detection and localization of multiple types of damage. In Proceedings of the Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems, Denver, CO, USA, 5–8 March 2018; SPIE: Bellingham, WA, USA, 2018; Volume 10598, pp. 197–204. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Zhang, H.; Liu, L.; Zhong, H. Rail surface defect detection method based on YOLOv3 deep learning networks. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1563–1568. [Google Scholar] [CrossRef]
- Guo, K.; He, C.; Yang, M.; Wang, S. A pavement distresses identification method optimized for YOLOv5s. Sci. Rep. 2022, 12, 3542. [Google Scholar] [CrossRef] [PubMed]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Forkan, A.R.M.; Kang, Y.B.; Jayaraman, P.P.; Liao, K.; Kaul, R.; Morgan, G.; Ranjan, R.; Sinha, S. CorrDetector: A framework for structural corrosion detection from drone images using ensemble deep learning. Expert Syst. Appl. 2022, 193, 116461. [Google Scholar] [CrossRef]
- Seijo-Pardo, B.; Porto-Díaz, I.; Bolón-Canedo, V.; Alonso-Betanzos, A. Ensemble feature selection: Homogeneous and heterogeneous approaches. Knowl. Based Syst. 2017, 118, 124–139. [Google Scholar] [CrossRef]
- Zhang, W.; Dong, L.; Xu, W. Retinex-inspired color correction and detail preserved fusion for underwater image enhancement. Comput. Electron. Agric. 2022, 192, 106585. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar] [CrossRef]
- Fan, M.; Wang, W.; Yang, W.; Liu, J. Integrating semantic segmentation and retinex model for low-light image enhancement. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2317–2325. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Ochotorena, C.N.; Yamashita, Y. Anisotropic guided filtering. IEEE Trans. Image Process. 2019, 29, 1397–1412. [Google Scholar] [CrossRef]
- Li, Z.; Song, X.; Chen, C.; Wang, C. Brightness level image enhancement algorithm based on retinex algorithm. J. Data Acquisit. Process 2019, 2019, 41–49. [Google Scholar]
- Xu, L.; Lu, C.; Xu, Y.; Jia, J. Image smoothing via L 0 gradient minimization. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, China, 12–15 December 2011; pp. 1–12. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | F1 Score | AP@0.5 | AP@0.5:0.95 | ||
|---|---|---|---|---|---|
| Faster-RCNN | 0.690 | 0.917 | 0.790 | 0.832 | 0.316 |
| YOLOv5s | 0.876 | 0.950 | 0.912 | 0.957 | 0.509 |
| YOLOv5n6 | 0.883 | 0.927 | 0.904 | 0.945 | 0.506 |
| YOLOv5n | 0.889 | 0.974 | 0.930 | 0.970 | 0.525 |
| YOLOv5n-EL (baseline) | 0.895 | 0.974 | 0.938 | 0.970 | 0.530 |
| MSR + YOLOv5s | 0.886 | 0.924 | 0.905 | 0.959 | 0.510 |
| MSR + YOLOv5n6 | 0.858 | 0.948 | 0.901 | 0.952 | 0.495 |
| MSR + YOLOv5n | 0.864 | 0.969 | 0.913 | 0.961 | 0.506 |
| MSR + YOLOv5n-EL | 0.880 | 0.970 | 0.922 | 0.965 | 0.515 |
| MSRCR + YOLOv5s | 0.877 | 0.933 | 0.904 | 0.961 | 0.509 |
| MSRCR + YOLOv5n6 | 0.889 | 0.962 | 0.924 | 0.970 | 0.514 |
| MSRCR + YOLOv5n | 0.912 | 0.970 | 0.940 | 0.966 | 0.533 |
| MSRCR + YOLOv5n-EL | 0.917 | 0.970 | 0.943 | 0.972 | 0.534 |
| IMSRCR + YOLOv5s | 0.881 | 0.933 | 0.906 | 0.965 | 0.512 |
| IMSRCR + YOLOv5n6 | 0.915 | 0.972 | 0.943 | 0.972 | 0.520 |
| IMSRCR + YOLOv5n | 0.914 | 0.970 | 0.941 | 0.971 | 0.535 |
| IMSRCR + YOLOv5n-EL | 0.921 | 0.975 | 0.947 | 0.975 | 0.537 |
| Faster-RCNN | YOLOv5s | YOLOv5n | YOLOv5n-EL | |
|---|---|---|---|---|
| FLOPs (G) | ∖ | 15.8 | 4.1 | 12.3 |
| Pre-process Time (ms) | ∖ | 0.677 | 0.614 | 0.643 |
| Inference Time (ms) | ∖ | 9.571 | 5.041 | 12.716 |
| NMS Time (ms) | ∖ | 1.475 | 1.405 | 1.008 |
| Total Time (ms) | 83.990 | 11.723 | 7.060 | 14.367 |
| MSR | MSRCR | IMSRCR | |
|---|---|---|---|
| Time Cost (ms) | 47.576 | 93.308 | 69.870 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, L.; Tang, T.; Yuan, D. An Ensemble Learning Aided Computer Vision Method with Advanced Color Enhancement for Corroded Bolt Detection in Tunnels. Sensors 2022, 22, 9715. https://doi.org/10.3390/s22249715
Tan L, Tang T, Yuan D. An Ensemble Learning Aided Computer Vision Method with Advanced Color Enhancement for Corroded Bolt Detection in Tunnels. Sensors. 2022; 22(24):9715. https://doi.org/10.3390/s22249715
Chicago/Turabian StyleTan, Lei, Tao Tang, and Dajun Yuan. 2022. "An Ensemble Learning Aided Computer Vision Method with Advanced Color Enhancement for Corroded Bolt Detection in Tunnels" Sensors 22, no. 24: 9715. https://doi.org/10.3390/s22249715