
Detection of Parkinson’s Disease Using Wrist Accelerometer Data and Passive Monitoring

Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
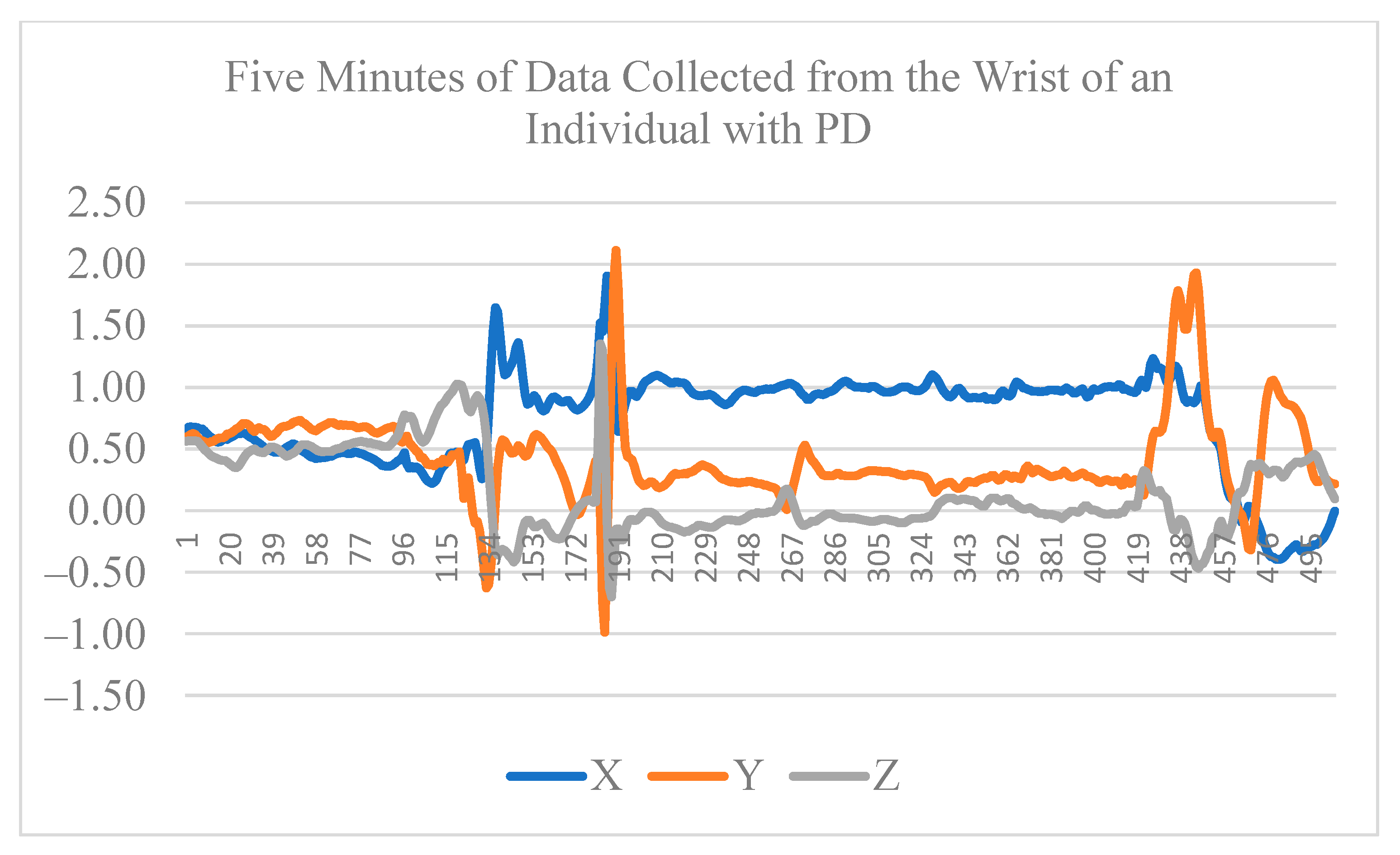
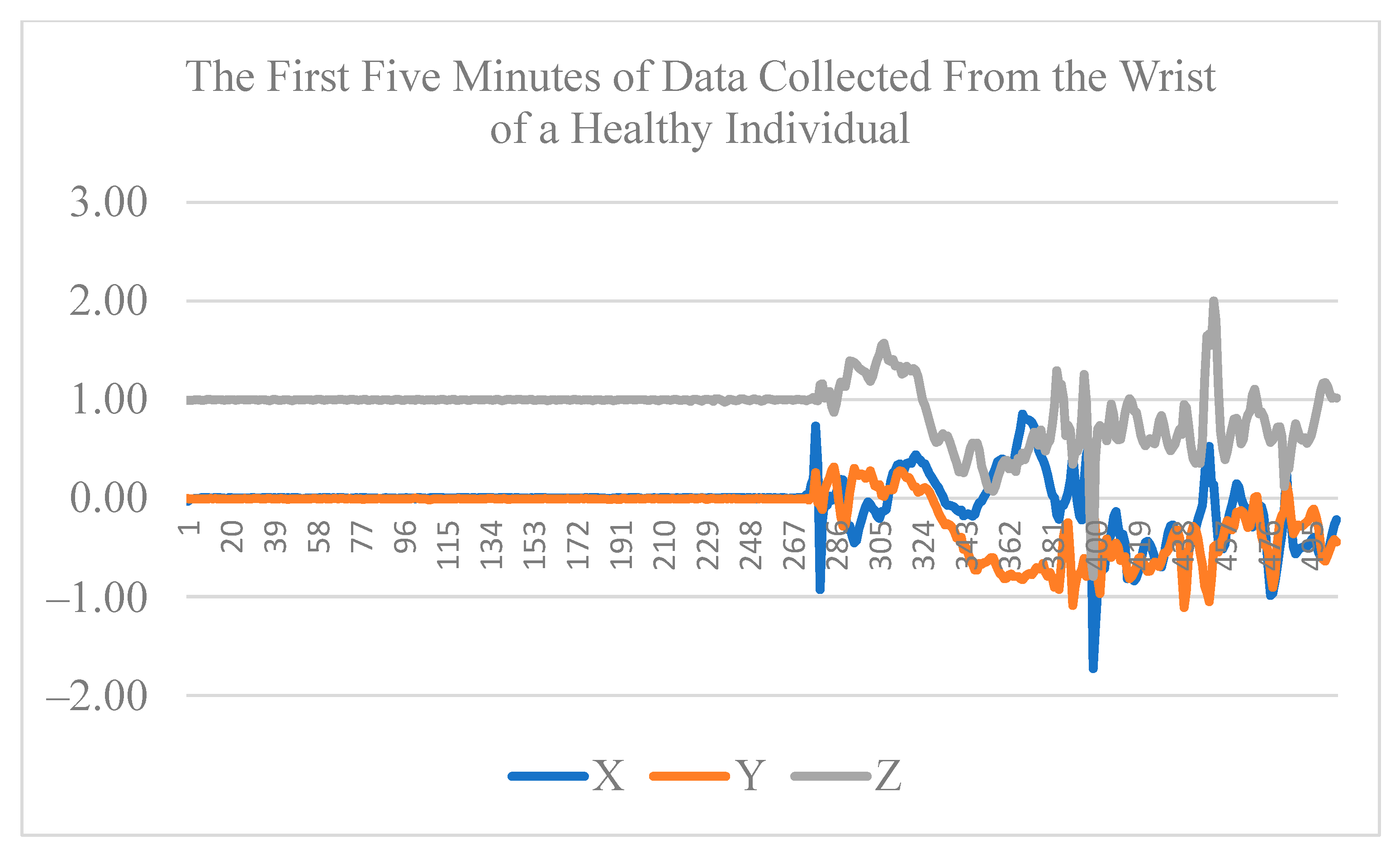
3.1. Data Collection
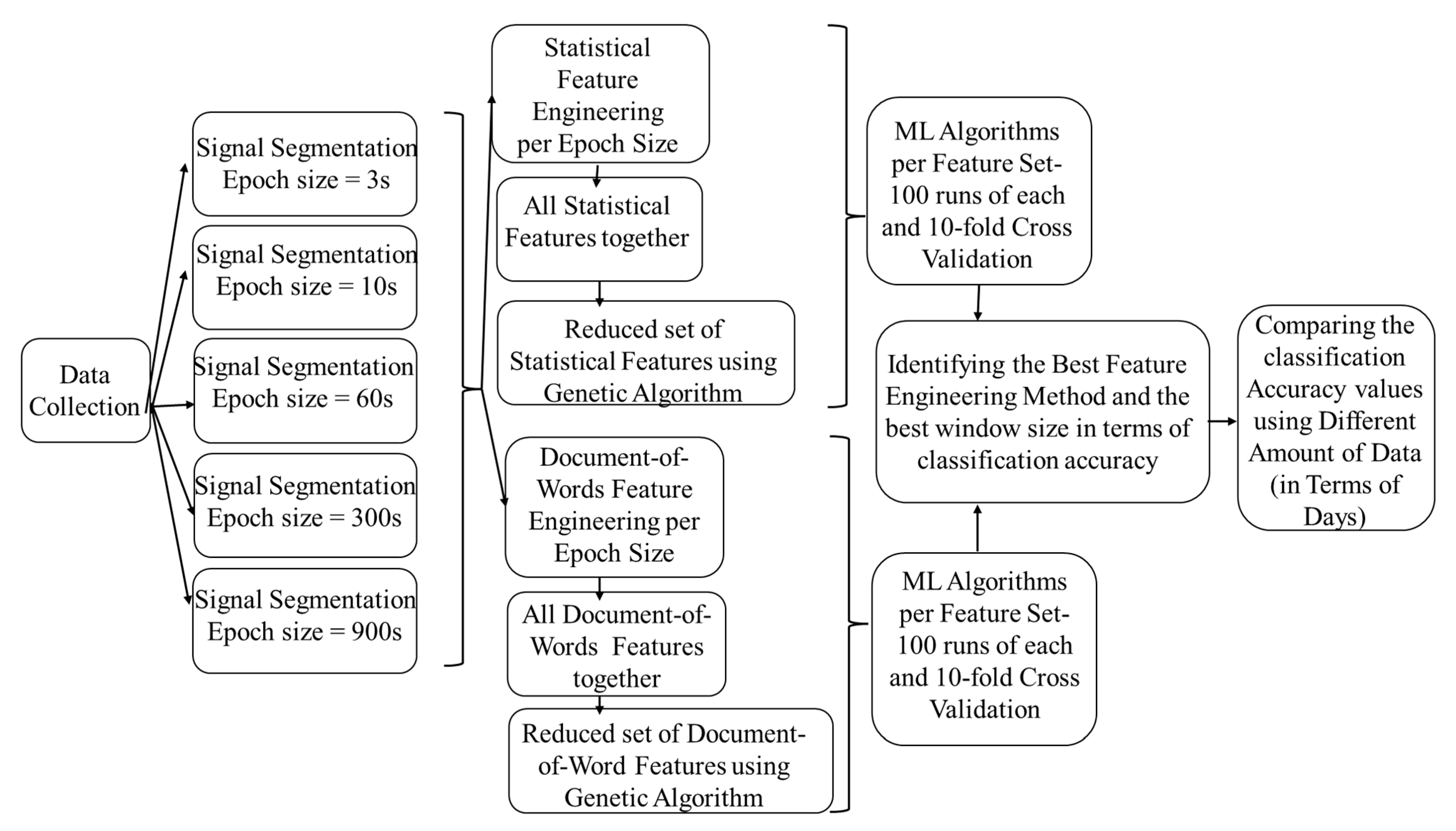
3.2. Signal Segmentation
3.3. Feature Extraction
3.3.1. Epoch-Based Statistical Features
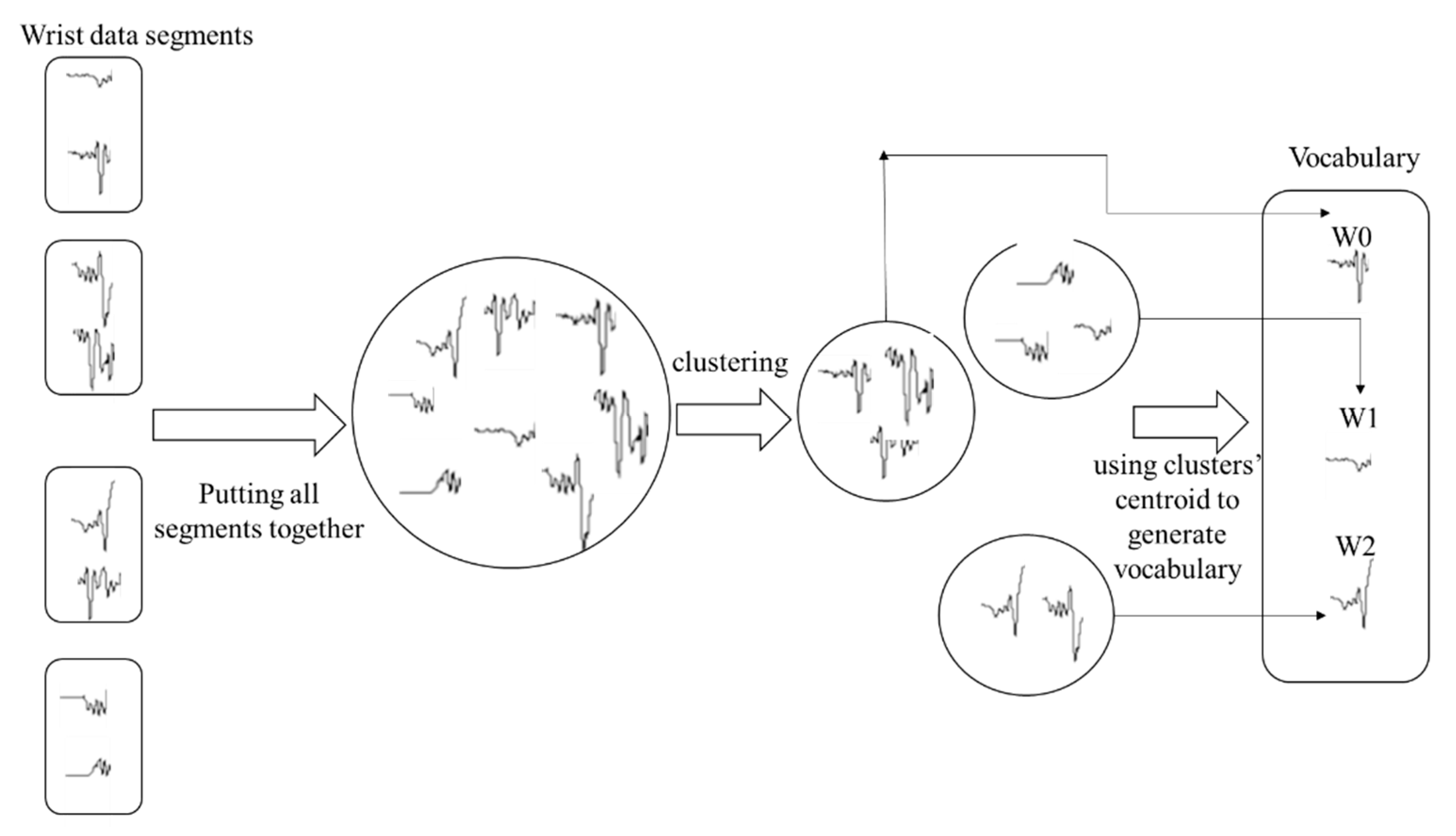
3.3.2. Epoch-Based Document-of-Words Features
3.4. Feature Selection, Classification Algorithms, and Validation
3.5. Hypotheses Testing
3.5.1. Comparing Statistical and Document-of-Words Feature Engineering Methods
3.5.2. Examining the Impact of Different Windowing Strategies on Classification Performance
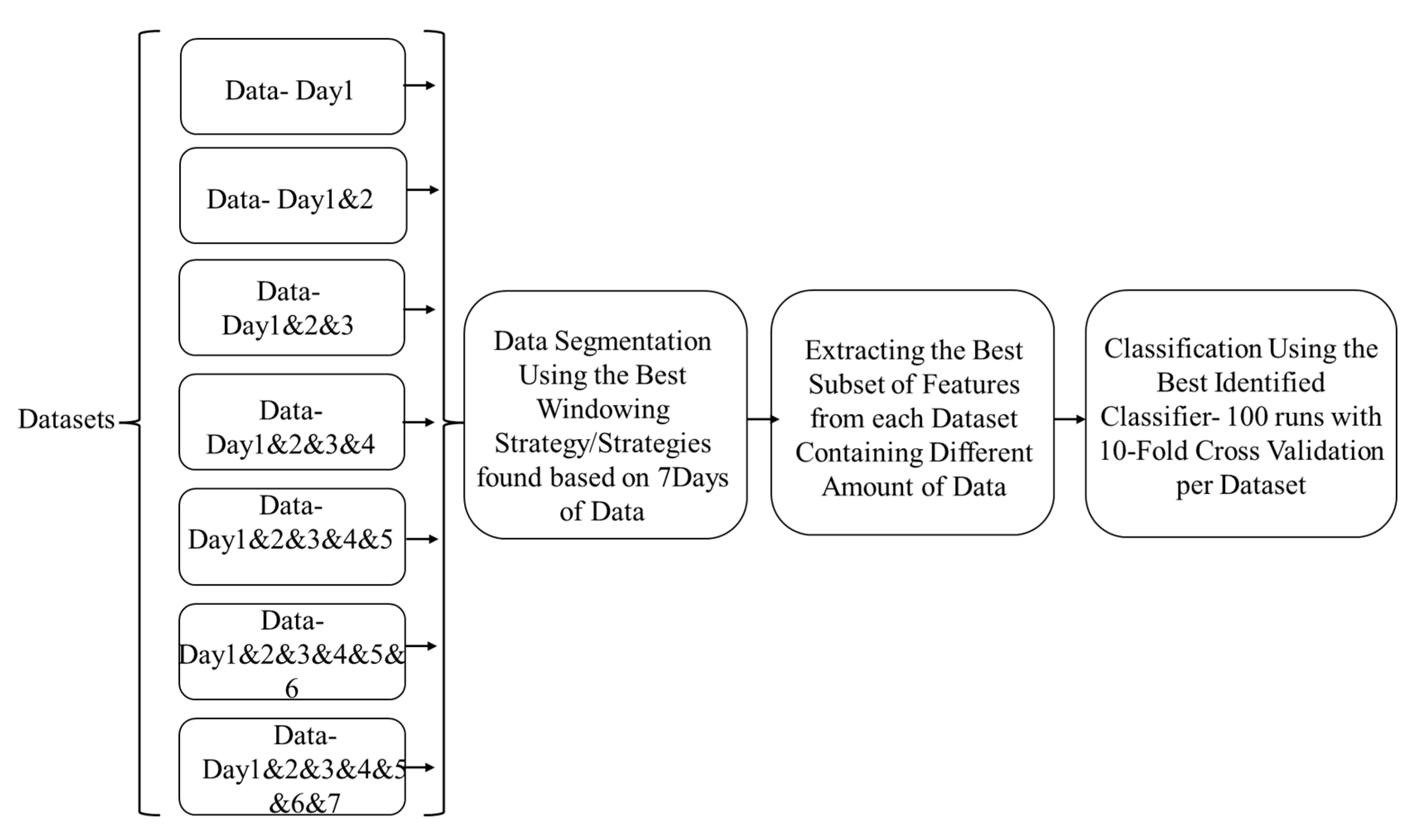
3.5.3. Examining the Impact of the Data Size on Classification Performance
4. Results
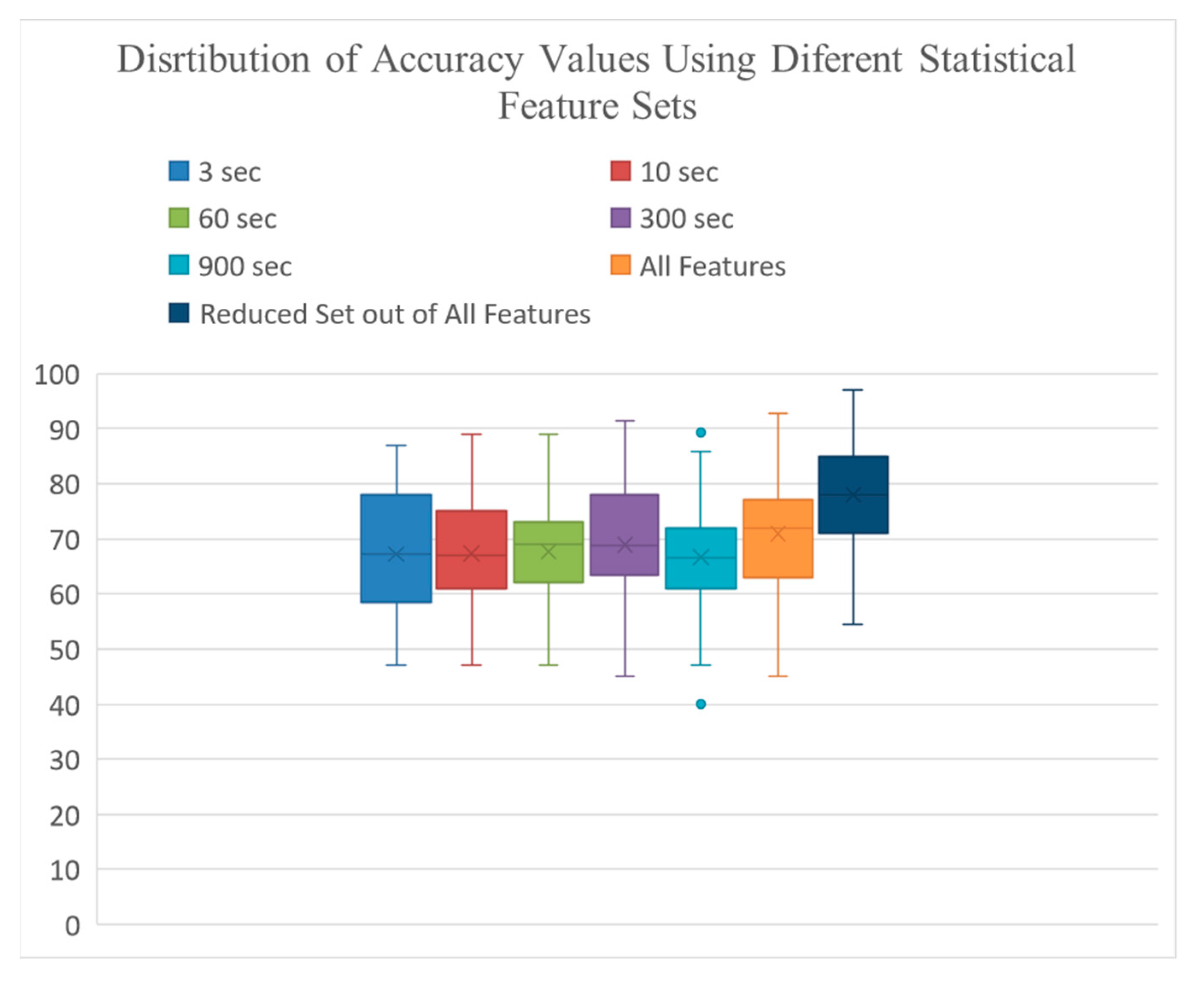
4.1. Classification Results Using Statistical Features
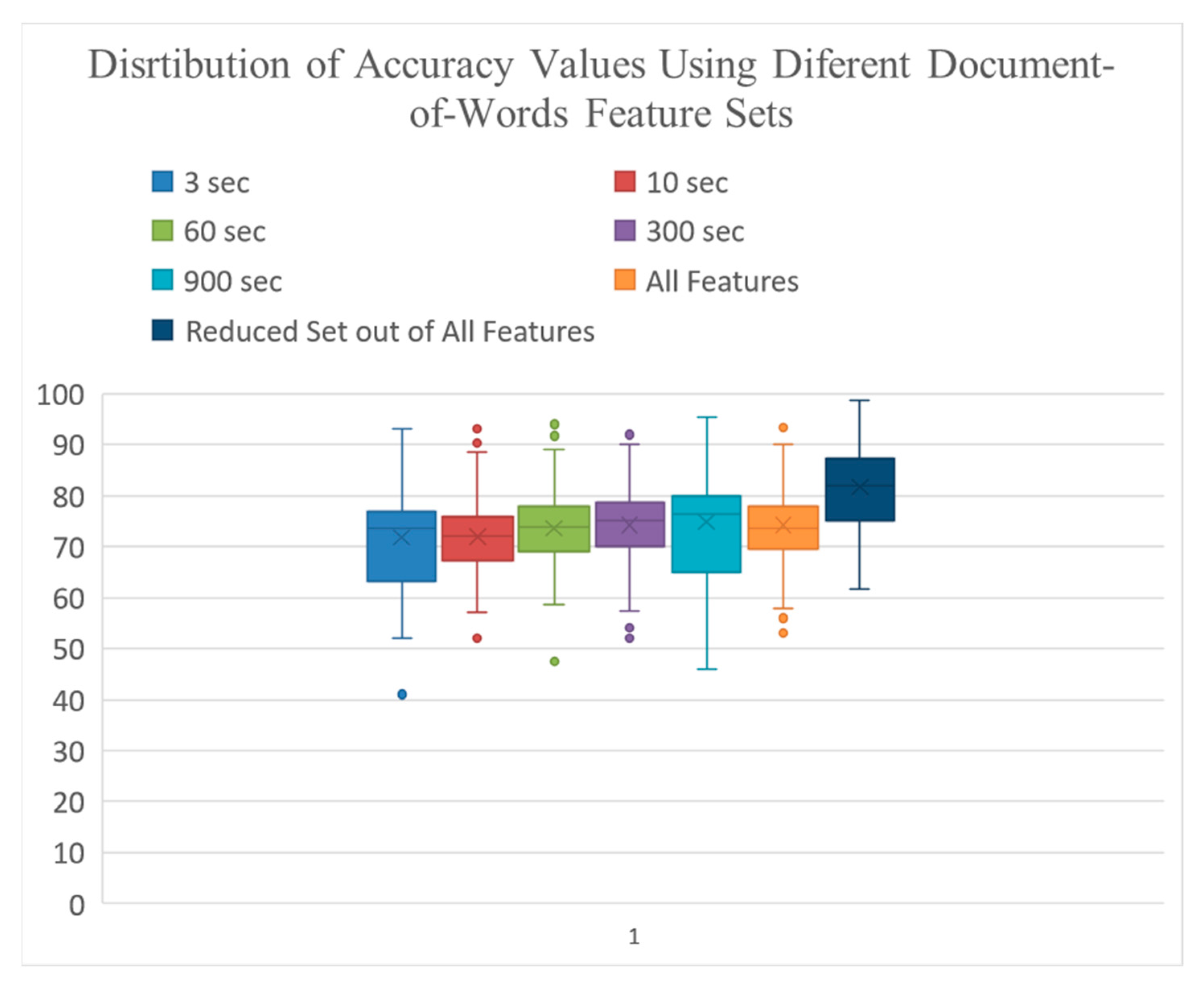
4.2. Classification Results Using Document-of-Words Features
4.3. Impact of Windowing Strategies
4.4. Comparing the Models Performance between Document-of-Words and Statistical Feature Engineering
4.5. Optimum Number of Days of Data Collection
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stamford, J.A.; Schmidt, P.N.; Friedl, K.E. What engineering technology could do for quality of life in Parkinson’s disease: A review of current needs and opportunities. IEEE J. Biomed. Health Inform. 2015, 19, 1862–1872. [Google Scholar] [CrossRef] [PubMed]
- Postuma, R.B.; Berg, D. Advances in markers of prodromal Parkinson disease. Nat. Rev. Neurol. 2016, 12, 622. [Google Scholar] [CrossRef]
- Habets, J.G.; Herff, C.; Kubben, P.L.; Kuijf, M.L.; Temel, Y.; Evers, L.J.; Bloem, B.R.; Starr, P.A.; Gilron, R.E.; Little, S. Rapid dynamic naturalistic monitoring of bradykinesia in Parkinson’s disease using a wrist-worn accelerometer. Sensors 2021, 21, 7876. [Google Scholar] [CrossRef] [PubMed]
- Patel, S.; Lorincz, K.; Hughes, R.; Huggins, N.; Growdon, J.; Standaert, D.; Akay, M.; Dy, J.; Welsh, M.; Bonato, P. Monitoring motor fluctuations in patients with Parkinson’s disease using wearable sensors. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 864–873. [Google Scholar] [CrossRef] [Green Version]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future di-rections. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Alemdar, H.; Ersoy, C. Wireless sensor networks for healthcare: A survey. Comput. Netw. 2010, 54, 2688–2710. [Google Scholar] [CrossRef]
- Mazilu, S.; Blanke, U.; Calatroni, A.; Gazit, E.; Hausdorff, J.M.; Tröster, G. The role of wrist-mounted inertial sensors in detecting gait freeze episodes in Parkinson’s disease. Pervasive Mob. Comput. 2016, 33, 1–16. [Google Scholar] [CrossRef]
- Mazilu, S.; Blanke, U.; Tröster, G. Gait, wrist, and sensors: Detecting freezing of gait in Parkinson’s disease from wrist movement. In Proceedings of the 2015 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), St. Louis, MI, USA, 23–27 March 2015; pp. 579–584. [Google Scholar]
- Roy, S.H.; Cole, B.T.; Gilmore, L.D.; De Luca, C.J.; Thomas, C.A.; Saint-Hilaire, M.M.; Nawab, S.H. High-resolution tracking of motor disorders in Parkinson’s disease during unconstrained activity. Mov. Disord. 2013, 28, 1080–1087. [Google Scholar] [CrossRef]
- Iosa, M.; Picerno, P.; Paolucci, S.; Morone, G. Wearable inertial sensors for human movement analysis. Expert Rev. Med. Devices 2016, 13, 641–659. [Google Scholar] [CrossRef]
- Williamson, J.R.; Telfer, B.; Mullany, R.; Friedl, K.E. Detecting Parkinson’s disease from wrist-worn accelerometry in the UK Biobank. Sensors 2021, 21, 2047. [Google Scholar] [CrossRef]
- Pradhan, S.; Kelly, V.E. Quantifying physical activity in early Parkinson disease using a commercial activity monitor. Park. Relat. Disord. 2019, 66, 171–175. [Google Scholar] [CrossRef] [PubMed]
- Mirelman, A.; Ben Or Frank, M.; Melamed, M.; Granovsky, L.; Nieuwboer, A.; Rochester, L.; Del Din, S.; Avanzino, L.; Pelosin, E.; Bloem, B.R.; et al. Detecting Sensitive Mobility Features for Parkinson’s Disease Stages Via Machine Learning. Mov. Disord. 2021, 36, 2144–2155. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.D.; Allen, N.E.; Canning, C.G.; Fung, V.S. Postural instability in patients with Parkinson’s disease. CNS Drugs 2012, 27, 97–112. [Google Scholar] [CrossRef] [PubMed]
- Jankovic, J. Parkinson’s disease: Clinical features and diagnosis. J. Neurol. Neurosurg. Psychiatry 2008, 79, 368–376. [Google Scholar] [CrossRef] [Green Version]
- Mahadevan, N.; Demanuele, C.; Zhang, H.; Volfson, D.; Ho, B.; Erb, M.K.; Patel, S. Development of digital biomarkers for resting tremor and bradykinesia using a wrist-worn wearable device. NPJ Digit. Med. 2020, 3, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhan, A.; Mohan, S.; Tarolli, C.; Schneider, R.B.; Adams, J.L.; Sharma, S.; Elson, M.J.; Spear, K.L.; Glidden, A.M.; Little, M.A.; et al. Using smartphones and machine learning to quantify Parkinson disease severity: The mobile Parkinson disease score. JAMA Neurol. 2018, 75, 876–880. [Google Scholar] [CrossRef] [PubMed]
- Balaji, E.; Brindha, D.; Balakrishnan, R. Supervised machine learning based gait classification system for early detection and stage classification of Parkinson’s disease. Appl. Soft Comput. 2020, 94, 106494. [Google Scholar]
- Doherty, A.; Jackson, D.; Hammerla, N.; Plötz, T.; Olivier, P.; Granat, M.H.; White, T.; Van Hees, V.T.; Trenell, M.I.; Owen, C.G.; et al. Large scale population assessment of physical activity using wrist worn accelerometers: The UK biobank study. PLoS ONE 2017, 12, e0169649. [Google Scholar] [CrossRef] [Green Version]
- Rastegari, E.; Ali, H. A Correlation Network Model Utilizing Gait Parameters for Evaluating Health Levels. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Boston, MA, USA, 20–23 August 2017; ACM: New York, NY, USA, 2017; pp. 568–574. Available online: http://dl.acm.org/citation.cfm?id=3107487 (accessed on 20 August 2017).
- Aich, S.; Youn, J.; Chakraborty, S.; Pradhan, P.M.; Park, J.H.; Park, S.; Park, J. A supervised machine learning approach to detect the on/off state in Parkinson’s disease using wearable based gait signals. Diagnostics 2020, 10, 421. [Google Scholar] [CrossRef] [PubMed]
- Kheirkhahan, M.; Mehta, S.; Nath, M.; Wanigatunga, A.A.; Corbett, D.B.; Manini, T.M.; Ranka, S. A bag-of-words approach for assessing activities of daily living using wrist accelerometer data. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 678–685. [Google Scholar]
- Rastegari, E.; Ali, H. A bag-of-words feature engineering approach for assessing health conditions using accelerometer data. Smart Health 2020, 16, 100116. [Google Scholar] [CrossRef]
- Habib, M.A.; Mohktar, M.S.; Kamaruzzaman, S.B.; Lim, K.S.; Pin, T.M.; Ibrahim, F. Smartphone-based solutions for fall detection and prevention: Challenges and open issues. Sensors 2014, 14, 7181–7208. [Google Scholar] [CrossRef] [PubMed]
- Powers, R.; Etezadi-Amoli, M.; Arnold, E.M.; Kianian, S.; Mance, I.; Gibiansky, M.; Trietsch, D.; Alvarado, A.S.; Kretlow, J.D.; Her-rington, T.M.; et al. Smartwatch inertial sensors continuously monitor real-world motor fluctuations in Parkinson’s disease. Sci. Transl. Med. 2021, 13, eabd7865. [Google Scholar] [CrossRef] [PubMed]
- Ossig, C.; Gandor, F.; Fauser, M.; Bosredon, C.; Churilov, L.; Reichmann, H.; Horne, M.K.; Ebersbach, G.; Storch, A. Correlation of quantitative motor state assessment using a kinetograph and patient diaries in advanced PD: Data from an observational study. PLoS ONE 2016, 11, e0161559. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lipsmeier, F.; Taylor, K.I.; Kilchenmann, T.; Wolf, D.; Scotland, A.; Schjodt-Eriksen, J.; Cheng, W.Y.; Fernandez-Garcia, I.; Siebourg-Polster, J.; Jin, L.; et al. Evaluation of smartphone-based testing to generate exploratory outcome measures in a phase 1 Parkinson’s disease clinical trial. Mov. Disord. 2018, 33, 1287–1297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rodríguez-Molinero, A.; Samà, A.; Pérez-López, C.; Rodríguez-Martín, D.; Alcaine, S.; Mestre, B.; Quispe, P.; Giuliani, B.; Vainstein, G.; Browne, P.; et al. Analysis of correlation between an accelerometer-based algorithm for detecting parkinsonian gait and UPDRS subscales. Front. Neurol. 2017, 8, 431. [Google Scholar] [CrossRef] [Green Version]
- Czech, M.; Demanuele, C.; Erb, M.K.; Ramos, V.; Zhang, H.; Ho, B.; Patel, S. The impact of reducing the number of wearable devices on measuring gait in parkinson disease: Noninterventional exploratory study. JMIR Rehabilitation Assist. Technol. 2020, 7, e17986. [Google Scholar] [CrossRef]
- Silva de Lima, A.L.; Evers, L.J.; Hahn, T.; Bataille, L.; Hamilton, J.L.; Little, M.A.; Okuma, Y.; Bloem, B.R.; Faber, M.J. Freezing of gait and fall detection in Parkinson’s disease using wearable sensors: A systematic review. J. Neurol. 2017, 264, 1642–1654. [Google Scholar] [CrossRef] [Green Version]
- Raiano, L.; di Pino, G.; di Biase, L.; Tombini, M.; Tagliamonte, N.L.; Formica, D. PDMeter: A wrist wearable device for an at-home assessment of the Parkinson’s disease ri-gidity. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1325–1333. [Google Scholar] [CrossRef] [PubMed]
- Gokul, H.; Suresh, P.; Vignesh, B.H.; Kumaar, R.P.; Vijayaraghavan, V. Gait recovery system for parkinson’s disease using machine learning on embedded platforms. In Proceedings of the 2020 IEEE International Systems Conference (SysCon), Montreal, QC, Canada, 24 August–20 September 2020; pp. 1–8. [Google Scholar]
- Goud, K.Y.; Moonla, C.; Mishra, R.K.; Yu, C.; Narayan, R.; Litvan, I.; Wang, J. Wearable electrochemical microneedle sensor for continuous monitoring of levodopa: Toward Parkinson management. ACS Sensors 2019, 4, 2196–2204. [Google Scholar] [CrossRef]
- Nóbrega, L.R.; Cabral, A.M.; Oliveira, F.H.; de Oliveira Andrade, A.; Krishnan, S.; Pereira, A.A. Wrist Movement Variability Assessment in Individuals with Parkinson’s Disease. Healthcare 2022, 10, 1656. [Google Scholar] [CrossRef] [PubMed]
- Juutinen, M.; Wang, C.; Zhu, J.; Haladjian, J.; Ruokolainen, J.; Puustinen, J.; Vehkaoja, A. Parkinson’s disease detection from 20-step walking tests using inertial sensors of a smartphone: Machine learning approach based on an observational case-control study. PLoS ONE 2020, 15, e0236258. [Google Scholar] [CrossRef] [PubMed]
- Rastegari, E.; Azizian, S.; Ali, H. Machine Learning and Similarity Network Approaches to Support Automatic Classification of Parkinson’s Diseases Using Accelerometer-Based Gait Analysis. 2019. Available online: http://scholarspace.manoa.hawaii.edu/handle/10125/59861 (accessed on 17 March 2019).
- Kheirkhahan, M.; Chakraborty, A.; Wanigatunga, A.A.; Corbett, D.B.; Manini, T.M.; Ranka, S. Wrist accelerometer shape feature derivation methods for assessing activities of daily living. BMC Med. Inform. Decis. Mak. 2018, 18, 124. [Google Scholar] [CrossRef]
- Del Din, S.; Godfrey, A.; Mazzà, C.; Lord, S.; Rochester, L. Free-living monitoring of Parkinson’s disease: Lessons from the field. Mov. Disord. 2016, 31, 1293–1313. [Google Scholar] [CrossRef]
- Warmerdam, E.; Hausdorff, J.M.; Atrsaei, A.; Zhou, Y.; Mirelman, A.; Aminian, K.; Espay, A.J.; Hansen, C.; Evers, L.J.; Keller, A.; et al. Long-term unsupervised mobility assessment in movement disorders. Lancet Neurol. 2020, 19, 462–470. [Google Scholar] [CrossRef] [PubMed]
- Pasluosta, C.F.; Gassner, H.; Winkler, J.; Klucken, J.; Eskofier, B.M. An Emerging Era in the Management of Parkinson’s Disease: Wearable Technologies and the Internet of Things. IEEE J. Biomed. Health Inform. 2015, 19, 1873–1881. [Google Scholar] [CrossRef]
- San-Segundo, R.; Zhang, A.; Cebulla, A.; Panev, S.; Tabor, G.; Stebbins, K.; Massa, R.E.; Whitford, A.; De la Torre, F.; Hodgins, J. Parkinson’s disease tremor detection in the wild using wearable accelerometers. Sensors 2020, 20, 5817. [Google Scholar] [CrossRef] [PubMed]
- Evers, L.J.; Raykov, Y.P.; Krijthe, J.H.; De Lima, A.L.; Badawy, R.; Claes, K.; Heskes, T.M.; Little, M.A.; Meinders, M.J.; Bloem, B.R. Real-life gait performance as a digital bi-omarker for motor fluctuations: The Parkinson@ Home validation study. J. Med. Internet Res. 2020, 22, e19068. [Google Scholar] [CrossRef]
- Kleanthous, N.; Hussain, A.J.; Khan, W.; Liatsis, P. A new machine learning based approach to predict Freezing of Gait. Pattern Recognit. Lett. 2020, 140, 119–126. [Google Scholar] [CrossRef]
- Shawen, N.; O’Brien, M.K.; Venkatesan, S.; Lonini, L.; Simuni, T.; Hamilton, J.L.; Ghaffari, R.; Rogers, J.A.; Jayaraman, A. Role of data measurement characteristics in the accurate detection of Parkinson’s disease symptoms using wearable sensors. J. Neuroeng. Rehabil. 2020, 17, 52. [Google Scholar] [CrossRef] [Green Version]
- Hssayeni, M.D.; Jimenez-Shahed, J.; Burack, M.A.; Ghoraani, B. Ensemble deep model for continuous estimation of Unified Parkinson’s Disease Rating Scale III. Biomed. Eng. Online 2021, 20, 32. [Google Scholar] [CrossRef]
- Kuijf, M.L.; Kubben, P.L.; Herff, C. Evaluation of Parkinson’s Disease at Home: Predicting Tremor from Wearable Sensors. In Prediction and Real-Life Monitoring of DBS Motor Response in Parkinson’s Disease; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar]
- Rastegari, E.; Orn, D.; Ali, H. Smart Computational Approaches with Advanced Feature Selection Algorithms for Optimiz-ing the Classification of Mobility Data in Health Informatics. In Proceedings of the 11th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Virtual, 21–24 September 2020; pp. 1–9. [Google Scholar]
- Pla, A.; Mordvanyuk, N.; López, B.; Raaben, M.; Blokhuis, T.J.; Holstlag, H.R. Bag-of-steps: Predicting lower-limb fracture rehabilitation length by weight loading analysis. Neurocomputing 2017, 268, 109–115. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Healthy Elderlies | PD | |
|---|---|---|
| Subjects | 32 | 28 |
| Gender (M/F) | 10/22 | 20/5 |
| Age | 64.2 ± 7 | 71 ± 6.2 |
| H&Y | - | 1.73 ± 0.83 |
| Window Size | Features | SVM | NB | DT | RF | KNN | AB |
|---|---|---|---|---|---|---|---|
| 3 s | 10 | 67.5 ± 18 | 68.4 ± 15 | 61.3 ± 18 | 67.1 ± 16 | 70.2 ± 18 | 62.2 ± 16 |
| 10 s | 10 | 68.1 ± 16 | 67.1 ± 14 | 62.3 ± 15 | 68.2 ± 17 | 71.6 ± 18 | 63.4 ± 15 |
| 60 s | 10 | 68.4 ± 17 | 69.4 ± 16 | 62.2 ± 19 | 69.2 ± 17 | 71 ± 18 | 62.3 ± 15 |
| 300 s | 10 | 68.8 ± 16 | 68.8 ± 18 | 63.5 ± 18 | 68.1 ± 16 | 74.5 ± 17 | 66.2 ± 19 |
| 900 s | 10 | 69.2 ± 16 | 61.9 ± 14 | 63.6 ± 16 | 69.4 ± 15 | 73.7 ± 16 | 60.8 ± 21 |
| All | 50 | 74.9 ± 18 | 74.2 ± 13 | 66.5 ± 16 | 74.8 ± 15 | 77.4 ± 14 | 61.8 ± 17 |
| All | 10 | 80.2 ± 14 | 81.1 ± 16 | 71.5 ± 17 | 79.2 ± 14 | 82.3 ± 14 | 71.1 ± 16 |
| Window Size | Features | SVM | NB | DT | RF | KNN | AB |
|---|---|---|---|---|---|---|---|
| 3 s | 22 | 76.2 ± 17 | 75.2 ± 15 | 61.1 ± 19 | 76.6 ± 13 | 74.4 ± 15 | 69.8 ± 17 |
| 10 s | 22 | 76.0 ± 17 | 74.1 ± 16 | 64.2 ± 17 | 75.3 ± 15 | 72.5 ± 15 | 70.5 ± 18 |
| 60 s | 20 | 78.1 ± 16 | 77.2 ± 16 | 63.5 ± 16 | 77.7 ± 14 | 76.5 ± 18 | 69.0 ± 19 |
| 300 s | 20 | 76.1 ± 16 | 75.3 ± 18 | 73.1 ± 19 | 76.2 ± 14 | 75.0 ± 17 | 70.1 ± 17 |
| 900 s | 16 | 79.2 ± 15 | 79.1 ± 16 | 63.2 ± 17 | 78.0 ± 15 | 76.0 ± 16 | 74.3 ± 17 |
| All | 100 | 77.8 ± 17 | 75.6 ± 18 | 69.3 ± 16 | 78.2 ± 15 | 73.0 ± 17 | 72.0 ± 18 |
| All-Reduced | 20 | 88.5 ± 10 | 84.4 ± 14 | 74.8 ± 13 | 82.1 ± 14 | 84.7 ± 14 | 81.2 ± 15 |
| Col-Mean Row Mean | Day1 | Day2 | Day3 | Day4 | Day5 | Day6 |
|---|---|---|---|---|---|---|
| Day2 | −2.74 0.064 | - | - | - | - | - |
| Day3 | −3.96 0.0008 * | −1.22 1.000 | - | - | - | - |
| Day4 | −4.42 0.0001 * | −1.84 0.68 | −0.69 1.000 | - | - | - |
| Day5 | −5.07 0.000 * | −2.70 0.07 | −1.64 1.000 | −0.96 1.000 | - | - |
| Day6 | −4.20 0.0003 * | −2.13 0.34 | −1.20 1.000 | −0.63 1.000 | 0.20 1.000 | - |
| Day7 | −4.32 0.0002 * | −2.25 0.25 | −1.33 1.000 | −0.75 1.000 | 0.095 1.000 | −0.10 1.000 |
| Study | Free Living Condition | Sensor Location | Task | Features | Investigating Different Windowing Strategies | Investigating the Impact of Amount of Data on Models’ Performance | Perfomrance Measure | Performance Measure Value |
|---|---|---|---|---|---|---|---|---|
| This study | Yes- passive monitoring | Wrist | PD diagnosis | Document-of-Words (20 features from all and each window size) | Yes | Yes (collected 7 days of data) | Accuracy and AUC | 0.88 and 0.86, respectively |
| [11] | Yes- passive monitoring | Wrist | PD diagnosis | {Dispersion, Correlation Structure Features} | No | Yes (collecrted 7 days of data) | AUC | 0.85 |
| [27] | Yes- passive and active monitoring | Smartphone | PD diagnosis | {Turning speed, sit-to-stand transitions per hour, activity ratio} | No | No (collected data over 6 months for PD and 45 days for Healty individuals | Specificity and sensitivity | 81% and 75%, respectively, reported only for turning speed feature |
| [3] | Yes-active monitoring | Wrist | Bradykinesia detection | Statistical features, {maximum acceleration, coefficent of determination, root mean square, spectral power} | Yes | No (collected data for one hour pre medication and one hour post medication) | AUC | 0.7 |
| [37] | No | Wrist | Identification of activities of daily living | Document-of-words features | No | No (collected data from 4 visits performing activities of daily living as instructed) | F1-score | 0.89 |
| [23] | No | Ankle | PD diagnosis | Document-of-words features | Yes | No (collected data from one session walking 10 meters for four times | Accuracy, precision and recall | 0.8, 0.7, and 0.9, respectively |
| [42] | Yes- passive monitoring | Wrist | PD diagnosis | {total power in 0.5–10 Hz, cadence, height of dominant peak, width of dominant peak} | No | No (collected data for one hour pre medication and one hour post medication) | AUC | 0.75 for the most affected wrist and 0.49 for the least affected one |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rastegari, E.; Ali, H.; Marmelat, V. Detection of Parkinson’s Disease Using Wrist Accelerometer Data and Passive Monitoring. Sensors 2022, 22, 9122. https://doi.org/10.3390/s22239122
Rastegari E, Ali H, Marmelat V. Detection of Parkinson’s Disease Using Wrist Accelerometer Data and Passive Monitoring. Sensors. 2022; 22(23):9122. https://doi.org/10.3390/s22239122
Chicago/Turabian StyleRastegari, Elham, Hesham Ali, and Vivien Marmelat. 2022. "Detection of Parkinson’s Disease Using Wrist Accelerometer Data and Passive Monitoring" Sensors 22, no. 23: 9122. https://doi.org/10.3390/s22239122