

Real-Time Video Synopsis via Dynamic and Adaptive Online Tube Resizing

Abstract
:1. Introduction
2. Related Works
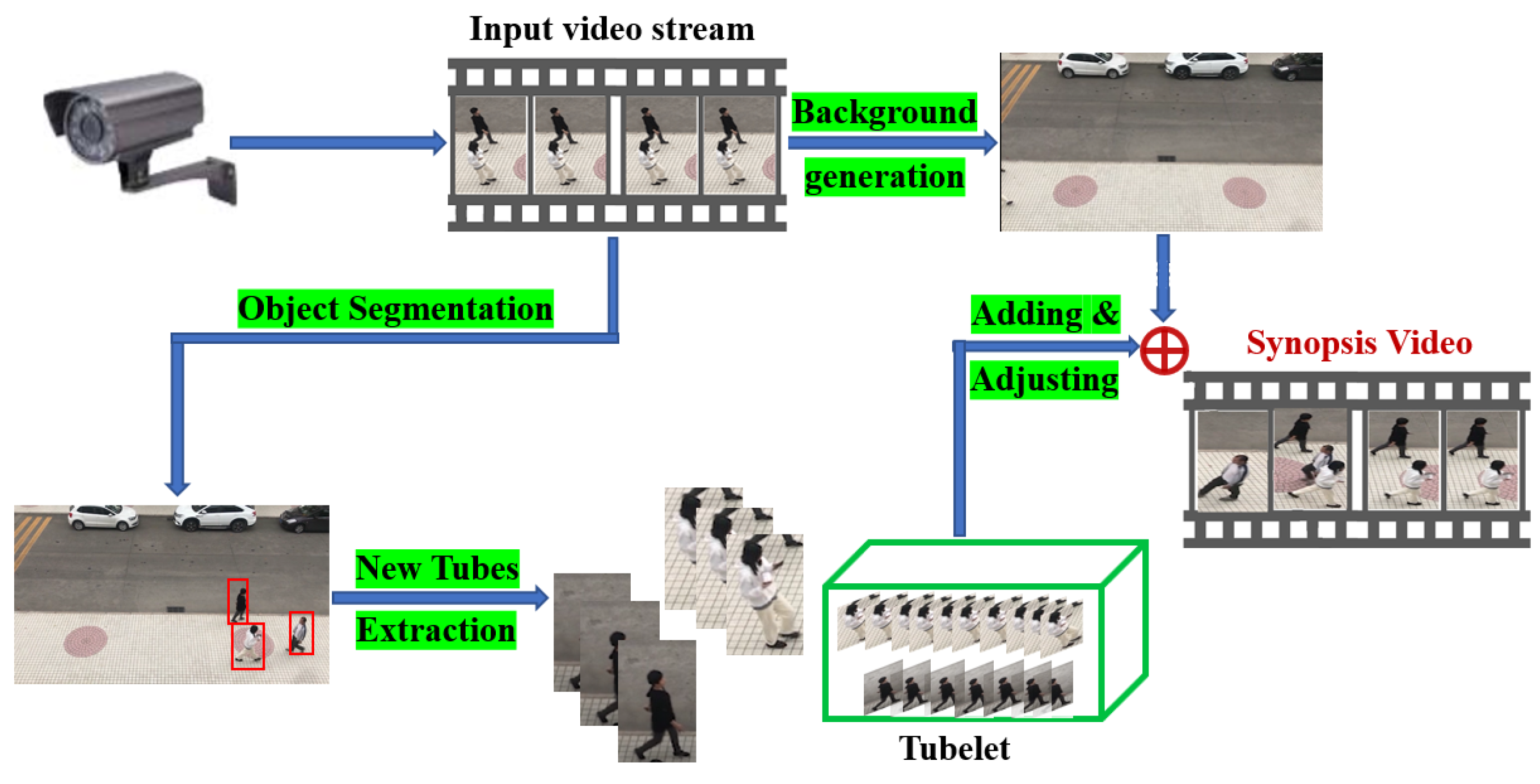
3. The Proposed Method
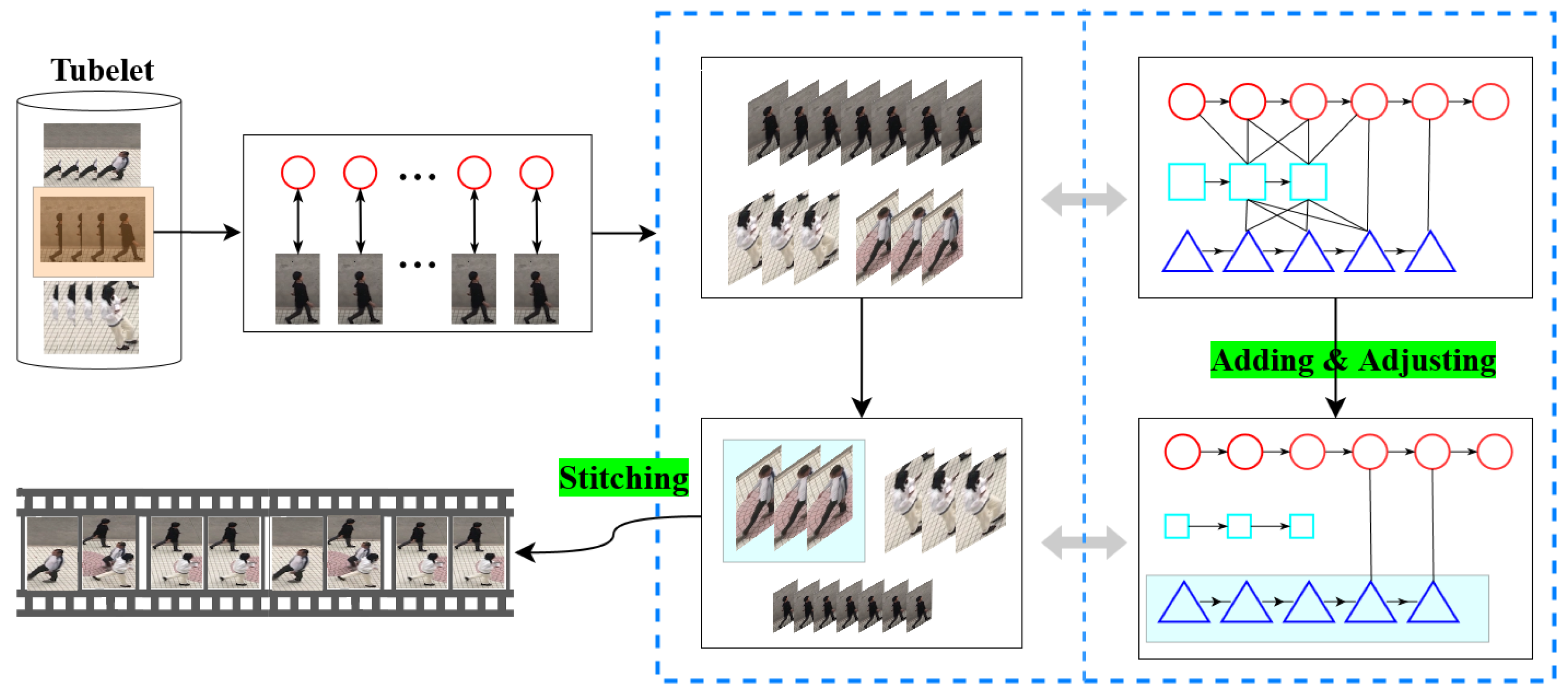
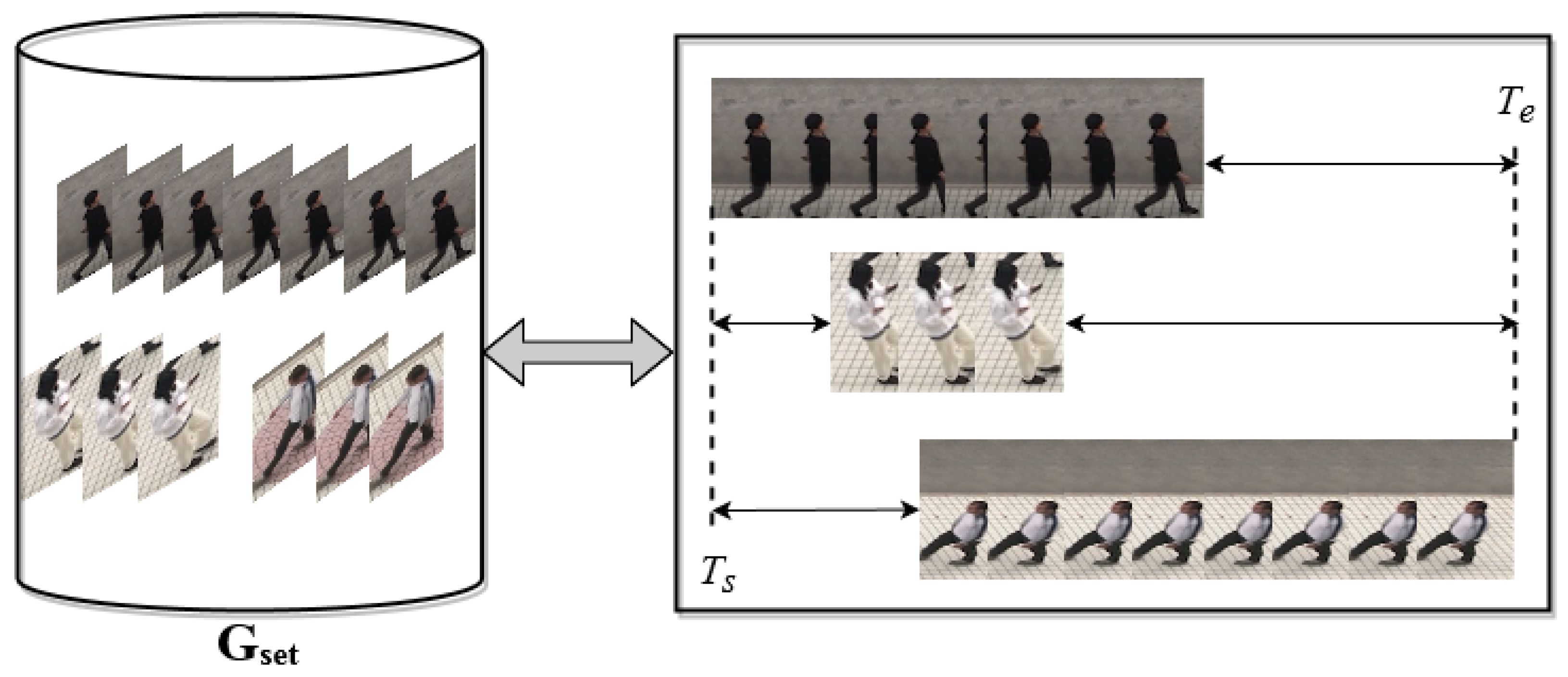
3.1. The Optimization Framework
| Algorithm 1: Procedure of optimization. |
 |
3.2. Implementation Details
| Algorithm 2: Pseudocode for the addition of new tubes. |
 |
3.3. Temporal Consistency Constraints
4. Experiments
4.1. Experimental Setup
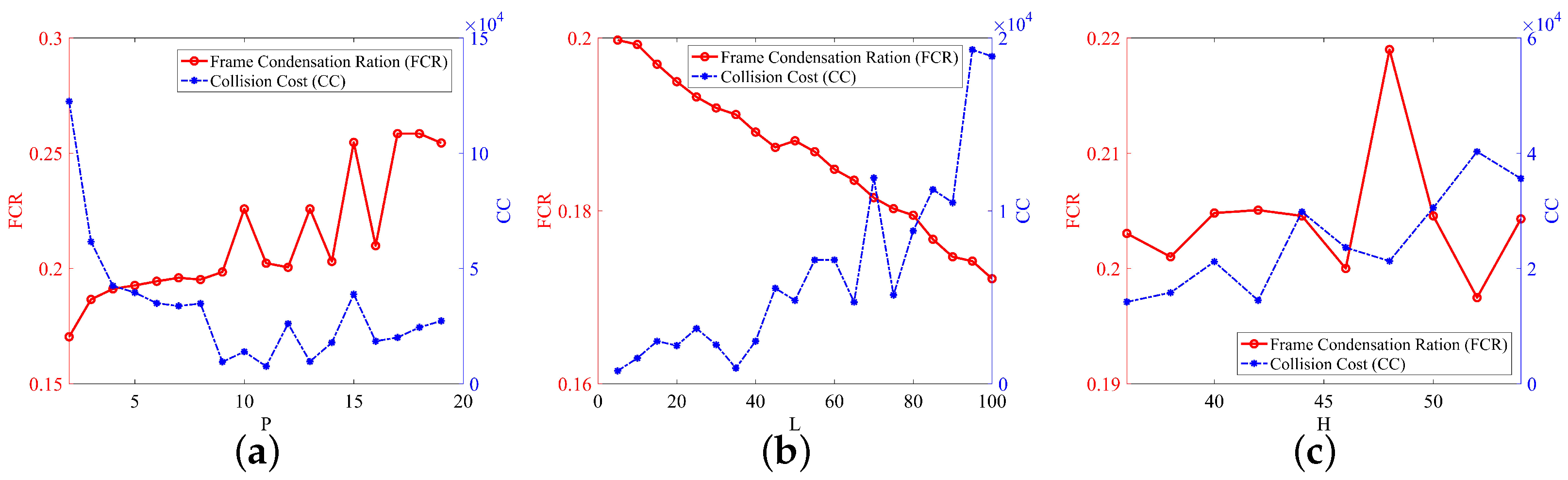
4.2. Parametric Analysis
4.3. State-of-the-Art Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Wray, M.; Doughty, H.; Damen, D. On Semantic Similarity in Video Retrieval. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3649–3659. [Google Scholar] [CrossRef]
- Zhang, C.; Gupta, A.; Zisserman, A. Temporal Query Networks for Fine-grained Video Understanding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4484–4494. [Google Scholar] [CrossRef]
- Li, Z.; Ishwar, P.; Konrad, J. Video condensation by ribbon carving. IEEE Trans. Image Process. 2009, 18, 2572–2583. [Google Scholar] [PubMed]
- Li, X.; Wang, Z.; Lu, X. Video synopsis in complex situations. IEEE Trans. Image Process. 2018, 27, 3798–3812. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Lei, Z.; Yi, D.; Li, S.Z. Online content-aware video condensation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2082–2087. [Google Scholar]
- Smith, M.; Kanade, T. Video skimming and characterization through the combination of image and language understanding. In Proceedings of the 1998 IEEE International Workshop on Content-Based Access of Image and Video Database, Bombay, India, 3 January 1998; pp. 61–70. [Google Scholar] [CrossRef]
- Truong, T.; Venkatesh, S. Video abstraction: A systematic review and classification. ACM Trans. Multimed. Comput. Commun. Appl. 2007, 3, 1–37. [Google Scholar] [CrossRef]
- Kang, H.W.; Chen, X.Q.; Matsushita, Y.; Tang, X. Space-Time Video Montage. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1331–1338. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, S.; Tickoo, O.; Iyer, R. Towards Distributed Video Summarization. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane Australia, 26–30 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 883–886. [Google Scholar] [CrossRef]
- Petrovic, N.; Jojic, N.; Huang, T.S. Adaptive video fast forward. Multimed. Tools Appl. 2005, 26, 327–344. [Google Scholar] [CrossRef]
- Liu, H.; Meng, W.; Liu, Z. Key frame extraction of online video based on optimized frame difference. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery, Chongqing, China, 29–31 May 2012; pp. 1238–1242. [Google Scholar]
- Rav-Acha, A.; Pritch, Y.; Peleg, S. Making a Long Video Short: Dynamic Video Synopsis. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 435–441. [Google Scholar]
- Pritch, Y.; Rav-Acha, A.; Gutman, A.; Peleg, S. Webcam Synopsis: Peeking Around the World. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Pritch, Y.; Rav-Acha, A.; Peleg, S. Nonchronological Video Synopsis and Indexing. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1971–1984. [Google Scholar] [CrossRef] [PubMed]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2010, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, H.; Li, X.; Yang, Y.; Cheng, G.; Zhang, J.; Tong, Y.; Zhang, L.; Tao, D. PolyphonicFormer: Unified Query Learning for Depth-Aware Video Panoptic Segmentation. In Proceedings of the Computer Vision—ECCV, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; 2022; pp. 582–599. [Google Scholar]
- Ventura, C.; Bellver, M.; Girbau, A.; Salvador, A.; Marques, F.; Giro-i Nieto, X. RVOS: End-To-End Recurrent Network for Video Object Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5272–5281. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Fan, B.; Gu, J.; Zhang, Q.; Xiang, S.; Prinet, V.; Pan, C. Progressive Sparse Local Attention for Video Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Long Beach, CA, USA, 15–20 June 2019; pp. 3908–3917. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- Moussa, M.; Shoitan, R. Object-based video synopsis approach using particle swarm optimization. Signal Image Video Process. 2021, 15, 761–768. [Google Scholar] [CrossRef]
- Ra, M.; Kim, W.Y. Parallelized tube rearrangement algorithm for online video synopsis. IEEE Signal Process. Lett. 2018, 25, 1186–1190. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Jung, S.W.; Won, C.S. Order-preserving condensation of moving objects in surveillance videos. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2408–2418. [Google Scholar] [CrossRef]
- Huang, C.R.; Chung, P.C.J.; Yang, D.K.; Chen, H.C.; Huang, G.J. Maximum a posteriori probability estimation for online surveillance video synopsis. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1417–1429. [Google Scholar] [CrossRef]
- Ruan, T.; Wei, S.; Li, J.; Zhao, Y. Rearranging online tubes for streaming video synopsis: A dynamic graph coloring approach. IEEE Trans. Image Process. 2019, 28, 3873–3884. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Li, S.Z.; Li, B.; Yuan, X.T.; Xiang, S.M. A set theoretical method for video synopsis. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–21 October 2008; pp. 366–370. [Google Scholar]
- Angadi, S.; Naik, V. Entropy based fuzzy C means clustering and key frame extraction for sports video summarization. In Proceedings of the 2014 Fifth International Conference on Signal and Image Processing, Bangalore, India, 8–10 January 2014; pp. 271–279. [Google Scholar]
- Mei, S.; Guan, G.; Wang, Z.; Wan, S.; He, M.; Feng, D.D. Video summarization via minimum sparse reconstruction. Pattern Recognit. 2015, 48, 522–533. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Lu, X. Surveillance Video Synopsis via Scaling Down Objects. IEEE Trans. Image Process. 2016, 25, 740–755. [Google Scholar] [CrossRef] [PubMed]
- Kolmogorov, V.; Zabin, R. What energy functions can be minimized via graph cuts? IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 147–159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Nie, Y.; Li, Z.; Zhang, Z.; Zhang, Q.; Ma, T.; Sun, H. Collision-free video synopsis incorporating object speed and size changes. IEEE Trans. Image Process. 2019, 29, 1465–1478. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Num | #Frame | #Object | Size |
|---|---|---|---|
| 4514 | 14 | 368 × 276 | |
| 3950 | 18 | 480 × 384 | |
| 9390 | 42 | 368 × 276 | |
| 970 | 11 | 720 × 480 | |
| 4660 | 27 | 268 × 276 |
| Methods | FCR(%) | TC | CC |
|---|---|---|---|
| Without resizing | 0.96 | 24,949 | |
| Ours | 1.30 | 9113 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, X.; Liu, S.; Cai, Z. Real-Time Video Synopsis via Dynamic and Adaptive Online Tube Resizing. Sensors 2022, 22, 9046. https://doi.org/10.3390/s22239046
Liao X, Liu S, Cai Z. Real-Time Video Synopsis via Dynamic and Adaptive Online Tube Resizing. Sensors. 2022; 22(23):9046. https://doi.org/10.3390/s22239046
Chicago/Turabian StyleLiao, Xiaoxin, Song Liu, and Zemin Cai. 2022. "Real-Time Video Synopsis via Dynamic and Adaptive Online Tube Resizing" Sensors 22, no. 23: 9046. https://doi.org/10.3390/s22239046