


Multi-Perspective Hierarchical Deep-Fusion Learning Framework for Lung Nodule Classification


Abstract
:1. Introduction
2. Related Works
3. Method
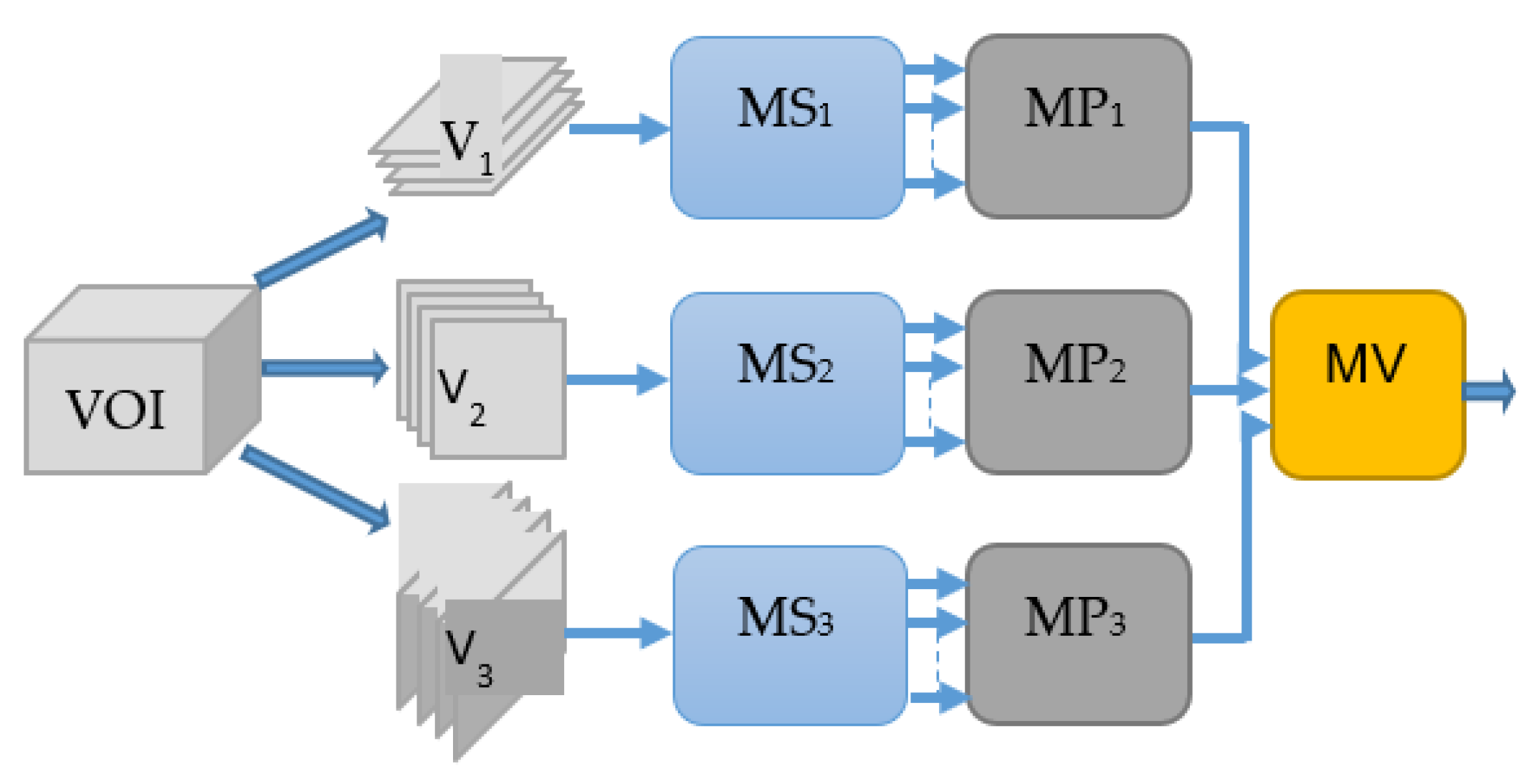
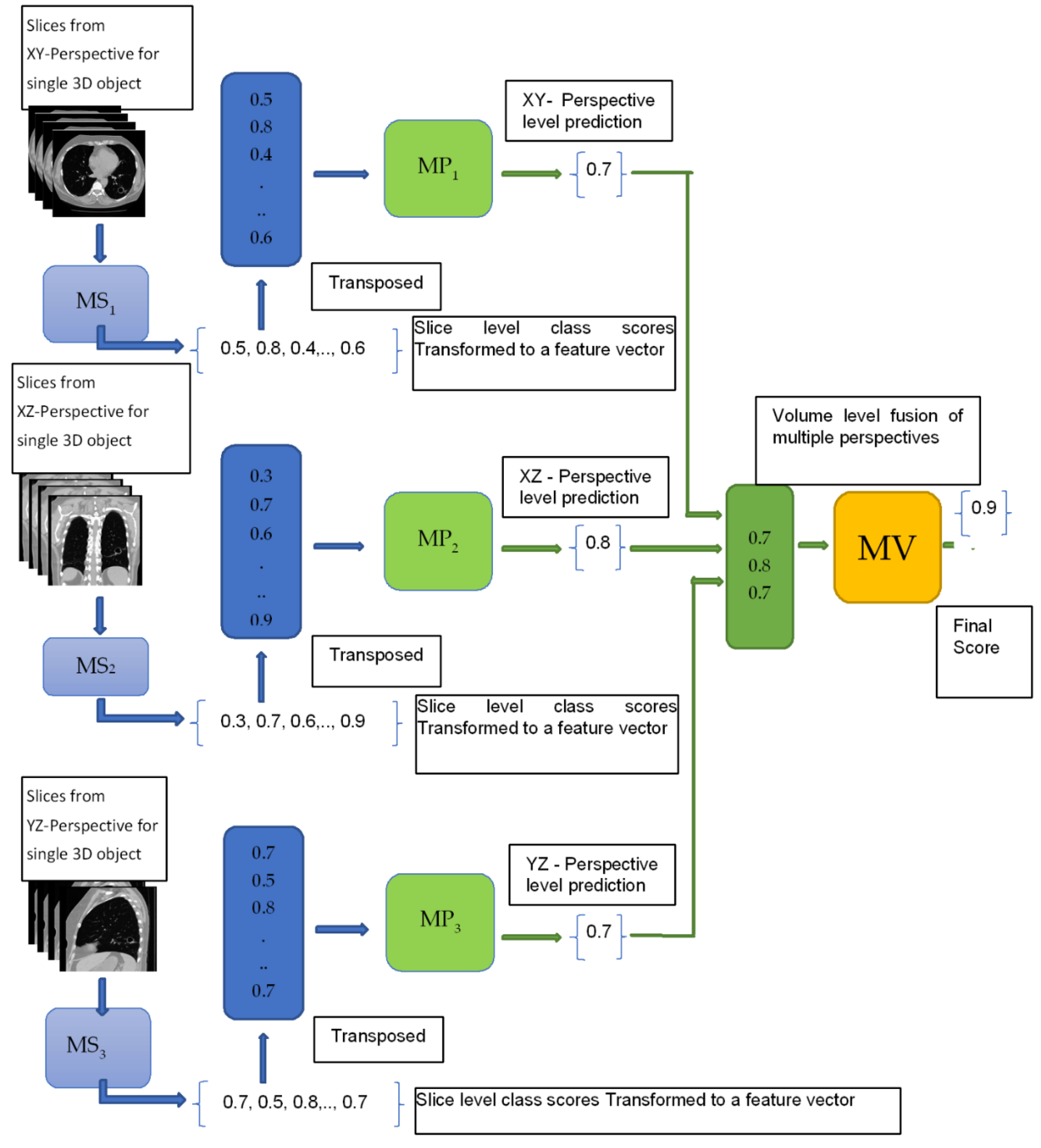
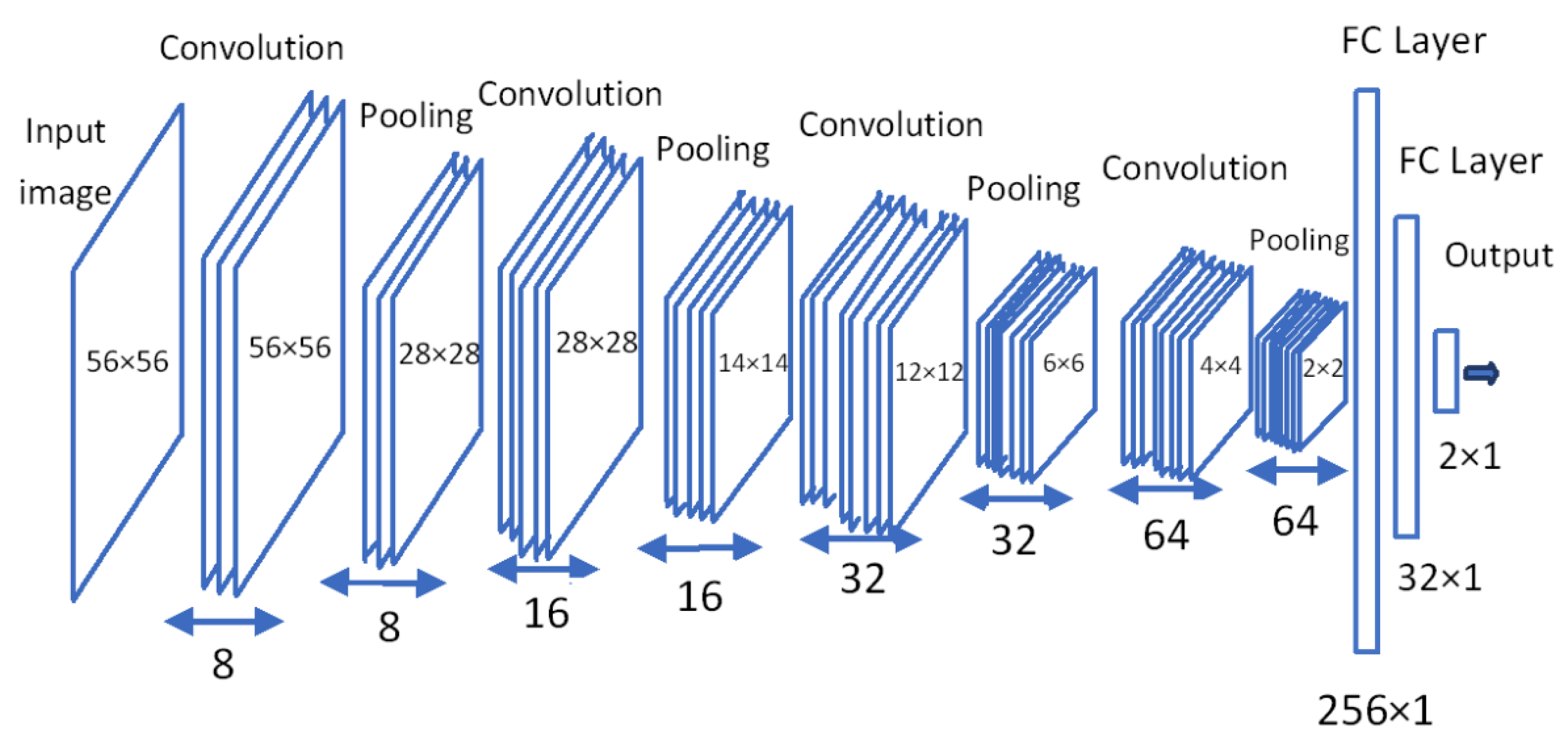
3.1. Multi-Perspective Hierarchical Deep-Fusion Learning Model (MPF)
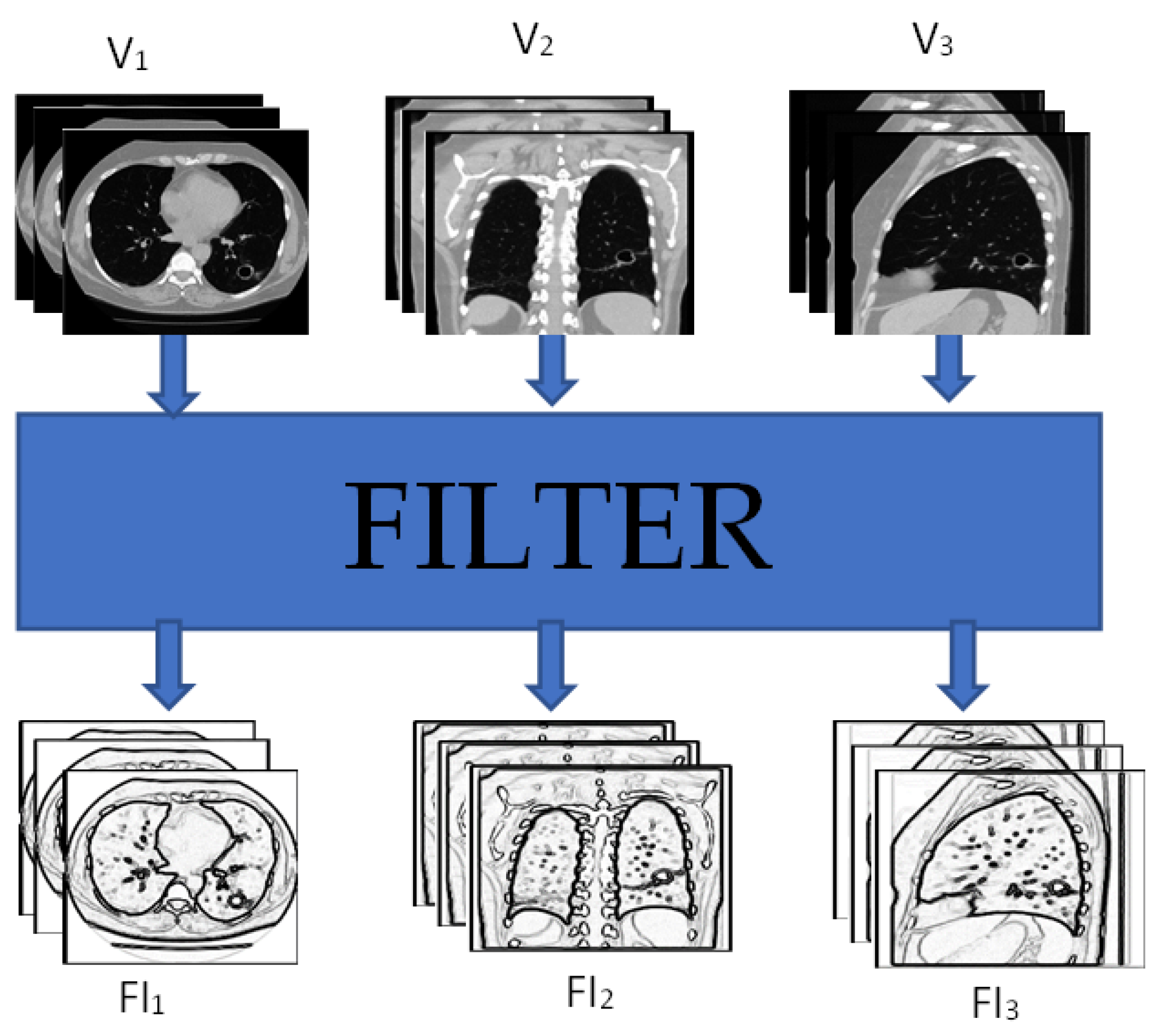
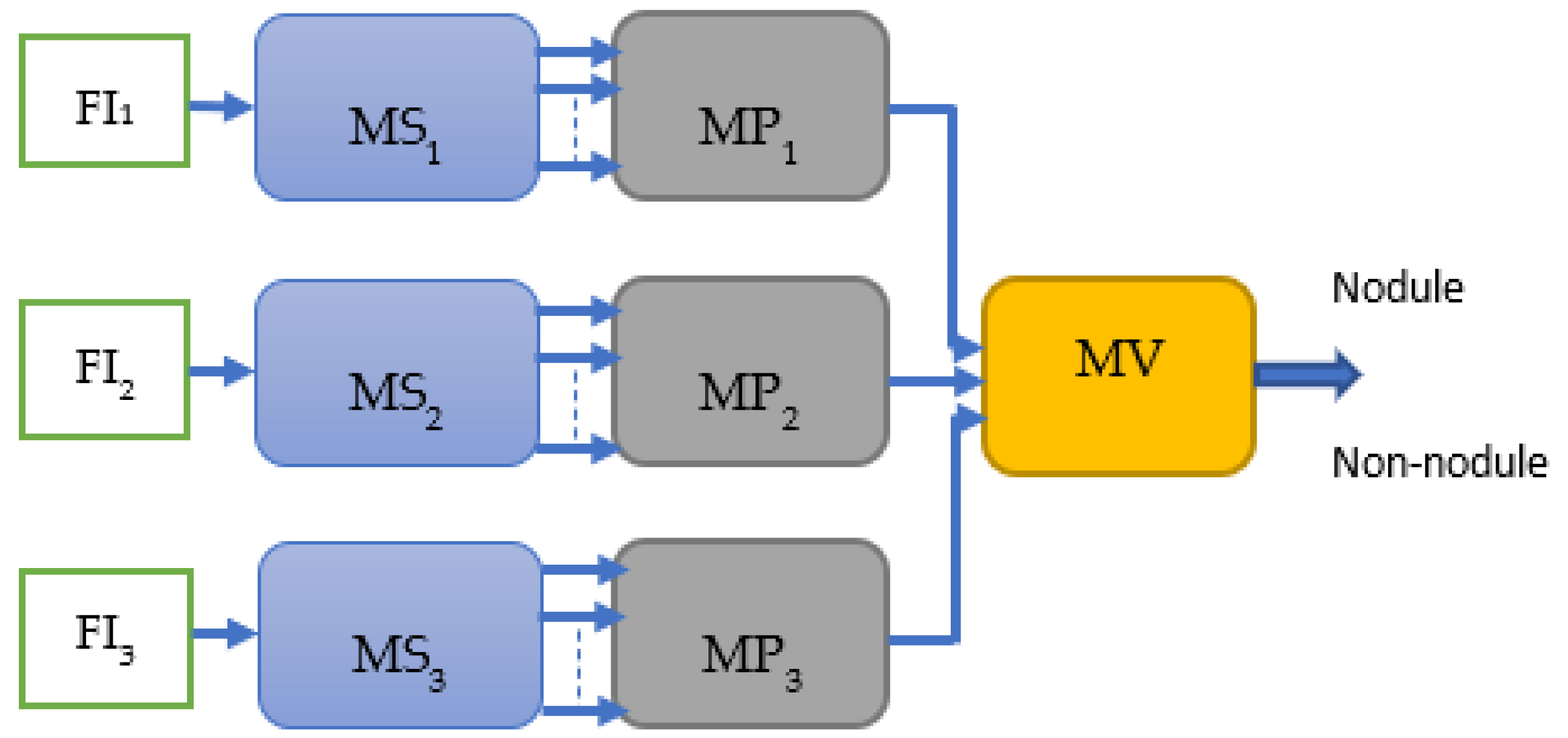
3.2. Single Feature & Multi-Perspective Hierarchical Deep-Fusion (SFMPF)
Creating Feature Images
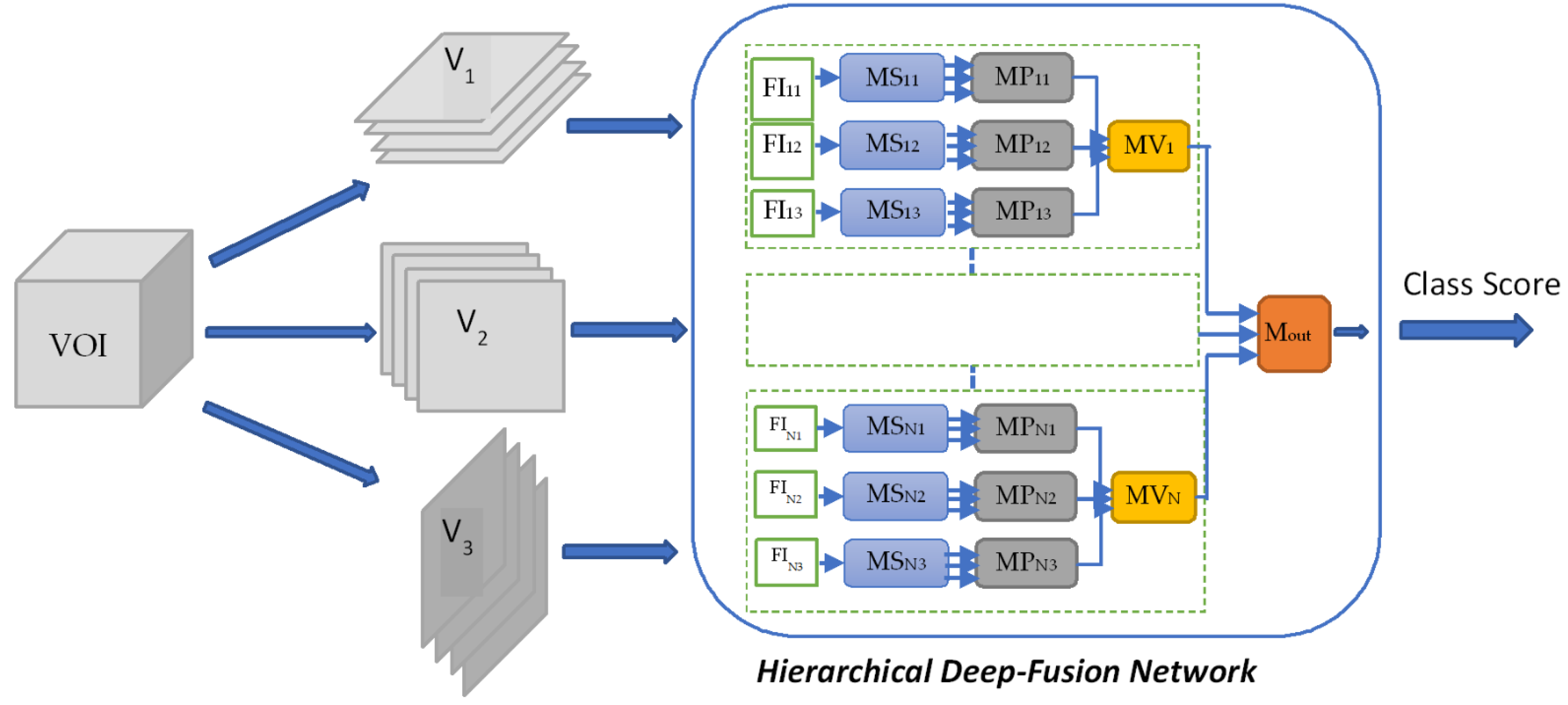
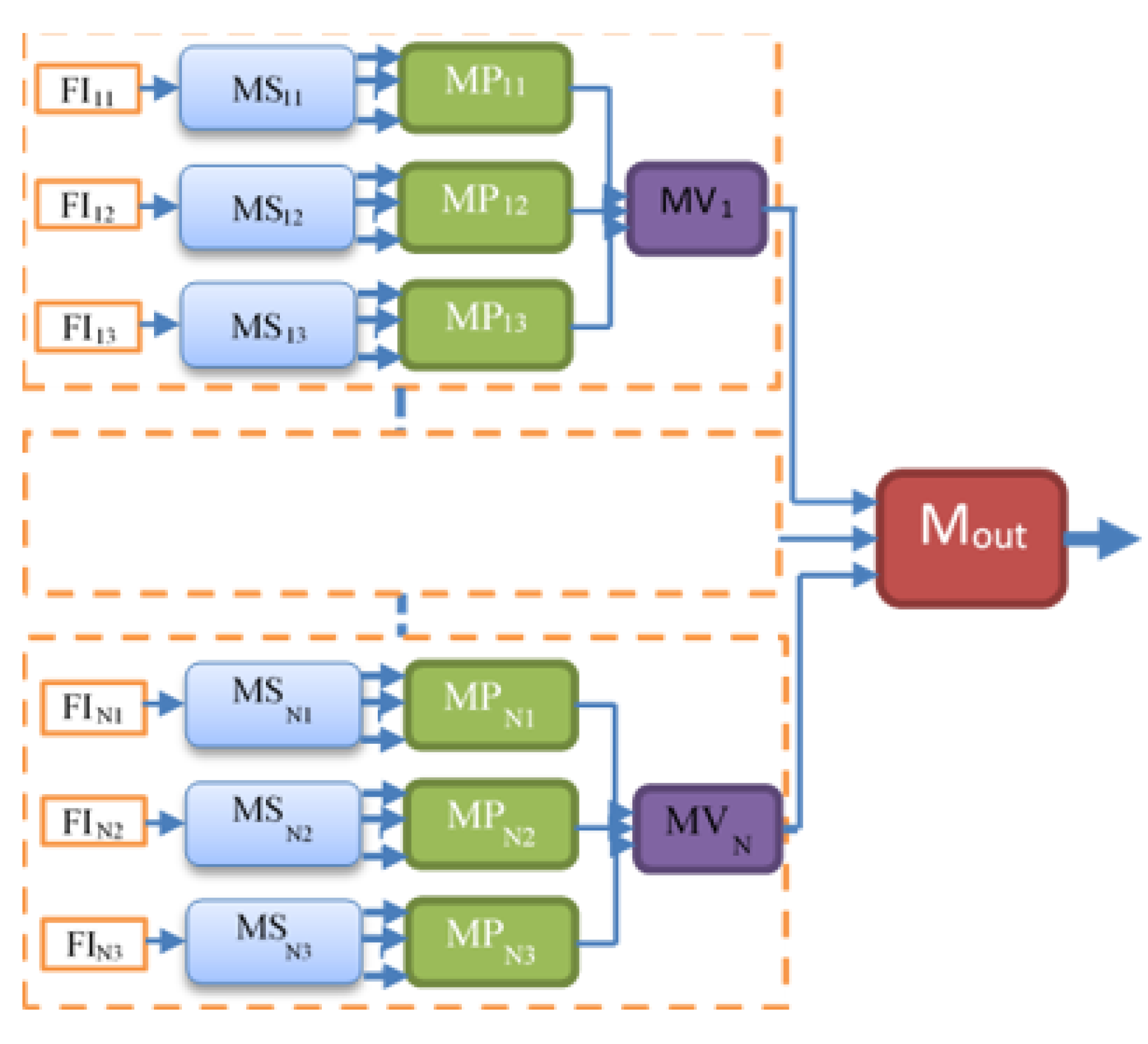
3.3. Multi-Feature & Multi-Perspective Hierarchical Deep-Fusion (MFMPF)
4. Experiments and Results
4.1. Data Preparation
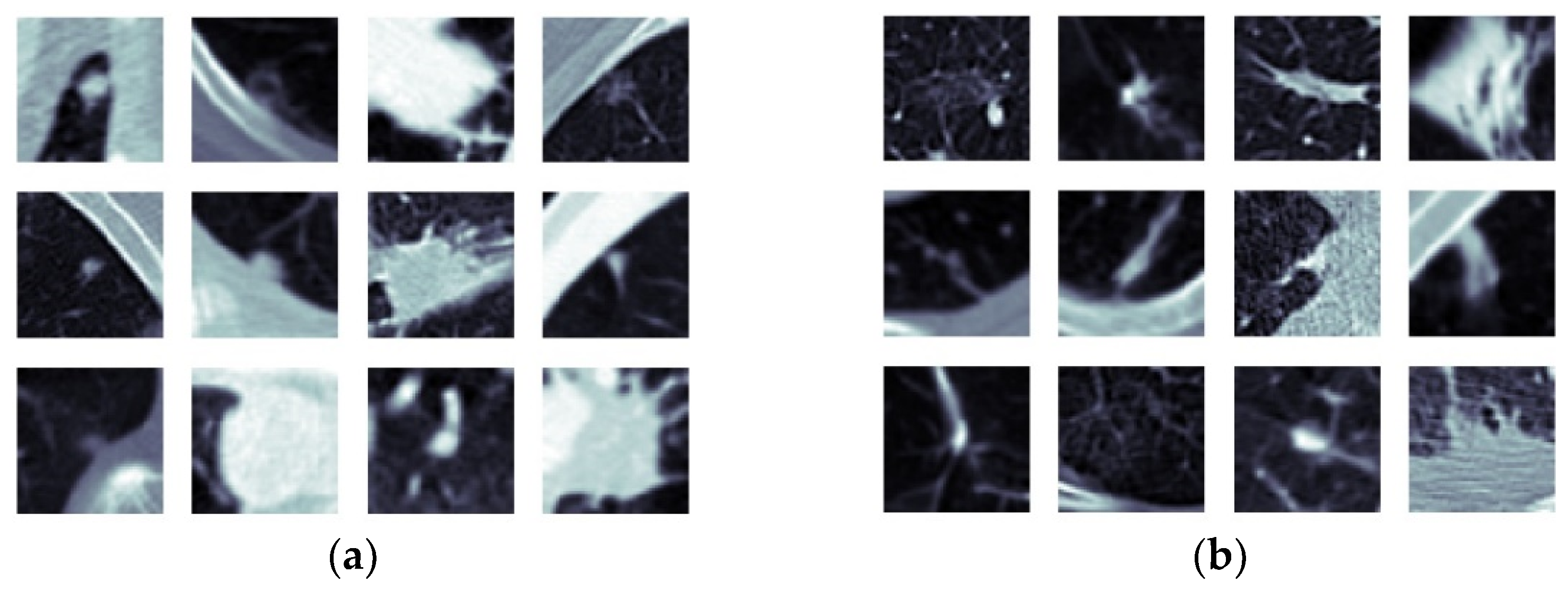
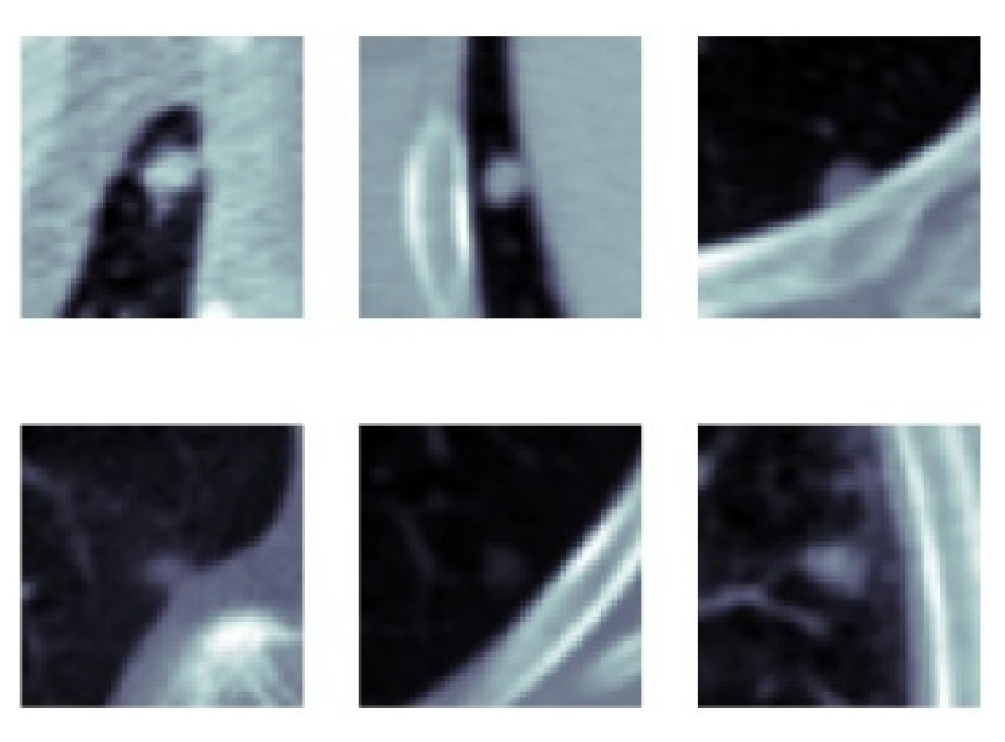
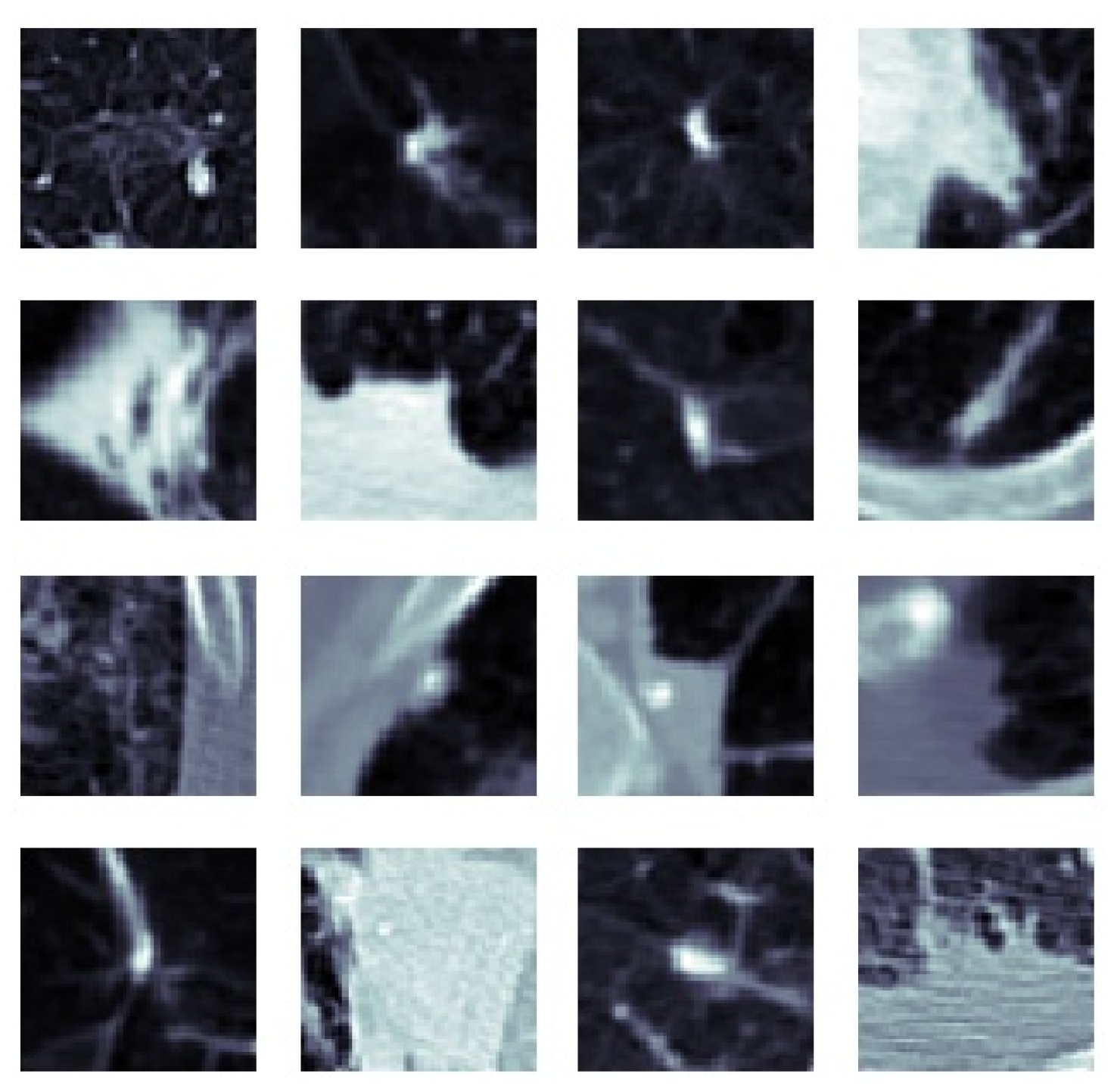
4.1.1. Data
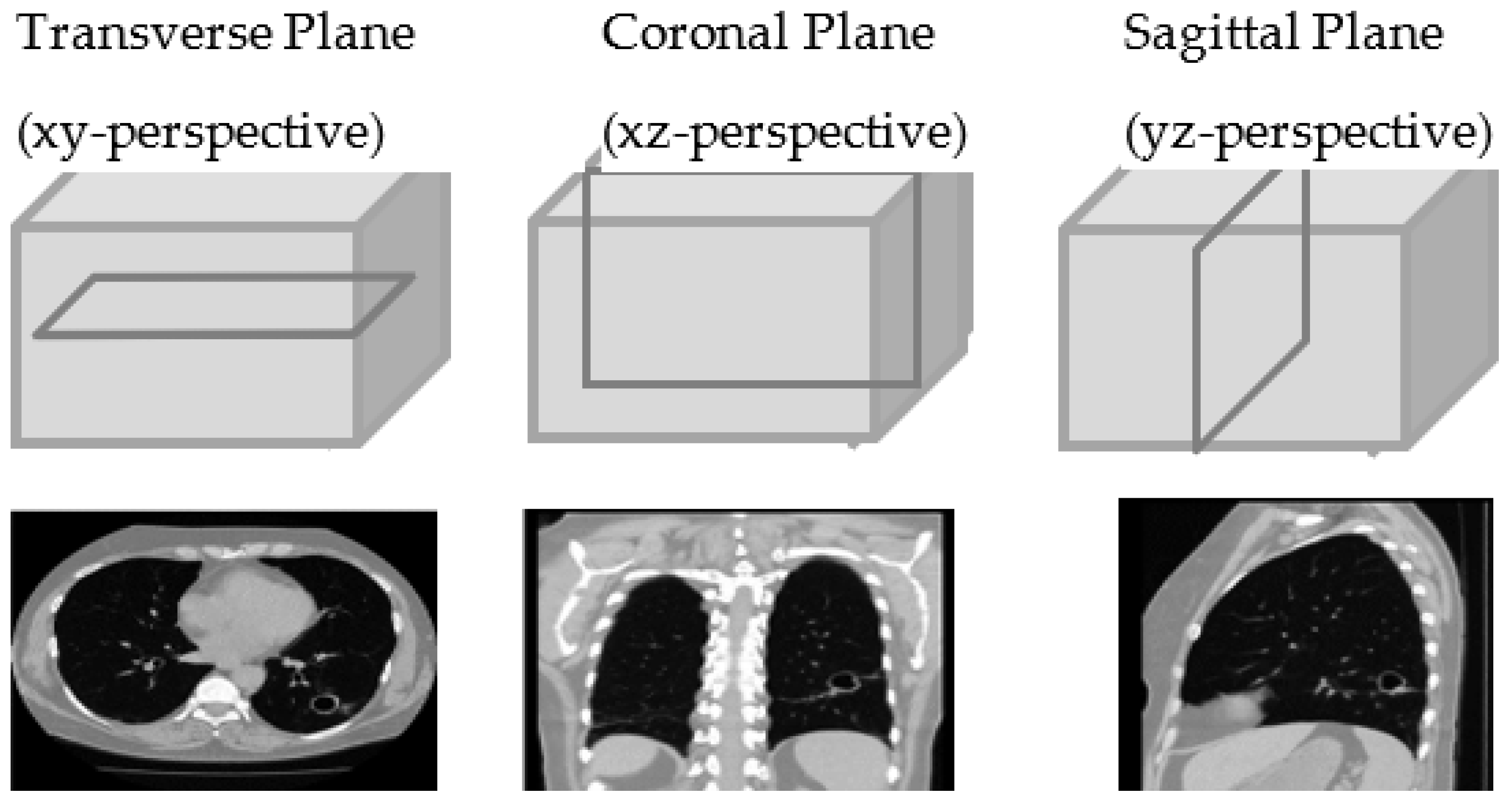
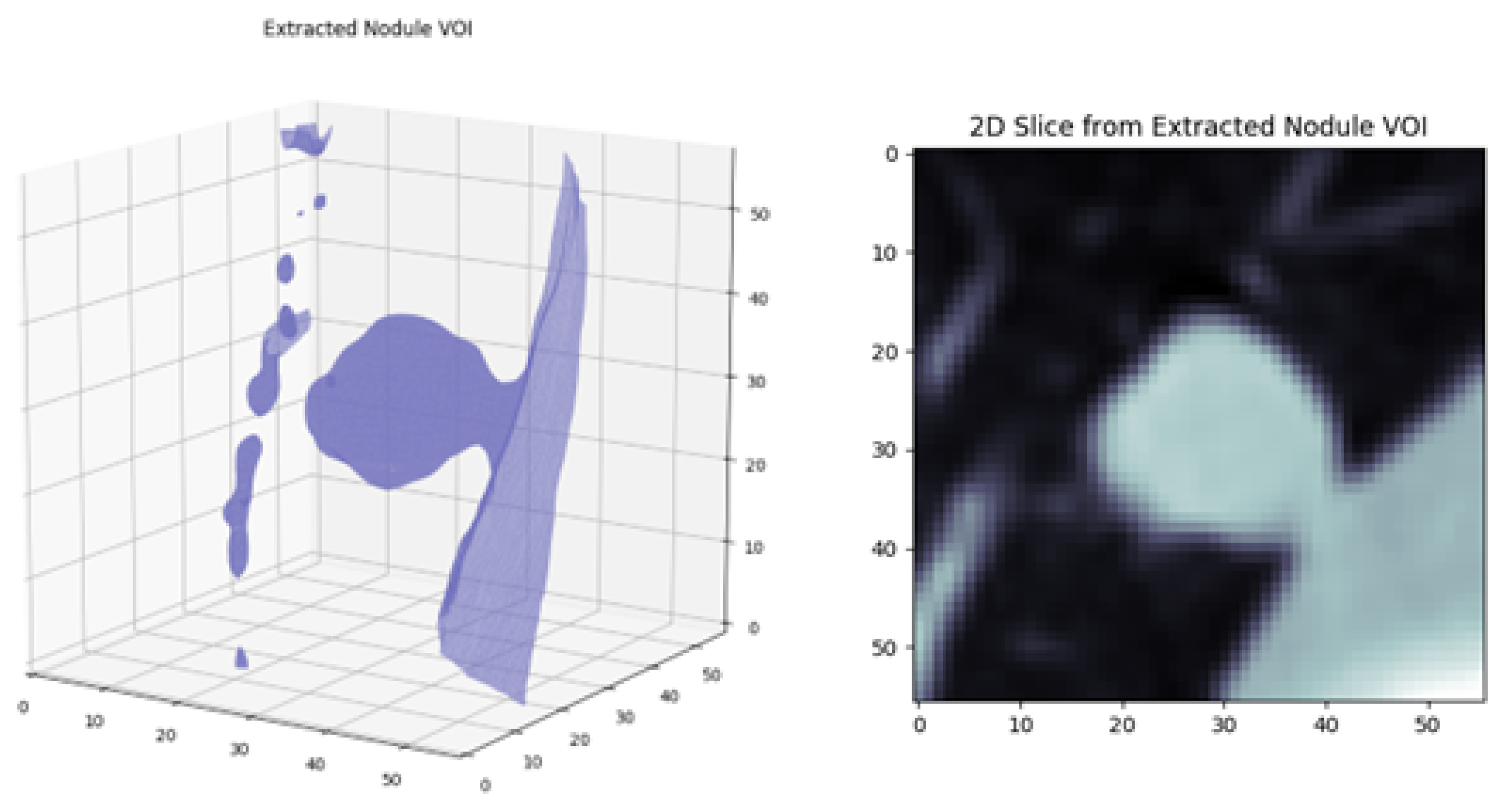
4.1.2. Extraction of Volume of Interest and Slice Selection
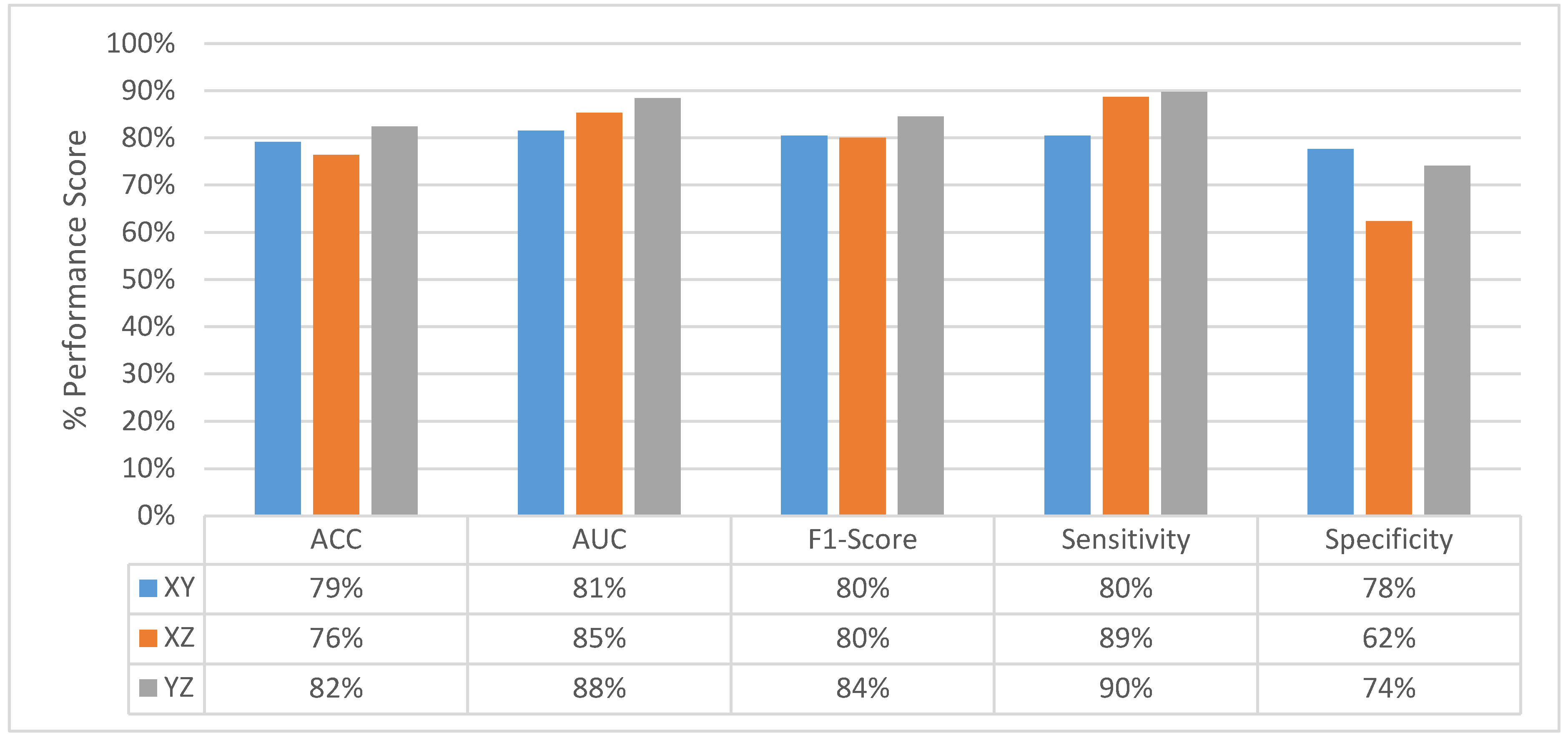
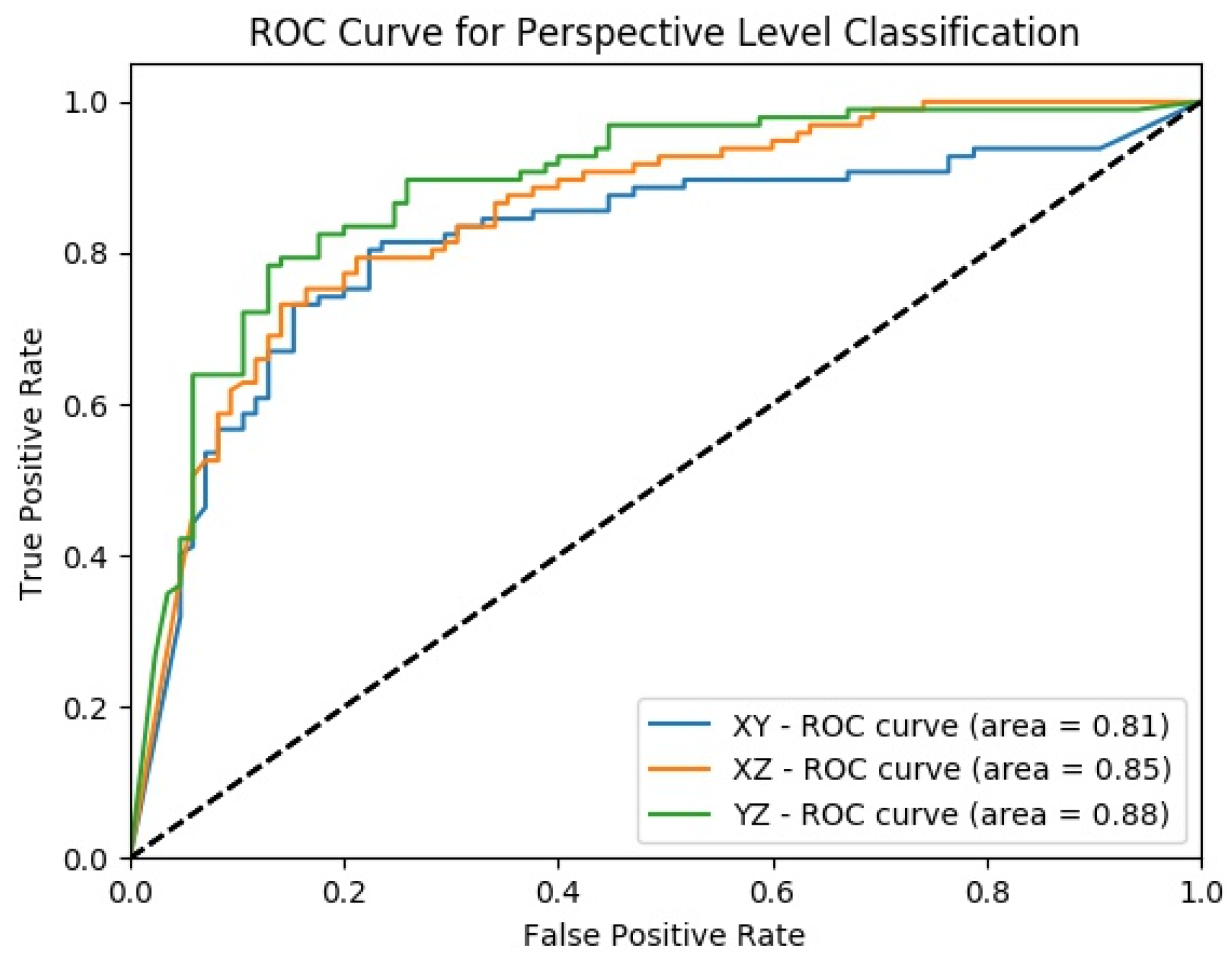
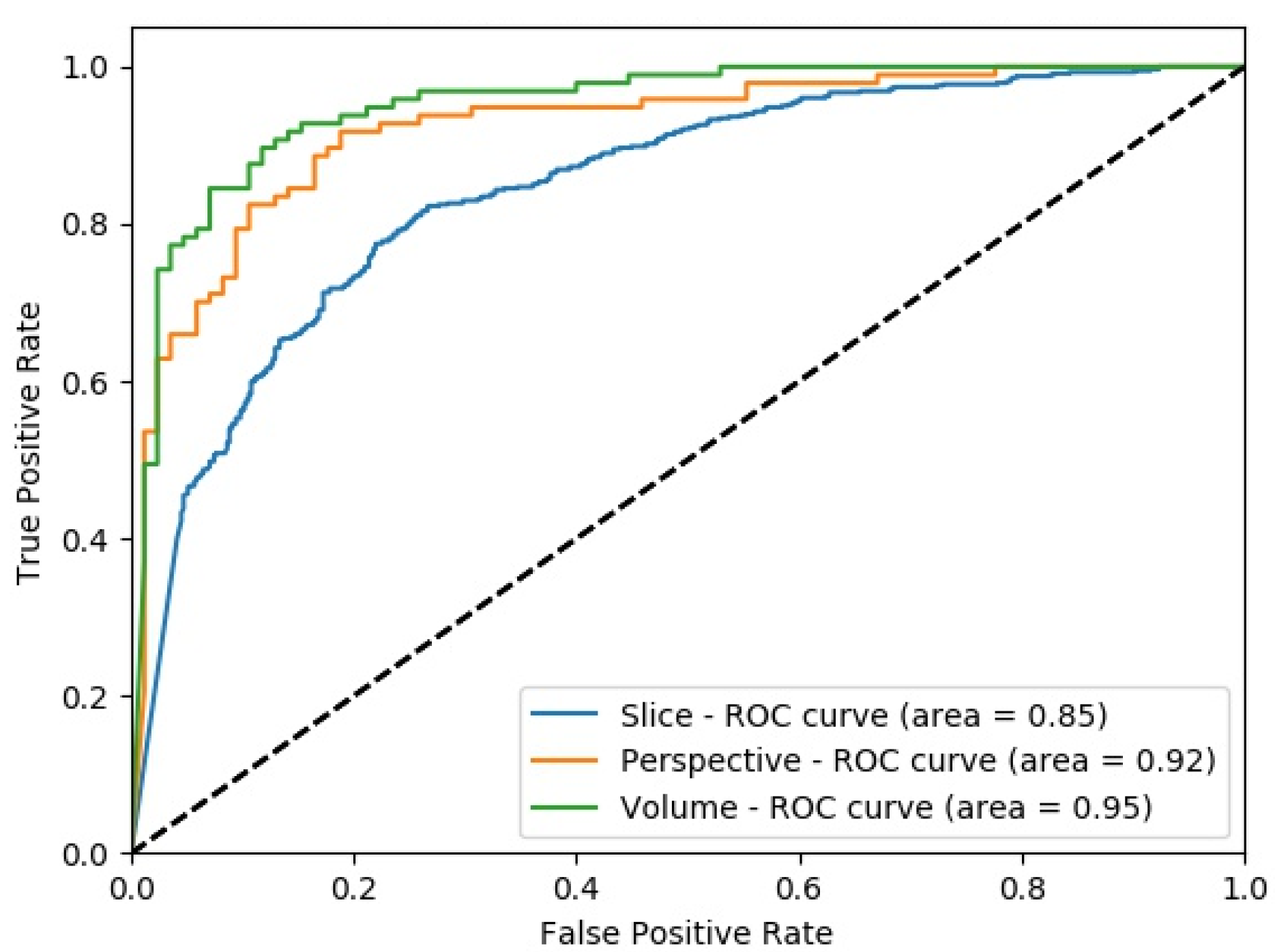
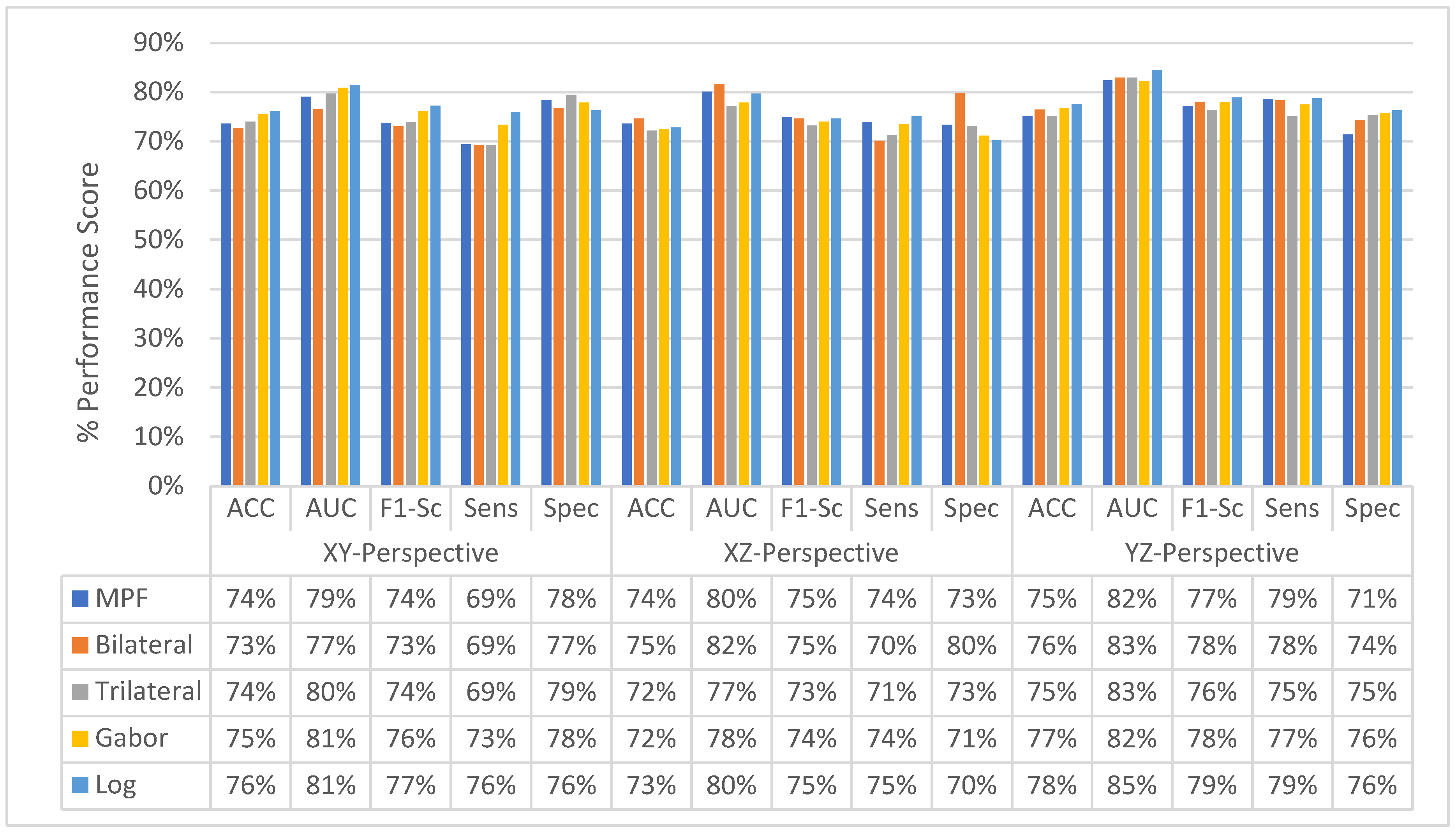
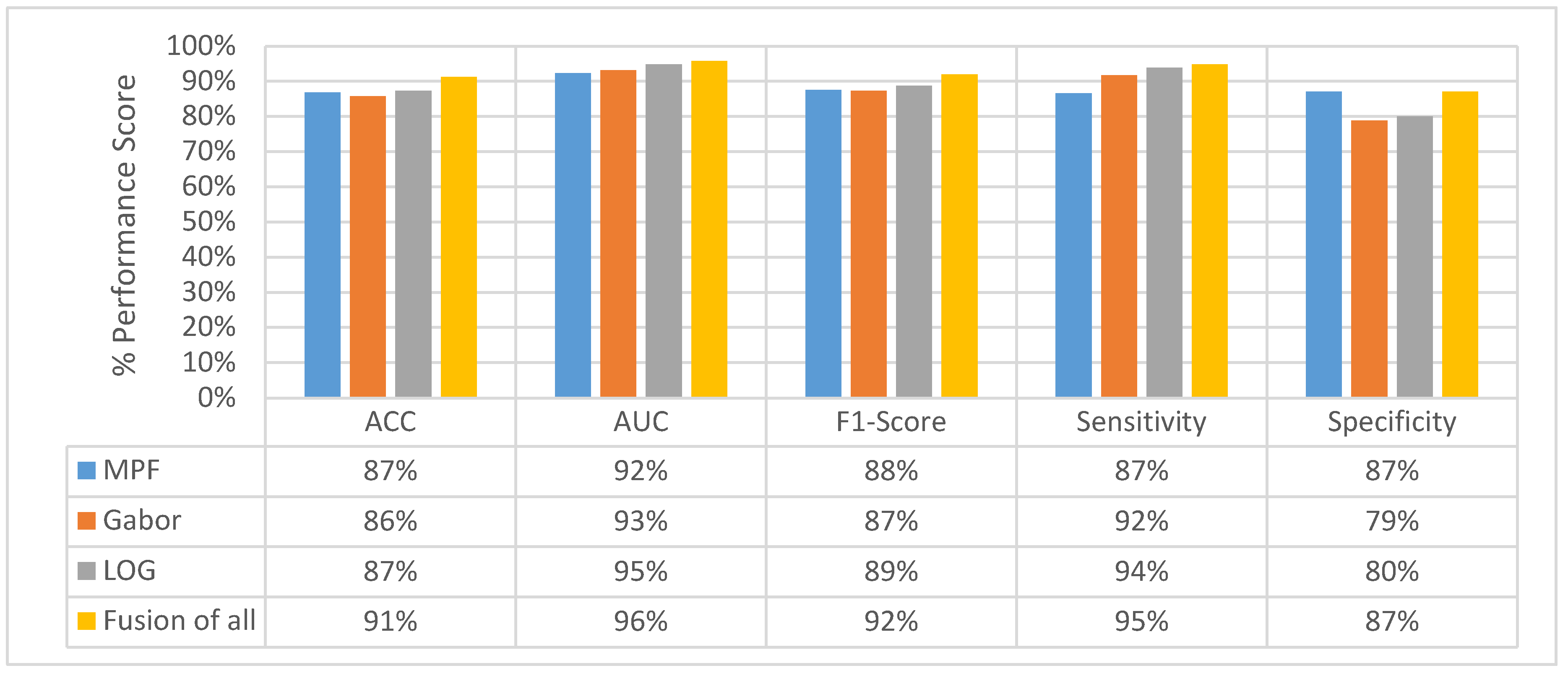
4.2. Experimental Results of MPF Model
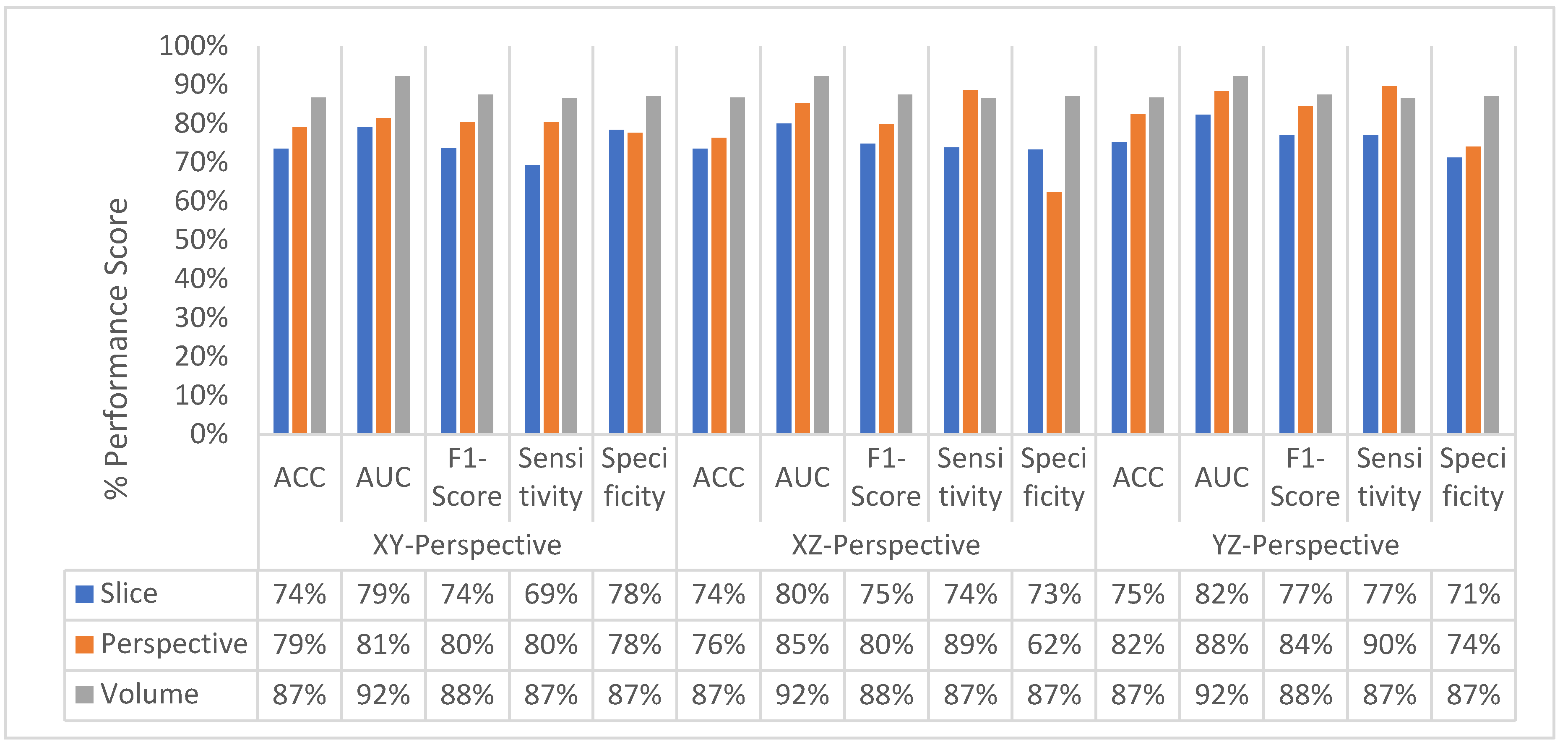
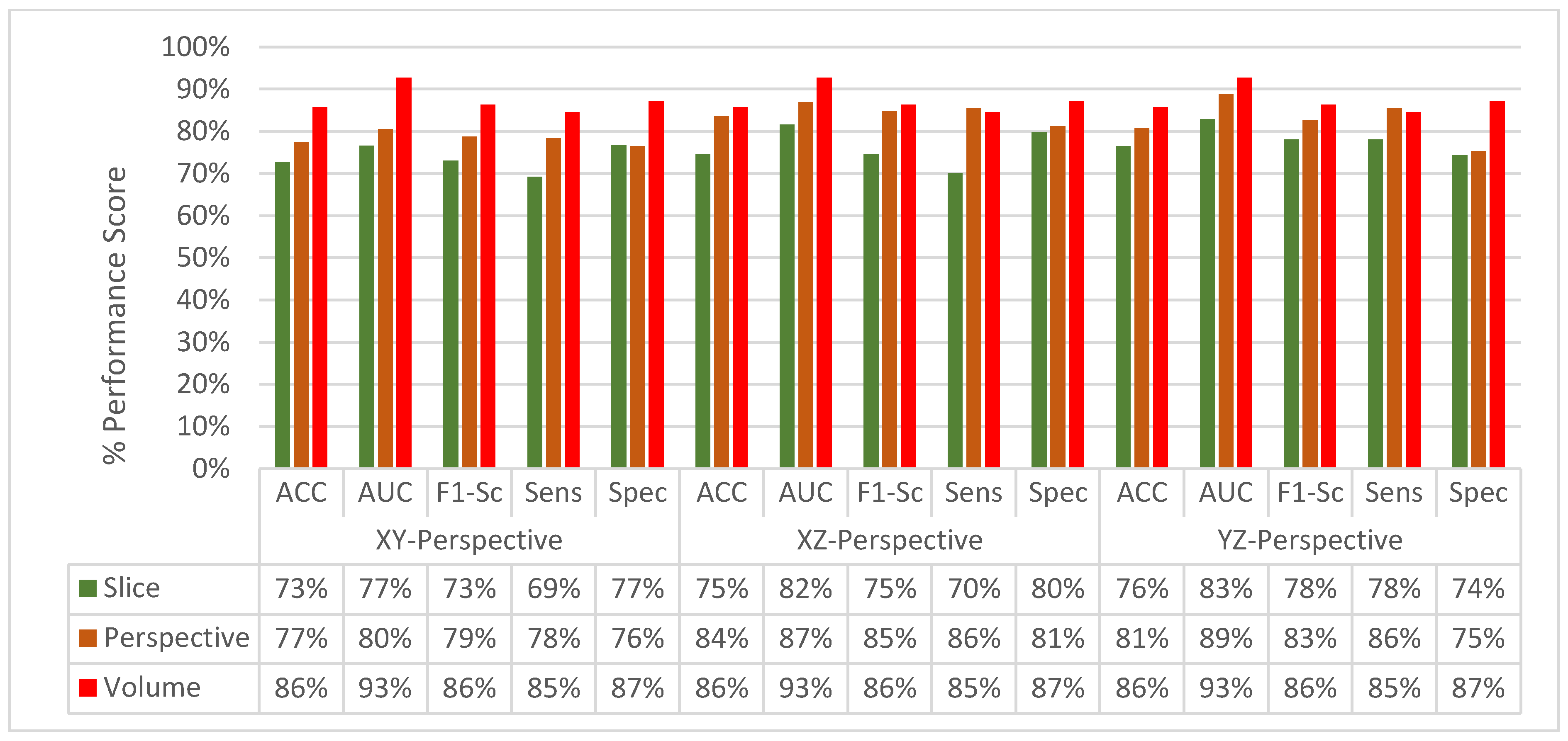
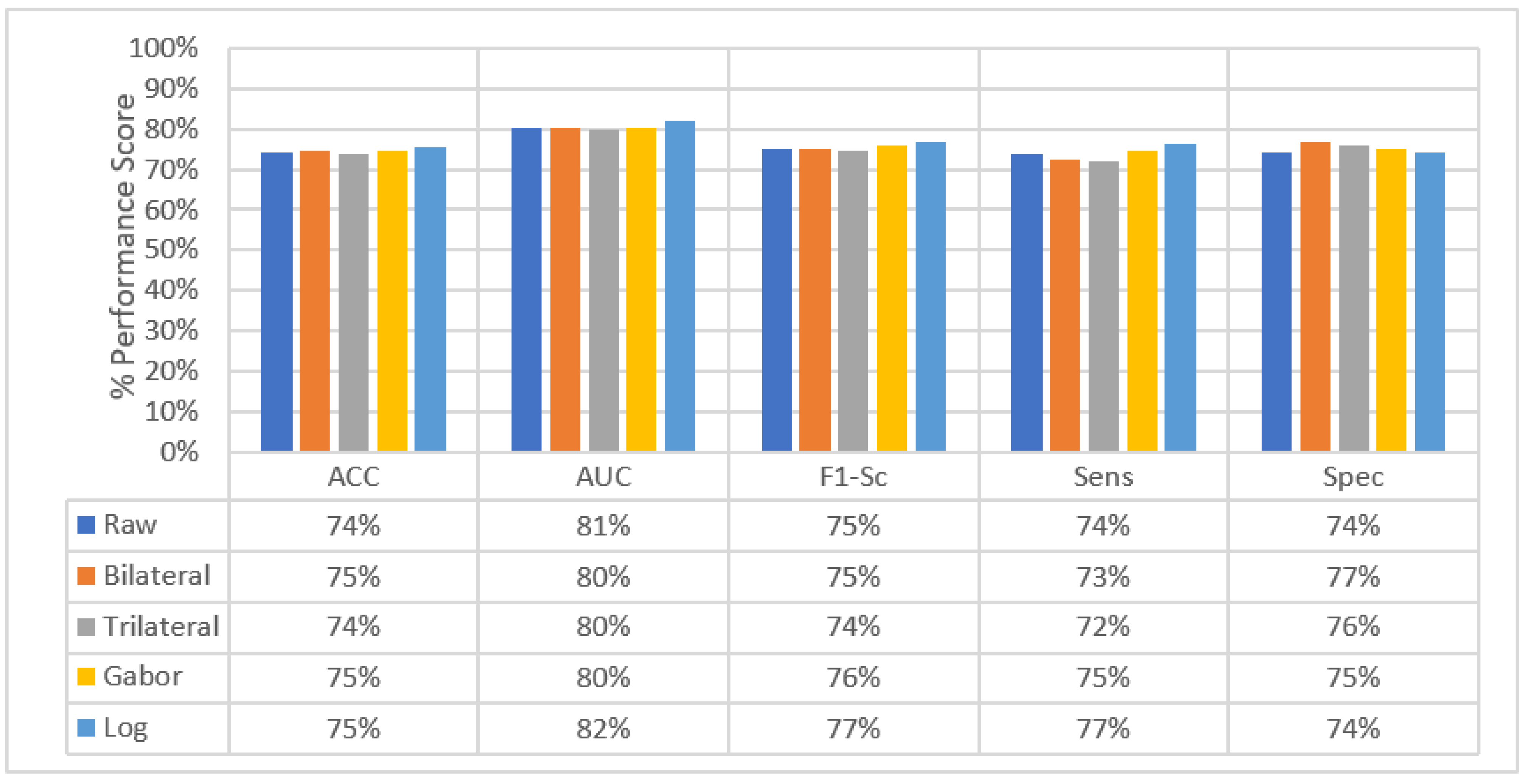
4.3. Experimental Results of SFMPF Models
4.3.1. Experimental Results of SFMPF Model Based on Bilateral Image
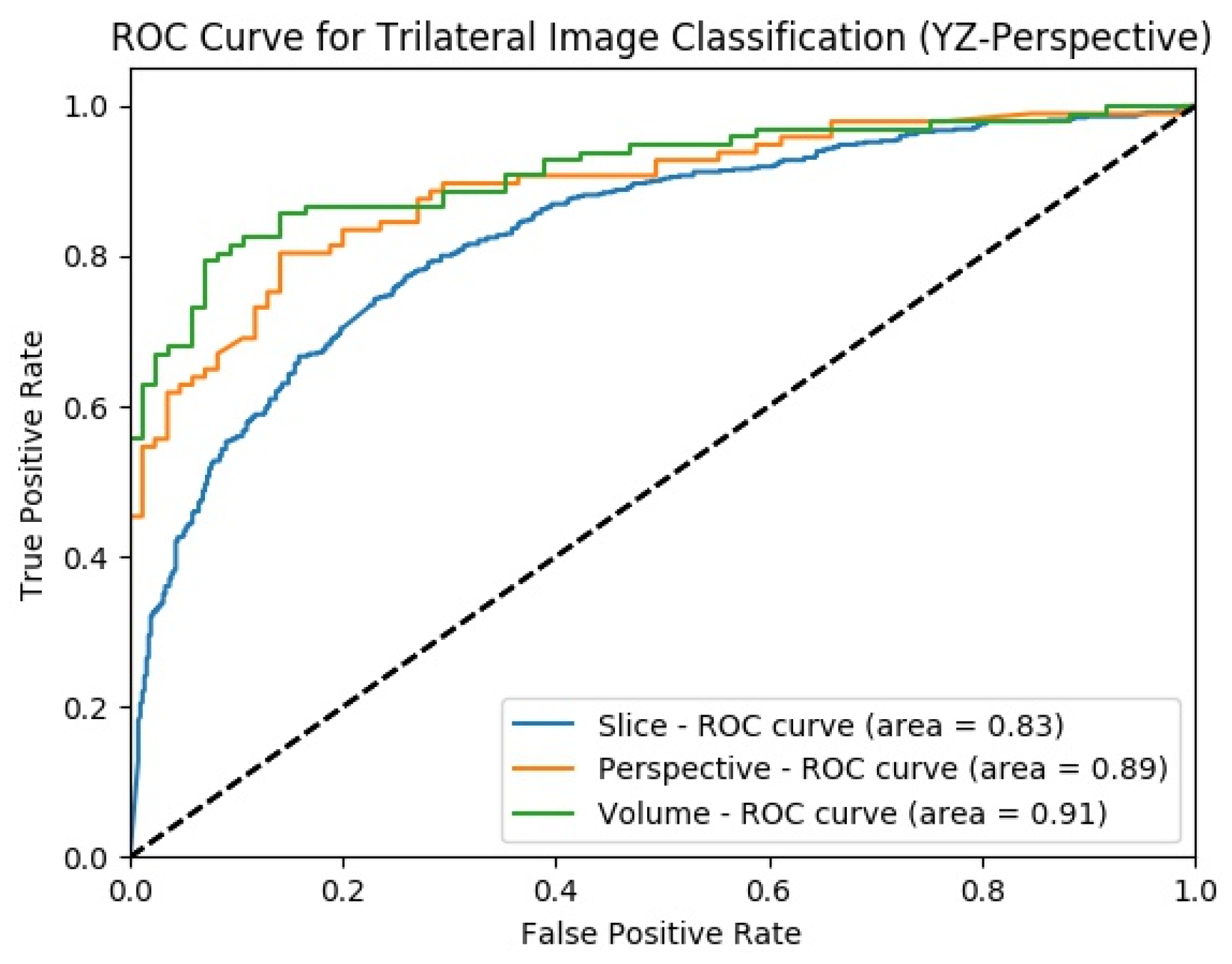
4.3.2. Experimental Results of SFMPF Model Based on Trilateral Image
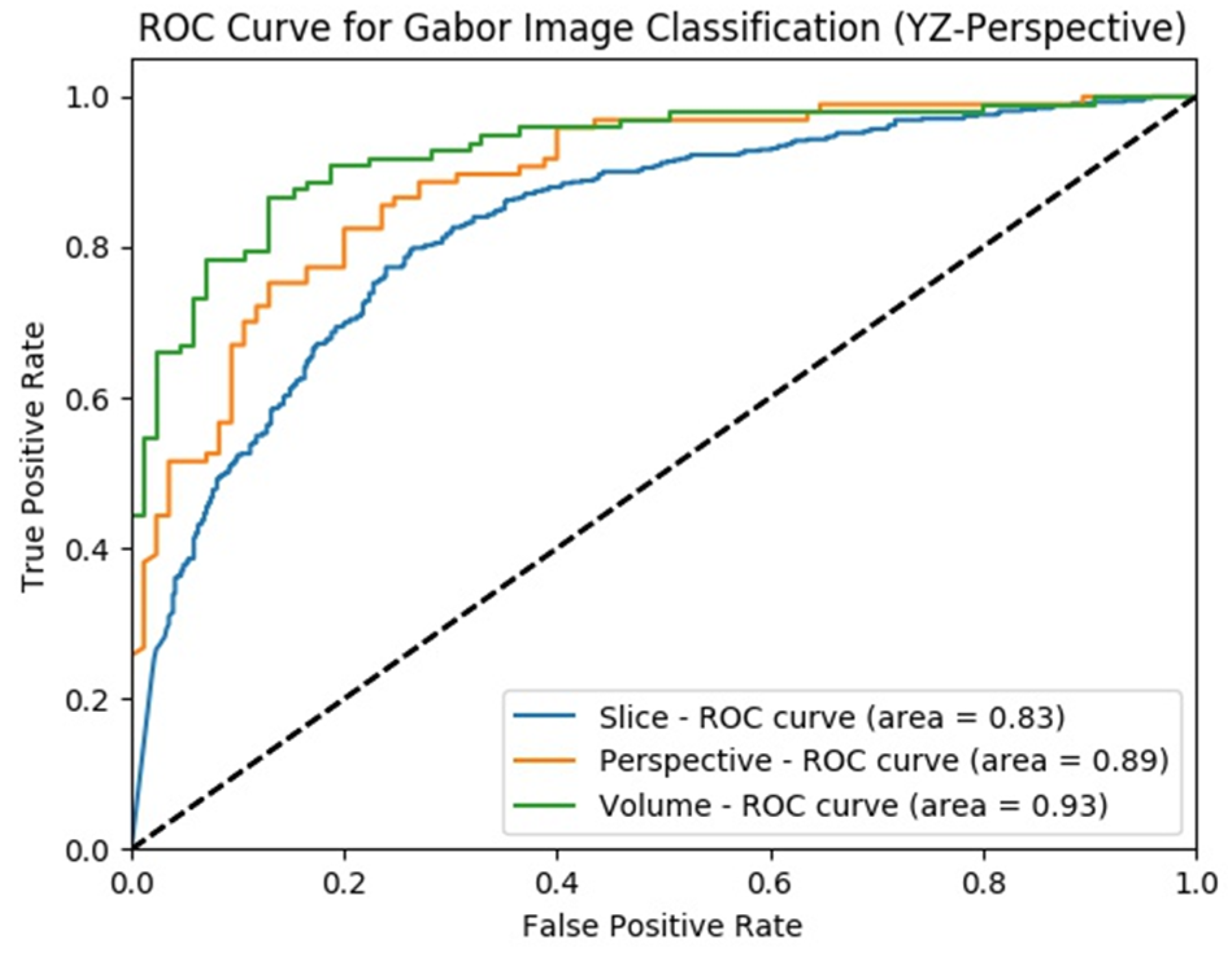
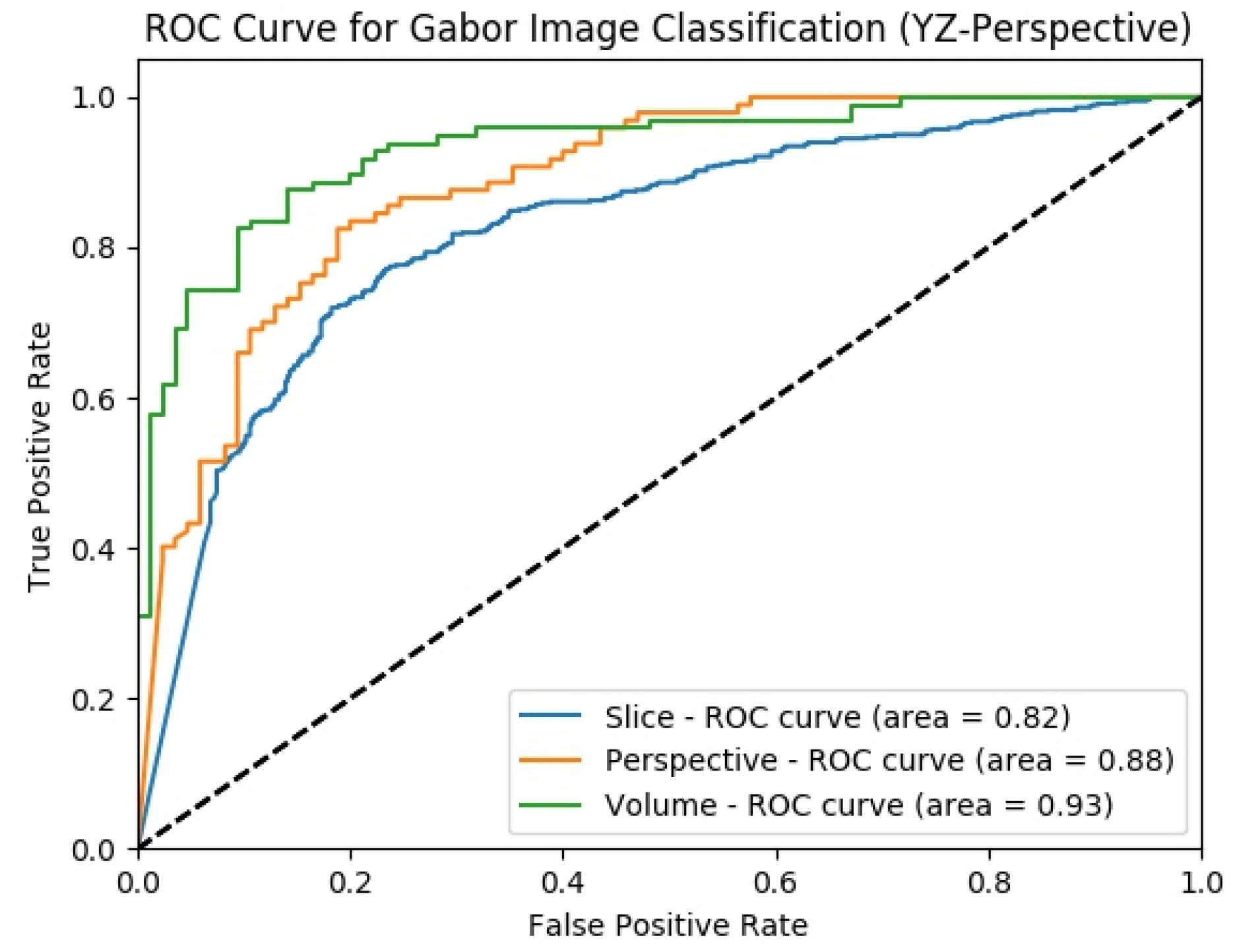
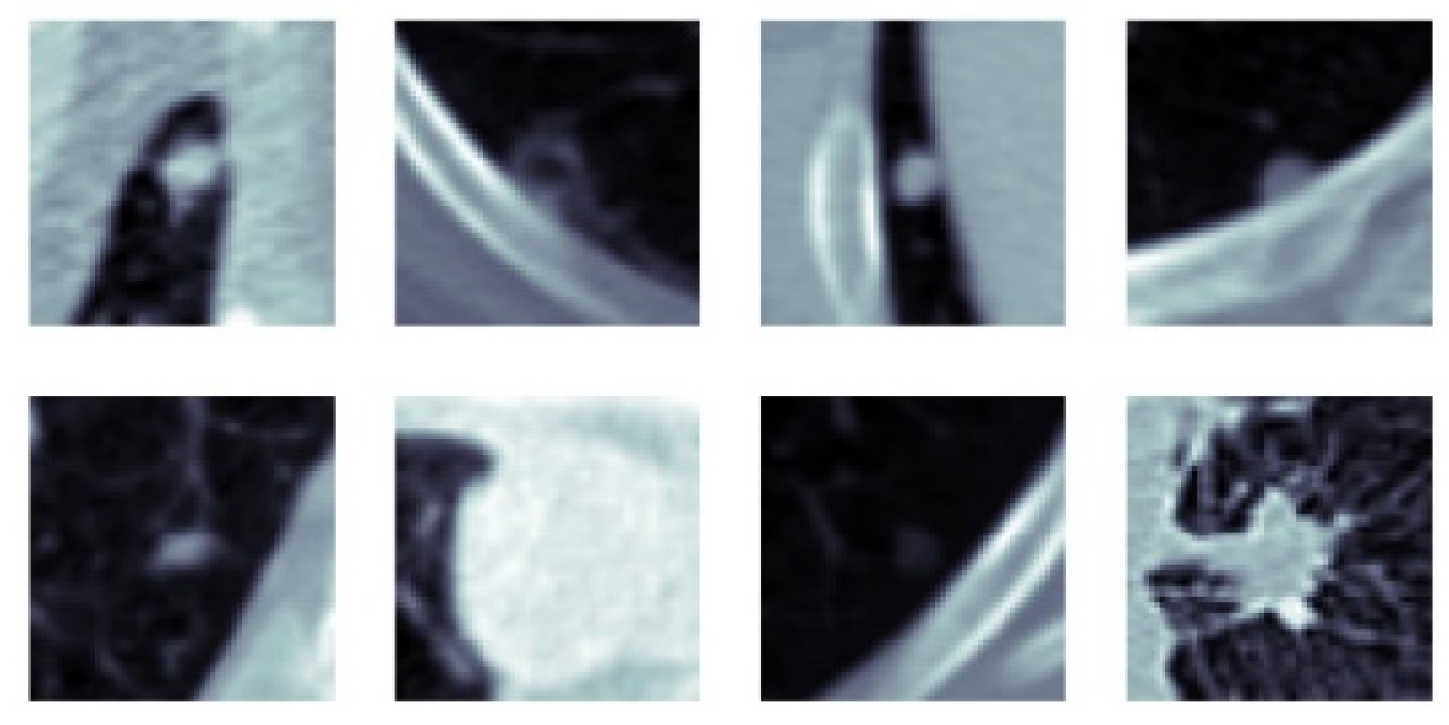
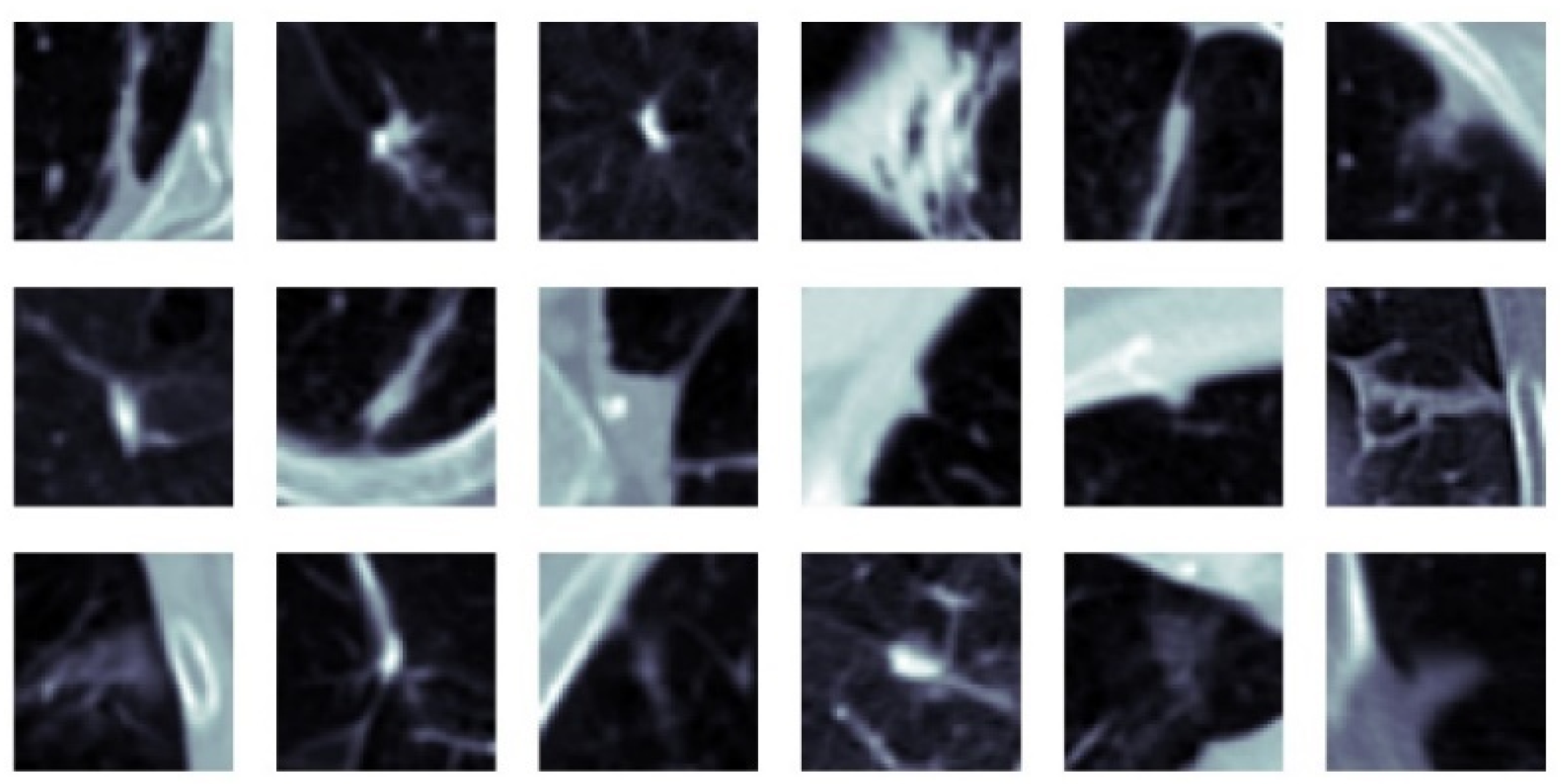
4.3.3. Experimental Results of SFMPF Model Based on Gabor Image
4.3.4. Experimental Results of SFMPF Model Based on LOG Image
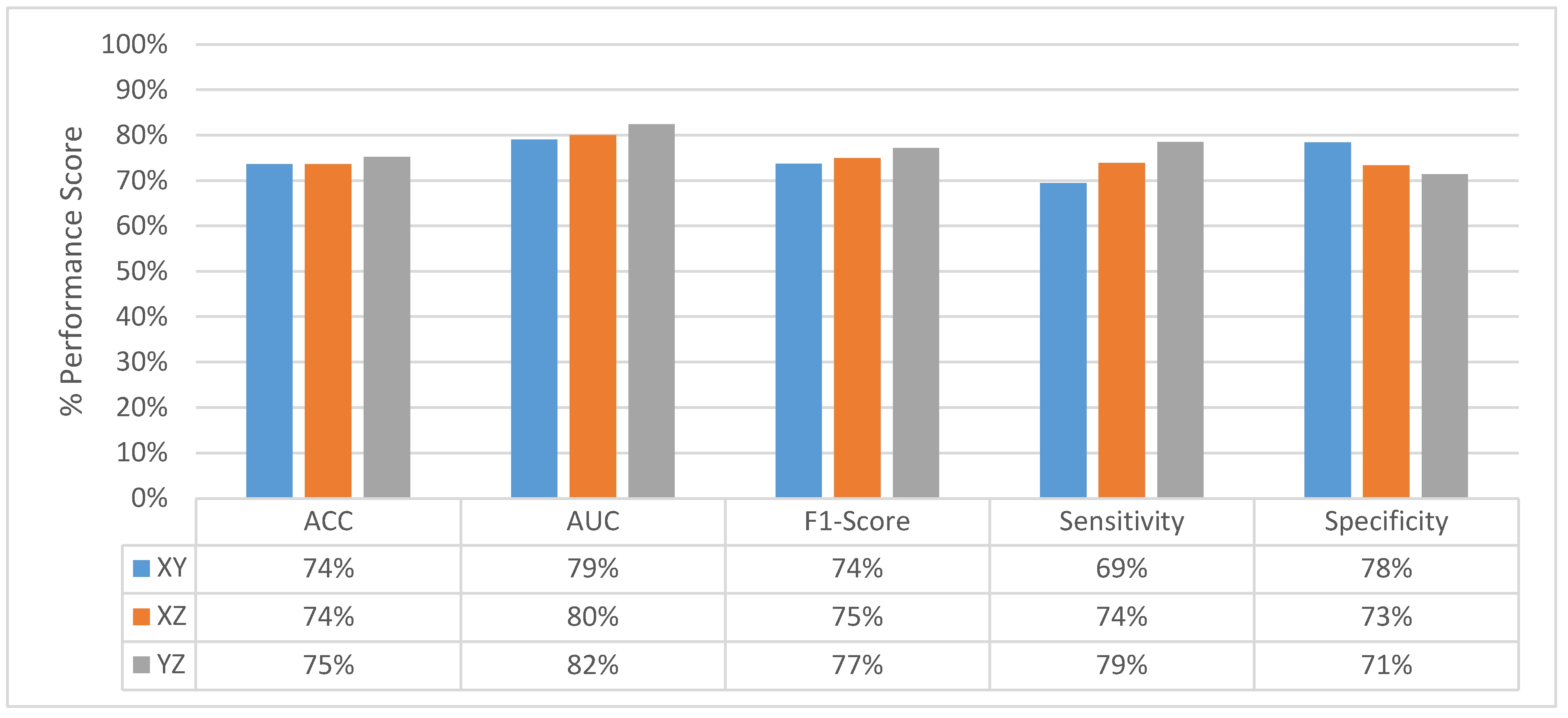
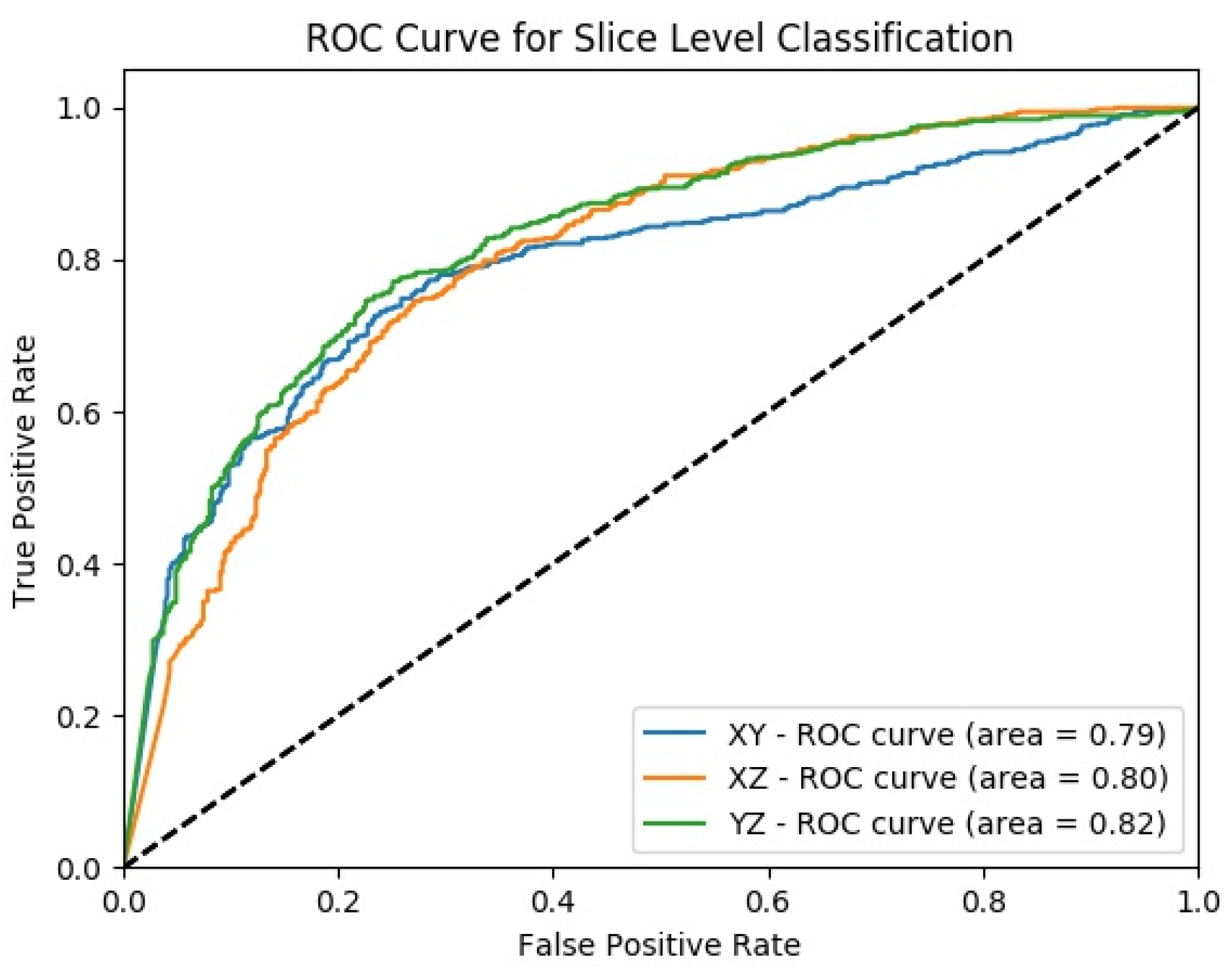
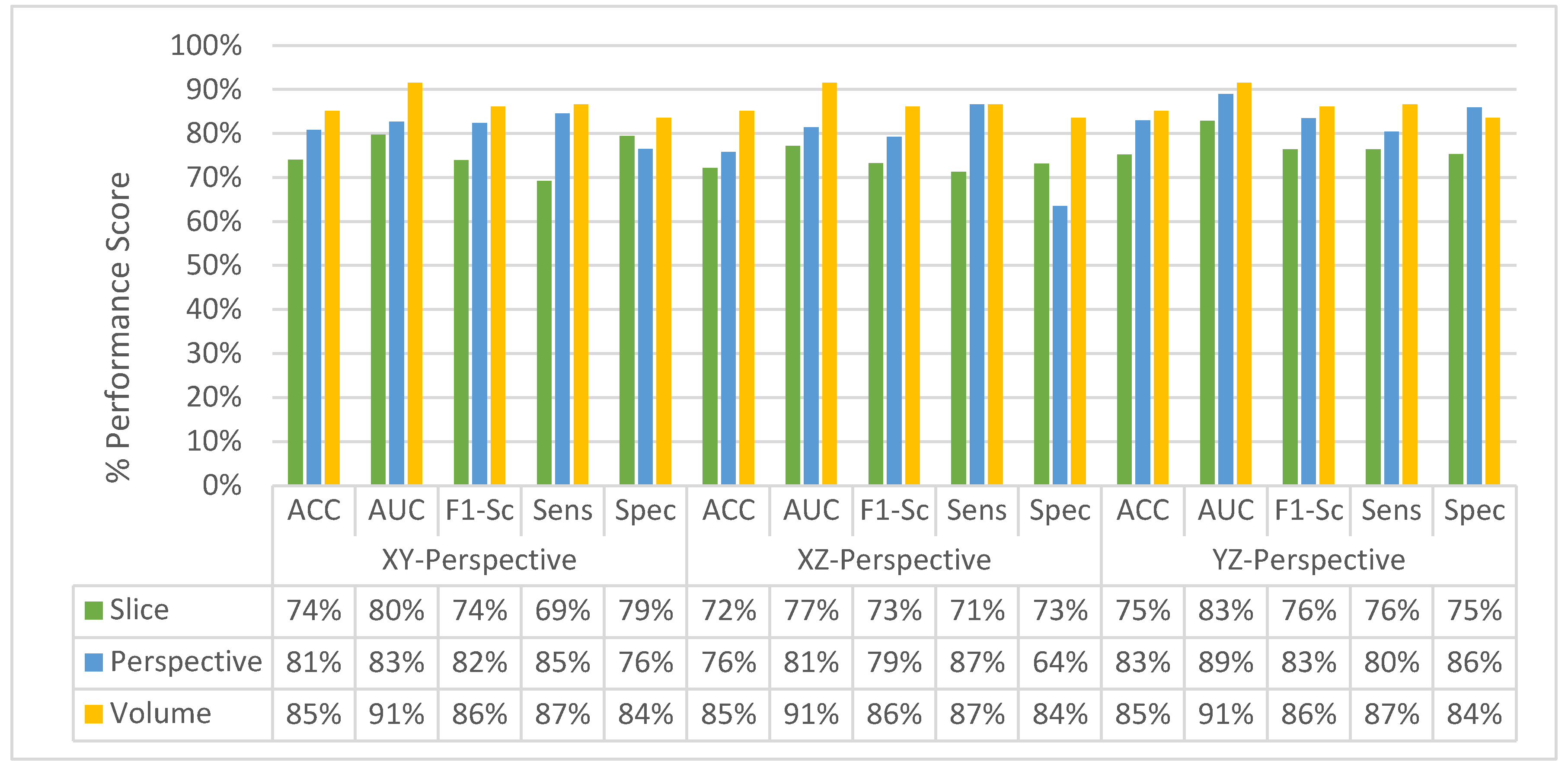
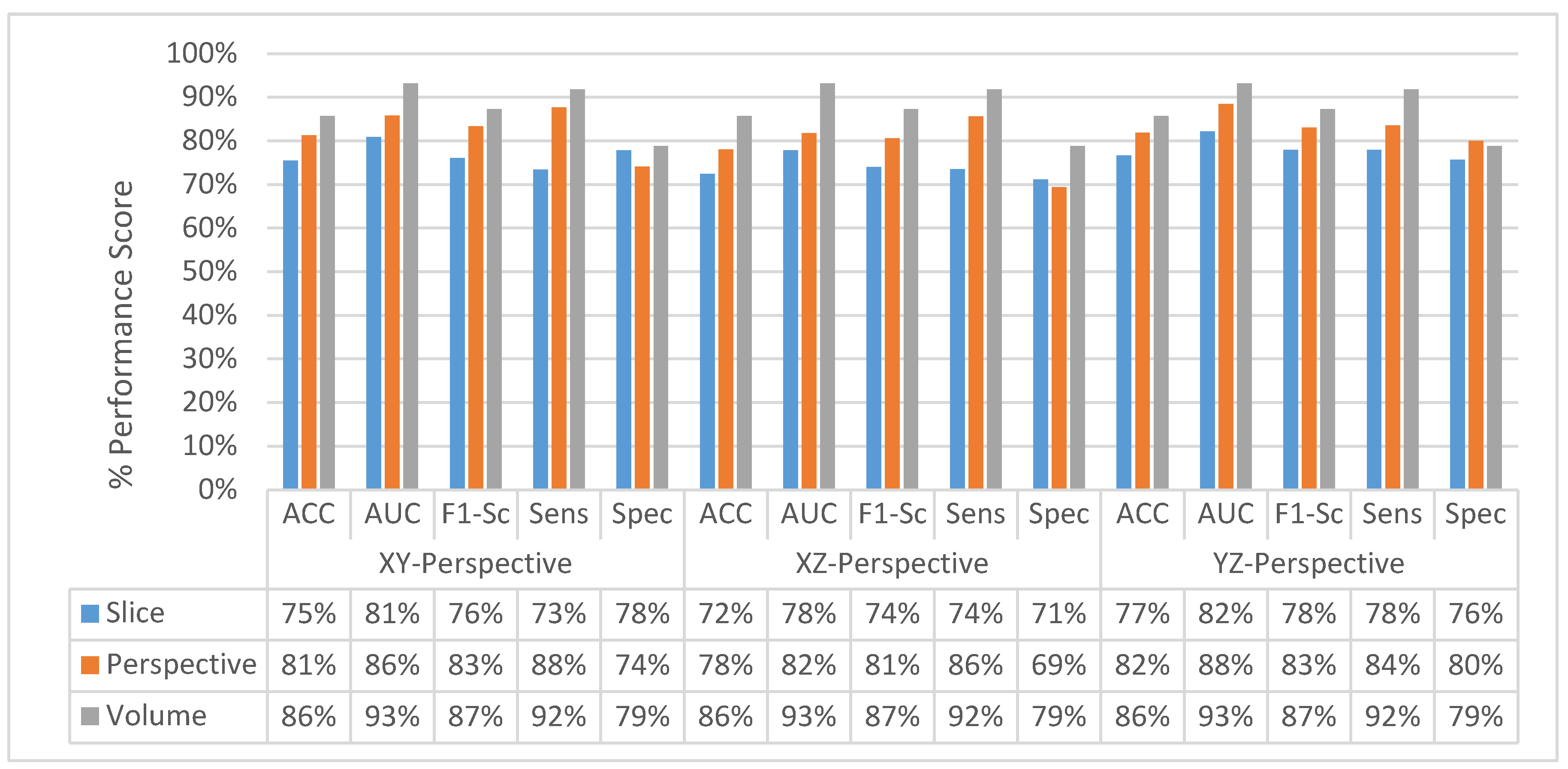
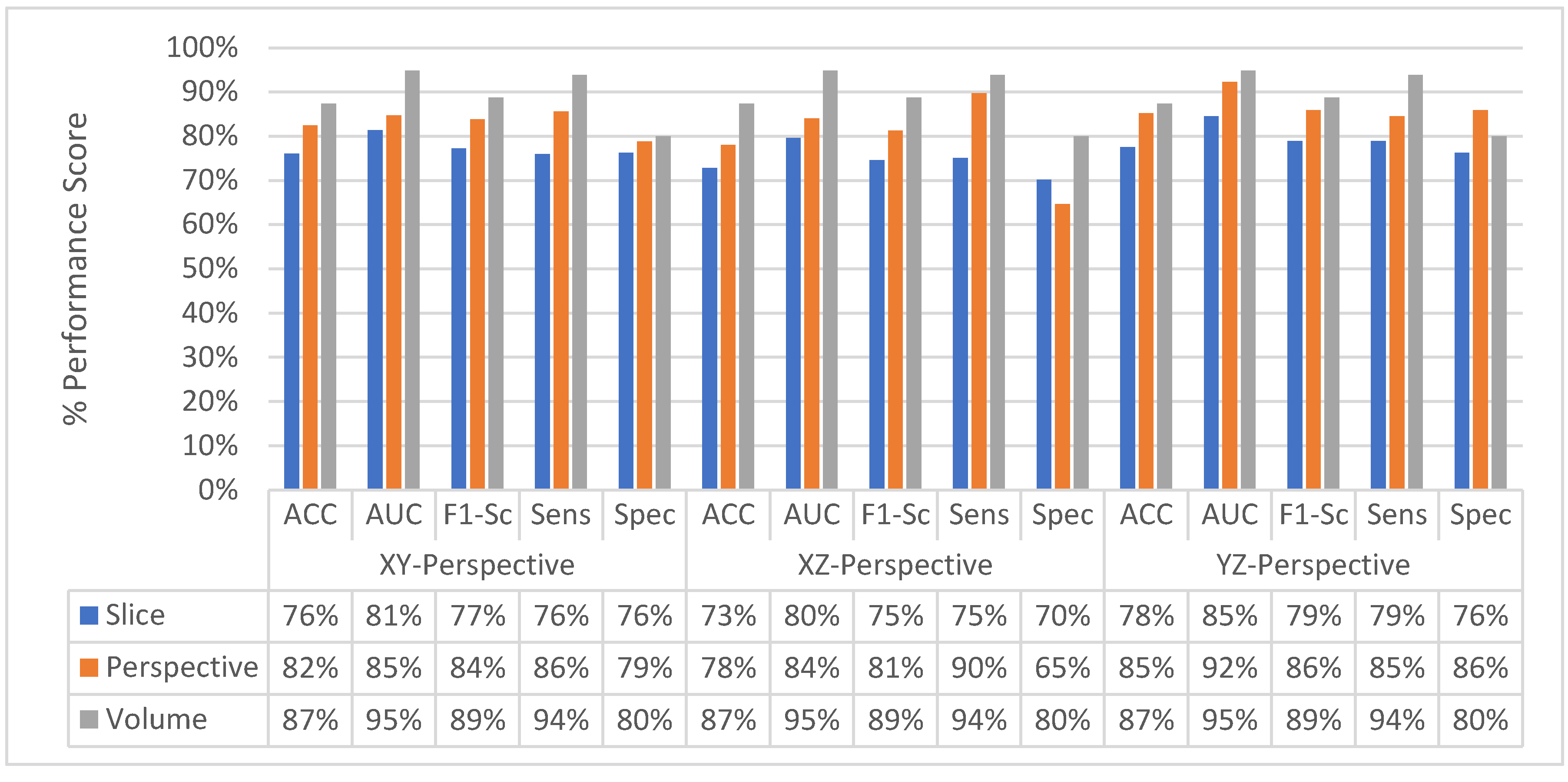
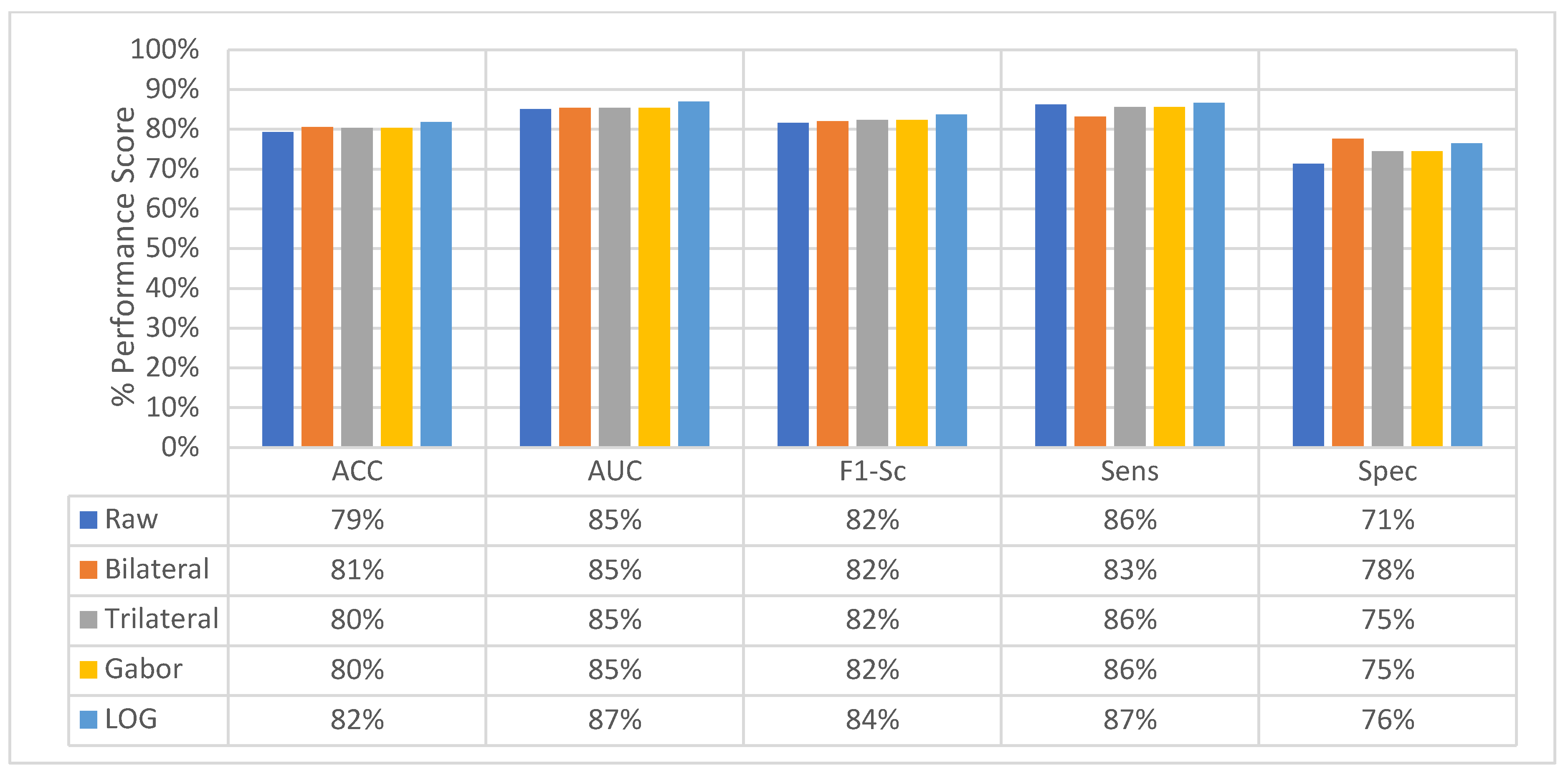
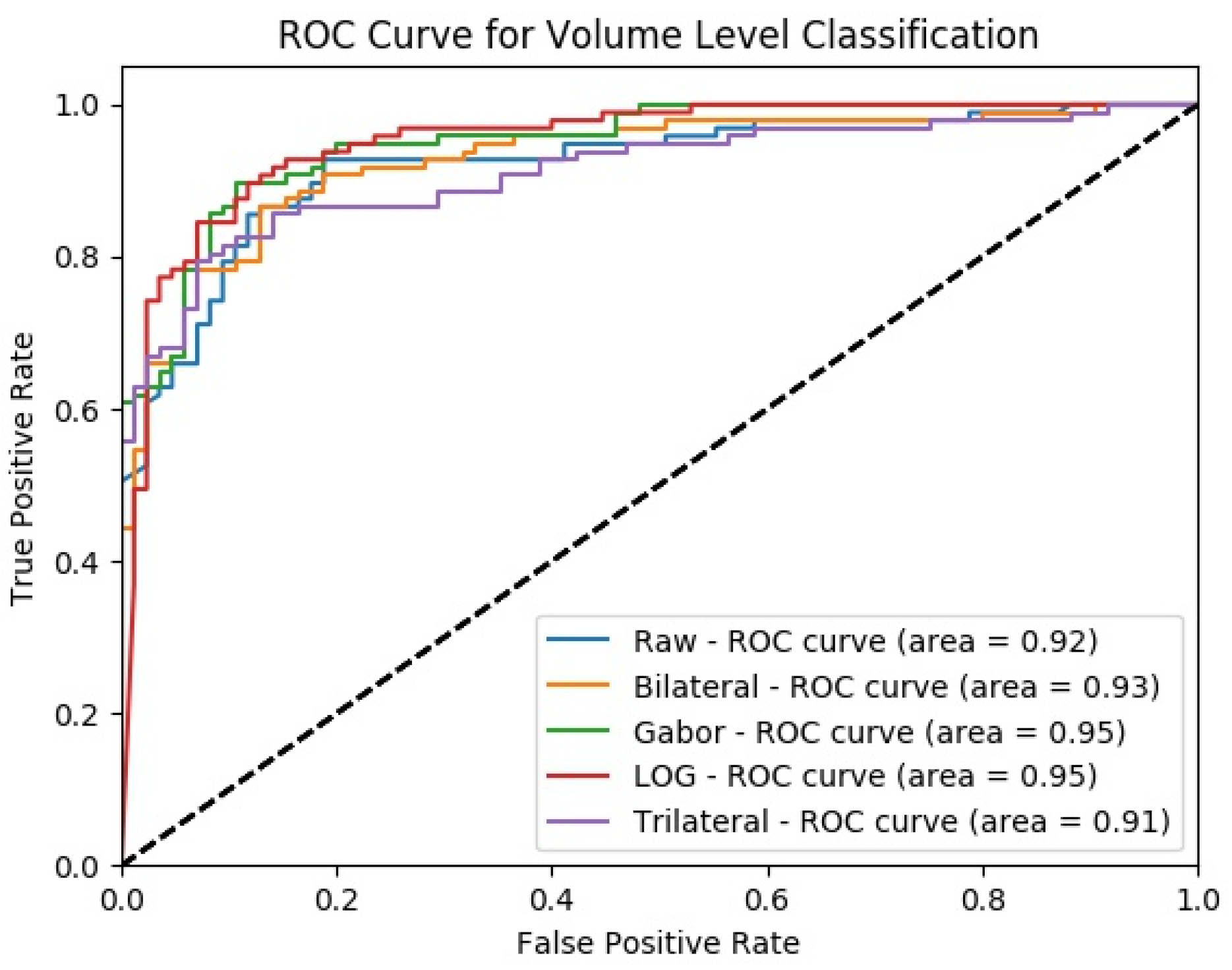
4.4. Classification Performance Comparison of SFMPF Models and MPF Model
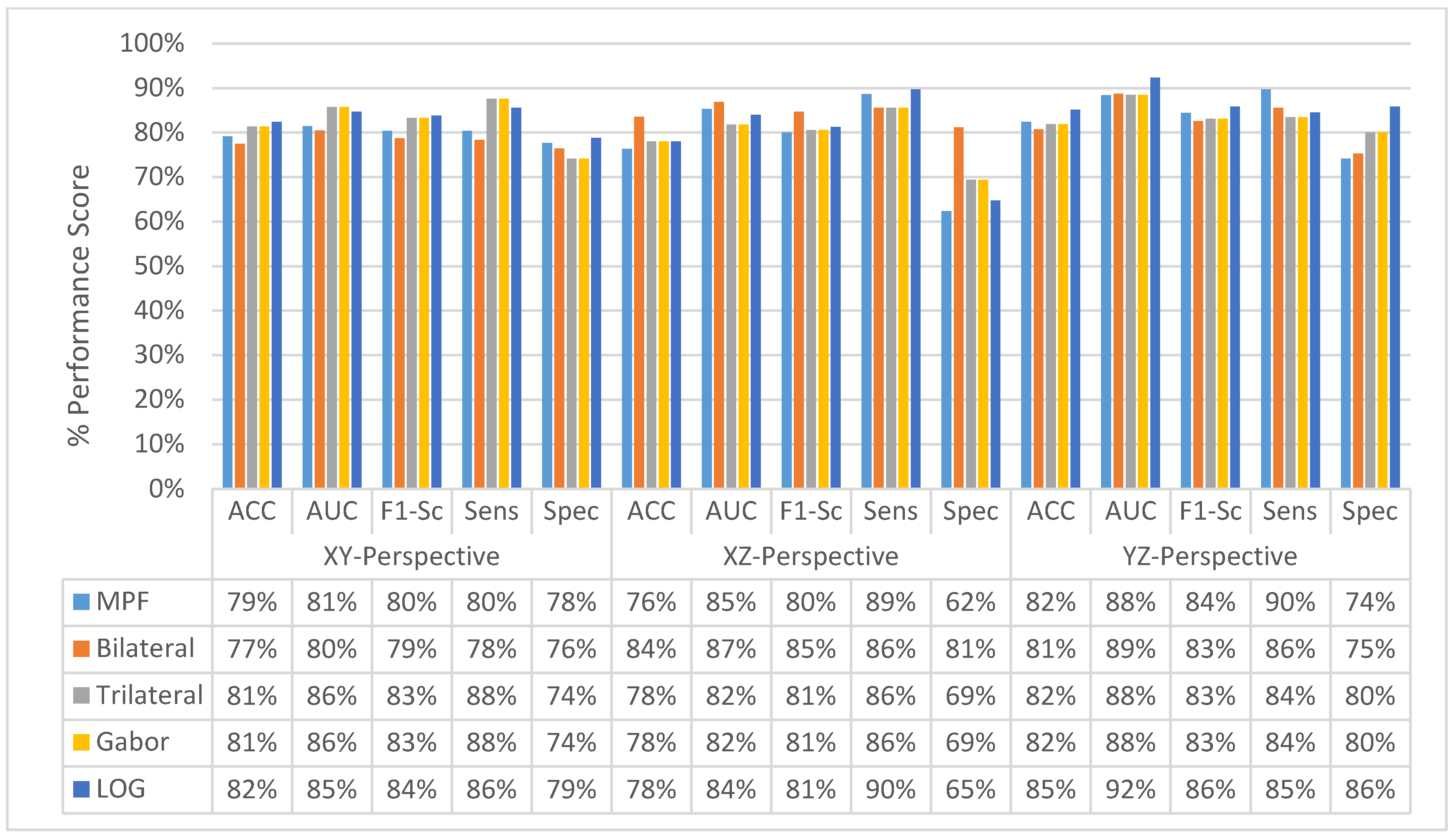
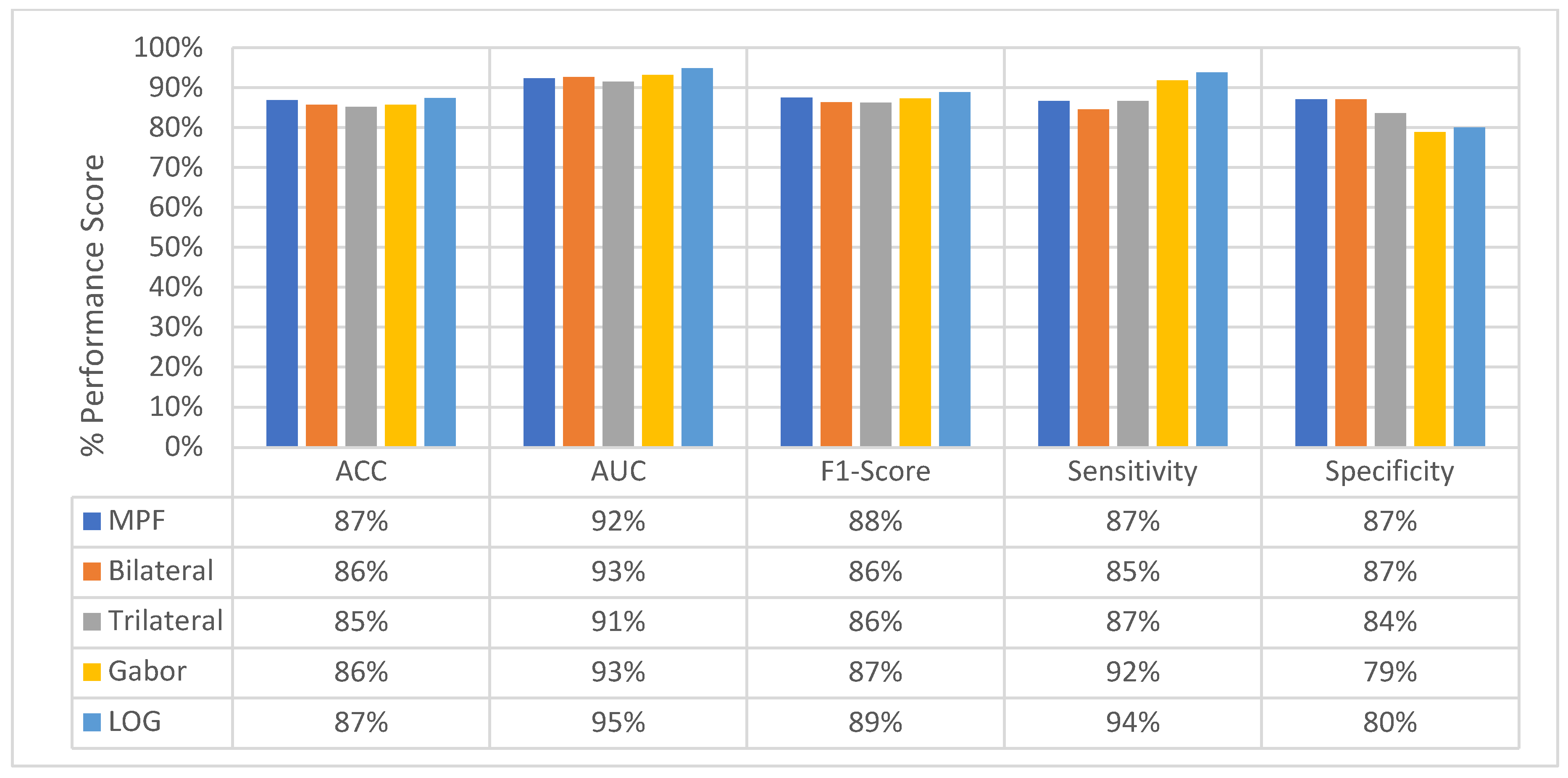
4.5. Experimental Results of MFMPF Model
4.6. Performance Comparison of the Proposed Method with Relevant Studies
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- American Cancer Society. Cancer Facts & Figures 2016; American Cancer Society, Inc.: Atlanta, GA, USA, 2016. [Google Scholar]
- National Lung Screening Trial Research Team. Reduced lung-cancer mortality with low-dose computed tomographic screening. N. Engl. J. Med. 2011, 2011, 395–409. [Google Scholar]
- Armato, S.G., III; Roberts, R.Y.; Kocherginsky, M.; Aberle, D.R.; Kazerooni, E.A.; Macmahon, H.; van Beek, E.J.; Yankelevitz, D.; McLennan, G.; McNitt-Gray, M.F.; et al. Assessment of radiologist performance in the detection of lung nodules: Dependence on the definition of “truth”. Acad. Radiol. 2009, 16, 28–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rubin, G.D.; Lyo, J.K.; Paik, D.S.; Sherbondy, A.J.; Chow, L.C.; Leung, A.N.; Mindelzun, R.; Schraedley-Desmond, P.K.; Zinck, S.E.; Naidich, D.P.; et al. Pulmonary nodules on multi detector row ct scans: Performance comparison of radiologists and computer-aided detection 1. Radiology 2005, 234, 274–283. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sahiner, B.; Chan, H.P.; Hadjiiski, L.M.; Cascade, P.N.; Kazerooni, E.A.; Chughtai, A.R.; Poopat, C.; Song, T.; Frank, L.; Stojanovska, J.; et al. Effect of CAD on radiologists’ detection of lung nodules on thoracic CT scans: Analysis of an observer performance study by nodule size. Acad. Radiol. 2009, 16, 1518–1530. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Y.; de Bock, G.H.; Vliegenthart, R.; van Klaveren, R.J.; Wang, Y.; Bogoni, L.; de Jong, P.A.; Mali, W.P.; van Ooijen, P.; Oudkerk, M.; et al. Performance of computer-aided detection of pulmonary nodules in low-dose CT: Comparison with double reading by nodule volume. Eur. Radiol. 2012, 22, 2076–2084. [Google Scholar]
- Murphy, K.; van Ginneken, B.; Schilham, A.M.; De Hoop, B.J.; Gietema, H.A.; Prokop, M. A large-scale evaluation of automatic pulmonary nodule detection in chest CT using local image features and k-nearest-neighbour classification. Med. Image Anal. 2009, 13, 757–770. [Google Scholar] [CrossRef]
- Messay, T.; Hardie, R.C.; Rogers, S.K. A new computationally efficient CAD system for pulmonary nodule detection in CT imagery. Med. Image Anal. 2010, 14, 390–406. [Google Scholar] [CrossRef]
- Cascio, D.; Magro, R.; Fauci, F.; Iacomi, M.; Raso, G. Automatic detection of lung nodules in CT datasets based on stable 3D mass—Spring models. Comput. Biol. Med. 2012, 42, 1098–1109. [Google Scholar] [CrossRef] [Green Version]
- Choi, W.J.; Choi, T.S. Automated pulmonary nodule detection system in computed tomography images: A hierarchical block classification approach. Entropy 2013, 15, 507–523. [Google Scholar] [CrossRef] [Green Version]
- Jacobs, C.; Van Rikxoort, E.M.; Twellmann, T.; Scholten, E.T.; De Jong, P.A.; Kuhnigk, J.M.; Oudkerk, M.; De Koning, H.J.; Prokop, M.; Schaefer-Prokop, C.; et al. Automatic detection of subsolid pulmonary nodules in thoracic computed tomography images. Med. Image Anal. 2014, 18, 374–384. [Google Scholar] [CrossRef]
- Lee, S.L.A.; Kouzani, A.Z.; Hu, E.J. Automated detection of lung nodules in computed tomography images: A review. Mach. Vis. Appl. 2012, 23, 151–163. [Google Scholar] [CrossRef]
- Van Ginneken, B.; Armato, S.G., III; de Hoop, B.; van Amelsvoort-van de Vorst, S.; Duindam, T.; Niemeijer, M.; Murphy, K.; Schilham, A.; Retico, A.; Fantacci, M.E.; et al. Comparing and combining algorithms for computer-aided detection of pulmonary nodules in computed tomography scans: The ANODE09 study. Med. Image Anal. 2010, 14, 707–722. [Google Scholar] [CrossRef]
- Niemeijer, M.; Loog, M.; Abramoff, M.D.; Viergever, M.A.; Prokop, M.; van Ginneken, B. On combining computer-aided detection systems. IEEE Trans. Med. Imaging 2011, 30, 215–223. [Google Scholar] [CrossRef]
- Jacobs, C.; van Rikxoort, E.M.; Murphy, K.; Prokop, M.; Schaefer-Prokop, C.M.; van Ginneken, B. Computer-aided detection of pulmonary nodules: A comparative study using the public LIDC/IDRI database. Eur. Radiol. 2015, 26, 2139–2147. [Google Scholar] [CrossRef]
- Firmino, M.; Morais, A.H.; Mendoça, R.M.; Dantas, M.R.; Hekis, H.R.; Valentim, R. Computer-aided detection system for lung cancer in computed tomography scans: Review and future prospects. Biomed. Eng. Online 2014, 13, 41. [Google Scholar] [CrossRef] [Green Version]
- Hua, K.L.; Hsu, C.H.; Hidayati, S.C.; Cheng, W.H.; Chen, Y.J. Computer-aided classification of lung nodules on computed tomography images via deep learning technique. OncoTargets Ther. 2015, 8, 2015–2022. [Google Scholar]
- Kumar, D.; Wong, A.; Clausi, D.A. Lung nodule classification using deep features in ct images. In Proceedings of the 2015 12th Conference on Computer and Robot Vision (CRV), Halifax, NS, Canada, 3–5 June 2015. [Google Scholar]
- Anirudh, R.; Thiagarajan, J.J.; Bremer, T.; Kim, H. Lung nodule detection using 3D convolutional neural networks trained on weakly labeled data. In Medical Imaging 2016: Computer-Aided Diagnosis; SPIE: Bellingham, WA, USA, 2016. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Setio, A.A.A.; Ciompi, F.; Litjens, G.; Gerke, P.; Jacobs, C.; Van Riel, S.J.; Wille, M.M.W.; Naqibullah, M.; Sánchez, C.I.; Van Ginneken, B. Pulmonary nodule detection in ct images: False positive reduction using multi-view convolutional networks. IEEE Trans. Med. Imaging 2016, 35, 1160–1169. [Google Scholar] [CrossRef]
- Van Ginneken, B.; Setio, A.A.; Jacobs, C.; Ciompi, F. Off-the-shelf convolutional neural network features for pulmonary nodule detection in computed tomography scans. In Proceedings of the IEEE 12th International Symposium on Biomedical Imaging, Brooklyn Bridge, NY, USA, 16–19 April 2015. [Google Scholar]
- Soysal, Ö.M.; Chen, J.; Schneider, H. Efficient photometric feature extraction in a hierarchical learning scheme for nodule detection. Int. J. Granul. Comput. Rough Sets Intell. Syst. 2012, 2, 314–326. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Kim, B.K.; Roh, J.; Dong, S.Y.; Lee, S.Y. Hierarchical committee of deep convolutional neural networks for robust facial expression recognition. J. Multimodal User Interfaces 2016, 10, 173–189. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Park, E.; Han, X.; Berg, T.L.; Berg, A.C. Combining multiple sources of knowledge in deep CNNs for action recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–9 March 2016. [Google Scholar]
- Sekeroglu, K.; Soysal, O.; Li, X. Hierarchical Deep-Fusion Learning Framework for Lung Nodule Classification. In Proceedings of the 15th International Conference on Machine Learning and Data Mining, MLDM 2019, New York, NY, USA, 20–25 July 2019. [Google Scholar]
- Şekeroğlu, K.; Soysal, Ö.M. Comparison of SIFT, Bi-SIFT, and Tri-SIFT and their frequency spectrum analysis. Mach. Vis. Appl. 2017, 28, 875–902. [Google Scholar] [CrossRef]
- Armato, S.G., III; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans. Med. Phys. 2011, 38, 915–931. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, H.; Wu, R.; Li, Y.; Peng, C. Self-Supervised Transfer Learning Based on Domain Adaptation for Benign-Malignant Lung Nodule Classification on Thoracic CT. IEEE J. Biomed. Health Inform. 2022, 26, 3860–3871. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Shen, F.; Gao, F.; Han, W. Learning efficient, explainable and discriminative representations for pulmonary nodules classification. Pattern Recognit. 2021, 113, 107825. [Google Scholar] [CrossRef]
- Mastouri, R.; Khlifa, N.; Neji, H.; Hantous-Zannad, S. A bilinear convolutional neural network for lung nodules classification on CT images. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 91–101. [Google Scholar] [CrossRef]
- Zhai, P.; Tao, Y.; Chen, H.; Cai, T.; Li, J. Multi-task learning for lung nodule classification on chest CT. IEEE Access 2020, 8, 180317–180327. [Google Scholar] [CrossRef]
- Liu, H.; Cao, H.; Song, E.; Ma, G.; Xu, X.; Jin, R.; Liu, C.; Hung, C.C. Multi-model ensemble learning architecture based on 3D CNN for lung nodule malignancy suspiciousness classification. J. Digit. Imaging 2020, 33, 1242–1256. [Google Scholar] [CrossRef]
- Ozdemir, O.; Russell, R.L.; Berlin, A.A. A 3D probabilistic deep learning system for detection and diagnosis of lung cancer using low-dose CT scans. IEEE Trans. Med. Imaging 2020, 39, 1419–1429. [Google Scholar] [CrossRef] [Green Version]
- Hamidian, S.; Sahiner, B.; Petrick, N.; Pezeshk, A. 3-D convolutional neural networks for automatic detection of pulmonary nodules in chest CT. IEEE J. Biomed. Health Inform. 2019, 23, 2080–2090. [Google Scholar]
- Monkam, P.; Qi, S.; Xu, M.; Han, F.; Zhao, X.; Qian, W. CNN models discriminating between pulmonary micro-nodules and non-nodules from CT images. Biomed. Eng. Online 2018, 17, 96. [Google Scholar] [CrossRef]










































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CAD System | Classification Method | Accuracy (%) | Sensitivity (%) | Specificity (%) | FPs/Scan |
|---|---|---|---|---|---|
| Our proposed method | Hierarchical Deep-Fusion | 91.20 | 95 | 87 | 0.4 |
| Haung et al., 2022 [31] | 3 D CNN-TL | 91.07 | 90.9 | 91.2 | - |
| Jiang et al., 2021 [32] | 3 D CNN-CBAM | 90.77 | 85.3 | 95 | - |
| Mastouri et al., 2021 [33] | Bilinear CNN | 91.99 | 91.8 | 92.2 | 0.07 |
| Zhai et al., 2020 [34] | MT-CNN | - | 87.7 | 88.8 | - |
| Liu et al., 2020 [35] | MMEL-3 D CNN | 90.60 | 83.7 | 93.9 | - |
| Ozdemir et al., 2020 [36] | 3 D CNN | - | 91 | - | 0.5 |
| Pezeshk et al., 2019 [37] | 3 D CNN | - | 91 | - | 2 |
| Monkam et al., 2018 [38] | Multi-patch CNNs | 88.20 | 83.8 | - | - |
| Rushil Anirudh et al., 2016 [19] | 3 D CNN | - | 80 | - | 10 |
| A. A. Adiyoso Setio et al., 2016 [21] | Multi-view CNN | - | 85.4 | - | 1 |
| C. Jacobs et al., 2014 [15] | GentleBoost | - | 80 | - | 1 |
| W. J. Choi et al., 2013 [10] | SVM | 97.61 | 95.28 | 96.23 | 2.27 |
| D. Cascio et al., 2012 [9] | ANN | - | 88 | - | 2.5 |
| T. Messay et al., 2010 [8] | FLD | - | 82.6 | - | 3 |
| K. Murphy et al., 2009 [7] | k-NN | - | 80 | - | 4.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sekeroglu, K.; Soysal, Ö.M. Multi-Perspective Hierarchical Deep-Fusion Learning Framework for Lung Nodule Classification. Sensors 2022, 22, 8949. https://doi.org/10.3390/s22228949
Sekeroglu K, Soysal ÖM. Multi-Perspective Hierarchical Deep-Fusion Learning Framework for Lung Nodule Classification. Sensors. 2022; 22(22):8949. https://doi.org/10.3390/s22228949
Chicago/Turabian StyleSekeroglu, Kazim, and Ömer Muhammet Soysal. 2022. "Multi-Perspective Hierarchical Deep-Fusion Learning Framework for Lung Nodule Classification" Sensors 22, no. 22: 8949. https://doi.org/10.3390/s22228949