

INV-Flow2PoseNet: Light-Resistant Rigid Object Pose from Optical Flow of RGB-D Images Using Images, Normals and Vertices

Abstract
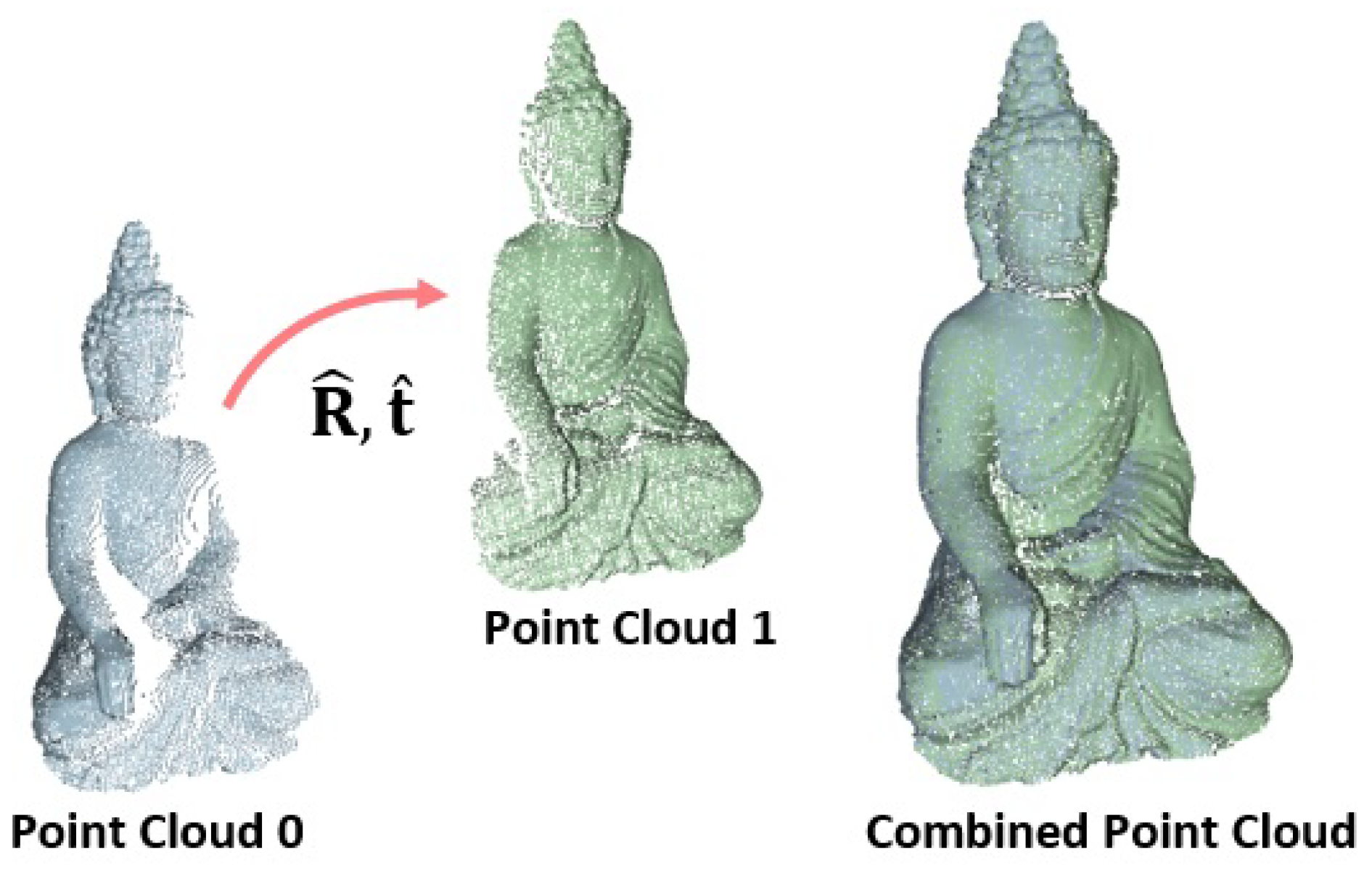
:1. Introduction
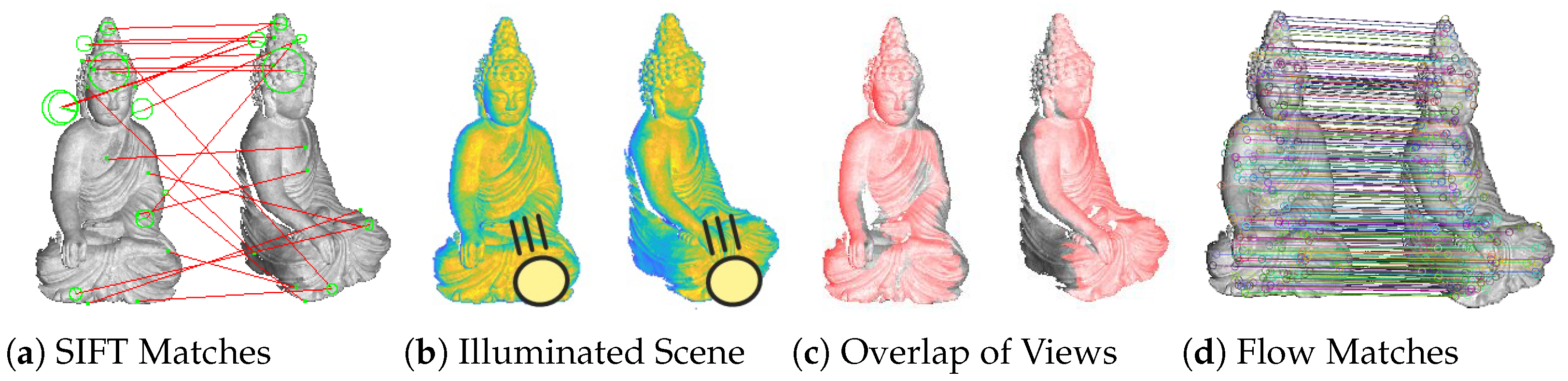
Motivation: Flow-Based Alignment
- Outdoor scenes where lighting conditions can change suddenly. This can occur from direct sun light, as well as indirect light reflections from other objects.
- Moving objects, especially rotating ones, inevitably change the direction of light incidence. This leads in particular to considerable difficulties in the application area of 3D reconstruction, where the object is often rotated in order to capture it successively from all sides.
- Driving cars in the dark may cause strong shading differences in the captured images of the environment. Visible elements in the scene are illuminated by the car’s headlights. These light sources move together with the car through the scene, which may yield strong variation of the direction of light incidence.
2. Related Work
3. Light-Resistant Optical Flow
- The optical flow between calibrated camera images from different perspectives of the same static scene allows theoretically dense point correspondences and accompanying depth data.
- The optical flow between static camera images of a moving scene theoretically allows the analysis of scene motion and object tracking. If depth data are additionally available, the scene flow, i.e., the spatial movement of the points in the scene, can be calculated.
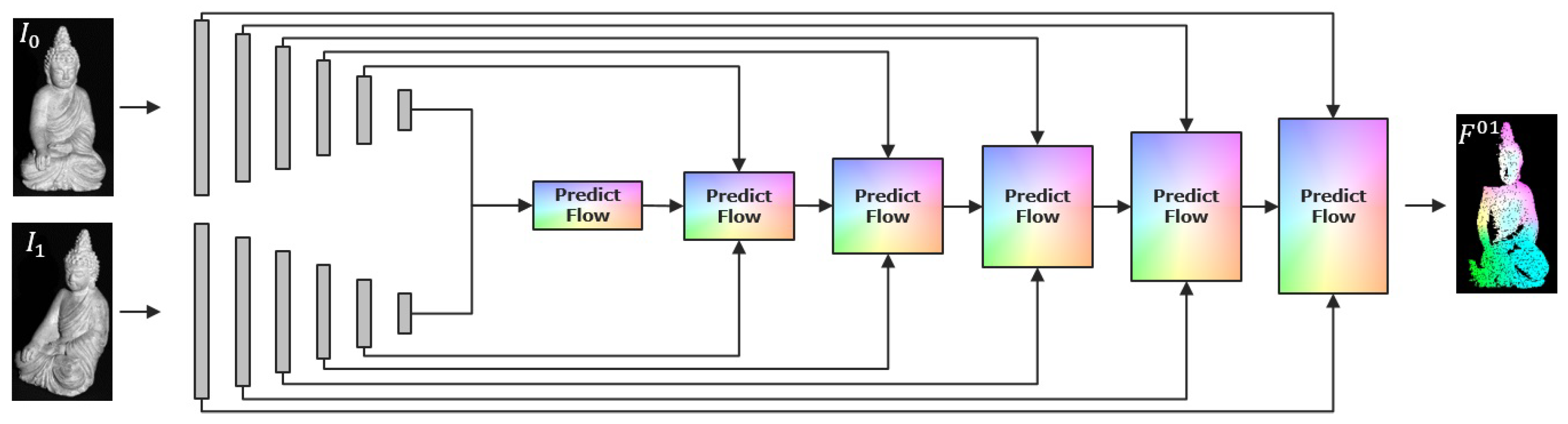
3.1. PWC-Net
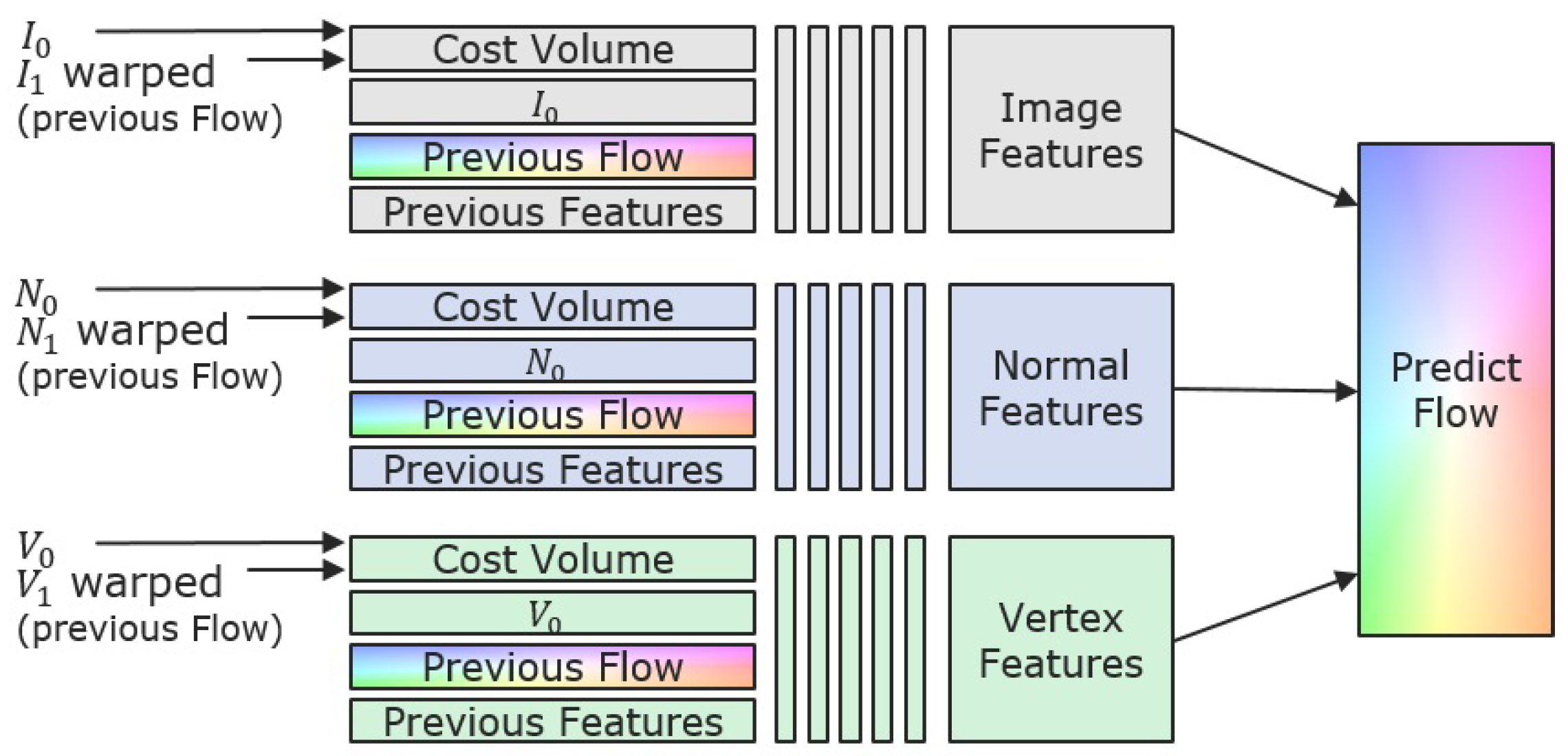
3.2. INV-Net Using Images, Normals and Vertices
- Texture images and that underlay shading effects. Nevertheless, they provide full and dense data, which can deliver local context.
- Depth maps and that store the relative geometrical information of the scene, light- and shading-invariant, with respect to the camera center. Due to measuring errors, there may be outliers or data-less pixels, resulting in semi-dense depth maps.
- Vertex maps and that store the spatial information of the scene, light- and shading-invariant in three channels of a map in image resolution. They are computed from the depth maps and the available camera calibration in order to store the geometrical information calibration independent. Therefore, they are similar to the depth maps semi-dense maps with masked pixels. Moreover, they are structured representations of point clouds that allow for performing neighboring operations on 3D data in 2D space, which yields large advantages in the following approach.
- Normal maps and that store spatial information of the surfaces in the scene. They are related to partial derivatives of the 3D vertices and do not underlay scaling and translation bias. They are in a specific range and responsible for a large amount of shading features of a scene (where standard methods based on fulfilled brightness assumption get a large amount of information from), without being disturbed by the light changes. They can be directly computed from the vertex maps, using the topological information given by the image grid (see [41]). Unfortunately, they thus also inherit the semi-density from underlying vertex maps.
3.2.1. Normalized Convolutions
3.2.2. Consistency Assumptions
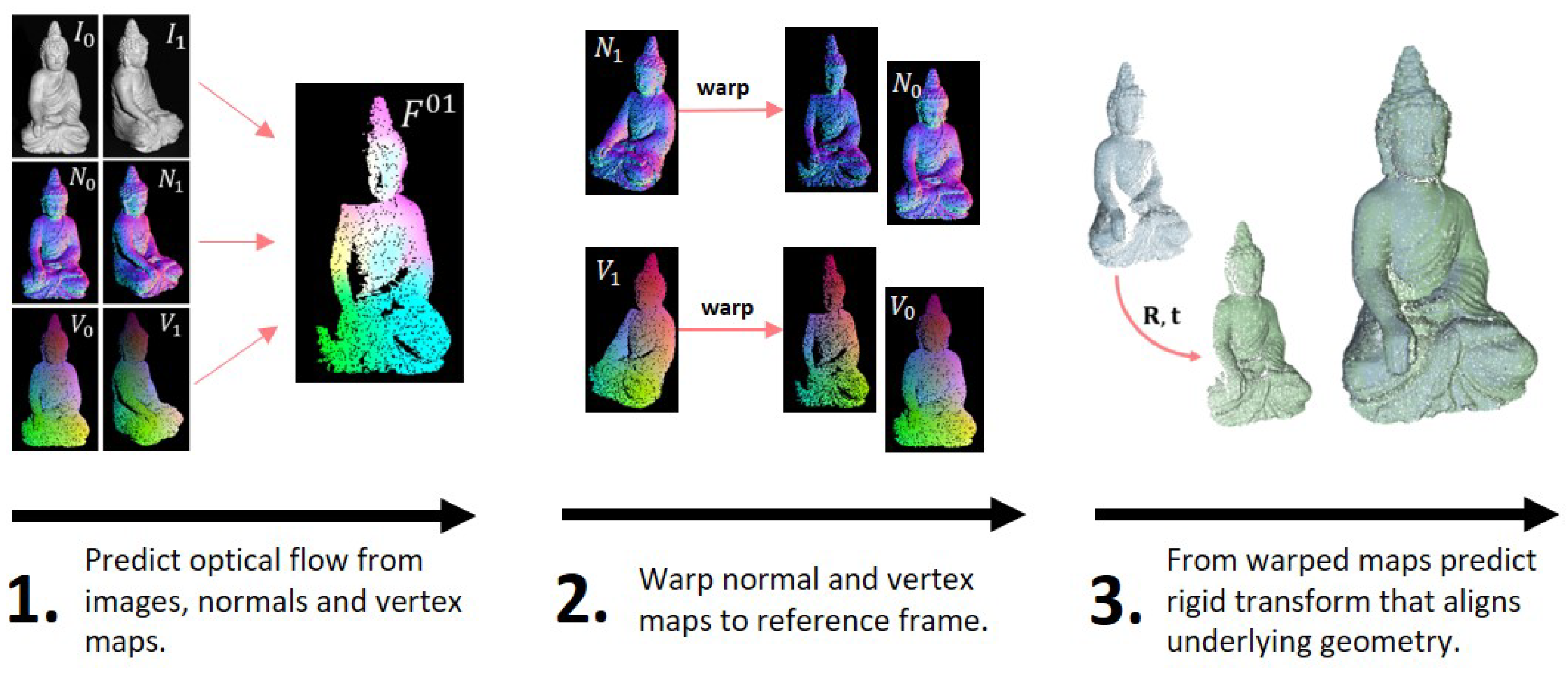
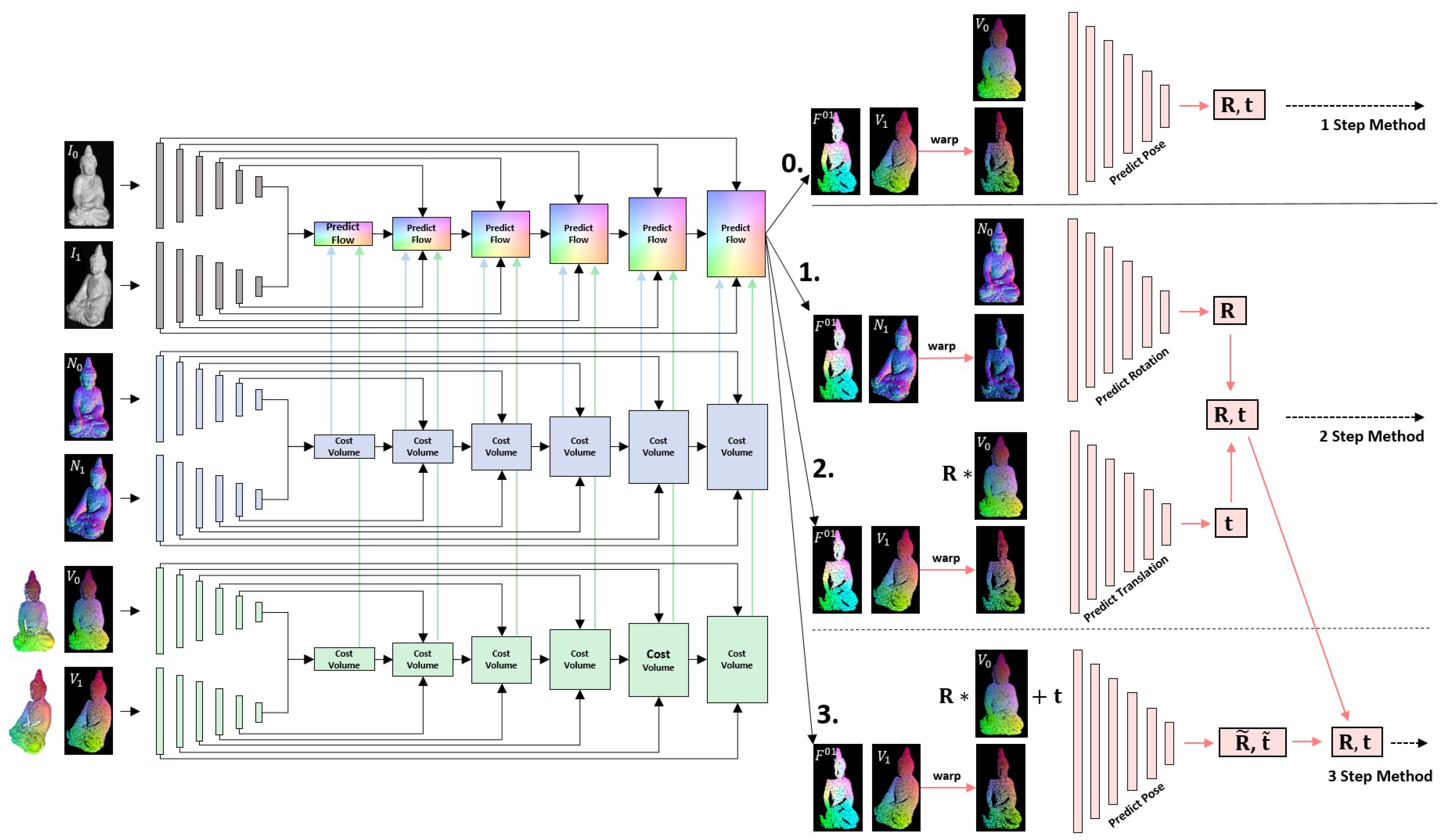
4. Pose from Warped Normals and Vertices
4.1. 1 Step Method
4.2. 2 Step Method
4.3. 3 Step Method
5. Data Sets and Data-Processing
5.1. Data Sources and Data Formats
- image0 and image1 contain the 8-bit integer grayscale images of the two camera views.
- data0 and data1 are .json files that contain the intrinsic calibration matrices , camera rotation and translation , the minimal and maximal depth values and , the minimal and maximals values of the horizontal and vertical optical flows , , and and the coordinates if the light source .
- depth0 and depth1 are 16-bit integer grayscale images that need to be scaled after loading using minimal and maximal depth values from the data files:
- normal0 and normal1 are 24-bit integer RGB images in tangent space that can be re-transformed to spatial space by:
- flow0 and flow1 contain the horizontal and vertical displacements of the respective flow fields between the views. The flows are stored as 16-bit integers in three channel images (flowX, flowY, zeros) and are scaled similar to the depth files.
5.2. Camera Pose and Scene Pose
5.3. Pre- and Post-Processing of Data
6. Coherent Learning of INV-Flow2PoseNet
6.1. Multiscale Endpoint Error
6.2. Alignment Error
6.3. Translational and Rotational Errors
6.4. Joint Training Loss
6.5. Representation of Rotation
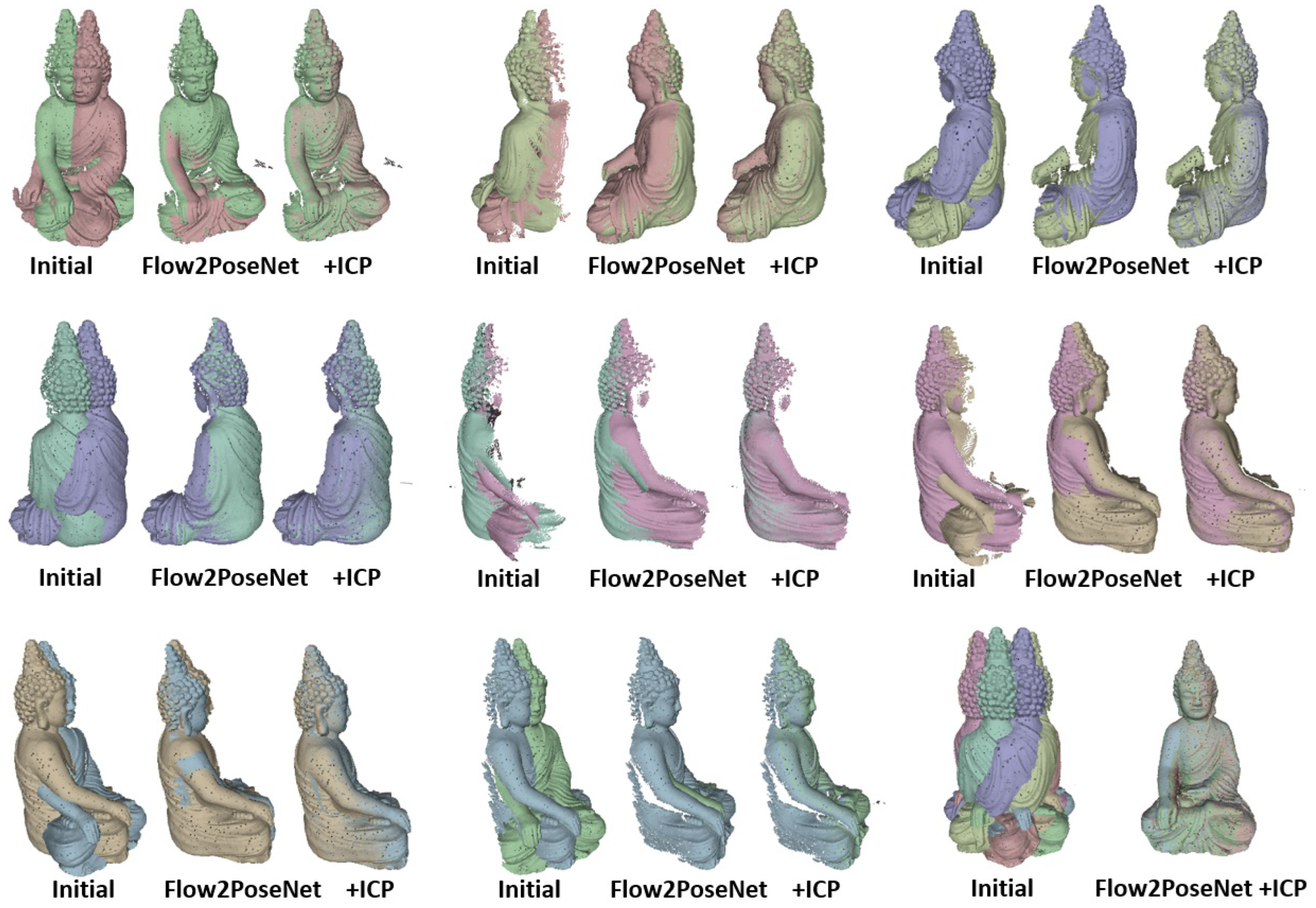
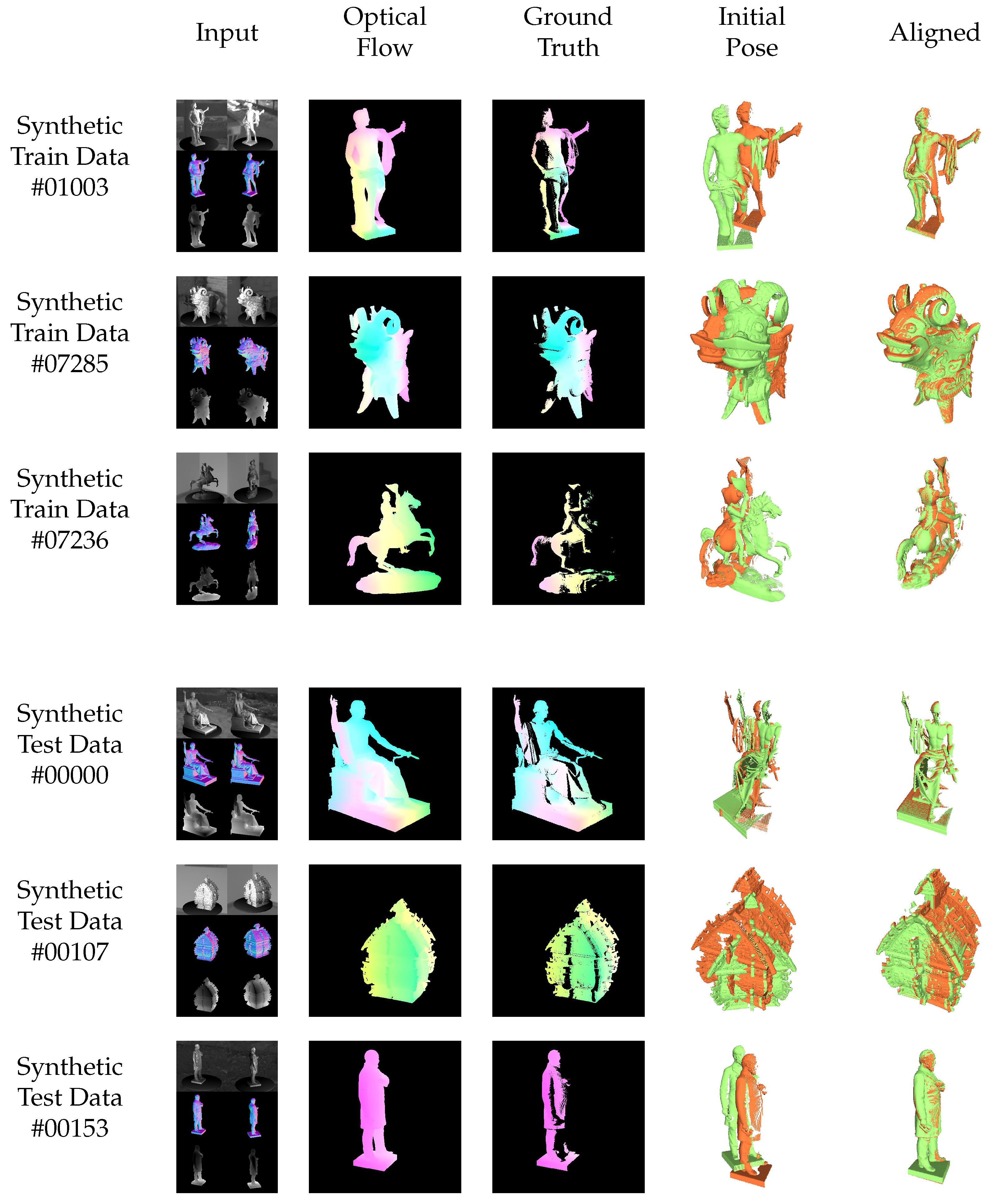
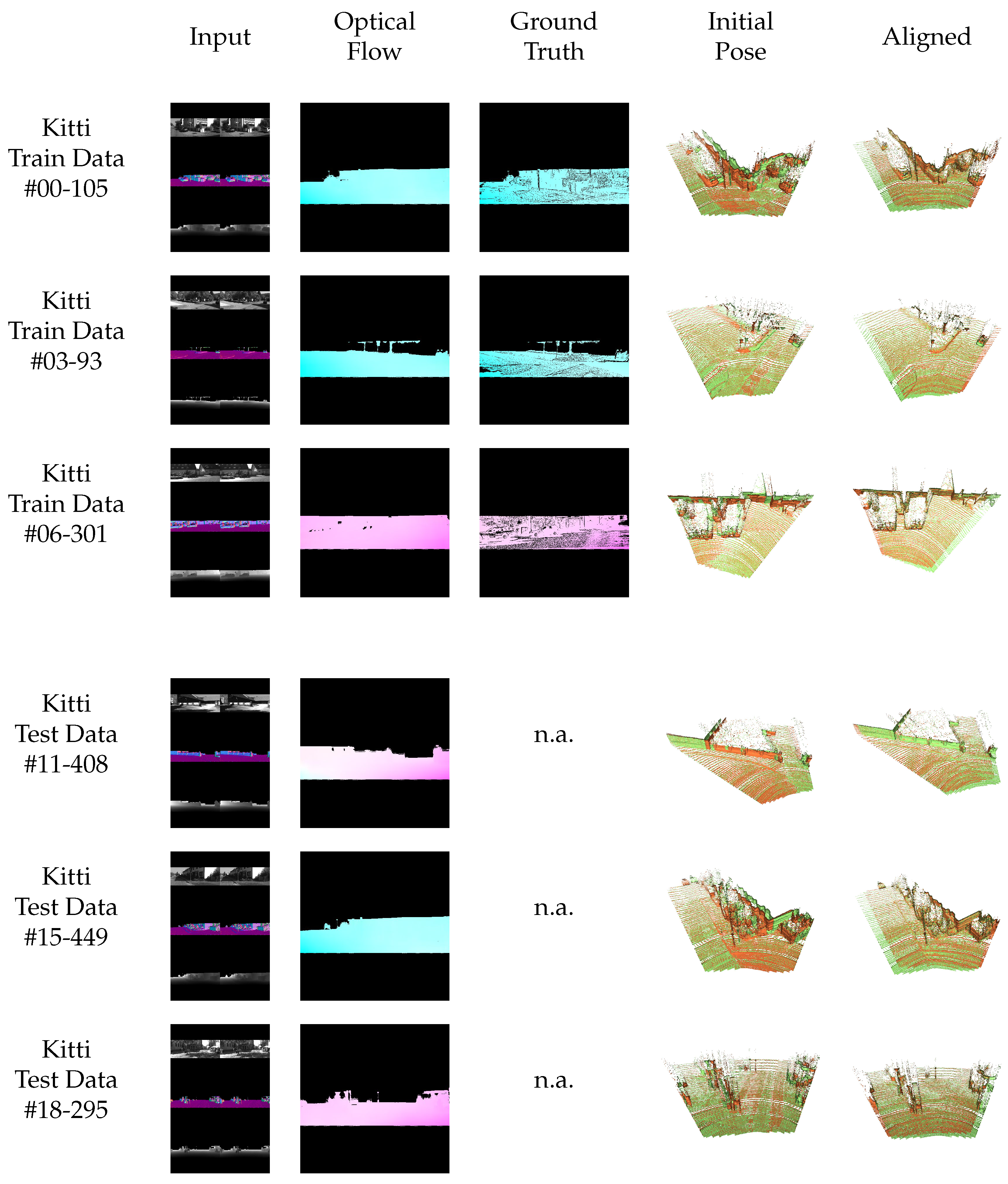
7. Evaluation
7.1. Quantitative Evaluation
7.2. Predicted Dense Optical Flow
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ferraz, L.; Binefa, X.; Moreno-Noguer, F. Very fast solution to the PnP problem with algebraic outlier rejection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 501–508. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Čech, J.; Sanchez-Riera, J.; Horaud, R. Scene flow estimation by growing correspondence seeds. In Proceedings of the CVPR 2011, Washington, DC, USA, 20–25 June 2011; IEEE: Manhattan, NY, USA; pp. 3129–3136. [Google Scholar]
- Huguet, F.; Devernay, F. A variational method for scene flow estimation from stereo sequences. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Daejeon, Korea, 5–6 November 2007; IEEE: Manhattan, NY, USA; pp. 1–7. [Google Scholar]
- Isard, M.; MacCormick, J. Dense motion and disparity estimation via loopy belief propagation. In Proceedings of the Asian Conference on Computer Vision, Hyderabad, India, 13–16 January 2006; Springer: Cham, Switzerland; pp. 32–41. [Google Scholar]
- Li, R.; Sclaroff, S. Multi-scale 3D scene flow from binocular stereo sequences. Comput. Vis. Image Underst. 2008, 110, 75–90. [Google Scholar] [CrossRef] [Green Version]
- Basha, T.; Moses, Y.; Kiryati, N. Multi-view scene flow estimation: A view centered variational approach. Int. J. Comput. Vis. 2013, 101, 6–21. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Oh, T.H.; Jung, J.; Tai, Y.W.; Kweon, I.S. A tensor voting approach for multi-view 3D scene flow estimation and refinement. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Cham, Switzerland; pp. 288–302. [Google Scholar]
- Zhang, X.; Chen, D.; Yuan, Z.; Zheng, N. Dense scene flow based on depth and multi-channel bilateral filter. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Cham, Switzerland; pp. 140–151. [Google Scholar]
- Ferstl, D.; Reinbacher, C.; Riegler, G.; Rüther, M.; Bischof, H. aTGV-SF: Dense variational scene flow through projective warping and higher order regularization. In Proceedings of the 2014 2nd International Conference on 3D Vision, Tokyo, Japan, 8–11 December 2014; IEEE: Manhattan, NY, USA; Volume 1, pp. 285–292. [Google Scholar]
- Letouzey, A.; Petit, B.; Boyer, E. Scene flow from depth and color images. In Proceedings of the BMVC 2011-British Machine Vision Conference, Dundee, Scotland, 30 August–1 September 2011; BMVA Press: Dundee, UK. [Google Scholar]
- Gottfried, J.M.; Fehr, J.; Garbe, C.S. Computing range flow from multi-modal kinect data. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 26–28 September 2011; Springer: Cham, Switzerland; pp. 758–767. [Google Scholar]
- Herbst, E.; Ren, X.; Fox, D. Rgb-d flow: Dense 3-d motion estimation using color and depth. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Kagawa, Japan, 6–10 May 2013; IEEE: Manhattan, NY, USA; pp. 2276–2282. [Google Scholar]
- Quiroga, J.; Brox, T.; Devernay, F.; Crowley, J. Dense semi-rigid scene flow estimation from rgbd images. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; Springer: Cham, Switzerland; pp. 567–582. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar]
- Hur, J.; Roth, S. MirrorFlow: Exploiting symmetries in joint optical flow and occlusion estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 312–321. [Google Scholar]
- Meister, S.; Hur, J.; Roth, S. Unflow: Unsupervised learning of optical flow with a bidirectional census loss. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, Y.; Yang, Y.; Yang, Z.; Zhao, L.; Wang, P.; Xu, W. Occlusion aware unsupervised learning of optical flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4884–4893. [Google Scholar]
- Hur, J.; Roth, S. Iterative residual refinement for joint optical flow and occlusion estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5754–5763. [Google Scholar]
- Hui, T.W.; Tang, X.; Loy, C.C. Liteflownet: A lightweight convolutional neural network for optical flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8981–8989. [Google Scholar]
- Hui, T.W.; Loy, C.C. Liteflownet3: Resolving correspondence ambiguity for more accurate optical flow estimation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland; pp. 169–184. [Google Scholar]
- Liu, P.; Lyu, M.; King, I.; Xu, J. Selflow: Self-supervised learning of optical flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4571–4580. [Google Scholar]
- Jonschkowski, R.; Stone, A.; Barron, J.T.; Gordon, A.; Konolige, K.; Angelova, A. What matters in unsupervised optical flow. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–18 August 2020; Springer: Cham, Switzerland; pp. 557–572. [Google Scholar]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 989–997. [Google Scholar]
- Janai, J.; Guney, F.; Ranjan, A.; Black, M.; Geiger, A. Unsupervised learning of multi-frame optical flow with occlusions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 690–706. [Google Scholar]
- Tu, Z.; Xie, W.; Zhang, D.; Poppe, R.; Veltkamp, R.C.; Li, B.; Yuan, J. A survey of variational and CNN-based optical flow techniques. Signal Process. Image Commun. 2019, 72, 9–24. [Google Scholar] [CrossRef]
- Rishav, R.; Battrawy, R.; Schuster, R.; Wasenmüller, O.; Stricker, D. DeepLiDARFlow: A Deep Learning Architecture For Scene Flow Estimation Using Monocular Camera and Sparse LiDAR. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Manhattan, NY, USA; pp. 10460–10467. [Google Scholar]
- Eldesokey, A.; Felsberg, M.; Khan, F.S. Confidence propagation through cnns for guided sparse depth regression. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2423–2436. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R. Every pixel counts: Unsupervised geometry learning with holistic 3d motion understanding. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 October 2018. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J.B. Df-net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 36–53. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Vijayanarasimhan, S.; Ricco, S.; Schmid, C.; Sukthankar, R.; Fragkiadaki, K. Sfm-net: Learning of structure and motion from video. arXiv 2017, arXiv:1704.07804. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Zhang, Z.; Dai, Y.; Sun, J. Deep learning based point cloud registration: An overview. Virtual Real. Intell. Hardw. 2020, 2, 222–246. [Google Scholar] [CrossRef]
- Villena-Martinez, V.; Oprea, S.; Saval-Calvo, M.; Azorin-Lopez, J.; Fuster-Guillo, A.; Fisher, R.B. When deep learning meets data alignment: A review on deep registration networks (drns). Appl. Sci. 2020, 10, 7524. [Google Scholar] [CrossRef]
- Fragkiadaki, K.; Hu, H.; Shi, J. Pose from flow and flow from pose. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2059–2066. [Google Scholar]
- Piga, N.A.; Onyshchuk, Y.; Pasquale, G.; Pattacini, U.; Natale, L. ROFT: Real-Time Optical Flow-Aided 6D Object Pose and Velocity Tracking. IEEE Robot. Autom. Lett. 2021, 7, 159–166. [Google Scholar] [CrossRef]
- Holzer, S.; Rusu, R.B.; Dixon, M.; Gedikli, S.; Navab, N. Adaptive neighborhood selection for real-time surface normal estimation from organized point cloud data using integral images. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; IEEE: Manhattan, NY, USA; pp. 2684–2689. [Google Scholar]
- Eldesokey, A.; Felsberg, M.; Khan, F.S. Propagating confidences through cnns for sparse data regression. arXiv 2018, arXiv:1805.11913. [Google Scholar]
- Unity Game Engine. Available online: https://unity.com (accessed on 2 December 2021).
- Stanford Scanning Repository. Available online: http://graphics.stanford.edu/data/3Dscanrep/ (accessed on 10 March 2022).
- Zhou, K.; Wang, X.; Tong, Y.; Desbrun, M.; Guo, B.; Shum, H.Y. Texturemontage. In ACM SIGGRAPH 2005 Papers; Association for Computing Machinery: New York, NY, USA, 2005; pp. 1148–1155. [Google Scholar]
- Smithsonian 3D Digitization. Available online: https://3d.si.edu/ (accessed on 10 March 2022).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Light | Consistent | Inconsistent | |||
|---|---|---|---|---|---|
| Data Type | Method | EPE | AE | EPE | AE |
| Train Data | 1 Step | 1.83 | 0.035 | 2.33 | 0.035 |
| Train Data | 3 Step | 1.83 | 0.012 | 2.33 | 0.013 |
| Test Data | 1 Step | 4.09 | 0.037 | 8.08 | 0.048 |
| Test Data | 3 Step | 4.09 | 0.023 | 8.08 | 0.035 |
| Method | EPE | AE | R | t |
|---|---|---|---|---|
| V-LOAM (#2) | n.a. | n.a. | 0.0013 | 0.54 |
| LOAM (#3) | n.a. | n.a. | 0.0013 | 0.55 |
| GLIM (#5) | n.a. | n.a. | 0.0015 | 0.59 |
| CT-ICP (#6) | n.a. | n.a. | 0.0014 | 0.59 |
| SDV-LOAM (#7) | n.a. | n.a. | 0.0015 | 0.60 |
| CT-ICP2 (#8) | n.a. | n.a. | 0.0012 | 0.60 |
| wPICP (#11) | n.a. | n.a. | 0.0015 | 0.62 |
| FBLO (#12) | n.a. | n.a. | 0.0014 | 0.62 |
| HMLO (#14) | n.a. | n.a. | 0.0014 | 0.62 |
| filter-reg (#16) | n.a. | n.a. | 0.0016 | 0.65 |
| MULLS (#19) | n.a. | n.a. | 0.0019 | 0.65 |
| SMTD-LO (#22) | n.a. | n.a. | 0.0020 | 0.66 |
| PICP (#23) | n.a. | n.a. | 0.0018 | 0.67 |
| ELO (#24) | n.a. | n.a. | 0.0021 | 0.68 |
| IMLS-SLAM (#25) | n.a. | n.a. | 0.0018 | 0.69 |
| MC2SLAM (#26) | n.a. | n.a. | 0.0016 | 0.69 |
| ISC-LOAM (#28) | n.a. | n.a. | 0.0022 | 0.72 |
| Test-W (#30) | n.a. | n.a. | 0.0033 | 0.79 |
| PSF-LO (#31) | n.a. | n.a. | 0.0032 | 0.82 |
| S4-SLAM2 (#35) | n.a. | n.a. | 0.0097 | 0.83 |
| LIMO2_GP (#39) | n.a. | n.a. | 0.0022 | 0.84 |
| CAE-LO (#40) | n.a. | n.a. | 0.0025 | 0.86 |
| LIMO2 (#42) | n.a. | n.a. | 0.0022 | 0.86 |
| CPFG-slam (#44) | n.a. | n.a. | 0.0025 | 0.87 |
| SD-DEVO (#49) | n.a. | n.a. | 0.0028 | 0.88 |
| PNDT LO (#50) | n.a. | n.a. | 0.0030 | 0.89 |
| LIMO (#58) | n.a. | n.a. | 0.0026 | 0.93 |
| SuMa-MOS (#67) | n.a. | n.a. | 0.0033 | 0.99 |
| SuMa++ (#69) | n.a. | n.a. | 0.0034 | 1.06 |
| DEMO (#74) | n.a. | n.a. | 0.0049 | 1.14 |
| STEAM-L WNOJ (#83) | n.a. | n.a. | 0.0058 | 1.22 |
| LiViOdo (#84) | n.a. | n.a. | 0.0042 | 1.22 |
| STEAM-L (#87) | n.a. | n.a. | 0.0061 | 1.26 |
| SALO (#93) | n.a. | n.a. | 0.0051 | 1.37 |
| SuMa (#95) | n.a. | n.a. | 0.0034 | 1.39 |
| Flow2PoseNet3 Step | 1.18 | 0.019 | 0.0019 | 2.73 |
| Deep-CLR (#134) | n.a. | n.a. | 0.0104 | 3.83 |
| SLL (#163) | n.a. | n.a. | 0.2645 | 90.05 |
| Consistent Light | ||
|---|---|---|
| Data Type | Visible Points EPE | Invisible Points EPE |
| Train Data | 2.7446 | 3.4978 |
| Test Data | 3.6411 | 4.9284 |
| Inconsistent Light | ||
| Data Type | Visible Points EPE | Invisible Points EPE |
| Train Data | 3.6974 | 5.4024 |
| Test Data | 4.7996 | 4.7703 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fetzer, T.; Reis, G.; Stricker, D. INV-Flow2PoseNet: Light-Resistant Rigid Object Pose from Optical Flow of RGB-D Images Using Images, Normals and Vertices. Sensors 2022, 22, 8798. https://doi.org/10.3390/s22228798
Fetzer T, Reis G, Stricker D. INV-Flow2PoseNet: Light-Resistant Rigid Object Pose from Optical Flow of RGB-D Images Using Images, Normals and Vertices. Sensors. 2022; 22(22):8798. https://doi.org/10.3390/s22228798
Chicago/Turabian StyleFetzer, Torben, Gerd Reis, and Didier Stricker. 2022. "INV-Flow2PoseNet: Light-Resistant Rigid Object Pose from Optical Flow of RGB-D Images Using Images, Normals and Vertices" Sensors 22, no. 22: 8798. https://doi.org/10.3390/s22228798