
One-Class Convolutional Neural Networks for Water-Level Anomaly Detection

Abstract
:1. Introduction
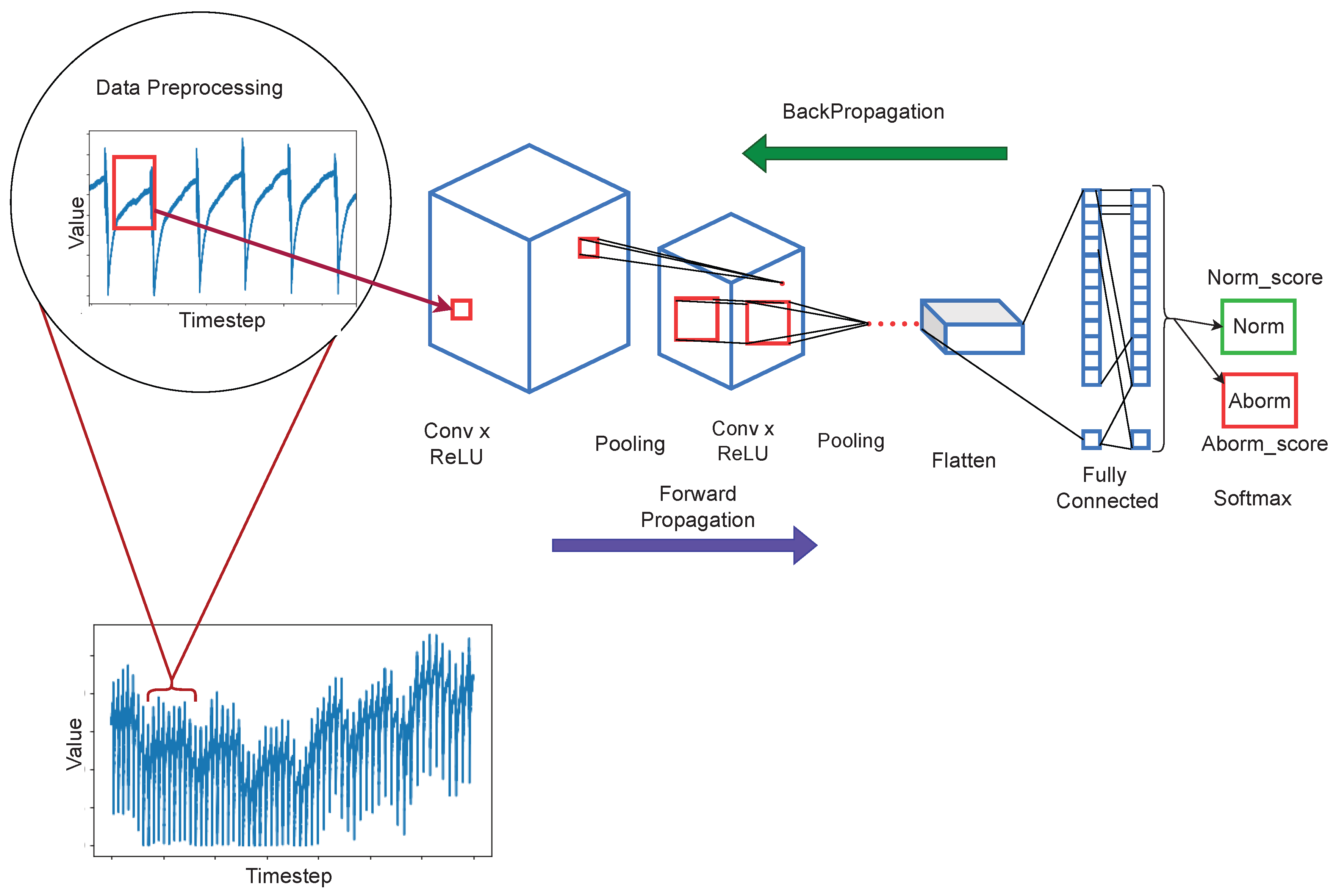
- We extensively investigated the potential of 2D Convolutional Neural Networks for temporal data one-class classification. We aimed to use CNN models as feature extractors and classifiers to build an end-to-end anomaly detection system. We successfully trained the system on normal (collected sensor) and abnormal (synthetic generated) data, then evaluated it using test data containing both normal and abnormal data points.
- We explored the knowledge transfer across domains that is between two unrelated tasks. This task intended to explore a similar learning paradigm as that of transfer learning between the image classification and natural language processing. The difference is that we used fully trained models for image classification which have never learned time-series data for classification. The OC-CNN achieved our goal by partially training the pre-trained images classification model using our dataset and performing a classification task.
- And we provide detailed experiments, results, analyses, and discussions that give new insights on how to deal with data absence in time-series problems and present the readers with informative findings.
2. Related Work
2.1. One-Class Classification
2.2. Transfer Learning
3. Methodology
3.1. Synthetic Data Generation
3.2. Anomaly Detector
3.2.1. Transfer Learning
3.2.2. Custom Model
3.3. Loss Function and Evaluation Metrics
3.4. Evaluation Metric
Receiver Operating Characteristics
4. Experiment
4.1. Datasets Description
4.2. Experiment Design
4.2.1. ARIMA
4.2.2. HS-TCN
5. Results
5.1. Data Validity Analysis
- Using synthetic data as the pseudo-class is a promising direction because of the model performance improvement achieved after only changing the pseudo-class data from random or Gaussian noise to synthetic generated data.
- Transfer learning should be dealt with consideration that underfitting can happen because the transferred model is too complicated for training data (see Section 5.2).
5.2. Model Architecture Analysis
5.3. Comparison with Other Methods
6. Discussion
6.1. Effectiveness of the OC-CNN
6.2. Limitation of the OC-CNN
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ARIMA | Autoregressive Integrated Moving Average Model |
| AUC | Area Under the Curve |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| DBN | Deep Belief Network |
| DNN | Deep Neural Network |
| AE | AutoEncoder |
| GAN | Generative Adversarial Network |
| IT | Information Technology |
| KNN | K-Nearest Neighbors |
| LSTM | Long Short-Term Memory |
| OCC | One-Class Classification |
| OC-SVM | One-Class Support Vector Machine |
| RNN | Recurrent Neural Network |
| SVVD | Support Vector Data Description |
References
- León, R.; Vittal, V.; Manimaran, G. Application of sensor network for secure electric energy infrastructure. IEEE Trans. Power Deliv. 2007, 22, 1021–1028. [Google Scholar] [CrossRef]
- Djurdjanovic, D.; Lee, J.; Ni, J. Watchdog Agent—An infotronics-based prognostics approach for product performance degradation assessment and prediction. Adv. Eng. Inform. 2003, 17, 109–125. [Google Scholar] [CrossRef]
- Sejnowski, T.J. The unreasonable effectiveness of deep learning in artificial intelligence. Proc. Natl. Acad. Sci. USA 2020, 117, 30033–30038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Abraham, B.; Chuang, A. Outlier detection and time series modeling. Technometrics 1989, 31, 241–248. [Google Scholar] [CrossRef]
- Duffield, N.; Haffner, P.; Krishnamurthy, B.; Ringberg, H. Rule-based anomaly detection on IP flows. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 424–432. [Google Scholar]
- Salvador, S.; Chan, P.K.; Brodie, J. Learning States and Rules for Time Series Anomaly Detection. In Proceedings of the FLAIRS, Miami, FL, USA, 17–19 May 2004. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Rebbapragada, U.; Protopapas, P.; Brodley, C.E.; Alcock, C. Finding anomalous periodic time series. Mach. Learn. 2009, 74, 281–313. [Google Scholar] [CrossRef]
- Nebauer, C. Evaluation of convolutional neural networks for visual recognition. IEEE Trans. Neural Netw. 1998, 9, 685–696. [Google Scholar] [CrossRef]
- Medsker, L.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015; Volume 89, pp. 89–94. [Google Scholar]
- Kim, J.; Kim, J.; Thu, H.L.T.; Kim, H. Long short term memory recurrent neural network classifier for intrusion detection. In Proceedings of the 2016 International Conference on Platform Technology and Service (PlatCon), Jeju, Korea, 15–17 February 2016; pp. 1–5. [Google Scholar]
- Wang, H.; Wang, L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 499–508. [Google Scholar]
- Xiao, T.; Zhang, J.; Yang, K.; Peng, Y.; Zhang, Z. Error-driven incremental learning in deep convolutional neural network for large-scale image classification. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 177–186. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, The 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lioutas, V.; Guo, Y. Time-aware large kernel convolutions. In Proceedings of the International Conference on Machine Learning. PMLR; ACM: New York, NY, USA, 2020; pp. 6172–6183. [Google Scholar]
- Binkowski, M.; Marti, G.; Donnat, P. Autoregressive convolutional neural networks for asynchronous time series. In Proceedings of the International Conference on Machine Learning. PMLR; ACM: New York, NY, USA, 2018; pp. 580–589. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Patcha, A.; Park, J.M. An overview of anomaly detection techniques: Existing solutions and latest technological trends. Comput. Netw. 2007, 51, 3448–3470. [Google Scholar] [CrossRef]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly Detection using One-Class Neural Networks. arXiv 2018, arXiv:1802.06360. [Google Scholar]
- Oza, P.; Patel, V.M. One-class convolutional neural network. IEEE Signal Process. Lett. 2018, 26, 277–281. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Cheng, Y.; Xu, Y.; Zhong, H.; Liu, Y. HS-TCN: A semi-supervised hierarchical stacking temporal convolutional network for anomaly detection in IoT. In Proceedings of the 2019 IEEE 38th International Performance Computing and Communications Conference (IPCCC), London, UK, 29–31 October 2019; pp. 1–7. [Google Scholar]
- Khan, S.S.; Madden, M.G. One-class classification: Taxonomy of study and review of techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef] [Green Version]
- Datta, P. Characteristic Concept Representations; University of California: Irvine, CA, USA, 1997. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef] [Green Version]
- Thill, M.; Konen, W.; Wang, H.; Bäck, T. Temporal Convolutional Autoencoder for Unsupervised Anomaly Detection in Time Series. Appl. Soft Comput. 2021, 112, 107751. [Google Scholar] [CrossRef]
- Nicholaus, I.T.; Park, J.R.; Jung, K.; Lee, J.S.; Kang, D.K. Anomaly Detection of Water Level Using Deep Autoencoder. Sensors 2021, 21, 6679. [Google Scholar] [CrossRef]
- Zhu, J.; Deng, F.; Zhao, J.; Chen, J. Adaptive Aggregation-distillation Autoencoder for Unsupervised Anomaly Detection. Pattern Recognit. 2022, 131, 108897. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Rajendran, A.; Pelusi, D.; Ponnusamy, V. Deep Belief Network Enhanced Intrusion Detection System to Prevent Security Breach In the Internet of Things. Internet Things 2021, 14, 100112. [Google Scholar] [CrossRef]
- Sohn, I. Deep Belief Network Based Intrusion Detection Techniques: A survey. Expert Syst. Appl. 2021, 167, 114170. [Google Scholar] [CrossRef]
- Kumar, T.S.; Arun, C.; Ezhumalai, P. An approach for Brain Tumor Detection Using Optimal Feature Selection and Optimized Deep Belief Network. Biomed. Signal Process. Control 2022, 73, 103440. [Google Scholar] [CrossRef]
- Wu, P.; Harris, C.A.; Salavasidis, G.; Lorenzo-Lopez, A.; Kamarudzaman, I.; Phillips, A.B.; Thomas, G.; Anderlini, E. Unsupervised Anomaly Detection for Underwater Gliders Using Generative Adversarial Networks. Eng. Appl. Artif. Intell. 2021, 104, 104379. [Google Scholar] [CrossRef]
- Montenegro, J.; Chung, Y. Semi-supervised Generative Adversarial Networks for Anomaly Detection. In Proceedings of the SHS Web of Conferences; EDP Sciences: Les Ulis, France, 2022; Volume 132, p. 01016. [Google Scholar]
- Sevyeri, L.R.; Fevens, T. AD-CGAN: Contrastive Generative Adversarial Network for Anomaly Detection. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; Springer: Cham, Switzerland, 2022; pp. 322–334. [Google Scholar]
- Perera, P.; Patel, V.M. Learning deep features for one-class classification. IEEE Trans. Image Process. 2019, 28, 5450–5463. [Google Scholar] [CrossRef] [Green Version]
- Zhu, G.; Zhao, H.; Liu, H.; Sun, H. A Novel LSTM-GAN Algorithm for Time Series Anomaly Detection. In Proceedings of the 2019 Prognostics and System Health Management Conference (PHM-Qingdao), Qingdao, China, 25–27 October 2019; pp. 1–6. [Google Scholar]
- Chadha, G.S.; Islam, I.; Schwung, A.; Ding, S.X. Deep Convolutional Clustering-Based Time Series Anomaly Detection. Sensors 2021, 21, 5488. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1367–1376. [Google Scholar]
- Wen, T.; Keyes, R. Time Series Anomaly Detection Using Convolutional Neural Networks and Transfer Learning. arXiv 2019, arXiv:1905.13628. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Maat, J.R.; Malali, A.; Protopapas, P. TimeSynth: A Multipurpose Library for Synthetic Time Series in Python. Available online: http://github.com/TimeSynth/TimeSynth (accessed on 5 September 2022).
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- He, Y.; Zhao, J. Temporal convolutional networks for anomaly detection in time series. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2019; p. 042050. [Google Scholar]



{kind=link}
{kind=link}
| Predicted–Positive | Predicted–Negative | |
|---|---|---|
| Actual–Positive | ||
| Actual–Negative |
| Dataset | ITs | Acc | PR | RC | F1 | AUC | |
|---|---|---|---|---|---|---|---|
| Res1 | T1 | 8000 | 0.464 | 0.609 | 0.372 | 0.462 | 0.522 |
| T1 | 10,000 | 0.830 | 0.828 | 0.392 | 0.494 | 0.564 | |
| T2 | 8000 | 0.893 | 0.793 | 0.569 | 0.662 | 0.595 | |
| T2 | 10,000 | 0.902 | 0.859 | 0.581 | 0.693 | 0.649 | |
| Res2 | T1 | 8000 | 0.884 | 0.706 | 0.186 | 0.294 | 0.509 |
| Res3 | T2 | 8000 | 0.818 | 0.232 | 0.235 | 0.234 | 0.505 |
| Dataset | ITs | Acc | PR | RC | F1 | AUC |
|---|---|---|---|---|---|---|
| T1 | 40,000 | 0.442 | 1.000 | 0.280 | 0.437 | 0.617 |
| 10,000 | 0.901 | 1.000 | 0.664 | 0.798 | 0.798 | |
| 4000 | 88.902 | 1.000 | 0.641 | 0.781 | 0.623 | |
| 2000 | 0.917 | 0.999 | 0.937 | 0.967 | 0.912 | |
| T2 | 40,000 | 0.544 | 0.890 | 0.28 | 0.437 | 0.532 |
| 10,000 | 0.839 | 0.901 | 0.693 | 0.798 | 0.624 | |
| 4000 | 0.968 | 0.983 | 0.845 | 0.887 | 0.841 | |
| 2000 | 0.909 | 0.987 | 0.902 | 0.943 | 0.896 |
| ARIMA | HS-TCN | Our OC-CNN | |||||
|---|---|---|---|---|---|---|---|
| F1 | AUC | F1 | AUC | F1 | AUC | ||
| Dataset | T1 | 0.494 | 0.521 | 0.812 | 0.733 | 0.963 | 0.922 |
| T2 | 0.029 | 0.500 | 0.693 | 0.652 | 0.954 | 0.887 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nicholaus, I.T.; Lee, J.-S.; Kang, D.-K. One-Class Convolutional Neural Networks for Water-Level Anomaly Detection. Sensors 2022, 22, 8764. https://doi.org/10.3390/s22228764
Nicholaus IT, Lee J-S, Kang D-K. One-Class Convolutional Neural Networks for Water-Level Anomaly Detection. Sensors. 2022; 22(22):8764. https://doi.org/10.3390/s22228764
Chicago/Turabian StyleNicholaus, Isack Thomas, Jun-Seoung Lee, and Dae-Ki Kang. 2022. "One-Class Convolutional Neural Networks for Water-Level Anomaly Detection" Sensors 22, no. 22: 8764. https://doi.org/10.3390/s22228764