1. Introduction
Type 1 diabetes (T1D) is a chronic autoimmune disease that impairs insulin production. As a consequence, T1D individuals are required to maintain their blood glucose (BG) in a safe range (70–180 mg/dL) via insulin injections, carbohydrate (CHO) intake, and physical exercise to avoid the consequences of harmful events, known as hyperglycemia (BG > 180 mg/dL) and hypoglycemia (BG < 70 mg/dL). Mitigating the duration and the occurrence of these episodes is the main goal of the standard T1D therapy, which also requires frequently monitoring BG concentrations to correctly tune the amount of CHO and insulin boluses to administer along the day. In the last 15 years, continuous glucose monitoring (CGM) sensors have become a widely used tool for real-time BG monitoring in T1D management. These devices provide BG levels almost continuously (i.e., from 1 up to 5 min) for several days [
1,
2] and often embed visual and acoustic alerts when BG exceeds the normal glucose ranges. These devices have been proven to ease the daily routine burden of T1D individuals and to improve the control of BG inside the desired glucose range (70–180 mg/dL) [
3]. However, CGM-based preventive alerts triggered before reaching critical levels would be even more helpful than detecting events already started. In fact, preventive warnings enable targeted measures to avoid or mitigate harmful episodes. The prediction of future BG levels enables several applications that can improve the management of T1D, for instance:
In insulin pump systems, it can (and in some systems, it does [
4]) trigger insulin delivery suspensions [
5,
6,
7], if a hypoglycemic episode is predicted;
In a decision support system (DSS)—a composite tool that implements multiple algorithms to support the patient in the decision-making process—glucose prediction can be used to suggest the correct amount of CHO to avoid low glucose values [
8,
9];
In artificial pancreas systems (AP) [
10,
11], BG prediction uses by closed-loop control algorithms to automatically increase or decrease insulin delivery.
For these reasons, there have been several research efforts investigated BG prediction [
12] in order to develop methodologies for an accurate prediction of the future BG concentrations. In particular, two main categories can be found: algorithms fed only by the past history of the CGM signal, such as [
6,
13,
14,
15], or fed by CGM data plus additional information such as insulin, CHO, or physical exercise, as in [
16,
17]. Moreover, as demonstrated in several comprehensive reviews about glucose prediction algorithms [
12,
18], the diabetes research community has intensively focused on developing black-box methodologies, using techniques developed in the field of time series forecasting, system identification, and machine and deep learning [
19,
20,
21,
22,
23,
24].
Among the possible approaches for glucose prediction, the use of stochastic seasonal models, as well as clustering techniques is still only partially explored in the literature. In fact, seasonal models were introduced for the first time in [
25], and the combined use of seasonal models along with clustering techniques was introduced in [
26,
27]. In these works, the methodology was developed and validated only on well-controlled datasets: the first [
26] was recorded during in-hospital clinical trials, while the second one [
27] was obtained by exploiting the educational version of the UVA/Padova simulator [
28]. In both cases, the results were encouraging since the proposed approach based on seasonal models and clustering outperformed all the state-of-the-art techniques for BG prediction. However, a real-time assessment on data recorded in free-living conditions is still needed. In fact, dealing with real data poses some issues about the completeness and reliability of stored information, which can degrade the ability of the algorithms to accurately forecast BG levels [
16,
18]. Moreover, glucose dynamics recorded in free-living conditions can be much more complex to describe than the ones obtained by simulations or others recorded during in-hospital trial sessions, since in the first case, the patient is exposed to substantially larger disturbances to glucose homeostasis.
The aim of this work is to fill this gap by providing an assessment of the clustering and seasonal local modeling methodology for glucose prediction proposed in [
26,
27] on two real datasets of different sizes (11 and 13 subjects monitored for 8 weeks and about 5 months, respectively) and obtained with different insulin dosing strategies (manual open-loop and closed-loop control). For each subject, CGM postprandial periods are grouped into clusters, and then, for each cluster, an optimal seasonal autoregressive integrated moving average (SARIMA) model is identified. Finally, the real-time BG forecasting is performed by weighting the prediction of each model. Considering several prediction horizons (PHs), the predictive performance of the proposed methodology (named C-SARIMA) is compared with that of different approaches: an individualized autoregressive integrated moving average (ARIMA) model and a feed-forward neural network (NN) based on CGM data only; an individualized autoregressive integrated moving average with exogenous inputs (ARIMAX) model and a variant of the NN, namely NN-X, fed by CGM, insulin, and CHO information (timing and amount). Notably, previous studies showed that the ARIMA is the best-performing linear algorithm for blood glucose forecasting using CGM data only [
29], while its extension, ARIMAX, is one of the most-suitable options when additional information, such as insulin and CHO information, is available. Notably, both the ARIMA and ARIMAX models allow achieving accurate prediction performance even if compared to other nonlinear and more complex algorithms [
16,
29,
30]. Our work demonstrates that, for PH > 45 min, the C-SARIMA outperforms individualized ARIMA models and there is no statistically significant difference when compared to individualized ARIMAX with the practical advantage of the minimal input information needed (i.e., meal timing).
3. Results
In this section, the performance of the proposed approach is presented. The novel approach is indicated as C-SARIMA in
Table 3 and
Table 4, with respect to the benchmark algorithms. All the algorithms were evaluated both on the OhioT1DM and CTR3 datasets.
Table 3 shows the results for OhioT1DM. Statistical significance was determined using a paired
t-test if normality was accepted and a Wilcoxon signed-rank test if normality was rejected. The cross (+) indicates that there was a statistically significant difference (ssd) between the C-SARIMA and ARIMA. The asterisk (*) indicates that there was an ssd between the C-SARIMA and ARIMAX. The circumflex (^) indicates that there was an ssd between the C-SARIMA and NN. " indicates that there was an ssd between the C-SARIMA and NN-X.
At the short-term prediction horizon (i.e., ≤45 min), the proposed approach achieved similar performance to the individualized ARIMA model: there was no statistically significant difference among the two techniques. In particular, the RMSE provided by the proposed methodology was slightly higher (20.13 mg/dL vs. 19.64 mg/dL and 27.23 mg/dL vs. 26.91 mg/dL, for PH = 30, 45, respectively). However, for the long-term prediction horizon (i.e., ≥60 min), the performance of the C-SARIMA outperformed the ARIMA models (RMSE = 31.96 mg/dL vs. 33.67 mg/dL and 38.82 mg/dL vs. 33.91 mg/dL). In particular, for PH = 60 and 75 min, the difference was found to be statistically significant (p-values < 0.05). The NN performed similarly to the C-SARIMA (median RMSE of 20.11 mg/dL, 26.41 mg/dL and 32.11 mg/dL), and no statistically significant difference in the RMSE was found for PH ≤ 60 min. On the contrary, the C-SARIMA outperformed the NN for PH = 75 min by granting an RMSE = 33.91 mg/dL vs. 35.18 mg/dL (p-value < 0.05). Comparing the C-SARIMA with individualized ARIMAX models, it can be found that, for PH ≤ 45 min, the best results were obtained by individualized ARIMAX models (RMSE 18.73 mg/dL vs. 20.13 mg/dL and 26.46 mg/dL vs. 27.23 mg/dL). However, for PH = 60, 75 min, the C-SARIMA models provided results that did not differ in a statistically significant manner from the ARIMAX. Finally, the NN-X provided better results with respect to the C-SARIMA for PH ≤ 60 min: the RMSE was 17.78 mg/dL, 25.68 mg/dL, and 30.67 mg/dL, while no significant improvement was found for PH = 75 min (RMSE = 33.91 mg/dL vs. 34.06 mg/dL).
Table 4 shows the results for the CTR3 dataset. As for OhioT1DM, for short-term PH, the C-SARIMA provided similar performance to an individualized ARIMA, i.e., there was no significant improvement if compared to individualized ARIMA models: the median RMSE was 21.63 mg/dL vs. 21.02 mg/dL and 29.67 mg/dL vs. 29.42 mg/dL, for PH = 30 and PH = 45 min. However, for PH = 60 min and PH = 75 min, the proposed methodology outperformed the competitor, providing a statistically significant difference (median RMSE = 33.47 mg/dL vs. 35.38 mg/dL and 40.18 mg/dL vs. 44.01 mg/dL, respectively). The NN had performance comparable to the C-SARIMA for all the PHs ≤ 60 (median RMSE of 21.78 mg/dL, 30.64 mg/dL, 34.21 mg/dL) and inferior prediction for PH = 75 min (42.60 mg/dL vs. 40.18,
p-value < 0.05).
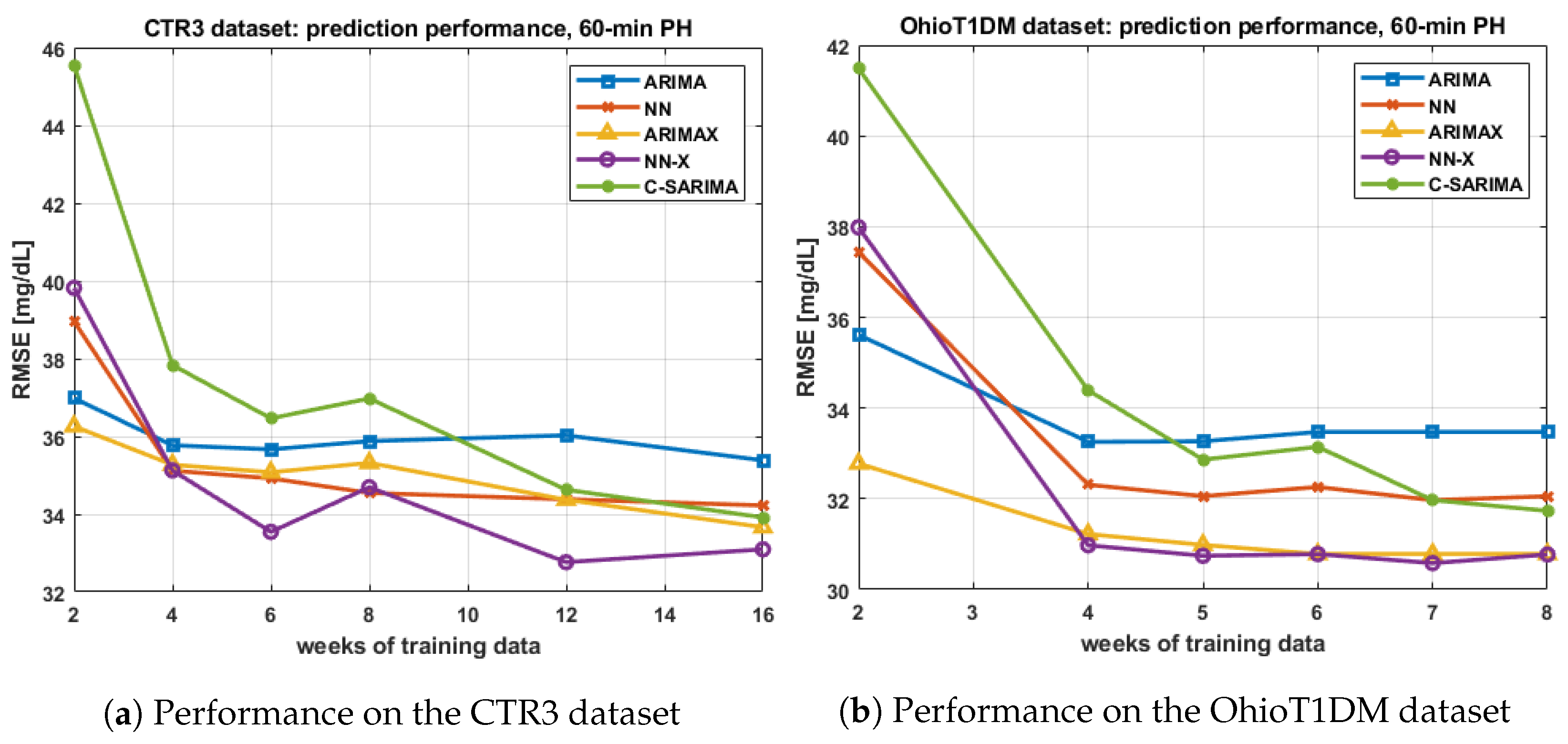
A further assessment of the performance of algorithms using the same amount of information and an analysis of the performance when the size of the training set is varied are reported in
Appendix A and
Appendix B, respectively.
4. Discussion
The results among the two datasets were consistent: the proposed methodology based on clustering and the SARIMA models had comparable or superior performance with respect to one of the best-performing linear algorithms based on CGM data only, i.e., the individualized ARIMA model. In particular, the C-SARIMA outperformed the ARIMA for PH = 60 and 75 min. Furthermore, the results showed that the C-SARIMA was able to provide similar performance or slightly superior performance to a state-of-the-art nonlinear method for glucose prediction (NN). In particular, such a difference was found to be statistically significant for PH = 75 min.
The second linear comparator was an individualized ARIMAX model, which was expected to enhance prediction performance due to the use of additional information carried by insulin and CHO. In this comparison, the proposed approach provided performance that was not significantly different from the ARIMAX for PH = 45, 60, and 75 min. This is remarkable since the SARIMA and clustering-based approach use less information, CGM and mealtime only, while the ARIMAX also requires information about the CHO ingested and the amount of insulin administered, which represents a non-negligible drawback since the estimation of the correct amount of CHO and insulin is critical for subjects with T1D [
37].
For the OhioT1DM dataset, a similar finding seems to hold also for the nonlinear comparator with inputs (NN-X). On the CTR3 dataset, no significant difference was found for PH = 60 min, whereas a significant (albeit hardly practically relevant) improvement was given by the NN-X with respect to the C-SARIMA for PH = 45 and 75 min. However, it is worth noting that on the OhioT1DM dataset, such an improvement was usually larger for short-term PH, but it became minor for long-term predictions.
When dealing with real data acquired in free-living conditions, the glucose response after meal intakes exhibits a wide range of variability. This variability forced the clustering step to use an increased number of clusters if compared to the results obtained on simulated datasets [
27]. In fact, after the cluster optimization procedure, the mean number of clusters per subject was 16, while in [
27], it was about 10. Being the first step of the pipeline, a successful clustering of the PPs is crucial for the success of the entire proposed methodology. In fact, if it provides several sets of “similar” glycemic responses, the resulting artificial seasonal CGM time series will show regular patterns periodically repeated. If this condition is satisfied, this leads to a better identification of SARIMA models and to an increased prediction accuracy.
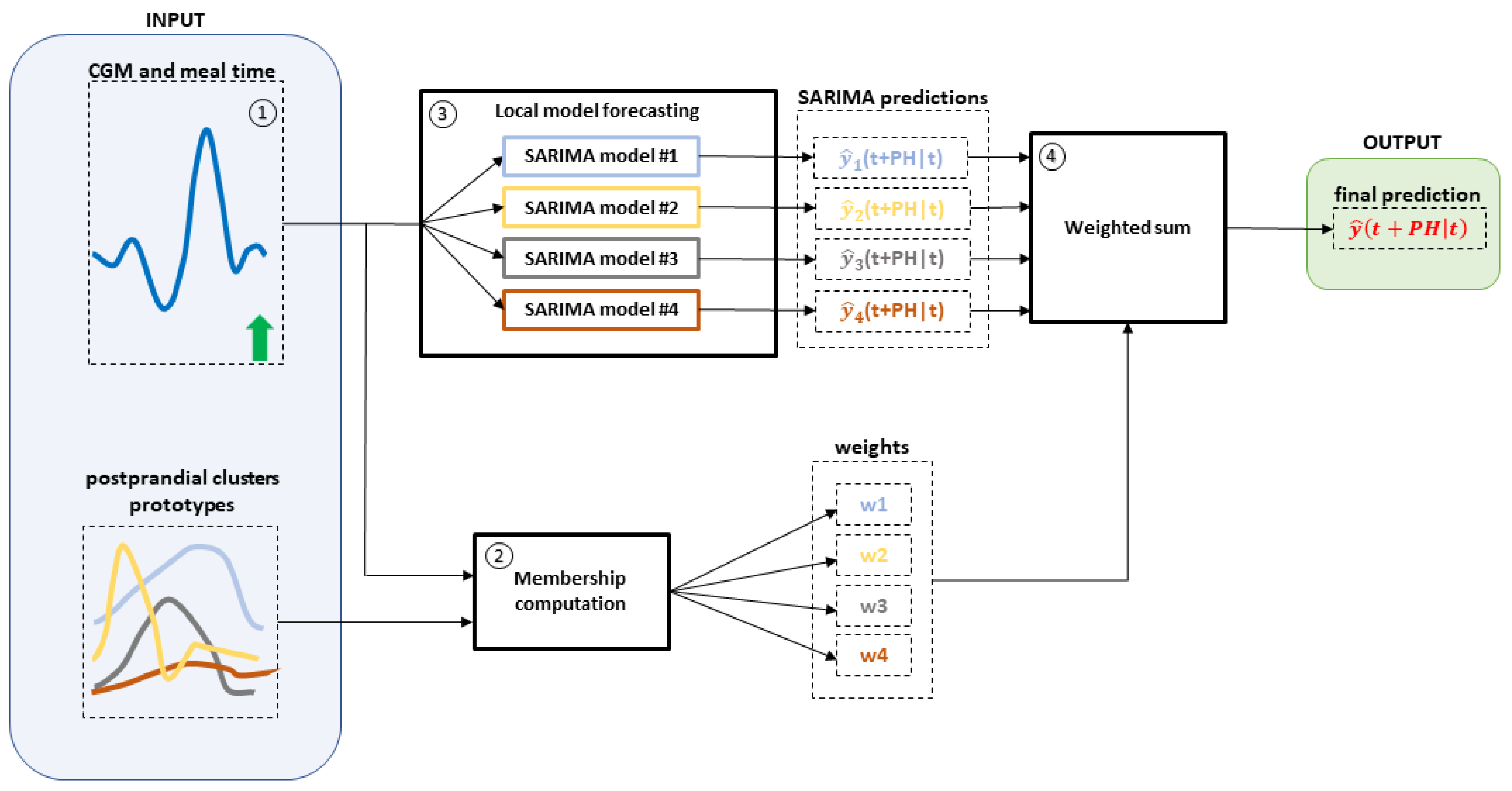
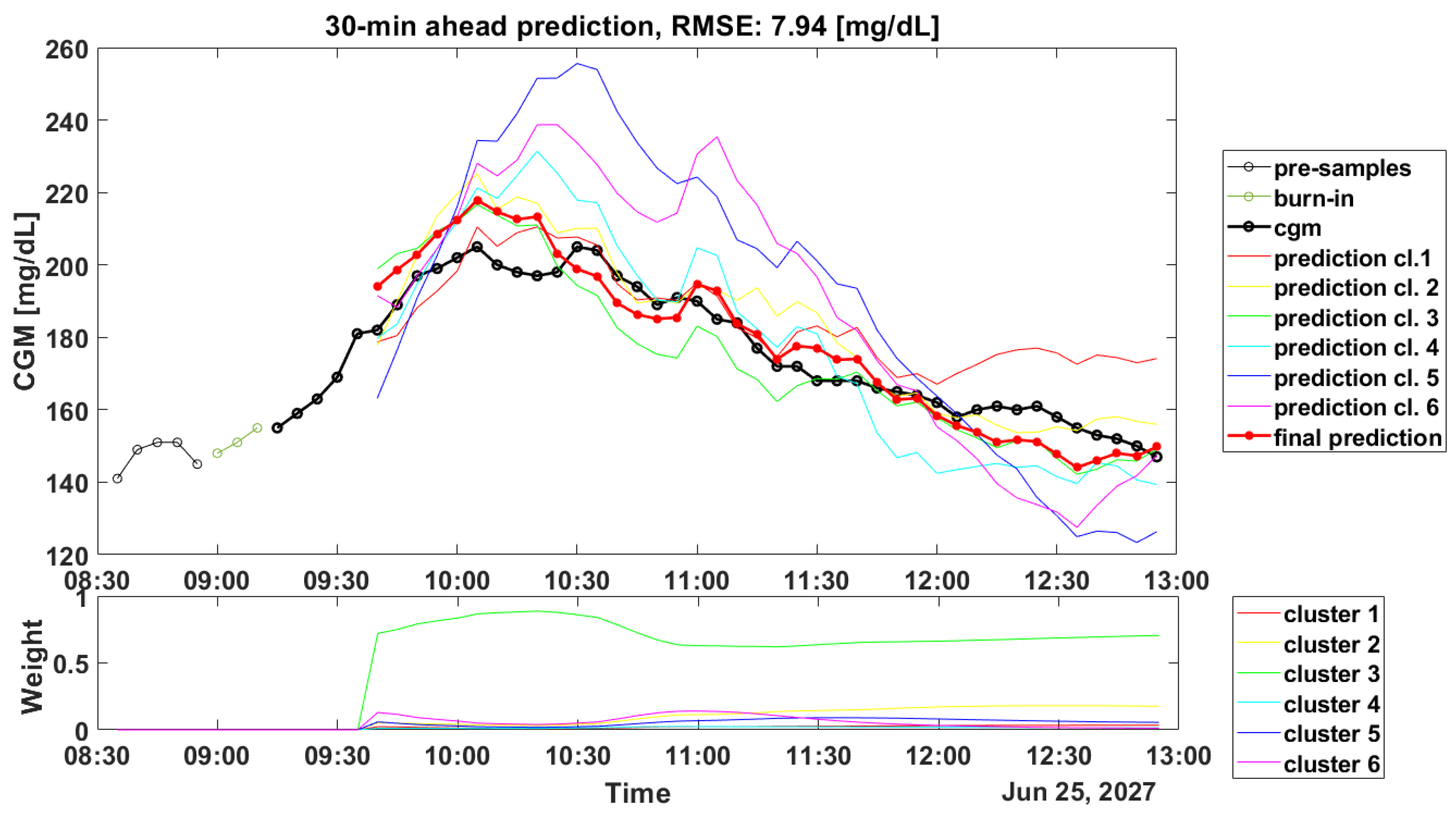
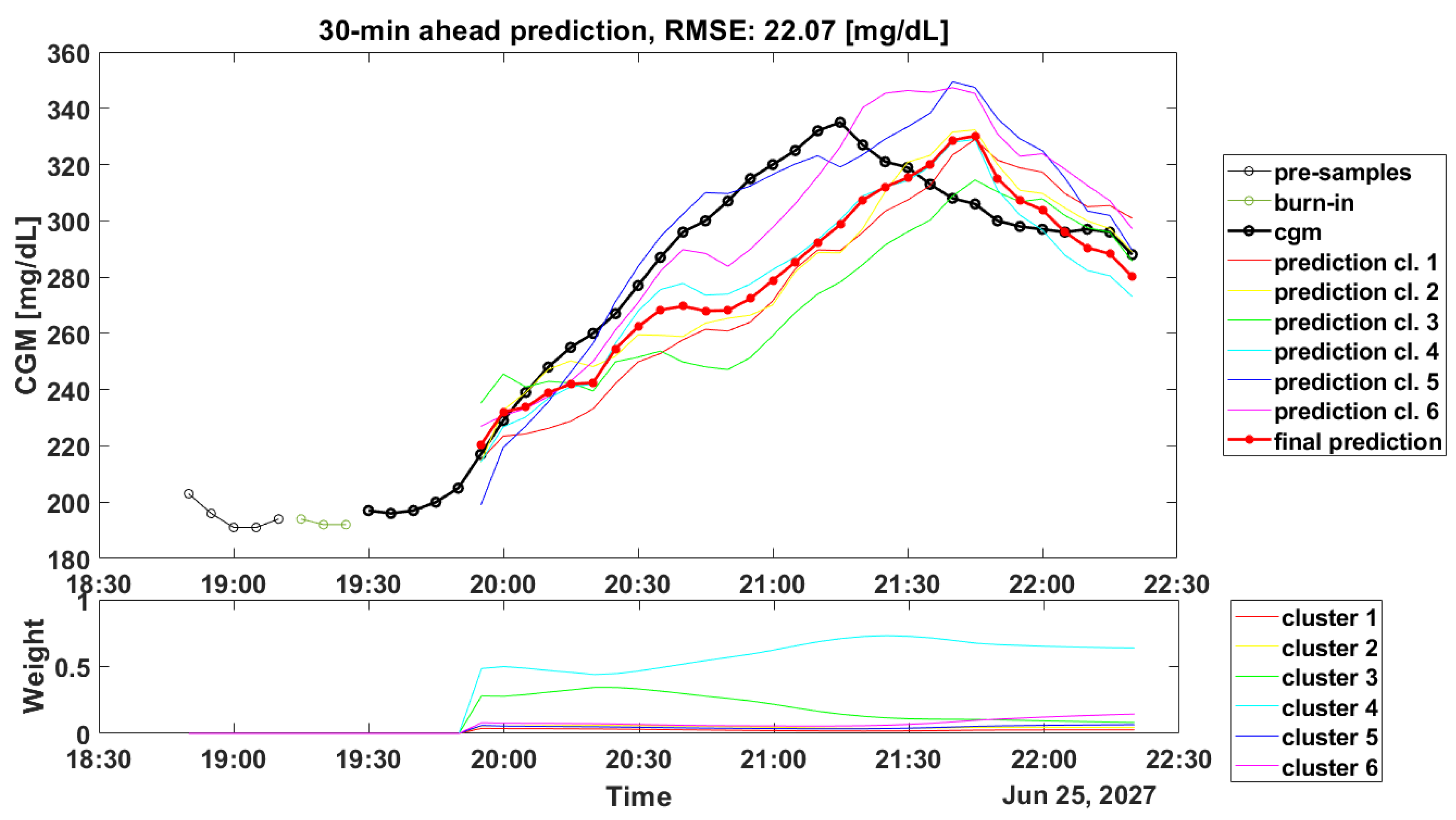
Another critical aspect linked to the clustering step is about the computation of the weights during the real-time glucose forecasting. Such computation is crucial for obtaining accurate predicted profiles: in
Figure 2 and
Figure 3, the prediction results for a representative subject of the OhioT1DM dataset are shown (ID: 544), and it can be seen how the weights’ computation can lead to good and poor accuracy in the prediction of the PPs.
Figure 2 shows in the top panel the PP trace (black line) and the final prediction (red bold line). For a better visualization, 6 out of 12 predicted profiles (colored lines) were discarded since their weights (visible in the bottom panel) were almost equal to zero. Furthermore, in the top panel are also reported the 5 CGM samples (black thin line) before the meal (in this case, there is breakfast at 8.55) and the 3 CGM samples (indicated as burn-in in the legend) after the meal intake, which were used to compute the initial weights as described in the schematic overview of the forecasting process in
Figure 1.
In
Figure 2, the computed weights gave an accurate final prediction, since they assign the CGM data points to the most-similar cluster, in this case Cluster 3.
On the contrary, in
Figure 3, which shows the CGM periods after dinner, the weights’ computation led to an incorrect assignment. Looking at the predicted profiles, it seems that the most-accurate predicted profile was the one obtained with the SARIMA model identified on Cluster 5 or on Cluster 6 (blue line and violet line, respectively). However, the highest weight was related to Cluster 4, which accurately forecast the initial samples (from 19.55 to 20.05), but then, it was not able to follow the target signal. Likely, the incorrect computation of the weights could be due to the fact that the prototypes in the training set were not completely able to describe the current PP, thus suggesting that a larger training set is required. Unfortunately, as shown in
Table 4, similar results can be found even if a larger dataset, i.e., CTR3, is considered.
This work focused only on postprandial periods, since the proposed C-SARIMA algorithm is designed to provide effective prediction in these portions. Nevertheless, in a practical implementation, the algorithm can be easily extended to predict glucose levels over the entire time series, for instance by using a simple ARIMA model outside the postprandial window.
One important challenge in obtaining accurate BG predictions is the fact that the physiological response of T1D individuals varies over time, requiring the periodic update of the prediction algorithms. To address this problem in a practical implementation, the C-SARIMA could be modified by periodically repeating the proposed training pipeline (i.e., clustering step + SARIMA identification) on recent patient data. Notice that this update can be performed much less frequently than glucose prediction (e.g., once a week) and possibly on a remote server with massive computational resources. Alternatively, the real-time prediction algorithm update could be implemented by resorting to adaptive clustering algorithms [
38] and adaptive SARIMA identification techniques [
39].
Although the comparison with other literature works is not straightforward due to the fact that only the PPs and not the entire CGM traces are considered in this work, the numerical results seem in line with the results reported in [
16,
23,
40,
41,
42]. In particular, the authors in [
16] used a reduced version of the CTR3 dataset presented in this work, and their proposed method, which employed CHO and insulin as the input information, achieved a median RMSE = 31.7 mg/dL, for a 60 min PH, slightly better than that achieved by the C-SARIMA. Furthermore, the proposed methodology provides a performance similar to the one obtained by more complex deep learning methodologies exploiting additional information, as described in [
43]. As a matter of fact, the C-SARIMA outperforms a multi-input and multi-step-ahead temporal convolutional network developed in [
44], which provides RMSE = 23.22 mg/dL for 30 min PH. The authors in [
45] employed a subset of the OhioT1DM dataset (only six subjects, corresponding to the 2018 release of the OhioT1DM dataset) and proposed a predictive algorithm based on stacked LSTM models and fed with more information than the C-SARIMA (i.e., meals, insulin, and step count). It is interesting to note that the results presented in [
45], when no Kalman smoothing was applied to data, are comparable to the ones achieved by the proposed methodology (RMSE = 18.57 mg/dL, RMSE = 30.32 mg/dL, for PH = 30 min and PH = 60 min). In contrast, when the Kalman smoother was applied as a preprocessing step, their approach gave an RMSE = 6.45 mg/dL and 17.24 mg/dL for 30 min and 60 min PH. Unfortunately, these excellent prediction performances cannot be achieved in real-time, since the Kalman smoother proposed is non-causal. As such, it is not comparable to the methods investigated in this paper.
The C-SARIMA provides results that are in line even if compared to more complex models fed only by CGM data, such as the Echo State Network proposed by the authors in [
46], which gave an RMSE = 21.7 mg/dL for 30 min PH. Instead, it should be noticed that our approach provides similar or slightly inferior performance if compared to algorithms that exploit physiological knowledge, as in [
47], where the authors developed a patient-specific feed-forward neural network based on the transfer learning approach and integrated essential physiological knowledge into the structure, and as in [
48], where the authors developed a predictive algorithms based on a simplified physiological model of glucose dynamics to generate features for a support vector regression computing the glucose prediction ahead in time. Such an approach granted an RMSE = 19.5 mg/dL and RMSE = 35.7 mg/dL.
Moreover, comparing the main findings with respect to previous works on this methodology shows quite different results in terms of performance metrics. In [
26], the forecasting accuracy of the proposed methodology was measured by computing the RMSE and the MAPE for several PHs. Of note, the proposed methodology gave an RMSE = 9.99 mg/dL, 15.70 mg/dL, and 19.29 mg/dL for PH = 30, 45, and 60 min. However, the authors focused on evaluating how successfully the predicted trajectory fit the actual CGM data, which is different from evaluating the predicted glucose levels at a certain PH ahead in time, as described in [
27] and in this work. Another limitation of [
26] is related to the dataset: data were acquired during a clinical trial, which comprised 18 60 h closed-loop experiments based on scheduled meal intakes and exercise sessions. Due to the limited dataset, the reported results are related to the validation set only.
In the last work [
27], the RMSE was computed as described in Equation (
9), making a fair comparison between this work and [
27] possible. In particular, the RMSE achieved by predicting postprandial periods and post-hypo treatment periods was about 15 mg/dL and 25 mg/dL for PH = 30 and 60 min, respectively. In this work, as shown in
Table 3 and
Table 4, the RMSE for PH = 30 and PH = 60 was about 21 mg/dL and 32 mg/dL. The main difference among these results can be found in the dataset: in [
27], the authors exploited simulated datasets. These in silico simulations have been performed by exploiting a modified setup of the educational version of the UVA/Padova simulator [
28]. In simulated datasets, glucose responses are quite similar and well defined: after meal intake, BG rises, and it comes back to the euglycemic range within 2.5 h from the meal.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}



