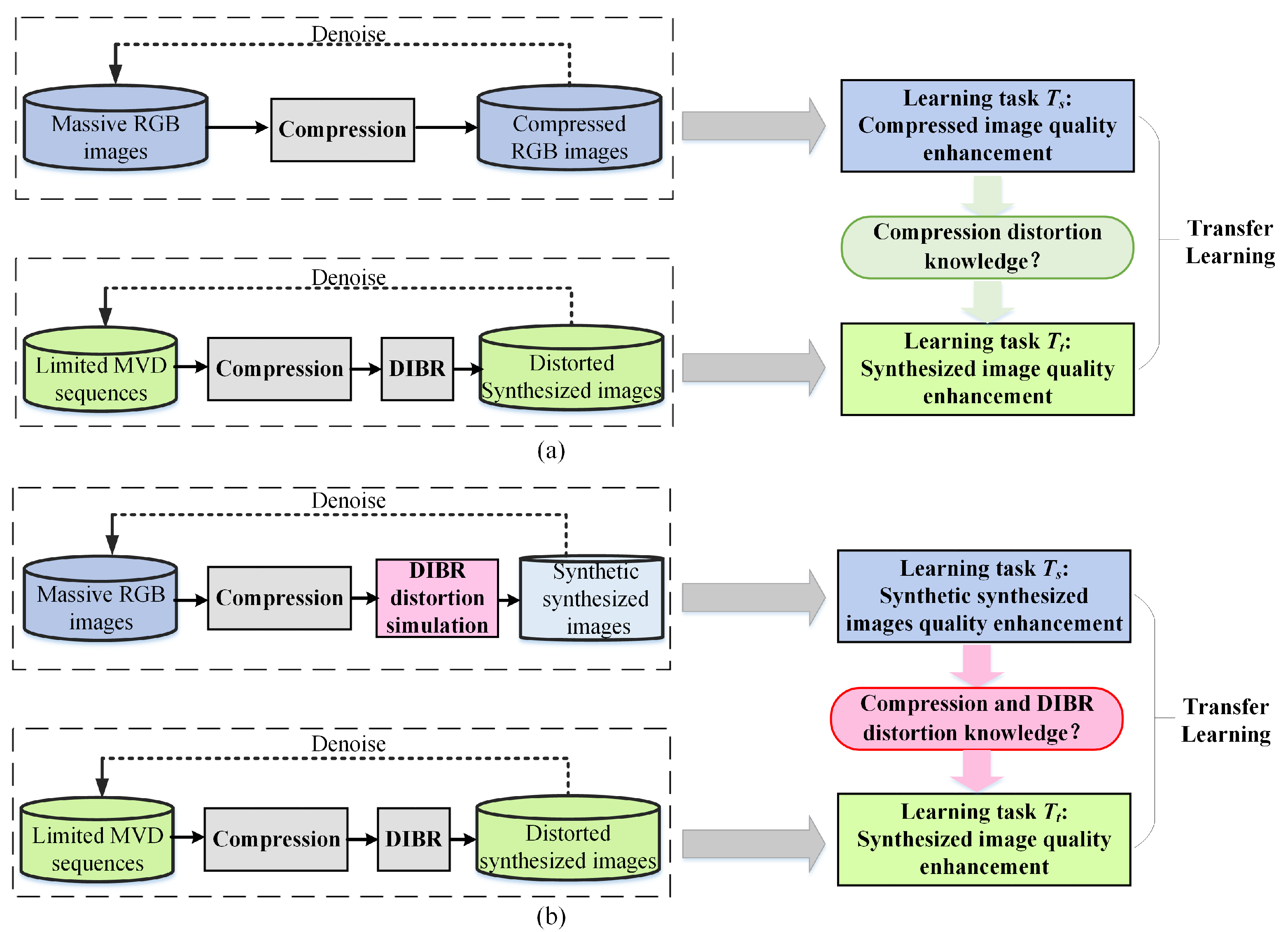
Figure 1.
Transferring from learning task to task . (a) Compressed image quality enhancement to synthesized image quality enhancement. (b) Synthetic synthesized image quality enhancement to synthesized image quality enhancement.
Figure 1.
Transferring from learning task to task . (a) Compressed image quality enhancement to synthesized image quality enhancement. (b) Synthetic synthesized image quality enhancement to synthesized image quality enhancement.
Figure 2.
Overview of DIBR distortion simulation pipeline.
Figure 2.
Overview of DIBR distortion simulation pipeline.
Figure 3.
Comparison of DIBR distortion simulation effects by local random noise. (a,b) are SVIs from sequences Lovebird1 and Balloons, respectively, and the enlarged areas are the representative areas with both compression and DIBR distortion. (c–j) represent the DIBR distortion simulation effects of rectangle areas in (a,b) by Gaussian, speckle, patch shuffle-based, and the proposed random irregular polygon-based noise on compressed captured views of Lovebird1 and Balloons, respectively.
Figure 3.
Comparison of DIBR distortion simulation effects by local random noise. (a,b) are SVIs from sequences Lovebird1 and Balloons, respectively, and the enlarged areas are the representative areas with both compression and DIBR distortion. (c–j) represent the DIBR distortion simulation effects of rectangle areas in (a,b) by Gaussian, speckle, patch shuffle-based, and the proposed random irregular polygon-based noise on compressed captured views of Lovebird1 and Balloons, respectively.
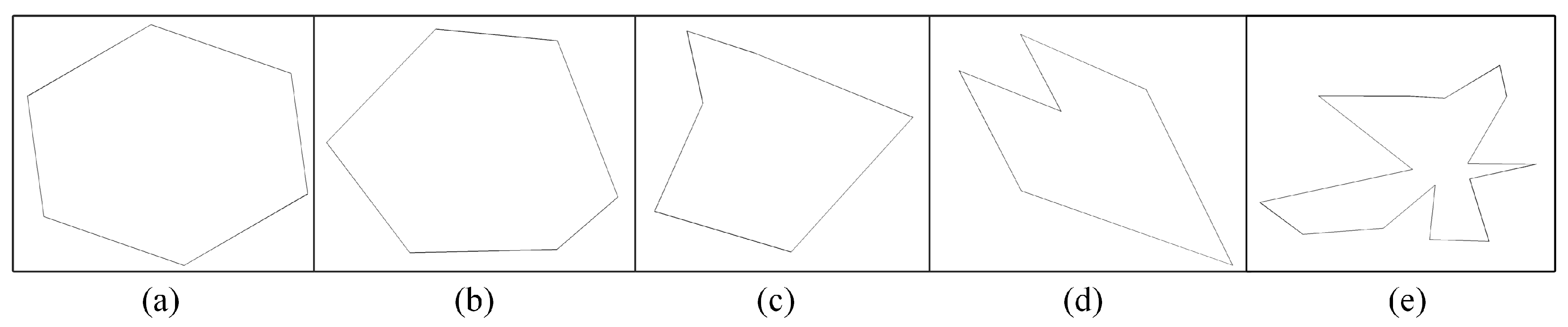
Figure 4.
Examples of generated random polygons. n denotes the number of vertices, denotes irregularity, and denotes spikiness. (a) n = 6, = 0, = 0. (b) n = 6, = 0.5, = 0. (c) n = 6, = 0, = 0.5. (d) n = 6, = 0.7, = 0.7. (e) n = 15, = 0.7, = 0.7.
Figure 4.
Examples of generated random polygons. n denotes the number of vertices, denotes irregularity, and denotes spikiness. (a) n = 6, = 0, = 0. (b) n = 6, = 0.5, = 0. (c) n = 6, = 0, = 0.5. (d) n = 6, = 0.7, = 0.7. (e) n = 15, = 0.7, = 0.7.
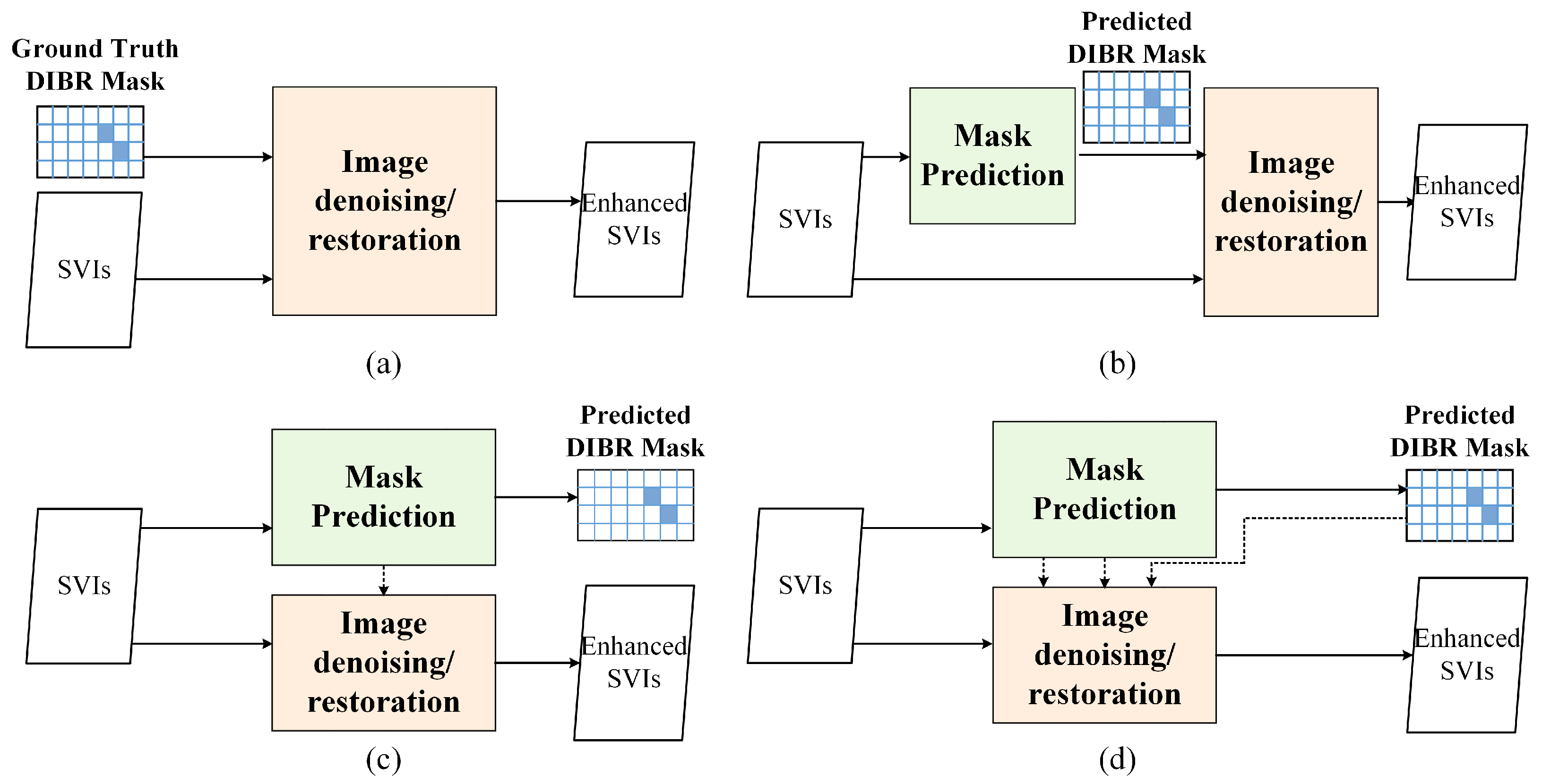
Figure 5.
Four possible ways of image denoising/restoration networks integrating with DIBR distortion position. (a) Intuitive way of integrating ground truth DIBR distortion position. (b) Successive networks with DIBR distortion prediction. (c) Parallel networks with DIBR distortion prediction. (d) Parallel interactive network with DIBR distortion prediction.
Figure 5.
Four possible ways of image denoising/restoration networks integrating with DIBR distortion position. (a) Intuitive way of integrating ground truth DIBR distortion position. (b) Successive networks with DIBR distortion prediction. (c) Parallel networks with DIBR distortion prediction. (d) Parallel interactive network with DIBR distortion prediction.
Figure 6.
Example images of NYU- and DIV2K-based synthetic image datasets. Zooming for better viewing of synthetic DIBR distortion. (a) NYU-based synthetic images. (b) DIV2K-based synthetic images.
Figure 6.
Example images of NYU- and DIV2K-based synthetic image datasets. Zooming for better viewing of synthetic DIBR distortion. (a) NYU-based synthetic images. (b) DIV2K-based synthetic images.
Figure 7.
Visual quality comparison of two denoising models, i.e., DnCNN, NAFNet, for SVQE of Dancer with pre-training on synthetic synthesized image database with different random noise types, i.e., compress, Gaussian, speckle, patch shuffle, randompoly (proposed DIBR distortion simulation method), generated from NYU database. ‘Mask’ represents the denoising models that were further integrated with a DIBR distortion mask prediction sub-network using synthetic images generated by ‘randompoly’ method.
Figure 7.
Visual quality comparison of two denoising models, i.e., DnCNN, NAFNet, for SVQE of Dancer with pre-training on synthetic synthesized image database with different random noise types, i.e., compress, Gaussian, speckle, patch shuffle, randompoly (proposed DIBR distortion simulation method), generated from NYU database. ‘Mask’ represents the denoising models that were further integrated with a DIBR distortion mask prediction sub-network using synthetic images generated by ‘randompoly’ method.
Figure 8.
Visual quality comparison of two denoising models, i.e., DnCNN, NAFNet, for SVQE of Poznanhall2 with pre-training on synthetic synthesized image database with different random noise types, i.e., compress, Gaussian, speckle, patch shuffle, randompoly (proposed DIBR distortion simulation method), generated from NYU database. ‘Mask’ represents the denoising models that were further integrated with a DIBR distortion mask prediction sub-network using synthetic images generated by ‘randompoly’ method.
Figure 8.
Visual quality comparison of two denoising models, i.e., DnCNN, NAFNet, for SVQE of Poznanhall2 with pre-training on synthetic synthesized image database with different random noise types, i.e., compress, Gaussian, speckle, patch shuffle, randompoly (proposed DIBR distortion simulation method), generated from NYU database. ‘Mask’ represents the denoising models that were further integrated with a DIBR distortion mask prediction sub-network using synthetic images generated by ‘randompoly’ method.
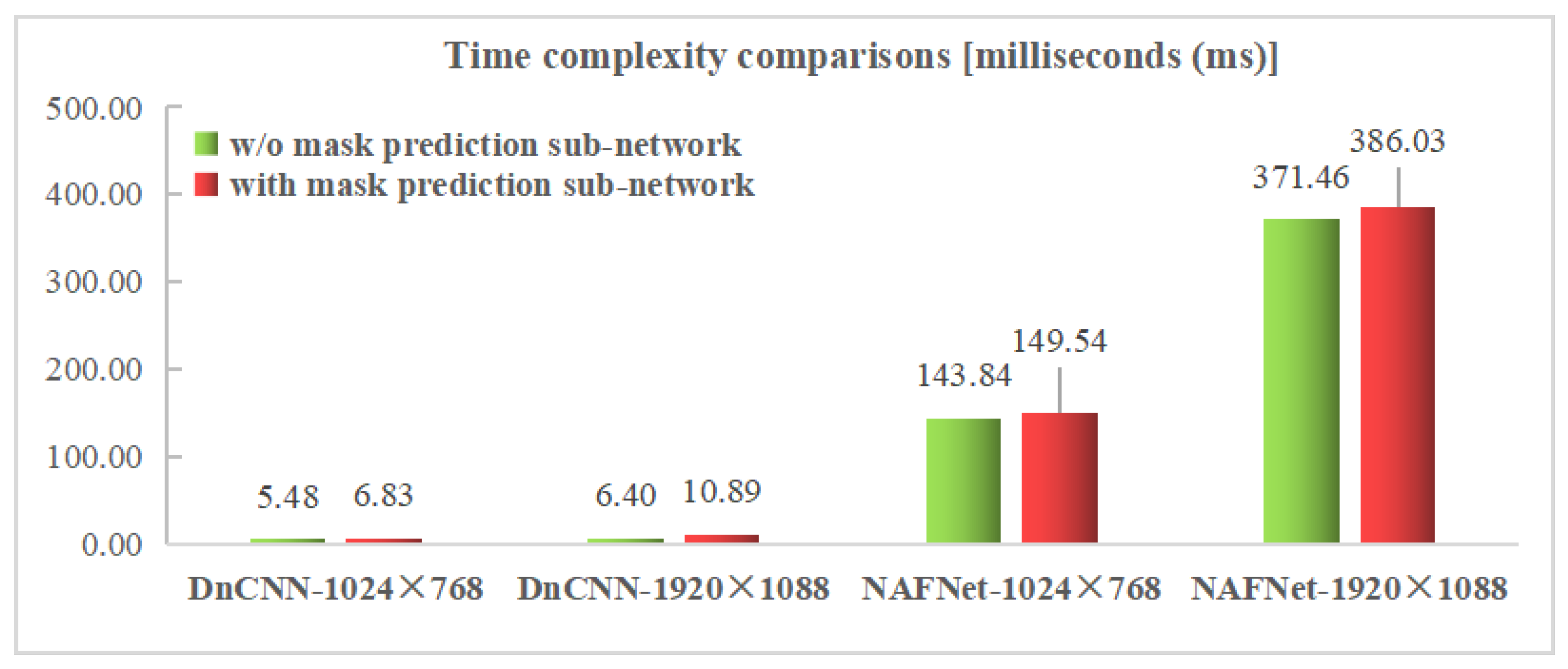
Figure 9.
Time complexity comparisons between SVQE models with and without DIBR distortion mask prediction sub-network.
Figure 9.
Time complexity comparisons between SVQE models with and without DIBR distortion mask prediction sub-network.
Table 2.
Definitions of key variables and acronyms.
Table 2.
Definitions of key variables and acronyms.
| Variables | Descriptions |
|---|
| /, , / | The source/target domain, feature space, and source/target learning task, respectively |
| Data samples set, which |
| Ground truth/distorted image pairs for source/target learning tasks |
| I, , , | A captured view image, I added with random noise, I added with synthetic geometric distortion generated by the proposed random polygon method, and synthetic synthesized image, respectively |
| M | Mask indicating whether the area in I corresponds to strong depth edges |
| , , n, R | The angle, the radius between the i-th point and assumed center point, and the number of vertices, the average value of radius of the generated random polygon, respectively. |
| , | Random variables indicating the irregularity and spikiness of the generated random polygon, respectively |
| MVD, SVQE, SVI, IQA | Acronyms for Multi-view Video plus Depth, synthesized view quality enhancement, synthesized view image, and image quality assessment, respectively |
Table 3.
Dataset descriptions.
Table 3.
Dataset descriptions.
| Datasets | Origins/Benchmark | Resolution | Contained Noise | Training | Testing |
|---|
Synthetic SVI datasets
(for pre-training) | NYU Depth Dataset V2 [36] | 640 × 480 | Compression and
synthetic DIBR distortion | 1449 images | / |
| DIV2K [37] | 2K 1 | 750 images | / |
| Real MVD dataset | SIAT Database [46] | 1920 × 1088
/1024 × 768 | Compression and
DIBR distortion | 94 images | 1200 images |
Table 4.
SVQE performance comparison of DnCNN on Sess-H.264 by pre-training on synthetic synthesized image database with different random noise types generated from NYU database. ‘Randompoly’ is the proposed DIBR distortion simulation method and highlighted. The best and second results are highlighted in bold and the best results are underlined again.
Table 4.
SVQE performance comparison of DnCNN on Sess-H.264 by pre-training on synthetic synthesized image database with different random noise types generated from NYU database. ‘Randompoly’ is the proposed DIBR distortion simulation method and highlighted. The best and second results are highlighted in bold and the best results are underlined again.
| Metrics | Models | Kendo | Newspaper | Lovebird1 | Poznanhall2 | Dancer | Outdoor | Poznancarpark | Average |
|---|
| PSNR | w/o pre-train | 33.58 | 29.79 | 31.98 | 34.94 | 30.90 | 33.15 | 30.96 | 32.19 |
| Compress | 34.05 | 29.93 | 32.15 | 35.31 | 31.89 | 33.73 | 31.50 | 32.65 |
| Gaussian | 34.12 | 29.96 | 32.21 | 35.31 | 31.97 | 33.64 | 31.51 | 32.67 |
| Speckle | 34.09 | 29.94 | 32.21 | 35.26 | 31.94 | 33.66 | 31.47 | 32.65 |
| Patch shuffle | 34.19 | 29.88 | 32.16 | 35.31 | 32.16 | 33.75 | 31.50 | 32.71 |
| Randompoly | 34.09 | 29.93 | 32.18 | 35.29 | 32.17 | 33.73 | 31.49 | 32.70 |
| IW-SSIM | w/o pre-train | 0.9318 | 0.9095 | 0.9402 | 0.9067 | 0.9332 | 0.9642 | 0.9215 | 0.9296 |
| Compress | 0.9365 | 0.9124 | 0.9420 | 0.9108 | 0.9421 | 0.9679 | 0.9253 | 0.9338 |
| Gaussian | 0.9355 | 0.9132 | 0.9424 | 0.9098 | 0.9433 | 0.9671 | 0.9249 | 0.9338 |
| Speckle | 0.9351 | 0.9136 | 0.9427 | 0.9087 | 0.9430 | 0.9675 | 0.9252 | 0.9337 |
| Patch shuffle | 0.9351 | 0.9136 | 0.9419 | 0.9094 | 0.9448 | 0.9675 | 0.9252 | 0.9339 |
| Randompoly | 0.9357 | 0.9132 | 0.9425 | 0.9100 | 0.9447 | 0.9678 | 0.9252 | 0.9342 |
| MPPSNRr | w/o pre-train | 36.62 | 31.53 | 36.05 | 37.73 | 29.40 | 34.42 | 34.27 | 34.29 |
| Compress | 36.98 | 31.98 | 36.58 | 37.82 | 31.99 | 35.10 | 34.79 | 35.03 |
| Gaussian | 37.05 | 32.07 | 36.58 | 37.71 | 32.38 | 35.02 | 34.79 | 35.09 |
| Speckle | 37.03 | 32.13 | 36.54 | 37.77 | 32.21 | 34.91 | 34.78 | 35.05 |
| Patch shuffle | 37.04 | 32.17 | 36.58 | 37.87 | 32.67 | 35.09 | 34.81 | 35.18 |
| Randompoly | 37.13 | 32.10 | 36.57 | 37.91 | 32.66 | 34.88 | 34.79 | 35.15 |
| SC-IQA | w/o pre-train | 19.77 | 17.06 | 19.32 | 20.32 | 15.66 | 21.86 | 16.56 | 18.65 |
| Compress | 20.22 | 17.55 | 19.76 | 20.45 | 18.01 | 24.48 | 17.39 | 19.70 |
| Gaussian | 20.26 | 17.55 | 19.88 | 20.49 | 18.06 | 23.96 | 17.46 | 19.67 |
| Speckle | 20.17 | 17.49 | 20.06 | 20.43 | 18.20 | 24.07 | 17.37 | 19.68 |
| Patch shuffle | 20.29 | 17.55 | 19.70 | 20.49 | 18.46 | 24.78 | 17.43 | 19.81 |
| Randompoly | 20.28 | 17.57 | 19.97 | 20.51 | 18.19 | 24.39 | 17.38 | 19.75 |
Table 5.
SVQE performance comparison of NAFNet on Sess-H.264 by pre-training on synthetic synthesized image database with different random noise types generated from NYU database. ‘Randompoly’ is the proposed DIBR distortion simulation method and highlighted. The best and second results are highlighted in bold and the best results are underlined again.
Table 5.
SVQE performance comparison of NAFNet on Sess-H.264 by pre-training on synthetic synthesized image database with different random noise types generated from NYU database. ‘Randompoly’ is the proposed DIBR distortion simulation method and highlighted. The best and second results are highlighted in bold and the best results are underlined again.
| Metrics | Models | Kendo | Newspaper | Lovebird1 | Poznanhall2 | Dancer | Outdoor | Poznancarpark | Average |
|---|
| PSNR | w/o pre-train | 34.00 | 29.86 | 32.32 | 35.39 | 31.28 | 33.42 | 31.50 | 32.54 |
| Compress | 34.30 | 30.02 | 32.30 | 35.43 | 32.19 | 33.90 | 31.66 | 32.83 |
| Gaussian | 34.16 | 29.96 | 32.27 | 35.45 | 32.49 | 33.86 | 31.62 | 32.83 |
| Speckle | 34.26 | 29.97 | 32.35 | 35.40 | 32.35 | 33.66 | 31.63 | 32.80 |
| Patch shuffle | 34.29 | 30.07 | 32.32 | 35.40 | 32.41 | 33.86 | 31.66 | 32.86 |
| Randompoly | 34.27 | 30.04 | 32.42 | 35.41 | 32.59 | 33.89 | 31.66 | 32.90 |
| IW-SSIM | w/o pre-train | 0.9386 | 0.9136 | 0.9434 | 0.9151 | 0.9342 | 0.9671 | 0.9245 | 0.9338 |
| Compress | 0.9417 | 0.9156 | 0.9444 | 0.9158 | 0.9454 | 0.9694 | 0.9284 | 0.9373 |
| Gaussian | 0.9413 | 0.9163 | 0.9448 | 0.9166 | 0.9477 | 0.9691 | 0.9279 | 0.9377 |
| Speckle | 0.9414 | 0.9158 | 0.9447 | 0.9156 | 0.9463 | 0.9685 | 0.9272 | 0.9371 |
| Patch shuffle | 0.9413 | 0.9159 | 0.9441 | 0.9156 | 0.9468 | 0.9693 | 0.9280 | 0.9373 |
| Randompoly | 0.9416 | 0.9164 | 0.9456 | 0.9158 | 0.9488 | 0.9694 | 0.9285 | 0.9380 |
| MPPSNRr | w/o pre-train | 36.99 | 32.04 | 36.57 | 37.93 | 32.09 | 34.76 | 34.80 | 35.02 |
| Compress | 37.20 | 32.20 | 36.82 | 37.97 | 32.71 | 35.41 | 34.91 | 35.32 |
| Gaussian | 37.15 | 32.23 | 36.87 | 37.95 | 33.08 | 35.40 | 34.96 | 35.38 |
| Speckle | 37.22 | 32.23 | 36.86 | 37.95 | 32.97 | 35.44 | 34.84 | 35.36 |
| Patch shuffle | 37.25 | 32.27 | 36.85 | 37.87 | 33.14 | 35.51 | 34.90 | 35.40 |
| Randompoly | 37.27 | 32.11 | 36.64 | 38.04 | 33.11 | 35.48 | 34.96 | 35.37 |
| SC-IQA | w/o pre-train | 20.04 | 17.63 | 20.02 | 20.59 | 17.71 | 23.59 | 17.28 | 19.55 |
| Compress | 20.33 | 17.56 | 20.06 | 20.54 | 18.10 | 24.20 | 17.48 | 19.75 |
| Gaussian | 20.35 | 17.53 | 20.36 | 20.60 | 18.64 | 24.34 | 17.36 | 19.88 |
| Speckle | 20.39 | 17.50 | 20.48 | 20.59 | 18.35 | 23.53 | 17.47 | 19.76 |
| Patch shuffle | 20.46 | 17.57 | 20.04 | 20.59 | 18.43 | 24.51 | 17.48 | 19.87 |
| Randompoly | 20.55 | 17.61 | 20.34 | 20.65 | 18.97 | 24.30 | 17.50 | 19.99 |
Table 6.
SVQE comparison measured by image quality metrics among DnCNN-, VRCNN-, TSAN-, NAFNet-based schemes by pre-training on synthetic databases from NYU and DIV2K on Seqs-H.264. Model (DnCNN, VRCNN, TSAN, NAFNet) represents the baselines, and model-syn-N/D represents the existing models (DnCNN, VRCNN, TSAN, NAFNet) combined with transfer learning scheme using our proposed synthetic images. The performance gains of the proposed model-syn-N/D over model are highlighted in bold.
Table 6.
SVQE comparison measured by image quality metrics among DnCNN-, VRCNN-, TSAN-, NAFNet-based schemes by pre-training on synthetic databases from NYU and DIV2K on Seqs-H.264. Model (DnCNN, VRCNN, TSAN, NAFNet) represents the baselines, and model-syn-N/D represents the existing models (DnCNN, VRCNN, TSAN, NAFNet) combined with transfer learning scheme using our proposed synthetic images. The performance gains of the proposed model-syn-N/D over model are highlighted in bold.
| Metrics | Models | Kendo | Newspaper | Lovebird1 | Poznanhall2 | Dancer | Outdoor | Poznancarpark | Average |
|---|
| PSNR | DnCNN | 33.58 | 29.79 | 31.98 | 34.94 | 30.90 | 33.15 | 30.96 | 32.19 |
| DnCNN-syn-N | 34.09 | 29.93 | 32.18 | 35.29 | 32.17 | 33.73 | 31.49 | 32.70 (+0.51)
|
| DnCNN-syn-D | 34.15 | 29.93 | 32.19 | 35.30 | 32.33 | 33.82 | 31.52 | 32.75 (+0.56) |
| VRCNN | 33.90 | 29.84 | 32.09 | 35.14 | 31.52 | 33.28 | 31.36 | 32.45 |
| VRCNN-syn-N | 33.99 | 29.87 | 32.08 | 35.20 | 31.59 | 33.55 | 31.39 | 32.52 (+0.08) |
| VRCNN-syn-D | 34.13 | 29.94 | 32.12 | 35.24 | 32.03 | 33.75 | 31.44 | 32.66 (+0.21) |
| TSAN | 33.93 | 29.99 | 32.27 | 35.03 | 31.64 | 33.42 | 31.08 | 32.48 |
| TSAN-syn-N | 34.12 | 29.88 | 32.16 | 35.32 | 32.48 | 33.84 | 31.40 | 32.74 (+0.26) |
| TSAN-syn-D | 34.20 | 30.04 | 32.30 | 35.38 | 32.45 | 33.80 | 31.53 | 32.81 (+0.33) |
| NAFNet | 34.00 | 29.86 | 32.32 | 35.39 | 31.28 | 33.42 | 31.50 | 32.54 |
| NAFNet-syn-N | 34.27 | 30.04 | 32.42 | 35.41 | 32.59 | 33.89 | 31.66 | 32.90 (+0.36) |
| NAFNet-syn-D | 34.40 | 30.09 | 32.34 | 35.51 | 32.73 | 34.04 | 31.71 | 32.97 (+0.44) |
| IW-SSIM | DnCNN | 0.9318 | 0.9095 | 0.9402 | 0.9067 | 0.9332 | 0.9642 | 0.9215 | 0.9296 |
| DnCNN-syn-N | 0.9357 | 0.9132 | 0.9425 | 0.9100 | 0.9447 | 0.9678 | 0.9252 | 0.9342 (+0.0046) |
| DnCNN-syn-D | 0.9377 | 0.9135 | 0.9436 | 0.9116 | 0.9454 | 0.9681 | 0.9261 | 0.9351 (+0.0056) |
| VRCNN | 0.9324 | 0.9115 | 0.9406 | 0.9062 | 0.9401 | 0.9662 | 0.9227 | 0.9314 |
| VRCNN-syn-N | 0.9337 | 0.9121 | 0.9404 | 0.9068 | 0.9408 | 0.9666 | 0.9234 | 0.9320 (+0.0006) |
| VRCNN-syn-D | 0.9336 | 0.9129 | 0.9410 | 0.9064 | 0.9449 | 0.9675 | 0.9240 | 0.9329 (+0.0015) |
| TSAN | 0.9330 | 0.9138 | 0.9399 | 0.9066 | 0.9407 | 0.9665 | 0.9209 | 0.9316 |
| TSAN-syn-N | 0.9330 | 0.9138 | 0.9399 | 0.9130 | 0.9471 | 0.9665 | 0.9270 | 0.93433 (+0.0027) |
| TSAN-syn-D | 0.9424 | 0.9160 | 0.9445 | 0.9151 | 0.9459 | 0.9686 | 0.9277 | 0.93716 (+0.0055) |
| NAFNet | 0.9386 | 0.9136 | 0.9434 | 0.9151 | 0.9342 | 0.9671 | 0.9245 | 0.9338 |
| NAFNet-syn-N | 0.9416 | 0.9164 | 0.9456 | 0.9158 | 0.9488 | 0.9694 | 0.9285 | 0.9380 (+0.0042) |
| NAFNet-syn-D | 0.9439 | 0.9171 | 0.9452 | 0.9169 | 0.9491 | 0.9702 | 0.9291 | 0.9388 (+0.0050) |
Table 7.
SVQE comparison measured by SVI metrics among DnCNN-, VRCNN-, TSAN-, NAFNet-based schemes by pre-training on synthetic databases from NYU and DIV2K on Seqs-H.264. Model (DnCNN, VRCNN, TSAN, NAFNet) represents the baselines, and model-syn-N/D represents the existing models (DnCNN, VRCNN, TSAN, NAFNet) combined with transfer learning scheme using our proposed synthetic images. The performance gains of the proposed model-syn-N/D over model are highlighted in bold.
Table 7.
SVQE comparison measured by SVI metrics among DnCNN-, VRCNN-, TSAN-, NAFNet-based schemes by pre-training on synthetic databases from NYU and DIV2K on Seqs-H.264. Model (DnCNN, VRCNN, TSAN, NAFNet) represents the baselines, and model-syn-N/D represents the existing models (DnCNN, VRCNN, TSAN, NAFNet) combined with transfer learning scheme using our proposed synthetic images. The performance gains of the proposed model-syn-N/D over model are highlighted in bold.
| Metrics | Models | Kendo | Newspaper | Lovebird1 | Poznanhall2 | Dancer | Outdoor | Poznancarpark | Average |
|---|
| MPPSNRr | DnCNN | 36.62 | 31.53 | 36.05 | 37.73 | 29.40 | 34.42 | 34.27 | 34.29 |
| DnCNN-syn-N | 37.13 | 32.10 | 36.57 | 37.91 | 32.66 | 34.88 | 34.79 | 35.15 (+0.86)
|
| DnCNN-syn-D | 37.11 | 31.89 | 36.51 | 37.92 | 33.01 | 35.24 | 34.77 | 35.21 (+0.92) |
| VRCNN | 36.89 | 32.06 | 36.54 | 37.78 | 31.69 | 34.69 | 34.71 | 34.91 |
| VRCNN-syn-N | 36.97 | 32.04 | 36.33 | 37.84 | 31.91 | 34.84 | 34.77 | 34.96 (+0.05) |
| VRCNN-syn-D | 36.96 | 32.22 | 36.64 | 37.79 | 32.89 | 35.44 | 34.71 | 35.24 (+0.33) |
| TSAN | 36.79 | 32.21 | 36.58 | 37.69 | 32.58 | 35.29 | 34.73 | 35.12 |
| TSAN-syn-N | 37.28 | 32.23 | 36.64 | 37.82 | 33.39 | 35.38 | 34.84 | 35.37 (+0.24) |
| TSAN-syn-D | 37.26 | 32.06 | 36.65 | 37.89 | 33.43 | 35.33 | 34.87 | 35.35 (+0.23) |
| NAFNet | 36.99 | 32.04 | 36.57 | 37.93 | 32.09 | 34.76 | 34.80 | 35.02 |
| NAFNet-syn-N | 37.27 | 32.11 | 36.64 | 38.04 | 33.11 | 35.48 | 34.96 | 35.37 (+0.25) |
| NAFNet-syn-D | 37.46 | 32.22 | 36.83 | 38.00 | 33.52 | 35.55 | 34.89 | 35.49 (+0.47) |
| SC-IQA | DnCNN | 19.77 | 17.06 | 19.32 | 20.32 | 15.66 | 21.86 | 16.56 | 18.65 |
| DnCNN-syn-N | 20.28 | 17.57 | 19.97 | 20.51 | 18.19 | 24.39 | 17.38 | 19.75 (+1.10) |
| DnCNN-syn-D | 20.30 | 17.58 | 19.95 | 20.47 | 18.31 | 24.01 | 17.37 | 19.71 (+1.06) |
| VRCNN | 20.11 | 17.46 | 19.51 | 20.27 | 18.14 | 22.88 | 17.30 | 19.38 |
| VRCNN-syn-N | 20.16 | 17.52 | 19.47 | 20.34 | 17.66 | 24.12 | 17.28 | 19.51 (+0.13) |
| VRCNN-syn-D | 20.14 | 17.55 | 19.47 | 20.32 | 17.60 | 24.97 | 17.16 | 19.60 (+0.22) |
| TSAN | 19.88 | 17.59 | 19.50 | 20.28 | 17.34 | 24.53 | 16.78 | 19.42 |
| TSAN-syn-N | 20.33 | 17.39 | 19.33 | 20.52 | 18.58 | 24.47 | 16.89 | 19.65 (+0.23) |
| TSAN-syn-D | 20.34 | 17.57 | 19.75 | 20.66 | 18.55 | 23.72 | 17.14 | 19.68 (+0.26) |
| NAFNet | 20.04 | 17.63 | 20.02 | 20.59 | 17.71 | 23.59 | 17.28 | 19.55 |
| NAFNet-syn-N | 20.55 | 17.61 | 20.34 | 20.65 | 18.97 | 24.30 | 17.50 | 19.99 (+0.44) |
| NAFNet-syn-D | 20.65 | 17.60 | 20.04 | 20.74 | 19.15 | 25.05 | 17.59 | 20.12 (+0.57) |
Table 8.
SVQE comparison measured by PSNR among DnCNN-based schemes and that with ground truth DIBR distortion masks on Seqs-H.264. DnCNN-syn-GTmask-N, and DnCNN-syn-GTmask-D are abbreviated as DnCNN-syn-GM-N and DnCNN-syn-GM-D, respectively. The performance gains of DnCNN-based schemes with ground truth DIBR distortion masks over DnCNN-based schemes without masks are highlighted in bold.
Table 8.
SVQE comparison measured by PSNR among DnCNN-based schemes and that with ground truth DIBR distortion masks on Seqs-H.264. DnCNN-syn-GTmask-N, and DnCNN-syn-GTmask-D are abbreviated as DnCNN-syn-GM-N and DnCNN-syn-GM-D, respectively. The performance gains of DnCNN-based schemes with ground truth DIBR distortion masks over DnCNN-based schemes without masks are highlighted in bold.
| Models | Kendo | Newspaper | Lovebird1 | Poznanhall2 | Dancer | Outdoor | Poznancarpark | Average |
|---|
| DnCNN | 33.58 | 29.79 | 31.98 | 34.94 | 30.90 | 33.15 | 30.96 | 32.19 |
| DnCNN-GTmask | 34.35 | 30.13 | 32.16 | 34.60 | 32.61 | 33.59 | 30.85 | 32.61 (+0.42) |
| DnCNN-syn-N | 34.09 | 29.92 | 32.18 | 35.30 | 32.14 | 33.74 | 31.50 | 32.70 |
| DnCNN-syn-GM-N | 35.20 | 30.72 | 32.44 | 35.09 | 33.05 | 34.00 | 31.03 | 33.07 (+0.37) |
| DnCNN-syn-D | 34.12 | 29.91 | 32.16 | 35.32 | 32.29 | 33.79 | 31.53 | 32.73 |
| DnCNN-syn-GM-D | 35.35 | 30.83 | 32.51 | 34.92 | 33.22 | 34.17 | 30.86 | 33.12 (+0.39) |
Table 9.
SVQE comparison among DnCNN- and NAFNet-based schemes (model-syn-N/D) and that with DIBR distortion prediction (model-syn-mask-N/D) on Seqs-H.264. Only when the SVQE models with DIBR distortion prediction (highlighted bold) are superior than the same model pre-trained on the same synthetic database, the results are highlighted bold.
Table 9.
SVQE comparison among DnCNN- and NAFNet-based schemes (model-syn-N/D) and that with DIBR distortion prediction (model-syn-mask-N/D) on Seqs-H.264. Only when the SVQE models with DIBR distortion prediction (highlighted bold) are superior than the same model pre-trained on the same synthetic database, the results are highlighted bold.
| Model | PSNR | IW-SSIM | MPPSNRr | SC-IQA |
|---|
| DnCNN-syn-N | 32.70 | 0.9342 | 35.148 | 19.75 |
| DnCNN-syn-mask-N
| 32.72
| 0.9341 | 35.152 | 19.80 |
| DnCNN-syn-D | 32.75 | 0.9352 | 35.208 | 19.71 |
| DnCNN-syn-mask-D | 32.78 | 0.9345 | 35.264 | 19.82 |
| NAFNet-syn-N | 32.90 | 0.9380 | 35.372 | 19.99 |
| NAFNet-syn-mask-N | 32.93 | 0.9380 | 35.493 | 20.00 |
| NAFNet-syn-D | 32.97 | 0.9388 | 35.493 | 20.12 |
| NAFNet-syn-mask-D | 32.98 | 0.9388 | 35.528 | 20.08 |
Table 10.
The computational complexity comparisons between different types of random noise for DIBR distortion simulation (milliseconds (ms)).
Table 10.
The computational complexity comparisons between different types of random noise for DIBR distortion simulation (milliseconds (ms)).
| Database | Gaussian | Speckle | Patch shuffle | Randompoly |
|---|
| NYU Depth Dataset V2 | 67.90 | 65.61 | 76.45 | 1268.82 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








