1. Introduction
Computer vision methods may offer more practical perceptual, contextual, and situational awareness to a highway intelligent transportation system (ITS) than any other types of sensors [
1]. Utilizing vision sensors in the development of the ITS focuses on challenges that are generally difficult to solve using other sensor approaches [
2]. For example, vehicles come in various sizes, shapes, and colors within the same class. Additionally, the projected shape of the vehicle differs due to pose variations concerning the camera sensor. All the previously mentioned points make the problem of vehicle detection and classification very challenging. Another complexity in ITS arises due to highway traffic outdoor scenes with varying visibility and lighting conditions. Furthermore, limited computing power may reduce the efficiency of an integrated system to perform in real time. Parallel computing techniques have decreased this limitation drastically. Finally, accounting for the unpredictable movement of vehicles through a highway traffic scene may be difficult. Off-road cameras are currently used by most state departments of transportation to monitor traffic conditions and to identify situations that disrupt traffic flow, such as road debris, stopped vehicles, or accidents. Computer vision algorithms allow these tasks to be performed automatically and efficiently [
3].
Tremendous efforts to tackle different challenging aspects have been investigated deeply in the literature. While there are several other non-vision sensor-based approaches, such as the one presented in [
4], the authors in this work focused on computer vision and machine-learning-related techniques utilizing monocular optical sensors.
The authors in [
5] proposed a pipeline for detecting vehicles from monocular videos based on transfer learning. They weakly calibrated the camera using a 3 × 3 transformation from the image domain to the real-world domain to estimate the vehicle length and speed. Additionally, the authors adopted three popular object detection approaches, namely: SSD [
6], YOLOV2 [
7], and faster R-CNN [
8] to classify traffic vehicles. The authors tested their approach on videos captured from different sites and demonstrated that they had achieved high accuracy and fast processing speed. The research in [
9] proposed a semi-supervised vehicle type classification approach based on a broad learning scheme (BLS) [
10] to reduce the cost of the training phase, and a dynamic ensemble structure is used to estimate the class type probabilities. Naghmeh et al. [
11] proposed a semi-supervised Fuzzy C-Means clustering to predict different vehicle types and labels. They utilized unlabeled and labeled data to extract useful information for classifying the vehicles. Additionally, random oversampling was used to handle the multi-class imbalanced datasets. Semi-supervised principal component analysis convolutional network (PCN) was adopted in [
12]. The authors generated a convolutional filter bank to leverage the effectiveness of traditional convolution neural networks against different image schemes, including translation, scale, noise, and rotations. The research incorporated PCN into softmax and support vector machine (SVM) classifiers to evaluate different structures.
Nadiya et al. [
13] proposed a monocular vision-based technique to detect vehicles for automatic toll collection. Their technique suggests using a group of convolutional neural networks to estimate the probability for vehicles class and feed them into a gradient-boosting classifier to complement the labels obtained from optical sensors. The research in [
14] introduced an automated approach for different vehicle classifications from rear-view images by fusing physical and spatial attributes. The physical features include height from the ground to the rear bumper and the distance from the bumper to the license plate. The spatial features are extracted by applying a convolutional neural network. The SVM classifier is employed to classify fused features.
Unsupervised Feature Learning was discussed and elaborated by Amir et al. [
15]. The approach depends upon the generation of a dictionary from a dense scale-invariant feature extractor [
16]. Bases are generated by applying the k-means clustering technique. The generated dictionary maps the input features to a new learned space by employing a coding vector with the trained bases. In classifying images, they utilized the spatial pyramid matching [
17] and SVM classifier. Zhanyu et al. [
18] introduced a fine-grained classification scheme based on convolutional neural networks. They added a new max-pooling layer between the fully connected and traditional layers. The proposed layer reduces the dimensions of feature space, and the computational cost is reduced.
Zhang et al. [
19] utilized single-shot multi-box feature detectors based on deconvolution and pooling to classify vehicles using convolutional neural networks. The authors in [
20] compared the performance of vehicle detection and classification using the mixture of Gaussian (MoG) background subtraction algorithm along with a support vector machine (SVM) vehicle classification model against the faster RCNN. Their experiments showed that faster R-CNN outperforms the SVM method. Xiang et al. [
21] proposed a method to count vehicles based on a moving-object detector that works with static and moving backgrounds. A pixel-level detector handles static objects, while camera registration is employed with moving backgrounds. In their approach, an online learning tracker counts vehicles under different situations. The authors in [
22] introduced an approach to identify vehicle make and model from front-facing images utilizing physical and visual characteristics. First, they extracted the logo and fed it into a classifier to identify the vehicle make. Then, they customized a hierarchical classifier to identify the vehicle type.
Farahani [
23] utilized the Gaussian mixture model for background segmentation, and the extended mean shift (EMS) algorithm based on color information was utilized for tracking. The EMS algorithm was adapted by applying an Epanechnikov kernel estimator function on the feature space. This feature space was derived from the color histogram. Roy et al. [
24] extracted foreground objects using GMM and proposed a new weighted mean approach to track vehicles. Das et al. [
25] classified vehicles into five classes using a bag of Speeded Up Robust Features (SURF). An SVM classifier was adopted in their work. The authors in [
26] suggested two-stage methods to classify vehicles. Firstly, they balanced the data samples by augmenting the acquired data. Secondly, the augmented data was classified utilizing an ensemble of convolutional neural networks (CNN) with different architectures and learned on the augmented training dataset. Cai et al. [
27] pioneered a scene-adjusted vehicle detection approach based on the concept of the bagging (bootstrap aggregating) technique. A composite deep-structure classifier was built using multiple classifiers of samples generated in the target scene based on a confidence score with a voting mechanism. The authors in [
28] adopted latent SVM in a vehicle make and model recognition. A novel greedy parts localization algorithm was employed to extract some descriptive parts in the vehicles used in the learning stages. Chavez-Garcia et al. [
29] located vehicles within a video frame using a two-dimensional Bayesian occupancy grid map. They experimented with a sparse version of the Histogram of Oriented Gradients (HOG) along with the Adaboost classifier in the classification stage. The authors in [
30] detected vehicle candidates utilizing the active basis model (ABM) based on Gabor wavelet elements. A random forest classifier is trained to classify vehicles into three categories based on the vehicle length extracted from the spatial domain image and the gray-level co-occurrence matrix of the detected vehicle image. Siddiqui et al. [
31] utilized a bag of SURF features of either the front- or rear-facing images of vehicles in conjunction with multi-class support vector machine (SVM) classifier and attribute-bagging-based ensemble of SVM (AB-SVM) to recognize vehicle make and model.
Toropov et al. [
32] employed adaptive GMM for segmenting vehicles and Viola–Jones cascade detector based on Haar features for vehicle tracking. Vehicles are counted using a probabilistic counting model. The authors in [
33] provided a method for detecting and tracking vehicles in videos captured from roadside cameras. Authors in [
34] proposed an integrated work of vehicle detection, tracking, and classification for purposes of emission estimation. Similarly, the work in [
35] provides a detection and tracking algorithm for on-road vehicles using a car-mounted camera. Vehicle detection and tracking are extended to include vehicle counting in [
36] and vehicle lane assignment and analysis in [
37]. The authors in [
38,
39] used classifiers to distinguish between moving objects that are considered cars as opposed to another type of vehicle. Similarly, classification was used to distinguish trucks from other highway traffic for a study on a truck and industrial vehicle density in [
40]. Techniques that apply multiclass classification have also been used to distinguish between vehicle categories on the highway, such as cars, buses, motorcycles, and trucks [
41,
42,
43]. The work in [
44] distinguishes multiple vehicles by size to assign correct toll rates.
When analyzing the previously discussed efforts, it is clear that a trend of strategies for completing a particular purpose has been developed. These efforts can be categorized into detection approaches, known as foreground segmentation, tracking algorithms, and (if applicable) feature extraction and vehicle categorization methods. Furthermore, some of the previously summarized approaches examined techniques utilizing enhancements in ROI extraction and camera alignment. While deep learning (DL) is a fast-growing area of research in vehicle segmentation for intelligent transportation systems (ITS), these methods need a lot of data to train. Thus, they cannot function properly without huge training data and imbalanced datasets. Additionally, optimizing DL architecture parameters requires plenty of experiments using deep learning networks and architecture combinations. The dataset utilized in this work is small and is not enough to adopt a deep learning approach [
15,
45,
46,
47,
48,
49,
50]. The results section compares the proposed technique for verification and performance evaluation against recent deep learning architectures with different deep neural networks.
In this work, the authors develop and implement a monocular camera viewpoint-independent and fully integrated method for vehicular traffic segmentation and classification. Key results reported in this work are evaluated using networked traffic camera videos obtained from the Virginia Department of Transportation (VDOT). More specifically, the following contributions are presented: (1) an automated region of interest (ROI) extraction approach; (2) an improved real-time foreground segmentation algorithm; (3) a classification scheme that is capable of sensing multiple vehicle clusters for handling occluded vehicles in dense traffic scenarios; and (4) performance evaluation of twenty-three object detection deep learning architectures that have been trained and adapted to the evaluated dataset employing transfer learning.
The rest of this paper is organized as follows:
Section 2 details the proposed system pipeline. Then,
Section 3 presents the results of the developed system where the performance of different system stages is evaluated to accurately segment individual vehicles and to classify the vehicles by type. Finally, in
Section 4, concluding statements are discussed.
2. Proposed Technique
Deep learning approaches combine both feature extraction and classification into a single procedure. They require massive training datasets to achieve high accuracy. Unlike deep learning approaches, traditional supervised machine-learning approaches have reported high accuracy in object detection and classification with limited and small amounts of data. These approaches require two substages: one for feature extraction and the other one for object classification. The histogram of oriented gradients approach has been widely used in object detection based on the gradients of visual and textural differences with reported high detection accuracy. Additionally, morphological, size, and shape features are utilized to separate various classes representing different objects. The proposed technique utilized the support vector machine classifier since it has been known for high classification accuracy in similar domains and requires few training samples compared to deep learning approaches.
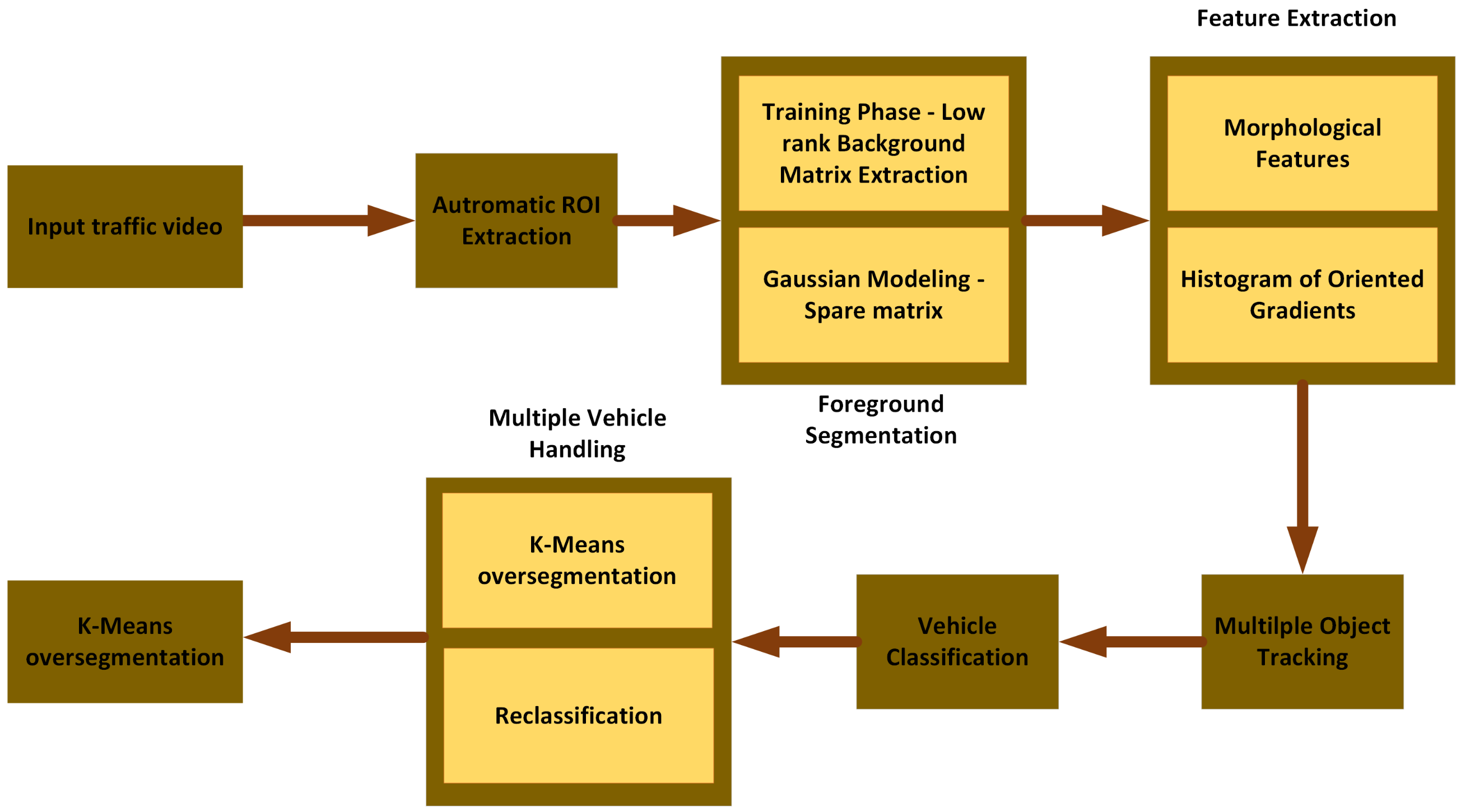
This section develops methods to solve the primary stated goal of autonomous vehicle segmentation and type classification in a traffic video database. The developed pipeline consists of the following steps: (1) automated development of an ROI; (2) foreground object segmentation using improved robust low-rank and sparse matrix decomposition; (3) extraction of vehicle size, shape, and texture features using morphological properties and histogram of oriented gradients (HOG); (4) vehicle tracking using the extended Kalman filter (EKF) method; (5) vehicle classification using a multiclass support vector machine (SVM) classifier; and finally, (6) multiple vehicle handling using a K-means over-segmentation and a two-pass classification scheme. The proposed pipeline is shown in
Figure 1, and the following subsections detail its steps.
2.1. Region of Interest Extraction
The proposed algorithm’s first step establishes an ROI in the image scene to reduce the computational complexity, accelerate processing, and retain the most visual features of the captured frames. Most practical traffic surveillance cameras are set at a viewing angle to monitor a large section of the highway. As vehicles progress through the image scene toward the horizon and move farther from the camera, the vehicle size becomes smaller and can appear as image noise. Likewise, as vehicles become smaller, there are not enough meaningful details to extract features for classification purposes, and detected vehicles at a far distance can interfere as outliers for training a classifier. In that regard, the processed frame is clipped to 70% of its height, considering the camera side. In this proposed vehicle detection algorithm, monitoring is optimized to only handle vehicles moving along one major angle. An automated ROI extraction approach is introduced to define the effective part of the image scene in which vehicles can be efficiently segmented and classified. The ROI is a binary mask applied to each video frame to filter pixel intensities outside the ROI and set them to zero.
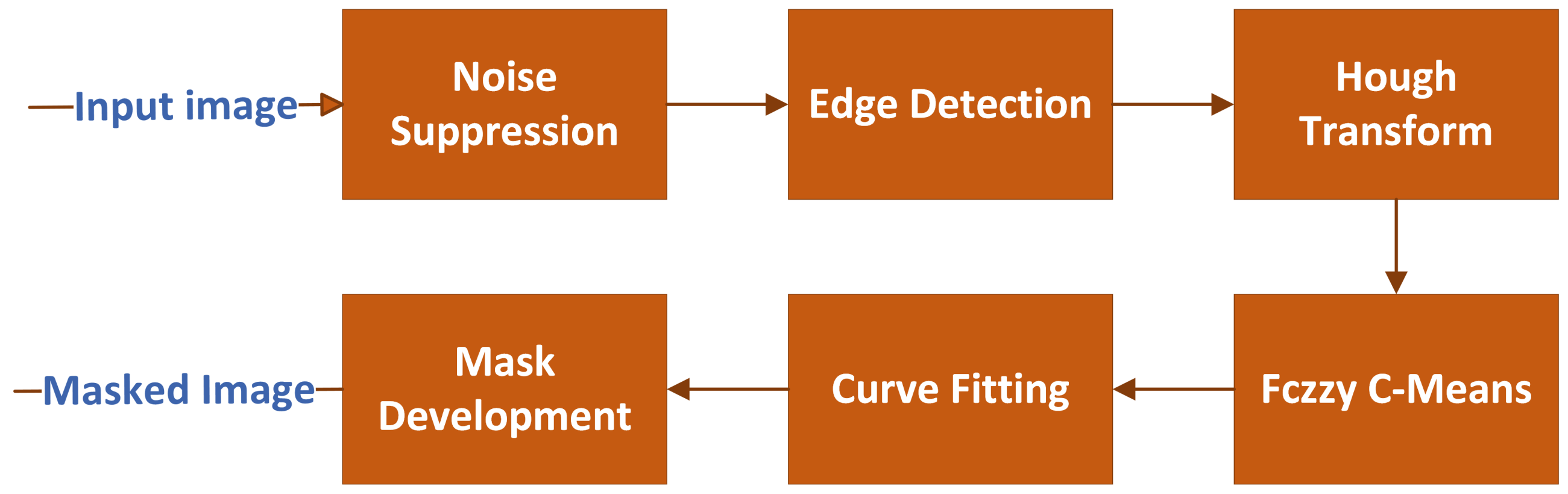
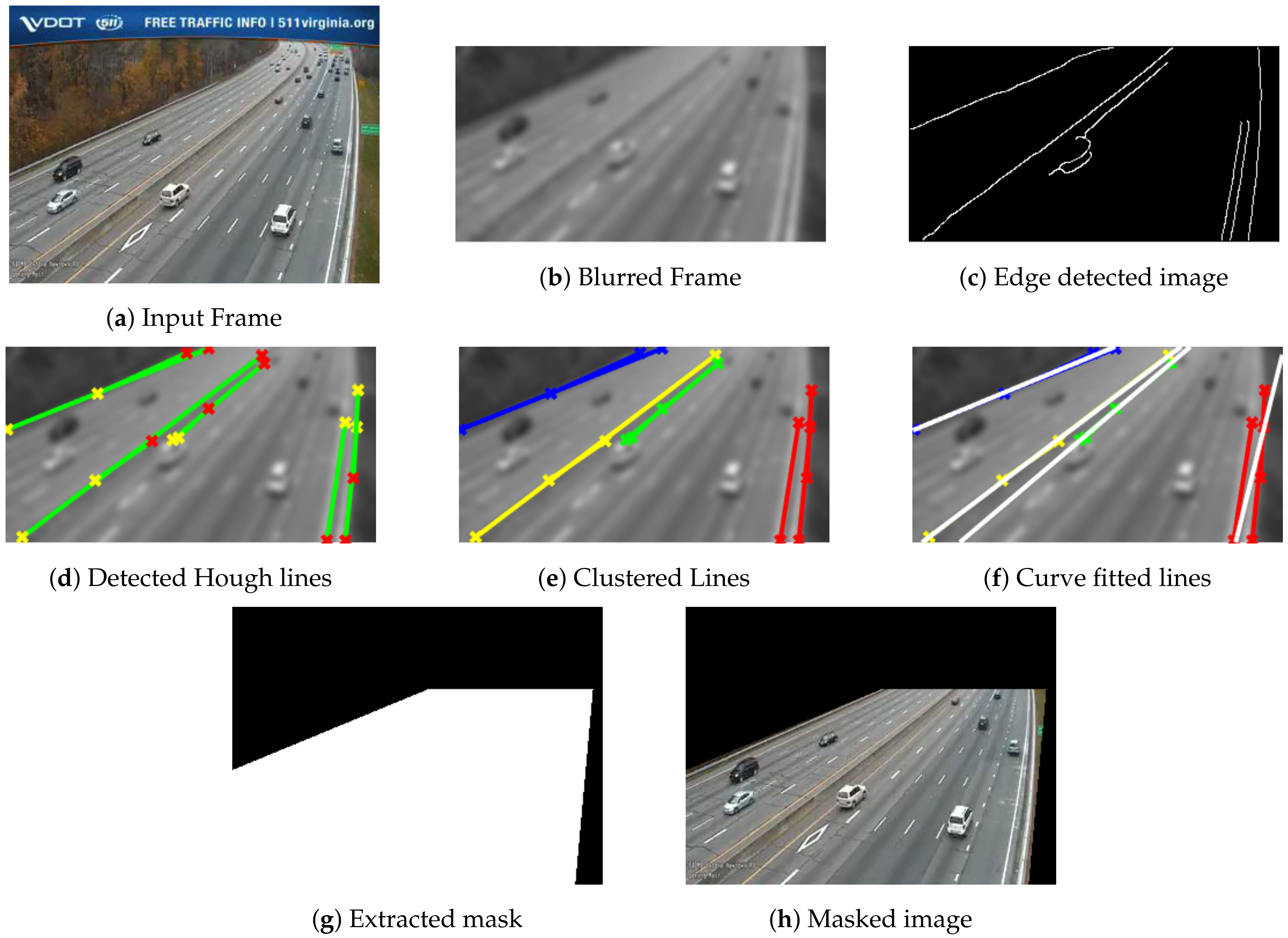
The proposed extraction of ROI includes a sequence of six steps, namely: (1) noise suppression, (2) edge detection, (3) Hough transform, (4) fuzzy C-means, (5) curve fitting, and (6) mask development. The pipeline for the ROI extraction approach is depicted in
Figure 2.
Since the captured frames are noisy and degraded and have artifacts due to environmental surroundings, a Gaussian kernel is utilized to suppress these artifacts and to keep strong edges representing potential highway lane sides. A canny edge detector is employed to detect candidate edges from blurred images, followed by connected components analysis to suppress unwanted edges in small areas. Then, the Hough transform is applied to detect possible lines in the edge image. Vertical lines whose angles are less than are suppressed. It is assumed that the possible lanes will not be vertical lines since these vertical lines may account for other objects within the scene, such as light poles. Applying the Hough transform to the image results in a feature space of two parameters, namely, and , where represents the normal from the origin to the detected lines, while represents the inclination to x-axis. Next, fuzzy C-mean is applied to the Hough space features to cluster the possible detected Hough lines using the two features, and . The number of clusters is set empirically to four clusters. Since the detected clustered lines may be represented as broken segments near each other, curve fitting is employed to fit a cluster of detected broken segments into a unique single line. Several 1D curve fitting techniques are tested, including linear and higher order polynomials, exponential, Gaussian, and cubic spline models. Empirically, it is found that the linear polynomial model provides the best results. Finally, a raster scan is utilized across the image overlaid by fitted curves. These curves are used as guidelines to define the masked areas.
2.2. Foreground Segmentation
The foreground segmentation process identifies moving vehicles through the highway image scene. This stage is a crucial step in the proposed algorithm since it is required to extract vehicles with high accuracy and low computational time to make the system suitable for real-time implementations. Plenty of approaches have been developed in the literature related to foreground segmentation. Of these approaches are the robust low-rank and sparse matrix decomposition in which a low-rank matrix represents the background image, and a sparse matrix represents the foreground objects [
51]. These techniques prove to achieve high accuracy and real-time implementations. Sobral et al. [
52] have reported several low-rank decomposition algorithms for background extraction from videos, and they ranked those algorithms in terms of their computational time.
In this research, the authors first investigated several approaches and applied them to the available dataset, which is noisy, degraded highway videos captured under different weather conditions. The evaluation is in terms of segmentation efficiency and computational time. Secondly, the proposed algorithm improves upon one of the evaluated algorithms named fast principal component pursuit (FPCP) introduced by Rodriguez and Wohlberg [
53]. The proposed approach improves the speed and segmentation accuracy and verifies the improved performance using a manually labeled dataset. The proposed algorithm utilizes the FPCP approach as an initial stage to pre-train the system. The pre-training provides a priori low-rank background representation that is used in subsequent stages. Once a low-rank representation is determined, a simple frame difference is utilized to extract the sparse foreground images. Another aspect is that FPCP and other robust low-rank and sparse matrix decomposition approaches utilize global thresholding to extract foreground objects. However, global thresholding extracts most of the segmented objects and labels them as foreground objects; it mislabels other foreground objects, especially when the pixel values of these objects are close to background pixel intensities. Additionally, frame difference provides negative values considered background objects when global thresholding is applied; however, they are not.
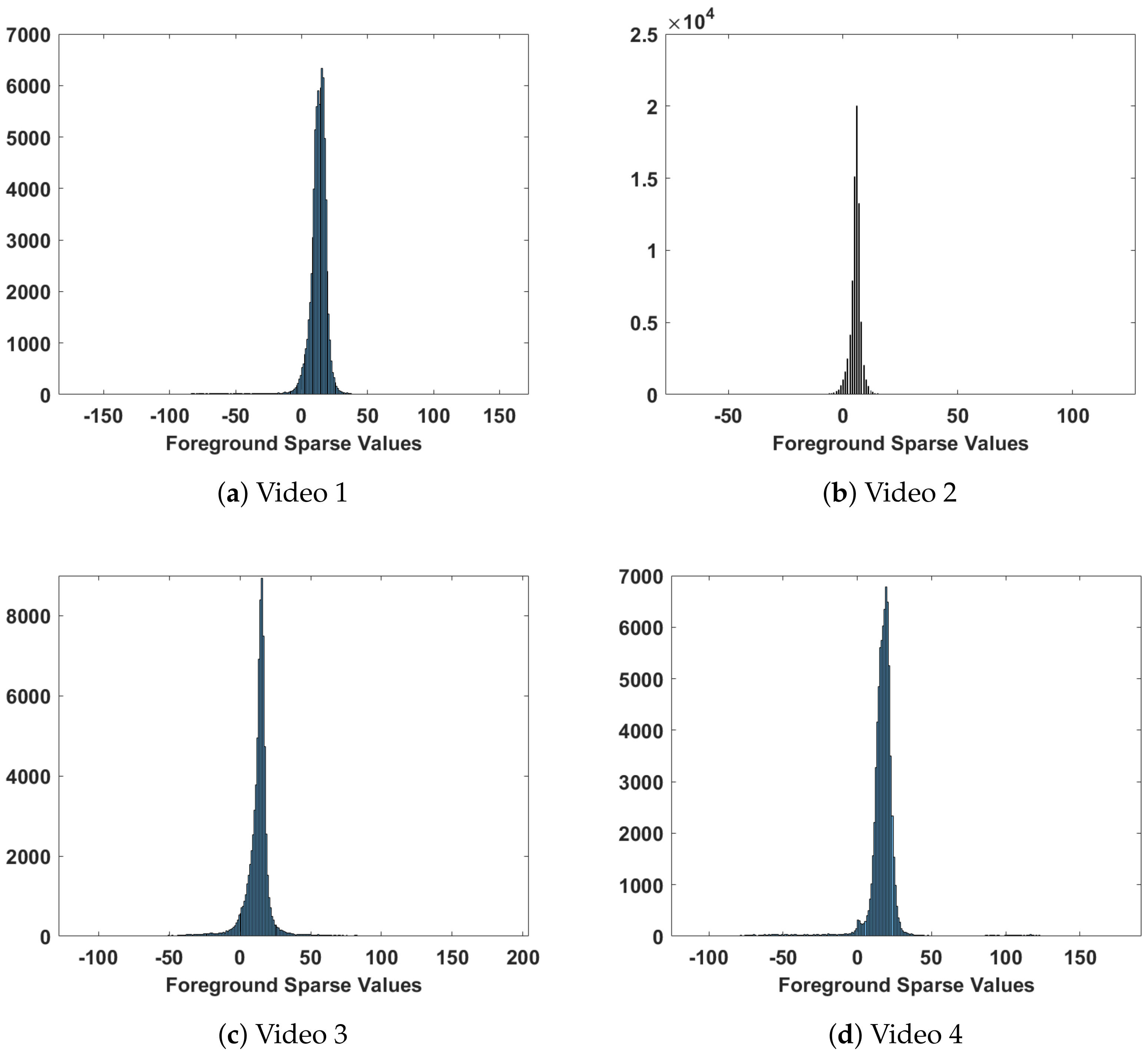
Figure 3 depicts the histogram of sparse frames that results from the difference between estimated low-rank background frames and a frame under processing. This gives intuition to fit the resultant sparse matrix into a Gaussian distribution with a mean representing the background pixel values. If values fall in the Gaussian distribution outer sides, they are mapped to the segmented foreground pixels.
In that sense, the proposed algorithm models the resultant difference matrix into a normal distribution and determines the threshold utilizing the fitted normal distribution mean and variance. The estimated mean is around or close to zero values. Those values represent the background pixel intensities. Considering that noises are present in the scenes, the background pixel values are mapped inside the interval defined by the bounds . In contrast, foreground pixel values are mapped outside that interval.
Following the same FPCP formulation, a data matrix
X can be written as
such that
L is a low-rank matrix, and
Z is a sparse matrix satisfying the following optimization problem:
where
is the data matrix,
is the nuclear norm, while
is the
norm of a given matrix. The data matrix
X is constructed by stacking the video frames shaped as columns of
X. The FPCP authors relaxed the nuclear norm, and the optimization function became:
where
is the Frobenius norm of the matrix, and
t represents the number of partially selected components of the spectral value decomposition (SVD). The FPCP approach proposed a solution to Equation (
2) using alternating minimization as follows:
Equation (
3) is addressed utilizing partial
t components of the SVD of
, while Equation (
4) is solved by soft thresholding
where the soft thresholding is defined by:
The videos’ set of
k frames are used to pre-train the system to estimate a low-rank matrix
that represents the background. A simple frame difference between the estimated background
and the current video frame
is used to determine the current spare matrix that represents the foreground,
, as given by:
Once
is computed, resultant difference values are fitted into a normal distribution of mean
and standard deviation
. The minimum variance unbiased estimator (MVUE) is utilized to estimate the parameters
and
. The sample mean,
, is defined as
while the sample variance,
, is defined as
The sample mean and variance are used to estimate the mean and standard deviation, respectively. Next, the foreground is segmented utilizing the following threshold:
where
is determined empirically from simulations, and
are spatial coordinates of the pixel values within the frame
. Finally, binary opening and closing operations are integrated to reduce the noise effects after thresholding.
2.3. Vehicle Features
The authors utilize the same approach presented in their previous work [
54] to extract segmented vehicle features. Size, shape, and texture descriptors are considered for classification. Morphological properties are used to describe the size and shape of each vehicle. Gradient-based texture features are calculated using a HOG algorithm on the rectangular boundary image of the detected vehicle.
Twelve extracted feature descriptors representing the size and shape of segmented vehicles are employed. These descriptors include area, bounding box, centroid, convex area, eccentricity, equivalent diameter, Euler number, extent, primary axis length, minor axis length, orientation, and perimeter [
54,
55].
In addition to the physical features, textural features are integrated by computing the histogram of oriented gradients of segmented vehicles. Due to its effectiveness in identifying an object’s visual texture, the HOG descriptor is widely used in image processing and computer vision for object detection [
56]. The HOG features are evaluated using both image gradient magnitudes and orientations and are slightly affected by local geometric and lighting distortions.
2.4. Vehicle Tracking
In order to keep an accurate count of vehicles within the highway image scene, each detected vehicle is tracked as it traverses the ROI. A Kalman filter tracking approach is used to track each detected vehicle through the ROI [
57]. The Kalman filter vector is created for each newly detected vehicle. It tracks the ID number of the vehicle, the centroid position, and the vehicle velocity assuming constant acceleration through the ROI. Image features derived from the foreground-segmented vehicle are also paired with the Kalman filter track for every frame in which the vehicle is present. Once the vehicle exits the ROI, the Kalman filter vehicle track is deleted.
2.5. Classification
Once a vehicle track has been deleted, as described in the previous section, the classification of the vehicle at every frame occurs. The classification of vehicles occurs in three steps: (1) training the classifier, (2) multiclass SVM classification, and (3) statistical analysis for final classification.
2.5.1. Training the Classifier
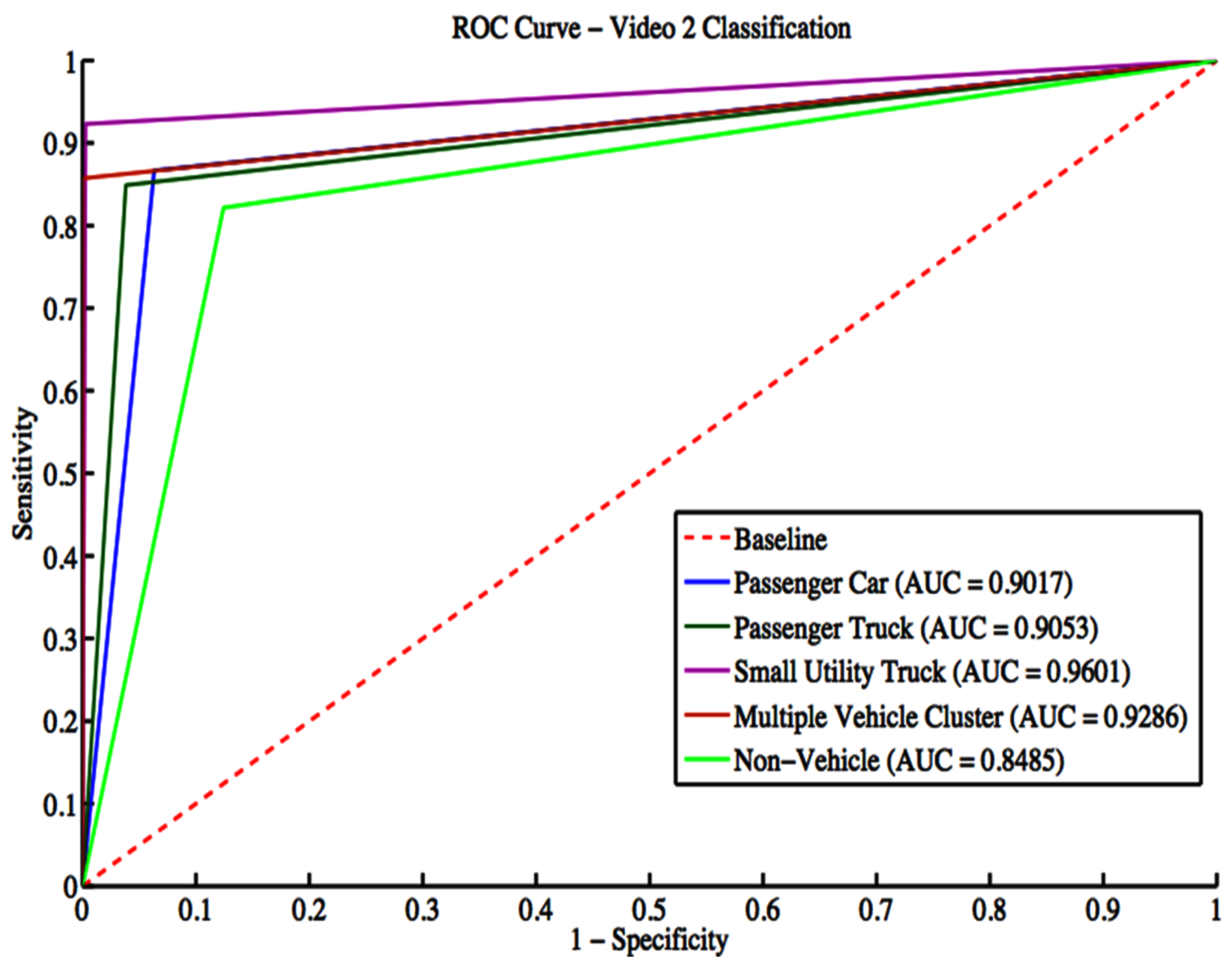
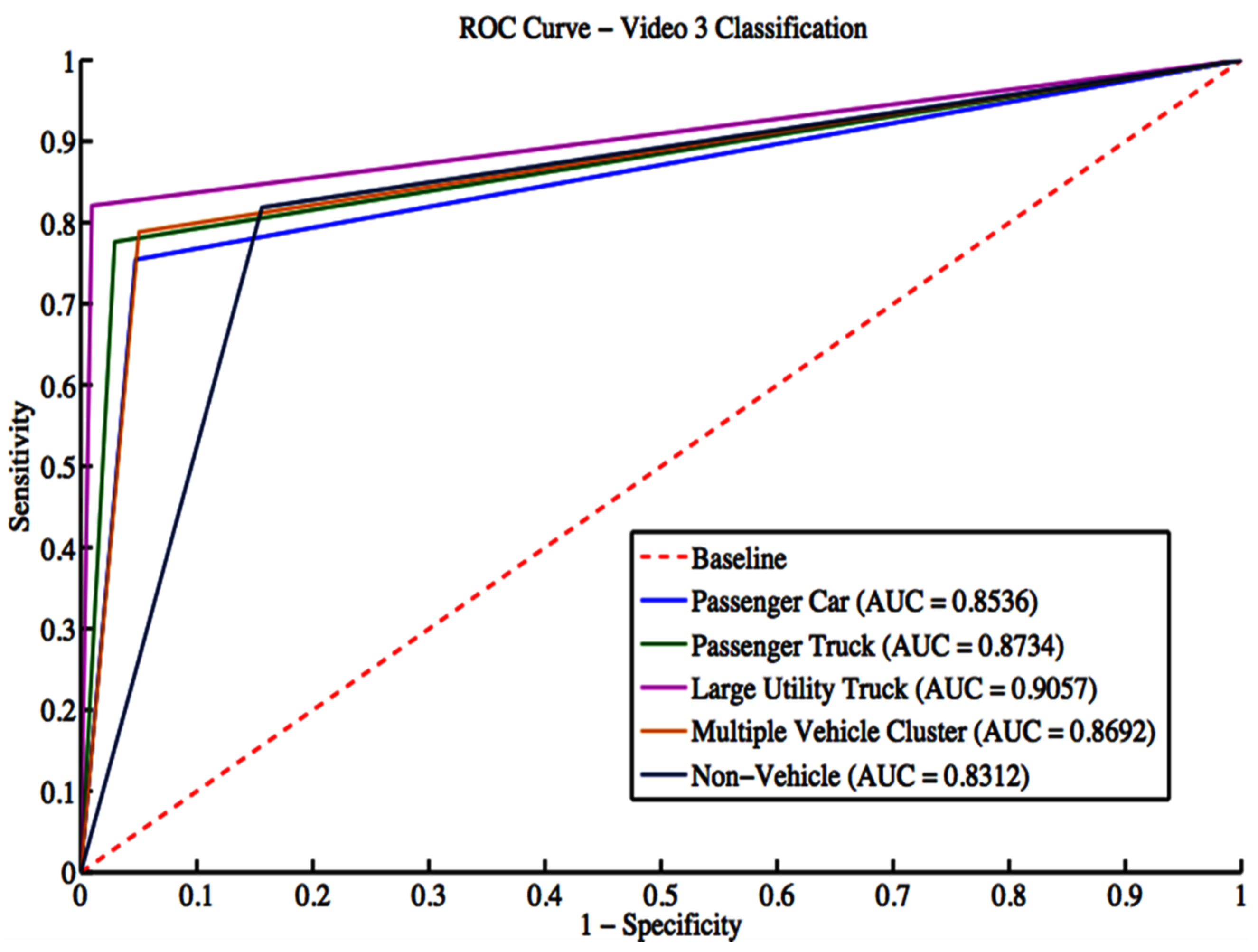
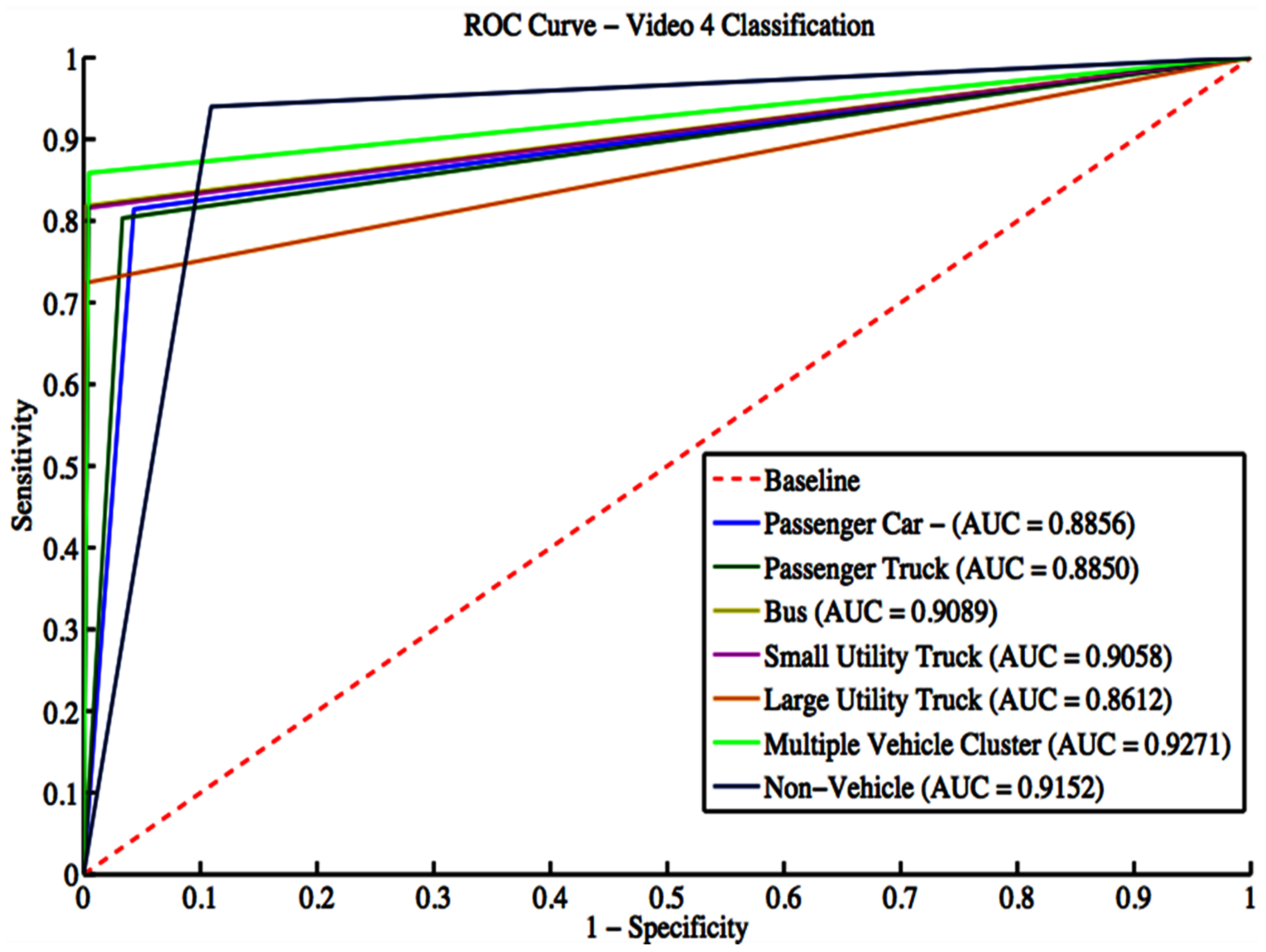
The classifier is trained using a manually labeled ground truth dataset for each camera. Eight classes are considered for training. These classes include the six vehicle classes: passenger car, passenger truck, bus, small utility truck, and large utility truck. In addition, classes representing a detection that is not a vehicle or a detection containing multiple vehicles are presented. The classifier is trained on a manually tagged dataset using 10-fold cross-validation in which the dataset is divided randomly into 10 groups. The training is conducted using nine groups; the remaining group is used for testing. The process is repeated ten times to estimate the classifier’s performance.
2.5.2. Multiclass SVM Classification
Multi-class SVM classifier is adopted to classify the segmented data into one of eight classes. The SVM classifier is known to be efficient in separating large feature vectors and does not require intensive memory allocations [
58]. A set of binary SVM classifiers is adopted to handle the multi-class separation. The SVM classifier with radial basis function (RBF) kernel is chosen for its better separation of nonlinear feature vectors. The RBF kernel has two parameters, called the sigma and box constraint, found by a grid search method. In the grid search method, each parameter varies over a range of 0.1 to 15, and the 10-fold cross-validation is performed. The parameters are set for the maximum cross-validation result.
Following the same approach discussed by Chen et al. [
59], the work presented here adopts eight binary SVM classifiers to handle the problem of multi-object classification. First, one SVM classifier is trained to separate a certain positive class from other classes treated as a single negative class. Then, after the training phase of the chosen classifier is over, the same process continues for training other classifiers.
2.5.3. Final Classification Result
The final classification result is found by taking the statistical mode of each frame classification result. For example, a single vehicle track may make a mistake in tracking and correct to the wrong detected vehicle. Furthermore, the tracked vehicle may also include partial detection at the ROI boundary and be classified as “Not a Vehicle”. Using the mode of the classification results eliminates these conditions and uses the most stable classification results from each frame in the vehicle track.
2.6. Multiple Vehicle Handling
Due to vehicular occlusion, some vehicles traveling nearby are clustered and appear as a single vehicle. The classification method in the previous step is trained to recognize multiple vehicle clusters. If the deleted track contains multiple vehicles, then occlusion is assumed. This occlusion is handled through an iterative over-segmentation and reclassification method.
2.6.1. K-Means Over-Segmentation
The first step in over-segmentation is to analyze the geometry of the boundary rectangle for the occluded vehicles. If the boundary rectangle width is greater than the height, it is assumed that the multiple vehicles are arranged from left to right, and the boundary rectangle is divided vertically. Otherwise, it is assumed that the multiple vehicles are arranged from top to bottom, and the boundary rectangle is divided horizontally. Two centroids are assumed in the newly divided boundary rectangle.
K-means clustering is used to perform over-segmentation of the multiple-vehicle cluster. K-means uses the image intensity and quantizes similar intensity levels into a single patch. This over-segmentation process uses up to 25 levels applied to the input image of each multiple-vehicle cluster.
After the newly segmented patches are created, the centroid of each patch is calculated. The minimum Euclidean distance of each patch to the new boundary box centroids is used to assign each patch to the new boundary box. Once the patches are assigned, the newly clustered vehicle is converted from the patches. Features are extracted from the new vehicle cluster.
2.6.2. Reclassification
The final step in multiple vehicle handling is to perform classification on the two detected vehicles from the k-means over-segmentation process. This reclassification follows the method described in
Section 2.5. The steps in this section are repeated if the vehicle cluster still contains multiple vehicles. If the vehicles cannot be separated, this iterative approach will only repeat three times.
4. Conclusions
In this work, an end-to-end integrated vision-based framework that is capable of segmenting moving vehicles and classifying them by type is presented. Novel contributions to intelligent transportation systems research have been presented by an integrated algorithm capable of vehicle segmentation and classification in a camera-viewpoint-independent highway image scene with the ability to handle multiple vehicle clusters. The algorithm was speeded up through an automated approach for extracting a region of interest, reducing 40% in the processed data. Vehicle segmentation was carried out using an improved speeded-up robust low-rank matrix decomposition technique. Utilizing a new and effective thresholding method improved segmentation accuracy and simultaneously sped up the segmentation processing. It improved segmentation accuracy by 15% on average compared to current approaches and was 55% quicker on average than recent segmentation techniques. Segmentation was shown to perform very well during the day. However, the segmentation and classification results degraded under low light conditions or poor environmental scenarios such as rain.
The algorithm adopted size and shape physical descriptors from morphological properties and textural features from the histogram of oriented gradients (HOG) extracted from the segmented traffic for feature extraction. Moreover, a multi-class support vector machine classifier was used to identify diverse traffic vehicle categories, such as passenger cars, passenger trucks, motorbikes, buses, and small and big utility vehicles. The proposed approach manages multiple vehicle clusters through an iterative k-means clustering over-segmentation procedure. It shows high classification performance for vehicle types, such as passenger cars and passenger trucks, while its performance was disappointing for classes with a poor showing in the training dataset. Additionally, the algorithm was compared against 23 different deep-learning architectures. The resulting algorithm outperformed the compared deep learning algorithms for the quality of vehicle classification accuracy.
The timing analysis results show that the algorithm’s current implementation can perform in real time for the 15 frames per second frame rate. However, future modifications to the algorithm to handle different weather scenarios, such as rainy conditions, can improve the segmentation and classification of the proposed algorithm and make it adaptable to different weather conditions. Additionally, the lack of enough training datasets close to the one utilized in this research makes using deep learning techniques not promising and challenging and leads to poor performance.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}