1. Introduction
Nowadays, litter is one of the greatest challenges [
1], due to its ubiquity, nature and scale, with dire consequences not only for freshwater and marine ecosystems [
2,
3,
4,
5], but also, arguably, for urban environments and human health. For example, plastic items can cause lethal damage to aquatic and terrestrial species through entanglement, gut perforation, and starvation [
6]. Moreover, plastic decomposes, creates microplastics and, ultimately, nanoplastics which easily enter the food chain [
7].
Additionally, one of the main concerns is the accumulation of litter not only in the urban area [
8], but, mainly, in ecological areas [
9,
10]. To investigate and tackle this challenge, decision-makers require reliable data—not only on the sources of waste, but also on its composition, distribution and magnitude over large geographic areas. One way of providing technological support is to automate the process of litter logging and litter detection, especially in areas of difficult access, such as forest and mountains, so as to make the process more effective for volunteers and researchers and enable the processing of large datasets, while minimizing resources, fatigue, and even risks.
During the last years, some research initiatives have investigated suitable computational approaches to support surveys on waste and litter occurrence and distribution. Several works are focused on the Internet of Things (IoT), where sensors are used to monitor city cleanliness [
11,
12,
13]. Researchers have also focused efforts on image-based approaches for marine debris, plastic and even microplastic identification [
14,
15,
16,
17,
18,
19]. However, image acquisition procedures rely on microscopes, webcams, and even aerial surveys, which are costly and often unavailable to volunteers and citizen scientists. Detection and recognition often explore color and shape information, combined with threshold-based classification methods, costly and time-consuming visual inspection. However, none of these alternatives consider the use of mobile-based image acquisition procedures. Moreover, the use of deep learning approaches, especially adapted for devices with constrained processing capabilities, such as mobile phones, has not yet been investigated, a gap that still needs to be filled.
Currently, most of the state-of-the-art solutions for object detection and recognition exploit CNN approaches [
20], which rely on the use of deep architectures, such as VGG [
21]. Despite their success, such solutions are computationally costly in terms of processing, as well as memory and storage footprints. Therefore, their use is unfeasible in practice, in several applications with computational constraints, such as mobile devices. A suitable alternative explored in the literature refers to the use of “mobile” CNN architectures [
22,
23,
24], i.e., lightweight CNN architectures specifically designed for mobile devices. However, to the best of our knowledge, there is currently no study concerning the assessment of suitable litter detectors using neural network architectures, especially in scenarios involving devices with low-processing capabilities.
Moreover, despite the numerous cloud computing services for machine learning, its response time is not enough for real-time applications, especially in natural settings, such as beaches and forests, among others, impacted by latency fluctuation or even without network coverage. Moreover, data transfer over the network involves more energy consumption [
25,
26]. In this vein, efficiency, local processing and lower energy consumption are some of the advantages of using lightweight neural networks [
25,
27].
We performed a comparative study in the context of litter and waste detection using well-known state-of-the-art CNN architectures (e.g., Faster RCNN [
28], Mask-RCNN [
29], EfficientDet [
30], RetinaNet [
31] and YOLO-v5 [
32]) and lightweight neural networks approaches (e.g., EfficientDet-d0 [
30] and YOLO-v5s [
32]). Those approaches were compared not only in terms of their effectiveness (detection quality), but also in terms of their efficiency, i.e., detection time and storage requirements. Additionally, the identification of effective machine learning approaches to confront the issue of litter demands the use of comprehensive datasets, i.e., the set of images used to train the models impacts the performance of the methods when tested in real-world settings. Detecting litter in such scenarios is a very challenging problem.
Figure 1 provides examples where complex natural backgrounds and the presence of different kinds of litter complicate the detection task. Currently, there exist some litter datasets; however, most of them were built in controlled setups, i.e., with only one instance of litter per image [
33,
34] or taken in indoor scenarios for recycling [
35,
36]. Approaches developed based on such image collections cannot be generalized for real-world scenarios. To the best of our knowledge, TACO [
37] is the only publicly available dataset containing 1500 images from realistic outdoor scenario. For this reason, herein, we present a new dataset, named “PlastOPol,” which is based on images taken through the Marine Debris Tracker with the goal of giving, to the computer science and environmental communities, a new set of 2418 images with the presence of litter in a realistic context covering several types of environments, i.e., urban, beaches, forests and flint fields, and including different types of litter, including plastic, glass, metal, paper, cloth and rubber, among others.
In summary, this paper aims to fill the following gaps in the literature: assessing the effectiveness of lightweight neural networks in detecting litter in real-world settings and crowded image backgrounds and their ability to run in mobile devices with memory constraints (henceforth referred to as efficiency). The ultimate aim is to aid the scientific community in developing simple, cost-effective tools to automate part of the work conducted by volunteers and citizen scientists when collecting and recording litter in the environment, to make more data available to science and ultimately inform targeted policies and management measures. Our contributions are twofold, as follows:
- (1)
Comparative study of state-of-the-art deep learning solutions to support image-based litter and waste detection;
- (2)
Introduction of a new dataset, PlastOPol, composed of 2418 images in real-world settings with 5300 litter annotations.
The experiments considered two datasets, namely, PlastOPol and TACO [
37], and aimed to assess the performance of the detectors using mobile devices. The experimental results showed that YOLO-v5x [
32] outperformed the other state-of-the-art methods in both datasets. Moreover, YOLO-v5s [
32] proved to be the most promising approach to be run in mobile devices due to its competitive results and its ability to process up to
frames per second (FPS) in a commercial smartphone.
The remaining of the paper is organized as follows:
Section 2 presents and discusses related work.
Section 3 introduces PlastOPol, a new dataset for litter detection.
Section 4 describes the evaluation protocol adopted for the purpose of the comparison.
Section 5 presents and discusses the results and possible limitations of the study. Finally,
Section 6 states our conclusions and points out possible research avenues for future work.
3. PlastOPol Dataset
There are few datasets dealing with the issue of littering. Proença and Simões [
37] presented TACO for litter segmentation with the presence of indoor and outdoor scenes. In the same vein, MJU [
33] is another dataset for segmentation; however, unlike TACO, this dataset contains only indoor images with people holding the litter instances in their hands. For its part, Aquatrash [
49] is an alternative dataset composed of a subset of images from TACO [
37]. Additionally, there are also datasets proposed for sorting recyclable litter, some of them involve detection of waste in industrial plants [
35,
36] and others for classification in a more controlled set-up with the presence of a single litter instance per image [
34]. Except for TACO [
37], none the above mentioned datasets present outdoor backgrounds, which is a limitation to build computational solutions for detecting litter in the environment.
Herein, as one of the main contributions of this work, we present a new dataset for litter detection, named “PlastOPol”. The proposal of this dataset has the goal of giving to the computer science and environmental science communities a new set of images with the presence of litter in several types of environments. We hope that PlastOPol serves as basis for the proposal of automatic detection methods which can support the furthering of research on litter in the environment. The images were collected by the Marine Debris Tracker available under an open access Creative Commons Attribution license.
Building the dataset involved the meticulous task of labeling each litter instance in each image. PlastOPol is a one-class labeled dataset, where all the data corresponds to the “litter” class as its super category. This dataset has 2418 images collected by the Marine Debris Tracker with a total of 5300 instances of litter. Each instance is wrapped within a rectangular bounding box represented by four values (, , and ), where (, ) corresponds to the upper left corner of the bounding box.
Based on the bounding boxes areas,
are considered as large,
medium and
small (see
Table 2 for details). Additionally, as can be observed in
Figure 2, our dataset presents images involving diverse types of environments as background, e.g., water, snow, sand, flint fields, streets, etc.; and various types of litter, including plastic, glass, wood, metal, paper, cloth and rubber, among others. Moreover, PlastOPol contains images with different lighting, occlusion and background conditions, which lead to very challenging detection scenarios. All these elements make the PlastOPol dataset very complete and ideal for training object detection models. Detecting litter from different materials, colors and shapes present in different natural backgrounds with varying illumination conditions increases the chance of confusing or not detecting litter, even more with the presence of small litter instances.
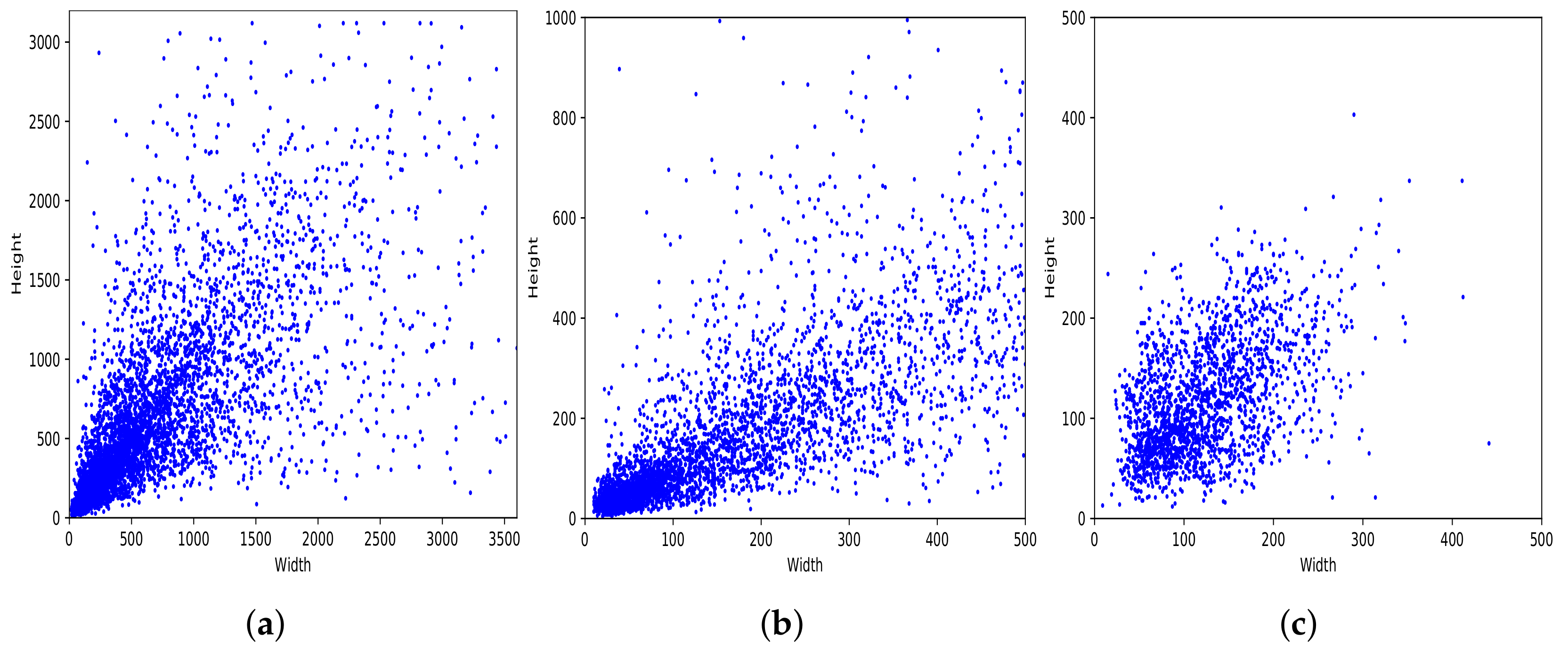
Figure 3a shows the distribution of bounding boxes based on their width and height. As we can see, our dataset has diverse bounding box sizes, ranging from
to
pixels. Moreover, it shows a large concentration in the area of
pixels.
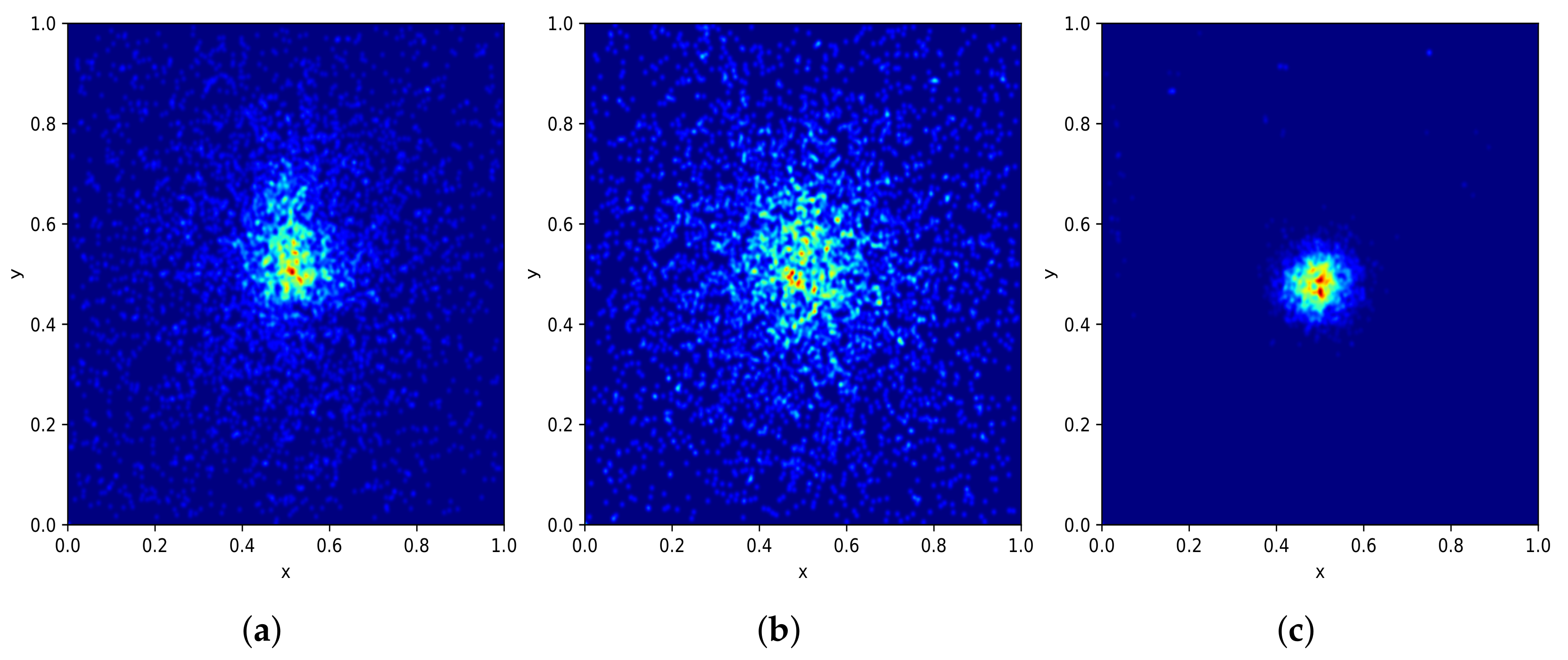
Figure 4a shows how the entire set of bounding boxes are located in the images, with most of them being in the center of their respective images; nevertheless, there are also bounding boxes located over the whole image area.
Figure 3 and
Figure 4 present some details about the PlastOPol (outdoor scenes), MJU [
33] (indoor scenes), and TACO [
37] (indoor/outdoor scenes) datasets. PlastOPol contains a wider diversity in terms of the size of bounding boxes, compared with TACO and MJU (see
Figure 3). Moreover, PlastOPol (
pixels) and TACO (
pixels) are composed of images with higher resolution than MJU (
pixels). Regarding the bounding box location,
Figure 4 shows the distribution of bounding boxes inside the images. MJU, an indoor dataset created in a controlled set-up, presents almost all their litter instances located in the center of the image, while PlastOPol and TACO have more sparse bounding boxes, covering most of the image area in a realistic and challenging scenario for litter detection.
6. Conclusions
One of the most pressing environmental challenges of our time is how to mitigate the impact of littering in the environment. In this work, we present a new dataset, called “PlastOPol,” which contains images of various types and sizes of litter with different real-world backgrounds (streets, forest and beaches, among others) and annotations locating the litter within the images. Our goal is to foster the creation of more effective and efficient machine learning solutions for litter detection and classification with the ultimate aim of automating the process.
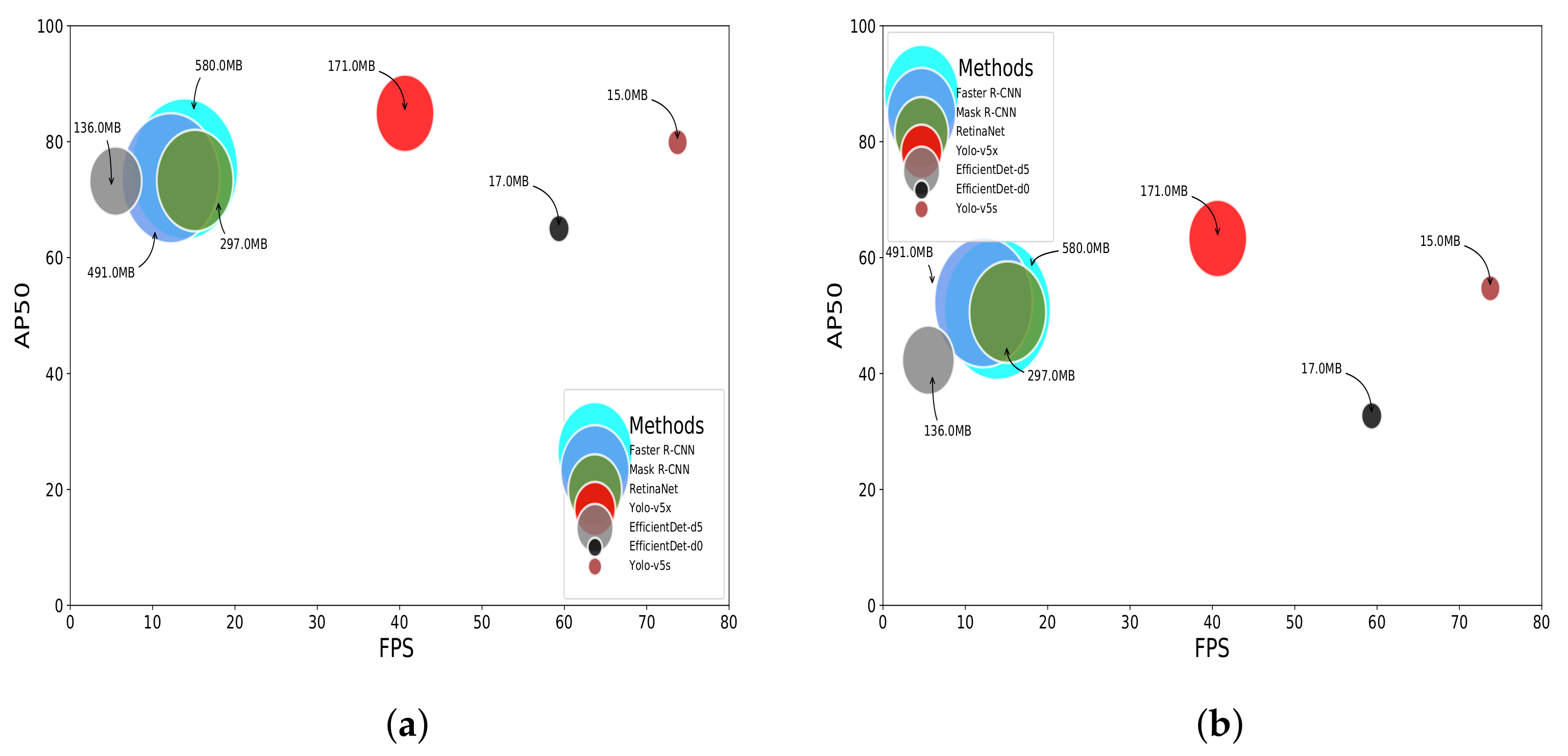
We performed a comparative study involving state-of-the-art approaches for object detection using the PlastOPol and TACO datasets. The overall performance of the evaluated methods was similar for both datasets. We also observed that the YOLO-v5-based object detectors performed best. On PlastOPol, YOLO-v5x reached an AP50 of , followed by YOLO-v5s with . On TACO, the AP50 observed was and for YOLO-v5x and YOLO-v5s, respectively. There were challenging backgrounds where several methods had false positives, confusing wood with litter, for instance. Moreover, all the methods had problems detecting small objects, such as cigarette butts.
We also evaluated the performance of the methods. On GPU, YOLO-v5s and EfficientDet-d0 were the fastest approaches, processing up to and FPS, respectively, and YOLO-v5x was capable of processing at FPS. As for the remaining methods, YOLO-v5s was , , and faster than RetinaNet, Faster R-CNN, Mask R-CNN and EfficientDet-d5, respectively.
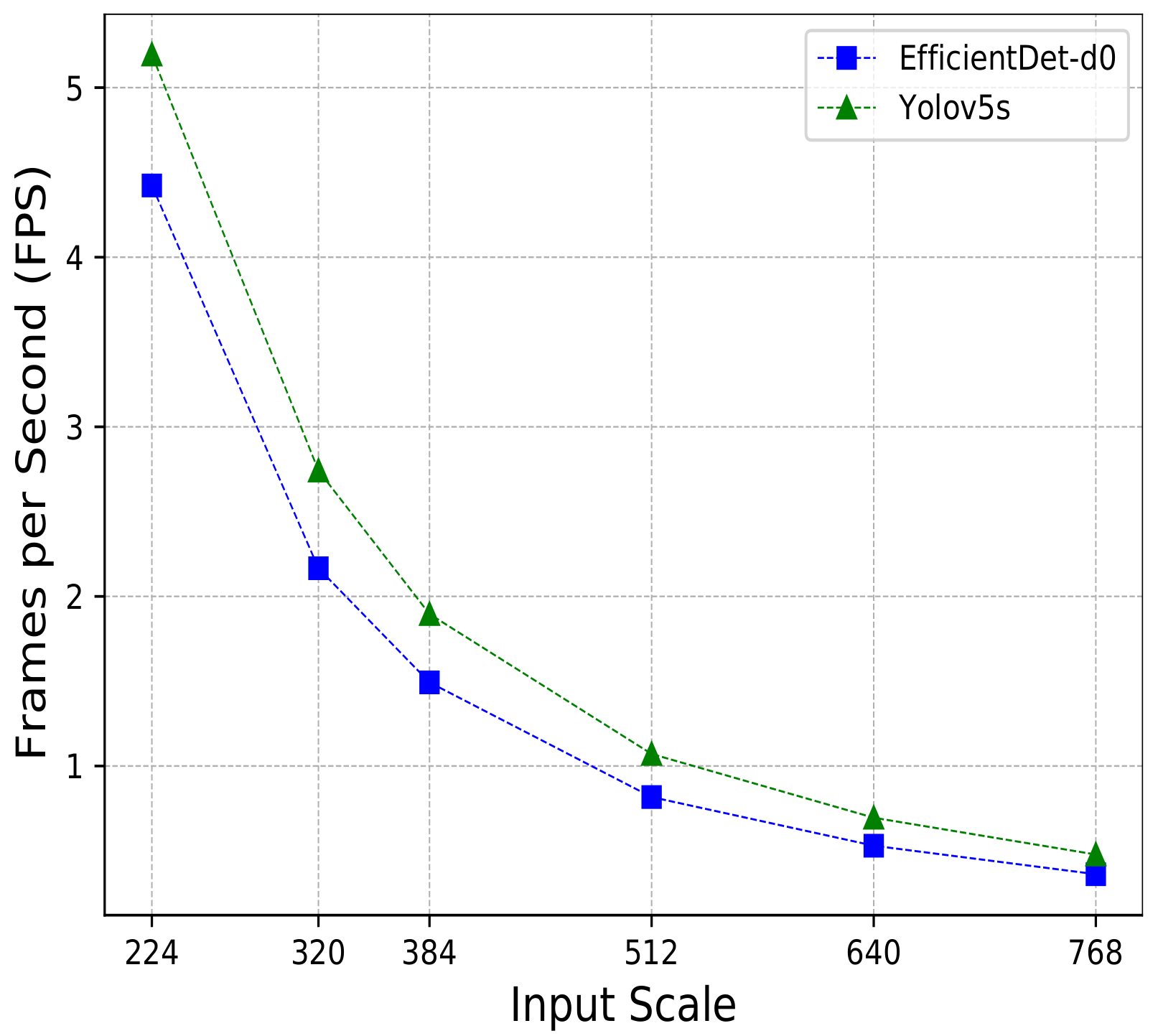
In the last years, most of the approaches proposed to improve object detection have been using very deep neural network architectures, which increases their model size, making it, in practice, almost impossible to use in devices with computational restrictions and real-time applications. Unlike other areas, the optimization of automatic litter detection involves searching for litter, even in areas of difficult access, using devices, such as drones or mobile devices. For this reason, we also compared the performance of EfficientDet-d0 and YOLO-v5s, which are two light models, in a real mobile set-up using a commercial smartphone. YOLO-v5s was the fastest one in all the experiments. With an image input size of , YOLO-v5s was capable of processing at FPS, being faster than EfficientDet-d0. Moreover, increasing the input size reduced the efficiency of the models drastically. With an input size of pixels, YOLO-v5s and EfficientDet-d0 processed at just and FPS, respectively.
In summary, we demonstrated how well state-of-the-art object detection methods performed on two challenging datasets for litter detection, as well as their strengths and weaknesses. All methods had limitations when presented with difficult scenarios, with complex natural background and very small litter instances. Future research efforts should focus on improving the litter detection of the state-of-the-art methods using fusion strategies [
51]. We also plan to continue investigating how tiny deep neural networks can run on devices with computational constraints, also considering well-known lightweight object detection methods, such as MobileNet [
52], ShuffleNet [
53] and Pelee [
54], among others. Moreover, having few samples of small instances impacts the detection rate in these types of instances, as the detectors do not have enough information to capture a better description of this type of litter during training. Therefore, there is a greater probability of not detecting these instances during testing. For this reason, the extension of our dataset using smart data augmentation strategies, especially for very small litter instances, will be investigated.
Finally, PlastOPol does not contain annotations related to the types of litters (e.g., plastic, paper and metal, among others) found within images. We plan to provide such multiclass annotations in the future, assess the performance of the state-of-the-art methods and also propose a new approach to detecting litter in a multiclass set-up. Furthermore, with the proposal of a multiclass dataset, we intend to analyze the balance of instances per class and its impact on efficiency. In addition, it is also important to evaluate the impact of the dataset size by evaluating the effectiveness of the methods on a subset of images with the goal of prioritizing the dataset distribution rather than its size.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}































































































