1. Introduction
The problem of acoustic source localization and tracking has always been one of the research hotspots in the field of speech processing. It has been widely used in many aspects, such as audio and video conferencing systems, human-computer interaction and speech enhancement, etc. [
1,
2,
3,
4]. Traditional acoustic localization and tracking methods usually require the microphone array to have a regular geometric structure, and generally use a centralized data processing method [
5]. With the continuous advancement of technology, some traditional microphone arrays gradually show some deficiencies. The distributed microphone network has attracted more and more research work because it has no strict restrictions on the arrangement of microphones, and is a network composed of multiple nodes arbitrarily distributed in space, usually each node contains a set of microphones [
6,
7,
8,
9,
10].
So far, there have been many studies on acoustic source localization using distributed microphone networks [
11]. But they only locate the acoustic source based on the current observations of multiple microphones, which can locate the acoustic source when the background noise and reverberation are small. In noisy and reverberant environments, spurious observations may even mask observations from real acoustic sources, degrading localization performance. To avoid this problem, a Bayesian filter [
12] combined the current observation with a series of past observations for current position estimation, which is more effective for dealing with the adverse effects of noise or reverberation. Theoretically, Bayesian filters describe the tracking problem with a state-space model that includes a dynamic model that describes the motion of the target and an observation model that describes the relationship between the observations and the state of the acoustic source. When the state space model is linear and Gaussian, Kalman filter can replace Bayesian filter. However, in acoustic source tracking scenarios, the observation function is usually nonlinear, and some conditions and properties applicable to linear systems no longer hold, and the performance of the Kalman filter may be severely degraded.
Extended Kalman filter (EKF) was first proposed in [
13] and is the simplest and most widely used nonlinear filtering method. EKF only intercepts the first-order term in the linearization process to approximate the system function, but its error is relatively large. In order to solve this problem, the literature [
14] proposed iterative extended Kalman filter (IEKF), which can improve the accuracy of EKF through several iterations. However, when the nonlinearity of the system model is very strong, whether it is EKF or IEKF, their effect is not good, and there are disadvantages such as poor stability and easy divergence. The particle filter (PF) is a Monte Carlo implementation of a Bayesian filter that approximates the state by a series of weighted particles extracted from the proposal function [
15]. PF can handle nonlinear and non-Gaussian situations well, and many PF-based sound source tracking methods have been developed. Vermaak and Blake [
16] first introduced PF to sound source tracking. The particle filter method breaks through the limitations of linearity and Gaussian, but its computational load is too large. In practical applications, particle filtering will only be considered when the approximate filter fails. The Sigama point Kalman filter method [
17] was similar to the idea of particle filter. It does not use the method of approximating nonlinear systems, but directly uses the real system and observation model by selecting a set of effective deterministic sampling sets, namely Sigama points, which can achieve second-order accuracy. According to the different selection methods of Sigama points, it can be divided into UKF, CKF, QKF and so on. In general, several Gaussian filtering methods introduced above are centralized, that is, the data of all nodes is collected and transmitted to the central processing unit to perform the task of acoustic source tracking. This method is generally unreliable, as any failure of the central processor renders the entire network untraceable.
In order to solve the unreliable problem of centralized methods, many distributed methods have been developed for sound source tracking. No central processor is needed in the distributed method, and all nodes realize the estimation of the global state only by exchanging data with their neighbors. In reference [
18], a distributed extended Kalman particle filter (DEKPF) for speaker tracking was developed, which combined the current TDOA observations into EKF to propose particle filter. In reference [
19], a distributed particle filter (DPF) was proposed, which applied the improved iterative covariance intersection (MICI) algorithm and interactive multiple model (IMM) to speaker tracking in distributed microphone networks. In reference [
20], a distributed iterative EKF was proposed to estimate the time-varying speaker position in the microphone array. In reference [
21], a Distributed Unscented Kalman Filter (DUKF) is proposed to overcome the nonlinearity of the measurement model in speaker tracking. The time difference of arrival (TDOA) was used as the observation and then the distributed IMM-UKF was used to track the location of the sound source.
In the actual environment, the existence of noise or reverberation usually produces unreliable observations with false peaks, which may lead to serious performance degradation. Usually, the current observations contained in these methods are only extracted from the largest peak value of a certain observation function. In some bad cases, the peak value related to the real acoustic source may be masked by the stray acoustic source. Therefore, it is more reasonable to extract multiple observations from the observation function, rather than one observation, and then incorporate it into the above tracking scheme. Probabilistic Data Association (PDA) [
22] is an effective method to combine multiple observations into Kalman filter state update, which has been proved to be suitable for target tracking in clutter environment. In reference [
23], an improved distributed unscented Kalman particle filter (DUKPF) was proposed to track a single moving acoustic source using a distributed microphone network in noise and reverberation environments. This method proposed to extract multiple observations from the observation function of each node and combined them into the status update of UKF through probabilistic data association (PDA) technology, so as to generate PDA-UKF, and then brought in particle filter. In reference [
24], a microphone array network distributed multi speaker tracking method based on tasteless particle filter and data association was proposed. The available observations were associated with each speaker at each node using data association technology to track the speaker. Reference [
25] proposed a volume information filter based on joint probabilistic data association (JPDA) for multi acoustic source tracking based on distributed acoustic vector sensor (AVS) array, in which JPDA was used to deal with the correlation between observations and targets. Issues related to multi-source tracking are beyond the scope of this article. However, most of particle filter-based methods require excessive computational costs, which limits them in real-time applications. Besides, in existing speaker tracking methods, the PDA algorithm is applied to sift the observations without considering the information from neighboring nodes.
Probabilistic data association with cubature Kalman filtering are combined in this paper, and they are applied to the problem of single-acoustic source tracking in noisy and reverberant environments with distributed acoustic sensor networks. The contributions of this paper are as follows:
Combining the cubature Kalman filter (CKF) with PDA, the probabilistic data association-cubature Kalman filter (PDA-CKF) was developed. In PDA-CKF, multiple possible observations were merged into the state update of CKF by the PDA technique.
In this paper, PDA-CKF was applied to the distributed acoustic sensor network, and the probabilistic data association-distributed cubature Kalman filter (PDA-DCKF) was developed by combining the observation information of each node’s neighbor nodes in the network.
Considering the reliability of the local state, it was proposed to combine the mean square error (MSE) of the position estimation of each node and the received signal energy to adjust the weighting coefficient of distributed acoustic sensor data fusion. In this way, the local state of high-quality nodes is enhanced, and each node can achieve global consistency and good speaker tracking performance.
The structure of this paper is as follows.
Section 2 presents the problem formulation, background knowledge, and some prior knowledge of acoustic source tracking.
Section 3 first introduces the single-node PDA-CKF and then details the distributed PDA-DCKF.
Section 4 presents the experimental results and discussion.
Section 5 summarizes some conclusions.
3. Improved Distributed Cubature Kalman Filter
In the CKF, the observation corresponding to the largest peak of the observation function is used for the state update. This approach works well under moderate acoustic environments, while its performance degrades in severe noise and reverberation conditions because the spurious peaks from noise or reverberation may cover up the peaks from real acoustic sources. To alleviate this problem, multiple observations are selected from the multiple local maxima of the observation function. A general framework for state updates that integrates multiple possible observations is provided by the probabilistic data association (PDA). Inspired by this idea, the probabilistic data association-cubature Kalman filter (PDA-CKF) was derived in this paper. Next, PDA-CKF was used for acoustic source tracking in distributed acoustic sensor networks, and an improved PDA-DCKF algorithm was developed. The observations of multiple nodes in the neighborhood are filtered by PDA and then merged into the state update of CKF to integrate the information of multiple nodes to realize distributed tracking.
Before introducing PDA-CKF, the preliminary knowledge of cubature Kalman—cubature point set
[
28]—should be introduce first.
The standard Gaussian weighted integral is calculated using the spherical-radial cubature rule, i.e., [
28]
In Equation (12),
is the nonlinear state transfer function or observation function,
is the dimension of the state variable,
is a Gaussian distribution function with a mean of zero and a variance of
, and
is the cubature points.
represents the point set of
(n-dimensional state) dimensional space, i.e.,
3.1. PDA-CKF Algorithm
- (a)
Initialization
When
, assuming
, the initial value of the process noise and observation noise matrix are set to
Q0 and
R0, respectively. Then, the optimal initialization of the filter is
- (b)
State Prediction
For each node
, the state estimate and covariance matrix
at time
are given, and the positive definite noise matrix
are given. Using Equations (13) and (14), the state predicted cubature points
is calculated as:
According to the state transition model, the cubature points are propagated nonlinearly, i.e.,
where
represents the dimension of the state variable, and
represents the number of nodes in the distributed acoustic sensor network. At this time, the state prediction
and its error matrix
are calculated as:
- (c)
Status Update
From the estimated
and variance
at time
, the state update cubature points
is calculated as:
is propagated through the observation equation,
Further, the observation prediction
and the observation prediction error variance
are, respectively, obtained by
Then, according to the probabilistic data association, the verification area of node
can be constructed by [
29]:
where
is the gate threshold. Suppose
observations fall into the validated region (27) at time
. Define validate observations
, i.e.,
Actually, only one of the above observations is related to the real source; the others are due to noise or reverberation, or none of them are related to the real source. Correspondingly, for
validated observations, there maybe be
possible hypothesis, i.e.,
According to Equation (29), the equation for calculating
is as follows:
where
is the prior probability of event
,
, and
,
is the updated estimate conditioned on the event
, and
where
is the innovation related to the observation
,
is the Kalman gain of node
, and
where
is the cross covariance between the state and observation
of node
.
Given the innovation
and its covariance
, the probability
is generally computed as [
30]
where
is the spatial probability,
is the probability that the acoustic source is detected by sensor
, and
is the gate probability.
Finally, the state estimate value
and error covariance
can be obtained by
where
is the probability weighted innovation, and the covariances
and
are respectively given by [
29,
30]
To summarize, the pseudo-code of the PDA-CKF method of using the observations from a single node is depicted in Algorithm 1.
|
Algorithm 1:
PDA-CKF Algorithm
|
|
Initialization:
|
|
Input:
|
|
Output:
|
|
Iteration: for
|
|
1: Prediction step:
|
|
2: Compute the state predicted cubature points
at time
with (18).
|
| 3: Compute the predicted estimate and covariance with (20) and (21), respectively. |
4: Update step:
5: Compute the state update cubature points
with (23). |
| 6: Compute the predicted observations with (25). |
| 7: Compute the innovation covariance with (26). |
| 8: Select the validated observations according to (28). |
9: Compute the cross-covariance with (33).
10: Compute the Kalman gain with (34). |
| 11: Compute the association probability with (35), |
12: Compute the covariances and with (38) and (39), respectively.
13: Compute the updated estimate and covariance with (36) and (37), respectively. |
The PDA-CKF algorithm makes full use of the observation information of the node itself, which improves the tracking accuracy. However, this algorithm will fail when a node is damaged or the environmental noise and reverberation are severe. Therefore, this paper generalized PDA-CKF to a distributed version that can be used in distributed sensor networks. The improved method was named the probabilistic data association-based distributed cubature Kalman filter (PDA-DCKF). The specific process is shown in
Section 3.2.
3.2. PDA-DCKF Algorithm
3.2.1. PDA-DCKF
The neighborhood information of nodes are fused in PDA-DCKF to form local node networks. Then, the local state estimations and error covariances for the local node networks are calculated separately. Finally, the local results are fused to obtain the global state estimation.
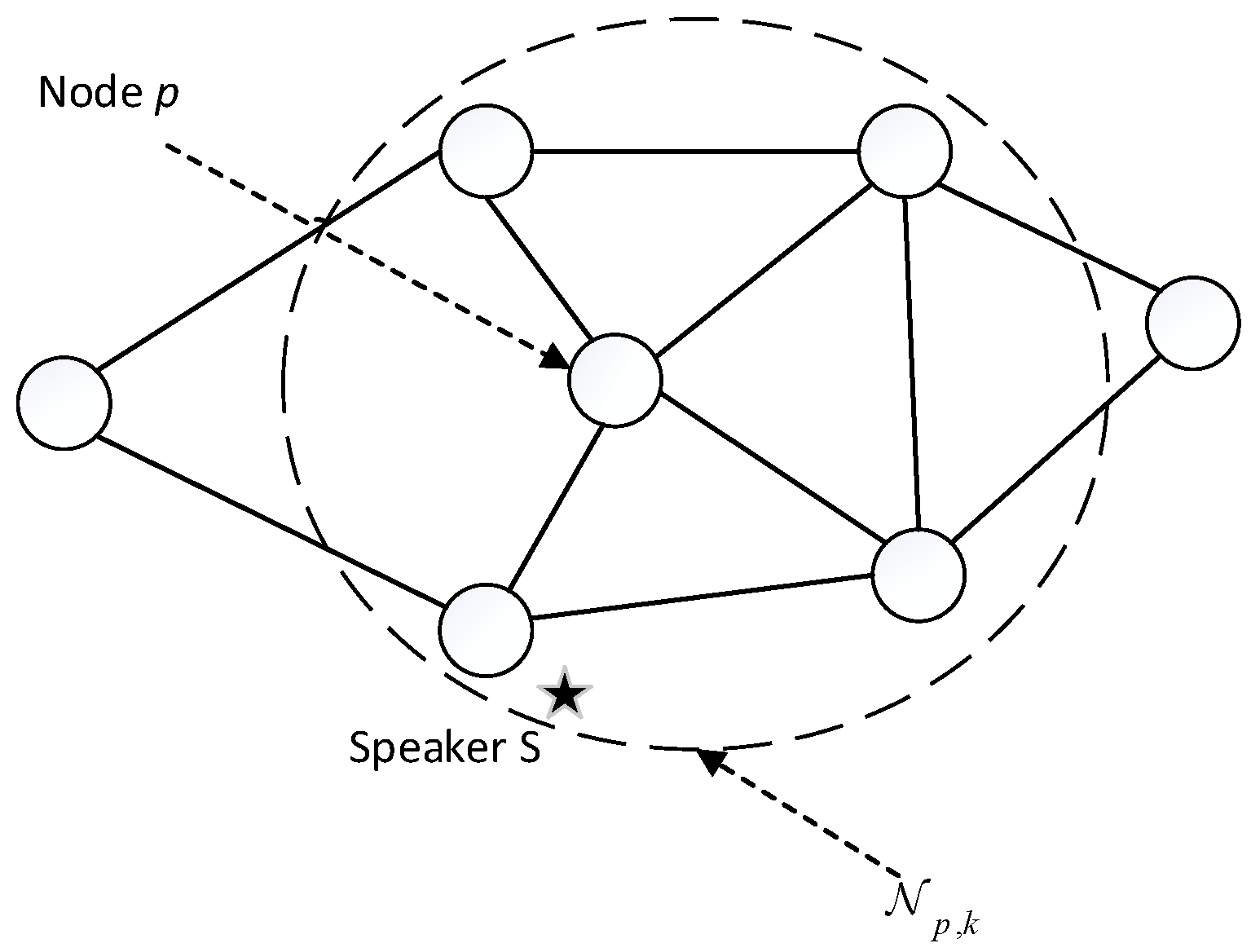
On the basis of the above steps, the following is defined:
where
represents the neighborhood nodes adjacent to node
,
is the vertex set,
is the edge set of the distributed acoustic sensor network,
indicates the number of nodes in the neighborhood of node
.
denotes the set of neighbors of node
at time
, where a node is a neighbor of itself certainly.
Further, the resulting observations are fused into a matrix. Then, the observed prediction and prediction error variance are, respectively, given by
For single node
,
is the innovation vector related to observation
, and
is the Kalman gain of node
. As far as multiple nodes are concerned, the information of node
and surrounding nodes
is fused to obtain
where
is the cross covariance between the state and the observed value of node
after fusing the information of neighboring nodes, and
is the Kalman gain of node
at time
after the fusion.
The probability weighted innovation vector of local nodes is defined as
The following is defined as
where
is defined in the covariance
of node
as
; when the information of node
and surrounding nodes is fused, the expression of
is computed as
where
.
Finally, the state estimate
and the error covariance
for node
are expressed as
3.2.2. Fusion Strategy
After calculating the estimation of each local node in the distributed acoustic sensor network, these data need to be fused to obtain a global estimate. Since nodes in a sensor network have different reliabilities, the final tracking result integrates the estimations from the local nodes, which are weighted with the parameters depending on the mean square error of the estimation and the energy of the received signal.
- (a)
Energy
The energy of the signal received by each node in the acoustic sensor network is calculated [
31], and the equation is described as:
where
represents the sound signal received by node
. In practice, analog signal
is converted into digital signal
, and
needs to be framed and windowed. Then, the framed signal is donated by
. In this paper, the Hamming window was selected for the window function
. Further, the energy of each frame can be obtained by
where
, and
represents the short-term energy of node
when the window function starts at the
point of the signal. The short-term energy can be regarded as the output of the square of the speech signal passing through a linear filter, and the unit impulse response of the linear filter is
.
- (b)
MSE
In Equation (48), the local estimate
of node
is calculated, and
is expressed as the estimated acoustic source position of node
at time k. The following is defined:
where
represents the global position estimation result weighted with the average consensus coefficients and calculates the MSE between the position obtained by each local node and
, defined as
After calculating the energy
and the mean square error
of node
at time
, the following is defined:
where
represents the weight of node
during global fusion. A global consistency analysis is performed on the results obtained by each node according to
:
To summarize, the PDA-DCKF is depicted in Algorithm 2.
| Algorithm 2: PDA-DCKF Algorithm |
|
Initialization:
|
|
Input:
|
| Output:
|
Iteration: for
For any node
in sensor network
|
|
1: Prediction step:
|
|
2: Compute the state predicted cubature points
at time
with (18).
|
3: Compute the predicted estimate and covariance
with (20) and (21), respectively. |
4: Update step:
5: Compute the state update cubature points with (23). |
|
6: Compute the observed values of predicted local nodes
with (41).
|
|
7: Compute the innovation covariance of predicted local nodes
with (42).
|
| 8: Select the validated observations according to (28), . |
9: Compute the cross-covariance of predicted local nodes with (43).
10: Compute the Kalman gain with (44).
11: Compute the probability weighted innovation vector of local nodes with (45)
12: Compute the association probability with (35), .
13: Compute the association probability with (46).
14: Compute with (47).
15: Compute the updated estimate and covariance of local nodes with (48) and (49), respectively.
16: Compute the weight of node with (57).
17: Compute the updated estimate and covariance with (58) and (59), respectively. |
The advantages of probabilistic data association and distributed acoustic sensor networks are combined in the PDA-DCKF proposed in this paper. In this method, the PDA algorithm is used to sift the observations from neighboring nodes. Then, the sifted observations are fused to update the state vectors in the CKF. This method not only makes the observation value obtained by each node more accurate, but also makes full use of the information of neighborhood nodes.
Meanwhile, a weighted fusion method based on local node-received signal energy and position estimation mean square error was proposed. This dynamic weighted consistency fusion considers the reliability of the local state of the nodes and provides a good global estimation performance.
4. Experiments and Results Discussion
To verify the performance of the proposed speaker tracking method, the evaluations are performed in a simulated room environment. Under the same conditions, the comparative experiments between PDA-DCKF and current methods are carried out, including centralized method (CCKF), DUKF, DCKF, iteration based DCKF [
20] (DICKF) and DEKF. The results obtained by all methods are the average of 100 Monte Carlo runs.
The root mean square error (RMSE) is used here to evaluate the tracking performance.
is expressed as the ground truth value of time
, and
represents the global consistency position calculated by the acoustic sensor network at this time. The RMSE is defined as [
32]
where
denotes the number of frames. Generally, the smaller the RMSE, the better the tracking result.
4.1. Simulation Setups
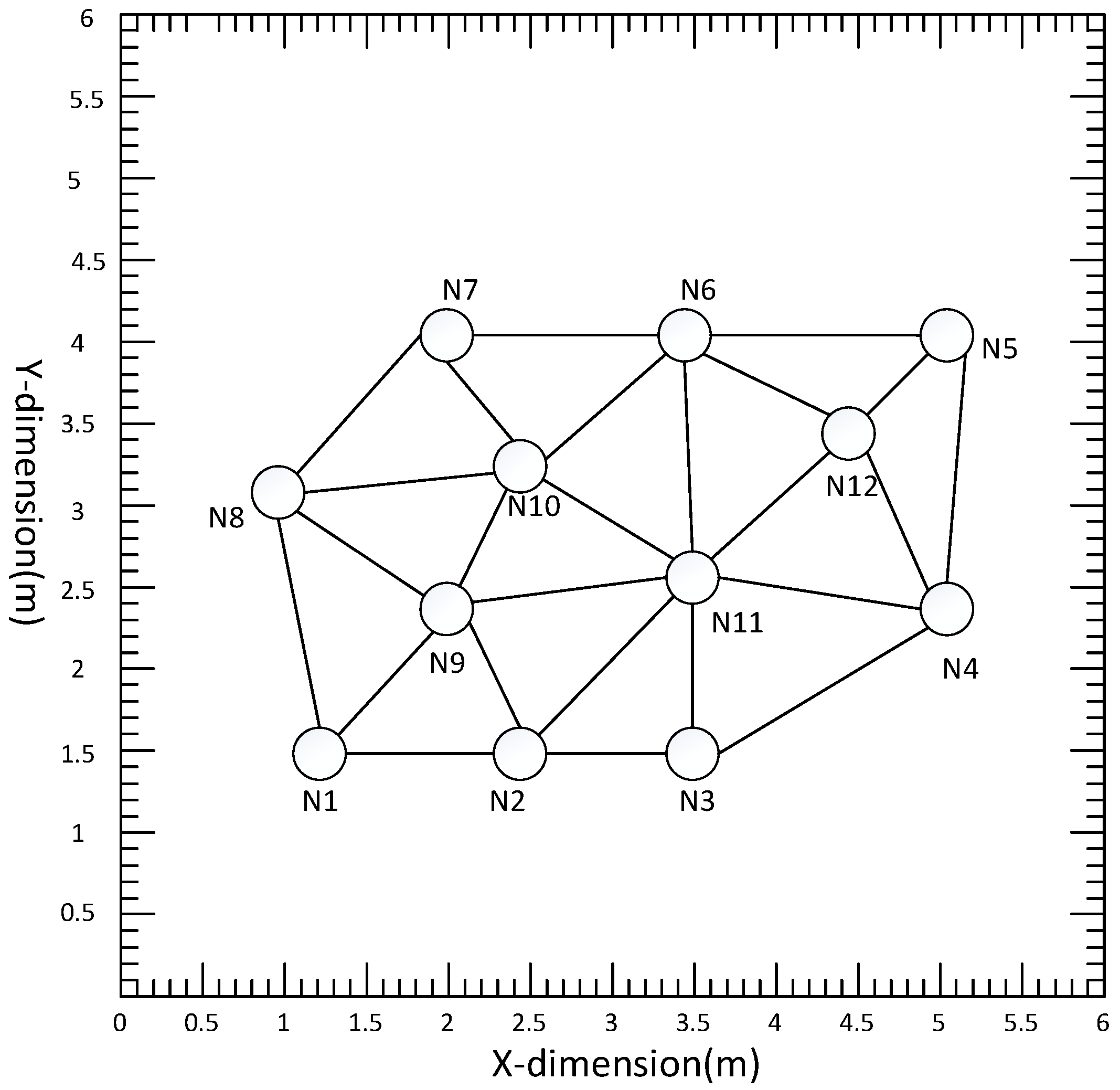
The simulation environment was a typical room of size 6 m × 6 m × 3 m, with an acoustic sensor network of 12 nodes (
). Each node contained a pair of microphones 0.5 m apart. The communication diagram of the distributed acoustic sensor network is shown in
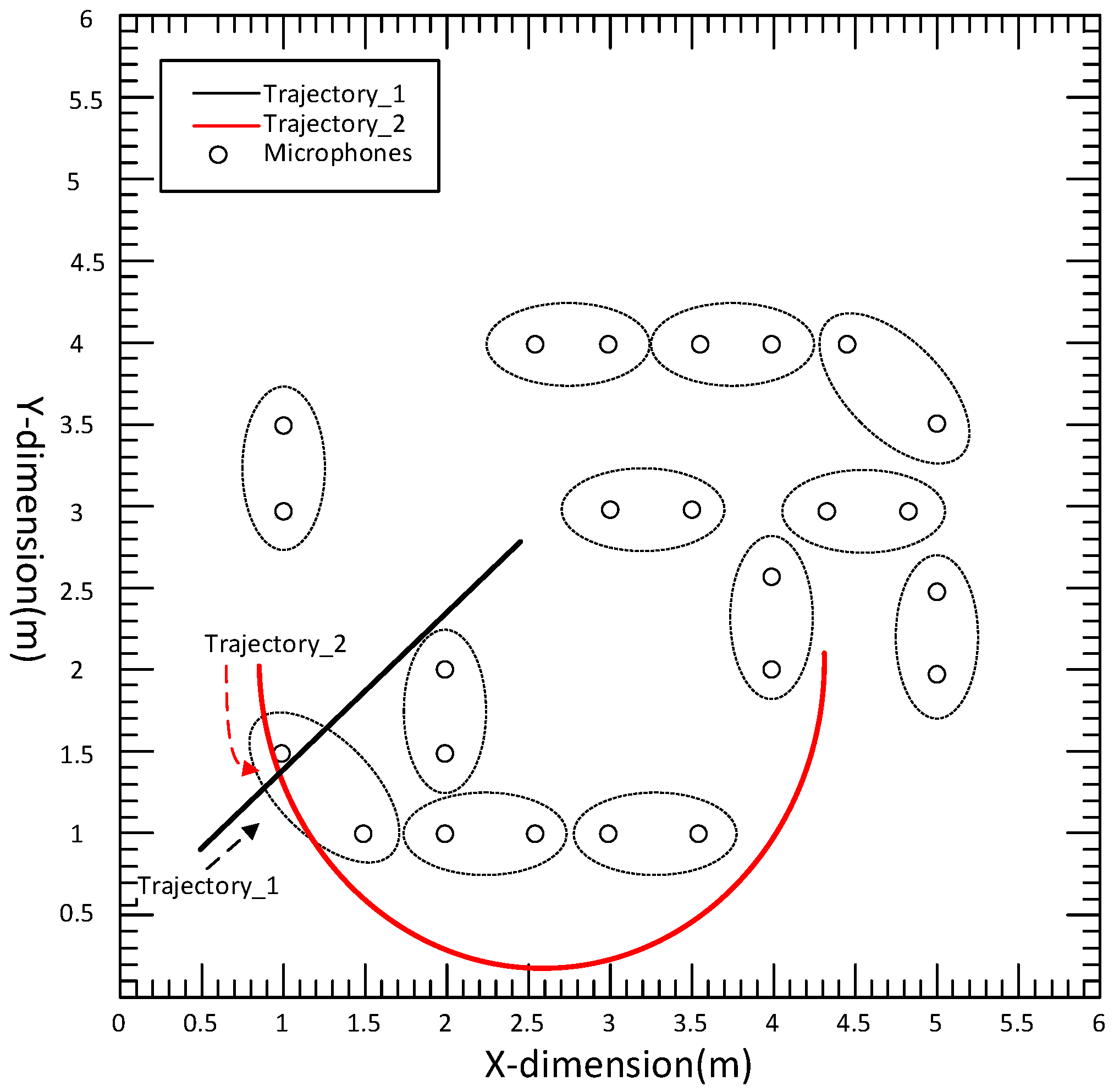
Figure 2, where the communication radius is 2.5 m, and each circle represents a node. The simulated trajectory 1 was a line from (0.5,0.8) to (2.5, 2.8), and trajectory 2 was an arc from (1, 2) to (4.86, 2.1), as shown in
Figure 3. In different experiments, the speech sampled at the frequency of
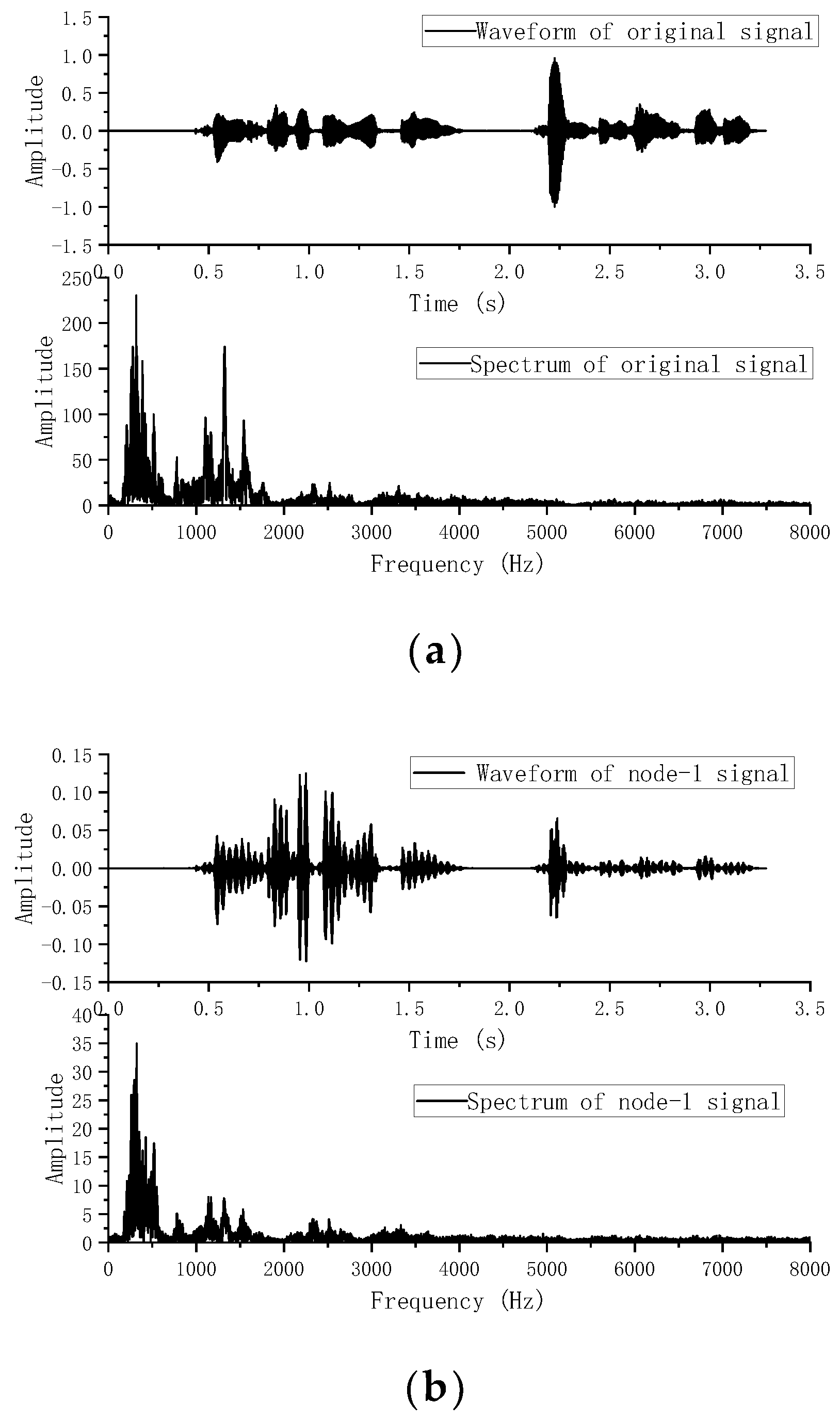
was used as the acoustic source signal; the speech was a female recording, and the waveform and spectrum of the signal are shown in
Figure 4a. The sound speed was
. The microphone signals were simulated with the Image method [
33]. Specifically, different RIRS are generated by virtual sound source method to reflect different reverberation time. These RIRSs were convolved with the speech signal and then added to the Gaussian white noise with a determined mean and covariance to produce a received microphone signal with a mixture of reverberation and noise. The different covariance of Gaussian noise determines the different value of the signal-to-noise ratio (SNR), which reflects different environmental noise conditions. The microphone signal was divided into different signal frames along the sound source track, where the frame length of speech signal was
and each signal frame was used for state estimation. Taking node 1 as an example,
Figure 4b shows the waveform and spectrum of the speech signal received by the first microphone of node 1. For the observation TDOA, a total of eight time delays were chosen according to the magnitude of the GCC peak. From these delays, further TDOA observations were selected, where the relevant parameters were set as
,
,
, and
. The standard deviation of TDOA measurement error was
. In the acoustic dynamical model, the parameters were
and
. In the average consistency calculation of the global state estimation and its error covariance, the Metropolis weight was used, the number of consistency iterations [
34] was
, and the number of iterations in the iterative CKF was 3.
This paper conducted four experiments to evaluate the tracking performance of PDA-DCKF. In Experiment 1, trajectory 1 was used as the acoustic source trajectory. The initial prior of the acoustic source position was set as a Gaussian distribution with mean and covariance . In experiment 2, the sound source signal and track were the same as experiment 1. Using simple average fusion rules, the influence of fusion rules on PDA-DCKF tracking performance was discussed. Experiment 3 discussed the robustness of the algorithm. The acoustic source and trajectory were the same as the previous two experiments. In Experiment 4, trajectory 2 was used as the acoustic source track to check the tracking results of the acoustic source when the track was nonlinear.
4.2. Simulation Results
4.2.1. Experiment 1
In this experiment, the tracking performance was evaluated under different ambient and reverberant conditions. First, the impact of environmental noise on tracking performance was investigated.
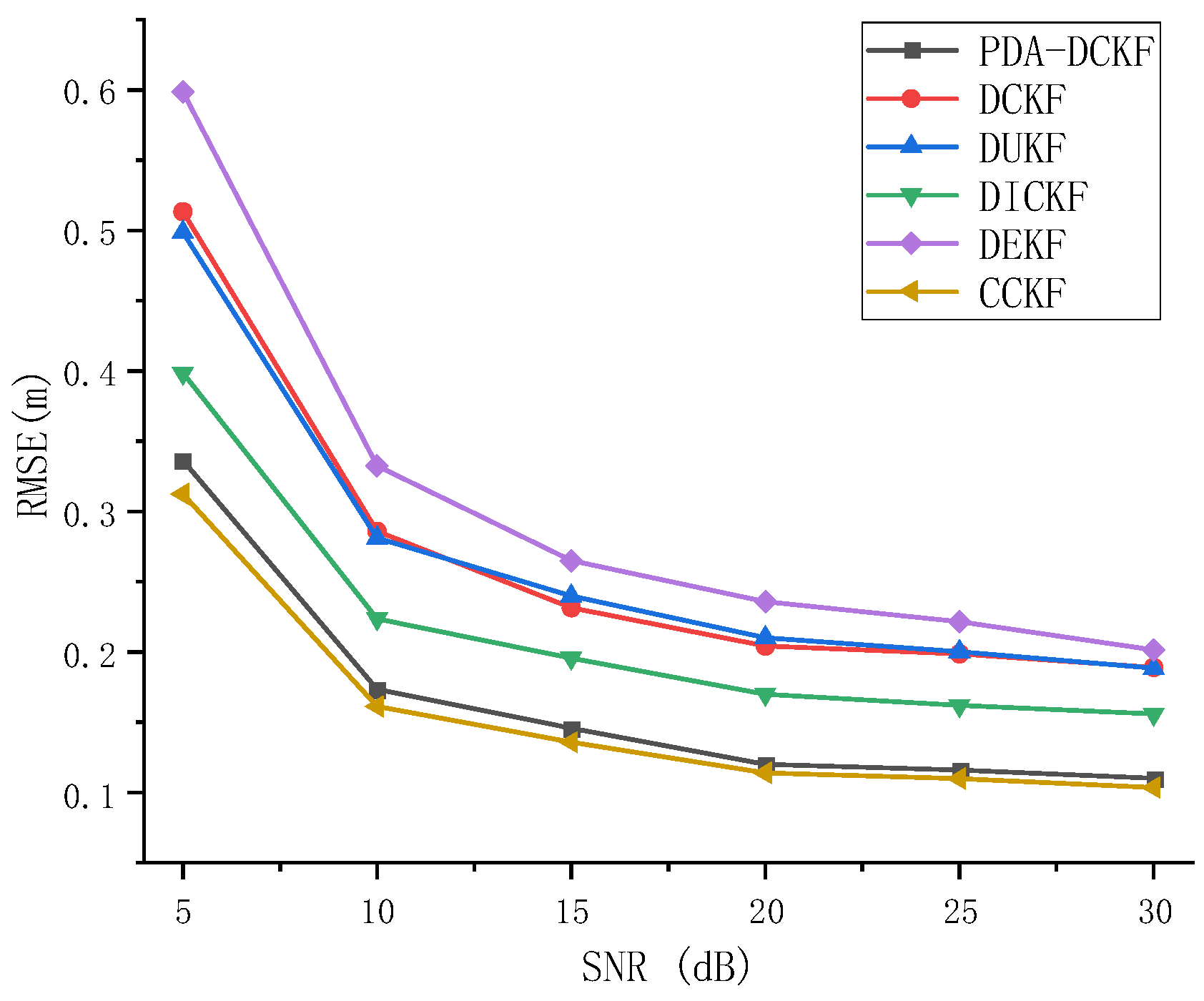
Figure 5 depicts the RMSE results as a function of SNR for a reverberation time of
T60 = 200 ms. In
Figure 5, it is observed that the RMSE of all methods decreases with the increase of SNR, which means that the tracking accuracy increases with the increase of SNR. This is because when the SNR becomes larger, the microphone signal is less affected by ambient noise, resulting in better tracking performance. In addition, under the same SNR, PDA-DCKF performs better than traditional distributed Kalman filtering, such as extended Kalman filtering, unscented Kalman filtering, and cubature Kalman filtering. Since only one time-delayed observation of the GCC largest peak is used in traditional methods, peaks associated with real sources may be masked by spurious peaks caused by noise or reverberation, resulting in erroneous state estimates. In contrast, multiple time-difference observations of multiple largest peaks of GCC are employed in PDA-DCKF, resulting in ideal tracking performance. At the same time, compared with DICKF in this experiment, the results show that the effect of PDA-DCKF is better than that of DICKF. Because DICKF is aimed at the DCKF method, and DCKF has problems such as slow response speed and low tracking accuracy. However, the tracking performance and convergence speed of the algorithm can be improved through several local iterations in DICKF. However, still only one time-delay observation of the GCC largest peak is used in DICKF, which also causes it to be inaccurate, but as can be seen from
Figure 5, as the SNR increases, the gap between DICKF and PDA-DCKF becomes smaller because the observations are more reliable when the SNR becomes larger. In addition,
Figure 5 shows that PDA-DCKF is not as good as CCKF because the observation information of all nodes is used in CCKF, but PDA-DCKF achieved an effect very close to the CCKF effect, and its computational cost and the burden of the network is less than that of CCKF.
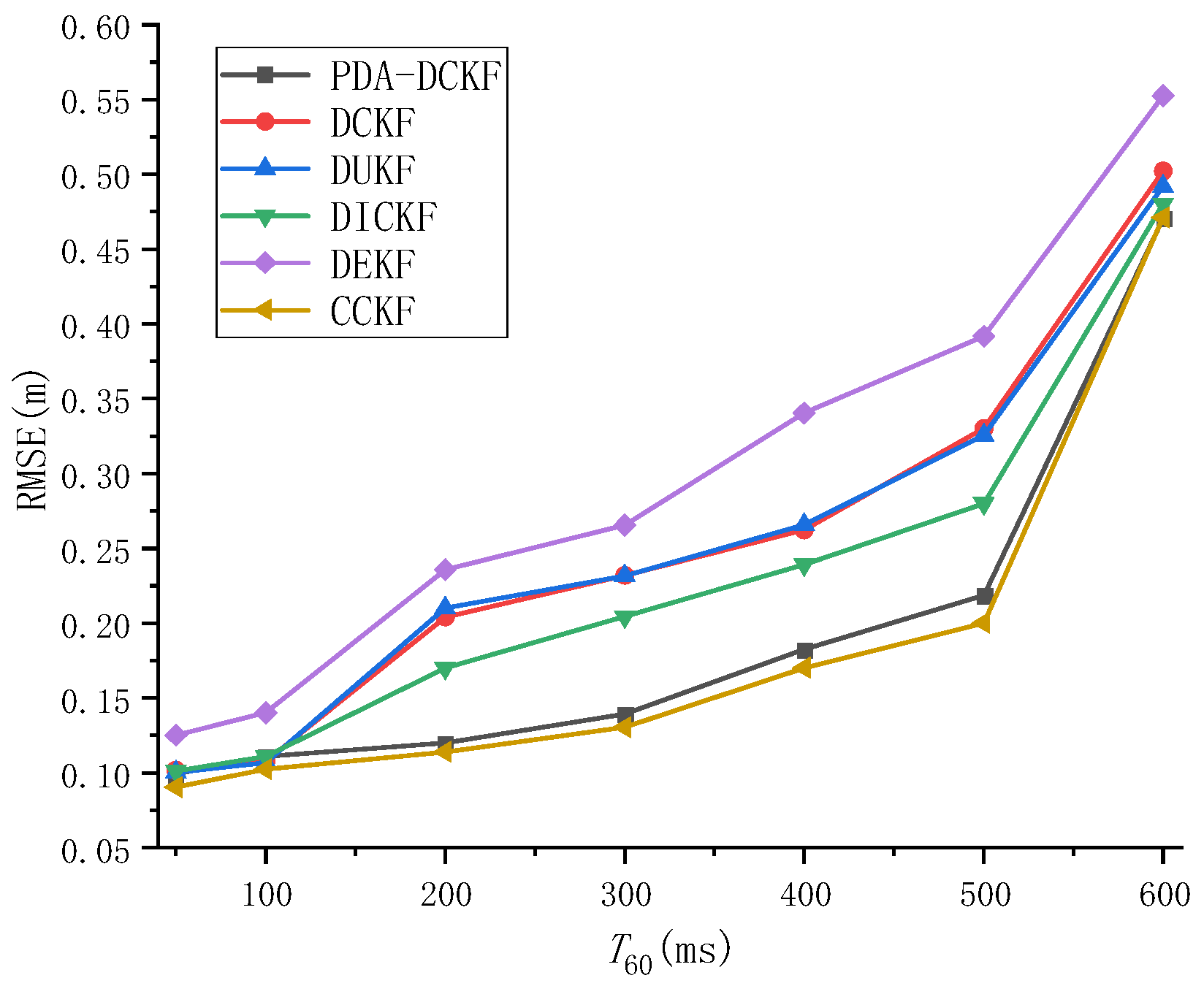
The effect of reverberation on tracking performance was also studied in this paper.
Figure 6 depicts the RMSE results as a function of
T60 with SNR = 20 dB. From the results, we can observe that the RMSEs of all the methods increased as
T60 became larger, which signifies the degradation of the tracking accuracies. This may be because the microphone signal is more affected by reverberation as
T60 becomes larger, the time difference observations extracted from only the largest peak or multiple largest peaks are not reliable, and the tracking performance of these methods deteriorates. In addition, it can be found from
Figure 6 that the tracking performance of PDA-DCKF is better than DEKF, DUKF, DCKF, and DICKF. In fact, in traditional methods, the time-difference observations included in the scheme are only extracted from the largest peak of the GCC, while the peaks associated with the true hypocenter may be masked by false peaks caused by reverberation. In contrast, PDA-DCKF incorporates TDOA observations of multiple largest peaks of GCC into the scheme, which can alleviate the adverse effects of reverberation to a certain extent. Furthermore, the effect is not as good as CCKF showed in
Figure 6, but it also achieves a very close effect.
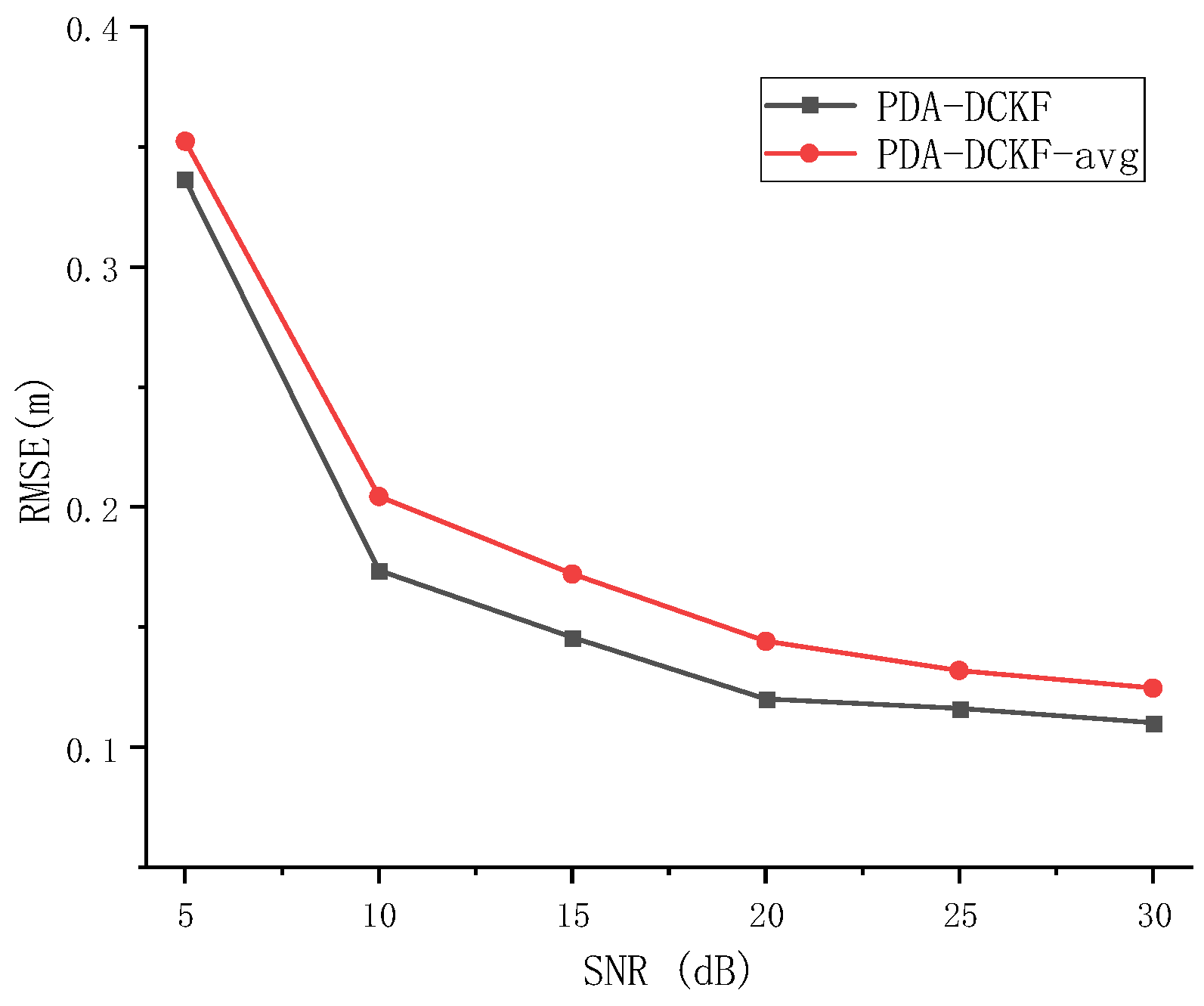
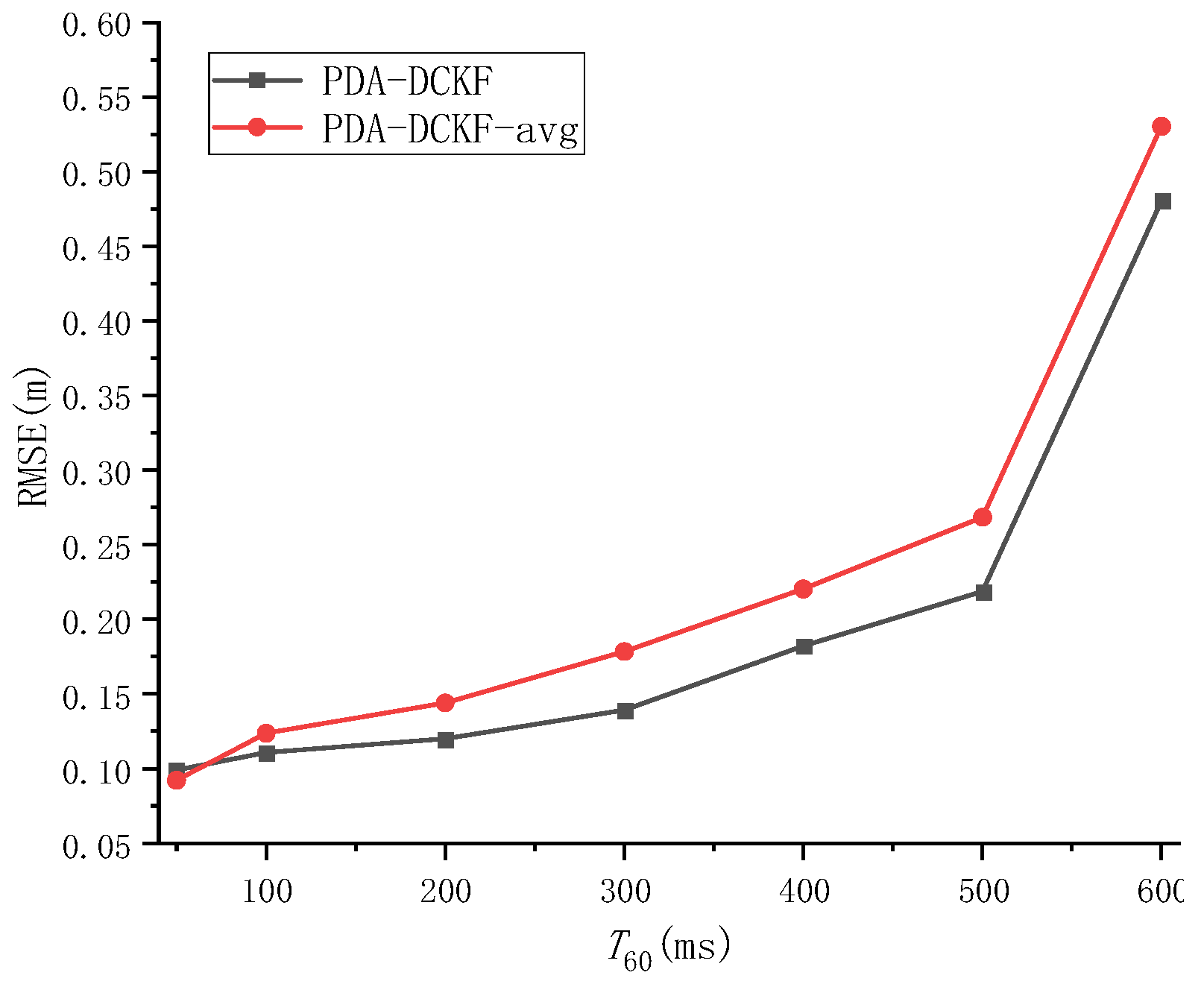
4.2.2. Experiment 2
The effect of the fusion strategy proposed in this paper on the results is discussed in Experiment 2. When PDA-DCKF adopts a simple average fusion rule, it is called PDA-DCKF-avg. In this section, different SNR and different reverberations are used to test the effectiveness of the fusion strategy. The experimental results are shown in
Figure 7 and
Figure 8.
As depicted in
Figure 7, with the increase of the SNR, the RMSEs for the PDA-DCKF methods with both these two fusion strategies decrease, but the proposed one is more effective.
Figure 8 also shows that, with the increase of the reverberation time, the error also increases. In addition, only under 50 ms reverberation, the error of the average fusion strategy is smaller than that proposed in this paper, and the fusion strategy proposed in this paper was better than the average fusion effect under 100–600 ms. Comparing
Figure 5,
Figure 6,
Figure 7 and
Figure 8, it can be found that, even if the average fusion strategy is used, the PDA-DCKF in this paper is still smaller than the error obtained by the above comparison test, which further proves the effectiveness of the method in this paper.
4.2.3. Experiment 3
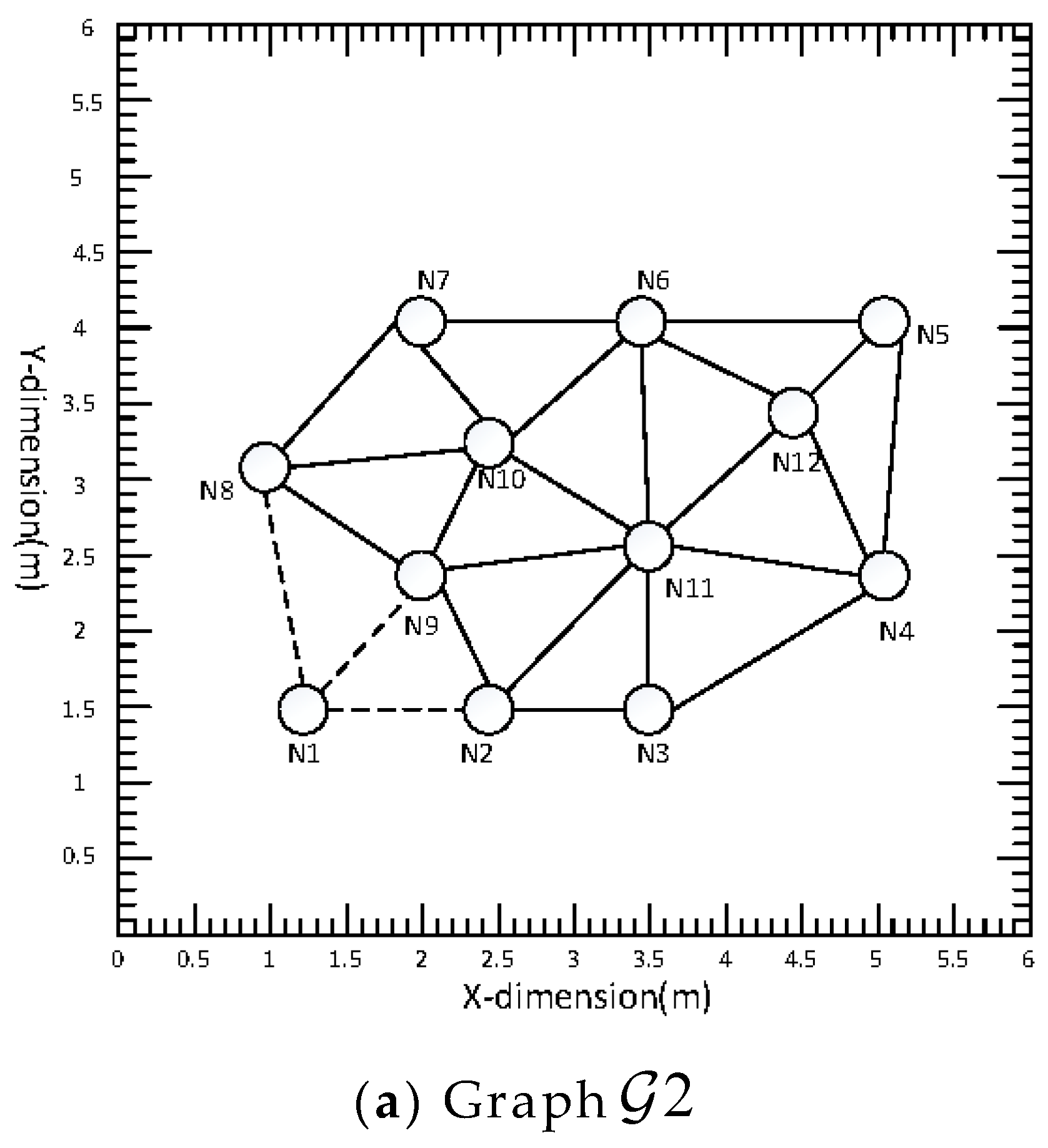
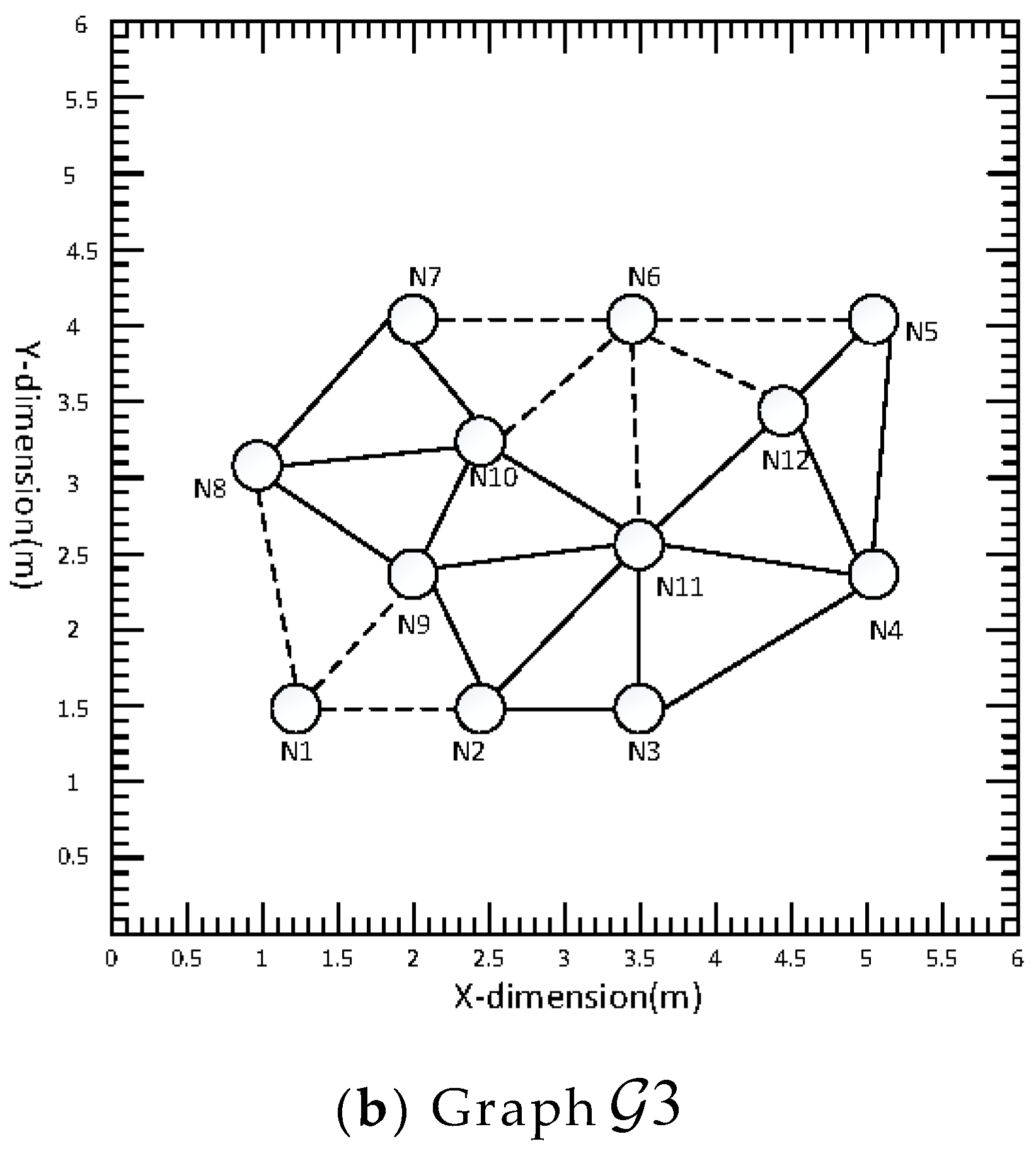
In practical applications, a network may be damaged by nodes, and when a node in a network is damaged, whether the network can still work normally will test the robustness of the system. In this subsection, the node damage in the distributed acoustic sensor network is simulated, and the tracking results of the acoustic source after the damage are compared with those before the damage. When node 1 in the network is damaged, it is called graph
, as shown in
Figure 9a. When node 1 and node 6 in the acoustic sensor network are damaged, it is called graph
, as shown in
Figure 9b. The experimental results are shown in
Table 1 and
Table 2.
It can be seen from
Table 1 and
Table 2 that the acoustic source can still be tracked in the case of node damage. Although the accuracy has decreased, the amplitude of the drop is not large and the acoustic source can still be tracked accurately. This can prove that the method proposed in this paper has good robustness under this network.
4.2.4. Experiment 4
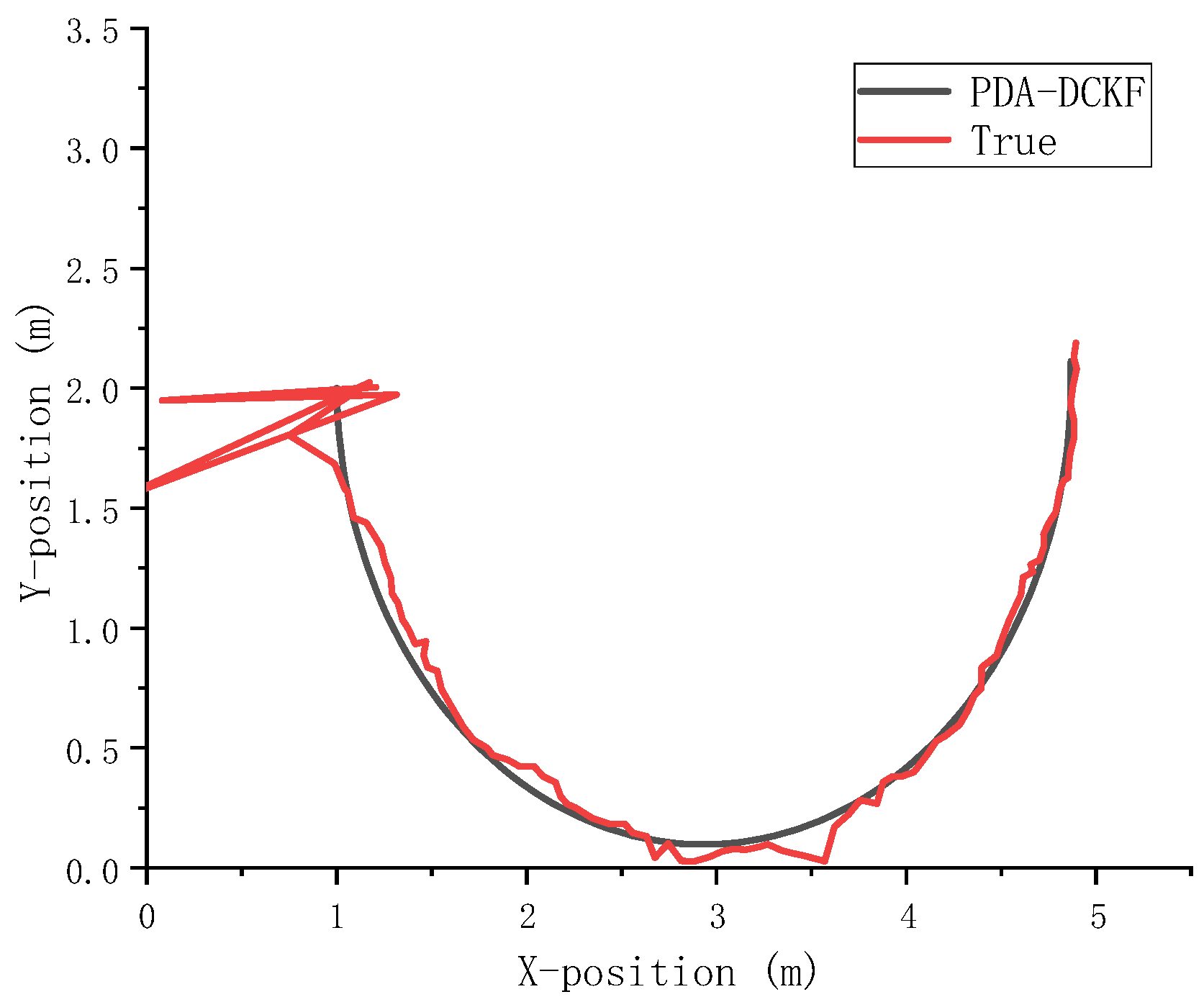
In order to further verify the effectiveness of the algorithm in this paper, the semicircle of trajectory 2 was used as the acoustic source trajectory, and comparative experiments were carried out under different SNR and reverberation. The experimental data are shown in
Table 3 and
Table 4.
Figure 10 shows the tracking results with SNR = 15 dB and
T60 = 400 ms.
From the above
Table 3 and
Table 4 and
Figure 10, it can be seen that the algorithm in this paper can still accurately track the sound source in the face of such a strong nonlinear trajectory.
5. Conclusions
An improved PDA-DCKF method was proposed in this paper, which proved to be able to solve the problem of tracking a single mobile acoustic source with distributed acoustic sensor networks in the noise and reverberation environment. First, in order to reduce the adverse effects of noise and reverberation, the prediction value of observation is obtained by using the prediction state and the observation model of distributed nodes. Secondly, the actual observations are screened according to the predicted value. Multiple TDOA observations are extracted at each node and incorporated into the status update of CKF through PDA to generate PDA-CKF. PDA-CKF was applied to distributed acoustic sensor networks, and PDA-DCKF was further developed. In PDA-DCKF, the PDA algorithm is first used to sift the observations from neighboring nodes. Then, the sifted observations are fused to update the state vectors in the CKF. Each node runs PDA-DCKF for local state estimation and TDOA observation. Then, a new fusion strategy is proposed using energy and MSE to merge all single local estimates in a distributed manner for global state estimation. In order to apply the improved PDA-DCKF to the acoustic source tracking problem, the Langevin model was used to model the acoustic source dynamics, and a method to extract the time difference observation was proposed. Finally, a distributed acoustic source tracking framework was obtained. In order to evaluate the effectiveness of PDA-DCKF in acoustic source tracking, comparative experiments were carried out with existing methods (DCKF, DUKF, DEKF, and DICKF) under different ambient noise and reverberation conditions. The results show that the PDA-DCKF has better tracking performance than DCKF, DUKF, DEKF, and DICKF under most noise and reverberation conditions. In addition, the PDA-DCKF achieved the same tracking performance as the centralized CKF. Furthermore, it can even track the acoustic source stably in the case of node damage.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}