
MDS-Net: Multi-Scale Depth Stratification 3D Object Detection from Monocular Images

 ,
,
Abstract
:1. Introduction
- We propose a one-stage monocular 3D object detection network, MDS-Net, based on a Multi-scale Depth-based Stratification structure, which can accurately predict the object’s localization in the 3D camera coordinate system from the monocular image in an end-to-end manner. The proposed MDS-Net achieves state-of-art performance on the KITTI benchmark for the monocular image of 3D object detection.
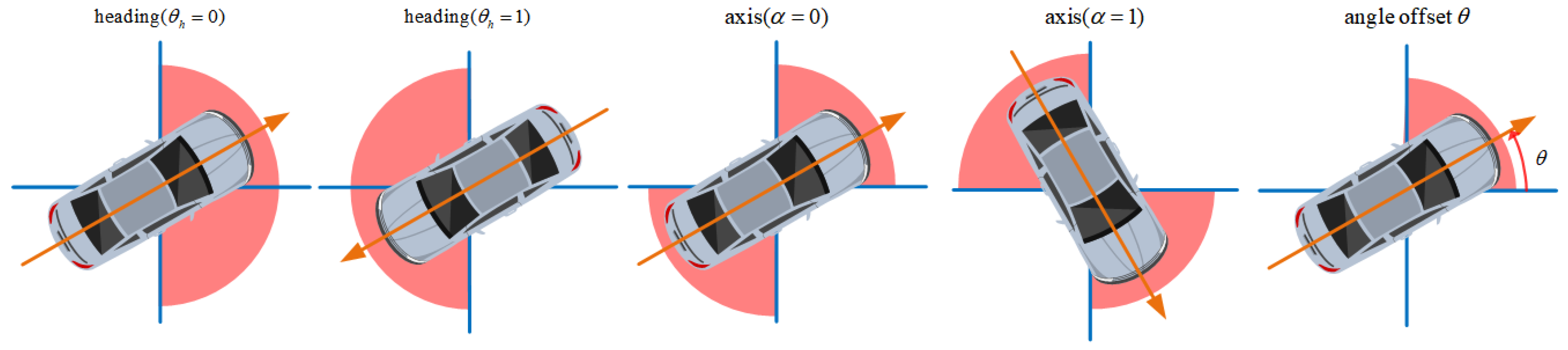
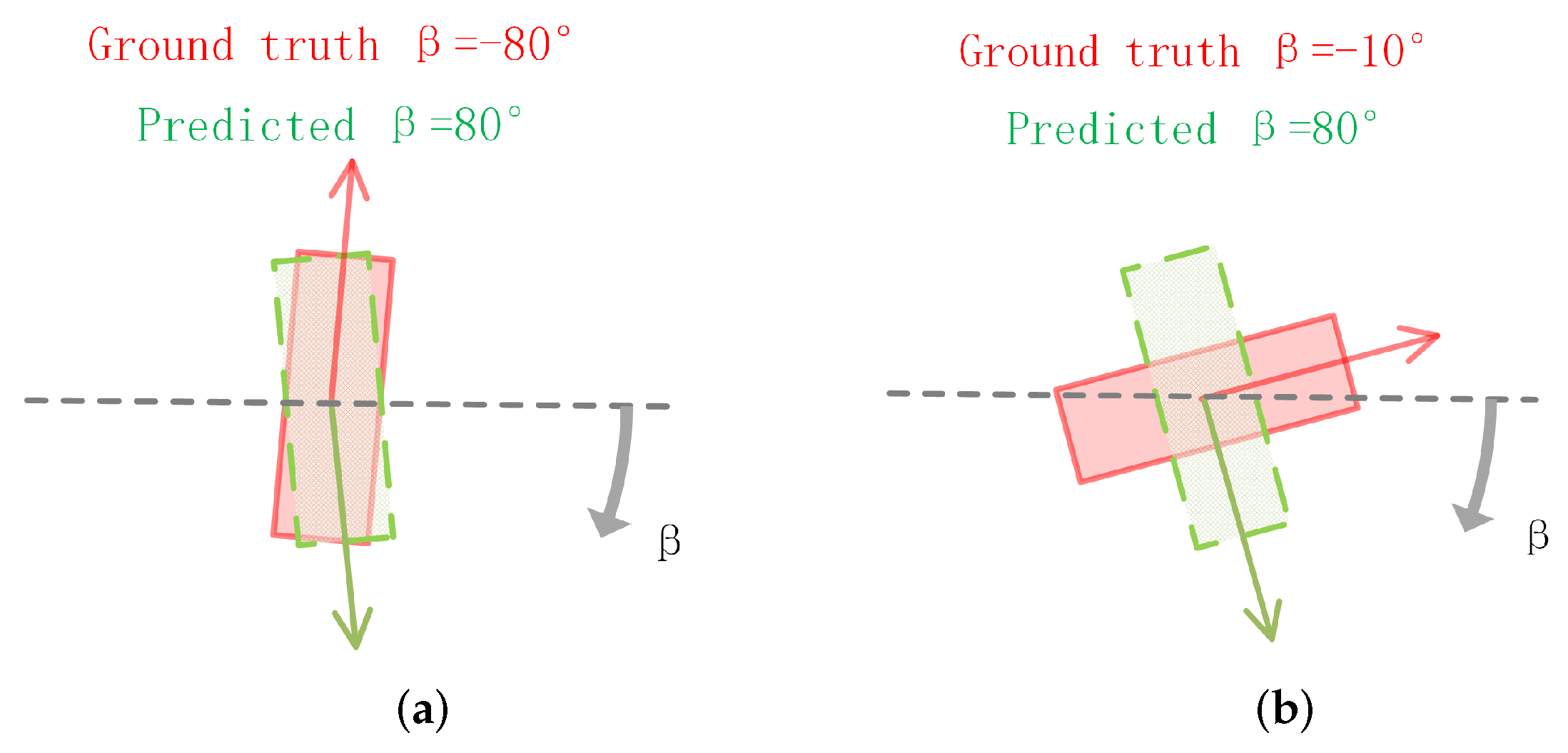
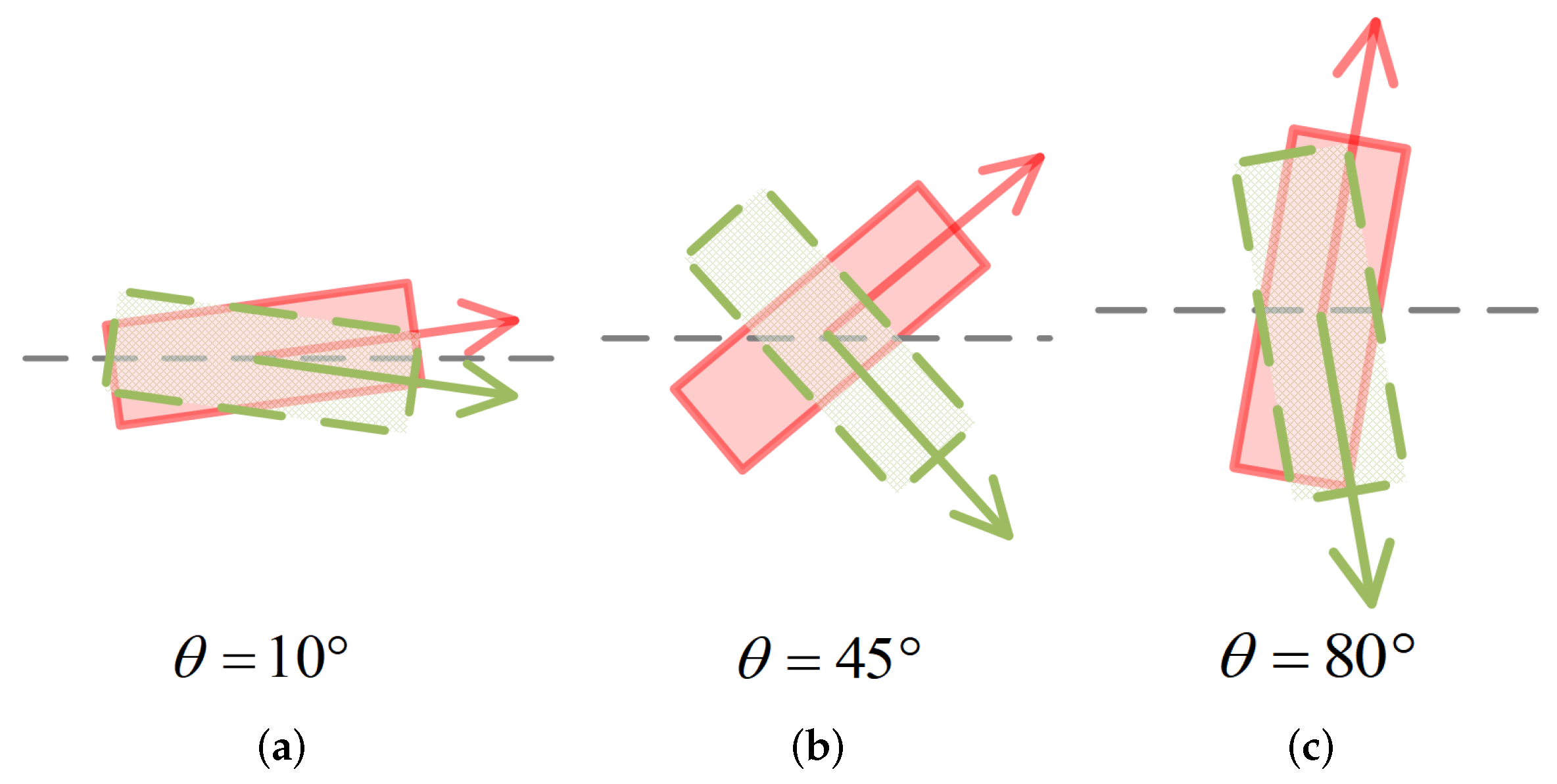
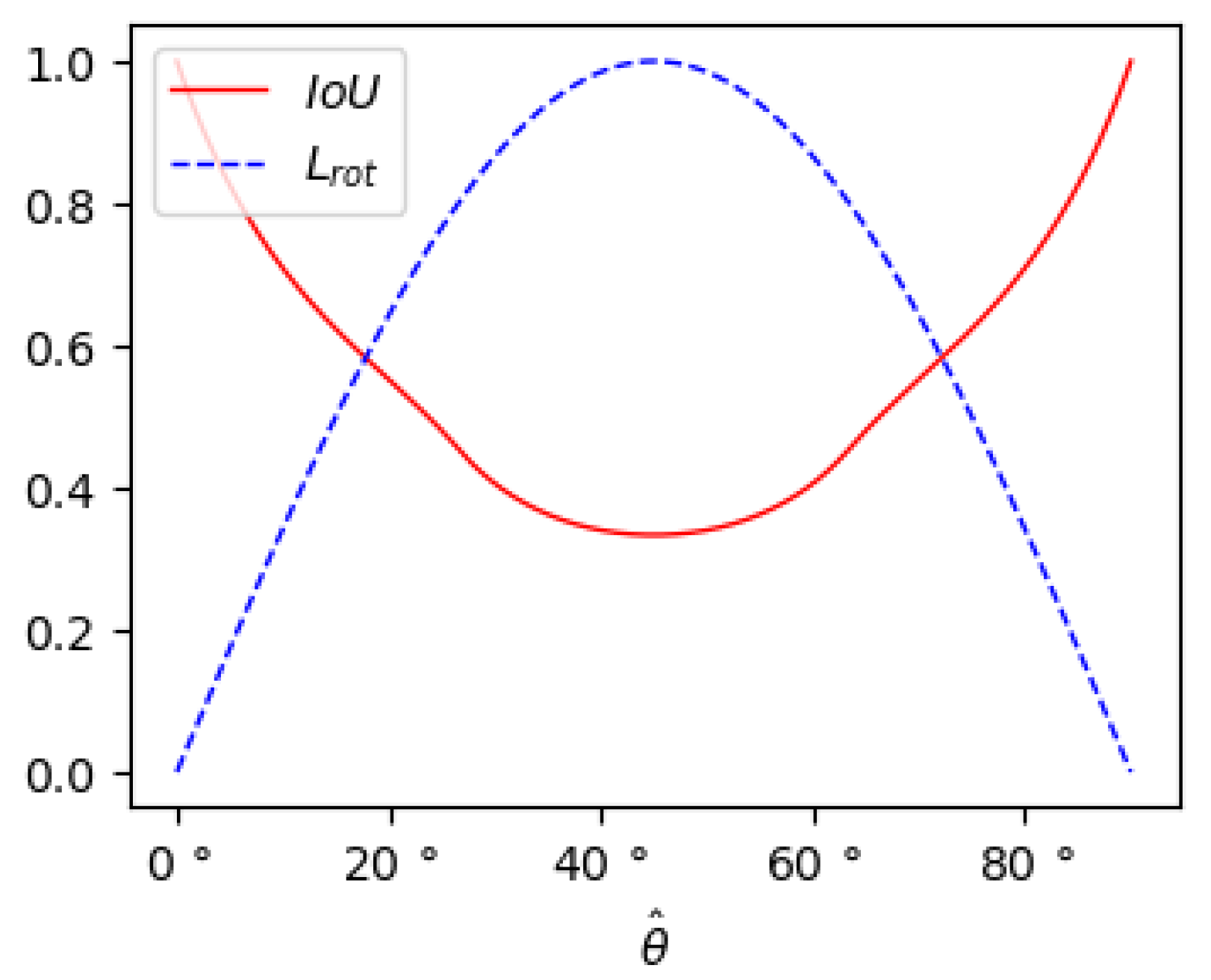
- We design a novel angle loss function to strengthen the network’s ability of angle prediction.
- We propose a density-based Soft-NMS method to improve the confidence of credible boxes.
2. The Proposed MDS-Net
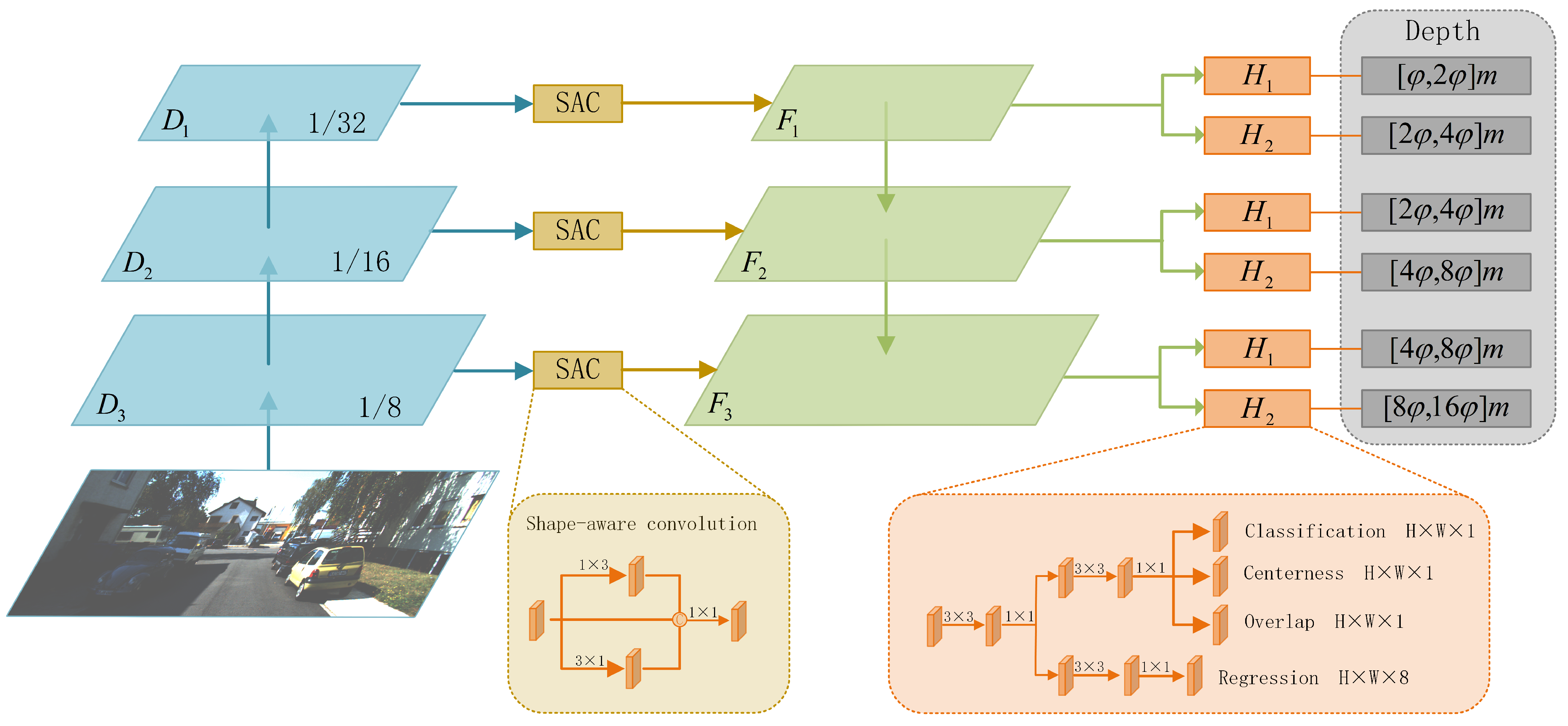
2.1. Network Architecture
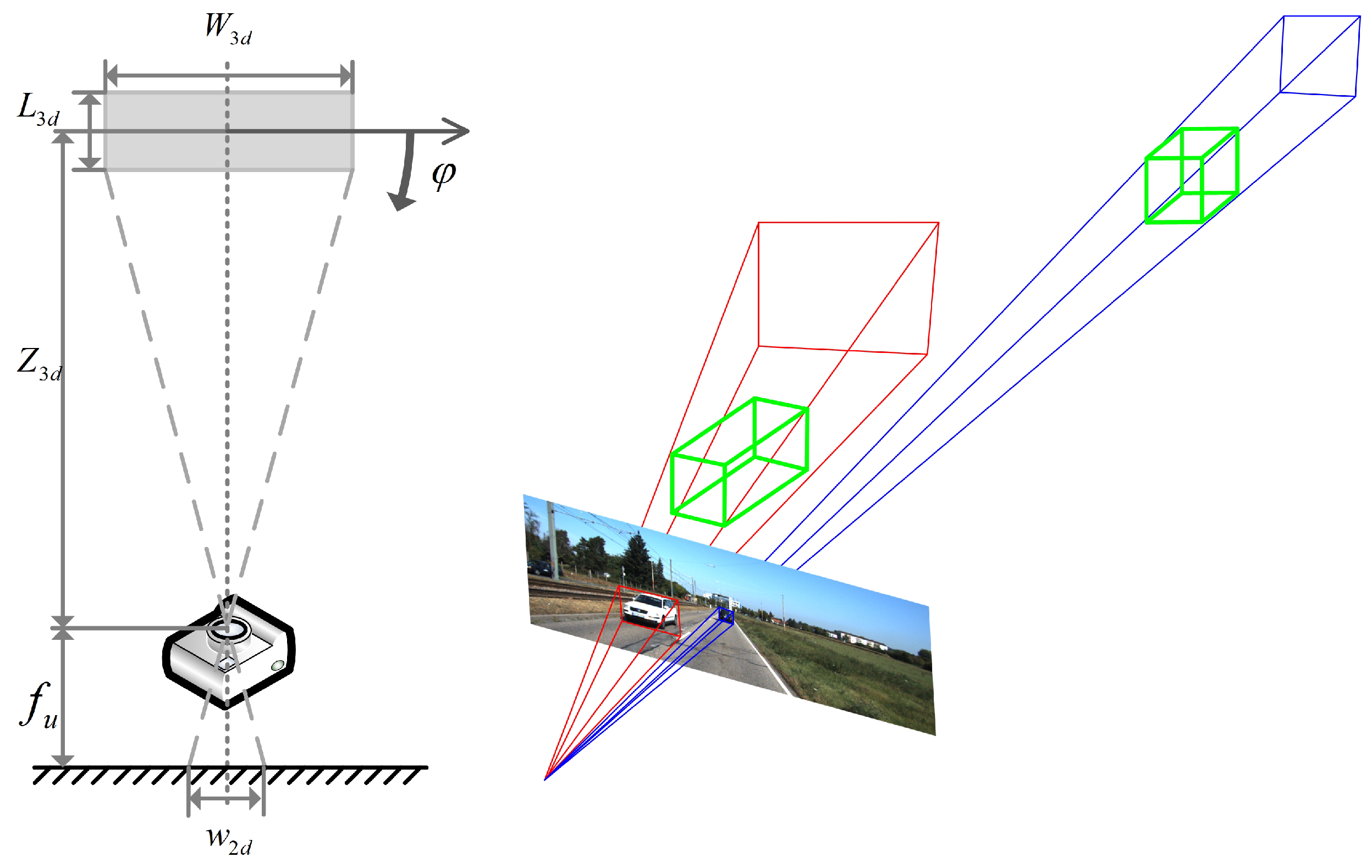
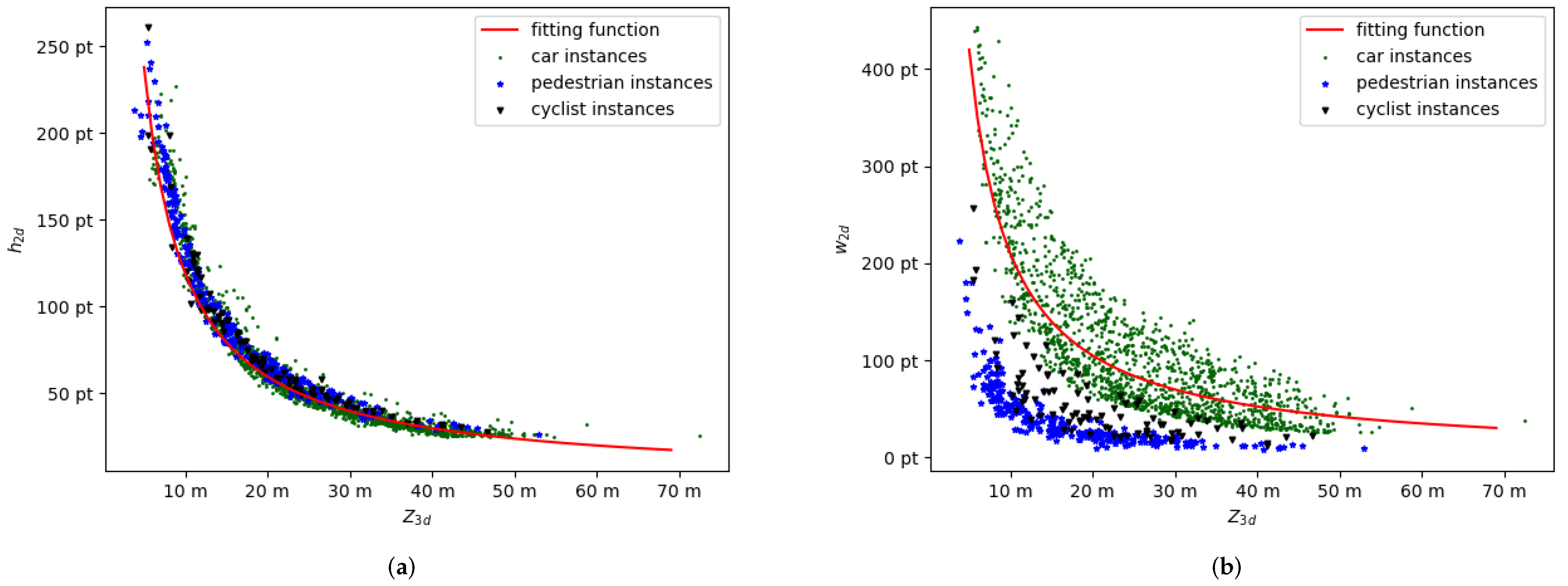
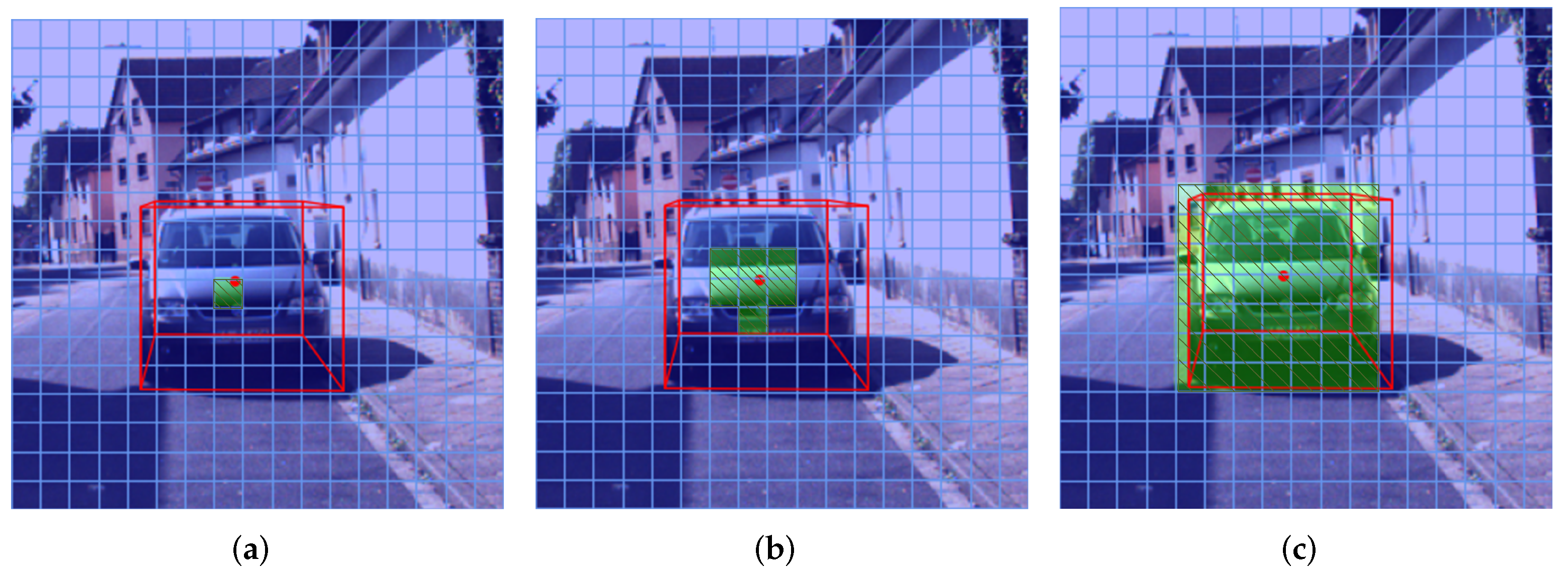
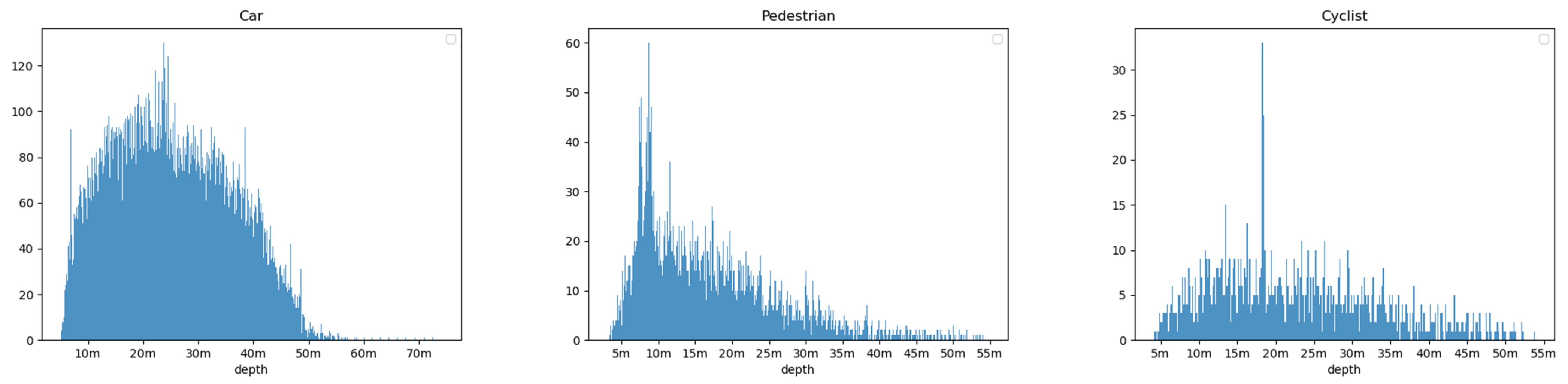
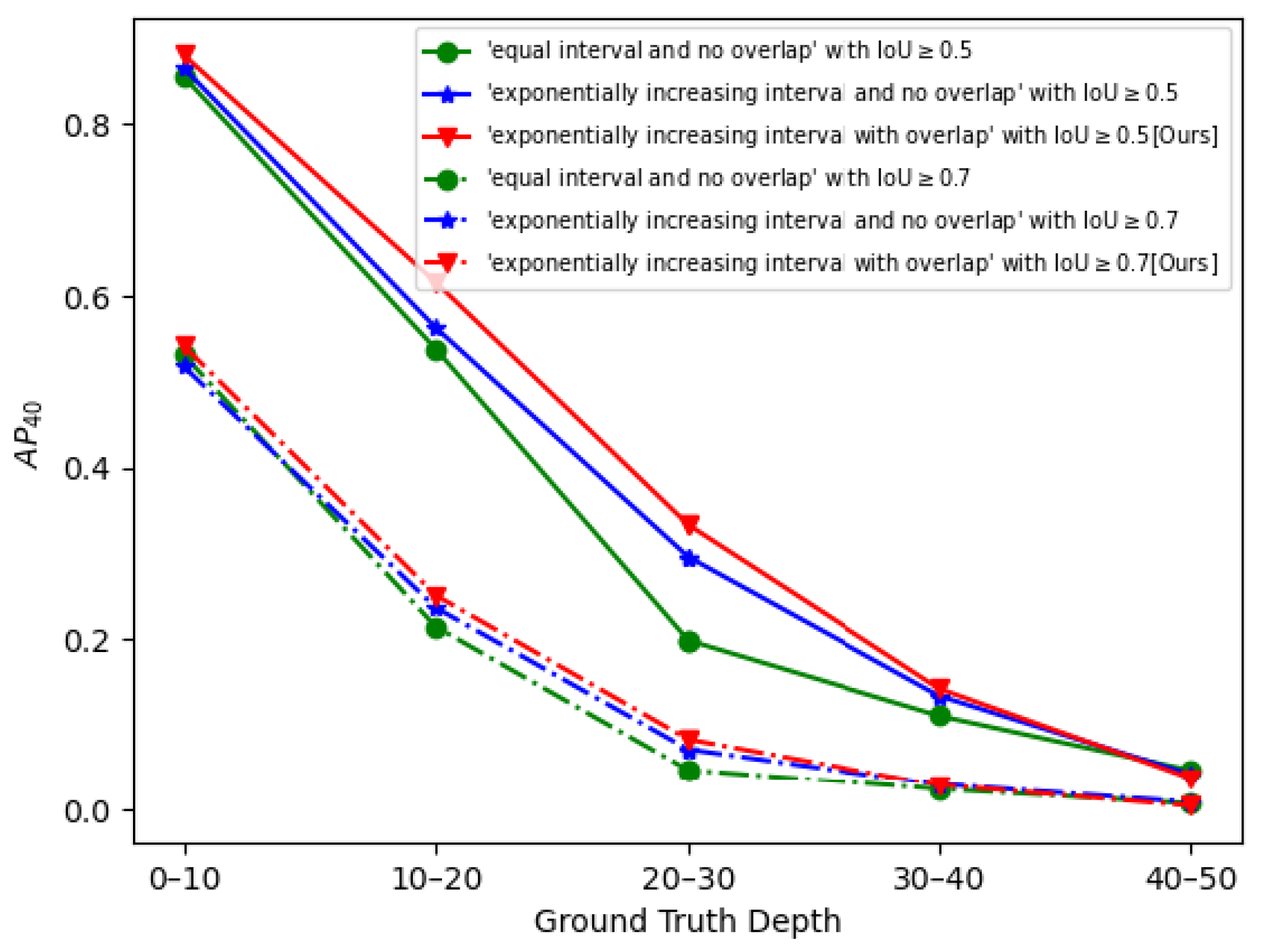
2.2. Depth Stratification
2.3. Network Predictions
2.3.1. 3D Prediction
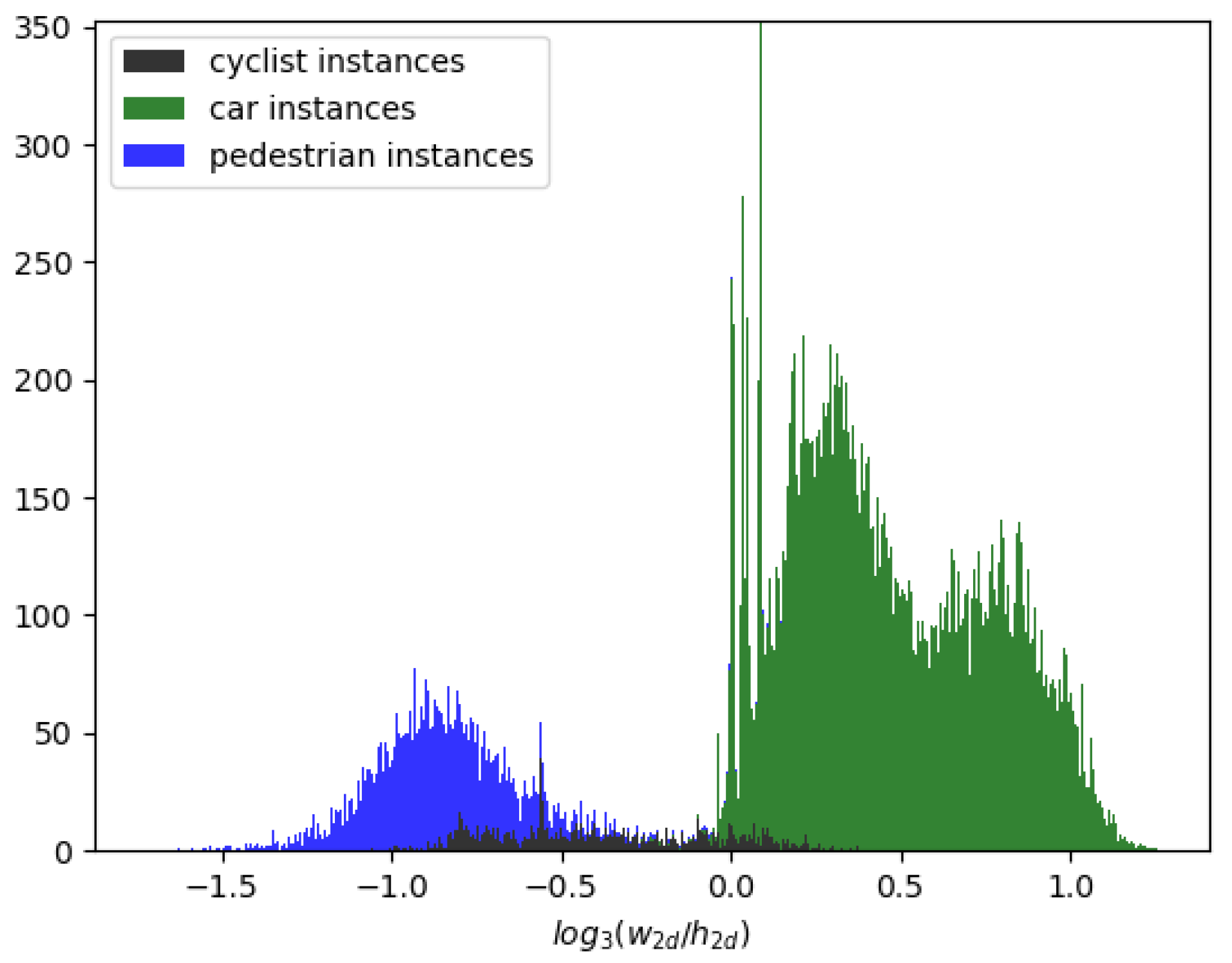
2.3.2. Score Prediction
2.4. Loss
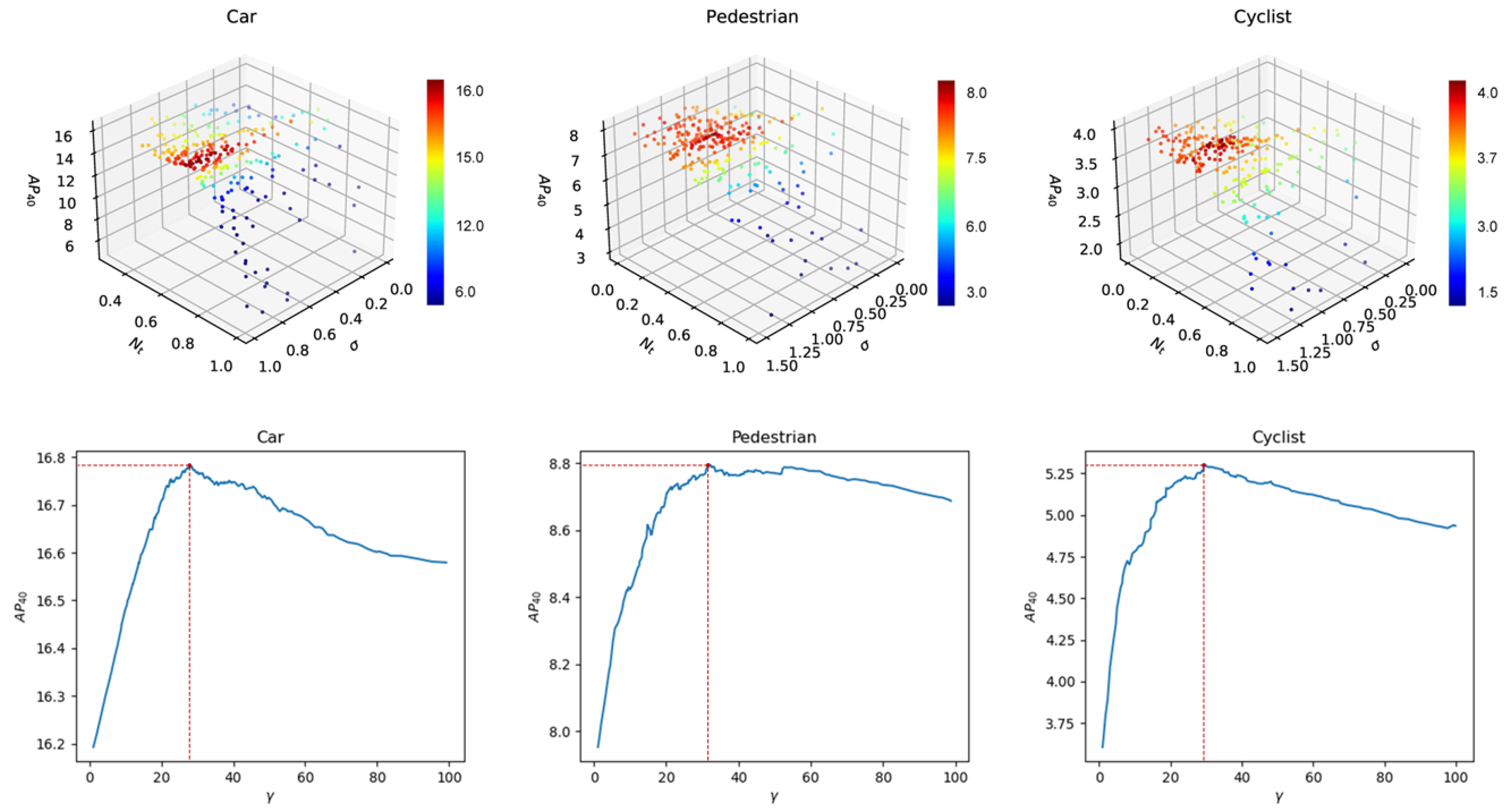
2.5. Density-Based Soft-NMS
| Algorithm 1: The pseudo-code of density-based Soft-NMS. |
| Input: |
| , |
| B is the list of initial detection boxes, |
| S contains corresponding detection scores, |
| is the NMS threshold, |
| 1: , |
| 2: , |
| 3: while do |
| 4: m ← argmax S |
| 5: M ← bm |
| 6: D ← D ∪ M, B ← B − M, |
| 7: for bi in B do |
| 8: if IoU (M,bi) ≥ Nt then |
| 9: si ← si · f (IoU(M, bi)) |
| 10: end if |
| 11: end for |
| 12: sm←sm · g (IoU(bm, B0)) |
| 13: end while |
| 14: return D, S |
3. Experimental Results
3.1. Dataset
3.2. Implementation Details
3.3. Evaluation Results
3.4. Ablation Study
3.4.1. Depth Stratification
3.4.2. Density-Based Soft-NMS and Piecewise Score
3.4.3. Assignment Strategy of Positive Samples
3.4.4. Angle Loss
3.4.5. Shape-Aware Convolution
3.5. Limitations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection From RGB-D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, C.; Zeng, H.; Huang, J.; Hua, X.S.; Zhang, L. Structure aware single-stage 3D object detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11873–11882. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3D object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1711–1719. [Google Scholar]
- Beltrán, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; García, F.; De La Escalera, A. BirdNet: A 3D Object Detection Framework from LiDAR Information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523. [Google Scholar] [CrossRef]
- Barrera, A.; Guindel, C.; Beltrán, J.; García, F. BirdNet+: End-to-End 3D Object Detection in LiDAR Bird’s Eye View. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable Object Detection using Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Weng, X.; Kitani, K. Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Xu, B.; Chen, Z. Multi-Level Fusion Based 3D Object Detection From Monocular Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ma, X.; Wang, Z.; Li, H.; Zhang, P.; Ouyang, W.; Fan, X. Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chabot, F.; Chaouch, M.; Rabarisoa, J.; Teuliere, C.; Chateau, T. Deep MANTA: A Coarse-To-Fine Many-Task Network for Joint 2D and 3D Vehicle Analysis From Monocular Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3D Bounding Box Estimation Using Deep Learning and Geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Brazil, G.; Liu, X. M3D-RPN: Monocular 3D Region Proposal Network for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. PVNet: Pixel-Wise Voting Network for 6DoF Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhou, Y.; He, Y.; Zhu, H.; Wang, C.; Li, H.; Jiang, Q. Monocular 3D object detection: An extrinsic parameter free approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 7556–7566. [Google Scholar]
- Lu, Y.; Ma, X.; Yang, L.; Zhang, T.; Liu, Y.; Chu, Q.; Yan, J.; Ouyang, W. Geometry uncertainty projection network for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021; pp. 3111–3121. [Google Scholar]
- Huang, K.C.; Wu, T.H.; Su, H.T.; Hsu, W.H. MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4012–4021. [Google Scholar]
- Shi, X.; Chen, Z.; Kim, T.K. Distance-Normalized Unified Representation for Monocular 3D Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Brazil, G.; Pons-Moll, G.; Liu, X.; Schiele, B. Kinematic 3D object detection in monocular video. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 135–152. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. arXiv 2020, arXiv:cs.CV/2006.04388. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.G.; Ma, H.; Fidler, S.; Urtasun, R. 3D object proposals for accurate object class detection. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Citeseer: Princeton, NJ, USA, 2015; pp. 424–432. [Google Scholar]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; Lopez-Antequera, M.; Kontschieder, P. Disentangling Monocular 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Ding, M.; Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, Z.; Luo, P. Learning depth-guided convolutions for monocular 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1000–1001. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. Probabilistic and Geometric Depth: Detecting Objects in Perspective. In Proceedings of the Conference on Robot Learning (CoRL), London, UK, 8–11 November 2021. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | |||||||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | ||
| M3D-RPN [25] | 0.16 s | 14.76 | 9.71 | 7.42 | 21.02 | 13.67 | 10.23 |
| D4LCN [42] | 0.2 s | 16.65 | 11.72 | 9.51 | 22.51 | 16.02 | 12.55 |
| UR3D [30] | 0.12 s | 15.58 | 8.61 | 6.00 | 21.85 | 12.51 | 9.20 |
| PGD [43] | 0.03 s | 19.05 | 11.76 | 9.39 | 26.89 | 16.51 | 13.49 |
| Ours | 0.05 s | 24.30 | 14.46 | 11.12 | 32.81 | 20.14 | 15.77 |
| Time | Pedestrian | Cyclist | |||||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | ||
| M3D-RPN [25] | 0.16s | 4.92 | 3.48 | 2.94 | 0.94 | 0.65 | 0.47 |
| D4LCN [42] | 0.2 s | 4.55 | 3.42 | 2.83 | 2.45 | 1.67 | 1.36 |
| PGD [43] | 0.1 s | 2.28 | 1.49 | 1.38 | 2.81 | 1.38 | 1.20 |
| Ours | 0.05 s | 10.68 | 7.09 | 6.06 | 5.37 | 2.68 | 2.22 |
| Time | |||||||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | ||
| MonoEF [27] | - | 21.29 | 13.87 | 11.71 | 29.03 | 19.7 | 17.26 |
| GUPNet [28] | 0.1 s | 20.11 | 14.20 | 11.77 | - | - | - |
| MonoDTR [29] | 0.08 s | 21.99 | 15.39 | 12.73 | 28.59 | 20.38 | 15.77 |
| Ours | 0.05 s | 24.30 | 14.46 | 11.12 | 32.81 | 20.14 | 15.77 |
| 5–20 m | 10–40 m | 20–80 m | 5–20 m | 10–40 m | 20–80 m | |
|---|---|---|---|---|---|---|
| M3D-RPN [25] | 17.92 | 6.82 | 1.59 | 50.07 | 24.51 | 10.55 |
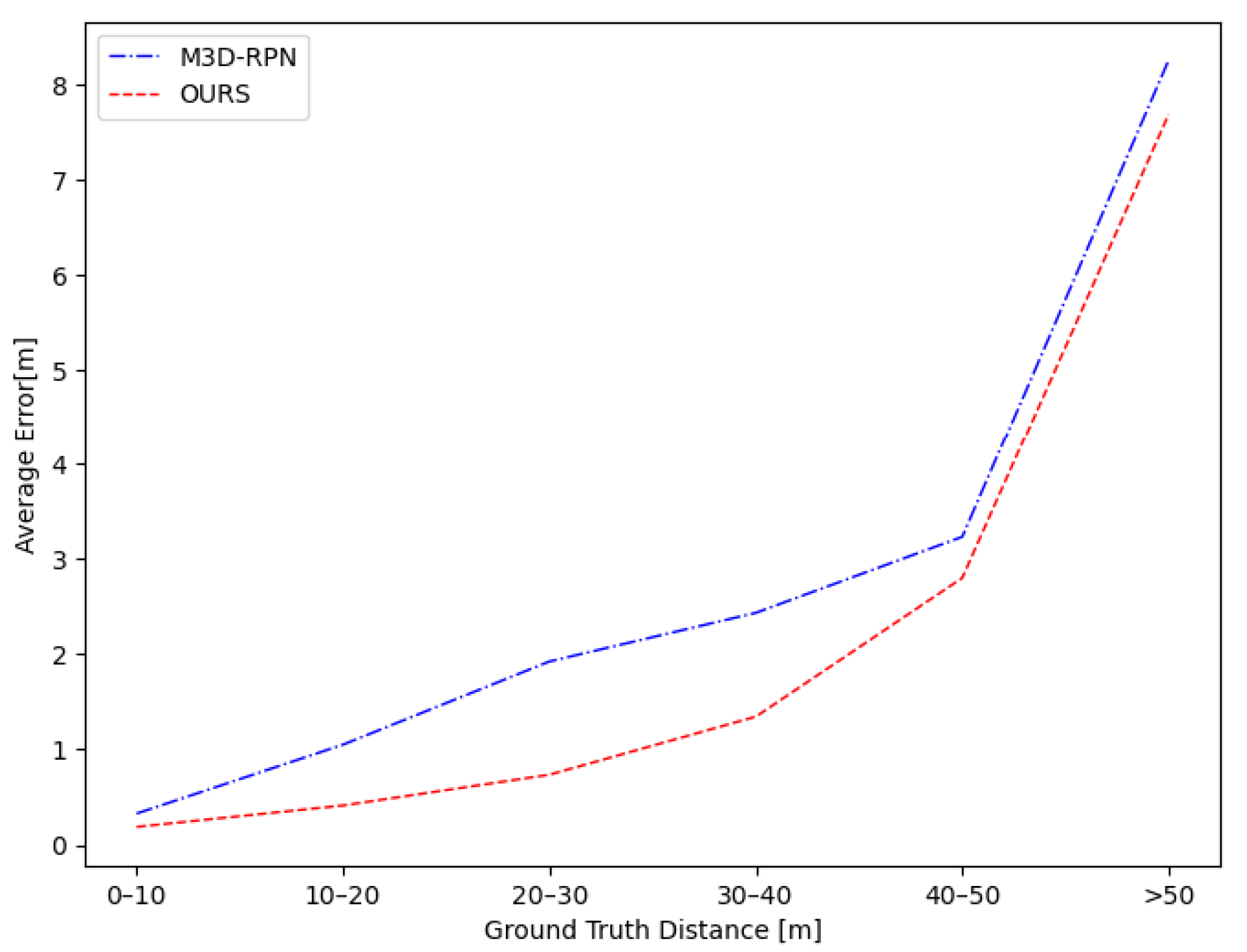
| Ours | 27.29 | 11.79 | 4.30 | 57.67 | 31.66 | 16.20 |
| Improvement | +52.29% | +72.87% | +169.81% | +15.16% | +29.21% | +53.55% |
| Depth Stratification | Density-Based Soft-NMS | Piecewise Confidence | ||||||
|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | |||
| 2.72 | 2.29 | 1.95 | 1.69 | 1.36 | 1.09 | |||
| ✓ | 14.99 | 12.32 | 10.86 | 9.83 | 7.71 | 6.84 | ||
| ✓ | ✓ | 20.69 | 17.09 | 15.16 | 14.67 | 12.03 | 10.43 | |
| ✓ | ✓ | 30.99 | 20.09 | 16.42 | 21.35 | 13.6 | 10.78 | |
| ✓ | ✓ | ✓ | 34.56 | 22.86 | 18.56 | 25.30 | 16.88 | 13.53 |
| Positive:Negative (Samples) | |||||||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | ||
| M3D-RPN [25] | 17.15 | 13.14 | 11.6 | 8.01 | 6.11 | 5.18 | 1:3716 |
| FCOS3D [35] | 24.34 | 17.23 | 14.84 | 17.62 | 11.76 | 9.93 | 1:429 |
| Ours | 30.99 | 20.09 | 16.42 | 21.35 | 13.6 | 10.78 | 1:92 |
| AHS | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | |
| AVOD [9] | 24.78 | 16.71 | 13.71 | 16.87 | 10.89 | 8.77 | 16.67 | 11.36 | 9.44 |
| SECOND [37] | 25.74 | 16.15 | 12.91 | 17.83 | 10.86 | 8.46 | 16.97 | 10.71 | 8.62 |
| Ours | 30.99 | 20.09 | 16.42 | 21.35 | 13.6 | 10.78 | 20.50 | 13.78 | 11.36 |
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | |
| Structure A | 19.41 | 12.45 | 9.79 | 8.42 | 6.52 | 5.18 | 5.31 | 2.67 | 2.4 |
| Structure B | 20.22 | 12.71 | 10.11 | 8.92 | 6.82 | 5.5 | 4.15 | 2.37 | 2.18 |
| Structure C | 20.16 | 12.81 | 10.17 | 9.03 | 6.9 | 5.67 | 4.55 | 2.06 | 1.87 |
| Structure D | 21.35 | 13.6 | 10.78 | 10.31 | 7.55 | 6.26 | 4.17 | 2.2 | 1.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Z.; Song, Y.; Wu, J.; Li, Z.; Song, C.; Xu, Z. MDS-Net: Multi-Scale Depth Stratification 3D Object Detection from Monocular Images. Sensors 2022, 22, 6197. https://doi.org/10.3390/s22166197
Xie Z, Song Y, Wu J, Li Z, Song C, Xu Z. MDS-Net: Multi-Scale Depth Stratification 3D Object Detection from Monocular Images. Sensors. 2022; 22(16):6197. https://doi.org/10.3390/s22166197
Chicago/Turabian StyleXie, Zhouzhen, Yuying Song, Jingxuan Wu, Zecheng Li, Chunyi Song, and Zhiwei Xu. 2022. "MDS-Net: Multi-Scale Depth Stratification 3D Object Detection from Monocular Images" Sensors 22, no. 16: 6197. https://doi.org/10.3390/s22166197