IFFMStyle: High-Quality Image Style Transfer Using Invalid Feature Filter Modules


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Style Transfer
2.2. MLP
3. Method
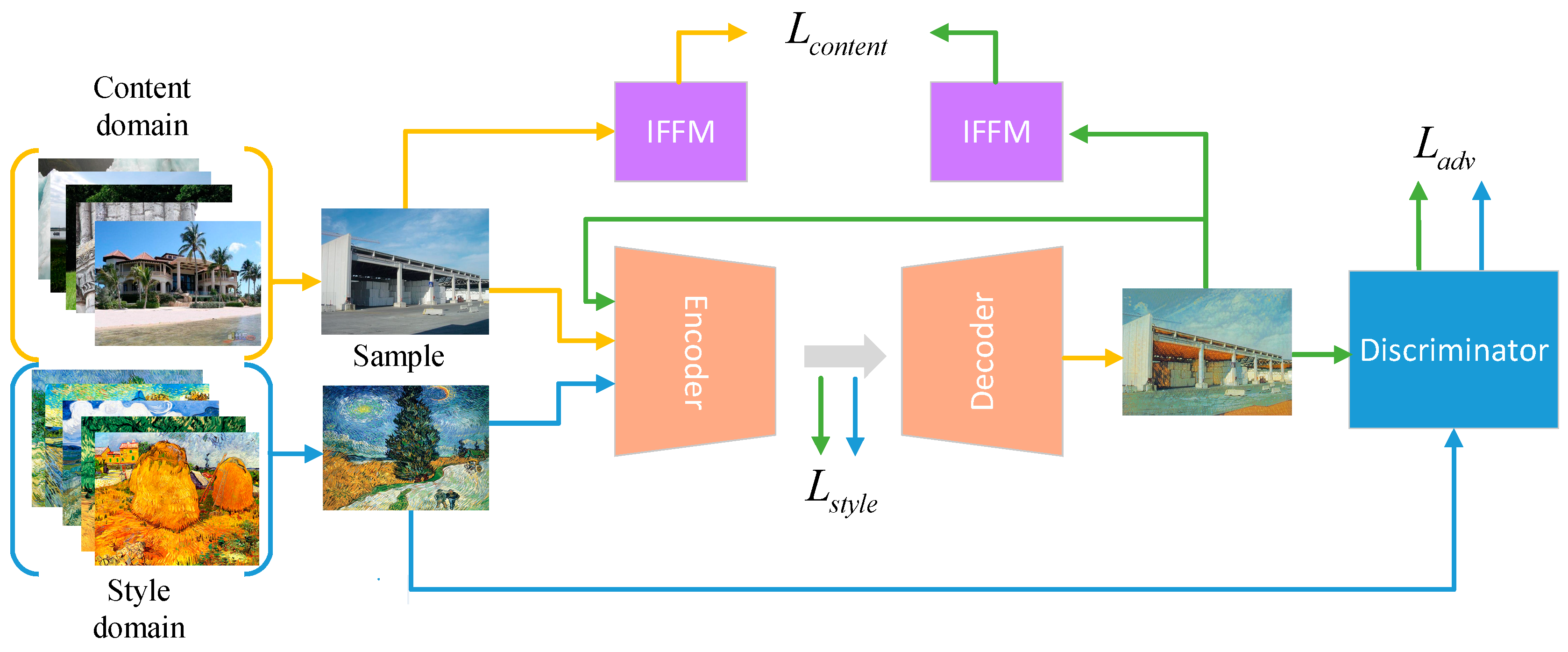
3.1. Network Architecture
3.2. Training
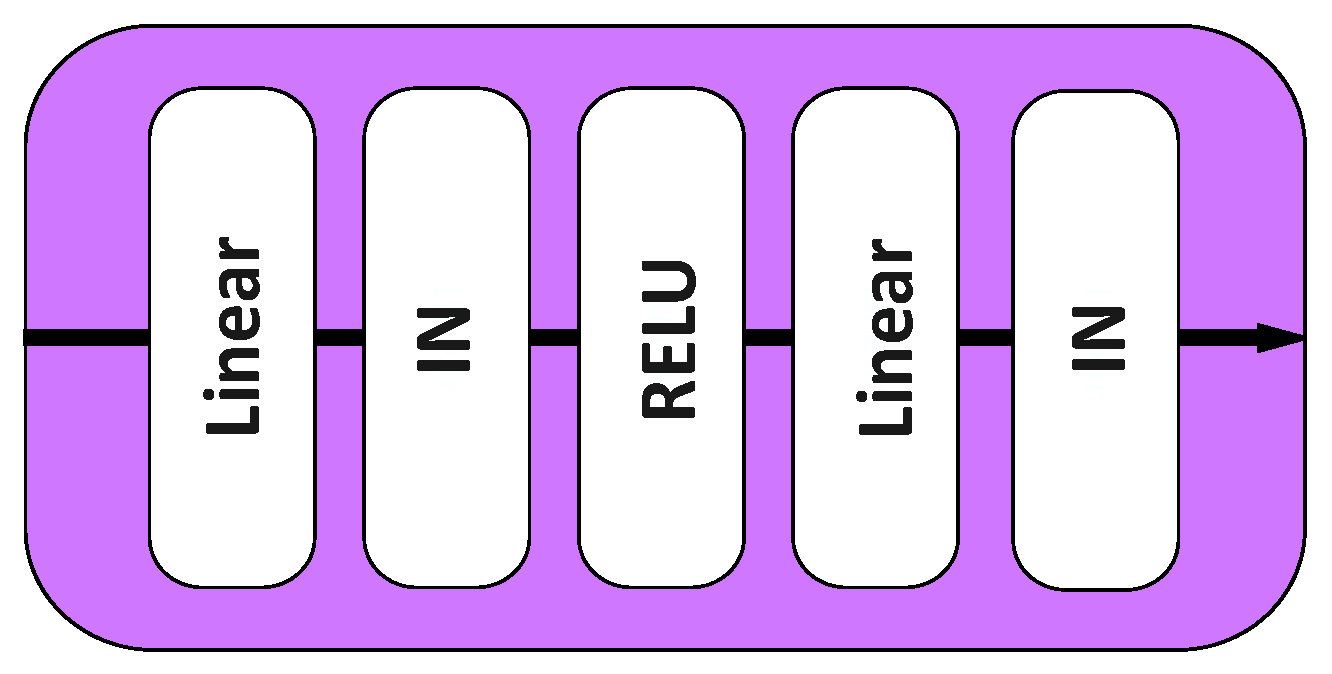
3.3. Invalid Feature Filtering Module
4. Experiments
4.1. Training Details
4.2. Data Composition
4.3. Experimental Results
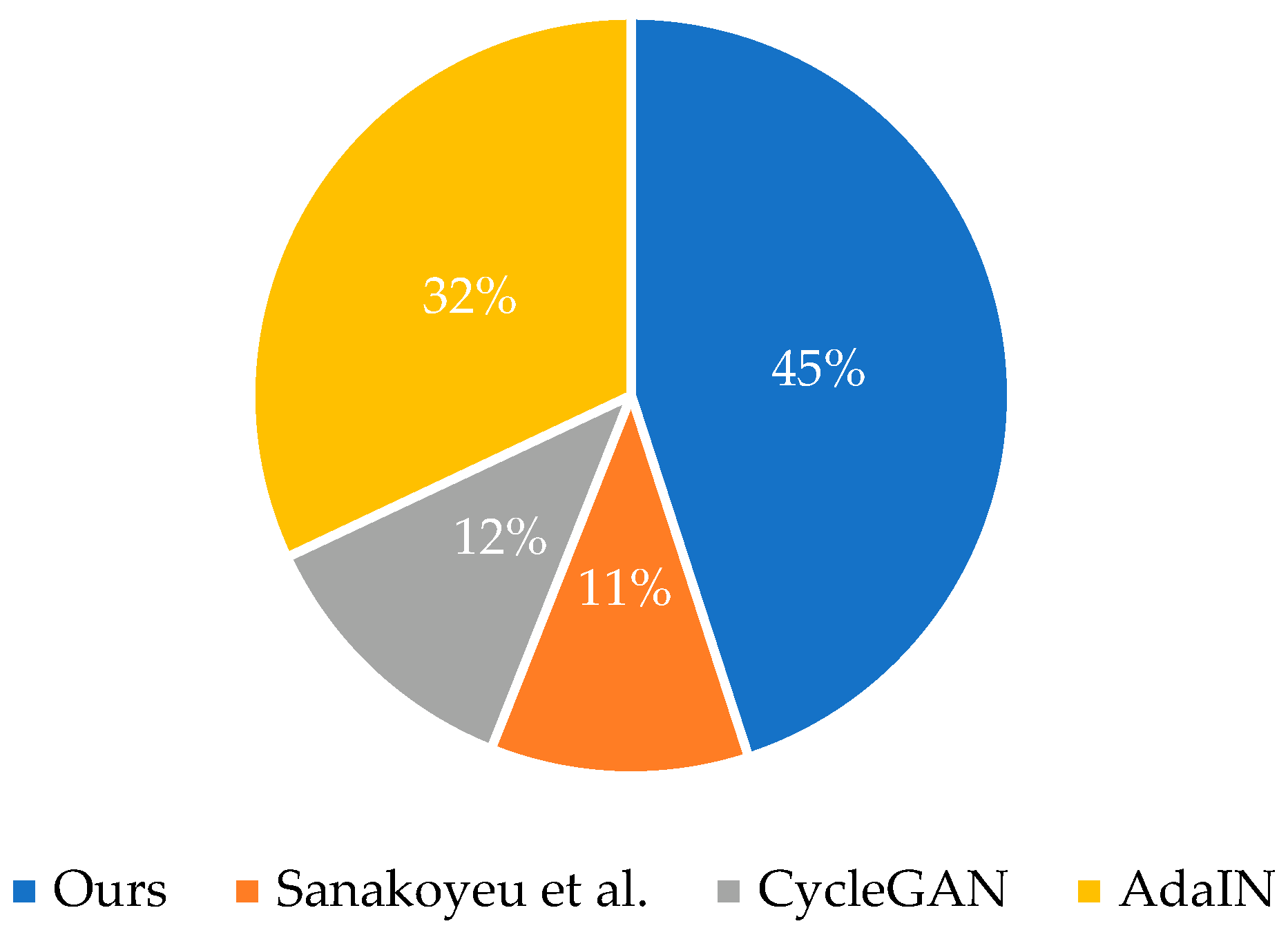
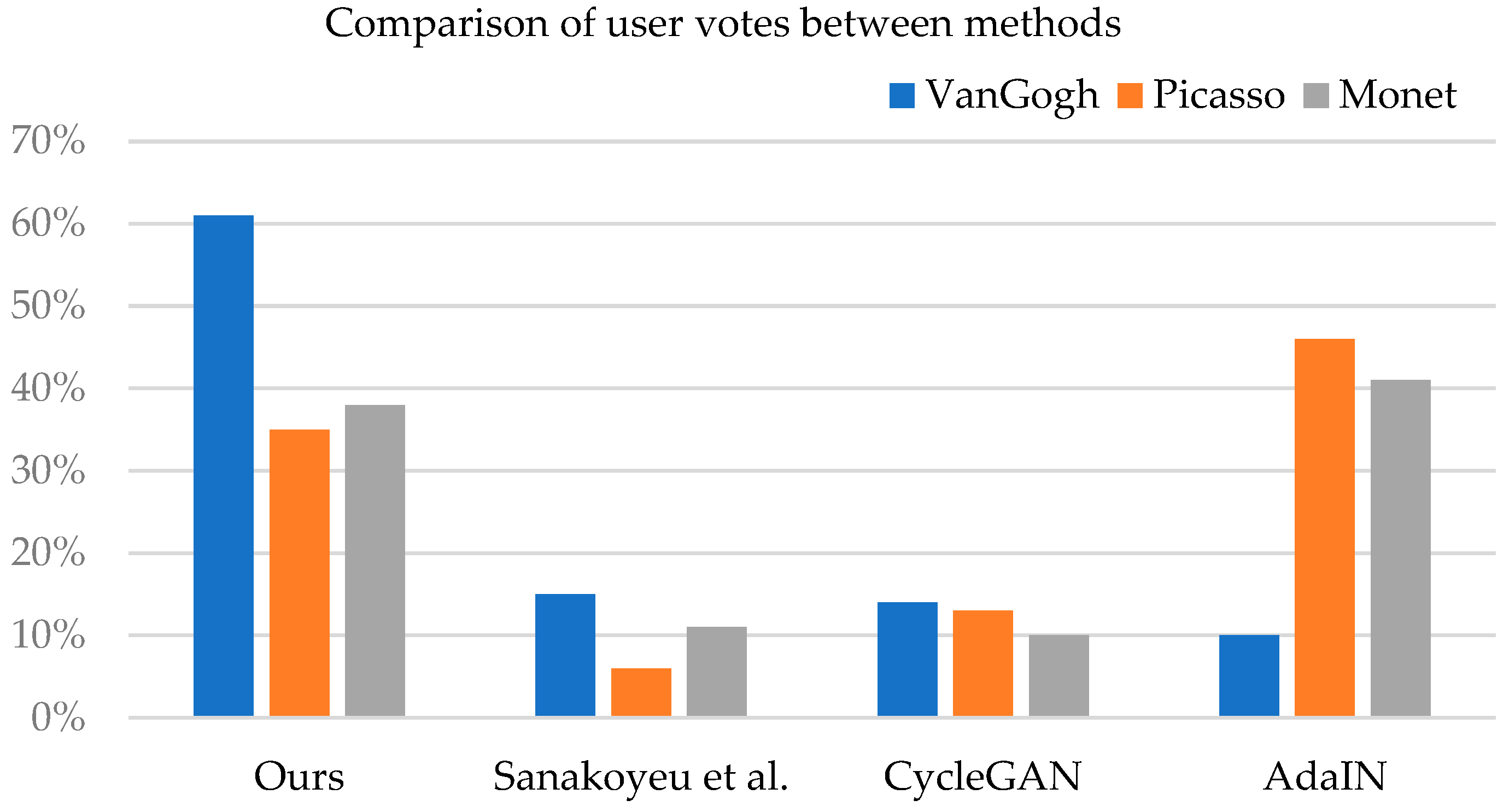
4.4. User Research
4.5. Ablation Experiment
4.5.1. Loss Function
4.5.2. Analysis of Weight Parameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2414–2423. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V. Texture Networks: Feed-forward Synthesis of Textures and Stylized Images. arXiv 2016, arXiv:1603.03417. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. arXiv 2017, arXiv:1701.02096. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1897–1906. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.-H. Universal Style Transfer via Feature Transforms. arXiv 2017, arXiv:1705.08086. [Google Scholar]
- Park, D.Y.; Lee, K.H. Arbitrary Style Transfer with Style-Attentional Networks. arXiv 2018, arXiv:1812.02342. [Google Scholar]
- Sheng, L.; Lin, Z.; Shao, J.; Wang, X. Avatar-net: Multi-scale zero-shot style transfer by feature decoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8242–8250. [Google Scholar]
- Ma, Z.; Li, J.; Wang, N.; Gao, X. Semantic-Related Image Style Transfer with Dual-Consistency Loss. Neurocomputing 2020, 406, 135–149. [Google Scholar] [CrossRef]
- Sanakoye, A.; Kotovenko, D.; Lang, S.; Ommer, B. A style-aware content loss for real-time hd style transfer. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 715–731. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Gooch, B.; Gooch, A. Non-Photorealistic Rendering; A. K. Peters, Ltd.: Natick, MA, USA, 2001. [Google Scholar]
- Strothotte, T.; Schlechtweg, S. Non-Photorealistic Computer Graphics: Modeling, Rendering, and Animation; Morgan Kaufmann: San Francisco, CA, USA, 2002. [Google Scholar]
- Li, S.; Xu, X.; Nie, L.; Chua, T.S. Laplacian-steered neural style transfer. In Proceedings of the 2017 ACM on Multimedia Conference, ACM, Mountain View, CA, USA, 23–27 October 2017; pp. 1716–1724. [Google Scholar]
- Li, Y.; Wang, N.; Liu, J.; Hou, X. Demystifying neural style transfer. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 2230–2236. [Google Scholar]
- Li, C.; Wand, M. Combining markov random fields and convolutional neural networks for image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2479–2486. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G. Big Self-Supervised Models are Strong Semi-Supervised Learners. arXiv 2020, arXiv:2006.10029. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. Available online: https://arxiv.org/pdf/2003.04297v1.pdf (accessed on 2 February 2021).
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. arXiv 2021, arXiv:2011.10566. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, J. RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition. arXiv 2021, arXiv:2105.01883. Available online: https://arxiv.org/pdf/2105.01883v1.pdf (accessed on 29 June 2021).
- Guo, M.H.; Liu, Z.N.; Mu, T.J.; Hu, S.M. Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks. arXiv 2021, arXiv:2105.02358. Available online: https://arxiv.org/pdf/2105.02358v1.pdf (accessed on 29 June 2021).
- Luke, M.K. Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet. arXiv 2021, arXiv:2105.02723. Available online: https://arxiv.org/pdf/2105.02723v1.pdf (accessed on 29 June 2021).
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP Architecture for Vision. arXiv 2021, arXiv:2105.01601. Available online: https://arxiv.org/abs/2105.01601 (accessed on 29 June 2021).
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization, in international Conference on Learning Representations. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers: Burlington, MA, USA, 2014; pp. 487–495. Available online: http://places.csail.mit.edu (accessed on 15 July 2022).
- Karayev, S.; Trentacoste, M.; Han, H.; Agarwala, A.; Darrell, T.; Hertzmann, A.; Winnemoeller, H. Recognizing image style. arXiv 2013, arXiv:1311.3715. [Google Scholar]














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Hou, L.; Zhang, J. IFFMStyle: High-Quality Image Style Transfer Using Invalid Feature Filter Modules. Sensors 2022, 22, 6134. https://doi.org/10.3390/s22166134
Xu Z, Hou L, Zhang J. IFFMStyle: High-Quality Image Style Transfer Using Invalid Feature Filter Modules. Sensors. 2022; 22(16):6134. https://doi.org/10.3390/s22166134
Chicago/Turabian StyleXu, Zhijie, Liyan Hou, and Jianqin Zhang. 2022. "IFFMStyle: High-Quality Image Style Transfer Using Invalid Feature Filter Modules" Sensors 22, no. 16: 6134. https://doi.org/10.3390/s22166134