
Recognition of Uni-Stroke Characters with Hand Movements in 3D Space Using Convolutional Neural Networks



Abstract
:1. Introduction
2. Materials and Methods
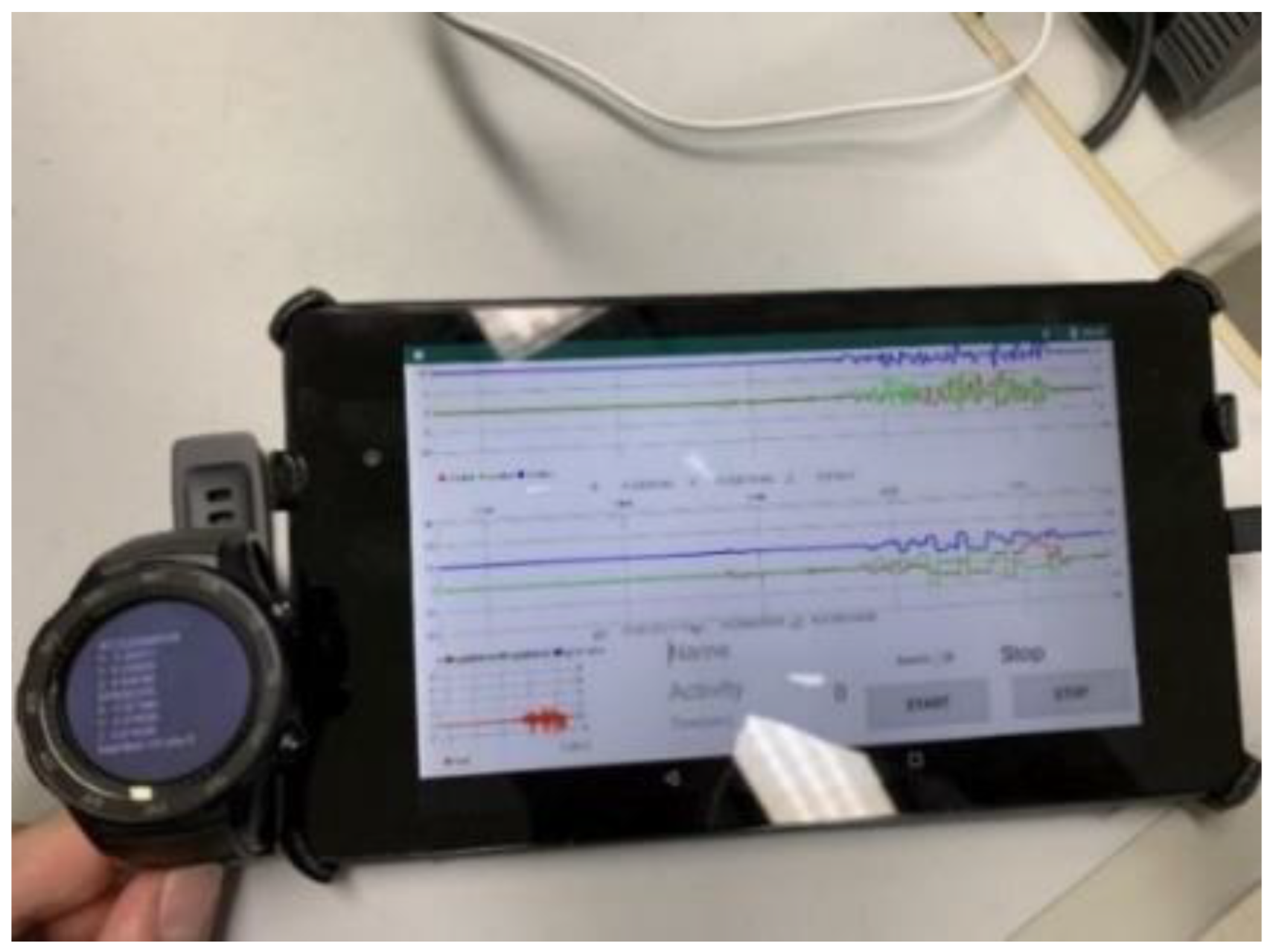
2.1. Device
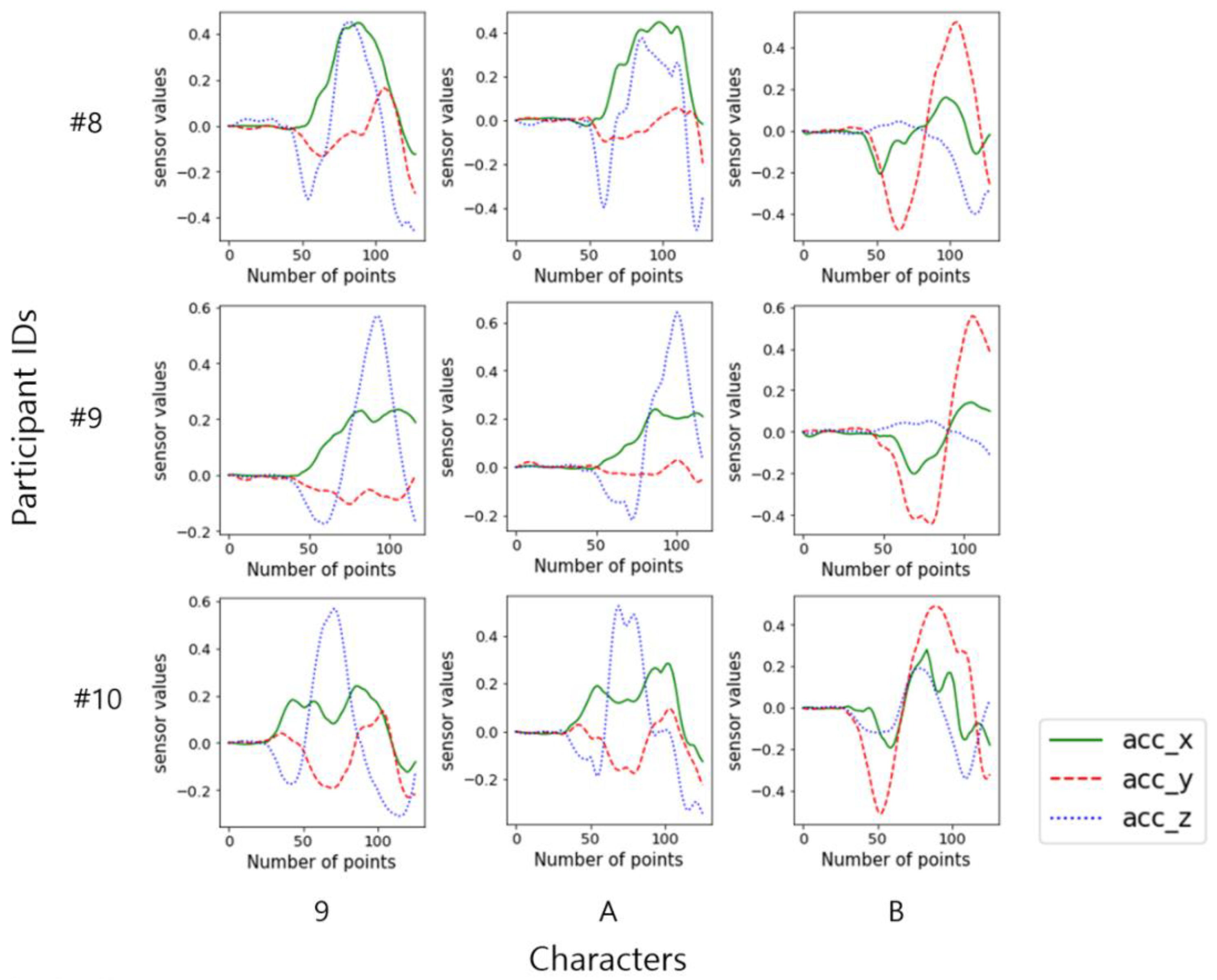
2.2. Data
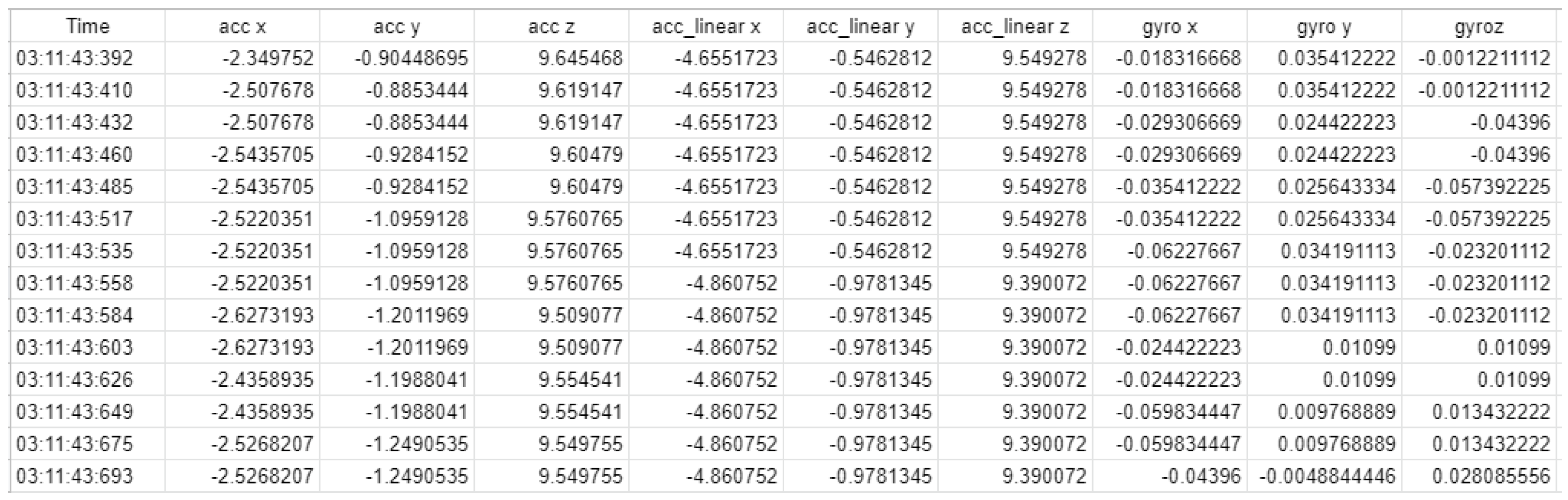
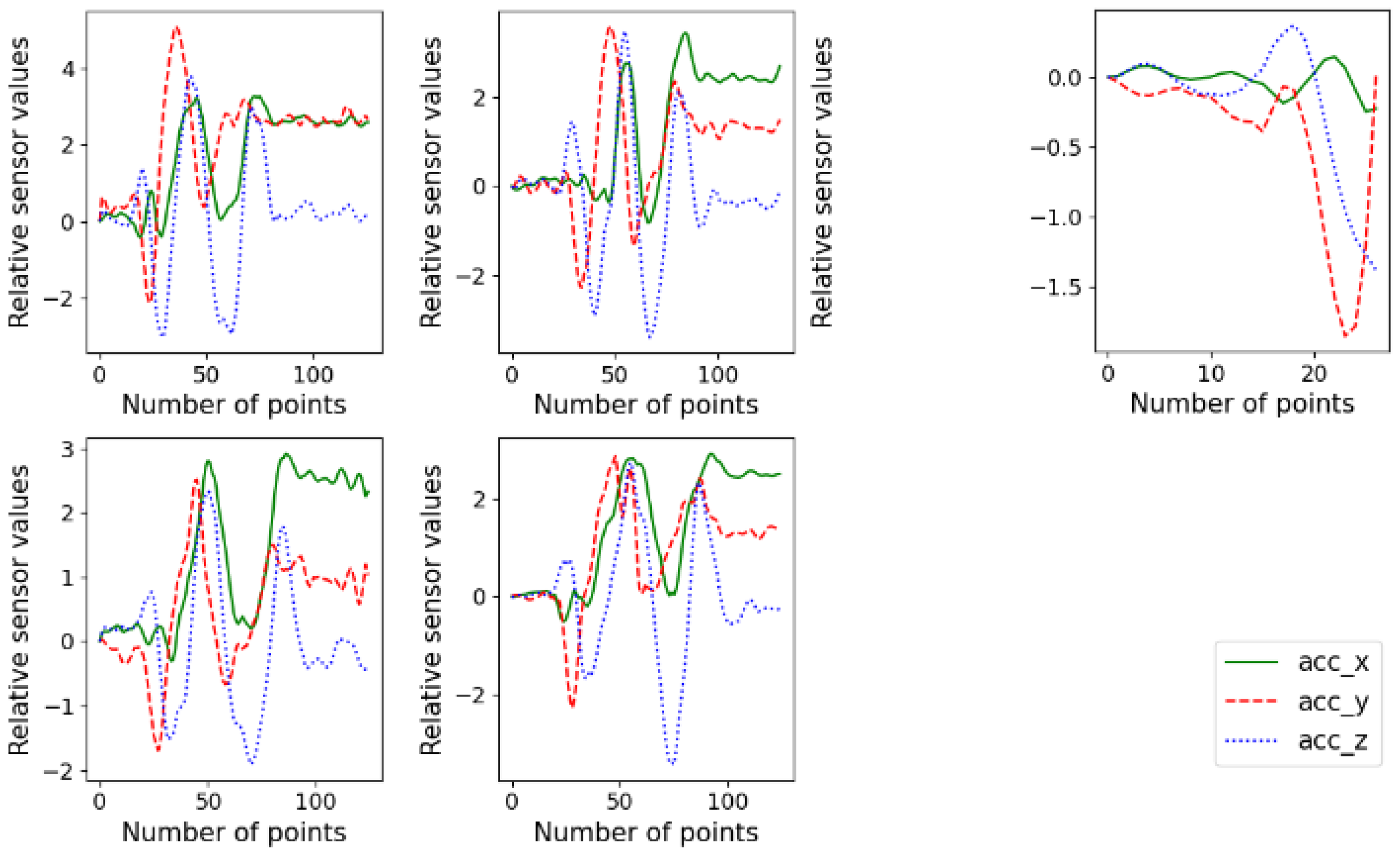
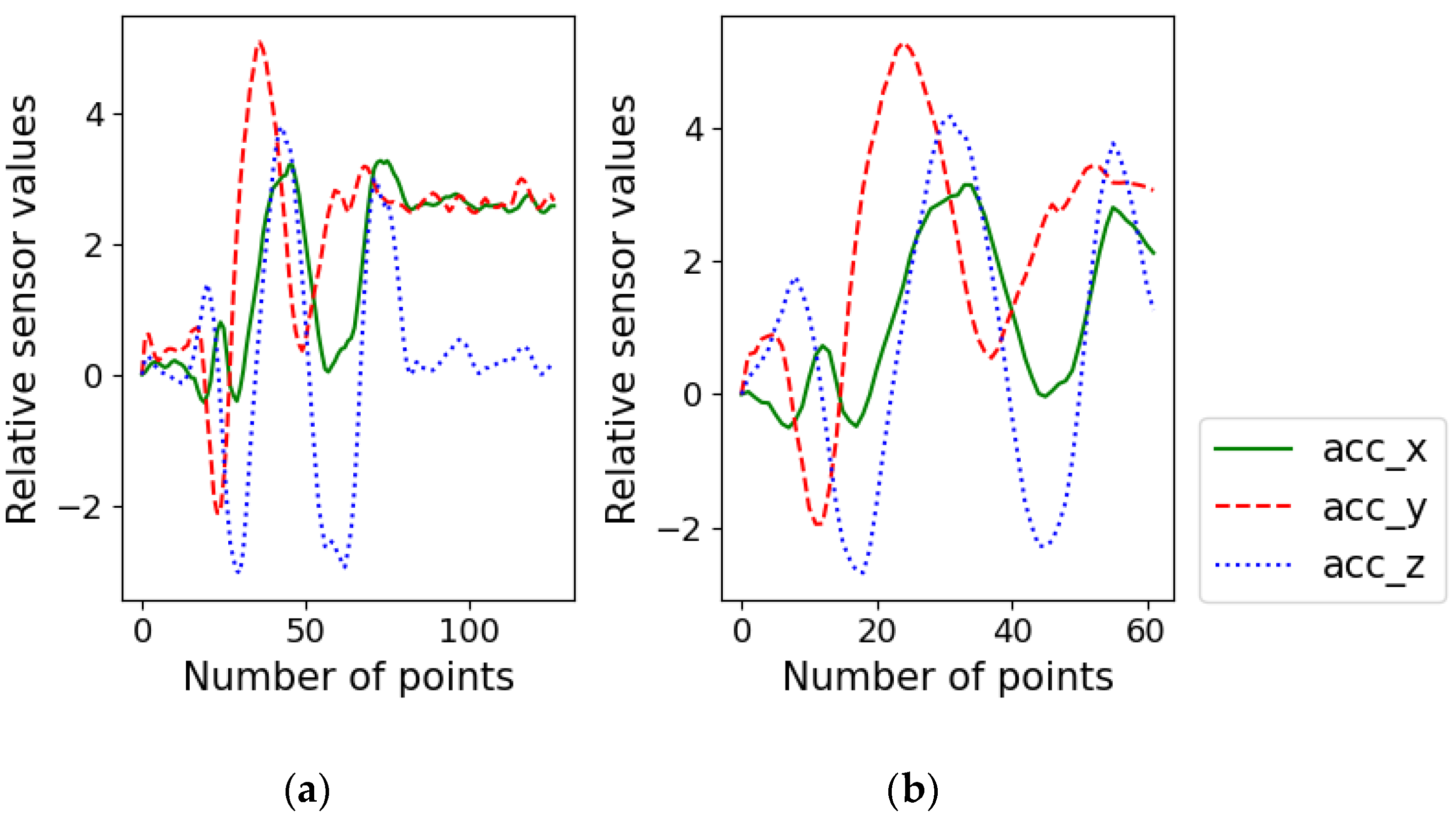
2.3. Preprocessing
- (1)
- Calculate detail coefficients from single-level wavelet transform for each channel of signals;
- (2)
- Interpolate and smooth with a Savitzky–Golay filter [18] as the length of the coefficient signal is half of the original signal;
- (3)
- Calculate the standard deviation of the signal for each channel, and set the minimum value among the channels as the threshold for the data;
- (4)
- Signal regions where the detail coefficients of all the channels are less than or equal to the threshold are marked as non-movement regions;
- (5)
- Remove the signals in the non-movement regions.
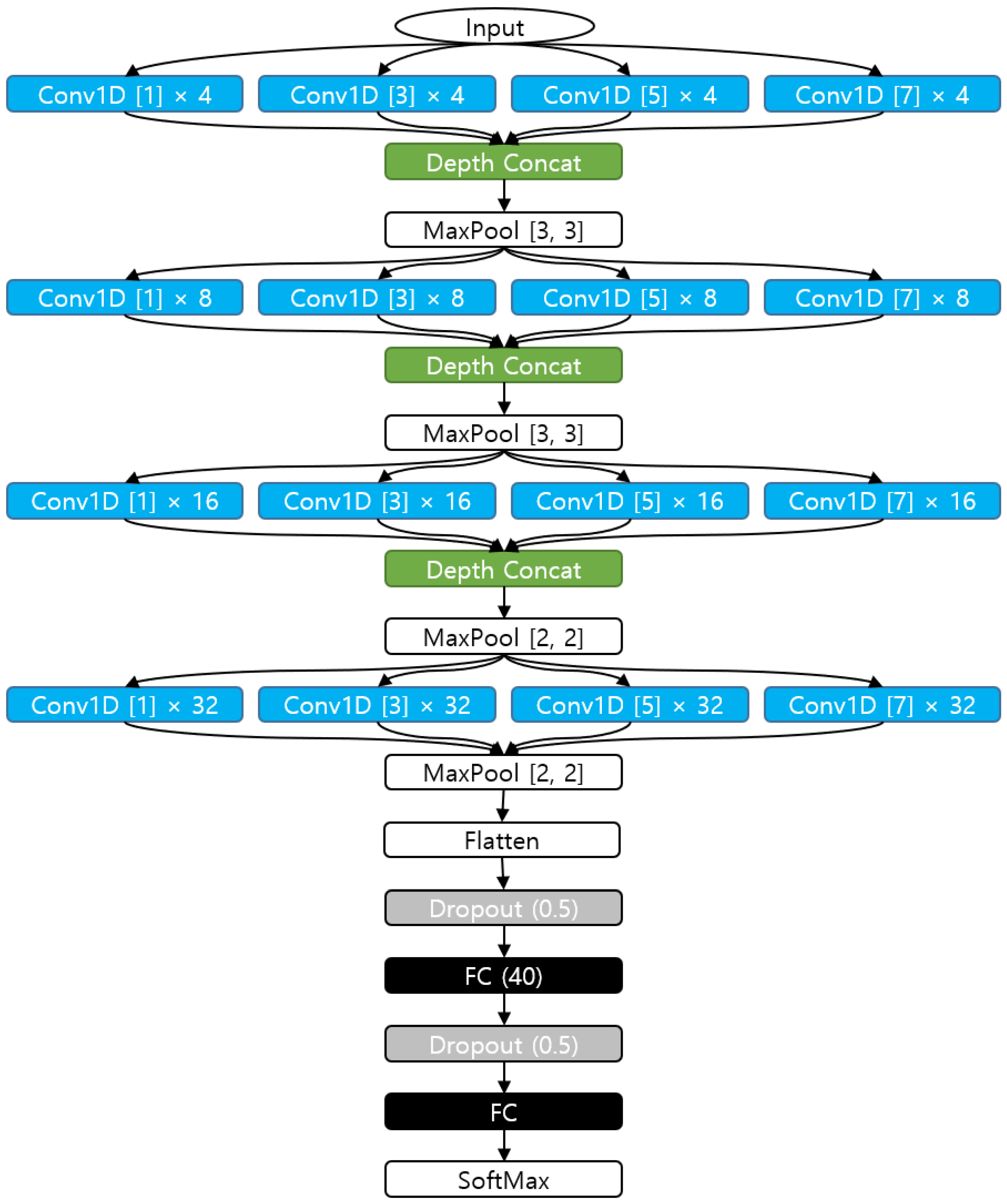
2.4. Convolutional Neural Network
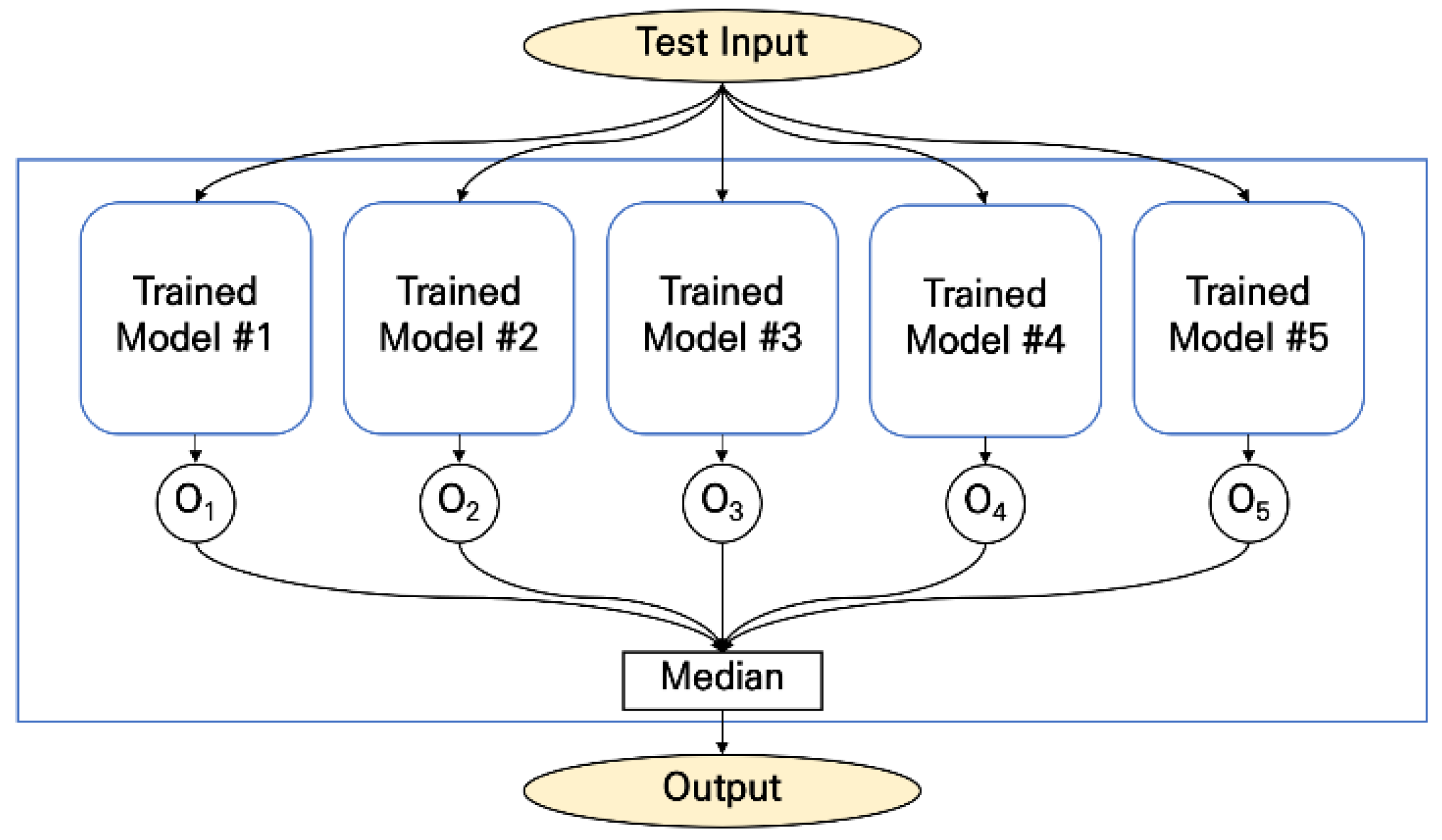
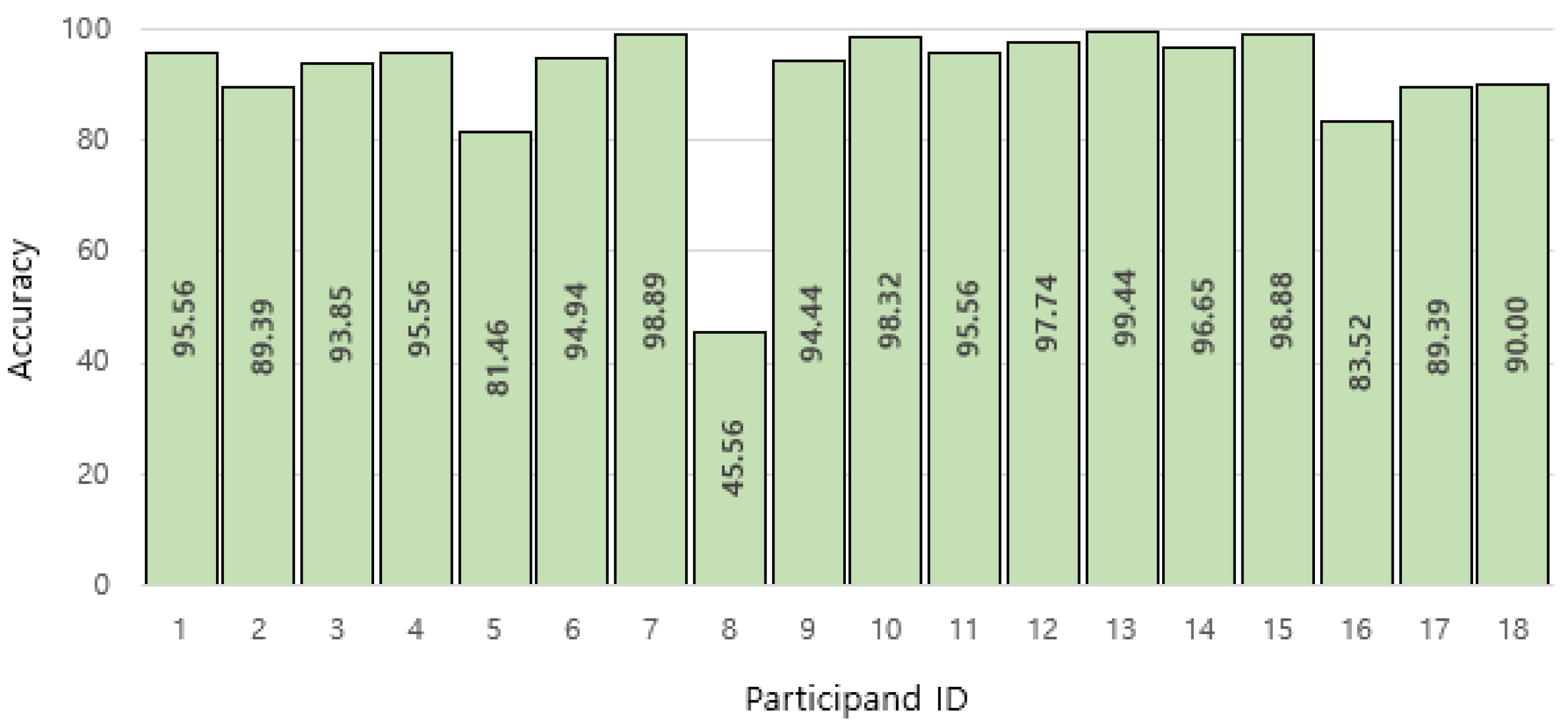
2.5. User-Independent Evaluation
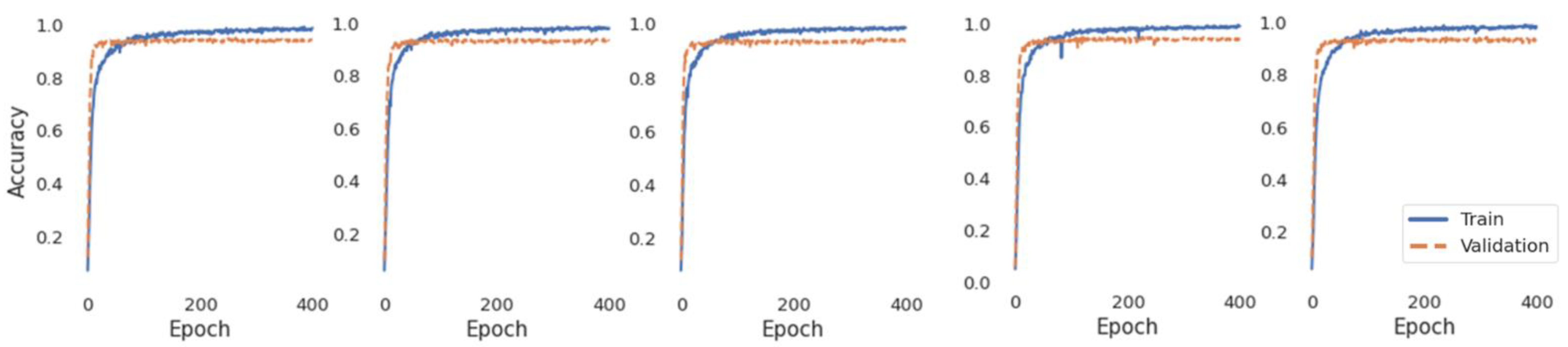
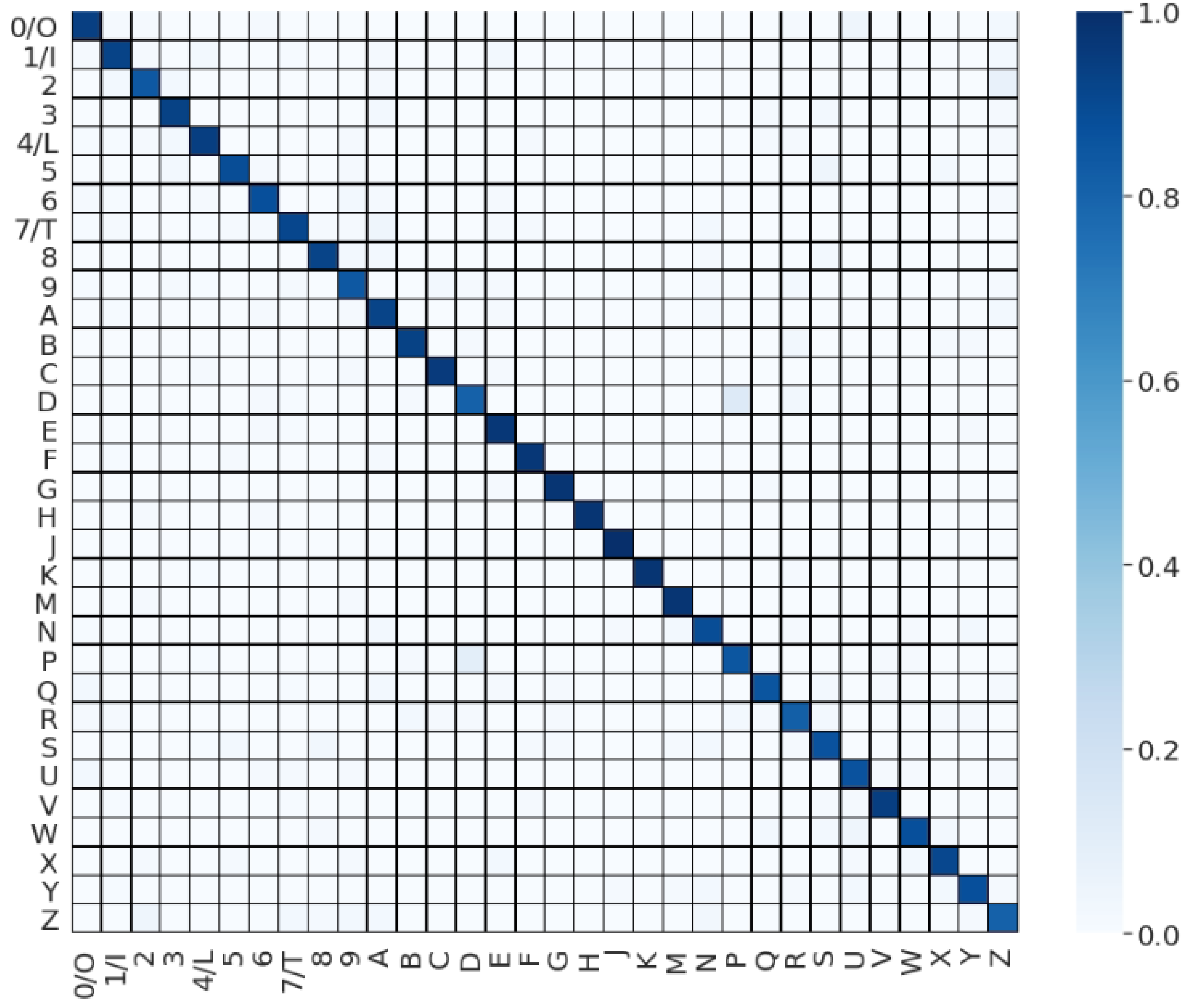
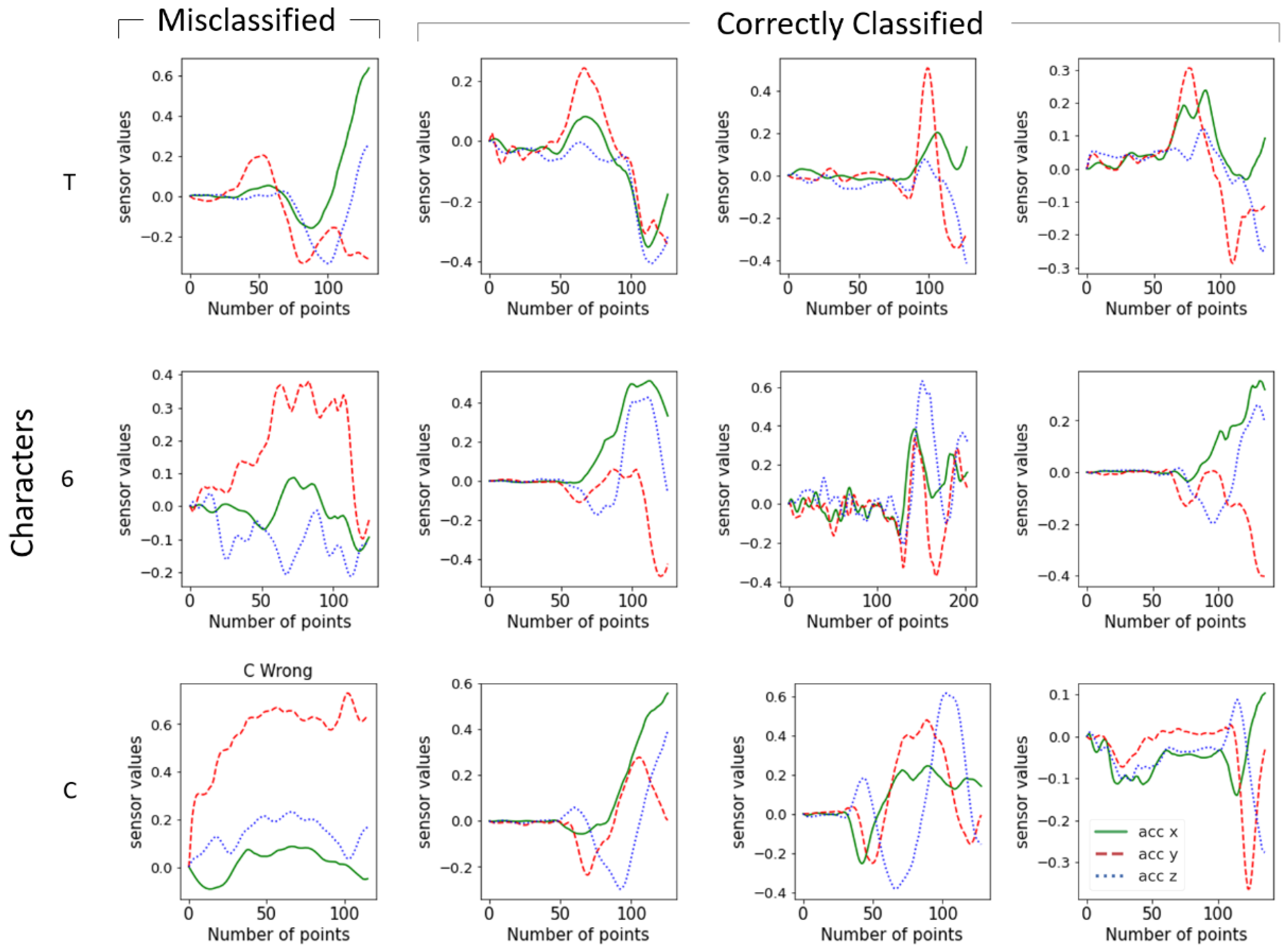
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hastie, T.; Simard, P.Y. Metrics and Models for Handwritten Character Recognition. Stat. Sci. 1998, 13, 54–65. [Google Scholar] [CrossRef]
- Singh, D.; Khan, M.A.; Bansal, A.; Bansal, N. An Application of SVM in Character Recognition with Chain Code. In Proceedings of the International Conference Communication, Control and Intelligent Systems, CCIS 2015; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2016; pp. 167–171. [Google Scholar]
- Alqudah, A.; Alqudah, A.M.; Alquran, H.; Al-zoubi, H.R.; Al-qodah, M.; Al-khassaweneh, M.A. Recognition of Handwritten Arabic and Hindi Numerals Using Convolutional Neural Networks. Appl. Sci. 2021, 11, 1573. [Google Scholar] [CrossRef]
- Bora, M.B.; Daimary, D.; Amitab, K.; Kandar, D. Handwritten Character Recognition from Images Using CNN-ECOC. In Proceedings of the Procedia Computer Science; Elsevier B.V.: Amsterdam, The Netherlands, 2020; Volume 167, pp. 2403–2409. [Google Scholar]
- Roy, P.; Ghosh, S.; Pal, U. A CNN Based Framework for Unistroke Numeral Recognition in Air-Writing. In Proceedings of the International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 404–409. [Google Scholar] [CrossRef]
- Sonoda, T.; Muraoka, Y. A Letter Input System Based on Handwriting Gestures. Electron. Commun. Jpn. Part III Fundam. Electron. Sci. (Engl. Transl. Denshi Tsushin Gakkai Ronbunshi) 2006, 89, 53–64. [Google Scholar] [CrossRef]
- Hsieh, C.-H.; Lo, Y.-S.; Chen, J.-Y.; Tang, S.-K. Air-Writing Recognition Based on Deep Convolutional Neural Networks. IEEE Access 2021, 9, 142827–142836. [Google Scholar] [CrossRef]
- Murata, T.; Shin, J. Hand Gesture and Character Recognition Based on Kinect Sensor. Int. J. Distrib. Sens. Netw. 2014, 2014, 1–6. [Google Scholar] [CrossRef]
- Kane, L.; Khanna, P. Vision-Based Mid-Air Unistroke Character Input Using Polar Signatures. IEEE Trans. Hum. -Mach. Syst. 2017, 47, 1077–1088. [Google Scholar] [CrossRef]
- Shin, J.; Kim, C.M. Non-Touch Character Input System Based on Hand Tapping Gestures Using Kinect Sensor. IEEE Access 2017, 5, 10496–10505. [Google Scholar] [CrossRef]
- Saez-Mingorance, B.; Mendez-Gomez, J.; Mauro, G.; Castillo-Morales, E.; Pegalajar-Cuellar, M.; Morales-Santos, D.P. Air-Writing Character Recognition with Ultrasonic Transceivers. Sensors 2021, 21, 6700. [Google Scholar] [CrossRef]
- Otsubo, Y.; Matsuki, K.; Nakai, M. A Study on Restoration of Acceleration Feature Vectors for Aerial Handwritten Character Recognition. In Proceedings of the Forum on Information Technology, Tottori, Japan, 4–6 September 2013; pp. 147–148. [Google Scholar]
- Kuramochi, K.; Tsukamoto, K.; Yanai, H.F. Accuracy Improvement of Aerial Handwritten Katakana Character Recognition. In Proceedings of the 2017 56th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Kanazawa, Japan, 19–22 September 2017; pp. 116–119. [Google Scholar] [CrossRef]
- Matsuki, K.; Nakai, M. Aerial Handwritten Character Recognition Using an Acceleration Sensor and Gyro Sensor. In Proceedings of the Forum on Information Technology 2011, Hakodate, Japan, 7–9 September 2011; pp. 237–238. [Google Scholar]
- Yanay, T.; Shmueli, E. Air-Writing Recognition Using Smart-Bands. Pervasive Mob. Comput. 2020, 66, 101183. [Google Scholar] [CrossRef]
- Amma, C.; Gehrig, D.; Schultz, T. Airwriting Recognition Using Wearable Motion Sensors. ACM Int. Conf. Proc. Ser. 2010, 10, 1–8. [Google Scholar] [CrossRef]
- Graffiti (Palm OS). Available online: https://en.wikipedia.org/wiki/Graffiti_%28Palm_OS%29#/media/File:Palm_Graffiti_gestures.png (accessed on 8 June 2022).
- Schafer, R.W. What Is a Savitzky-Golay Filter? [Lecture Notes]. IEEE Signal Processing Mag. 2011, 28, 111–117. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Livieris, I.E.; Pintelas, E.; Stavroyiannis, S.; Pintelas, P. Ensemble Deep Learning Models for Forecasting Cryptocurrency Time-Series. Algorithms 2020, 13, 121. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Tanveer, M.; Suganthan, P.N. Ensemble Deep Learning: A Review. Eng. Appl. Artif. Intell. 2021, 115. [Google Scholar] [CrossRef]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April –3 May 2018; pp. 1–23. [Google Scholar]
- Esterman, M.; Tamber-Rosenau, B.J.; Chiu, Y.C.; Yantis, S. Avoiding Non-Independence in FMRI Data Analysis: Leave One Subject Out. Neuroimage 2010, 50, 572–576. [Google Scholar] [CrossRef] [PubMed]
- Gholamiangonabadi, D.; Kiselov, N.; Grolinger, K. Deep Neural Networks for Human Activity Recognition with Wearable Sensors: Leave-One-Subject-Out Cross-Validation for Model Selection. IEEE Access 2020, 8, 133982–133994. [Google Scholar] [CrossRef]
- Xu, C.; Pathak, P.H.; Mohapatra, P. Finger-Writing with Smartwatch. In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, Santa Fe, NM, USA, 12–13 February 2015; pp. 9–14. [Google Scholar] [CrossRef]
- Taherkhani, A.; Cosma, G.; McGinnity, T.M. AdaBoost-CNN: An Adaptive Boosting Algorithm for Convolutional Neural Networks to Classify Multi-Class Imbalanced Datasets Using Transfer Learning. Neurocomputing 2020, 404, 351–366. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
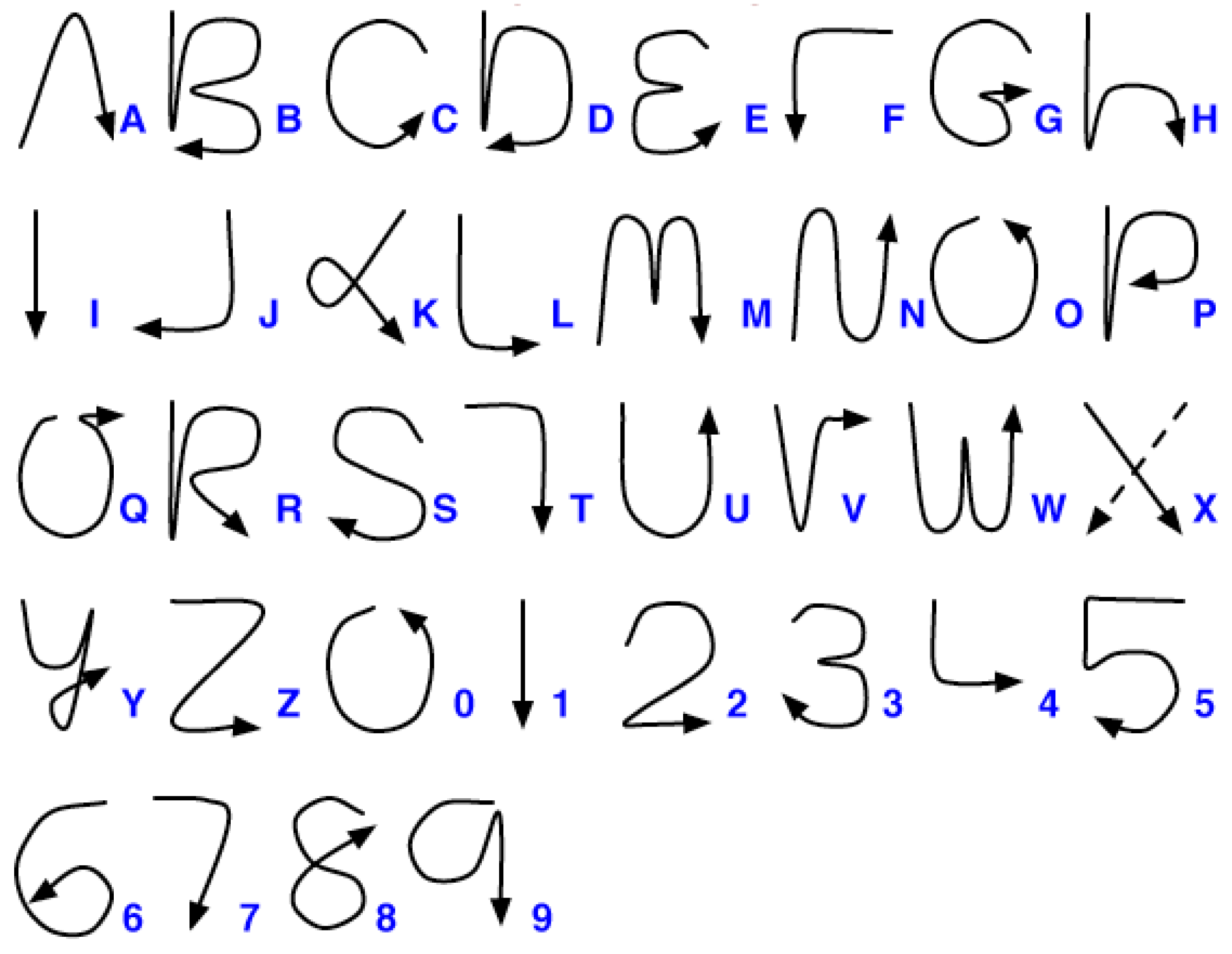{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Recording Devices | Algorithms | Patterns | Number of Participants | Accuracy |
|---|---|---|---|---|---|
| [8] | Kinect | DP matching | Alphanumeric characters | 10 | 95.0% (Alphanumeric character) |
| 98.9% (Arabic digits) | |||||
| [9] | Kinect | Benchmarks | Arabic digits, alphabets, and symbols | 8 | 96.5% |
| [10] | Kinect | Template matching | Japanese (Hiragana) and alphabets | - | 94.3% |
| [7] | Optical camera | Convolutional neural network (CNN) | Arabic digits and 16 directional symbols | 14 | 99.571% (writer-independent) |
| [5] | Optical camera | CNN | Arabic digits | 20 | 97.7% |
| [11] | Ultrasonic transceiver | CNN with long short-term memory (LSTM) | Arabic digits (1 to 4) and alphabets (A to D) | - | 98.28% |
| [6] | Wearable optical/infrared camera | DP matching | Alphanumeric characters | 5 | 75.5% |
| [26] | Smartwatch | Naive Bayes | Alphabets | 1 | 90.00% (Naive Bayes) |
| Logistic regression | 94.62% (logistic regression) | ||||
| decision tree | 88.08% (decision tree) | ||||
| [16] | Wearable motion sensors | Hidden Markov model (HMM) | Alphabets | 10 | 95.3% (writer-dependent) |
| 81.9% (writer-independent) | |||||
| [15] | Smart bands | K-nearest neighbor (k-NN) with dynamic-time-warping (DTW) | Alphabets | 55 | 89.2% (writer-dependent, k-NN + DTW) |
| CNN | 83.2% (writer-independent, CNN, character level) | ||||
| [14] | Wii Remote Controller | Hidden Markov model (HMM) | Japanese (Hiragana) | 5 | 88.1% |
| [13] | Laser pointer with accelerometer | K-NN | Japanese (Katakana) | 10 | 79.6% |
| - | Proposed | CNN with ensemble structure | Alphanumeric characters | 18 | 91.06% (writer-independent) |
| Epochs | 50 | 100 | 150 | 200 | 300 | 400 | 500 | 600 |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 89.48 | 89.66 | 90.41 | 90.35 | 90.75 | 91.06 | 90.78 | 90.29 |
| Character | Precision | Recall | F1 Score |
|---|---|---|---|
| 0/O | 89.89 | 93.89 | 91.85 |
| 1/I | 91.26 | 92.78 | 92.01 |
| 2 | 88.37 | 84.45 | 86.36 |
| 3 | 92.05 | 93.10 | 92.57 |
| 4/L | 92.86 | 94.41 | 93.63 |
| 5 | 94.12 | 88.89 | 91.43 |
| 6 | 90.80 | 87.78 | 89.27 |
| 7/T | 91.62 | 91.11 | 91.36 |
| 8 | 93.26 | 92.22 | 92.74 |
| 9 | 84.09 | 84.09 | 84.09 |
| A | 82.18 | 92.22 | 86.91 |
| B | 95.40 | 93.26 | 94.32 |
| C | 96.62 | 95.56 | 96.09 |
| D | 85.71 | 80.90 | 83.24 |
| E | 88.54 | 96.59 | 92.39 |
| F | 95.60 | 96.67 | 96.13 |
| G | 96.67 | 97.75 | 97.20 |
| H | 100.00 | 97.75 | 98.86 |
| J | 97.83 | 100.00 | 98.90 |
| K | 100.00 | 97.75 | 98.86 |
| M | 95.65 | 97.78 | 96.70 |
| N | 86.96 | 88.89 | 87.91 |
| P | 85.23 | 85.23 | 85.23 |
| Q | 92.77 | 85.56 | 89.02 |
| R | 83.91 | 82.02 | 82.95 |
| S | 83.87 | 86.67 | 85.25 |
| U | 86.67 | 86.67 | 86.67 |
| V | 96.59 | 94.44 | 95.51 |
| W | 94.05 | 87.78 | 90.80 |
| X | 91.01 | 91.01 | 91.01 |
| Y | 92.86 | 87.64 | 90.17 |
| Z | 78.49 | 81.11 | 79.78 |
| Avg. | 91.09 | 90.81 | 90.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, W.-D.; Matsuoka, A.; Kim, K.-T.; Shin, J. Recognition of Uni-Stroke Characters with Hand Movements in 3D Space Using Convolutional Neural Networks. Sensors 2022, 22, 6113. https://doi.org/10.3390/s22166113
Chang W-D, Matsuoka A, Kim K-T, Shin J. Recognition of Uni-Stroke Characters with Hand Movements in 3D Space Using Convolutional Neural Networks. Sensors. 2022; 22(16):6113. https://doi.org/10.3390/s22166113
Chicago/Turabian StyleChang, Won-Du, Akitaka Matsuoka, Kyeong-Taek Kim, and Jungpil Shin. 2022. "Recognition of Uni-Stroke Characters with Hand Movements in 3D Space Using Convolutional Neural Networks" Sensors 22, no. 16: 6113. https://doi.org/10.3390/s22166113