
A Pipeline for the Implementation and Visualization of Explainable Machine Learning for Medical Imaging Using Radiomics Features


Abstract
:1. Introduction
2. Materials and Methods
- Imaging. Images need to be captured and processed for consistency. Details of this step will vary by imaging modality, but common elements of post-processing include standardizing voxel intensity and co-registering multiple imaging sequences such that subject anatomy exists within the same volume as images from other sequences.
- Segmentation. It may be desirable to limit the analysis of an image to some region of interest (ROI) within the image. Segmentation can be achieved by manually defining a bounded volume within the image with the help of software such as 3D Slicer, or either fully or semi-autonomously extracted using deep learning models e.g., V-nets [35].
- Feature Extraction. Radiomics features are extracted from the ROI and outputted in one of two formats: Tabular data, where each feature has a numeric measurement for each image, and Feature maps, which visualize radiomics measures in the space of the ROI.
- Model Training and Evaluation. Radiomics features are used as predictors of the clinical outcome of interest in a ML model. Any ML model for tabular data can be used here. Common model choices include elastic nets, gradient boosting machines, or support vector machines. Common model training workflows include testing many modeling algorithms, tuning model parameters, and validating predictive performance on new data.
- Model Explanation. The behavior of the predictive model is estimated using an explainer model (i.e., LIME or SHAP).
- Explanation Visualization. Presenting a visualization of the explanation can help summarize the model behavior. Explanations can be shown at the subject-level by plotting the variable importance for all predictors for a given subject. Alternatively, cohort-level explanations can be explored by aggregating all subject-level explanations into a single plot.
3. Application
3.1. Imaging
3.2. Segmentation
3.3. Feature Extraction
3.4. Model Training and Evaluation
3.5. Model Explanation
3.6. Explanation Visualization
- Image. The MRI can be viewed and navigated using included controls for selecting the sequence (T2 or FLAIR), the view (Axial, Sagittal, or Coronal), and the slice (2D slices within a 3D image). The region of interest (ROI) can be toggled on or off and is overlayed on the image. A button to jump to the highest cross-sectional area slice of the ROI is also present.
- Prediction. The probability of IDH mutation from the ML model, expressed as a percentage.
- Feature Map. A visual map of radiomics features in the space of the ROI. A drop-down menu of extracted features can be used to explore maps of all extracted features.
- Subject Feature Importance. A bar plot of the feature importances for the selected subject ordered by magnitude of importance and colored by the subject’s value relative to the rest of the cohort. Negative SHAP values correspond with an associated decrease in IDH mutation probability while positive SHAP values correspond with an increase in probability. Hovering over each bar will show the precise SHAP and feature values for the selected subject, and clicking a given feature bar will change the feature map to that feature and the image to the corresponding MRI sequence (e.g., T2-weighted, FLAIR).
- Model Feature Importance. A bar plot of mean |SHAP| values for each feature in the cohort across all subjects. This plot provides a summary of the overall most important features within the cohort as a reference when viewing importances for a selected subject. Similarly to the subject feature importance plot, clicking a bar will change the displays of the feature map and image to match.
- Model Feature Influence. A scatter plot of the SHAP values by feature value. This plot provides a visualization of how SHAP values change with respect to the underlying feature measure. For linear models, this will appear as a slope, but may be non-linear for more complex models.
4. Results
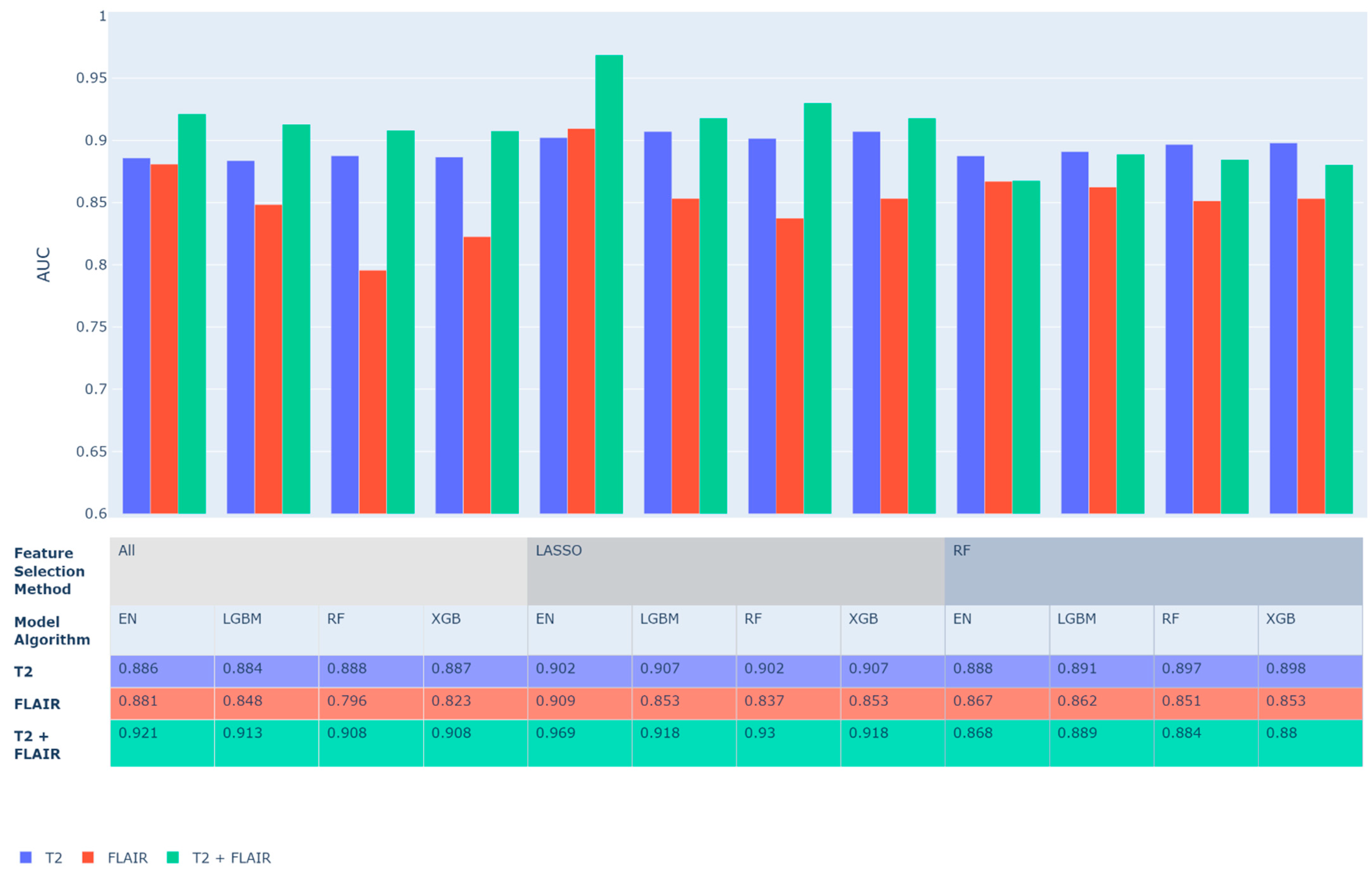
4.1. ML Model Performance
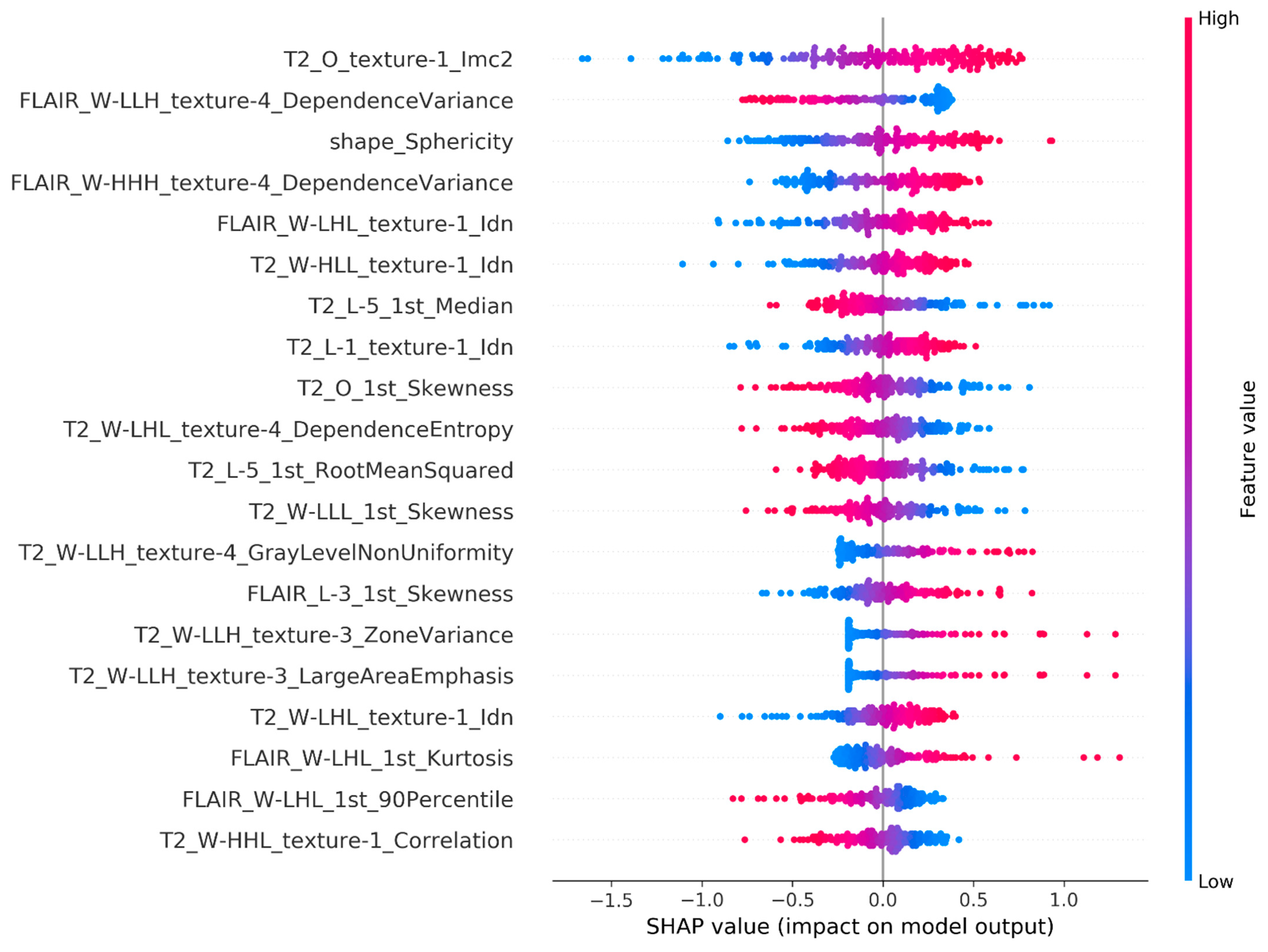
4.2. Model Explanations
4.3. Interactive Visualization
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Search Space |
|---|---|---|
| XGBoost | eta | Uniform (0.001–0.2) |
| gamma | Uniform (0, 1) | |
| max_depth | Integers (3, 10) | |
| min_child_weight | Uniform (1, 10) | |
| subsample | Uniform (0.5, 1) | |
| colsample_by_tree | Uniform (0.5, 1) | |
| lambda | Uniform (0, 0.2) | |
| alpha | Uniform (0, 2) | |
| LightGBM | num_leaves | Integers (30, 1000) |
| learning_rate | Uniform (0.01, 0.2) | |
| min_child_samples | Integers (1, 10) | |
| reg_alpha | Uniform (0.1, 0.2) | |
| reg_lambda | Uniform (0.1, 0.9) | |
| subsample | Uniform (0.5, 1) | |
| Random Forest | max_depth | Integers (3, 20) |
| n_estimators | Integers (100, 1000) | |
| Elastic Net | l1_ratio | Uniform (0, 1) |
References
- Wernick, M.N.; Yang, Y.; Brankov, J.G.; Yourganov, G.; Strother, S.C. Machine Learning in Medical Imaging. IEEE Signal Process Mag. 2010, 27, 25–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McBee, M.P.; Awan, O.A.; Colucci, A.T.; Ghobadi, C.W.; Kadom, N.; Kansagra, A.P.; Auffermann, W.F. Deep Learning in Radiology. Acad. Radiol. 2018, 25, 1472–1480. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust you?” Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Covert, I.; Lundberg, S.M.; Lee, S.-I. Explaining by Removing: A Unified Framework for Model Explanation. J. Mach. Learn. Res. 2021, 22, 209:1–209:90. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.-W.; Newman, S.-F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef]
- Artzi, N.S.; Shilo, S.; Hadar, E.; Rossman, H.; Barbash-Hazan, S.; Ben-Haroush, A.; Balicer, R.D.; Feldman, B.; Wiznitzer, A.; Segal, E. Prediction of gestational diabetes based on nationwide electronic health records. Nat. Med. 2020, 26, 71–76. [Google Scholar] [CrossRef]
- Sarzynska-Wawer, J.; Wawer, A.; Pawlak, A.; Szymanowska, J.; Stefaniak, I.; Jarkiewicz, M.; Okruszek, L. Detecting formal thought disorder by deep contextualized word representations. Psychiatry Res. 2021, 304, 114135. [Google Scholar] [CrossRef]
- Rajaraman, S.; Candemir, S.; Kim, I.; Thoma, G.; Antani, S. Visualization and interpretation of convolutional neural network predictions in detecting pneumonia in pediatric chest radiographs. Appl. Sci. 2018, 8, 1715. [Google Scholar] [CrossRef] [Green Version]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Lambin, P.; Rios-Velazquez, E.; Leijenaar, R.; Carvalho, S.; van Stiphout, R.G.P.M.; Granton, P.; Zegers, C.M.L.; Gillies, R.; Boellard, R.; Dekker, A.; et al. Radiomics: Extracting more information from medical images using advanced feature analysis. Eur. J. Cancer 2012, 48, 441–446. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Forghani, R.; Savadjiev, P.; Chatterjee, A.; Muthukrishnan, N.; Reinhold, C.; Forghani, B. Radiomics and artificial intelligence for biomarker and prediction model development in oncology. Comput. Struct. Biotechnol. J. 2019, 17, 995. [Google Scholar] [CrossRef] [PubMed]
- Park, Y.W.; Oh, J.; You, S.C.; Han, K.; Ahn, S.S.; Choi, Y.S.; Chang, J.H.; Kim, S.H.; Lee, S.-K. Radiomics and machine learning may accurately predict the grade and histological subtype in meningiomas using conventional and diffusion tensor imaging. Eur. Radiol. 2019, 29, 4068–4076. [Google Scholar] [CrossRef]
- Rahmim, A.; Huang, P.; Shenkov, N.; Fotouhi, S.; Davoodi-Bojd, E.; Lu, L.; Mari, Z.; Soltanian-Zadeh, H.; Sossi, V. Improved prediction of outcome in Parkinson’s disease using radiomics analysis of longitudinal DAT SPECT images. NeuroImage Clin. 2017, 16, 539–544. [Google Scholar] [CrossRef]
- Won, S.Y.; Park, Y.W.; Park, M.; Ahn, S.S.; Kim, J.; Lee, S.K. Quality reporting of radiomics analysis in mild cognitive impairment and Alzheimer’s disease: A roadmap for moving forward. Korean J. Radiol. 2020, 21, 1345. [Google Scholar] [CrossRef]
- Gore, S.; Chougule, T.; Jagtap, J.; Saini, J.; Ingalhalikar, M. A review of radiomics and deep predictive modeling in glioma characterization. Acad. Radiol. 2021, 28, 1599–1621. [Google Scholar] [CrossRef]
- Meyes, R.; de Puiseau, C.W.; Posada-Moreno, A.; Meisen, T. Under the hood of neural networks: Characterizing learned representations by functional neuron populations and network ablations. arXiv 2020, arXiv:2004.01254. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. Int. Conf. Mach. Learn. PMLR 2017, 70, 3319–3328. [Google Scholar]
- Hallinan, J.T.P.D.; Zhu, L.; Yang, K.; Makmur, A.; Algazwi, D.A.R.; Thian, Y.L.; Lau, S.; Choo, Y.S.; Eide, S.E.; Yap, Q.V.; et al. Deep learning model for automated detection and classification of central canal, lateral recess, and neural foraminal stenosis at lumbar spine MRI. Radiology 2021, 300, 130–138. [Google Scholar] [CrossRef]
- de Souza, L.A., Jr.; Mendel, R.; Strasser, S.; Ebigbo, A.; Probst, A.; Messmann, H.; Papa, J.P.; Palm, C. Convolutional Neural Networks for the evaluation of cancer in Barrett’s esophagus: Explainable AI to lighten up the black-box. Comput. Biol. Med. 2021, 135, 104578. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Singh, A.; Sengupta, S.; Lakshminarayanan, V. Explainable deep learning models in medical image analysis. J. Imaging 2020, 6, 52. [Google Scholar] [CrossRef] [PubMed]
- van der Velden, B.H.; Janse, M.H.; Ragusi, M.A.; Loo, C.E.; Gilhuijs, K.G. Volumetric breast density estimation on MRI using explainable deep learning regression. Sci. Rep. 2020, 10, 18095. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.; Scott, J.; Chaudhury, B.; Hall, L.; Goldgof, D.; Yeom, K.; Iv, M.; Ou, Y.; Kalpathy-Cramer, J.; Napel, S.; et al. Radiomics in brain tumor: Image assessment, quantitative feature descriptors, and machine-learning approaches. Am. J. Neuroradiol. 2018, 39, 208–216. [Google Scholar] [CrossRef] [PubMed]
- Gillies, R.J.; Kinahan, P.E.; Hricak, H. Radiomics: Images are more than pictures, they are data. Radiology 2016, 278, 563–577. [Google Scholar] [CrossRef] [Green Version]
- Kumarakulasinghe, N.B.; Blomberg, T.; Liu, J.; Leao, A.S.; Papapetrou, P. Evaluating Local Interpretable Model-Agnostic Explanations on Clinical Machine Learning Classification Models. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020. [Google Scholar]
- van Doorn, W.P.; Stassen, P.M.; Borggreve, H.F.; Schalkwijk, M.J.; Stoffers, J.; Bekers, O.; Meex, S.J. A comparison of machine learning models versus clinical evaluation for mortality prediction in patients with sepsis. PLoS ONE 2021, 16, e0245157. [Google Scholar] [CrossRef]
- Parmar, C.; Grossmann, P.; Bussink, J.; Lambin, P.; Aerts, H.J.W.L. Machine learning methods for quantitative radiomic biomarkers. Sci. Rep. 2015, 5, 13087. [Google Scholar] [CrossRef]
- Krajnc, D.; Papp, L.; Nakuz, T.S.; Magometschnigg, H.F.; Grahovac, M.; Spielvogel, C.P.; Ecsedi, B.; Bago-Horvath, Z.; Haug, A.; Karanikas, G.; et al. Breast tumor characterization using [18F] FDG-PET/CT imaging combined with data preprocessing and radiomics. Cancers 2021, 13, 1249. [Google Scholar] [CrossRef]
- Osman, A.F. A multi-parametric MRI-based radiomics signature and a practical ML model for stratifying glioblastoma patients based on survival toward precision oncology. Front. Comput. Neurosci. 2019, 13, 58. [Google Scholar] [CrossRef] [Green Version]
- Ohgaki, H. Epidemiology of brain tumors. Cancer Epidemiol. 2009, 472, 323–342. [Google Scholar]
- Dang, L.; Jin, S.; Su, S.M. IDH mutations in glioma and acute myeloid leukemia. Trends Mol. Med. 2010, 16, 387–397. [Google Scholar] [CrossRef] [PubMed]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Scarpace, L.; Mikkelsen, T.; Cha, S.; Rao, S.; Tekchandani, S.; Gutman, D.; Saltz, J.H.; Erickson, B.J.; Pedano, N.; Flanders, A.E.; et al. Radiology data from the cancer genome atlas glioblastoma multiforme [TCGA-GBM] collection. Cancer Imaging Arch. 2016, 11, 1. [Google Scholar]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The Cancer Imaging Archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef] [Green Version]
- Jenkinson, M.; Beckmann, C.F.; Behrens, T.E.; Woolrich, M.W.; Smith, S.M. Fsl. Neuroimage 2012, 62, 782–790. [Google Scholar] [CrossRef] [Green Version]
- Shinohara, R.T.; Sweeney, E.M.; Goldsmith, J.; Shiee, N.; Mateen, F.J.; Calabresi, P.; Jarso, S.; Pham, D.L.; Reich, D.S.; Crainiceanu, C.M. Statistical normalization techniques for magnetic resonance imaging. NeuroImage Clin. 2014, 6, 9–19. [Google Scholar] [CrossRef] [Green Version]
- van Griethuysen, J.J.M.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.H.; Fillion-Robin, J.-C.; Pieper, S.; Aerts, H.J.W.L. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef] [Green Version]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 3149–3157. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Bergstra, J.; Komer, B.; Eliasmith, C.; Yamins, D.; Cox, D. Hyperopt: A python library for model selection and hyperparameter optimization. Comput. Sci. Discov. 2015, 8, 014008. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Hossain, S.; Calloway, C.; Lippa, D.; Niederhut, D.; Shupe, D. Visualization of Bioinformatics Data with Dash Bio. In Proceedings of the 18th Python in Science Conference, Austin, TX, USA, 8–14 July 2019. [Google Scholar]
- Patel, S.H.; Poisson, L.M.; Brat, D.J.; Zhou, Y.; Cooper, L.; Snuderl, M.; Thomas, C.; Franceschi, A.M.; Griffith, B.; Flanders, A.E.; et al. T2–FLAIR Mismatch, an Imaging Biomarker for IDH and 1p/19q Status in Lower-grade Gliomas: A TCGA/TCIA ProjectT2–FLAIR Mismatch Predicts Low-Grade Glioma Molecular Class. Clin. Cancer Res. 2017, 23, 6078–6085. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, S.; Ravikumar, V.; Warner, E.; Patel, S.; Bakas, S.; Rao, A.; Jain, R. Quantifying T2-FLAIR Mismatch Using Geographically Weighted Regression and Predicting Molecular Status in Lower-Grade Gliomas. Am. J. Neuroradiol. 2022, 43, 33–39. [Google Scholar] [CrossRef]
- Bernatz, S.; Zhdanovich, Y.; Ackermann, J.; Koch, I.; Wild, P.J.; dos Santos, D.P.; Vogl, T.J.; Kaltenbach, B.; Rosbach, N. Impact of rescanning and repositioning on radiomic features employing a multi-object phantom in magnetic resonance imaging. Sci. Rep. 2021, 11, 14248. [Google Scholar] [CrossRef]
- Nishikawa, R.M.; Bae, K.T. Importance of better human-computer interaction in the era of deep learning: Mammography computer-aided diagnosis as a use case. J. Am. Coll. Radiol. 2018, 15, 49–52. [Google Scholar] [CrossRef]





| [Image]_[Filter]_[Feature Group]_[Feature Name] | ||
|---|---|---|
| Position | Abbreviation | Description |
| Image | T2 | T2-weighted MRI. The sequence weighting highlights differences in the T2 relaxation time of tissues. |
| FLAIR | Fluid-Attenuated Inversion Recovery is a special inversion recovery sequence with a long inversion time. This removes signal from the cerebrospinal fluid in the resulting images 1. Brain tissue on FLAIR images appears similar to T2 weighted images with grey matter brighter than white matter but CSF is dark instead of bright. | |
| Filter | O | Original image. No additional filters are used to extract these features. |
| W | Wavelet filtering yields 8 decompositions per level (all possible combinations of applying either a High (H) or a Low (L) pass filter in each of the three dimensions. Wavelet feature names are accompanied by a 3-letter sequence representing these filters. | |
| L | Laplacian of Gaussian filter, edge enhancement filter. Emphasizes areas of gray level change, where sigma (1, 3, or 5) defines how coarse the emphasized texture should be. A low sigma emphasis on fine textures (change over a short distance), where a high sigma value emphasizes coarse textures (gray level change over a large distance). | |
| Feature Group | 1st | First-order statistics describe the distribution of voxel intensities within the image region. (19 features) |
| texture1 * | Gray level co-occurrence matrix (GLCM). (22 features) | |
| texture2 * | Gray level size zone matrix (GLSZM). (16 features) | |
| texture3 * | Gray level run length matrix (GLRLM). (16 features) | |
| texture4 * | Gray level dependence matrix (GLDM). (14 features) | |
| shape | 3-dimensional shapes. (10 features) | |
| Feature Name | Measured feature from feature group. See pyRadiomics documentation for feature descriptions. | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Severn, C.; Suresh, K.; Görg, C.; Choi, Y.S.; Jain, R.; Ghosh, D. A Pipeline for the Implementation and Visualization of Explainable Machine Learning for Medical Imaging Using Radiomics Features. Sensors 2022, 22, 5205. https://doi.org/10.3390/s22145205
Severn C, Suresh K, Görg C, Choi YS, Jain R, Ghosh D. A Pipeline for the Implementation and Visualization of Explainable Machine Learning for Medical Imaging Using Radiomics Features. Sensors. 2022; 22(14):5205. https://doi.org/10.3390/s22145205
Chicago/Turabian StyleSevern, Cameron, Krithika Suresh, Carsten Görg, Yoon Seong Choi, Rajan Jain, and Debashis Ghosh. 2022. "A Pipeline for the Implementation and Visualization of Explainable Machine Learning for Medical Imaging Using Radiomics Features" Sensors 22, no. 14: 5205. https://doi.org/10.3390/s22145205