3.1. From OSM to LiDAR
Challenges. The biggest challenge when attempting to solve this task is to bridge the modality gap between unsorted LiDAR point clouds and RGB images from OSM. The most common feature between these two representations is the fact that they both contain geometric information on the shapes of the structures that form the surrounding environment of the vehicle, namely roads, buildings, and sometimes trees. On the other hand, the biggest difference is how both formats represent the data: point clouds are unsorted arrays containing the location information, in a predefined frame, of any point that was reached by the LiDAR sensor, whereas OSM visual maps are top-view RGB images containing rough shapes and class data.
The typical first step when attempting to localize LiDAR point clouds that were collected by a vehicle in a 2D aerial map is to start with a BEV projection, which displays the point cloud data from a top view, giving us a more similar visual appearance to the 2D top-view maps, and thus a first step toward breaching the cross-modality. Unfortunately, this step alone is not enough to accurately localize the vehicle in OSM, mainly due to the sparsity of the BEV image and the effects of occlusion of the point cloud data. This is why we need to use the data provided by OSM, namely the roads and buildings, to produce a simulated LiDAR image, which has similar characteristics as the input LiDAR BEV image.
Road and Building Masks. Two of the most clearly labeled classes of objects in OSM are buildings and roads. This information is valuable because those are the classes that are the most present in the point clouds produced by LiDAR sensors when traveling in an urban environment.
By using color segmentation (mostly solid white for roads and a specific shade of grey for buildings), combined with morphological transformations such as dilation and erosion, we are able to generate buildings and road masks that we can later use to generate simulated LiDAR top-view images. When extracting the roads, we use the standard OSM layer style. However, for the buildings, we use the public transport layer, to avoid noise resulting from building numbers and business names. The morphological transformations are mostly applied to the road mask, in order to close holes caused by overlaid street names on the images, with a kernel size (5,5) for the dilation and (3,3) for the erosion. It is possible generate our own layers with styles that do not include any overlaid text, but that is out of the scope of this work, and we would rather use already available data. The resulting roads and buildings masks of an area in OSM are shown in
Figure 3.
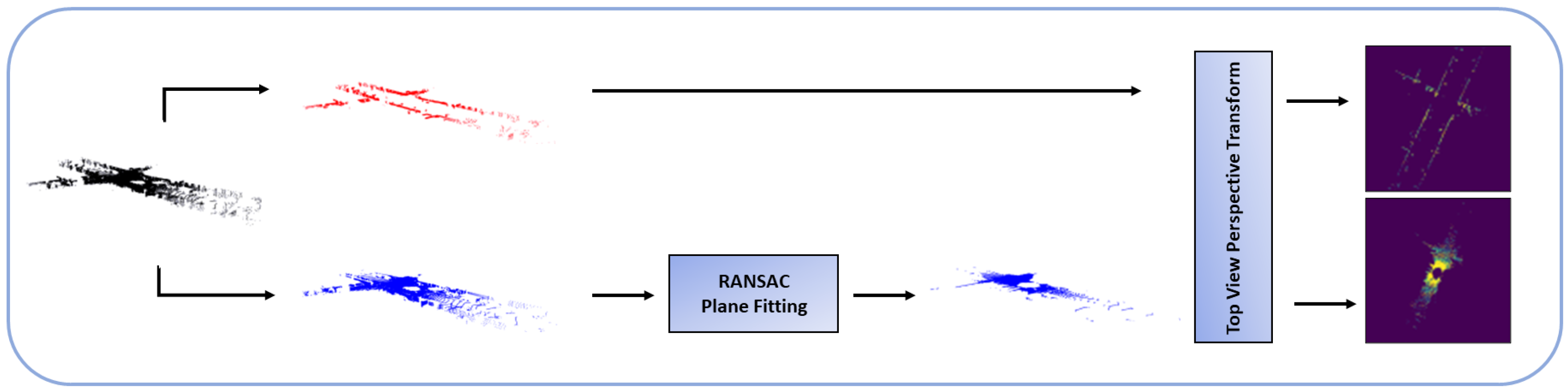
Simulated and Real LiDAR images. Before attempting to localize the vehicle, our method first starts by generating two pairs of images: a pair of road top-view point cloud images, and a pair of building edges, also from the top view. Both pairs share an important characteristic: they contain an image generated by using the true LiDAR input point cloud, and a simulated LiDAR image generated by using either the road or building masks, previously extracted from OSM. Next, we will explain how the true LiDAR images are generated, in what we call the LiDAR processing module (LPM), followed by how the simulated LiDAR images are generated, in the map processing module (MPM).
In the LPM, we define
, the frame attached to the LiDAR sensor, with the
axis pointing upward. The LiDAR sensor itself is fixed to the roof of the car, which makes the
and ground planes parallel to each other. We first start by splitting our input LiDAR point cloud in two by using the height values
of each point: a top section, meant to capture the edges of the buildings reached by the LiDAR sensor, and a bottom section, which after being filtered by using RANSAC plane fitting [
38], represents the road on top of which the vehicle is traveling. The two point clouds are then projected onto the
plane to generate two BEV LiDAR images. The LPM can be seen in
Figure 4.
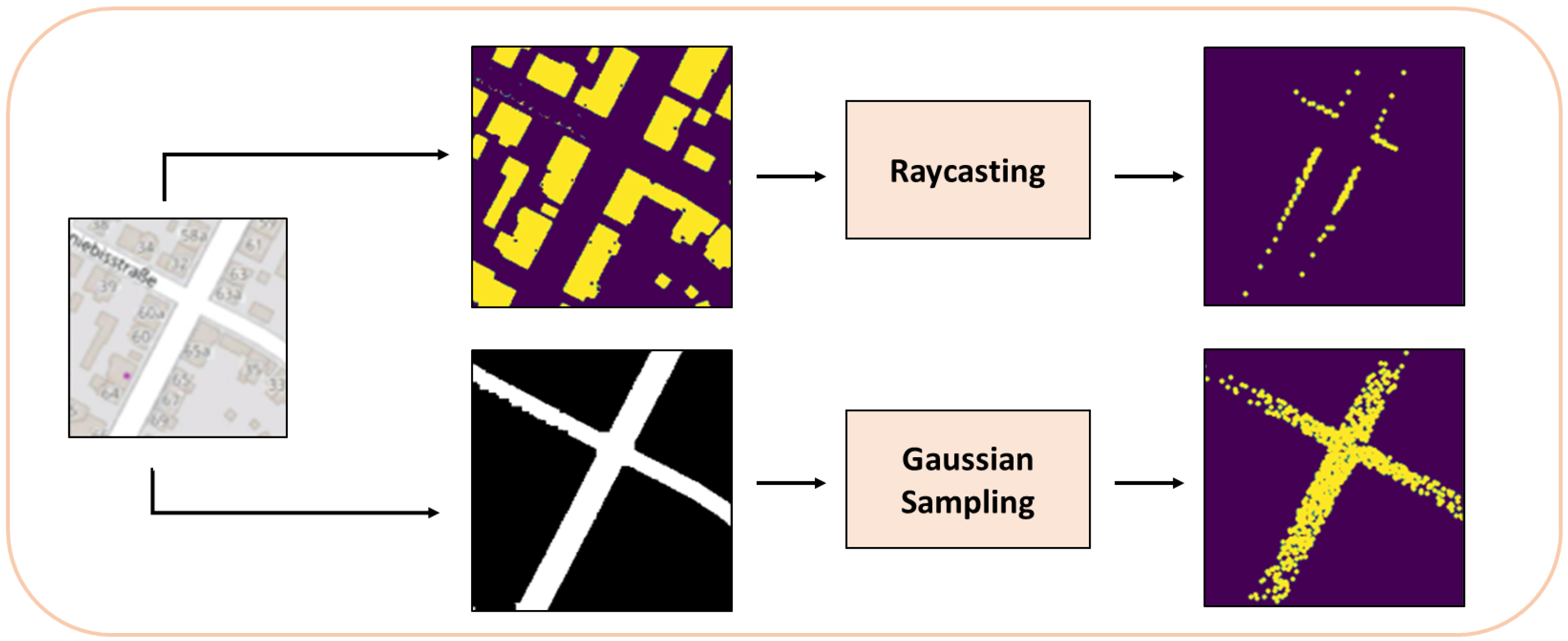
In the MPM, for the simulated road point cloud, we apply rejection sampling on the road mask with a Gaussian proposal, centered on the supposed vehicle location in OSM (according to the initial guess of the starting position or the previous frame results), and limited to a predefined region of interest. The sampling here is done for two main reasons: first, to simulate the point distribution returned by the LiDAR sensor, which is typically denser around the center of the scan, and becomes sparser the more we move away from the sensor, and second to improve the speed processing, because using all non-zero pixel values in the later calculations would result in a significant slow-down of the whole method.
For the simulated top section of the point cloud, we proceed to use raycasting on the building mask at the same position and region of interest used to generate the simulated road point cloud. Raycasting is a common method used to simulate LiDAR point clouds in autonomous driving cars simulators such as Carla [
39]. By first detecting the obstacles in the surrounding environment (which are shown in the building mask in our case), we can use 2D raycasting and simulate a beam of light that stops when it hits an obstacle. By doing that in a 360-degree fashion, we are able to generate simulated LiDAR images. An example of this approach can be seen in
Figure 5, and its results are compared with the images from the LiDAR sensor in
Figure 6. The MPM is illustrated in
Figure 7.
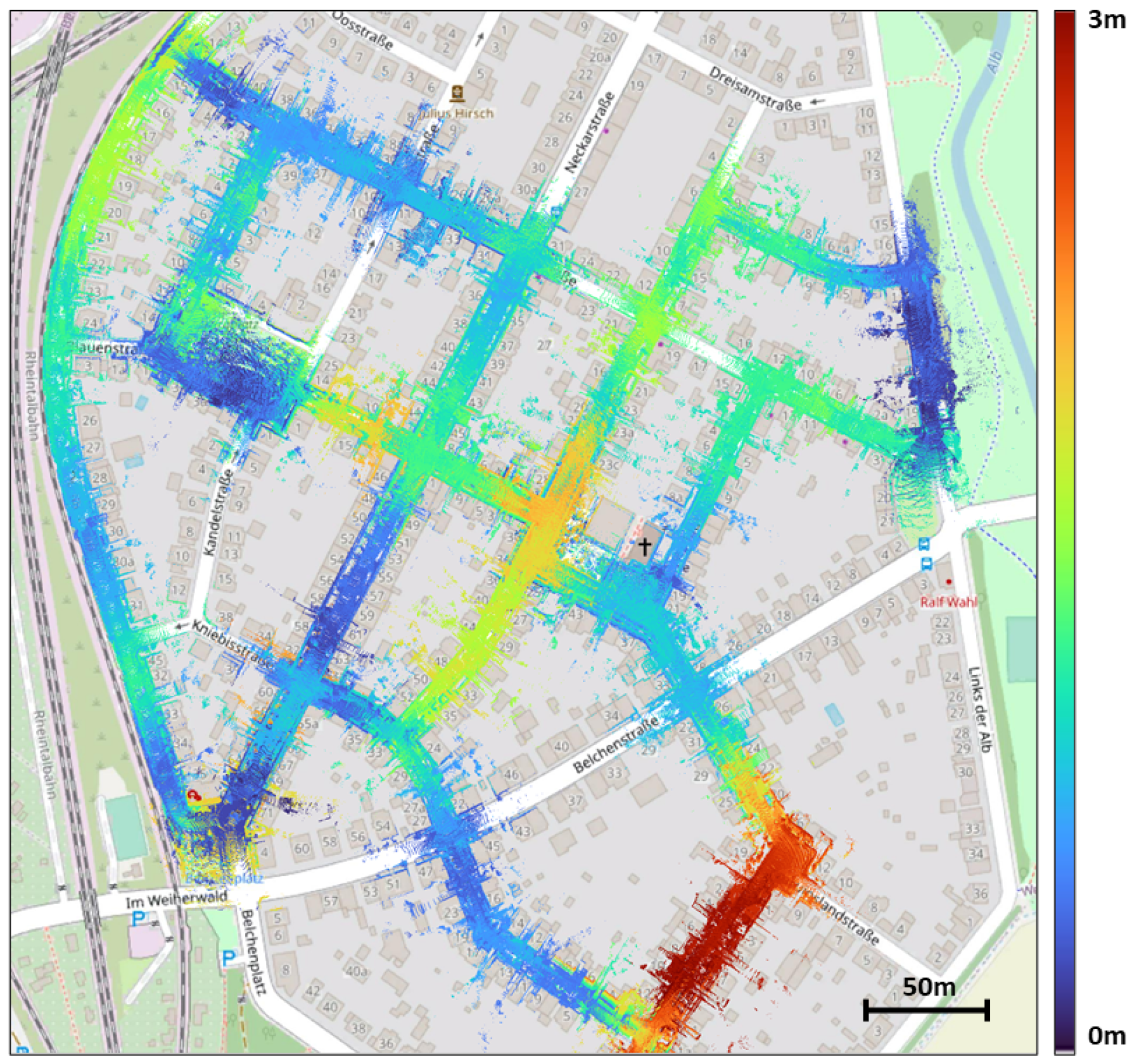
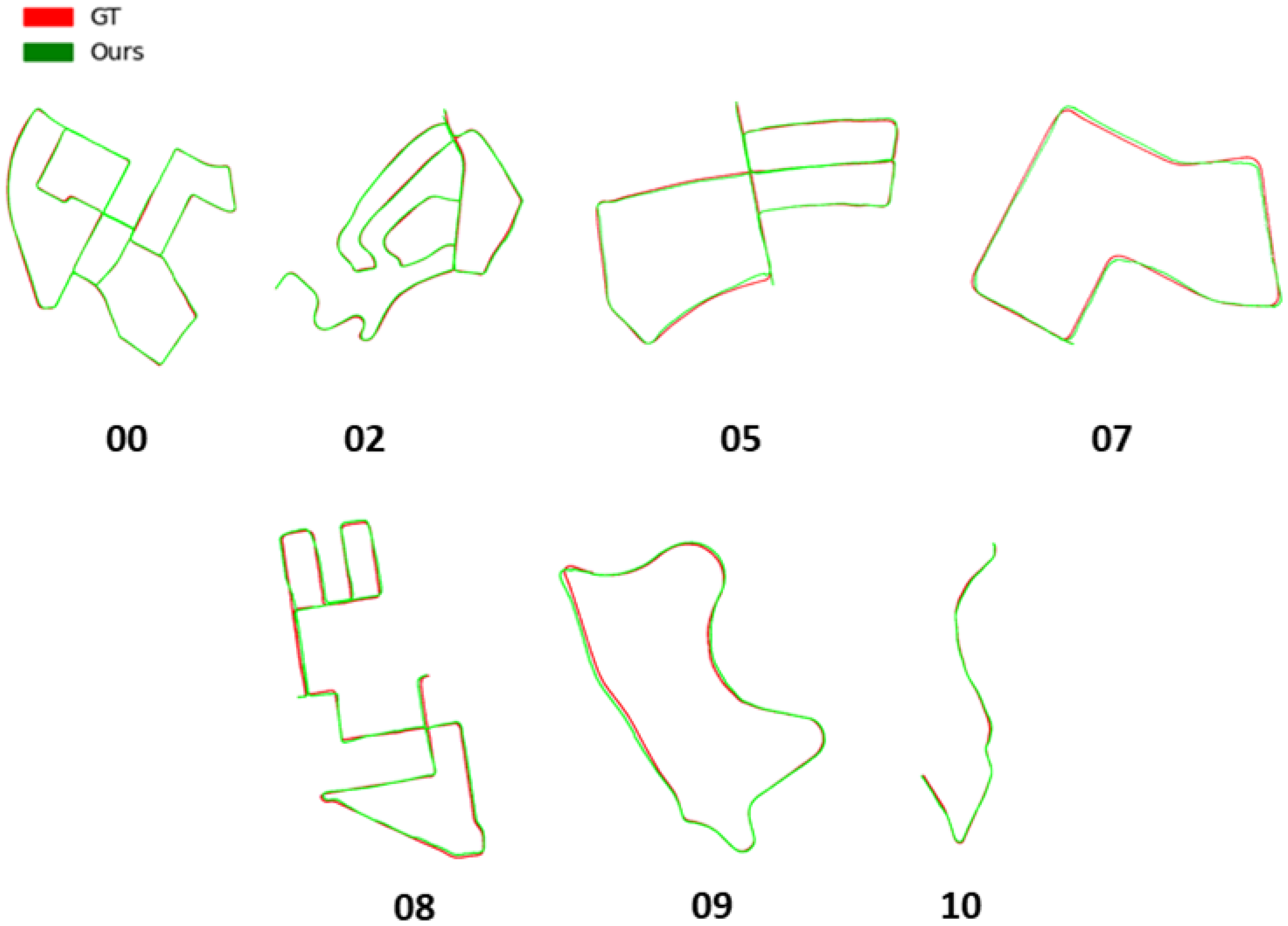
Simulated LiDAR and OSM accuracy analysis. In our case, providing an accurate localization result depends heavily on the accuracy of the map used. We start by building a 3D point cloud road map and a building map by using the ground truth odometry and segmentation provided by KITTI (note: this is only used here for visualization purposes and not during the rest of the manuscript), which we then proceed to project onto an image by using the previously discussed BEV projection. Following that, we also build a simulated LiDAR road map and building map from OSM by using color segmentatin and raycasting. By overlaying both maps from both modalities, we can see in
Figure 8 that the maps generated by using OSM and raycasting are pretty accurate and match the maps created by using the LiDAR sensor. In come cases, occlusion of some buildings or the misrepresentation of road width on OSM can cause some mismatches; however, in the majority of cases, the shapes represented in both maps match.
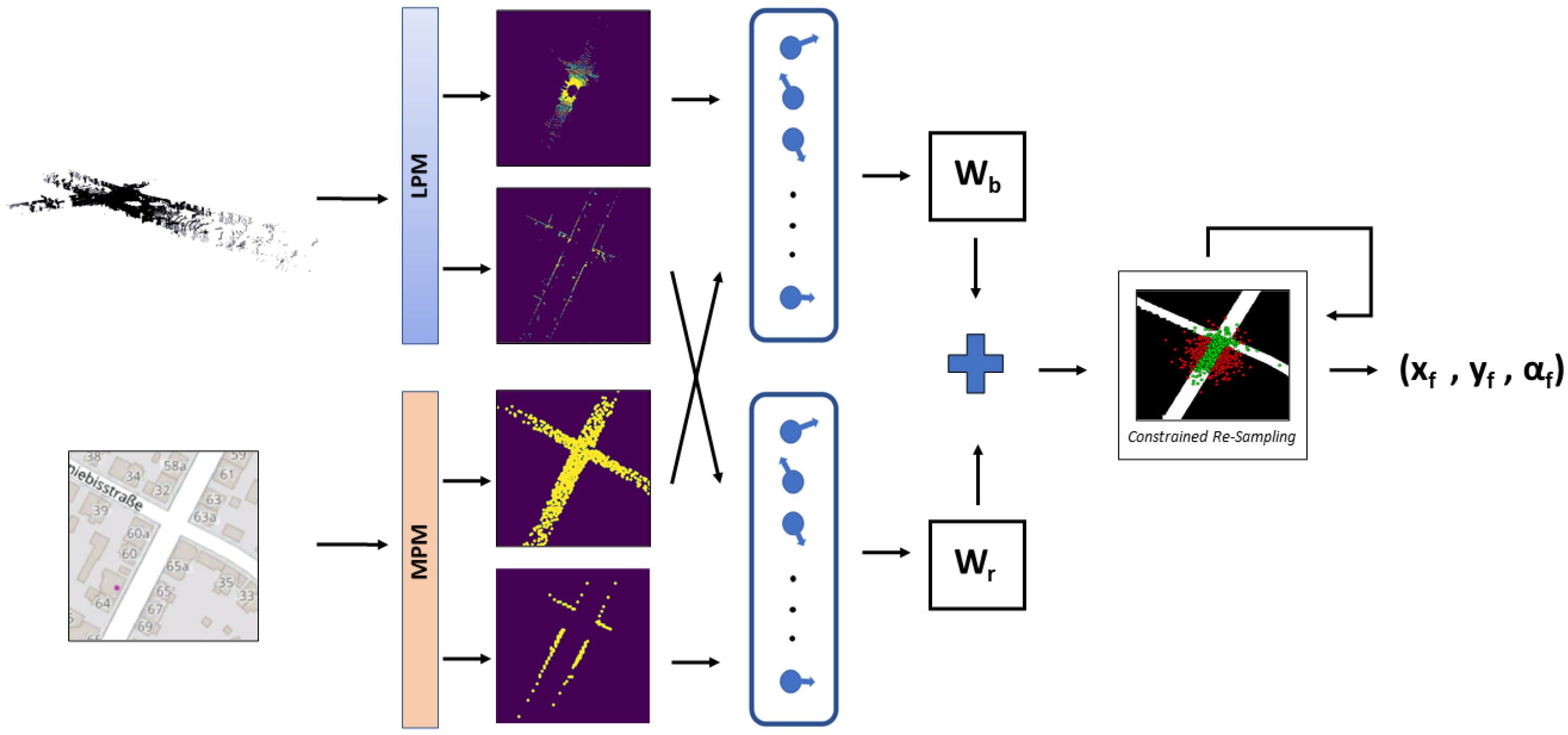
3.2. Constrained Particle Filter
Problem Formulation. In order to localize our vehicle’s LiDAR in OSM, we use a constrained particle filter. In our configuration, we suppose that we have a guess of the initial pose of the vehicle in OSM (thanks to an external place recognition solution, or a GPS signal that was eventually lost) and each particle corresponds to a hypothetical position
. The scale of the map is approximated by using the map size and its corner coordinates. After each LiDAR frame, we rely on our ICP based motion model to predict the particle positions by using two voxel-downsampled 3D LiDAR point clouds, and then update the particles weights by using results from the observation model. Low variance resampling [
40] is triggered or not depending on the effective size of the particles [
41], and finally the road check and subsequent constrained resampling is used if needed.
Motion Model. Our motion model relies on an ICP-based LiDAR odometry. We approximate the transformation between two subsequent LiDAR point clouds by using the Point-to-Point ICP algorithm [
42]. We do not assume access to the vehicle controls, and only use the ICP output to update the particles positions.
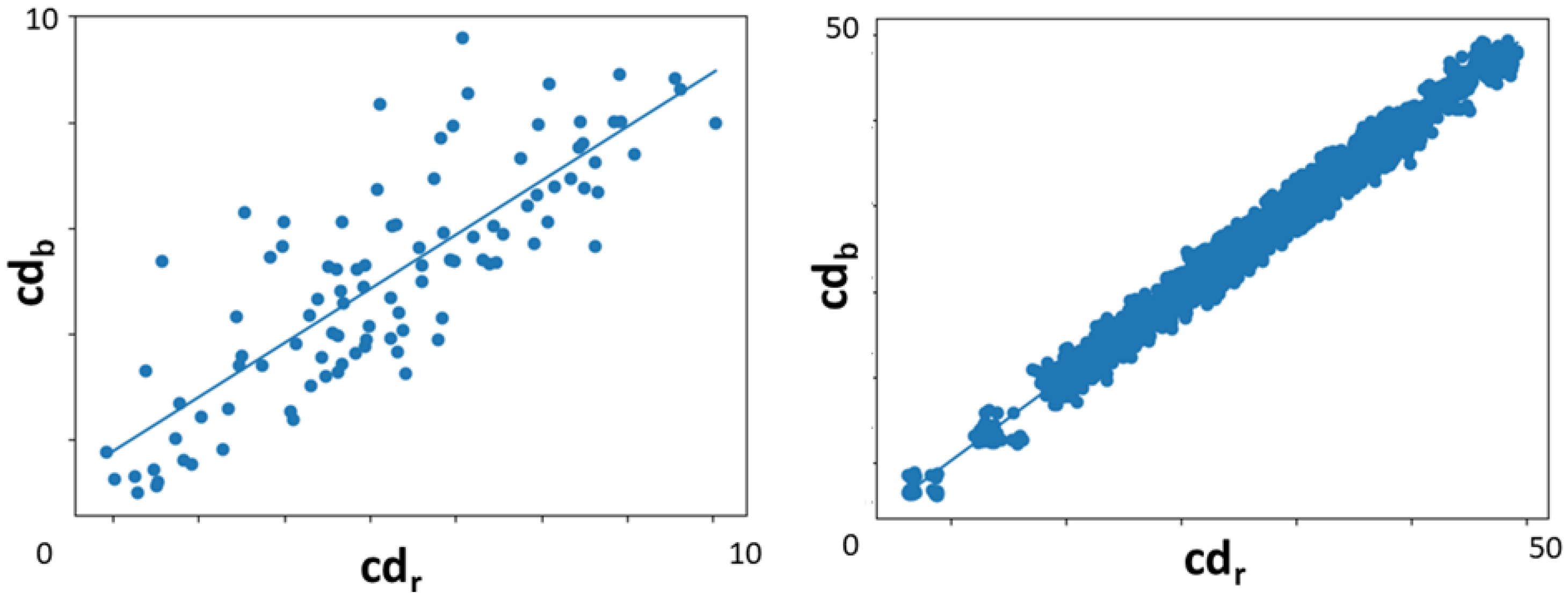
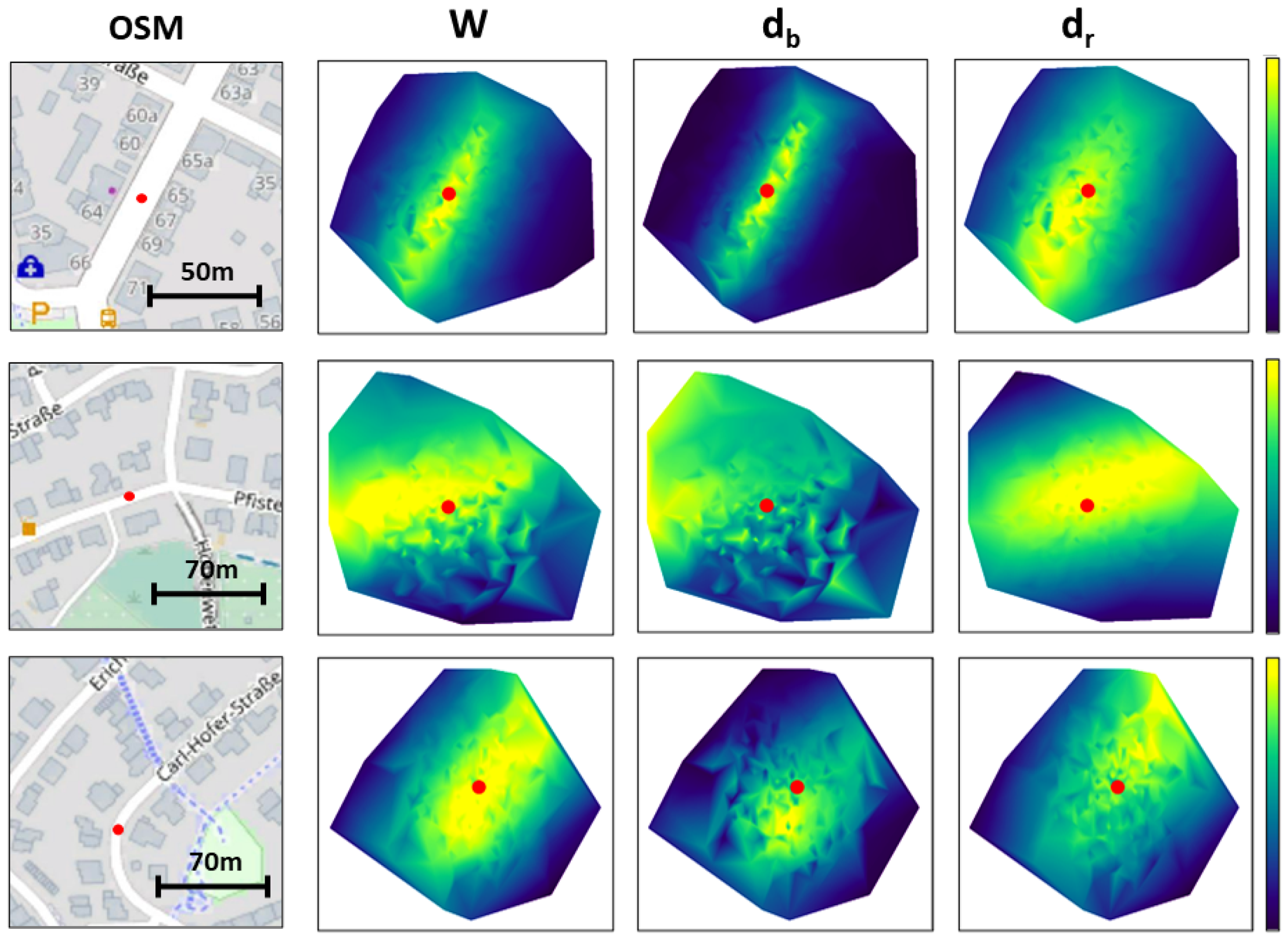
Observation Model. Our observation model is the pre-processed input LiDAR point cloud, so we can match it to our simulated LiDAR images. As it was explained in the previous section, for each frame, we have access to four top-view images, two resulting from the LiDAR point cloud and two resulting from the simulated LiDAR, containing the road and the building edges in both modalities. Inspired by [
20], we propose to calculate the weights of our particles based on combining the reciprocal chamfer distance between the pixel locations of the point clouds in each pair of images. The two terms forming the cost function are weighted by the reciprocal of the standard deviation of all the distances calculated above, as a form of uncertainty constraint on the weight’s distribution.
In summary, if is the chamfer distance, N the number of particles, and the list of all pixel positions of the points in the road and buildings LiDAR point clouds top-view images respectively, transformed according to the ith particle, and and the list of all pixel positions of the points in the top-view images of the simulated point clouds. We define and , and calculate and , which are the standard deviations of and , respectively.
Finally, the weight of each
ith particle can be defined as:
We choose to use the reciprocal of the chamfer distance in order to emphasize strong particle candidates that align the most with the map. The inclusion of the standard deviation terms is there to favor the data source that produce the most “concentrated” set of particles, which can be interpreted as being less uncertain about the final position. We attempted to calculate weights by using instead of , but found the results to be very sensitive to the value of the parameter . We have also tested the use of a joint-probability formulation rather than the summed one, but saw no major difference in the final results.
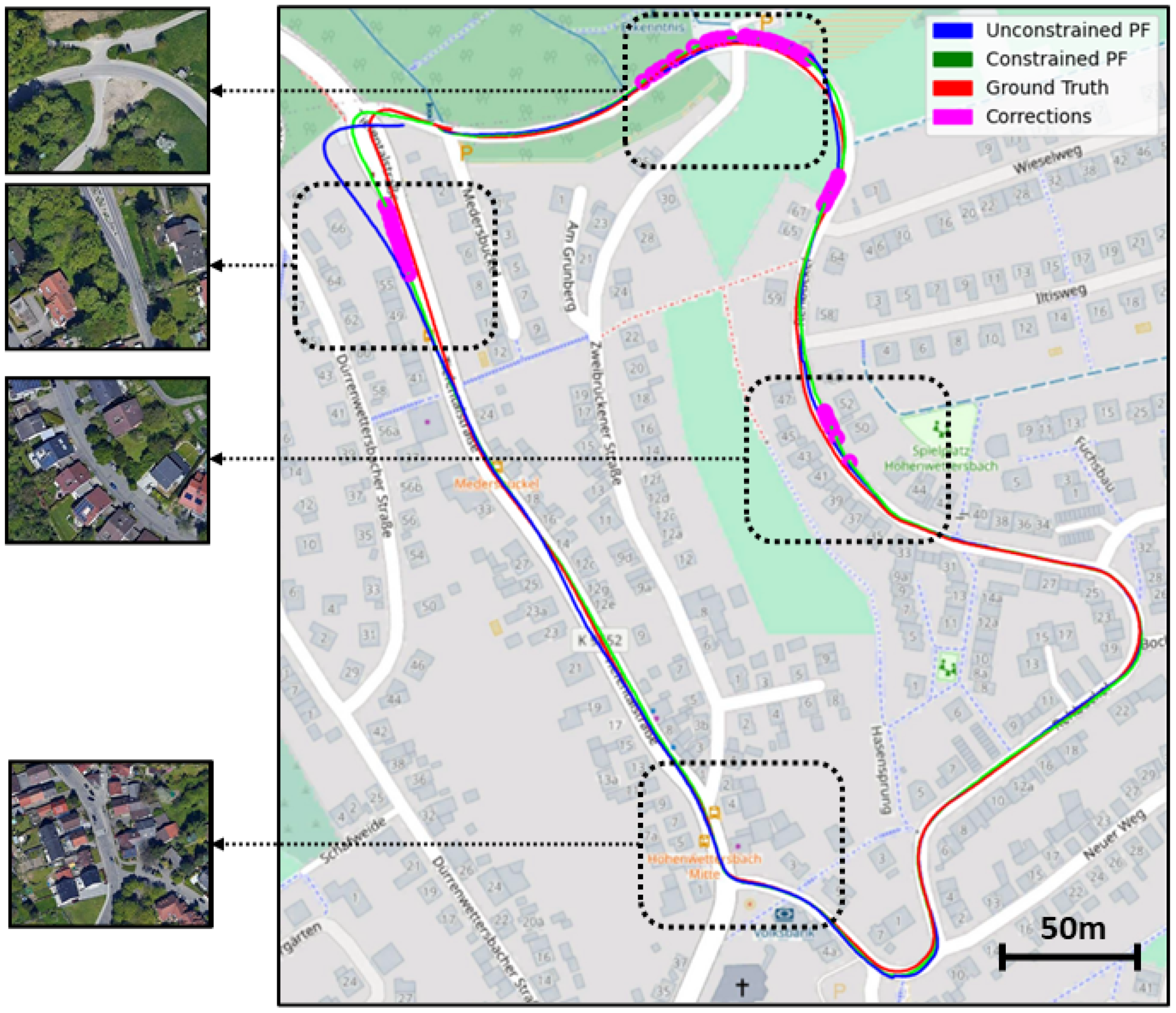
Constrained resampling. When trying to approximate the correct position of the vehicle, we try to enforce a simple constraint: the vehicle position should always be on the road. This is done in the particle filter through a resampling procedure, inspired by the methods proposed in [
36,
37], that aims to gently push the final weighted position toward the correct region (in our case, the road). This is done by enforcing the constraint on the weighted mean value of the particles, rather than the particles themselves.
After updating the weights of the particles, we check to see if the weighted mean vehicle position resulting from the particle filter is on the road. If it is the case, no intervention is needed. Otherwise, we discard one of the particles outside of the road and resample one from the most highly weighted area on the road. Typically, only a few resampling steps (less than 50) are needed to validate our road check. If we reach the maximum resampling iteration, we relax the sampling criteria for the next step of the particle filter. For speed purposes, when resampling good particles to replace bad ones, we use inductive sampling: meaning we resample from the particles that are already available to us. A global view of our constrained particle filter method for localization of LiDAR point clouds in OSM is presented in Algorithm 1 and
Figure 2.
| Algorithm 1 LiDAR-OSM Constrained Particle Filter Localization. |
| Input: Point cloud P, OSM Region of Interest J. |
| Output: Vehicle Position |
| |
|
|
|
|
| Ifthen |
|
| |
| // Split the particles on and off the road |
|
| |
| // Constrained Resampling |
| whileand |
|
|
|
|
|
| |
| return |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}