1. Introduction
In the weaving process of fabrics, due to the influence of the technological process, weaving equipment, or weaving environment, it is inevitable to cause various defects on the surface of fabrics. The appearance of defects will not only affect the appearance of the fabric, but also reduce the commercial value of the fabric. Relevant reports [
1] show that if there are obvious defects in the surface of the fabric, its price will be reduced by more than 50%; therefore, defect detection is an important step in fabric quality control; however, at present, most textile enterprises still rely on manual cloth inspection, which not only has the shortcomings of low efficiency and high cost, but is also prone to false detection or missed inspection after visual fatigue. With the advancement of digitization and intelligence, the development of fabric defect detection towards automation is an inevitable trend.
The automatic detection of fabric defects mainly includes two steps: firstly, images of the fabric surface are captured by using an industrial camera, and then the existence and type of defect in the image are judged by designing a recognition algorithm. The detection methods based on computer vision have the advantages of high precision, high efficiency, and strong stability; therefore, the automatic detection of fabric defects by machine vision instead of human vision has become a research hotspot; however, as shown in
Figure 1, the main characteristics of the defects in the fabric are as follows: (1) rich types and different shapes and (2) low visual significance, which makes the identification task very challenging.
Efficient defect detection methods can greatly reduce labor consumption, so many methods have been proposed. The existing work on fabric defect detection can be roughly divided into four categories: (1) statistical-based, (2) spectral-based, (3) model-based, and (4) learning-based. The statistical methods [
2,
3] employ various statistical properties of texture and defects to estimate defects; however, the diversity of fabric texture and defect shape seriously affects the detection accuracy of such methods. In particular, it is very expensive to design different statistical indicators for defects of different complexity; therefore, statistical methods have great limitations in actual fabric defect detection. The spectral methods [
4,
5] convert the image in the spatial domain to the frequency domain and achieve the detection of defects in the fabric by using the strong periodicity in the fabric image; however, such methods do not work well when the contrast between defect areas and defect-free areas is low or when the defects are small. The model-based methods [
6,
7] represent fabric texture as a stochastic process and assume that texture images can be viewed as samples generated by stochastic processes in the image space. Defect detection is treated as a hypothesis testing problem with statistics from the model. Such methods usually have large computational overhead, and thus cannot meet the real-time requirements of detection; however, if a model-based algorithm is introduced into defect detection of fabric, a specific model for each texture is required, and the cost of each model is prohibitive.
Recently, significant progress [
8,
9,
10,
11] has been made on image analysis by moving low feature-based algorithms to deep-learning-based end-to-end frameworks. Compared with other kinds of methods, the deep-learning-based methods weaken the influence of feature engineering on recognition accuracy, adopt supervised or semi-supervised learning to make the network automatically extract the most representative features, simplify the design difficulty of the algorithm, automatically learn the salient features of the image, and complete the recognition task. Many researchers [
12,
13] use deep learning technology to solve the problem of fabric defect detection. Compared with earlier combined methods, deep-learning-based methods can extract higher-level features of images. According to the different learning manner, it can be divided into supervised learning and unsupervised learning. In the unsupervised manner, model learning is guided through designed pre-tasks. The general steps are: first reconstruct the fabric image, then compute the residual between the reconstructed image and the original image, and finally determine the location and category of the defect by identifying the residual image. Convolutional autoencoders (CAE) [
14] and generative adversarial networks (GAN) [
15] are the commonly used reconstruction models. Li et al. [
16] first introduced deep learning technology into field of fabric defect detection by proposed an autoencoder model. Even with some success, such indirect methods are difficult to identify for many non-obvious defects.
In fact, fabric defect detection can be regarded as an object detection task, where the object is the defect. Compared with unsupervised methods, object detection can obtain more sufficient defect information, which is convenient for subsequent visual display and equality in judgment. Due to the different emphasis on detection speed and detection accuracy, object detection methods are gradually developed in two directions: one stage and two stage. The two-stage methods, of which RCNN [
17,
18,
19] is the most representative method, achieve high accuracy, but lose a certain detection speed. According to reports, the detection speed of Cascade RCNN [
20] can only reach 14 fps, which cannot meet the real-time requirements of fabric defect detection. The classic one-step object detection methods are SSD [
21] and YOLO [
22]. Jing et al. [
23] used the improved YOLOv3 to achieve efficient detection of six classical defects. The defect area in the fabric usually only occupies a small part, that is, the background area is much larger than the foreground area. This characteristic of fabric defects limits the performance of these methods. Recently Duan et al. [
24] proposed a detector, named CenterNet, which detects each object as triplet keypoints, which can avoid the confusion brought by a large amount of background. CenterNet achieves a good trade-off between accuracy and speed, promising real-time defect detection.
Although deep-learning-based object detection methods have been partially studied in the industrial field, most of them are still in the laboratory stage and are difficult to implement for two reasons: (1) fabric defects are complex and diverse, making it difficult to detect and locate them in complex background areas; (2) online detection has high requirements for real-time performance, but most of the existing research ignores its speed; however, there is still potential for improvement when it is applied to fabric defect detection.
In this paper, we propose a fabric defect detection method based on CenterNet with deformable Convolution for online detection.
3. Hardware System
In this section, the key components in hardware system are introduced in detail.
Figure 6 shows the overall diagram of the developed equipment, which consist of an unwinding mechanism, traction mechanism, winding mechanism, image acquisition component, and computer. The frequency conversion motor realizes the unwinding, pulling and winding of the cloth by controlling the rotation of the roller. When the cloth passes through the image acquisition area, the camera automatically captures the fabric image and sends it to the software system in the computer for detection, as shown in
Figure 7. Apart from the image acquisition component, the developed equipment is similar to other automatic defect inspection equipment; therefore, this section focuses on the introduction of image acquisition component.
In real-time inspection, the choice of camera is an important factor to obtain high-quality fabric images. There are two types of industrial cameras commonly used in defect detection: line-scan cameras and area-scan cameras. This paper studies defect detection technology on the basis of surface images, so the area-scan camera was selected as the image acquisition device. In the developed equipment, eight industrial cameras (MER-502-79U3M) were arranged linearly, which can realize the rapid acquisition of fabric images. To ensure stability, a lighting system with three light sources and a reflector was designed.
In practical applications, the size of the fabric image captured by each camera is 2430 × 1200 pixel, which corresponds to the actual size of the fabric is 29.0 × 14.3 cm (84 pixels/cm, 0.119 mm/pixel). The width of the overlapping area between the images captured by adjacent cameras is about 1.8 cm. The equipment can realize defect detection of fabrics with a maximum width of 2.2 m. If the detection time is ignored, the developed device can achieve image acquisition of 65 m of cloth per minute.
4. Detection Algorithm
In this section, we introduce the proposed detection algorithm in detail, and the network architecture is presented in
Figure 8. Similar to the original CenterNet, we still use ResNet50 [
25] as the backbone, but some of the convolutional layers are replaced by deformable convolutions. Secondly, an implicit feature pyramid network (i-FPN) is introduced for two purposes: (1) to enhance the detection performance of the model for small defects; (2) to speed up the detection. Then, we introduce the objective function of the improved CenterNet. Finally, an online detection framework for fabric defects is built using the trained model. It is stated here that
Figure 2 and
Figure 8 are not the same, we replace the original explicit FPN with i-FPN.
4.1. Backbone Network
Although defects of various shapes and sizes only destroy the original texture structure of the fabric, the task of defect detection is a highly abstract task to a certain extent, because many defects are not the most prominent in the fabric image. In general, the deeper the convolutional neural network can extract, the more abstract features present; however, increasing the network depth brings some problems: (1) difficulty of convergence and (2) overfitting. ResNet introduces a residual structure into the network model, making it possible for the network depth to exceed 100 layers. The introduced residual makes it easier for the network to learn the identity mapping at some layers, which is a constructive solution. Residual networks behave similar to an ensemble of relatively shallow networks. In addition, the residual network allows information to flow between layers, and features can be reused during forward propagation, which alleviates the risk of gradient disappearance or gradient explosion during back propagation. In summary, ResNet can extract more abstract features without overfitting. ResNet50 and ResNet101 are two architectures that are often used as backbones; however, considering the real-time requirements of defect detection, we chose the former as the backbone of the proposed detection model.
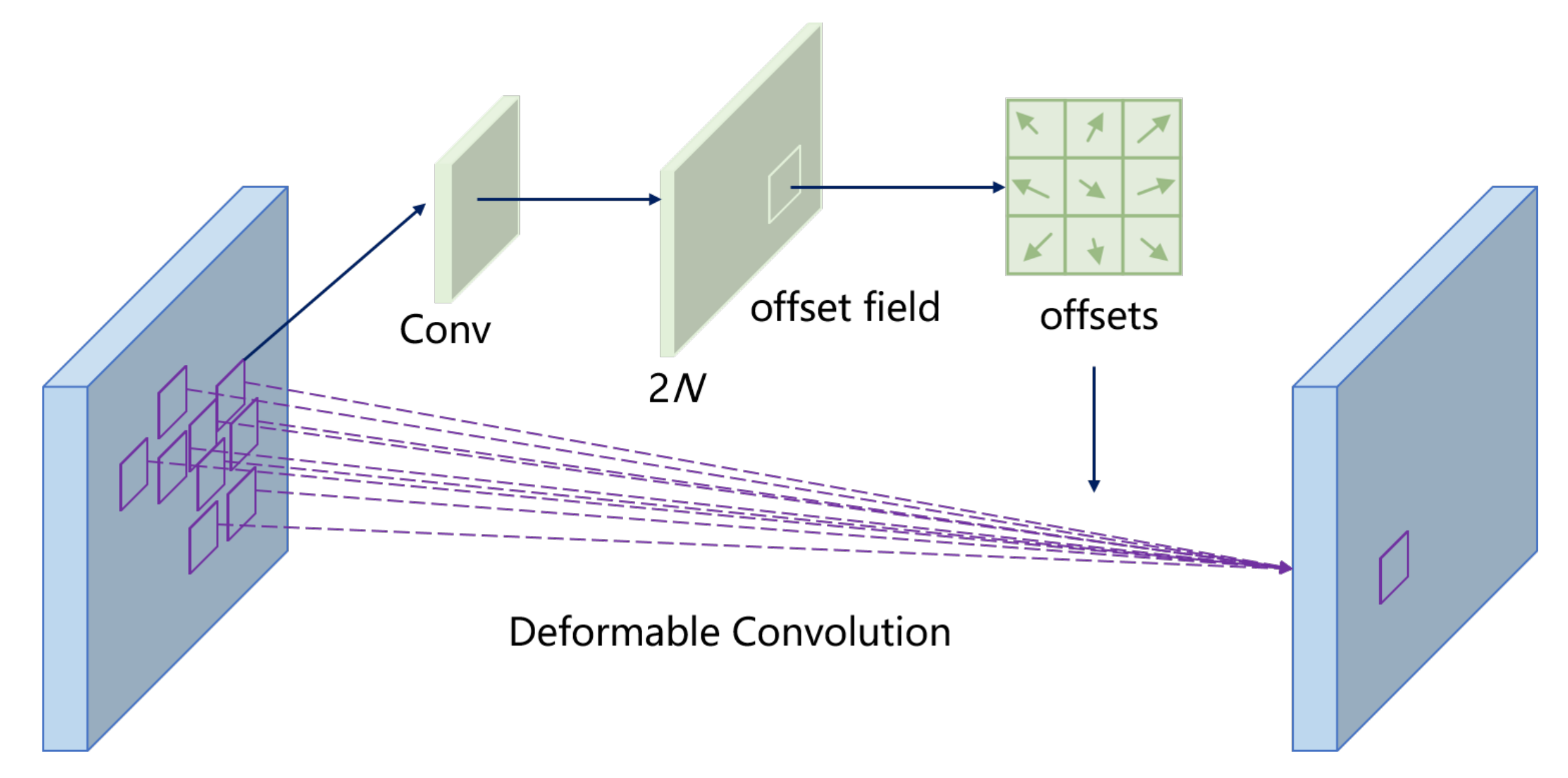
To accommodate defects of different shapes, we introduce deformable convolutions in the backbone network. The idea of deformable convolution is very simple, that is, the original fixed-shape convolution kernel becomes variable. Taking the 3 × 3 convolution kernel as an example, the mathematical expression is as follows:
where
represents the set of points in the neighborhood of
, and
is the index of the point in the
. For the output
of each convolution, it needs to sample from nine positions on the feature map
, of which, nine positions are determined by the center position
. The deformable convolution operation does not change the calculation operation of the convolution, but adds a learnable parameter
to the convolution region. Similarly, for each output
, nine positions must be sampled from the input feature map. These nine positions are obtained by diffusing the center position
to the surroundings, but with more
, the sampling points are allowed to spread into a non-grid shape. The deformable convolution operation can be expressed as:
To learn the offset
, another 3 × 3 convolutional layer needs to be defined. In fact, as shown in
Figure 4, the size of the output offset field is the same as that of the original feature map, but the number of channels is twice the original (representing the offset in the x and y directions, respectively). In this case, with the input feature map and the offset field of the same size as the feature map, we can perform deformable convolution operations. The above operations are all differentiable processes, so the parameters can be learned through backpropagation.
To combine the advantages of ResNet and deformable convolution, we improve some residual blocks of ResNet50. As shown in
Figure 8, the improvement is mainly reflected in the latter three series of residual blocks. Specifically, as shown in
Figure 9, for each residual structure, we use a 3 × 3 deformable convolution to replace the original 3 × 3 ordinary convolution; the other architectures are exactly the same as the original ResNet50—we refer the interested reader to [
25].
4.2. Implicit Feature Pyramid Network
To enhance the performance of the detector for objects of different scales, the commonly used method is explicit feature pyramid network (FPN), which stacks several cross-scale blocks to obtain large receptive field. It has been proved that implicit FPN (i-FPN) has better performance than explicit FPN, mainly in terms of detection speed and robustness. Different from explicit FPN, i-FPN directly produces equilibrium feature of global receptive field based on fixed point iteration. In addition, a recurrent mechanism, named residual-like iteration, is introduced to efficiently update the hidden states for feature pyramid design.
The architecture of i-FPN can be seen in
Figure 8. i-FPN generates an equilibrium feature pyramid based on fixed point iteration. The initial features P
–P
are all initialized to zeros. It is then fed into the i-FPN along with the backbone feature. The summed feature is input into the nonlinear transformation
, which serves as the implicit function. The equilibrium feature solver is further employed to generate the equilibrium feature pyramid by solving the fixed point of the implicit model. Finally, the resulting equilibrium feature pyramids are injected into the detection head to generate the final classification and regression predictions.
Figure 10 presents the explicit form of i-FPN, which is named residual-like iteration, to simulate explicit FPN with infinite depth. The residual-like iteration can be formulated as:
where P* can be computed by the unrolling solver or Broyden solver in DEQ [
28]. Similar to ResNet [
25], the residual-like iteration can also benefits from the residual learning by shortcut connection. The backbone features, which are extracted by backbone network and served as the strong prior, guide the residual learning of nonlinear transformation
, as shown in
Figure 11; therefore, the residual-like iteration can prevent i-FPN from suffering from the vanishing gradient problem, and theoretically, an FPN of infinite depth can be obtained. The ingenious structure of iFPN enables smooth information propagation, which enhances feature learning. Consequently, the equilibrium feature pyramid is input into detection head to recognize the keypoints, bounding boxes, and classes.
4.3. Detection Head
As shown in
Figure 3, the keypoints serve as the basic object representation throughout CenterNet. The keypoints are obtained via regressing offsets over the center points, which are predicted by KPN (mentioned in
Section 2.1). The learning of the keyponts are driven by two loss function: the bottom-right and top-left IoU loss between the induced pseudo box and the ground truth bounding box; the object recognition loss of the subsequent stage. The architecture of the detection head is illustrated in
Figure 12. The proposed head architecture consists of two non-shared subnets, aiming at localization and classification, respectively. The localization subnet first uses three 3 × 3 convolutional layers, followed by two consecutive small networks to compute the offsets of the two sets of keypoints. The classification subnet also uses three 3 × 3 convolutional layers to abstract the feature maps, followed by a deformable convolutional layer whose input offset field is shared with the first deformable convolutional layer in the localization subnet. The group normalization layer is applied after each of the first three 3 × 3 convolutional layers in the two subnets. The anchor-free design reduces the burden on the final classification layer, resulting in a slight reduction in computation.
As shown in
Figure 12, localization subnet consist of two stages: generating the first set of keypoints by abstraction from object center point hypotheses (feature map bins); generating the second set of keypoints based on the first set of keypoints. During training, only positive target hypotheses are assigned to localize targets for both stages. For the first localization stage, there are two conditions for a feature map bin to be considered positive: (1) the pyramid level of this feature map bin is equal to the logarithmic scale of the real object; (2) the projection of the center point of this real object is located in this feature map bin. For the second localization stage, it is positive if the induced pseudo-box of the first keypoints have enough overlap with a real object, and their intersection over-union is greater than 0.5. Classification is only conducted on the first set of keypoints. The classification assignment criteria follow: IoU (between the induced pseudo-box and the ground-truth bounding box) greater than 0.5 means positive, less than 0.4 means background, otherwise ignored. Focal loss [
29] is used for classification task training.
5. Experiment
5.1. Experimental Dataset
As we all know, the defect detection method based on deep learning learns the defect localization and recognition ability from a certain amount of training data; therefore, data are the basis for model learning. To train the model and verify the effectiveness of the method, we use the public fabric defect dataset (Smart Diagnosis of Cloth Flaw Dataset, SDCFD) [
30], in which the samples are all from the production line of the textile factory. SDCFD contains 11,918 fabric RGB images, of which 2842 are used as a testing set to test the method performance and 9076 are used as a training set to train the model. There are 5913 defect images in the training set, which cover 34 defect types. The size of the images in this dataset is 2446 pixel × 1000 pixel. For defect detection, SDCFD provides bounding box annotations which are saved as an json document, indicating the category and the location of defect in each image. To facilitate the analysis, the fabric defects are visually divided into three categories: warp defects (length-width ratio less than 0.5), weft defects (length-width ratio greater than 2), and regional defects (otherwise).
The size of the fabric image collected by the proposed equipment in this paper is 2430 × 1200 pixels, which is similar to the image resolution of SDCFD, and the shooting scale is basically the same; therefore, the model trained on this dataset can be directly grafted onto the equipment for online detection.
5.2. Evaluation Criteria
Different from the classification task, the fabric defect detection not only needs to predict the correct category but also the location information of the defect. In this study, we use three types of indicators to evaluate the performance of the defect detection methods from different perspectives; we also use three types of metrics to evaluate the performance of the defect detection methods from different perspectives. The recall R, detection rate , false detection rate , and detection accuracy are used to evaluate the recognition performance of the detection method; the mean average precision is used to evaluate the localization performance of the detection method; the FPS (frames per second) is used to evaluate the time complexity of the method.
R and
measure the ability of the model detection for positives,
measures the accuracy of the model prediction, and
reflects the robustness of the model. The three metrics are computed as follows:
where
and
, respectively, denote the total number of detective and defect-free images. The definitions of
, and
are presented in
Table 1.
is the area under the P-R curve corresponding to a certain category of detection results, and
is the average value of the area under the P-R curve corresponding to the detection results of all categories. In this study, we calculate the
based on 11-point interpolation method, which can be defined as:
where
where
is the measured precision at recall
. When AP for classes are obtained, the
can be computed by:
where
K represents the number of classes.
FPS represents the number of images that can be recognized per second, which is used to measure the time complexity of the detection algorithm. It is stated here that smaller FR values indicate better model performance, while the values of other metrics are positively correlated with method performance.
5.3. Implementation Details
The appearance of defects in solid-colored fabrics generally destroys the original texture characteristics of the fabrics; therefore, defects can be visually identified only from grayscale images. To meet the real-time requirements of defect detection, this paper proposes to grayscale the RGB image first, and then input the model for training or testing.
Compared to large-scale datasets, such as COCO [
31], the SDCFD used in this paper are relatively small. Under such conditions, data augmentation is an effective means to enhance the recognition accuracy and generalization of the model. During the training process, we randomly perform some transformations on the input fabric image, including grayscale transformation, rotation transformation, flip transformation, cropping, affine transformation, and so on. In terms of parameter setting, the input size is 1333 × 800 pixel, the initial learning rate is
, weight decay is
and the total epoch is 50. To avoid training falling into local optimum, at the 30th and 40th epoch, the learning rate is adjusted to
of the previous epoch.
In this study, the proposed method is implemented by using the Pytorch toolkit 1.9.0 + CUDA11.4 + cuDNN8.2.1. The hardware environment is as follows: CPU = E5 2623V4@ 2.60 GHz, RAM = DDR4 32G, and GPU = GeForce RTX 3090(24 G) × 2. Partial of visual results of detection on SDCFD-testing dataset are shown in
Figure 13.
5.4. Ablation Study
To validate the efficacy and efficiency of the proposed approach, we conduct a thorough ablation study in this subsection. Compared with the original CenterNet, our main improvements are as follows: (1) Deformable convolution is introduced to improve the adaptability to defects of various shapes; (2) FPN is replaced with i-FPN to improve the accuracy of small targets. All ablation experiments are conducted with ResNet50 backbone and evaluated on SDCFD-testing dataset.
We first explore the effect of using two different convolutions, namely common convolution and deformable convolution.
Table 2 presents the performance comparison results. It is stated here that “Common convolution” in the table indicates that all the convolutions in the model are common convolutions, and “Deformable convolution” indicates that the partial convolutions (mentioned in the previous section) in the model are deformable convolutions. The baseline is “Common convolution”, producing 0.527 box
. From the results, it can be found that the model has a higher recognition rate for regional defects, but lower for warp and weft defects. It has been demonstrated that deformable convolution has strong detection performance for irregular objects. Moreover, most fabric defects are often irregular in shape. The model with deformable convolution achieves a average
of 0.648 with
improvement. Except
, other detection performance indicators for all categories have been improved to a certain extent, which proves the rationality and effectiveness of using deformable convolution instead of common convolution.
As mentioned before, i-FPN is another key component used to improve the recognition accuracy of the model for small defects. Here, we conduct the comparative experiment on SDCFD to analyze the effect of it, and define the defects that occupy an area less than 300 (the number of pixels in the area) in the original image as small defects.
Table 3 and
Figure 14 present the quantitative comparison results when adopting different FPN architectures as the cross-scale connection. The baseline is “None” (the first row in the
Table 3) without the cross-scale connection. It is clearly observed that the detection performance of the model is significantly improved when cross-scale connection is adopted, especially for small defects. For example, comparing “None” and “FPN”,
achieves an improvement of 0.102 for small defects. In addition, adopting Bi-FPN [
32] or NAS-FPN [
33] as cross-scale connection produces a decent performance with the
score of 0.531 and 0.548 while Dense-FPN provides more improvements. Moreover, as shown in
Figure 14, i-FPN has great advantages in the detection performance of each category of defects. Further, i-FPN achieves more improvements on all evaluation criteria; therefore, using iFPN as the cross-scale connection can effectively improve the detection performance of the model for various defects, especially small defects.
To verify the superiority of the proposed method for fabric defect detection, we compare it with 10 other classical object detection methods, including one two-stage method: Faster R-CNN [
19]; one multi-stage method: Cascade R-CNN [
20]; two transformer-based methods: DETR [
36] and Deformable DETR [
37]; seven one-stage methods: YOLOv3 [
38], SSD [
21], CornerNet (anchor-free method) [
39], M2det [
40], RetinaNet [
29], CenterNet-RT (anchor-free method), [
24] and FCOS (anchor-free method) [
41]. The performance comparison results are reported in
Table 4.
5.5. Comparisons
Regardless of the detection speed, Faster R-CNN and Cascade R-CNN must be the best choices for fabric defect detection. As shown in the first two rows of
Table 4, these two methods achieve certain advantages in detection accuracy; however, their FPS indicators only reach 13.5 and 11.8, which cannot meet the real-time requirements of defect detection. DETR and Deformable DETR are all based on the transformer architecture [
42], which is greatly affected by the size of the training data and thus achieve limited performance. As classic one-stage object detectors, YOLOv2 and SSD have great advantages in detection speed, which can detect 43 and 45 images per second, respectively; however, the performance achieved by these two detectors is not ideal in terms of accuracy, mainly due to their limited detection capability for small defects. Moreover, their false detection rate
is relatively high, which cannot be tolerated by textile enterprises. Although the three anchor-free methods CornerNet, CenterNet-RT, and FCOS have certain advantages in terms of computational complexity, their performance cannot meet the needs of defect detection. It is clear that the proposed method outperforms other methods for fabric defect detection, in terms of all evaluation criteria. The proposed method can detect 34.8 images per second, and when this model is grafted onto the proposed online detection device, the maximum detection speed can reach 34.8 × 14.3 × 60 ÷ 8 ÷ 100 = 37.3 m/min. The average speed of manual cloth inspection is only 30m/min. In summary, the comparison results demonstrate that our methods achieves the best performance in all indicators, which proves the superiority of our proposed method. Combined with the proposed detection algorithm and the developed equipment, the detection speed can reach 37.3 m/min, which can meet the real-time requirements of defect detection.
5.6. Error Detection Analysis
By analyzing the samples of false detections, it is found that false detections mainly include over detection and missing detection. In
Figure 15, we present some examples of false detections. The proposed method detects defects based on key points, and repeated detection may occur for independent defects that are close to each other, as shown in
Figure 15(r1,g1); however, this false detection generally does not affect the final result of detection. Wrinkles and imperfections in fabrics are visually very similar and can therefore cause false detections, which are difficult to avoid, as shown in
Figure 15(r2,g2). In addition, some defects only have a small number in the training set, making it difficult for the model to locate and identify them, as shown in
Figure 15(r3,g3,r4,g4,r5,g5); however, we believe that when there are enough training samples in the training set, the proposed model can be sufficiently trained to accurately identify such defects.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}