
Online Domain Adaptation for Rolling Bearings Fault Diagnosis with Imbalanced Cross-Domain Data


Abstract
:1. Introduction
- (1)
- A novel bearing fault diagnosis framework is proposed. The characteristics of fault diagnosis problems and the situation of imbalanced cross-domain data are both considered.
- (2)
- Replace the fully connected layers with the so-called adaptive neuro-fuzzy inference system (ANFIS) by transfer learning. In order to improve the lack of transparency and interpretability in ML model.
- (3)
- As a result, our proposed method achieves a significant improvement by comparing with other traditional methods in the situation of few target samples.
2. Preliminaries
- A.
- Short-Time Fourier Transform
- B.
- Convolutional neural network and Batch Normalization
- C.
- Maximum Mean Discrepancy
- D.
- Adaptive Neuro-Fuzzy Inference System
3. On-Line Domain Adaptation
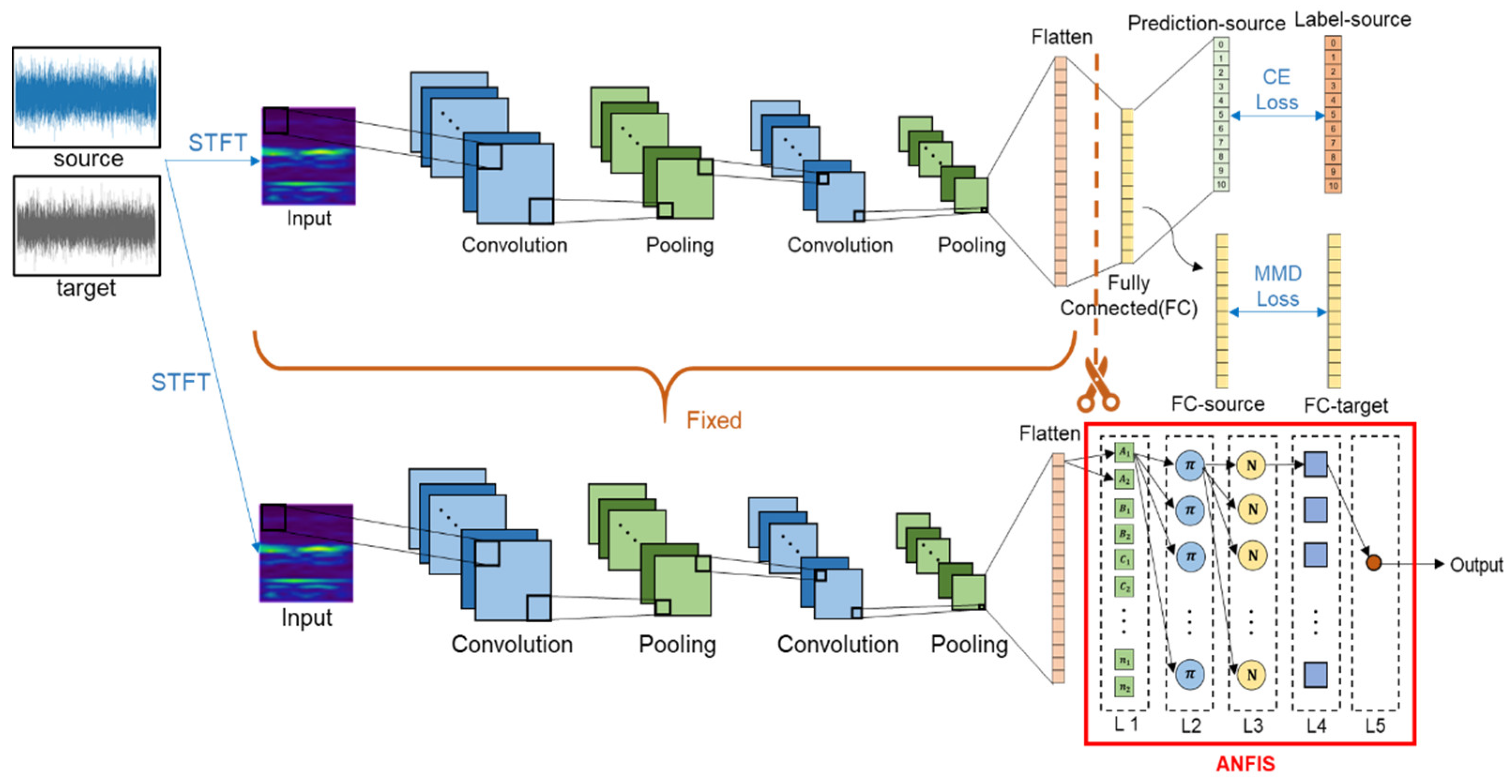
3.1. Model Architecture
3.2. Optimization Objective
3.3. General Procedure of the Proposed Method
4. Experiments and Results
4.1. Dataset Description
4.2. Results and Discussion
- (1)
- When the number of target domain data reaches 26, the accuracy of the proposed method will be over 90%, whereas a traditional method needs 40 target data to achieve a prediction accuracy of 90%. When the number of target domain data reaches 150, the accuracy will be over 99% for our proposed method, while a traditional method needs 1000 data to achieve over 99% accuracy.
- (2)
- When the target domain data starts out very low (<40), the testing accuracy will increase rapidly as the target data increases. If the target domain data is over 50, the standard deviation of the testing accuracy starts to decrease as the target data increases.
- (3)
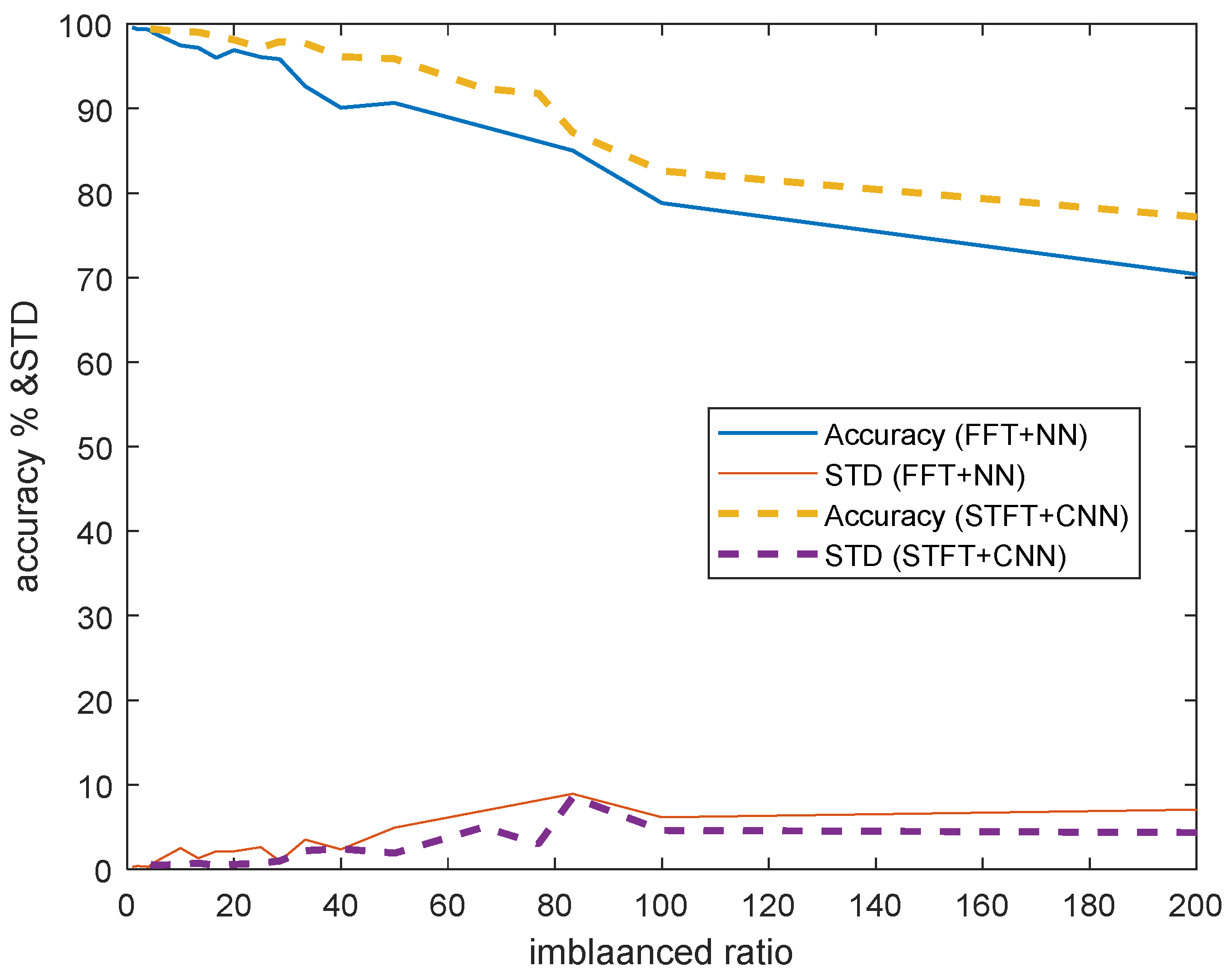
- The comparison results of the accuracy and standard deviation (STD) of ten independent trials are shown in Figure 5: solid lines denote the results of FFT + NN; and dashed-lines denotes the results of STFT + CNN. Obviously, it can be observed that the proposed method outperforms (higher accuracy and smaller STD) the traditional method for imbalanced cross-domain data.
- (4)
- Note that the imbalanced ratio with a value of infinity means that there is no domain adaptation process. This means that the model is trained by source data and then obtains the inference results using target inputs directly. We can observe that the accuracies of STFT + CNN and FFT + NN are both lower (74.54% and 67.84%) than results with domain adaptation. This illustrates the advantage of domain adaptation. In addition, the performance of STFT + CNN is better than the result of FFT + NN, which demonstrate the improved performance of the proposed approach.
- (5)
- Figure 6 shows that the proposed method (STFT + CNN) has better performance than traditional cross-domain fault diagnosis methods (FFT + NN) when there is a lack of target domain data (from 0 to 2000). Although the traditional method is good enough (99%) to use in the condition that source domain and target domain data are both sufficient, its accuracy will drop rapidly when two domains data are imbalanced. For example, when we have 40 target samples, the proposed method could reach an accuracy of about 95%, but the traditional fault diagnosis method only has an accuracy of roughly 90%.
4.3. Transfer Learning Model by ANFIS
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, W.; Randall, R. Rolling element bearing diagnostics using the case western reserve university data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part II: Fault diagnosis with knowledge-based and hybrid/active approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef] [Green Version]
- Dolenc, B.; Boškoski, P.; Juričić, Đ. Distributed bearing fault diagnosis based on vibration analysis. Mech. Syst. Signal Process. 2016, 66–67, 521–532. [Google Scholar]
- Chegini, S.N.; Bagheri, A.; Najafi, F. Application of a new EWT-based denoising technique in bearing fault diagnosis. Measurement 2019, 144, 275–297. [Google Scholar] [CrossRef]
- Ali, J.B.; Fnaiech, N.; Saidi, L.; Chebel-Morello, B.; Fnaiech, F. Application of empirical mode decomposition and artificial neural network for automatic bearing fault diagnosis based on vibration signals. Appl. Acoust. 2015, 89, 16–27. [Google Scholar]
- Zheng, H.; Wang, R.; Yang, Y.; Yin, J.; Li, Y.; Li, Y.; Xu, M. Cross-Domain Fault Diagnosis Using Knowledge Transfer Strategy: A Review. IEEE Access 2019, 7, 129260–129290. [Google Scholar] [CrossRef]
- Jiang, J. A Literature Survey on Domain Adaptation of Statistical Classifiers. 2008. Available online: http://www.mysmu.edu/faculty/jingjiang/papers/da_survey.pdf (accessed on 19 June 2020).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Dziugaite, G.K.; Roy, D.M.; Ghahramani, Z. Training generative neural networks via maximum mean discrepancy optimization. arXiv 2015, arXiv:1505.03906. [Google Scholar]
- Lu, W.; Liang, B.; Cheng, Y.; Meng, D.; Yang, J.; Zhang, T. Deep Model Based Domain Adaptation for Fault Diagnosis. IEEE Trans. Ind. Electron. 2017, 64, 2296–2305. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. Cross-Domain Fault Diagnosis of Rolling Element Bearings Using Deep Generative Neural Networks. IEEE Trans. Ind. Electron. 2019, 66, 5525–5534. [Google Scholar] [CrossRef]
- Case Western Reserve University Bearing Data Center. Available online: https://engineering.case.edu/bearingdatacenter/download-data-file (accessed on 1 December 2021).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Derivation of fuzzy control rules from human operator’s control actions. In Proceedings of the IFAC Symposium on Fuzzy Information, Knowledge Representation and Decision Analysis, Marseille, France, 19–21 July 1983; pp. 55–60. [Google Scholar]
- Chen, H.-Y.; Lee, C.-H. Vibration Signals Analysis by Explainable Artificial Intelligence (XAI) Approach: Application on Bearing Faults Diagnosis. IEEE Access 2020, 8, 134246–134256. [Google Scholar] [CrossRef]
- Patel, R.A.; Bhalja, B.R. Condition monitoring and fault diagnosis of induction motor using support vector machine. Electr. Power Compon. Syst. 2016, 44, 683–692. [Google Scholar] [CrossRef]
- Kankar, P.K.; Sharma, S.C.; Harsha, S.P. Fault diagnosis of ball bearings using machine learning methods. Expert Syst. Appl. 2011, 38, 1876–1886. [Google Scholar] [CrossRef]
- Li, X.; Ma, J.; Wang, X.; Wu, J.; Li, Z. An improved local mean decomposition method based on improved composite interpolation envelope and its application in bearing fault feature extraction. ISA Trans. 2020, 97, 365–383. [Google Scholar] [CrossRef]
- Shenfield, A.; Howarth, M. A novel deep learning model for the detection and identification of rolling element-bearing faults. Sensors 2020, 20, 5112. [Google Scholar] [CrossRef]
- Hasan, M.J.; Sohaib, M.; Kim, J.M. 1D CNN-Based transfer learning model for bearing fault diagnosis under variable working conditions. In Proceedings of the International Conference on Computational Intelligence in Information System, Berlin/Heidelberg, Germany, 16–18 November 2018; pp. 13–23. [Google Scholar]
- Liu, Z.-H.; Lu, B.-L.; Wei, H.-L.; Chen, L.; Li, X.-H.; Ratsch, M. Deep Adversarial Domain Adaptation Model for Bearing Fault Diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 4217–4226. [Google Scholar] [CrossRef]
- Chimatapu, R.; Hagras, H.; Starkey, A.; Owusu, G. Explainable AI and Fuzzy Logic Systems. In Theory and Practice of Natural Computing; Fagan, D., Martín-Vide, C., O’Neill, M., Vega-Rodríguez, M.A., Eds.; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Parameters |
|---|---|
| 2D Convolutional Layer (1st) | Filter Number = 6 Filter Size = (9, 9) |
| Batch Normalization layer (1st) | Activation Function = Leaky ReLU |
| Max Pooling Layer (1st) | Filter Size = (2, 2) |
| 2D Convolutional Layer (2nd) | Filter Number = 12 Filter Size = (3, 3) |
| Batch Normalization layer (2nd) | Activation Function = Leaky ReLU |
| Max Pooling Layer (2nd) | Filter Size = (2, 2) |
| Flatten | - |
| Fully Connected Layer | 100 neurons |
| Softmax Output Layer | 10 neurons |
| Hyperparameters | Value |
|---|---|
| Epochs | 40 |
| Learning rate | 0.0001 |
| Optimizer | Adam |
| Batch size | 64 |
| Sample length | 500 |
| Source domain training sample | 2000 |
| Target domain training sample | 0~2000 |
| Target domain testing sample | 400 |
| Number of Source Domain Data | Number of Target Domain Data | Imbalanced Ratio | Average Accuracy (%) | Standard Deviation (10 Trials) |
|---|---|---|---|---|
| 2000 | 0 (without DA) | ∞ (without DA) | 74.54 | 4.590 |
| 2000 | 10 | 200 | 77.17 | 4.326 |
| 2000 | 20 | 100 | 82.61 | 4.595 |
| 2000 | 24 | 83.33 | 87.19 | 8.518 |
| 2000 | 26 | 76.92 | 91.79 | 2.994 |
| 2000 | 30 | 66.67 | 92.36 | 4.976 |
| 2000 | 40 | 50 | 95.89 | 1.895 |
| 2000 | 50 | 40 | 96.13 | 2.417 |
| 2000 | 60 | 33.33 | 97.71 | 2.194 |
| 2000 | 70 | 28.57 | 97.92 | 0.982 |
| 2000 | 80 | 25 | 97.19 | 0.718 |
| 2000 | 100 | 20 | 98.13 | 0.570 |
| 2000 | 120 | 16.67 | 98.56 | 0.464 |
| 2000 | 150 | 13.33 | 99.03 | 0.714 |
| 2000 | 200 | 10 | 99.06 | 0.561 |
| 2000 | 400 | 5 | 99.39 | 0.480 |
| 2000 | 500 | 4 | 99.44 | 0.644 |
| 2000 | 1000 | 2 | 99.71 | 0.325 |
| 2000 | 2000 | 1 | 99.78 | 0.245 |
| Number of Source Domain Data | Number of Target Domain Data | Imbalanced Ratio | Average Accuracy (%) | Standard Deviation (10 Times) |
|---|---|---|---|---|
| 2000 | 0 (without DA) | ∞ (without DA) | 67.84 | 3.760 |
| 2000 | 10 | 200 | 70.38 | 7.043 |
| 2000 | 20 | 100 | 78.81 | 6.139 |
| 2000 | 30 | 83.33 | 85.03 | 8.919 |
| 2000 | 40 | 50 | 90.66 | 4.913 |
| 2000 | 50 | 40 | 90.09 | 2.353 |
| 2000 | 60 | 33.33 | 92.63 | 3.493 |
| 2000 | 70 | 28.57 | 95.84 | 0.970 |
| 2000 | 80 | 25 | 96.09 | 2.611 |
| 2000 | 100 | 20 | 96.91 | 2.124 |
| 2000 | 150 | 16.67 | 96.00 | 2.113 |
| 2000 | 200 | 13.33 | 97.19 | 1.304 |
| 2000 | 400 | 10 | 97.47 | 2.496 |
| 2000 | 800 | 5 | 98.93 | 0.768 |
| 2000 | 1000 | 4 | 99.36 | 0.274 |
| 2000 | 1200 | 2 | 99.39 | 0.375 |
| 2000 | 2000 | 1 | 99.58 | 0.274 |
| Source: 2 hp Target: 0 hp | ||||||
| Methods | The number of target domain training data | |||||
| 20 | 50 | 100 | 500 | 1000 | 2000 | |
| DADA | 87.42% | 88.08% | 88.17% | 88.58% | 88.92% | 91.25% |
| FFT + NN | 85.92% | 93.42% | 96.08% | 99.17% | 99.75% | 99.92% |
| FFT + CNN | 93.81% | 96.67% | 98.83% | 99.33% | 99.67% | 99.92% |
| STFT + CNN (Proposed) | 92.50% | 98.25% | 98.92% | 99.42% | 99.50% | 99.92% |
| Source: 0 hp Target: 2 hp | ||||||
| Methods | The number of target domain training data | |||||
| 20 | 50 | 100 | 500 | 1000 | 2000 | |
| DADA | 84.83% | 88.58% | 91.17% | 91.42% | 92.50% | 93.00% |
| FFT + NN | 82.17% | 92.00% | 96.50% | 99.75% | 99.67% | 99.83% |
| FFT + CNN | 90.58% | 97.33% | 98.42% | 99.73% | 99.92% | 99.92% |
| STFT + CNN (Proposed) | 95.75% | 97.42% | 99.17% | 99.83% | 99.83% | 100.00% |
| Source: 1 hp Target: 3 hp | ||||||
| Methods | The number of target domain training data | |||||
| 20 | 50 | 100 | 500 | 1000 | 2000 | |
| DADA | 95.75% | 95.92% | 96.67% | 97.33% | 97.42% | 97.75% |
| FFT + NN | 88.75% | 93.58% | 97.17% | 99.17% | 99.50% | 99.58% |
| FFT + CNN | 94.33% | 97.67% | 99.00% | 99.67% | 99.75% | 99.92% |
| STFT + CNN (Proposed) | 94.83% | 98.50% | 98.87% | 99.42% | 99.83% | 99.83% |
| Source: 3 hp Target: 1 hp | ||||||
| Methods | The number of target domain training data | |||||
| 20 | 50 | 100 | 500 | 1000 | 2000 | |
| DADA | 81.00% | 84.33% | 85.50% | 86.17% | 86.25% | 86.83% |
| FFT + NN | 80.67% | 89.00% | 88.92% | 97.33% | 99.50% | 99.67% |
| FFT + CNN | 87.67% | 96.25% | 97.00% | 99.08% | 99.58% | 99.67% |
| STFT + CNN (Proposed) | 89.92% | 97.00% | 97.17% | 98.92% | 99.58% | 99.75% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chao, K.-C.; Chou, C.-B.; Lee, C.-H. Online Domain Adaptation for Rolling Bearings Fault Diagnosis with Imbalanced Cross-Domain Data. Sensors 2022, 22, 4540. https://doi.org/10.3390/s22124540
Chao K-C, Chou C-B, Lee C-H. Online Domain Adaptation for Rolling Bearings Fault Diagnosis with Imbalanced Cross-Domain Data. Sensors. 2022; 22(12):4540. https://doi.org/10.3390/s22124540
Chicago/Turabian StyleChao, Ko-Chieh, Chuan-Bi Chou, and Ching-Hung Lee. 2022. "Online Domain Adaptation for Rolling Bearings Fault Diagnosis with Imbalanced Cross-Domain Data" Sensors 22, no. 12: 4540. https://doi.org/10.3390/s22124540