
Recent Advances in Video Analytics for Rail Network Surveillance for Security, Trespass and Suicide Prevention—A Survey

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Overview of Surveillance Systems for Rail Networks
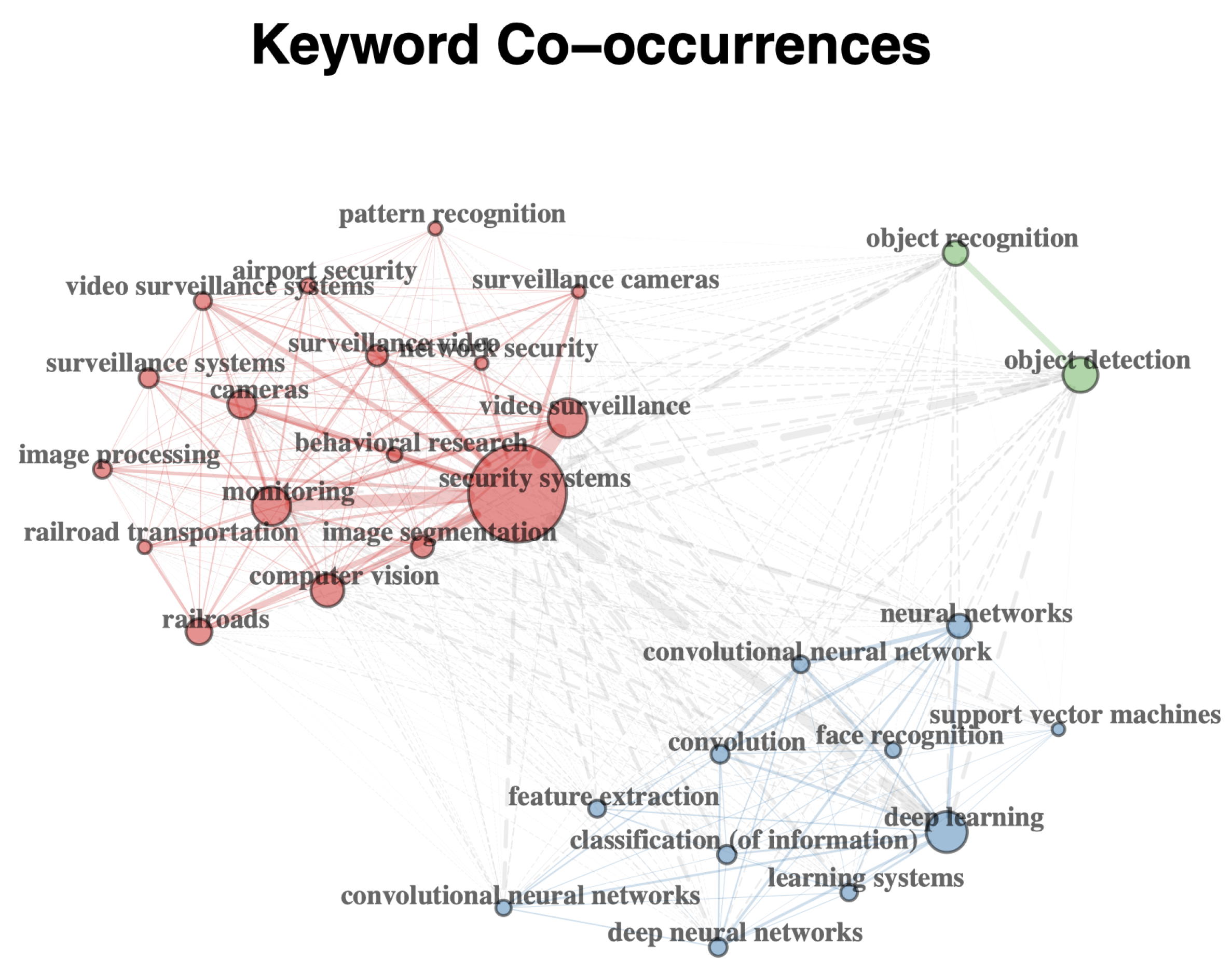
2.1. Bibliometric Analysis
2.1.1. Trends in Computer Vision Technologies in Video Surveillance
2.2. Objectives of CCTV Surveillance Systems
2.3. Sensors
2.3.1. Cameras
2.3.2. Chemical Sensors
2.3.3. Concealed Weapon Sensors
2.3.4. Health Sensors
2.3.5. Acoustic and Vibration Sensors
2.4. Monitoring and Recording System
- Size: Size is usually specified as the length of the diagonal measurement of the monitor. The size is selected based on the number of simultaneous camera displays. As a rule, the operator to screen distance is three to five times the screen size.
- Resolution (Number of pixels): The number of pixels specifies the display resolution. The pixel number has a one-to-one correspondence to the resolution of the camera output image. For best performance, these should match.
- Aspect Ratio: Aspect ratio is defined as the ratio of the number of pixels in the horizontal to those in the vertical. For best results, the aspect ratio of the monitor should match that of the camera.
2.5. Video Analytics
2.5.1. Deep Learning Methods for Video Analytics
Convolutional Neural Networks
Recurrent Neural Networks
Vision Transformer (ViT)
2.6. Motion or Moving Object Detection
2.6.1. Static Object Detection
2.6.2. Multiple Object Tracking
2.7. Video Face Recognition
2.8. Person Re-Identification
2.9. Human Activity Recognition
- Gestures. These are elementary motions of the human body, such as stretching of arms or raising a leg.
- Action. These are the combinations of human gestures, for example, running and punching.
- Interactions. These involve interactions among multiple individuals and objects. These can be classified into human–object, human–human and human–object–human interactions. The human–object interaction deals with recognising the interaction of a human with an object, for instance, an individual abandoning an object or loitering. An individual interacting with another is human–human, such as a brawl. The interaction between two humans and an object leads to human–object–human activity, such as stealing a bag from another individual.
2.10. Video Anomaly Detection
2.11. Trajectory Analysis
2.12. Crowd Analysis
3. The Impact of Uncertainties in Computer Vision Technologies for Surveillance Systems
3.1. Uncertainty in Deep Learning
- (1)
- Noisy data/out of distribution data.
- (2)
- Uncertainty on the deep network parameters that are chosen during the training stage. This is also known as uncertainty in model parameters.
- (3)
- Model structure difference depending on the chosen algorithm for building the model (also called structure uncertainty). This uncertainty can be reflected in the following ways: an absence of theory and causal models and computational costs.
3.1.1. Types of Uncertainty
3.1.2. Adversarial Attacks
Adversarial Samples
3.1.3. Impact of COVID-19
3.2. Uncertainty Quantification with Bayesian Deep Learning Methods
4. About the Next Generation of CCTV Surveillance Systems for Railway Stations
4.1. Data Centre
4.2. Data Analytics
5. Ethics and General Data Protection Regulatory
6. Conclusions
Author Contributions
Funding

Conflicts of Interest
References
- Coaffee, J.; Moore, C.; Fletcher, D.; Bosher, L. Resilient design for community safety and terror-resistant cities. In Proceedings of the Institution of Civil Engineers-Municipal Engineer, London, UK, 1 June 2008; Thomas Telford Ltd.: London, UK, 2015; Volume 161, pp. 103–110. [Google Scholar]
- Media Guidelines for Reporting Suicide. 2019. Available online: https://media.samaritans.org/documents/Media_guidelines_-_Rail_suicides_factsheet_UK_Final.pdf (accessed on 7 April 2022).
- Suicide Prevention on the Railway—Network Rail. 2021. Available online: https://www.networkrail.co.uk/communities/safety-in-the-community/suicide-prevention-on-the-railway/ (accessed on 7 April 2022).
- Kawamura, A.; Yoshimitsu, Y.; Kajitani, K.; Naito, T.; Fujimura, K.; Kamijo, S. Smart camera network system for use in railway stations. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AL, USA, 9–12 October 2011; pp. 85–90. [Google Scholar]
- Li, Y.; Qin, Y.; Xie, Z.; Cao, Z.; Jia, L.; Yu, Z.; Zheng, J.; Zhang, E. Efficient SSD: A Real-Time Intrusion Object Detection Algorithm for Railway Surveillance. In Proceedings of the 2020 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Beijing, China, 5–7 August 2020; pp. 391–395. [Google Scholar]
- Langran-Wheeler, C.; Fletcher, D.; Rigby, S. In2Stempo D9.2. Database: Initial Structural Response Calculations for Glass, Fixings and Station Geometry; Technical Report; The University of Sheffield: Sheffield, UK, 2020. [Google Scholar]
- Davies, A.C.; Velastin, S.A. A Progress Review of Intelligent CCTV Surveillance Systems. In Proceedings of the 2005 IEEE Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Sofia, Bulgaria, 5–7 September 2005; pp. 417–423. [Google Scholar]
- Tsakanikas, V.; Dagiuklas, T. Video surveillance systems-current status and future trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]
- Bashbaghi, S.; Granger, E.; Sabourin, R.; Parchami, M. Deep Learning Architectures for Face Recognition in Video Surveillance. In Deep Learning in Object Detection and Recognition; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–154. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, J.K.; Ryoo, M.S. Human Activity Analysis: A Review. ACM Comput. Surv. (CSUR) 2011, 43, 1–43. [Google Scholar] [CrossRef]
- Kong, Y.; Fu, Y. Human Action Recognition and Prediction: A Survey. arXiv 2018, arXiv:1806.11230. [Google Scholar] [CrossRef]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep Learning in Video Multi-Object Tracking: A Survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef] [Green Version]
- Smeureanu, S.; Ionescu, R.T. Real-Time Deep Learning Method for Abandoned Luggage Detection in Video. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO), Eternal, Italy, 3–7 September 2018; pp. 1775–1779. [Google Scholar]
- Chalapathy, R.; Chawla, S. Deep Learning for Anomaly Detection: A Survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Tripathi, G.; Singh, K.; Vishwakarma, D.K. Convolutional Neural Networks for Crowd Behaviour Analysis: A Survey. Visual Comput. 2019, 35, 753–776. [Google Scholar] [CrossRef]
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. CNN-based Density Estimation and Crowd Counting: A Survey. arXiv 2020, arXiv:2003.12783. [Google Scholar]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Inf. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- National Security Inspectorate. NSI Code of Practice for Design, Installation and Maintenance of Access Control Systems; Technical Report November; National Security Inspectorate: Maidenhead, UK, 2017. [Google Scholar]
- The British Standards Institution. Closed Circuit Television (CCTV)—Management and Operation Code of Practice; Technical Report BS 7958:2009; BSI Standards Limited: London, UK, 2009. [Google Scholar]
- The British Standards Institution. Video Surveillance Systems for Use in Security Applications Part 1–2: System Requirements Performance Requirements for Video Transmission; Technical Report BS EN 62676-1-2-2014; BSI Standards Limited: London, UK, 2016. [Google Scholar]
- The British Standards Institution. Installation and Remote Monitoring of Detector-Activated CCTV Systems—Code of Practice; Technical Report BS 8418-2015+A1-2017; BSI Standards Limited: London, UK, 2017. [Google Scholar]
- The British Standards Institution. Remote Centres Receiving Signals from Alarm Systems—Code of Practice; Technical Report BS 8591-2014; BSI Standards Limited: London, UK, 2014. [Google Scholar]
- The British Standards Institution. Video Surveillance Systems for Use in Security Applications Part 2–1: Video Transmission Protocols General Requirements; Technical Report BS EN 62676-2-1-2014; BSI Standards Limited: London, UK, 2014. [Google Scholar]
- The British Standards Institution. Video Surveillance Systems for Use in Security Applications Part 2–3: Video Transmission Protocols—IP Interoperability Implementation Based on Web Services; Technical Report BS EN 62676-2-3-2014; BSI Standards Limited: London, UK, 2014. [Google Scholar]
- The British Standards Institution. Video Surveillance Systems for Use in Security Applications Part 3: Analog and Digital Video Interfaces; Technical Report BS EN 62676-3-2015; BSI Standards Limited: London, UK, 2014. [Google Scholar]
- The British Standards Institution. Video Surveillance Systems for Use in Security Applications Part 1–1: System Requirements General; Technical Report BS EN 62676-1-1:2014; BSI Standards Limited: London, UK, 2014. [Google Scholar]
- The British Standards Institution. Video Surveillance Systems for Use in Security Applications Part 2–2: Video Transmission Protocols IP Interoperability Implementation Based on HTTP and REST Services; Technical Report BS EN 62676-2-2-2014; BSI Standards Limited: London, UK, 2014. [Google Scholar]
- The British Standards Institution. Video Surveillance Systems for Use in Security Applications Part 4: Application Guidelines; Technical Report BS EN 62676-4:2015; BSI Standards Limited: London, UK, 2015. [Google Scholar]
- Ferryman, J. Video Surveillance Standardisation Activities, Process and Roadmap; Technical Report JRC103650; Joint Research Centre (JRC), Science Hub, European Union: Brussels, Belgium, 2016. [Google Scholar]
- Marcenaro, L. Access to Data Sets; Technical Report; Erncip Thematic Group on Video Surveillance for Security of Critical Infrastructure: Ispra, Italy, 2016. [Google Scholar]
- Medel, J.R.; Savakis, A. Anomaly Detection in Video Using Predictive Convolutional Long Short-Term Memory Networks. arXiv 2016, arXiv:1612.00390. [Google Scholar]
- Shidik, G.F.; Noersasongko, E.; Nugraha, A.; Andono, P.N.; Jumanto, J.; Kusuma, E.J. A Systematic Review of Intelligence Video Surveillance: Trends, Techniques, Frameworks, and Datasets. IEEE Access 2019, 7, 170457–170473. [Google Scholar] [CrossRef]
- Gautam, A.; Singh, S. Trends in Video Object Tracking in Surveillance: A Survey. In Proceedings of the Third International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 12–14 December 2019; pp. 729–733. [Google Scholar]
- Ma, H.; Tian, J.; Qiu, K.; Lo, D.; Gao, D.; Wu, D.; Jia, C.; Baker, T. Deep-Learning–Based App Sensitive Behavior Surveillance for Android Powered Cyber–Physical Systems. IEEE Trans. Ind. Inform. 2021, 17, 5840–5850. [Google Scholar] [CrossRef]
- Koch, W. Towards Cognitive Tools: Systems Engineering Aspects for Public Safety and Security. IEEE Aerosp. Electron. Syst. Mag. 2014, 29, 14–26. [Google Scholar] [CrossRef]
- Scanner, L.A. Flickr. 2018. Available online: https://www.flickr.com/photos/36016325@N04/39682091582 (accessed on 7 April 2022).
- Sun, G.; Nakayama, Y.; Dagdanpurev, S.; Abe, S.; Nishimura, H.; Kirimoto, T.; Matsui, T. Remote Sensing of Multiple Vital Signs Using a CMOS Camera-Equipped Infrared Thermography System and Its Clinical Application in Rapidly Screening Patients with Suspected Infectious Diseases. Int. J. Infect. Dis. 2017, 55, 113–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Skinner, D. Flickr. 2015. Available online: https://www.flickr.com/photos/28051469@N02/23783501012 (accessed on 7 April 2022).
- Yao, R.; Lin, G.; Xia, S.; Zhao, J.; Zhou, Y. Video object segmentation and tracking: A survey. In ACM Transactions on Intelligent Systems and Technology (TIST); ACM: New York, NY, USA, 2020; Volume 11, pp. 1–47. [Google Scholar]
- Aafaq, N.; Mian, A.; Liu, W.; Gilani, S.Z.; Shah, M. Video description: A survey of methods, datasets, and evaluation metrics. In AACM Computing Surveys (CSUR); ACM: New York, NY, USA, 2019; Volume 52, pp. 1–37. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. In Proceedings of the Techniques and Applications of Image Understanding, International Society for Optics and Photonics, Washington, DC, USA, 21–23 April 1981; Volume 281, pp. 319–331. [Google Scholar]
- Liu, M.; Wu, C.; Zhang, Y. Motion Vehicle Tracking Based on Multi-Resolution Optical Flow and Multi-Scale Harris Corner Detection. In Proceedings of the 2007 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 15–18 December 2007; pp. 2032–2036. [Google Scholar]
- Roth, S.; Black, M.J. On the Spatial Statistics of Optical Flow. Int. J. Comput. Vis. 2007, 74, 33–50. [Google Scholar] [CrossRef]
- Rasheed, N.; Khan, S.A.; Khalid, A. Tracking and Abnormal Behavior Detection in Video Surveillance Using Optical Flow and Neural Networks. In Proceedings of the 2014 28th International Conference on Advanced Information Networking and Applications Workshops, Victoria, BC, Canada, 13–16 May 2014; pp. 61–66. [Google Scholar]
- Bui, T.; Hernández-Lobato, D.; Hernandez-Lobato, J.; Li, Y.; Turner, R. Deep Gaussian processes for regression using approximate expectation propagation. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 1472–1481. [Google Scholar]
- Nguyen-Tuong, D.; Peters, J.R.; Seeger, M. Local Gaussian Process Regression for Real Time Online Model Learning. In Proceedings of the Advances in Neural Information Processing Systems, Nice, France, 22–26 September 2008; pp. 1193–1200. [Google Scholar]
- Nguyen-Tuong, D.; Seeger, M.; Peters, J. Model Learning with Local Gaussian Process Regression. Adv. Robot. 2009, 23, 2015–2034. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 17 July 2009; pp. 253–256. [Google Scholar]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chavan, V.D.; Bharate, A.A. A Review Paper on Face Detection and Recognition in Video. Int. J. Innov. Res. Electr. Electron. Instrum. Control Eng. 2016, 4, 97–100. [Google Scholar] [CrossRef]
- Samadiani, N.; Huang, G.; Cai, B.; Luo, W.; Chi, C.H.; Xiang, Y.; He, J. A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data. Sensors 2019, 19, 1863. [Google Scholar] [CrossRef] [Green Version]
- Giles, C.L.; Kuhn, G.M.; Williams, R.J. Dynamic recurrent neural networks: Theory and applications. IEEE Trans. Neural Netw. 1994, 5, 153–156. [Google Scholar] [CrossRef]
- Mandic, D.; Chambers, J. Recurrent Neural Networks for Prediction: Learning Algorithms, Architectures and Stability; Wiley: Hoboken, NJ, USA, 2001. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Patraucean, V.; Handa, A.; Cipolla, R. Spatio-temporal video autoencoder with differentiable memory. arXiv 2015, arXiv:1511.06309. [Google Scholar]
- Chong, Y.S.; Tay, Y.H. Abnormal event detection in videos using spatiotemporal autoencoder. In Lecture Notes in Computer Science, Proceedings of the International Symposium on Neural Networks, Hokkaido, Japan, 21–26 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 189–196. [Google Scholar]
- Zhao, Y.; Deng, B.; Shen, C.; Liu, Y.; Lu, H.; Hua, X.S. Spatio-temporal autoencoder for video anomaly detection. In Proceedings of the 25th ACM International Conference on Multimedia, New York, NY, USA, 23–27 October 2017; pp. 1933–1941. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 7–9 December 2017; pp. 5998–6008. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. arXiv 2021, arXiv:2103.15691. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Chapel, M.; Bouwmans, T. Moving Objects Detection with a Moving Camera: A Comprehensive Review. Comput. Sci. Rev. 2020, 38, 100310. [Google Scholar] [CrossRef]
- Zhu, H.; Wei, H.; Li, B.; Yuan, X.; Kehtarnavaz, N. Real-time moving object detection in high-resolution video sensing. Sensors 2020, 20, 3591. [Google Scholar] [CrossRef]
- Yazdi, M.; Bouwmans, T. New trends on moving object detection in video images captured by a moving camera: A survey. Comput. Sci. Rev. 2018, 28, 157–177. [Google Scholar] [CrossRef]
- Liu, H.; Meng, W.; Liu, Z. Key frame extraction of online video based on optimized frame difference. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery, Chongqing, China, 15 January 2012; pp. 1238–1242. [Google Scholar]
- Lei, M.; Geng, J. Fusion of Three-frame Difference Method and Background Difference Method to Achieve Infrared Human Target Detection. In Proceedings of the IEEE 1st International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Kunming, China, 17–19 October 2019; pp. 381–384. [Google Scholar]
- Srinivasan, K.; Porkumaran, K.; Sainarayanan, G. Improved background subtraction techniques for security in video applications. In Proceedings of the 3rd International Conference on Anti-Counterfeiting, Security, and Identification in Communication, Hong Kong, China, 20–22 August 2009; pp. 114–117. [Google Scholar]
- Mohamed, S.S.; Tahir, N.M.; Adnan, R. Background modelling and background subtraction performance for object detection. In Proceedings of the 2010 6th International Colloquium on Signal Processing & Its Applications, Malacca City, Malaysia, 21–23 May 2010; pp. 1–6. [Google Scholar]
- Xu, D.; Xie, W.; Zisserman, A. Geometry-Aware Video Object Detection for Static Cameras. arXiv 2019, arXiv:1909.03140. [Google Scholar]
- Rehman Butt, W.U.; Servin, M.; Samara, K.; Al Rahman, E.A.; Kouki, S.; Bouchahma, M. Static and Moving Object Detection and Segmentation in Videos. In Proceedings of the 2019 Sixth HCT Information Technology Trends (ITT), Ras Al Khaimah, United Arab Emirates, 20–21 November 2019; pp. 197–201. [Google Scholar]
- Ariffa Begum, S.; Askarunisa, A. Performance Analysis of Machine Learning Classification Algorithms in Static Object Detection for Video Surveillance Applications. Wirel. Pers. Commun. 2020, 115, 1291–1307. [Google Scholar] [CrossRef]
- CAVIAR: Context Aware Vision Using Image-Based Active Recognition. 2006. Available online: https://homepages.inf.ed.ac.uk/rbf/CAVIAR (accessed on 7 April 2022).
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Meyerhoff, H.S.; Papenmeier, F.; Huff, M. Studying visual attention using the multiple object tracking paradigm: A tutorial review. Atten. Percept. Psychophys 2017, 79, 1255–1274. [Google Scholar] [CrossRef]
- Isupova, O.; Kuzin, D.; Mihaylova, L. Learning Methods for Dynamic Topic Modeling in Automated Behavior Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3980–3993. [Google Scholar] [CrossRef] [Green Version]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.N.; Lee, B.A. A Survey of Modern Deep Learning based Object Detection Models. arXiv 2021, arXiv:2104.11892. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Shah, A.P.; Lamare, J.B.; Nguyen-Anh, T.; Hauptmann, A. CADP: A Novel Dataset for CCTV Traffic Camera Based Accident Analysis. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–9. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 1–26 July 2016; pp. 779–788. [Google Scholar]
- Prakash, U.M.; Thamaraiselvi, V.G. Detecting and tracking of multiple moving objects for intelligent video surveillance systems. In Proceedings of the Second International Conference on Current Trends In Engineering and Technology—ICCTET 2014, Coimbatore, India, 8 July 2014; pp. 253–257. [Google Scholar]
- Mask Dataset. Available online: https://makeml.app/datasets/mask (accessed on 7 April 2022).
- Al-Obaydy, W.N.I.; Suandi, S.A. Open-Set Face Recognition in Video Surveillance: A Survey. In InECCE2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 425–436. [Google Scholar]
- How Facial Recognition Could Replace Train Tickets. 2017. Available online: https://www.bbc.co.uk/news/av/technology-40676084 (accessed on 7 April 2022).
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep Learning for Person Re-identification: A Survey and Outlook. Image Vis. Comput. 2022, 119, 104394. [Google Scholar] [CrossRef]
- Wang, H.; Hu, J.; Zhang, G. Multi-source transfer network for cross domain person re-identification. IEEE Access 2020, 8, 83265–83275. [Google Scholar] [CrossRef]
- Sekh, A.A.; Dogra, D.P.; Choi, H.; Chae, S.; Kim, I.J. Person Re-identification in Videos by Analyzing Spatio-temporal Tubes. Multimed. Tools Appl. 2020, 79, 24537–24551. [Google Scholar] [CrossRef]
- Wu, L.F.; Wang, Q.; Jian, M.; Qiao, Y.; Zhao, B.X. A Comprehensive Review of Group Activity Recognition in Videos. Int. J. Autom. Comput. 2021, 18, 334–350. [Google Scholar] [CrossRef]
- Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Sierra, B.; Rodriguez, I.; Jauregi, E. Video Activity Recognition: State-of-the-art. Sensors 2019, 19, 3160. [Google Scholar] [CrossRef] [Green Version]
- Hosmer, P. i-LIDS bag and vehicle detection challenge. In Proceedings of the 2007 IEEE International Conference on Advanced Video and Signal based Surveillance (AVSS 2007), London, UK, 5–7 September 2007; Available online: http://www.eecs.qmul.ac.uk/~andrea/avss2007_ss_challenge.html (accessed on 7 April 2022).
- Van Beeck, K.; Van Engeland, K.; Vennekens, J.; Goedemé, T. Abnormal Behavior Detection in LWIR Surveillance of Railway Platforms. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Geng, X.; Li, G.; Ye, Y.; Tu, Y.; Dai, H. Abnormal Behavior Detection for Early Warning of Terrorist Attack. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1002–1009. [Google Scholar]
- Zhu, S.; Chen, C.; Sultani, W. Video Anomaly Detection for Smart Surveillance. arXiv 2020, arXiv:2004.00222. [Google Scholar]
- Mohammadi, B.; Fathy, M.; Sabokrou, M. Image/Video Deep Anomaly Detection: A Survey. arXiv 2021, arXiv:2103.01739. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning Temporal Regularity in Video Sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 1–26 June 2016; pp. 733–742. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. Remembering History with Convolutional Lstm for Anomaly Detection. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 439–444. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.V.D. Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 1705–1714. [Google Scholar]
- Mescheder, L.; Nowozin, S.; Geiger, A. Adversarial variational bayes: Unifying variational autoencoders and generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, International Convention Centre, Sydney, Australia, 6–11 August 2017; pp. 2391–2400. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Nishino, K.; Inaba, M. Bayesian AutoEncoder: Generation of Bayesian networks with hidden nodes for features. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Ye, M.; Peng, X.; Gan, W.; Wu, W.; Qiao, Y. Anopcn: Video Anomaly Detection via Deep Predictive Coding Network. In Proceedings of the 27th ACM International Conference on Multimedia, New York, NY, USA, 21–25 October 2019; pp. 1805–1813. [Google Scholar]
- Anjum, N.; Cavallaro, A. Unsupervised Fuzzy Clustering for Trajectory Analysis. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; Volume 3, pp. III-213–III-216. [Google Scholar]
- Zhang, H.; Ma, L.; Qian, L. Trajectory optimization by Gauss pseudospectral method and it’s realization in flight. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 1007–1012. [Google Scholar]
- Jin, Z.; Bhanu, B. Analysis-by-synthesis: Pedestrian tracking with crowd simulation models in a multi-camera video network. Comput. Vis. Image Underst. 2015, 134, 48–63. [Google Scholar] [CrossRef] [Green Version]
- Haghani, M.; Sarvi, M. Crowd behaviour and motion: Empirical methods. Transp. Res. Part Methodol. 2018, 107, 253–294. [Google Scholar] [CrossRef]
- Ahmed, S.A.; Dogra, D.P.; Kar, S.; Roy, P.P. Surveillance Scene Representation and Trajectory Abnormality Detection Using Aggregation of Multiple Concepts. Expert Syst. Appl. 2018, 101, 43–55. [Google Scholar] [CrossRef]
- Solmaz, B.; Moore, B.E.; Shah, M. Identifying Behaviors in Crowd Scenes Using Stability Analysis for Dynamical Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2064–2070. [Google Scholar] [CrossRef]
- Yuan, Y.; Feng, Y.; Lu, X. Structured Dictionary Learning for Abnormal Event Detection in Crowded Scenes. Pattern Recognit. 2018, 73, 99–110. [Google Scholar] [CrossRef]
- Wang, H.; Yeung, D.Y. A survey on Bayesian deep learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Hüllermeier, E.; Waegeman, W. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Mach. Learn. 2021, 110, 457–506. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Khosravi, A.; Acharya, U.R.; Makarenkov, V.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 75, 243–297. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? arXiv 2017, arXiv:1703.04977. [Google Scholar]
- Kwon, Y.; Won, J.-H.; Kim, B.J.; Paik, M.C. Uncertainty quantification using Bayesian neural networks in classification: Application to biomedical image segmentation. Comput. Stat. Data Anal. 2020, 142, 106816. [Google Scholar] [CrossRef]
- Shukla, S.N.; Sahu, A.K.; Willmott, D.; Kolter, J.Z. Black-box adversarial attacks with bayesian optimization. arXiv 2019, arXiv:1909.13857. [Google Scholar]
- Su, L.; Vaidya, N.H. Defending non-Bayesian learning against adversarial attacks. Distrib. Comput. 2019, 32, 277–289. [Google Scholar] [CrossRef] [Green Version]
- Wan, X.; Kenlay, H.; Ru, R.; Blaas, A.; Osborne, M.; Dong, X. Adversarial Attacks on Graph Classifiers via Bayesian Optimisation. Adv. Neural Inf. Process. Syst. 2021, 34, 6983–6996. [Google Scholar]
- Ye, N.; Zhu, Z. Bayesian adversarial learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 6892–6901. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–11. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Google AI Blog: Introducing the Unrestricted Adversarial Examples Challenge. Available online: https://ai.googleblog.com/2018/09/introducing-unrestricted-adversarial.html (accessed on 7 April 2022).
- Qiu, S.; Liu, Q.; Zhou, S.; Wu, C. Review of artificial intelligence adversarial attack and defense technologies. Appl. Sci. 2019, 9, 909. [Google Scholar] [CrossRef] [Green Version]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–28. [Google Scholar]
- Quilty, B.J.; Clifford, S.; CMMID nCoV Working Group; Flasche, S.; Eggo, R.M. Effectiveness of airport screening at detecting travellers infected with novel coronavirus (2019-nCoV). Euro Surveill. Bull. Eur. Sur Les Mal. Transm. 2020, 25, 2000080. [Google Scholar] [CrossRef]
- Index Page. 2022. Available online: https://cvd.lti.cmu.edu (accessed on 7 April 2022).
- Covid-19 Sounds App—University of Cambridge. 2022. Available online: https://www.covid-19-sounds.org/en (accessed on 7 April 2022).
- Deshpande, G.; Schuller, B. An Overview on Audio, Signal, Speech, & Language Processing for COVID-19. arXiv 2020, arXiv:2005.08579. [Google Scholar]
- Wang, Z.; Wang, G.; Huang, B.; Xiong, Z.; Hong, Q.; Wu, H.; Yi, P.; Jiang, K.; Wang, N.; Pei, Y.; et al. Masked Face Recognition Dataset and Application. arXiv 2020, arXiv:2003.09093. [Google Scholar]
- Jiang, M.; Fan, X. RetinaMask: A Face Mask detector. arXiv 2020, arXiv:2005.03950. [Google Scholar]
- Schuller, B.W.; Batliner, A.; Bergler, C.; Messner, E.M.; Hamilton, A.; Amiriparian, S.; Baird, A.; Rizos, G.; Schmitt, M.; Stappen, L.; et al. The Interspeech 2020 Computational Paralinguistics Challenge: Elderly Emotion, Breathing & Masks. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020. [Google Scholar]
- David, J. A practical Bayesian framework for backprop networks. Neural Comput. 1992, 4, 448–472. [Google Scholar]
- Bai, S.; He, Z.; Lei, Y.; Wu, W.; Zhu, C.; Sun, M.; Yan, J. Traffic Anomaly Detection via Perspective Map based on Spatial-temporal Information Matrix. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 117–124. [Google Scholar]
- Taha, A.; Chen, Y.T.; Misu, T.; Shrivastava, A.; Davis, L. Unsupervised data uncertainty learning in visual retrieval systems. arXiv 2019, arXiv:1902.02586. [Google Scholar]
- Asai, A.; Ikami, D.; Aizawa, K. Multi-Task Learning based on Separable Formulation of Depth Estimation and its Uncertainty. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 21–24. [Google Scholar]
- Liu, C.; Gu, J.; Kim, K.; Narasimhan, S.G.; Kautz, J. Neural rgb (r) d sensing: Depth and uncertainty from a video camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10986–10995. [Google Scholar]
- Postels, J.; Ferroni, F.; Coskun, H.; Navab, N.; Tombari, F. Sampling-free epistemic uncertainty estimation using approximated variance propagation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2931–2940. [Google Scholar]
- Gast, J.; Roth, S. Lightweight probabilistic deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3369–3378. [Google Scholar]
- Gundavarapu, N.B.; Srivastava, D.; Mitra, R.; Sharma, A.; Jain, A. Structured Aleatoric Uncertainty in Human Pose Estimation. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; Volume 2, p. 2. [Google Scholar]
- Ul Abideen, Z.; Ghafoor, M.; Munir, K.; Saqib, M.; Ullah, A.; Zia, T.; Tariq, S.A.; Ahmed, G.; Zahra, A. Uncertainty Assisted Robust Tuberculosis Identification With Bayesian Convolutional Neural Networks. IEEE Access 2020, 8, 22812–22825. [Google Scholar] [CrossRef]
- Park, J.G.; Jo, S. Bayesian Weight Decay on Bounded Approximation for Deep Convolutional Neural Networks. IEEE Trans. Neural. Netw. Learn Syst. 2019, 30, 2866–2875. [Google Scholar] [CrossRef]
- Zafar, U.; Ghafoor, M.; Zia, T.; Ahmed, G.; Latif, A.; Malik, K.R.; Sharif, A.M. Face Recognition with Bayesian Convolutional Networks for Robust Surveillance Systems. EURASIP J. Image Video Process. 2019, 2019, 10. [Google Scholar] [CrossRef] [Green Version]
- Gal, Y.; Ghahramani, Z. Bayesian convolutional neural networks with Bernoulli approximate variational inference. arXiv 2015, arXiv:1506.02158. [Google Scholar]
- Murray, S.M. An Exploratory Analysis of Multi-Class Uncertainty Approximation in Bayesian Convolutional Neural Networks. Master’s Thesis, The University of Bergen, Bergen, Norway, 2018. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Networks. arXiv 2015, arXiv:1505.05424. [Google Scholar]
- Kingma, D.P.; Salimans, T.; Welling, M. Variational Dropout and the Local Reparameterization Trick. arXiv 2015, arXiv:1506.02557. [Google Scholar]
- Shridhar, K.; Laumann, F.; Liwicki, M. A comprehensive guide to bayesian convolutional neural network with variational inference. arXiv 2019, arXiv:1901.02731. [Google Scholar]
- Shridhar, K.; Laumann, F.; Liwicki, M. Uncertainty estimations by softplus normalization in bayesian convolutional neural networks with variational inference. arXiv 2018, arXiv:1806.05978. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. arXiv 2015, arXiv:1506.02142. [Google Scholar]
- Nalisnick, E.; Smyth, P. Stick-breaking variational autoencoders. arXiv 2016, arXiv:1605.06197. [Google Scholar]
- Wang, H.; Shi, X.; Yeung, D.Y. Natural-parameter networks: A class of probabilistic neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Saatci, Y.; Wilson, A.G. Bayesian GAN. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- He, H.; Wang, H.; Lee, G.H.; Tian, Y. Probgan: Towards probabilistic gan with theoretical guarantees. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 Apri–3 May 2018. [Google Scholar]
- Daxberger, E.; Nalisnick, E.; Allingham, J.U.; Antorán, J.; Hernández-Lobato, J.M. Bayesian deep learning via subnetwork inference. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 2510–2521. [Google Scholar]
- Dorta, G.; Vicente, S.; Agapito, L.; Campbell, N.D.; Simpson, I. Structured uncertainty prediction networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18—22 June 2018; pp. 5477–5485. [Google Scholar]
- Harakeh, A.; Smart, M.; Waslander, S.L. Bayesod: A bayesian approach for uncertainty estimation in deep object detectors. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 87–93. [Google Scholar]
- Le, M.T.; Diehl, F.; Brunner, T.; Knol, A. Uncertainty Estimation for Deep Neural Object Detectors in Safety-Critical Applications. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3873–3878. [Google Scholar] [CrossRef] [Green Version]
- Huang, P.Y.; Hsu, W.T.; Chiu, C.Y.; Wu, T.F.; Sun, M. Efficient uncertainty estimation for semantic segmentation in videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 520–535. [Google Scholar]
- Pascual, G.; Seguí, S.; Vitria, J. Uncertainty gated network for land cover segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 276–279. [Google Scholar]
- Martinez, C.; Potter, K.M.; Smith, M.D.; Donahue, E.A.; Collins, L.; Korbin, J.P.; Roberts, S.A. Segmentation certainty through uncertainty: Uncertainty-refined binary volumetric segmentation under multifactor domain shift. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ilg, E.; Çiçek, Ö.; Galesso, S.; Klein, A.; Makansi, O.; Hutter, F.; Brox, T. Uncertainty estimates for optical flow with multi-hypotheses networks. arXiv 2018, arXiv:1802.07095. [Google Scholar]
- Loquercio, A.; Segu, M.; Scaramuzza, D. A general framework for uncertainty estimation in deep learning. IEEE Robot. Autom. Lett. 2020, 5, 3153–3160. [Google Scholar] [CrossRef] [Green Version]
- Bertoni, L.; Kreiss, S.; Alahi, A. Monoloco: Monocular 3d pedestrian localization and uncertainty estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6861–6871. [Google Scholar]
- Prokudin, S.; Gehler, P.; Nowozin, S. Deep directional statistics: Pose estimation with uncertainty quantification. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 534–551. [Google Scholar]
- Yu, T.; Li, D.; Yang, Y.; Hospedales, T.M.; Xiang, T. Robust person re-identification by modelling feature uncertainty. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 552–561. [Google Scholar]
- Zheng, J. Augmented Deep Representations for Unconstrained Still/Video-Based Face Recognition. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2019. [Google Scholar]
- Peterson, J.C.; Battleday, R.M.; Griffiths, T.L.; Russakovsky, O. Human uncertainty makes classification more robust. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9617–9626. [Google Scholar]
- Carbone, G.; Wicker, M.; Laurenti, L.; Patane, A.; Bortolussi, L.; Sanguinetti, G. Robustness of bayesian neural networks to gradient-based attacks. arXiv 2020, arXiv:2002.04359. [Google Scholar]
- RDG’s Policing & Security Implementation Group. National Rail & Underground Closed Circuit Television (CCTV) Guidance Document; Technical Report; Rail Delivery Group: London, UK, 2015; Available online: https://www.raildeliverygroup.com/media-centre-docman/archive/384-2015-10-national-rail-underground-cctv-guidance/file.html (accessed on 7 April 2022).
- hAnnaidh, B.O.; Fitzgerald, P.; Berney, H.; Lakshmanan, R.; Coburn, N.; Geary, S.; Mulvey, B. Devices and Sensors Applicable to 5G System Implementations. In Proceedings of the Proc. of the IEEE MTT-S International Microwave Workshop Series on 5G Hardware and System Technologies (IMWS-5G), Dublin, Ireland, 30–31 August 2018; pp. 1–3. [Google Scholar]
- Kim, H.; Cha, Y.; Kim, T.; Kim, P. A Study on the Security Threats and Privacy Policy of Intelligent Video Surveillance System Considering 5G Network Architecture. In Proceedings of the 2020 International Conference on Electronics, Information, and Communication (ICEIC), Barcelona, Spain, 19–22 January 2020; pp. 1–4. [Google Scholar]
- Ben Mabrouk, A.; Zagrouba, E. Abnormal Behavior Recognition for Intelligent Video Surveillance Systems: A Review. Expert Syst. Appl. 2018, 91, 480–491. [Google Scholar] [CrossRef]
- Ribeiro, M.; Lazzaretti, A.E.; Lopes, H.S. A Study of Deep Convolutional Auto-Encoders for Anomaly Detection in Videos. Pattern Recognit. Lett. 2018, 105, 13–22. [Google Scholar] [CrossRef]
- Milgram, P.; Takemura, H.; Utsumi, A.; Kishino, F. Augmented reality: A class of displays on the reality-virtuality continuum. In Proceedings of the Telemanipulator and Telepresence Technologies, International Society for Optics and Photonics, Bellingham, WA, USA, 21 December 1995; Volume 2351, pp. 282–292. [Google Scholar]
- Xie, Y.; Wang, M.; Liu, X.; Mao, B.; Wang, F. Integration of Multi-Camera Video Moving Objects and GIS. ISPRS Int. J. Geo-Inf. 2019, 8, 561. [Google Scholar] [CrossRef] [Green Version]
- Brey, P. Ethical Aspects of Information Security and Privacy. In Security, Privacy, and Trust in Modern Data Management; Petković, M., Jonker, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 21–36. [Google Scholar] [CrossRef]
- Sharon, T.; Koops, B.J. The ethics of inattention: Revitalising civil inattention as a privacy-protecting mechanism in public spaces. Ethics Inf. Technol. 2021, 23, 331–343. [Google Scholar] [CrossRef]
- Chang, V. An ethical framework for big data and smart cities. Technol. Forecast. Soc. Chang. 2021, 165, 120559. [Google Scholar] [CrossRef]
- Boyer, M.; Veigl, S. Privacy preserving video surveillance infrastructure with particular regard to modular video analytics. In Proceedings of the 6th International Conference on Imaging for Crime Prevention and Detection (ICDP-15), London, UK, 15–17 July 2015. [Google Scholar]
- McStay, A. Emotional AI, soft biometrics and the surveillance of emotional life: An unusual consensus on privacy. Big Data Soc. 2020, 7, 2053951720904386. [Google Scholar] [CrossRef] [Green Version]
- Šidlauskas, A. Video Surveillance and the GDPR. Soc. Transform. Contemp. Soc. Open J. 2019, 7, 55–65. [Google Scholar]
- Denham, E. Information Commissioner’s Opinion: The Use of Live Facial Recognition Technology by Law Enforcement in Public Places; Technical Report 2019/01; Information Commissioner’s Office: Wilmslow, UK, 2019. [Google Scholar]
- Steel, A.; Olive, A. R Bridges v Chief Constable South Wales Police and Information Commissioner; Technical Report Citation Number: [2020] EWCA Civ 1058; Royal Courts of Justice: London, UK, 2020. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computer Vision Techniques Used in Rail Networks Surveillance | Number of Publications Shown in Google Scholar |
|---|---|
| Motion or Moving Object Detection | 83 |
| Video Face Recognition | 137 |
| Person Re-Identification | 6250 |
| Human Activity Recognition | 6160 |
| Video Anomaly Detection | 1060 |
| Trajectory Analysis | 1440 |
| Crowd Analysis | 1500 |
| Feature | Options | Pros/Cons |
|---|---|---|
| Connectivity Type | Analogue | Analogue point to point connection. Low-cost solution when upgrading conventional (analogue) CCTV system. Secure against cyber security threats. |
| Digital | Digital (IP) interface. Flexible point to multipoint connection. High-cost solution when upgrading conventional CCTV system. Vulnerable to cyber security threats. | |
| Connectivity Medium | Wired | Secure against cybersecurity intrusion. Less noise interference. |
| Wireless | Flexible in terms of installation. | |
| Field of view (FOV) | Fixed | Stationary mount. Monitor one small area of interest. |
| Pan-tilt-zoom (PTZ) camera | Monitor large area using automatic/remote controlled pan (left/right), tilt (up/down) and zoom (in/out). | |
| Lighting conditions | Day/night | Automatically adjust to light conditions. Coloured video during day and black and white at night. Used for conditions such as glare, direct sunlight, reflections and strong backlight. |
| Low light | Used in low light, e.g., indoor restaurants, streetlights, etc. Cannot be used in completely dark conditions. | |
| Night vision/ Fog/Smoke | Used in complete darkness. Detect through obstructions such as fog and smoke. These are either active infrared (IR) or thermal cameras. The IR cameras use built-in IR illuminators and near IR (NIR) and IR cameras for monitoring. The thermal cameras are passive and might not provide video through glass or water. Thermal cameras are more costly than IR cameras. | |
| Image sensor | Colour | Used in daylight or well-lit conditions. Provide accurate colours at the monitoring and recording systems. |
| Monochrome | Used in near dark situations and give more details than a naked human eye can perceive. Might give low contrast during the day. | |
| Housing | Dome | Spherical in shape to reduce wind and vibration effects. Protect and conceal camera direction. Some advanced units, called speed domes, rotate the camera and give an all around view. |
| Sealed | Used in hostile situations. All electrical components are sealed to avoid explosion hazards. | |
| Impact resistant | Military grade. Used in high crime areas. | |
| Tamper resistant | Similar to impact-resistant but are additionally protected against tool vandalism. Usually resistant to cutting, hammering and prying. | |
| Bullet resistant | Similar to impact-resistant with additional safety for the glass. | |
| Mount | Indoor | Wall. A bracket supports housing, and camera FOV is adjustable. Pendant. Suspend the camera from the ceiling. Corner. Used where two walls meet at the right angle (both interior and exterior). Dome. These are installed on the ceiling or other surfaces for dome type housings. These are susceptible to vibrations. |
| Outdoor | Pole. These are used for unobstructed FOV. Corner. These are installed where two walls meet at the right angle. The best FOV is achieved by installing it close to the roof. | |
| Image sensor | CCD | Stands for charged coupled devices. Used in daylight, lowlight and NIR cameras. Generate less heat. Susceptible to blooming (blooming is when a bright light source in the FOV hides some of the image details). Used for high resolution and quality images. |
| CMOS | Stands for Complementary Metal Oxide Semiconductor. Low power and suitable for mobile devices or power constraint environments. Cheaper. Better video quality in outdoor areas on a bright sunny day. | |
| Focal length (Lens) | Fixed | Used in fixed cameras for focusing on one area only. |
| Varifocal | Focal length can be varied in a range, and focus is manually adjusted. Capture close-ups of activities at longer distances. | |
| Zoom | Used in PTZ cameras. Focal length can be varied in a range, but the focus is automatically adjusted. | |
| Optical zoom factor | Optical zoom factor is calculated from the focal length range of the varifocal and zoom lens. For example, a range of 2–10 mm focal length represents a (10/2 =) 5× zoom factor. It does not mean 5 times enlargement of the image. | |
| Aperture control | Fixed | Suitable for constant lighting conditions. |
| Manual | Used for fixed cameras with controlled lighting. Less expensive as compared to the automatic. Requires a technician to operate. | |
| Automatic | Used in outdoor situations or where extreme changes in lighting conditions are expected. | |
| Aperture size | Large | Used in dim light conditions. Image fore- and background are out of focus and blurred in daylight. |
| Small | Complete scene will be in focus. | |
| Filter | Neutral Density (ND) | Control the level of visible light and reduce it when it is too high. |
| Polarising | Orient the light in a specific direction. Used to eliminate reflected light and glare. Improve image contrast. | |
| IR-cut | To control the NIR light sources such as the sun. Most image sensors are sensitive to NIR light. The NIR sources during the day can degrade the performance of image sensors. Without the IR-cut filter, the image will have unpredictable colours and poor contrast. |
| Options | Pros/Cons |
|---|---|
| External synchronization | The internal clock is synchronised to an external clock. It is important for any automation system, including CCTV, to have a synchronised clock. |
| Remote configuration | The cameras, especially the image properties, are remotely configurable. |
| Privacy masking | Selective blocking of private areas. |
| Covert cameras | These are hidden cameras and are preferably battery operated and wireless. |
| Dummy or drone cameras | These are non-functioning cameras and are installed for deterrence. |
| Auto scan of PTZ | Camera can perform automatic scanning of an area of interest. |
| Pre-set of PTZ | Camera orientation and lens setting can be programmed to scan/focus specific areas. |
| Slip ring PTZ | This allows the PTZ camera to rotate without twisting the cable. These are prone to contamination and temperature changes. |
| Motion detection | Camera can detect and provide alarm using built-in motion detection. |
| Backlight compensation (BLC) | The camera with BLC provides high-contrast images with a bright background. |
| Digital noise reduction (DNR) | The camera with DNR reduces the noise in the video. This noise is prominent in low-light or dark environments. |
| Mobile compatibility | The camera video can be viewed on a mobile device. The preferred choice is viewing without the installation of an additional application on the remote device. |
| Sun shields on housing | This protects the camera from direct sunlight, which can dramatically reduce the life of the camera. |
| Wipers on housing | These are similar to car windshield wipers. These are not recommended as they might erode the optical surface of the glass. |
| Heaters and ventilators for housing | Temperature differences between the interior and exterior of the housing can cause fog or icing on the glass. The heaters/ventilators help in maintaining the temperature inside the housing. |
| Smart camera | A smart camera is a small version of the CCTV system. It consists of a sensor, processor, video analytics and communication interface with a remote monitoring device. |
| Type of Display | Pros/Cons |
|---|---|
| Monochrome | Provides better details in some scenarios. |
| Plasma | Wider viewing angles. Higher contrast ratio. Higher black levels. |
| LCD | Compact and lightweight. Less power requirement. Low heat dissipation. Less prone to burn-in. No flicker. Long life. Low image contrast. True black colour is not produced. Restricted viewing angle. |
| LED | All benefits of the LCD. Better contrast. Wide colour range. Shorter life span. More expensive. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Aftab, W.; Mihaylova, L.; Langran-Wheeler, C.; Rigby, S.; Fletcher, D.; Maddock, S.; Bosworth, G. Recent Advances in Video Analytics for Rail Network Surveillance for Security, Trespass and Suicide Prevention—A Survey. Sensors 2022, 22, 4324. https://doi.org/10.3390/s22124324
Zhang T, Aftab W, Mihaylova L, Langran-Wheeler C, Rigby S, Fletcher D, Maddock S, Bosworth G. Recent Advances in Video Analytics for Rail Network Surveillance for Security, Trespass and Suicide Prevention—A Survey. Sensors. 2022; 22(12):4324. https://doi.org/10.3390/s22124324
Chicago/Turabian StyleZhang, Tianhao, Waqas Aftab, Lyudmila Mihaylova, Christian Langran-Wheeler, Samuel Rigby, David Fletcher, Steve Maddock, and Garry Bosworth. 2022. "Recent Advances in Video Analytics for Rail Network Surveillance for Security, Trespass and Suicide Prevention—A Survey" Sensors 22, no. 12: 4324. https://doi.org/10.3390/s22124324