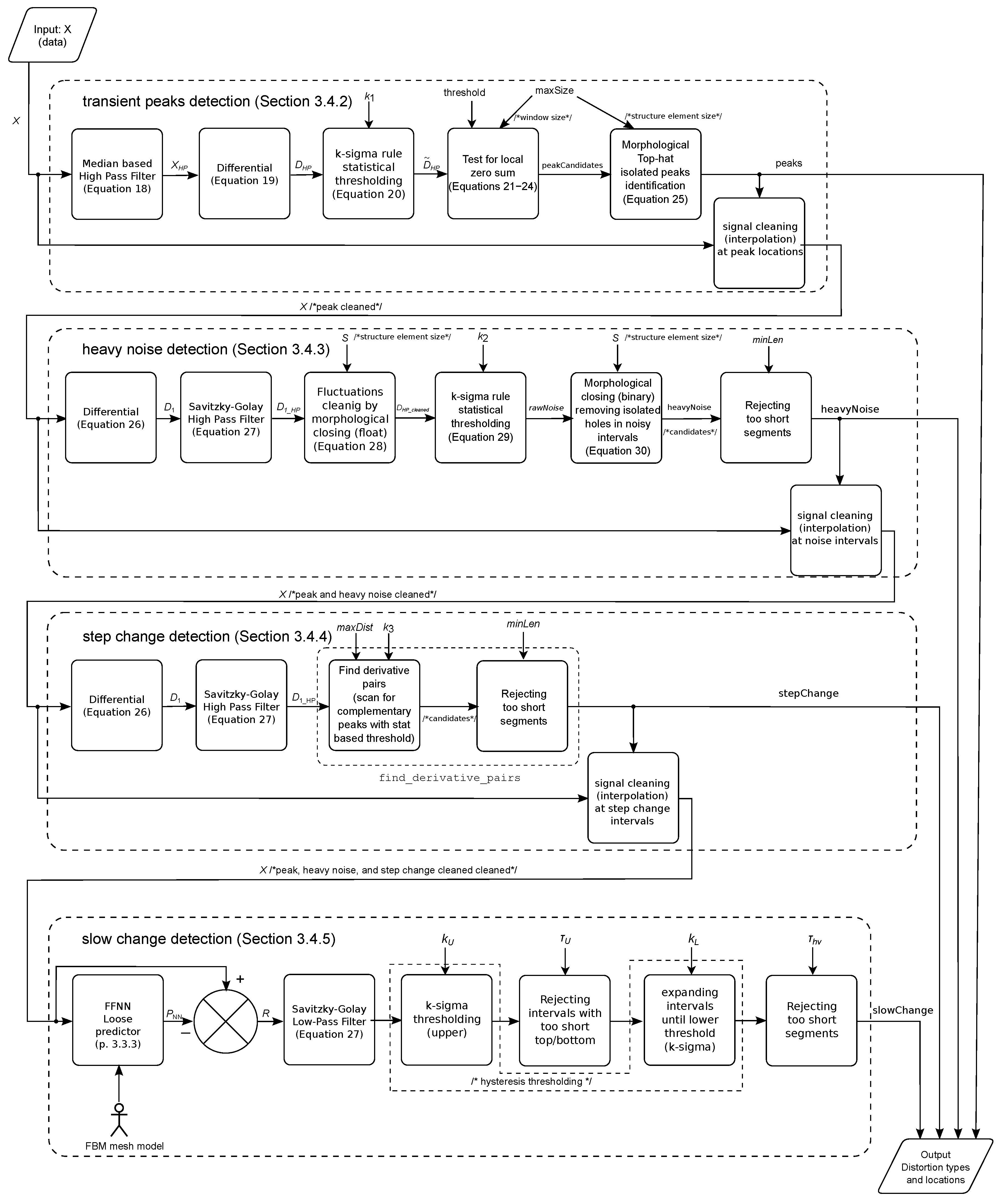
The outcomes of all three experiments are provided in the successive sub-paragraphs. They are accompanied by interpretations and discussions.
4.2.1. Synthetic Distortion Classification
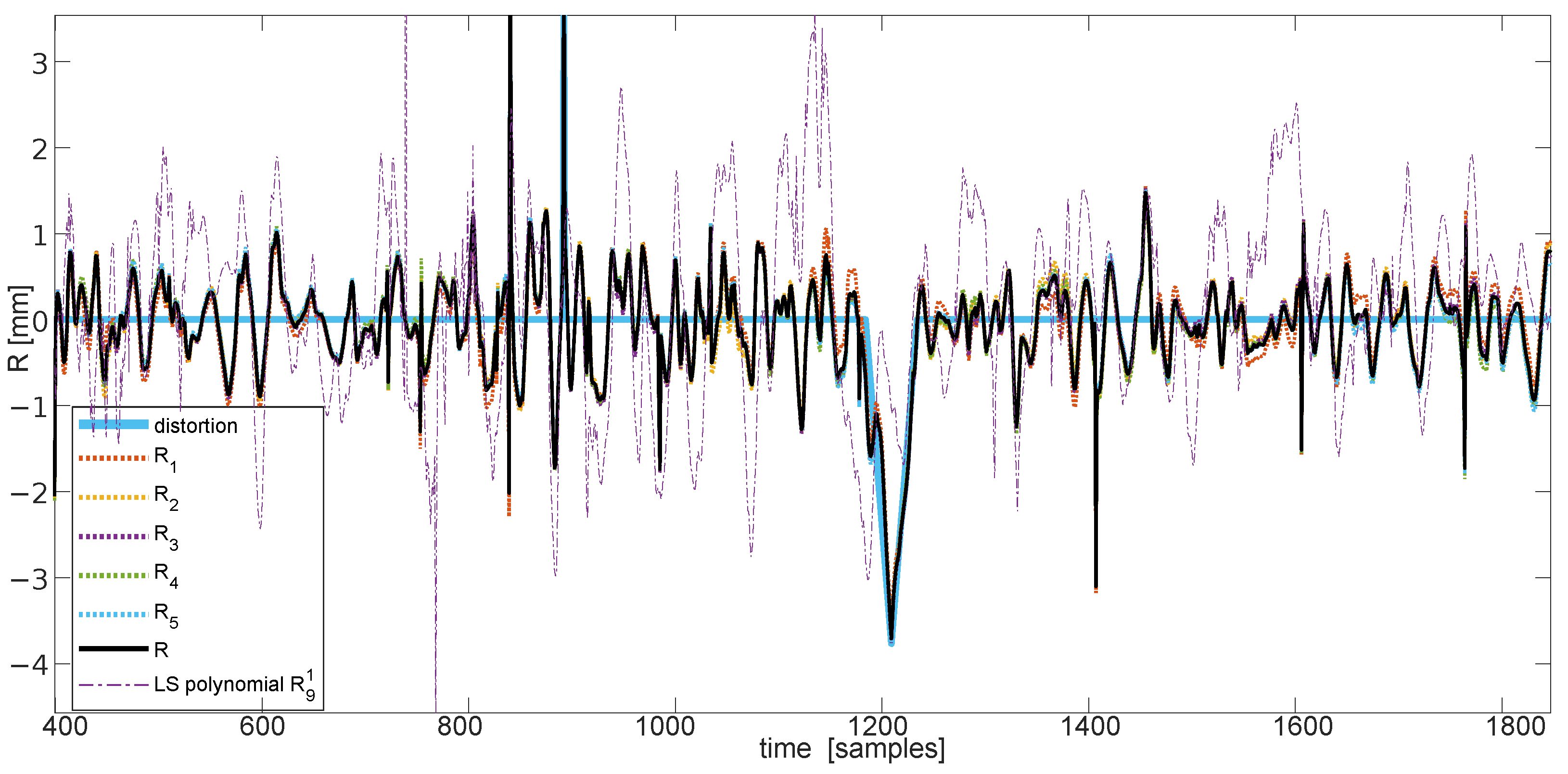
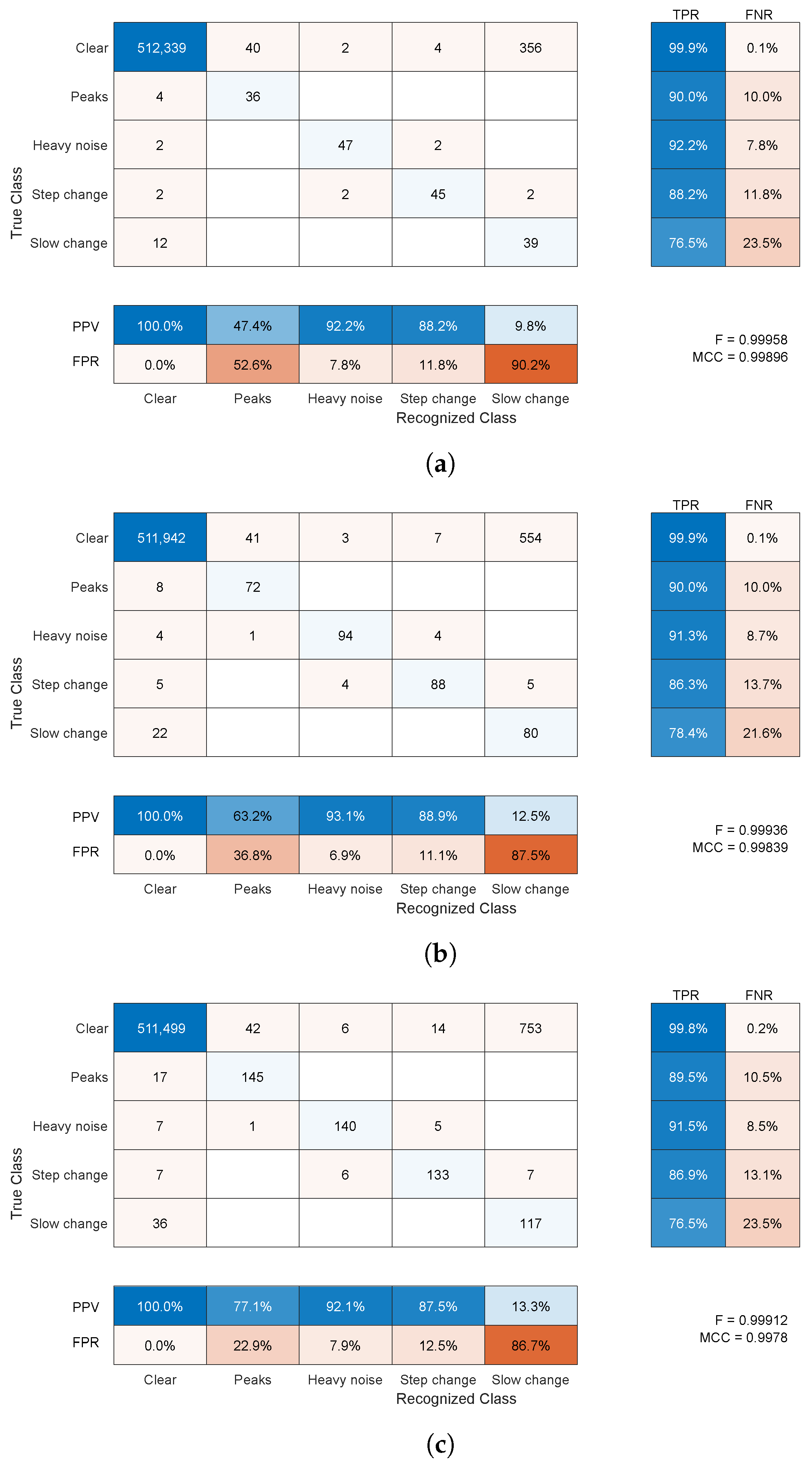
The classification for synthetic noise outcomes are demonstrated in
Figure 13 and
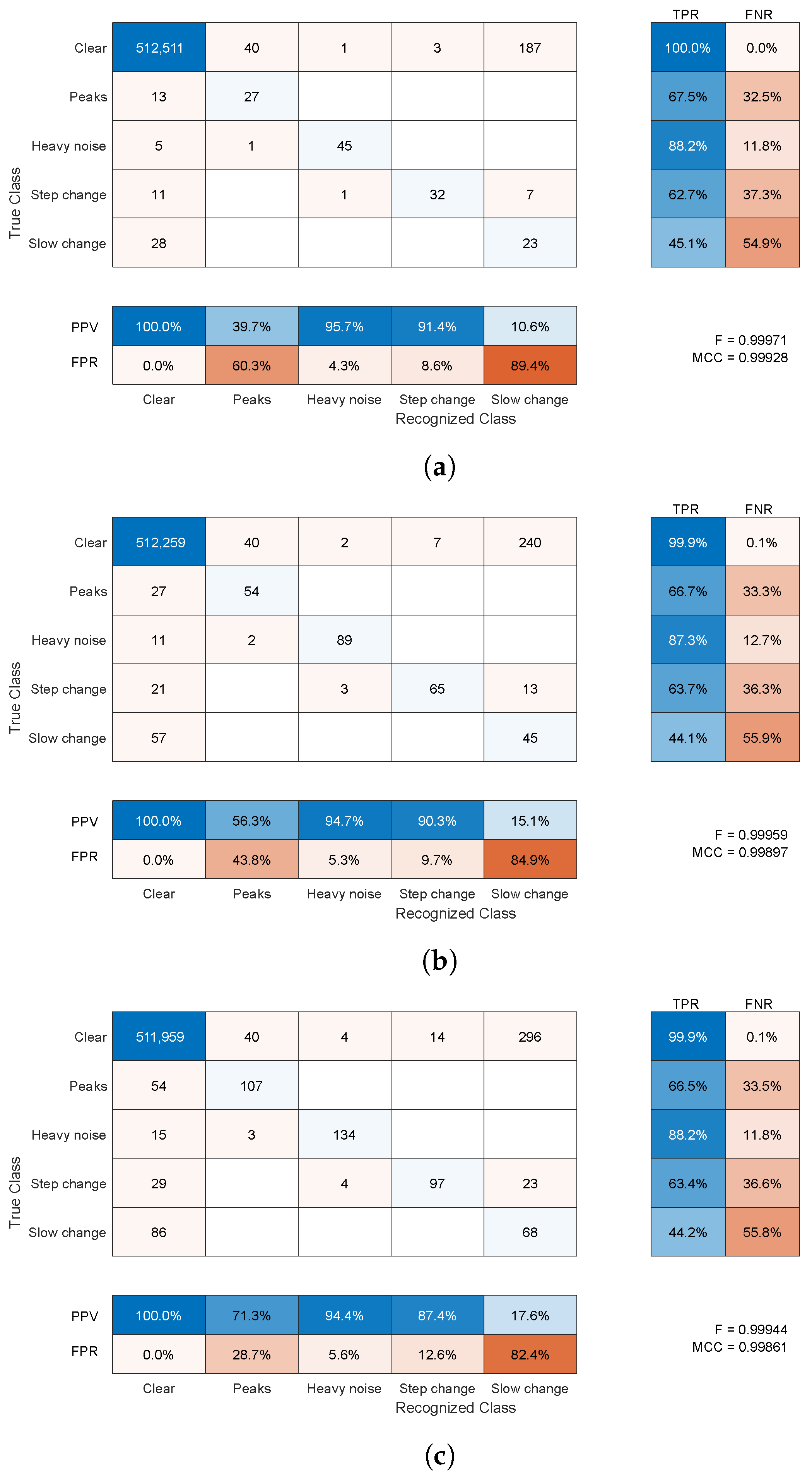
Figure 14 for average amplitudes of 5 and 10 mm, respectively. The raw results in confusion matrices demonstrate the average number of samples (rounded toward the whole sample) assigned to specific classes (correct or not) for 1000 simulations. They present averaged confusion matrices for three distortion shares 5%, 10%, and 20% of the overall time of the sequences with two average amplitudes—5 and 10 mm. According to the length of the recording in a simulation, the contamination procedure should produce approximately 160, 320, and 640 distorted samples, respectively, of each distortion type, and should be in equal proportions.
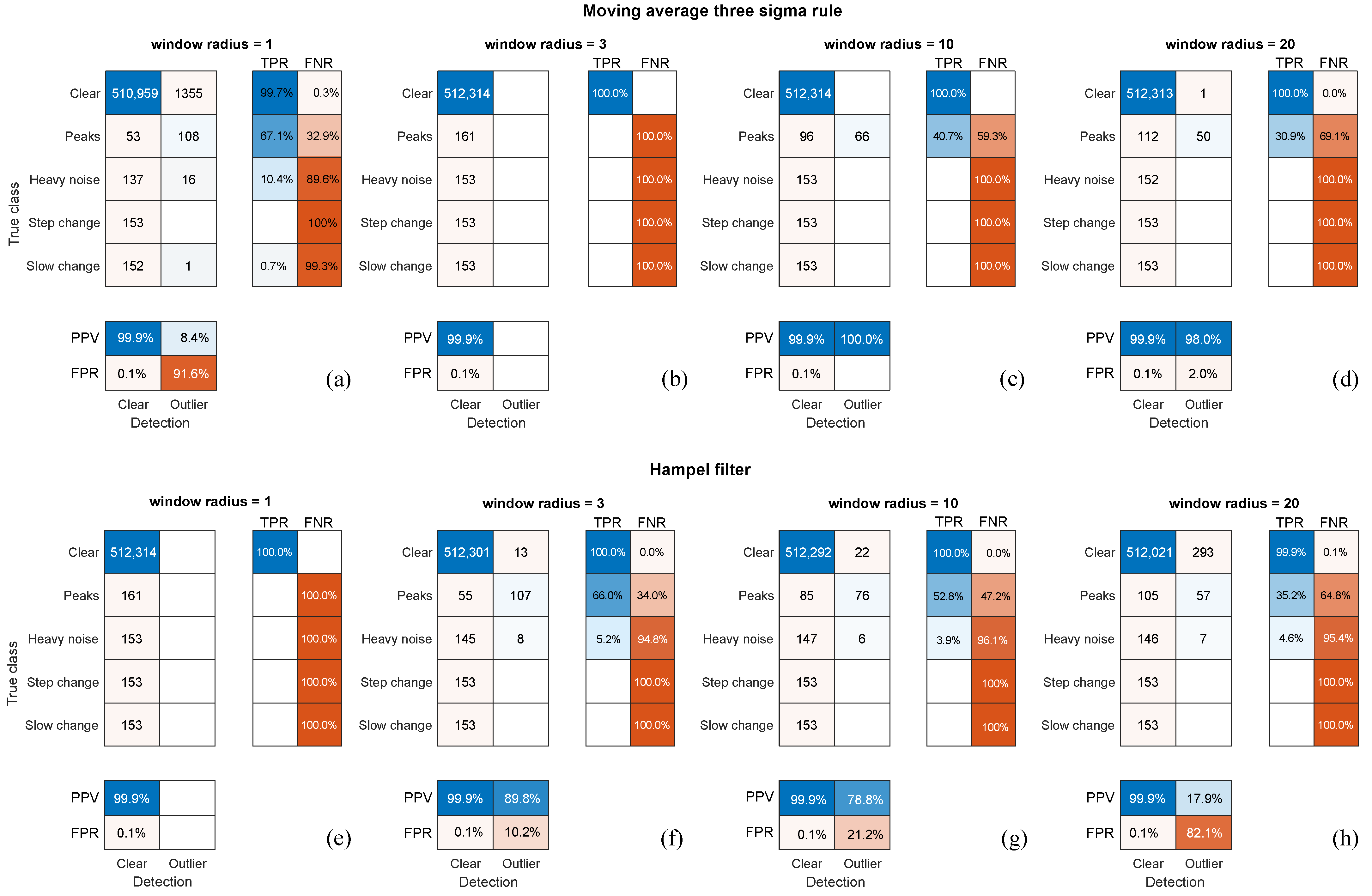
The comparative results for the generic anomaly detectors, HF and M3S in different configurations of the moving window, are demonstrated in
Figure 15 as confusion matrices. The true anomalies are subdivided into classes, whereas the output is binary, whether it is detected as an outlier or not. The figure presents only the best of the results for 10 mm of amplitude and a 20% share of distortions, so it should be compared with the results in
Figure 14c. We did not include the results for other distortion configurations, because they were either very similar (about recognition ratios) for 10 mm amplitudes or significantly worse for 5 mm.
Regardless of the number of distortions (shares), the results were pretty consistent; they were also very similar for numerous additional simulation runs, which are not included here. The fractions of true and false classifications hold across the runs. The same almost holds for F-scores and MCC values to a lesser extent. Therefore, the confusion matrix is the most informative presentation of results as it is near 0.999 for both amplitudes and all distortion shares—these large F-score/MCC values are due to the dominance of the properly classified clear signal samples. Nevertheless, they offer some insight into the results, with an increase in the share of distortions in the test sequence, we observe a very slight decrease in the classification performance expressed with the F-score/MCCs. These differences stem mainly from a slightly increased number of clear samples falsely classified as artifact-contaminated, since the classification rates remain on par between the artifact shares.
Each specific class requires separate insight into the results. These are as follows:
The clear signal was identified properly for more than 99% of samples; a negligibly small amount of distorted samples was erroneously identified as clean signals (compared to the overall cardinality of the class).
For the peak change, sensitivity was approximately 66% and 90%, and the main misclassification was in a clear signal; this class was not a cause of confusion for the other classes compared to a clean signal (usually below ).
Heavy noise sensitivity was above 88%; the main confusions were step change and a clear signal; this class was rarely erroneously recognized in place of the others ( = 4–8%); the main confused class was a clear signal.
For the step change, sensitivity was approximately 70% and the main confusion was slow change; this class was erroneously recognized in place of others at a moderate rate ( = 12–27%)—here, a clean signal and heavy noise were wrongly identified.
For the slow change, was a bit more than 50% and the main confusion was a clear signal; this class was often difficult and erroneously recognized in place of others ( = 80–90%)—usually, it was a clear signal, but a step change and heavy noise were also wrongly identified.
Considering the above results, the proposed method has moderate to high sensitivity (depending on the class) and quite high precision for all classes but one (slow change). False negative detection (having relatively small values) was way more undesirable than the others; this was notable from a practical point of view. False positive, or detecting a wrong class of the distortion, would still result in pointing out the operator to the potential error location, or in the case of automatic error filtering, it would lead to the use of a repair procedure (see
Section 4.2.3).
The difficulty in identification of slow change was expected; it comes from the fact that this change can be subtle and poorly distinguishable in predictor residuals, which resemble pink noise in our case. The latter is also a cause of high FPR. We analyzed alternative regression methods as a model—neural networks (simple FFNN and NARX-NN models), ridge, lasso, and SVR. However, the results were either poor or impractical (due to long training time), or both. On the other hand, a false positive error (quite frequent) is of much lesser importance than a false negative; the former might result in suggesting additional locations to the operator for reviewing, or using the interpolating method, which should not degrade the signal significantly; whereas the latter might result in preserving the distortion in the signal.
The comparison to the other anomaly detectors shows that the proposed solution outperforms these methods. In the best-tested configurations, they were capable to identify (as outliers) approximately 2/3 of peaks, and a small part (5–10%) of heavy noise-contaminated samples (usually the initial ones before the local variance or MAD value increased in the presence of the noise, so much that the thresholds did not intercept the noise anymore). The two other signal anomalies—step and slow change—remained invisible to these methods (excluding a single accidental case in M3S. Meanwhile, our approach (
Figure 14c) was capable of identifying approximately 90% of the first two anomalies and above 75% of the latter two, which were ‘invisible’ to the generic detectors.
Regarding false detections, in most cases (all but one), both the generic methods returned small numbers of false positive detections. We attributed this to the overall low sensitivity of these methods, and in cases when the detection rates were a bit higher, false positives were also elevated (
Figure 15a,f,g).
Both the M3S and Hampel filter are methods that consider each coordinate separately; therefore, they do not use inter-marker dependencies. This allowed us to identify individual anomalous coordinates. Regrettably, because of the latter, we had to reject the other (more sophisticated) methods of anomaly detection based on machine learning, such as clustering, one-class SVM, or autoencoders as insufficient. In their basic variants, they considered the whole frame of a recording as a single observation with coordinates as features. This implies that they could potentially point out anomalous frames in sequence, but they would not identify what marker/dimension is the problem. One might think of adopting such approaches to anomaly detections; however, it would require a separate in-depth study.
4.2.2. Comparing to Human Operators
Table 2 comprises the numbers of detected distortions in the recording processed in a standard pipeline, and the recording processed by each of the four operators. The detected distortions were compared and verified by human operators, who either approved the classifications or rejected them.
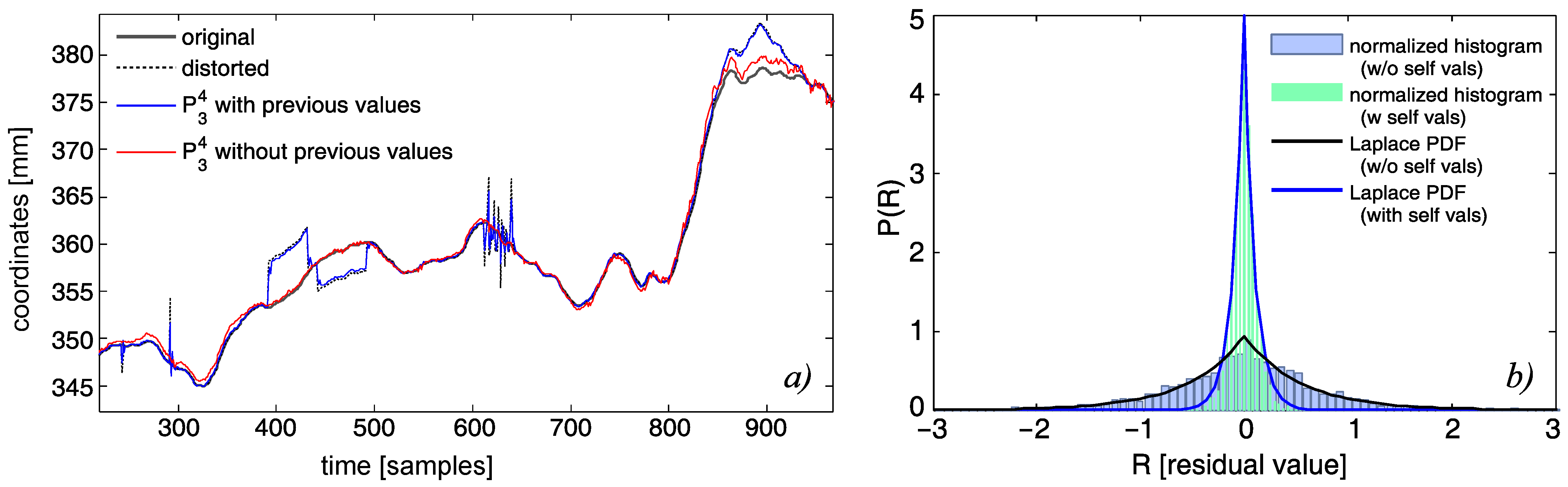
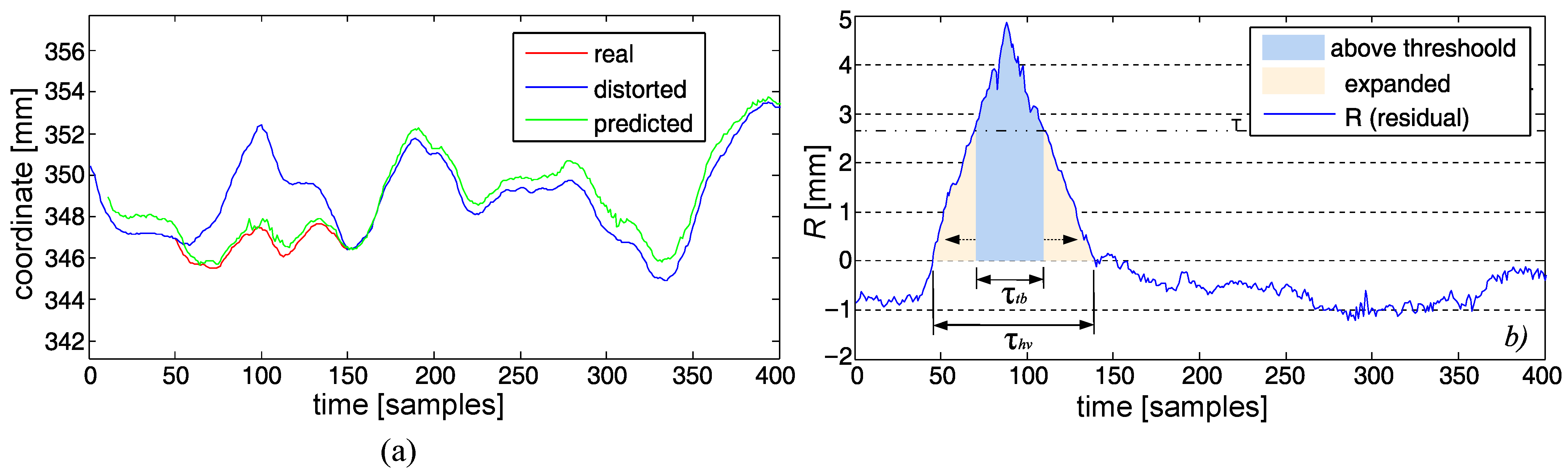
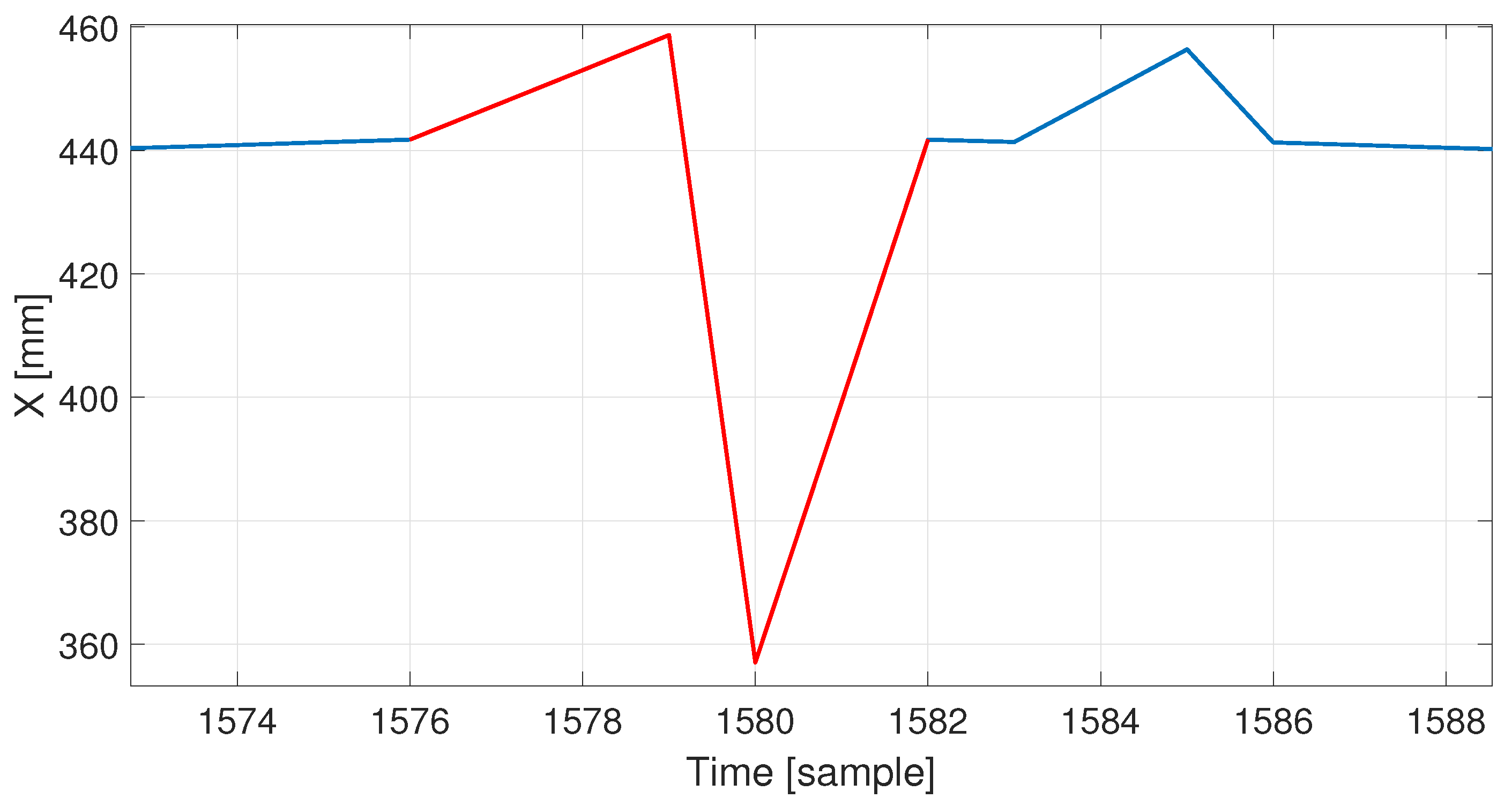
In the recording processed by the machine, the proposed algorithm found 29 errors—peaks, step, and slow changes; 16 of these errors were correctly classified. The algorithm classified sudden, very dynamic hand movements in a relatively static recording as slow changes (13 incorrectly classified errors). In addition, the algorithm did not detect four errors; after careful analysis, it turned out that these errors did not belong to any of the previously defined classes—they were a combination of a single peak and a slow change. An example of such an error is shown in
Figure 16. Such an artifact (having a relatively large amplitude) could be intercepted if the slow change detector had different parameters, but it would require setting up a smaller value for a minimal length of an artifact. It could result in an increased number of false positives for this class, as this parameter prevents false alerts of the short-term fluctuations of the NN predictor. It is worth mentioning that the slow change detector reacts properly for a mixed class of artifacts—step changes followed by slow relaxing to the proper trajectory (or slow error accumulation followed by immediate correction) do not cause detection for any of the detectors based on finding derivative pairs, but they properly trigger detection for the deviations from the predictor if they are long enough. In fact, all the deviations that are large and long enough would be identified as slow changes. It is a matter of human interpretation whether we can name them as slow; however, that name distinguishes them well from all of a sudden changes we identified based on the differential analysis.
In the recording processed by the expert, the algorithm again incorrectly classified the hand movements as slow changes. The result was similar for the intermediate operator, with the difference that the algorithm found two errors omitted by the human (two small peaks).
In the case of a recording repaired by beginners, both the algorithm and the expert found more errors after the repair than before. This was due to the selection of an inappropriate method of repairing a given artifact. For example, when the distortion occurred only on one axis, the person, in order to correct the error, removed the marker trajectory for those few frames when the error occurred. This resulted in the creation of an additional gap, which the beginner operator filled using simple interpolation. In the case of longer artificial gaps, interpolation caused the data to be incorrectly reconstructed, and the errors no longer appeared on one axis, but on all three.
4.2.3. Applicability Testing
The results are presented in
Table 3,
Table 4 and
Table 5. Each field presents the averaged
RMSE of a 200-fold repeated simulation process, distorting the test sequence and its reconstruction using various procedures. Each distortion type was considered separately. It allowed us to quantify how each reconstruction method reduced the distortion.
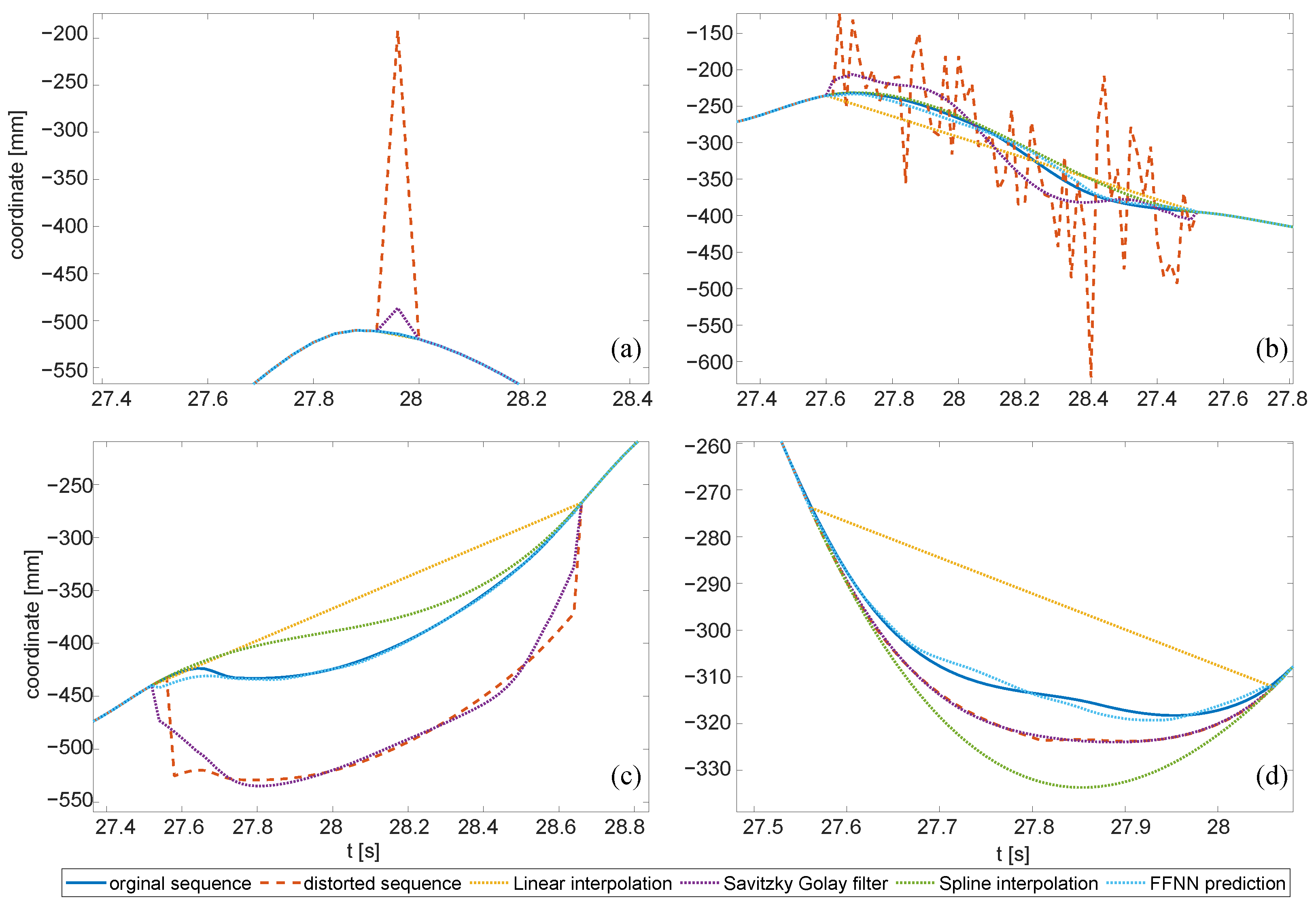
Figure 17 illustrates the reconstruction results, demonstrating the ground truth, distorted signal value, and outcomes of four variants of reconstruction. In the tables, for each distortion type and reconstruction method, we compare two
RMSE values: hypothetical perfect classification and actual classification with the proposed algorithm.
In the results, we recognize the different efficiencies of the tested reconstruction methods for different distortions. We could also clearly observe that the efficiency of detection of the artifacts directly affects the ability to restore the signal. The key observations are summarized in a few points:
Peak changes were effectively removed with interpolation methods—simple linear or spline (piecewise cubic polynomial); the other two methods in perfect detection would not offer even comparable efficiency, yet in actual classification, they offered just slightly worse performances.
FFNN offered the best performance for all ‘bulky’ distortions (of longer durations), both hypothetical and classified cases.
Heavy noise, aside from FFNN, was well cleaned with the Savitzky–Golay filter (see
Figure 17b).
Step changes could be effectively removed with FFNN only.
Slow changes were the most contradictory—the only appropriate reconstruction method was FFNN; in the case of perfect detection, the efficiency was high, but due to the limited actual detection, the results were quite poor. These results correspond well to the detection of slow changes in E1—low sensitivity and high fall out.
The above outcomes of reconstruction are just preliminary results. They should be further analyzed in a separate study for the possible reconstruction methods involving other predictors, interpolations, the rigid body model, and projections on geometric constraints.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}