
A Hybrid Deep Learning and Visualization Framework for Pushing Behavior Detection in Pedestrian Dynamics



Abstract
:1. Introduction
- 1.
- To the best of our knowledge, we proposed the first framework dedicated to automatically detecting when and where pushing occurs in videos.
- 2.
- An integrated EfficientNet-B0-based CNN, RAFT, and wheel visualization within a unique framework for pushing behavior detection.
- 3.
- A new patch-based approach to enlarge the data and alleviate the class imbalance problem in the used video recording datasets.
- 4.
- To the best of our knowledge, we created the first publicly available dataset to serve this field of research.
- 5.
- A false reduction algorithm to improve the accuracy of the proposed framework.
2. Related Works
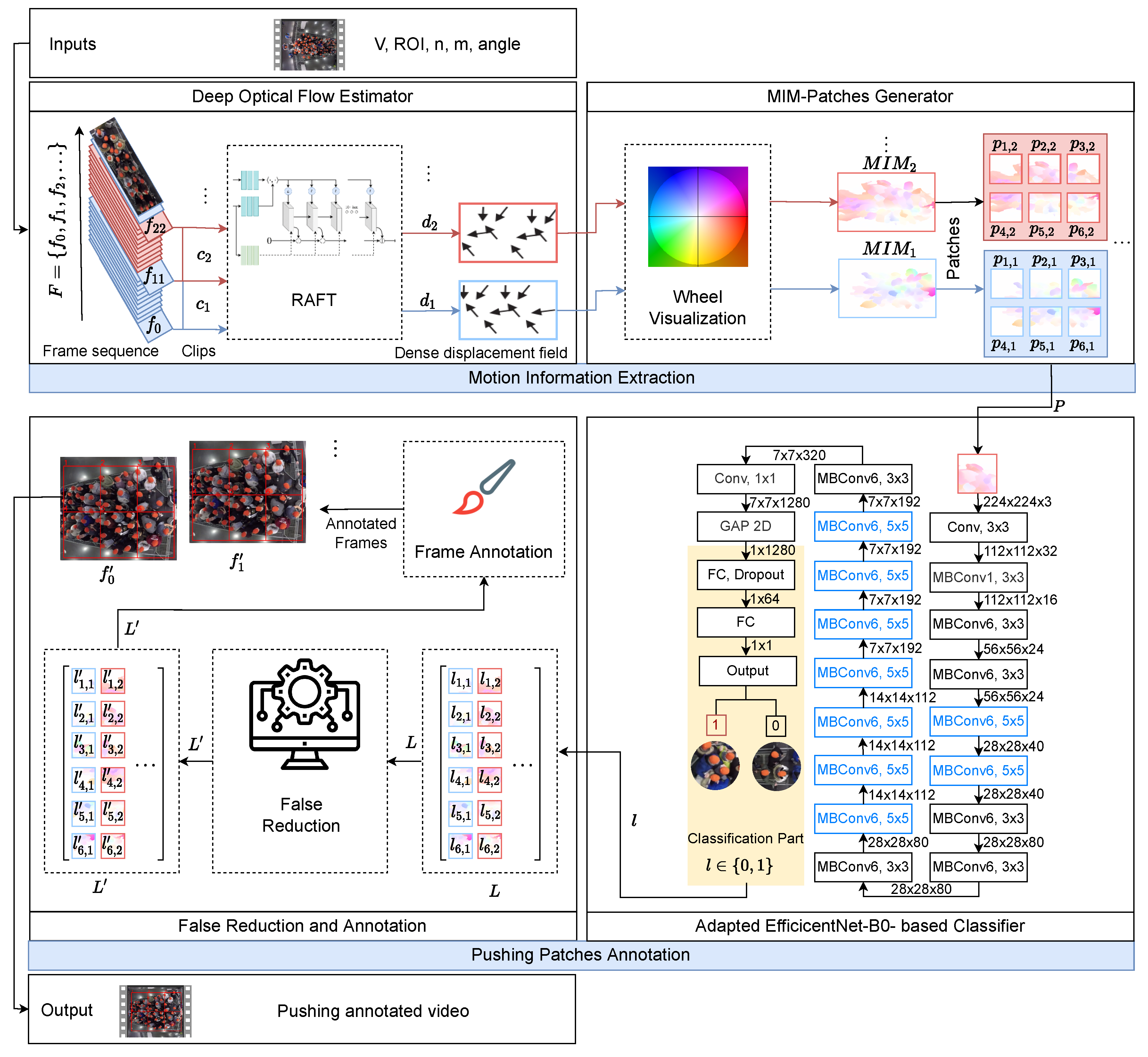
3. The Proposed Framework
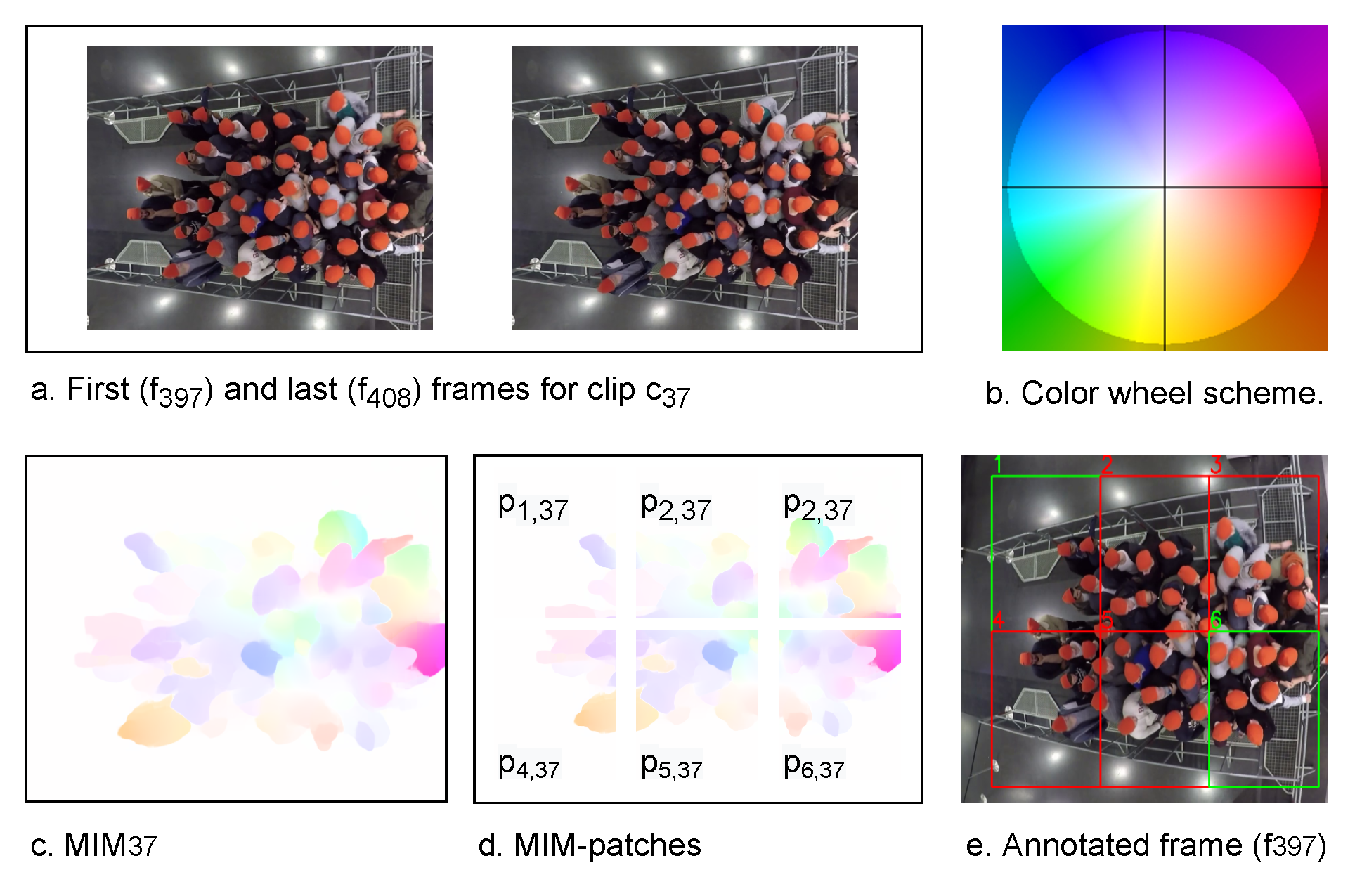
3.1. Motion Information Extraction
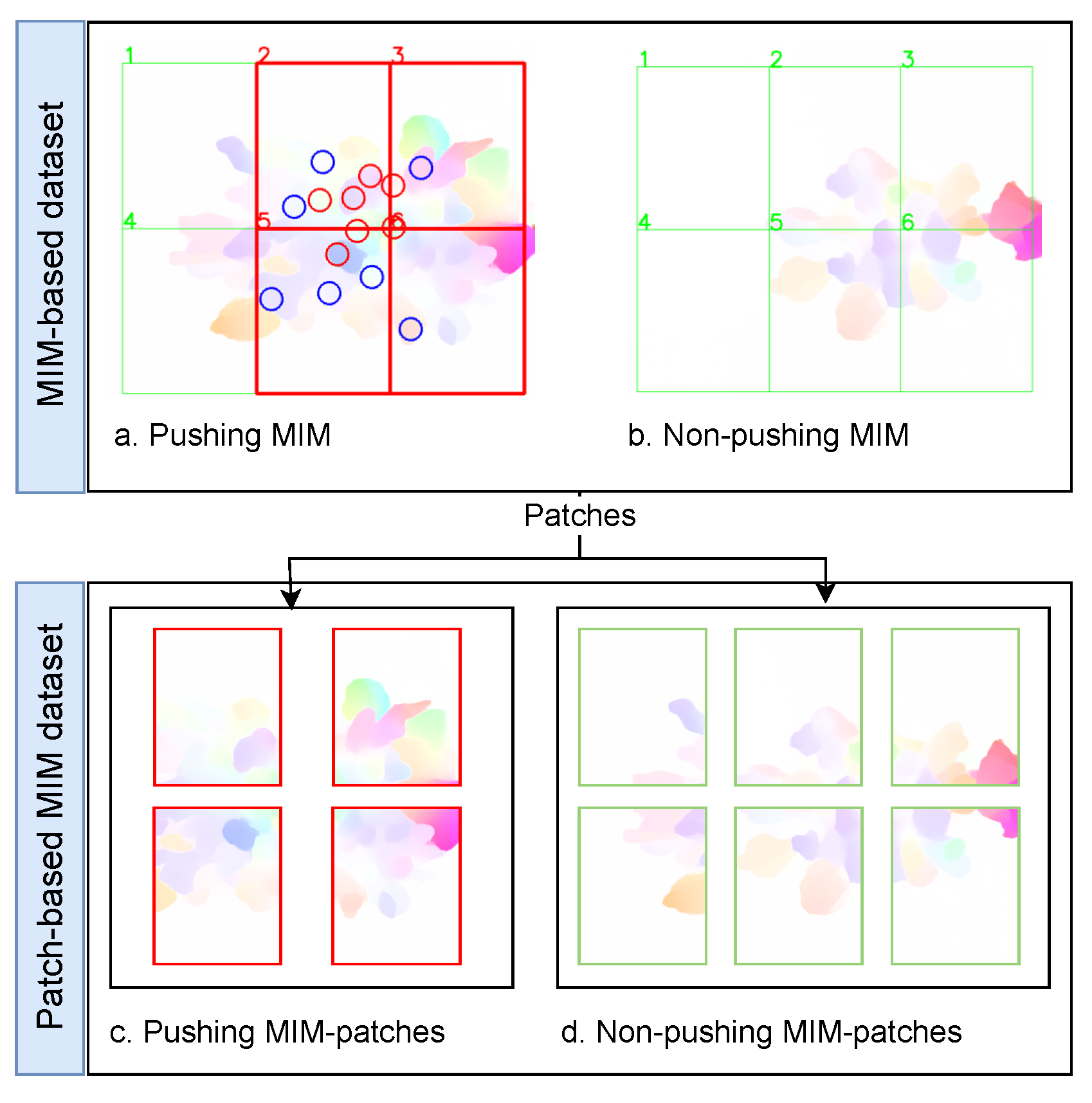
3.2. Pushing Patches Annotation
| Algorithm 1 False Reduction. | |
Input: Output: | |
1: fordo | |
2: for do | |
▹ Excepting the last two clips | |
3: if matrix[i, j] ≠ matrix[i, ] then | |
4: if count(matrix[i, j] in matrix[i, to ]) > 1 then | |
5: matrix[i, ] ← not matrix[i, ] | |
6: end if | |
7: end if | |
8: end for | |
▹ Recheck the first two clips | |
9: if matrix[i, 0 to 2] is not identical then | |
10: if matrix[i, 1] is not in matrix[i, 2 to 4] then | |
11: matrix[i, 1] ← not matrix[i, 1] | |
12: end if | |
13: if matrix[i, 0] not in matrix[i, 1 to 3] then | |
14: matrix[i, 0] ← not matrix[i, 0] | |
15: end if | |
16: end if | |
▹ For the last two clips | |
17: if matrix[i, ] ≠ matrix[i, ] then | |
18: if matrix[i, ] ≠ matrix[i, ] then | |
19: matrix[i, ] ← not matrix[i, ] | |
20: end if | |
21: end if | |
22: if matrix[i, ] ≠ matrix[i, ] then | |
23: if matrix[i, ] = matrix[i, ] then | |
24: matrix[i, ] ← not matrix[i, ] | |
25: end if | |
26: end if | |
27: if matrix[i, ] = matrix[i, ] then | |
28: if matrix[i, ] not in matrix[i, to ] then | |
29: matrix[i, ] ← not matrix[i, ] | |
30: matrix[i, ] ← not matrix[i, ] | |
31: end if | |
32: end if | |
33: end for | |
34:
| |
4. Datasets Preparation
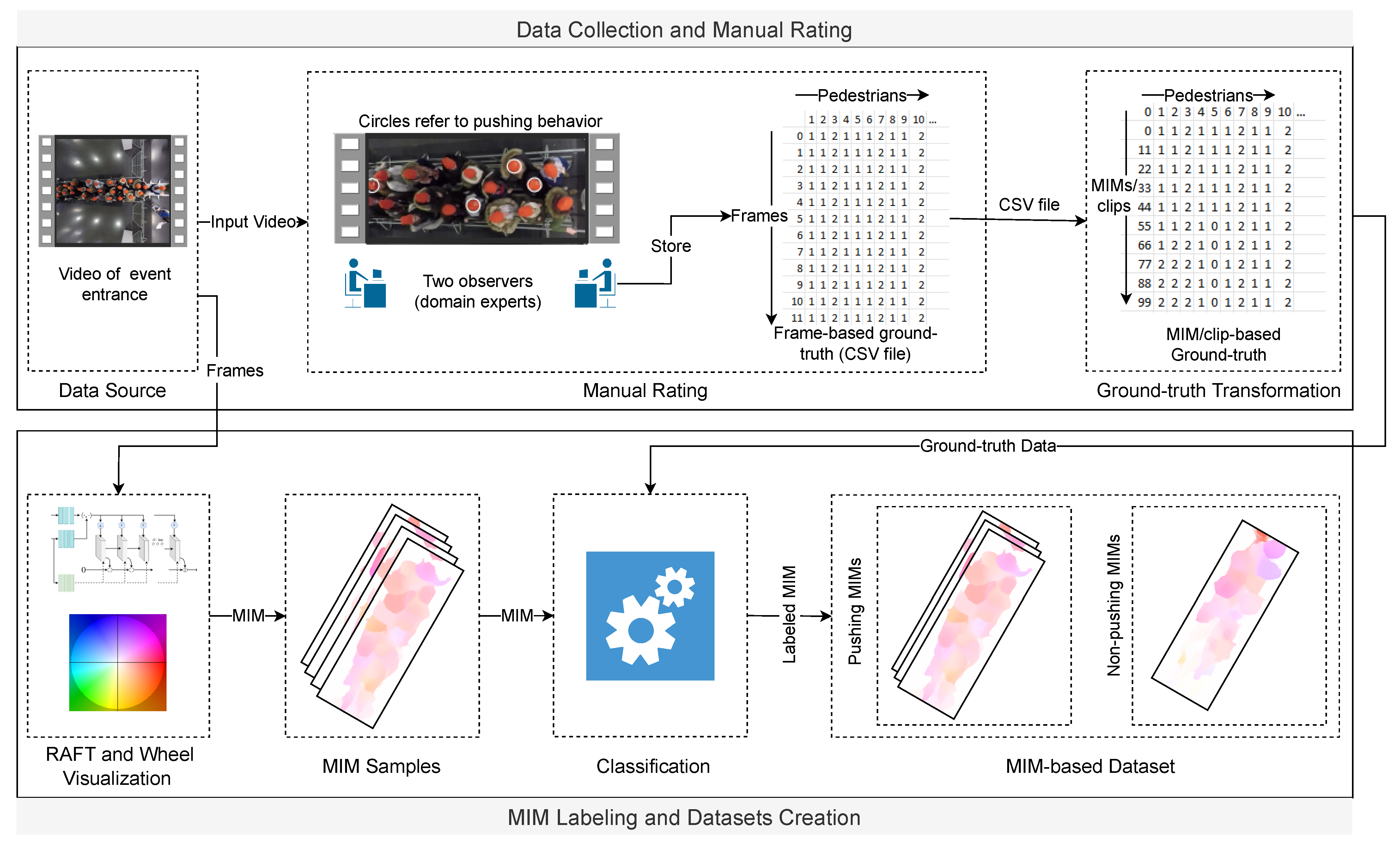
4.1. MIM-Based Datasets Preparation
4.1.1. Data Collection and Manual Rating
4.1.2. MIM Labeling and Dataset Creation
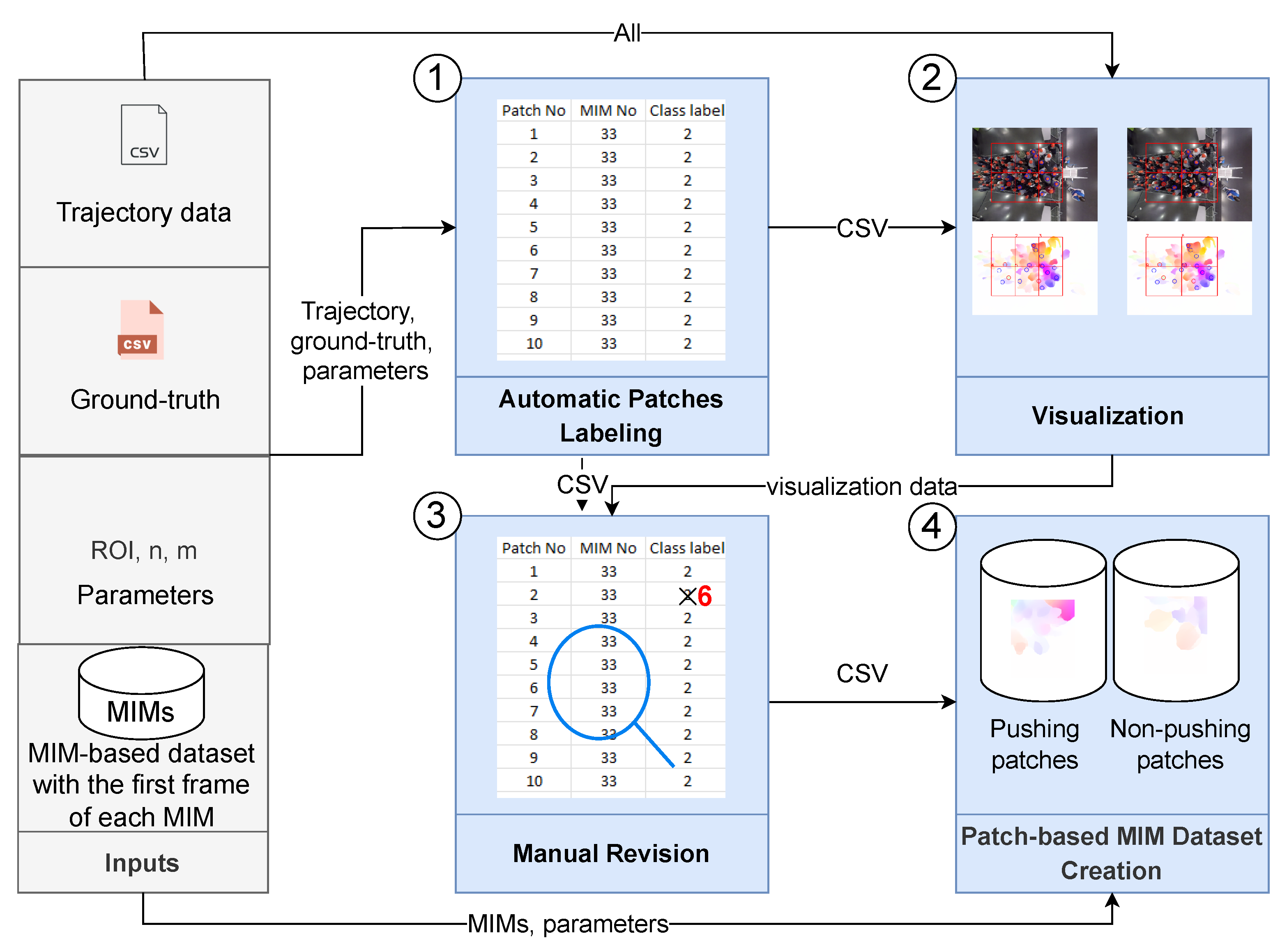
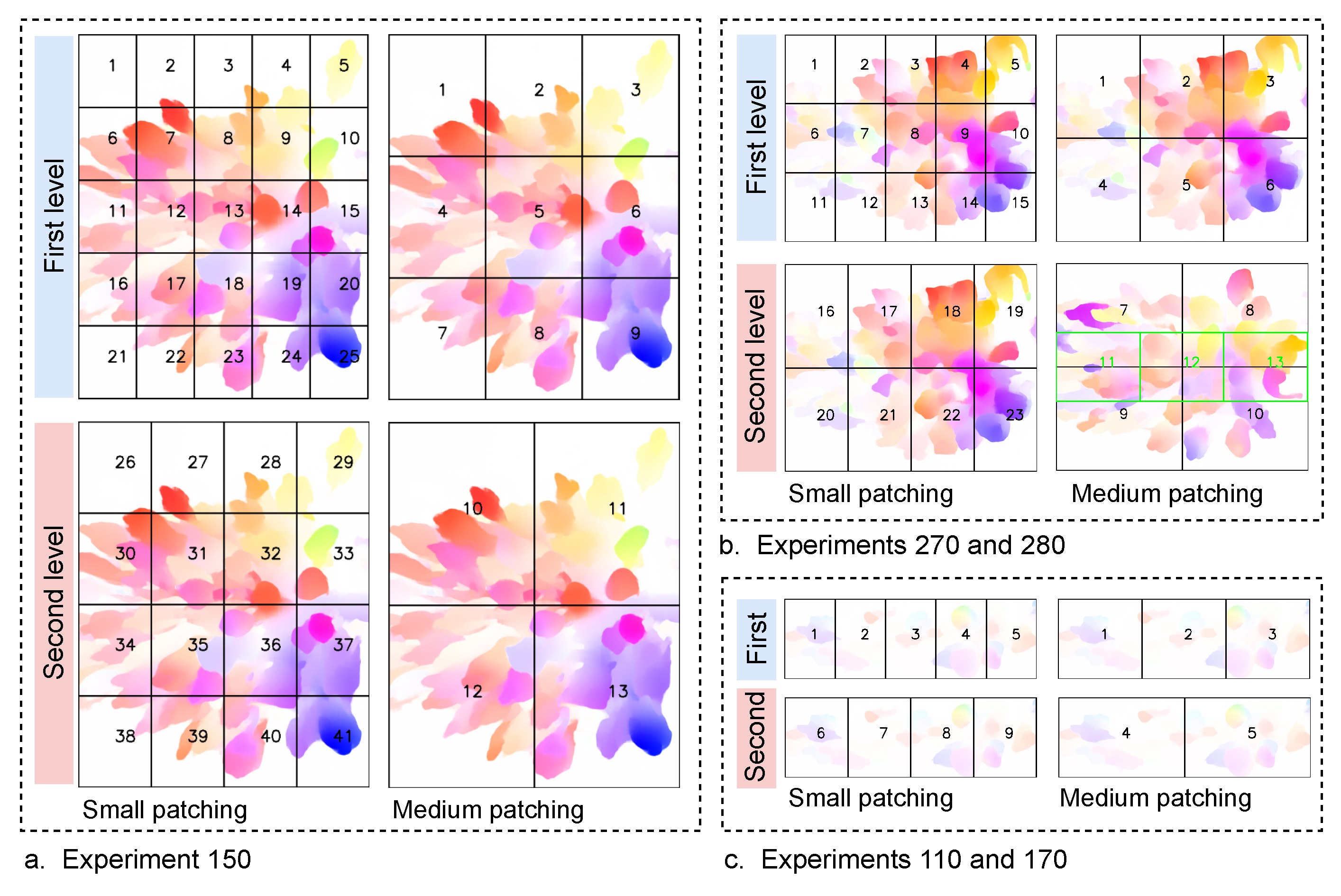
4.2. The Proposed Patch-Based Approach
| Algorithm 2 Patch-Based Approach. | |
Inputs: dataset ← collection of MIMs with the first frame of each MIM ROI ← the numbers of rows and columns that are used to divide ROI into regions. trajectory ← CSV file, each row represents ground_truth ← CSV file, each row represents Outputs: pushing_folder, non-pushing_folder | |
1: | ▹ Automatic patches labeling |
2:
| |
3:
| |
4: fordo | |
5: for do | |
6: | |
7: end for | |
8: end for | |
9:
| |
10:
| |
11: fordo | |
12: for do | |
13: | |
14: end for | |
15: end for | |
16:
| |
17: for each do | |
18: | |
19: | |
20: | |
21: for each do | |
22: //non-pushing | |
23: for each do | |
24: if then | |
25: //pushing | |
26: break | |
27: end if | |
28: end for | |
29: | |
30: | |
31: | |
32: end for | |
33: end for | |
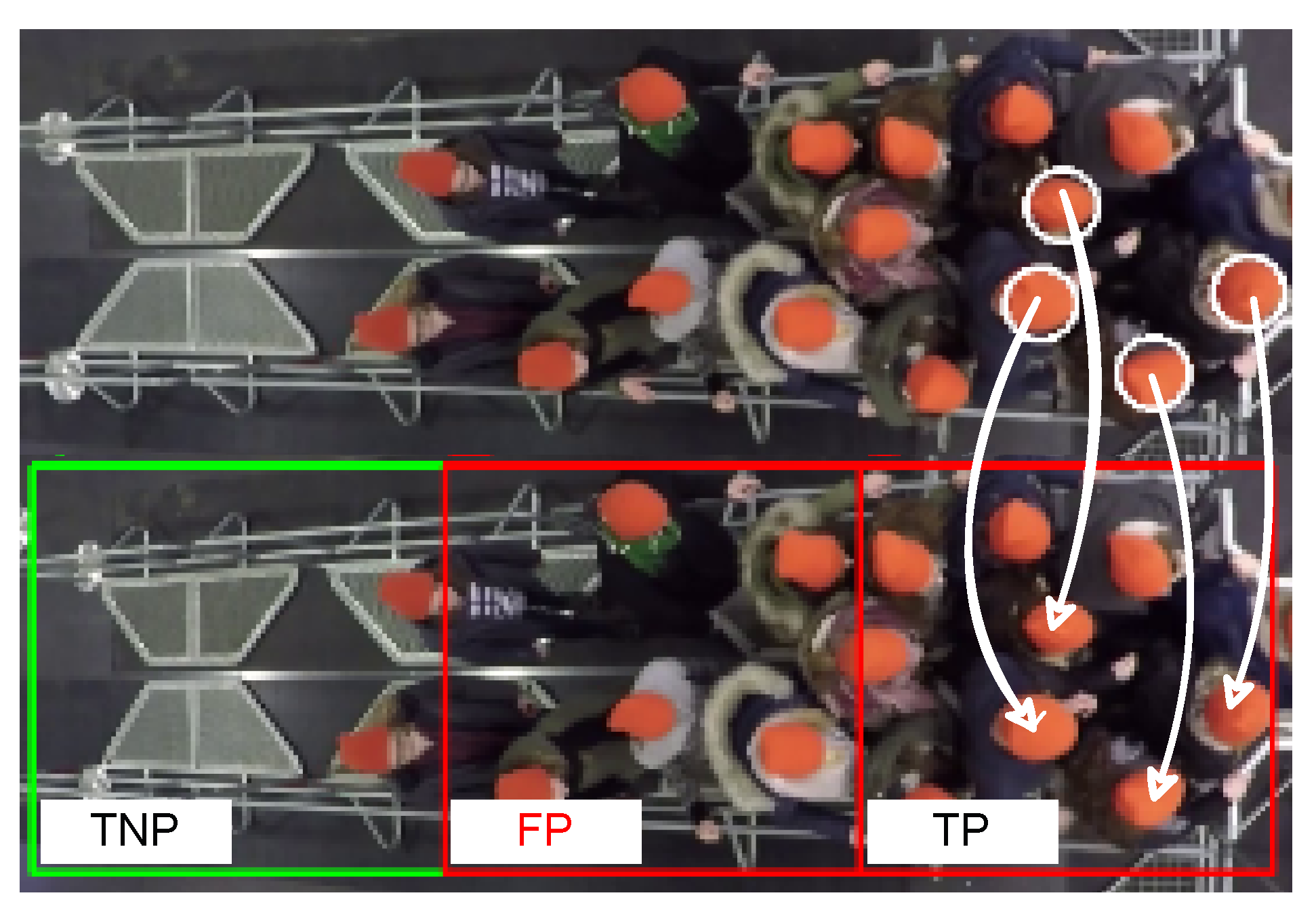
▹ Visualization | |
34: for eachdo | |
35: | |
36: | |
37: for each do | |
38: | |
39: if behavior ==2 then | |
40: draw a circle around the position of pedestrian over | |
41: end if | |
42: end for | |
43: for do | |
44: if then | |
45: draw a red rectangle around over | |
46: else | |
47: draw a green rectangle around over | |
48: end if | |
49: end for | |
50: end for | |
▹ Manual revision | |
51: for each do | |
52: for each do | |
53: manual revision of in | |
54: if then | |
55: manually updating the label of the patch_region in to 6, where 6 means unknown patch | |
56: end if | |
57: end for | |
58: end for | |
▹ Patch-based MIM dataset creation | |
59: for each do | |
60: | |
61: for do | |
62: | |
63: if then | |
64: save to pushing_folder under name “" | |
65: else if then | |
66: save to non-pushing_folder under name “" | |
67: end if | |
68: end for | |
69: end for | |
4.3. Patch-Based MIM Dataset Creation
5. Experimental Results
5.1. Parameter Setup and Performance Metrics
5.2. Our Classifier Training and Evaluation, the Impact of Patch Area and Clip Size
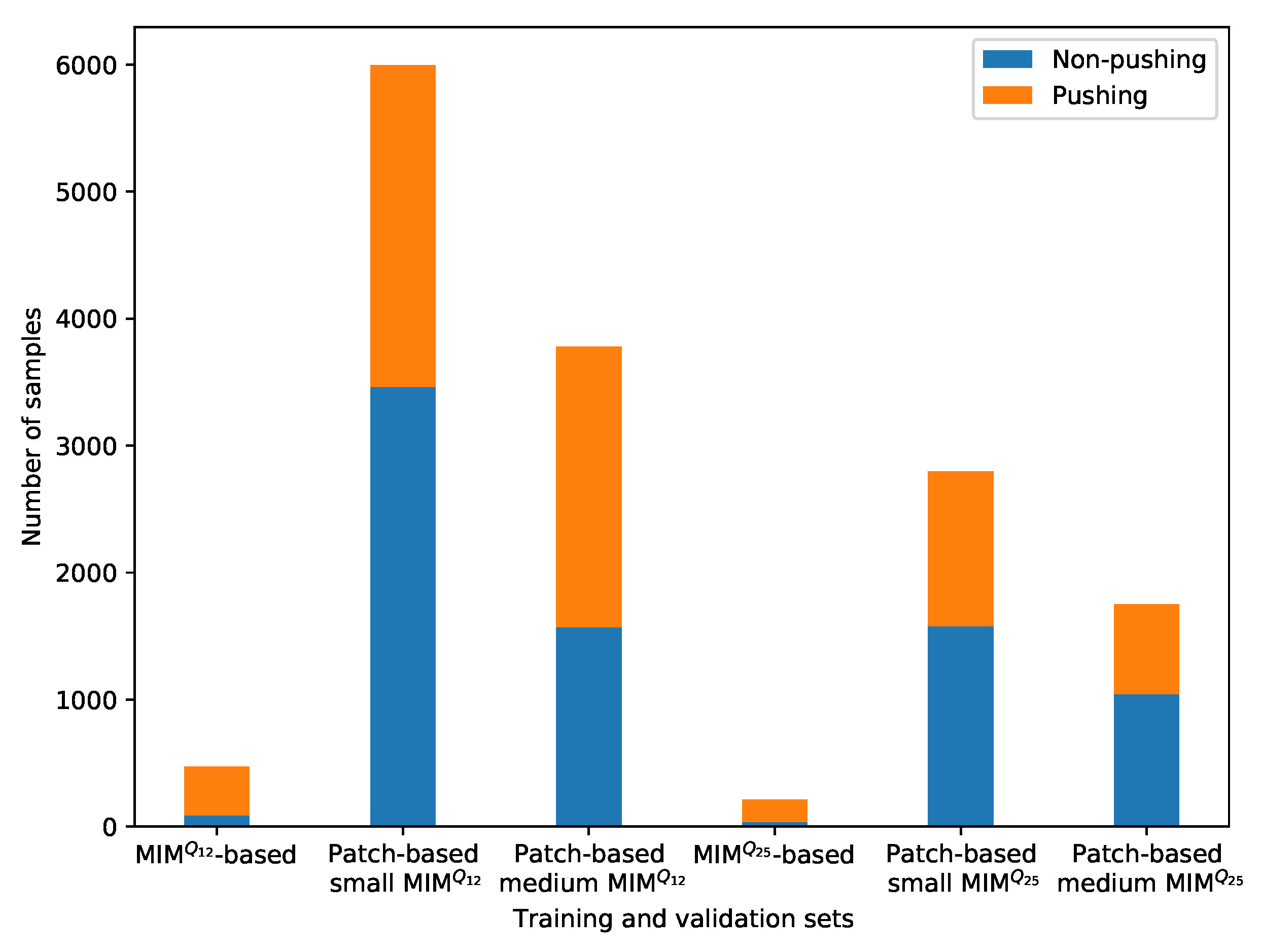
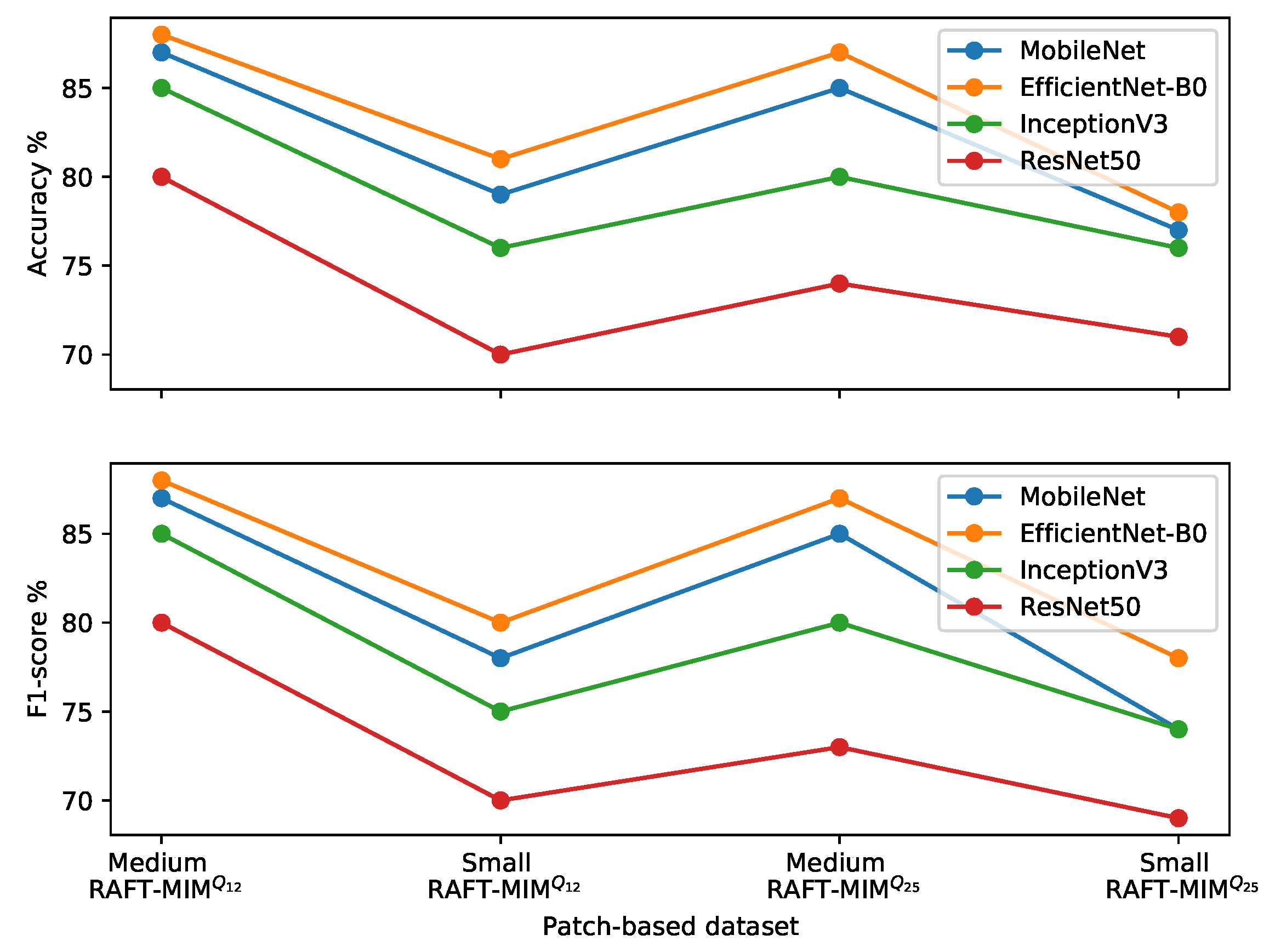
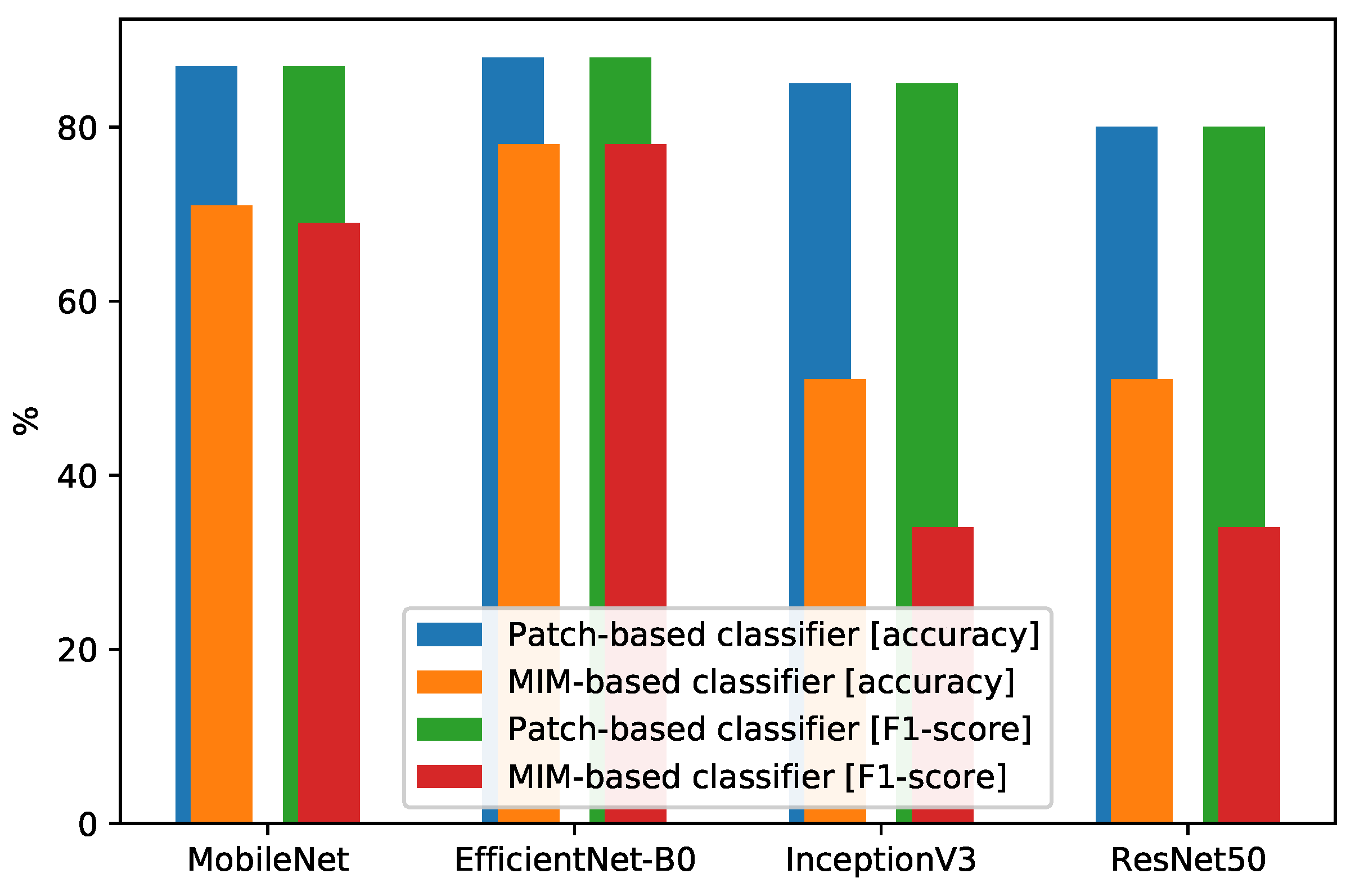
5.3. The Impact of the Patch-Based Approach
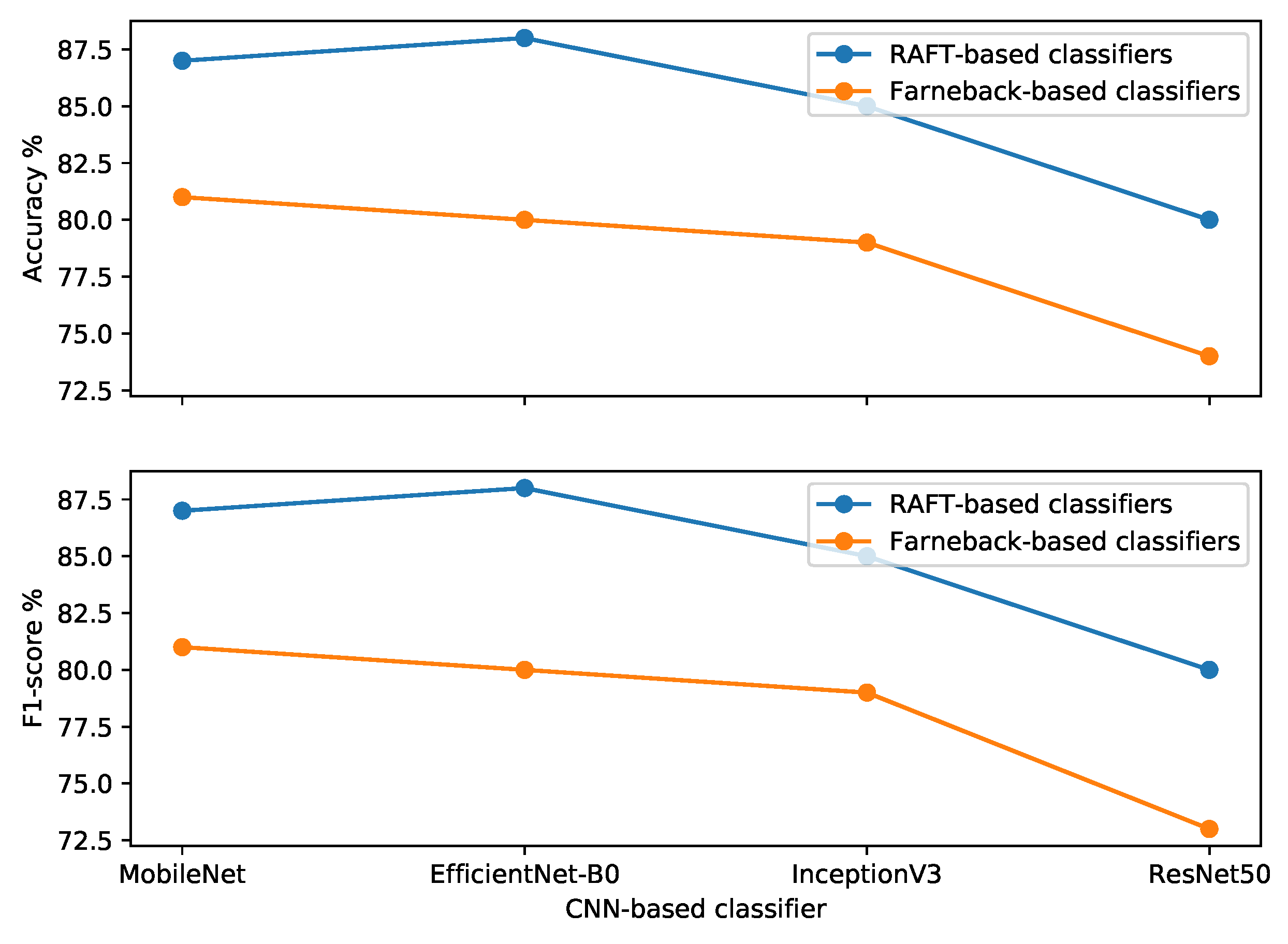
5.4. The Impact of RAFT
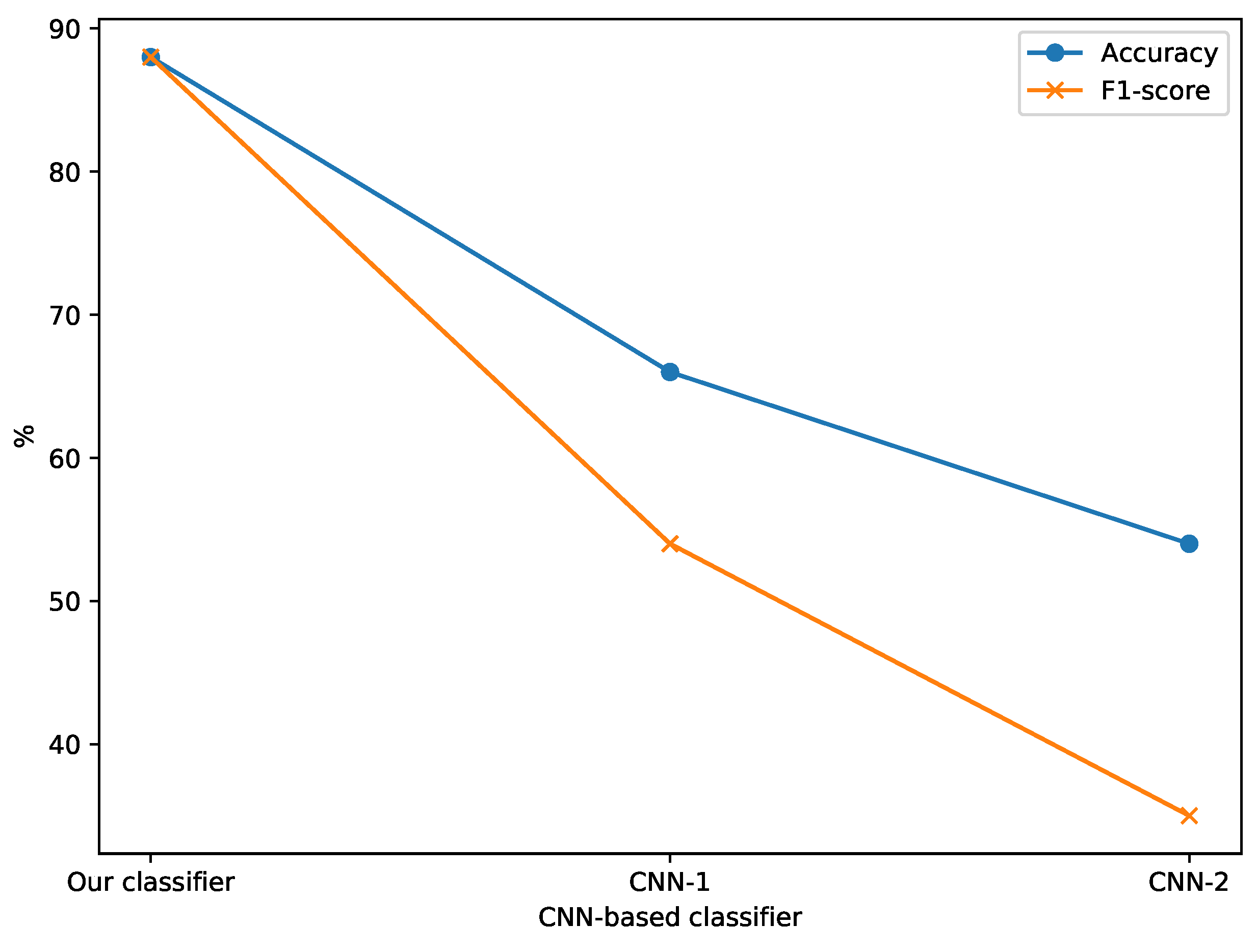
5.5. Comparison between the Proposed Classifier and the Customized CNN-Based Classifiers in Related Works
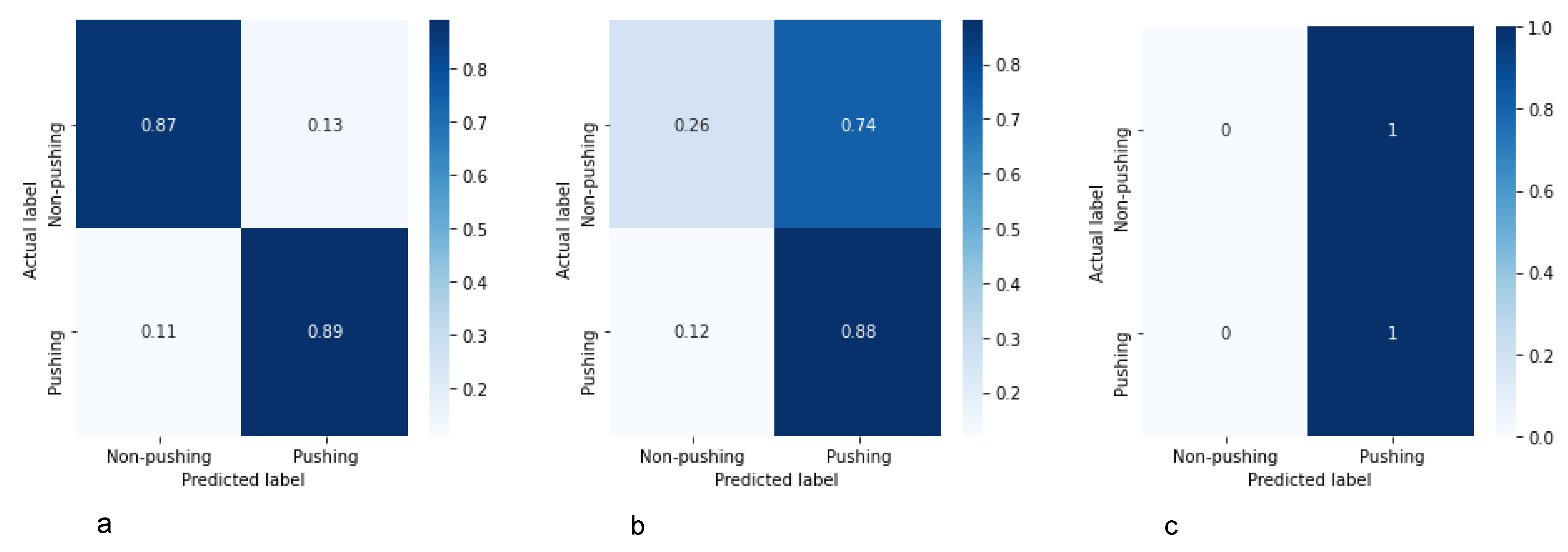
5.6. Framework Performance Evaluation
6. Conclusions, Limitations, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adrian, J.; Boltes, M.; Sieben, A.; Seyfried, A. Influence of Corridor Width and Motivation on Pedestrians in Front of Bottlenecks. In Traffic and Granular Flow 2019; Springer: Berlin, Germany, 2020; pp. 3–9. [Google Scholar]
- Adrian, J.; Seyfried, A.; Sieben, A. Crowds in front of bottlenecks at entrances from the perspective of physics and social psychology. J. R. Soc. Interface 2020, 17, 20190871. [Google Scholar] [CrossRef] [PubMed]
- Lügering, H.; Üsten, E.; Sieben, A. Pushing and Non-Pushing Forward Motion in Crowds: A Systematic Psychological Method for Rating Individual Behavior in Pedestrian Dynamics. 2022; Manuscript submitted for publication. [Google Scholar]
- Haghani, M.; Sarvi, M.; Shahhoseini, Z. When ‘push’does not come to ‘shove’: Revisiting ‘faster is slower’in collective egress of human crowds. Transp. Res. Part A Policy Pract. 2019, 122, 51–69. [Google Scholar] [CrossRef]
- Sieben, A.; Schumann, J.; Seyfried, A. Collective phenomena in crowds—Where pedestrian dynamics need social psychology. PLoS ONE 2017, 12, e0177328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adrian, J.; Boltes, M.; Holl, S.; Sieben, A.; Seyfried, A. Crowding and queuing in entrance scenarios: Influence of corridor width in front of bottlenecks. arXiv 2018, arXiv:1810.07424. [Google Scholar] [CrossRef]
- Boltes, M.; Seyfried, A.; Steffen, B.; Schadschneider, A. Automatic extraction of pedestrian trajectories from video recordings. In Pedestrian and Evacuation Dynamics 2008; Springer: Berlin, Germany, 2010; pp. 43–54. [Google Scholar]
- Nayak, R.; Pati, U.C.; Das, S.K. A comprehensive review on deep learning-based methods for video anomaly detection. Image Vis. Comput. 2021, 106, 104078. [Google Scholar] [CrossRef]
- Roshtkhari, M.J.; Levine, M.D. An on-line, real-time learning method for detecting anomalies in videos using spatio-temporal compositions. Comput. Vis. Image Underst. 2013, 117, 1436–1452. [Google Scholar] [CrossRef]
- Singh, G.; Khosla, A.; Kapoor, R. Crowd escape event detection via pooling features of optical flow for intelligent video surveillance systems. Int. J. Image Graph. Signal Process. 2019, 10, 40. [Google Scholar] [CrossRef] [Green Version]
- George, M.; Bijitha, C.; Jose, B.R. Crowd panic detection using autoencoder with non-uniform feature extraction. In Proceedings of the 8th International Symposium on Embedded Computing and System Design (ISED), Cochin, India, 13–15 December 2018; pp. 11–15. [Google Scholar]
- Santos, G.L.; Endo, P.T.; Monteiro, K.H.D.C.; Rocha, E.D.S.; Silva, I.; Lynn, T. Accelerometer-based human fall detection using convolutional neural networks. Sensors 2019, 19, 1644. [Google Scholar] [CrossRef] [Green Version]
- Mehmood, A. LightAnomalyNet: A Lightweight Framework for Efficient Abnormal Behavior Detection. Sensors 2021, 21, 8501. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Hu, S.; Guo, C.; Yu, H. Energy level-based abnormal crowd behavior detection. Sensors 2018, 18, 423. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kooij, J.F.; Liem, M.C.; Krijnders, J.D.; Andringa, T.C.; Gavrila, D.M. Multi-modal human aggression detection. Comput. Vis. Image Underst. 2016, 144, 106–120. [Google Scholar] [CrossRef]
- Gan, H.; Xu, C.; Hou, W.; Guo, J.; Liu, K.; Xue, Y. Spatiotemporal graph convolutional network for automated detection and analysis of social behaviours among pre-weaning piglets. Biosyst. Eng. 2022, 217, 102–114. [Google Scholar] [CrossRef]
- Gan, H.; Ou, M.; Huang, E.; Xu, C.; Li, S.; Li, J.; Liu, K.; Xue, Y. Automated detection and analysis of social behaviors among preweaning piglets using key point-based spatial and temporal features. Comput. Electron. Agric. 2021, 188, 106357. [Google Scholar] [CrossRef]
- Vu, T.H.; Boonaert, J.; Ambellouis, S.; Taleb-Ahmed, A. Multi-Channel Generative Framework and Supervised Learning for Anomaly Detection in Surveillance Videos. Sensors 2021, 21, 3179. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Zhang, S.; Wang, B. Apple leaf disease identification with a small and imbalanced dataset based on lightweight convolutional networks. Sensors 2021, 22, 173. [Google Scholar] [CrossRef]
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Duman, E.; Erdem, O.A. Anomaly detection in videos using optical flow and convolutional autoencoder. IEEE Access 2019, 7, 183914–183923. [Google Scholar] [CrossRef]
- Farnebäck, G. Two-frame motion estimation based on polynomial expansion. In Proceedings of the 13th Scandinavian Conference on Image Analysis, Gothenburg, Sweden, 29 June–2 July 2003; pp. 363–370. [Google Scholar]
- Ilyas, Z.; Aziz, Z.; Qasim, T.; Bhatti, N.; Hayat, M.F. A hybrid deep network based approach for crowd anomaly detection. Multimed. Tools Appl. 2021, 80, 1–15. [Google Scholar] [CrossRef]
- Direkoglu, C. Abnormal crowd behavior detection using motion information images and convolutional neural networks. IEEE Access 2020, 8, 80408–80416. [Google Scholar] [CrossRef]
- Almazroey, A.A.; Jarraya, S.K. Abnormal Events and Behavior Detection in Crowd Scenes Based on Deep Learning and Neighborhood Component Analysis Feature Selection. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision (AICV2020), Cairo, Egypt, 8–10 April 2020; pp. 258–267. [Google Scholar]
- Teed, Z.; Deng, J. Raft: Recurrent all-pairs field transforms for optical flow. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 402–419. [Google Scholar]
- Tom Runia, D.F. Optical Flow Visualization. Available online: https://github.com/tomrunia/OpticalFlow_Visualization (accessed on 2 April 2020).
- Baker, S.; Scharstein, D.; Lewis, J.; Roth, S.; Black, M.J.; Szeliski, R. A database and evaluation methodology for optical flow. Int. J. Comput. Vis. 2011, 92, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Coşar, S.; Donatiello, G.; Bogorny, V.; Garate, C.; Alvares, L.O.; Brémond, F. Toward abnormal trajectory and event detection in video surveillance. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 683–695. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, X.; Gao, M.; Pan, J.; Zhao, C.; Wang, J. Abnormal behavior detection using streak flow acceleration. Appl. Intell. 2022, 1–18. [Google Scholar] [CrossRef]
- Xu, M.; Yu, X.; Chen, D.; Wu, C.; Jiang, Y. An efficient anomaly detection system for crowded scenes using variational autoencoders. Appl. Sci. 2019, 9, 3337. [Google Scholar] [CrossRef] [Green Version]
- Tay, N.C.; Connie, T.; Ong, T.S.; Goh, K.O.M.; Teh, P.S. A robust abnormal behavior detection method using convolutional neural network. In Computational Science and Technology; Springer: Berlin, Germany, 2019; pp. 37–47. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Moayed, Z.; Klette, R. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes. Comput. Vis. Image Underst. 2018, 172, 88–97. [Google Scholar] [CrossRef] [Green Version]
- Smeureanu, S.; Ionescu, R.T.; Popescu, M.; Alexe, B. Deep appearance features for abnormal behavior detection in video. In Proceedings of the International Conference on Image Analysis and Processing, Catania, Italy, 11–15 September 2017; pp. 779–789. [Google Scholar]
- Khan, S.S.; Madden, M.G. One-class classification: Taxonomy of study and review of techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y. Design and implementation of abnormal behavior detection based on deep intelligent analysis algorithms in massive video surveillance. J. Grid Comput. 2020, 18, 227–237. [Google Scholar] [CrossRef]
- Zhou, S.; Shen, W.; Zeng, D.; Fang, M.; Wei, Y.; Zhang, Z. Spatial–temporal convolutional neural networks for anomaly detection and localization in crowded scenes. Signal Process. Image Commun. 2016, 47, 358–368. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, Y.; Xu, Z.; Huang, J.; Lu, J. Hybrid handcrafted and learned feature framework for human action recognition. Appl. Intell. 2022, 1–17. [Google Scholar] [CrossRef]
- Adrian, J.; Seyfried, A.; Sieben, A. Crowds in Front of Bottlenecks from the Perspective of Physics and Social Psychology. Available online: http://ped.fz-juelich.de/da/2018crowdqueue (accessed on 2 April 2020). [CrossRef]
- Hollows, G.; James, N. Understanding Focal Length and Field of View. Retrieved Oct. 2016, 11, 2018. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Genc, B.; Tunc, H. Optimal training and test sets design for machine learning. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1534–1545. [Google Scholar] [CrossRef]
- Ismael, S.A.A.; Mohammed, A.; Hefny, H. An enhanced deep learning approach for brain cancer MRI images classification using residual networks. Artif. Intell. Med. 2020, 102, 101779. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Van der Jeught, S.; Buytaert, J.A.; Dirckx, J.J. Real-time geometric lens distortion correction using a graphics processing unit. Opt. Eng. 2012, 51, 027002. [Google Scholar] [CrossRef]
- Stankiewicz, O.; Lafruit, G.; Domański, M. Multiview video: Acquisition, processing, compression, and virtual view rendering. In Academic Press Library in Signal Processing; Elsevier: Amsterdam, The Netherlands, 2018; Volume 6, pp. 3–74. [Google Scholar]
- Vieira, L.H.; Pagnoca, E.A.; Milioni, F.; Barbieri, R.A.; Menezes, R.P.; Alvarez, L.; Déniz, L.G.; Santana-Cedrés, D.; Santiago, P.R. Tracking futsal players with a wide-angle lens camera: Accuracy analysis of the radial distortion correction based on an improved Hough transform algorithm. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2017, 5, 221–231. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
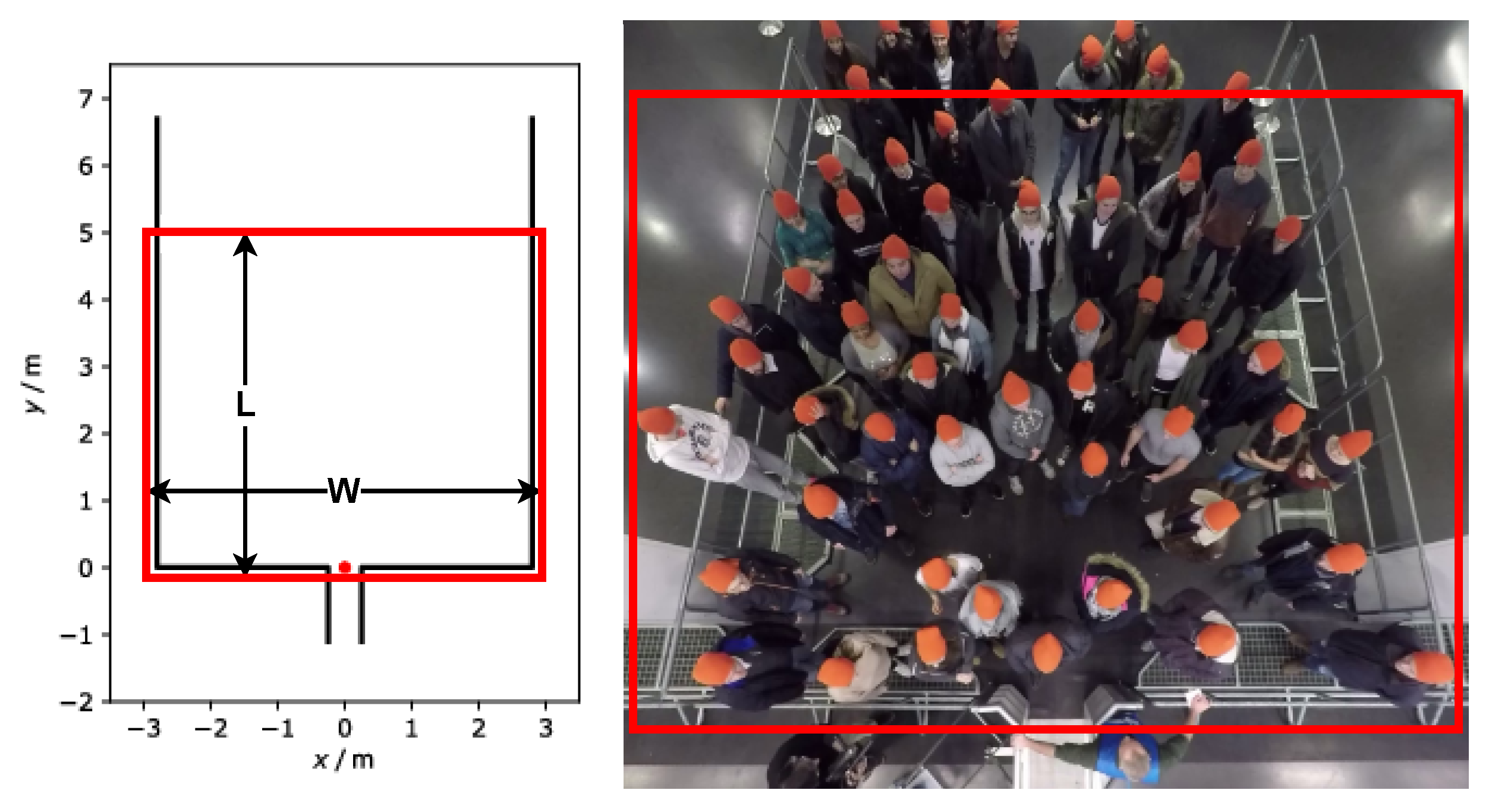
| Experiment * | Width (m) | Pedestrians | Direction | Frames ** |
|---|---|---|---|---|
| 110 | 1.2 | 63 | Left to right | 1285 |
| 150 | 5.6 | 57 | Left to right | 1408 |
| 170 | 1.2 | 25 | Left to right | 552 |
| 270 | 3.4 | 67 | Right to left | 1430 |
| 280 | 3.4 | 67 | Right to left | 1640 |
| Experiment | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | 110 | 150 | 170 | 270 | 280 | All | ||||||||
| P | NP | P | NP | P | NP | P | NP | P | NP | P | NP | Total | ||
| Training | 66 | 16 | 76 | 14 | 28 | 5 | 61 | 29 | 86 | 11 | 317 | 75 | 392 | |
| RAFT-MIM | Validation | 13 | 3 | 15 | 3 | 5 | 1 | 13 | 6 | 18 | 2 | 64 | 15 | 79 |
| Test | 13 | 3 | 15 | 3 | 5 | 1 | 13 | 6 | 18 | 2 | 64 | 15 | 79 | |
| Total | 92 | 22 | 106 | 20 | 38 | 7 | 87 | 41 | 122 | 15 | 445 | 105 | 550 | |
| Training | 30 | 6 | 35 | 6 | 13 | 1 | 29 | 13 | 40 | 4 | 147 | 30 | 177 | |
| RAFT-MIM | Validation | 6 | 2 | 7 | 1 | 3 | 1 | 6 | 2 | 8 | 1 | 30 | 7 | 37 |
| Test | 6 | 2 | 7 | 1 | 3 | 1 | 6 | 2 | 8 | 1 | 30 | 7 | 37 | |
| Total | 42 | 10 | 49 | 8 | 19 | 3 | 41 | 17 | 56 | 6 | 207 | 44 | 251 | |
| Farnebäck-MIM | It has the same samples as the RAFT sets while they are generated using Farnebäck. | |||||||||||||
| Farnebäck-MIM | It has the same samples as the RAFT sets while they are generated using Farnebäck. | |||||||||||||
| Experiment | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | 110 | 150 | 170 | 270 | 280 | All | ||||||||
| P | NP | P | NP | P | NP | P | NP | P | NP | P | NP | Total | ||
| Training | 350 | 279 | 523 | 932 | 121 | 97 | 528 | 784 | 634 | 806 | 2156 | 2898 | 5054 | |
| Patch-based small RAFT-MIM | Validation | 67 | 53 | 89 | 161 | 20 | 21 | 91 | 169 | 108 | 162 | 375 | 566 | 941 |
| Total | 417 | 332 | 612 | 1093 | 141 | 118 | 619 | 953 | 742 | 968 | 2531 | 3464 | 5995 | |
| Training | 156 | 124 | 249 | 419 | 53 | 42 | 236 | 379 | 324 | 354 | 1018 | 1318 | 2336 | |
| Patch-based small RAFT-MIM | Validation | 33 | 26 | 35 | 82 | 9 | 12 | 56 | 53 | 67 | 89 | 200 | 262 | 462 |
| Total | 189 | 150 | 284 | 501 | 62 | 54 | 292 | 432 | 391 | 443 | 1218 | 1580 | 2798 | |
| Training | 237 | 131 | 298 | 354 | 95 | 38 | 540 | 439 | 698 | 326 | 1868 | 1288 | 3156 | |
| Patch-based medium RAFT-MIM | Validation | 45 | 26 | 55 | 64 | 16 | 8 | 98 | 105 | 126 | 81 | 340 | 284 | 624 |
| Total | 282 | 157 | 353 | 418 | 111 | 46 | 638 | 544 | 824 | 407 | 2208 | 1572 | 3780 | |
| Training | 107 | 58 | 142 | 151 | 42 | 14 | 242 | 219 | 338 | 146 | 871 | 585 | 1459 | |
| Patch-based medium RAFT-MIM | Validation | 22 | 14 | 20 | 37 | 8 | 6 | 56 | 27 | 68 | 32 | 174 | 116 | 290 |
| Total | 129 | 72 | 162 | 188 | 50 | 20 | 298 | 246 | 406 | 178 | 1045 | 704 | 1749 | |
| Experiment | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test Set | 110 | 150 | 170 | 270 | 280 | All | |||||||
| P | NP | P | NP | P | NP | P | NP | P | NP | P | NP | Total | |
| Patch-based small RAFT-MIM test | 40 | 28 | 47 | 99 | 9 | 13 | 59 | 112 | 61 | 108 | 216 | 360 | 576 |
| Patch-based small RAFT-MIM test | 18 | 15 | 19 | 44 | 7 | 8 | 28 | 54 | 25 | 36 | 97 | 157 | 254 |
| Patch-based medium RAFT-MIM test | 26 | 16 | 25 | 47 | 8 | 6 | 47 | 41 | 50 | 40 | 156 | 150 | 306 |
| Patch-based medium RAFT-MIM test | 13 | 8 | 8 | 26 | 5 | 5 | 22 | 19 | 20 | 18 | 68 | 76 | 144 |
| Patch-Based MIM Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| CNN-Based Classifier | Medium RAFT-MIM | Small RAFT-MIM | Medium RAFT-MIM | Small RAFT-MIM | ||||
| Accuracy% | F1 Score% | Accuracy% | F1 Score% | Accuracy% | F1 Score% | Accuracy% | F1 Score% | |
| MobileNet | 87 | 87 | 79 | 78 | 85 | 85 | 77 | 74 |
| EfficientNet-B0 | 88 | 88 | 81 | 80 | 87 | 87 | 78 | 78 |
| InceptionV3 | 85 | 85 | 76 | 75 | 80 | 80 | 76 | 74 |
| ResNet50 | 80 | 80 | 70 | 70 | 74 | 73 | 71 | 69 |
| Patch-Based Classifier | MIM-Based Classifier | |||
|---|---|---|---|---|
| CNN-Based Classifier | Accuracy% | F1 Score% | Accuracy% | F1 Score% |
| MobileNet | 87 | 87 | 71 | 69 |
| EfficientNet-B0 | 88 | 88 | 78 | 78 |
| InceptionV3 | 85 | 85 | 51 | 34 |
| ResNet50 | 80 | 80 | 51 | 34 |
| RAFT-Based Classifier | Farnebäck-Based Classifier | |||
|---|---|---|---|---|
| Classifier | Accuracy% | F1 Score% | Accuracy% | F1 Score% |
| MobileNet | 87 | 87 | 81 | 81 |
| EfficientNet-B0 | 88 | 88 | 80 | 80 |
| InceptionV3 | 85 | 85 | 79 | 79 |
| ResNet50 | 80 | 80 | 74 | 73 |
| Classifier | Accuracy% | F1 Score% |
|---|---|---|
| EfficientNet-B0 (our classifier) | 88 | 88 |
| CNN-1 [25] | 60 | 54 |
| CNN-2 [35] | 54 | 35 |
| Framework | Accuracy% | F1 Score% |
|---|---|---|
| Without false reduction | 84 | 84 |
| With false reduction | 86 | 86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alia, A.; Maree, M.; Chraibi, M. A Hybrid Deep Learning and Visualization Framework for Pushing Behavior Detection in Pedestrian Dynamics. Sensors 2022, 22, 4040. https://doi.org/10.3390/s22114040
Alia A, Maree M, Chraibi M. A Hybrid Deep Learning and Visualization Framework for Pushing Behavior Detection in Pedestrian Dynamics. Sensors. 2022; 22(11):4040. https://doi.org/10.3390/s22114040
Chicago/Turabian StyleAlia, Ahmed, Mohammed Maree, and Mohcine Chraibi. 2022. "A Hybrid Deep Learning and Visualization Framework for Pushing Behavior Detection in Pedestrian Dynamics" Sensors 22, no. 11: 4040. https://doi.org/10.3390/s22114040