
A Novel Method Based on GAN Using a Segmentation Module for Oligodendroglioma Pathological Image Generation



Abstract
:1. Introduction
2. Related Work
2.1. Oligodendroglioma
2.2. Histology Image Synthesis
2.3. Segmentation
2.4. GANs in Digital Pathology
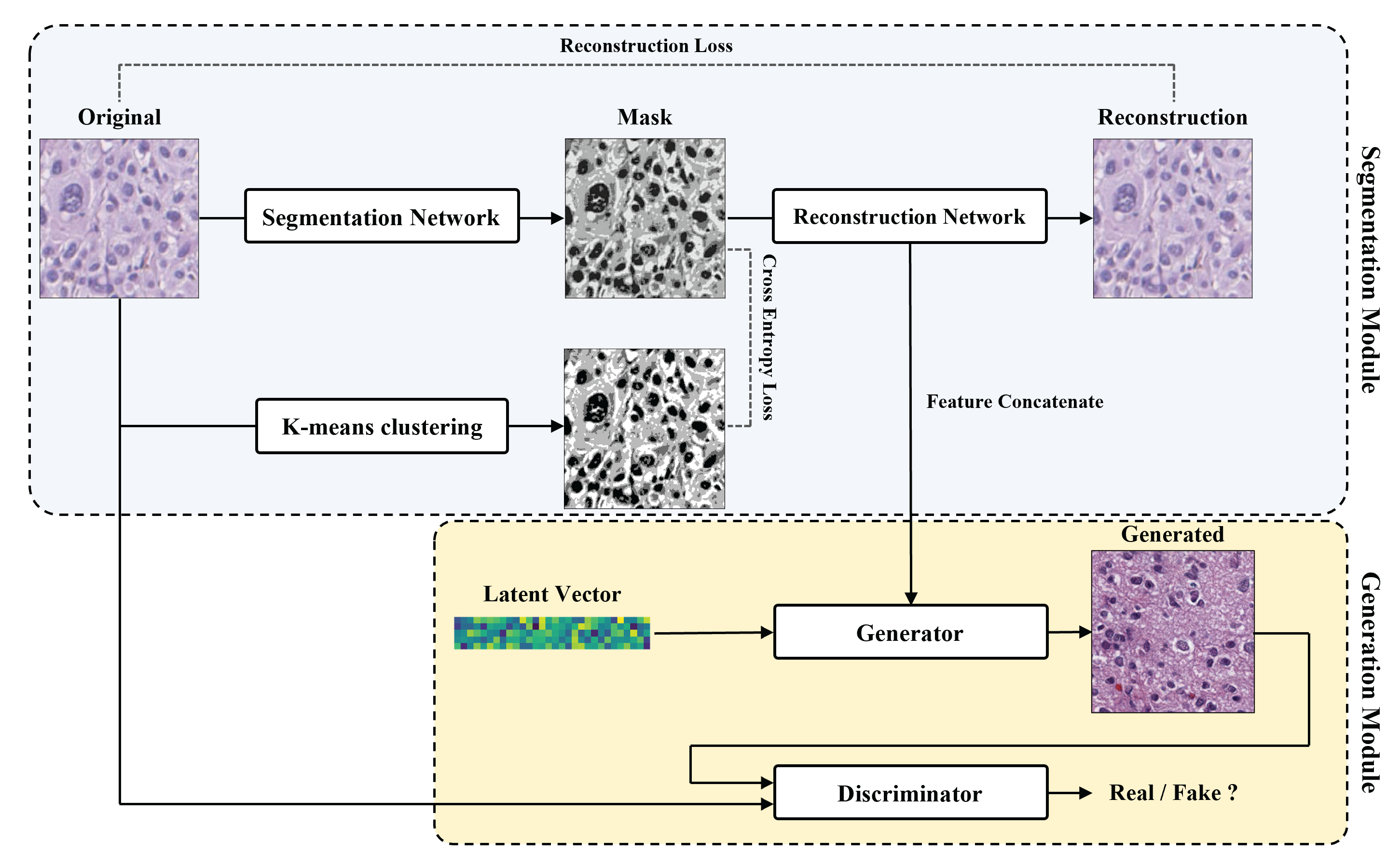
3. Method
- The segmentation module creates masked images from the reference images and extracts meaningful features in the reconstruction process.
- The generation module generates pathological images from the features of the segmentation module and latent vectors by the embedding feature concatenation method.
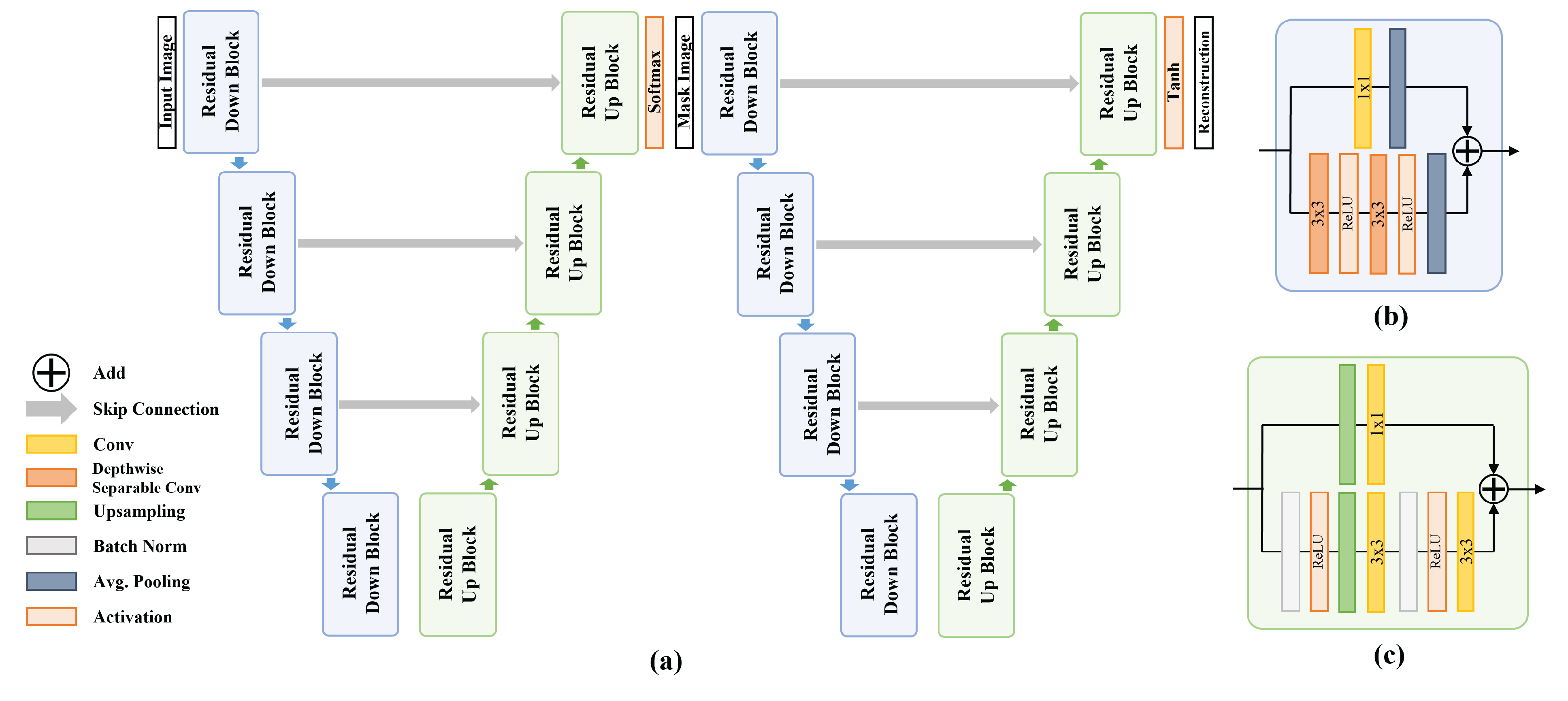
3.1. Segmentation and Reconstruction Module
3.2. Concatenating Embedding Features in the Generation Module
3.3. Training
4. Experimental Results
4.1. Preparing Data
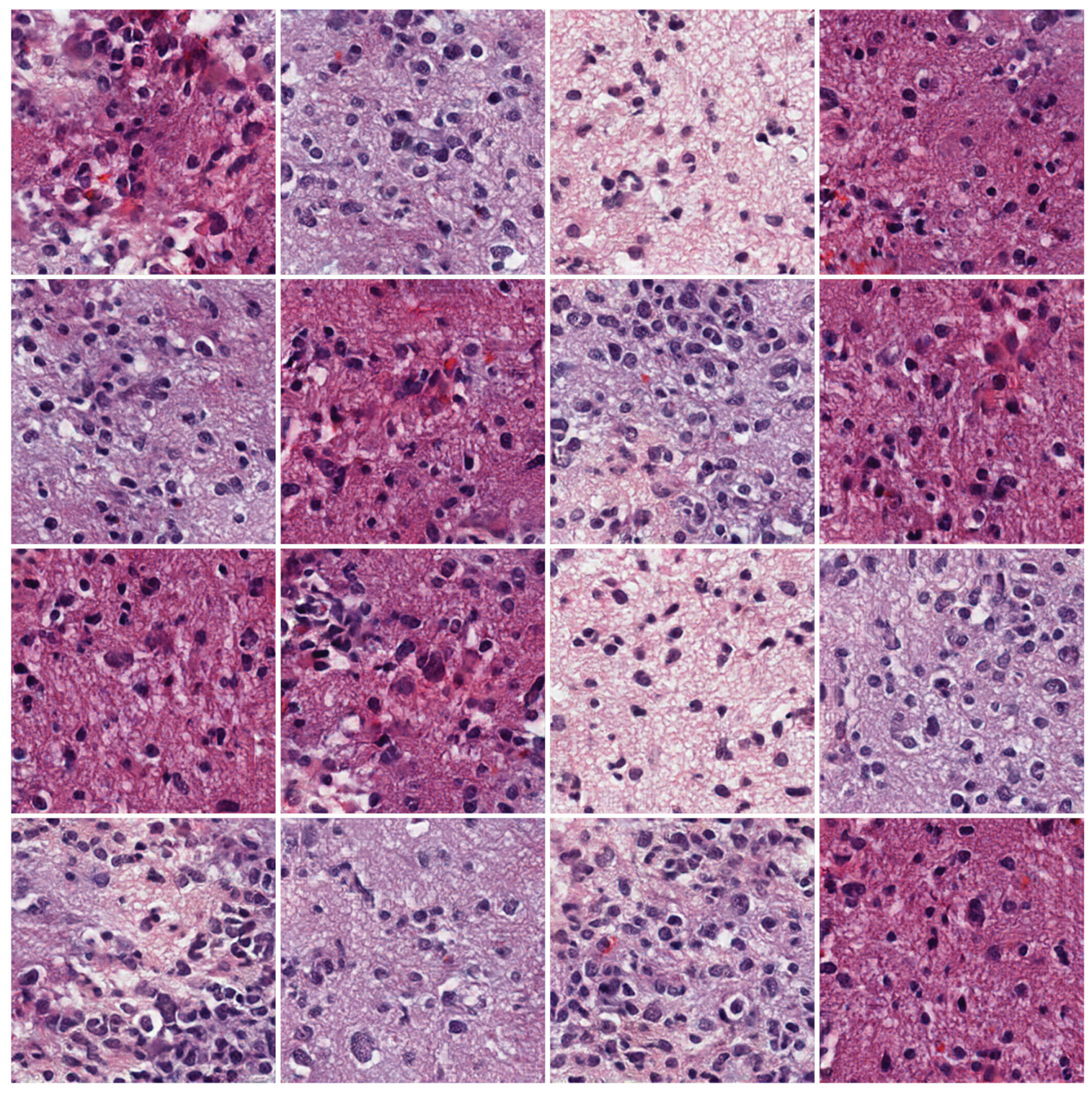
4.2. Examples of the Proposed Method
4.3. Qualitative Evaluation
- Paired Setting: Subjects are shown sequences of real and synthetic image pairs for four seconds. Each trial required them to choose which they thought was the real image. The experiment consisted of 200 trials per subject, and the first 20 trials gave the correct answers as feedback.
- Unpaired Setting: Subjects were randomly shown one of the WGAN-GP results, the PGGAN results, the results of Boyd et al., our results, or the real images. The subjects were asked to choose whether the images shown in each trial were either real or synthetic. This survey included a total of 250 trials, and the first 25 trials provided the correct answers as feedback.
4.4. Quantitative Evaluation Metrics
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Kleihoues, P. Pathology and Genetics of Tumors of the Nervous System; International Agency for Research Cancer: Lyon, France, 1997; pp. 78–79. [Google Scholar]
- Van den Bent, M.J.; Reni, M.; Gatta, G.; Vecht, C. Oligodendroglioma. Crit. Rev. Oncol./Hematol. 2008, 66, 262–272. [Google Scholar] [CrossRef]
- Ostrom, Q.T.; Gittleman, H.; Truitt, G.; Boscia, A.; Kruchko, C.; Barnholtz-Sloan, J.S. CBTRUS statistical report: Primary brain and other central nervous system tumors diagnosed in the United States in 2011–2015. Neuro-oncology 2018, 20, iv1–iv86. [Google Scholar] [CrossRef] [Green Version]
- Suh, Y.L.; Koo, H.; Kim, T.S.; Chi, J.G.; Park, S.H.; Khang, S.K.; Choe, G.; Lee, M.C.; Hong, E.K.; Sohn, Y.K.; et al. Tumors of the Central Nervous System in Korea A Multicenter Study of 3221 Cases. J. Neuro-Oncol. 2002, 56, 251–259. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Gecer, B.; Aksoy, S.; Mercan, E.; Shapiro, L.G.; Weaver, D.L.; Elmore, J.G. Detection and classification of cancer in whole slide breast histopathology images using deep convolutional networks. Pattern Recognit. 2018, 84, 345–356. [Google Scholar] [CrossRef]
- Gu, F.; Burlutskiy, N.; Andersson, M.; Wilén, L.K. Multi-resolution networks for semantic segmentation in whole slide images. In Computational Pathology and Ophthalmic Medical Image Analysis; Springer: Berlin/Heidelberg, Germany, 2018; pp. 11–18. [Google Scholar]
- Guo, Z.; Liu, H.; Ni, H.; Wang, X.; Su, M.; Guo, W.; Wang, K.; Jiang, T.; Qian, Y. A fast and refined cancer regions segmentation framework in whole-slide breast pathological images. Sci. Rep. 2019, 9, 882. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.; Chen, H.; Graham, S.; Dou, Q.; Rajpoot, N.; Heng, P.A. Fast scannet: Fast and dense analysis of multi-gigapixel whole-slide images for cancer metastasis detection. IEEE Trans. Med. Imaging 2019, 38, 1948–1958. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Lin, H.; Chen, H.; Heng, P.A. PFA-ScanNet: Pyramidal feature aggregation with synergistic learning for breast cancer metastasis analysis. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 586–594. [Google Scholar]
- BenTaieb, A.; Hamarneh, G. Topology aware fully convolutional networks for histology gland segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 460–468. [Google Scholar]
- Xu, Y.; Li, Y.; Wang, Y.; Liu, M.; Fan, Y.; Lai, M.; Eric, I.; Chang, C. Gland instance segmentation using deep multichannel neural networks. IEEE Trans. Biomed. Eng. 2017, 64, 2901–2912. [Google Scholar]
- Van Eycke, Y.R.; Balsat, C.; Verset, L.; Debeir, O.; Salmon, I.; Decaestecker, C. Segmentation of glandular epithelium in colorectal tumours to automatically compartmentalise IHC biomarker quantification: A deep learning approach. Med. Image Anal. 2018, 49, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Graham, S.; Chen, H.; Gamper, J.; Dou, Q.; Heng, P.A.; Snead, D.; Tsang, Y.W.; Rajpoot, N. MILD-Net: Minimal information loss dilated network for gland instance segmentation in colon histology images. Med. Image Anal. 2019, 52, 199–211. [Google Scholar] [CrossRef] [Green Version]
- Ding, H.; Pan, Z.; Cen, Q.; Li, Y.; Chen, S. Multi-scale fully convolutional network for gland segmentation using three-class classification. Neurocomputing 2020, 380, 150–161. [Google Scholar] [CrossRef]
- Qu, H.; Riedlinger, G.; Wu, P.; Huang, Q.; Yi, J.; De, S.; Metaxas, D. Joint segmentation and fine-grained classification of nuclei in histopathology images. In Proceedings of the 2019 IEEE 16th international symposium on biomedical imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 900–904. [Google Scholar]
- Tokunaga, H.; Teramoto, Y.; Yoshizawa, A.; Bise, R. Adaptive weighting multi-field-of-view cnn for semantic segmentation in pathology. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12597–12606. [Google Scholar]
- Bulten, W.; Pinckaers, H.; van Boven, H.; Vink, R.; de Bel, T.; van Ginneken, B.; van der Laak, J.; Hulsbergen-van de Kaa, C.; Litjens, G. Automated deep-learning system for Gleason grading of prostate cancer using biopsies: A diagnostic study. Lancet Oncol. 2020, 21, 233–241. [Google Scholar] [CrossRef] [Green Version]
- Bulten, W.; Bándi, P.; Hoven, J.; van de Loo, R.; Lotz, J.; Weiss, N.; van de Laak, J.; Ginneken, B.V.; Hulsbergen-van de Kaa, C.; Litjens, G. Epithelium segmentation using deep learning in H&E-stained prostate specimens with immunohistochemistry as reference standard. Sci. Rep. 2019, 9, 864. [Google Scholar]
- Xie, Y.; Kong, X.; Xing, F.; Liu, F.; Su, H.; Yang, L. Deep voting: A robust approach toward nucleus localization in microscopy images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 374–382. [Google Scholar]
- Graham, S.; Vu, Q.D.; Raza, S.E.A.; Azam, A.; Tsang, Y.W.; Kwak, J.T.; Rajpoot, N. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Med. Image Anal. 2019, 58, 101563. [Google Scholar] [CrossRef] [Green Version]
- Xing, F.; Cornish, T.C.; Bennett, T.; Ghosh, D.; Yang, L. Pixel-to-pixel learning with weak supervision for single-stage nucleus recognition in Ki67 images. IEEE Trans. Biomed. Eng. 2019, 66, 3088–3097. [Google Scholar] [CrossRef]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Nuclei segmentation with recurrent residual convolutional neural networks based U-Net (R2U-Net). In Proceedings of the NAECON 2018-IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 23–26 July 2018; pp. 228–233. [Google Scholar]
- Li, X.; Wang, Y.; Tang, Q.; Fan, Z.; Yu, J. Dual U-Net for the segmentation of overlapping glioma nuclei. IEEE Access 2019, 7, 84040–84052. [Google Scholar] [CrossRef]
- Xie, Y.; Xing, F.; Kong, X.; Su, H.; Yang, L. Beyond classification: Structured regression for robust cell detection using convolutional neural network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 358–365. [Google Scholar]
- Xie, Y.; Xing, F.; Shi, X.; Kong, X.; Su, H.; Yang, L. Efficient and robust cell detection: A structured regression approach. Med. Image Anal. 2018, 44, 245–254. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Lim, J.H.; Ye, J.C. Geometric gan. arXiv 2017, arXiv:1705.02894. [Google Scholar]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled generative adversarial networks. arXiv 2016, arXiv:1611.02163. [Google Scholar]
- Che, T.; Li, Y.; Jacob, A.P.; Bengio, Y.; Li, W. Mode regularized generative adversarial networks. arXiv 2016, arXiv:1612.02136. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Denton, E.L.; Chintala, S.; Szlam, A.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1486–1494. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International conference on machine learning, ICML, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Quiros, A.C.; Murray-Smith, R.; Yuan, K. PathologyGAN: Learning deep representations of cancer tissue. arXiv 2019, arXiv:1907.02644. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Deshpande, S.; Minhas, F.; Rajpoot, N. Train Small, Generate Big: Synthesis of Colorectal Cancer Histology Images. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Lima, Peru, 4 October 2020; pp. 164–173. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Fossen-Romsaas, S.; Storm-Johannessen, A.; Lundervold, A.S. Synthesizing Skin Lesion Images Using CycleGANs-A Case Study. Norsk IKT-Konferanse Forskning Utdanning, no. 1. 2020. Available online: https://ojs.bibsys.no/index.php/NIK/article/view/837 (accessed on 20 February 2022).
- Boyd, J.; Liashuha, M.; Deutsch, E.; Paragios, N.; Christodoulidis, S.; Vakalopoulou, M. Self-Supervised Representation Learning using Visual Field Expansion on Digital Pathology. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 639–647. [Google Scholar]
- Bandi, P.; Geessink, O.; Manson, Q.; Van Dijk, M.; Balkenhol, M.; Hermsen, M.; Bejnordi, B.E.; Lee, B.; Paeng, K.; Zhong, A.; et al. From detection of individual metastases to classification of lymph node status at the patient level: The camelyon17 challenge. IEEE Trans. Med. Imaging 2018, 38, 550–560. [Google Scholar] [CrossRef] [Green Version]
- Kather, J.N.; Halama, N.; Marx, A. 100,000 Histological Images of Human Colorectal Cancer and Healthy Tissue. Zenodo10. 2018. Available online: https://zenodo.org/record/1214456#.YotTvFRBxPZ (accessed on 20 February 2022).
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 649–666. [Google Scholar]
- Shaham, T.R.; Dekel, T.; Michaeli, T. Singan: Learning a generative model from a single natural image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4570–4580. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6627–6638. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Survey Setting | Model | Confusion Rate (%) ↑ |
|---|---|---|
| paired | WGAN-GP [38] | 15.28 ± 12.63 |
| PGGAN [45] | 42.96 ± 12.76 | |
| Boyd et al. [57] | 52.13 ± 10.37 | |
| Ours | 55.19 ± 11.18 | |
| unpaired | WGAN-GP [38] | 13.89 ± 18.08 |
| PGGAN [45] | 38.75 ± 16.26 | |
| Boyd et al. [57] | 50.89 ± 18.58 | |
| Ours | 51.25 ± 13.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kweon, J.; Yoo, J.; Kim, S.; Won, J.; Kwon, S. A Novel Method Based on GAN Using a Segmentation Module for Oligodendroglioma Pathological Image Generation. Sensors 2022, 22, 3960. https://doi.org/10.3390/s22103960
Kweon J, Yoo J, Kim S, Won J, Kwon S. A Novel Method Based on GAN Using a Segmentation Module for Oligodendroglioma Pathological Image Generation. Sensors. 2022; 22(10):3960. https://doi.org/10.3390/s22103960
Chicago/Turabian StyleKweon, Juwon, Jisang Yoo, Seungjong Kim, Jaesik Won, and Soonchul Kwon. 2022. "A Novel Method Based on GAN Using a Segmentation Module for Oligodendroglioma Pathological Image Generation" Sensors 22, no. 10: 3960. https://doi.org/10.3390/s22103960