
Edge-Based Transfer Learning for Classroom Occupancy Detection in a Smart Campus Context

 , ,
, ,  ,
,  , and
, and
Abstract
:1. Introduction
2. Background and Related Work
- Texture-based analysis: this analysis represents an active and interesting topic within image processing and plays a significant role in many applications, such as image retrieval and face recognition. It relies on texture modeling through the analysis of image patches [46,47]. Among the texture-based analysis methods, there are gray-level co-occurrence matrices, Fourier analyses and fractal dimensions [48];
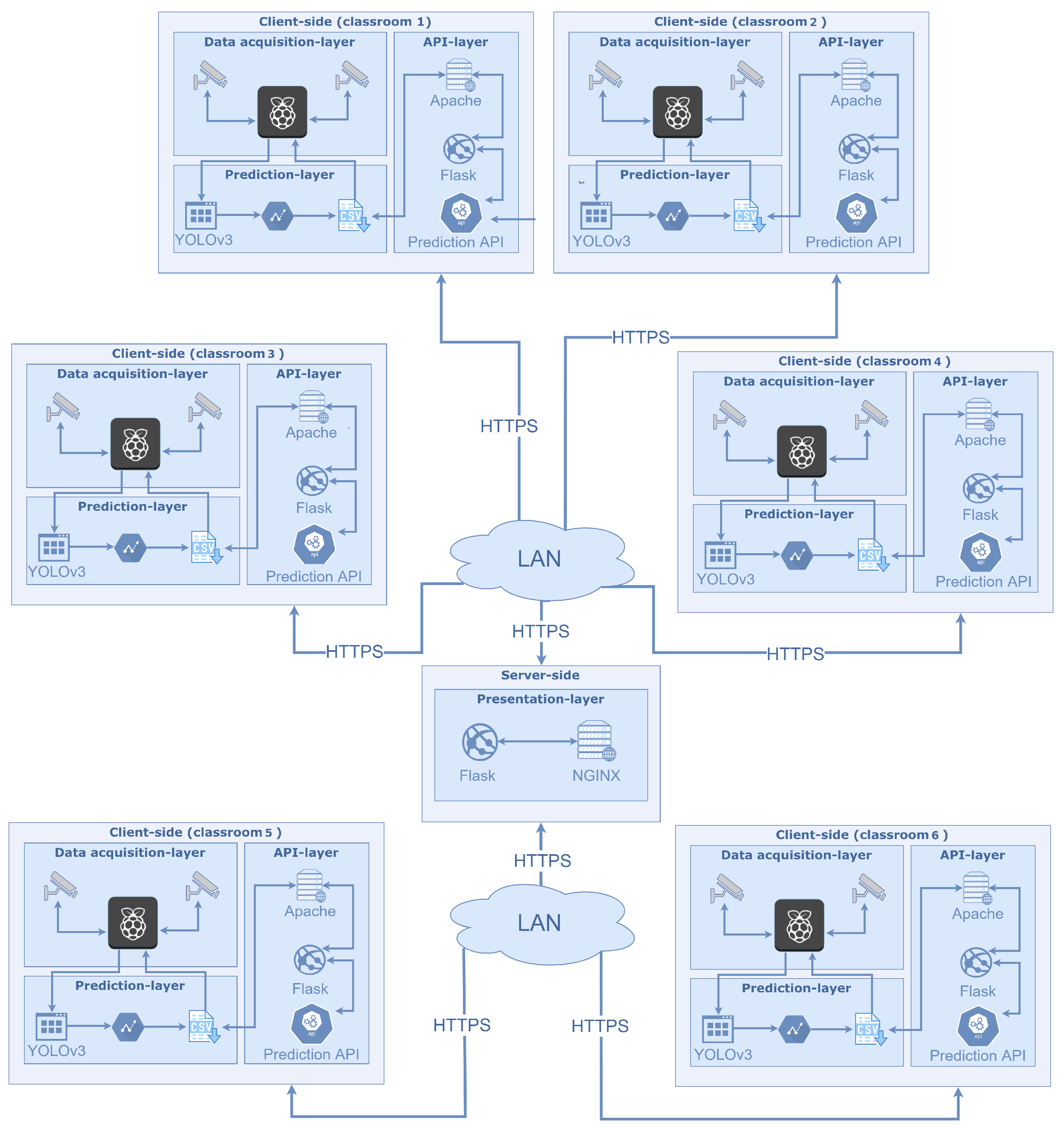
3. Our Proposed Architecture
- Higher scalability: fat clients can complete jobs independently from other clients and then send their results to the server;
- Working semi-offline: in this way, it is possible to predict the number of people in a scene and store that result directly on a single-board computer without the need to send the data immediately;
- Higher availability: instead of having a single point of failure, there are different clients that work independently. This allows the system to be more robust;
- Privacy compliant: the number of people and the time at which the frame was analyzed are the only data that are stored in the client node and sent to the server side.
3.1. Data Acquisition Layer
- The Intel RealSense D415 Depth camera: RealSense technologies provide a suite of depth and tracking technologies, which make it possible to count the number of people within a given area. This camera is USB-powered and consists of an infrared projector, a pair of depth sensors and an RGB sensor. The depth output resolution can be set at up to 1280 × 720 pixels and the depth frame rate can be set at up to 90 fps. The RGB frame resolution is 1920 × 1080 pixels and the maximum frame rate is 30 fps. For this case study, the camera was plugged (via USB) into a Raspberry Pi 4 model B and 1280 × 720 pixel frame images were acquired every five minutes (we set this time interval in order to better support the storing operations);
- The Microsoft Kinect camera: initially, the Kinect was developed as a gaming tool for Xbox 360. It contains three main components that work together to detect the motions of the user and create their physical image on the screen: an RGB color VGA video camera, a depth sensor and a multi-array microphone. As for the camera, both the video and depth sensor have a 640 × 480 pixel resolution and run at 30 fps. This camera was also plugged (via USB) into the Raspberry Pi 4 model B and 640 × 480 pixel frame images were acquired every five minutes.
3.2. Prediction Layer
3.3. API Layer
3.4. Presentation Layer
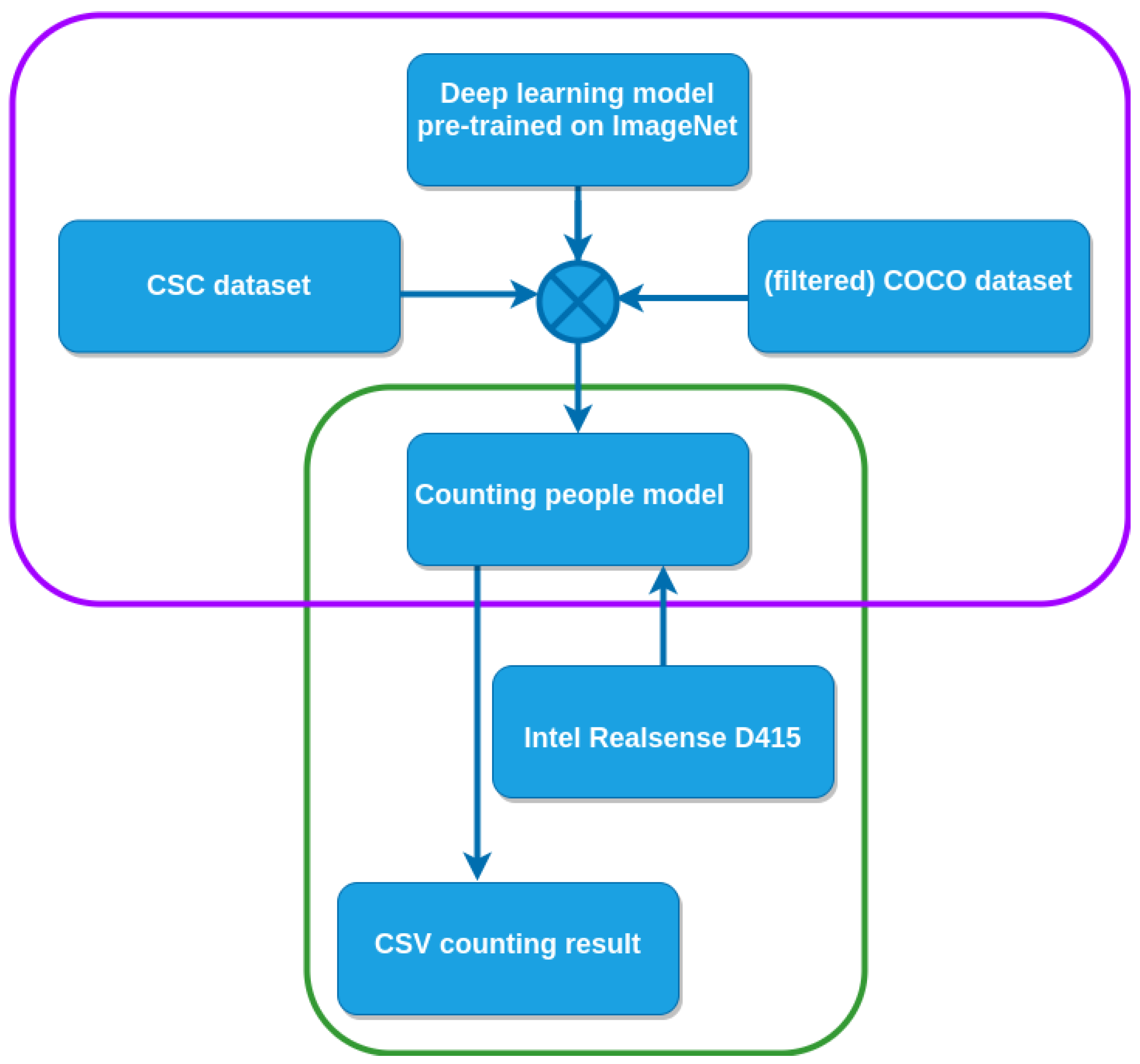
4. Methodology
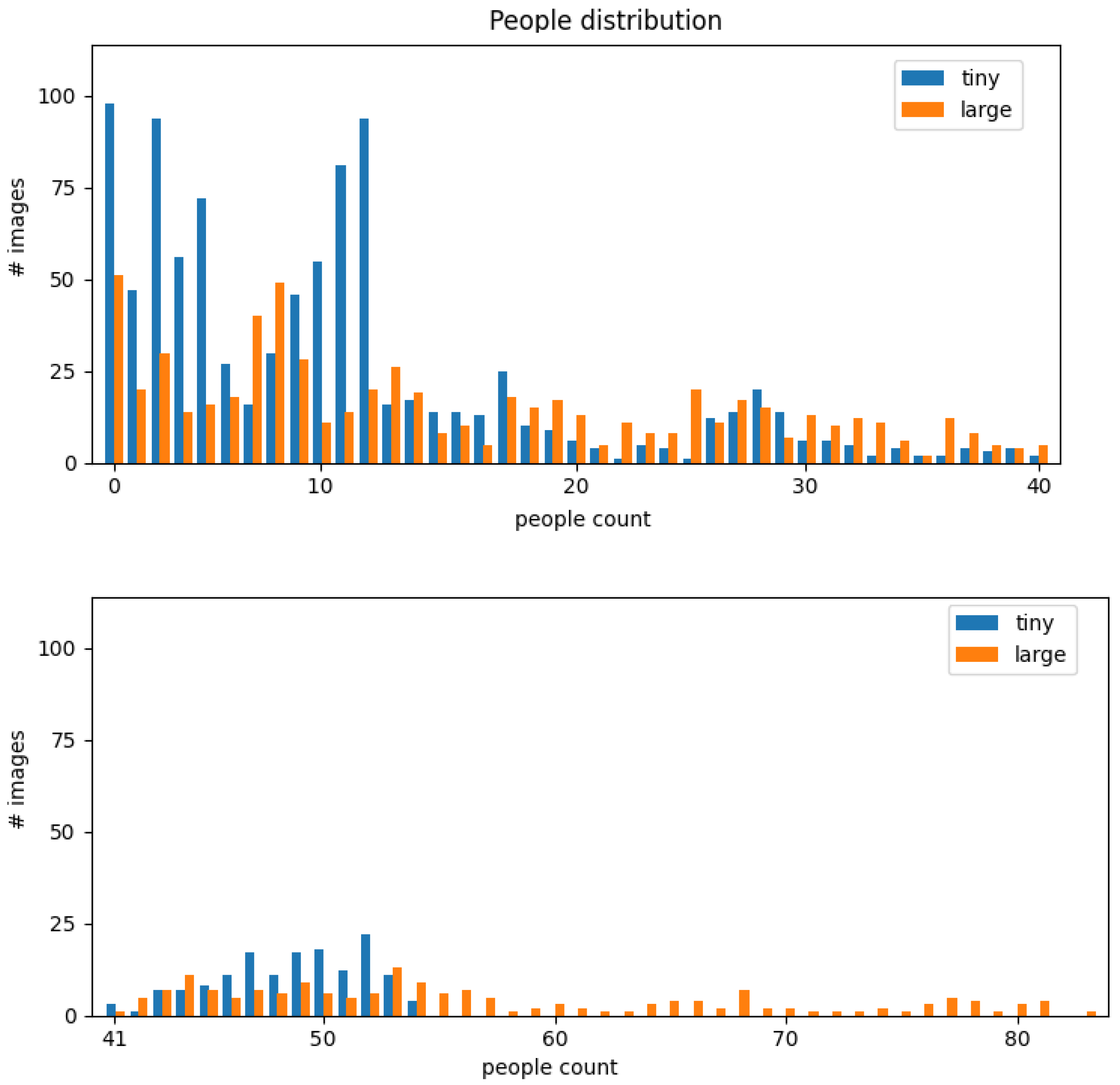
4.1. Dataset Description
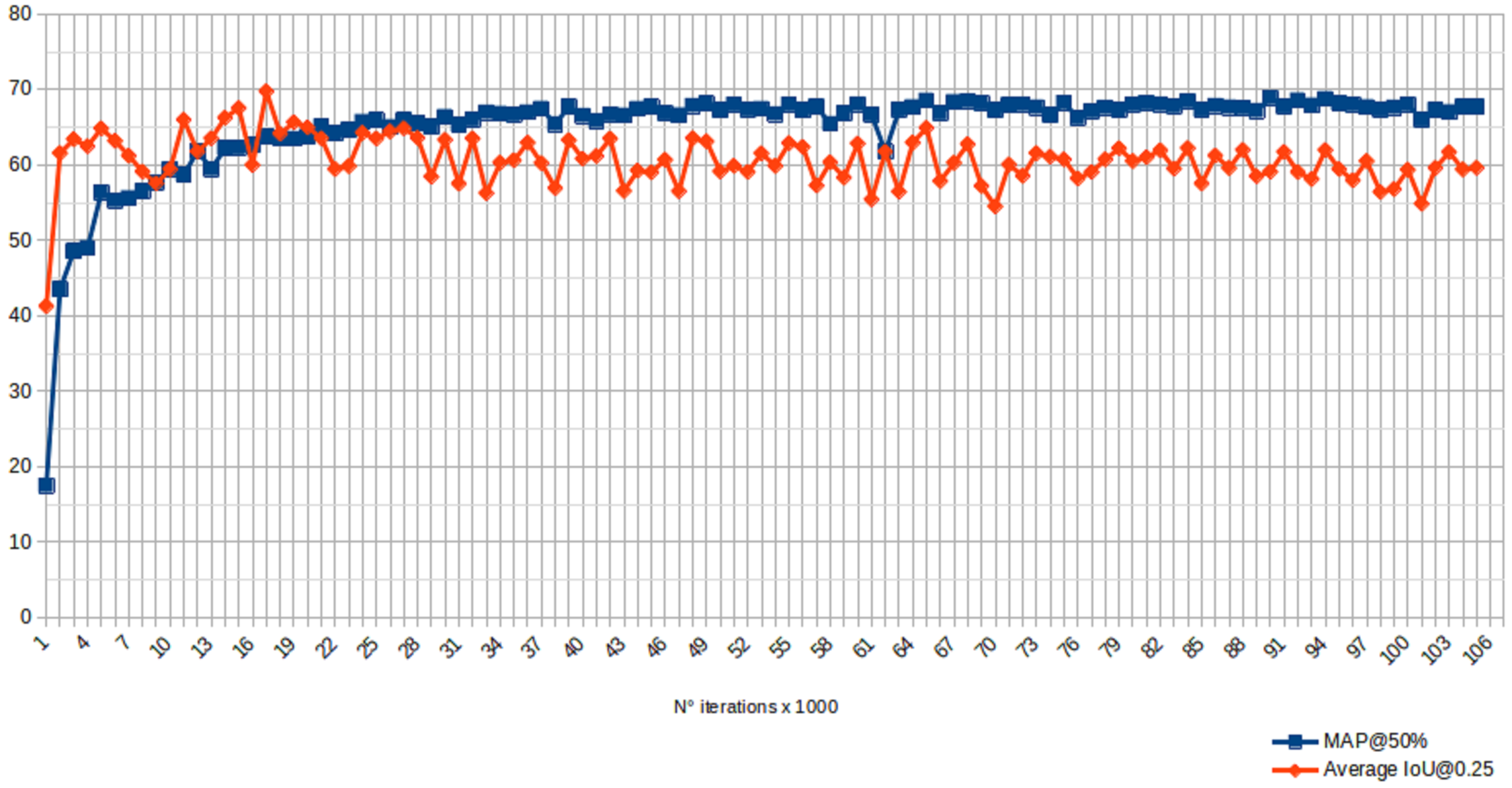
4.2. Training Process
5. Results and Discussion
- Real number (RN): the exact number of people who were present at the time of the image, as counted by a human operator;
- False counting number (FCN): the errors that were made by the system, such as situations when a person was counted twice as a result of the person’s movement or when the print on a t-shirt was counted as a face;
- Predicted number (PN): the number of people that was predicted by our customized YOLOv3 model.
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CSC | Classroom Student Counting |
| IOU | Intersection over union |
| FCN | False counting number |
| LOI | Line of interest |
| MAE | Mean absolute error |
| MAP | Mean average precision |
| PN | Predicted number |
| R-CNN | Region-based convolutional neural network |
| RMSE | Root mean square error |
| RN | Real number |
| ROI | Region of interest |
References
- Caivano, D.; Fogli, D.; Lanzilotti, R.; Piccinno, A.; Cassano, F. Supporting end users to control their smart home: Design implications from a literature review and an empirical investigation. J. Syst. Softw. 2018, 144, 295–313. [Google Scholar] [CrossRef]
- Mohammadmoradi, H.; Munir, S.; Gnawali, O.; Shelton, C. Measuring people-flow through doorways using easy-to-install ir array sensors. In Proceedings of the 2017 13th International Conference on Distributed Computing in Sensor Systems (DCOSS), Ottawa, ON, Canada, 5–7 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 35–43. [Google Scholar]
- Rezaei, M.; Azarmi, M. Deepsocial: Social distancing monitoring and infection risk assessment in COVID-19 pandemic. Appl. Sci. 2020, 10, 7514. [Google Scholar] [CrossRef]
- Thunström, L.; Newbold, S.C.; Finnoff, D.; Ashworth, M.; Shogren, J.F. The benefits and costs of using social distancing to flatten the curve for COVID-19. J. Benefit Cost Anal. 2020, 11, 179–195. [Google Scholar] [CrossRef]
- Moreno, M.V.; Zamora, M.A.; Skarmeta, A.F. User-centric smart buildings for energy sustainable smart cities. Trans. Emerg. Telecommun. Technol. 2014, 25, 41–55. [Google Scholar] [CrossRef]
- Prandi, C.; Monti, L.; Ceccarini, C.; Salomoni, P. Smart campus: Fostering the community awareness through an intelligent environment. Mob. Networks Appl. 2019, 25, 945–952. [Google Scholar] [CrossRef]
- Monti, L.; Prandi, C.; Mirri, S. Iot and data visualization to enhance hyperlocal data in a smart campus context. In Proceedings of the 4th EAI International Conference on Smart Objects and Technologies for Social Good, Bologna, Italy, 28–30 November 2018; European Alliance for Innovation (EAI): Ghent, Belgium, 2018; pp. 1–6. [Google Scholar]
- Prandi, C.; Ceccarini, C.; Salomoni, P. Augmenting good behaviour: Mixing digital and reality to promote sustainability in a campus community. In Proceedings of the 5th EAI International Conference on Smart Objects and Technologies for Social Good, Valencia, Spain, 25–27 September 2019; European Alliance for Innovation (EAI): Ghent, Belgium, 2019; pp. 189–194. [Google Scholar]
- Mangano, S.; Saidinejad, H.; Veronese, F.; Comai, S.; Matteucci, M.; Salice, F. Bridge: Mutual reassurance for autonomous and independent living. IEEE Intell. Syst. 2015, 30, 31–38. [Google Scholar] [CrossRef]
- Masciadri, A.; Comai, S.; Salice, F. Wellness assessment of Alzheimer’s patients in an instrumented health-care facility. Sensors 2019, 19, 3658. [Google Scholar] [CrossRef] [Green Version]
- Bujari, A.; Ciman, M.; Gaggi, O.; Palazzi, C.E. Using gamification to discover cultural heritage locations from geo-tagged photos. Pers. Ubiquitous Comput. 2017, 21, 235–252. [Google Scholar] [CrossRef]
- Tse, R.; Aguiari, D.; Chou, K.S.; Tang, S.K.; Giusto, D.; Pau, G. Monitoring cultural heritage buildings via low-cost edge computing/sensing platforms: The Biblioteca Joanina de Coimbra case study. In Proceedings of the 4th EAI International Conference on Smart Objects and Technologies for Social Good, Bologna, Italy, 28–30 November 2018; European Alliance for Innovation (EAI): Ghent, Belgium, 2018; pp. 148–152. [Google Scholar]
- Ceccarini, C.; Prandi, C. Tourism for all: A mobile application to assist visually impaired users in enjoying tourist services. In Proceedings of the 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Boschetti, M.A.; Maniezzo, V.; Strappaveccia, F. Route relaxations on GPU for vehicle routing problems. Eur. J. Oper. Res. 2017, 258, 456–466. [Google Scholar] [CrossRef]
- Monti, L.; Mirri, S.; Prandi, C.; Salomoni, P. Smart Sensing Supporting Energy-Efficient Buildings: On Comparing Prototypes for People Counting. In Proceedings of the 5th EAI International Conference on Smart Objects and Technologies for Social Good, Valencia, Spain, 25–27 September 2019; European Alliance for Innovation (EAI): Ghent, Belgium, 2019; pp. 171–176. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tse, R.; Monti, L.; Im, M.; Mirri, S.; Pau, G.; Salomoni, P. DeepClass: Edge based class occupancy detection aided by deep learning and image cropping. In Proceedings of the Twelfth International Conference on Digital Image Processing (ICDIP 2020), Osaka, Japan, 19–22 May 2020; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; Volume 11519, p. 1151904. [Google Scholar]
- Kouyoumdjieva, S.T.; Danielis, P.; Karlsson, G. Survey of non-image-based approaches for counting people. IEEE Commun. Surv. Tutor. 2019, 22, 1305–1336. [Google Scholar] [CrossRef]
- Dong, B.; Prakash, V.; Feng, F.; O’Neill, Z. A review of smart building sensing system for better indoor environment control. Energy Build. 2019, 199, 29–46. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Q.; Zou, J. A review of building occupancy measurement systems. Energy Build. 2020, 216, 109965. [Google Scholar] [CrossRef]
- Trivedi, D.; Badarla, V. Occupancy detection systems for indoor environments: A survey of approaches and methods. Indoor Built Environ. 2020, 29, 1053–1069. [Google Scholar] [CrossRef]
- Andrews, J.; Kowsika, M.; Vakil, A.; Li, J. A motion induced passive infrared (PIR) sensor for stationary human occupancy detection. In Proceedings of the 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, OR, USA, 20–23 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1295–1304. [Google Scholar]
- Yun, J.; Lee, S.S. Human Movement Detection and Identification Using Pyroelectric Infrared Sensors. Sensors 2014, 14, 8057–8081. [Google Scholar] [CrossRef]
- Raykov, Y.P.; Ozer, E.; Dasika, G.; Boukouvalas, A.; Little, M.A. Predicting room occupancy with a single passive infrared (PIR) sensor through behavior extraction. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing—UbiComp’16, Heidelberg, Germany, 12–16 September 2016; ACM Press: New York, NY, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Shih, O.; Lazik, P.; Rowe, A. Aures: A wide-band ultrasonic occupancy sensing platform. In Proceedings of the 3rd ACM International Conference on Systems for Energy-Efficient Built Environments, Palo Alto, CA, USA, 16–17 November 2016; ACM Press: New York, NY, USA, 2016; pp. 157–166. [Google Scholar]
- Khalil, N.; Benhaddou, D.; Gnawali, O.; Subhlok, J. Nonintrusive occupant identification by sensing body shape and movement. In Proceedings of the 3rd ACM International Conference on Systems for Energy-Efficient Built Environments, Palo Alto, CA, USA, 16–17 November 2016; ACM Press: New York, NY, USA, 2016; pp. 1–10. [Google Scholar]
- Angeles, R. RFID technologies: Supply-chain applications and implementation issues. Inf. Syst. Manag. 2005, 22, 51–65. [Google Scholar] [CrossRef]
- Weekly, K.; Zou, H.; Xie, L.; Jia, Q.S.; Bayen, A.M. Indoor occupant positioning system using active RFID deployment and particle filters. In Proceedings of the 2014 IEEE International Conference on Distributed Computing in Sensor Systems, Marina Del Rey, CA, USA, 26–28 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 35–42. [Google Scholar]
- Li, X.; Zhang, Y.; Marsic, I.; Sarcevic, A.; Burd, R.S. Deep Learning for RFID-Based Activity Recognition. In Proceedings of the 14th ACM Conference on Embedded Network Sensor Systems (SenSys’16), Stanford, CA, USA, 14–16 November 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 164–175. [Google Scholar] [CrossRef]
- Yaik, O.B.; Wai, K.Z.; Tan, I.K.; Sheng, O.B. Measuring the accuracy of crowd counting using Wi-Fi probe-request-frame counting technique. J. Telecommun. Electron. Comput. Eng. (JTEC) 2016, 8, 79–81. [Google Scholar]
- Li, K.; Yuen, C.; Kanhere, S.S.; Hu, K.; Zhang, W.; Jiang, F.; Liu, X. Understanding crowd density with a smartphone sensing system. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 517–522. [Google Scholar]
- Longo, S.; Cheng, B. Privacy preserving crowd estimation for safer cities. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2015 ACM International Symposium on Wearable Computers (UbiComp)’15, Osaka, Japan, 7–11 September 2015; ACM Press: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Li, T.; Fong, S. Counting Passengers in Public Buses by Sensing Carbon Dioxide Concentration: System Design and Implementation. In Proceedings of the 2018 2nd International Conference on Big Data and Internet of Things, Beijing, China, 24–26 October 2018; ACM: New York, NY, USA, 2018; pp. 218–221. [Google Scholar]
- Ekwevugbe, T.; Brown, N.; Pakka, V.; Fan, D. Real-time building occupancy sensing using neural-network based sensor network. In Proceedings of the 2013 7th IEEE International Conference on Digital Ecosystems and Technologies (DEST), Menlo Park, CA, USA, 24–26 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 114–119. [Google Scholar]
- Wang, F.; Feng, Q.; Chen, Z.; Zhao, Q.; Cheng, Z.; Zou, J.; Zhang, Y.; Mai, J.; Li, Y.; Reeve, H. Predictive control of indoor environment using occupant number detected by video data and CO 2 concentration. Energy Build. 2017, 145, 155–162. [Google Scholar] [CrossRef]
- Masood, M.K.; Soh, Y.C.; Chang, V.W.C. Real-time occupancy estimation using environmental parameters. In Proceedings of the 2015 international joint conference on neural networks (IJCNN), Killarney, Ireland, 12–17 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–8. [Google Scholar]
- Ma, Z.; Chan, A.B. Crossing the line: Crowd counting by integer programming with local features. In Proceedings of the IEEE conference on computer vision and pattern recognition 2013 (CVPR), Portland, OR, USA, 23–28 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 2539–2546. [Google Scholar]
- Del Pizzo, L.; Foggia, P.; Greco, A.; Percannella, G.; Vento, M. Counting people by RGB or depth overhead cameras. Pattern Recognit. Lett. 2016, 81, 41–50. [Google Scholar] [CrossRef]
- Luna, C.A.; Losada-Gutierrez, C.; Fuentes-Jimenez, D.; Fernandez-Rincon, A.; Mazo, M.; Macias-Guarasa, J. Robust people detection using depth information from an overhead Time-of-Flight camera. Expert Syst. Appl. 2017, 71, 240–256. [Google Scholar] [CrossRef]
- Iguernaissi, R.; Merad, D.; Drap, P. People Counting based on Kinect Depth Data. In Proceedings of the International Conference on Pattern Recognition Applications and Methods 2018 (ICPRAM), Funchal, Madeira, Portugal, 16–18 January 2018; SciTePress: Setubal, Portugal, 2018. pp. 364–370.
- Zhu, L.; Wong, K.H. Human tracking and counting using the kinect range sensor based on adaboost and kalman filter. In Proceedings of the 2013 International Symposium on Visual Computing, Rethymnon, Greece, 29–31 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 582–591. [Google Scholar]
- Bondi, E.; Seidenari, L.; Bagdanov, A.D.; Del Bimbo, A. Real-time people counting from depth imagery of crowded environments. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 337–342. [Google Scholar]
- Fernandez-Rincon, A.; Fuentes-Jimenez, D.; Losada-Gutierrez, C.; Romera, M.M.; Luna, C.A.; Guarasa, J.M.; Mazo, M. Robust People Detection and Tracking from an Overhead Time-of-Flight Camera. In Proceedings of the International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP) (4: VISAPP), Porto, Portugal, 27 February–1 March 2017; SciTePress: Setubal, Portugal, 2017; pp. 556–564. [Google Scholar]
- Zhao, T.; Nevatia, R.; Wu, B. Segmentation and tracking of multiple humans in crowded environments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1198–1211. [Google Scholar] [CrossRef] [PubMed]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–7. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Counting people with low-level features and Bayesian regression. IEEE Trans. Image Process. 2012, 21, 2160–2177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bansal, A.; Venkatesh, K. People counting in high density crowds from still images. arXiv 2015, arXiv:1507.08445. [Google Scholar]
- Fekri-Ershad, S. A Review on Image Texture Analysis Methods. arXiv 2018, arXiv:1804.00494. [Google Scholar]
- Kim, M.; Kim, W.; Kim, C. Estimating the number of people in crowded scenes. In Proceedings of the Visual Information Processing and Communication II, San Francisco, CA, USA, 23–27 January 2011; International Society for Optics and Photonics: Bellingham, WA, USA, 2011; Volume 7882, p. 78820L. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 2547–2554. [Google Scholar]
- Maniezzo, V.; Boschetti, M.A.; Carbonaro, A.; Marzolla, M.; Strappaveccia, F. Client-side Computational Optimization. ACM Trans. Math. Softw. 2019, 45, 19:1–19:16. [Google Scholar] [CrossRef] [Green Version]
- Smilkov, D.; Thorat, N.; Assogba, Y.; Yuan, A.; Kreeger, N.; Yu, P.; Zhang, K.; Cai, S.; Nielsen, E.; Soergel, D.; et al. TensorFlow.js: Machine Learning for the Web and Beyond. arXiv 2019, arXiv:1901.05350. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Won, J.H.; Lee, D.H.; Lee, K.M.; Lin, C.H. An improved YOLOv3-based neural network for de-identification technology. In Proceedings of the 2019 34th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Jeju Shinwha World, Jeju Island, Korea, 23–26 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–2. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Batch | mAP@50% | Precision@0.25 | Recall@0.25 | F1@0.25 | AIoU@0.25 |
|---|---|---|---|---|---|
| 1000 | 17.49 | 0.61 | 0.24 | 0.34 | 41.27 |
| 5000 | 56.35 | 0.83 | 0.57 | 0.67 | 64.83 |
| 10,000 | 59.42 | 0.76 | 0.63 | 0.69 | 59.41 |
| 15,000 | 62.27 | 0.85 | 0.6 | 0.7 | 67.54 |
| 20,000 | 63.74 | 0.83 | 0.63 | 0.71 | 64.97 |
| 25,000 | 65.93 | 0.8 | 0.6 | 0.72 | 63.48 |
| 30,000 | 66.34 | 0.79 | 0.67 | 0.73 | 63.31 |
| 35,000 | 66.66 | 0.76 | 0.69 | 0.72 | 60.61 |
| 40,000 | 66.51 | 0.77 | 0.69 | 0.72 | 60.81 |
| 45,000 | 67.7 | 0.74 | 0.71 | 0.73 | 59.02 |
| 50,000 | 67.25 | 0.74 | 0.7 | 0.72 | 59.13 |
| 55,000 | 67.99 | 0.78 | 0.69 | 0.73 | 62.89 |
| 60,000 | 68.03 | 0.78 | 0.69 | 0.73 | 62.83 |
| 65,000 | 68.51 | 0.81 | 0.67 | 0.73 | 64.9 |
| 70,000 | 67.26 | 0.69 | 0.73 | 0.71 | 54.5 |
| 75,000 | 68.23 | 0.76 | 0.71 | 0.73 | 60.73 |
| 80,000 | 68 | 0.75 | 0.7 | 0.73 | 60.51 |
| 85,000 | 67.31 | 0.72 | 0.72 | 0.72 | 57.54 |
| 90,000 | 68.89 | 0.74 | 0.72 | 0.73 | 59.11 |
| 95,000 | 68.17 | 0.74 | 0.72 | 0.73 | 59.45 |
| 100,000 | 67.99 | 0.74 | 0.72 | 0.73 | 59.36 |
| 105,000 | 67.67 | 0.74 | 0.71 | 0.73 | 59.6 |
| Classroom | Average Accuracy | Standard Deviation | RMSE | MAE |
|---|---|---|---|---|
| Small Classrooms | ||||
| 1 | 97.10% | 6.78 | 0.65 | 0.33 |
| 2 | 96.76% | 9.05 | 0.55 | 0.21 |
| 3 | 94.07% | 13.83 | 0.62 | 0.25 |
| 4 | 95.10% | 8.58 | 0.79 | 0.47 |
| 5 | 95.80% | 8.09 | 2.89 | 1.22 |
| Large Classrooms | ||||
| 1 | 95.58% | 6.70 | 2.23 | 1.14 |
| 2 | 93.44% | 15.17 | 1.93 | 1.23 |
| 3 | 91.00% | 14.76 | 1.78 | 1.12 |
| Large Classrooms | ||||
|---|---|---|---|---|
| Left Camera | Right Camera | |||
| Classroom | Accuracy | Standard Deviation | Accuracy | Standard Deviation |
| 1 | 94.73% | 7.43 | 96.42% | 5.80 |
| 2 | 93.91% | 17.51 | 92.97% | 12.47 |
| 3 | 90.42% | 15.03 | 91.57% | 14.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Monti, L.; Tse, R.; Tang, S.-K.; Mirri, S.; Delnevo, G.; Maniezzo, V.; Salomoni, P. Edge-Based Transfer Learning for Classroom Occupancy Detection in a Smart Campus Context. Sensors 2022, 22, 3692. https://doi.org/10.3390/s22103692
Monti L, Tse R, Tang S-K, Mirri S, Delnevo G, Maniezzo V, Salomoni P. Edge-Based Transfer Learning for Classroom Occupancy Detection in a Smart Campus Context. Sensors. 2022; 22(10):3692. https://doi.org/10.3390/s22103692
Chicago/Turabian StyleMonti, Lorenzo, Rita Tse, Su-Kit Tang, Silvia Mirri, Giovanni Delnevo, Vittorio Maniezzo, and Paola Salomoni. 2022. "Edge-Based Transfer Learning for Classroom Occupancy Detection in a Smart Campus Context" Sensors 22, no. 10: 3692. https://doi.org/10.3390/s22103692