
Multilocation and Multiscale Learning Framework with Skip Connection for Fault Diagnosis of Bearing under Complex Working Conditions

Abstract
:1. Introduction
- All features are naturally hand-crafted. The process of feature extraction requires much prior knowledge about diagnostic experience and signal processing technology, which needs to consume much labor and time resources. Complex and sophisticated modern equipment is difficult to extract the comprehensive and detailed internal features of rolling bearings.
- The feature extraction and fault classification of the diagnostic system are separately designed and performed, both of which impact the final classification result. However, the strategy cannot be optimized simultaneously.
- The limited inductive feature ability of shallow learning models cannot flexibly identify the complex state changes of the bearing. Fault diagnosis methods of the specific domain cannot be applied to other engineering fields. Therefore, a general-purpose method is needed to extend to new application areas.
- This article combines the skip connection and encoder network and proposes a multilocation scale learning network that extracts global and local features from the network layers of different depths. The advantages of this feature extraction can be accumulated in the entire network by adding multiple skip connections.
- Multikernel scale learning is introduced into the CNN integration module of the DL with different kernel sizes to simultaneously learn vibration characteristics at the different time scales. The advantages will be accumulated in the entire network by adding multiple kernel scale branches.
- The feature information fusion layer is employed to automatically fuse the feature space and optimize the rich features extracted from the multilocation learning network and multiscale learning network.
- The PBiLSTM network is used to deeply excavate the efferent robustness features of the GMSL network and captures dependent and sensitive fault features.
- Based on the above improvements, the MLKDCE-PBiLSTM scheme is proposed to extract comprehensive fault features. The MLKDCE-based network can autonomously extract and fuse useful and comprehensive features using multilocation and multiscale learning. However, the PBiLSTM-based network is designed to deeply excavate and protect high-purity features of GMSL network output. Consequently, under the complicated working conditions of varying speeds and loads, the proposed feature learning method is used to accurately diagnose various fault types of rolling bearings.
2. Theoretical Background
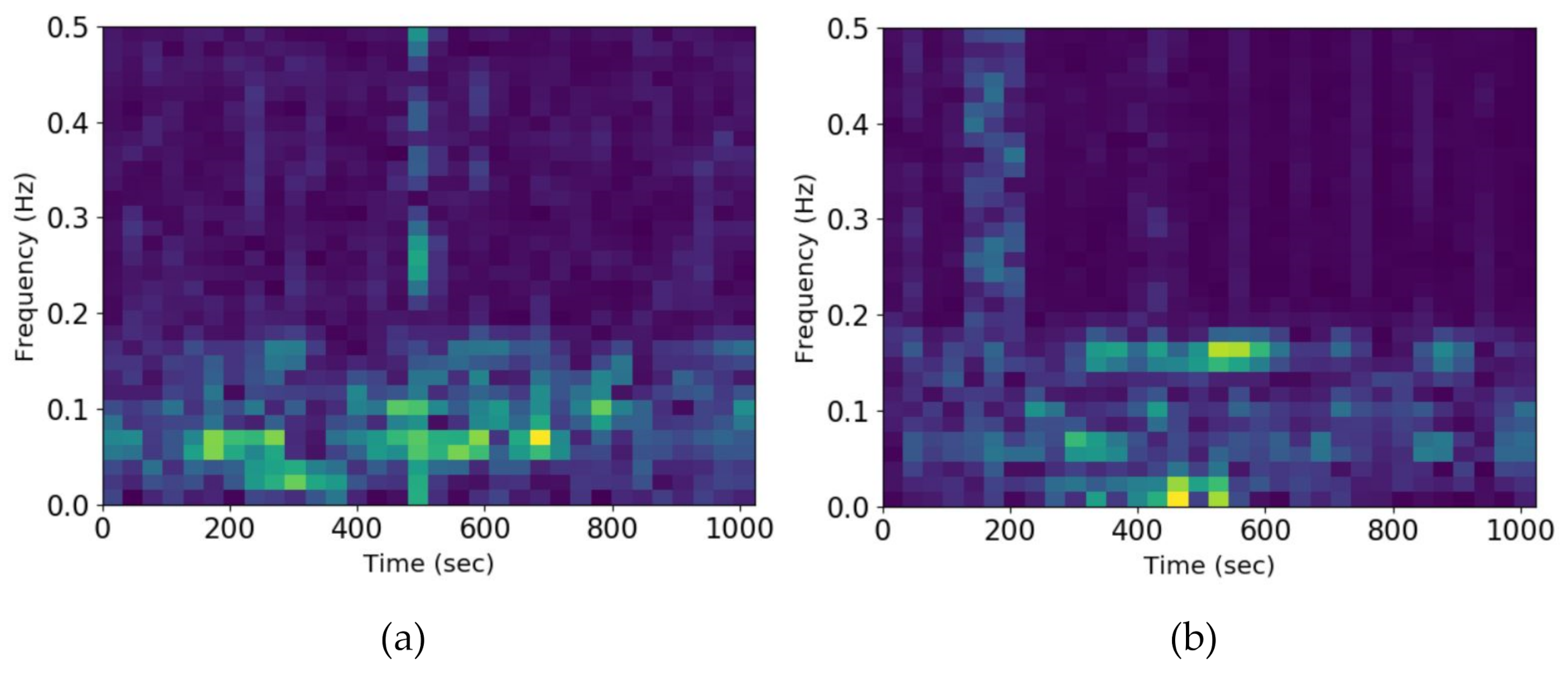
2.1. Multiscale Wavelet Transform (MSWT)
2.2. Activation Function
- The functions have three characteristics of lower bounds, no upper bounds, and non-monotonic.
- Both Swish and its first derivative have smooth characteristics.
2.3. Deep Convolutional Autoencoder (DCAE)
- In the coding process, the autoencoder can perform both linear transformations with a linear activation function and a nonlinear transformation with a nonlinear activation function. When PCA performs a nonlinear data process, it is assumed that the data conform to ideal data distribution. Otherwise, PCA can only perform linear transformations [31].
- In this article, the input data is processed into an image by the Wavelet Transform. The bearing dataset is highly nonlinear and complicated. For the autoencoder, it can learn the linear and nonlinear features with encoder and decoder. However, PCA can only learn the linear features.
- The dimensions of the kernel PCA method are dependent on the number of input data in the eigen-decomposition. The autoencoder is flexible. In structure construction, because of the network representation form of an autoencoder, multiple nonlinear layers can be used for feature extraction.
- The structure of the autoencoder is much more flexible than PCA, which can process more diversified vibration data.
- The application of autoencoder is wider, such as data denoising, visualization and dimension reduction, image compression, and feature learning.
- PCA is just a special case of a single-layer autoencoder with a linear activation function.
2.4. Bidirectional Long Short-Term Memory Network
3. Comprehensive Feature Learning Method
3.1. Generalized Multiscale Learning (GMSL)
3.1.1. Multilocation Scale Module (MLS)
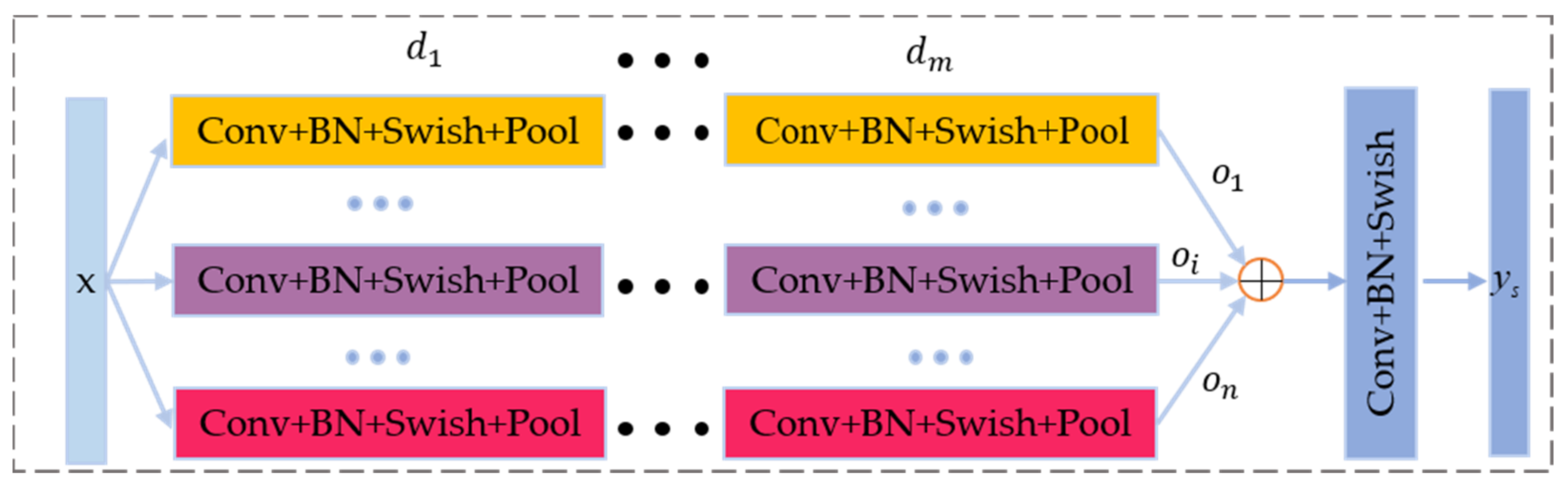
3.1.2. Multikernel Scale Module (MKS)
3.2. Multifeature Fusion
3.3. Multifeature Protection Layer
3.4. Fault Classification
4. Experimental Setup
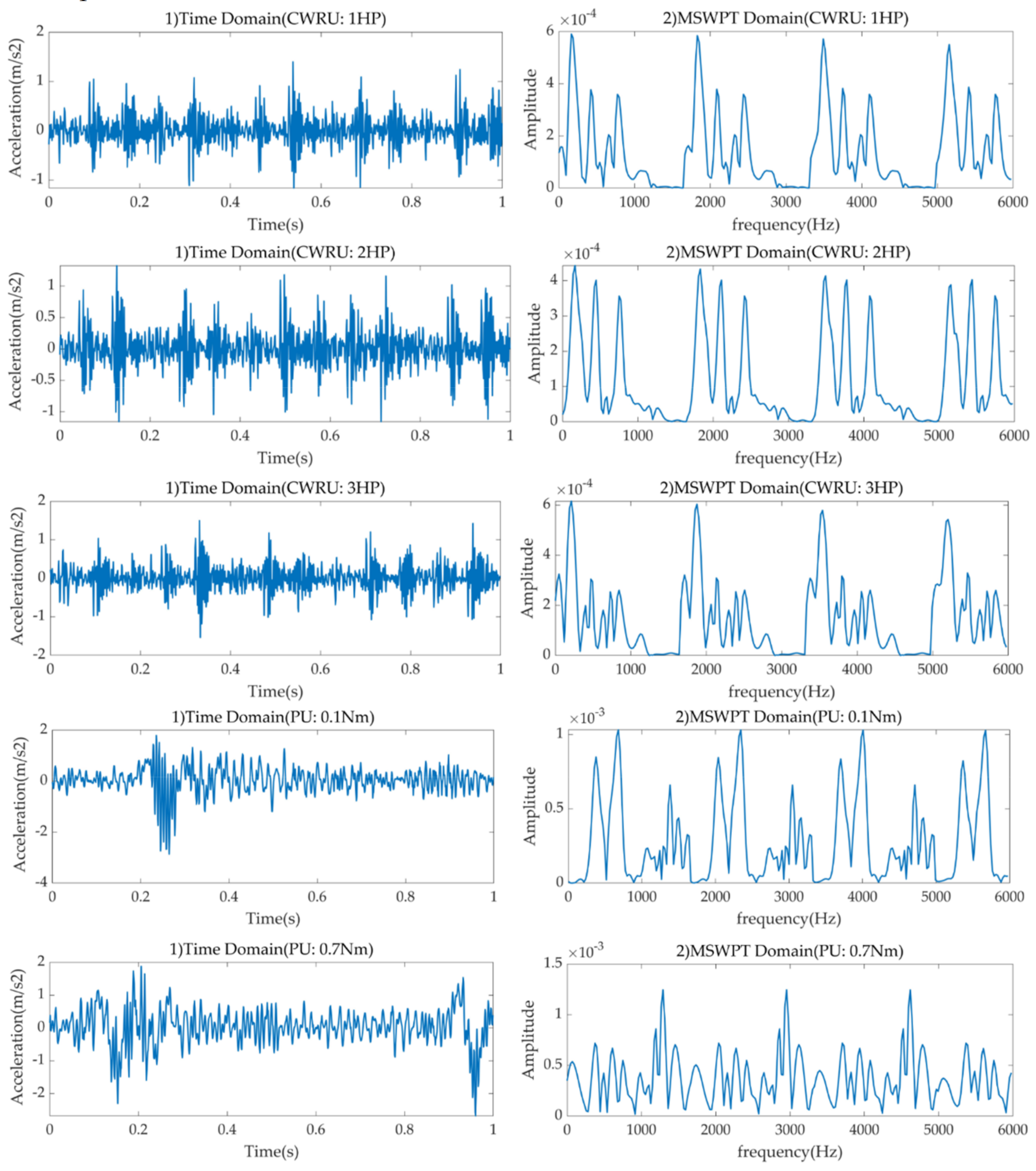
4.1. Description of PU Datasets
4.2. Description of CWRU Datasets
4.3. Data Processing and Augmentation
5. Performance Verification
5.1. Comparison Settings with Other Methods
- Multilocation learning: The MLKDCE-PBiLSTM employs skip connections in the branch network to perform multilocation feature learning. The MSCNN neural network employs multiscale coarse-grained operations to down-sample the raw signal, which is probable to lose some features of the input signals.
- Multikernal operation: In the MSCNN structure, three branches are copy networks, and the extraction of information is insufficient. However, MLKDCE-PBiLSTM uses multiple parallel encoder branches with different convolution kernels and network parameters to extract multiscale fault features.
- Multifeature fusion: MSCNN does not adopt any feature fusion method, and directly puts the learned features into the final classification layer. The MLKDCE-PBiLSTM uses a multifeature fusion layer to optimize the fusion and optimization of the characteristics learned from multilocation learning and multiscale learning. The network scheme improves the accuracy of the model.
- Multifeature integration and protection operation: The MLKDCE-PBiLSTM uses a multifeature protection layer to extract long-term dependent fault information in the vibration signal after multifeature integration processing. It is used to maximize the integrity and accuracy of the fault features. However, other comparison networks directly perform dropout or classification operations, which will affect the accuracy or even lose important information.
5.2. Performance Comparison with Other Advanced Methods
5.2.1. Comparison Experiment under PU Dataset
5.2.2. Comparison Experiment under CWRU Dataset
5.2.3. Computational Burden of the Networks
5.3. Verify the Necessity of Each Component of the Model
5.3.1. Necessity of the Multilocation Scale Learning
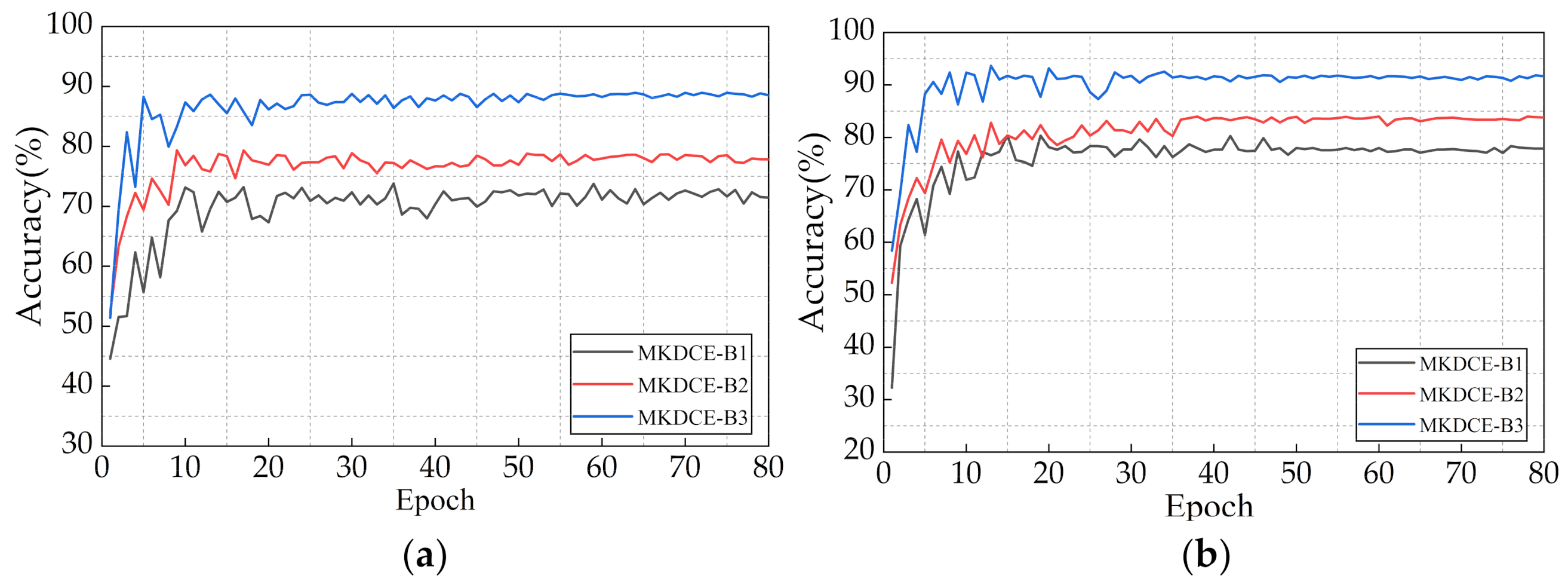
5.3.2. Necessity of the Multikernel Scale Learning
5.3.3. Necessity of the Fault Multifeature Fusion
5.3.4. Necessity of the Multifeature Protection
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, H.; Wang, Y.; Wang, B.; Sun, J.; Li, Y. The application of a general mathematical morphological particle as a novel indicator for the performance degradation assessment of a bearing. Mech. Syst. Signal Process. 2017, 82, 490–502. [Google Scholar] [CrossRef]
- Wang, L.; Liu, Z. An improved local characteristic-scale decomposition to restrict end effects, mode mixing and its application to extract incipient bearing fault signal. Mech. Syst. Signal Process. 2021, 156. [Google Scholar] [CrossRef]
- Li, X.; Ma, J.; Wang, X.; Wu, J.; Li, Z. An improved local mean decomposition method based on improved composite interpolation envelope and its application in bearing fault feature extraction. Isa Trans. 2020, 97, 365–383. [Google Scholar] [CrossRef]
- Tao, X.; Ren, C.; Wu, Y.; Li, Q.; Guo, W.; Liu, R.; He, Q.; Zou, J. Bearings fault detection using wavelet transform and generalized Gaussian density modeling. Measurement 2020, 155. [Google Scholar] [CrossRef]
- Elbouchikhi, E.; Choqueuse, V.; Amirat, Y.; Benbouzid, M.E.H.; Turri, S. An Efficient Hilbert–Huang Transform-Based Bearing Faults Detection in Induction Machines. IEEE Trans. Energy Convers. 2017, 32, 401–413. [Google Scholar] [CrossRef]
- Goyal, D.; Choudhary, A.; Pabla, B.S.; Dhami, S.S. Support vector machines based non-contact fault diagnosis system for bearings. J. Intell. Manuf. 2019, 31, 1275–1289. [Google Scholar] [CrossRef]
- Shevchik, S.A.; Saeidi, F.; Meylan, B.; Wasmer, K. Prediction of Failure in Lubricated Surfaces Using Acoustic Time–Frequency Features and Random Forest Algorithm. IEEE Trans. Ind. Inform. 2017, 13, 1541–1553. [Google Scholar] [CrossRef]
- Christodoulou, E.; Ma, J.; Collins, G.S.; Steyerberg, E.W.; Verbakel, J.Y.; Van Calster, B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J. Clin. Epidemiol. 2019, 110, 12–22. [Google Scholar] [CrossRef]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.N.; Rueckert, D. A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 491–503. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, G.; Nie, L.; Wang, Q.; Tan, W. Distance metric optimization driven convolutional neural network for age invariant face recognition. Pattern Recognit. 2018, 75, 51–62. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Gan, M.; Wang, C.; Zhu, C.A. Construction of hierarchical diagnosis network based on deep learning and its application in the fault pattern recognition of rolling element bearings. Mech. Syst. Signal Process. 2016, 72–73, 92–104. [Google Scholar] [CrossRef]
- Fuan, W.; Hongkai, J.; Haidong, S.; Wenjing, D.; Shuaipeng, W. An adaptive deep convolutional neural network for rolling bearing fault diagnosis. Meas. Sci. Technol. 2017, 28. [Google Scholar] [CrossRef]
- Cabrera, D.; Guamán, A.; Zhang, S.; Cerrada, M.; Sánchez, R.-V.; Cevallos, J.; Long, J.; Li, C. Bayesian approach and time series dimensionality reduction to LSTM-based model-building for fault diagnosis of a reciprocating compressor. Neurocomputing 2020, 380, 51–66. [Google Scholar] [CrossRef]
- Zhao, K.; Jiang, H.; Li, X.; Wang, R. An optimal deep sparse autoencoder with gated recurrent unit for rolling bearing fault diagnosis. Meas. Sci. Technol. 2020, 31. [Google Scholar] [CrossRef]
- Guo, X.; Shen, C.; Chen, L. Deep Fault Recognizer: An Integrated Model to Denoise and Extract Features for Fault Diagnosis in Rotating Machinery. Appl. Sci. 2016, 7, 41. [Google Scholar] [CrossRef]
- Guo, S.; Yang, T.; Gao, W.; Zhang, C. A Novel Fault Diagnosis Method for Rotating Machinery Based on a Convolutional Neural Network. Sensors 2018, 18, 1429. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, M.; Jiang, Z.; Feng, K. Research on variational mode decomposition in rolling bearings fault diagnosis of the multistage centrifugal pump. Mech. Syst. Signal Process. 2017, 93, 460–493. [Google Scholar] [CrossRef] [Green Version]
- Tang, S.; Yuan, S.; Zhu, Y. Data Preprocessing Techniques in Convolutional Neural Network Based on Fault Diagnosis Towards Rotating Machinery. IEEE Access 2020, 8, 149487–149496. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhang, H.; Liang, T. Electric Locomotive Bearing Fault Diagnosis Using a Novel Convolutional Deep Belief Network. IEEE Trans. Ind. Electron. 2018, 65, 2727–2736. [Google Scholar] [CrossRef]
- Xia, M.; Li, T.; Xu, L.; Liu, L.; de Silva, C.W. Fault Diagnosis for Rotating Machinery Using Multiple Sensors and Convolutional Neural Networks. IEEE/ASME Trans. Mechatron. 2018, 23, 101–110. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, J.; Cheng, Y.; Lu, C. Fault diagnosis of gearbox using empirical mode decomposition and multi-fractal detrended cross-correlation analysis. J. Sound Vib. 2016, 385, 350–371. [Google Scholar] [CrossRef]
- An, Z.; Li, S.; Wang, J.; Jiang, X. A novel bearing intelligent fault diagnosis framework under time-varying working conditions using recurrent neural network. Isa Trans. 2020, 100, 155–170. [Google Scholar] [CrossRef] [PubMed]
- Rao, M.; Li, Q.; Wei, D.; Zuo, M.J. A deep bi-directional long short-term memory model for automatic rotating speed extraction from raw vibration signals. Measurement 2020, 158. [Google Scholar] [CrossRef]
- Zhang, S.; Ye, F.; Wang, B.; Habetler, T.G. Semi-Supervised Bearing Fault Diagnosis and Classification Using Variational Autoencoder-Based Deep Generative Models. IEEE Sens. J. 2021, 21, 6476–6486. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, X.; Liu, Y.; Jia, M. Multiscale cascading deep belief network for fault identification of rotating machinery under various working conditions. Knowl. Based Syst. 2020, 193. [Google Scholar] [CrossRef]
- Ding, X.; He, Q.; Luo, N. A fusion feature and its improvement based on locality preserving projections for rolling element bearing fault classification. J. Sound Vib. 2015, 335, 367–383. [Google Scholar] [CrossRef]
- Wang, L.; Liu, Z.; Cao, H.; Zhang, X. Subband averaging kurtogram with dual-tree complex wavelet packet transform for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2020, 142. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish a Self-Gated Activation Function. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Deng, X.; Cai, P.; Cao, Y.; Wang, P. Two-Step Localized Kernel Principal Component Analysis Based Incipient Fault Diagnosis for Nonlinear Industrial Processes. Ind. Eng. Chem. Res. 2020, 59, 5956–5968. [Google Scholar] [CrossRef]
- Wang, J.; Li, S.; An, Z.; Jiang, X.; Qian, W.; Ji, S. Batch-normalized deep neural networks for achieving fast intelligent fault diagnosis of machines. Neurocomputing 2019, 329, 53–65. [Google Scholar] [CrossRef]
- Yildirim, O. A novel wavelet sequence based on deep bidirectional LSTM network model for ECG signal classification. Comput. Biol. Med. 2018, 96, 189–202. [Google Scholar] [CrossRef]
- Ghosh, L.; Saha, S.; Konar, A. Bi-directional Long Short-Term Memory model to analyze psychological effects on gamers. Appl. Soft Comput. 2020, 95. [Google Scholar] [CrossRef]
- Liang, T.; Meng, Z.; Xie, G.; Fan, S. Multi-Running State Health Assessment of Wind Turbines Drive System Based on BiLSTM and GMM. IEEE Access 2020, 8, 143042–143054. [Google Scholar] [CrossRef]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Gao, H. A Data-Driven-Based Fault Diagnosis Approach for Electrical Power DC-DC Inverter by Using Modified Convolutional Neural Network With Global Average Pooling and 2-D Feature Image. IEEE Access 2020, 8, 73677–73697. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition Monitoring of Bearing Damage in Electromechanical Drive 941 Systems by Using Motor Current Signals of Electric Motors: A Benchmark Data Set for Data-Driven Classification. In Proceedings of the European Conference of the Prognostics and Health Management Society, Bilbao, Spain, 5–8 July 2016; p. 17. [Google Scholar]
- Seyfioglu, M.S.; Ozbayoglu, A.M.; Gurbuz, S.Z. Deep convolutional autoencoder for radar-based classification of similar aided and unaided human activities. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1709–1723. [Google Scholar] [CrossRef]
- Wang, S.; Wang, D.; Kong, D.; Wang, J.; Li, W.; Zhou, S. Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning. Sensors 2020, 20, 6437. [Google Scholar] [CrossRef] [PubMed]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale Convolutional Neural Networks for Fault Diagnosis of Wind Turbine Gearbox. IEEE Trans. Ind. Electron. 2019, 66, 3196–3207. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setting Name | Rotational Speed (rpm) | Load Torque (nm) |
|---|---|---|
| M07_N15_ F10 | 1500 | 0.7 |
| M07_N09_ F10 | 900 | 0.7 |
| M01_N15_ F10 | 1500 | 0.1 |
| M07_N15_F04 | 1500 | 0.7 |
| Name | Fault Location | Fault Description |
|---|---|---|
| K001 | Healthy | |
| KA04 | Outer ring | Fatigue: pitting |
| KA15 | Outer ring | Plastic deform: indentations |
| KA22 | Outer ring | Fatigue: pitting |
| KA30 | Outer ring | Plastic deform: Indentations |
| KI18 | Inner ring | Fatigue: pitting |
| KI21 | Inner ring | Fatigue: pitting |
| KI16 | Inner ring | Fatigue: pitting |
| KI04 | Inner + outer | Fatigue: pitting; Plastic deform: indentations |
| KI14 | Inner + outer | Fatigue: pitting; Plastic deform: indentations |
| KB23 | Outer + inner | Fatigue: pitting |
| KB27 | Outer + inner | Plastic deform: indentations |
| KA16 | Outer +outer | Fatigue: pitting |
| KI17 | Inner + inner | Fatigue: pitting |
| Index | Loads(nm) of Training/Testing | Speeds | Ntrain | Ntest | Category |
|---|---|---|---|---|---|
| A | 0.7/0.7 | 900/900 | 4800 | 800 | 13 |
| B | 0.1/0.1 | 1500/1500 | 4800 | 800 | 13 |
| C | (0.1,0.7)/(0.1,0.7) | (1500,900)/(1500,900) | 4800 | 800 | 13 |
| D | 0.1/0.7 | 1500/900 | 4800 | 800 | 13 |
| E | 0.7/0.1 | 900/1500 | 4800 | 800 | 13 |
| Inside | Ball | Outside | Thickness | Pitch |
|---|---|---|---|---|
| 0.9843 | 0.3126 | 2.0472 | 0.5906 | 1.537 |
| Index | Loads(hp) of Training/Testing | Speeds(rmp) | Ntrain | Ntest |
|---|---|---|---|---|
| Normal | / | 1796 | 4800 | 800 |
| F | 1/1 | 1772 | 4800 | 800 |
| G | 3/3 | 1730 | 4800 | 800 |
| H | (1,3)/2 | (1772,1730)/1750 | 4800 | 800 |
| I | 1/3 | 1772/1730 | 4800 | 800 |
| J | 3/1 | 1730/1772 | 4800 | 800 |
| MLKDCE-PBiLSTM | DCAE | BiLSTM | LeNet-5 | MSCNN | LSTM | |
|---|---|---|---|---|---|---|
| PU | 1.8151 | 1.6007 | 0.7243 | 0.7553 | 0.8365 | 0.4496 |
| CWRU | 2.7327 | 2.5140 | 1.1260 | 1.3548 | 1.5623 | 1.1496 |
| Accuracy (%) | MLDCE-M0 | MLDCE-M1 | MLDCE-M2 | MLDCE-M3 |
|---|---|---|---|---|
| PU Load | 74.277 | 83.198 | 77.668 | 90.522 |
| CWRU Load | 77.199 | 87.468 | 85.303 | 91.522 |
| Accuracy (%) | MKDCE-B1 | MKDCE-B2 | MKDCE-B3 |
|---|---|---|---|
| PU Load | 72.039 | 78.009 | 88.702 |
| CWRU Load | 77.668 | 83.509 | 91.360 |
| Accuracy (%) | MLKDCE-NLF | MLKDCE-NKF | MLKDCE-NLF-KF | MLKDCE |
|---|---|---|---|---|
| PU Load | 88.702 | 82.492 | 79.911 | 93.522 |
| CWRU Load | 91.360 | 88.114 | 81.492 | 96.512 |
| Accuracy (%) | MLKDCE | MLKDCE-PBiLSTM |
|---|---|---|
| PU Load | 93.522 | 96.795 |
| CWRU Load | 96.522 | 97.946 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ban, H.; Wang, D.; Wang, S.; Liu, Z. Multilocation and Multiscale Learning Framework with Skip Connection for Fault Diagnosis of Bearing under Complex Working Conditions. Sensors 2021, 21, 3226. https://doi.org/10.3390/s21093226
Ban H, Wang D, Wang S, Liu Z. Multilocation and Multiscale Learning Framework with Skip Connection for Fault Diagnosis of Bearing under Complex Working Conditions. Sensors. 2021; 21(9):3226. https://doi.org/10.3390/s21093226
Chicago/Turabian StyleBan, Hongwei, Dazhi Wang, Sihan Wang, and Ziming Liu. 2021. "Multilocation and Multiscale Learning Framework with Skip Connection for Fault Diagnosis of Bearing under Complex Working Conditions" Sensors 21, no. 9: 3226. https://doi.org/10.3390/s21093226