
The Effects of Individual Differences, Non-Stationarity, and the Importance of Data Partitioning Decisions for Training and Testing of EEG Cross-Participant Models


Abstract
:1. Introduction
2. Background
2.1. Covariate Shift
2.2. Non-Stationarity and Individual Differences
2.3. Approaches to Data and Problem Formulation
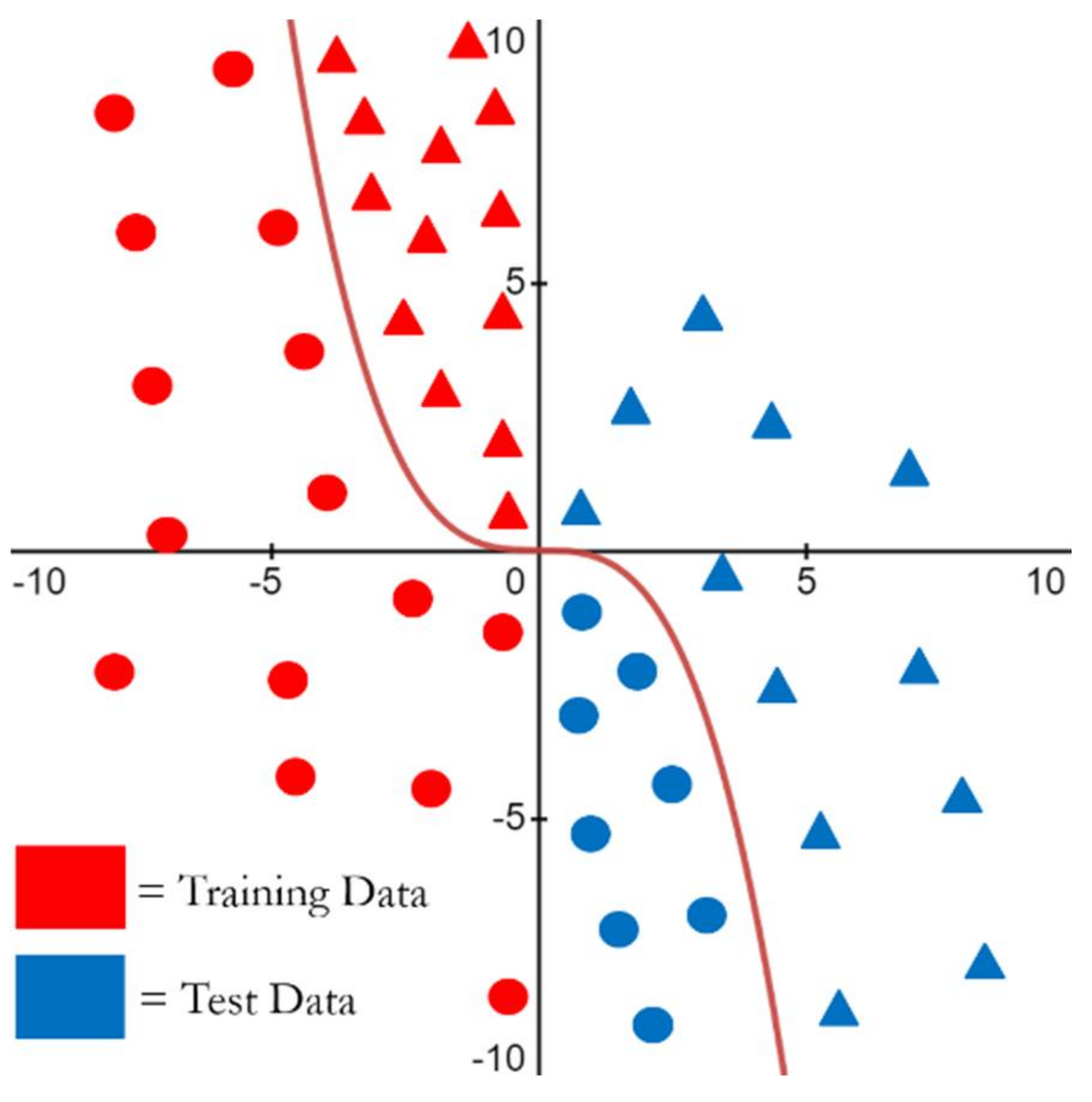
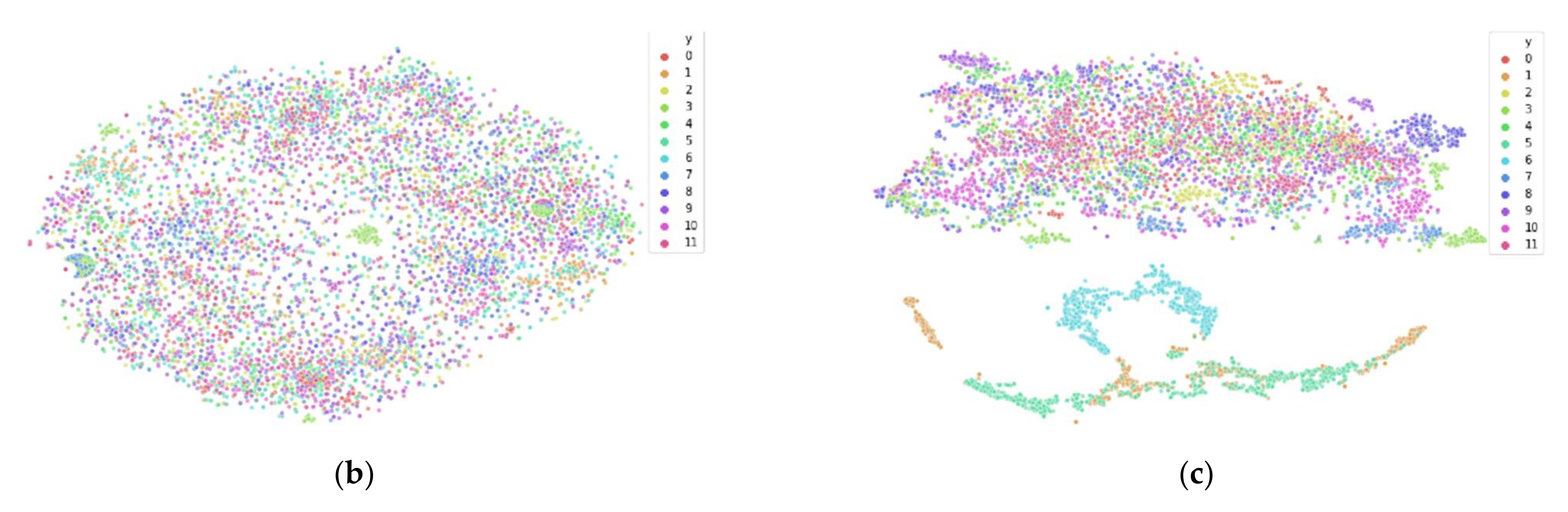
3. Initial Demonstration
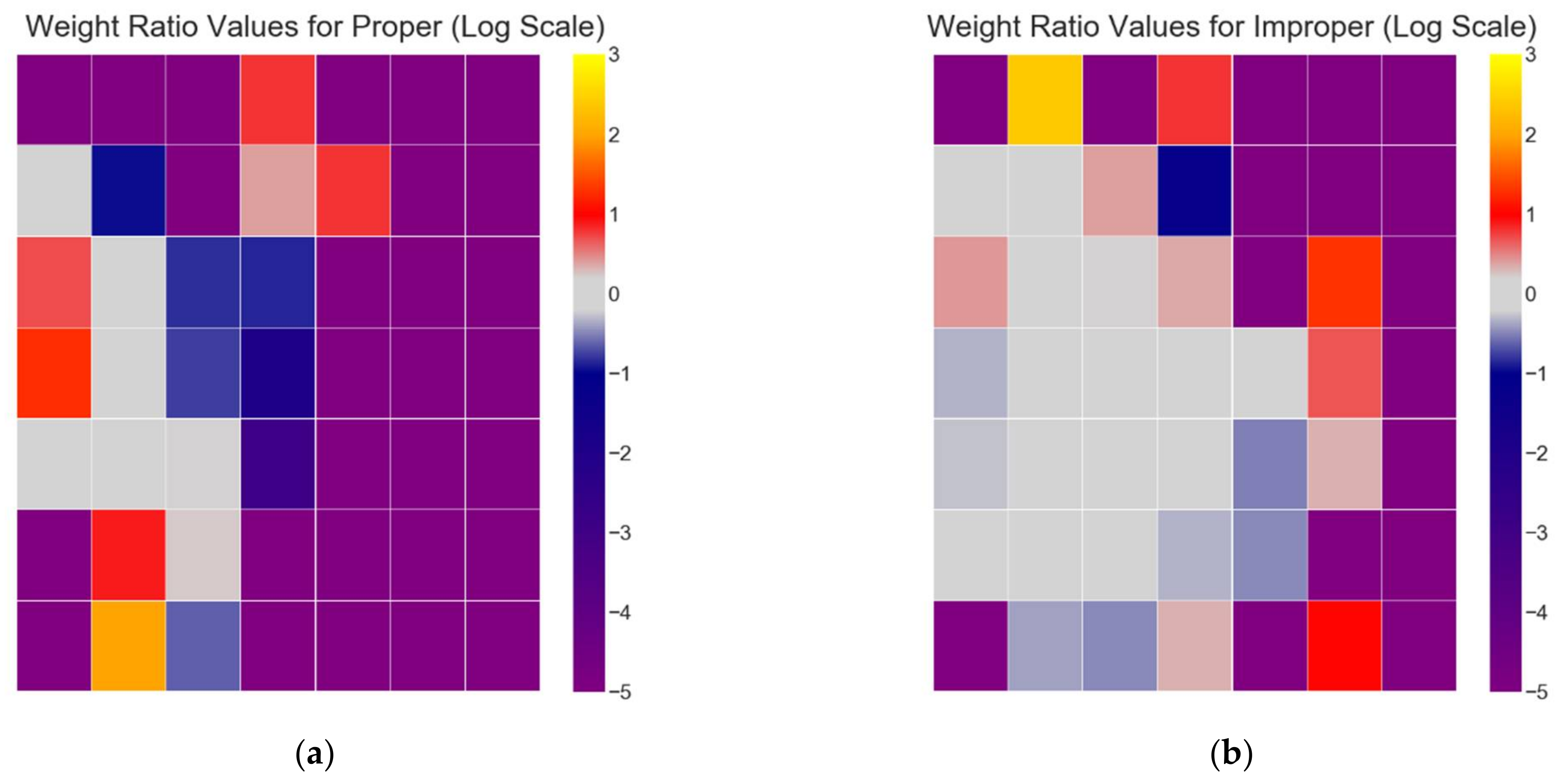
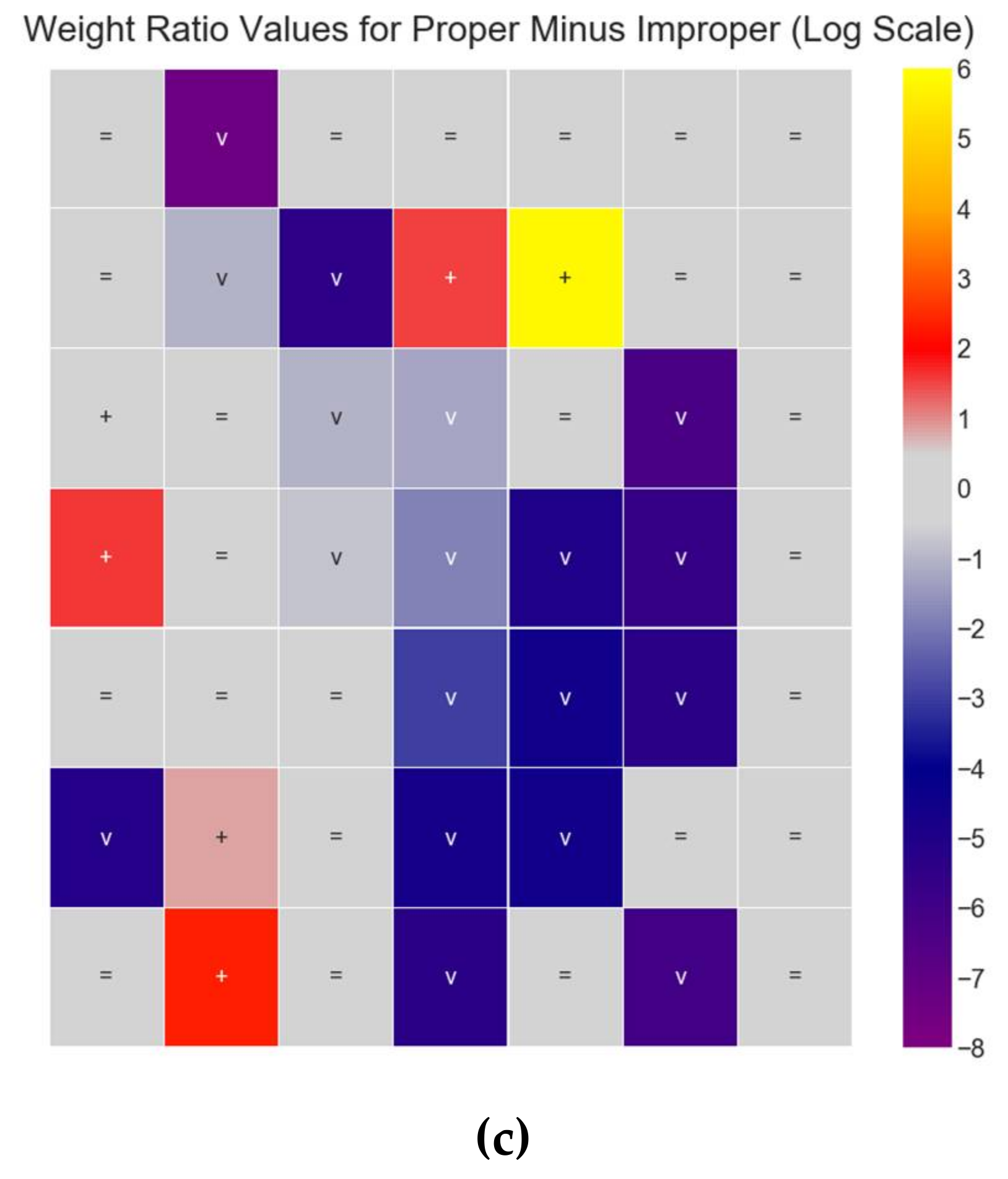
3.1. Defining and Estimating the Effects of Covariate Shift
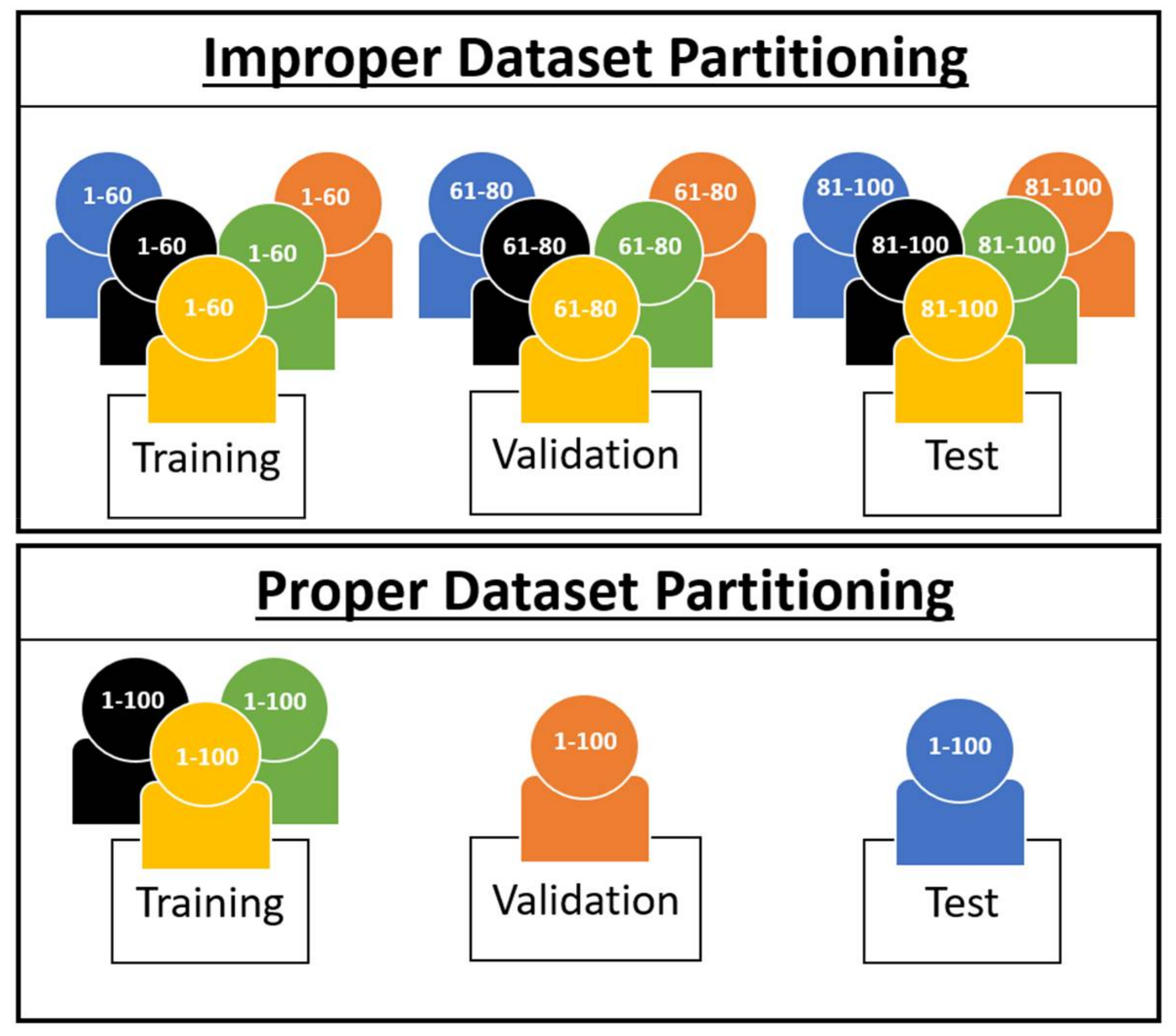
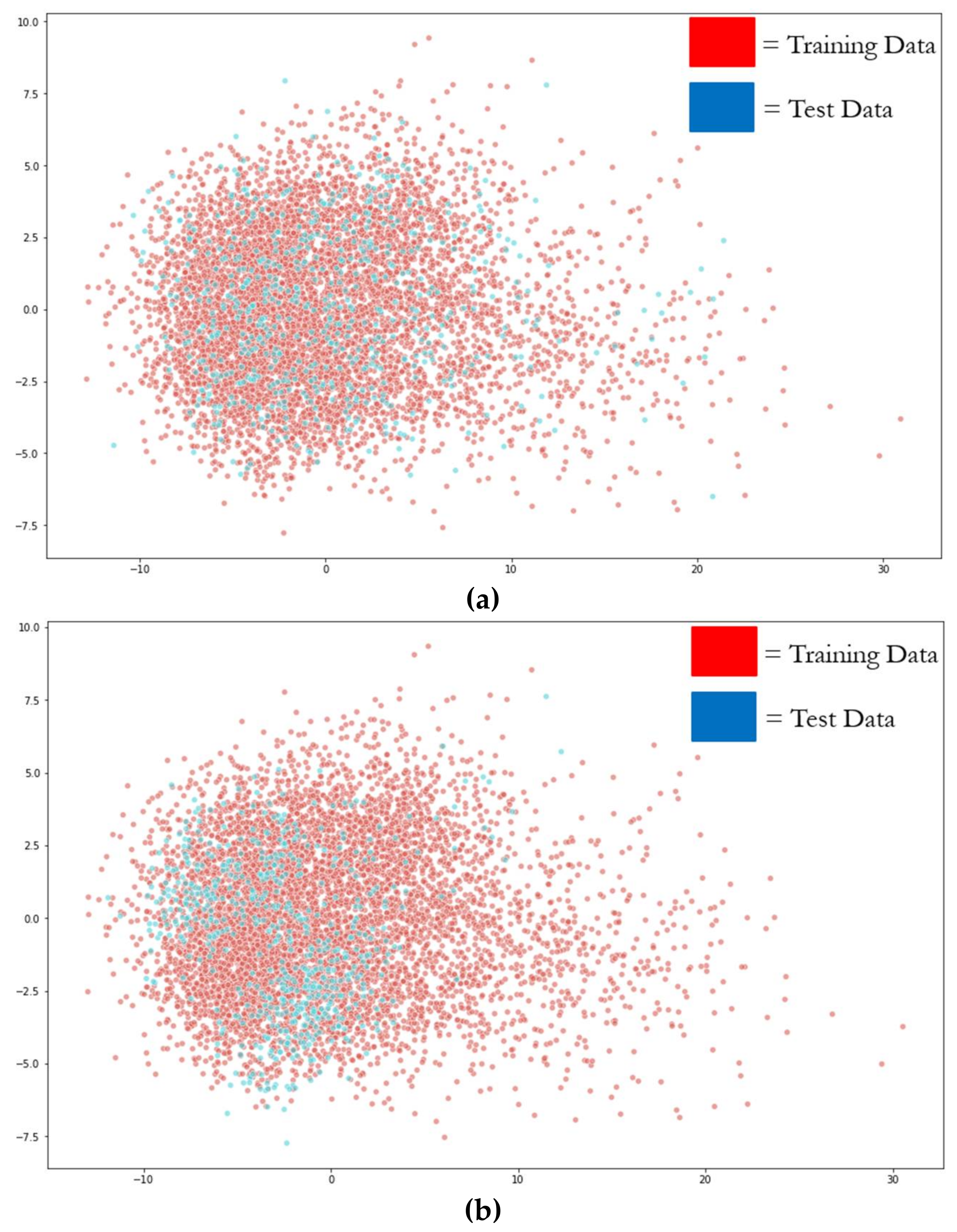
- For improper dataset partitioning, all participant data were shuffled together and one-twelfth of the data were randomly selected for the test set, with the remaining data selected for the training set.
- For proper dataset partitioning, one participant was selected for the test set, and the remaining 11 participants were selected for the training set.
3.2. Covariate Shift in EEG
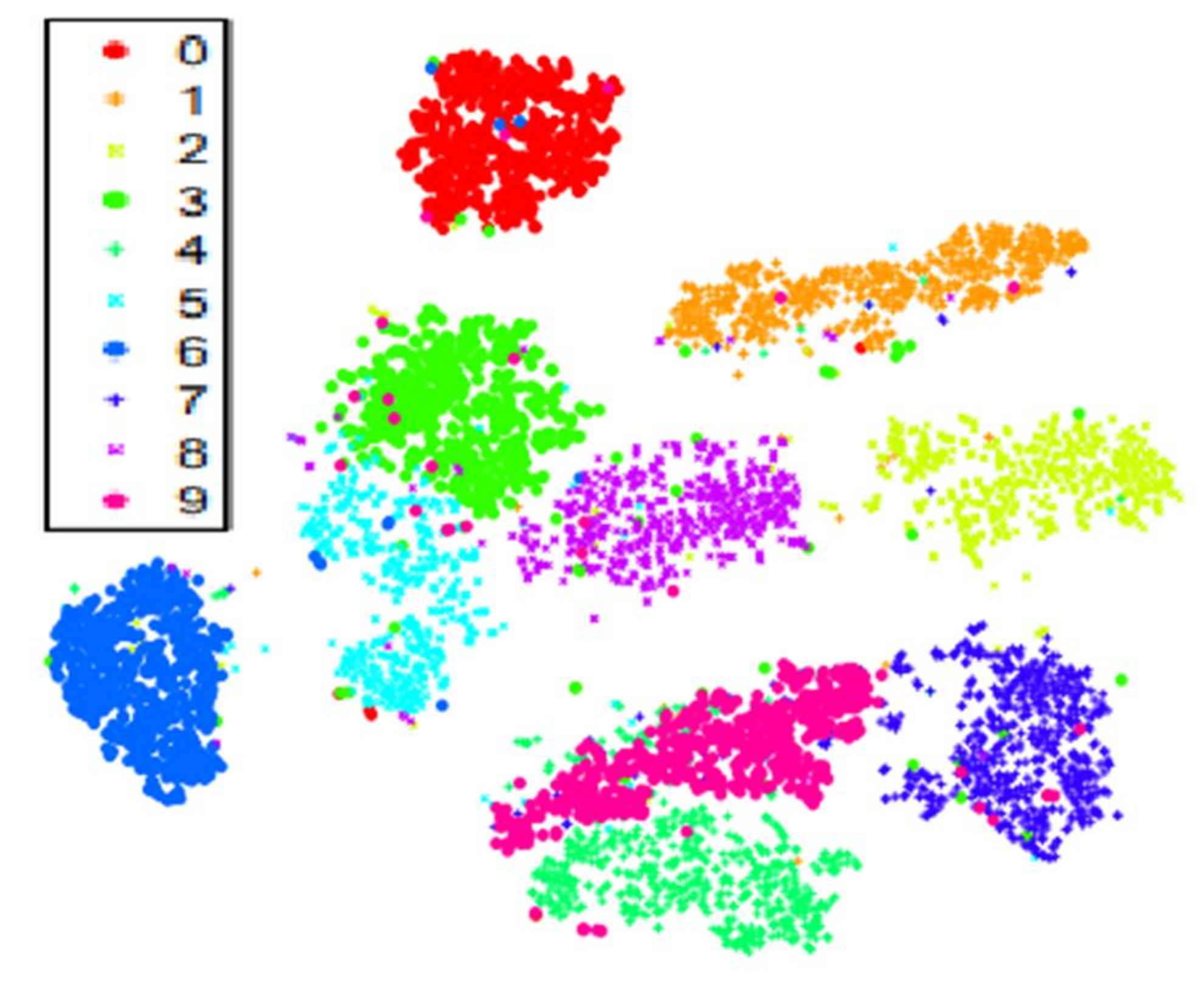
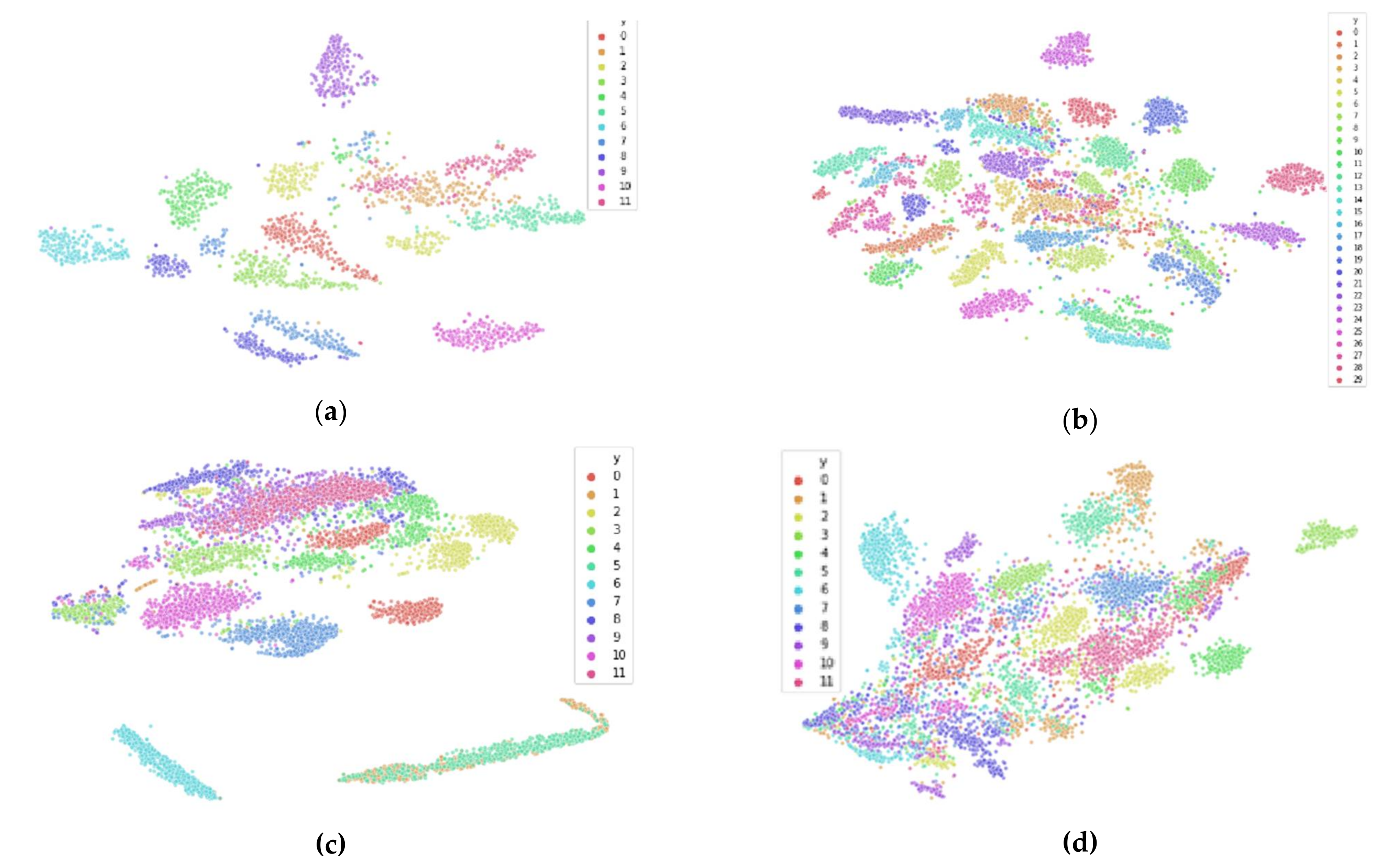
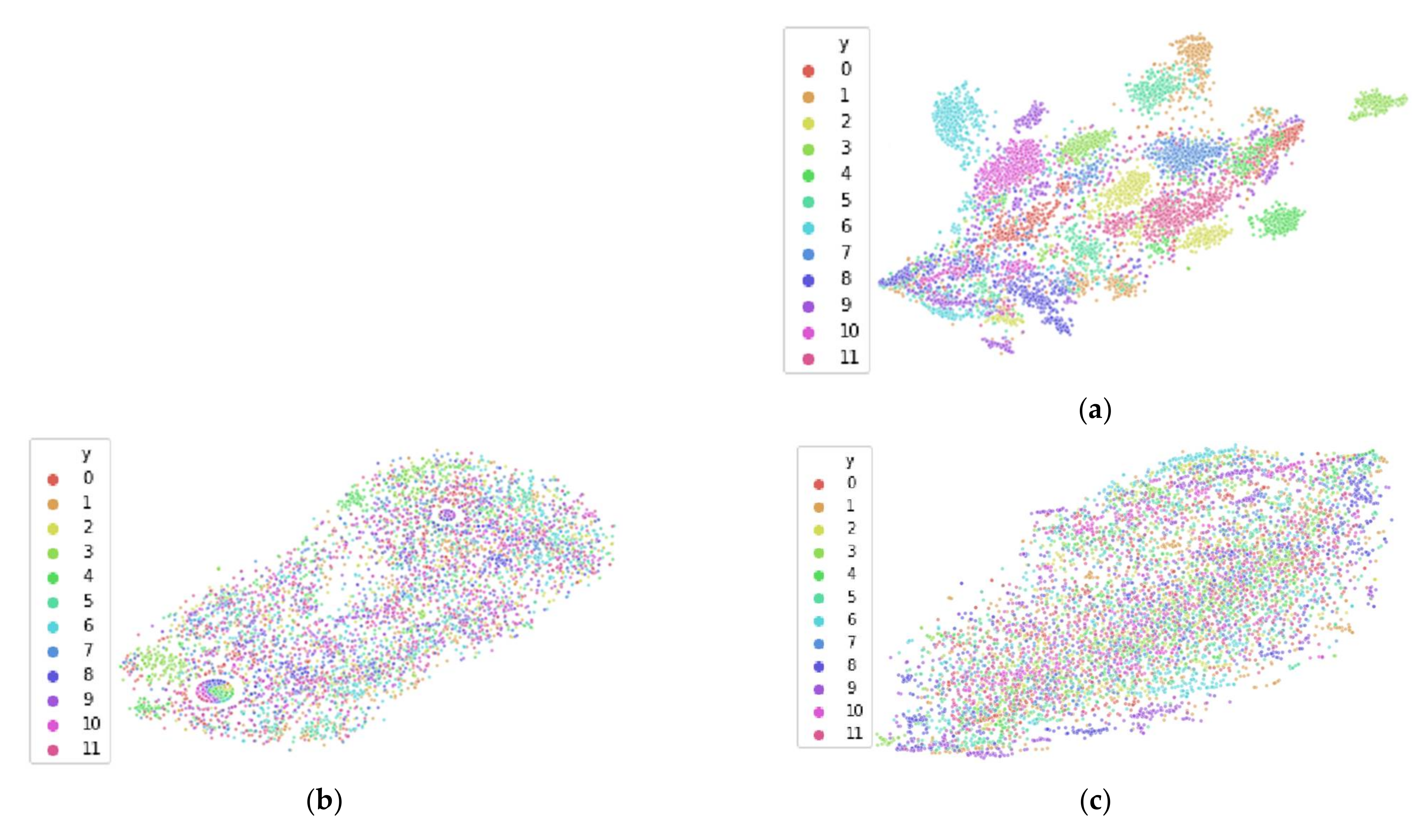
3.3. Reducing Inter-Participant Variability
- Calculate median vector across all feature vectors of all participants p = 1, … , P
- a.
- Calculate median centroid of p
- b.
- Compute shifted vector = +
4. Empirical Demonstrations in Diverse EEG Case Studies
- Improper: trained, tuned, and evaluated during tests using all participant data.
- Proper: trained and tuned using data from a subset of the participants, then, during the test, evaluated using only data from participant(s) that were not used to train or tune the model.
4.1. Driver Fatigue
4.2. Confused Students
4.3. Alcoholism
4.4. Post-Traumatic Stress Disorder (PTSD)
4.5. Schizophrenia
5. Discussion
6. Conclusions
- Data from participants used for model training must not be used for model validation or testing.
- Participants that are utilized for validation must not be used for testing.
- Any EEG data that are made available for download should always have (de-identified) participant labels available so that users may properly partition the data themselves.
- If the data contributors or maintainers decide to pre-partition the data into separate training and test datasets (as is sometimes done for competitions of machine learning models), then proper dataset partitioning guidelines should be followed for preparing those training and test datasets before they are made available for download by the general public.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| BMI | Brain–Machine Interface |
| CI | Confidence Interval |
| CV | Cross-Validation |
| DL | Deep Learning |
| DR | Dropout Rate |
| EEG | Electroencephalography |
| EOG | Electrooculography |
| GRU | Gated Recurrent Unit |
| HC | Healthy Control |
| HU | Hidden Unit |
| IEEE SA | Institute of Electrical and Electronics Engineers Standards Association |
| iid | Independent and Identically Distributed |
| KL | Kullback-Leibler |
| LOPO | Leave-One-Participant-Out |
| LOOCV | Leave-One-Out Cross-Validation |
| LR | Learning Rate |
| LSTM | Long Short-Term Memory |
| MLPNN | Multi-Layer Perceptron Neural Network |
| Opt | Optimizer |
| PCA | Principal Component Analysis |
| PTSD | Post-Traumatic Stress Disorder |
| ReLU | Rectified Linear Unit |
| RFC | Random Forest Classifier |
| RNNt-SNE | Recurrent Neural Networkt-Distributed Stochastic Neighbor Embedding |
| UCI | University of California, Irvine |
Appendix A
Appendix A.1. Driver Fatigue Data
Appendix A.2. Confused Students Data
Appendix A.3. Alcoholism Data
Appendix A.4. PTSD Data
Appendix A.5. Schizophrenia Data
References
- Hefron, R.G.; Borghetti, B.J.; Christensen, J.C.; Kabban, C.M.S. Deep long short-term memory structures model temporal dependencies improving cognitive workload estimation. Pattern Recognit. Lett. 2017, 94, 96–104. [Google Scholar] [CrossRef]
- Hefron, R.; Borghetti, B.; Kabban, C.S.; Christensen, J.; Estepp, J. Cross-participant EEG-based assessment of cognitive workload using multi-path convolutional recurrent neural networks. Sensors 2018, 18, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef] [PubMed]
- Kaplan, A.Y.; Fingelkurts, A.A.; Borisov, S.V.; Darkhovsky, B.S. Nonstationary nature of the brain activity as revealed by EEG/MEG: Methodological, practical and conceptual challenges. Signal Process. 2005, 85, 2190–2212. [Google Scholar] [CrossRef]
- Cohen, M.X. Analyzing Neural Time Series Data. In Analyzing Neural Time Series Data; The MIT Press: Cambridge, MA, USA, 2019; pp. 151–174, 499–502. [Google Scholar]
- Sugiyama, M.; Krauledat, M.; Müller, K.R. Covariate shift adaptation by importance weighted cross validation. J. Mach. Learn. Res. 2007, 8, 985–1005. [Google Scholar]
- Raza, H. Adaptive Learning for Modelling Non-Stationarity in EEG-Based Brain-Computer Interfacing. Ph.D. Thesis, Ulster University, Belfast, UK, 2016. [Google Scholar]
- Raza, H.; Prasad, G.; Li, Y. Dataset shift detection in non-stationary environments using EWMA charts. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 3151–3156. [Google Scholar]
- Raza, H.; Prasad, G.; Li, Y. EWMA based two-stage dataset shift-detection in non-stationary environments. In IFIP Advances in Information and Communication Technology; Springer: Berlin, Heidelberg, 2013; Volume 2, pp. 625–635. [Google Scholar]
- Raza, H.; Prasad, G.; Li, Y. Adaptive learning with covariate shift-detection for non-stationary environments. In Proceedings of the 2014 14th UK Workshop on Computational Intelligence (UKCI), Bradford, UK, 8–10 September 2014. [Google Scholar]
- Sugiyama, M.; Kawanabe, M. Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Begleiter, H.; Neurodynamics Laboratory. State University of New York Health Center at Brooklyn. Available online: http://www.downstate.edu/hbnl/ (accessed on 1 October 2020).
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 1 August 2019).
- Raza, H.; Samothrakis, S. Bagging Adversarial Neural Networks for Domain Adaptation in Non-Stationary EEG. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Van Der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2625. [Google Scholar]
- Wattenberg, M.; Viégas, F.; Johnson, I. How to Use t-SNE Effectively. Distill. 2016. Available online: http://doi.org/10.23915/distill.00002 (accessed on 1 September 2020).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Birjandtalab, J.; Pouyan, M.B.; Nourani, M. An unsupervised subject identification technique using EEG signals. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 816–819. [Google Scholar]
- Rasoulzadeh, V.; Erkus, E.C.; Yogurt, T.A.; Ulusoy, I.; Zergeroğlu, S.A. A comparative stationarity analysis of EEG signals. Ann. Oper. Res. 2017, 258, 133–157. [Google Scholar] [CrossRef]
- Li, Y.; Kambara, H.; Koike, Y.; Sugiyama, M. Application of covariate shift adaptation techniques in brain-computer interfaces. IEEE Trans. Biomed. Eng. 2010, 57, 1318–1324. [Google Scholar]
- Matthews, G.; Amelang, M. Extraversion, arousal theory and performance: A study of individual differences in the eeg. Pers. Individ. Dif. 1993, 14, 347–363. [Google Scholar] [CrossRef]
- Medrano, P.; Nyhus, E.; Smolen, A.; Curran, T.; Ross, R.S. Individual differences in EEG correlates of recognition memory due to DAT polymorphisms. Brain Behav. 2017, 7, e00870. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Landolt, H.-P. Genetic determination of sleep EEG profiles in healthy humans. Progress Brain Res. 2011, 193, 51–61. [Google Scholar]
- Smit, D.J.A.; Boomsma, D.I.; Schnack, H.G.; Hulshoff Pol, H.E.; De Geus, E.J.C. Individual Differences in EEG Spectral Power Reflect Genetic Variance in Gray and White Matter Volumes. Twin Res. Hum. Genet. 2012, 15, 384–392. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muthukumaraswamy, S.D.; Edden, R.A.E.; Jones, D.K.; Swettenham, J.B.; Singh, K.D. Resting GABA concentration predicts peak gamma frequency and fMRI amplitude in response to visual stimulation in humans. Proc. Natl. Acad. Sci. USA 2009, 106, 8356–8361. [Google Scholar] [CrossRef] [Green Version]
- Muthukumaraswamy, S.D.; Singh, K.D. Visual gamma oscillations: The effects of stimulus type, visual field coverage and stimulus motion on MEG and EEG recordings. Neuroimage 2013, 69, 223–230. [Google Scholar] [CrossRef]
- Cohen, M.X. Hippocampal-prefrontal connectivity predicts midfrontal oscillations and long-term memory performance. Curr. Biol. 2011, 21, 1900–1905. [Google Scholar]
- Raza, H.; Rathee, D.; Zhou, S.M.; Cecotti, H.; Prasad, G. Covariate shift estimation based adaptive ensemble learning for handling non-stationarity in motor imagery related EEG-based brain-computer interface. Neurocomputing 2019, 343, 154–166. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Bickel, S. Learning under Differing Training and Test Distributions. Ph.D. Thesis, Universität Potsdam, Potsdam, Germany, 2008. [Google Scholar]
- Shimodaira, H. Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Inference 2000, 90, 227–244. [Google Scholar] [CrossRef]
- Min, J.; Wang, P.; Hu, J. The Original EEG Data for Driver Fatigue Detection. Available online: https://figshare.com/articles/dataset/The_original_EEG_data_for_driver_fatigue_detection/5202739 (accessed on 12 February 2021).
- Rahmani, B.; Wong, C.K.; Norouzzadeh, P.; Bodurka, J.; McKinney, B. Dynamical hurst analysis identifies eeg channel differences between ptsd and healthy controls. PLoS ONE 2018, 13, e0214527. [Google Scholar] [CrossRef] [Green Version]
- Roach, B. EEG Data from Basic Sensory Task in Schizophrenia. Available online: https://www.kaggle.com/broach/button-tone-sz (accessed on 17 December 2020).
- Arevalillo-Herráez, M.; Cobos, M.; Roger, S.; García-Pineda, M. Combining inter-subject modeling with a subject-based data transformation to improve affect recognition from EEG signals. Sensors 2019, 19, 2999. [Google Scholar] [CrossRef] [Green Version]
- Donnelly, P.; Ellis, R.S. Entropy, Large Deviations, and Statistical Mechanics. J. Am. Stat. Assoc. 1987, 82, 399. [Google Scholar] [CrossRef]
- Min, J.; Wang, P.; Hu, J. Driver fatigue detection through multiple entropy fusion analysis in an EEG-based system. PLoS ONE 2017, 12, e0188756. [Google Scholar]
- Lee, K.A.; Hicks, G.; Nino-Murcia, G. Validity and reliability of a scale to assess fatigue. Psychiatry Res. 1991, 36, 291–298. [Google Scholar] [CrossRef]
- Chalder, T.; Berelowitz, G.; Pawlikowska, T.; Watts, L.; Wessely, S.; Wright, D.; Wallace, E.P. Development of a fatigue scale. J. Psychosom. Res. 1993, 37, 147–153. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Wilamowski, B.M. Levenberg-marquardt training. Ind. Electron. Handb. 2011, 5, 1–16. [Google Scholar]
- Wang, H.; Li, Y.; Hu, X.; Yang, Y.; Meng, Z.; Chang, K.M. Using EEG to improve massive open online courses feedback interaction. In Proceedings of the 16th Annual Conference on Artificial Intelligence in Education (AIED), Memphis, TN, USA, 9–13 July 2013. [Google Scholar]
- Ni, Z.; Yuksel, A.C.; Ni, X.; Mandel, M.I.; Xie, L. Confused or not confused?: Disentangling Brain activity from EEG data using Bidirectional LSTM Recurrent Neural Networks. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Boston, MA, USA, 20–23 August 2017. [Google Scholar]
- Wang, H.; Wu, Z.; Xing, E.P. Removing confounding factors associated weights in deep neural networks improves the prediction accuracy for healthcare applications. In Proceedings of the Pacific Symposium on Biocomputing, Waimea, HI, USA, 3–7 January 2019. [Google Scholar]
- Ingber, L. Statistical mechanics of neocortical interactions: Canonical momenta indicators of electroencephalography. Phys. Rev. E 1997, 55, 4578–4593. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.L.; Begleiter, H.; Porjesz, B.; Litke, A. Electrophysiological Evidence of Memory Impairment in Alcoholic Patients. Biol. Psychiatry 1997, 42, 1157–1171. [Google Scholar] [CrossRef]
- Farsi, L.; Siuly, S.; Kabir, E.; Wang, H. Classification of Alcoholic EEG Signals Using a Deep Learning Method. IEEE Sens. J. 2021, 21, 3552–3560. [Google Scholar] [CrossRef]
- Ford, J.M.; Palzes, V.A.; Roach, B.J.; Mathalon, D.H. Did i do that? Abnormal predictive processes in schizophrenia when button pressing to deliver a tone. Schizophr. Bull. 2014, 40, 804–812. [Google Scholar] [CrossRef] [Green Version]
- Buettner, R.; Hirschmiller, M.; Schlosser, K.; Rossle, M.; Fernandes, M.; Timm, I.J. High-performance exclusion of schizophrenia using a novel machine learning method on EEG data. In Proceedings of the 2019 IEEE International Conference on E-health Networking, Application & Services (HealthCom), Bogota, Colombia, 14–16 October 2019. [Google Scholar]
- Casella, G.; Fienberg, S.; Olkin, I. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Li, R.; Johansen, J.S.; Ahmed, H.; Ilyevsky, T.V.; Wilbur, R.B.; Bharadwaj, H.M.; Siskind, J.M. The Perils and Pitfalls of Block Design for EEG Classification Experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 316–333. [Google Scholar]
- Standards Roadmap: Neurotechnologies for Brain-Machine Interfacing, IEEE Standards Association, Piscataway, NJ, USA, Industry Connections Report IC17-007. Available online: https://standards.ieee.org/content/dam/ieee-standards/standards/web/documents/presentations/ieee-neurotech-for-bmi-standards-roadmap.pdf (accessed on 20 April 2021).
- Chavarriaga, R.; Carey, C.; Contreras-Vidal, J.L.; Mckinney, Z.; Bianchi, L. Standardization of Neurotechnology for Brain-Machine Interfacing: State of the Art and Recommendations. IEEE Open J. Eng. Med. Biol. 2021, 2, 71–73. [Google Scholar] [CrossRef]
- Nolan, H.; Whelan, R.; Reilly, R.B. FASTER: Fully Automated Statistical Thresholding for EEG artifact Rejection. J. Neurosci. Methods 2010, 92, 152–162. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entropy | Spectral | |
|---|---|---|
| Improper | ||
| Untransformed | 0.91 (0.89, 0.93) | 0.82 (0.79, 0.85) |
| Shifted Heaviside | 0.72 (0.68, 0.76) | 0.66 (0.62, 0.70) |
| Shift to Median | 0.91 (0.89, 0.93) | 0.82 (0.79, 0.85) |
| Proper | ||
| Untransformed | 0.50 (0.46, 0.54) | 0.50 (0.46, 0.54) |
| Shifted Heaviside | 0.50 (0.46, 0.54) | 0.47 (0.43, 0.51) |
| Shift to Median | 0.80 (0.77, 0.83) | 0.72 (0.68, 0.76) |
| Dataset | Year Collected | Binary Classification Task | # of Participants |
|---|---|---|---|
| Driver Fatigue [33] | 2017 | Normal vs. Fatigue | 12 |
| Confused Students [12] | 2013 | Confused vs. Not Confused | 10 |
| Alcoholism [13] | 1999 | Alcoholic vs. Non-Alcoholic | 122 |
| PTSD [34] | 2018 | Pre-Treatment vs. Post-Treatment | 12 |
| Schizophrenia [35] | 2014 | Schizophrenia vs. Healthy Control | 30 |
| Dataset | Architecture Used | Error Rate– Improper Method | Error Rate– Proper Method |
|---|---|---|---|
| Driver Fatigue | MLPNN | 0.09 (0.083, 0.097) | 0.466 (0.448, 0.472) |
| Confused Students | Bi-LSTM | 0.31 (0.274, 0.346) | 0.416 (0.372, 0.448) |
| Alcoholism | LSTM | 0.16 (0.12, 0.18) | 0.31 (0.29, 0.33) |
| PTSD | MLPNN | 0.005 (0.0022, 0.0078) | 0.197 (0.1811, 0.2129) |
| Schizophrenia | MLPNN | 0.008 (0.0061, 0.01) | 0.50 (0.44, 0.56) |
| Schizophrenia | RFC | 0.059 (0.054, 0.064) | 0.50 (0.44, 0.56) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamrud, A.; Borghetti, B.; Schubert Kabban, C. The Effects of Individual Differences, Non-Stationarity, and the Importance of Data Partitioning Decisions for Training and Testing of EEG Cross-Participant Models. Sensors 2021, 21, 3225. https://doi.org/10.3390/s21093225
Kamrud A, Borghetti B, Schubert Kabban C. The Effects of Individual Differences, Non-Stationarity, and the Importance of Data Partitioning Decisions for Training and Testing of EEG Cross-Participant Models. Sensors. 2021; 21(9):3225. https://doi.org/10.3390/s21093225
Chicago/Turabian StyleKamrud, Alexander, Brett Borghetti, and Christine Schubert Kabban. 2021. "The Effects of Individual Differences, Non-Stationarity, and the Importance of Data Partitioning Decisions for Training and Testing of EEG Cross-Participant Models" Sensors 21, no. 9: 3225. https://doi.org/10.3390/s21093225