
Incremental Learning in Modelling Process Analysis Technology (PAT)—An Important Tool in the Measuring and Control Circuit on the Way to the Smart Factory


 ,
, 

Abstract
:1. Introduction
- Can learn additional information from new data
- Does not require access to the original data used to train the existing classifier
- Preserves previously acquired knowledge
2. Materials and Methods
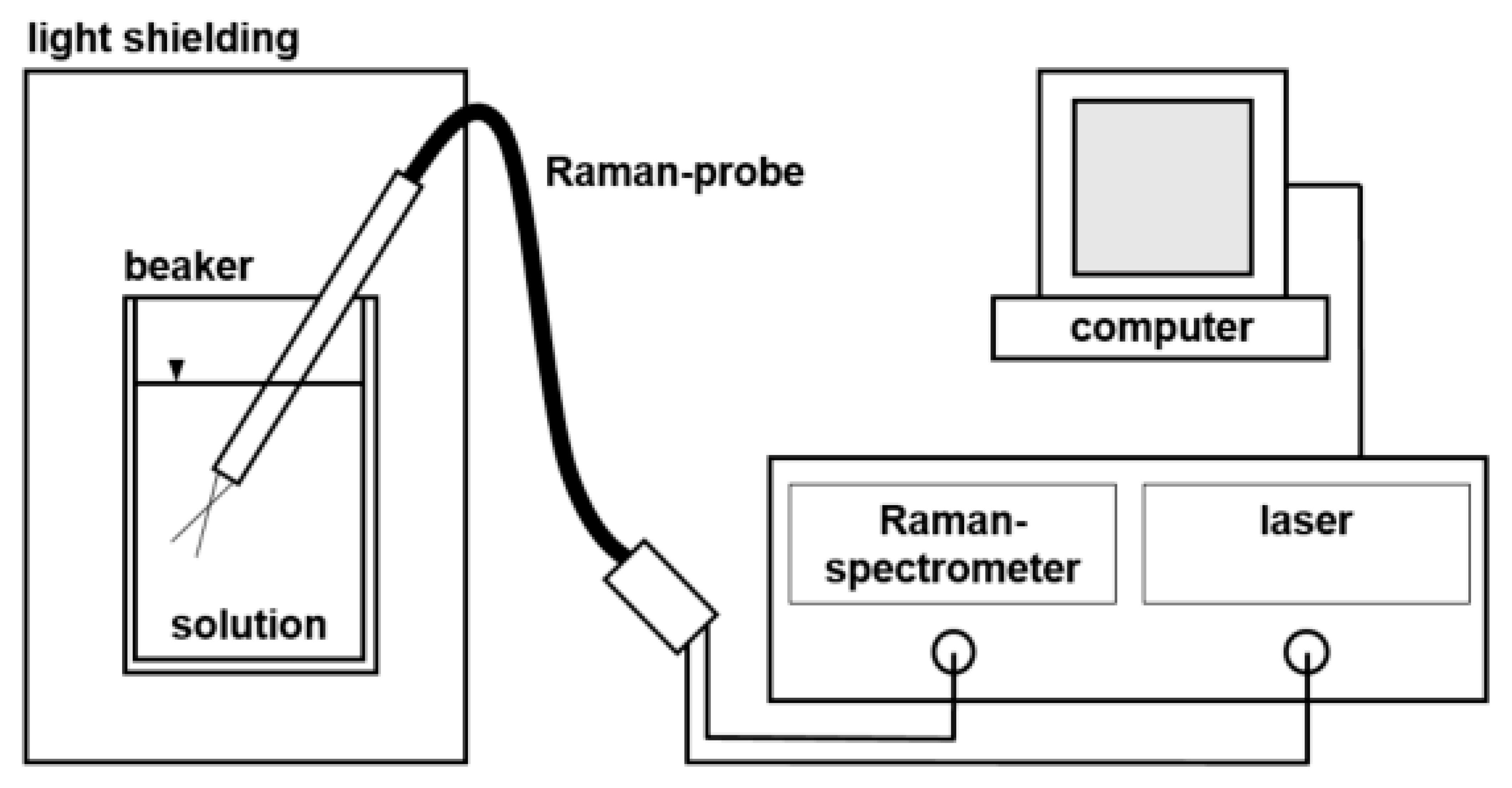
2.1. Experimental Setup Raman-Spectroscopy
2.2. Algorithm
2.3. Mathematics
- Training data The data set consisted of training data points with , where d represents the number of dimensions and the associated class. The data points were randomly selected from the database ().
- A primary classifier to generate hypothesis h. The classifier required that at least 50 percent of the training data record was classified correctly.
- An integer that specified the number of iteration steps for each data set, with . The prediction error could be reduced sufficiently with .
2.4. Evaluation
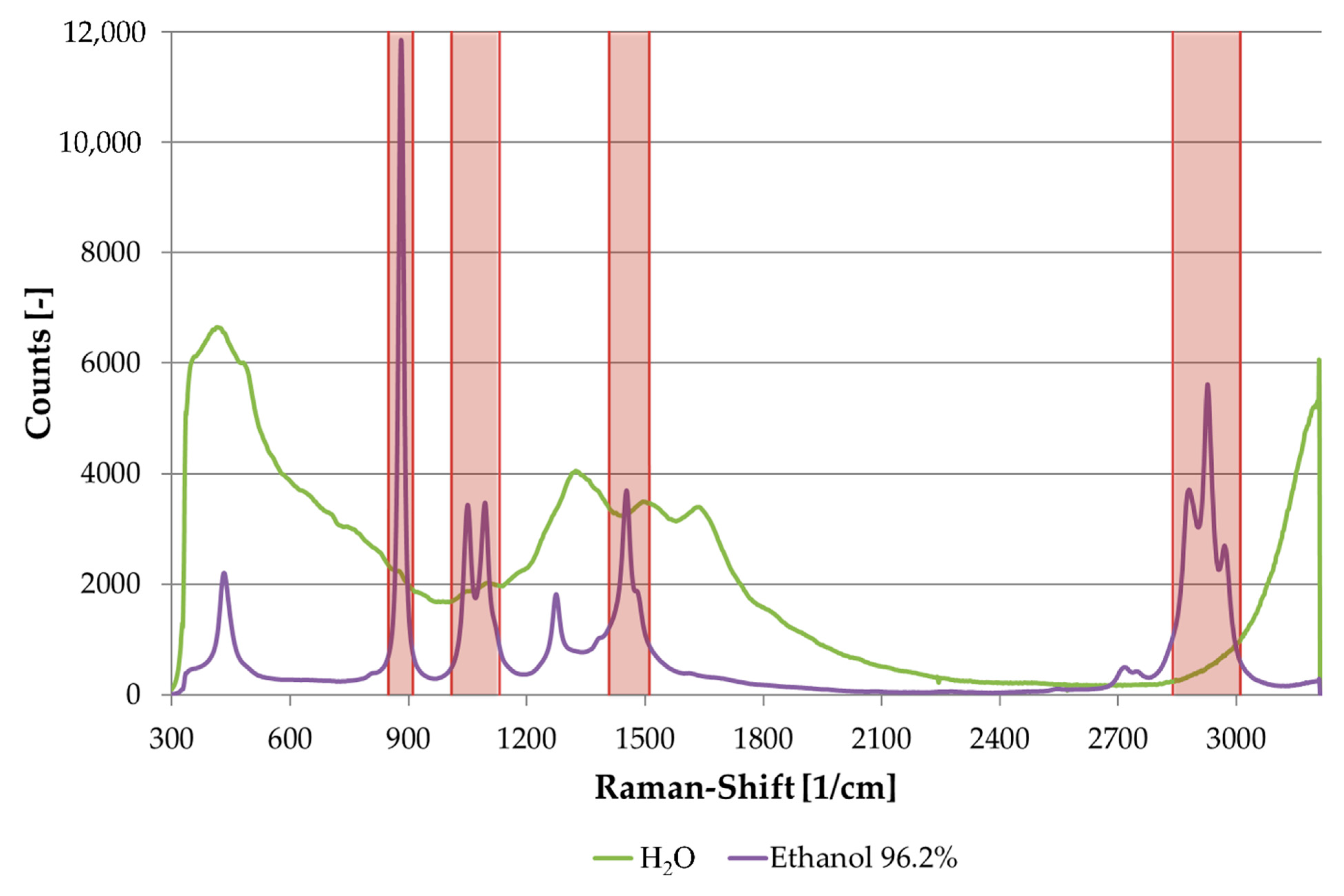
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Breitkopf, A. Energieverbrauch in Deutschland Nach Wirtschaftszweig 2018: Energieverbrauch Des Verarbeitenden Gewerbes in Deutschland Nach Ausgewählten Sektoren im Jahr 2018. Available online: https://de.statista.com/statistik/daten/studie/432596/umfrage/energieverbrauch-im-verarbeitenden-gewerbe-in-deutschland-nach-sektor/ (accessed on 31 March 2020).
- Hohmann, M. Entwicklung von Produktion, Energieverbrauch und Treibhausgasemissionen der Chemisch-Pharmazeutischen Industrie in Deutschland im Zeitraum 1990 bis 2018. Available online: https://de.statista.com/statistik/daten/studie/186496/umfrage/entwicklung-der-chemischen-industrie-in-deutschland/ (accessed on 31 March 2020).
- Schalk, R.; Braun, F.; Frank, R.; Rädle, M.; Gretz, N.; Methner, F.-J.; Beuermann, T. Non-contact Raman spectroscopy for in-line monitoring of glucose and ethanol during yeast fermentations. Bioprocess Biosyst. Eng. 2017, 40, 1519–1527. [Google Scholar] [CrossRef] [PubMed]
- Braun, F.; Schalk, R.; Brunner, J.; Eckhardt, H.S.; Theuer, M.; Veith, U.; Hennig, S.; Ferstl, W.; Methner, F.-J.; Beuermann, T.; et al. Nicht-invasive Prozesssonde zur Inline-Ramananalyse durch optische Schaugläser. tm—Tech. Messen 2016, 83. [Google Scholar] [CrossRef]
- Ai, H.; Wu, X.; Zhang, L.; Qi, M.; Zhao, Y.; Zhao, Q.; Zhao, J.; Liu, H. QSAR modelling study of the bioconcentration factor and toxicity of organic compounds to aquatic organisms using machine learning and ensemble methods. Ecotoxicol. Environ. Saf. 2019, 179, 71–78. [Google Scholar] [CrossRef] [PubMed]
- Zaidi, S. Novel application of support vector machines to model the two phase boiling heat transfer coefficient in a vertical tube thermosiphon reboiler. Chem. Eng. Res. Des. 2015, 98, 44–58. [Google Scholar] [CrossRef]
- Li, M.; Wei, D.; Liu, T.; Liu, Y.; Yan, L.; Wei, Q.; Du, B.; Xu, W. EDTA functionalized magnetic biochar for Pb(II) removal: Adsorption performance, mechanism and SVM model prediction. Sep. Purif. Technol. 2019, 227, 115696. [Google Scholar] [CrossRef]
- French, R. Catastrophic forgetting in connectionist networks. Trends Cognit. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef]
- Polikar, R.; Upda, L.; Upda, S.S.; Honavar, V. Learn++: An incremental learning algorithm for supervised neural networks. IEEE Trans. Syst. Man Cybern. C 2001, 31, 497–508. [Google Scholar] [CrossRef] [Green Version]
- Erdem, Z.; Polikar, R.; Gurgen, F.; Yumusak, N. Ensemble of SVMs for Incremental Learning. In Multiple Classifier Systems, Proceedings of the 6th International Workshop, MCS 2005, Seaside, CA, USA, 13–15 June 2005; Oza, N.C., Ed.; Springer: Berlin, Germany, 2005; pp. 246–256. ISBN 978-3-540-26306-7. [Google Scholar]
- Kho, J.B.; Lee, W.; Choi, H.; Kim, J. An incremental learning method for spoof fingerprint detection. Expert Syst. Appl. 2019, 116, 52–64. [Google Scholar] [CrossRef]
- Li, Y.; Su, B.; Liu, G. An Incremental Learning Algorithm for SVM Based on Combined Reserved Set. J. Shanghai Jiaotong Univ. 2016. [Google Scholar] [CrossRef]
- Liu, J.; Pan, T.-J.; Zhang, Z.-Y. Incremental Support Vector Machine Combined with Ultraviolet-Visible Spectroscopy for Rapid Discriminant Analysis of Red Wine. J. Spectrosc. 2018, 2018, 4230681. [Google Scholar] [CrossRef] [Green Version]
- Ardakani, M.; Escudero, G.; Graells, M.; Espuña, A. Incremental Learning Fault Detection Algorithm Based on Hyperplane-Distance. In 26th European Symposium on Computer Aided Process Engineering: Part A; Kravanja, Z., Ed.; Elsevier Science: Amsterdam, The Netherlands, 2016; pp. 1105–1110. ISBN 9780444634283. [Google Scholar]
- García Molina, J.F.; Zheng, L.; Sertdemir, M.; Dinter, D.J.; Schönberg, S.; Rädle, M. Incremental learning with SVM for multimodal classification of prostatic adenocarcinoma. PLoS ONE 2014, 9, e93600. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Zhou, H.; Chen, J. CNC internal data based incremental cost-sensitive support vector machine method for tool breakage monitoring in end milling. Eng. Appl. Artif. Intell. 2018, 74, 90–103. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Cosme, R.D.C.; Krohling, R.A. Support Vector Machines Applied to Noisy Data Classification Using Differential Evolution with Local Search; Technical Report; Universidade Federal do Espirito Santo: Vitória, Espírito Santo, Brazil, 2011. [Google Scholar]
- Nelder, J.A.; Mead, R. A Simplex Method for Function Minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- García Molina, J.F. Modeling and Analysis of Prostate Cancer Structures Alongside an Incremental and Supervised Learning Algorithm. Ph.D. Thesis, Ruprecht-Karls University of Heidelberg, Heidelberg, Germany, 2014. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Number | Volume H2O/mL | Volume EtOH/mL | Calculated EtOH Concentration/Vol% |
|---|---|---|---|
| 0 | 50.000000000 | 0.000000000 | 0.000000000 |
| 1 | 49.500000000 | 0.500000000 | 0.962000000 |
| 2 | 49.750000000 | 0.250000000 | 0.481000000 |
| 3 | 49.875000000 | 0.125000000 | 0.240500000 |
| 4 | 49.937500000 | 0.062500000 | 0.120250000 |
| 5 | 49.968750000 | 0.031250000 | 0.060125000 |
| 6 | 49.984375000 | 0.015625000 | 0.030062500 |
| 7 | 49.992187500 | 0.007812500 | 0.015031250 |
| 8 | 49.996093750 | 0.003906250 | 0.007515625 |
| 9 | 49.998046875 | 0.001953125 | 0.003757813 |
| Calculated EtOH Concentration (Vol%) | Accuracy Unscrambler (Unscrambler Parameters) (%) | Precision (-) | Recall/Sensitivity (-) |
|---|---|---|---|
| 0.9620 | 100.0 | 1.00 | 1.00 |
| 0.4810 | 100.0 | 1.00 | 1.00 |
| 0.2405 | 100.0 | 1.00 | 1.00 |
| 0.1203 | 98.7 | 0.99 | 0.98 |
| 0.0601 | 95.8 | 0.95 | 0.97 |
| 0.0301 | 90.9 | 0.95 | 0.90 |
| 0.0150 | 83.4 | 0.90 | 0.87 |
| 0.0075 | 84.7 | 0.90 | 0.92 |
| 0.0038 | 90.7 | 0.93 | 0.98 |
| Calculated EtOH Concentration (Vol%) | Accuracy MATLAB Algorithm (MATLAB Algorithm Parameters) (%) | Precision (-) | Recall/ Sensitivity (-) | Training and Validation Time (s) |
|---|---|---|---|---|
| 0.9620 | 100.0 | 1.00 | 1.00 | 14.5748 |
| 0.4810 | 100.0 | 1.00 | 1.00 | 17.8897 |
| 0.2405 | 99.9 | 0.99 | 1.00 | 43.3492 |
| 0.1203 | 99.9 | 0.98 | 0.98 | 40.5498 |
| 0.0601 | 99.0 | 0.97 | 0.97 | 148.2467 |
| 0.0301 | 96.2 | 0.96 | 0.95 | 225.5823 |
| 0.0150 | 91.9 | 0.97 | 0.93 | 140.3069 |
| 0.0075 | 89.1 | 0.98 | 0.93 | 92.7786 |
| 0.0038 | 83.7 | 0.99 | 0.94 | 48.4829 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choudhary, S.; Herdt, D.; Spoor, E.; García Molina, J.F.; Nachtmann, M.; Rädle, M. Incremental Learning in Modelling Process Analysis Technology (PAT)—An Important Tool in the Measuring and Control Circuit on the Way to the Smart Factory. Sensors 2021, 21, 3144. https://doi.org/10.3390/s21093144
Choudhary S, Herdt D, Spoor E, García Molina JF, Nachtmann M, Rädle M. Incremental Learning in Modelling Process Analysis Technology (PAT)—An Important Tool in the Measuring and Control Circuit on the Way to the Smart Factory. Sensors. 2021; 21(9):3144. https://doi.org/10.3390/s21093144
Chicago/Turabian StyleChoudhary, Shivani, Deborah Herdt, Erik Spoor, José Fernando García Molina, Marcel Nachtmann, and Matthias Rädle. 2021. "Incremental Learning in Modelling Process Analysis Technology (PAT)—An Important Tool in the Measuring and Control Circuit on the Way to the Smart Factory" Sensors 21, no. 9: 3144. https://doi.org/10.3390/s21093144