
Fully Automated DCNN-Based Thermal Images Annotation Using Neural Network Pretrained on RGB Data


Abstract
:1. Introduction
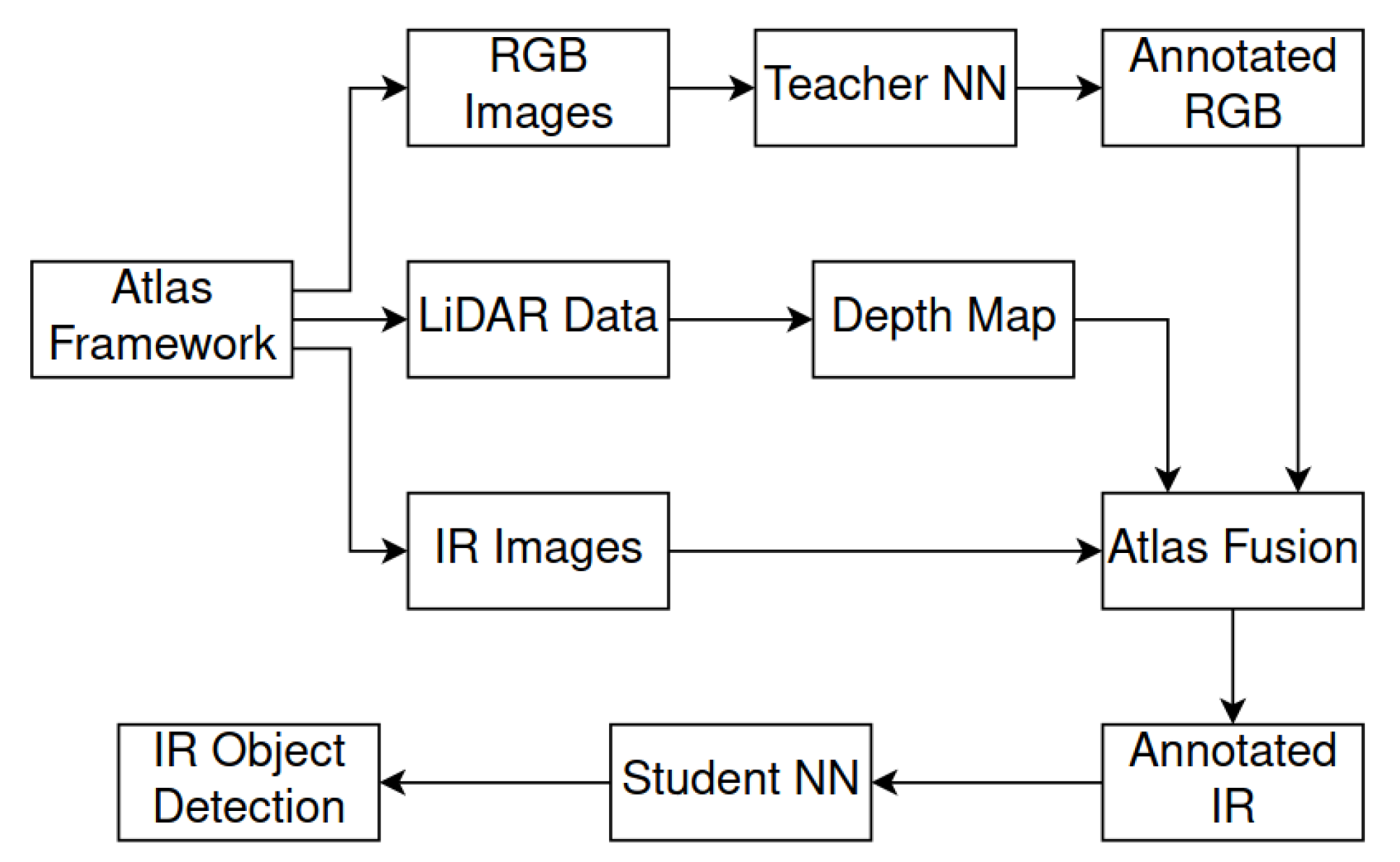
1.1. Our Research
1.2. Related Work
2. Datasets
2.1. FLIR ADAS Dataset
2.2. Brno Urban Dataset
3. Software Backend
3.1. YOLOv5
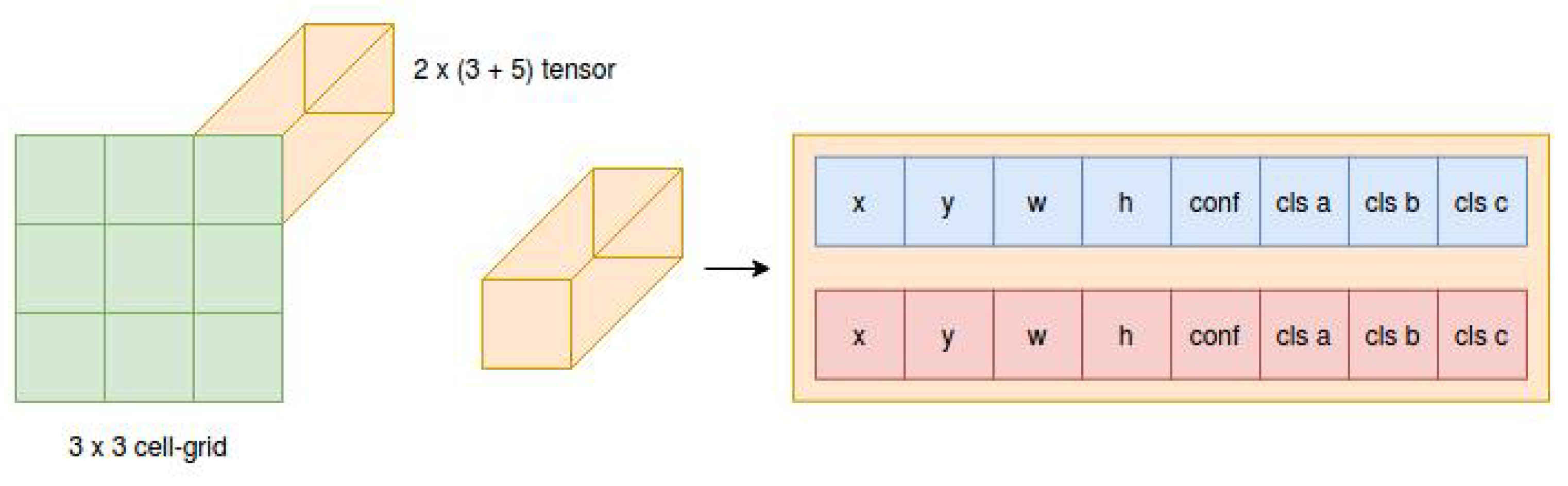
3.2. YOLO Architecture Principles
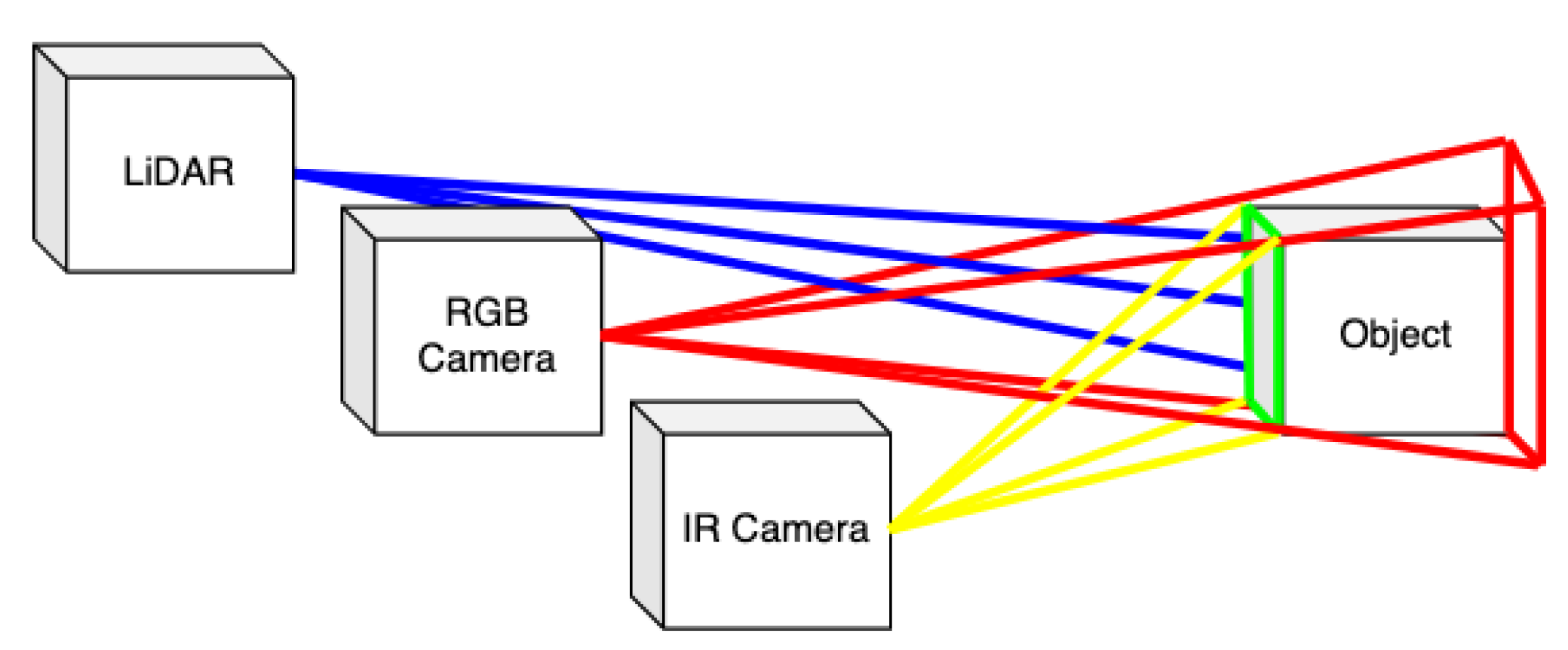
3.3. Atlas Fusion
4. Generating Synthetic Dataset
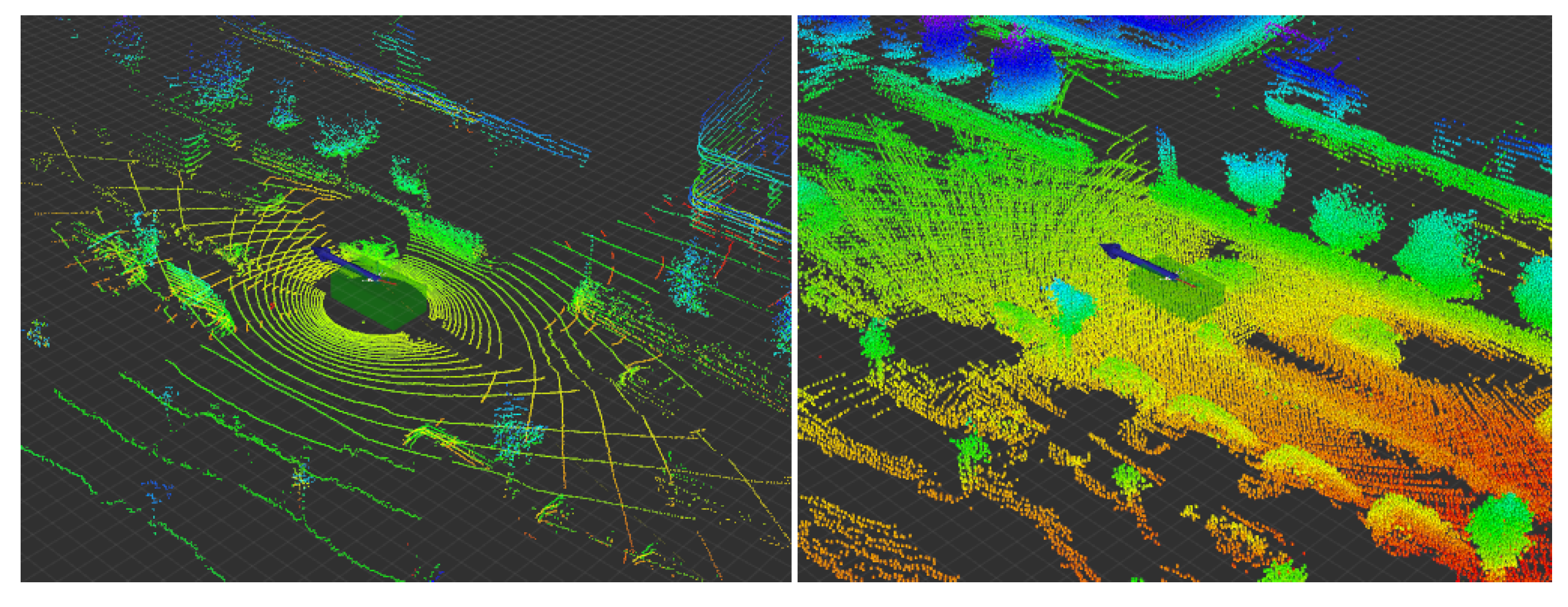
4.1. LiDAR Data Aggregation
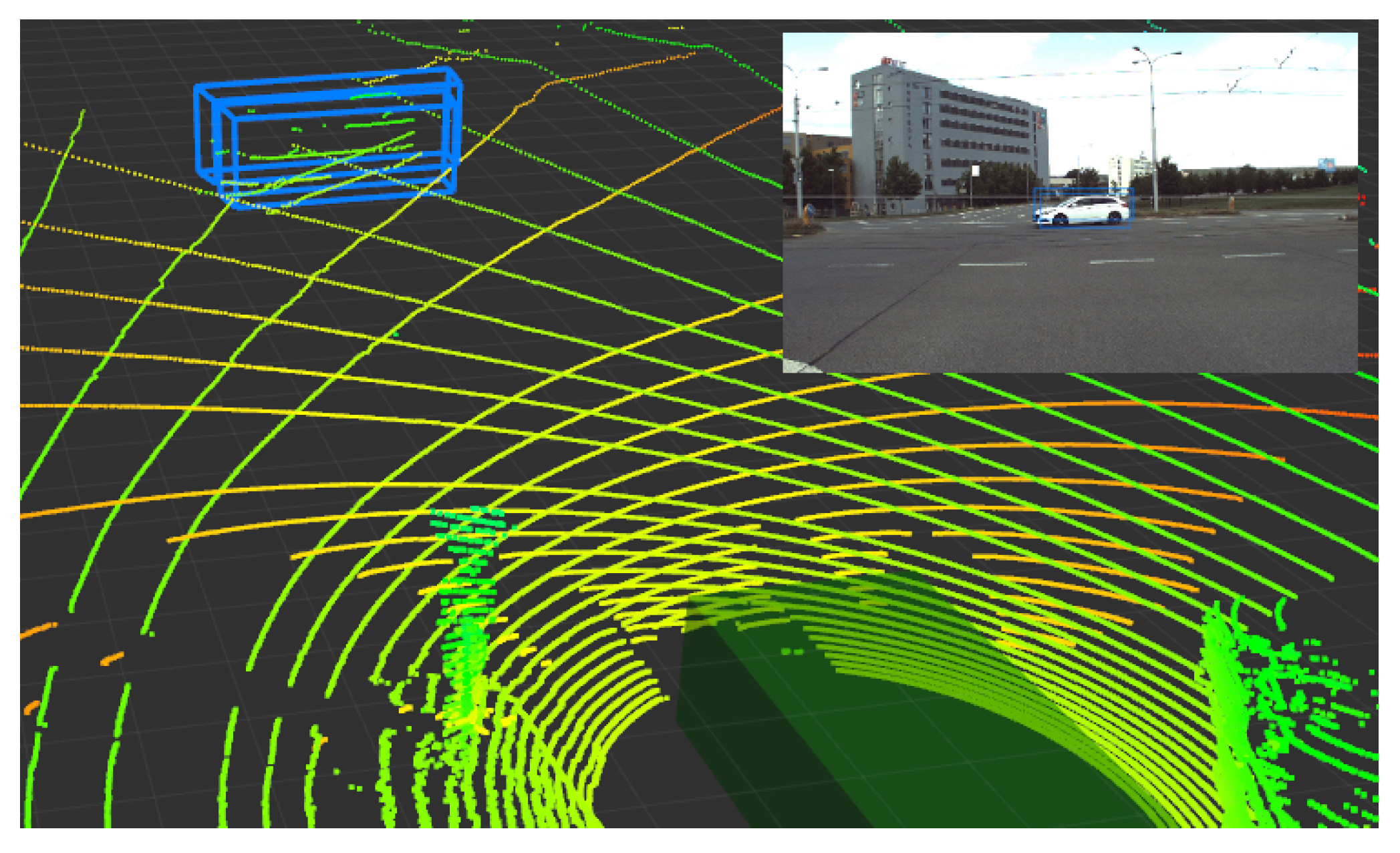
4.2. 3D Detection in the RGB Image
4.3. Thermal Images Annotation
4.4. Reducing No. of Classes
5. Training Neural Networks on the New Dataset
5.1. Metrics
5.2. Methodology
5.3. Training Details
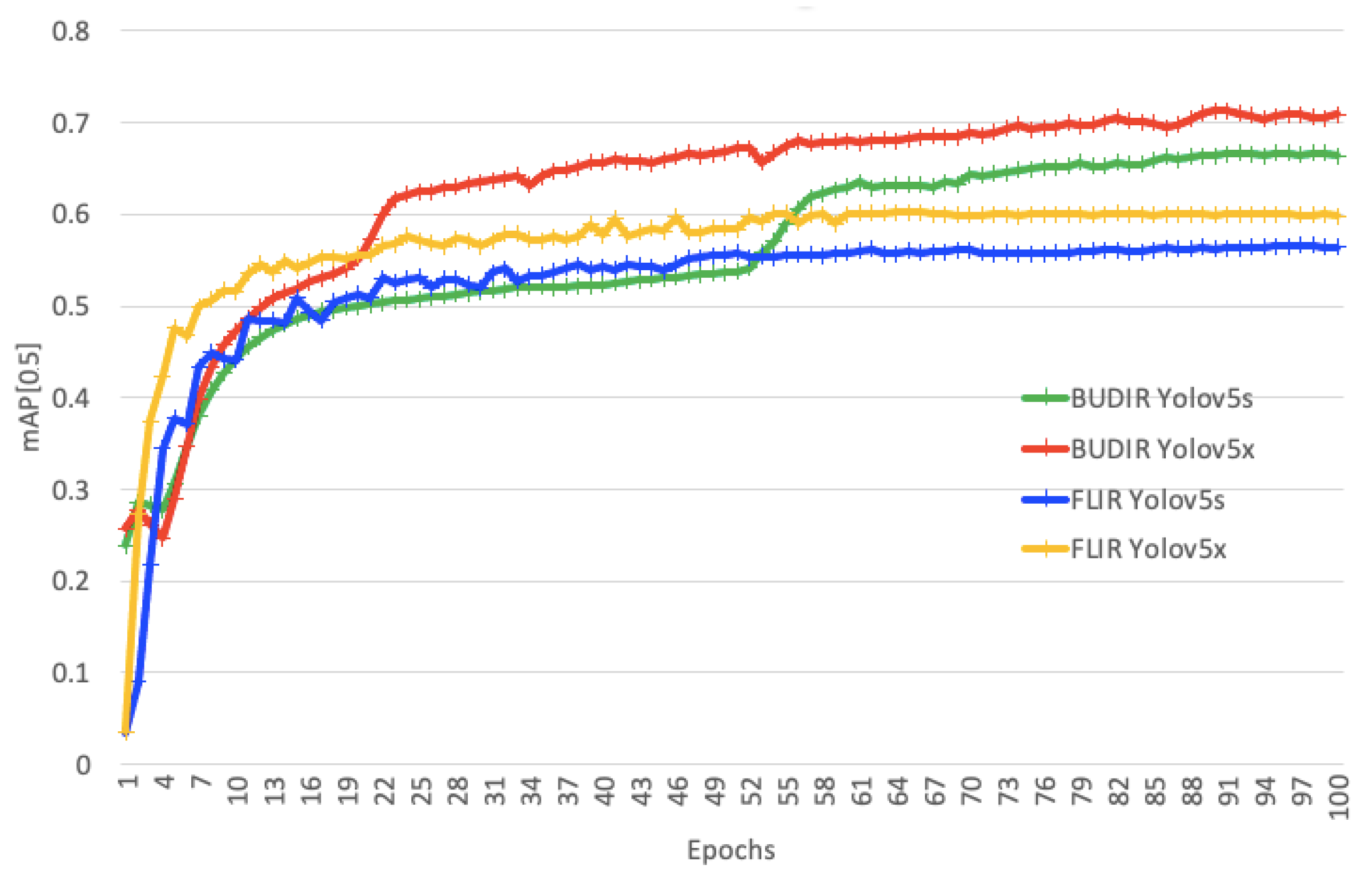
5.4. Training from Scratch
5.5. Transfer Learning
6. Fine-Tuning the Results
7. Experiment Reproducibility
8. Discussion
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zalud, L.; Kocmanova, P. Fusion of thermal imaging and CCD camera-based data for stereovision visual telepresence. In Proceedings of the 2013 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Linköping, Sweden, 21–26 October 2013; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ligocki, A.; Jelinek, A.; Zalud, L. Brno Urban Dataset–The New Data for Self-Driving Agents and Mapping Tasks. arXiv 2019, arXiv:1909.06897. [Google Scholar]
- Ligocki, A.; Jelinek, A.; Zalud, L. Atlas Fusion–Modern Framework for Autonomous Agent Sensor Data Fusion. arXiv 2020, arXiv:2010.11991. [Google Scholar]
- FLIR Systems, I. FREE FLIR Thermal Dataset for Algorithm Training. Available online: https://www.flir.com/oem/adas/adas-dataset-form/ (accessed on 1 June 2020).
- FLIR Systems, I. Enhanced San Francisco Dataset. Available online: https://www.flir.eu/oem/adas/dataset/san-francisco-dataset/ (accessed on 1 June 2020).
- FLIR Systems, I. FLIR European Regional Thermal Dataset for Algorithm Training. Available online: https://www.flir.eu/oem/adas/dataset/european-regional-thermal-dataset/ (accessed on 1 June 2020).
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral Pedestrian Detection: Benchmark Dataset and Baselines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Torabi, A.; Massé, G.; Bilodeau, G.A. An iterative integrated framework for thermal–visible image registration, sensor fusion, and people tracking for video surveillance applications. Comput. Vis. Image Underst. 2012, 116, 210–221. [Google Scholar] [CrossRef]
- Khellal, A.; Ma, H.; Fei, Q. Pedestrian classification and detection in far infrared images. In International Conference on Intelligent Robotics and Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 511–522. [Google Scholar]
- Portmann, J.; Lynen, S.; Chli, M.; Siegwart, R. People detection and tracking from aerial thermal views. In Proceedings of the 2014 IEEE international conference on robotics and automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1794–1800. [Google Scholar]
- Davis, J.W.; Sharma, V. Background-subtraction using contour-based fusion of thermal and visible imagery. Comput. Vis. Image Underst. 2007, 106, 162–182. [Google Scholar] [CrossRef]
- Wu, Z.; Fuller, N.; Theriault, D.; Betke, M. A thermal infrared video benchmark for visual analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 201–208. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Nyberg, A. Transforming Thermal Images to Visible Spectrum Images Using Deep Learning. Available online: https://www.diva-portal.org/smash/get/diva2:1255342/FULLTEXT01.pdf (accessed on 20 February 2021).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Zhang, L.; Gonzalez-Garcia, A.; van de Weijer, J.; Danelljan, M.; Khan, F.S. Synthetic data generation for end-to-end thermal infrared tracking. IEEE Trans. Image Process. 2018, 28, 1837–1850. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. Thermalgan: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tumas, P.; Serackis, A. Automated image annotation based on YOLOv3. In Proceedings of the 2018 IEEE 6th Workshop on Advances in Information, Electronic and Electrical Engineering (AIEEE), Vilnius, Lithuania, 8–10 November 2018; pp. 1–3. [Google Scholar]
- Ivašić-Kos, M.; Krišto, M.; Pobar, M. Human detection in thermal imaging using YOLO. In Proceedings of the 2019 5th International Conference on Computer and Technology Applications, Istanbul, Turkey, 16–17 April 2019; pp. 20–24. [Google Scholar]
- Gomez, A.; Conti, F.; Benini, L. Thermal image-based CNN’s for ultra-low power people recognition. In Proceedings of the 15th ACM International Conference on Computing Frontiers, Ischia, Italy, 8–10 May 2018; pp. 326–331. [Google Scholar]
- Park, J.; Chen, J.; Cho, Y.K.; Kang, D.Y.; Son, B.J. CNN-based person detection using infrared images for night-time intrusion warning systems. Sensors 2020, 20, 34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghose, D.; Desai, S.M.; Bhattacharya, S.; Chakraborty, D.; Fiterau, M.; Rahman, T. Pedestrian Detection in Thermal Images using Saliency Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 11–17. [Google Scholar]
- Adam, L.; Ales, J.L.Z. Brno Urban Dataset. Available online: https://github.com/Robotics-BUT/Brno-Urban-Dataset (accessed on 20 January 2021).
- Ultralytics. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 January 2021).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Adam, L.; Ales, J.L.Z. Atlas Fusion. Available online: https://github.com/Robotics-BUT/Atlas-Fusion (accessed on 20 January 2021).
- Merriaux, P.; Dupuis, Y.; Boutteau, R.; Vasseur, P.; Savatier, X. LiDAR point clouds correction acquired from a moving car based on CAN-bus data. arXiv 2017, arXiv:1706.05886. [Google Scholar]
- Zhang, B.; Zhang, X.; Wei, B.; Qi, C. A Point Cloud Distortion Removing and Mapping Algorithm based on Lidar and IMU UKF Fusion. In Proceedings of the 2019 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Hong Kong, China, 8–12 July 2019; pp. 966–971. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Jung, A.B. imgaug. Available online: https://github.com/aleju/imgaug (accessed on 30 October 2018).
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.Y.; Shlens, J.; Le, Q.V. Learning data augmentation strategies for object detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 566–583. [Google Scholar]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A review. arXiv 2019, arXiv:1909.00169. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Free FLIR ADAS Dataset | ||||
|---|---|---|---|---|
| Train | Validation | Video | Total | |
| Pedestrians | 22,372 | 5779 | 21,965 | 50,116 |
| Bikes | 3986 | 471 | 1205 | 5662 |
| Vehicles | 41,260 | 5432 | 14,013 | 60,705 |
| Animals | 226 | 14 | 0 | 240 |
| Sensor | Type | Details | Freq. | Output Data |
|---|---|---|---|---|
| 4× RGB camera | DFK33- -GX174 | FoV 1920 × 1200 px | 10 | h265 video |
| Thermal camera | FLIR Tau 2 | FoV 640 × 512 px | 30 | h265 video |
| 2× LiDAR | Velodyne HDL-32e | 32 beams ∼2000 pts/turn | 10 | point cloud |
| GNSS receiver | Trimble BX982 | RTK accuracy Direct heading | 20 20 | global pose time |
| IMU | Xsens MTi-G-710 | Combined non-electrical quantities sensor | 400 400 100 400 400 400 50 | accelerometer gyroscope magnetometer temperature global pose time pressure |
| Brno Urban Dataset-Automatically Annotated Dataset | |||
|---|---|---|---|
| Training | Validation | Total | |
| Pedestrians | 247,133 | 45,352 | 292,485 |
| Vehicles | 1,163,403 | 213,755 | 1,377,158 |
| Bikes | 15,904 | 3009 | 18,913 |
| Animals | 347 | 75 | 422 |
| YOLOv5s | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP (0.5) | mAP (0.5:0.95) | F1 | Precisoin | Recall | ||||||
| Training Dataset | FLIR | BUDIR | FLIR | BUDIR | FLIR | BUDIR | FLIR | BUDIR | FLIR | BUDIR |
| Pedestrians | 0.613 | 0.334 | 0.234 | 0.106 | 0.458 | 0.378 | 0.336 | 0.356 | 0.719 | 0.402 |
| Bikes | 0.525 | 0.317 | 0.185 | 0.133 | 0.343 | 0.308 | 0.231 | 0.258 | 0.665 | 0.382 |
| Vehicles | 0.643 | 0.718 | 0.312 | 0.370 | 0.556 | 0.622 | 0.477 | 0.544 | 0.666 | 0.727 |
| Animals | 0.126 | 0.556 | 0.126 | 0.256 | 0.196 | 0.559 | 0.236 | 0.554 | 0.168 | 0.564 |
| Average | 0.476 | 0.481 | 0.214 | 0.216 | 0.388 | 0.467 | 0.320 | 0.428 | 0.555 | 0.518 |
| YOLOv5x | ||||||||||
| mAP (0.5) | mAP (0.5:0.95) | F1 | Precisoin | Recall | ||||||
| Training Dataset | FLIR | BUDIR | FLIR | BUDIR | FLIR | BUDIR | FLIR | BUDIR | FLIR | BUDIR |
| Pedestrians | 0.621 | 0.451 | 0.253 | 0.141 | 0.488 | 0.476 | 0.366 | 0.459 | 0.733 | 0.495 |
| Bikes | 0.565 | 0.344 | 0.203 | 0.150 | 0.413 | 0.365 | 0.301 | 0.340 | 0.657 | 0.395 |
| Vehicles | 0.660 | 0.753 | 0.327 | 0.396 | 0.595 | 0.656 | 0.529 | 0.581 | 0.679 | 0.753 |
| Animals | 0.245 | 0.628 | 0.068 | 0.329 | 0.328 | 0.690 | 0.425 | 0.758 | 0.267 | 0.634 |
| Average | 0.522 | 0.544 | 0.213 | 0.254 | 0.456 | 0.547 | 0.405 | 0.535 | 0.584 | 0.569 |
| YOLOv5s | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mAP (0.5) | mAP (0.5:0.95) | F1 | Precisoin | Recall | |||||||||||
| Train. Dataset | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB |
| Pedestrians | 0.611 | 0.344 | 0.609 | 0.240 | 0.144 | 0.282 | 0.453 | 0.392 | 0.484 | 0.328 | 0.410 | 0.379 | 0.731 | 0.376 | 0.671 |
| Bikes | 0.582 | 0.315 | 0.326 | 0.196 | 0.139 | 0.135 | 0.426 | 0.338 | 0.353 | 0.311 | 0.304 | 0.333 | 0.676 | 0.380 | 0.375 |
| Vehicles | 0.658 | 0.717 | 0.550 | 0.319 | 0.381 | 0.251 | 0.581 | 0.630 | 0.459 | 0.509 | 0.561 | 0.372 | 0.677 | 0.718 | 0.598 |
| Animals | 0.183 | 0.644 | 0.088 | 0.048 | 0.275 | 0.029 | 0.265 | 0.675 | 0.161 | 0.264 | 0.733 | 0.247 | 0.266 | 0.625 | 0.119 |
| Average | 0.509 | 0.505 | 0.393 | 0.201 | 0.227 | 0.174 | 0.431 | 0.509 | 0.364 | 0.353 | 0.502 | 0.333 | 0.588 | 0.525 | 0.441 |
| YOLOv5x | |||||||||||||||
| mAP (0.5) | mAP (0.5:0.95) | F1 | Precisoin | Recall | |||||||||||
| Train. Dataset | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB | FLIR | BUDIR | RGB |
| Pedestrians | 0.652 | 0.380 | 0.686 | 0.268 | 0.117 | 0.349 | 0.492 | 0.432 | 0.541 | 0.360 | 0.446 | 0.422 | 0.777 | 0.419 | 0.755 |
| Bikes | 0.617 | 0.380 | 0.389 | 0.234 | 0.138 | 0.153 | 0.423 | 0.355 | 0.391 | 0.298 | 0.301 | 0.320 | 0.726 | 0.434 | 0.503 |
| Vehicles | 0.672 | 0.742 | 0.629 | 0.325 | 0.390 | 0.294 | 0.572 | 0.647 | 0.518 | 0.485 | 0.570 | 0.423 | 0.699 | 0.749 | 0.667 |
| Animals | 0.267 | 0.678 | 0.344 | 0.069 | 0.357 | 0.119 | 0.279 | 0.755 | 0.443 | 0.244 | 0.861 | 0.539 | 0.327 | 0.673 | 0.376 |
| Average | 0.552 | 0.545 | 0.512 | 0.224 | 0.251 | 0.229 | 0.442 | 0.548 | 0.473 | 0.347 | 0.545 | 0.426 | 0.632 | 0.569 | 0.575 |
| mAP (0.5) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5x | YOLOv5s | |||||||||||
| Train. Dataset | RGB | FLIR | p-FLIR | p-FLIR-f | BUDIR | p-BUDIR | p-BUDIR-f | RGB | FLIR | p-FLIR | BUDIR | p-BUDIR |
| Pedestrians | 0.686 | 0.621 | 0.652 | 0.629 | 0.451 | 0.380 | 0.729 | 0.609 | 0.613 | 0.611 | 0.334 | 0.344 |
| Bikes | 0.389 | 0.565 | 0.617 | 0.599 | 0.344 | 0.380 | 0.592 | 0.326 | 0.525 | 0.582 | 0.317 | 0.315 |
| Vehicles | 0.629 | 0.660 | 0.672 | 0.701 | 0.753 | 0.742 | 0.780 | 0.550 | 0.643 | 0.658 | 0.718 | 0.717 |
| Animals | 0.344 | 0.245 | 0.267 | 0.290 | 0.628 | 0.678 | 0.543 | 0.088 | 0.126 | 0.183 | 0.556 | 0.644 |
| Average | 0.512 | 0.523 | 0.552 | 0.555 | 0.544 | 0.545 | 0.661 | 0.393 | 0.477 | 0.509 | 0.481 | 0.505 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ligocki, A.; Jelinek, A.; Zalud, L.; Rahtu, E. Fully Automated DCNN-Based Thermal Images Annotation Using Neural Network Pretrained on RGB Data. Sensors 2021, 21, 1552. https://doi.org/10.3390/s21041552
Ligocki A, Jelinek A, Zalud L, Rahtu E. Fully Automated DCNN-Based Thermal Images Annotation Using Neural Network Pretrained on RGB Data. Sensors. 2021; 21(4):1552. https://doi.org/10.3390/s21041552
Chicago/Turabian StyleLigocki, Adam, Ales Jelinek, Ludek Zalud, and Esa Rahtu. 2021. "Fully Automated DCNN-Based Thermal Images Annotation Using Neural Network Pretrained on RGB Data" Sensors 21, no. 4: 1552. https://doi.org/10.3390/s21041552