
Weakly Supervised Video Anomaly Detection Based on 3D Convolution and LSTM



Abstract
:1. Introduction
2. Materials and Methods
2.1. Related Work
2.2. Proposed Method
2.2.1. Convolutional Layers
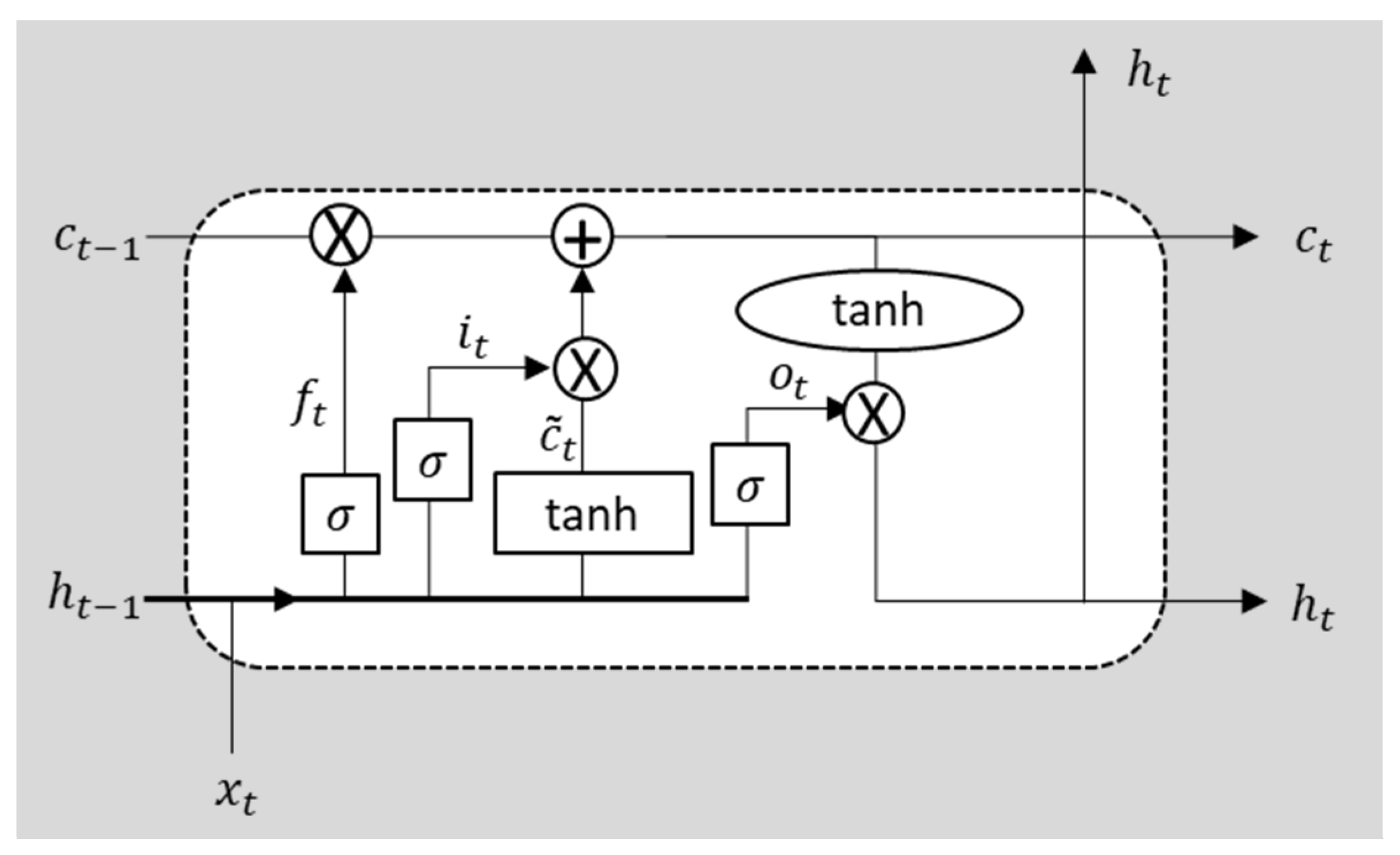
2.2.2. LSTM Architecture
2.2.3. Dense Layers
3. Results
3.1. Data Pre-Processing and Augmentation
3.2. Data Training
4. Discussion
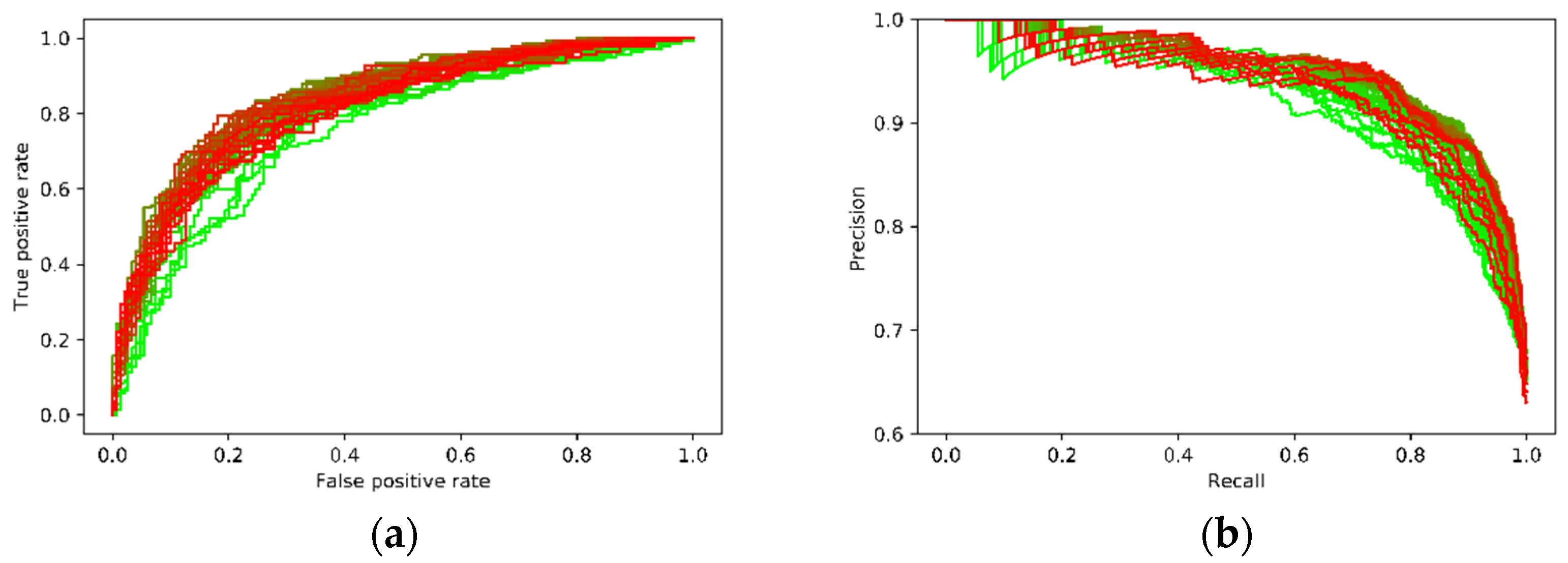
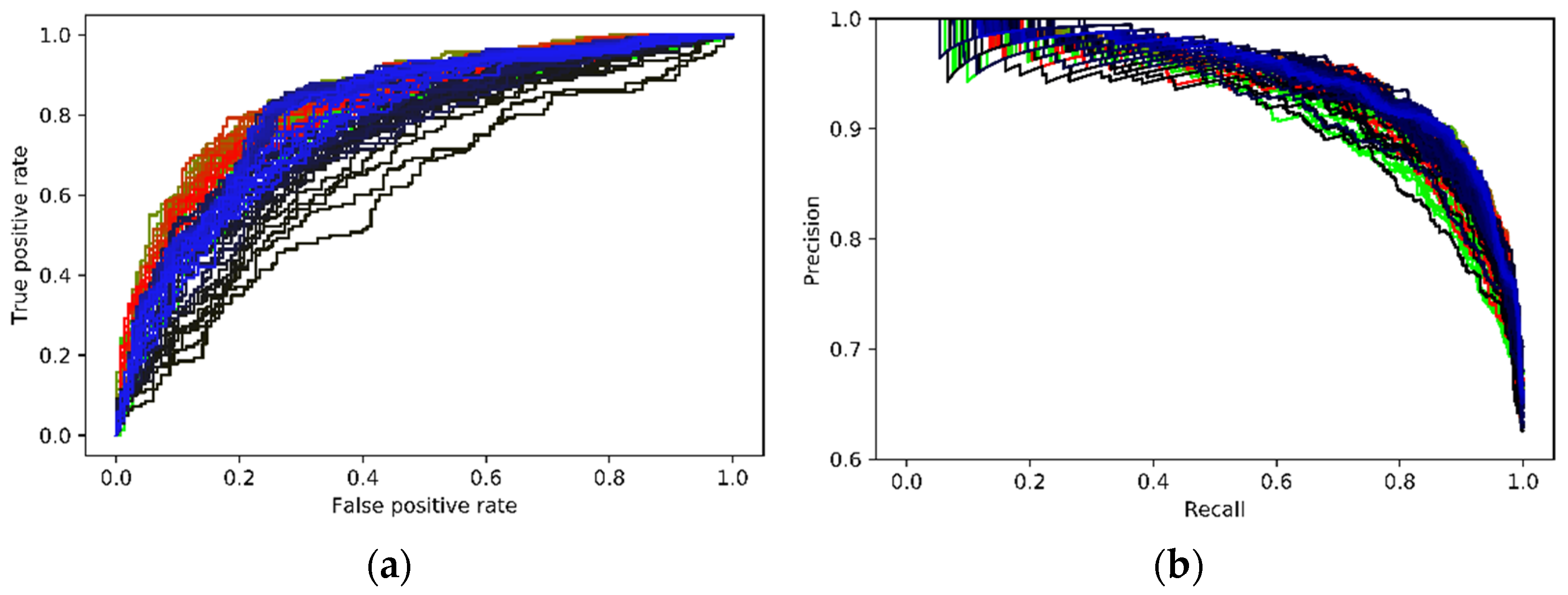
4.1. Quantitative Analysis
4.2. Further Discussions
5. Conclusions and Future Work
- A new framework that provides an effective way of detecting anomalies by combining three-dimensional convolutions and the LSTM network.
- The structure of the new framework has high computational efficiency, which enables its application to videos with different resolutions and for different tasks.
- Experiments carried out in this study not only demonstrated the effectiveness of the new framework, but also improved the benchmarks on two large-scale datasets.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Jiang, F.; Yuan, J.; Tsaftaris, S.A.; Katsaggelos, A.K. Video anomaly detection in spatiotemporal context. In Proceedings of the IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Nayak, R.; Pati, U.C.; Das, S.K. A comprehensive review on deep learning-based methods for video anomaly detection. Image Vis. Comput. 2021, 106, 104078. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ghadiyaram, D.; Feiszli, M.; Tran, D.; Yan, X.; Wang, H.; Mahajan, D. Large-scale weakly-supervised pre-training for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only look, but also listen: Learning multimodal violence detection under weak supervision. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. Remembering history with convolutional LSTM for anomaly detection. In Proceedings of the IEEE International Conference on Multimedia and Expo, Hong Kong, China, 10–14 July 2017. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. A revisit of sparse coding based anomaly detection in stacked rnn framework. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Nguyen, T.N.; Meunier, J. Anomaly detection in video sequence with appearance-motion correspondence. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Erfani, S.M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and largescale anomaly detection using a linear one-class svm with deep learning. Pattern Recognit. 2016, 58, 121–134. [Google Scholar] [CrossRef]
- Ionescu, R.T.; Smeureanu, S.; Alexe, B.; Popescu, M. Unmasking the abnormal events in video. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Georgescu, M.I.; Ionescu, R.T. Clustering images by unmasking—A new baseline. In Proceedings of the IEEE International Conference on Computer Vision, Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Ionescu, R.T.; Khan, F.S.; Georgescu, M.I.; Shao, L. Object-centric auto-encoders and dummy anomalies for abnormal event detection in video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, W.; Lian, D.; Luo, W.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ye, M.; Peng, X.; Gan, W.; Wu, W.; Qiao, Y. Anopcn: Video anomaly detection via deep predictive coding network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Zhang, J.; Qing, L.; Miao, J. Temporal convolutional network with complementary inner bag loss for weakly supervised anomaly detection. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Zhu, Y.; Newsam, S. Motion-aware feature for improved video anomaly detection. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Wan, B.; Fang, Y.; Xia, X.; Mei, J. Weakly supervised video anomaly detection via center-guided discriminative learning. In Proceedings of the IEEE International Conference on Multimedia and Expo, London, UK, 6–10 July 2020. [Google Scholar]
- Zhong, J.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Image Processing, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Astrid, M.; Lee, S. CLAWS: Clustering assisted weakly supervised learning with normalcy suppression for anomalous event detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Feng, J.; Hong, F.; Zheng, W. MIST: Multiple instance self-training framework for video anomaly detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Tian, Y.; Pang, G.; Chen, Y.; Singh, R.; Verjans, J.W.; Carneiro, G. Weakly-supervised video anomaly detection with robust temporal feature magnitude learning. arXiv 2021, arXiv:2101.10030. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Main Features | AUC (%) |
|---|---|---|
| [5] | C3D [24] | 75.41 |
| [20] | C3D, TCN | 78.66 |
| [23] | TSN | 82.12 |
| [25] | C3D | 83.03 |
| [26] | I3D | 82.30 |
| [27] | C3D/I3D, RTFM | 84.03 |
| Our method | 3D Convolution, LSTM | 85.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Machado, J.J.M.; Tavares, J.M.R.S. Weakly Supervised Video Anomaly Detection Based on 3D Convolution and LSTM. Sensors 2021, 21, 7508. https://doi.org/10.3390/s21227508
Ma Z, Machado JJM, Tavares JMRS. Weakly Supervised Video Anomaly Detection Based on 3D Convolution and LSTM. Sensors. 2021; 21(22):7508. https://doi.org/10.3390/s21227508
Chicago/Turabian StyleMa, Zhen, José J. M. Machado, and João Manuel R. S. Tavares. 2021. "Weakly Supervised Video Anomaly Detection Based on 3D Convolution and LSTM" Sensors 21, no. 22: 7508. https://doi.org/10.3390/s21227508