1. Introduction
Digital image matching is a technique that searches for homologous feature points, also named matches or correspondences, between two or more images. The generation of spatial products and the wide variety of environmental applications using remote sensing images require such a technique to achieve their goals. For example, image registration [
1,
2,
3,
4], object detection and change detection [
5], three-dimensional (3D) reconstruction [
6,
7], mapping tasks [
8], and structure-from-motion (SfM) algorithms [
9,
10] all require a digital image matching stage. Unlike earlier handcrafted operation, advances in technology now allow semi- or fully automatic digital image matching by incorporating computer vision methods, saving both time and labor costs. In addition, several photogrammetric techniques, such as bundle adjustment and image connection, can be carried out more effectively.
Classic automatic image matching techniques can be classified into three categories: area-based matching techniques (ABMs), feature-based matching techniques (FBMs), and hybrid methods [
11]. ABMs, also known as template matching, use a window template as a feature point with pixel intensities to compute the feature similarities or resemblances. The typical procedure defines a window template in a master image and moves it across a target image to search for the most similar correspondence. Well-known examples of ABMs include normalize cross-correlation coefficient (NCC), zero-mean NCC [
12], least-squares matching (LSM, [
13]), and mutual information [
14]. Although ABMs can achieve high positional accuracy, e.g., 1/50 pixels according to [
15], they may suffer from image occlusions, uniform textures, image distortions, and illumination changes [
11]. FBMs extract image feature points of interest, also known as keypoints (e.g., points, lines, and areas), and compute their similarities in different images by using feature descriptors [
16,
17]. Scale invariant feature transform (SIFT) [
18] may be the most representative algorithm in the FBM family. Most FBMs can achieve scale- and rotation-invariant feature descriptors that increase the distinctiveness and robustness among different keypoints; thus, the image matching results can be more precise than those of ABMs [
11,
19]. However, Sedaghat et al. [
11] indicated that FBMs are less accurate than ABMs, and eliminating mismatches/outliers is usually required. Finally, hybrid methods can address the individual limitations of the above two families by combining ABMs and FBMs; otherwise, adding ancillary data such as wavelet information for image matching is also feasible [
20]. However, hybrid methods usually require prior knowledge before data processing, so they are not utilized frequently.
More recently, deep learning (DL)-based approaches developed in the field of artificial intelligence (AI) have had great impacts on image matching [
21,
22,
23,
24,
25,
26,
27,
28,
29]. The development of deep features—pre-trained convolutional neural network (CNN) features—is one of the breakthroughs in this study field. However, Refs. [
30,
31] found that pre-trained CNN features perform similarly or even worse than FBMs. Long et al. [
32] tested the capabilities of deep features for semantic alignment and compared the results derived from SIFT and pre-trained CNN features. They concluded that pre-trained CNN features only perform slightly better than the SIFT algorithm. Ufer and Ommer [
33] further incorporated a semantic matching algorithm with an object guiding technique into pre-trained CNN features, improving the capacity for deep feature matching. However, pre-trained CNN features mainly concentrate on the salient objects with bounding boxes to constrain the specific regions for matching [
23,
24,
33,
34].
Although DL-based methods can achieve very precise results, their requirements, i.e., a large amount of training data and an extensive period for data training, are critical concerns. For example, prior knowledge, such as ground truth and pre-trained CNN features, must be available to implement data training [
33,
35,
36,
37]. DL-based methods cannot perform with the lack of such supporting data or when the number of required datasets is inadequate. Revaud et al. [
38] proposed the DeepMatching (DM) algorithm and compared its performance with the SIFT method. In terms of memory usage, they reported that the DM algorithm consumed approximately 100 times more than the SIFT method when utilizing the MPI-Sintel dataset and the KITTI dataset (9.9 GB versus 0.2 GB). As for the matching time, the DM algorithm spent 8.1 min, while the SIFT method required only 1.4 s when using the Mikolajczky dataset. After investigating the performance among classical approaches and the LF-Net with SuperPoint models [
23,
24], Bojanić et al. [
39] concluded that their DL-based model indeed does not significantly improve the image matching results compared to classic approaches. Bhowmik et al. [
40] also indicated that the high precision is caused by matching low-level features rather than improving the image matching performance itself. In addition, the applicability of the prediction map generated by a specific training dataset is limited to the related imagery data only, and their high computational complexity also inhibits the practical application of DL-based methods [
41]. Indeed, classic image matching approaches are still favorable in terms of their universality and practicality [
42,
43], particularly FBMs.
Image matching exploiting FBMs, also known as local feature matching, undergoes three steps: feature detection, feature description, and feature matching [
44]. The feature character using FBMs can be further divided into two types: vector-based features and binary-based features. Matching vector-based features utilizes Euclidean distance and a ratio test to determine the resemblance between two keypoints [
18]. In addition to SIFT, several variations, such as principal component analysis SIFT (PCA-SIFT) [
45], gradient location-orientation histogram (GLOH) [
46], speed up robust features (SURF) [
47], affine SIFT (ASIFT) [
48], uniform robust SIFT (UR-SIFT) [
11], and adaptive-binning SIFT (AB-SIFT) [
44], are also included in the family of vector-based features. These methods either enhance the feature distinctiveness or reduce the dimensions of the feature descriptors to improve the performance of SIFT-like image matching. On the other hand, binary-based features employ the Hamming distance [
49], an XOR operation, to evaluate the similarity between two keypoints. Approaches in this category include binary robust independent elementary features (BRIEF) [
50], orientation FAST and rotated BRIEF (ORB) [
51], and binary robust invariant scalable keypoints (BRISK) [
52]. As the ORB technique lacks the trait of scale invariance [
53], the BRISK technique can be considered the most powerful method in the family of binary-based features because it is scale- and rotation-invariant. Based on this technique, Liu et al. [
54] fused the depth information into the BRISK feature descriptor to enhance the scale invariance using a specific camera for capturing depth information with optical images simultaneously, leading to the BRISK-D algorithm. One of the most significant advantages of this approach is that it can perform image matching properly under illumination changes. However, they observed that the precision of the image matching results decreases when the image has a large-scale change, and the algorithm may be unstable when using blur images. Additional modifications, such as the accelerated BRISK (ABRISK) [
4] and enhanced ABRISK (EABRISK) [
55] algorithms, further improve the performance of image matching using BRISK in terms of the data processing time and the number of matches.
Tsai and Lin [
4] compared the capacities among the SIFT, SURF, and ABRISK algorithms, discovering that the ABRISK method can perform 312 times and 202 times faster than the SIFT and SURF methods, respectively, when using the image size of 4000 × 4000. They concluded that vector-based features provide more robust results, but they consume more time for data processing; on the contrary, binary-based features take less time for image matching, and the outcomes are acceptable. Their results also indicated that the number of matches becomes sparser, implying the inability to obtain redundant correspondences for more rigorous geometric computation when performing spatial tasks such as image registration and SfM. Similarly, Kamel et al. [
53] compared the results by utilizing hybrid features with the airport dataset and found that ORB-BRISK requires 0.238 s for 37 matches and SURF-SFIT consumes 3.518 s for 161 matches, respectively. Shao et al. [
56] also utilized a hybrid method by integrating SIFT and ASIFT to improve the accuracy of the image matching results for land monitoring. Cheng and Matsuoka [
55] further improved the ABRISK by incorporating the human retina mechanism and showed that the EABRISK reduces the data processing time by approximately 10%. In addition, EABRISK can achieve approximately 1.732 times more matches than ABRISK when applying drone image pairs.They also explored the performances of the AB-SIFT and EABRISK methods, showing that these two algorithms almost have a comparable data processing time and number of matches obtained. For several practical cases, EABRISK can provide better image matching results than AB-SIFT.
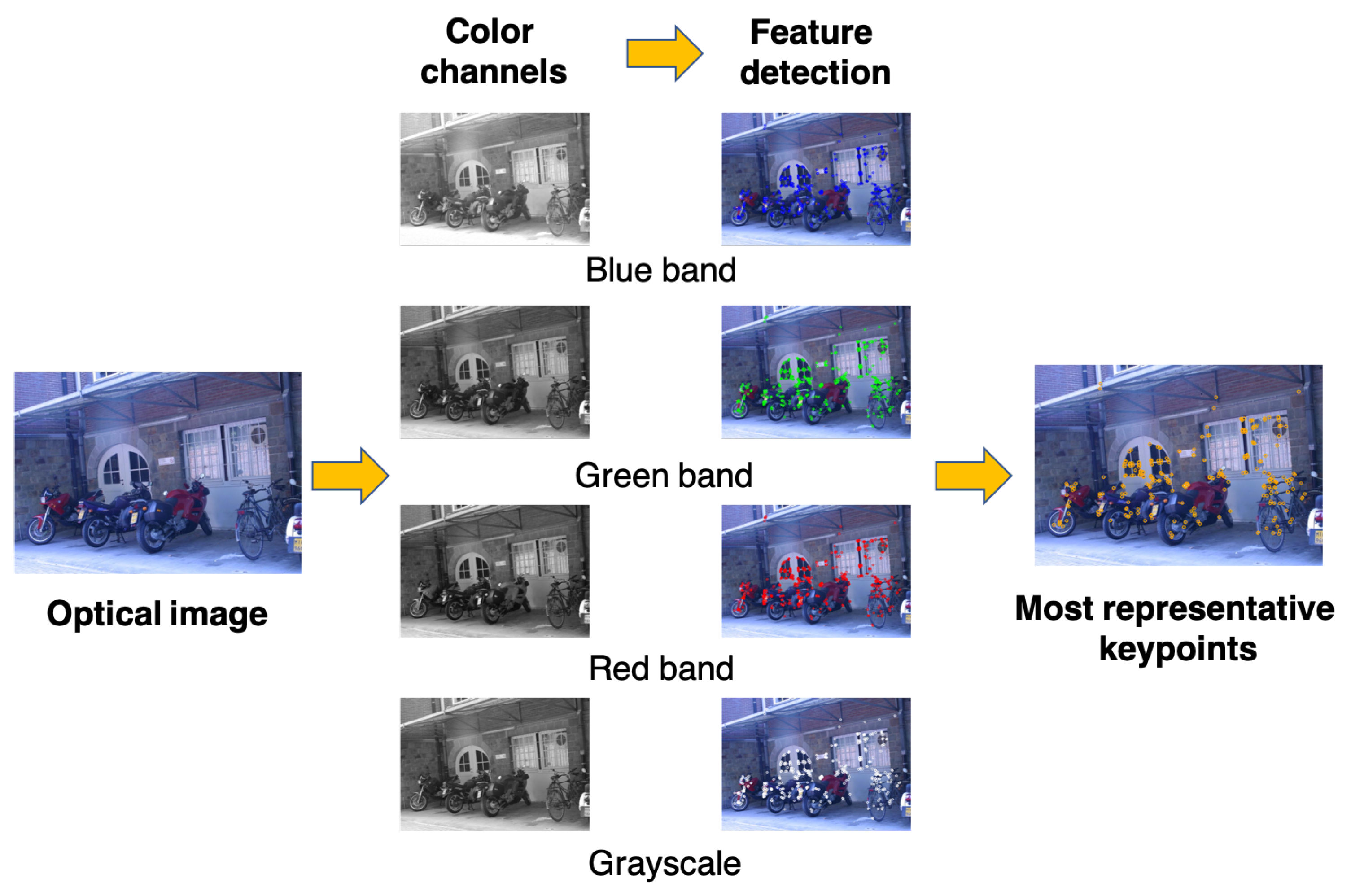
Currently, most image matching algorithms convert an optical image into a grayscale image and utilize pixel intensities to match different images; color information, namely the red, green, and blue frequency bands, is not involved. A few methods, such as the colored SIFT (CSIFT) [
57] and colored BRISK (CBRISK) [
58] techniques, use a spectrum model to normalize color spaces to generate color-invariant images and thus avoid the influences of different illumination conditions caused by radiometric changes. However, both techniques may alter the true electromagnetic information stored in the original imagery data, thus leading to some mismatches with unknown causes. Alitappeh et al. [
59] indicated that such color-invariant techniques are only suitable for specific cases. The color-based retina keypoints (CREAK) method [
60], based on the fast retina keypoint (FREAK) technique [
61], performs feature detection and assesses descriptor changes in the red, green, and blue (R-G-B) color spaces. These three color spaces have distinct impacts on feature detection and descriptor formation and therefore should be treated separately in image matching.
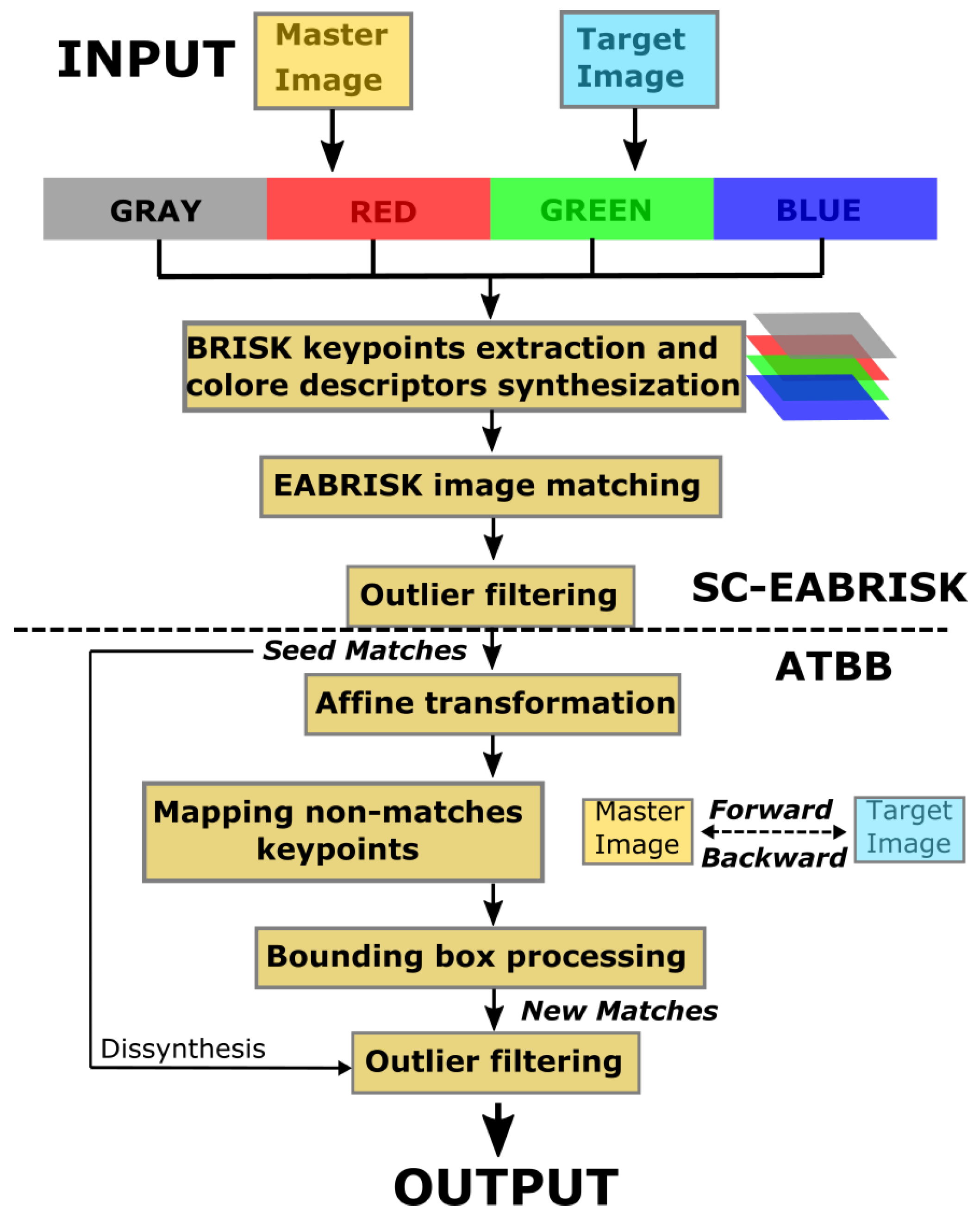
For stereomatching that has two images only, the DL-based approaches may not be suitable to address the issue because the ground truth is not known and the number of training datasets is not sufficient. In most past studies, FBMs are crucial in solving this issue. To further improve the performance of stereomatching, this paper develops an integrated approach with two steps to achieve substantial precise matches and balance the image matching efficiency. The first step exploits the EABRISK method as the fundamental by considering its data processing efficiency and the matching result obtained. Different from the EABRISK method using the grayscale image, this research further adds color information into the feature descriptors to increase the distinctiveness and robustness for image matching. Instead of applying the spectrum model to normalize color spaces, this study utilizes R-G-B images and simulates the human retina mechanism to achieve the purpose. The second phase aims to increase the number of matches for stereomatching by geometric mapping since FBMs can usually yield sparse results. By this means, the feature point detected has an opportunity to find its correspondence to increase the number of matches. The rest of this paper is organized as follows.
Section 2 describes the proposed methodology in this research.
Section 3 demonstrates and analyzes the experimental results by using imagery datasets with different conditions.
Section 4 discusses the abilities and the limitations of the proposed method.
Section 5 draws the conclusions and proposes future works so that further improvements can be made.
4. Discussion
Automatic remote sensing optical image matching is fundamental and crucial for many spatial applications. In addition to the reliability and robustness of the local features themselves, the efficiency of the data processing step has gained more attention in recent years [
4]. This paper aimed to develop a systematic workflow that is able to adopt a portion of the most robust keypoints and a subsequent geometric mapping to generate the greatest number of feature correspondences. Different from previously advanced studies that used only grayscale images for feature detection and descriptor formation [
4,
44], this study aimed to also synthesize color information extracted from R-G-B images into the feature descriptors acquired from the grayscale image to improve their robustness by utilizing BRISKs.
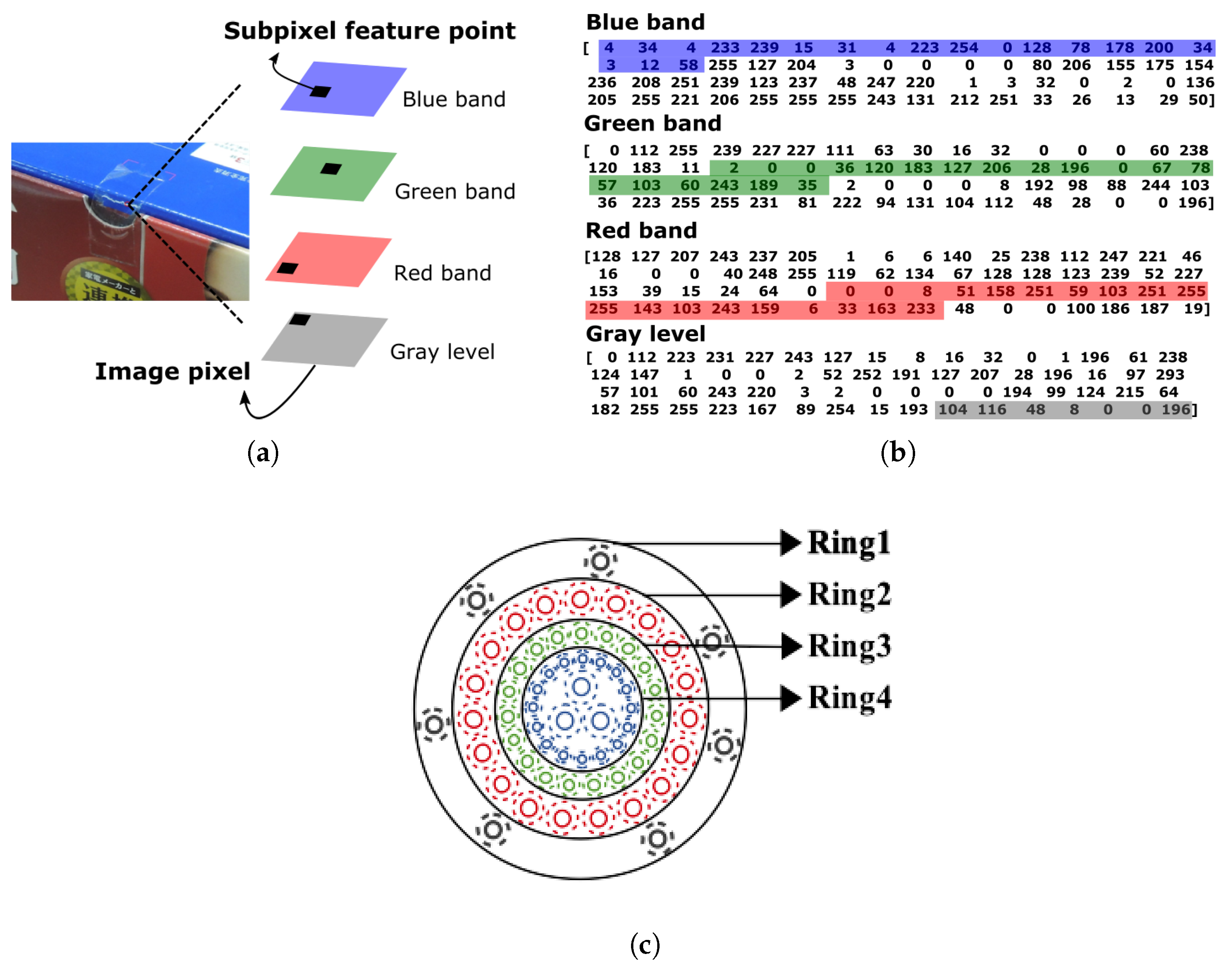
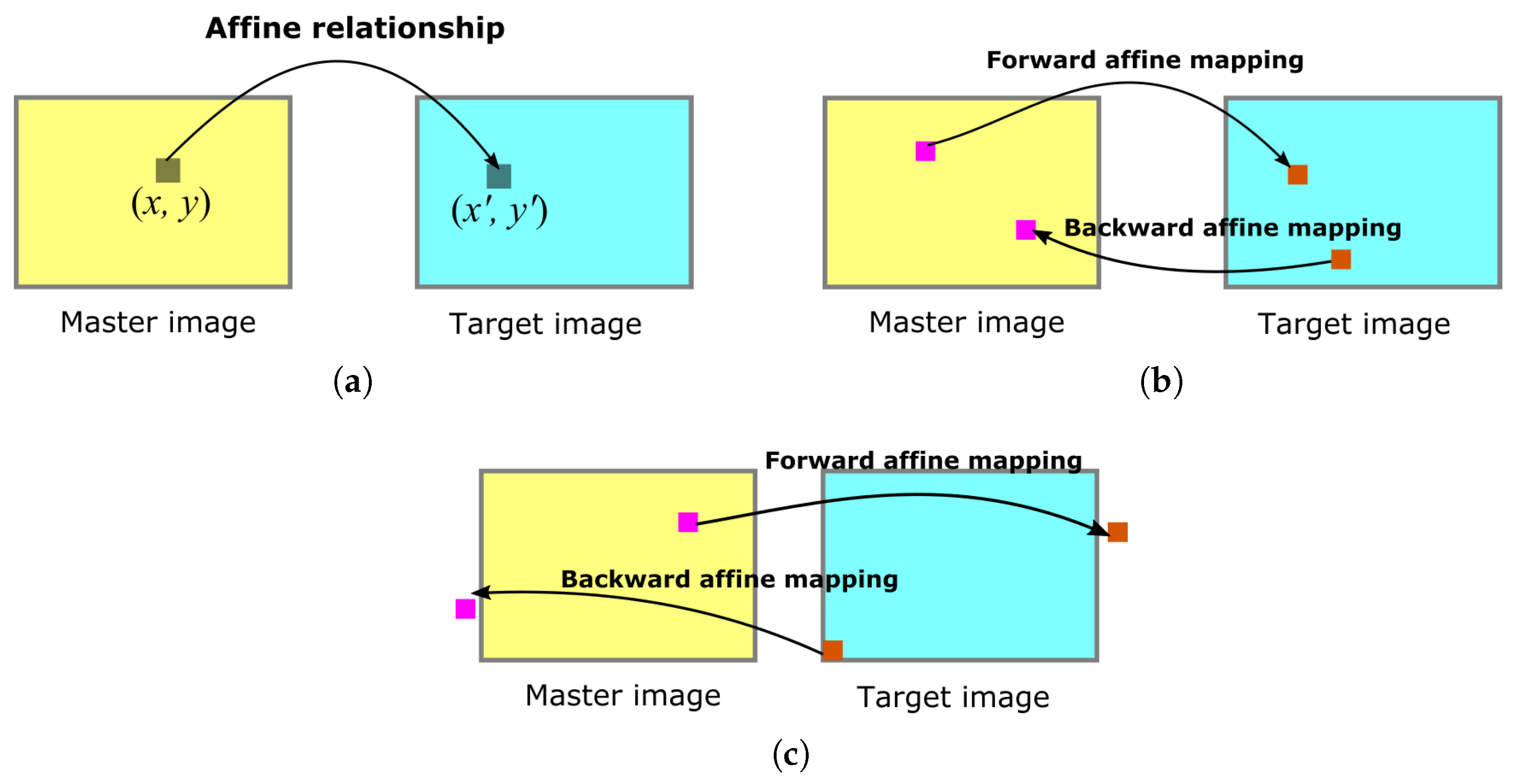
However, the displacements of possibly identical keypoints caused by subpixel-level BRISK detection and extraction in the four images prevent direct color synthesis. To achieve this objective, the proposed method groups four points with very close pixel coordinates emerging in the grayscale and R-G-B images as the most representative keypoints. Thereafter, color synthesis for the feature descriptors is addressed by these four group points from four color images. Compared with color-invariant methods [
57,
58], the proposed method generates SC keypoints that can preserve the true color information in the image without deteriorating the spectral information. Therefore, the SC descriptors of the most representative keypoints are expected to be more distinctive than those obtained via the grayscale image alone. The arrangement of the SC descriptors is then modified by the ISR pattern, the cell sensitivity, and the distribution of color information across the human retina. Based on this mechanism, image matching can be carried out more efficiently by eliminating unlikely matches as early as possible.
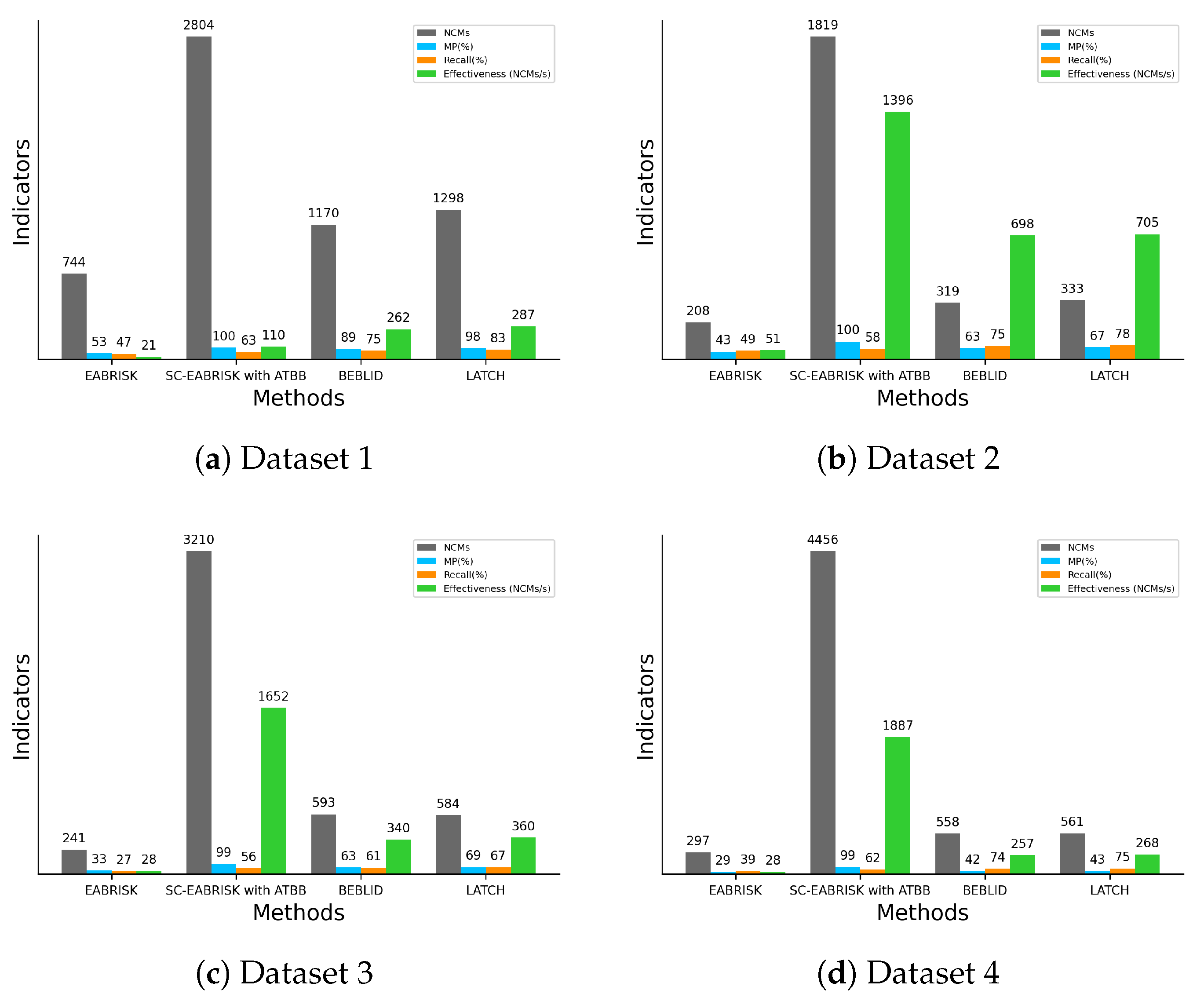
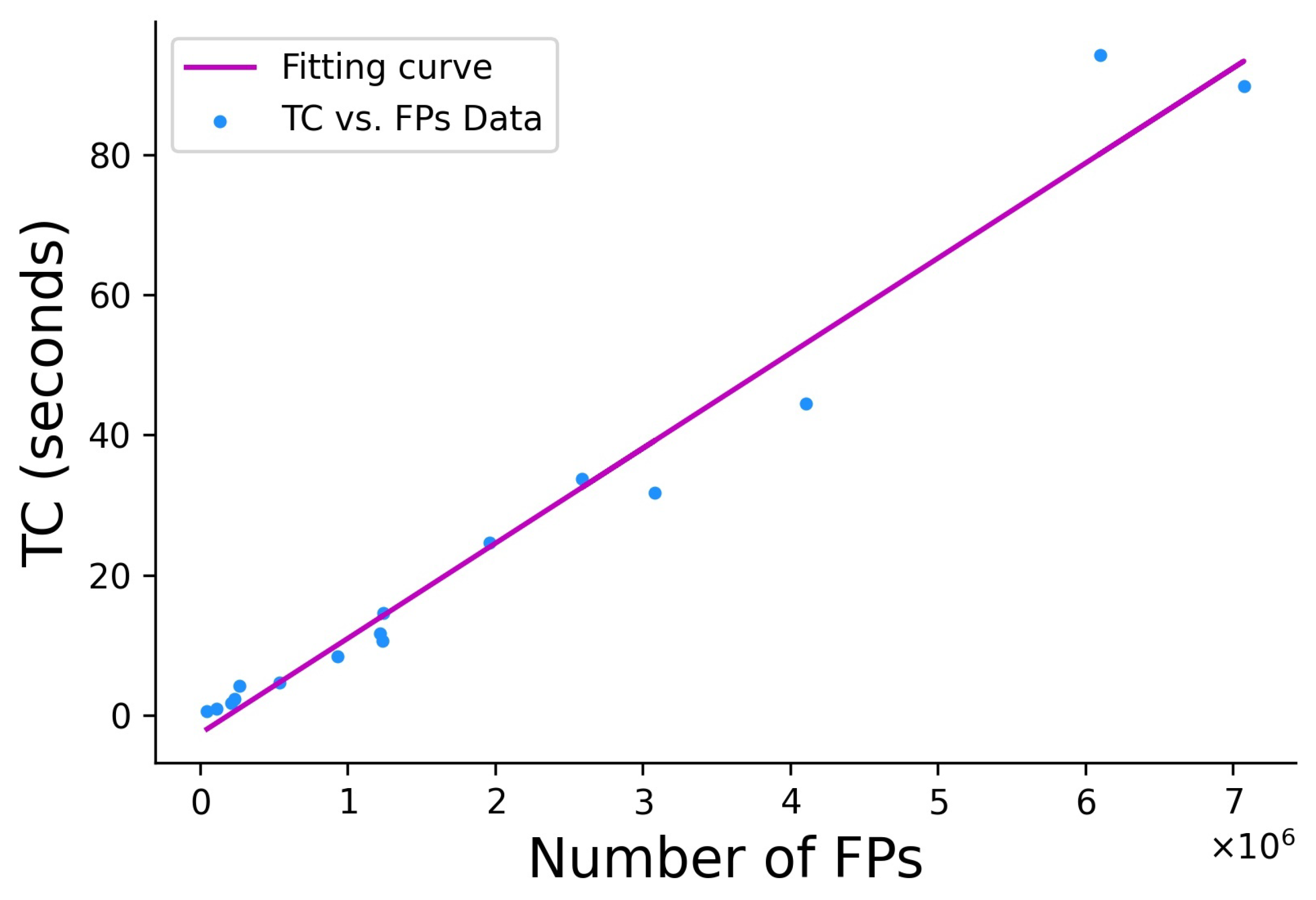
Figure 12 shows a linear fitting curve between the TC and the FPs obtained by the eight experimental examples (16 datasets analyzed with the EABRISK and SC-EABRISK operations) to estimate the processing time required when supplying different numbers of FPs. Although the estimation may be biased due to differences in the computer environments, the curve is approximated as TC = 0.000136 × FPs − 2.569 in this study, allowing prediction of the processing time needed when applying the proposed method to different imagery data.
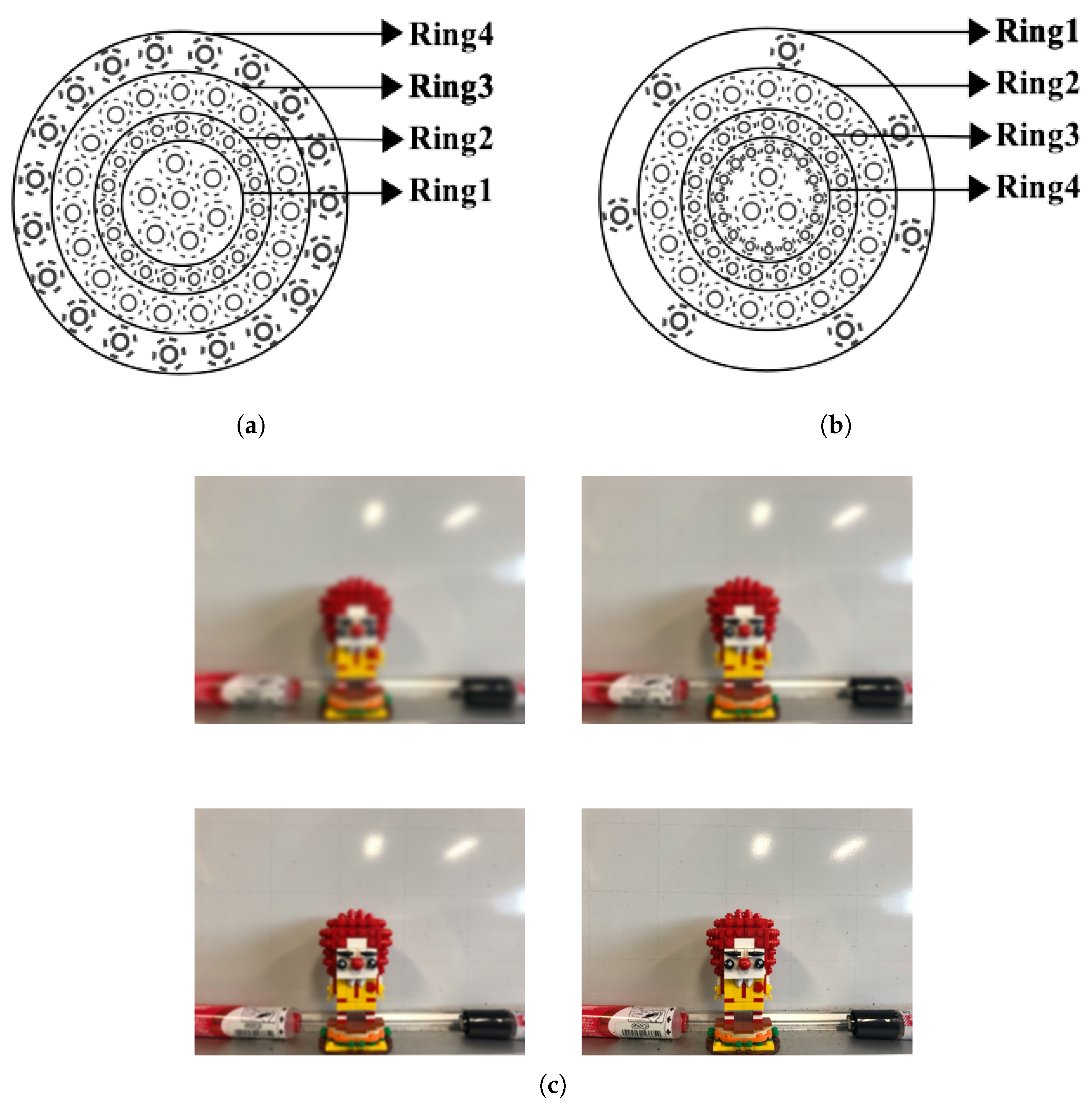
There are two significant limitations to the proposed method. First, the number of SC keypoints may be very low in some specific cases, e.g.,
Figure 7b,c, caused by the discrete keypoints found in the four color images. It should be noted that too few SC keypoints may lead to both unsuccessful image matching due to a lack of feature correspondences and failure of the geometric mapping using affine transformation for achieving more feature correspondences. Therefore, further examination of the number of SC keypoints and their distribution across the image is recommended to ensure successful outcomes. The second limitation is related to the radiometric variation within the two images; for instance,
Figure 7b and
Figure 11b show that the result derived from SC-EABRISK weakens when the radiometric condition changes. In terms of this issue, Tsai and Lin [
4] illustrated that the use of grayscale images is not influenced by the limitation of radiometric condition changes, and Ye et al. [
82] also used such images to build structure features for multimodal image matching by the use of grayscale images. Based on the previous achievements, this paper suggests using the LATCH, ABRISK, EABRISK, feature structures, or BEBLID algorithm when the two images have drastic radiometric differences. Therefore, the developed SC-EABRISK with the ATBB method may be ineffective in coping with images of low temporal resolution (e.g., spanning month and year) due to unpredictable changes in the illumination conditions of the same region.
5. Conclusions
This paper proposes an integrated approach for improving the efficiency and performance of image matching based on BRISKs. In addition to using grayscale images, the proposed method adds color information extracted from R-G-B images to enhance the distinctiveness and robustness of the feature descriptors and improve the precision of the image matching. To suitably utilize the color information, the proposed method selects the keypoints that emerge in the four color spaces simultaneously and uses them as the most representative keypoints. For each of these representative keypoints, the 64-byte feature descriptors are rearranged following the mechanism underlying the human retina in terms of cell distribution and color recognition, and each keypoint in its corresponding color space contributes a portion of descriptors to form the SC feature descriptors. Every group containing four keypoints derived from the four color images is synthesized as an individual keypoint; thereafter, the EABRISK algorithm, which imitates visual accommodation, is applied to the SC feature descriptors for image matching, and thus, the SC-EABRISK algorithm aims to match the most representative keypoints and their more robust SC feature descriptors. The subsequent ATBB procedure further utilizes the results derived from the SC-EABRISK phase to extensively geometrically map the unused keypoints to find their likely correspondences. Both forward and backward geometric mapping thus involve all keypoints in the master and target images and the ATBB procedure allows the acquisition of a greater number of NCMs simply and effectively without additional TC.
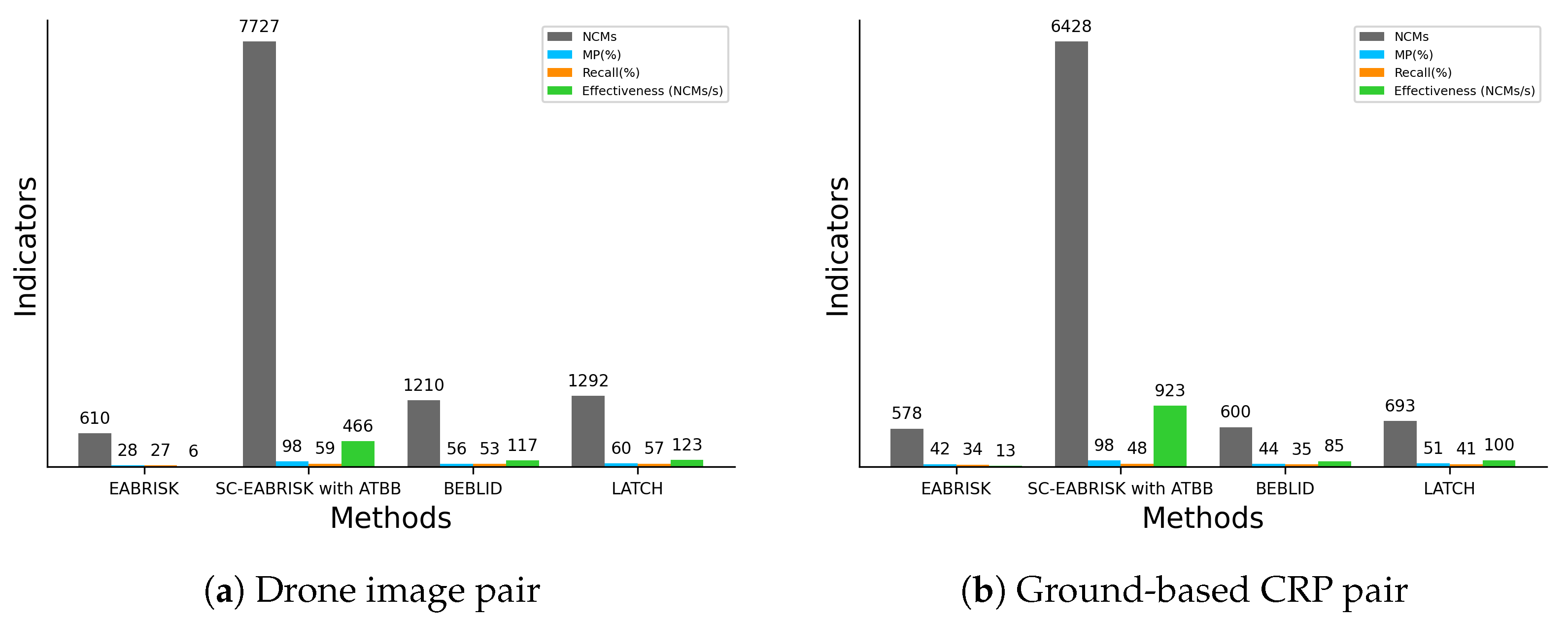
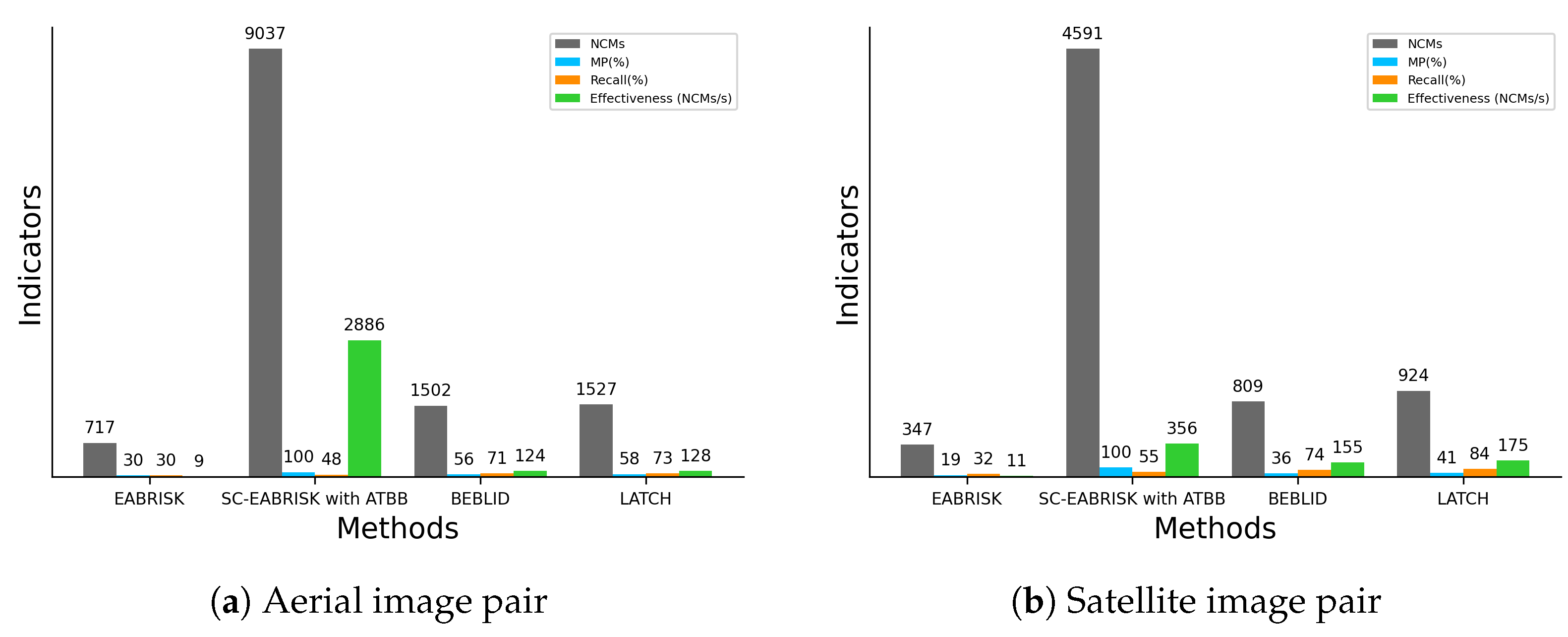
The experimental results using benchmark imagery datasets, CRPs, and aerial and satellite images ensure the generalizability and practicability of the developed SC-EABRISK with ATBB method because the images were captured by different platforms and cameras. In terms of performance evaluation, this paper employed four indicators, the NCMs, MP, recall, and effectiveness, to assess the proposed method. Since the most representative keypoints are selected, the SC-EABRISK algorithm has a reduced number of NCMs and recall values, but the increased MPs and effectiveness values imply that image matching can be performed more precisely and efficiently. Following ATBB processing, the four indicators are significantly improved, indicating that most of the detected keypoints and their correspondences are found successfully. Therefore, all experimental outcomes indicate that the proposed method balances the NCMs and the TC, a profound issue when addressing image matching by previously proposed FBMs. Although the proposed method still presents some limitations, it is expected to improve the capacities of FBMs, leading to better spatial products and applications, such as image registration, SfM, and 3D reconstruction. For future works, the proposed SC-EABRISK algorithm may be extended to multispectral and hyperspectral satellite image matching by involving additional bands to make the feature descriptors more robust and distinctive. In addition, the image matching results may serve as training data for DL-based approaches to match additional images in the future.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}