
Device-Free Human Identification Using Behavior Signatures in WiFi Sensing

Abstract
:1. Introduction
1.1. Motivation
1.2. Contributions
- We leverage, for the first time, the joint human fine-grained behavior and body physical signature embedded in CSI for human identification;
- We propose a novel DFB system, WirelessID. To evaluate the performance, commercial WiFi devices are used for prototyping WirelessID in a real laboratory environment. The recognition rate of the test has an average accuracy of 93.14% and a best accuracy of 97.72% for five individuals.
1.3. Organization
2. Related Work
2.1. Human Identification
2.2. Device-Free Wireless Sensing for Human Detection
2.2.1. Model-Based Methods for DFWS
2.2.2. Data-Driven Methods for DFWS
2.3. Attention Model
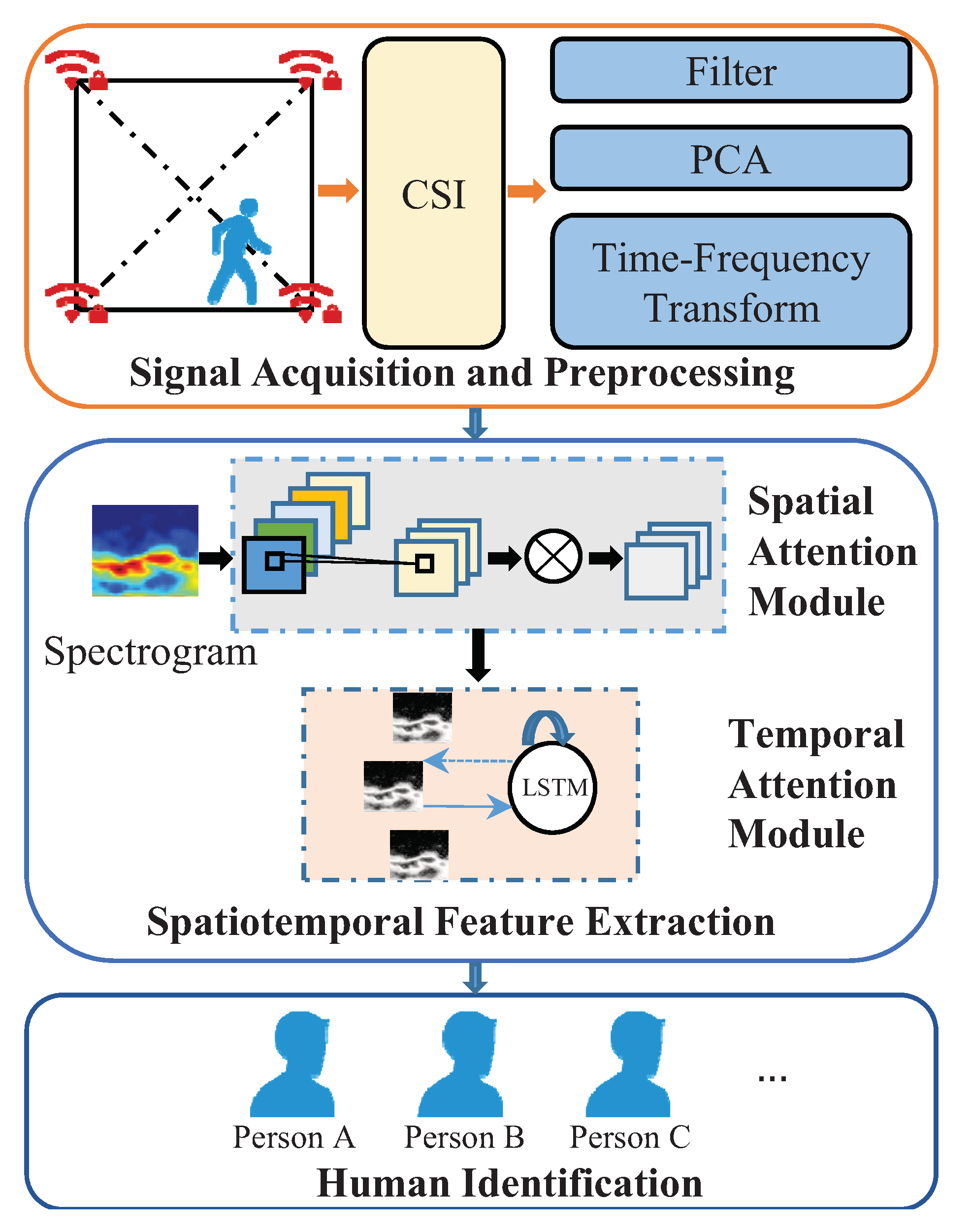
3. WirelessID
3.1. Sensing Signal Acquisition and Preprocessing
3.2. Spatiotemporal Feature Extraction
3.2.1. Attention-Spatial Model
3.2.2. Attention-Temporal Model
3.3. Human Identification
4. Experiment and Evaluation
4.1. Experiment Setup
4.2. Performance Evaluation
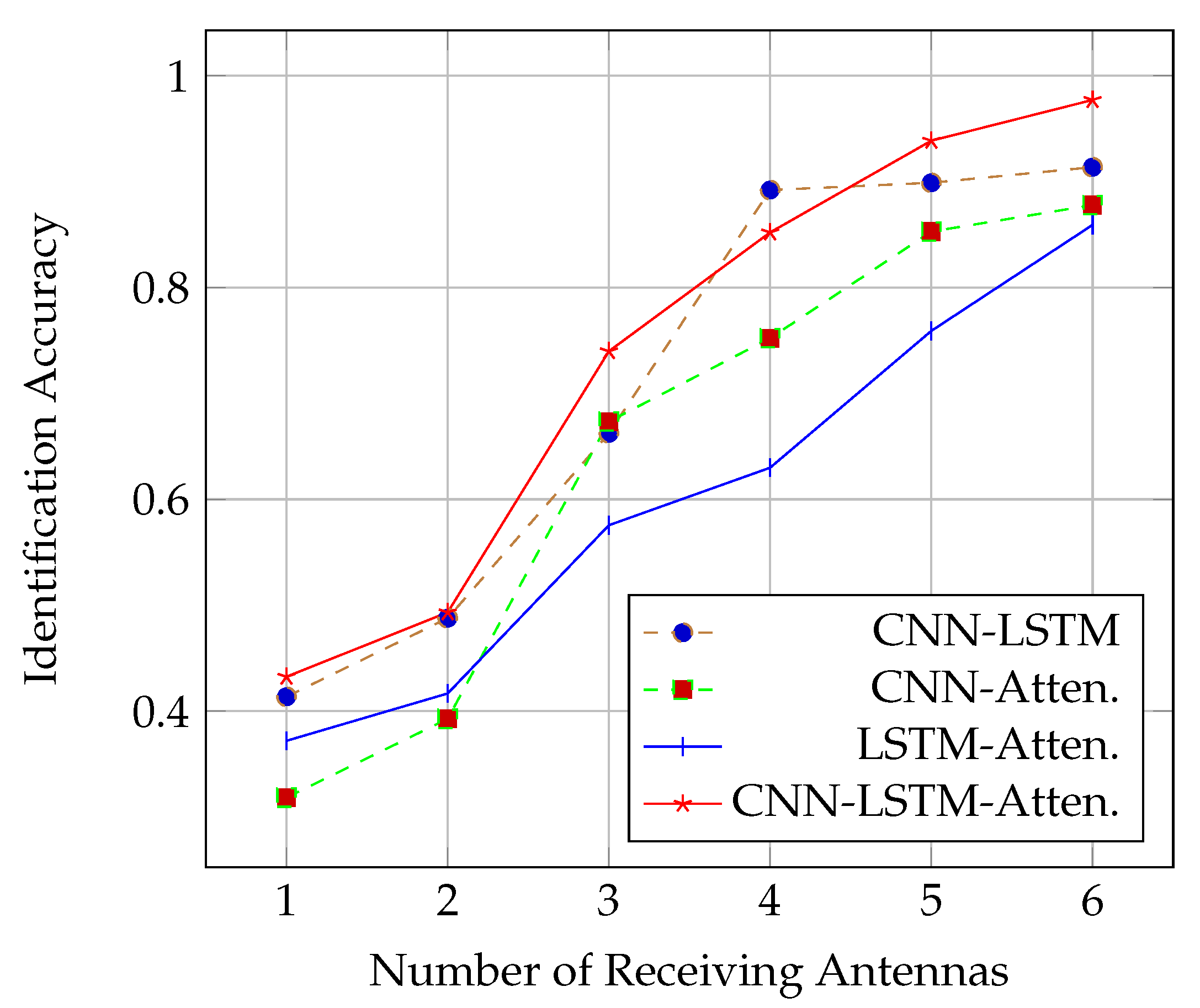
4.2.1. Impact of the Number of Receiving Antennas
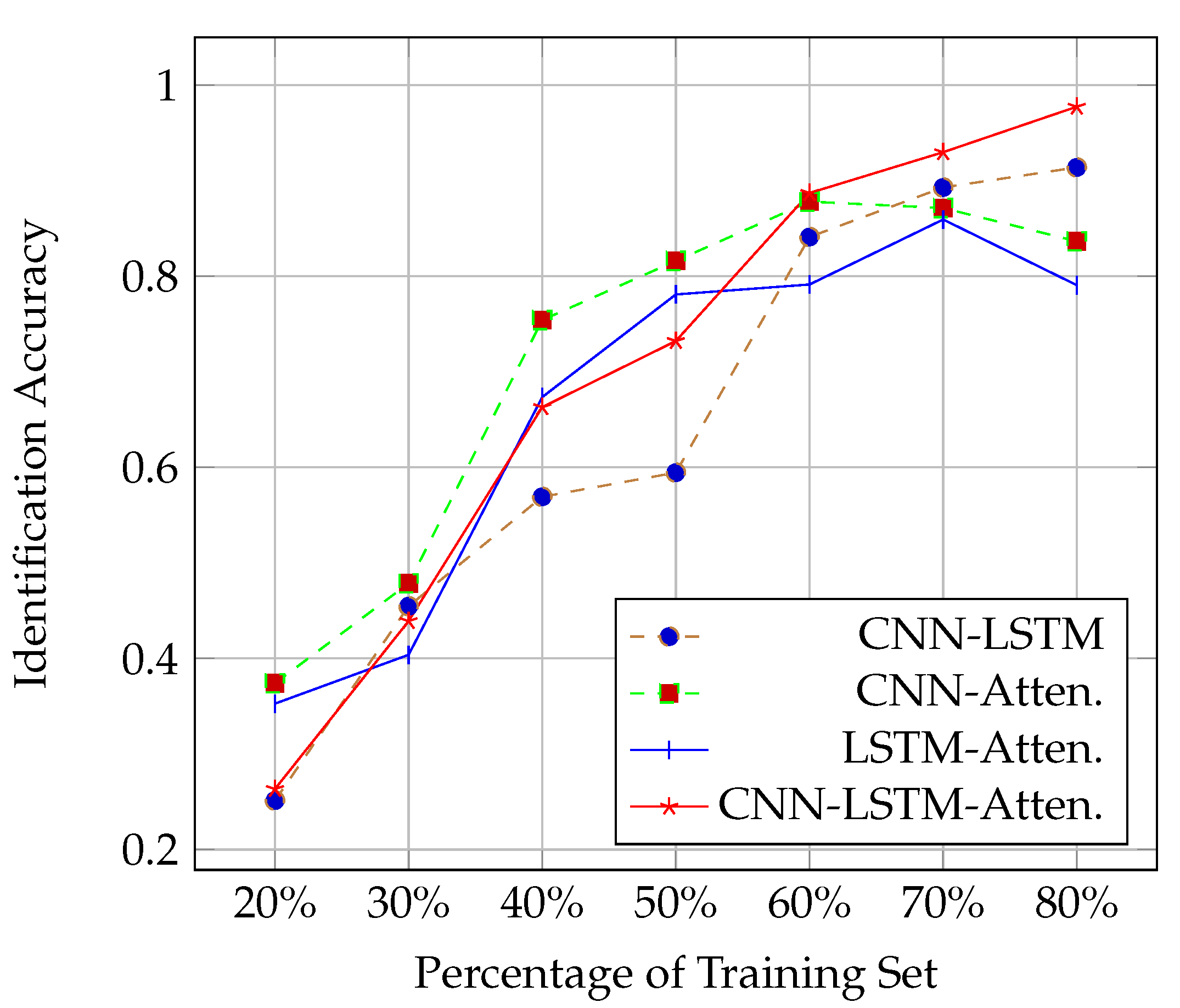
4.2.2. Impact of the Usage Percentage of the Training Set
4.2.3. Comparison of the Deep Models
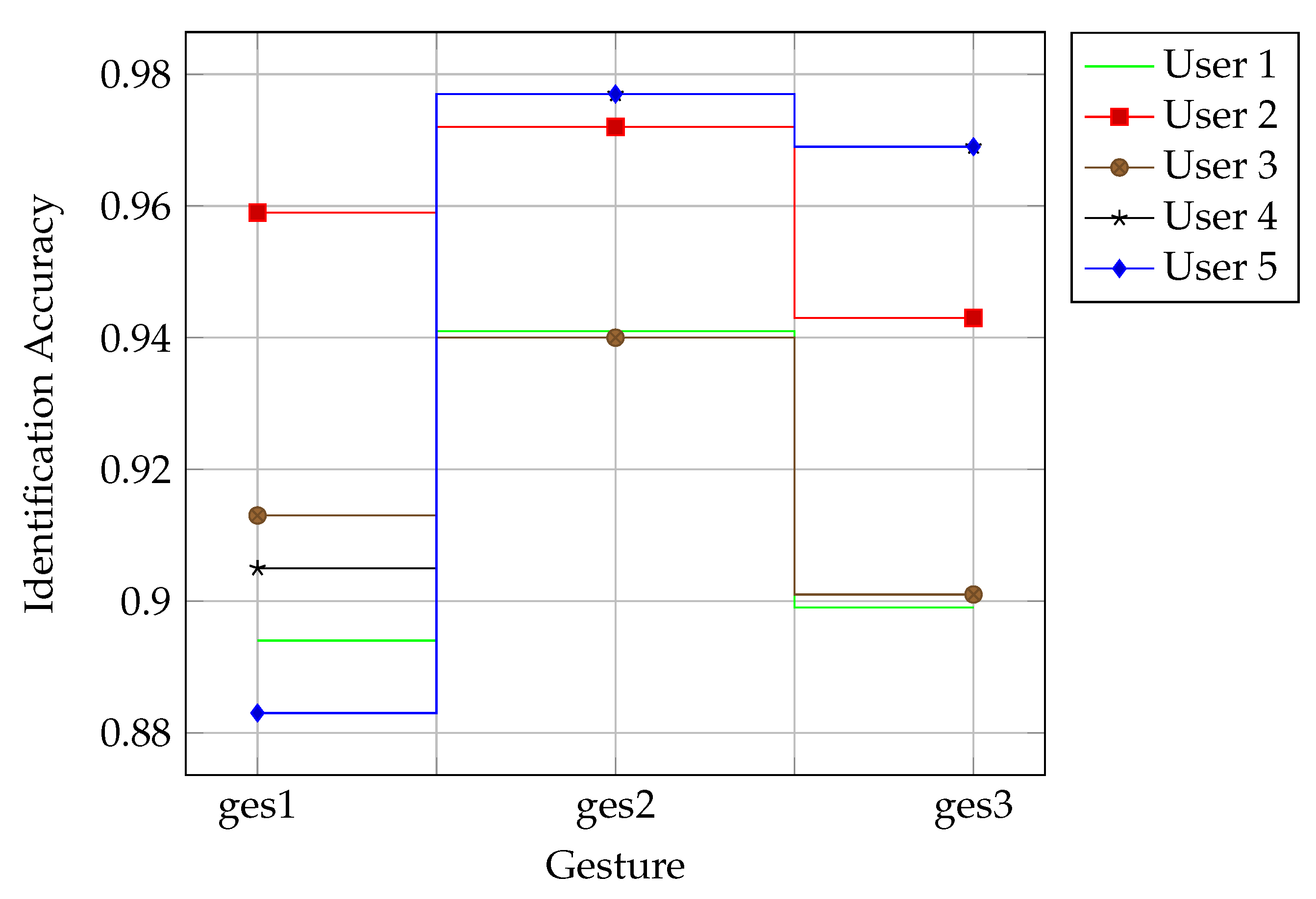
4.2.4. Cross-Behavior Performance Evaluation
5. Comparisons with the Baselines
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, R.; Jing, X.; Wu, S.; Jiang, C.; Mu, J.; Yu, F.R. Device-Free Wireless Sensing for Human Detection: The Deep Learning Perspective. IEEE Internet Things J. 2021, 8, 2517–2539. [Google Scholar] [CrossRef]
- Jain, A.K.; Nandakumar, K.; Ross, A. 50 years of biometric research: Accomplishments, challenges, and opportunities. Pattern Recognit. Lett. 2016, 79, 80–105. [Google Scholar] [CrossRef]
- Zeng, Y.; Pathak, P.H.; Mohapatra, P. WiWho: WiFi-based person identification in smart spaces. In Proceedings of the 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Vienna, Austria, 11–14 April 2016; pp. 1–12. [Google Scholar]
- Wang, W.; Liu, A.X.; Shahzad, M. Gait recognition using wifi signals. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 363–373. [Google Scholar]
- Wang, J.; Zhao, Y.; Fan, X.; Gao, Q.; Ma, X.; Wang, H. Device-free identification using intrinsic CSI features. IEEE Trans. Veh. Technol. 2018, 67, 8571–8581. [Google Scholar] [CrossRef]
- Xu, Q.; Chen, Y.; Wang, B.; Liu, K.J.R. Radio biometrics: Human recognition through a wall. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1141–1155. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiserand, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kumar, A.; Zhou, Y. Human identification using finger images. IEEE Trans. Image Process. 2011, 21, 2228–2244. [Google Scholar] [CrossRef]
- Boles, W.W.; Boashash, B. A human identification technique using images of the iris and wavelet transform. IEEE Trans. Signal Process. 1998, 46, 1185–1188. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Cheng, Y.; Xu, Y.; Xiong, L.; Li, J.; Zhao, F.; Jayashree, K.; Pranata, S.; Shen, S.; Xing, J.; et al. Towards pose invariant face recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2207–2216. [Google Scholar]
- Zhang, Z.; Tran, L.; Yin, X.; Atoum, Y.; Liu, X.; Wan, J.; Wang, N. Gait recognition via disentangled representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4710–4719. [Google Scholar]
- Bai, X.; Hui, Y.; Wang, L.; Zhou, F. Radar-based human gait recognition using dual-channel deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9767–9778. [Google Scholar] [CrossRef]
- Seifert, A.K.; Amin, M.G.; Zoubir, A.M. Toward unobtrusive in-home gait analysis based on radar micro-Doppler signatures. IEEE Trans. Biomed. Eng. 2019, 66, 2629–2640. [Google Scholar] [CrossRef] [Green Version]
- Nipu, M.N.A.; Talukder, S.; Islam, M.S.; Chakrabarty, A. Human identification using wifi signal. In Proceedings of the 2018 Joint 7th International Conference on Informatics, Electronics & Vision (ICIEV) and 2018 2nd International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Kitakyushu, Japan, 25–29 June 2018; pp. 300–304. [Google Scholar]
- Liu, J.; Teng, G.; Hong, F. Human activity sensing with wireless signals: A survey. Sensors 2020, 20, 1210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, D.; Zhang, D.; Xu, C.; Wang, H.; Li, X. Device-free WiFi human sensing: From pattern-based to model-based approaches. IEEE Commun. Mag. 2017, 55, 91–97. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, H.; Wu, D. Toward centimeter-scale human activity sensing with WiFi signals. Computer 2017, 50, 48–57. [Google Scholar] [CrossRef]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Device-free human activity recognition using commercial WiFi devices. IEEE J. Sel. Areas Commun. 2017, 35, 1118–1131. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Mao, S. Deep convolutional neural networks for indoor localization with CSI images. IEEE Trans. Netw. Sci. Eng. 2018, 7, 316–327. [Google Scholar] [CrossRef]
- Xiao, C.; Han, D.; Ma, Y.; Qin, Z. CsiGAN: Robust channel state information-based activity recognition with GANs. IEEE Internet Things J. 2019, 6, 10191–10204. [Google Scholar] [CrossRef]
- Wang, F.; Gong, W.; Liu, J. On spatial diversity in WiFi-based human activity recognition: A deep learning-based approach. IEEE Internet Things J. 2018, 6, 2035–2047. [Google Scholar] [CrossRef]
- Rensink, R.A. The dynamic representation of scenes. Vis. Cogn. 2000, 7, 17–42. [Google Scholar] [CrossRef]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order boltzmann machine. Adv. Neural Inf. Process. Syst. 2010, 23, 1243–1251. [Google Scholar]
- Denil, M.; Bazzani, L.; Larochelle, H.; de Freitas, N. Learning where to attend with deep architectures for image tracking. Neural Comput. 2012, 24, 2151–2184. [Google Scholar] [CrossRef]
- Yao, L.; Torabi, A.; Cho, K.; Ballas, N.; Pal, C.; Larochelle, H.; Courville, A. Describing videos by exploiting temporal structure. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4507–4515. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Du, W.; Wang, Y.; Qiao, Y. Recurrent spatial-temporal attention network for action recognition in videos. IEEE Trans. Image Process. 2017, 27, 1347–1360. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Peng, Y.; Zhao, Y.; Zhang, J. Two-stream collaborative learning with spatial-temporal attention for video classification. IEEE Trans. Circ. Syst. Video Technol. 2018, 29, 773–786. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Zhang, Y.; Qian, K.; Zhang, G.; Liu, Y.; Wu, C.; Yang, Z. Zero-effort cross-domain gesture recognition with WiFi. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Korea, 17–21 June 2019; pp. 313–325. [Google Scholar]
- Li, X.; Zhang, D.; Lv, Q.; Xiong, J.; Li, S.; Zhang, Y.; Mei, H. IndoTrack: Device-free indoor human tracking with commodity WiFi. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 72. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2019, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Komodakis, N.; Zagoruyko, S. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the ICLR 2017 Conference, Toulon, France, 24–26 April 2017. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Shahzad, M.; Zhang, S. Augmenting user identification with WiFi based gesture recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 134. [Google Scholar] [CrossRef]
- Bianchi, G.; Di Domenico, S.; De Sanctis, M.; Liberati, L.; Perrotta, V.; Cianca, E. Unveiling access point signal instability in WiFi-based passive sensing. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–1 August 2017; pp. 1–9. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Users | Gender | Height (cm) | Weight (kg) |
|---|---|---|---|
| 1 | Female | 155 | 45 |
| 2 | Female | 160 | 59 |
| 3 | Male | 164 | 56 |
| 4 | Male | 176 | 62 |
| 5 | Male | 181 | 75 |
| No. | Operation | Configuration |
|---|---|---|
| 1 | Input | 121 × 30 × 6 |
| 2 | Conv1 | Kernel = 3 × 3, Stride = [1, 1, 1, 1] |
| 3 | Activation | ReLU |
| 4 | Pooling | Max pooling, ksize = [1, 2, 2, 1], Strides = [1, 2, 2, 1] |
| 5 | Conv2 | Kernel = 5 × 5, Stride = [1, 1, 1, 1] |
| 6 | Activation | ReLU |
| 7 | Conv3 | Kernel = 5 × 5, Stride = [1, 1, 1, 1] |
| 8 | Activation | ReLU |
| 9 | Spatial Attention | Max pooling = [1, 2, 2, 1], Average pooling = [1, 2, 2, 1], Concatenate, Conv (Kernel = 5 × 5, Stride = [1, 1, 1, 1]), Sigmoid |
| 10 | Multiplication | Element-wise multiplication |
| 11 | LSTM | Input_size = 1500, Hidden_size = 128, Output_size = 128, Num_layers = 5 |
| 12 | Temporal Attention | Attention_vec = 1 × 128 |
| 13 | Multiplication | Dot product |
| 14 | Dense | Softmax |
| Method | CNN-LSTM | CNN with Attention | LSTM with Attention | CNN-LSTM with Attention |
|---|---|---|---|---|
| Top-1 accuracy | 0.9137 | 0.8779 | 0.8592 | 0.9772 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Jing, X. Device-Free Human Identification Using Behavior Signatures in WiFi Sensing. Sensors 2021, 21, 5921. https://doi.org/10.3390/s21175921
Zhang R, Jing X. Device-Free Human Identification Using Behavior Signatures in WiFi Sensing. Sensors. 2021; 21(17):5921. https://doi.org/10.3390/s21175921
Chicago/Turabian StyleZhang, Ronghui, and Xiaojun Jing. 2021. "Device-Free Human Identification Using Behavior Signatures in WiFi Sensing" Sensors 21, no. 17: 5921. https://doi.org/10.3390/s21175921