
A Systematic Review of Recommender Systems and Their Applications in Cybersecurity


Abstract
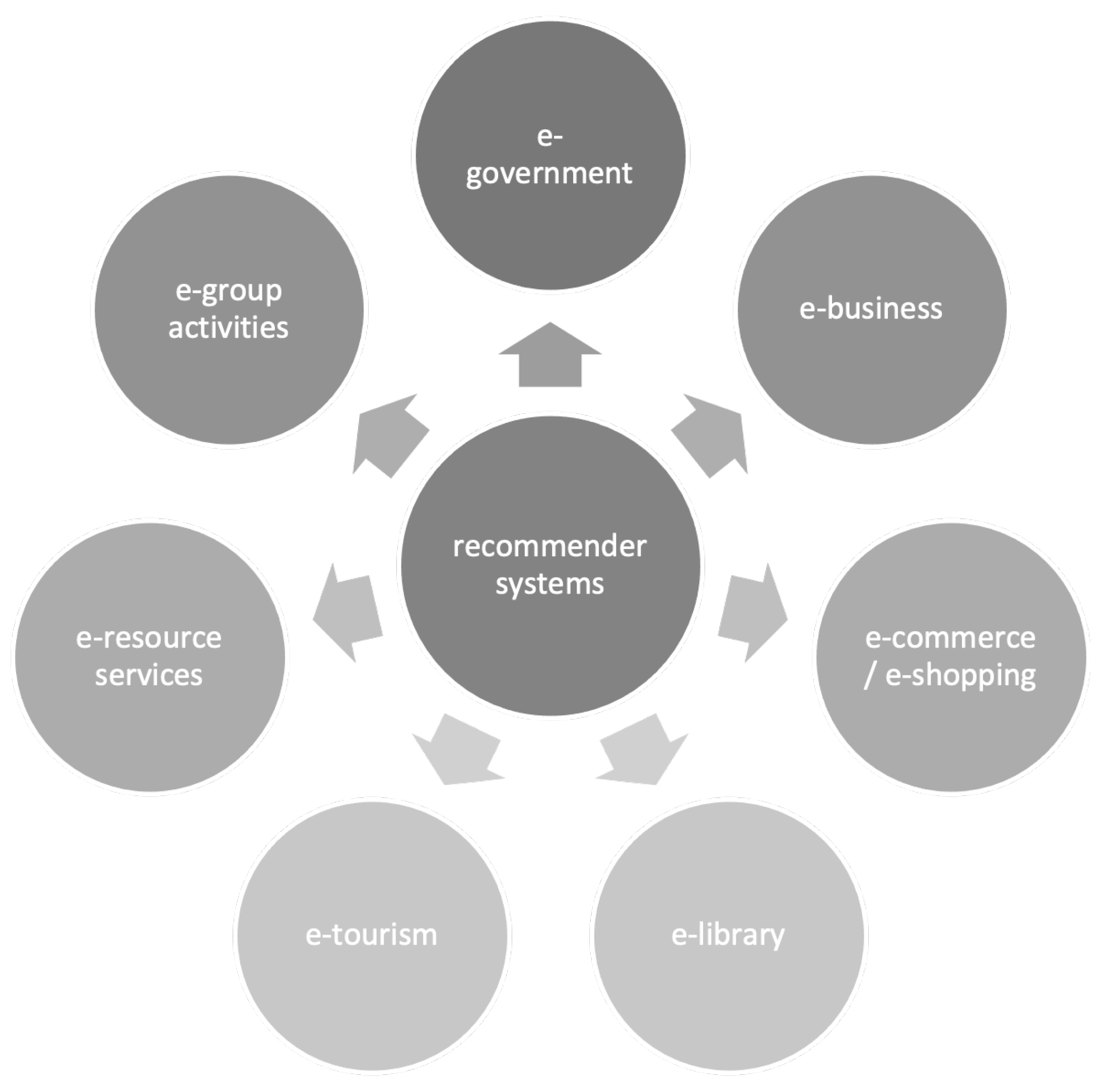
:1. Introduction
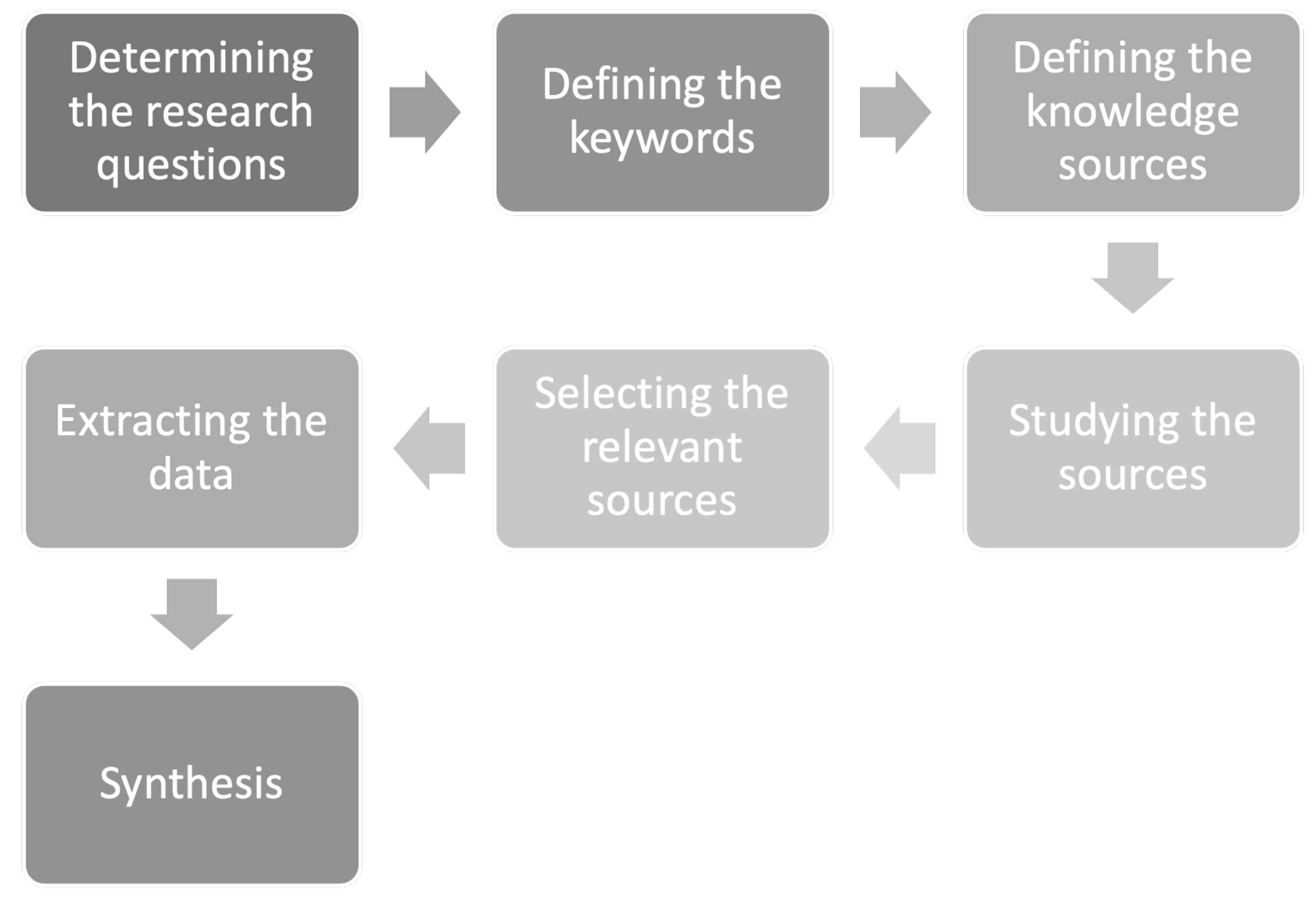
2. The Conduct of the Study
- RQ1: What is the current state of the art regarding the application of recommender systems for cybersecurity?
- RQ 2: What is the actual, up-to-date and the most comprehensive division of the recommender system types?
3. What Are Recommender Systems?
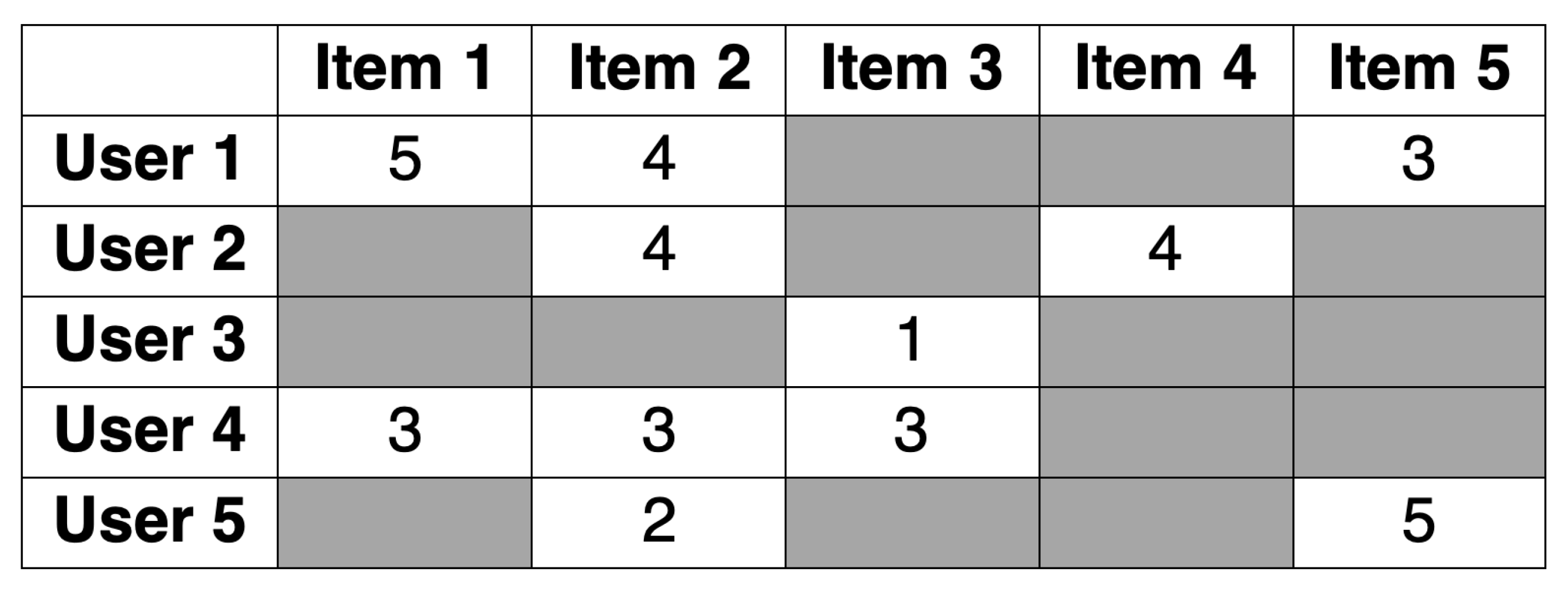
3.1. Basic Terms
- items
- users
- transactions.
3.2. Creating a Recommender System: The Principles
- “Users: who are the users of the system? What are their goals?
- Data: What are the characteristics of the data the recommendations are based on?
- Application: what is the application the recommender is part of? [34]”
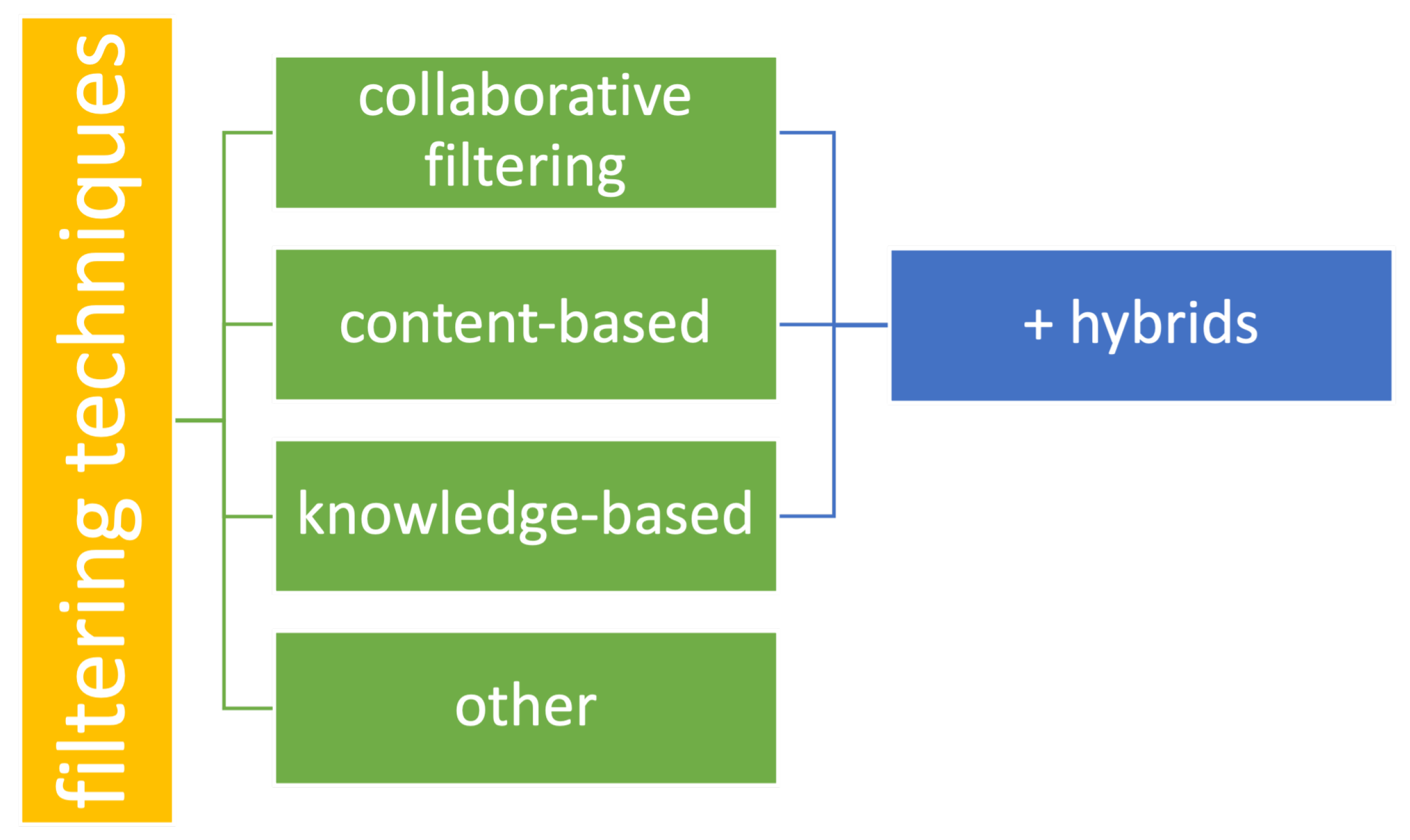
3.3. Filtering Techniques
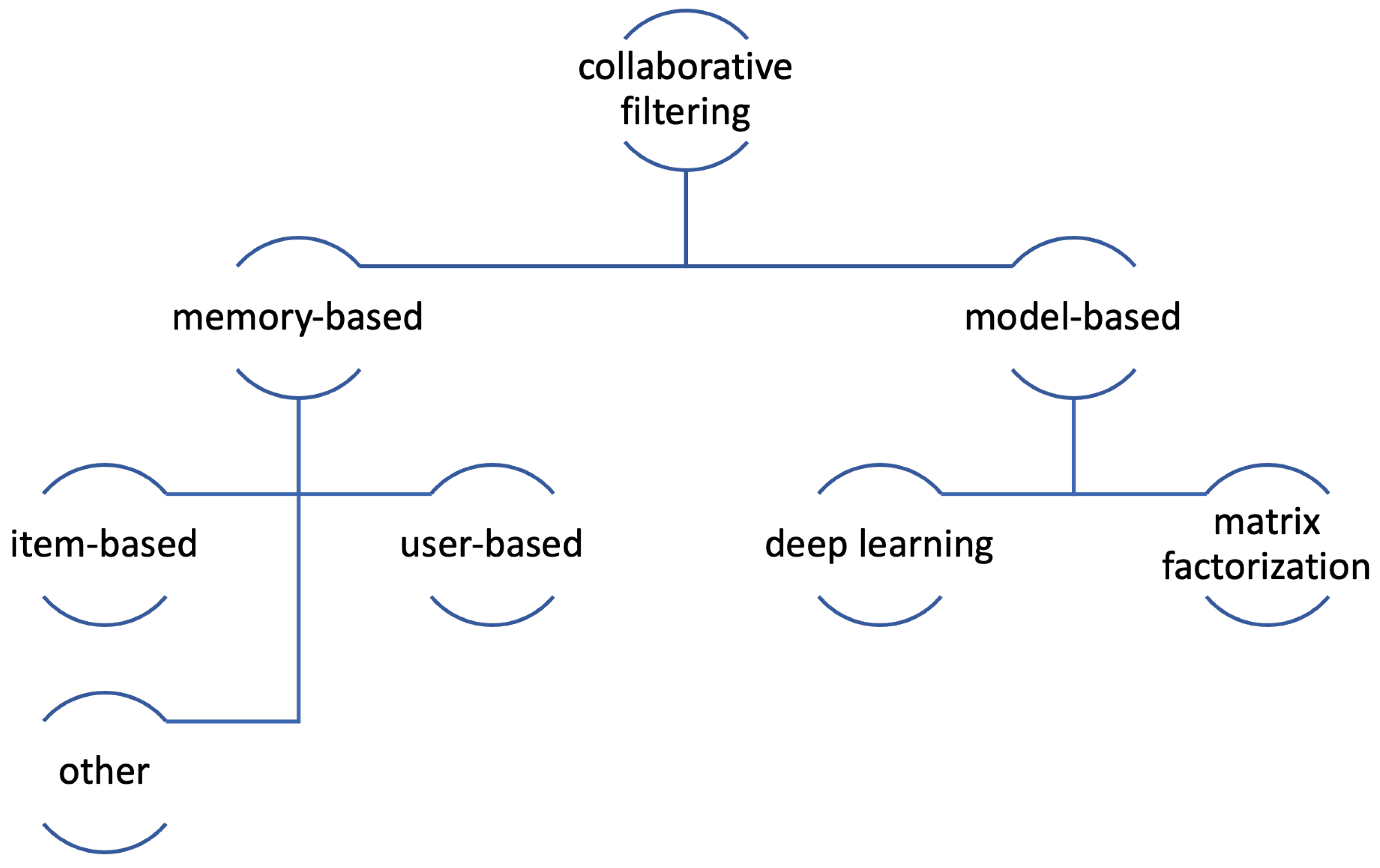
3.3.1. Collaborative Filtering (CF)
Memory-Based Collaborative Filtering
- User-based CFBy this approach, the users are matched by the recommender engine based on their taste in the product in question [43]. Simply put, in the user-based collaborative filtering, the user U and the set of users similar to them are selected. Then, the rating for an item is searched for; the user has not rated the item. By choosing N of the similar users who did rate the item, the rating is then calculated.
- Item-based CFThis type of recommendation is based on the concept that customers tend to choose items similar to the ones they expressed an interest in, and at the same time will not buy the items they are not interested in. In this kind of system, the user–item matrices are used as an input for finding the relations among various items. The analysis of how the items interact is the basis for generating a personalized recommendation.The item-based algorithms tend to perform better than the user-based ones, as the latter ones are known to have scalability issues, i.e., when the user–item matrix is of substantial size, the computational time becomes very considerable. As the relations between items are more stable than those among users, item-based algorithms usually need less computational time to make correct predictions, or the computations may be performed offline. Then, the rating may be calculated from the Pearson’s correlation coefficient and the N nearest neighbor.
- Other types of memory-based collaborative filteringVery seldom, the researchers classify other methods as memory-based collaborative filtering, such as Predictability Paths, cluster-based smoothing and trust inferences in [41], and so on.
Model-Based Collaborative Filtering
- Matrix factorizationIt consists of breaking a large matrix down into a product of smaller ones [16,41]. The algorithms employed for factorizing matrices are Singular Value Decomposition (SVD), Principal Component Analysis (PCA), Non-negative Matrix Factorization (NMF), and so on [41]. Using the algorithms, the features may be extracted for every product that has been rated. Then, a comparison is made between them and the items which do not have any ratings and finally, based on this, the rating is predicted [35,36].
- Clustering-based algorithmsUsually, by this type of algorithms, one means the k-Nearest Neighbors (kNN), a Machine Learning (ML) technique. The aim of this algorithm is to search for clusters of similar users, the similarity being based on the users’ past behavior (like their ratings, the items they had already bought, etc.). Although the user-based collaborative filtering is based on the same concept, with the kNN the similarities are found based on an unsupervised machine learning model. Additionally, the number of similar users is limited to k [42]. It is worth noting that some researchers argue this technique does not belong to the model-based recommenders, but rather, it should be classified as a memory-based one, as though it is a machine learning technique, it is of non-parametric nature [42].
3.3.2. Content-Based Filtering
3.3.3. Knowledge-Based Filtering
3.3.4. The Comparison of the Three Main Filtering Approaches
3.3.5. Hybrid Recommender Systems
3.3.6. Other Types of Recommender Systems
- Computational Intelligence-based Recommendation TechniquesSometimes called CIRS, the computational intelligence recommender systems are the ones which include Artificial Neural Networks (ANN), Bayesian techniques, clustering techniques, genetic algorithms, fuzzy set techniques, etc., in their recommendation models. Bayesian classifiers solve classification problems based on probabilistics. They often are part of model-based recommenders, or help create a model for the content-based recommenders. With a Bayesian network being used for recommendations, the nodes correspond to items, while the states correspond to all the vote values possible. Thus, each item in the network will have a set of parent items—they will be its best predictors [3].Artificial neural networks have also been used as part of recommendation engines. For example, ref. [79] have applied one in a personalized TV recommendation system. They trained an ANN of three layers with the back-propagation method. A hybrid movie recommender was presented by [80]. The trained ANN representing the preferences of individual users was responsible for content filtering.To make the computational cost of finding k-nearest neighbors lower, clustering may be applied. Clustering consists of assigning items to groups. This way, the items within groups are more similar than the ones in other groups. With recommender systems, this may result in, e.g., smoothing the unrated data for users, by predicting the unrated items from a group of related items. Additionally, with the assumption that the nearest neighbor is within the Top-N most similar clusters to the active user, there is only the need for selecting the nearest neighbors in the Top-N clusters. This results in greater scalability of the system [3,81]. Furthermore, the technique can help tackle the cold start issue, by grouping items [82].Genetic Algorithms (GA), i.e., stochastic search techniques, have mainly been applied in K-means clustering, for improved online shopping market segmentation, such as in [83]. Similarly, ref. [84] have used a GA method for obtaining optimal similarity function. Finally, several techniques based on the fuzzy set theory have been used to handle the non-stochastic uncertainty, e.g., the information being imprecise, or the classes of objects not being sharp enough [3].
- Social-network-based recommendationsThe rapid increase in the social networking tools has directly resulted in social network analysis becoming an important part of recommender systems. Recommender systems offer the possibility for the users to make social interactions among one another, such as comments, adding to friendlist, etc. Based on these interactions, recommendations can be made. The social network recommendations rely heavily on the concept of “trust”. In human interactions, a person’s decision (to buy something) is more likely to be influenced by friends’ opinions than by an advertisement. Trust, i.e., the level of how one user trusts others concerning a product, is helpful in making predictions where the data on similar neighbors would be too sparse otherwise. Indeed, a positive correlation between trust and user similarity has been found scientifically [85]. In addition, the authors of [3] discuss other social interactions and relations which are used for making recommendations, namely social bookmarks, physical context, social tag, “co-authorship” relations, “co-citations”, and more.
- Context-awareness-based recommendation methodsIn recommender systems, context is understood as any kind of information which may characterize a situation or an entity, such as a person, place or an object that is relevant to the user–item interaction [86]. Context may thus mean time or the company of other people. Applying context in recommendation process makes the results more personalized and appropriate. As [87] claim, the rating function is no longer two-dimensional, i.e., (R: User × Item → Rating); instead, it has become multi-dimensional (R: User × Item × Context → Rating).
- Group Recommender Systems (GRS; also called e-group activity recommendation systems)Group recommendations are a method of making group suggestions “when group members are unable to gather for face-to-face negotiation, or their preferences are not clears despite meeting each other [3]”. They are used for recommending films, music, websites, evens or travels. The process of clustering people into a group may follow several strategies, based on the research of decision-making or social choice theory, such as the theory of average, least misery, most pleasure, and so on [44], as well as the strategies of sum or approval voting.
- Demographic filteringSome researchers, such as [23,88], describe the demographic filtering as a separate filtering technique. By this method, the system gathers the information such as age, gender, education level, place of residence, as well as users’ opinions on items. Then, the similarities are found between the users’ ratings; finally, the data are filtered by users’ age or the area they live in. According to [18], these methods form similar correlations to the ones present in collaborative filtering, but unlike the collaborative and content-based techniques, they may not need a history of user ratings. However, they may raise some security issues, due to the nature of data they gather [23].
- Utility-based recommender systemsLastly, there are utility-based recommenders. In them, the utility of an item for a user is calculated, with gathered the users’ interest level in that attribute. As with the knowledge-based recommenders, the utility-based systems are not based on building long-term generalizations concerning the users. Rather, the recommendation is made based on the assessed match between the set of available options and the users’ needs. Specifically, the utility-based recommenders calculate the utility of each object to a user and then make recommendations based on that. The weight of the attribute may also be calculated by the system, lowering the load on users. To do so, the total utility must be determined. It is the sum of all the item values, i.e., the weight multiplied by the similarity function. The system returns a list of items ranked according to their similarity level to the user requirements [59]. There are various approaches to what makes utility and how to compute it, but the general idea is that the utility function should be based on item ratings that the users offered to describe their preferences [37]. One of the main advantages of this filtering technique is that the utility computation can be influenced by some non-product attributes (e.g., product availability). This way, for a user who needs to receive an item as soon as possible, such a system could enable trading off price against delivery schedule [18]. As mentioned before, utility-based recommender systems are either seen as separate method of filtering [18], or as being part of knowledge-based recommenders [19].
4. The Result of the Study—The State of the Art of Recommender Systems for Cybersecurity
5. Discussion of the Results
5.1. The Answers to the Research Questions
5.2. Threats to Validity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pawlicka, A.; Choraś, M.; Pawlicki, M. The stray sheep of cyberspace a.k.a. the actors who claim they break the law for the greater good. Pers. Ubiquitous Comput. 2021. [Google Scholar] [CrossRef]
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Zhong, C.; Yen, J.; Liu, P.; Erbacher, R.F. Learning From Experts Experience: Toward Automated Cyber Security Data Triage. IEEE Syst. J. 2019, 13, 603–614. [Google Scholar] [CrossRef]
- Vielberth, M.; Bhm, F.; Fichtinger, I.; Pernul, G. Security Operations Center: A Systematic Study and Open Challenges. IEEE Access 2020, 8, 227756–227779. [Google Scholar] [CrossRef]
- Kozik, R.; Choraś, M.; Flizikowski, A.; Theocharidou, M.; Rosato, V.; Rome, E. Advanced services for critical infrastructures protection. J. Ambient Intell. Humaniz. Comput. 2015, 6, 783–795. [Google Scholar] [CrossRef] [Green Version]
- Zhong, C.; Yen, J.; Liu, P.; Erbacher, R.F. Automate Cybersecurity Data Triage by Leveraging Human Analysts’ Cognitive Process. In Proceedings of the 2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016; pp. 357–363. [Google Scholar] [CrossRef]
- Sawyer, B.D.; Hancock, P.A. Hacking the Human: The Prevalence Paradox in Cybersecurity. Hum. Factors 2018, 60, 597–609. [Google Scholar] [CrossRef]
- Zhong, C.; Yen, J.; Liu, P. Can Cyber Operations Be Made Autonomous? An Answer from the Situational Awareness Viewpoint. In Adaptive Autonomous Secure Cyber Systems; Jajodia, S., Cybenko, G., Subrahmanian, V., Swarup, V., Wang, C., Wellman, M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 63–88. [Google Scholar] [CrossRef]
- Łaskawiec, S.; Choraś, M.; Kozik, R.; Varadarajan, V. Intelligent operator: Machine learning based decision support and explainer for human operators and service providers in the fog, cloud and edge networks. J. Inf. Secur. Appl. 2021, 56, 102685. [Google Scholar]
- Khan, S.W. Cyber security issues and challenges in E-commerce. In Proceedings of the 10th International Conference on Digital Strategies for Organizational Success, Gwalior, India, 5–7 January 2019. [Google Scholar]
- Selznick, L.F.; LaMacchia, C. Cybersecurity liability: How technically savvy can we expect small business owners to be. J. Bus. Tech. L. 2017, 13, 217. [Google Scholar]
- O’Rourke, M. The Small Business Cybersecurity Knowledge Gap. Risk Manag. 2019, 66, 36. [Google Scholar]
- Budgen, D.; Brereton, P.; Drummond, S.; Williams, N. Reporting systematic reviews: Some lessons from a tertiary study. Inf. Softw. Technol. 2018, 95, 62–74. [Google Scholar] [CrossRef] [Green Version]
- Isinkaye, F.; Folajimi, Y.; Ojokoh, B. Recommendation systems: Principles, methods and evaluation. Egypt. Inf. J. 2015, 16, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Liphoto, M.; Du, C.; Ngwira, S. A survey on recommender systems. In Proceedings of the 2016 International Conference on Advances in Computing and Communication Engineering (ICACCE), Durban, South Africa, 28–29 November 2016; pp. 276–280. [Google Scholar] [CrossRef]
- Deldjoo, Y.; Di Noia, T.; Merra, F.A. A survey on Adversarial Recommender Systems: From Attack/Defense strategies to Generative Adversarial Networks. ACM Comput. Surv. 2020, 54, 1–38. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model. User Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Lyons, K.B. A Recommender System in the Cyber Defense Domain. Ph.D. Thesis, Air University, Maxwell Air Force Base, AL, USA, 2014. [Google Scholar]
- Wohlin, C. Guidelines for snowballing in systematic literature studies and a replication in software engineering. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering, London, UK, 13–14 May 2014; pp. 1–10. [Google Scholar]
- Ramer, S.L. Site-ation pearl growing: Methods and librarianship history and theory. J. Med. Libr. Assoc. 2005, 93, 397. [Google Scholar] [PubMed]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, M.H.; Khafagy, M.H.; Ibrahim, M.H. Recommender Systems Challenges and Solutions Survey. In Proceedings of the 2019 International Conference on Innovative Trends in Computer Engineering (ITCE), Aswan, Egypt, 2–4 February 2019; pp. 149–155. [Google Scholar] [CrossRef]
- Bouraga, S.; Jureta, I.; Faulkner, S.; Herssens, C. Knowledge-Based Recommendation Systems. Int. J. Intell. Inf. Technol. 2014, 10, 1–19. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y.S.; Wang, B.; Zhang, L.; Kong, X. A Survey of Collaborative Filtering-Based Recommender Systems: From Traditional Methods to Hybrid Methods Based on Social Networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Nagarnaik, P.; Thomas, A. Survey on recommendation system methods. In Proceedings of the 2015 2nd International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 26–27 February 2015; pp. 1603–1608. [Google Scholar] [CrossRef]
- Gupta, K.D. A Survey on Recommender System. Int. J. Appl. Eng. Res. 2019, 14, 3274–3277. [Google Scholar]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A Survey on Knowledge Graph-Based Recommender Systems. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Monti, D.; Rizzo, G.; Morisio, M. A systematic literature review of multicriteria recommender systems. Artif. Intell. Rev. 2021, 54, 427–468. [Google Scholar] [CrossRef]
- Gomez-Uribe, C.A.; Hunt, N. The Netflix Recommender System. ACM Transact. Manag. Inf. Syst. 2016, 6, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Qin, S.; Menezes, R.; Silaghi, M. A Recommender System for Youtube Based on its Network of Reviewers. In Proceedings of the 2010 IEEE Second International Conference on Social Computing, Minneapolis, MN, USA, 20–22 August 2010; pp. 323–328. [Google Scholar] [CrossRef]
- Smith, B.; Linden, G. Two Decades of Recommender Systems at Amazon.com. IEEE Internet Comput. 2017, 21, 12–18. [Google Scholar] [CrossRef]
- Hong, S.-E.; Kim, H.-J. A comparative study of video recommender systems in big data era. In Proceedings of the 2016 Eighth International Conference on Ubiquitous and Future Networks (ICUFN), Vienna, Austria, 6–8 July 2016; pp. 125–127. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B.; Kantor, P.B. (Eds.) Recommender Systems Handbook; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Sula, E. ProtecDDoS: A Recommender System for Distributed Denial-of-Service Protection Services. Ph.D. Thesis, University of Zürich, Zürich, Switzerland, 2019. [Google Scholar]
- Wang, J.; Tang, Q. Recommender Systems and Their Security Concerns; University of Luxembourg: Luxembourg, 2015. [Google Scholar]
- Feng, J.; Fengs, X.; Zhang, N.; Peng, J. An improved collaborative filtering method based on similarity. PLoS ONE 2018, 13, e0204003. [Google Scholar] [CrossRef]
- Burke, R.; Felfernig, A.; Göker, M.H. Recommender Systems: An Overview. AI Mag. 2011, 32, 13–18. [Google Scholar] [CrossRef] [Green Version]
- Ajisaria, A. Build a Recommendation Engine with Collaborative Filtering. Available online: https://realpython.com/build-recommendation-engine-collaborative-filtering/ (accessed on 4 July 2021).
- Franco, M.F.; Rodrigues, B.; Stiller, B. On the Recommendation of Protection Services; Technical Report; Communication Systems Group CSG, Department of Informatics IfI, University of Zurich UZH: Zurich, Switzerland, 2019. [Google Scholar]
- Lousame, F.P.; Sánchez, E. A Taxonomy of Collaborative-Based Recommender Systems. In Web Personalization in Intelligent Environments; Springer: Berlin/Heidelberg, Germany, 2009; pp. 81–117. [Google Scholar] [CrossRef]
- Grover, P. Various Implementations of Collaborative Filtering. Towards Data Science. 2017. Available online: https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0 (accessed on 4 July 2021).
- Gai, P.J.; Klesse, A.K. Making Recommendations More Effective Through Framings: Impacts of User- Versus Item-Based Framings on Recommendation Click-Throughs. J. Mark. 2019, 83, 61–75. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Zeng, D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. 2004, 22, 116–142. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; de Vries, A.P.; Reinders, M.J.T. Unifying user-based and item-based collaborative filtering approaches by similarity fusion. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval-SIGIR’06; ACM Press: New York, NY, USA, 2006; p. 501. [Google Scholar] [CrossRef]
- Alabdulrahman, R.; Viktor, H. Catering for unique tastes: Targeting grey-sheep users recommender systems through one-class machine learning. Expert Syst. Appl. 2021, 166, 114061. [Google Scholar] [CrossRef]
- Ghazanfar, M.; Prugel-Bennett, A. Fulfilling the needs of gray-sheep users in recommender systems, a clustering solution. In Proceedings of the 2011 International Conference on Information Systems and Computational Intelligence, Harbin, China, 18–20 January 2011. [Google Scholar]
- Hallinan, B.; Striphas, T. Recommended for you: The Netflix Prize and the production of algorithmic culture. New Media Soc. 2016, 18, 117–137. [Google Scholar] [CrossRef] [Green Version]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. SoRec: Social recommendation using probabilistic matrix factorization. In Proceeding of the 17th ACM Conference on Information and Knowledge Mining-CIKM’08; ACM Press: New York, NY, USA, 2008; p. 931. [Google Scholar] [CrossRef]
- Khusro, S.; Ali, Z.; Ullah, I. Recommender Systems: Issues, Challenges, and Research Opportunities. In Information Science and Applications (ICISA); Springer: Singapore, 2016; pp. 1179–1189. [Google Scholar] [CrossRef]
- Jannach, D.; Zanker, M.; Felfernig, A.; Friedrich, G. Recommender Systems—An Introduction; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mac. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Singapore, 2006; Volume 4. [Google Scholar]
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the 14th International Conference on World Wide Web-WWW’05; ACM Press: New York, NY, USA, 2005; p. 22. [Google Scholar] [CrossRef] [Green Version]
- Burke, R. Knowledge-Based Recommender Systems. Encycl. Libr. Inf. Syst. 2000, 32, 175–186. [Google Scholar]
- Felfernig, A.; Mandl, M.; Schippel, S.; Schubert, M.; Teppan, E. Adaptive Utility-Based Recommendation. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 641–650. [Google Scholar] [CrossRef]
- McSherry, D. Similarity and Compromise. In Proceedings of the 5th International Conference on Case-Based Reasoning: Research and Development; ICCBR’03; Springer: Berlin/Heidelberg, Germany, 2003; pp. 291–305. [Google Scholar]
- Wu, J. Knowledge-Based Recommender Systems: An Overview. 2019. Available online: https://medium.com/@jwu2/knowledge-based-recommender-systems-an-overview-536b63721dba (accessed on 4 July 2021).
- Smyth, B. Case-Based Recommendation. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 342–376. [Google Scholar] [CrossRef] [Green Version]
- Bridge, D.; Goeker, M.H.; McGinty, L.; Smyth, B. Case-based recommender systems. Knowl. Eng. Rev. 2005, 20, 315–320. [Google Scholar] [CrossRef] [Green Version]
- Junker, U. QUICKXPLAIN: Preferred Explanations and Relaxations for over-Constrained Problems. In Proceedings of the 19th National Conference on Artifical Intelligence; AAAI’04; AAAI Press: Palo Alto, CA, USA, 2004; pp. 167–172. [Google Scholar]
- Makadia, M. Explained Working and Advantages of a Recommendation Engine. 2020. Available online: https://www.business2community.com/business-intelligence/explained-working-and-advantages-of-a-recommendation-engine-02344556 (accessed on 4 July 2021).
- Mustafa, N.; Ibrahim, A.O.; Ahmed, A.; Abdullah, A. Collaborative filtering: Techniques and applications. In Proceedings of the 2017 International Conference on Communication, Control, Computing and Electronics Engineering (ICCCCEE), Khartoum, Sudan, 16–18 January 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Esposte, A.d.M.D.; Campiolo, R.; Kon, F.; Batista, D. A Collaboration Model to Recommend Network Security Alerts Based on the Mixed Hybrid Approach. 2016. Available online: http://www.sbrc2016.ufba.br/downloads/SessoesTecnicas/152330.pdf (accessed on 4 July 2021).
- Göksedef, M.; Gündüz-Öüdücü, S. Combination of Web page recommender systems. Expert Syst. Appl. 2010, 37, 2911–2922. [Google Scholar] [CrossRef]
- Mobasher, B. Recommender systems. Kunstl. Intell. Spec. Issue Web Min. 2007, 3, 41–43. [Google Scholar]
- Agrawal, P.; Agnihotri, P.; Khan, I.A.; Tiwari, D. An Hybrid Approach for an Improved Recommendation System by Combining the Concepts of Fuzzy Clustering and Voting Theory Techniques. Recent Trends in Information Processing, Computing, Electrical and Electronics. 2017. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjg1pT33pTyAhUHAYgKHQyHDDkQFjAAegQIBRAD&url=http%3A%2F%2Fthegrenze.com%2Fpages%2Fservec.php%3Ffn%3D8.pdf%26name%3DAn%2520Hybrid%2520Approach%2520for%2520an%2520Improved%2520RecommendationSystem%2520by%2520Combining%2520the%2520Concepts%2520of%2520Fuzzy%2520Clusteringand%2520Voting%2520Theory%2520Techniques%26id%3D1452%26association%3DMcGraw-Hill%26conference%3DIPCEE%26confyear%3D2017&usg=AOvVaw0Tu1vEGwBB_SuOjgzzarJ9 (accessed on 4 July 2021).
- Tran, T.; Cohen, R. Hybrid Recommender Systems for Electronic Commerce. In Knowledge-Based Electronic Markets; Papers from the AAAI Workshop; AAAI Press: San Francisco, CA, USA, 2000; pp. 78–83. [Google Scholar]
- Phuong, N.D.; Thang, L.Q.; Phuong, T.M. A Graph-Based Method for Combining Collaborative and Content-Based Filtering. In Pacific Rim International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2008; pp. 859–869. [Google Scholar] [CrossRef]
- Lab, K. An Efficient Recommender System Based on Graph Database. 2016. Available online: https://www.kernix.com/article/an-efficient-recommender-system-based-on-graph-database/ (accessed on 4 July 2021).
- Dharmawan, I.N.P.W.; Sarno, R. Book recommendation using Neo4j graph database in BibTeX book metadata. In Proceedings of the 2017 3rd International Conference on Science in Information Technology (ICSITech), Bandung, Indonesia, 25–26 October 2017; pp. 47–52. [Google Scholar] [CrossRef]
- Huang, Z.; Chung, W.; Ong, T.H.; Chen, H. A graph-based recommender system for digital library. In Proceedings of the Second ACM/IEEE-CS Joint Conference on Digital Libraries-JCDL’02; ACM Press: New York, NY, USA, 2002; p. 65. [Google Scholar] [CrossRef] [Green Version]
- Shams, B.; Haratizadeh, S. Graph-based Collaborative Ranking. Expert Syst. Appl. 2017, 67, 59–70. [Google Scholar] [CrossRef] [Green Version]
- Stark, B.; Knahl, C.; Aydin, M.; Samarah, M.; Elish, K.O. BetterChoice: A migraine drug recommendation system based on Neo4J. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 8–11 September 2017; pp. 382–386. [Google Scholar] [CrossRef]
- Brams, A. Movie Recommendations Powered by Knowledge Graphs and Neo4j. 2020. Available online: https://towardsdatascience.com/movie-recommendations-powered-by-knowledge-graphs-and-neo4j-33603a212ad0 (accessed on 4 July 2021).
- Cimini, M. Graph-Based Real-Time Recommendation Systems. Quantyca. 2019. Available online: https://medium.com/quantyca/graph-based-real-time-recommendation-systems-8a6b3909b603 (accessed on 4 July 2021).
- Hsu, S.H.; Wen, M.H.; Lin, H.C.; Lee, C.C.; Lee, C.H. AIMED-A Personalized TV Recommendation System. In Interactive TV: A Shared Experience; Springer: Berlin/Heidelberg, Germany, 2007; pp. 166–174. [Google Scholar] [CrossRef]
- Christakou, C.; Vrettos, S.; Stafylopatis, A. A hybrid movie recommender system based on neural networks. Int. J. Artif. Intell. Tools 2007, 16, 771–792. [Google Scholar] [CrossRef]
- Xue, G.R.; Lin, C.; Yang, Q.; Xi, W.; Zeng, H.J.; Yu, Y.; Chen, Z. Scalable collaborative filtering using cluster-based smoothing. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval-SIGIR’05; ACM Press: New York, NY, USA, 2005; p. 114. [Google Scholar] [CrossRef]
- Shinde, S.K.; Kulkarni, U. Hybrid personalized recommender system using centering-bunching based clustering algorithm. Expert Syst. Appl. 2012, 39, 1381–1387. [Google Scholar] [CrossRef]
- Kim, K.; Ahn, H. A recommender system using GA K-means clustering in an online shopping market. Expert Syst. Appl. 2008, 34, 1200–1209. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Alcalá, J. Improving collaborative filtering recommender system results and performance using genetic algorithms. Knowl. Based Syst. 2011, 24, 1310–1316. [Google Scholar] [CrossRef]
- Ziegler, C.N.; Lausen, G. Analyzing Correlation between Trust and User Similarity in Online Communities. In Proceedings of the 2nd International Conference on Trust Management, Oxford, UK, 29 March–1 April 2004; pp. 251–265. [Google Scholar] [CrossRef] [Green Version]
- Dey, A.K.; Abowd, G.D.; Salber, D. A Conceptual Framework and a Toolkit for Supporting the Rapid Prototyping of Context-Aware Applications. Hum. Comput. Interact. 2001, 16, 97–166. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Jain, S.; Grover, A.; Thakur, P.S.; Choudhary, S.K. Trends, problems and solutions of recommender system. In Proceedings of the International Conference on Computing, Communication & Automation (ICCCA), Greater Noida, India, 15–16 May 2015. [Google Scholar]
- Polatidis, N.; Pimenidis, E.; Pavlidis, M.; Papastergiou, S.; Mouratidis, H. From product recommendation to cyber-attack prediction: Generating attack graphs and predicting future attacks. Evol. Syst. 2020, 11, 479–490. [Google Scholar] [CrossRef] [Green Version]
- Raulerson, E.L. Modeling Cyber Situational Awareness through Data Fusion. Ph.D. Thesis, Air University, Maxwell Air Force Base, AL, USA, 2013. [Google Scholar]
- Soldo, F.; Le, A.; Markopoulou, A. Predictive Blacklisting as an Implicit Recommendation System. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 15–19 March 2010; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Franco, M.F.; Rodrigues, B.; Stiller, B. MENTOR: The Design and Evaluation of a Protection Services Recommender System. In Proceedings of the 2019 15th International Conference on Network and Service Management (CNSM), Halifax, NS, Canada, 21–25 October 2019; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Casey, W.; Wright, E.; Morales, J.A.; Appel, M.; Gennari, J.; Mishra, B. Agent-based trace learning in a recommendation-verification system for cybersecurity. In Proceedings of the 2014 9th International Conference on Malicious and Unwanted Software: The Americas (MALWARE), Fajardo, PR, USA, 28–30 October 2014; pp. 135–143. [Google Scholar] [CrossRef]
- Du, M.; Jiang, J.; Jiang, Z.; Lu, Z.; Du, X. PRTIRG: A Knowledge Graph for People-Readable Threat Intelligence Recommendation. In Proceedings of the Knowledge Science, Engineering and Management, Athens, Greece, 28–30 August 2019; pp. 47–59. [Google Scholar] [CrossRef]
- Sayan, C.; Hariri, S.; Ball, G. Cyber Security Assistant: Design Overview. In Proceedings of the 2017 IEEE 2nd International Workshops on Foundations and Applications of Self* Systems (FAS*W), Tucson, AZ, USA, 18–22 September 2017; pp. 313–317. [Google Scholar] [CrossRef]
- Panda, M.; Patra, M.R.; Dehuri, S. Building Recommender Systems for Network Intrusion Detection Using Intelligent Decision Technologies. In Intelligent Techniques in Recommendation Systems: Contextual Advancements and New Methods; IGI Global: Hershey, PA, USA, 2013. [Google Scholar]
- Gadepally, V.N.; Hancock, B.J.; Greenfield, K.B.; Campbell, J.P.; Campbell, W.M.; Reuther, A.I. Recommender Systems for the Department of Defense and Intelligence Community. Linc. Lab. J. 2016, 22, 74–89. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IEEEXplore | SpringerLink | arXiv | ACM Digital Library | Science Direct | ||
|---|---|---|---|---|---|---|
| recommender system + cybersecurity | 20 | 296 | 11 | 549,218 | 1881 | |
| recommender system + threat intelligence | 15 | 1165 | 8 | 562,218 | 12,413 | |
| recommender system + attack mitigation | 3 | 235 | 10 | 552,639 | 19,935 | |
| total | 38 | 1696 | 29 | 1,664,075 | 34,229 | 1,700,067 |
| Useful in Recommending: | Advantages | Disadvantages | |
|---|---|---|---|
| Collaborative filtering |
|
| |
| Content-based |
|
|
|
| Knowledge-based |
|
|
| Hybridization Method | Description |
|---|---|
| Weighted | The scores/votes of all the available recommendation techniques are combined together to produce a single recommendation. |
| Switching | The system uses a criterion dependent on the situation to switch between recommendation techniques. |
| Mixed | Recommendations from more than one technique are presented at the same time. |
| Feature combination | Features from different recommendation data sources are thrown together into a single recommendation algorithm. |
| Cascade | One recommender produces a recommendation which is then refined by another technique. |
| Feature augmentation | Output (a rating/classification) from one recommender is incorporated into the processing of the next recommender. |
| Meta-level | The model generated by one recommendation technique is used as the input to another. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pawlicka, A.; Pawlicki, M.; Kozik, R.; Choraś, R.S. A Systematic Review of Recommender Systems and Their Applications in Cybersecurity. Sensors 2021, 21, 5248. https://doi.org/10.3390/s21155248
Pawlicka A, Pawlicki M, Kozik R, Choraś RS. A Systematic Review of Recommender Systems and Their Applications in Cybersecurity. Sensors. 2021; 21(15):5248. https://doi.org/10.3390/s21155248
Chicago/Turabian StylePawlicka, Aleksandra, Marek Pawlicki, Rafał Kozik, and Ryszard S. Choraś. 2021. "A Systematic Review of Recommender Systems and Their Applications in Cybersecurity" Sensors 21, no. 15: 5248. https://doi.org/10.3390/s21155248