
Classifying Ingestive Behavior of Dairy Cows via Automatic Sound Recognition


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Description
2.2. Statstical Analysis for Evaluating Effects of Forage on Acoustic Features
2.3. Overall Deep Learning Algorithm Workflow
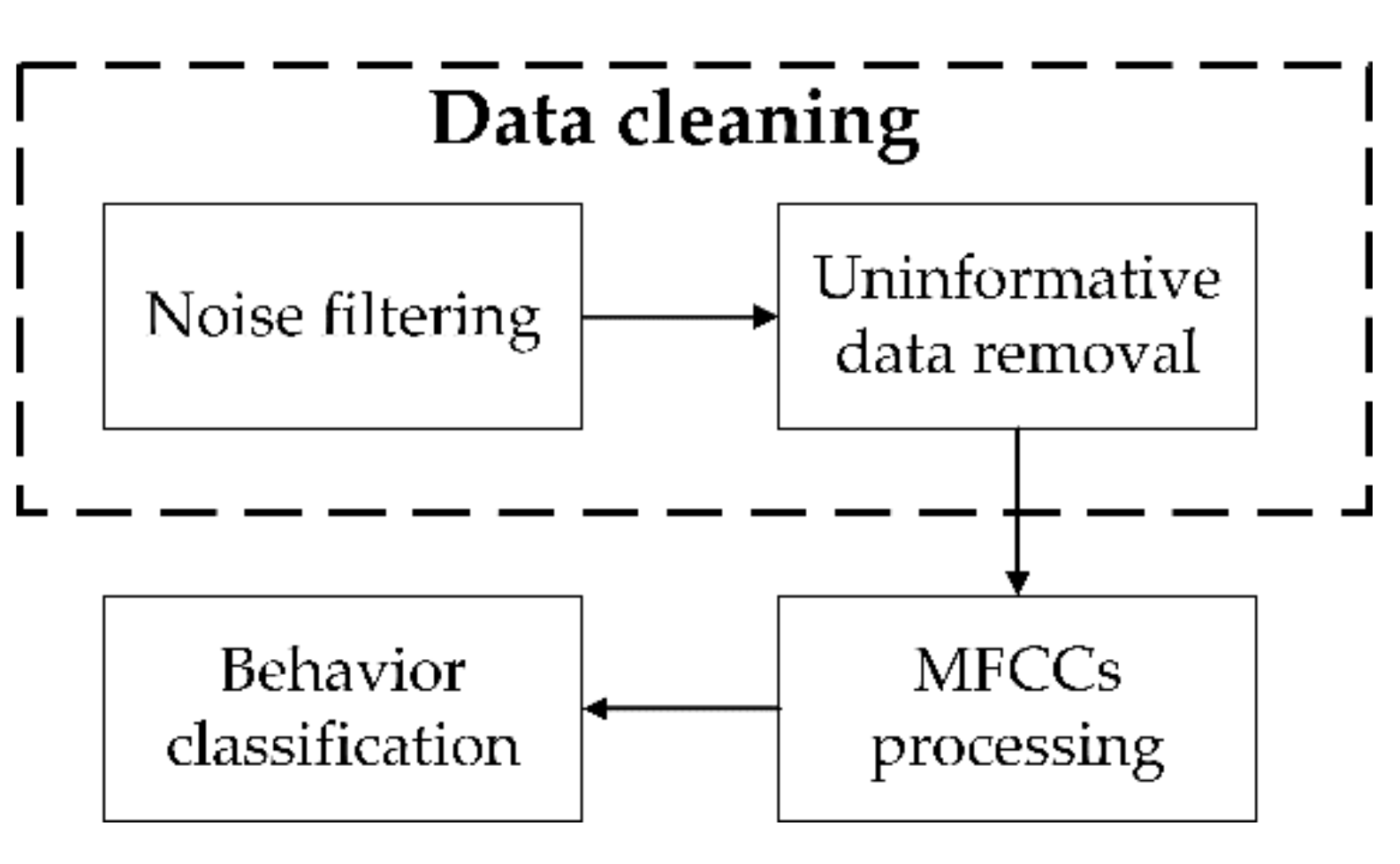
2.4. Data Cleaning
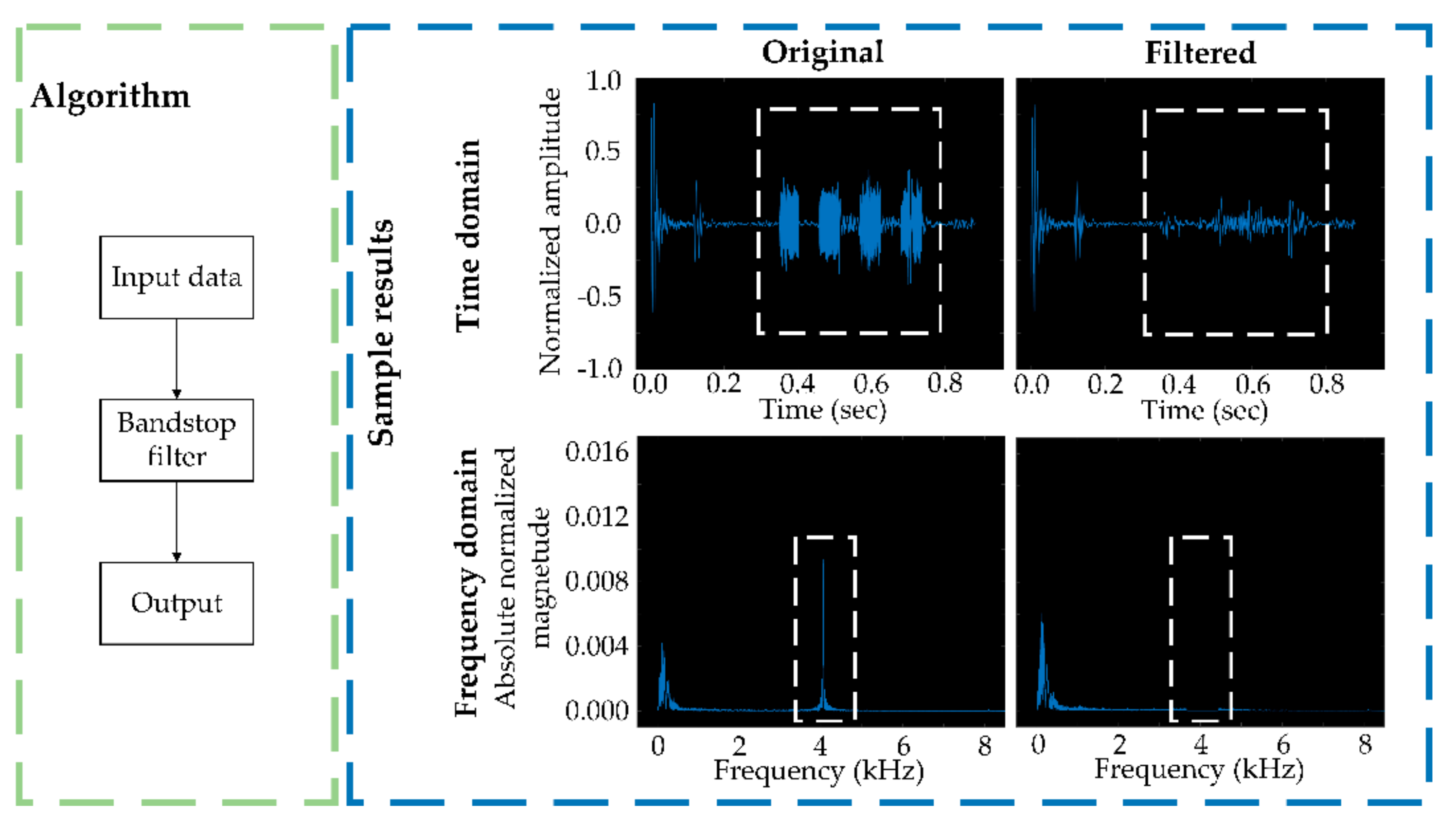
2.4.1. Noise Filtering
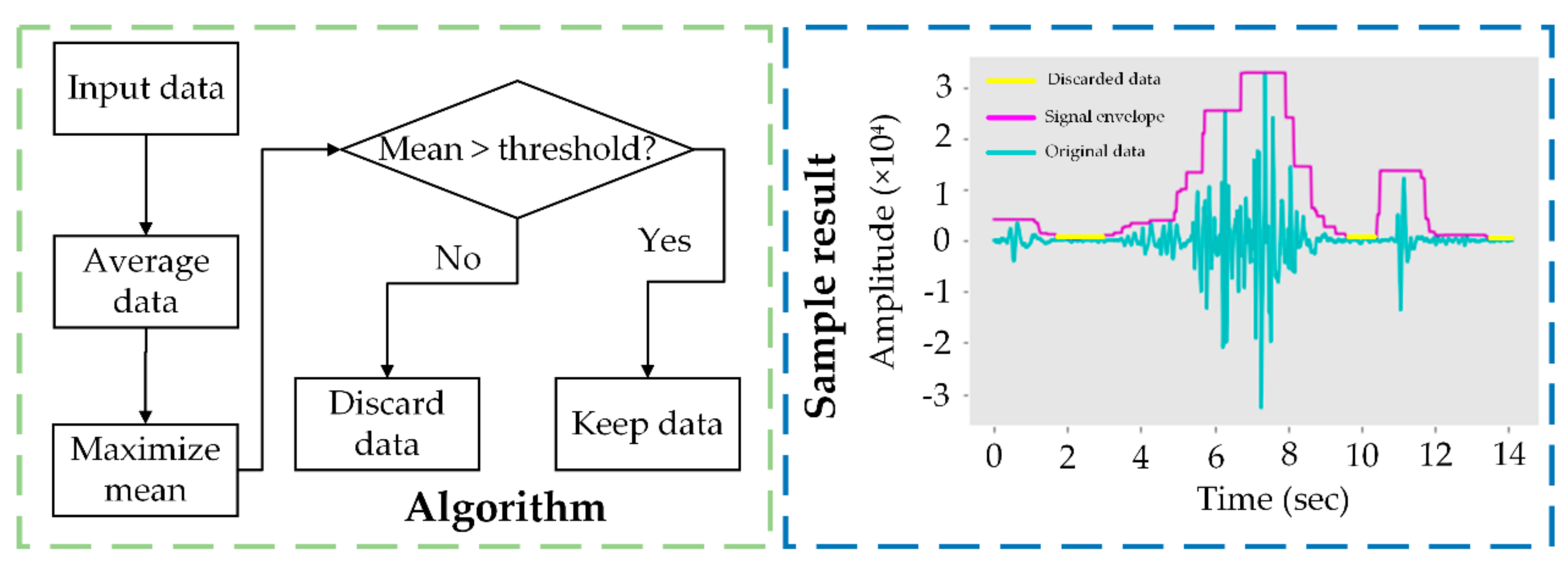
2.4.2. Uninformative Data Removal
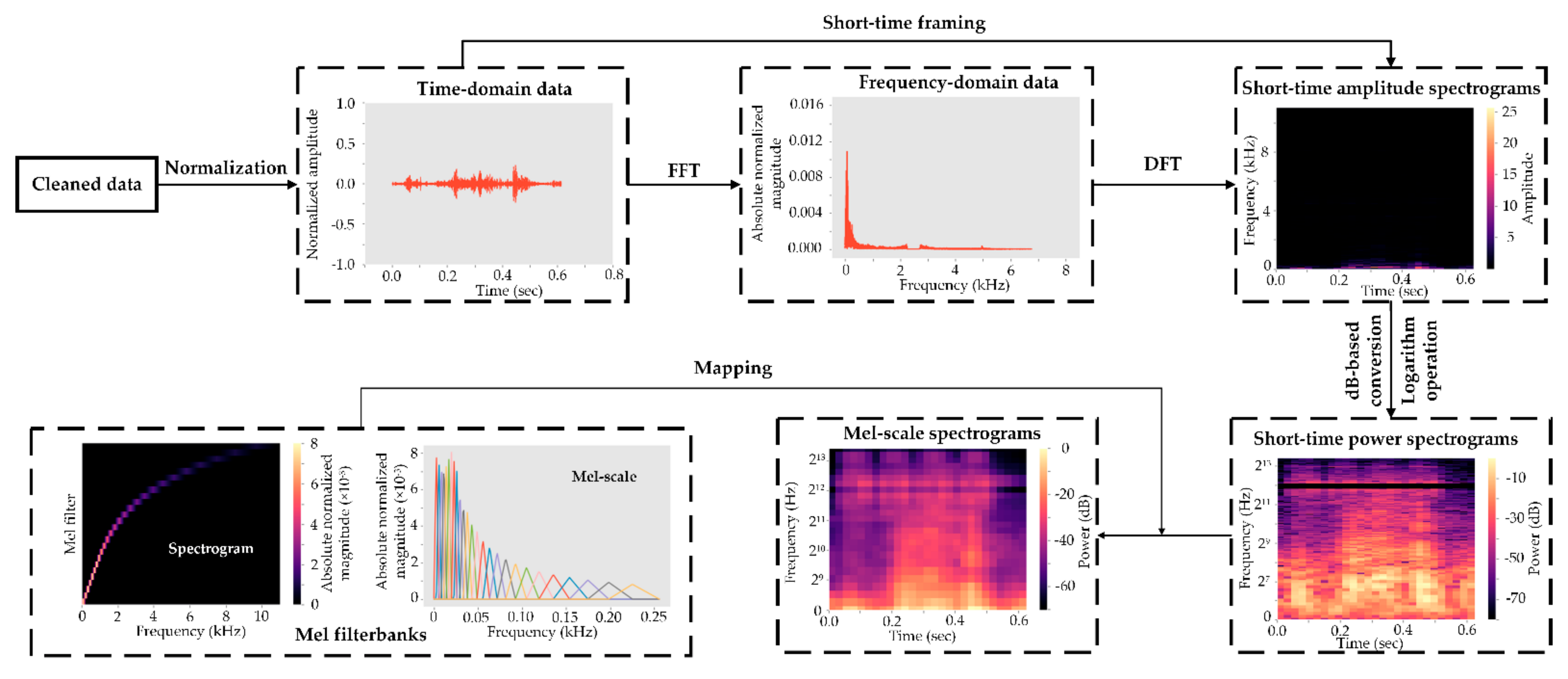
2.5. Mel-Frequency Cepstral Coefficients Processing
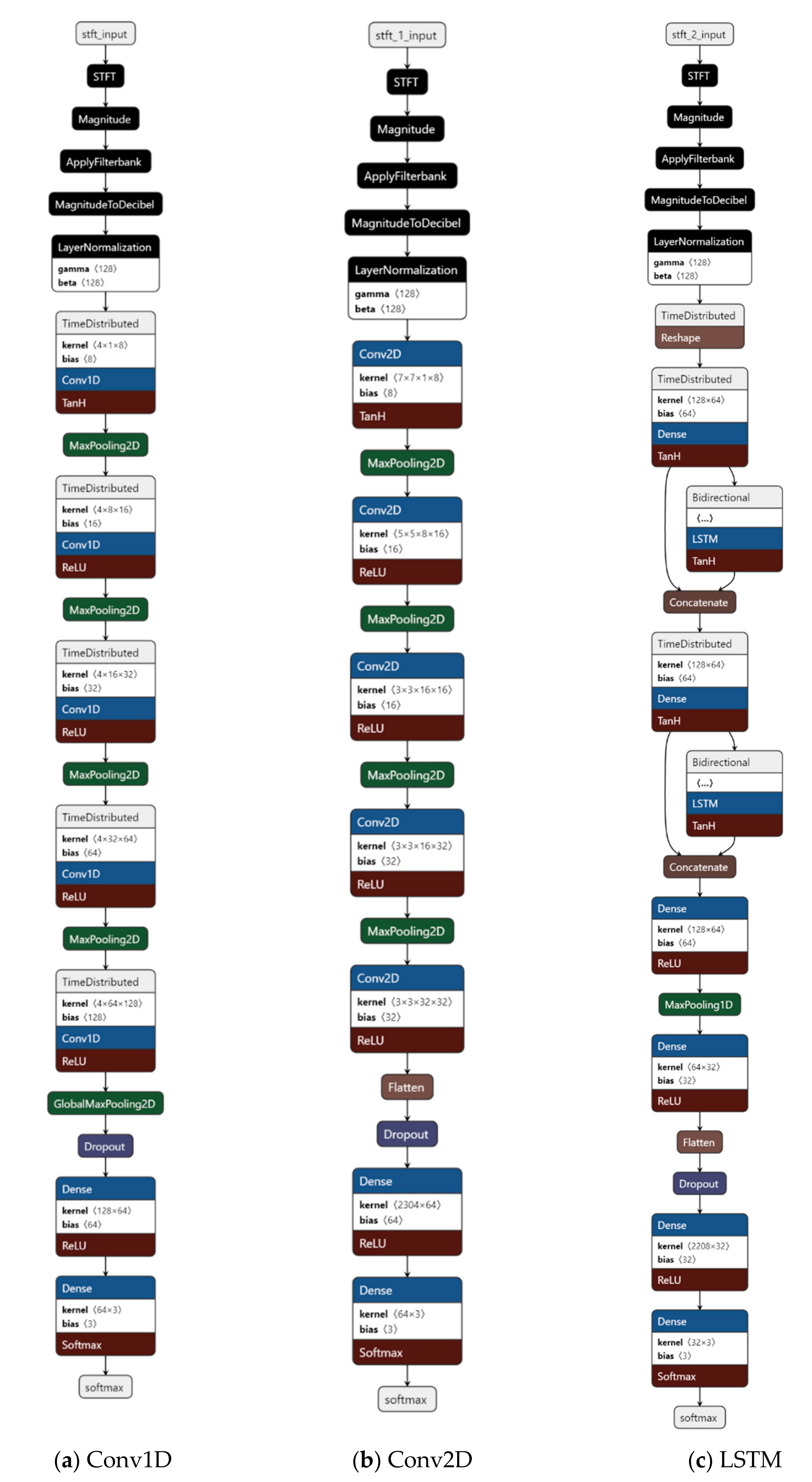
2.6. Architectures of Deep Learning Models
2.7. Optimization for Classifying the Ingestive Behaviors
2.8. Evaluation of Classification Performance under Various Forage Characteristics
2.9. Evaluation Metrics
3. Results
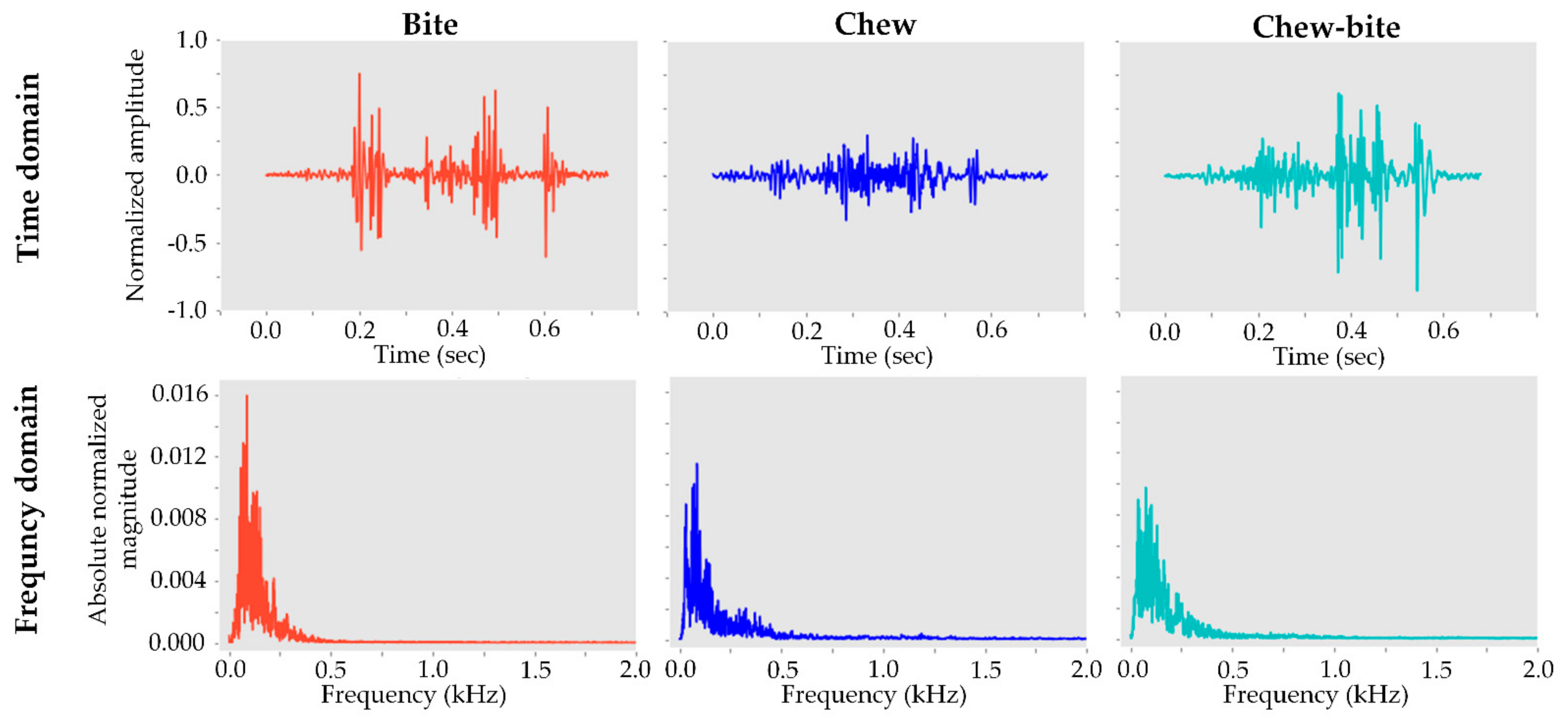
3.1. Ingestive Sound Characteristics under Various Forage Characteristics
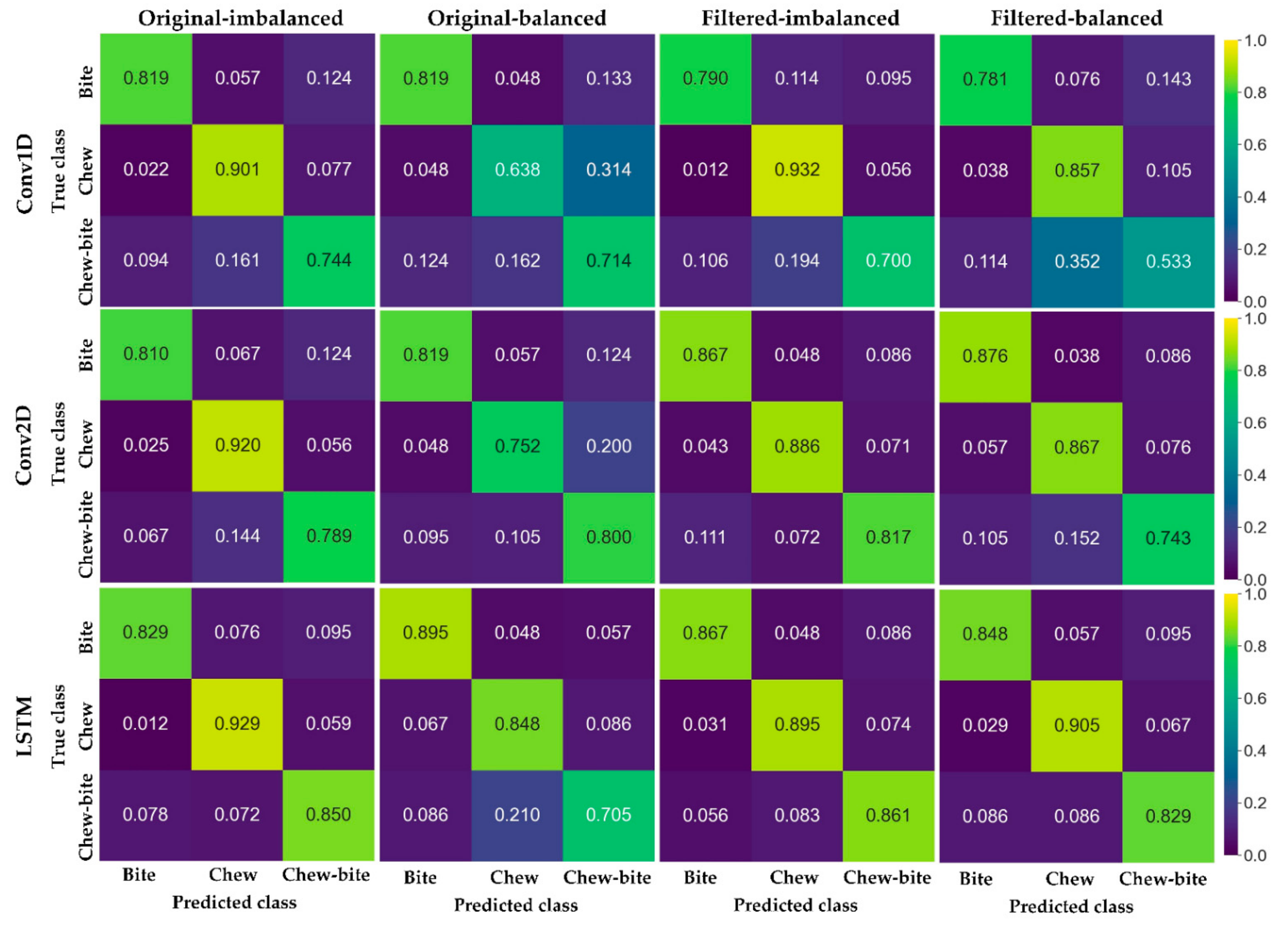
3.2. Performance for Classifying the Ingestive Behaviors
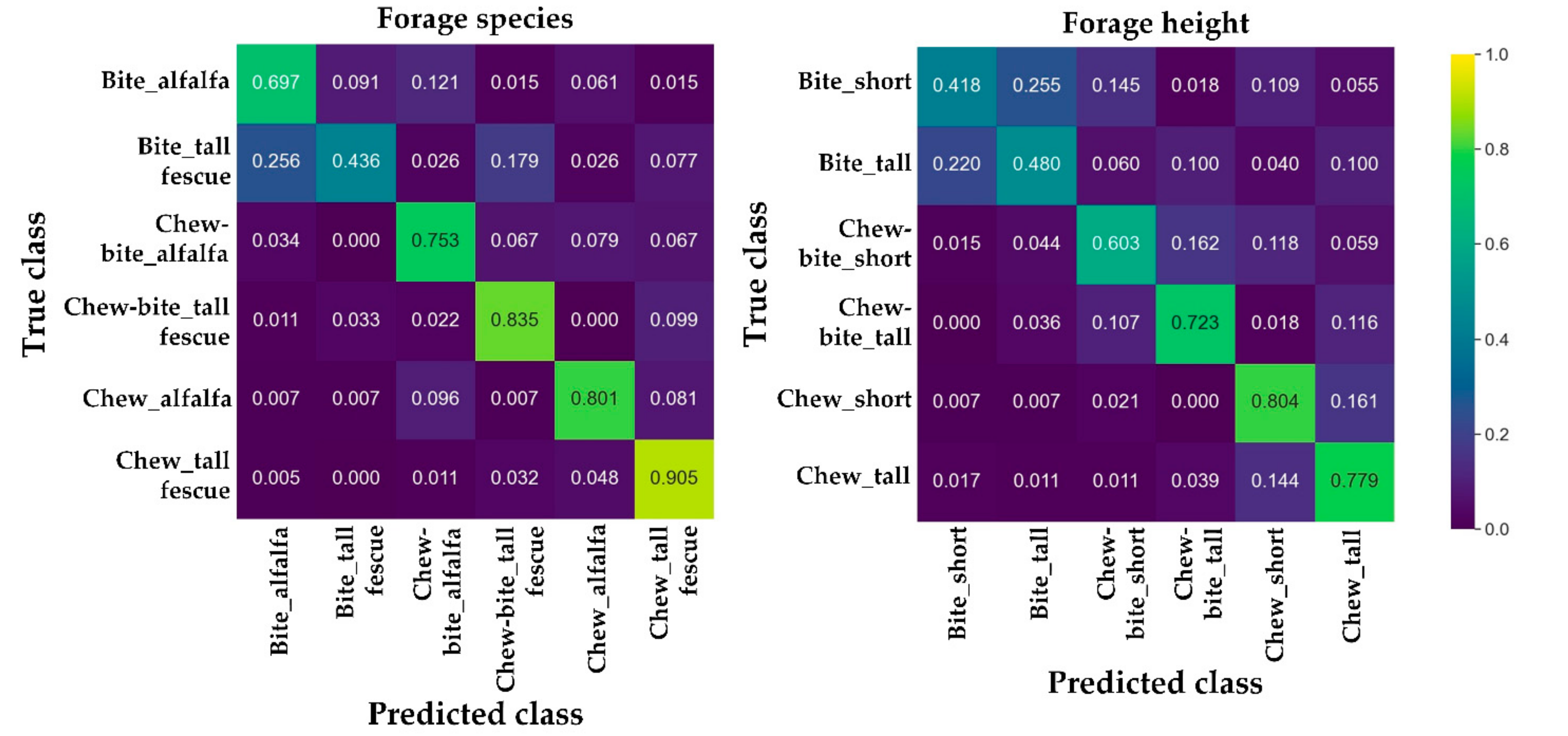
3.3. Performance for Classifying the Ingestive Behaviors under Various Forage Conditions
4. Discussion
4.1. Effects of Forage on Ingestive Sound Characteristics
4.2. Overall Classification Performance
4.3. Deep Learning Models
4.4. Other Factors Influencing Classification Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, G.; Huang, Y.; Chen, Z.; Chesser, G.D.; Purswell, J.L.; Linhoss, J.; Zhao, Y. Practices and applications of convolutional neural network-based computer vision systems in animal farming: A review. Sensors 2021, 21, 1492. [Google Scholar] [CrossRef] [PubMed]
- U.S. Department of Agriculture. Milk Production. 2021. Available online: https://www.nass.usda.gov/Publications/Todays_Reports/reports/mkpr0321.pdf (accessed on 21 May 2021).
- MacDonald, J.M.; Law, J.; Mosheim, R. Consolidation in U.S. Dairy Farming; U.S. Department of Agriculture: Washington, DC, USA, 2020. [Google Scholar]
- Perdue, S.; Hamer, H. Census of Agriculture; U.S. Department of Agriculture: Washington, DC, USA, 2019. [Google Scholar]
- Galli, J.R.; Cangiano, C.A.; Pece, M.A.; Larripa, M.J.; Milone, D.H.; Utsumi, S.A.; Laca, E.A. Monitoring and assessment of ingestive chewing sounds for prediction of herbage intake rate in grazing cattle. Animal 2018, 12, 973–982. [Google Scholar] [CrossRef] [Green Version]
- Chelotti, J.O.; Vanrell, S.R.; Galli, J.R.; Giovanini, L.L.; Rufiner, H.L. A pattern recognition approach for detecting and classifying jaw movements in grazing cattle. Comput. Electron. Agric. 2018, 145, 83–91. [Google Scholar] [CrossRef]
- Andriamandroso, A.; Bindelle, J.; Mercatoris, B.; Lebeau, F. A review on the use of sensors to monitor cattle jaw movements and behavior when grazing. Biotechnol. Agron. Société Environ. 2016, 20, 1–14. [Google Scholar] [CrossRef]
- Forbes, T.D.A. Researching the Plant-Animal Interface: The investigation of Ingestive Behavior in Grazing Animals. J. Anim. Sci. 1988, 66, 2369–2379. [Google Scholar] [CrossRef] [Green Version]
- Milone, D.H.; Rufiner, H.L.; Galli, J.R.; Laca, E.A.; Cangiano, C.A. Computational method for segmentation and classification of ingestive sounds in sheep. Comput. Electron. Agric. 2009, 65, 228–237. [Google Scholar] [CrossRef]
- Barrett, P.D.; Laidlaw, A.S.; Mayne, C.S.; Christie, H. Pattern of herbage intake rate and bite dimensions of rotationally grazed dairy cows as sward height declines. Grass Forage Sci. 2001, 56, 362–373. [Google Scholar] [CrossRef]
- Chelotti, J.O.; Vanrell, S.R.; Milone, D.H.; Utsumi, S.A.; Galli, J.R.; Rufiner, H.L.; Giovanini, L.L. A real-time algorithm for acoustic monitoring of ingestive behavior of grazing cattle. Comput. Electron. Agric. 2016, 127, 64–75. [Google Scholar] [CrossRef] [Green Version]
- Chelotti, J.O.; Vanrell, S.R.; Rau, L.S.M.; Galli, J.R.; Planisich, A.M.; Utsumi, S.A.; Milone, D.H.; Giovanini, L.L.; Rufiner, H.L. An online method for estimating grazing and rumination bouts using acoustic signals in grazing cattle. Comput. Electron. Agric. 2020, 173, 105443. [Google Scholar] [CrossRef]
- Clapham, W.M.; Fedders, J.M.; Beeman, K.; Neel, J.P. Acoustic monitoring system to quantify ingestive behavior of free-grazing cattle. Comput. Electron. Agric. 2011, 76, 96–104. [Google Scholar] [CrossRef]
- Milone, D.H.; Galli, J.R.; Cangiano, C.A.; Rufiner, H.L.; Laca, E.A. Automatic recognition of ingestive sounds of cattle based on hidden Markov models. Comput. Electron. Agric. 2012, 87, 51–55. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Vanrell, S.R.; Chelotti, J.O.; Bugnon, L.A.; Rufiner, H.L.; Milone, D.H.; Laca, E.A.; Galli, J.R. Audio recordings dataset of grazing jaw movements in dairy cattle. Data Brief 2020, 30, 105623. [Google Scholar] [CrossRef]
- Saxton, A. A Macro for Converting Mean Separation Output to Letter Groupings in Proc Mixed. In Proceedings of the 23rd SAS Users Group International, Nashville, TN, USA, 22–25 March 1998; SAS Institute Inc.: Nashville, TN, USA, 1998; pp. 1243–1246. [Google Scholar]
- Muda, L.; Begam, M.; Elamvazuthi, I. Voice recognition algorithms using mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques. J. Comput. 2010, 2, 138–143. [Google Scholar]
- Seth18. Audio Classification. 2020. Available online: https://github.com/seth814/Audio-Classification (accessed on 21 May 2021).
- Galli, J.R.; Cangiano, C.A.; Demment, M.W.; Laca, E.A. Acoustic monitoring of chewing and intake of fresh and dry forages in steers. Anim. Feed Sci. Technol. 2006, 128, 14–30. [Google Scholar] [CrossRef]
- Rook, A.J.; Huckle, C.A.; Penning, P.D. Effects of sward height and concentrate supplementation on the ingestive behaviour of spring-calving dairy cows grazing grass-clover swards. Appl. Anim. Behav. Sci. 1994, 40, 101–112. [Google Scholar] [CrossRef]
- Gibb, M.J.; Huckle, C.A.; Nuthall, R.; Rook, A.J. Effect of sward surface height on intake and grazing behaviour by lactating Holstein Friesian cows. Grass Forage Sci. 1997, 52, 309–321. [Google Scholar] [CrossRef]
- Ungar, E.D.; Rutter, S.M. Classifying cattle jaw movements: Comparing IGER Behaviour Recorder and acoustic techniques. Appl. Anim. Behav. Sci. 2006, 98, 11–27. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; IEEE Xplore: London, UK, 2014; pp. 372–378. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. ISPM 2012, 29, 82–97. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Caesars Palace: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/11231 (accessed on 21 May 2021).
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE conference on computer vision and pattern recognition, Hawaiʻi Convention Center, Honolulu, HI, USA, 21–26 July 2017; Hawaiʻi Convention Center: Honolulu, HI, USA, 2017; pp. 7310–7311. [Google Scholar]
- Jung, D.-H.; Kim, N.Y.; Moon, S.H.; Jhin, C.; Kim, H.-J.; Yang, J.-S.; Kim, H.S.; Lee, T.S.; Lee, J.Y.; Park, S.H. Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering. Animals 2021, 11, 357. [Google Scholar] [CrossRef] [PubMed]
- Rau, L.M.; Chelotti, J.O.; Vanrell, S.R.; Giovanini, L.L. Developments on real-time monitoring of grazing cattle feeding behavior using sound. In Proceedings of the 2020 IEEE International Conference on Industrial Technology (ICIT), Buenos Aires, Argentina, 26–28 February 2020; IEEE Xplore: Buenos Aires, Argentina, 2020; pp. 771–776. [Google Scholar] [CrossRef]
- Wu, A. A Chat with Andrew on MLOps: From Model-Centric to Data-Centric AI. 2021. Available online: https://www.youtube.com/watch?v=06-AZXmwHjo&t=1048s (accessed on 21 May 2021).
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Świnoujście, Poland, 9–12 May 2018; IEEE Xplore: Świnoujście, Poland, 2018; pp. 117–122. [Google Scholar] [CrossRef]
- Jan, B.; Farman, H.; Khan, M.; Imran, M.; Islam, I.U.; Ahmad, A.; Ali, S.; Jeon, G. Deep learning in big data Analytics: A comparative study. Comput. Electr. Eng. 2019, 75, 275–287. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forage Species | Forage Height | Number of Audio Files | Duration of Audio Files Used (s) | ||||
|---|---|---|---|---|---|---|---|
| Bites | Chews | Chew-Bites | Bites | Chews | Chew-Bites | ||
| Alfalfa | Short | 179 | 260 | 123 | 72.78 | 74.24 | 71.99 |
| Tall | 148 | 416 | 322 | 175.20 | 184.56 | 182.90 | |
| Tall fescue | Short | 94 | 454 | 217 | 143.87 | 144.79 | 141.59 |
| Tall | 100 | 487 | 238 | 155.19 | 149.78 | 150.48 | |
| Total | 521 | 1617 | 900 | 547.04 | 553.37 | 546.96 | |
| Factors | Bite | Chew | Chew-Bite | |||
|---|---|---|---|---|---|---|
| Amplitude | Duration (s) | Amplitude | Duration (s) | Amplitude | Duration (s) | |
| Forage species | ||||||
| Alfalfa | 0.355b | 0.176b | 0.105 | 0.110b | 0.389b | 0.262b |
| Tall fescue | 0.454a | 0.208a | 0.105 | 0.132a | 0.520a | 0.301a |
| SEM | 0.012 | 0.004 | 0.002 | 0.003 | 0.008 | 0.004 |
| Forage height | ||||||
| Tall | 0.403 | 0.206a | 0.117a | 0.138a | 0.464 | 0.297a |
| Short | 0.406 | 0.178b | 0.093b | 0.105b | 0.446 | 0.266b |
| SEM | 0.012 | 0.005 | 0.002 | 0.003 | 0.009 | 0.004 |
| Interaction | ||||||
| Alfalfa-Tall | 0.387b | 0.200a | 0.127a | 0.148a | 0.435c | 0.294a |
| Alfalfa-Short | 0.323c | 0.152b | 0.084c | 0.073c | 0.343d | 0.230b |
| Tall fescue-Tall | 0.420b | 0.212a | 0.107b | 0.128b | 0.492b | 0.301a |
| Tall fescue-Short | 0.488a | 0.205a | 0.102b | 0.137ab | 0.549a | 0.301a |
| SEM | 0.017 | 0.006 | 0.003 | 0.005 | 0.012 | 0.005 |
| p-Value | ||||||
| Forage species | <0.01 | <0.01 | 0.79 | <0.01 | <0.01 | <0.01 |
| Forage height | 0.89 | <0.01 | <0.01 | <0.01 | 0.16 | <0.01 |
| Forage species × Forage height | <0.01 | <0.01 | <0.01 | <0.01 | <0.01 | <0.01 |
| Model | Behavior | Original-Imbalanced | Original-Balanced | Filtered-Imbalanced | Filtered-Balanced | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | ||
| Conv1D | Bite | 0.782 | 0.819 | 0.800 | 0.827 | 0.819 | 0.823 | 0.783 | 0.790 | 0.786 | 0.837 | 0.781 | 0.808 |
| Chew | 0.893 | 0.901 | 0.897 | 0.753 | 0.638 | 0.691 | 0.865 | 0.932 | 0.897 | 0.667 | 0.857 | 0.750 | |
| Chew-bite | 0.779 | 0.744 | 0.761 | 0.615 | 0.714 | 0.661 | 0.818 | 0.700 | 0.754 | 0.683 | 0.533 | 0.599 | |
| Overall | 0.840 | 0.841 | 0.840 | 0.731 | 0.724 | 0.725 | 0.837 | 0.839 | 0.838 | 0.729 | 0.724 | 0.726 | |
| Conv2D | Bite | 0.810 | 0.810 | 0.810 | 0.851 | 0.819 | 0.835 | 0.728 | 0.867 | 0.791 | 0.844 | 0.876 | 0.860 |
| Chew | 0.900 | 0.920 | 0.910 | 0.823 | 0.752 | 0.786 | 0.941 | 0.886 | 0.913 | 0.820 | 0.867 | 0.843 | |
| Chew-bite | 0.821 | 0.789 | 0.805 | 0.712 | 0.800 | 0.753 | 0.821 | 0.817 | 0.819 | 0.821 | 0.743 | 0.780 | |
| Overall | 0.861 | 0.862 | 0.861 | 0.795 | 0.790 | 0.792 | 0.869 | 0.862 | 0.865 | 0.828 | 0.829 | 0.828 | |
| LSTM | Bite | 0.829 | 0.829 | 0.829 | 0.855 | 0.895 | 0.874 | 0.820 | 0.867 | 0.843 | 0.881 | 0.848 | 0.864 |
| Chew | 0.935 | 0.929 | 0.932 | 0.767 | 0.848 | 0.805 | 0.935 | 0.895 | 0.915 | 0.864 | 0.905 | 0.884 | |
| Chew-bite | 0.841 | 0.850 | 0.845 | 0.831 | 0.705 | 0.763 | 0.824 | 0.861 | 0.842 | 0.837 | 0.829 | 0.833 | |
| Overall | 0.889 | 0.888 | 0.888 | 0.818 | 0.816 | 0.817 | 0.883 | 0.880 | 0.881 | 0.860 | 0.860 | 0.860 | |
| Behavior | Forage Species | Precision | Recall | F1 Score | Behavior | Forage Height | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|---|---|---|
| Bite | Alfalfa | 0.742 | 0.697 | 0.719 | Bite | Short | 0.590 | 0.418 | 0.489 |
| Tall fescue | 0.630 | 0.436 | 0.515 | Tall | 0.500 | 0.480 | 0.490 | ||
| Chew | Alfalfa | 0.720 | 0.753 | 0.736 | Chew | Short | 0.594 | 0.603 | 0.599 |
| Tall fescue | 0.784 | 0.835 | 0.809 | Tall | 0.771 | 0.723 | 0.746 | ||
| Chew-bite | Alfalfa | 0.838 | 0.801 | 0.819 | Chew-bite | Short | 0.723 | 0.804 | 0.761 |
| Tall fescue | 0.851 | 0.905 | 0.877 | Tall | 0.746 | 0.779 | 0.762 | ||
| Overall | 0.793 | 0.797 | 0.795 | Overall | 0.694 | 0.698 | 0.696 | ||
| Positive Performance | Reference | ||
|---|---|---|---|
| Bites | Chews | Chew-Bites | |
| 0.728–0.895 | 0.638–0.941 | 0.533–0.861 | Current study |
| 0.620–0.900 | 0.880–0.990 | 0.430–0.940 | [11] |
| 0.760–0.900 | 0.880–0.990 | 0.610–0.940 | [14] |
| -- | 0.670–0.990 | -- | [23] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Xiong, Y.; Du, Q.; Shi, Z.; Gates, R.S. Classifying Ingestive Behavior of Dairy Cows via Automatic Sound Recognition. Sensors 2021, 21, 5231. https://doi.org/10.3390/s21155231
Li G, Xiong Y, Du Q, Shi Z, Gates RS. Classifying Ingestive Behavior of Dairy Cows via Automatic Sound Recognition. Sensors. 2021; 21(15):5231. https://doi.org/10.3390/s21155231
Chicago/Turabian StyleLi, Guoming, Yijie Xiong, Qian Du, Zhengxiang Shi, and Richard S. Gates. 2021. "Classifying Ingestive Behavior of Dairy Cows via Automatic Sound Recognition" Sensors 21, no. 15: 5231. https://doi.org/10.3390/s21155231