1. Introduction
Cancer detection plays a vital role in improving the survival rate and living quality of patients. Methods of detecting cancer mainly include clinical symptom analysis, pathological analysis of cancer tissue, radiology, biochemical examination and molecular diagnosis, etc. At present, using the approach to detect the gene expression profile data has emerged as a potential method for detecting cancer. For example, it is reported that the gene expression profile data of platelets can be used to detect cancer [
1,
2]. Platelets are the primary cell type of blood and known for their hemostatic property. Platelets play a crucial role in the process of tumor growth and metastasis, thereby altering their gene expression profile in cancer patients [
1,
2]. It shows that the platelets may be used as an all-in-one bio-source for the diagnosis of different types of cancer and precancerous tumors. Using the gene expression profile data of platelets to detect cancer has the unique advantage of micro-invasive molecular diagnostics, overcoming the difficulty of obtaining tissues [
3].
Cancers are complex diseases, and are related to many etiological factors, especially in the early stage of cancer development [
4,
5]. It is hard to observe the expression levels of several marker genes for effective cancer diagnosis. Therefore, classification methods via machine learning algorithms are used to detect cancer with the gene expression profile data [
6,
7]. However, the gene expression profile data encompasses the expression levels of many genes assayed in relatively few samples. This is also called the “large
, small
” problem [
8,
9,
10,
11], which has been a difficulty in the field of machine learning. For the expression profile data with the “large
, small
” problem, feature selection has a direct effect on the generalization and the training efficiency of the classifier. The conventional methods of feature selection, such as Relieff and support vector machine recursive feature elimination (SVM-RFE), apply either single-variable ranking or recursive variable selection to reduce the number of features that are finally substituted into the classifier [
12,
13,
14,
15,
16,
17,
18,
19]. As a regularized regression method with automatic feature selection, the elastic net [
20,
21] naturally mitigates the “large
p, small
n” problem. Besides, the gene expression profile data is collinear as multiple genes tend to function together, e.g., in the shared biological pathways, and thus the correlations in expression level among those genes can be high. As for collinear data, the elastic net is able to select groups of features, rather than individual features, which are highly correlated.
In the field of machine learning, researches on the feature selection method for the multi-classification problem is mostly based on global features. It is actually the same case for cancer detection with gene expression profile data. In addition to the global feature selection method, there is another way to select features for the multi-classification problem, which is the class-specific feature selection method. There are few studies investigating on solving multi-class classification problems from the angle of the class-specific feature selection method. The class-specific feature selection method is related to the one-vs-all (OVA) strategy [
22], which is commonly used in the multi-class classification problem. With the OVA strategy, the multi-class classification problem is decomposed into multiple binary classification problems, whose features can be optimized individually, and the selected features are called the class-specific features. Therefore, the class-specific features for these obtained binary classification problems are different, and increases the optimization space of the classification algorithm relative to the one based on the global features. Besides, the multi-class classification algorithm proposed on the basis of class-specific features is more complex than that based on the global features, and that how to fuse the outputs of the binary classifiers based on the class-specific features to get the final classification result of the initial multi-classification problem is an ongoing concern.
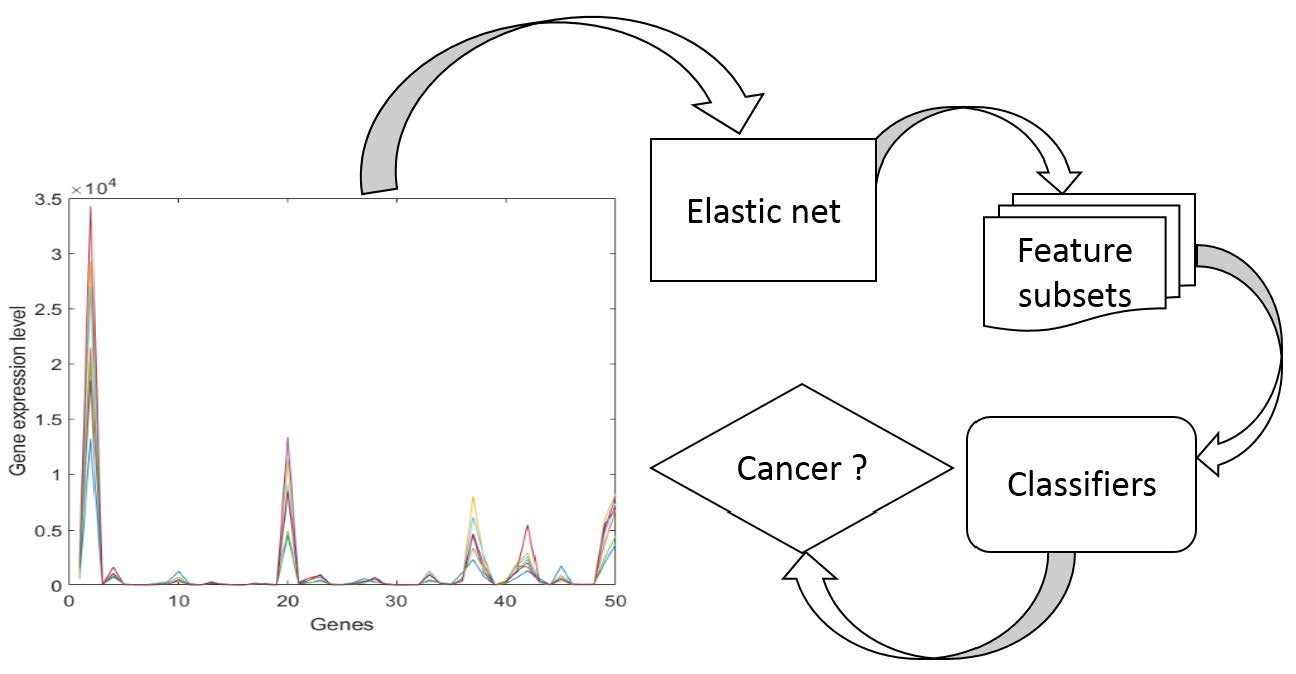
In this study, it was focused on the problem of how to use the class-specific feature selection method to enhance the performance of the classification algorithm in cancer detection with gene expression profile data. In this work, it was presented a new multi-class classification algorithm, which integrates the elastic net and probabilistic support vector machine. The OVA strategy was used to decompose the multi-class classification problem of cancer detection with gene expression profile data into multiple binary classification problems. The elastic net was conducted to select class-specific features for the obtained binary classification problems, on consideration of the characteristics of the elastic net and gene expression profile data. Besides, the probabilistic support vector machine was employed to construct the binary classifiers with the selected class-specific features. The probabilistic support vector machine inherits advantages of support vector machine (SVM), such as excellent generalization ability for the problem with nonlinear, small sample and high dimension. The probabilistic support vector machine converts the decision output of SVM into the form of probability, which makes the outputs of the binary classifiers based on the class-specific features comparable. The simulation data and gene expression profile data were obtained to verify the effectiveness of the proposed method and the results were compared with the conventional methods, such as SVM classifier combined with global feature selection methods, including Relieff and SVM-RFE [
23,
24,
25].
Statement of Societal Impact
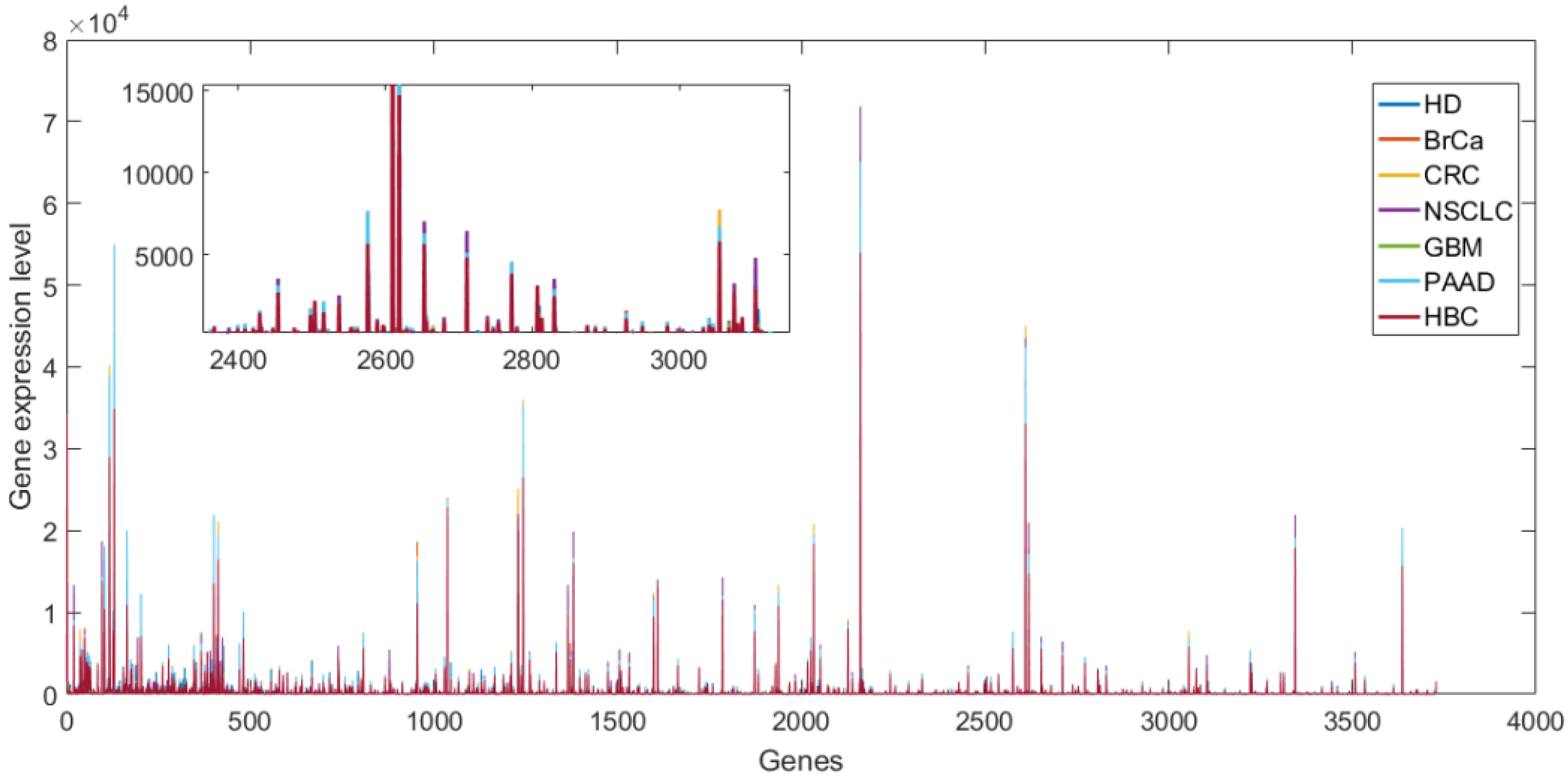
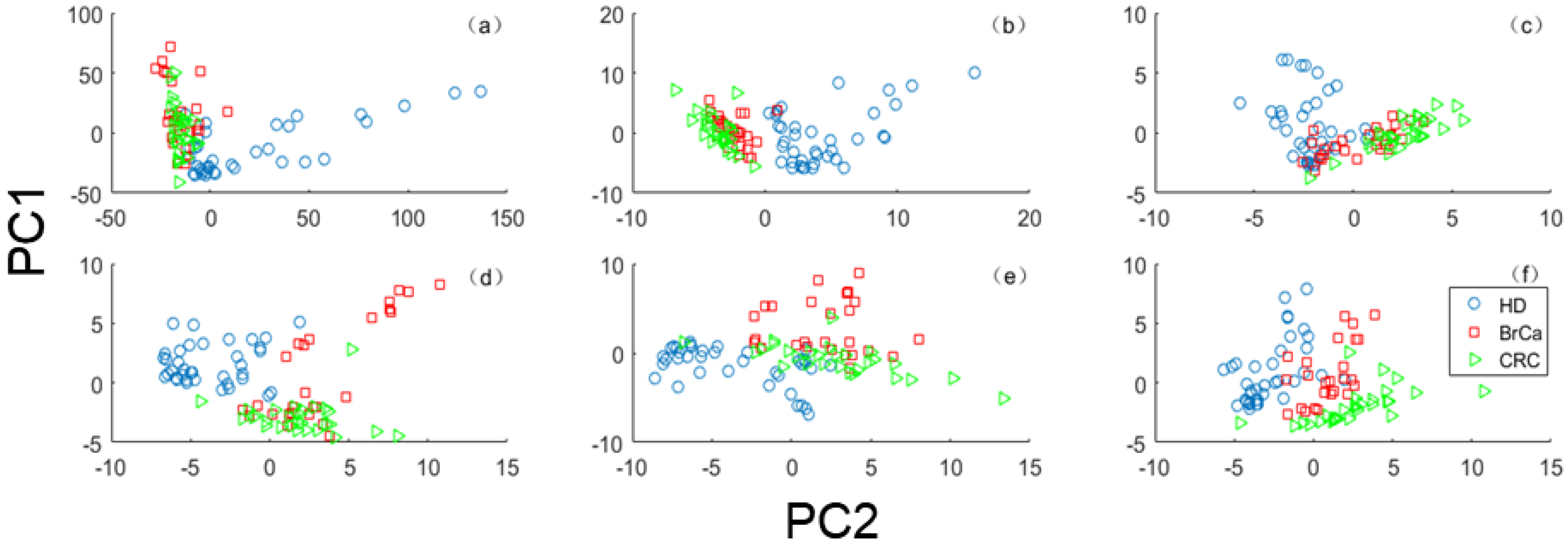
The blood-based liquid biopsies belong to a noninvasive cancer detection technology receiving increasing attention nowadays. The blood plate is an excellent biomarker among various biomarker sources for blood-based liquid biopsies. The mRNA profiles of tumor-educated blood plates have been used to train classifiers to detect cancers. This paper proposed a new idea that embedding elastic net in classifiers for solving the problem of detecting cancer using tumor-educated platelets dataset. We adopt classifiers of SVM and probabilistic SVM to implement this idea, named as ESVM and EPSVM respectively.
The proposed classifiers are applied to detection cancer with the transcriptomic data derived from tumor-educated platelets from individuals. The experiment results show that the proposed methods have the advantage of automatically selecting the feature subsets to improve the generalization ability of classifiers comparing to the conventional multi-classification methods.
The rest of the context is organized as follows: the related theories are described in
Section 2. Original contributions are introduced in
Section 3. The experimental procedures are presented in
Section 4.
Section 5 covers the results and discussion, and
Section 6 gives the conclusion.
3. The Proposed Method of Embedding Elastic Net in PSVM
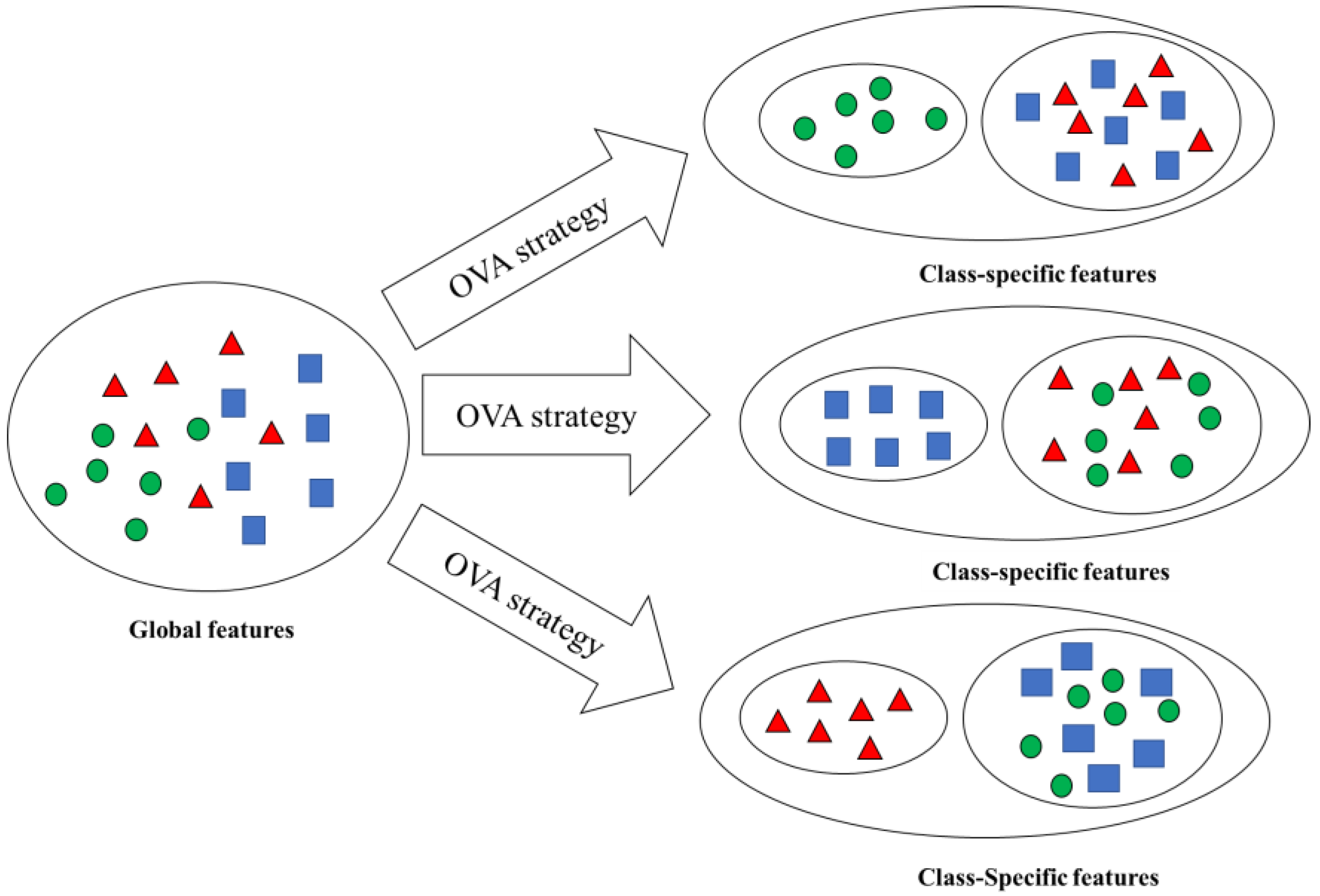
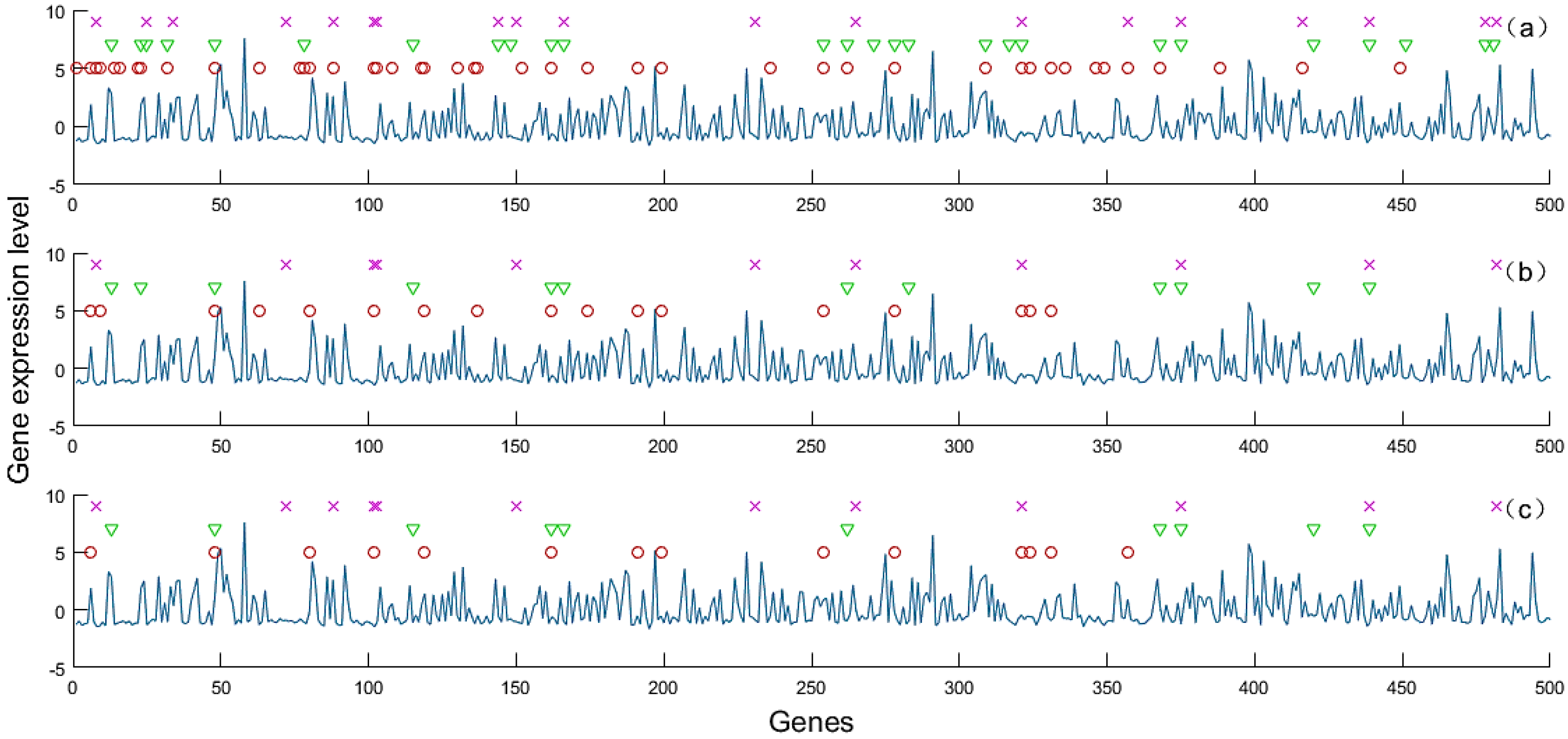
The multi-class classification problems can be decomposed into a series of binary classification problems by OVA strategy, where one class is treated as the positive class and the rest classes are treated as the negative class. These binary classification problems are solved with global features in general. However, for a special positive class, the global features may not be the best class-specific features. If the class-specific features of positive classes are similar, then using the global features are suitable for these binary classification problems. However, if the class-specific features of positive classes are very different from one another, then using class-specific features to solve these binary classification problems will achieve better results than using global features. The idea of solving the multi-class classification problems was demonstrated by using class-specific features by the OVA strategy in
Figure 1.
As shown in
Figure 1, the global features may not be the optimal features for the multi-class classification problem, and using the class-specific features of each binary classification problem obtained by the decomposition strategy would be easier to distinguish the positive class from the negative class. Therefore, if the effects of the binary classifiers can be improved by the class-specific features, then the classification result of the multi-class classification problem can be improved as well.
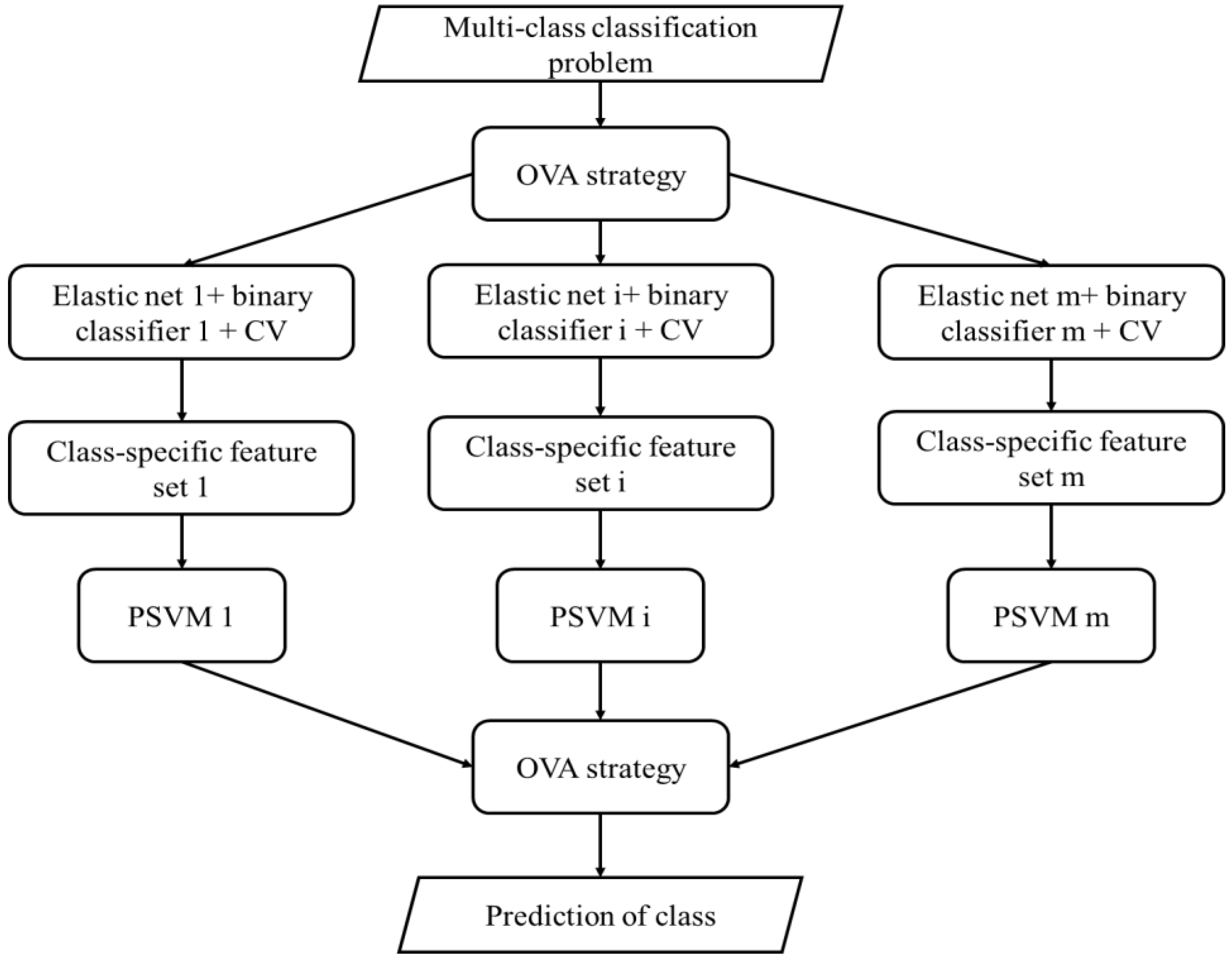
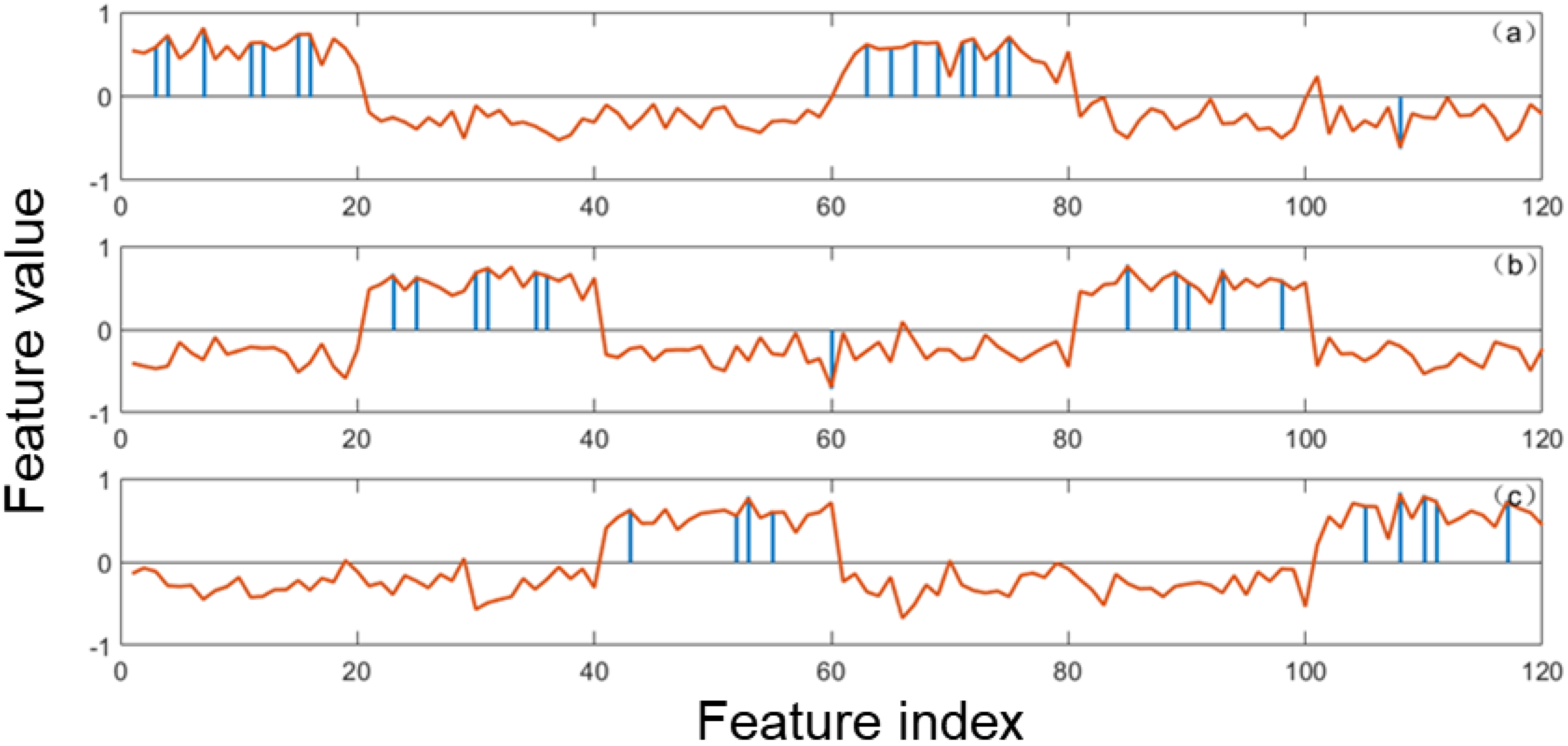
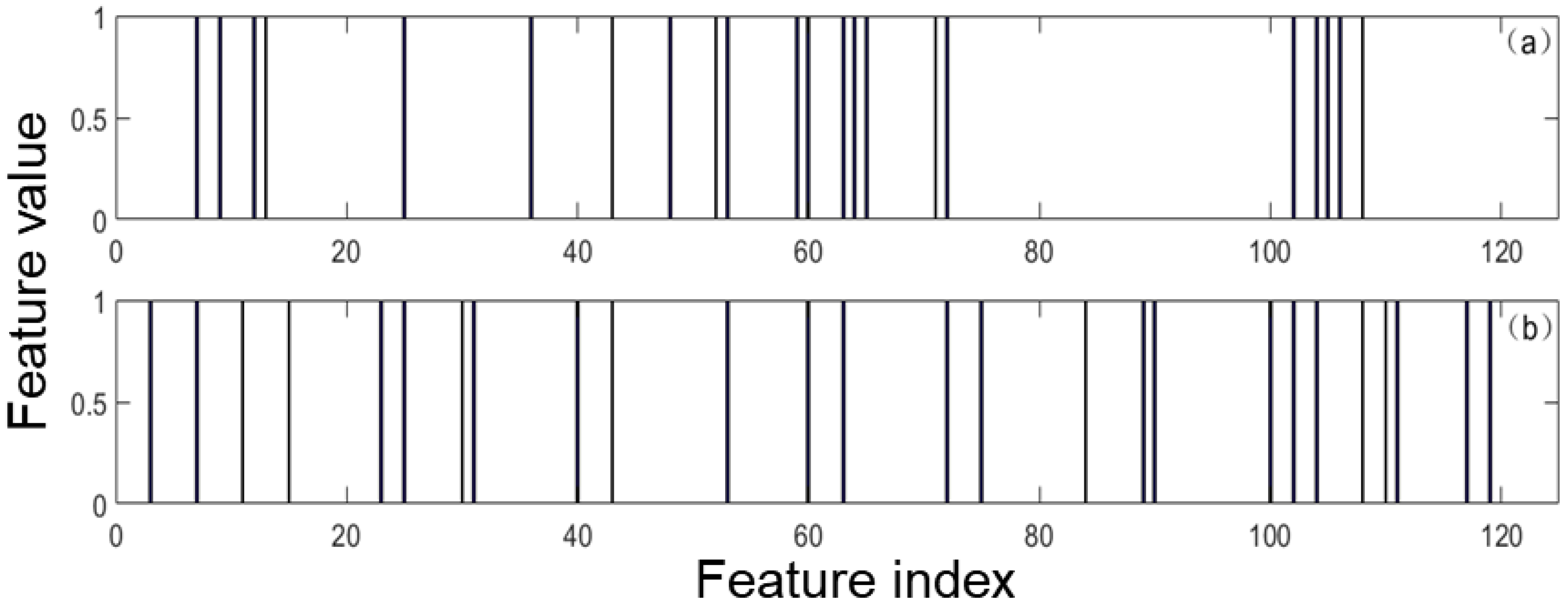
Using gene expression profile data for detecting cancers is a kind of multi-class classification and these data encounter the following problems: a large number of highly correlated features and limited data samples. Considering the characteristics of expression profile data and class-specific feature selection method, an idea of embedding the elastic net was proposed in the probabilistic SVM to improve the effect of cancer detection, and the working principle is discussed as follows. For the multi-classification problem, the OVA strategy was used to decompose the initial problem into multiple binary classification problems. For each binary classification problem, the elastic net is built using the class label as the dependent variable and features as independent variables. A series of are taken into the elastic net to generate coefficients with different degree of sparsity indicating candidate class-specific feature sets. Then these candidate class-specific feature sets are fed into binary classifiers to test their effectiveness and the one achieves the highest accuracy with cross-validation (CV) is chosen as the optimal class-specific feature set. In this way, multiple class-specific feature sets can be obtained for the multi-class classification problem.
Using the OVA strategy to deal with the multi-class classification problem, the predicted class is taken from the binary classifier with maximum confidence:
where
is the estimated confidence measure of the i-th classifier. Using global features, if the SVM classifier is chosen, then the
can be measured as the decision output of the SVM classifier. However, using the class-specific features, the decision outputs of the SVM classifiers based on different features are not comparable. In order to solve this problem, it is to choose the PSVM classifier, which changes the decision output of the SVM classifier into probability, and this algorithm was named as EPSVM. The probabilistic outputs of the PSVM classifiers normalize the decision outputs of the SVM classifiers, which make the decision outputs of SVM classifiers comparable regardless of whether they are fed with the same features or not. The flowchart of using class-specific features to solve the multi-class classification problem with elastic net and EPSVM is given in
Figure 2.
6. Conclusions
In this work, a novel multi-class classification method was proposed to detect cancer diseases with the gene expression profile data, which has the problem of high dimension, small sample, and collinearity. In the proposed method, the class-specific feature selection, OVA strategy and probabilistic support vector machine were innovatively combined to enhance the effect of cancer detection with gene expression profile data. The experiment results show that the proposed method can achieve better classification results than conventional methods based on global feature selection methods. So that the proposed method is suitable for the problem of cancer detection with gene expression profile data.
In general, the proposed method is suitable for multi-class classification problems, where the class-feature set of each class is significantly different from others. Besides, the idea behind the proposed method in this paper can be easily extended to the combination of other feature selection methods and classifiers, which is flexibly in solving the multi-feature and multi-class classification problems encountered in practice. However, for the adopted classifiers, how to normalize the outputs of classifiers with different feature subsets is a key problem. The following work will further study the effect of different normalization methods on the class-feature based multi-class classification method.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}