Distillation of an End-to-End Oracle for Face Verification and Recognition Sensors †

 , ,
, ,
Abstract
:1. Introduction
1.1. Face Recognition Sensors
1.2. Framework
1.3. Paper Outcome
2. Materials and Methods
2.1. Transfer Learning and Model Compression
2.2. Model Distillation and Teacher–Student Approach
2.3. Alignment Procedure and Spatial Transformer Network
2.4. Contribution
2.4.1. Network Architecture
2.4.2. Multiclass Open Set Problem
3. Distillation Experiments
3.1. Distillation Process
3.2. Model Testing
3.2.1. LFW Face Verification Test
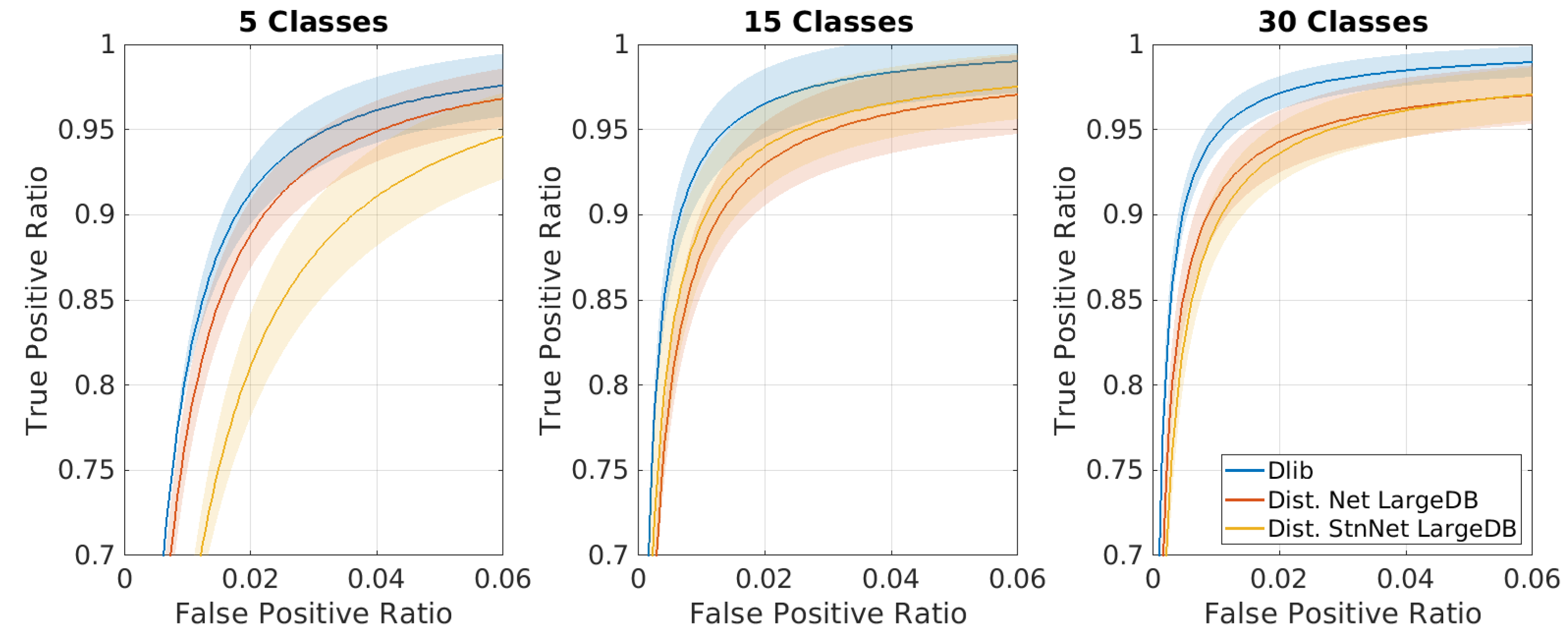
3.2.2. Multi Class Face Recognition in an Open Set
3.3. Hardware Implementation
4. Results and Discussion
4.1. LFW Verification Test
4.2. Recognition Test
4.3. STN Analysis: Co-Adaptation and Difficult Poses
4.4. Distillation Strategy as a “Transfer Learning” for the New Model
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1
References
- DeBortoli, L.; Guzzi, F.; Marsi, S.; Carrato, S.; Ramponi, G. A fast face recognition CNN obtained by distillation. In Proceedings of the 7th International Workshop Applications in Electronics Pervading Industry, Environment and Society, ApplePies, Pisa, Italy, 11–13 September 2019. [Google Scholar]
- Yang, Y.; Wen, C.; Xie, K.; Wen, F.; Sheng, G.; Tang, X. Face Recognition Using the SR-CNN Model. Sensors 2018, 18, 4237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, G.; Zhang, N. A survey on deep learning based face recognition. Comput. Vis. Image Underst. 2019, 189. [Google Scholar] [CrossRef]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. From Facial Parts Responses to Face Detection: A Deep Learning Approach. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV, Santiago, Chile, 7–13 December 2015; pp. 3676–3684. [Google Scholar]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. DenseBox: Unifying Landmark Localization with End to End Object Detection. CoRR 2015. Available online: http://arxiv.org/abs/1509.04874 (accessed on 31 January 2020).
- King, D.E. Max-Margin Object Detection. CoRR 2015. Available online: http://arxiv.org/abs/1502.00046 (accessed on 31 January 2020).
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Hua, G.; Wen, F.; Sun, J. Supervised Transformer Network for Efficient Face Detection. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 122–138. [Google Scholar] [CrossRef] [Green Version]
- Marsi, S.; Bortoli, L.D.; Guzzi, F.; Bhattacharya, J.; Cicala, F.; Carrato, S.; Canziani, A.; Ramponi, G. A Face Recognition System Using Off-the-Shelf Feature Extractors and an Ad-Hoc Classifier. In Applications in Electronics Pervading Industry, Environment and Society, APPLEPIES 2018; Saponara, S., Gloria, A.D., Eds.; Springer: Berlin, Germany, 2018; pp. 145–151. [Google Scholar] [CrossRef]
- Dlib API. Available online: http://blog.dlib.net/2017/02/high-quality-face-recognition-with-deep.html (accessed on 31 January 2020).
- Dlib Models. Available online: https://github.com/davisking/dlib-models (accessed on 31 January 2020).
- ARM Neon. Available online: https://developer.arm.com/architectures/instruction-sets/simd-isas/neon (accessed on 31 January 2020).
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Viola, P.A.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Herranz, L.; Jiang, S. Depth CNNs for RGB-D Scene Recognition: Learning from Scratch Better than Transferring from RGB-CNNs. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4271–4277. [Google Scholar]
- Guzzi, F.; DeBortoli, L.; Marsi, S.; Carrato, S.; Ramponi, G. Distillation of a CNN for a high accuracy mobile face recognition system. In Proceedings of the 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics, MIPRO 2019, Opatija, Croatia, 20–24 May 2019; pp. 989–994. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. Model Compression and Acceleration for Deep Neural Networks: The principles, progress, and challenges. IEEE Signal Process Mag. 2018, 35, 126–136. [Google Scholar] [CrossRef]
- Luo, P.; Zhu, Z.; Liu, Z.; Wang, X.; Tang, X. Face Model Compression by Distilling Knowledge from Neurons. 2016, pp. 3560–3566. Available online: https://www.researchgate.net/publication/319770258_Face_Model_Compression_by_Distilling_Knowledge_from_Neurons (accessed on 28 February 2020).
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. CoRR 2015. Available online: http://arxiv.org/abs/1503.02531 (accessed on 28 February 2020).
- Ba, J.; Caruana, R. Do Deep Nets Really Need to be Deep? In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2654–2662. [Google Scholar]
- Zhao, S.; Gao, X.; Li, S.; Ge, S. Low-Resolution Face Recognition in the Wild with Mixed-Domain Distillation. In Proceedings of the Fifth IEEE International Conference on Multimedia Big Data, BigMM 2019, Singapore, 11–13 September 2019; pp. 148–154. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.S.; Guo, X.; Lai, J.H. Distilled Person Re-Identification: Towards a More Scalable System. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Kim, J.; Ahn, G.; Kim, S.; Kim, Y.; López, J.; Kim, T. (Eds.) Detection under Privileged Information. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, AsiaCCS 2018, Incheon, Korea, 4–8 June 2018. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Ren, S.; Cao, X.; Wei, Y.; Sun, J. Face Alignment at 3000 FPS via Regressing Local Binary Features. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 1685–1692. [Google Scholar]
- Chen, D.; Ren, S.; Wei, Y.; Cao, X.; Sun, J. Joint Cascade Face Detection and Alignment. In Proceedings of the Computer Vision—ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 109–122. [Google Scholar]
- Keras MTCNN Implementation. Available online: https://github.com/xiangrufan/keras-mtcnn (accessed on 31 January 2020).
- Zhuang, W.; Chen, L.; Hong, C.; Liang, Y.; Wu, K. FT-GAN: Face Transformation with Key Points Alignment for Pose-Invariant Face Recognition. Electronics 2019, 8, 807. [Google Scholar] [CrossRef] [Green Version]
- Hassner, T.; Harel, S.; Paz, E.; Enbar, R. Effective face frontalization in unconstrained images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 4295–4304. [Google Scholar]
- Zhou, E.; Cao, Z.; Sun, J. GridFace: Face Rectification via Learning Local Homography Transformations. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–20. [Google Scholar]
- Chen, T.; Goodfellow, I.J.; Shlens, J. Net2Net: Accelerating Learning via Knowledge Transfer. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zhong, Y.; Chen, J.; Huang, B. Toward End-to-End Face Recognition Through Alignment Learning. IEEE Signal Process. Lett. 2017, 24, 1213–1217. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. CoRR 2015. Available online: http://arxiv.org/abs/1505.04597 (accessed on 31 January 2020).
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning Face Representation from Scratch. CoRR 2014. Available online: http://arxiv.org/abs/1411.7923 (accessed on 31 January 2020).
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database forStudying Face Recognition in Unconstrained Environments. In Proceedings of the Workshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Erik Learned-Miller and Andras Ferencz and Frédéric Jurie, Marseille, France, October 2008; Available online: https://hal.inria.fr/inria-00321923 (accessed on 28 February 2020).
- Nech, A.; Kemelmacher-Shlizerman, I. Level Playing Field for Million Scale Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3406–3415. [Google Scholar] [CrossRef] [Green Version]
- LFW Protocol. Available online: http://vis-www.cs.umass.edu/lfw/#views (accessed on 31 January 2020).
- TensorFlow Lite. Available online: https://www.tensorflow.org/lite (accessed on 31 January 2020).
- Intel NCS. Available online: https://software.intel.com/en-us/neural-compute-stick (accessed on 31 January 2020).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CLASSES | # TRAIN Imgs (Known IDs Only) | # VALIDATION Imgs (Known IDs Only) | # TESTING Imgs (Known IDs) | # TESTING Imgs Unknown IDs |
|---|---|---|---|---|
| 5 | 5 × (2 or 5 or 15) | 5 × 5 | 5 × 10 = 50 | 50 |
| 15 | 15 × (2 or 5 or 15) | 15 × 5 | 15 × 10 = 150 | 150 |
| 30 | 30 × (2 or 5 or 15) | 30 × 5 | 30 × 10 = 300 | 300 |
| Network | Accuracy | TPR @ FPR=1% | TPR @ FPR=0.1% |
|---|---|---|---|
| dlib-resnet-v1 | 0.9918 ± 0.0033 | 0.9923 ± 0.0049 | 0.9344 ± 0.1365 |
| Distilled net | 0.9852 ± 0.0050 | 0.9819 ± 0.0106 | 0.8931 ± 0.1051 |
| Distilled stn+net | 0.9852 ± 0.0058 | 0.9908 ± 0.0137 | 0.9067 ± 0.1241 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guzzi, F.; De Bortoli, L.; Molina, R.S.; Marsi, S.; Carrato, S.; Ramponi, G. Distillation of an End-to-End Oracle for Face Verification and Recognition Sensors. Sensors 2020, 20, 1369. https://doi.org/10.3390/s20051369
Guzzi F, De Bortoli L, Molina RS, Marsi S, Carrato S, Ramponi G. Distillation of an End-to-End Oracle for Face Verification and Recognition Sensors. Sensors. 2020; 20(5):1369. https://doi.org/10.3390/s20051369
Chicago/Turabian StyleGuzzi, Francesco, Luca De Bortoli, Romina Soledad Molina, Stefano Marsi, Sergio Carrato, and Giovanni Ramponi. 2020. "Distillation of an End-to-End Oracle for Face Verification and Recognition Sensors" Sensors 20, no. 5: 1369. https://doi.org/10.3390/s20051369