Data Efficient Reinforcement Learning for Integrated Lateral Planning and Control in Automated Parking System


Abstract
:1. Introduction
- A model-based RL addressing the ability to continuous learning for APS is proposed. A truncated MCTS algorithm is used to implement this method, of which the data efficiency is improved by designing an adaptive exploration encouragement factor and weighted policy learning to enhance the network updating toward the direction of the trajectory with high return. Thus, the influence of vehicle model and sensor systems can be reduced.
- The proposed approach continuously plans and controls motion, which has lower requirements for the perception system at the initial parking position, in principle. For its data-driven feature, the parking trajectory given by the pose estimator can be used to improve the system’s performance.
- The novel training method consists of two phases of learning for the greedy parking lateral action policy—classification network and state value estimate—fitting network, which do not need human input at the early stage of APS training.
- The proposed method is verified on a full-size vehicle and is shown to achieve acceptable performance without time-consuming training on the real platform.
2. Related Work
2.1. Environmental Perception
2.2. Motion Generation
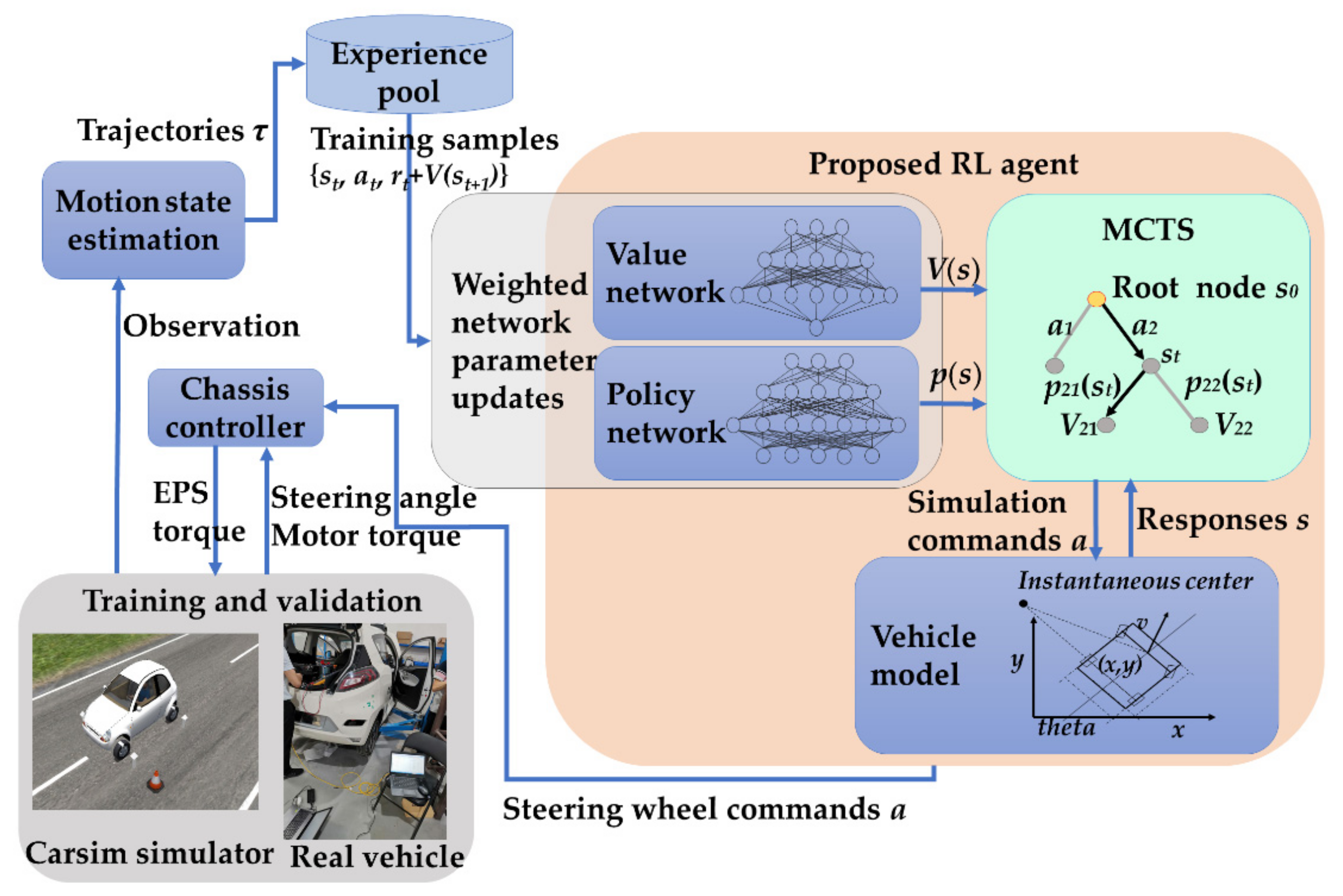
3. System Structure and Problem Definition
3.1. Structure of Automatic Parking System
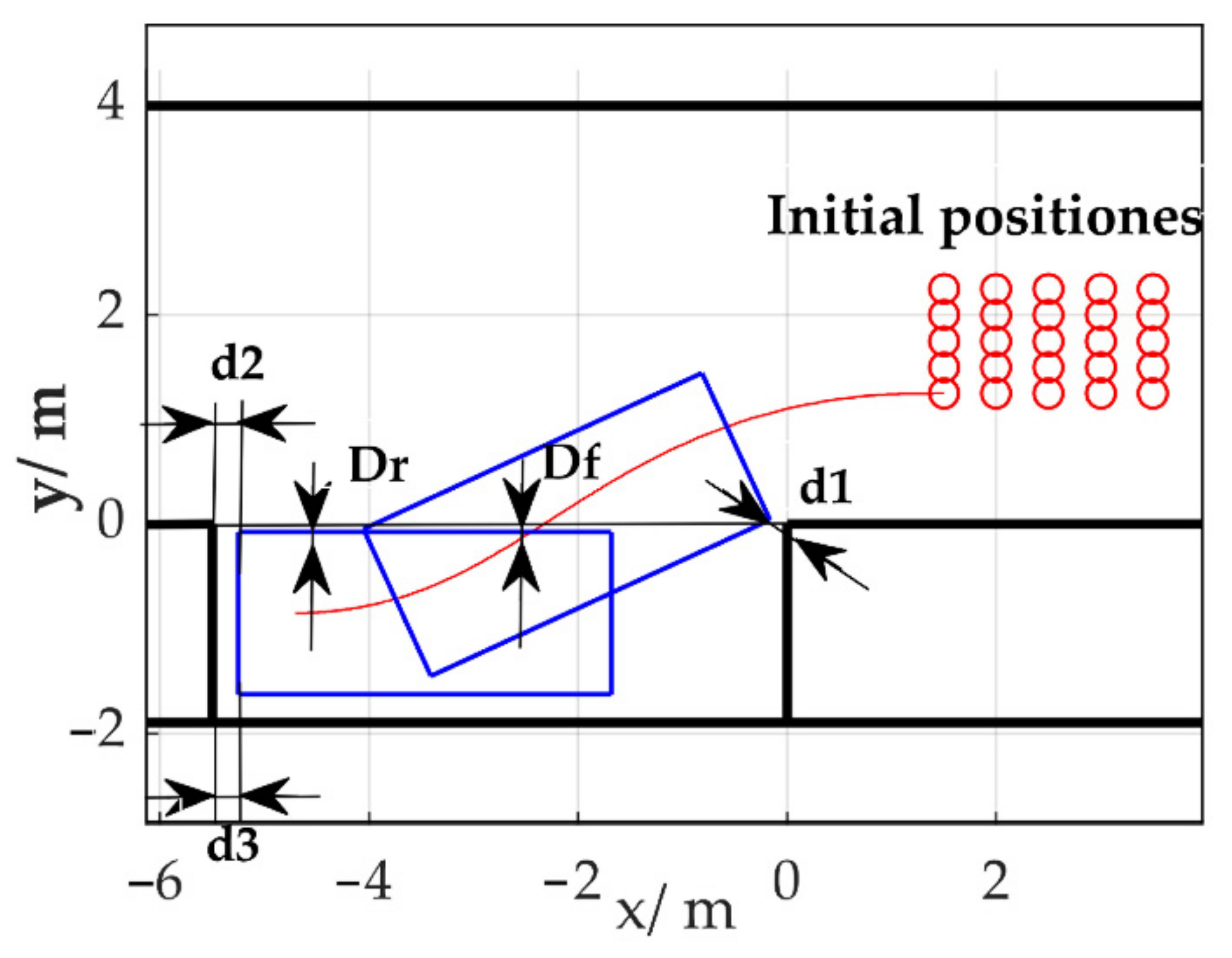
3.2. Problem Definition of Parking
y′ = v(t)sinθ(t)
θ′ = v(t)tanφ(t)/l.
4. Data-Efficient RL Algorithm Design
4.1. Truncated MCTS for Approximate Modified Policy Iteration
4.1.1. Approximate Modified Policy Iteration
| Algorithm 1 Approximate Modified Policy Iteration |
| Input: Value function V0, policy function P0 |
| Output: Optimal value function V*, optimal policy function P* |
| 1. for: l = 0, 1, 2, …, L do |
| 2. Generate rollouts using Vl and Pl by Equation (10) |
| 3. Approximate value by Equation (11) |
| 4. Approximate policy by Equation (12) |
| 5. end for |
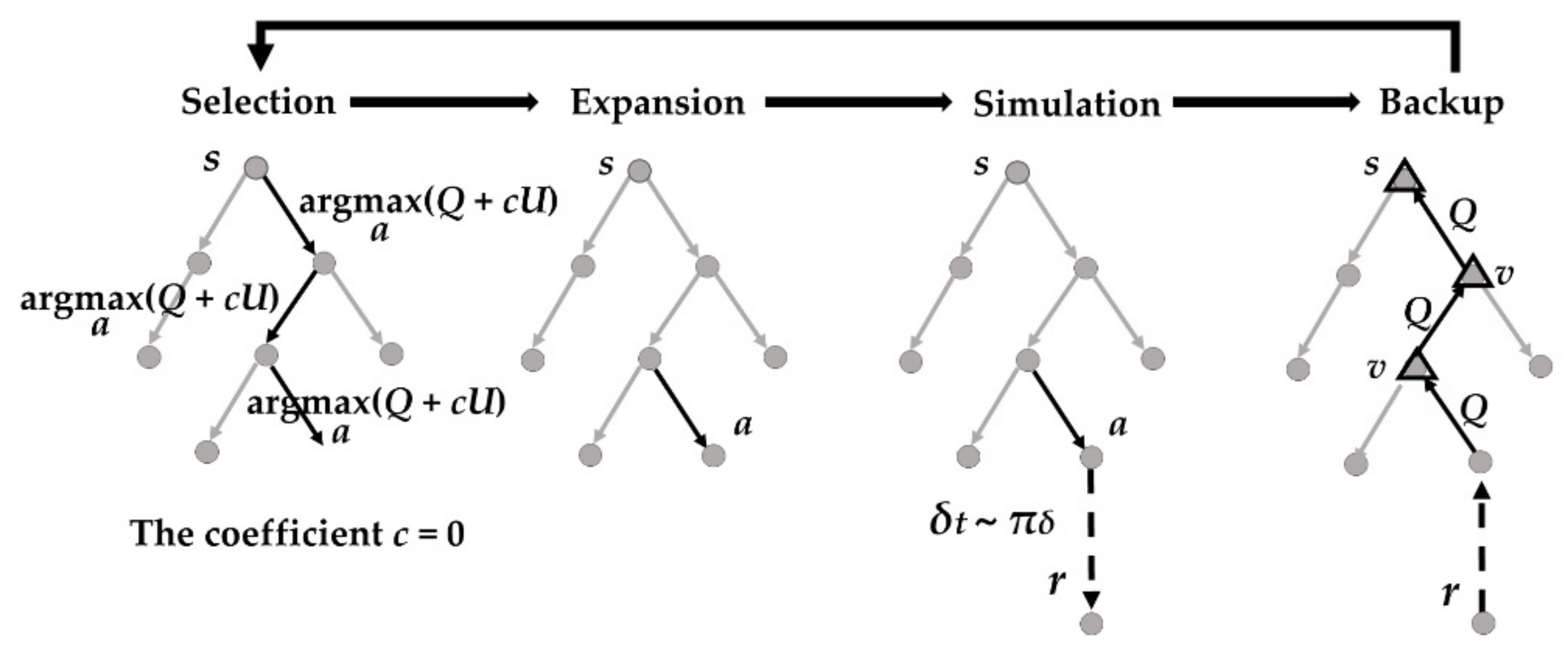
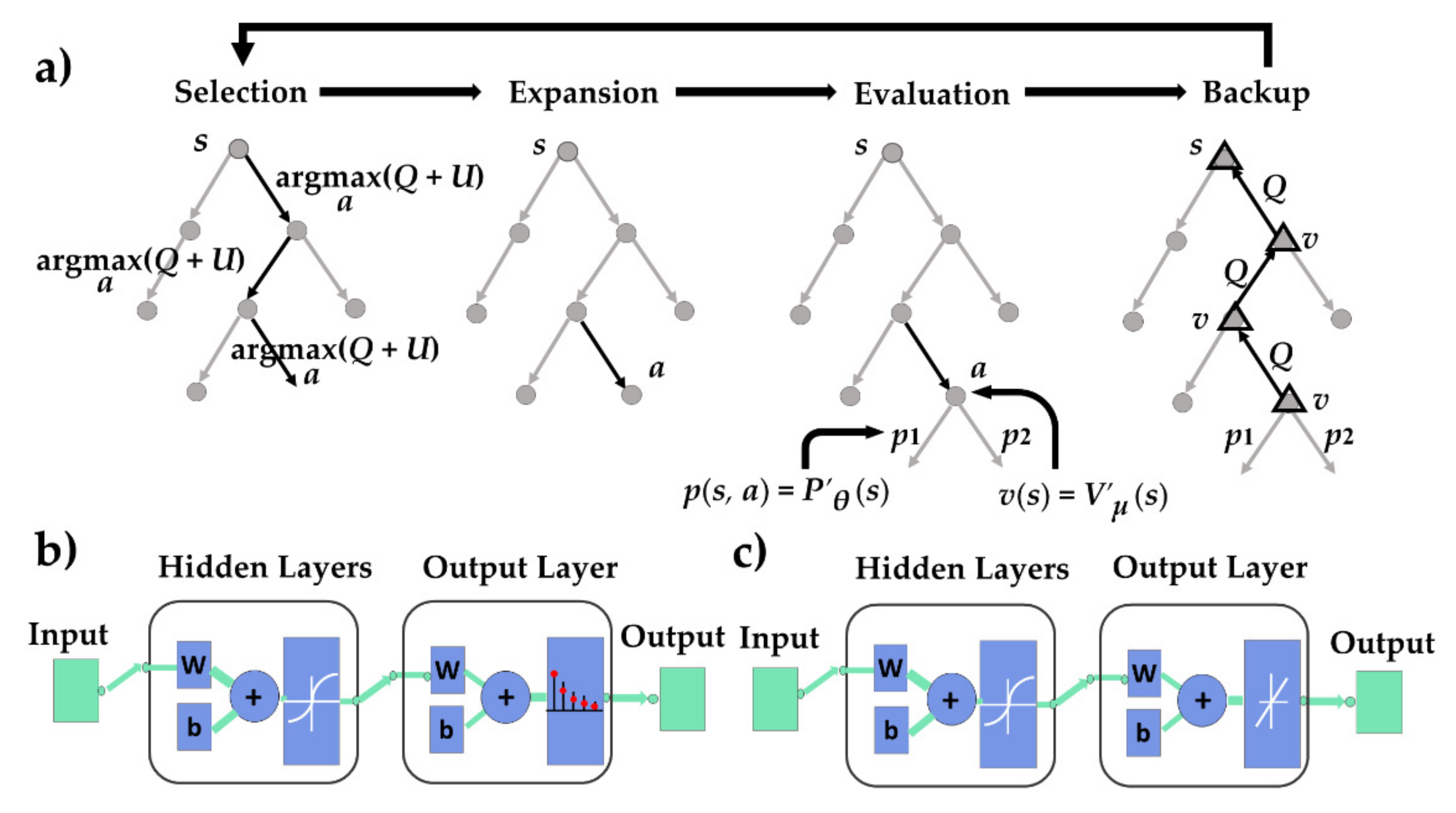
4.1.2. Truncated MCTS Guided by Artificial Neural Networks
- Truncated MCTS
- ANN Approximation for State Value and Greedy Policy
4.2. Data-Efficient Promotion Methods for RL
4.2.1. Policy Learning by Weighting Exploration with Trajectory Returns
= E[rt + 1 + Vπ (st + 1)|At = π′(st)]
= Eπ′ [rt + 1 + γVπ(st + 1)]
≤ Eπ′ [rt + 1 + γQπ(st + 1, π′(st + 1))]
≤ Eπ′ [rt + 1 + γrt + 2 + γ2rt + 3 + γ3rt + 4 + …] = Vπ′(st).
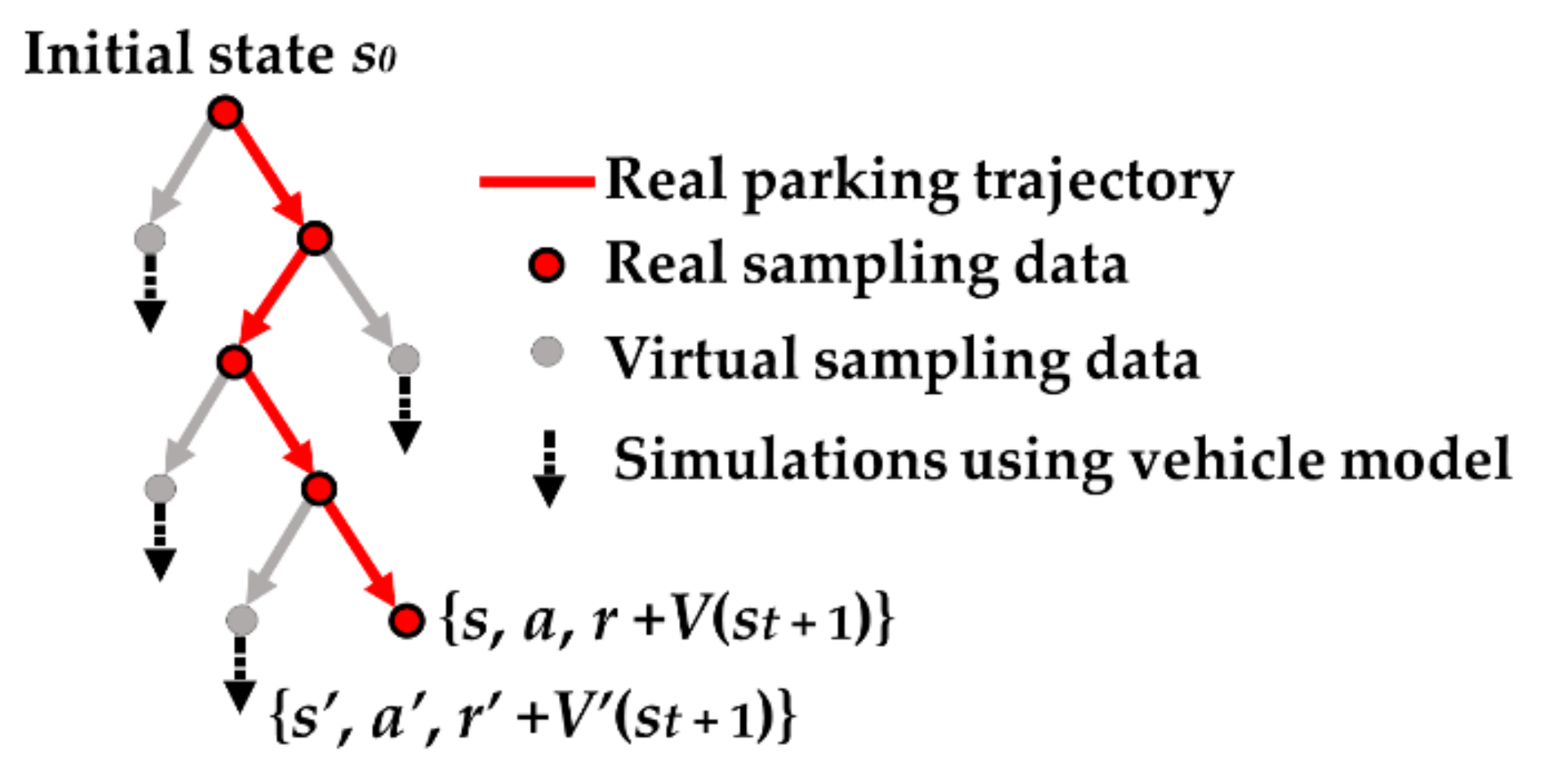
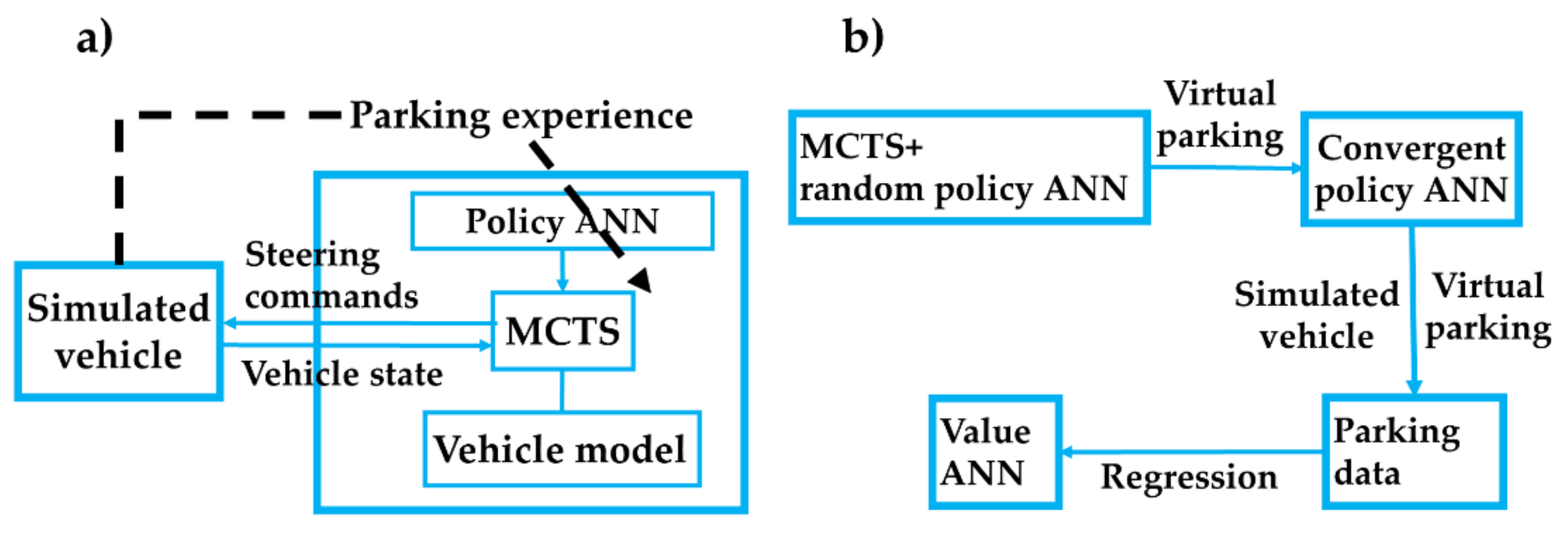
4.2.2. Experience Augmentation with Imagination Rollouts
4.2.3. Warm Start with Pre-Trained RL Model
| Algorithm 2 Proposed overall algorithm |
| Input: Value function V0, policy function P0 |
| Output: Optimal value function V*, optimal policy function P* |
| 1. for: t = 0, 1, 2, …, T do |
| 2. Generate rollouts using MCTS guided by Pt, Equation (15), where Q is obtained by simulation |
| 3. Approximate policy Pt + 1 by Equation (12) using the loss function Equation (18) |
| 4. end for |
| 5. Generate rollout samples τ = {st, at, rt + V(st + 1)} using MCTS and PT + 1 |
| 6. Approximate value network V0 by Equation (11) using the loss function Equation (17) |
| 7. for: i = 0, 1, 2, …, I do |
| 8. Generate rollouts using MCTS guided by Pi + (T + 1) and Vi + 0, Equation (15) |
| 9. for: s = s0, …, st do |
| 10. calculate recommend action by Pi + (T + 1) |
| 11. pr = {increase_ angle, decrease_ angle, no_action} |
| 12. execute MCTS obtain a |
| 13. if termination |
| 14. r = rewardfunction(st) |
| 15. end if |
| 16. end for |
| 17. Experience augmentation as Figure 4 |
| 18. Approximate value by Equations (11) and (17) |
| 19. Approximate policy by Equations (12) and (18) |
| 20. end for |
| 21. function MCTS(s0, P, V, pr, char) |
| 22. execute Equations (15) and (16) with |
| 23. if char = = ’pretrain’ |
| 24. v(s) = simulation from s to end with P |
| 25. else |
| 26. v(s) = V(s) |
| 27. end if |
| 28. if a_child ∈ char |
| 29. μ = 0.5 |
| 30. else |
| 31. μ = 1.5 |
| 32. end if |
| 33. return a |
| 34. end function |
5. Simulations
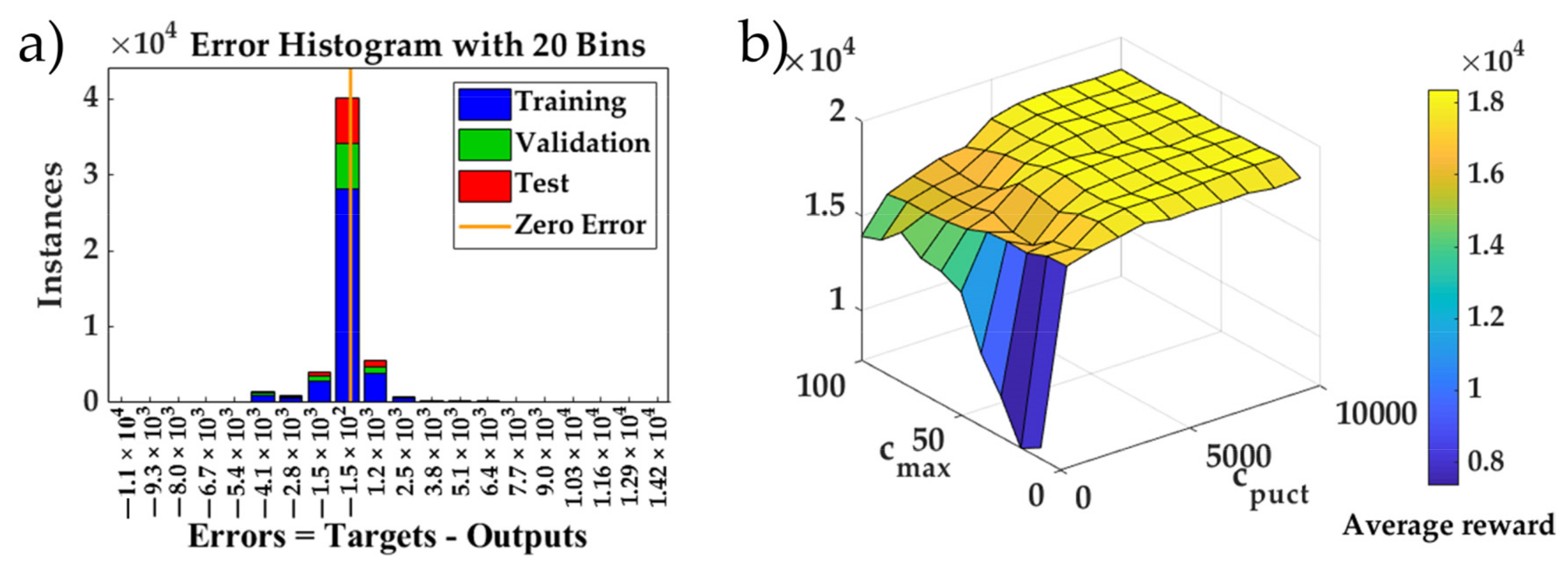
5.1. Feasibility of the Learning Algorithm
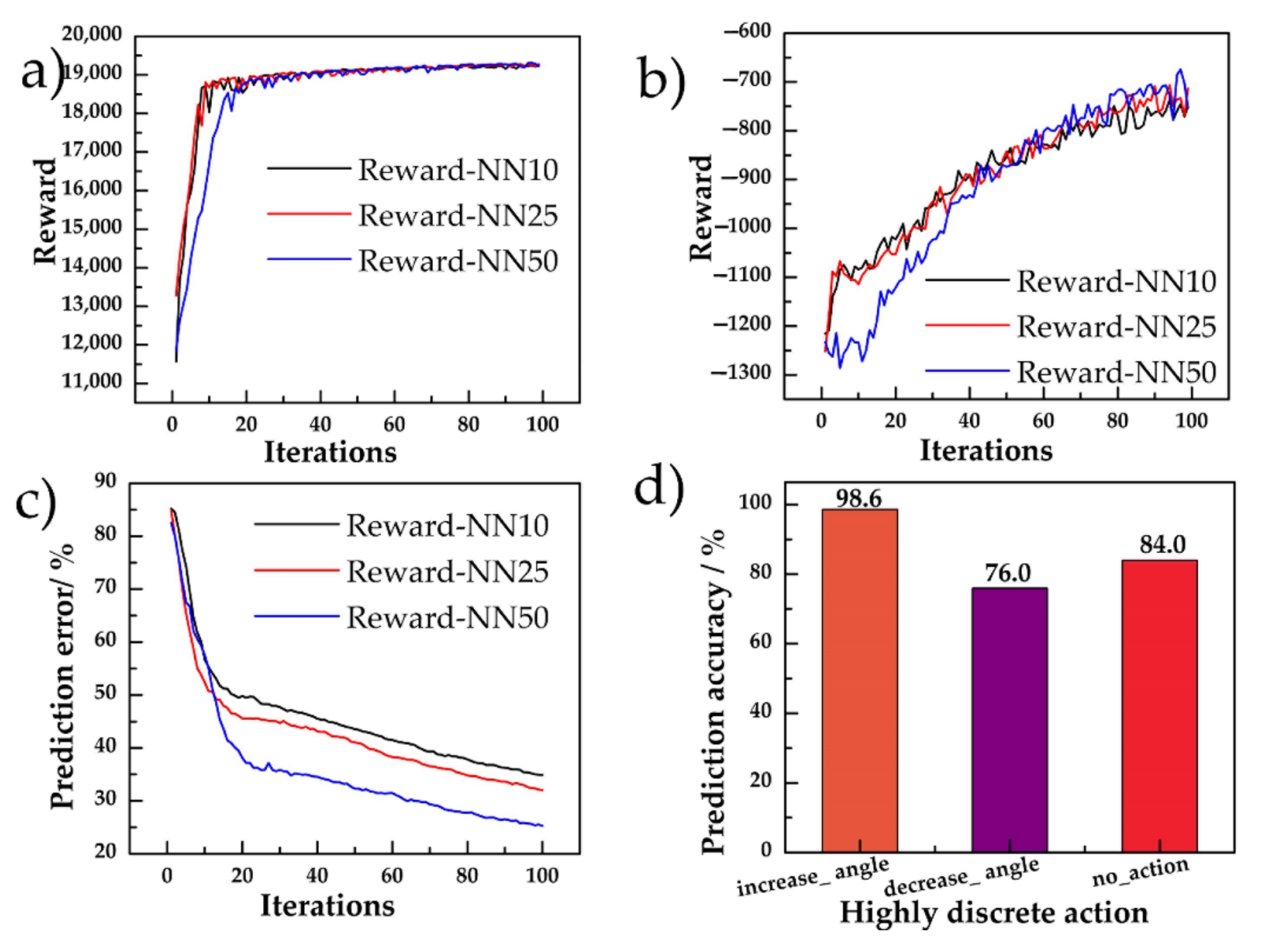
5.1.1. Model Pre-Trained with the Policy Network and MCTS
5.1.2. Complete Training of RL Model
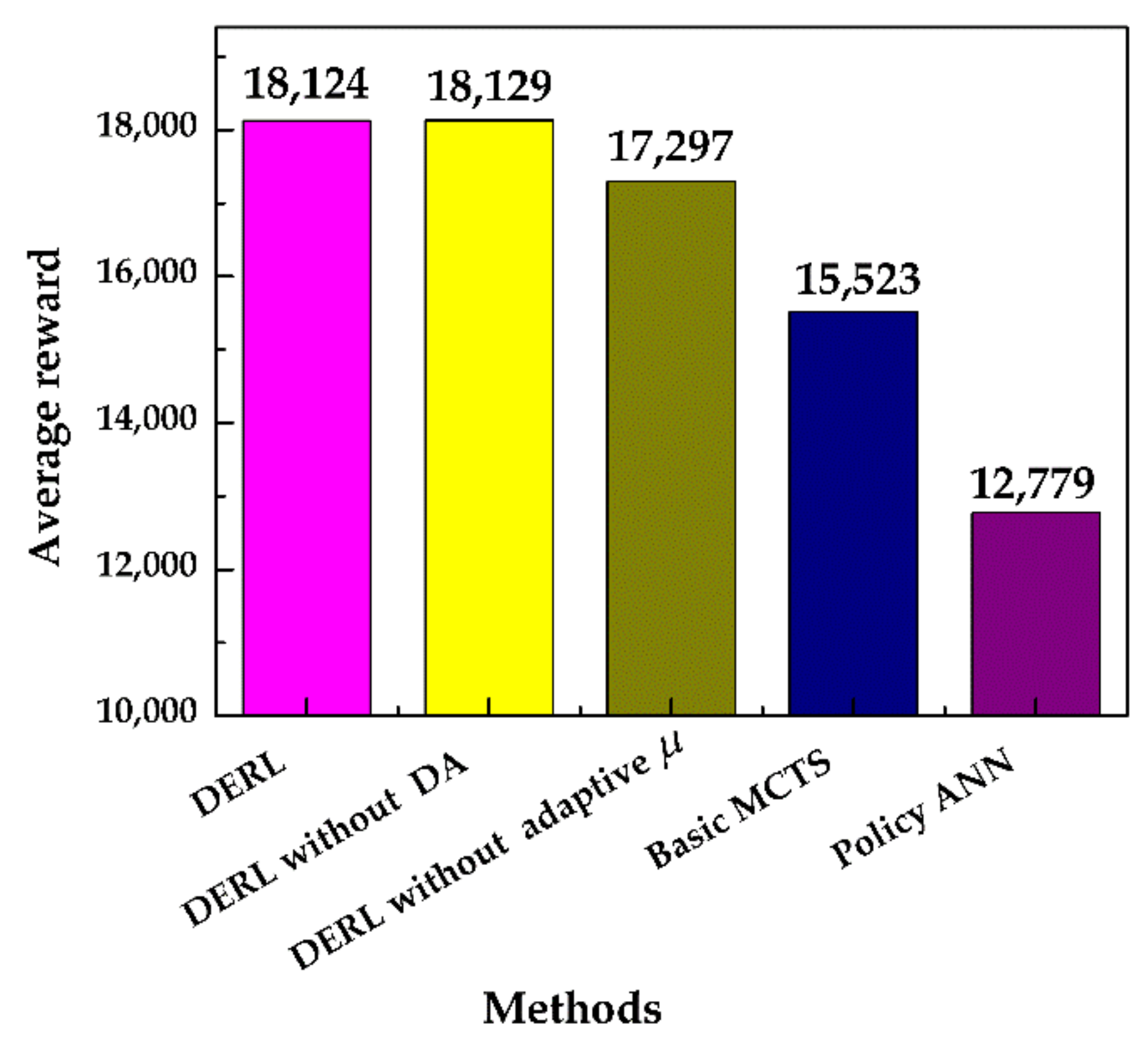
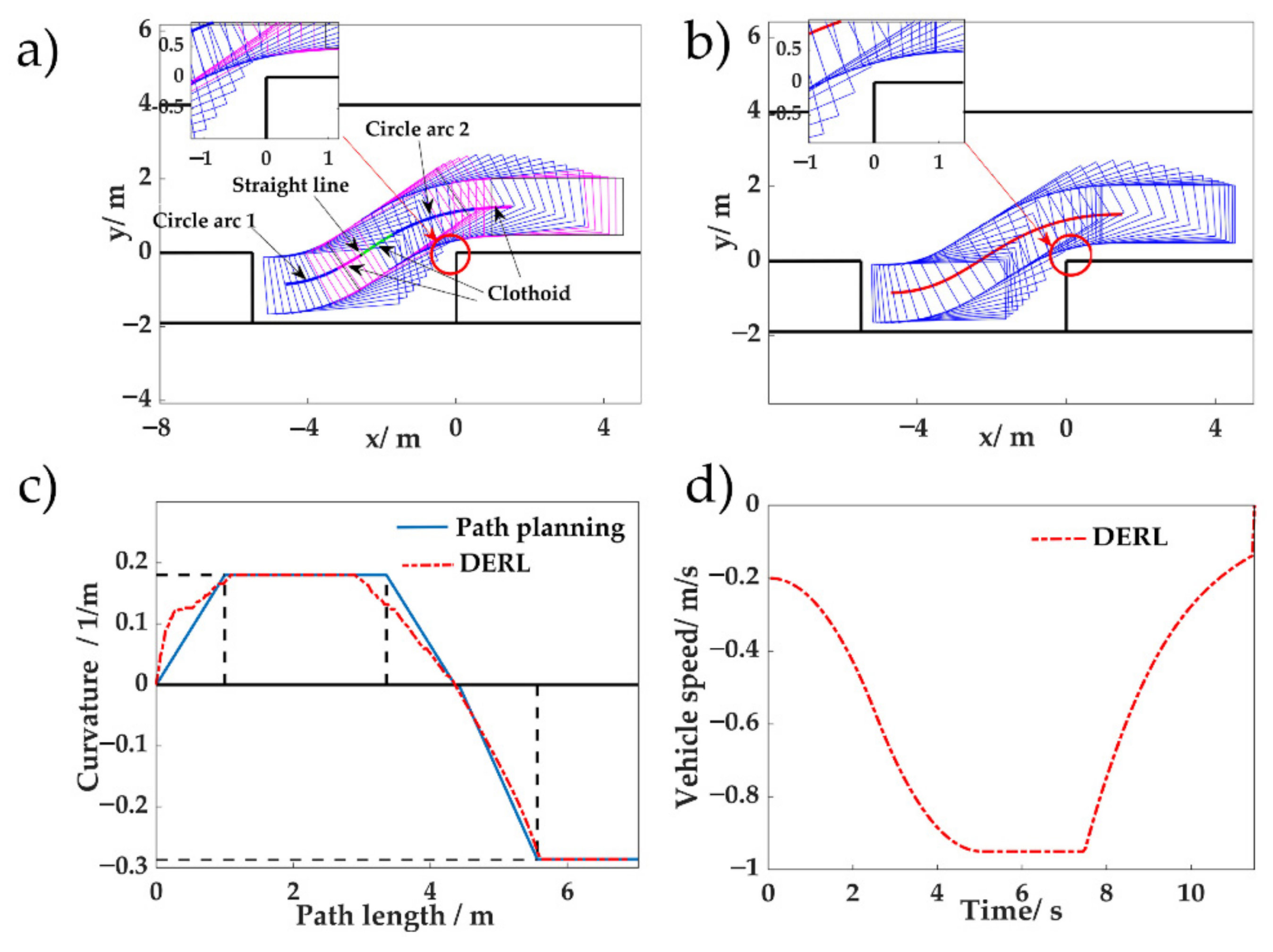
5.2. Comparison with Curve-Based Path Planning Method
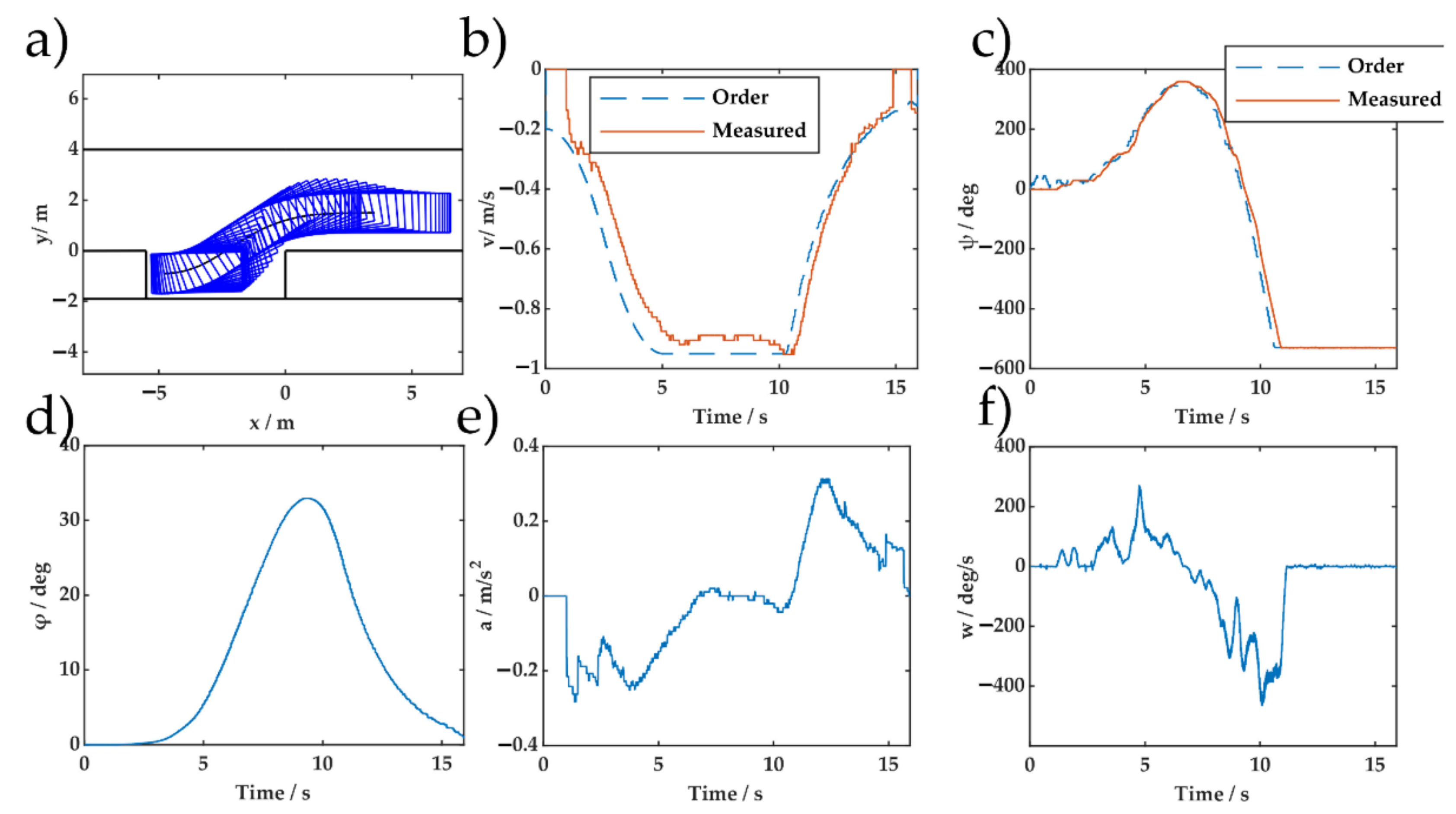
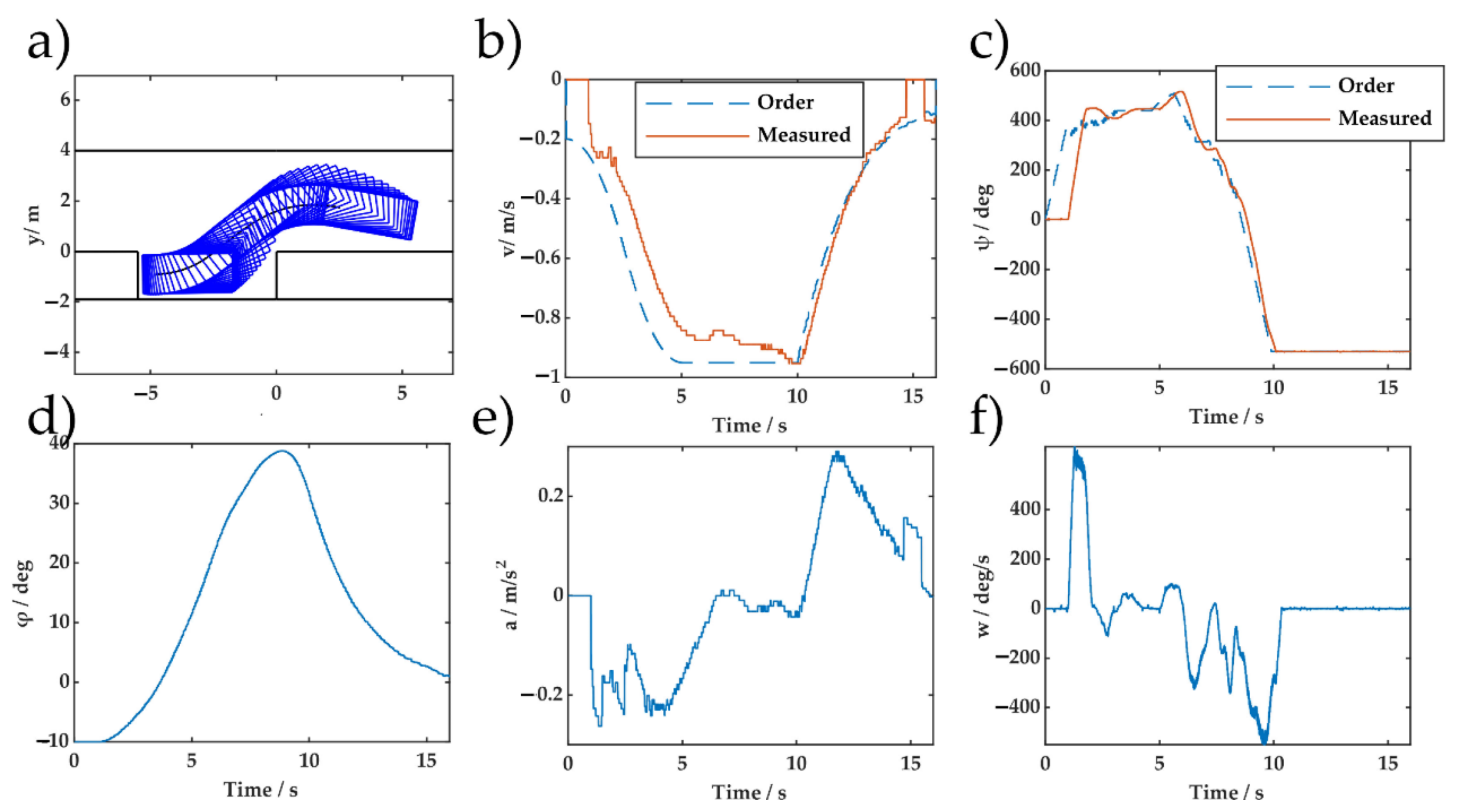
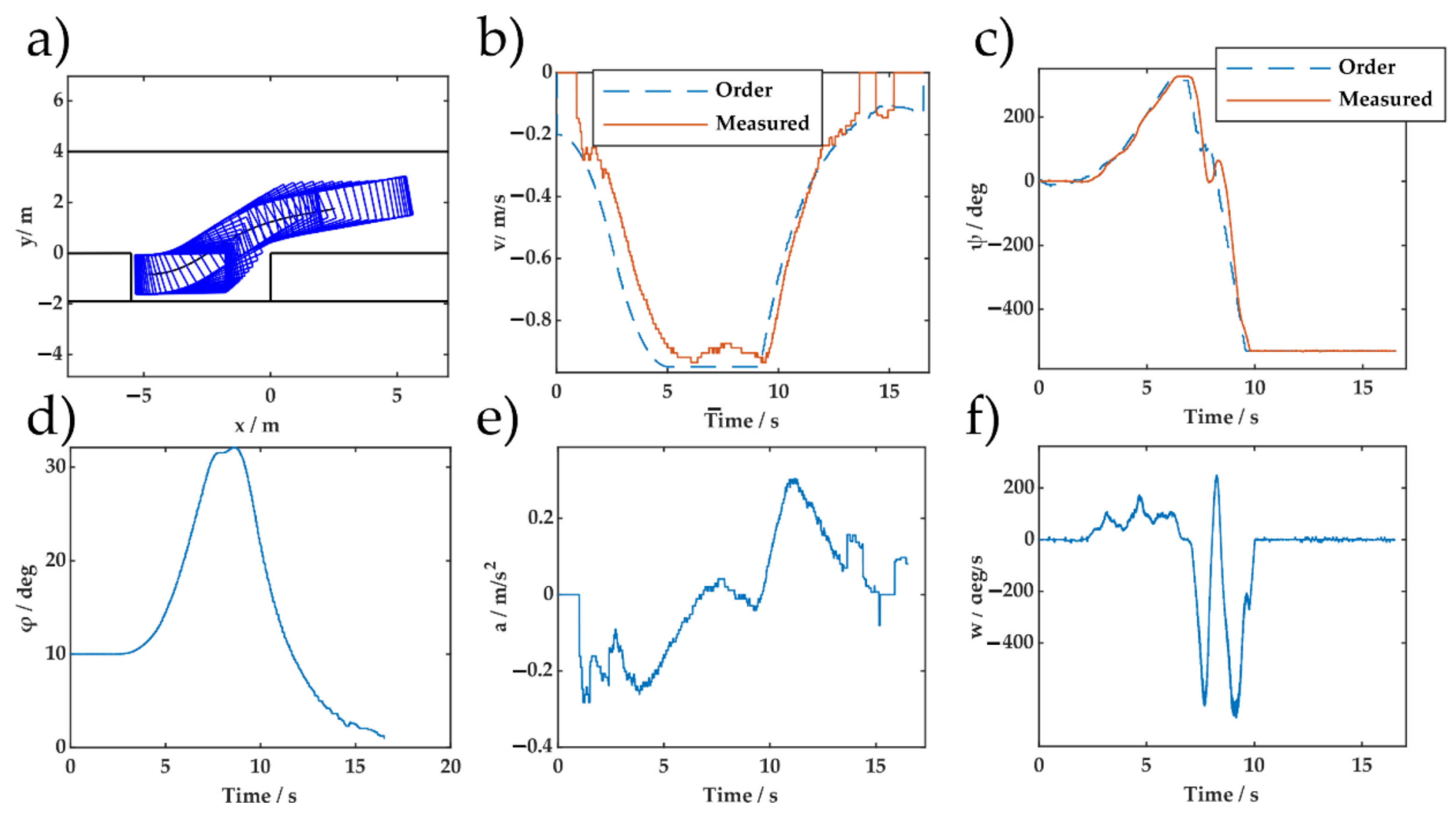
5.3. Data Efficiency Verification During Adaptability to Changes in Vehicle Model
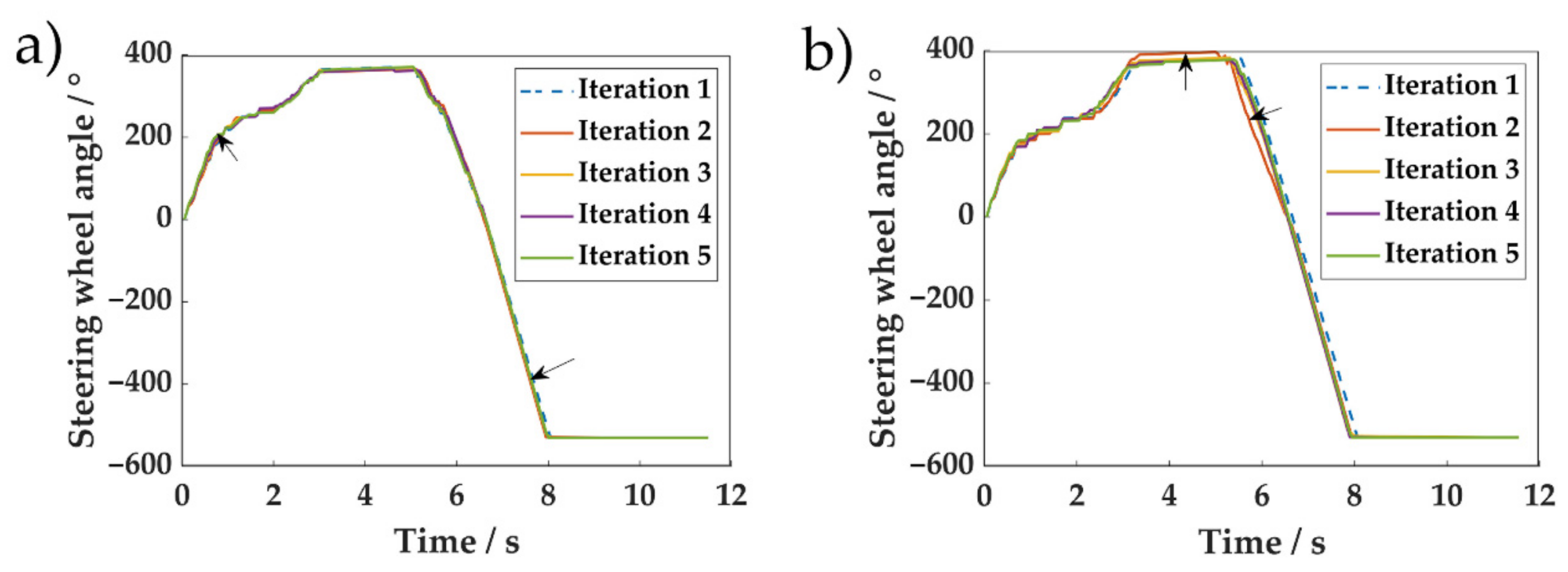
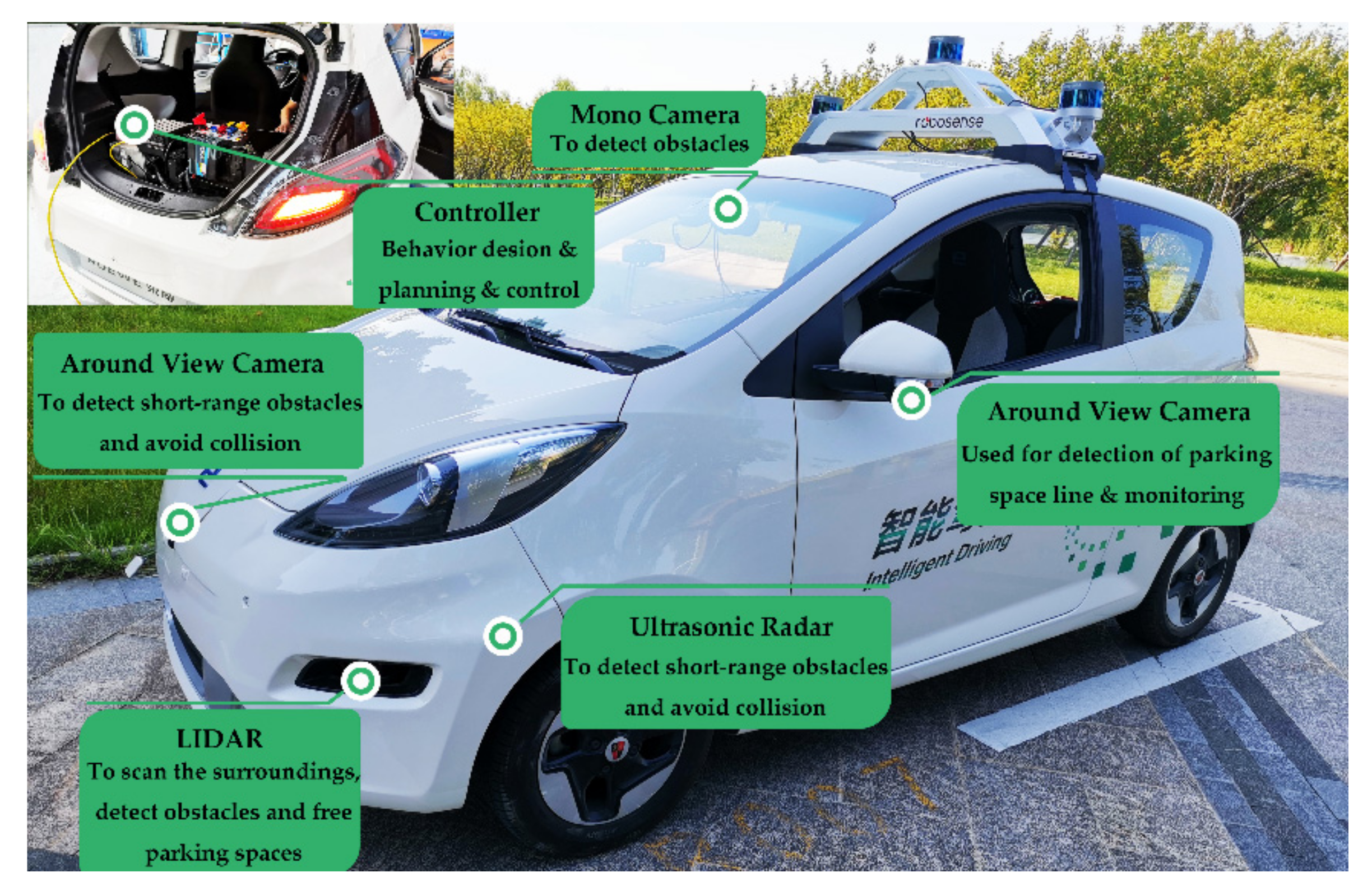
6. Real Vehicle Experiments
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle Parameters | |
| Overall length | 3.569 m |
| Overall width | 1.551 m |
| Front overhang | 0.72 m |
| Rear overhang | 0.544 m |
| Wheel base | 2.305 m |
| Transmission ratio | 15.88 |
| Neural network parameters | |
| Size of policy network’s hidden layers | [25, 25] |
| Size of value network’s hidden layers | [50, 50] |
| Data divide | {80%, 10%, 10%} |
| Number of ANNs | 10 |
| Control setup | |
| Steering wheel angle resolution | 5° |
| Number of discrete actions | 9 |
| Control interval | 50 ms |
| Maximum steering order speed | 400°/s |
| MCTS | |
| cpuct | 0–10,000 |
| Sampling times | 10–100 |
| μ, τ | {0.5, 1.5}, 0.1 |
| Reward function | |
| c1, c2, c3 | 1.1, 0.3, 0.5 |
| Data augmentation | |
| Action repeat numbers | 10 |
| Simulation numbers | 36 |
Appendix B
| Variable | DERL | MCTS + Policy ANN + Refined Vehicle Model | MCTS + Policy ANN | |||
|---|---|---|---|---|---|---|
| Max | Min | Max | Min | Max | Min | |
| Δy (m) | 0.0827 | 0.0021 | 0.1465 | 0.037 | 1.6275 | 0.0943 |
| Δθ (°) | 0.9927 | 0.7335 | 5.0014 | 0.0753 | −2.1382 | −23.7052 |
| Dr (m) | 0.1573 | −0.0040 | 0.2213 | 0.1115 | −0.0192 | −1.4875 |
| Df (m) | 0.1197 | −0.0405 | 0.1532 | −0.0281 | 0.3293 | −0.5608 |
| Safe d1 (m) | 0.2975 | 0.1611 | 0.3518 | 0.168 | 0.4318 | 0.0154 |
| Safe d2 (m) | 0.2986 | 0.1695 | 0.3515 | 0.1993 | 0.1878 | −0.377 |
| Safe d3 (m) | 0.2727 | 0.1453 | 0.2761 | 0.1724 | 0.2492 | 0.2374 |
| Time (s) | 17.875 | 13.825 | 16.875 | 14.285 | 16.155 | 13.32 |
| Variable | DERL | MCTS + Policy ANN + Refined Vehicle Model | MCTS + Policy ANN | |||
|---|---|---|---|---|---|---|
| Max | Min | Max | Min | Max | Min | |
| Δy (m) | 0.0474 | 0.0018 | 0.1269 | 0.0374 | 1.0407 | 0.0006 |
| Δθ (°) | 0.9887 | 0.6989 | 8.9211 | −0.1239 | 25.3742 | −19.9785 |
| Dr (m) | 0.1219 | 0.0575 | 0.2046 | 0.1119 | 0.1502 | −0.9195 |
| Df (m) | 0.0874 | 0.0178 | 0.1168 | −0.1696 | 0.1541 | −0.8375 |
| Safe d1 (m) | 0.2930 | 0.1761 | 0.5076 | 0.0104 | 0.4184 | 0.0087 |
| Safe d2 (m) | 0.2878 | 0.1203 | 0.4331 | 0.1892 | 1.6144 | −0.2839 |
| Safe d3 (m) | 0.2610 | 0.1005 | 0.2652 | 0.1783 | 0.9498 | 0.238 |
| Time (s) | 16.5250 | 14.175 | 16.14 | 14.83 | 15.085 | 8.7 |
References
- Jang, C.; Kim, C.; Lee, S.; Kim, S.; Lee, S.; Sunwoo, M. Re-Plannable Automated Parking System With a Standalone Around View Monitor for Narrow Parking Lots. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1–14. [Google Scholar] [CrossRef]
- Banzhaf, H.; Nienhuser, D.; Knoop, S.; Zollner, J.M. The Future of Parking: A Survey on Automated Valet Parking with an Outlook on High Density Parking. In Proceedings of the 2017 28th IEEE Intelligent Vehicles Symposium, Los Angeles, CA, USA, 11–14 June 2017; pp. 1827–1834. [Google Scholar]
- Qin, T.; Chen, T.; Chen, Y.; Su, Q. AVP-SLAM: Semantic Visual Mapping and Localization for Autonomous Vehicles in the Parking Lot. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2020, Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Yan, W.; Tao, Y.; Junqiao, Z.; Linting, G.; Wei, J. VH-HFCN based Parking Slot and Lane Markings Segmentation on Panoramic Surround View. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Piscataway, NJ, USA, 26–30 June 2018; pp. 1767–1772. [Google Scholar]
- Yang, Q.; Chen, H.; Su, J.; Li, J. Towards High Accuracy Parking Slot Detection for Automated Valet Parking System. In Proceedings of the SAE 2019 New Energy and Intelligent Connected Vehicle Technology Conference, Shanghai, China, 21–22 May 2019; pp. 1–10. [Google Scholar]
- Kant, K.; Zucker, S.W. Toward Efficient Trajectory Planning—The Path-Velocity Decomposition. Int. J. Robot. Res. 1986, 5, 72–89. [Google Scholar] [CrossRef]
- Du, Z.; Miao, Q.; Zong, C. Trajectory Planning for Automated Parking Systems Using Deep Reinforcement Learning. Int. J. Automot. Technol. 2020, 21, 881–887. [Google Scholar] [CrossRef]
- Zhang, P.; Xiong, L.; Yu, Z.; Fang, P.; Yan, S.; Yao, J.; Zhou, Y. Reinforcement Learning-Based End-to-End Parking for Automatic Parking System. Sensors 2019, 19, 3996. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bejar, E.; Moran, A. Reverse Parking a Car-Like Mobile Robot with Deep Reinforcement Learning and Preview Control. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference, Las Vegas, NV, USA, 7–9 January 2019; pp. 377–383. [Google Scholar]
- Zhang, J.R.; Chen, H.; Song, S.Y.; Hu, F.W. Reinforcement Learning-Based Motion Planning for Automatic Parking System. IEEE Access 2020, 8, 154485–154501. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; The MIT Press: London, UK, 2018; pp. 323–339. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Scherrer, B.; Ghavamzadeh, M.; Gabillon, V.; Lesner, B.; Geist, M. Approximate Modified Policy Iteration and its Application to the Game of Tetris. J. Mach. Learn. Res. 2015, 16, 1629–1676. [Google Scholar]
- Rosin, C.D. Multi-armed bandits with episode context. Ann. Math. Artif. Intell. 2011, 61, 203–230. [Google Scholar] [CrossRef] [Green Version]
- Browne, C.B.; Powley, E.; Whitehouse, D.; Lucas, S.M.; Cowling, P.I.; Rohlfshagen, P.; Tavener, S.; Perez, D.; Samothrakis, S.; Colton, S. A Survey of Monte Carlo Tree Search Methods. IEEE Trans. Comput. Intell. AI Games 2012, 4, 1–43. [Google Scholar] [CrossRef] [Green Version]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354. [Google Scholar] [CrossRef]
- Song, J.; Zhang, W.W.; Wu, X.C.; Cao, H.T.; Gao, Q.M.; Luo, S.Y. Laser-based SLAM automatic parallel parking path planning and tracking for passenger vehicle. IET Intell. Transp. Syst. 2019, 13, 1557–1568. [Google Scholar] [CrossRef]
- Chen, X.; Xu, X.; Yang, Y.; Wu, H.; Tang, J.; Zhao, J. Augmented Ship Tracking Under Occlusion Conditions From Maritime Surveillance Videos. IEEE Access 2020, 8, 42884–42897. [Google Scholar] [CrossRef]
- Lee, S.; Lim, W.; Sunwoo, M. Robust Parking Path Planning with Error-Adaptive Sampling under Perception Uncertainty. Sensors 2020, 20, 3560. [Google Scholar] [CrossRef]
- Li, B.; Wang, K.; Shao, Z. Time-Optimal Maneuver Planning in Automatic Parallel Parking Using a Simultaneous Dynamic Optimization Approach. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3263–3274. [Google Scholar] [CrossRef]
- Chao, C.; Rickert, M.; Knoll, A. Path planning with orientation-aware space exploration guided heuristic search for autonomous parking and maneuvering. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Piscataway, NJ, USA, 28 June–1 July 2015; pp. 1148–1153. [Google Scholar]
- Banzhaf, H.; Sanzenbacher, P.; Baumann, U.; Zoellner, J.M. Learning to Predict Ego-Vehicle Poses for Sampling-Based Nonholonomic Motion Planning. IEEE Robot. Autom. Lett. 2019, 4, 1053–1060. [Google Scholar] [CrossRef] [Green Version]
- Vorobieva, H.; Glaser, S.; Minoiu-Enache, N.; Mammar, S. Automatic Parallel Parking in Tiny Spots: Path Planning and Control. IEEE Trans. Intell. Transp. Syst. 2015, 16, 396–410. [Google Scholar] [CrossRef] [Green Version]
- Fan, Z.; Chen, H. Study on Path Following Control Method for Automatic Parking System Based on LQR. SAE Int. J. Passeng. Cars Electron. Electr. Syst. 2016, 10, 41–49. [Google Scholar] [CrossRef]
- Du, X.X.; Tan, K.K. Autonomous Reverse Parking System Based on Robust Path Generation and Improved Sliding Mode Control. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1225–1237. [Google Scholar] [CrossRef]
- Ballinas, E.; Montiel, O.; Castillo, O.; Rubio, Y.; Aguilar, L.T. Automatic parallel parking algorithm for a car-like robot using fuzzy pd+i control. Eng. Lett. 2018, 26, 447–454. [Google Scholar]
- Bernhard, J.; Gieselmann, R.; Esterle, K.; Knoll, A. Experience-Based Heuristic Search: Robust Motion Planning with Deep Q-Learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018; pp. 3175–3182. [Google Scholar]
- Hu, F.; Chen, H.; Zhang, J. Study on Robust Motion Planning Method for Automatic Parking Assist System Based on Neural Network and Tree Search. In Proceedings of the SAE 2019 New Energy and Intelligent Connected Vehicle Technology Conference, Shanghai, China, 21–22 May 2019. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kober, J.; Peters, J. Policy search for motor primitives in robotics. Mach. Learn. 2011, 84, 171–203. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Song, Y.; Zhang, J.; Deng, H. Automatic Parking of Vehicles: A Review of Literatures. Int. J. Automot. Technol. 2014, 15, 967–978. [Google Scholar] [CrossRef]
- Choi, S.; Boussard, C.; D’Andrea-Novel, B. Easy path planning and robust control for automatic parallel parking. In Proceedings of the 18th IFAC World Congress, Milano, Italy, 28 August–2 September 2011; pp. 656–661. [Google Scholar]
- Wang, W.; Yu, N.; Gao, Y.; Shi, J. Safe Off-Policy Deep Reinforcement Learning Algorithm for Volt-VAR Control in Power Distribution Systems. IEEE Trans. Smart Grid 2020, 11, 3008–3018. [Google Scholar] [CrossRef]
- Janner, M.; Fu, J.; Zhang, M.; Levine, S. When to trust your model: Model-based policy optimization. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Hamada, K.; Zhencheng, H.; Mengyang, F.; Hui, C. Surround view based parking lot detection and tracking. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Piscataway, NJ, USA, 28 June–1 July 2015; pp. 1106–1111. [Google Scholar]
- British Standards Institution. Intelligent Transport Systems-Assisted Parking System (APS)-Performance Requirements and Test Procedures; BS ISO 16787:2017; BSI Standards Limited: UK, 2017. [Google Scholar]
- Jeon, Y.-S.; Lee, N.; Poor, H.V. Robust Data Detection for MIMO Systems with One-Bit ADCs: A Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 1663–1676. [Google Scholar] [CrossRef]
















| Networks | Inputs | Outputs |
|---|---|---|
| Value network | Pose (x, y, φ) Steering wheel angle ψ Brother number br | State value Vest |
| Policy network | Pose (x, y, φ) Steering wheel angle ψ | Angle increment probability distribution p |
| Steering Rate | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Steering wheel angle (°) | −530 | −430 | −330 | −230 | −130 | 130 | 230 | 330 | 430 | 530 |
| Steering rate | 15.90 | 16.11 | 16.21 | 16.23 | 16.53 | 16.45 | 16.32 | 16.20 | 16.07 | 15.79 |
| Variable | DERL | MCTS + Policy ANN + Refined Vehicle Model | MCTS + Policy ANN | |||
|---|---|---|---|---|---|---|
| Mean | Std. Deviation | Mean | Std. Deviation | Mean | Std. Deviation | |
| Δy (m) | 0.0224 | 0.0229 | 0.0944 | 0.0267 | 0.6566 | 0.3882 |
| Δθ (°) | 0.8867 | 0.0728 | 2.2475 | 0.9722 | −13.3821 | 6.4556 |
| Dr (m) | 0.0872 | 0.0297 | 0.1697 | 0.0269 | −0.5565 | 0.3711 |
| Df (m) | 0.0516 | 0.0302 | 0.0793 | 0.0363 | −0.0260 | 0.1852 |
| Safe d1 (m) | 0.2025 | 0.0314 | 0.2166 | 0.0347 | 0.1124 | 0.0922 |
| Safe d2 (m) | 0.2298 | 0.0443 | 0.2643 | 0.0365 | −0.1112 | 0.1707 |
| Safe d3 (m) | 0.2058 | 0.0434 | 0.2034 | 0.0215 | 0.2457 | 0.0030 |
| Time (s) | 14.9602 | 0.8968 | 15.5552 | 0.7277 | 14.8658 | 0.8314 |
| Success (%) | 100 | 84 | 8 | |||
| Variable | DERL | MCTS + Policy ANN + Refined Vehicle Model | MCTS + Policy ANN | |||
|---|---|---|---|---|---|---|
| Mean | Std. Deviation | Mean | Std. Deviation | Mean | Std. Deviation | |
| Δy (m) | 0.0169 | 0.0148 | 0.0892 | 0.0263 | 0.4389 | 0.3143 |
| Δθ (°) | 0.9038 | 0.0800 | 2.8832 | 2.5573 | −7.8702 | 10.1951 |
| Dr (m) | 0.0846 | 0.0173 | 0.1603 | 0.0277 | −0.3454 | 0.3064 |
| Df (m) | 0.0485 | 0.0186 | 0.0445 | 0.0854 | −0.0311 | 0.2066 |
| Safe d1 (m) | 0.2182 | 0.0373 | 0.2178 | 0.1344 | 0.1105 | 0.0902 |
| Safe d2 (m) | 0.2162 | 0.0507 | 0.2861 | 0.0719 | 0.0791 | 0.4118 |
| Safe d3 (m) | 0.1917 | 0.0502 | 0.2081 | 0.0225 | 0.2906 | 0.1601 |
| Time (s) | 15.0560 | 0.6546 | 15.5248 | 0.3983 | 14.1632 | 1.3715 |
| Success (%) | 100 | 70 | 10 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, S.; Chen, H.; Sun, H.; Liu, M. Data Efficient Reinforcement Learning for Integrated Lateral Planning and Control in Automated Parking System. Sensors 2020, 20, 7297. https://doi.org/10.3390/s20247297
Song S, Chen H, Sun H, Liu M. Data Efficient Reinforcement Learning for Integrated Lateral Planning and Control in Automated Parking System. Sensors. 2020; 20(24):7297. https://doi.org/10.3390/s20247297
Chicago/Turabian StyleSong, Shaoyu, Hui Chen, Hongwei Sun, and Meicen Liu. 2020. "Data Efficient Reinforcement Learning for Integrated Lateral Planning and Control in Automated Parking System" Sensors 20, no. 24: 7297. https://doi.org/10.3390/s20247297