3D Human Pose Estimation with a Catadioptric Sensor in Unconstrained Environments Using an Annealed Particle Filter



Abstract
:1. Introduction
2. Related Work
3. 3D Human Pose Estimation
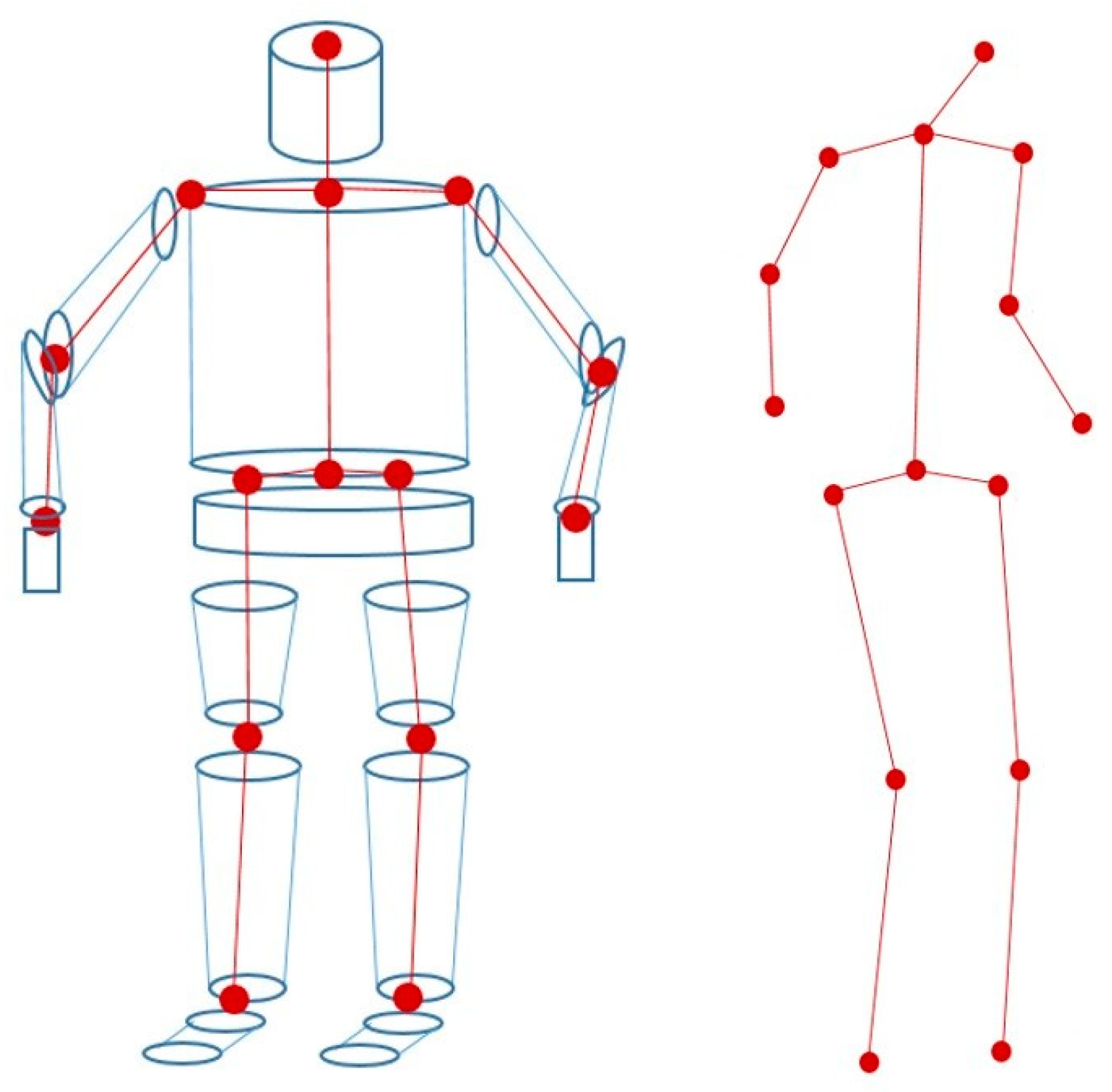
3.1. The 3D Human Model
3.2. The Filtering
- Prediction step:
- Update step
3.3. Likelihood Functions
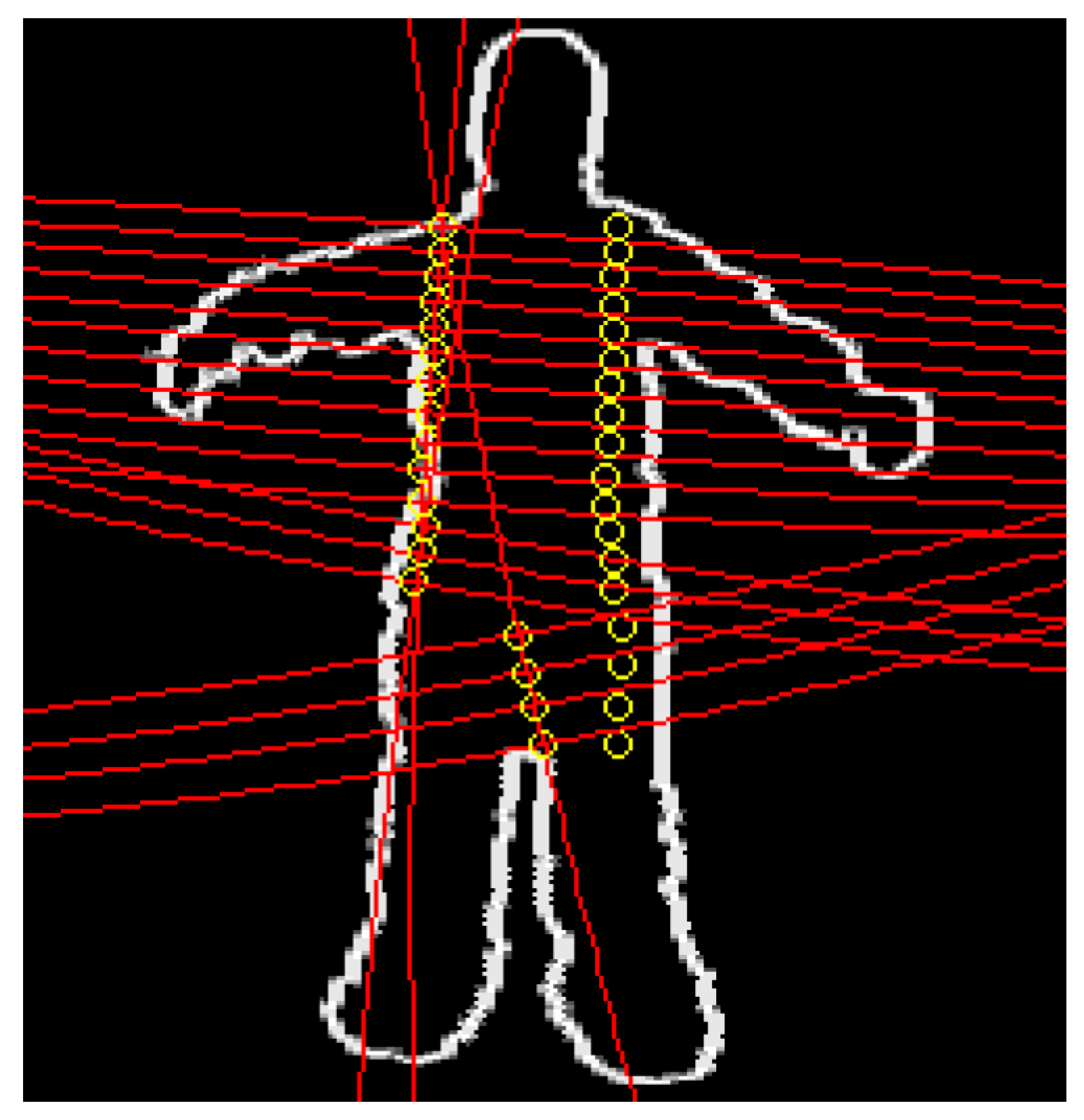
3.3.1. Edge-Based Likelihood Function
3.3.2. Silhouette-Based Likelihood Function
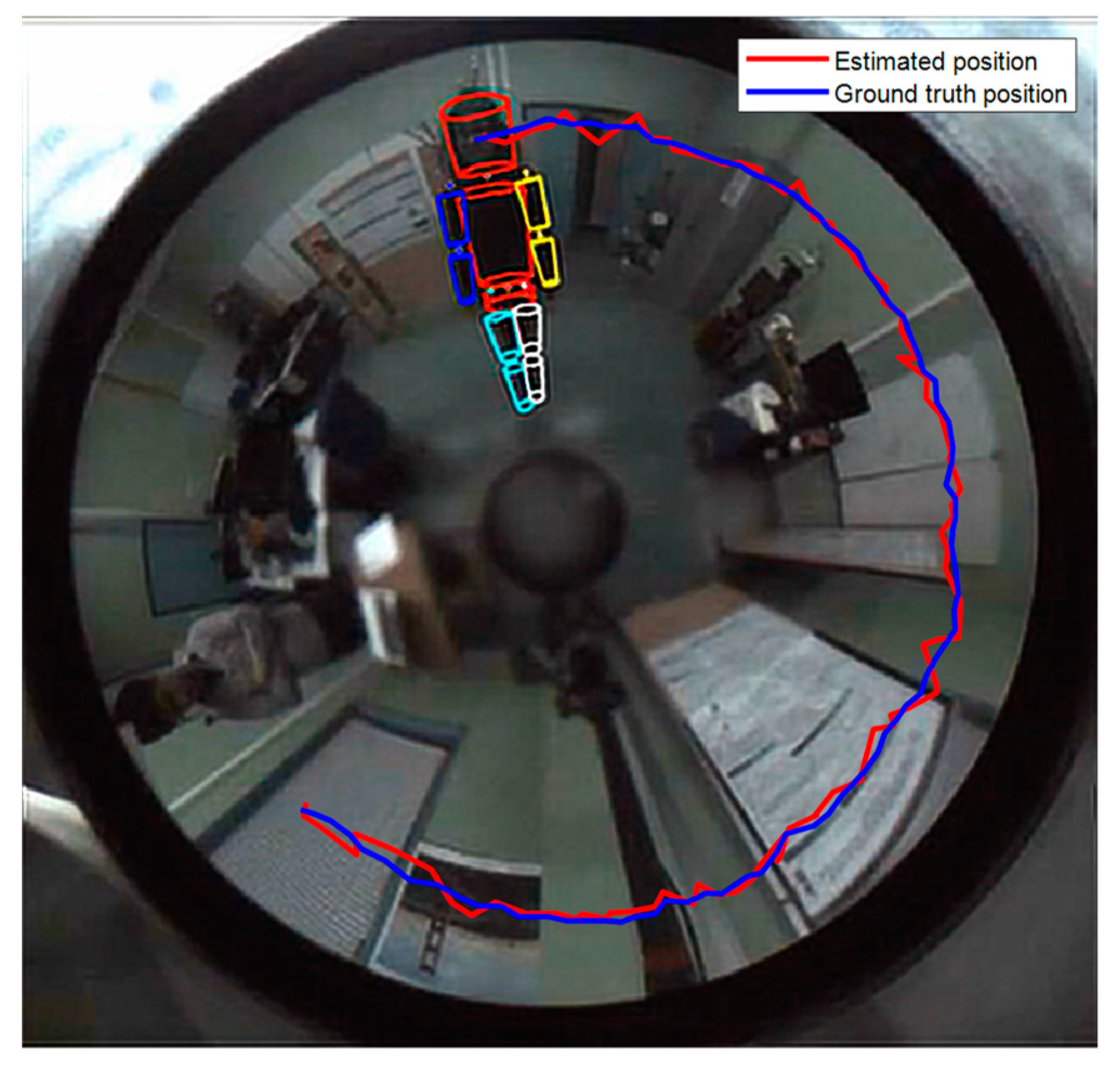
4. Experimental Results
4.1. Acquisition System Setup
4.2. Database Construction
4.3. Performance Criteria
4.4. Evaluation of the APF Parameters
4.5. Comparing of Likelihood Functions
4.6. Evaluation of the Computation Time
4.7. Comparison with Other Works
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Boui, M.; Hadj-Abdelkader, H.; Ababsa, F. New approach for human detection in spherical images. In Proceedings of the IEEE International Conference on In Image Processing (ICIP), Chicago, IL, USA, 25–28 September 2016; pp. 604–608. [Google Scholar]
- Agarwal, A.; Triggs, B. Recovering 3D human pose from monocular images. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 44–58. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, S.; Chan, A.B. 3D human pose estimation from monocular images with deep convolutional neural network. In Proceedings of the Asian Conference on Computer Vision (ACCV); Springer: Berlin/Heidelberg, Germany, 2014; pp. 332–347. [Google Scholar]
- Tekin, B.; Rozantsev, A.; Lepetit, V.; Fua, P. Direct prediction of 3D body poses from motion compensated sequences. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 991–1000. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-Fine volumetric prediction for single-image 3D human pose. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 21–26 July 2017; pp. 1263–1272. [Google Scholar]
- Zhou, X.; Zhu, M.; Leonardos, S.; Derpanis, K.G.; Daniilidis, K. Sparseness meets deepness: 3D human pose estimation from monocular video. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4966–4975. [Google Scholar]
- Fang, H.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S. Learning pose grammar to encoder human body configuration for 3D pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, C.H.; Ramanan, D. 3D human pose estimation = 2D pose estimation + matching. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 21–26 July 2017; pp. 7035–7043. [Google Scholar]
- Chou, C.; Chien, J.; Chen, H. Self-adversarial training for human pose estimation. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 17–30. [Google Scholar]
- Chen, Y.; Shen, C.; Wei, X.; Liu, L.; Yang, J. Adversarial posenet: A structure-aware convolutional network for human pose estimation. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 22–29 October 2017; pp. 1221–1230. [Google Scholar]
- Chen, C.H.; Tyagi, A.; Agrawal, A.; Drover, D.; MV, R.; Stojanov, S.; Rehg, J.M. Unsupervised 3D Pose Estimation with Geometric Self-Supervision. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5714–5724. [Google Scholar]
- Habibie, I.; Xu, W.; Mehta, D.; Pons-Moll, G.; Theobalt, C. In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10905–10914. [Google Scholar]
- Rogez, G.; Orrite, G.; Martinez-del Rincon, J. A spatiotemporal 2D-models framework for human pose recovery in monocular sequences. Pattern Recognit. 2008, 41, 2926–2944. [Google Scholar] [CrossRef]
- Simo-Serra, E.; Quattoni, A.; Torras, C. A joint model for 2D and 3D pose estimation from a single image. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3634–3641. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated pose estimation with flexible mixtures-of-parts. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 1385–1392. [Google Scholar]
- Geyer, C.; Daniilidis, K. A unifying theory for central panoramic systems and practical implications. In Proceedings of the European Conference on Computer Vision (ECCV), Dublin, Ireland, 26 June–1 July 2000; pp. 445–461. [Google Scholar]
- Bazin, J.C.; Demonceaux, C.; Vasseur, P. Motion estimation by decoupling rotation and translation in catadioptric vision. J. Comput. Vis. Image Underst. 2010, 114, 254–273. [Google Scholar] [CrossRef] [Green Version]
- Mei, C.; Sommerlade, E.; Sibley, G. Hidden view synthesis using real-time visual SLAM for simplifying video surveillance analysis. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 4240–4245. [Google Scholar]
- Hadj-Abdelkader, H.; Mezouar, Y.; Martinet, P. Decoupled visual servoing based on the spherical projection of a set of points. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 1110–1115. [Google Scholar]
- Delibasis, K.; Georgakopoulos, S.V.; Kottari, K. Geodesically-corrected Zernike descriptors for pose recognition in omni-directional images. Integr. Comput. Aided Eng. 2016, 23, 185–199. [Google Scholar] [CrossRef]
- Elhayek, A.; Aguiar, E.; Jain, A. MARCOnI-ConvNet-based MARker-less motion capture in outdoor and indoor scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 501–514. [Google Scholar] [CrossRef]
- Caron, G.; Mouaddib, E.M.; Marchand, E. 3D model based tracking for omnidirectional vision: A new spherical approach. J. Robot. Auton. Syst. 2012, 60, 1056–1068. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Li, Y.; Sam, S. Parameterized Distortion-Invariant Feature for Robust Tracking in Omnidirectional Vision. IEEE Trans. Autom. Sci. Eng. 2016, 13, 743–756. [Google Scholar] [CrossRef]
- Bristow, H.; Lucey, S. Why do linear SVMs trained on HOG features perform so well? arXiv 2014, arXiv:1406.2419. [Google Scholar]
- Kostrikov, I.; Gall, J. Depth Sweep Regression Forests for Estimating 3D Human Pose from Images. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014; pp. 1–13. [Google Scholar]
- Gall, J.; Yao, A.; Razavi, N. Hough forests for object detection, tracking and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2188–2202. [Google Scholar] [CrossRef] [PubMed]
- Sanzari, M.; Ntouskos, V.; Pirri, F. Bayesian image based 3D pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 566–582. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear mode. ACM Trans. Graph. 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Lee, J.M. Riemannian Manifolds: An Introduction to Curvature; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006; Volume 176. [Google Scholar]
- Wirth, B.; Bar, L.; Rumpf, M.; Sapiro, G. A continuum mechanical approach to geodesics in shape space. Int. J. Comput. Vis. 2011, 93, 293–318. [Google Scholar] [CrossRef] [Green Version]
- Arulampalam, M.S.; Maskell, S.; Gordon, N. A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Migniot, C.; Ababsa, F. Hybrid 3D/2D human tracking in a top view. J. Real-Time Image Process. 2016, 11, 769–784. [Google Scholar] [CrossRef]
- Migniot, C.; Ababsa, F. 3D Human Tracking in a Top View Using Depth Information Recorded by the Xtion Pro-Live Camera. In Proceedings of the International Symp. on Visual Computing (ISVC), Crete, Greece, 29–31 July 2013; pp. 603–612. [Google Scholar]
- Isard, M.; Blake, A. Condensation conditional density propagation for visual tracking. Int. J. Comput. Vis. 1999, 29, 5–28. [Google Scholar] [CrossRef]
- Deutscher, J.; Blake, A.; Reid, I. Articulated body motion capture by annealed particle filtering. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 13–15 June 2000; Volume 2, pp. 126–133. [Google Scholar]
- Available online: https://ar-tracking.com/products/tracking-systems/smarttrack/ (accessed on 7 December 2020).
- Ning, H.; Xu, W.; Gong, Y. Discriminative learning of visual words for 3D human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AL, USA, 15–18 June 2008; pp. 1–8. [Google Scholar]
- Navaratnam, R.; Fitzgibbon, A.W.; Cipolla, R. The joint manifold model for semi-supervised multi-valued regression. In Proceedings of the IEEE Proceedings International Conference on Computer Vision (ICCV), Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Wang, C.; Wang, Y.; Lin, Z.; Yuille, A.L.; Gao, W. Robust estimation of 3D human poses from a single image. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2361–2368. [Google Scholar]
- Makris, A.; Argyros, A. Robust 3D Human Pose Estimation Guided by Filtered Subsets of Body Keypoints. In Proceedings of the 16th International Conference on Machine Vision Applications, Tokyo, Japan, 27–31 May 2019; pp. 1–6. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Sequence 1 | Sequence 2 | Sequence 3 | Sequence 4 |
|---|---|---|---|---|
| Number of frames | 600 | 682 | 768 | 432 |
| Duration (second) | 49 | 56 | 63 | 35 |
| Kind of movement | Circular | Circular with arms | Forward/Backward | Walk/occlusion |
| Sequences | |||
|---|---|---|---|
| Sequence 1 | |||
| Sequence 2 | |||
| Sequence 3 | |||
| Sequence 4 |
| Likelihood Functions | Sequence 1 | Sequence 2 | Sequence 3 | Sequence 4 |
|---|---|---|---|---|
| DS | 6.86 ± 0.70 | 7.15 ± 0.65 | 7.95 ± 0.76 | 20.15 ± 1.51 |
| OG | 6.37 ± 0.60 | 8.15 ± 0.72 | 7.01 ± 0.73 | 22.00 ± 1.86 |
| GG | 4.40 ± 0.45 | 5.70 ± 0.53 | 7.20 ± 0.62 | 18.40 ± 1.63 |
| DS + GG | 4.15 ± 0.63 | 5.30 ± 0.58 | 6.72 ± 0.61 | 15.20 ± 1.26 |
| Image Size | 800 × 600 | 1028 × 738 |
|---|---|---|
| Subtracting the background | 0.0067 s (1%) | 0.0073 s (1%) |
| Gradient + geodesic distance computation | 0.39 s (59%) | 0.46 s (58%) |
| Propagation | 0.032 s (5%) | 0.043 s (5%) |
| Likelihood functions computation (dual silhouette) | 0.23 s (35%) | 0.28 s (36%) |
| Total | 0.66 s | 0.79 s |
| Methods | Evaluation Datasets | Error |
|---|---|---|
| Pavlakos et al. [6] | Human3.6M | 59.1 |
| Fang et al. [8] | Human3.6M | 47.5 |
| Chen et al. [9] | Human3.6M | 55.7 |
| Habibie et al. [13] | Human3.6M | 54.3 |
| Wang et al. [40] | HumanEva-I | 71.1 |
| Makris et al. [41] | Berkeley MHAD | 80.0 |
| Our approach | Our own dataset | 64.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ababsa, F.; Hadj-Abdelkader, H.; Boui, M. 3D Human Pose Estimation with a Catadioptric Sensor in Unconstrained Environments Using an Annealed Particle Filter. Sensors 2020, 20, 6985. https://doi.org/10.3390/s20236985
Ababsa F, Hadj-Abdelkader H, Boui M. 3D Human Pose Estimation with a Catadioptric Sensor in Unconstrained Environments Using an Annealed Particle Filter. Sensors. 2020; 20(23):6985. https://doi.org/10.3390/s20236985
Chicago/Turabian StyleAbabsa, Fakhreddine, Hicham Hadj-Abdelkader, and Marouane Boui. 2020. "3D Human Pose Estimation with a Catadioptric Sensor in Unconstrained Environments Using an Annealed Particle Filter" Sensors 20, no. 23: 6985. https://doi.org/10.3390/s20236985