Internet of Things and Machine Learning for Healthy Ageing: Identifying the Early Signs of Dementia †


Abstract
:1. Introduction
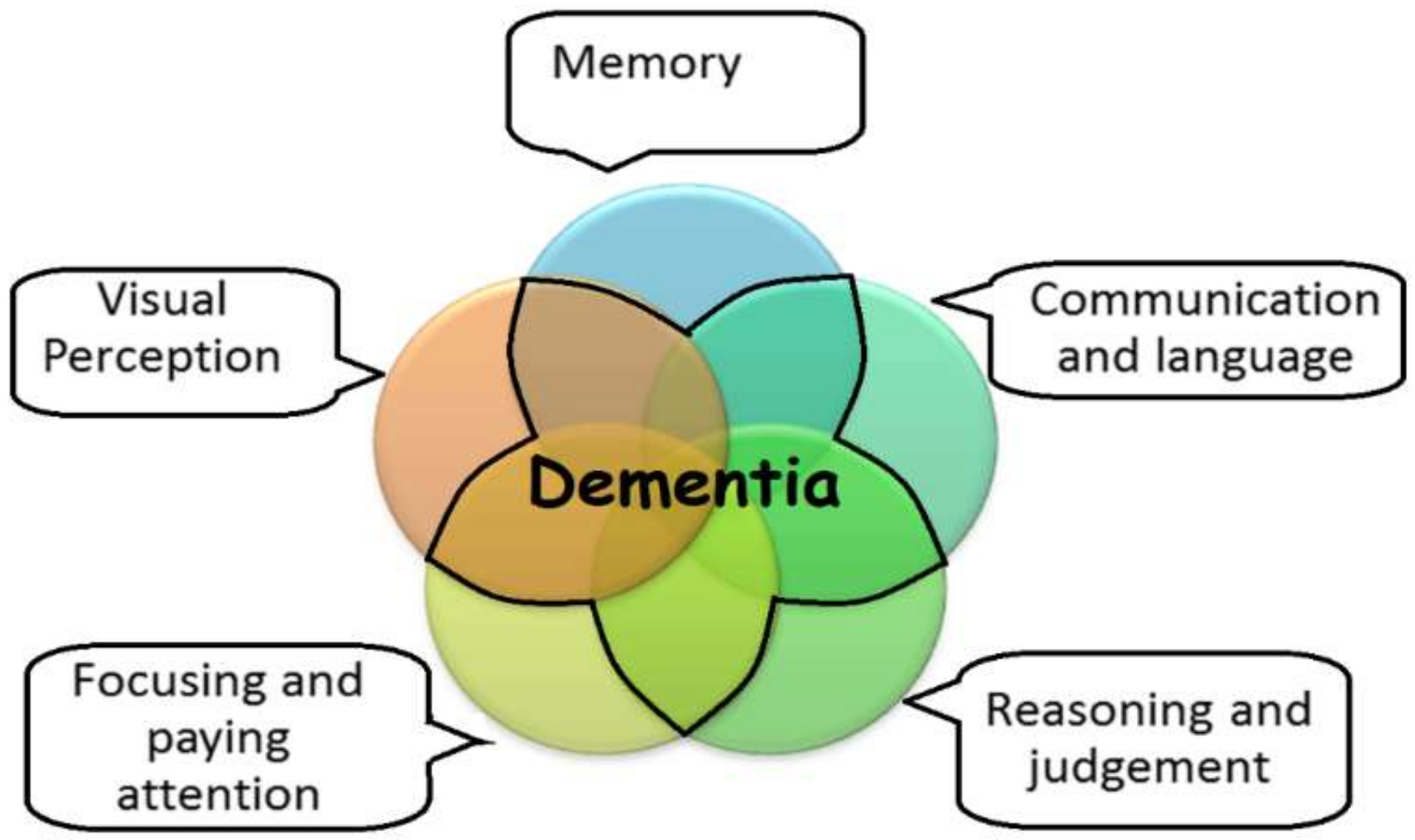
1.1. Characteristics and Adverse Effects of Dementia
- Anxiety
- Depression
- Hallucinations
- Delusions
- Psychomotor agitation
- Aggression
- Wandering
- Screaming
- Shouting
- Biting
- Spitting
- Sexually inappropriate behaviour
- Sleep disturbances
- Personality change
- Repetitive vocalisation
- Apathy
1.2. IoT and Continuous Monitoring
2. Background and Related Works
2.1. Wearable Sensor-Based Monitoring to Identify the Onset of Cognitive Anomaly
2.2. Remote Monitoring to Identify the Onset of Cognitive Anomaly
2.3. Activity Simulation to Identify the Onset of Dementia
2.4. Machine Learning Approaches to Identify the Onset of Dementia
2.5. Machine Learning Algorithms to Build the Model
- Linear Discriminant Analysis (LDA)
- Logistic Regression
- Naive Bayes
- Feed-Forward neural network (FFNN)
- Support Vector Machine (SVM)
- Ensemble RUSBoost
- K-nearest neighbour (KNN)
- K-fold Cross Validation:
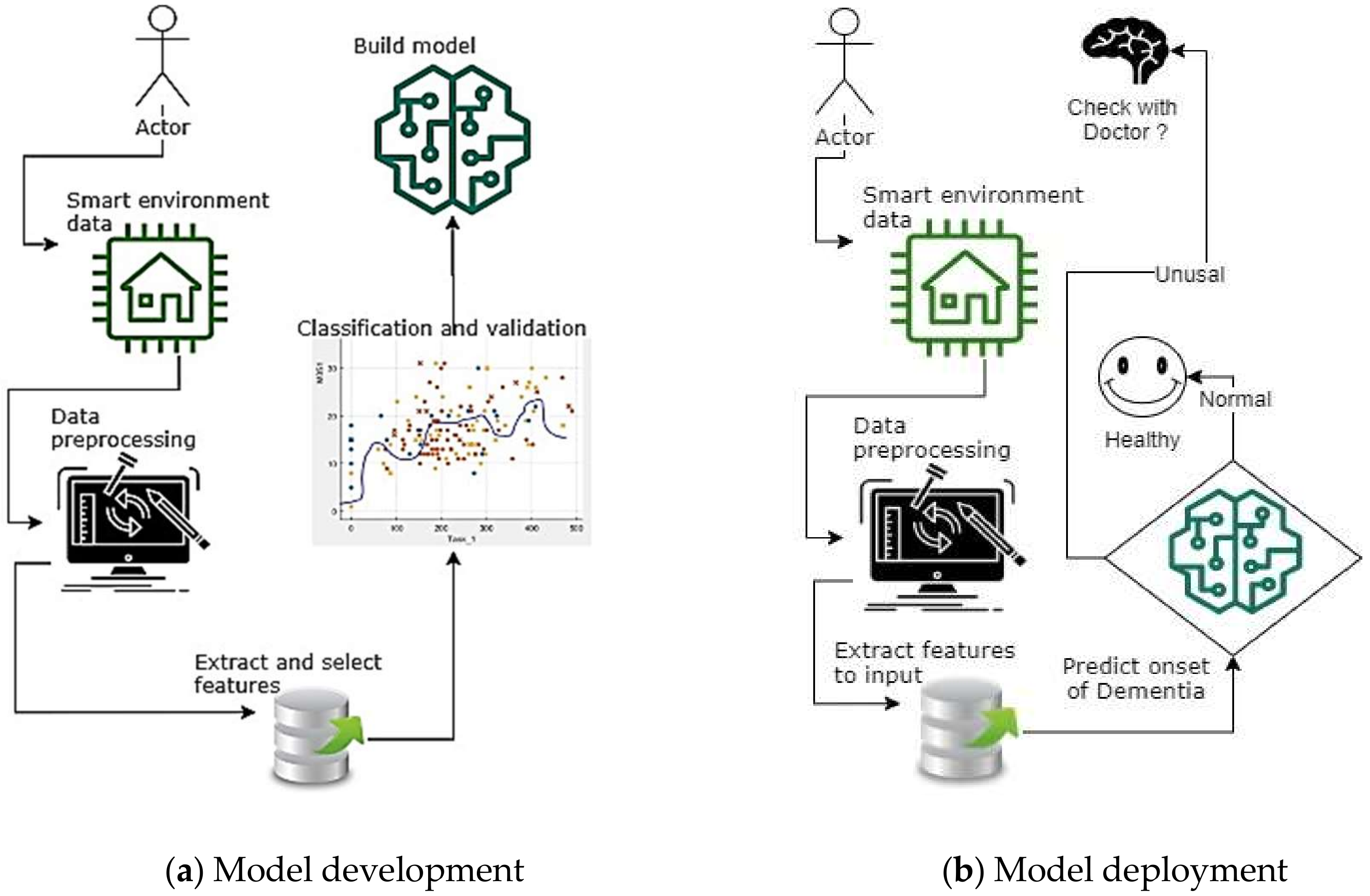
3. Scheme of Identifying the Onset of Dementia
3.1. Identification Method of the Onset of Dementia with IoT
4. Data Analysis and Feature Extraction
4.1. Dataset Overview
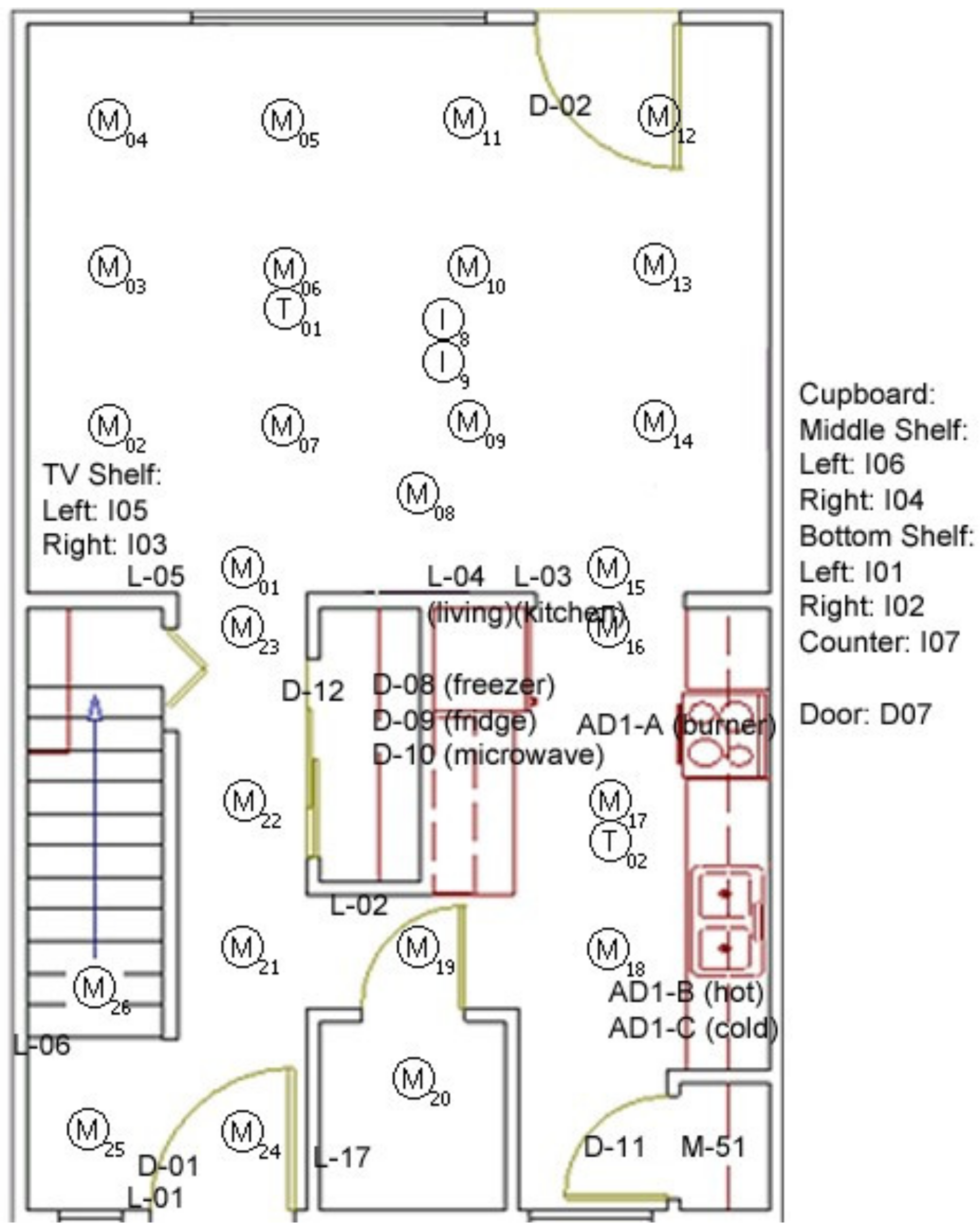
4.1.1. The Layout of the IoT Devices
4.1.2. IoT Architecture of CASAS Environment
- 09:07:02.27948 M015 OFF
- 09:07:03.6804 M013 ON
- 09:07:06.29772 M013 OFF
- 09:07:07.3707 D007 CLOSE
- 09:07:10.67025 M018 ON
- 09:07:10.90595 M019 ON
4.1.3. Activities of the Participants
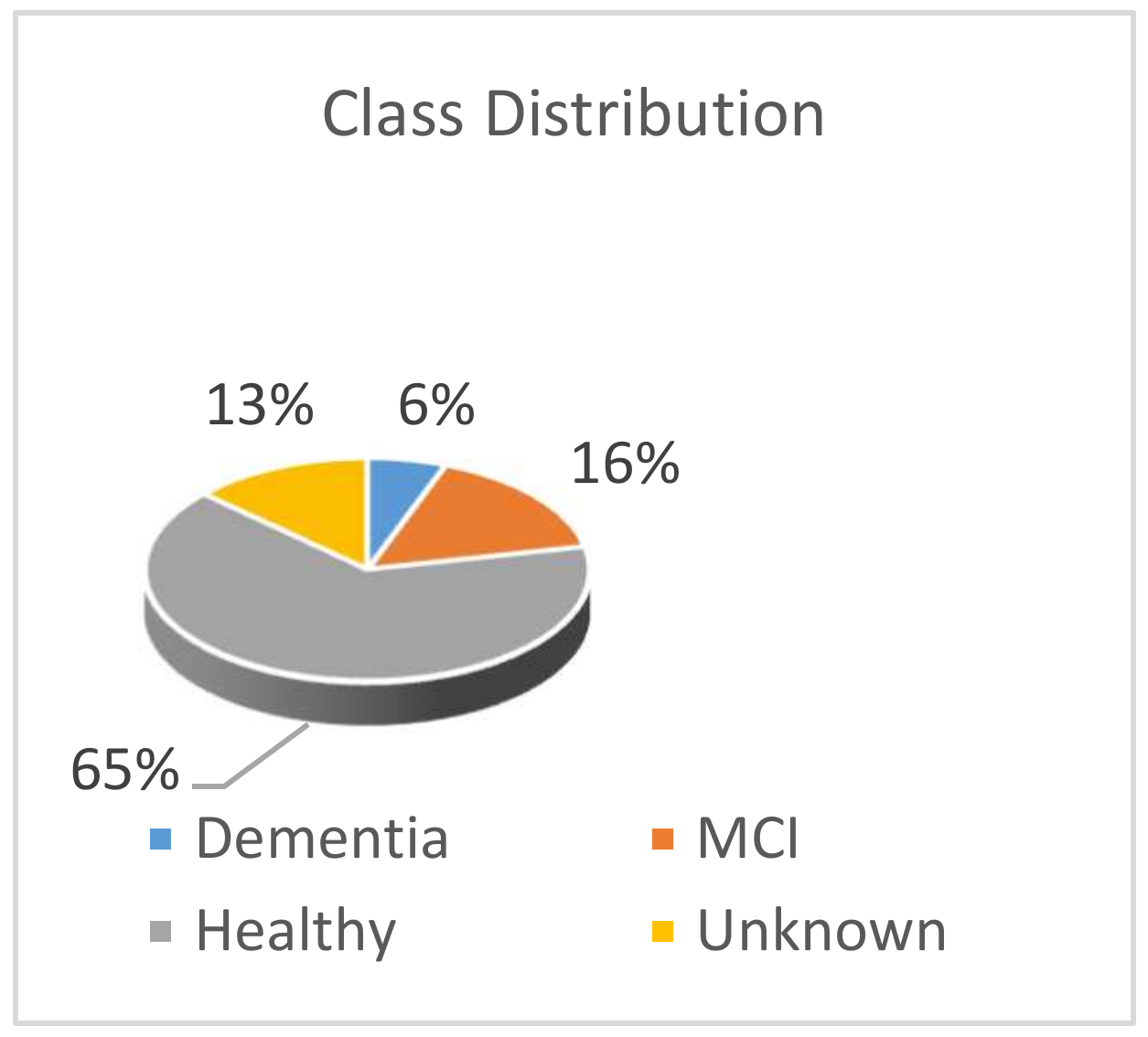
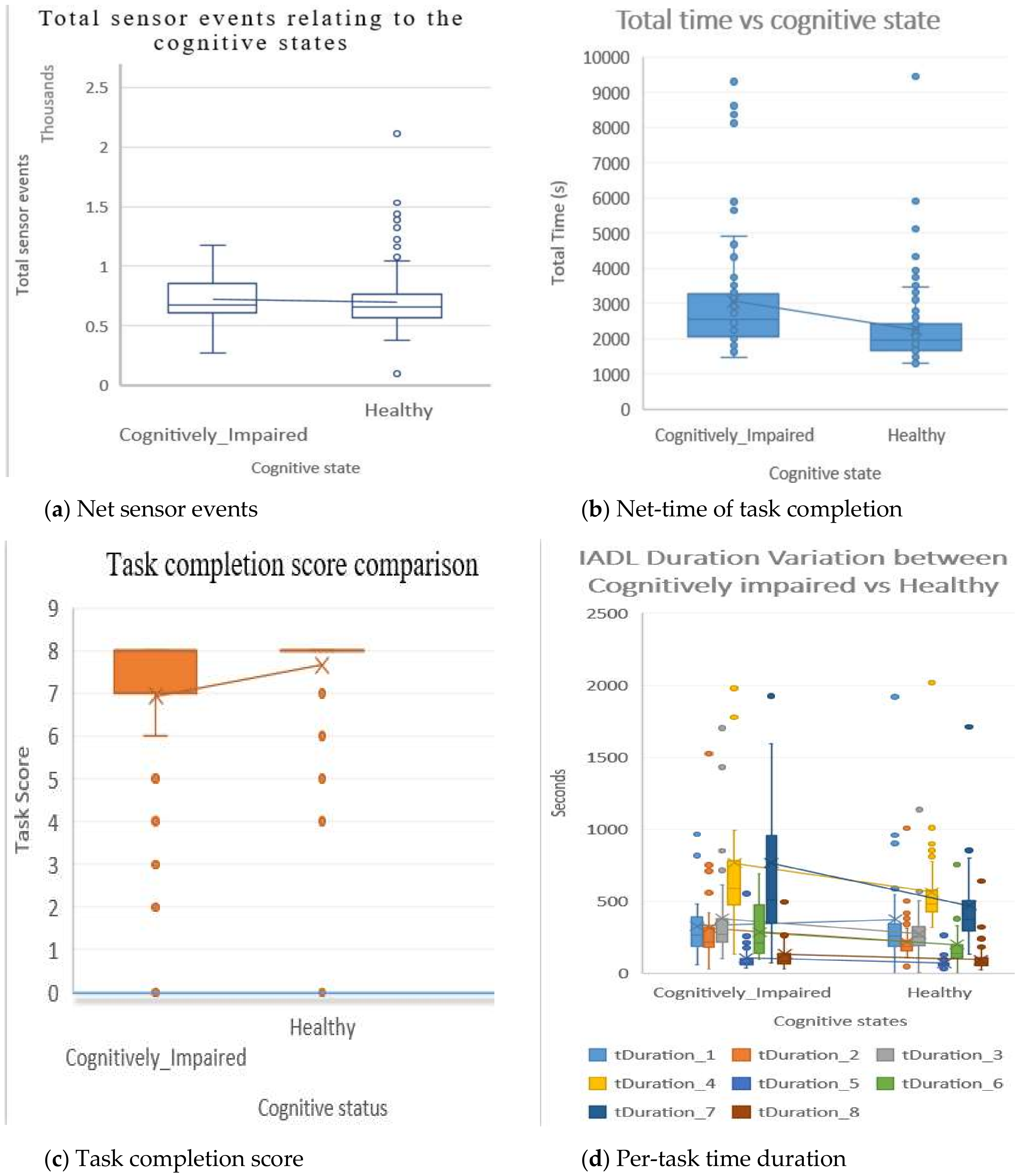
4.2. Data Preprocessing
- Cognitively Impaired
- ◦
- Dementia
- ◦
- MCI
- Healthy
- ◦
- Middle age 45–59
- ◦
- Young-old 60–74
- ◦
- Old 75+
- ◦
- Younger adults
- ◦
- Younger adults, English second language
- Unknown
- ◦
- Other medical
- ◦
- At-risk—follow longitudinally
- ◦
- Diagnosis not available
4.3. Feature Extraction from the Dataset
| Algorithm 1 Procedure to extract features from the dataset |
| Step 1. Start a loop up to the total number of data sample files. For each loop feature will be extracted and will be stored as a row of records. Step 2. Trim the loaded file in each loop to keep the relevant sensor data for the task 1 to 8. Step 2. Calculate the duration of each task (total of eight tasks) and store the record using an inner loop. Step 3. Counting sensor firing events for each relevant sensor (51 sensors) using an inner loop and store the record. Step 4. Repeat the steps (1 to 4) until all the data files are extracted for features. Export the output in a feature matrix table for Machine learning. |
5. Feature Analysis
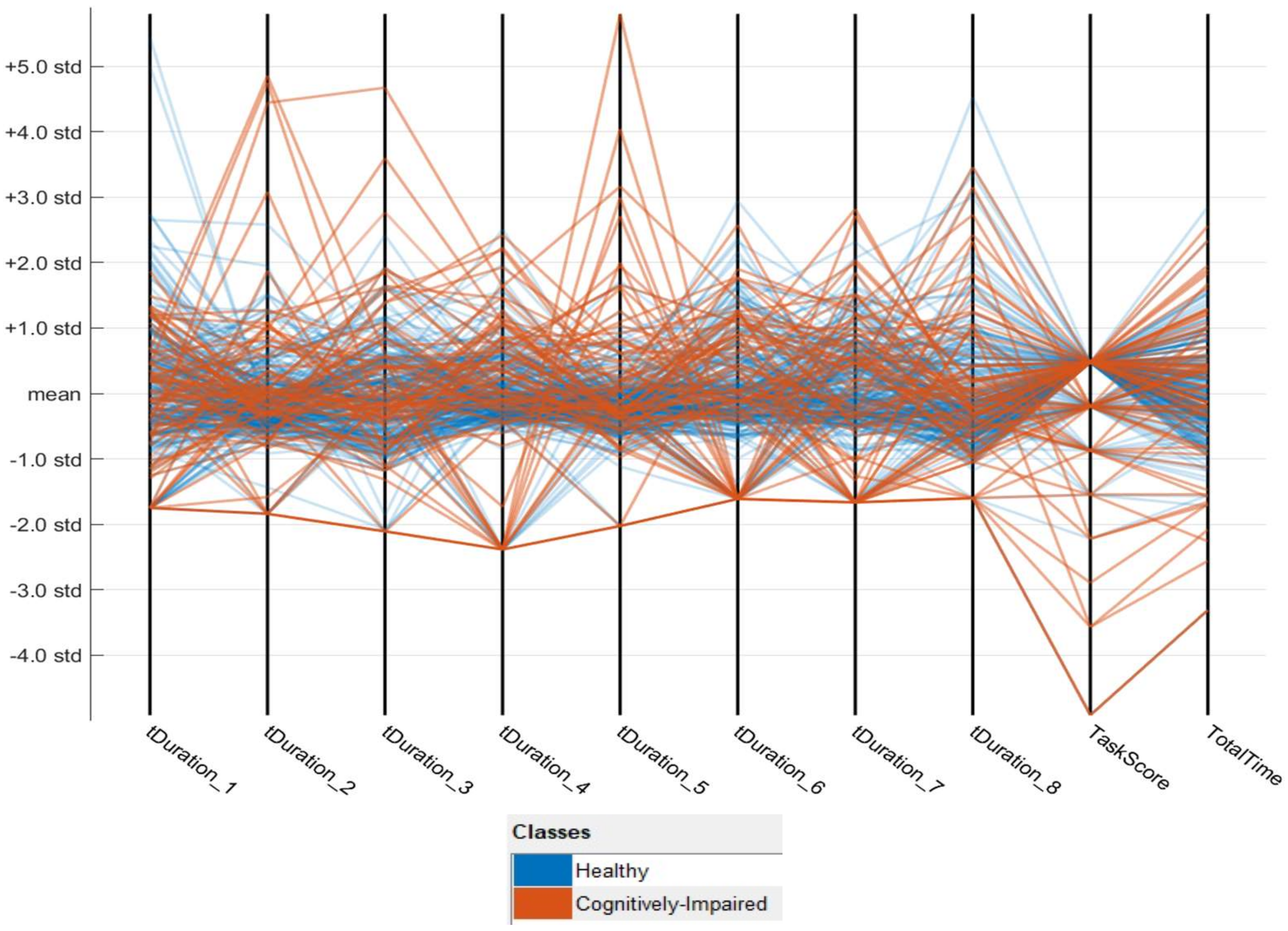
5.1. Feature Data Preview
- X = the features of each data point
- s = sample standard deviation
- = sum of
- = sample mean
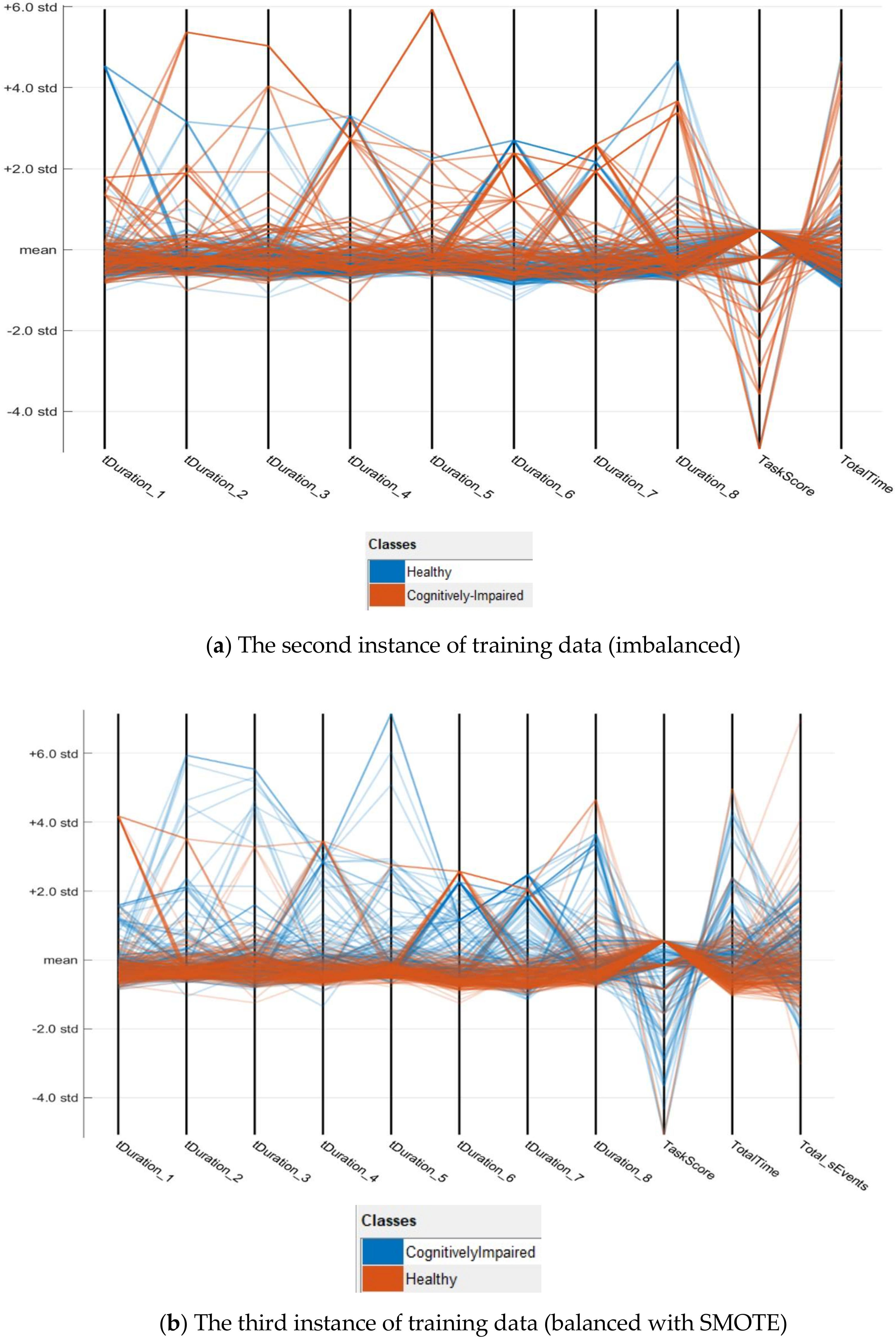
- N = number of records (250 for imbalanced data and 400 for balanced data).
| Algorithm 2 Procedure to replace missing values |
| Start of Loop, For each missing values of task durations (tDuration_1 to tDuration_8) Step 1. tDuration = Column name of the missing value Step 2. Category = category of the missing value (Cognitively-Impaired or Cognitively-Healthy) Step 3. MaxValue = Maximum value from the set [Category, tDuration] Step 4. Replace the missing value with two times of “MaxValue”.Continue the loop till the last missing value of the task durations. Step 5. Re-calculate the “TotalTime” parameter with the updated values from tDuration_1 to tDuration_8 |
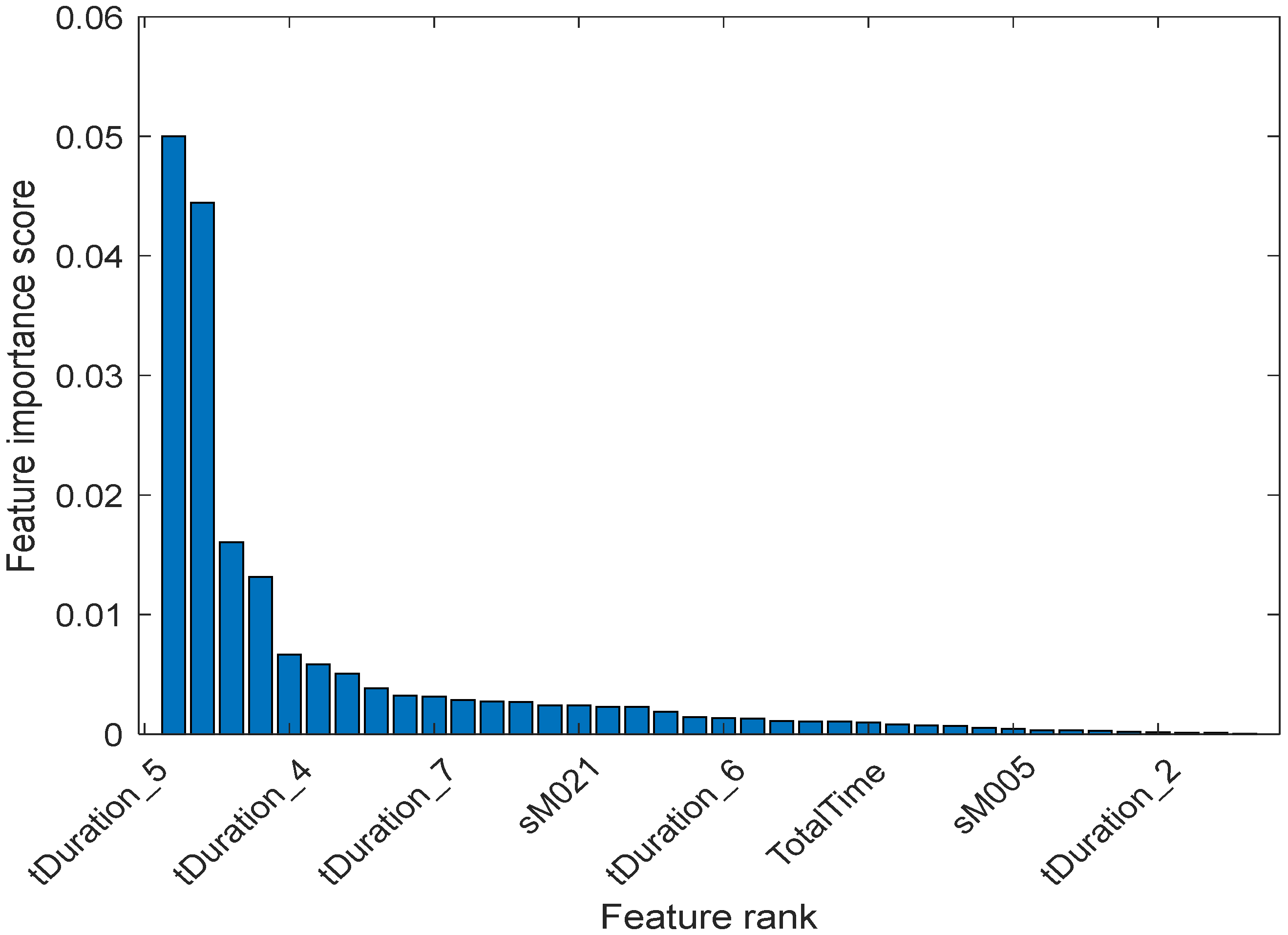
5.2. Feature Ranking
- ‘tDuration_5’
- ‘tDuration_4’
- ‘tDuration_7’
- ‘sM021’
- ‘tDuration_6’
- ‘TotalTime’
- ‘sM005’
- ‘tDuration_2’
- ‘TaskScore’
- ‘tDuration_8’
- ‘tDuration_3’
- ‘tDuration_1’
- ‘Total_sEvents’
6. Model Development and Performance Analysis
6.1. Model Building and Training Performance
6.2. Testing Performance
6.3. Discussion
6.4. Limitation
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Moradi, E.; Pepe, A.; Gaser, C.; Huttunen, H.; Tohka, J. Alzheimer’s Disease Neuroimaging Initiative. Machine learning framework for early MRI-based Alzheimer’s conversion prediction in MCI subjects. Neuroimage 2015, 104, 398–412. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adeli, H.; Ghosh-Dastidar, S.; Dadmehr, N. A spatio-temporal wavelet-chaos methodology for EEG-based diagnosis of Alzheimer’s disease. Neurosci. Lett. 2008, 444, 190–194. [Google Scholar] [CrossRef]
- Cichocki, A.; Shishkin, S.L.; Musha, T.; Leonowicz, Z.; Asada, T.; Kurachi, T. EEG filtering based on blind source separation (BSS) for early detection of Alzheimer’s disease. Clin. Neurophysiol. 2005, 116, 729–737. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jack, C.R.; Petersen, R.C.; Xu, Y.C.; O’Brien, P.C.; Smith, G.E.; Ivnik, R.J.; Boeve, B.F.; Waring, S.C.; Tangalos, E.G.; Kokmen, E. Prediction of AD with MRI-based hippocampal volume in mild cognitive impairment. Neurology 1999, 52, 1397. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, K.-J.; Hassan, M.M.; Na, S.-H.; Huh, E.-N. Dementia wandering detection and activity recognition algorithm using tri-axial accelerometer sensors. In Proceedings of the 4th International Conference on Ubiquitous Information Technologies & Applications, Fukuoka, Japan, 20–22 December 2009; pp. 1–5. [Google Scholar]
- Lin, Q.; Zhang, D.; Huang, X.; Ni, H.; Zhou, X. Detecting wandering behavior based on GPS traces for elders with dementia. In Proceedings of the 2012 12th International Conference on Control Automation Robotics & Vision (ICARCV), Guangzhou, China, 5–7 December 2012; pp. 672–677. [Google Scholar]
- Qassem, T.; Tadros, G.; Moore, P.; Xhafa, F. Emerging Technologies for Monitoring Behavioural and Psychological Symptoms of Dementia. In Proceedings of the 2014 Ninth International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Guangdong, China, 8–10 November 2014; pp. 308–315. [Google Scholar]
- Ahamed, F.; Shahrestani, S.; Cheung, H. Identification of the Onset of Dementia of Older Adults in the Age of Internet of Things. In Proceedings of the 2018 International Conference on Machine Learning and Data Engineering (iCMLDE), Sydney, Australia, 3–7 December 2018; pp. 1–7. [Google Scholar]
- ABO Data Statistics. Causes of Death, Australia. Statistics; Australian Bureau of Statistics: Canberra, ACT, Australia, 2018.
- Blessed, G.; Tomlinson, B.E.; Roth, M. The association between quantitative measures of dementia and of senile change in the cerebral grey matter of elderly subjects. Br. J. Psychiatry 1968, 114, 797–811. [Google Scholar] [CrossRef] [PubMed]
- Ahamed, F. CASAS Feature Extraction. Available online: https://github.com/fsumon/CASAS/ (accessed on 31 August 2020).
- Cerejeira, J.; Lagarto, L.; Mukaetova-Ladinska, E. Behavioral and Psychological Symptoms of Dementia. Front. Neurol. 2012, 3, 73. [Google Scholar] [CrossRef] [Green Version]
- Piguet, O.; Hornberger, M.; Mioshi, E.; Hodges, J.R. Behavioural-variant frontotemporal dementia: Diagnosis, clinical staging, and management. Lancet Neurol. 2011, 10, 162–172. [Google Scholar] [CrossRef]
- Cook, D.J.; Schmitter-Edgecombe, M.; Dawadi, P. Analyzing activity behavior and movement in a naturalistic environment using smart home techniques. IEEE J. Biomed. Health Inform. 2015, 19, 1882–1892. [Google Scholar] [CrossRef]
- Fleury, A.; Vacher, M.; Noury, N. SVM-based multimodal classification of activities of daily living in health smart homes: Sensors, algorithms, and first experimental results. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 274–283. [Google Scholar] [CrossRef] [Green Version]
- Ordónez, F.J.; de Toledo, P.; Sanchis, A. Activity recognition using hybrid generative/discriminative models on home environments using binary sensors. Sensors 2013, 13, 5460–5477. [Google Scholar] [CrossRef]
- Fleury, A.; Noury, N.; Vacher, M. Introducing knowledge in the process of supervised classification of activities of Daily Living in Health Smart Homes. In Proceedings of the 12th IEEE International Conference on e-Health Networking, Applications and Services, Lyon, France, 1–3 July 2010; pp. 322–329. [Google Scholar]
- Peetoom, K.K.; Lexis, M.A.; Joore, M.; Dirksen, C.D.; De Witte, L.P. Literature review on monitoring technologies and their outcomes in independently living elderly people. Disabil. Rehabil. Assist. Technol. 2015, 10, 271–294. [Google Scholar] [CrossRef] [PubMed]
- Silva de Lima, A.L.; Hahn, T.; de Vries, N.M.; Cohen, E.; Bataille, L.; Little, M.A.; Baldus, H.; Bloem, B.R.; Faber, M.J. Large-Scale Wearable Sensor Deployment in Parkinson’s Patients: The Parkinson@Home Study Protocol. JMIR Res. Protoc. 2016, 5, e172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pirsiavash, H.; Ramanan, D. Detecting activities of daily living in first-person camera views. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2847–2854. [Google Scholar]
- Bianchi, V.; Bassoli, M.; Lombardo, G.; Fornacciari, P.; Mordonini, M.; De Munari, I. IoT Wearable Sensor and Deep Learning: An Integrated Approach for Personalized Human Activity Recognition in a Smart Home Environment. IEEE Internet Things J. 2019, 6, 8553–8562. [Google Scholar] [CrossRef]
- Franco, A.; Magnani, A.; Maio, D. A multimodal approach for human activity recognition based on skeleton and RGB data. Pattern Recognit. Lett. 2020, 131, 293–299. [Google Scholar] [CrossRef]
- Intille, S.S.; Larson, K.; Beaudin, J.; Tapia, E.M.; Kaushik, P.; Nawyn, J.; McLeish, T.J. The PlaceLab: A live-in laboratory for pervasive computing research (video). In Proceedings of the PERVASIVE 2005 Video Program, Munich, Germany, 8–13 May 2005. [Google Scholar]
- AlBeiruti, N.; Begain, K.A. Using Hidden Markov Models to Build Behavioural Models to Detect the Onset of Dementia. In Proceedings of the 2014 Sixth International Conference on Computational Intelligence, Communication Systems and Networks, Tetova, Macedonia, 27–29 May 2014; pp. 18–26. [Google Scholar]
- Abe, Y.; Toya, M.; Inoue, M. Early detection system of senile dementia by behavior sensing. In Proceedings of the 2013 IEEE International Symposium on Consumer Electronics (ISCE), Hsinchu, Taiwan, 3–6 June 2013; pp. 67–68. [Google Scholar]
- Suryadevara, N.K.; Mukhopadhyay, S.C.; Wang, R.; Rayudu, R. Forecasting the behavior of an elderly using wireless sensors data in a smart home. Eng. Appl. Artif. Intell. 2013, 26, 2641–2652. [Google Scholar] [CrossRef]
- Choi, S.; Kim, E.; Oh, S. Human behavior prediction for smart homes using deep learning. In Proceedings of the 2013 IEEE RO-MAN, Gyeongju, Korea, 26–29 August 2013; pp. 173–179. [Google Scholar]
- Zhou, Z.; Chen, X.; Chung, Y.-C.; He, Z.; Han, T.X.; Keller, J.M. Video-based activity monitoring for indoor environments. In Proceedings of the 2009 IEEE International Symposium on Circuits and Systems, Taipei, Taiwan, 24–27 May 2009; pp. 1449–1452. [Google Scholar]
- Ercolano, G.; Riccio, D.; Rossi, S. Two deep approaches for adl recognition: A multi-scale lstm and a cnn-lstm with a 3d matrix skeleton representation. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28 August–1 September 2017; pp. 877–882. [Google Scholar]
- Tóth, L.; Hoffmann, I.; Gosztolya, G.; Vincze, V.; Szatlóczki, G.; Bánréti, Z.; Pákáski, M.; Kálmán, J. A speech recognition-based solution for the automatic detection of mild cognitive impairment from spontaneous speech. Curr. Alzheimer Res. 2018, 15, 130–138. [Google Scholar] [CrossRef]
- Ishii, H.; Kimino, K.; Aljehani, M.; Ohe, N.; Inoue, M. Early Detection System for Dementia using M2M/IoT Platform. Proc. Comput. Sci. 2016, 96, 1332–1340. [Google Scholar] [CrossRef] [Green Version]
- Enshaeifar, S.; Zoha, A.; Markides, A.; Skillman, S.; Acton, S.T.; Elsaleh, T.; Hassanpour, M.; Ahrabian, A.; Kenny, M.; Klein, S.; et al. Health management and pattern analysis of daily living activities of people with dementia using in-home sensors and machine learning techniques. PLoS ONE 2018, 13, e0195605. [Google Scholar] [CrossRef] [Green Version]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Izenman, A.J. Linear discriminant analysis. In Modern Multivariate Statistical Techniques; Springer: Berlin/Heidelberg, Germany, 2013; pp. 237–280. [Google Scholar]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An introduction to logistic regression analysis and reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; pp. 41–46. [Google Scholar]
- Schmidt, W.F.; Kraaijveld, M.A.; Duin, R.P. Feed forward neural networks with random weights. In Proceedings of the International Conference on Pattern Recognition, The Hague, The Netherlands, 30 August–3 September 1992; p. 1. [Google Scholar]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. RUSBoost: A hybrid approach to alleviating class imbalance. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2009, 40, 185–197. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest Neighbour Classifiers. arXiv 2020, arXiv:2004.04523. [Google Scholar]
- Bengio, Y.; Grandvalet, Y. No unbiased estimator of the variance of k-fold cross-validation. J. Mach. Learn. Res. 2004, 5, 1089–1105. [Google Scholar]
- Tombaugh, T.N.; McIntyre, N.J. The mini-mental state examination: A comprehensive review. J. Am. Geriatr. Soc. 1992, 40, 922–935. [Google Scholar] [CrossRef]
- Peres, K.; Helmer, C.; Amieva, H.; Orgogozo, J.M.; Rouch, I.; Dartigues, J.F.; Barberger-Gateau, P. Natural history of decline in instrumental activities of daily living performance over the 10 years preceding the clinical diagnosis of dementia: A prospective population-based study. J. Am. Geriatr. Soc. 2008, 56, 37–44. [Google Scholar] [PubMed]
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A smart home in a box. Computer 2012, 46, 62–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dawadi, P.; Cook, D.; Parsey, C.; Schmitter-Edgecombe, M.; Schneider, M. An approach to cognitive assessment in smart home. In Proceedings of the 2011 Workshop on Data Mining for Medicine and Healthcare, San Diego, CA, USA, 21–24 August 2011; pp. 56–59. [Google Scholar]
- DSM, I. Diagnostic and Statistical Manual of Mental Disorders; American Psychiatric Association: Washington, DC, USA, 1994. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Bangkok, Thailand, 27–30 April 2009; pp. 475–482. [Google Scholar]
- Michio. Oversampling Imbalanced Data: SMOTE Related Algorithms. Available online: https://github.com/minoue-xx/Oversampling-Imbalanced-Data/releases/tag/1.0.1 (accessed on 13 September 2020).
- Ding, C.; Peng, H. Minimum redundancy feature selection from microarray gene expression data. J. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Activities | Tag Name |
|---|---|---|
| 1. | Sweep the kitchen and dust the living room. | Task 1 |
| 2. | Obtain a set of medicines and fill a weekly medicine dispenser. | Task 2 |
| 3. | Write a birthday card, enclose a check, and address an envelope. | Task 3 |
| 4. | Find the appropriate DVD and watch the corresponding news clip. | Task 4 |
| 5. | Obtain a watering can and water all plants in the living space. | Task 5 |
| 6. | Answer the phone and respond to questions of the video from task 4. | Task 6 |
| 7. | Prepare a cup of soup using the microwave. | Task 7 |
| 8. | Pick a complete outfit for an interview from a selection of clothing. | Task 8 |
| Cognitively Impaired Class | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model Type | TN | FN | FP | TP | Sensitivity | Specificity | Precision | Accuracy | F-Score |
| Coarse Decision Tree | 169 | 25 | 25 | 31 | 55.36% | 87.11% | 55.36% | 80.00% | 67.70% |
| Linear Discriminant | 185 | 42 | 9 | 14 | 25.00% | 95.36% | 60.87% | 79.60% | 39.61% |
| Logistics Regression | 184 | 39 | 10 | 17 | 30.36% | 94.85% | 62.96% | 80.40% | 45.99% |
| Kernel Naïve Bayes | 178 | 18 | 16 | 38 | 67.86% | 91.75% | 70.37% | 86.40% | 78.02% |
| Quadratic SVM | 182 | 30 | 12 | 26 | 46.43% | 93.81% | 68.42% | 83.20% | 62.12% |
| Cubic KNN | 186 | 39 | 8 | 17 | 30.36% | 95.88% | 68.00% | 81.20% | 46.11% |
| Ensemble Bagged Trees | 187 | 30 | 7 | 26 | 46.43% | 96.39% | 78.79% | 85.20% | 62.67% |
| Ensemble RUSBoosted | 155 | 14 | 39 | 42 | 75.00% | 79.90% | 51.85% | 78.80% | 77.37% |
| FFNN | 175 | 19 | 29 | 177 | 90.31% | 85.78% | 85.92% | 88.00% | 87.99% |
| Cognitively Impaired Class (Imbalanced Data) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model Type | TN | FN | FP | TP | Sensitivity | Specificity | Precision | Accuracy | F-Score | Cost |
| Fine Decision Tree | 159 | 14 | 35 | 42 | 75.00% | 81.96% | 54.55% | 80.40% | 78.33% | 455 |
| Discriminant Linear | 59 | 2 | 135 | 54 | 96.43% | 30.41% | 28.57% | 45.20% | 46.24% | 175 |
| Naïve Bayes Kernel | 150 | 11 | 44 | 45 | 80.36% | 77.32% | 50.56% | 78.00% | 78.81% | 264 |
| SVM Quadratic | 133 | 21 | 61 | 35 | 62.50% | 68.56% | 36.46% | 67.20% | 65.39% | 481 |
| KNN Cubic | 173 | 30 | 21 | 26 | 46.43% | 89.18% | 55.32% | 79.60% | 61.06% | 621 |
| Ensemble RUSBoosted | 158 | 14 | 36 | 42 | 75.00% | 81.44% | 53.85% | 80.00% | 78.09% | 456 |
| Cognitively Impaired | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model Type | TN | FN | FP | TP | Sensitivity | Specificity | Precision | Accuracy | F-Score |
| Fine Decision Tree | 158 | 36 | 24 | 173 | 82.78% | 86.81% | 87.82% | 84.65% | 84.75% |
| Linear Discriminant | 147 | 47 | 86 | 111 | 70.25% | 63.09% | 56.35% | 65.98% | 66.48% |
| Logistics Regression | 147 | 47 | 81 | 116 | 71.17% | 64.47% | 58.88% | 67.26% | 67.65% |
| Kernel Naïve Bayes | 157 | 37 | 52 | 145 | 79.67% | 75.12% | 73.60% | 77.24% | 77.33% |
| Fine Gaussian SVM | 144 | 50 | 15 | 182 | 78.45% | 90.57% | 92.39% | 83.38% | 84.07% |
| Fine KNN | 149 | 45 | 10 | 187 | 80.60% | 93.71% | 94.92% | 85.93% | 86.66% |
| Ensemble Boosted Tree | 174 | 20 | 13 | 184 | 90.20% | 93.05% | 93.40% | 91.56% | 91.60% |
| Ensemble RUSBoosted | 155 | 39 | 19 | 178 | 82.03% | 89.08% | 90.36% | 85.17% | 85.41% |
| FFNN | 149 | 45 | 51 | 146 | 76.44% | 74.50% | 74.11% | 75.45% | 75.46% |
| Cognitively Impaired | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model Type | TN | FN | FP | TP | Sensitivity | Specificity | Precision | Accuracy | F-Score |
| Median Tree | 34 | 16 | 0 | 6 | 27.27% | 100.00% | 100.00% | 71.43% | 42.86% |
| Kernel Naïve Bayes | 33 | 11 | 1 | 9 | 45.00% | 97.06% | 90.00% | 77.78% | 61.49% |
| SVM | 33 | 13 | 1 | 7 | 35.00% | 97.06% | 87.50% | 74.07% | 51.45% |
| KNN | 31 | 14 | 3 | 6 | 30.00% | 91.18% | 66.67% | 68.52% | 45.15% |
| RUSBoosted Ensemble | 34 | 4 | 0 | 16 | 80.00% | 100.00% | 100.00% | 92.59% | 88.89% |
| FFNN | 34 | 0 | 6 | 14 | 100.00% | 85.00% | 70.00% | 88.89% | 91.89% |
| Cognitively Impaired | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model Type | TN | FN | FP | TP | Sensitivity | Specificity | Precision | Accuracy | F-Score |
| Fine Decision Tree | 31 | 2 | 3 | 18 | 90.00% | 91.18% | 85.71% | 90.74% | 90.58% |
| Kernel Naïve Bayes | 29 | 6 | 5 | 14 | 70.00% | 85.29% | 73.68% | 79.63% | 76.89% |
| Fine Gaussian SVM | 27 | 1 | 5 | 19 | 95.00% | 84.38% | 79.17% | 88.46% | 89.37% |
| Fine KNN | 24 | 1 | 10 | 19 | 95.00% | 70.59% | 65.52% | 79.63% | 80.99% |
| Boosted Tree Ensemble | 27 | 0 | 7 | 20 | 100.00% | 79.41% | 74.07% | 87.04% | 88.52% |
| RUSBoosted Ensemble | 30 | 4 | 2 | 18 | 81.82% | 93.75% | 90.00% | 88.89% | 87.38% |
| FFNN | 28 | 6 | 6 | 14 | 70.00% | 82.35% | 70.00% | 77.78% | 75.68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahamed, F.; Shahrestani, S.; Cheung, H. Internet of Things and Machine Learning for Healthy Ageing: Identifying the Early Signs of Dementia. Sensors 2020, 20, 6031. https://doi.org/10.3390/s20216031
Ahamed F, Shahrestani S, Cheung H. Internet of Things and Machine Learning for Healthy Ageing: Identifying the Early Signs of Dementia. Sensors. 2020; 20(21):6031. https://doi.org/10.3390/s20216031
Chicago/Turabian StyleAhamed, Farhad, Seyed Shahrestani, and Hon Cheung. 2020. "Internet of Things and Machine Learning for Healthy Ageing: Identifying the Early Signs of Dementia" Sensors 20, no. 21: 6031. https://doi.org/10.3390/s20216031