Q-LBR: Q-Learning Based Load Balancing Routing for UAV-Assisted VANET


Abstract
:1. Introduction
- (1)
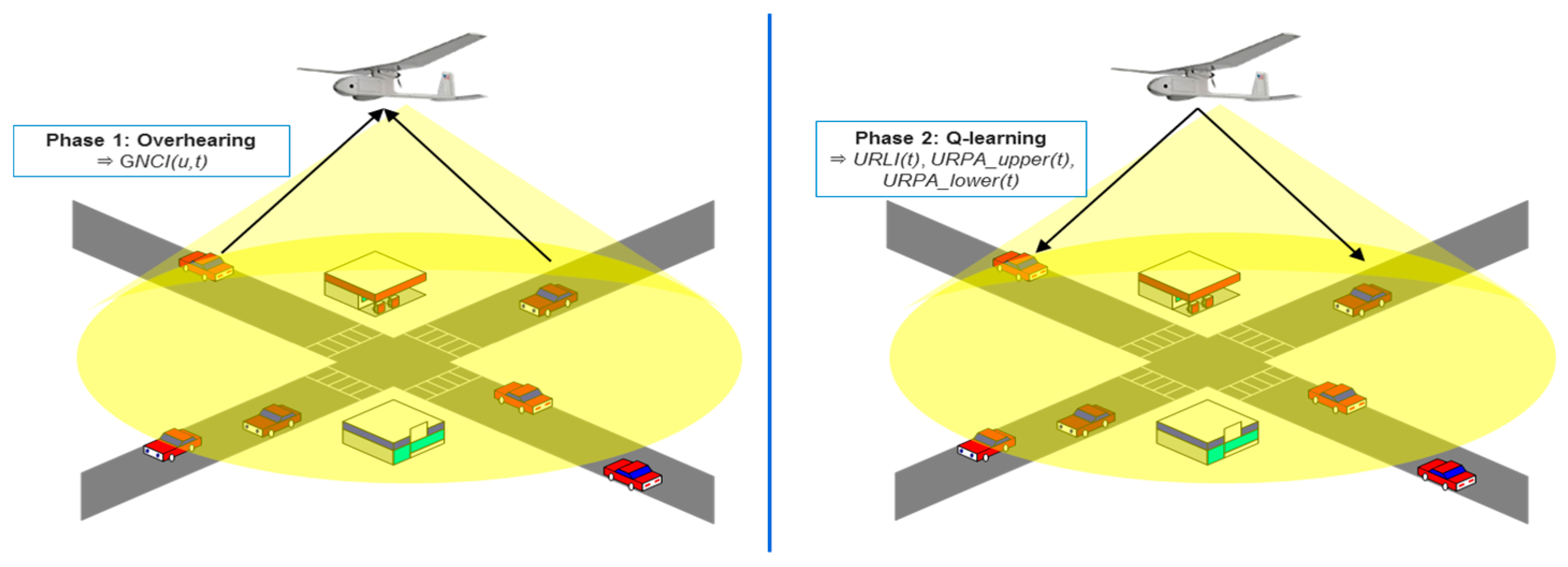
- We propose a low-overhead technique for estimating the network load through the queue status obtained by the URN from each GVN. To estimate a network load with low overhead, we design a technique using overhearing and broadcast messages received from the GVNs. This is possible because the URN can cover an area wider than that of the GVNs.
- (2)
- We propose a load balancing scheme based on Q-learning, which can enable dynamic network load control within the usable capacity of the URN. Q-LBR defines the URPA when considering the traffic characteristics and the existence of a route independently from the ground network routing.
- (3)
- We propose a reward control function (RCF) to enable rapid learning feedback of the reward values in consideration of a dynamic network environment. Q-LBR adjusts the reward value based on the URN load and ground network congestion.
- (4)
- We implemented the Q-LBR on a network-level simulator using the Riverbed Modeler (formerly OPNET) and experimentally evaluated its performance. Our evaluation results showed that Q-LBR achieved a significantly better packet delivery ratio (PDR) and network utilization and latency according to the traffic load conditions than existing algorithms and Q-LBR without Q-learning.
2. Related Studies
2.1. UAV-Assisted Routing Protocols
2.2. Load-Balancing Routing Protocols
2.3. Q-Learning-Based Routing Protocols
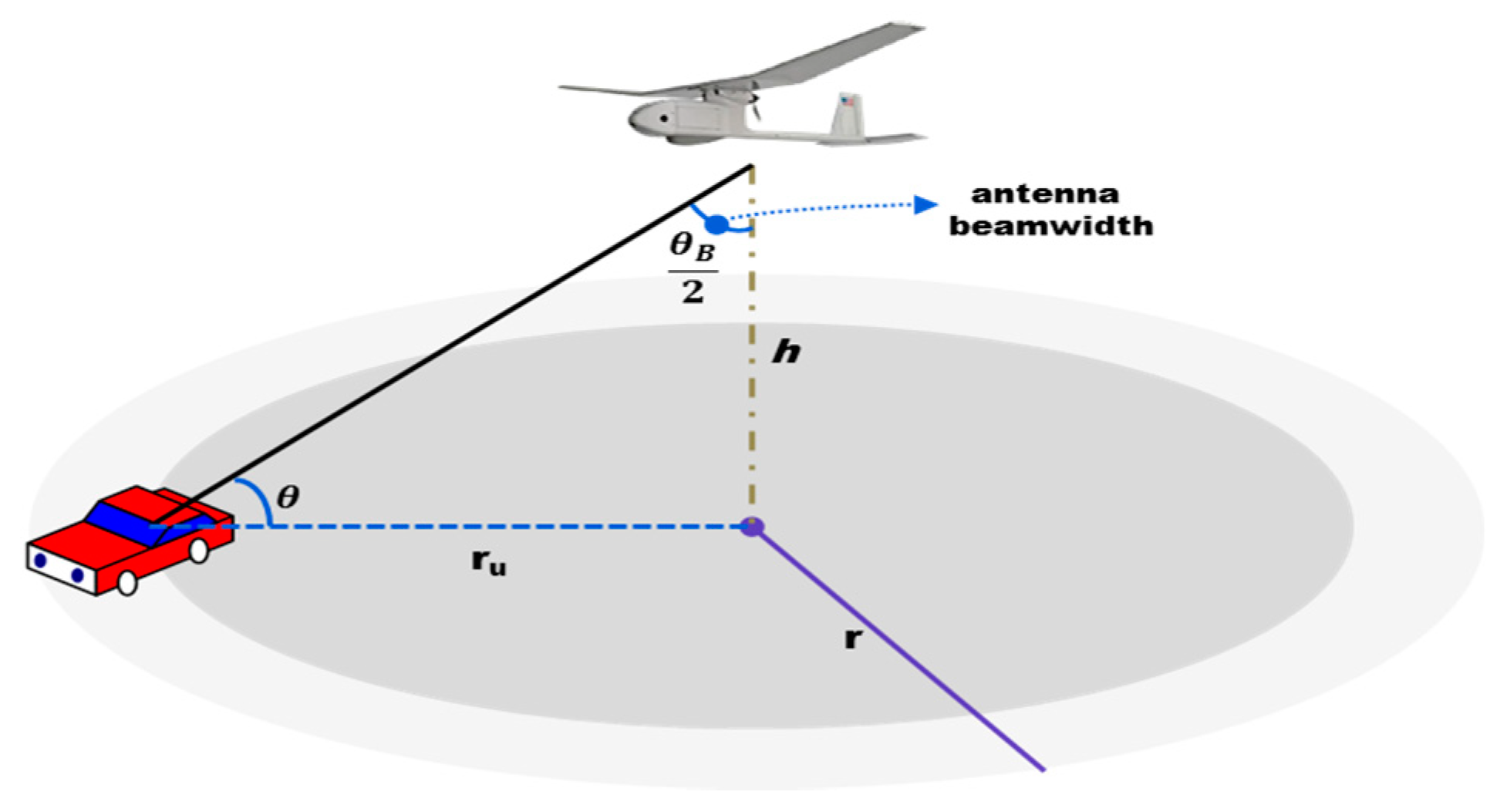
3. System Model and Assumptions
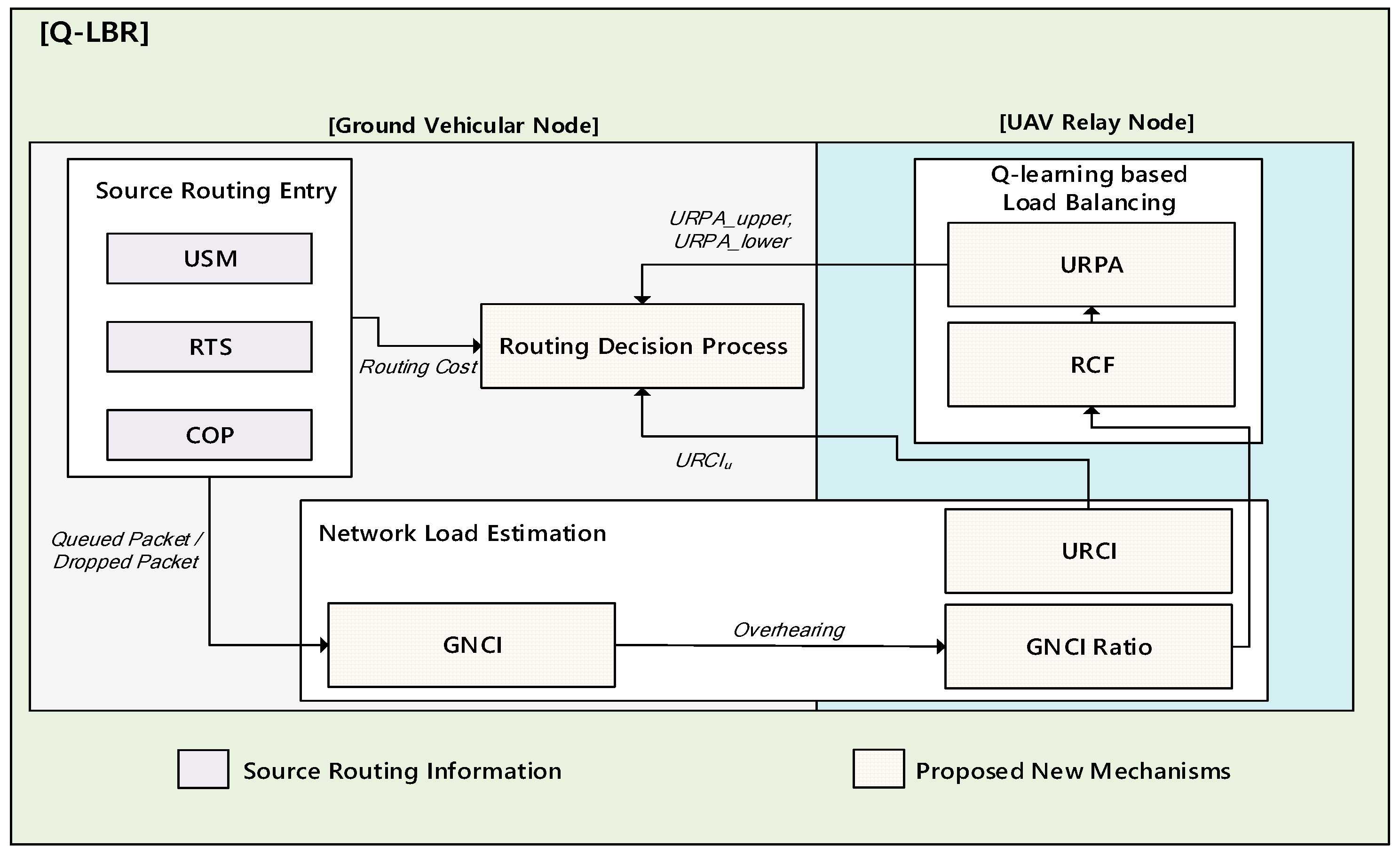
4. Proposed Q-LBR Design
4.1. Path Discovery and Maintenance
4.2. Network Load Estimation
4.2.1. Ground Network Congestion Identifier
4.2.2. UAV Relay Congestion Identification
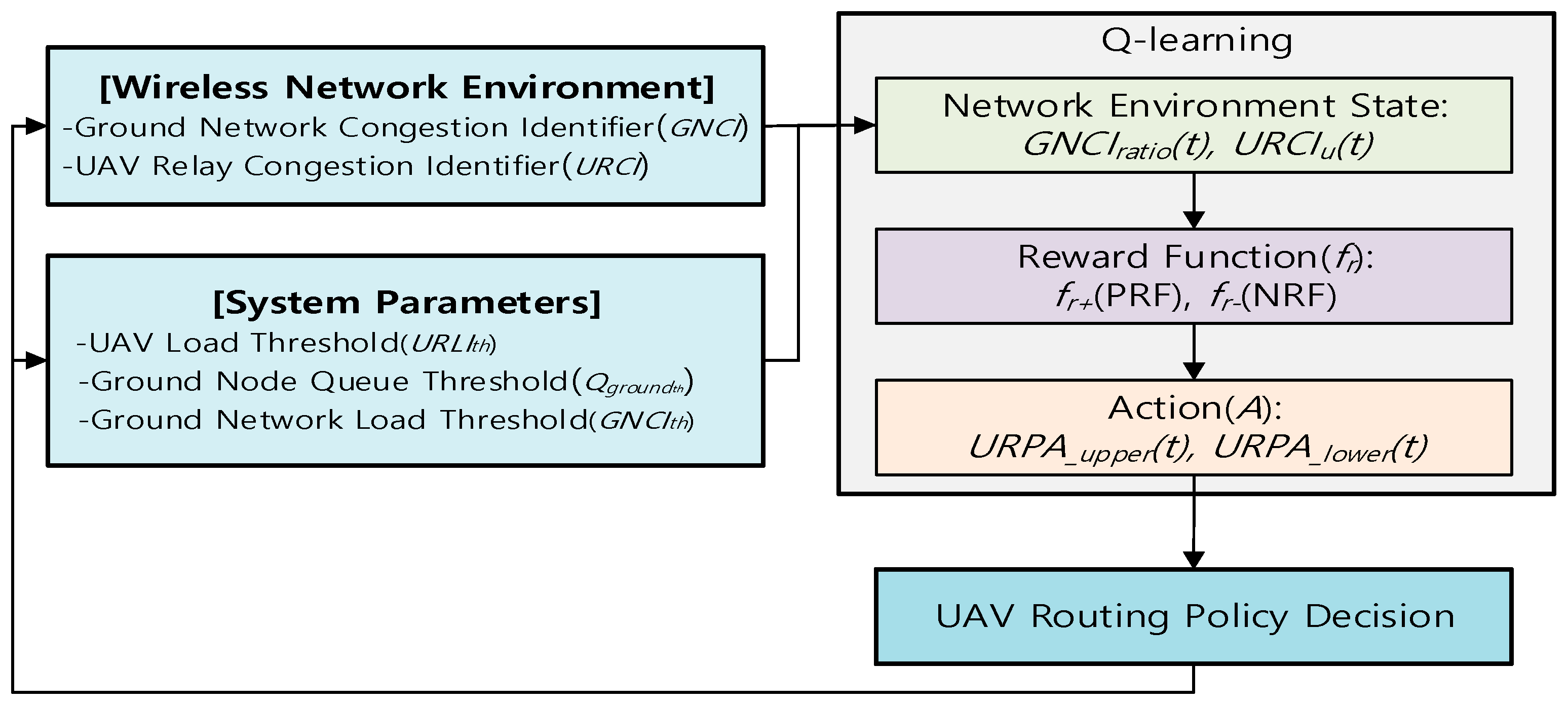
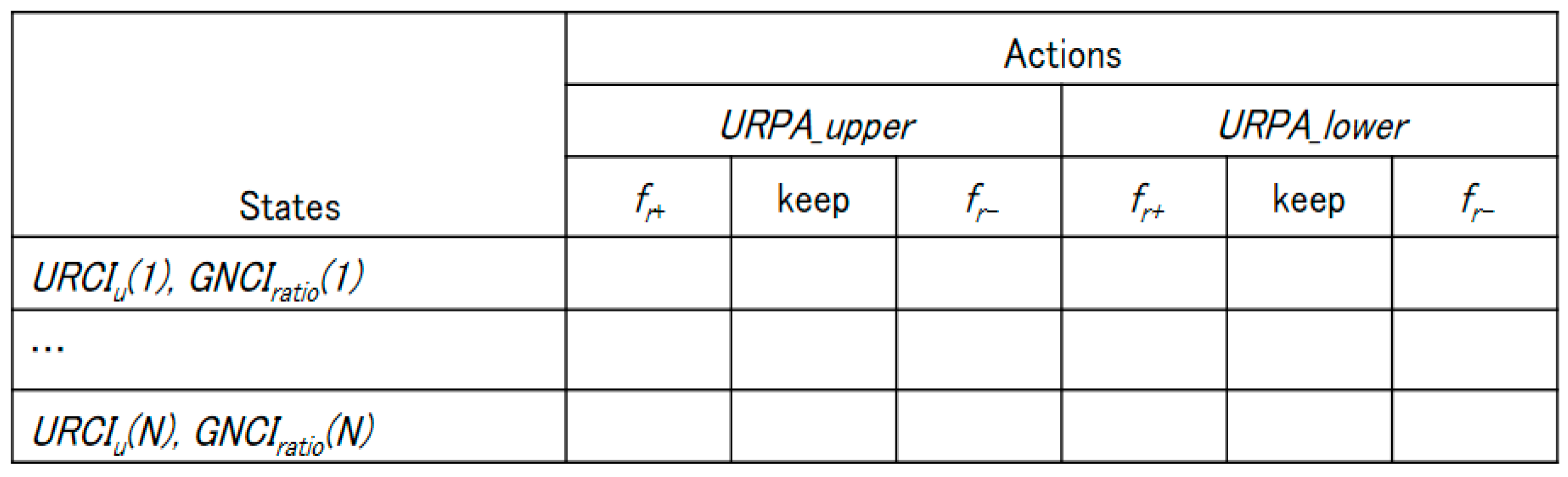
4.3. Q-Learning-Based Load Balancing
4.3.1. Q-Learning Design for UAV-Assisted Network
| Algorithm 1: Q-learning based Load Balancing | ||
| 1: | URN ← UAV relay node; | |
| 2: | GVN ← Ground vehicular node; | |
| 3: | GNCIi ← Ground node congestion identifier from node i; | |
| 4: | GNCIratio ← Ratio of congested GVNs; | |
| 5: | URCIu ← UAV relay congestion identifier from URN; | |
| 6: | URCIth ← Threshold of URCI; | |
| 7: | URPA_upper ← Upper boundary value of UAV routing policy area; | |
| 8: | URPA_lower ← Lower boundary value of UAV routing policy area; | |
| 9: | ← Reward function | |
| 10: | ||
| 11: | for → 1, n do | |
| 12: | for → 1, N do | |
| 13: | URN listens to using overhearing or broadcast messages from node i | |
| 14: | URN calculates at time t received from total number of N | |
| 15: | URN calculates at time t from its own queue load | |
| 16: | ||
| 17: | if ( && ) then | |
| 18: | URN maintains its current state | |
| 19: | Else | |
| 20: | URN calculates the reward (t-1) for the previous action a(t-1) at state s(t-1) | |
| 21: | URN updates the Q-value of (s(t-1), a(t-1)) in Q-table | |
| 22: | URN determines the current state s(t) based on the and | |
| 23: | URN selects the optimal action a(t) for the next t+1 time period | |
| 24: | end if | |
| 25: | ||
| 26: | URN distributes and URPA_upper and URPA_lower to GVN | |
| 27: | end for | |
| 28: | end for | |
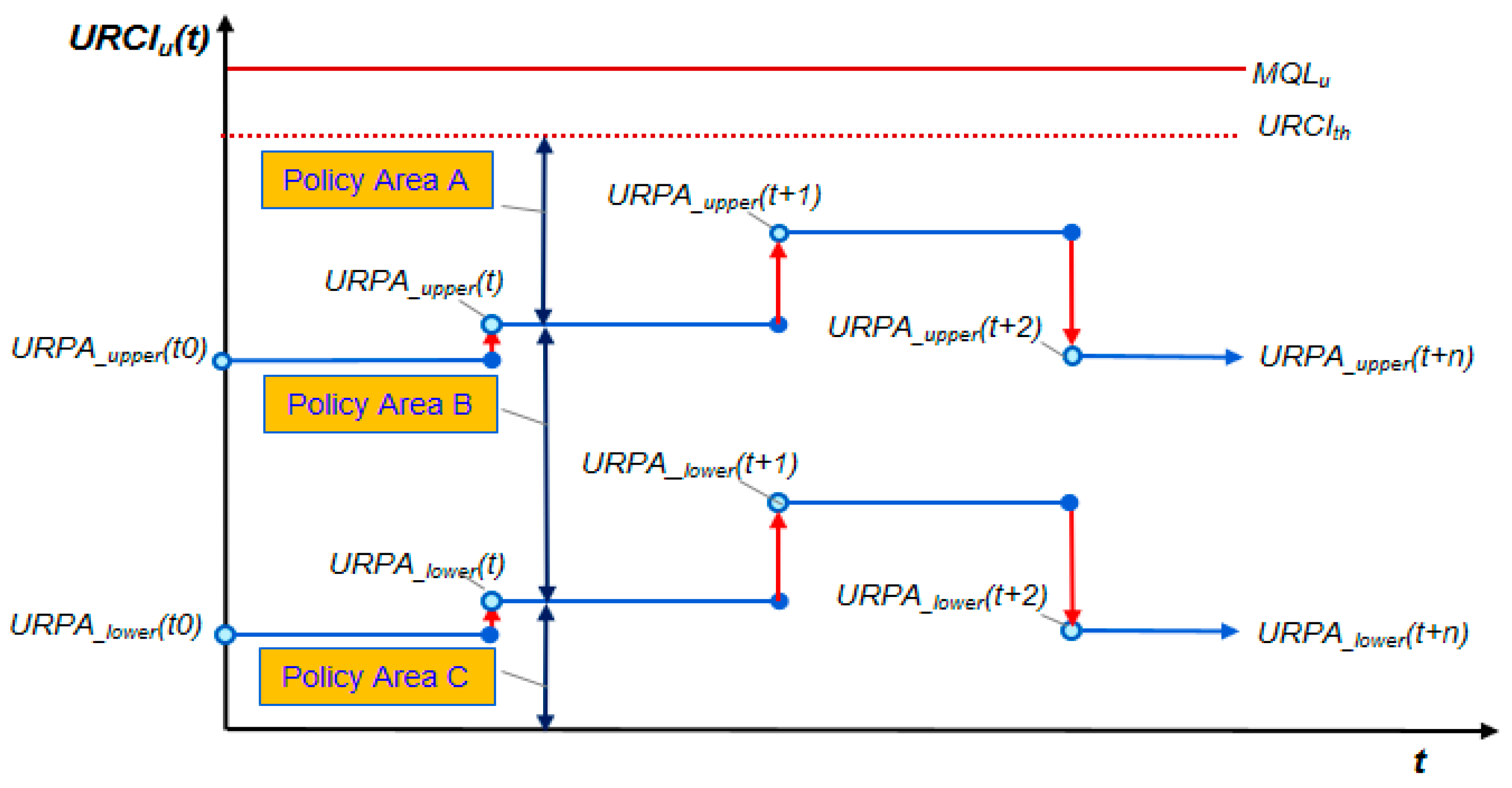
4.3.2. UAV Routing Policy Area
- Policy Area A: Allow a UAV relay only when there is no ground path with a high-priority packet
- Policy Area B: Allow a UAV relay only when there is no ground path without considering the packet priority.
- Policy Area C: Allow a UAV relay without considering the packet priority or existence of the ground path (allow all traffic)
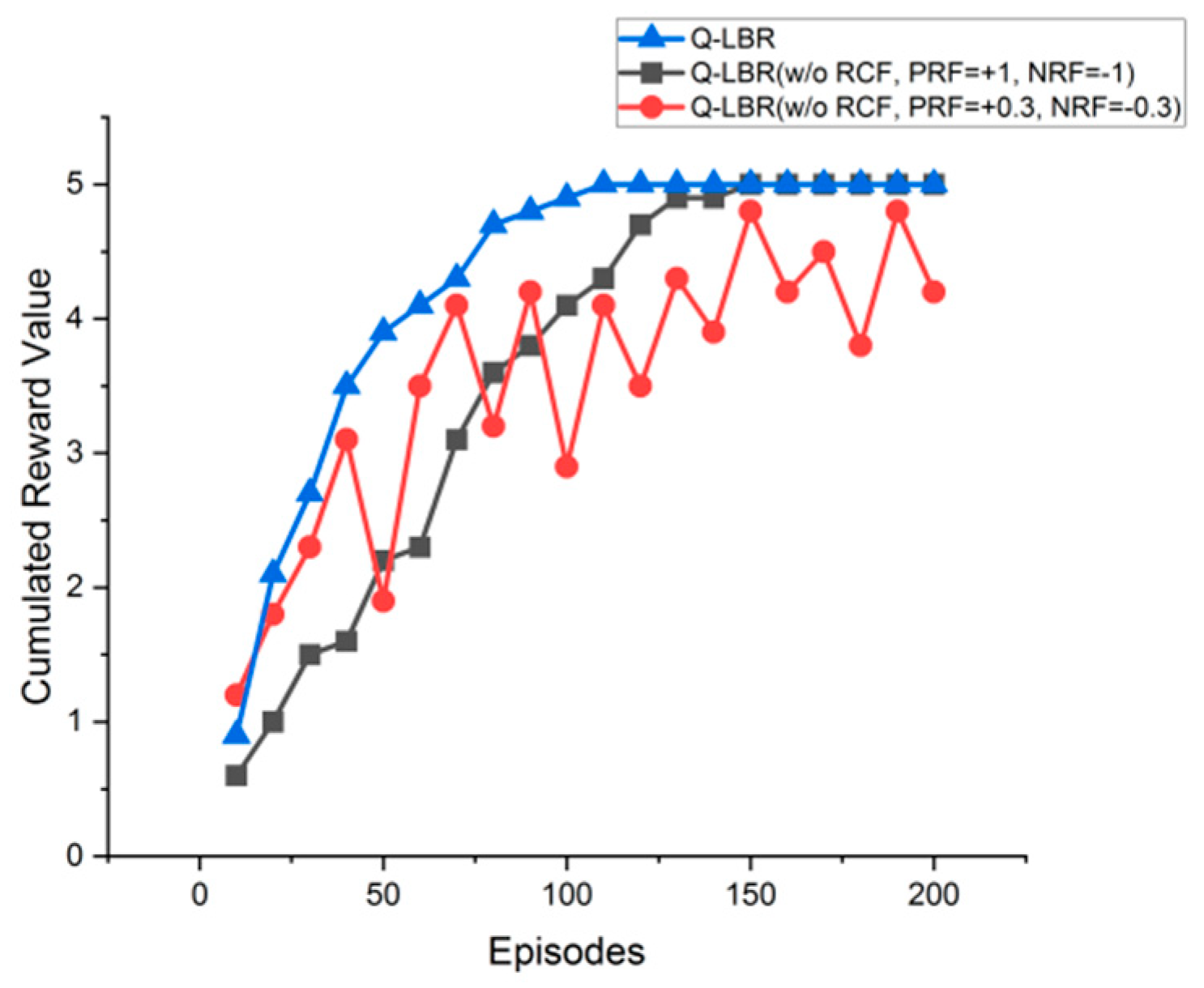
4.3.3. Reward Control Function Design for Rapid Convergence
4.4. Routing Decision Process
| Algorithm 2: Routing Decision Process | |||
| 1: | S ← Ground source node; | ||
| 2: | D ← Ground destination node; | ||
| 3: | URN ← UAV relay node; | ||
| 4: | RCU ← Routing cost including UAV path; | ||
| 5: | RCG ← Routing cost with GVN only; | ||
| 6: | URPA ← UAV routing policy area; | ||
| 7: | URCIu ← UAV relay congestion identifier from URN; | ||
| 8: | TP ← Traffic priority | ||
| 9: | |||
| 10: | forp → 1, n do | ||
| 11: | if S receives packet then | ||
| 12: | Calculate routing cost using metric information collected in packet | ||
| 13: | if ( path contains URN || RCU < RCG) then | ||
| 14: | if ( and satisfy URPA’s UAV relay conditions) then | ||
| 15: | Select the routing path that includes the URN as the optimal route | ||
| 16: | else | ||
| 17: | Select the suboptimal ground path | ||
| 18: | end if | ||
| 19: | Else | ||
| 20: | Select the optimal ground path | ||
| 21: | end if | ||
| 22: | end if | ||
| 23: | end for | ||
5. Simulation Results and Analysis
5.1. Simulation Environments
5.2. Perforamnce Analysis
6. Discussions
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kashyap, A.; Ghose, D.; Menon, P.P.; Sujit, P.; Das, K. UAV aided dynamic routing of resources in a flood scenario. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 328–335. [Google Scholar]
- Zeng, F.; Zhang, R.; Cheng, X.; Yang, L. UAV-assisted data dissemination scheduling in VANETs. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Cheng, C.-M.; Hsiao, P.-H.; Kung, H.T.; Vlah, D. Maximizing throughput of UAV-relaying networks with the load-carry-and-deliver paradigm. In Proceedings of the 2007 IEEE Wireless Communications and Networking Conference, Kowloon, China, 11–15 March 2007; pp. 4417–4424. [Google Scholar] [CrossRef] [Green Version]
- Oubbati, O.S.; Lakas, A.; Zhou, F.; Güneş, M.; Lagraa, N.; Yagoubi, M.B. Intelligent UAV-assisted routing protocol for urban VANETs. Comput. Commun. 2017, 107, 93–111. [Google Scholar] [CrossRef]
- Oubbati, O.S.; Chaib, N.; Lakas, A.; Bitam, S.; Lorenz, P. U2RV: UAV-assisted reactive routing protocol for VANETs. Int. J. Commun. Syst. 2019, 33, e4104. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Yao, H.; Wang, J.; Jiang, C.; Benslimane, A.; Liu, Y. Multi-UAV Enabled Load-Balance Mobile Edge Computing for IoT Networks. IEEE Internet Things J. 2020, 7, 1. [Google Scholar] [CrossRef]
- Guo, Y.; Li, X.; Yousefi’Zadeh, H.; Jafarkhani, H. UAV-aided cross-layer routing for MANETs. In Proceedings of the 2012 IEEE Wireless Communications and Networking Conference (WCNC), Paris, France, 1–4 April 2012; pp. 2928–2933. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, Z.; Zhao, D.; Zhang, Y.; Luo, T. A hierarchical routing scheme with load balancing in software defined vehicular ad hoc networks. IEEE Access. 2018, 6, 73774–73785. [Google Scholar] [CrossRef]
- Yao, H.; Yuan, X.; Zhang, P.; Wang, J.; Jiang, C.; Guizani, M. A machine learning approach of load balance routing to support next-generation wireless networks. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1317–1322. [Google Scholar]
- Jang, B.; Kim, M.; Harerimana, G.; Kim, J.W. Q-Learning algorithms: A comprehensive classification and applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar] [CrossRef]
- Simon, P. Too Big to Ignore: The Business Case for Big Data; Wiley: Hoboken, NJ, USA, 2013; Volume 72. [Google Scholar]
- Mammeri, Z. Reinforcement learning based routing in networks: Review and classification of approaches. IEEE Access 2019, 7, 55916–55950. [Google Scholar] [CrossRef]
- Littman, M.L. Reinforcement learning improves behavior from evaluative feedback. Nature 2015, 521, 445–451. [Google Scholar] [CrossRef] [PubMed]
- Jung, W.-S.; Yim, J.; Ko, Y.-B. QGeo: Q-Learning-based geographic ad hoc routing protocol for unmanned robotic networks. IEEE Commun. Lett. 2017, 21, 2258–2261. [Google Scholar] [CrossRef]
- Jafarzadeh, S.Z.; Yaghmaee, M.H. Design of energy-aware QoS routing protocol in wireless sensor networks using reinforcement learning. In Proceedings of the 2014 IEEE 27th Canadian Conference on Electrical and Computer Engineering (CCECE), Toronto, ON, Canada, 4–7 May 2014; pp. 1–5. [Google Scholar]
- Dong, S.; Agrawal, P.; Sivalingam, K.M. Reinforcement learning based geographic routing protocol for uwb wireless sensor network. In Proceedings of the IEEE GLOBECOM 2007—IEEE Global Telecommunications Conference, Washington, DC, USA, 26–30 November 2007; pp. 652–656. [Google Scholar] [CrossRef]
- Yang, Q.; Jang, S.-J.; Yoo, S.-J. Q-learning-based fuzzy logic for multi-objective routing algorithm in flying ad hoc networks. Wirel. Pers. Commun. 2020, 113, 115–138. [Google Scholar] [CrossRef]
- Al-Hourani, A.; Kandeepan, S.; Jamalipour, A. Modeling air-to-ground path loss for low altitude platforms in urban environments. In Proceedings of the 2014 IEEE Global Communications Conference, Austin, TX, USA, 8–12 December 2014; pp. 2898–2904. [Google Scholar] [CrossRef]
- Mozaffari, M.; Saad, W.; Bennis, M.; Debbah, M. Efficient deployment of multiple unmanned aerial vehicles for optimal wireless coverage. IEEE Commun. Lett. 2016, 20, 1647–1650. [Google Scholar] [CrossRef]
- Lijun, D.; GANG, W.; JINGWEI, F.; Yizhong, Z.; YIFU, Y. Joint Resource Allocation and Trajectory Control for UAV-Enabled Vehicular Communications. IEEE Access. 2019, 7, 132806–132815. [Google Scholar] [CrossRef]
- Jiang, D.; Delgrossi, L. IEEE 802.11p: Towards an international standard for wireless access in vehicular environments. In Proceedings of the VTC Spring 2008—IEEE Vehicular Technology Conference, Singapore, 11–14 May 2008; pp. 2036–2040. [Google Scholar] [CrossRef]
- Ahmed, A.; Sidi-Mohammed, S.; Samira, M.; Hichem, S.; Mohamed-Ayoub, M. Efficient Data Processing In Software-Defined Uav-Assisted Vehicular Networks: A Sequential Game Approach; Springer Wireless Personal Comm.: Berlin/Heidelberg, Germany, 2018; Volume 101, pp. 2255–2286. [Google Scholar]
- Jobaer, S.; Zhang, Y.; Hussain, M.A.I.; Ahmed, F. UAV-assisted hybrid scheme for urban road safety based on VANETs. Electronics 2020, 9, 1499. [Google Scholar] [CrossRef]
- Yuan, Y.; Yu, Z.L.; Gu, Z.; Yeboah, Y.; Wei, W.; Deng, X.; Li, J.; Li, Y. A novel multi-step Q-learning method to improve data efficiency for deep reinforcement learning. Knowl. Based Syst. 2019, 175, 107–117. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | LCAD 1 | U2RV 2 | UCLR 3 | HRLB 4 | Q-LBR 5 |
|---|---|---|---|---|---|
| Multipath | No | Yes | Yes | Yes | Yes |
| UAV-assisted Relay | Yes | Yes | Yes | No | Yes |
| Traffic Characteristics | No | No | No | No | Yes |
| Load Balancing | No | No | Yes | Yes | Yes |
| Dynamic Load Control | No | No | No | No | Yes |
| Machine Learning | No | No | No | No | Yes |
| Type of network | UAV/MANET | UAV/VANET | UAV/MANET | VANET | UAV/VANET |
| Layers | Parameters | Settings |
|---|---|---|
| PHY | Data Rate | 1 Mbps |
| Propagation Loss Model | Urban Propagation Model | |
| Coverage Probability (Air-to-Ground) | [13] | |
| Frequency Band | 5.9 GHz | |
| MAC | Protocol | 802.11p |
| Slot Time | ||
| SIFS | ||
| AIFNSN[AC0:USM/AC1:RTS/AC2:COP] | 2, 3, 6 | |
| Network | Hello Interval | 30 s |
| Active Route Timeout | 90 s | |
| Application | USM Traffic (Size/Rate) | Exp. 256 bytes/Exp. 10 rps |
| RTS Traffic (Size/Rate) | Con. 1500 bytes/Con. 10 rps | |
| COP Traffic (Size/Rate) | Exp. 256 bytes/Exp. 10 rps | |
| Q-learning | Learning rate(α) | 0.3 |
| Discount Factor(γ) | 0.7 | |
| 5 | ||
| UAV | Altitude Antenna | 1000 m Omni-directional |
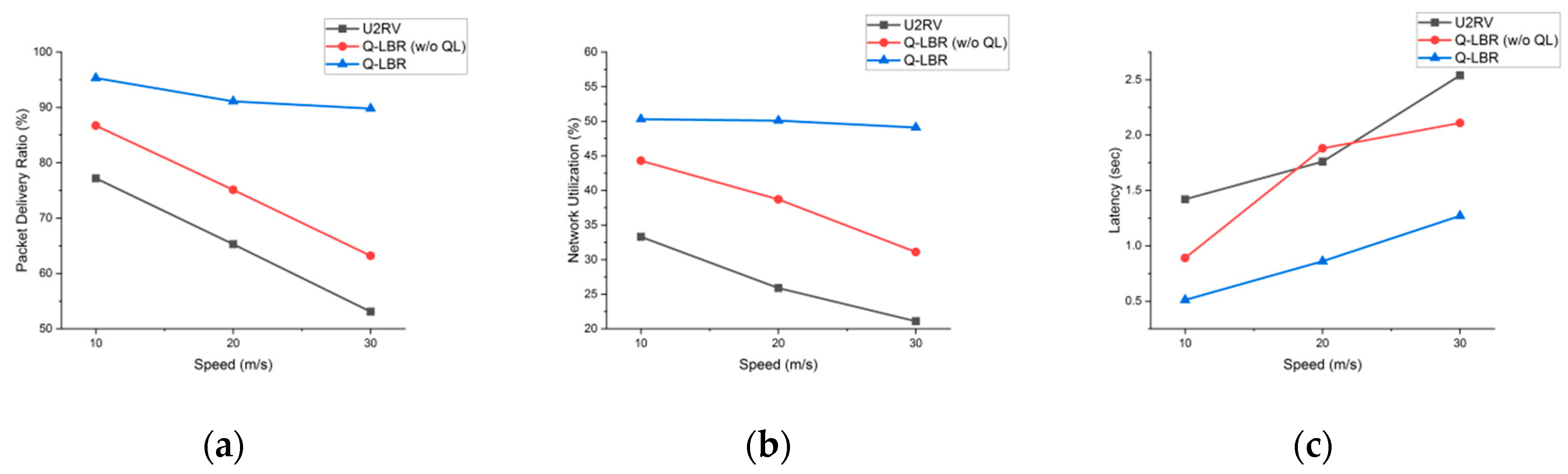
| Protocol | Speed (m/s) | Traffic Type | Packet Delivery Ratio (%) | Network Utilization (%) | Latency (s) |
|---|---|---|---|---|---|
| U2RV | 10 | USM | 78.3 | 33.6 | 1.3 |
| RTS | 77.1 | 1.5 | |||
| COP | 79.7 | 1.6 | |||
| 20 | USM | 65.4 | 27.3 | 1.5 | |
| RTS | 69.1 | 1.8 | |||
| COP | 67.3 | 1.9 | |||
| 30 | USM | 66.7 | 24.3 | 2.1 | |
| RTS | 63.5 | 2.7 | |||
| COP | 61.1 | 2.8 | |||
| Q-LBR | 10 | USM | 83.1 | 44.8 | 0.8 |
| (w/o QL) | RTS | 82.4 | 1.1 | ||
| COP | 50.5 | 1.2 | |||
| 20 | USM | 81.7 | 42.1 | 1.4 | |
| RTS | 78.5 | 1.9 | |||
| COP | 52.1 | 2.1 | |||
| 30 | USM | 72.1 | 28.6 | 1.9 | |
| RTS | 68.5 | 2.1 | |||
| COP | 58.7 | 2.2 | |||
| Q-LBR | 10 | USM | 93.3 | 50.3 | 0.5 |
| RTS | 91.1 | 0.8 | |||
| COP | 67.5 | 1.8 | |||
| 20 | USM | 92.6 | 50.1 | 0.6 | |
| RTS | 90.8 | 0.9 | |||
| COP | 62.1 | 2.3 | |||
| 30 | USM | 92.5 | 49.8 | 0.8. | |
| RTS | 89.7 | 0.9 | |||
| COP | 61.8 | 2.8 |
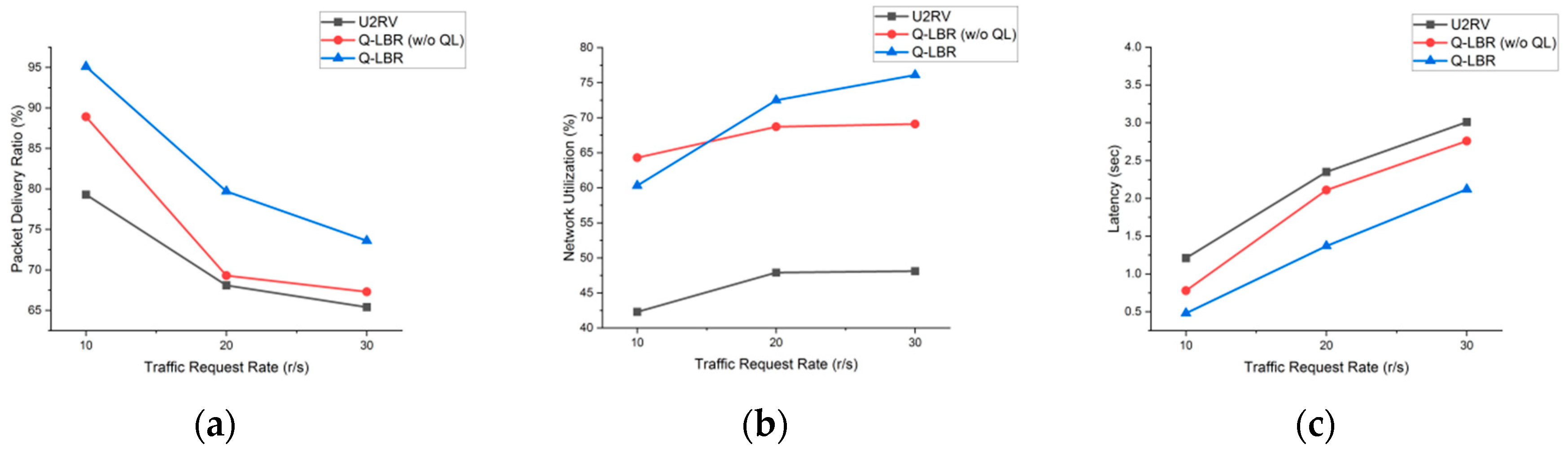
| Protocol | Traffic (r/s) | Traffic Type | Packet Delivery Ratio (%) | Network Utilization (%) | Latency (s) |
|---|---|---|---|---|---|
| U2RV | 10 | USM | 79.2 | 42.8 | 1.24 |
| RTS | 76.3 | 1.31 | |||
| COP | 78.1 | 1.35 | |||
| 20 | USM | 68.5 | 47.7 | 2.11 | |
| RTS | 67.6 | 2.35 | |||
| COP | 68.1 | 2.42 | |||
| 30 | USM | 64.3 | 47.9 | 2.72 | |
| RTS | 66.5 | 2.77 | |||
| COP | 66.8 | 2.83 | |||
| Q-LBR | 10 | USM | 88.9 | 64.9 | 0.81 |
| (w/o QL) | RTS | 86.5 | 0.92 | ||
| COP | 75.4 | 0.98 | |||
| 20 | USM | 76.3 | 67.4 | 1.98 | |
| RTS | 72.7 | 2.37 | |||
| COP | 64.5 | 2.61 | |||
| 30 | USM | 69.2 | 67.3 | 2.57 | |
| RTS | 65.2 | 2.81 | |||
| COP | 60.7 | 2.99 | |||
| Q-LBR | 10 | USM | 96.7 | 60.8 | 0.44 |
| RTS | 94.2 | 0.56 | |||
| COP | 64.3 | 0.99 | |||
| 20 | USM | 87.4 | 72.5 | 1.18 | |
| RTS | 83.5 | 1.22 | |||
| COP | 62.2 | 2.76 | |||
| 30 | USM | 77.5 | 75.9 | 1.39 | |
| RTS | 74.1 | 1.98 | |||
| COP | 61.9 | 2.95 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roh, B.-S.; Han, M.-H.; Ham, J.-H.; Kim, K.-I. Q-LBR: Q-Learning Based Load Balancing Routing for UAV-Assisted VANET. Sensors 2020, 20, 5685. https://doi.org/10.3390/s20195685
Roh B-S, Han M-H, Ham J-H, Kim K-I. Q-LBR: Q-Learning Based Load Balancing Routing for UAV-Assisted VANET. Sensors. 2020; 20(19):5685. https://doi.org/10.3390/s20195685
Chicago/Turabian StyleRoh, Bong-Soo, Myoung-Hun Han, Jae-Hyun Ham, and Ki-Il Kim. 2020. "Q-LBR: Q-Learning Based Load Balancing Routing for UAV-Assisted VANET" Sensors 20, no. 19: 5685. https://doi.org/10.3390/s20195685