A Feature Optimization Approach Based on Inter-Class and Intra-Class Distance for Ship Type Classification


Abstract
:1. Introduction
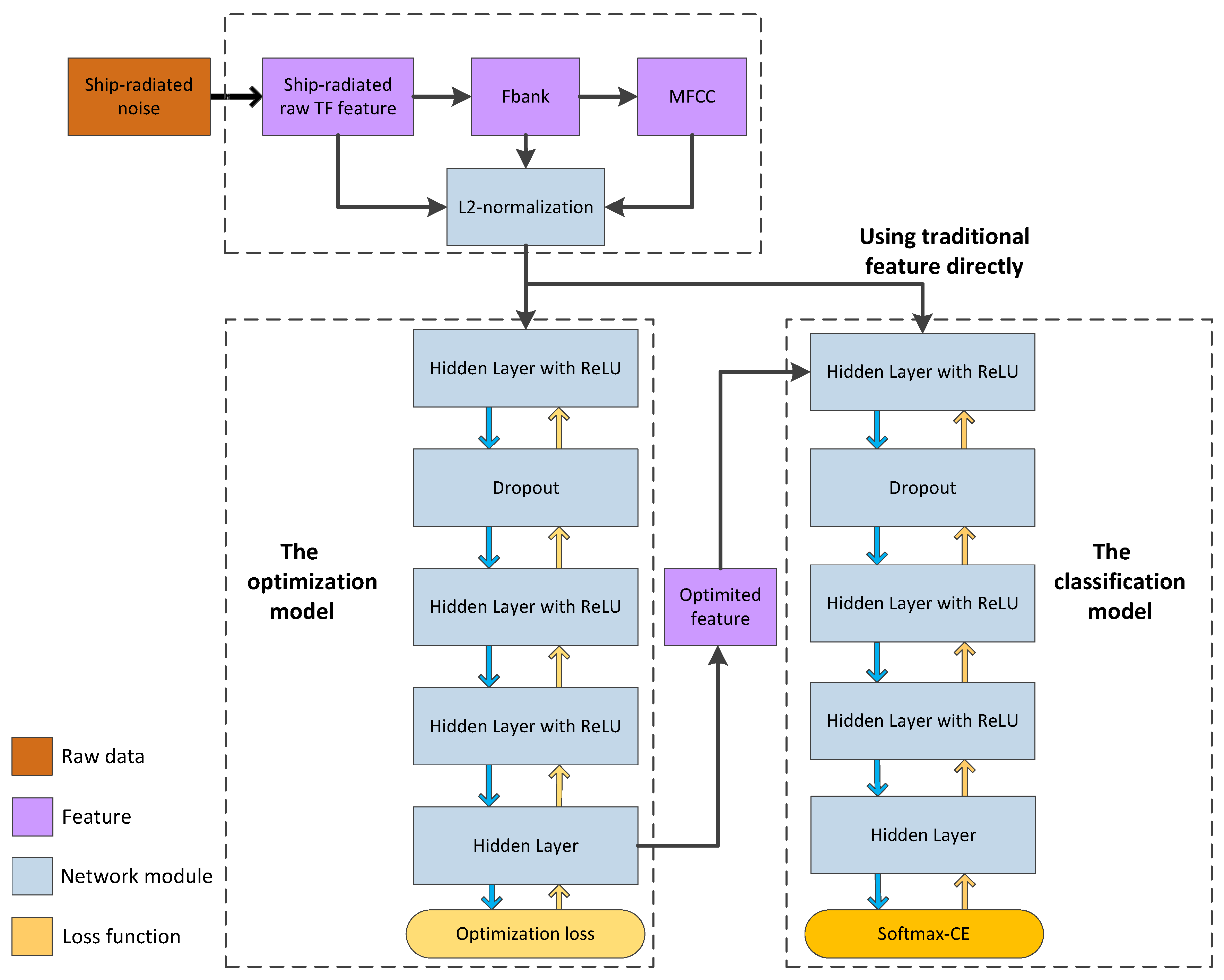
2. Architecture of Deep Neural Network for Ship Classification
3. Feature Optimization Learning for Ship Classification
3.1. Motivation
3.2. Center Loss
3.3. Triplet Loss
3.4. The Proposed Feature Optimizer
3.5. Joint Training with Classifier
4. Experiment
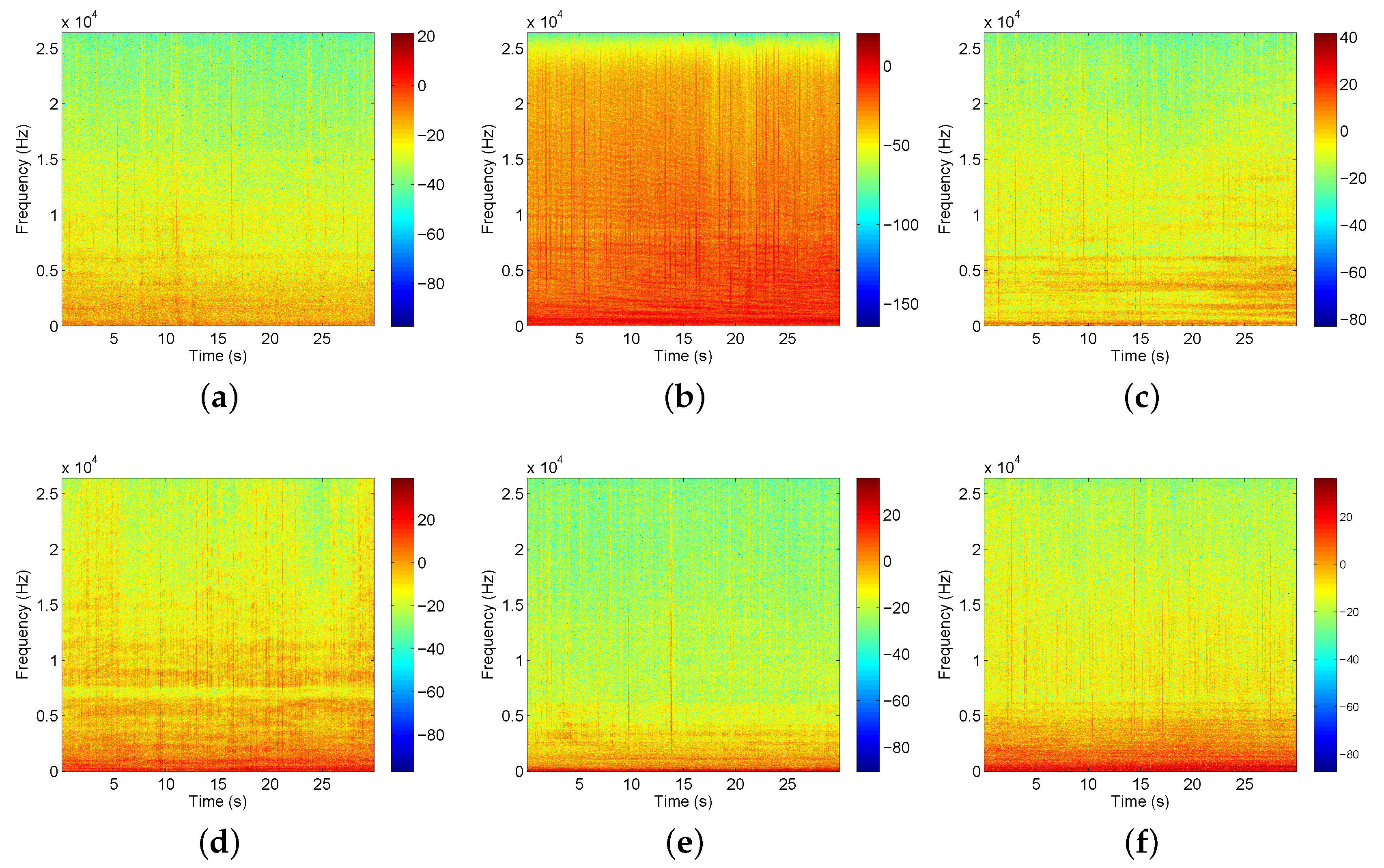
4.1. Data Description
4.2. Parameters for Feature Extraction
4.3. Parameters for Feature Optimization Model
4.4. Parameters for Classification Model
4.5. Result
4.5.1. Parameter Selection.
4.5.2. Experiment Results and Discussion.
4.5.3. Comparison with Other Loss Functions and Optimization Models.
4.5.4. Visualization of Learned Representations.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Van Haarlem, M.P.; Wise, M.W.; Gunst, A.W.; Heald, G.; McKean, J.P.; Hessels, J.W.; de Bruyn, A.G.; Nijboer, R.; Swinbank, J.; Fallows, R.; et al. LOFAR: The low-frequency array. Astron. Astrophys. 2013, 556, A2. [Google Scholar] [CrossRef] [Green Version]
- Dai, W.; Cheng, Y.; Wang, Y. Classification and Recognition of DEMON Spectrum of Ship Noise by Support Vector Machine. J. Appl. Acoust. 2010, 29, 206–211. [Google Scholar]
- Meng, Q.; Yang, S.; Piao, S. The classification of underwater acoustic target signals based on wave structure and support vector machine. J. Acoust. Soc. Am. 2014, 136, 2265. [Google Scholar] [CrossRef]
- Ward, M.K.; Stevenson, M. Sonar signal detection and classification using artificial neural networks. Can. Conf. Electr. Comput. Eng. 2000, 2, 717–721. [Google Scholar]
- Li, C.; Huang, Z.; Xu, J.; Yan, Y. Underwater target classification using deep learning. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018. [Google Scholar]
- Hu, G.; Wang, K.; Peng, Y.; Qiu, M.; Shi, J.; Liu, L. Deep learning methods for underwater target feature extraction and recognition. Comput. Intell. Neurosci. 2018, 2018, 1214301. [Google Scholar] [CrossRef] [PubMed]
- Mu, L.; Peng, Y.; Qiu, M.; Yang, X.; Hu, C.; Zhang, F. Study on modulation spectrum feature extraction of ship radiated noise based on auditory model. In Proceedings of the 2016 IEEE/OES China Ocean Acoustics, Harbin, China, 9–11 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5, 22. [Google Scholar]
- Ghosh, J.; Deuser, L.; Beck, S.D. A neural network based hybrid system for detection, characterization, and classification of short-duration oceanic signals. IEEE J. Ocean. Eng. 2002, 17, 351–363. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Liu, Z.; Xiong, Y. Underwater Target Recognition Based on Wavelet Packet Energy Spectrum and Support Vector Machine. J. Wuhan Univ. Technol. 2012, 36, 361–365. [Google Scholar]
- Zeng, X.Y.; Wang, S.G. Bark-wavelet Analysis and Hilbert–Huang Transform for Underwater Target Recognition. Def. Technol. 2013, 9, 115–120. [Google Scholar] [CrossRef] [Green Version]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In ECCV; Springer: Cham, Switzerland, 2016; pp. 499–515. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Ranjan, R.; Castillo, C.D.; Chellappa, R. L2-constrained Softmax Loss for Discriminative Face Verification. arXiv 2017, arXiv:1703.09507. [Google Scholar]
- Tabassum, M.N.; Ollila, E. Compressive regularized discriminant analysis of high-dimensional data with applications to microarray studies. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4204–4208. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.F.; Gerstoft, P.; Hodgkiss, W.S. Effect of ocean sound speed uncertainty on matched-field geoacoustic inversion. J. Acoust. Soc. Am. 2008, 123, EL162–EL168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Domingo, M.C. Overview of channel models for underwater wireless communication networks. Phys. Commun. 2008, 1, 163–182. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhou, Z.; Bai, S.; Bai, X. Triplet-center loss for multi-view 3d object retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1945–1954. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Pham, A.T.; Raich, R.; Fern, X.Z. Discriminative Clustering with Cardinality Constraints. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2291–2295. [Google Scholar]
- Yang, H.; Shen, S.; Yao, X.; Sheng, M.; Wang, C. Competitive deep-belief networks for underwater acoustic target recognition. Sensors 2018, 18, 952. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Celeux, G.; Soromenho, G. An entropy criterion for assessing the number of clusters in a mixture model. J. Classif. 1996, 13, 195–212. [Google Scholar] [CrossRef] [Green Version]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Hilton Waikoloa Village, Big Island, HI, USA, 11–15 December 2011. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: A system for largescale machine learning. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. International Conference on Artificial Intelligence and Statistics. 2012, pp. 315–322. Available online: Http://www.jmlr.org/proceedings/papers/v15/glorot11a/glorot11a.pdf (accessed on 8 May 2012).
- Zhang, Z. Improved Adam Optimizer for Deep Neural Networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class A | fishing boats, trawlwes, mussel boats, tugboats and dredger |
| Class B | motorboats, pilot boats and sailboats |
| Class C | passenger ferries |
| Class D | ocean liners and ro-ro vessels |
| Class E | background noise recordings |
| Class | ||||||
|---|---|---|---|---|---|---|
| A | B | C | D | E | ||
| Database material | number of recordings | 17 | 19 | 17 | 10 | 12 |
| number of samples | 7503 | 6239 | 7898 | 9122 | 4555 | |
| Method | Basic Feature | Class A | Class B | Class C | Class D | Class E | Average |
|---|---|---|---|---|---|---|---|
| Santos-Dominguez’s [25] | 0.625 | 0.800 | 0.764 | 0.555 | 1.000 | 0.754 | |
| DNN | raw TF feature | 0.529 | 0.579 | 0.588 | 0.500 | 0.833 | 0.600 |
| Fbank | 0.706 | 0.684 | 0.647 | 0.800 | 1.000 | 0.760 | |
| MFCC | 0.706 | 0.684 | 0.647 | 0.700 | 0.900 | 0.733 | |
| op+DNN | raw TF feature | 0.588 | 0.632 | 0.647 | 0.600 | 1.000 | 0.680 |
| Fbank | 0.824 | 0.789 | 0.765 | 0.900 | 1.000 | 0.840 | |
| MFCC | 0.749 | 0.737 | 0.706 | 0.800 | 1.000 | 0.787 | |
| Predicted Sound | ||||||
|---|---|---|---|---|---|---|
| A | B | C | D | E | ||
| Actual sound | A | 14 (82.4%) | 2 (11.8%) | 0 (0%) | 1 (5.9%) | 0(0%) |
| B | 1 (5.3%) | 15 (78.9%) | 2 (10.5%) | 1 (5.3%) | 0 (0%) | |
| C | 1 (5.9%) | 3 (17.6%) | 13 (76.5%) | 0 (0%) | 0 (0%) | |
| D | 0 (0%) | 1 (10%) | 0 (0%) | 9 (90%) | 0 (0%) | |
| E | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 12 (100%) | |
| Optimization Model | Loss Function | Accuracy % |
|---|---|---|
| DNN | Center loss + Softmax | 0.803 |
| Triplet loss + softmax | 0.786 | |
| Proposed loss function | 0.840 | |
| TDNN | Center loss + Softmax | 0.813 |
| Triplet loss + softmax | 0.786 | |
| Proposed loss function | 0.840 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Liu, Z.; Ren, J.; Wang, W.; Xu, J. A Feature Optimization Approach Based on Inter-Class and Intra-Class Distance for Ship Type Classification. Sensors 2020, 20, 5429. https://doi.org/10.3390/s20185429
Li C, Liu Z, Ren J, Wang W, Xu J. A Feature Optimization Approach Based on Inter-Class and Intra-Class Distance for Ship Type Classification. Sensors. 2020; 20(18):5429. https://doi.org/10.3390/s20185429
Chicago/Turabian StyleLi, Chen, Ziyuan Liu, Jiawei Ren, Wenchao Wang, and Ji Xu. 2020. "A Feature Optimization Approach Based on Inter-Class and Intra-Class Distance for Ship Type Classification" Sensors 20, no. 18: 5429. https://doi.org/10.3390/s20185429