4.3.1. Classification Based on Textual Features
In this part, we evaluate the performance of the website classification based on textual features using Doc2Vec and an SVM. Our first set of experiments explored the optimal performance settings of the Doc2Vec model. For this purpose, different Doc2Vec models were trained by combining different textual feature dimensions, model frames, and context window size parameter settings. First, we explored how the framework and text window sizes of the Doc2Vec could influence the classification efficiency. In the experiment, the text vector dimension was set to 200, while the text window was chosen from {5,10} and the framework was chosen from {DM, DBOW}.
Table 3 provides a performance comparison of Doc2Vec using different text window and framework combinations on our pornographic and gambling website datasets.
From
Table 3, we found that the Doc2Vec model trained with DBOW had a better performance in terms of all evaluation metrics than DM for both gambling and pornographic websites. The most notable was the recall, which increased by 4.85% for pornographic websites (window = 5). Furthermore, it was also shown that the smaller the window size, the better the performance of the Doc2Vec model, even though the recall dropped slightly (keeping the same framework). The reason might have been that textual information on a website was not as short and clever as blog posts, and therefore choosing a larger text window size means selecting more context words. This made it easy to mix in unnecessary redundant information, leading to a reduction in the classification effect. It was also noted that in all our datasets (gambling and porn), Doc2Vec with parameter settings of DBOW being selected and a context window size of 5 performed the best in terms of all the evaluation indicators; therefore, this parameter setting was used for subsequent experiments.
Next, we evaluated the impact of the dimensionality of the textual feature and built the best Doc2Vec model. In this experiment, the vector dimensions of 100, 200, 300, and 400 were considered. The performance comparisons of Doc2Vec using different vector dimensions on pornographic websites and gambling websites are shown in
Table 4 and
Table 5. As shown in
Table 4, for the pornographic websites, when the vector size parameter was raised from 100 to 200, the performance of the Doc2Vec improved and then degraded when it was further raised to 400. The model with 200 dimensions achieved the best performance, with an accuracy of 91.94%, a recall of 89.14%, and an F1-measure of 91.23%. As shown in
Table 5, similar to the pornographic websites, the performance of the classification on gambling website datasets showed a trend of first increasing and then decreasing, and reached the peak when the dimension was 300, with an accuracy of 90.39% and an F-measure of 89.39%. As a consequence, dimension = 200 was chosen as the optimal vector size parameter for the pornographic website classification, while dimension = 300 was chosen as the optimal vector size parameter for the gambling website classification.
Furthermore, to further illustrate the effectiveness of learning textual features using Doc2Vec, we also present the experimental results comparing the classification performance of feature representation using Doc2Vec and Word2Vec in
Table 4 and
Table 5. From the above experimental results, it can be observed that Doc2Vec yielded higher performance compared to Word2Vec in terms of all evaluation metrics. The most important reason was that Word2Vec only represents features based on word dimensions but does not consider the semantic relationship of the context. Doc2Vec introduces the semantic relationships of text based on Word2Vec; therefore, it was more suitable for our document-level text data set.
4.3.2. Classification Based on Visual Features
The purpose of the experiments in this subsection was twofold. First of all, we varied the clustering center number to obtain the most effective Spa-BoVW model for image feature representation. The second and more important goal was to verify the effectiveness of Spa-BoVW by comparing its performance with that of traditional BoVW.
The cluster number is the number of visual words in the visual codebook and the dimension of the feature vector represented by the histogram of each screenshot sub-image in our experiment, which was the important influencing factor of the detection performance. In this set of experiments, we compared the performance of Spa-BoVW and BoVW using different cluster numbers on pornographic and gambling websites datasets, where the experimental results are shown in
Table 6 and
Table 7. The cluster numbers [100, 200, 300, 400, 500] were considered.
We first discuss the relationship between the number of clusters used in Spa-BoVW and the classification results. From the results in
Table 6, it can be found that all the evaluation indicators increased first and then decreased when the cluster number increased. The best classification performance of pornographic websites was obtained when the number of clusters was 300, with the accuracy, precision, recall, and F-measure reaching 95.03%, 96.72%, 92.57%, and 94.60%, respectively. The results in
Table 7 show that the classification performance of the gambling websites also peaked at cluster number = 300, where the accuracy, precision, and F-measure all exceeded 93%. By comprehensively analyzing the results of
Table 6 and
Table 7, it can be concluded that having a cluster number (visual vocabulary numbers) that was too high or too low was not conducive to the representation of visual features. This was because having fewer clusters resulted in feature points with a low similarity being assigned to the same cluster, while having too many clusters led to similar feature points being divided into different clusters. These all affected the representation of the cluster center, resulting in the reduction of the Spa-BoVW performance.
The experimental results reported in
Table 6 and
Table 7 also suggest that when keeping the same number of cluster centers, the proposed Spa-BoVW outperformed the traditional BoVW on each dataset with a large margin. For instance, for pornographic websites (see
Table 6), the accuracy increased from 87.77% to 95.03% (an increase of 7.26%), while the precision increased from 88.43% to 96.72% (an increase of 8.29%), which was the most obvious improvement (cluster number = 200). As can be seen from
Table 7, even in the case of the weakest improvement in the classification performance of gambling websites (cluster number = 500), all four evaluation metrics increased by at least 4.47%. As specified in
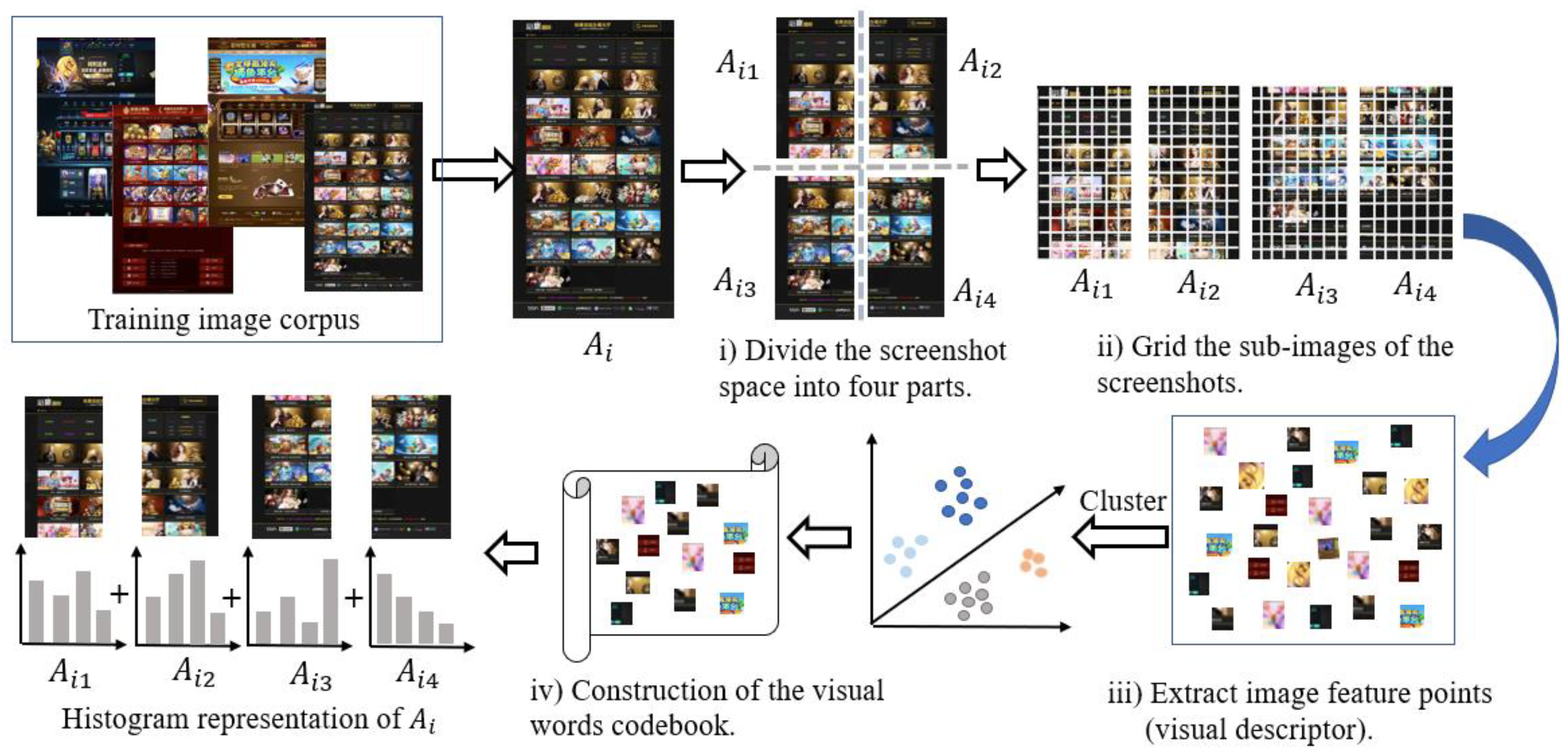
Section 3.3.2, notwithstanding that traditional BoVW can extract visual feature points from screenshots for image classification, it has a well-known shortcoming in that it overlooks spatial information among extracted feature points, which ultimately affected the classification performance in this study. The excellent performance of Spa-BoVW can be mainly explained by the fact that the Spa-BoVW considered the positional relationship of feature points between space blocks, which was useful for capturing discriminative visual patterns and obtaining effective visual feature representations.
4.3.3. Textual and Visual Combination-Based Classification
From the above experimental results presented in
Section 4.3.1 and
Section 4.3.2, it can be clearly seen that models using a single type of feature (textual or visual) cannot have a satisfactory classification performance. In this section, we try to comprehensively consider the textual features and visual features of the website in classification prediction to achieve an improvement in the detection performance of the website.
In the following experiments, we used the Doc2Vec and the Spa-BoVW with the optimal parameter settings. For pornographic websites, we chose Doc2Vec with model = DBOW, window = 5, and dimensions = 200 to extract the textual features and classify them using an SVM. Spa-BoVW with cluster number = 300 was used to extract the visual features and an RF was used for the visual features classification. For gambling websites, except for the dimension of the vector size of the Doc2Vec model being set to 300, the rest of the parameters of the Doc2Vec and Spa-BoVW models were consistent with those used for pornographic websites. Furthermore, the importance coefficient of the features (the probability of
and
in LR were used to visualize the weight coefficients
and
, and the results for different types of websites obtained in our experiment are shown in
Table 8.
From
Table 8, we can see that for both gambling and pornographic websites, the weighting coefficient
was greater than the weighting coefficient
. This means that the prediction result of the visual-features-based classification had a greater impact on the final classification. It can be seen that the weight coefficient
of pornographic websites was larger than that of gambling websites, which indicates that for pornographic website detection, the prediction probability of visual-features-based classification contributed more to the final prediction result. This may have been due to pornographic websites being more colorful and having a greater proportion of images compared to gambling websites. This made it possible to use Spa-BoVW extract more contrasting feature points from the screenshot of the pornographic website and thus was more conducive to distinguishing pornographic websites from normal websites.
Section 3.4 details our website classification decision method. In this method, the threshold parameter
th played a crucial role in our decision process. The following experiments focused on exploring the influence of the threshold on the prediction performance of pornographic and gambling websites. The experiments were conducted by varying the threshold, whose values ranged from 0.2 to 0.6.
Table 9 shows a comparison of the experimental results using different thresholds. It can be seen from
Table 9, when the
th = 0.4, the method obtained the best classification performance for pornographic websites, with the accuracy, precision, and F-measure all exceeding 99%. On the other hand, the classification method for gambling websites performed the best when
th = 0.5, with the highest accuracy of 99.18% and the highest F-measure of 99.13%. It is worth mentioning that as the threshold increased, the accuracy continuously improved and the recall rate decreased. This was mainly because raising the threshold was equivalent to raising the requirement to predict websites as gambling or pornography websites, which reduced the likelihood of predicting a normal website as a gambling or pornography website, and therefore the accuracy went up. At the same time, there were more gambling or pornographic websites with nonobvious characteristics that were predicted to be normal websites, which reduced the recall rate.
To verify the effectiveness of the proposed PG-VTDM, a performance comparison between the best single-feature-detection methods (discussed in
Section 4.3.1 and
Section 4.3.2) and PG-VTDM for each dataset is shown in
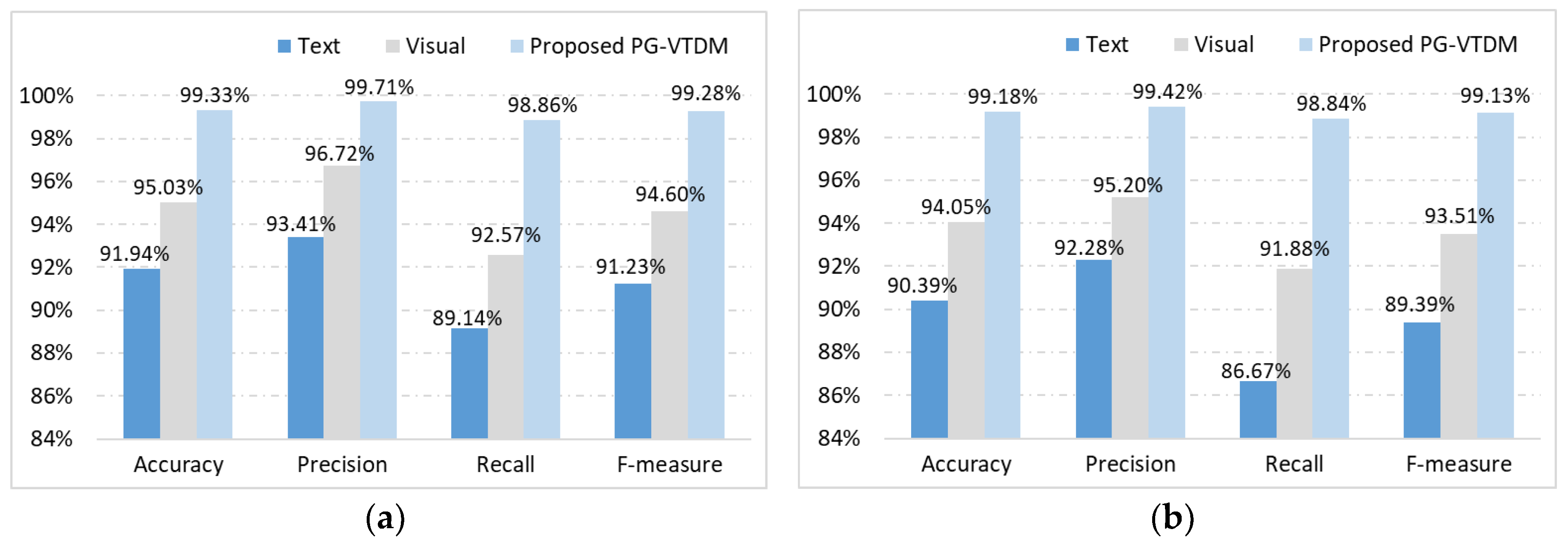
Figure 5. It can be seen from
Figure 5 that the classifier combination algorithm based on a category decision mechanism performed significantly better at detecting gambling and pornography websites. Compared with the best visual-features-based models, the combined-feature model achieved better recall values by 6.29% (porn) and 6.96% (gambling), and better F-measure values by 4.68% (porn) and 5.62% (gambling). Similarly, the combined-feature model achieved better recall values by 9.72% (porn) and 12.17% (gambling), and better F-measure values by 8.05% (porn) and 9.74% (gambling) compared with the best textual-features-based model. In summary, our method with the category decision mechanism that takes advantage of the complementarity between textual and image features significantly improved the classification performance of detecting illegal websites.
Table 10 shows the detection time of the proposed system for different types of websites, which includes the time spent in the process of blacklist and whitelist filtering, website content acquisition, feature extraction, and the final classification prediction. As can be seen from
Table 10, no matter what type of website detection, the longest detection time of the system does not exceed 1.157s and the shortest time was as low as 0.427s, with the average detection time being within 1 s. Based on the above results, the proposed system is believed to be capable of real-time detection.
Furthermore, the performance of the proposed method was compared with some state-of-the-art porn and gambling website detection approaches. We simulated the method used in References [
9,
21] on our experimental set and compared their performance with that of our proposed method in
Table 11. The approaches from References [
9,
21] analyze website features from the perspective of textual content [
21] or visual content [
9]. From
Table 11, it can be observed that our proposed approach outperformed other approaches for all testing indicators. Compared with these approaches, our method showed superior performance, mainly because the detection process relied on features from multiple aspects, which enabled a more comprehensive analysis of gambling and pornography websites, thus improving the recognition rate of these websites. The design of the decision mechanism also made the prediction result more reliable.
In addition, we also analyzed some possible reasons why the performance metrics did not reach 100%. For instance, some textual content on the website data set was relatively short and informal, thus the effect was slightly reduced when using Doc2Vec for textual content analysis. Moreover, a relatively small amount of training data may have affected the performance of Doc2Vec to a certain extent, and we expect to alleviate this problem by collecting more data sets in the future. There were also some unavoidable reasons caused by human operations, such as insufficient model tuning and errors in manual labeling.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}