Reference-Driven Compressed Sensing MR Image Reconstruction Using Deep Convolutional Neural Networks without Pre-Training


Abstract
:1. Introduction
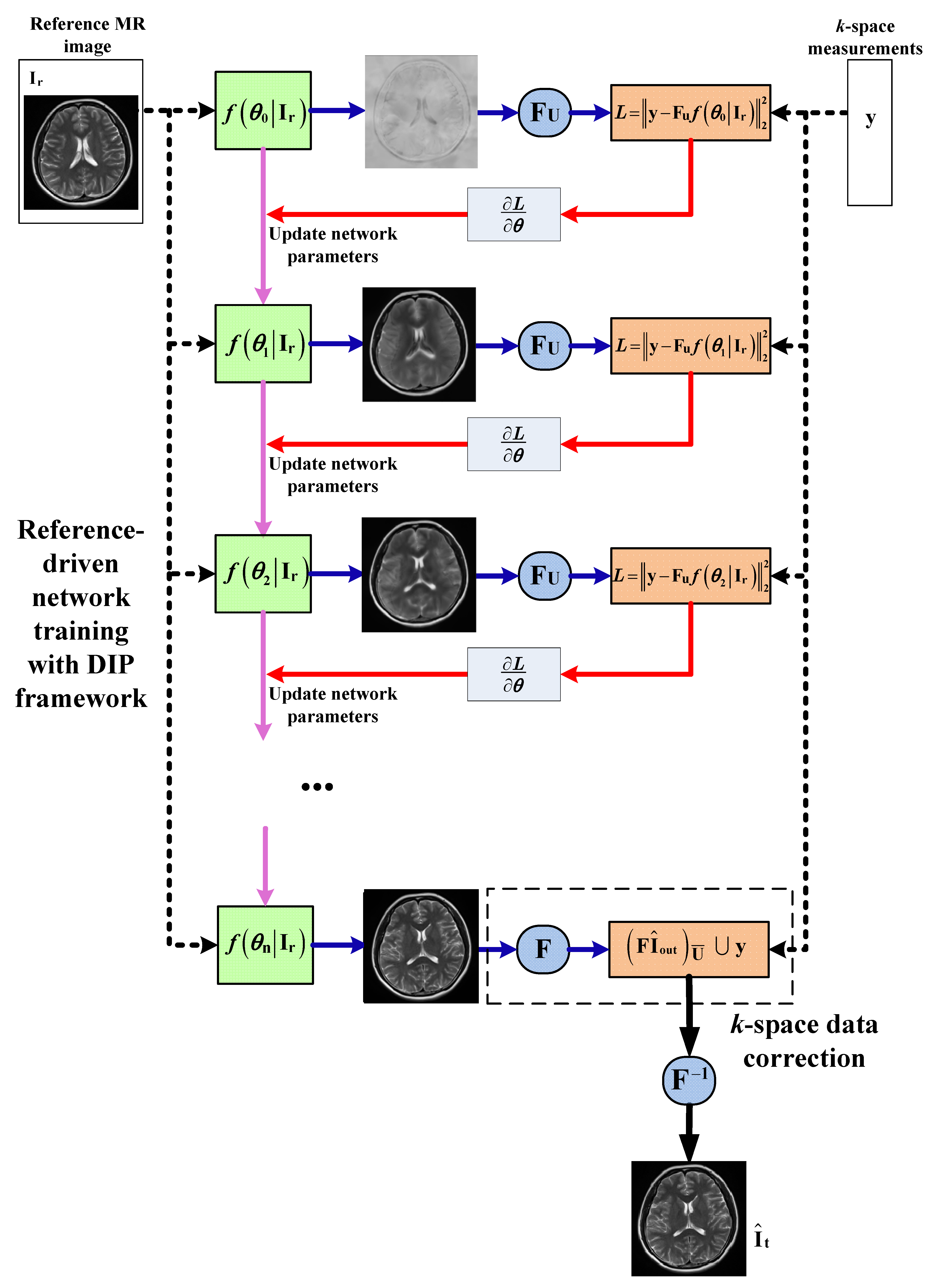
2. Methodology
2.1. Proposed Method
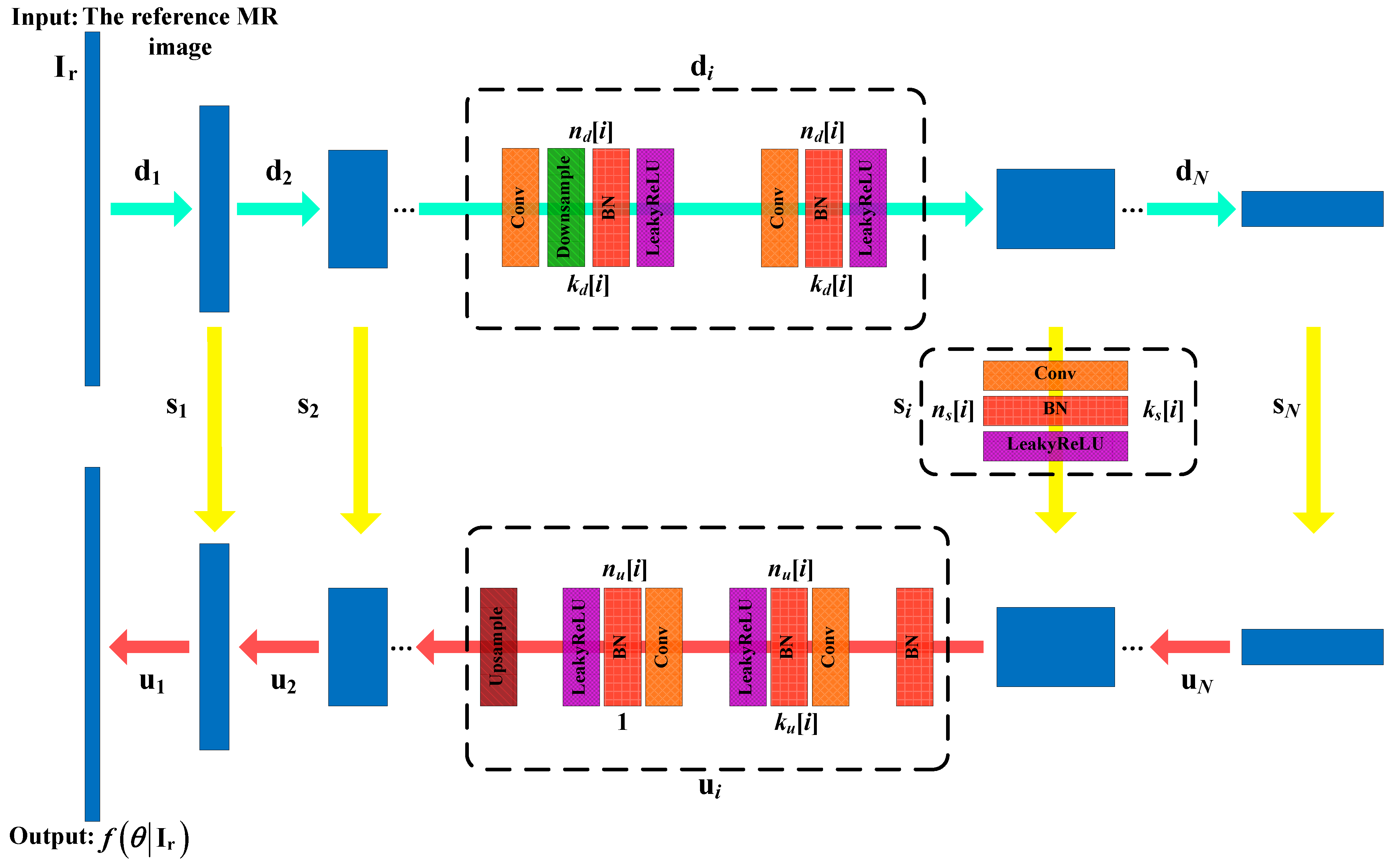
2.2. Network Architecture
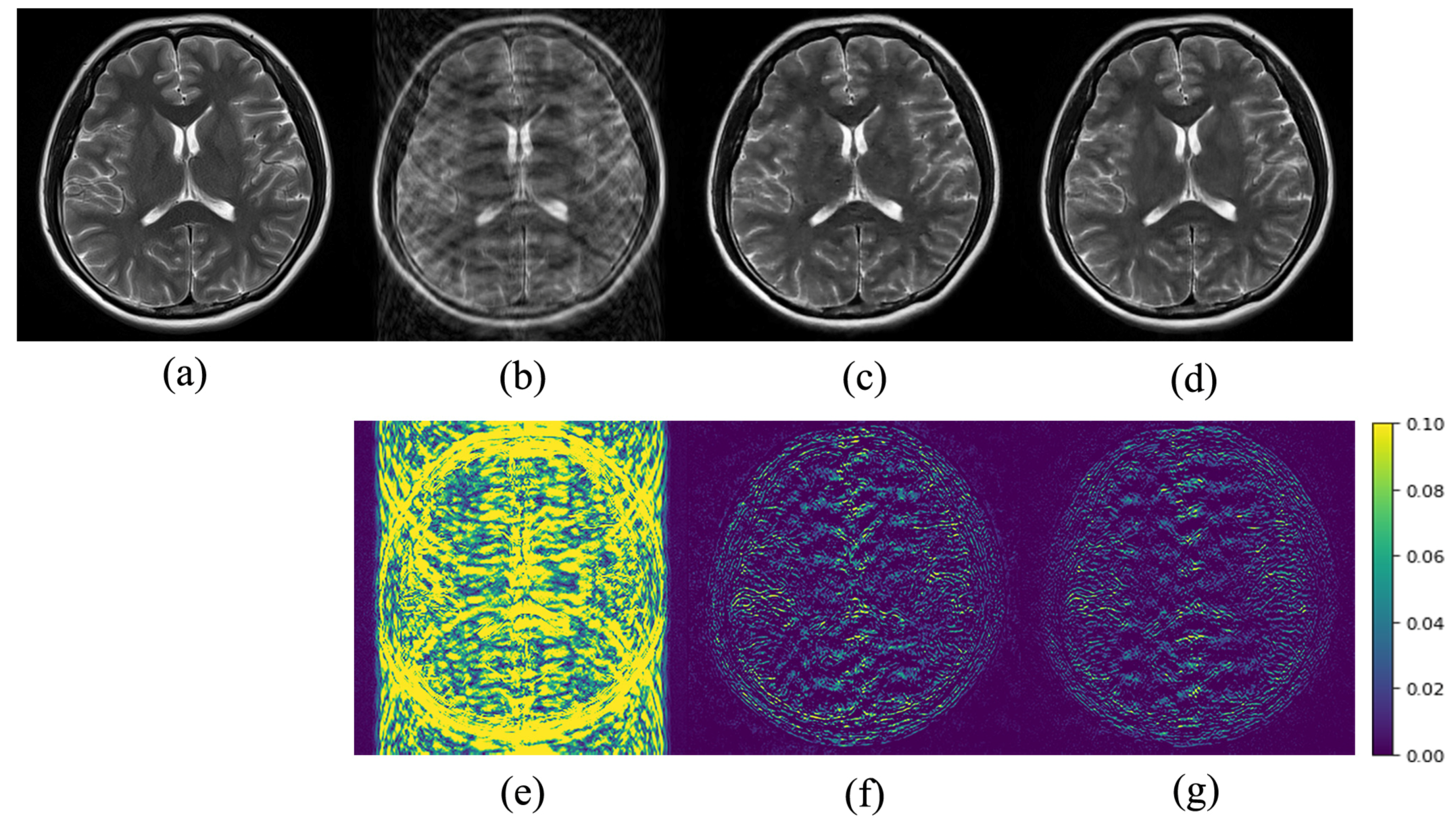
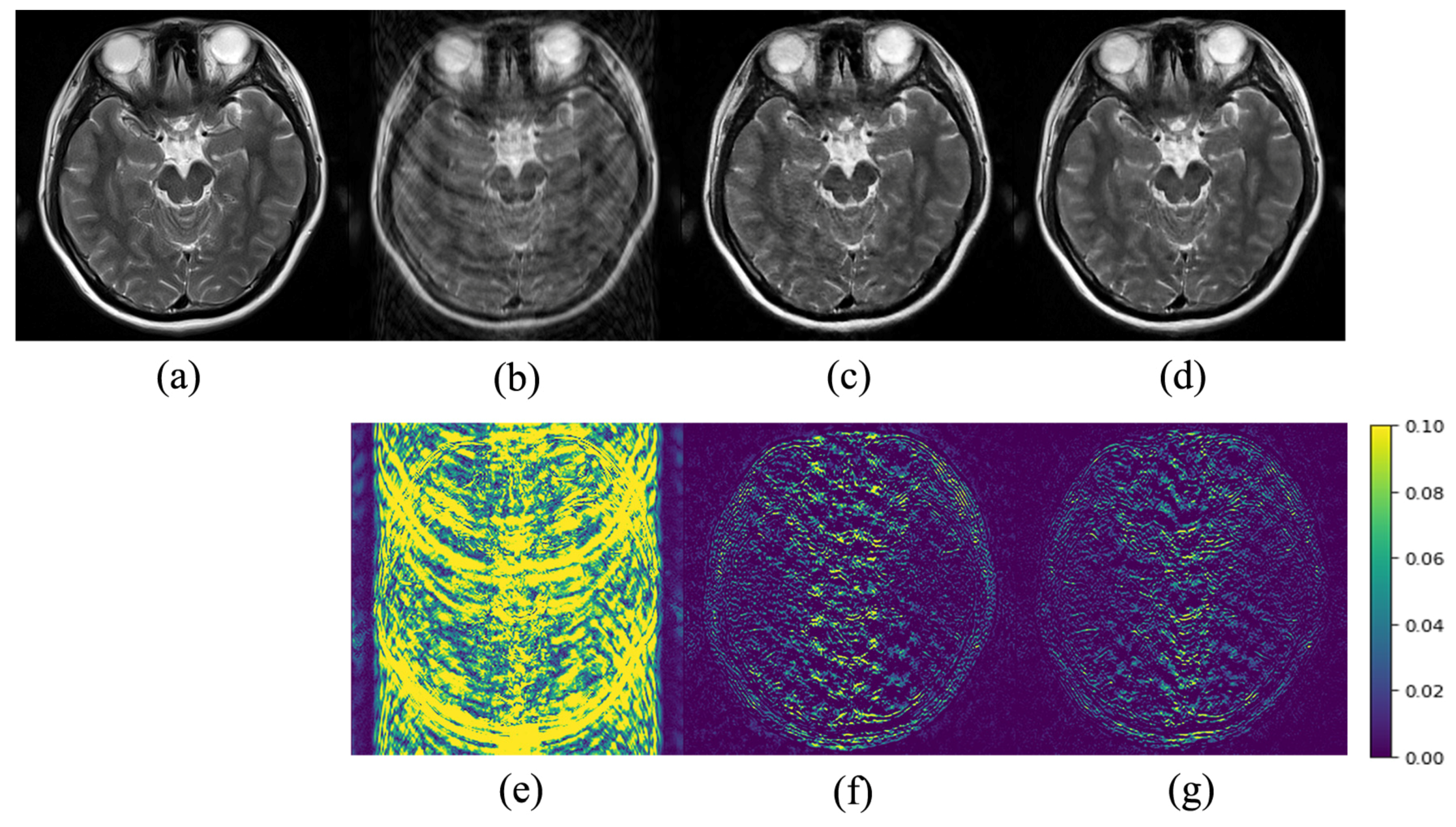
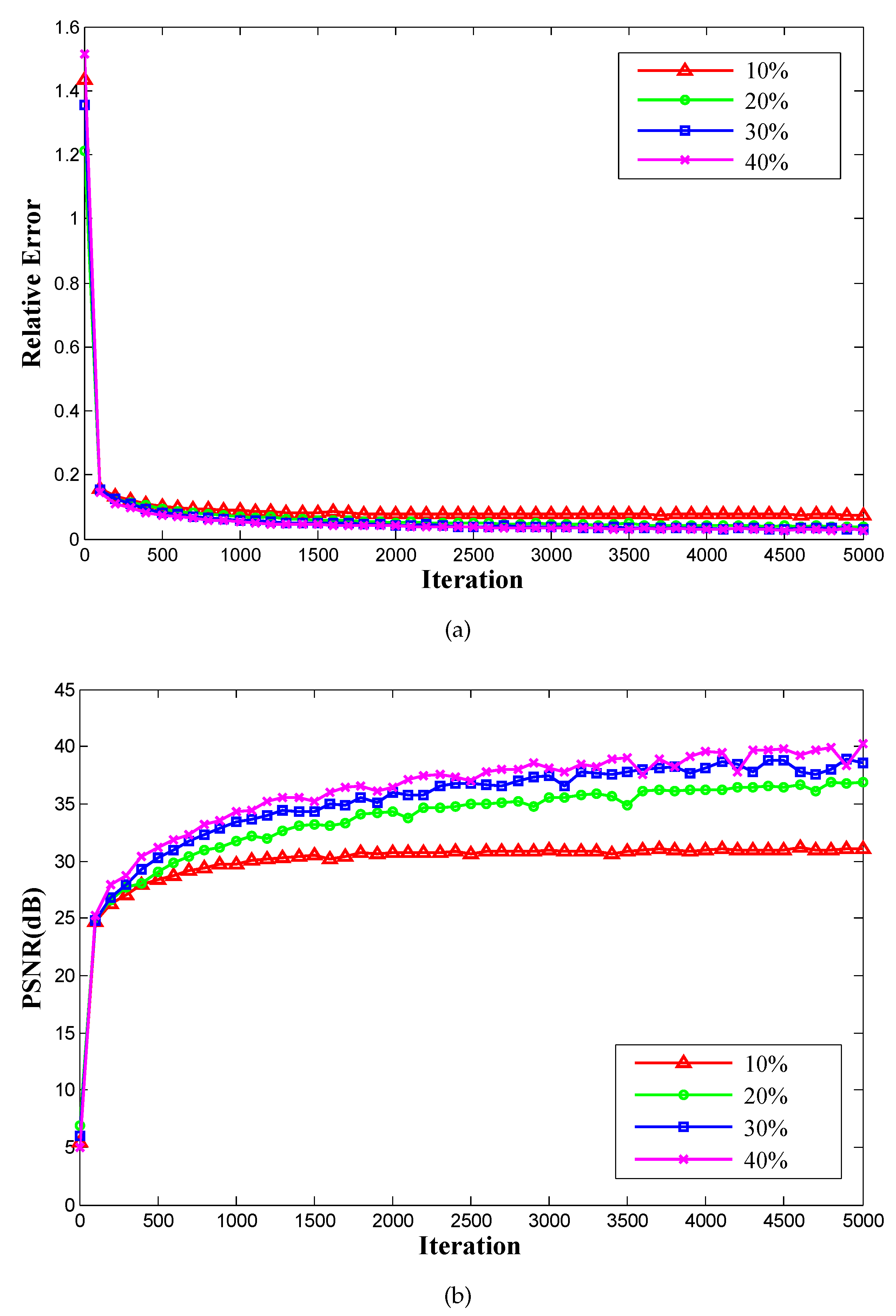
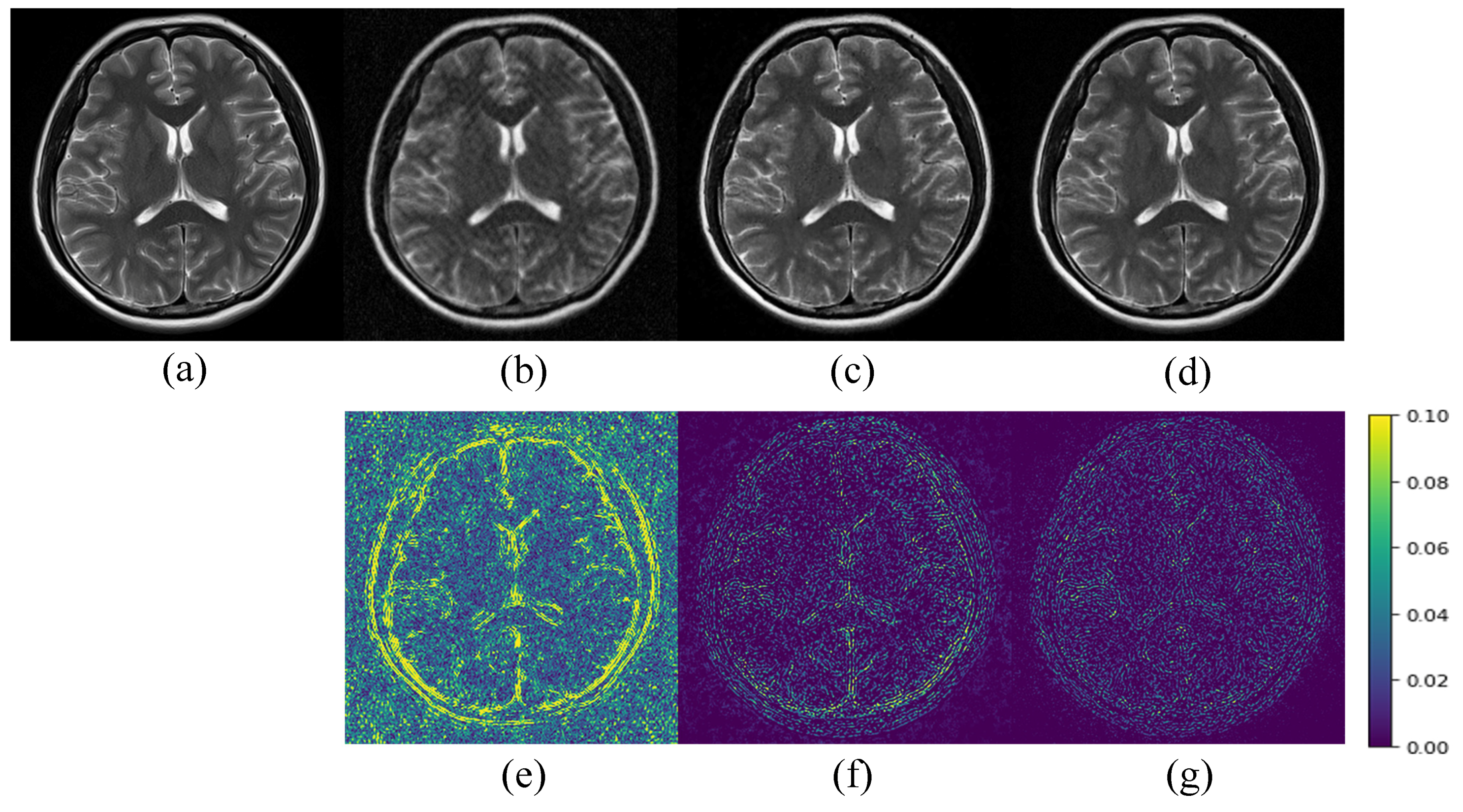
3. Experiments and Results
3.1. Experimental Setup
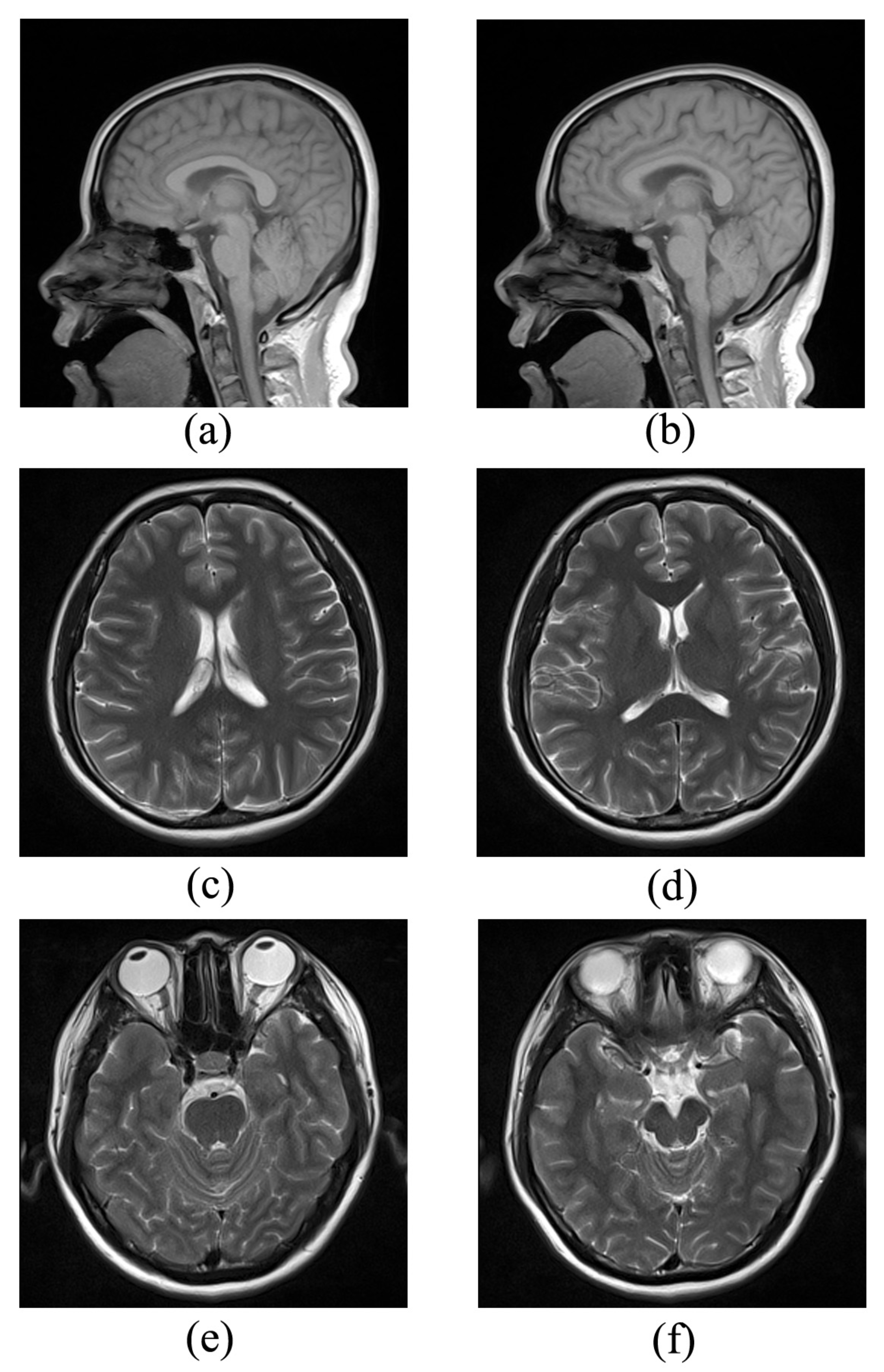
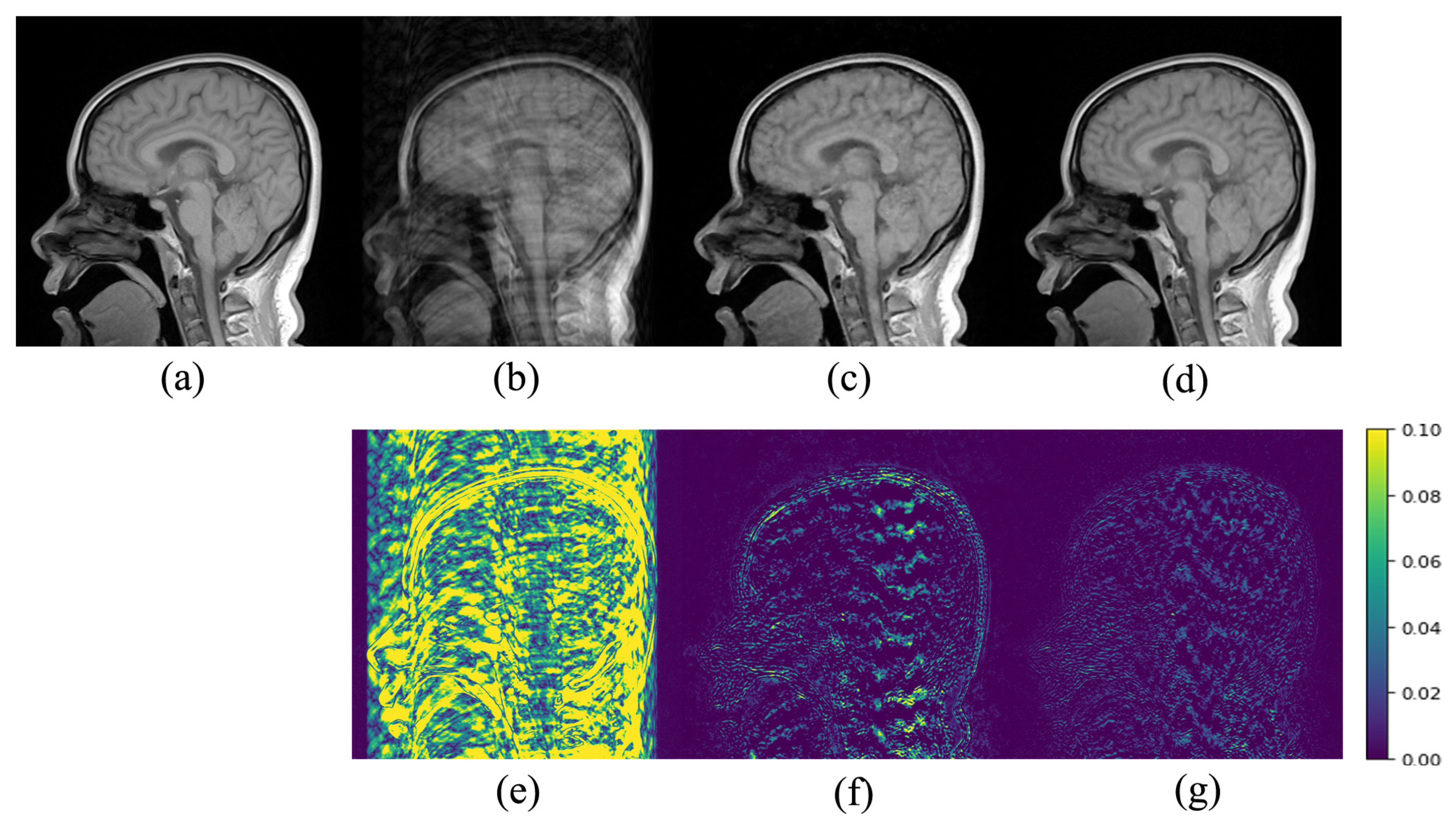
3.2. Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lustig, M.; Donoho, D.L.; Santos, J.M.; Pauly, J.M. Compressed Sensing MRI. IIEEE Signal Process. Mag. 2008, 25, 72–82. [Google Scholar] [CrossRef]
- Lustig, M.; Donoho, D.L.; Pauly, J.M. Sparse MRI: The Application of Compressed Sensing for Rapid MR Imaging. Magn. Reson. Med. 2007, 58, 1182–1195. [Google Scholar] [CrossRef]
- Qu, X.B.; Cao, X.; Guo, D.; Hu, C.W.; Chen, Z. Combined Sparsifying Transforms for Compressed Sensing MRI. Electron. Lett. 2010, 46, 121–123. [Google Scholar] [CrossRef] [Green Version]
- Trzasko, J.; Manduca, A. Highly undersampled magnetic resonance image reconstruction via homotopic l0-minimization. IEEE Trans. Med. Imaging 2010, 28, 106–121. [Google Scholar] [CrossRef]
- Kim, D.O.; Park, R.H. Evaluation of image quality using dual-tree complex wavelet transform and compressive sensing. Electron. Lett. 2010, 46, 494–495. [Google Scholar] [CrossRef]
- Qu, X.B.; Guo, D.; Ning, B.D.; Hou, Y.K.; Lin, Y.L.; Cai, S.H.; Chen, Z. Undersampled MRI Reconstruction with the Patch based Directional Wavelets. Magn. Reson. Imaging 2012, 30, 964–977. [Google Scholar] [CrossRef]
- Zhan, Z.F.; Cai, J.F.; Guo, D.; Liu, Y.S.; Chen, Z.; Qu, X.B. Fast Mul-ticlass Dictionaries Learning With Geometrical Directions in MRI Reconstruction. IEEE. Trans. Biomed. Eng. 2016, 63, 1850–1861. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.G.; Wang, S.S.; Ying, L.; Peng, X.; Zhu, Y.J.; Liang, D. Adaptive Dictionary Learning in Sparse Gradient Domain for Image Recovery. IEEE Trans. Image Process. 2013, 22, 4652–4663. [Google Scholar] [CrossRef] [PubMed]
- Aharon, M.; Elad, M.; Bruckstein, A.M. The K-SVD: An algorithm for designing overcomplete dictionaries for sparse representations. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Ophir, B.; Lustig, M.; Elad, M. Multi-scale dictionary learning using wavelets. IEEE J. Sel. Top. Signal Process. 2011, 5, 1014–1024. [Google Scholar] [CrossRef]
- Du, H.Q.; Lam, F. Compressed Sensing MR Image Reconstruction Using A Motion-compensated Reference. Magn. Reson. Imaging 2012, 30, 954–963. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Du, H.Q.; Lam, F.; Babacan, D.; Liang, Z.P. Reference driven MR Image Reconstruction with Sparsity and Support Constraints. In Proceedings of the IEEE International Symposium on Biomedical Imaging, Chicago, IL, USA, 30 March–2 April 2011; pp. 89–92. [Google Scholar]
- Lam, F.; Haldar, J.P.; Liang, Z.P. Motion Compensation for Reference-constrained Image Reconstruction from Limited Data. In Proceedings of the IEEE International Symposium on Biomedical Imaging. Chicago, IL, USA, 30 March–2 April 2011; pp. 73–76. [Google Scholar]
- Vaswani, N.; Lu, W. Modified-CS: Modifying compressive sensing for problems with partially known support. IEEE Trans. Signal Process. 2010, 58, 4595–4607. [Google Scholar] [CrossRef] [Green Version]
- Manduca, A.; Trzasko, J.D.; Li, Z.B. Compressive sensing of images with a priori known spatial support. In Proceedings of the SPIE, The International Society for Optical Engineering, San Diego, CA, USA, 22 March 2010. [Google Scholar]
- Stojnic, M.; Parvaresh, F.; Hassibi, B. On the reconstruction of block-sparse signals with an optimal number of measurements. IEEE Trans. Signal Process. 2009, 57, 3075–3085. [Google Scholar] [CrossRef] [Green Version]
- Usman, M.; Prieto, C.; Schaeffter, T.; Batchelor, P.G. k-t group sparse: A method for accelerating dynamic MRI. Magn. Reson. Med. 2011, 66, 1163–1176. [Google Scholar] [CrossRef]
- Han, Y.; Du, H.Q.; Gao, X.Z.; Mei, W.B. MR image reconstruction using cosupport constraints and group sparsity regularisation. IET Image Process. 2017, 11, 155–163. [Google Scholar] [CrossRef]
- Blumensath, T. Sampling and reconstructing signals from a union of linear subspaces. IEEE Trans. Inf. Theory 2011, 57, 4660–4671. [Google Scholar] [CrossRef]
- Eldar, Y.; Mishali, M. Robust recovery of signals from a structured union of subspaces. IEEE Trans. Inf. Theory 2009, 55, 5302–5316. [Google Scholar] [CrossRef] [Green Version]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.S.; Su, Z.H.; Ying, L.; Peng, X.; Zhu, S.; Liang, F.; Feng, D.G.; Liang, D. Accelerating magnetic resonance imaging via deep learning. In Proceedings of the 2016 IEEE 13th International Sympo-sium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 514–517. [Google Scholar]
- Lee, D.; Yoo, J.; Ye, J.C. Deep Residual Learning for Compressed Sensing MRI. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging, Melbourne, VIC, Australia, 18–21 April 2017; pp. 15–18. [Google Scholar]
- Hyun, C.M.; Kim, H.P.; Lee, S.M.; Lee, S.; Seo, K. Deep Learning for Undersampled MRI Reconstruction. Phys. Med. Biol. 2018, 63, 135007. [Google Scholar] [CrossRef]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.N.; Rueckert, D. A Deep Cascade of Con-volutional Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 491–503. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.J.; Liu, F.D.; Arridge, S.; Keegan, J.; Guo, Y.K.; et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1310–1321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, C.; Schlemper, J.; Caballero, J.; Price, A.N.; Hajnal, J.V.; Rueckert, D. Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans. Med. Imaging 2019, 38, 280–290. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Y.; Sun, J.; Li, H.B.; Xu, Z.B. Deep ADMM-Net for Compressive Sensing MRI. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 10–18. [Google Scholar]
- Hammernik, K.; Klatzer, T.; Kobler, E.; Recht, M.P.; Sodickson, D.K.; Pock, T.; Knoll, F. Learning a Variational Network for Reconstruction of Accelerated MRI Data. Magn. Reson. Med. 2018, 79, 3055–3071. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, H.K.; Mani, M.P.; Jacob, M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans. Med. Imaging 2019, 38, 394–405. [Google Scholar] [CrossRef] [PubMed]
- Tezcan, K.C.; Baumgartner, C.F.; Luechinger, R.; Pruessmann, K.P.; Konukoglu, E. MR Image Reconstruction Using Deep Density Priors. IEEE Trans. Med. Imaging 2019, 38, 1633–1642. [Google Scholar] [CrossRef] [PubMed]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep Image Prior. arXiv 2017, arXiv:1711.10925v3. [Google Scholar]
- Liu, J.M.; Sun, Y.; Xu, X.J.; Ulugbek, S. Kamilov. Image Restoration using Total Variation Regularized Deep Image Prior. arXiv 2018, arXiv:1810.12864. [Google Scholar]
- Mataev, G.; Elad, M.; Milanfar, P. Deep RED: Deep Image Prior Powered by RED. arXiv 2019, arXiv:1903.10176. [Google Scholar]
- Gong, K.; Catana, C.; Qi, J.Y.; Li, Q.Z. PET Image Reconstruction Using Deep Image Prior. IEEE Trans. Med. Imaging 2019, 38, 1655–1665. [Google Scholar] [CrossRef]
- Hashimoto, F.; Ohba, H.; Ote, K.; Teramoto, A.; Tsukada, H. Dynamic PET Image Denoising Using Deep Convolutional Neural Networks Without Prior Training Datasets. IEEE Access 2019, 7, 96594–96603. [Google Scholar] [CrossRef]
- Veen, D.V.; Jalal, A.; Soltanolkotabi, M.; Price, E.; Vishwanath, S.; Dimakis, A.G. Compressed Sensing with Deep Image Prior and Learned Regularization. arXiv 2018, arXiv:1806.06438. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image. Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Images | ||
|---|---|---|---|
| Brain A | Brain B | Brain C | |
| L | 5 | 6 | 6 |
| [8, 16, 32, 64, 128] | [6, 32, 64, 128, 128, 128] | [6, 32, 64, 128, 128, 128] | |
| [8, 16, 32, 64, 128] | [6, 32, 64, 128, 128, 128] | [6, 32, 64, 128, 128, 128] | |
| [8, 8, 8, 8, 8] | [4, 4, 4, 4, 4, 4] | [4, 4, 4, 4, 4, 4] | |
| [3, 3, 3, 3, 3] | [3, 3, 3, 3, 3, 3] | [3, 3, 3, 3, 3, 3] | |
| [3, 3, 3, 3, 3] | [3, 3, 3, 3, 3, 3] | [3, 3, 3, 3, 3, 3] | |
| [1, 1, 1, 1, 1] | [1, 1, 1, 1, 1, 1] | [1, 1, 1, 1, 1, 1] | |
| Number of iterations | 5000 | 5000 | 5000 |
| Learning rate | 0.01 | 0.01 | 0.01 |
| Images | Methods | 10% | 20% | ||||
| Relative Error (%) | PSNR (dB) | SSIM | Relative Error (%) | PSNR (dB) | SSIM | ||
| Brain A | Zero-filling | 23.19 | 21.2991 | 0.6658 | 16.96 | 24.0131 | 0.7340 |
| DIP | 17.76 | 23.6856 | 0.8169 | 6.59 | 32.4196 | 0.9505 | |
| Proposed method | 7.50 | 31.1077 | 0.9443 | 3.69 | 37.2870 | 0.9793 | |
| Brain B | Zero-filling | 39.71 | 18.3797 | 0.5671 | 20.79 | 23.9985 | 0.7116 |
| DIP | 34.94 | 19.5328 | 0.6738 | 13.86 | 27.5478 | 0.9023 | |
| Proposed method | 19.37 | 24.6170 | 0.8443 | 9.43 | 30.8447 | 0.9516 | |
| Brain C | Zero-filling | 33.65 | 18.9034 | 0.5874 | 17.02 | 24.8250 | 0.7216 |
| DIP | 31.13 | 19.5803 | 0.6770 | 13.28 | 27.0063 | 0.8877 | |
| Proposed method | 20.93 | 23.0289 | 0.8027 | 10.15 | 29.3177 | 0.9317 | |
| Images | Methods | 30% | 40% | ||||
| Relative Error (%) | PSNR (dB) | SSIM | Relative Error (%) | PSNR (dB) | SSIM | ||
| Brain A | Zero-filling | 5.92 | 33.1598 | 0.8215 | 4.27 | 35.9904 | 0.8409 |
| DIP | 4.08 | 36.6919 | 0.9734 | 3.82 | 37.3045 | 0.9768 | |
| Proposed method | 2.31 | 41.3355 | 0.9900 | 2.02 | 42.5144 | 0.9918 | |
| Brain B | Zero-filling | 20.93 | 23.9418 | 0.7185 | 10.70 | 29.7719 | 0.8024 |
| DIP | 9.67 | 30.6624 | 0.9455 | 7.45 | 32.9221 | 0.9644 | |
| Proposed method | 7.39 | 32.9747 | 0.9665 | 5.58 | 35.4324 | 0.9781 | |
| Brain C | Zero-filling | 16.42 | 25.1364 | 0.7408 | 8.94 | 30.4097 | 0.8071 |
| DIP | 10.26 | 29.2226 | 0.9287 | 8.05 | 31.3531 | 0.9513 | |
| Proposed method | 7.83 | 31.5733 | 0.9559 | 5.83 | 34.1343 | 0.9718 |
| Images | Methods | Computational Time | |||
|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | ||
| Brain B | DIP | 3 m 12 s | 3 m 9 s | 3 m 14 s | 3 m 4 s |
| Proposed method | 3 m 21 s | 3 m 8 s | 3 m 14 s | 3 m 12 s | |
| Brain C | DIP | 3 m 7 s | 3 m 19 s | 3 m 9 s | 3 m 8 s |
| Proposed method | 3 m 14 s | 3 m 19 s | 3 m 6 s | 3 m 16 s | |
| Images | Methods | Radial Undersampled Mask (20%) | Variable Density Undersampled Mask (20%) | ||||
|---|---|---|---|---|---|---|---|
| Relative Error (%) | PSNR (dB) | SSIM | Relative Error (%) | PSNR (dB) | SSIM | ||
| Brain A | Zero-filling | 6.03 | 33.0053 | 0.8902 | 8.61 | 29.9079 | 0.8346 |
| DIP | 3.98 | 36.8254 | 0.9754 | 5.08 | 34.6761 | 0.9638 | |
| Proposed method | 2.23 | 41.6545 | 0.9897 | 2.93 | 39.2628 | 0.9830 | |
| Brain B | Zero-filling | 17.61 | 25.4440 | 0.7424 | 22.49 | 23.3150 | 0.6674 |
| DIP | 9.43 | 30.8724 | 0.9492 | 11.09 | 29.4899 | 0.9250 | |
| Proposed method | 3.98 | 36.8254 | 0.9754 | 5.08 | 34.6761 | 0.9638 | |
| Brain C | Zero-filling | 14.57 | 26.1770 | 0.7744 | 18.41 | 24.1433 | 0.7102 |
| DIP | 9.18 | 30.1892 | 0.9355 | 11.01 | 28.6124 | 0.9077 | |
| Proposed method | 7.27 | 32.2166 | 0.9597 | 8.13 | 31.2440 | 0.9458 | |
| Methods | Relative Error (%) | PSNR (dB) | SSIM |
|---|---|---|---|
| Zero-filling | 11.28 | 29.3139 | 0.8694 |
| DIP | 8.61 | 31.6610 | 0.9339 |
| Proposed method | 6.98 | 33.4717 | 0.9490 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Zhao, F.; Gan, Y. Reference-Driven Compressed Sensing MR Image Reconstruction Using Deep Convolutional Neural Networks without Pre-Training. Sensors 2020, 20, 308. https://doi.org/10.3390/s20010308
Zhao D, Zhao F, Gan Y. Reference-Driven Compressed Sensing MR Image Reconstruction Using Deep Convolutional Neural Networks without Pre-Training. Sensors. 2020; 20(1):308. https://doi.org/10.3390/s20010308
Chicago/Turabian StyleZhao, Di, Feng Zhao, and Yongjin Gan. 2020. "Reference-Driven Compressed Sensing MR Image Reconstruction Using Deep Convolutional Neural Networks without Pre-Training" Sensors 20, no. 1: 308. https://doi.org/10.3390/s20010308