Next Location Prediction Based on an Adaboost-Markov Model of Mobile Users †

Abstract
:1. Introduction
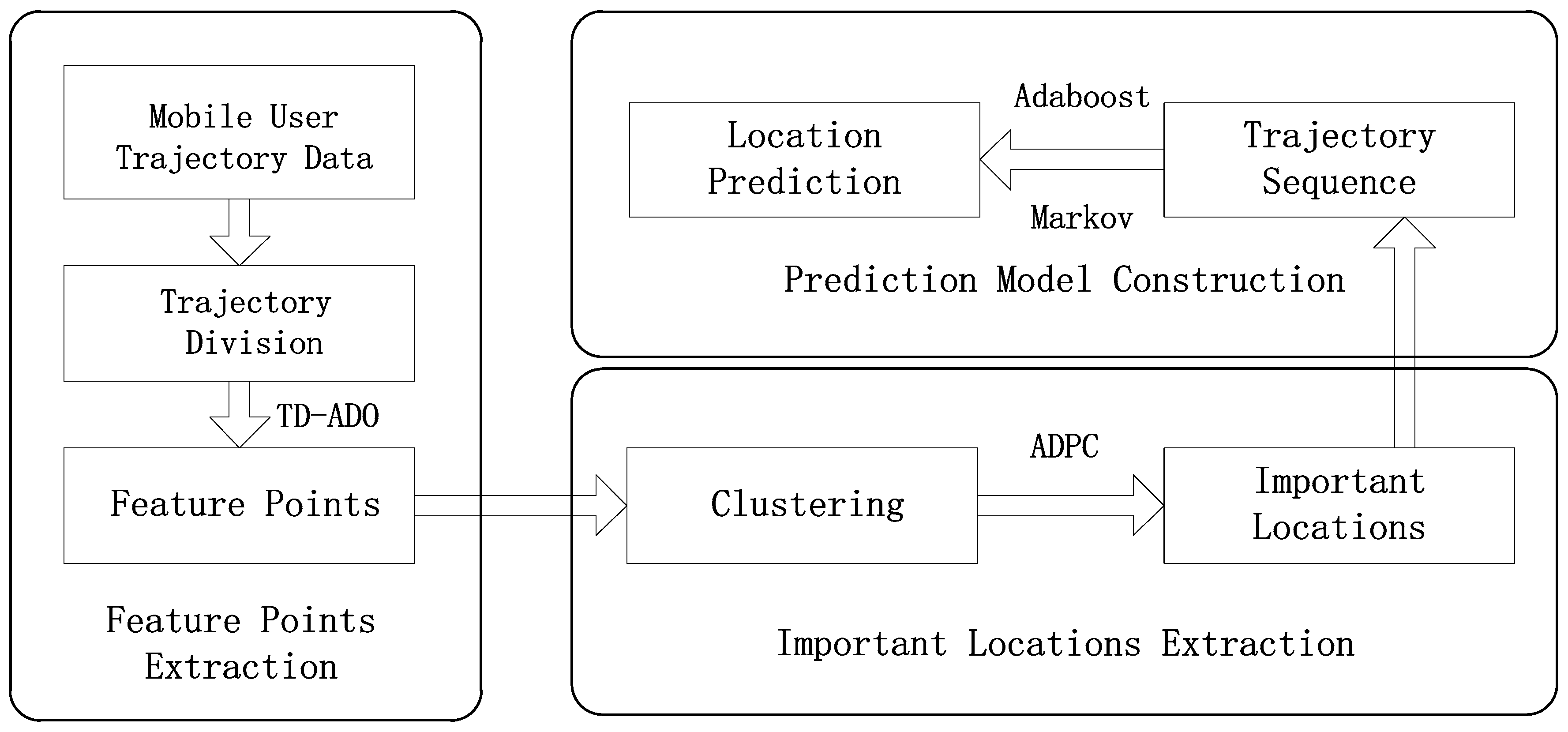
2. Proposed Framework
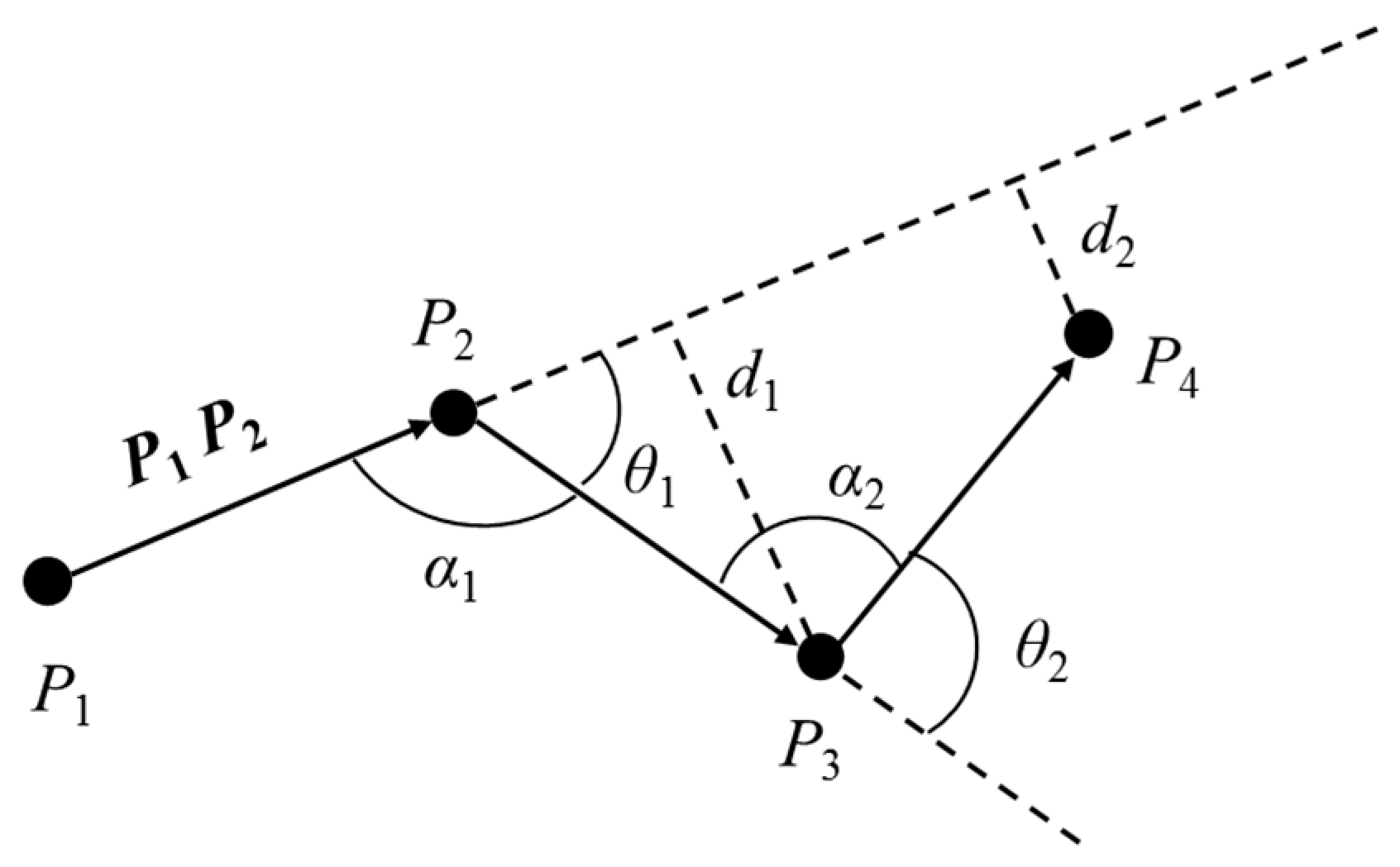
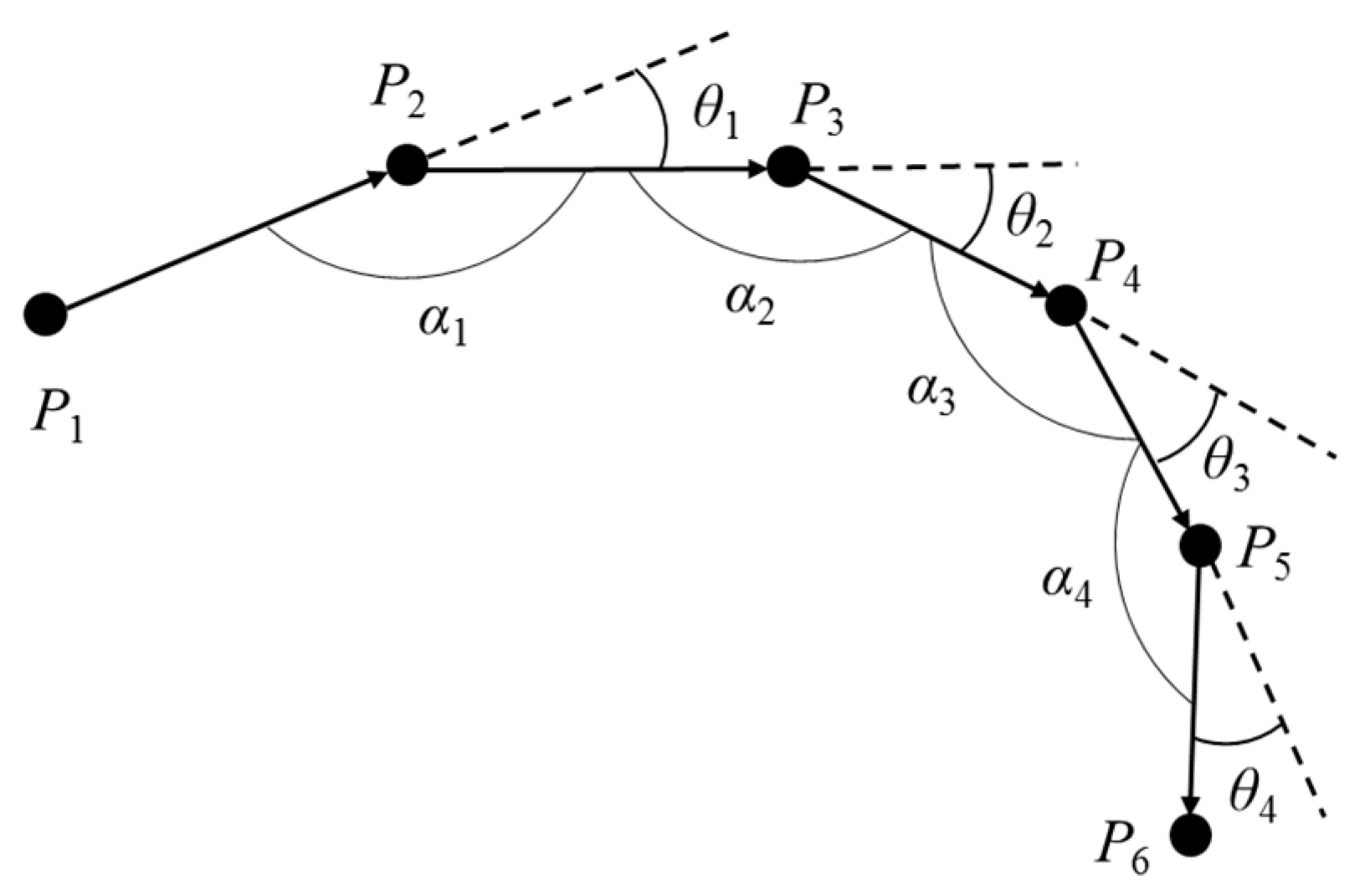
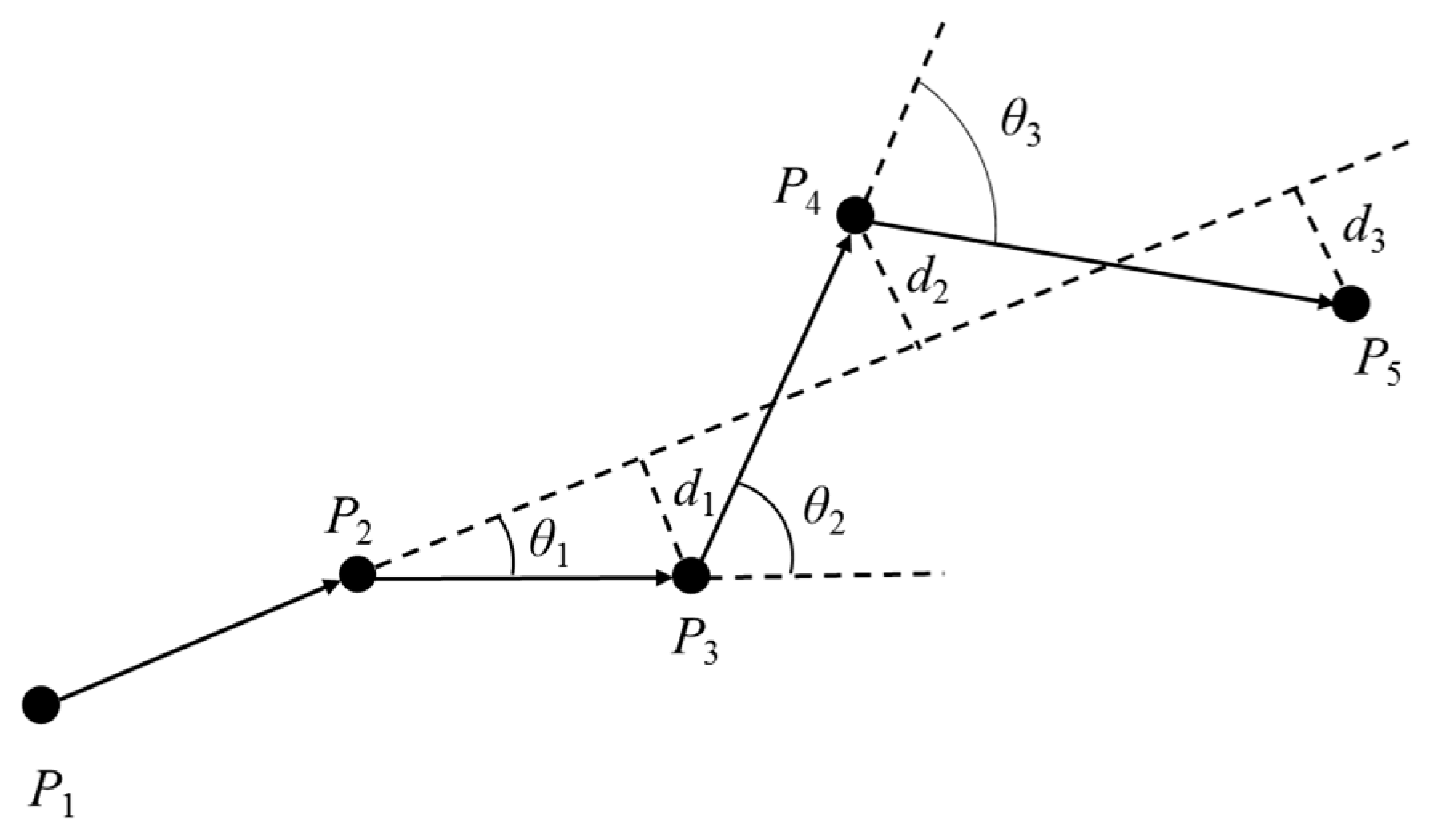
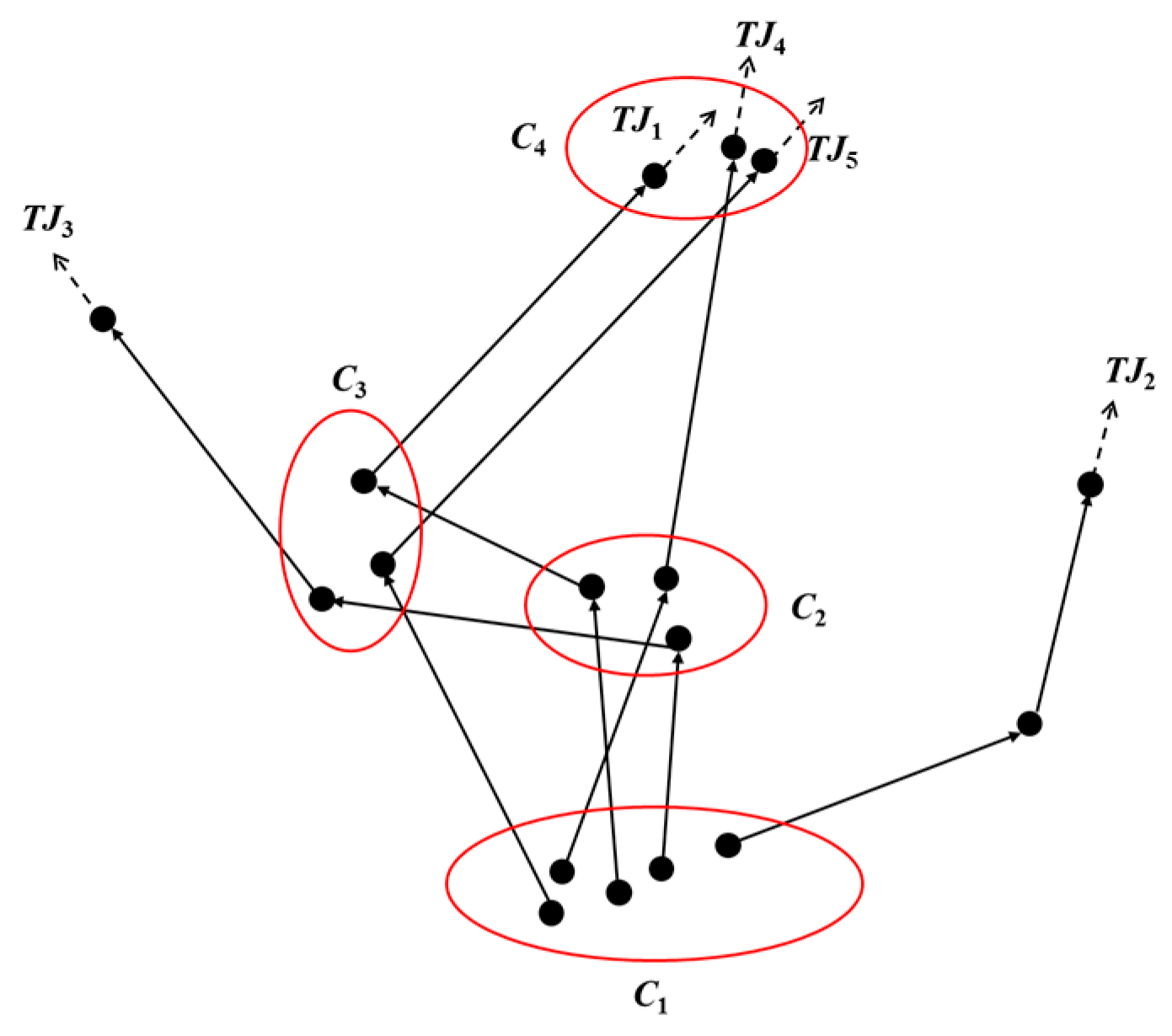
2.1. Trajectory Preprocessing Algorithm
| Algorithm: TD-ADO |
| 1: Input: TJi = {P1, P2, …, Pm}, angle offset threshold θth, distance offset threshold dth; 2: Output: Feature Points FP; 3: P1→FP; 4: i = 1; 5: repeat 6: initial movement behavior = PiPi+1; 7: for j = 1 to m−2 do 8: if θj > θth || dj > dth then 9: Pj+2→FP; 10: i = j+2; 11: break; 12: else 13: if j = m−2 then 14: Pj+2→FP; 15: end if 16: end if 17: end for 18: until Pm→FP. |
| 19: return FP. |
2.2. The Important Locations Extraction Algorithm
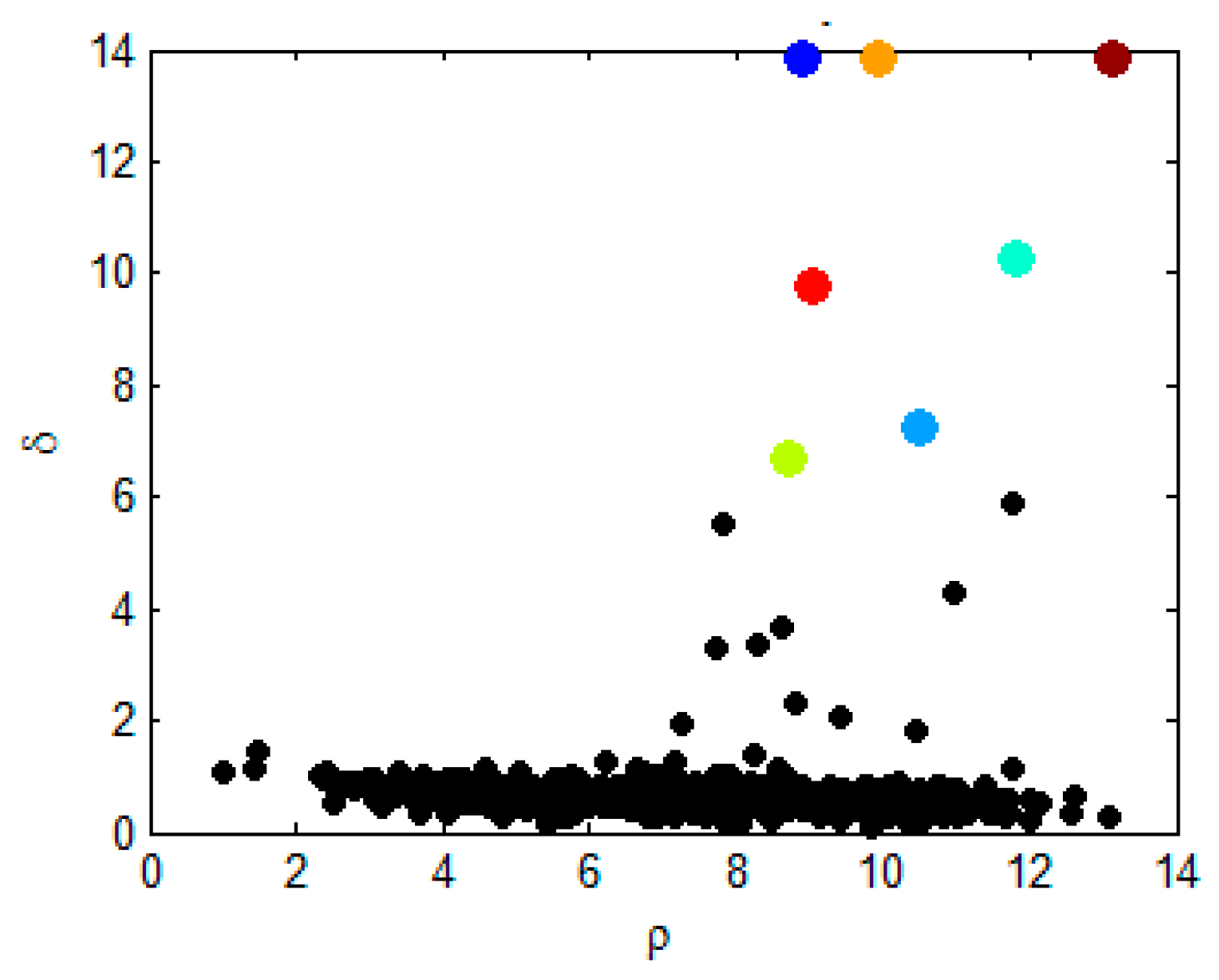
- Step 1.
- Calculate the product γi of normalized ρi and δi for each data point.
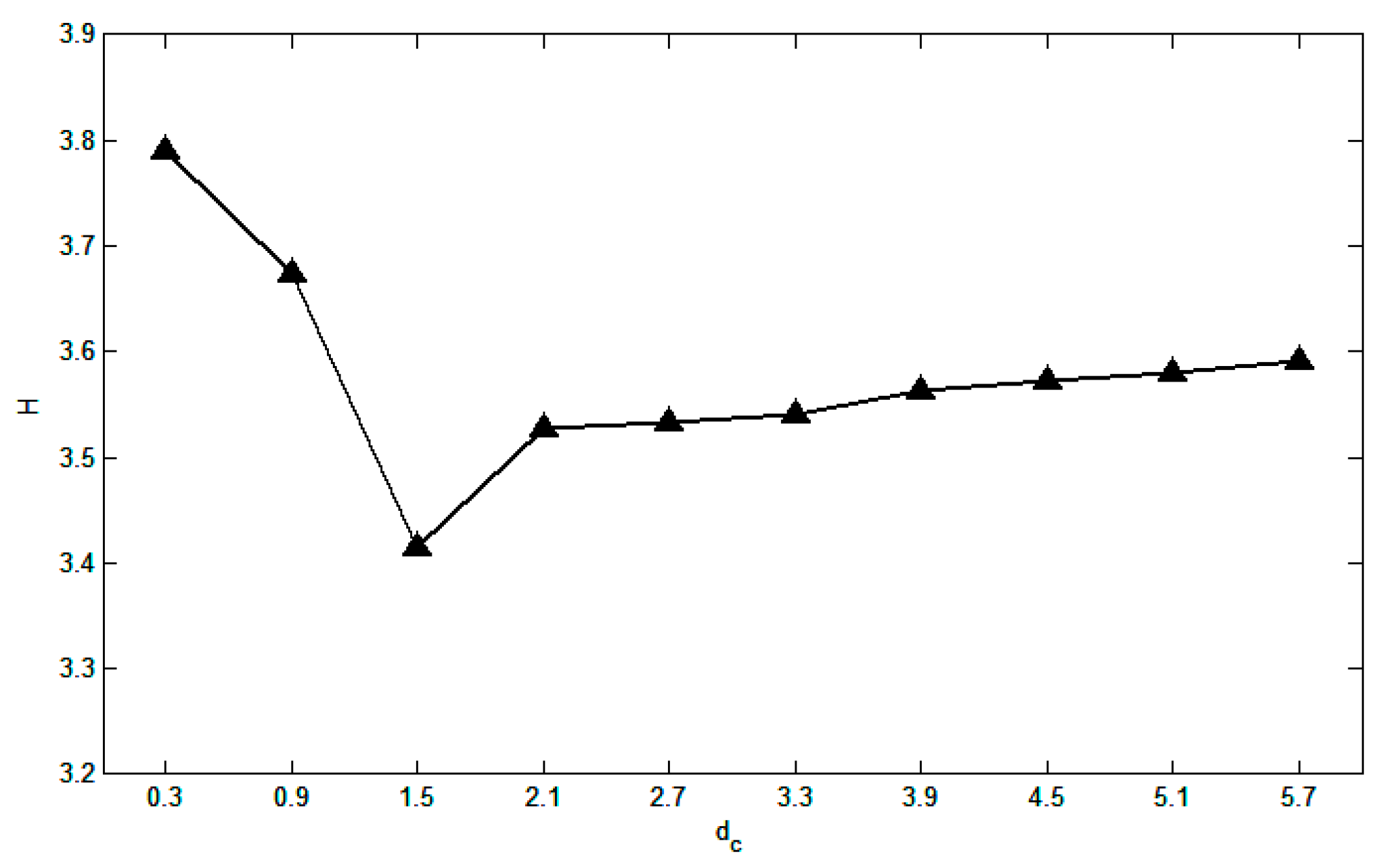
- Step 2.
- Find dc that minimizes the entropy.
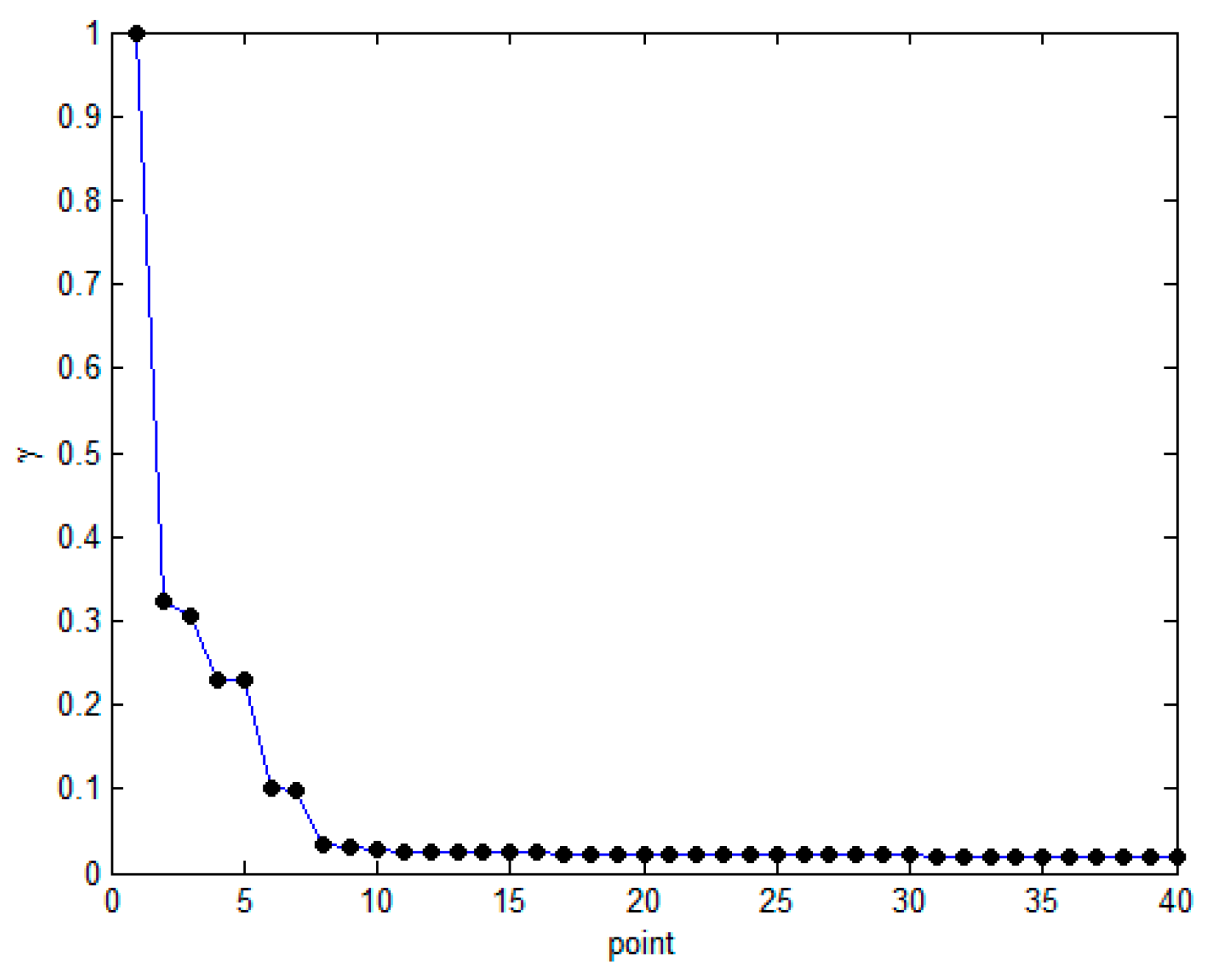
- Step 3.
- Sort γi of each data point in descending order, and select the appropriate number of points according to the total number of points in the data set and generate sorting charts in descending order.
- Step 4.
- Calculate the average value θ of γ in the γi sort diagram and use θ as the threshold to filter out data points with γi greater than θ.
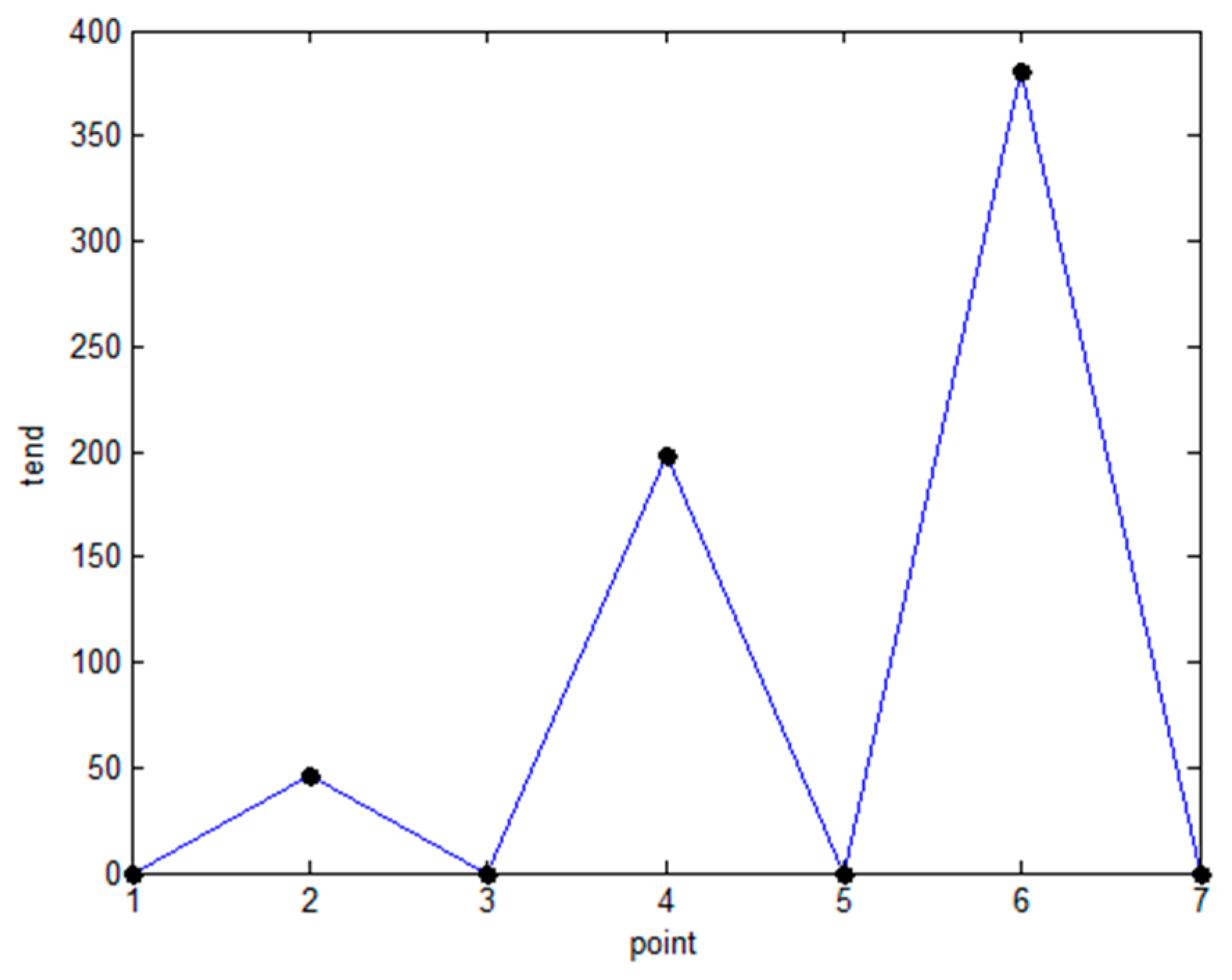
- Step 5.
- According to the slope change trend formula, the tend of the filtered data points is obtained.
- Step 6.
- The i−1 data points before the data point i with the largest tend are regarded as potential cluster centers.
- Step 7.
- First, use the first data point as the actual cluster center to determine whether the distance between the second data point and its distance is less than the distance threshold dc. If it is less than, then the second data point is treated as a non-clustering center; otherwise, use the second data point as the actual clustering center.
- Step 8.
- By analogy, determine whether the distance between the kth potential cluster center and all actual cluster centers are greater than the distance threshold, and then treat it as the actual cluster center or non-cluster center according to the judgment result.
- Step 9.
- Finally, according to all the selected actual cluster centers, cluster the remaining data points.
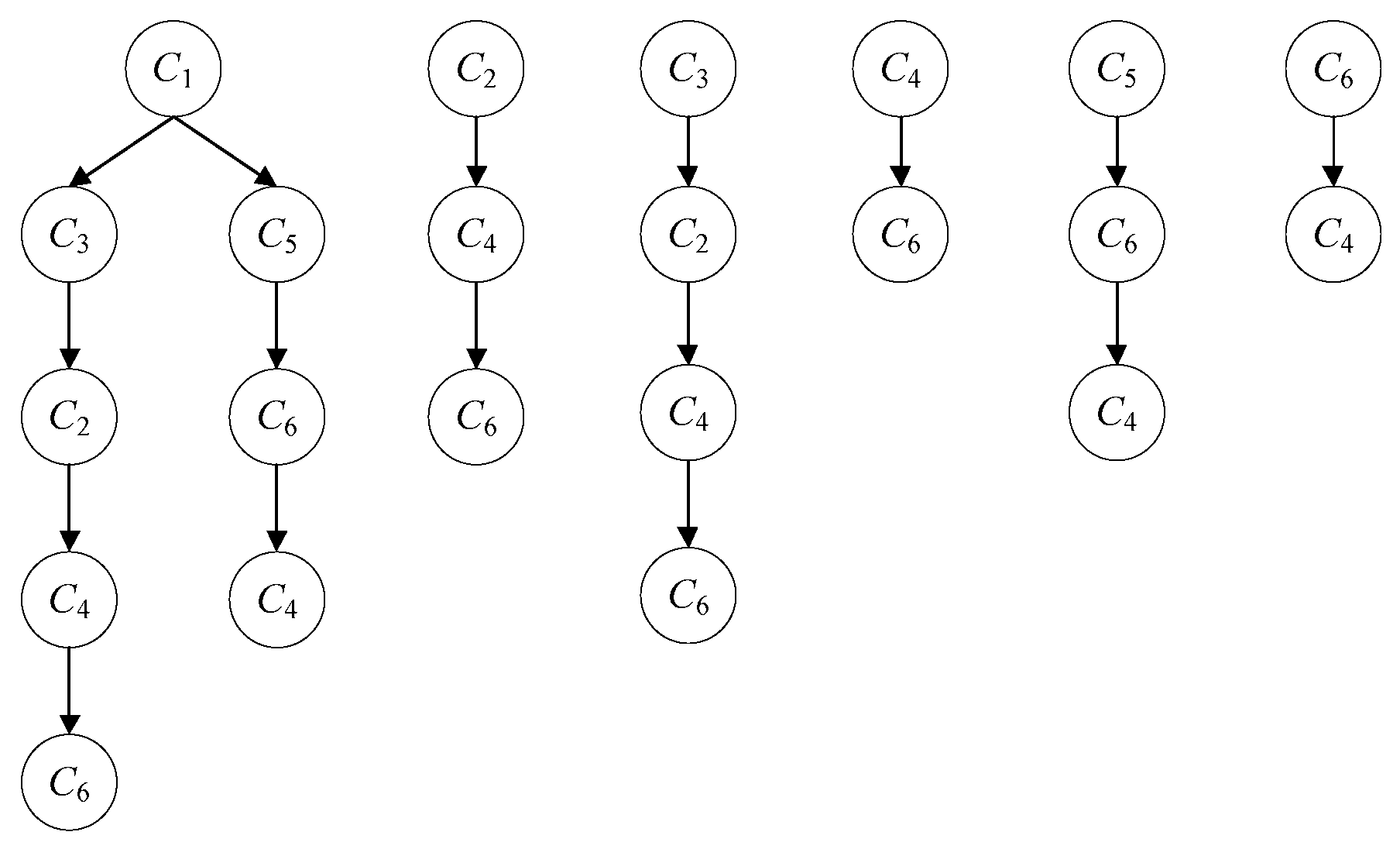
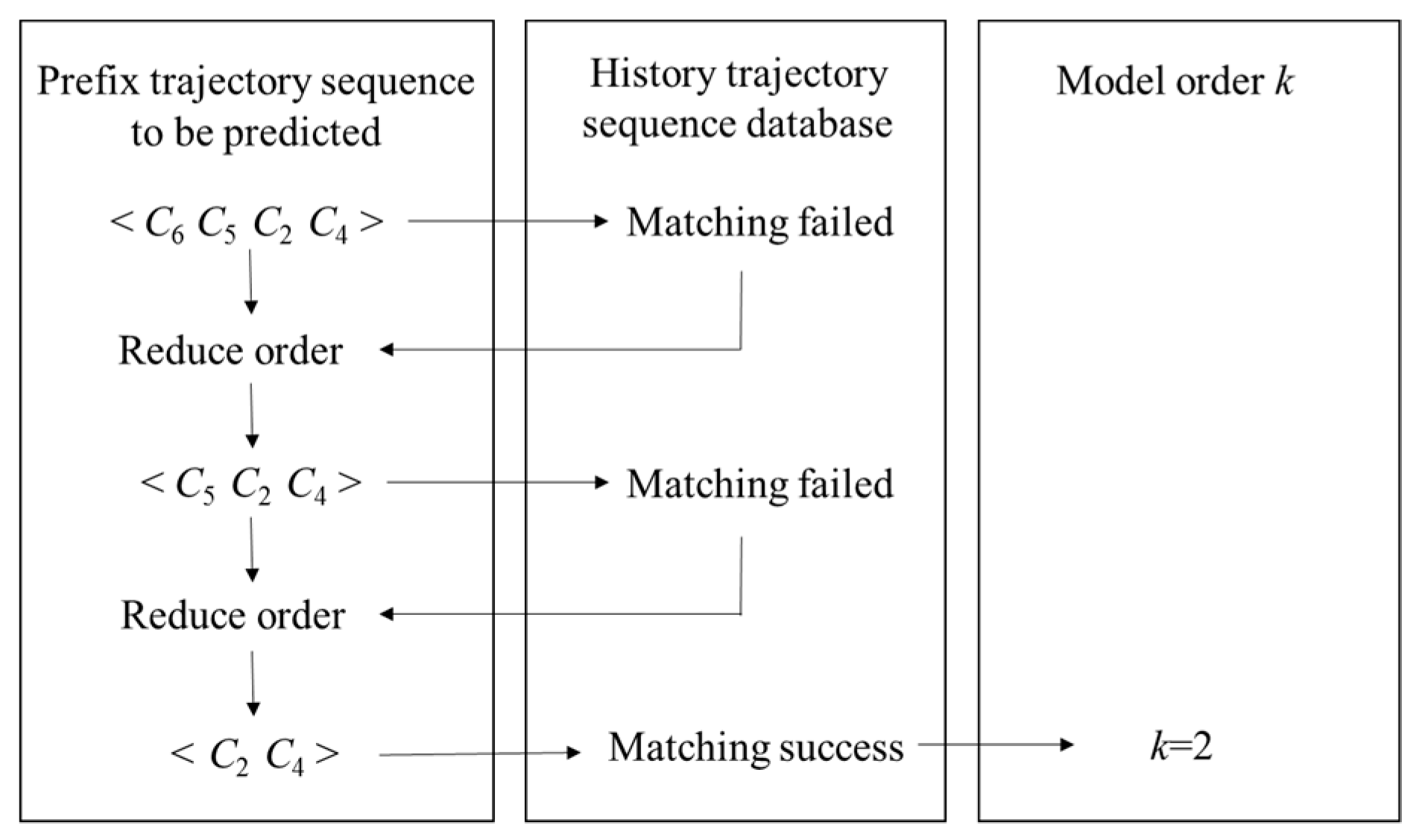
2.3. Locations Prediction Model
3. Experiments
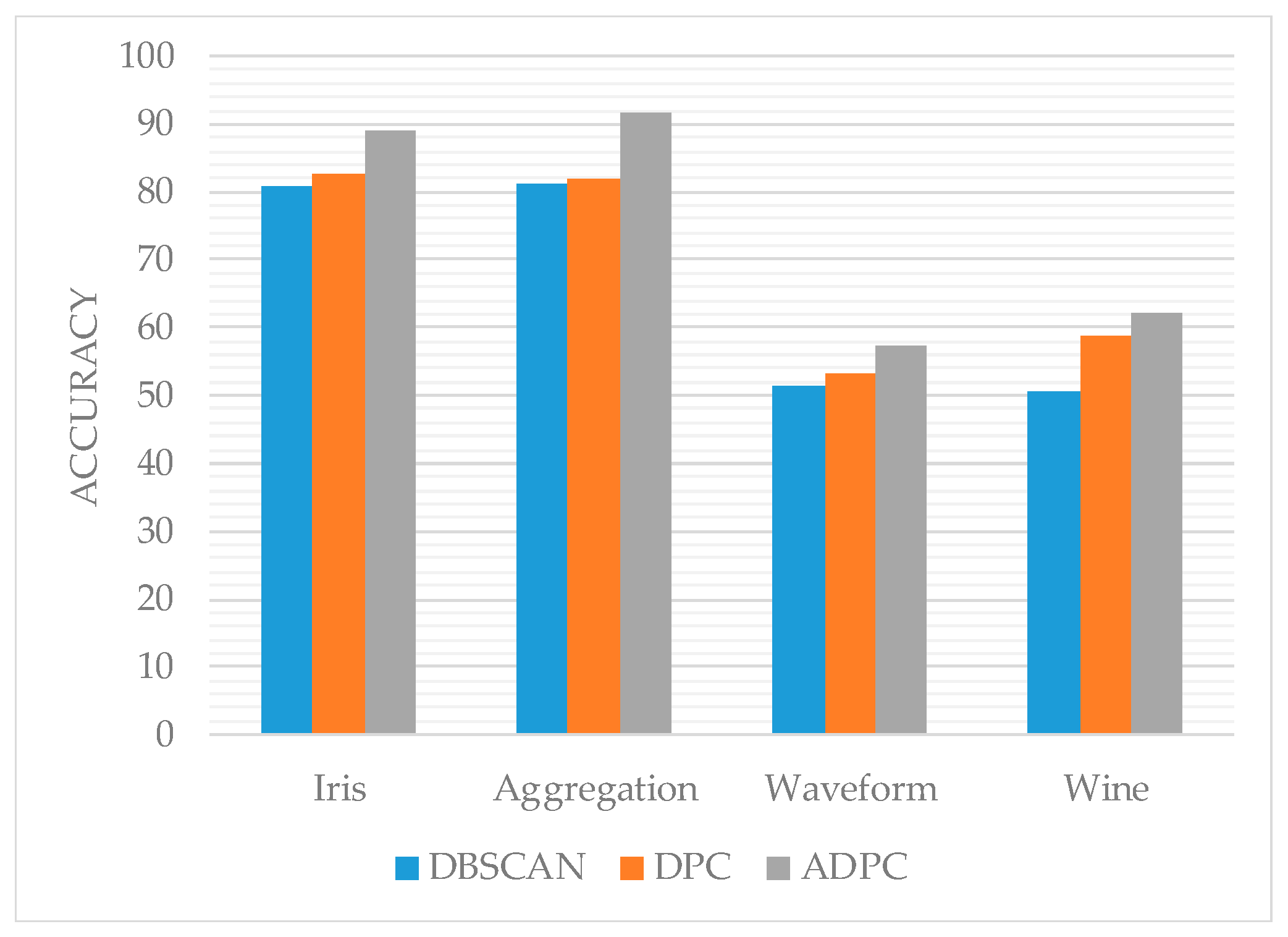
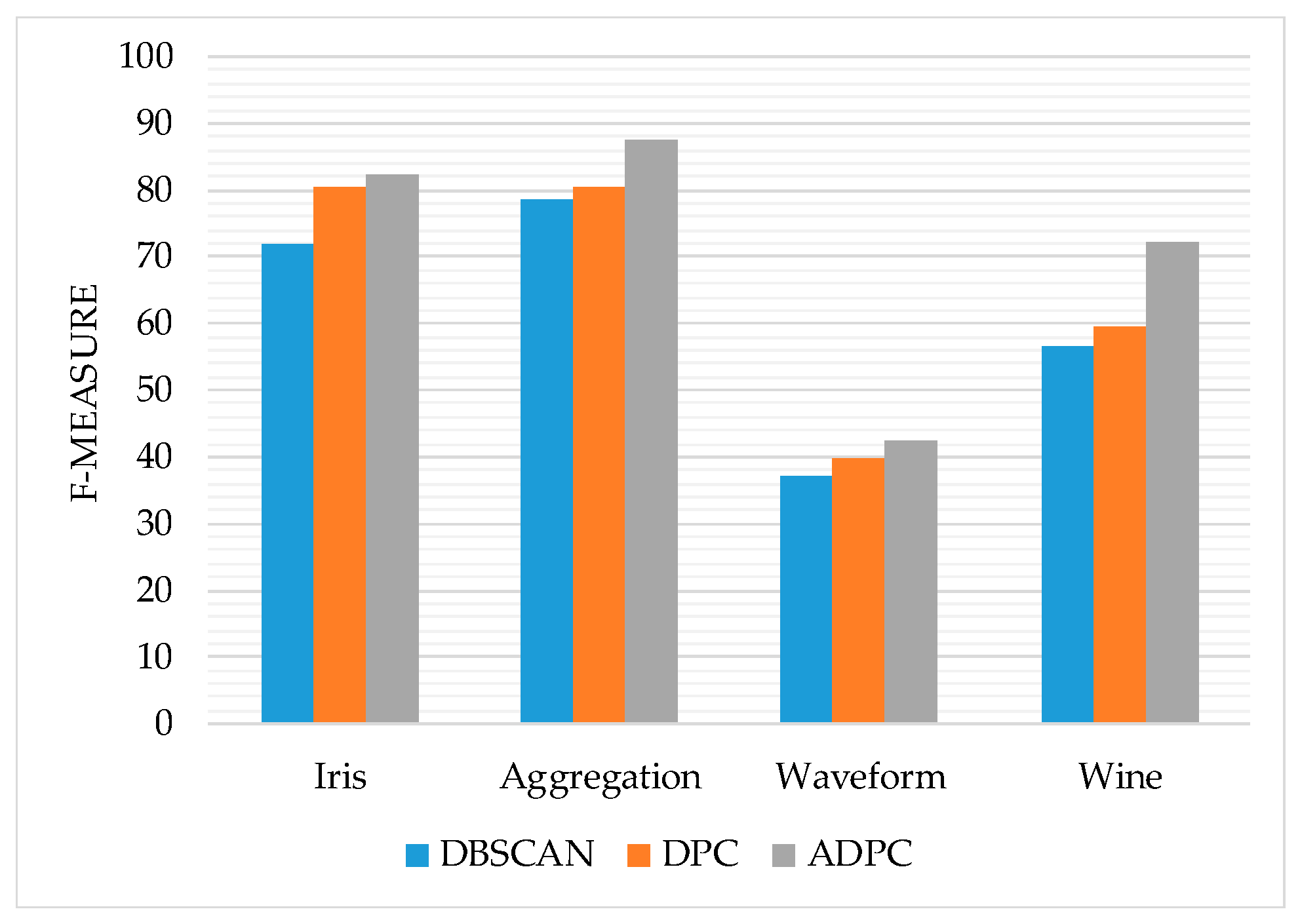
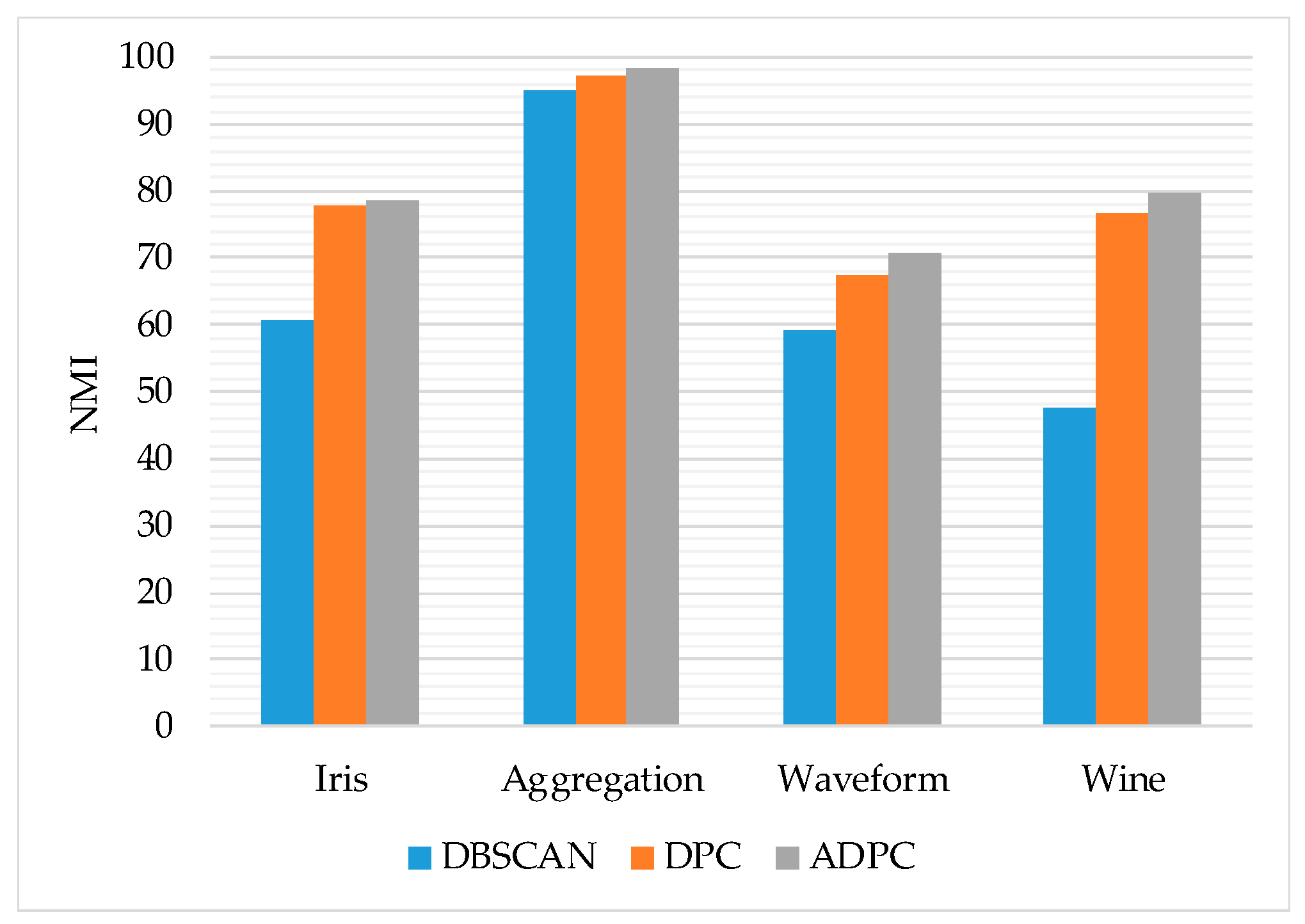
3.1. Clustering Performance
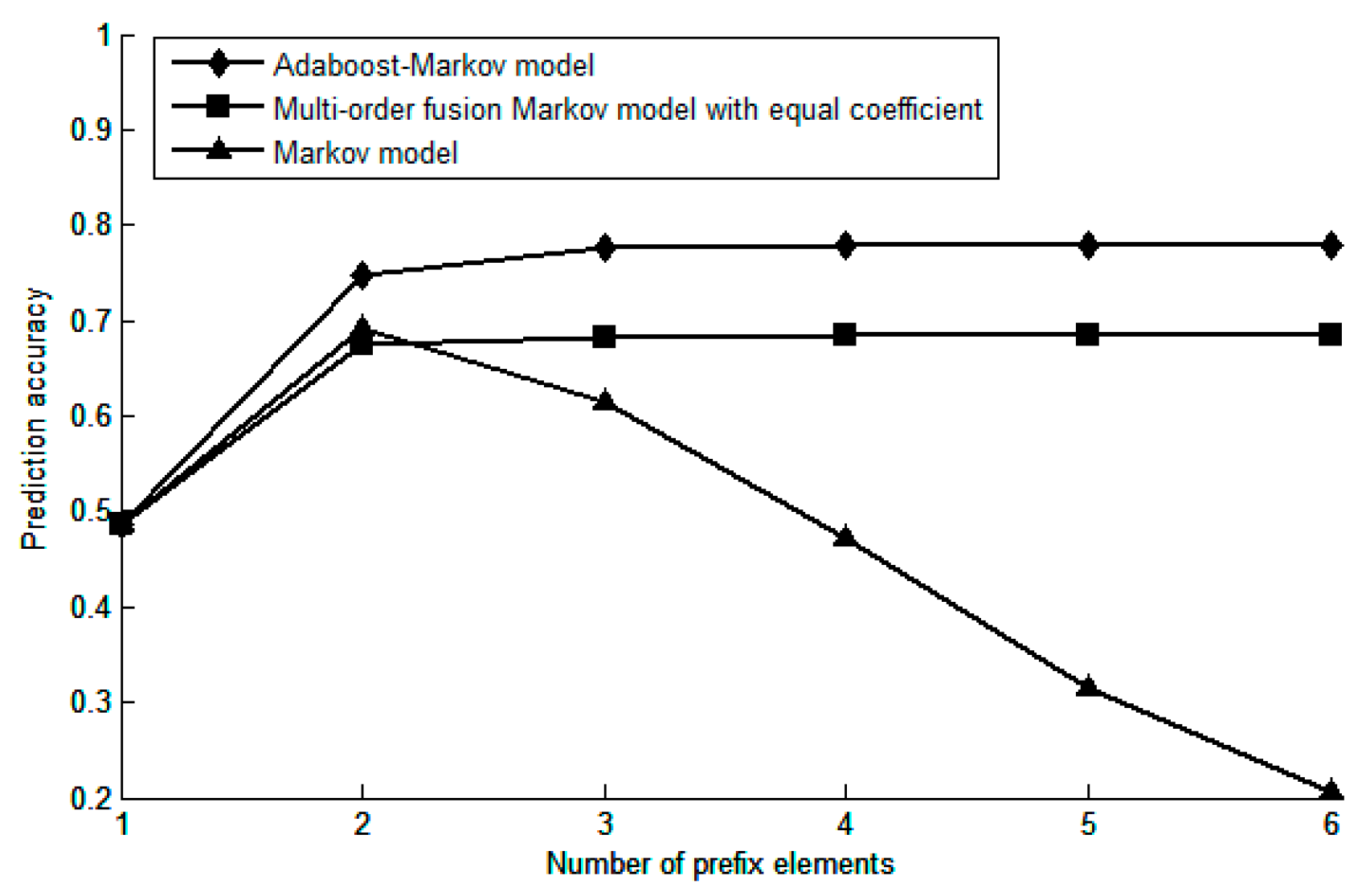
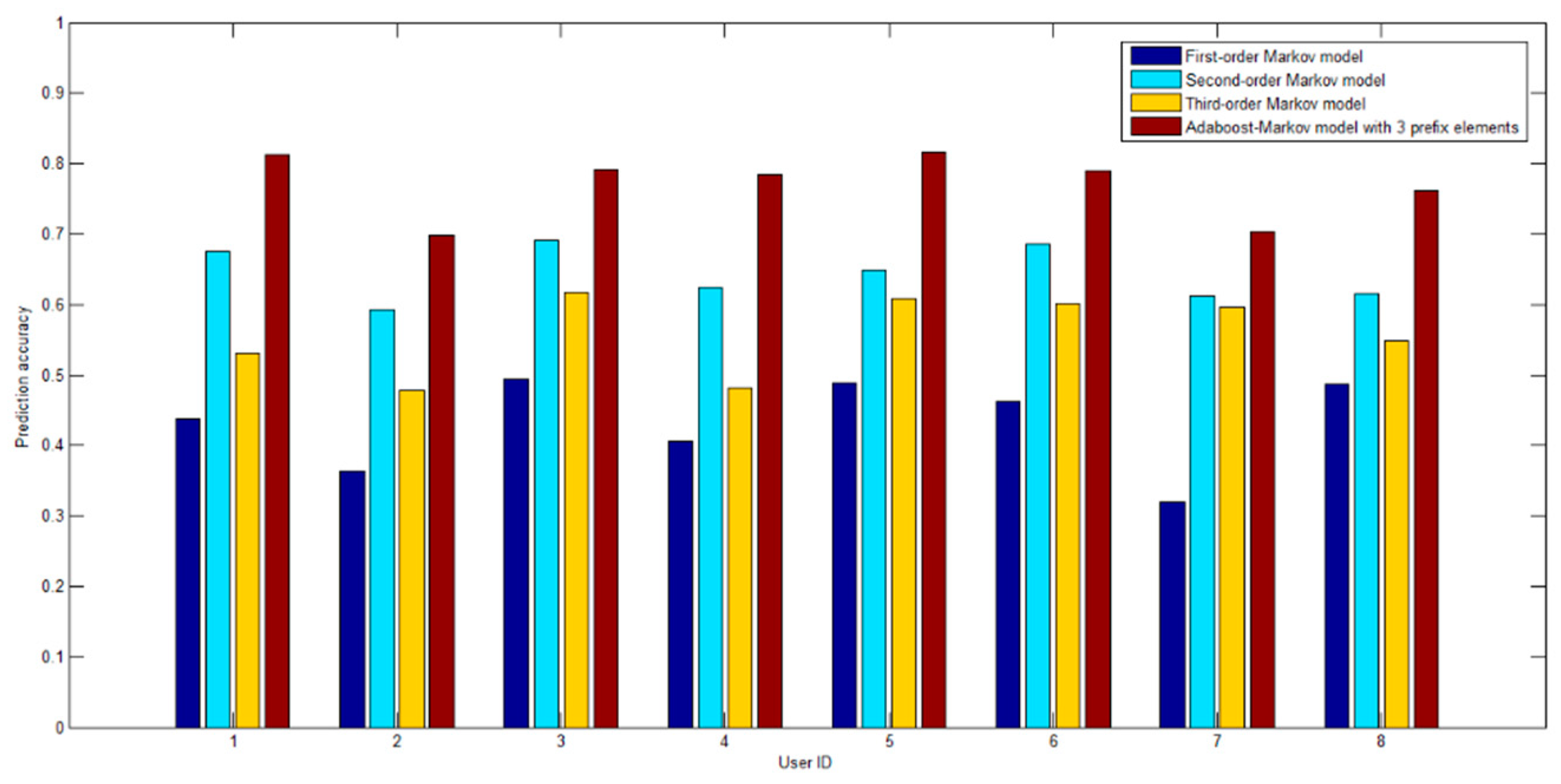
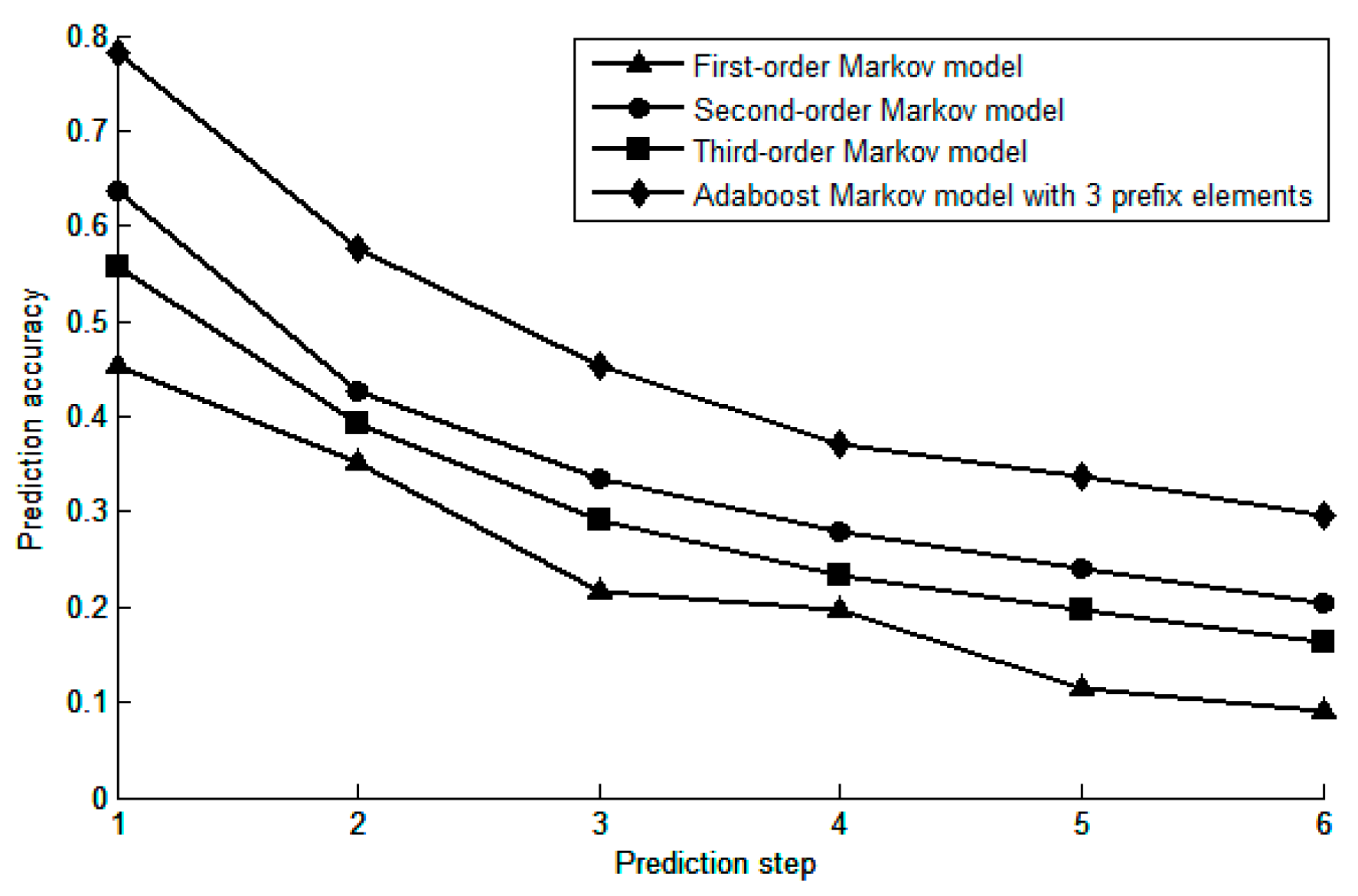
3.2. Prediction Performance Analysis of Various Model
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guo, C.; Liu, J.N.; Fang, Y.; Luo, M.; Cui, J.S. Value Extraction and Collaborative Mining Methods for Location Big Data. J. Softw. 2014, 25, 713–730. [Google Scholar]
- Widhalm, P.; Nitsche, P.; Brandie, N. Transport mode detection with realistic Smartphone sensor data. In Proceedings of the International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2015; IEEE: Piscataway, NJ, USA, 2012; pp. 573–576. [Google Scholar]
- Shih, D.H.; Shih, M.H.; Yen, D.C.; Hsu, J.H. Personal mobility pattern mining and anomaly detection in the GPS era. Am. Cartogr. 2016, 43, 55–67. [Google Scholar] [CrossRef]
- Gunduz, S.; Yavanoglu, U.; Sagiroglu, S. Predicting Next Location of Twitter Users for Surveillance. In Proceedings of the 2013 13th International Conference on Machine Learning and Applications, Miami, FL, USA, 4–7 December 2013; IEEE Computer Society: Piscataway, NJ, USA, 2013; pp. 267–273. [Google Scholar]
- Bogomolov, A.; Lepri, B.; Staiano, J.; Oliver, N.; Pianesi, F.; Pentland, A. Once Upon a Crime: Towards Crime Prediction from Demographics and Mobile Data. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; ACM: New York, NY, USA, 2014; pp. 427–434. [Google Scholar]
- Yuan, J.; Zheng, Y.; Zhang, L.; Xie, X.; Sun, G. Where to find my next passenger. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011. [Google Scholar]
- Pang, L.X.; Chawla, S.; Liu, W.; Zheng, Y. On mining anomalous patterns in road traffic streams. In Proceedings of the 7th International Conference on Advanced Data Mining and Applications, Beijing, China, 17–19 December 2011. [Google Scholar]
- Zheng, Y.; Liu, Y.; Yuan, J.; Xie, X. Urban Computing with Taxicabs. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011; pp. 89–98. [Google Scholar]
- Zheng, Y.; Xie, X.; Ma, W.Y. GeoLife: A collaborative social networking service among user, location and trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]
- Kotz, D.; Henderson, T. CRAWDAD: A Community Resource for Archiving Wireless Data at Dartmouth. IEEE Pervasive Comput. 2005, 4, 12–14. [Google Scholar] [CrossRef]
- Scellato, S.; Musolesi, M.; Mascolo, C.; Latora, V.; Campbell, A.T. NextPlace: A Spatio-temporal Prediction Framework for Pervasive Systems. In Proceedings of the International Conference on Pervasive Computing, Seattle, WA, USA, 21–25 March 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 152–159. [Google Scholar]
- Li, H.; Shou, G.; Hu, Y.; Guo, Z. Mobile Edge Computing: Progress and Challenges. In Proceedings of the 2016 4th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (Mobile Cloud), Oxford, UK, 29 March–1 April 2016. [Google Scholar]
- Wang, B.; Hu, Y.; Shou, G.; Guo, Z. Trajectory Prediction in Campus Based on Markov Chains. In Proceedings of the International Conference on Big Data Computing & Communications, Shenyang, China, 29–31 July 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Lee, S.; Lim, J.; Park, J.; Kim, K. Next Place Prediction Based on Spatiotemporal Pattern Mining of Mobile Device Logs. Sensors 2016, 16, 145. [Google Scholar] [CrossRef]
- Eagle, N.; Pentland, A. Reality mining: Sensing complex social systems. Pers. Ubiquitous Comput. 2006, 10, 255–268. [Google Scholar] [CrossRef]
- Lu, X.; Wetter, E.; Bharti, N.; Tatem, A.J.; Bengtsson, L. Approaching the Limit of Predictability in Human Mobility. Sci. Rep. 2013, 3, 2923. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User Movement in Location-Based Social Networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, San Diego, CA, USA, 21–24 August 2011. [Google Scholar]
- Wei, L.Y.; Zheng, Y.; Peng, W.C. Constructing popular routes from uncertain trajectories. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Chen, M.; Liu, Y.; Yu, X. NLPMM: A Next Location Predictor with Markov Modeling. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Tainan, Taiwan, 13–16 May 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Chen, M.; Yu, X.; Liu, Y. Mining moving patterns for predicting next location. Inf. Syst. 2015, 54, 156–168. [Google Scholar] [CrossRef]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of Predictability in Human Mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Feitosa, R.M.; Labidi, S.; dos Santos, A.L.S.; Santos, N. Social Recommendation in Location-Based Social Network Using Text Mining. In Proceedings of the 2013 4th International Conference on Intelligent Systems, Bangkok, Thailand, 29–31 January 2013; IEEE Computer Society: Piscataway, NJ, USA, 2013. [Google Scholar]
- Bao, J.; Zheng, Y.; Mokbel, M.F. Location-based and preference-aware recommendation using sparse geo-social networking data. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Beach, CA, USA, 7–9 November 2012. [Google Scholar]
- Symeonidis, P.; Ntempos, D.; Manolopoulos, Y. Location-Based Social Networks. In Recommender Systems for Location-Based Social Networks; Springer: New York, NY, USA, 2014. [Google Scholar]
- Wernke, M.; Skvortsov, P.; Dürr, F.; Rothermel, K. A classification of location privacy attacks and approaches. Pers. Ubiquitous Comput. 2014, 18, 163–175. [Google Scholar] [CrossRef]
- Michael, K.; Clarke, R. Location privacy under dire threat as uberveillance stalks the streets. Precedent (Sydney NSW) 2012, 108, 24–29. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X.; Sun, G. T-Drive: Enhancing Driving Directions with Taxi Drivers. IEEE Trans. Knowl. Data Eng. 2012, 25, 220–232. [Google Scholar] [CrossRef]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Zhu, T.; Wan, X.; Wang, X. Identifying significant places using multi-day call detail records. In Proceedings of the 2014 IEEE 26th International Conference on Tools with Artificial Intelligence (ICTAI), Limassol, Cyprus, 10–12 November 2014. [Google Scholar]
- Montoliu, R.; Blom, J.; Gatica-Perez, D. Discovering places of interest in everyday life from smartphone data. Multimed. Tools Appl. 2013, 62, 179–207. [Google Scholar] [CrossRef]
- Killijian, M.O. Next place prediction using mobility Markov chains. In Proceedings of the First Workshop on Measurement, Privacy, and Mobility, Bern, Switzerland, 10 April 2012. [Google Scholar]
- Gidófalvi, G.; Dong, F. When and where next: Individual mobility prediction. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Mobile Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 57–64. [Google Scholar]
- Yu, X.-G.; Liu, Y.-H.; Wei, D.; Tian, M. Hybrid Markov model for mobile path prediction. J. Commun. 2006, 27, 61–69. [Google Scholar]
- Lv, M.; Chen, L.; Chen, G. Position prediction based on adaptive multi-order Markov model. J. Comput. Res. Dev. 2010, 47, 1764–1770. [Google Scholar]
- Rodriguez-Carrion, A.; Garcia-Rubio, C.; Campo, C. Performance evaluation of LZ-based location prediction algorithms in cellular networks. IEEE Commun. Lett. 2010, 14, 707–709. [Google Scholar] [CrossRef]
- Rawassizadeh, R.; Dobbins, C.; Akbari, M.; Pazzani, M. Indexing Multivariate Mobile Data through Spatio-Temporal Event Detection and Clustering. Sensors 2019, 19, 448. [Google Scholar] [CrossRef] [PubMed]
- Qiao, S.; Shen, D.; Wang, X.; Han, N.; Zhu, W. A Self-Adaptive Parameter Selection Trajectory Prediction Approach via Hidden Markov Models. IEEE Trans. Intell. Transp. Syst. 2015, 16, 284–296. [Google Scholar] [CrossRef]
- Qiao, S.-J.; Jin, K.; Han, N.; Tang, C.J.; Gesangduoji, G.L. Trajectory prediction algorithm based on Gaussian mixture model. J. Softw. 2015, 26, 1048–1063. [Google Scholar]
- Pathirana, P.N.; Savkin, A.V.; Jha, S. Robust extended Kalman filter applied to location tracking and trajectory prediction for PCS networks. In Proceedings of the 2004 IEEE International Conference on Control Applications, Taipei, Taiwan, 2–4 September 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 63–68. [Google Scholar]
- Yang, Z.; Wang, H.-J. Important Location Identification and Personal Location Inference Based on Mobile Subscriber Location Data. MATEC Web Conf. 2018, 173, 03086. [Google Scholar] [CrossRef]
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604. [Google Scholar]
- Rodriguez, A.; Latio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, H. Statistical Learning Method; Tsinghua University Press: Beijing, China, 2012; pp. 137–139. [Google Scholar]
- Lichman, M. UCI Machine Learning Repository; University of California: Irvine, CA, USA, 2013; Available online: http://archive.ics.uci.edu/ml (accessed on 19 March 2019).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Category | Sample | Dimension |
|---|---|---|---|
| Iris | 3 | 150 | 4 |
| Aggregation | 7 | 788 | 2 |
| Waveform | 3 | 500 | 21 |
| Wine | 3 | 178 | 13 |
| Data Collection Time | Number of Users | Number of Trajectories |
|---|---|---|
| 2007.4~2012.8 | 182 | 17624 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Yang, Z.; Shi, Y. Next Location Prediction Based on an Adaboost-Markov Model of Mobile Users. Sensors 2019, 19, 1475. https://doi.org/10.3390/s19061475
Wang H, Yang Z, Shi Y. Next Location Prediction Based on an Adaboost-Markov Model of Mobile Users. Sensors. 2019; 19(6):1475. https://doi.org/10.3390/s19061475
Chicago/Turabian StyleWang, Hongjun, Zhen Yang, and Yingchun Shi. 2019. "Next Location Prediction Based on an Adaboost-Markov Model of Mobile Users" Sensors 19, no. 6: 1475. https://doi.org/10.3390/s19061475