1. Introduction
Reliability is one of the most significant aspects in evaluating mechatronic systems and rotating machinery accounts for most of the reliability problems [
1]. To eliminate safety risks, property and customer satisfaction loss to the maximum extent, the intelligent maintenance of rotating machinery is necessary. The superior maintenance method— Condition-Based Maintenance (CBM)—which takes maintenance actions based on condition monitoring, has become the preferred choice instead of the run-to-failure maintenance and the time-based preventive maintenance [
2,
3]. The core idea of CBM is to assess the degradation of mechatronic systems through diagnosis and prognosis methods using measured signals, and to take maintenance actions only when there is evidence of abnormal operating states [
4]. As one of the key components of CBM, intelligent fault diagnosis has captured increasing attention. The typical intelligent diagnosis methods usually encapsulate two distinct blocks of feature extraction and classification, in which feature extraction is realized by signal processing techniques (fast Fourier transform, wavelet transform, etc.) and classification by machine learning methods (Artificial Neural Network, Support Vector Machine, etc.) [
5,
6]. However, the manual feature extraction customized for specific issues relies heavily on expert knowledge and may not be suitable for other cases, so lots of studies have turned to the end-to-end diagnosis, fusing the feature extraction and classification into a single learning body.
Because of their multilayer-structure, deep learning methods are powerful in both feature extraction and classification and are considered as the most effective end-to-end approaches. In recent years, deep learning has not only made great breakthroughs in the field of computer vision [
7], natural language processing [
8] and speech recognition [
9], but some methods, such as deep brief network (DBN) [
10], CNN [
11] and stacked autoencoder (SAE) [
12], have also found their way into CBM diagnosis applications. Among these methods, the CNNs hold the potential to be the end-to-end approaches because of the powerful feature learning ability of the convolutional structure. Since CNN was proposed by LeCun in 1998 and applied in handwriting recognition [
13], lots of CNN models have been presented, such as AlexNet [
14], VGGnet [
15], GoogleNet [
16] and ResNet [
17]. With the 1D-to-2D conversion of vibration signals or 1-D convolutional structure, the CNN models have successfully applied in fault diagnosis directly using raw signals. Long et al. presented a 2-D convolutional neural network based on LeNet-5 through converting raw signals to 2-D images [
18]. In 2016 [
19], Turker et al. proposed a 1-D convolutional neural network with three improved convolutional layers and two fully-connected layers, which takes raw current signals as input and achieves 97.2% accuracy. In [
20], a 2-D convolutional neural network with single convolutional layer and two fully-connected layers is proposed for fault diagnosis of gearbox.
Although lots of studies based on CNN have achieved high diagnosis accuracy, most of these prior studies focus on proposing new CNN models to speed up processing [
19] and improve diagnostic accuracy [
18,
20], which demonstrate the effectiveness of the proposed models only using the noise-free experimental data. However, the signals measured in real industrial environments are always mixed with noise due to the complex operation conditions, and the CNN models with large numbers of parameters brought by the multilayer-structure are easy to overfit. As a result, depth models with excellent performance under experimental conditions may severely degrade in real industrial applications. In recent years, some training tricks (e.g., convolutional kernel dropout and ensemble learning [
21]) and structure improvements (e.g., add AdaBN layers [
22]) have been proposed to improve the anti-noise diagnosis ability of the deep CNN models, however, it is not enough to improve only the anti-noise ability of the model. On the one hand, the improvements proposed in the prior studies are used for reducing the overfitting of CNN models, but may not be that effective in anti-noise diagnosis. On the other hand, it is difficult to diagnose accurately only by improving the anti-noise ability when the signal is mixed with a lot of noise. Therefore, in order to solve the problem, not only the anti-noise ability should be improved, but also the noise mixed in raw signal should be removed as much as possible. In the area of image denoising, deep learning methods are widespread. In 2018 [
23], a method based on deep CNN was proposed, which is trained by the image with non-fixed noise masks. Mao et al. proposed a deep DCAE-based method aiming at image denoising and super-resolution [
24]. However, these methods are only applied in denosing of 2-D or 3-D images, and to the best of our knowledge, no research on similar methods aiming at the denoising of 1-D vibration signals has been reported so far.
In this paper, a novel method combining a 1-D denoising convolutional autoencoder (DCAE-1D) and a 1-D convolutional neural network with anti-noise improvement (AICNN-1D) is proposed to address the above problem. The former is used for noise reduction of raw vibration signals and the latter for fault diagnosis using the de-noised signals output by DCAE-1D. In summary, the contributions of this paper can be listed as follows:
- (1)
This paper proposes an effective denoising model based on 1-D convolutional autoencoder named DCAE-1D, which works pretty well directly on raw vibration signals with simple training.
- (2)
This paper proposes an improved 1-D convolutional neural network named AICNN-1D for fault diagnosis, which applies global average pooling and is trained with randomly corrupted signals to improve the anti-noise ability of the model.
- (3)
Both DCAE-1D and AICNN-1D model can work directly on vibration signals due to the use of 1-D convolution and 1-D pooling. Consequently, the method combining the two models can realize the end-to-end diagnosis.
The rest of this paper is organized as follows: a brief introduction of DCAE and CNN is provided in
Section 2. In
Section 3, the intelligent models based on 1-D convolutional structure are proposed: DCAE-1D for denoising and AICNN-1D for feature learning and classification. Bearing and gearbox experiments carried out to validate the proposed methods are detailed in
Section 4. Finally, the conclusions are drawn in
Section 5.
3. Proposed Intelligent Diagnosis Method
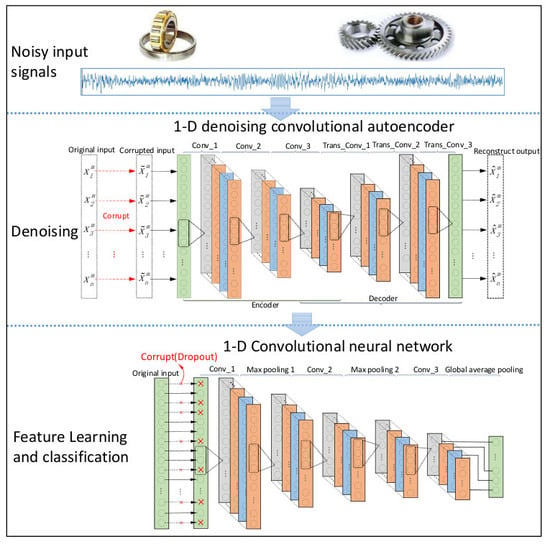
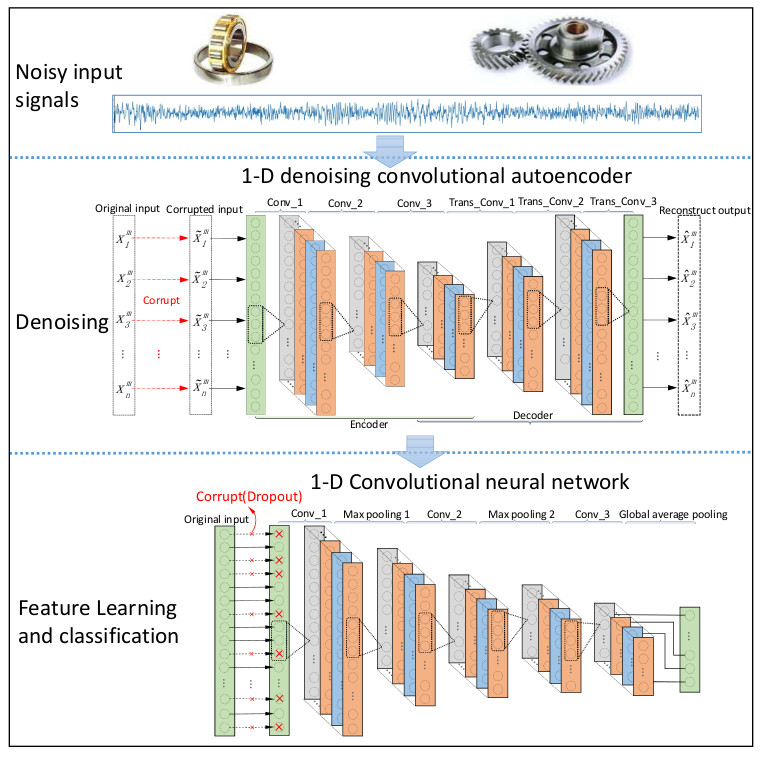
The proposed intelligent method consists of two key stages as denoising and diagnosis, which are related to two convolutional models, namely DCAE-1D and AICNN-1D. DCAE-1D is used for noise reduction of raw vibration signals and AICNN-1D for fault diagnosis using the de-noised signals output by DCAE-1D.
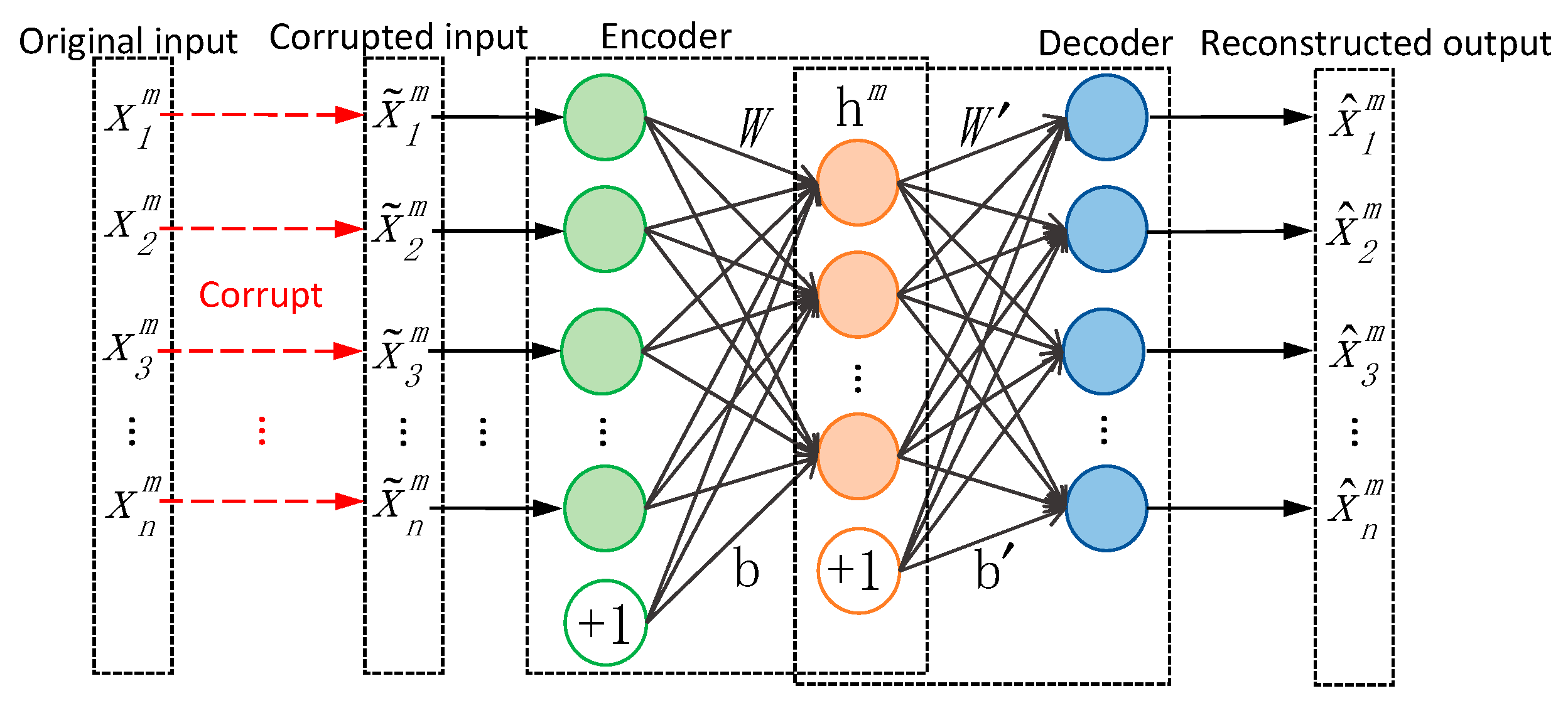
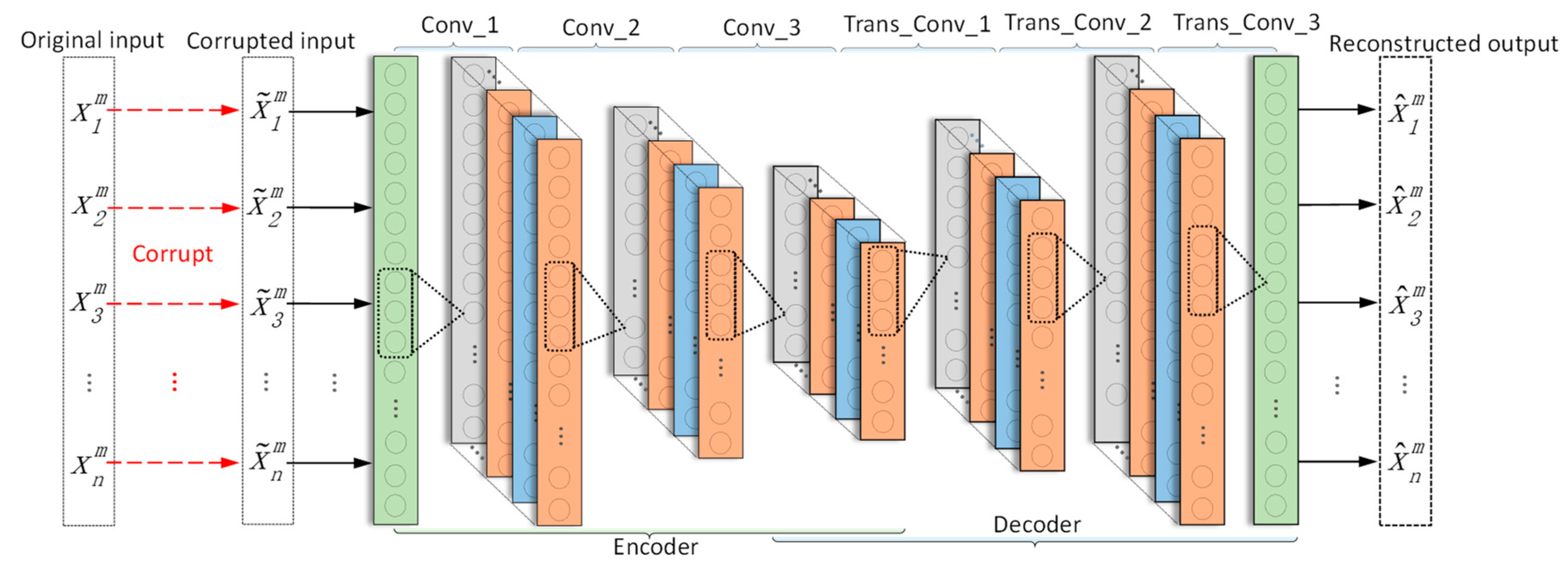
3.1. DCAE-1D
Since vibration signals are one-dimensional time series, DCAE-1D employs a denoising autoencoder with 1-D convolutional layers to process the noisy input. As a result, the model can directly take raw signals as input without any extra preprocessing. DCAE-1D consists of three convolutional layers as coder and three transposed convolutional layers as decoder. The model architecture is shown in
Figure 2 and the details are outlined in
Table 1.
The training and testing of DCAE-1D utilize the noisy signals mixed by raw signal and Gaussian noise. Considering the continuous change of the noise in industrial environment, the noisy signals feed into the model should be with different SNR, which is defined as the ratio of signal power to the noise power as Equation (8):
To compose the noisy signals with different SNR, the noise with different power are superposed to the same original signal respectively in whole area. The noise power is calculated according to the power of the original signal and the specified SNR value. Then each composited noisy signal is divided into multi-segments, which compose an original dataset with the specified SNR. Each original dataset is divided into two parts in a certain proportion, namely the training set and the testing set. Then all the training sets are gathered and shuffled to form the training dataset for training DACE-1D, while all the testing sets are respectively used for model testing.
3.2. AICNN-1D
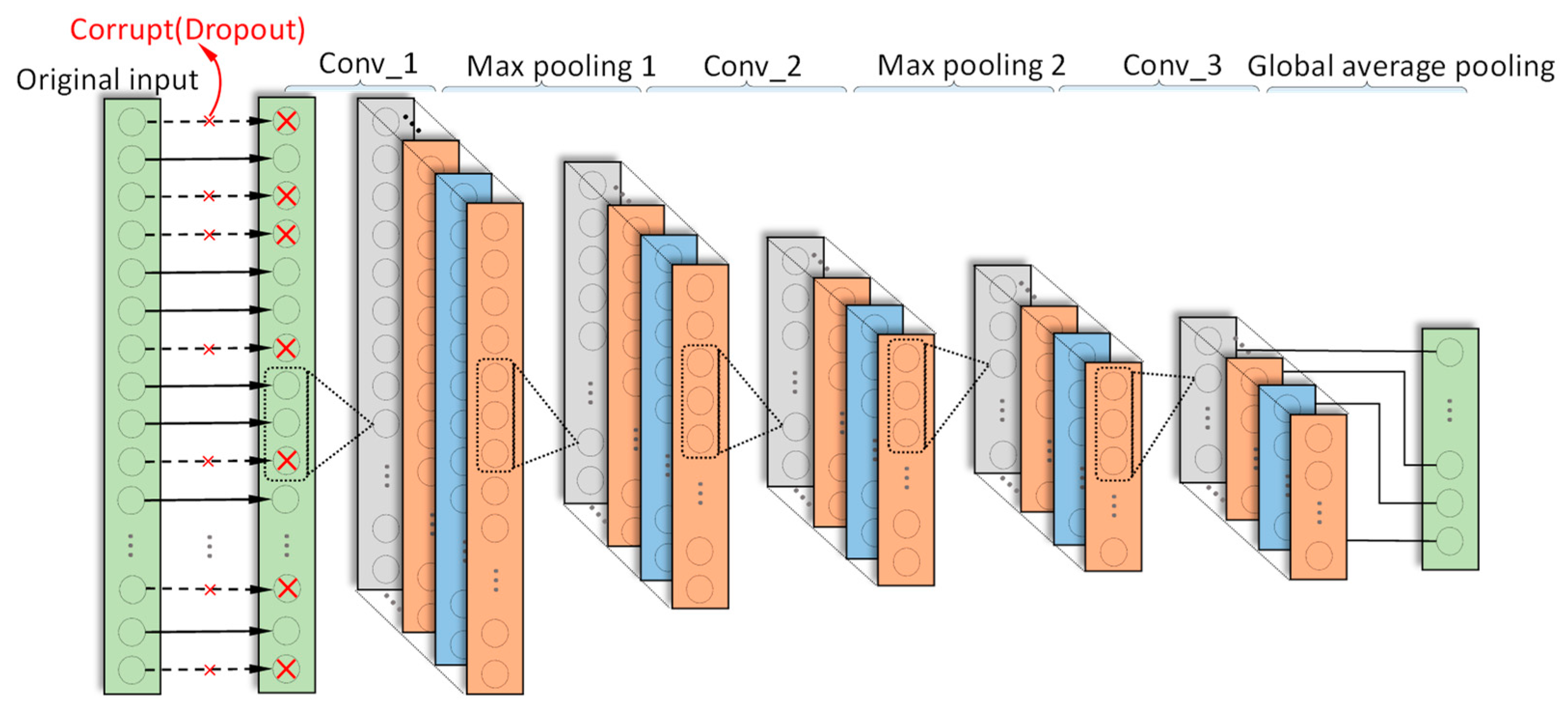
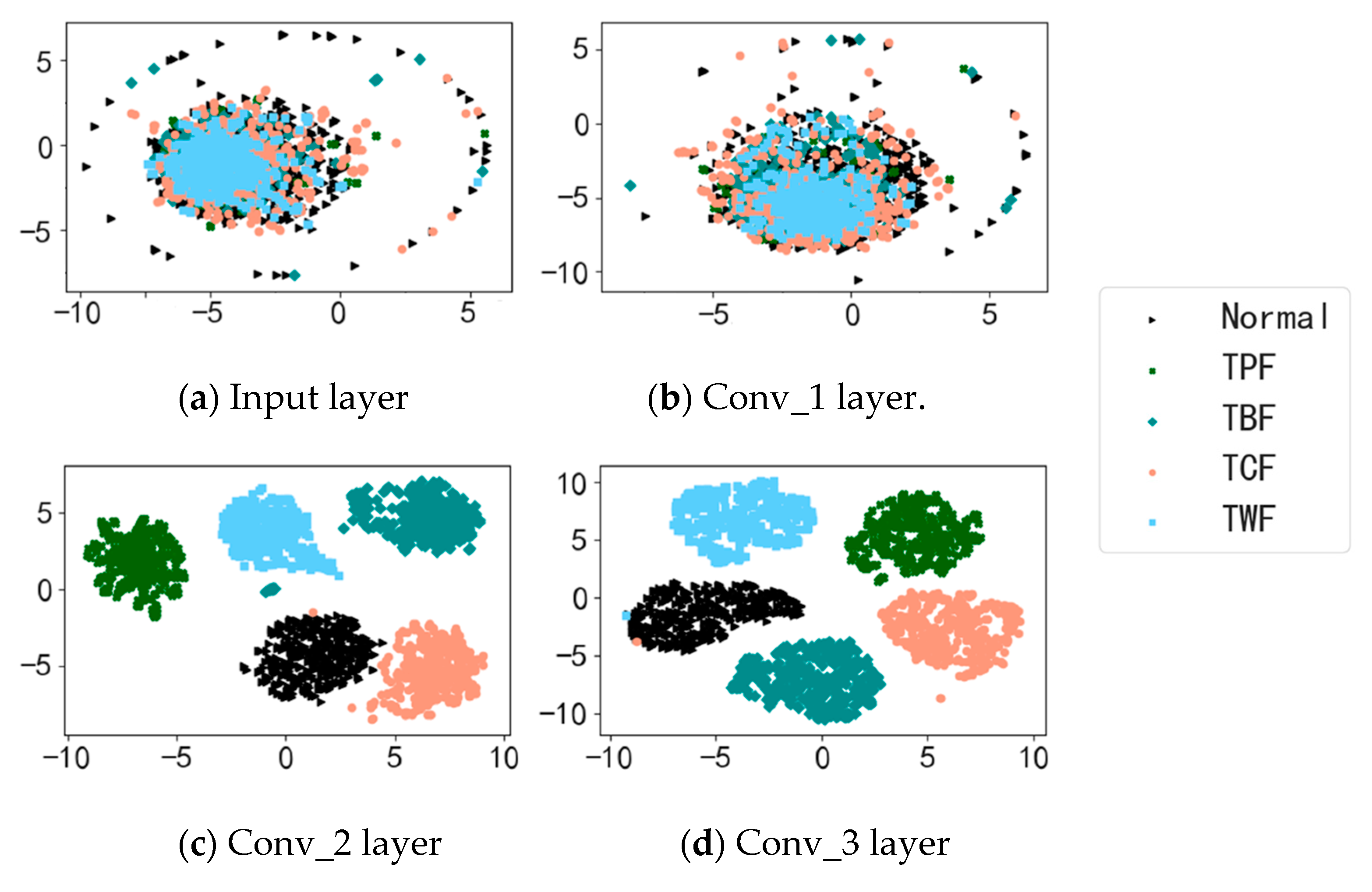
AICNN-1D also employs 1-D convolution and pooling layers to adapt to the processing of vibration signals. Feature learning is realized by alternating convolutional and max-pooling layers, while classification by global average pooling layer. Compared with the existing CNN diagnosis models, improvements made in AICNN-1D are as follows:
- (1)
In order to reduce the number of parameters and the risk of overfitting, AICNN-1D adopts global average pooling as classifier instead of the fully-connected layers. The global average pooling layer does not bring any parameters and is faster in forward and backward propagation.
- (2)
AICNN-1D is trained with randomly corrupted signals for improving the anti-noise diagnosis ability. The “corrupt” refers to the random selection of some data points of a sample in a certain proportion and the zeroization of the points, which is very similar to the “dropout”. The proportion is called “corruption rate”. Vincent et al. point out that the random-corruption can create noise for the input signals, which makes the trained model performs better even when the training set and testing set have different distributions [
28].
AICNN-1D consists of three convolutional layers, two max-pooling layers and a global average pooling layer. The model architecture is shown in
Figure 3 and the details are outlined in
Table 2.
3.3. Construction of the Proposed Method
As shown in
Figure 4, construction of the proposed method can be divided into three stages: (1) Training of DCAE-1D with datasets that mixed with Gaussian noise, (2) training of AICNN-1D using randomly corrupted datasets and (3) diagnosis test of the combination of the trained DCAE-1D and AICNN-1D using noisy datasets.
The samples used to train DCAE-1D vary in SNR from −2 dB to 12 dB. Training parameters and hyper-parameters are set as follows: the initial network weights are set by Xavier initialization [
29], the biases initial values are set to 0. The learning rate uses exponential decay with 0.0035 base learning rate and 0.99 decay rate, the maximum training step
N is set to 5000. The signals fed to the model in each step are randomly chosen from training dataset and the batch size is set to 100. Training is stopped after reaching the maximum step.
Training of AICNN-1D employs corrupted signals and the corruption rate is randomly set between 0 and 0.8. Training parameters and hyper-parameters are set as follows: the network weights and biases use the same initialization as DCAE-1D, the learning rate uses exponential decay with 0.005 base learning rate and 0.99 decay rate. The maximum training step and the batch size are set the same as DCAE-1D.
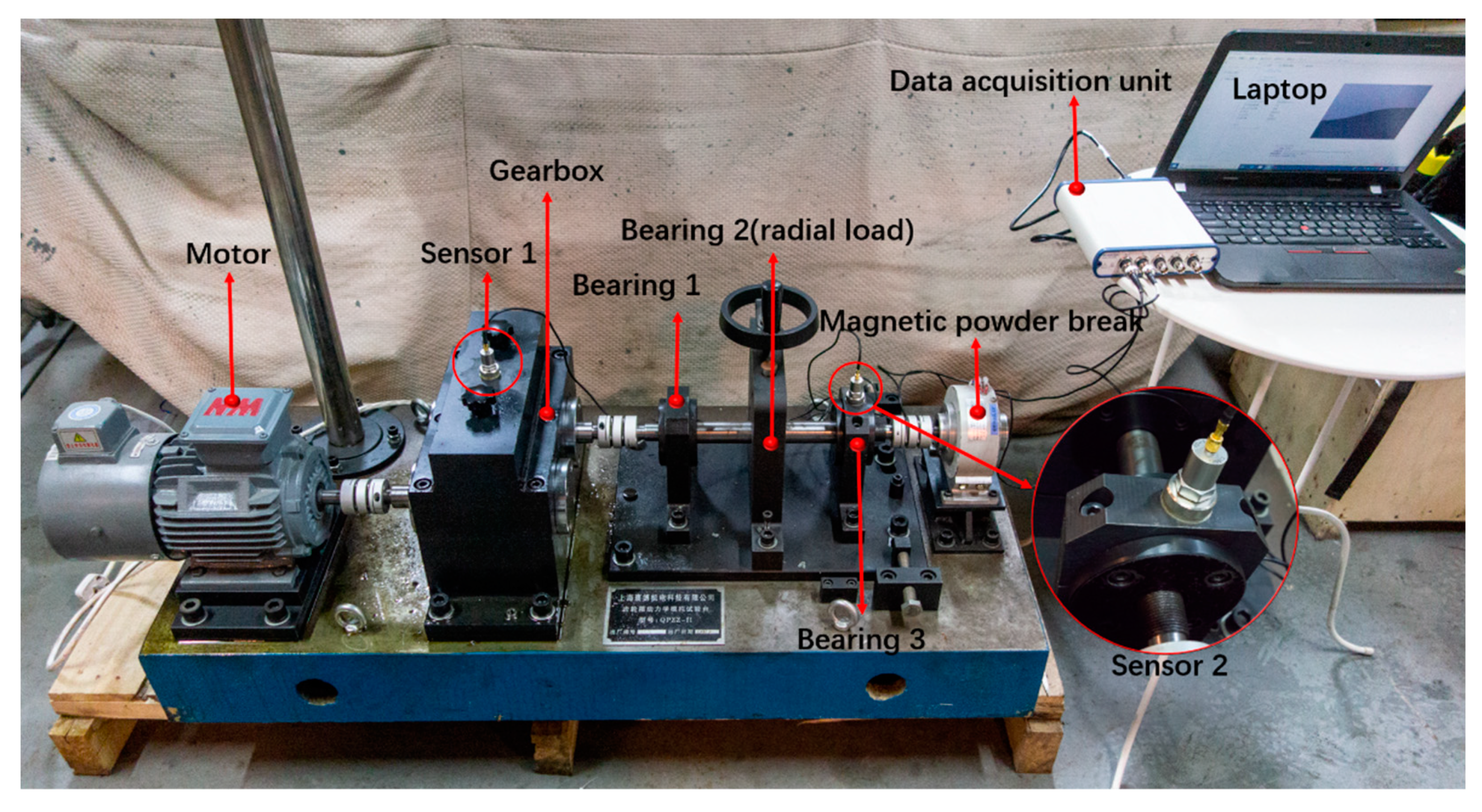
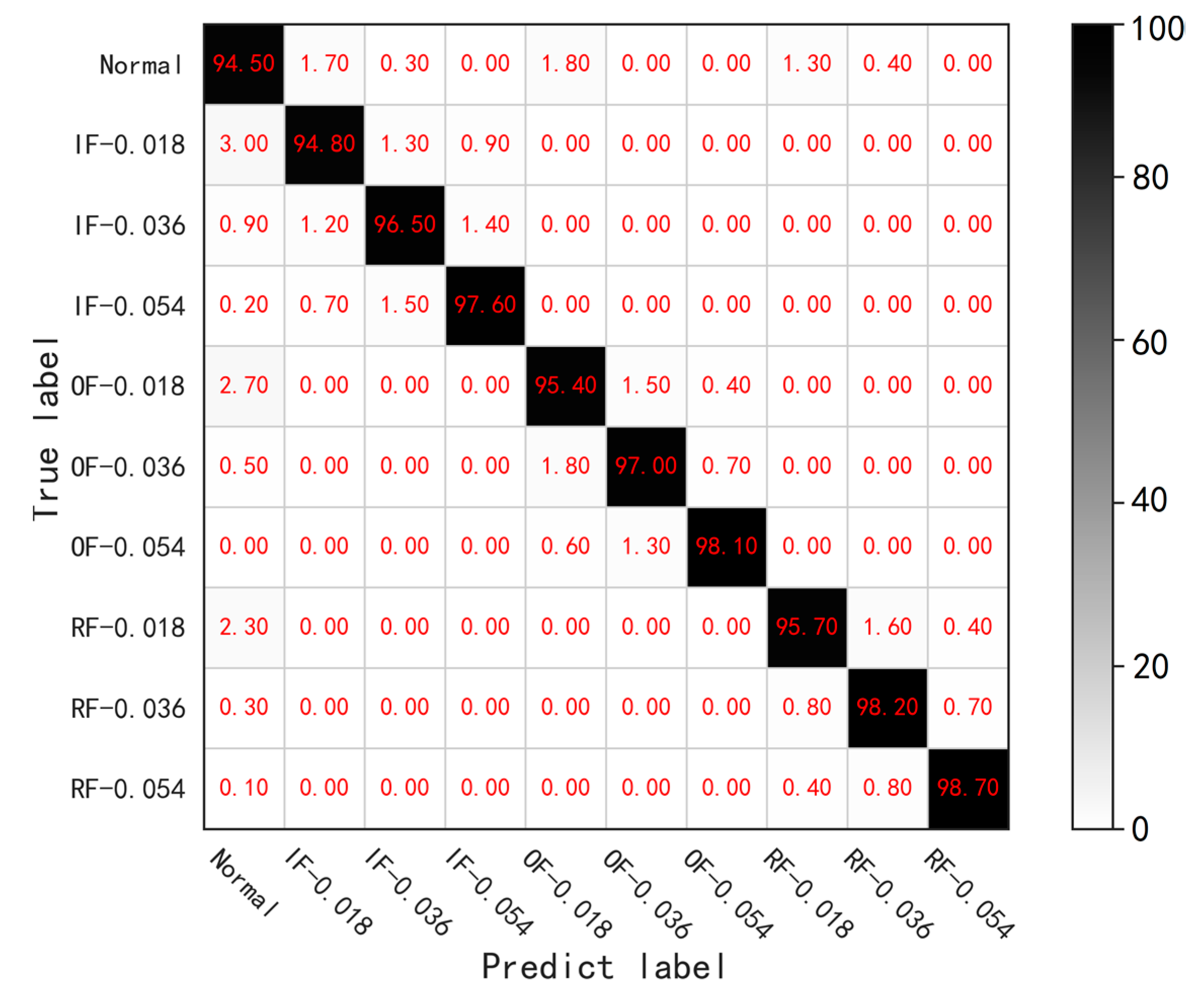
After training, diagnosis test is done by the combination of the trained DCAE-1D and AICNN-1D. DCAE-1D is used for denoising while AICNN-1D for diagnosis with the de-noised signals output by DCAE-1D. The reconstruct error is taken to evaluate the denoising effect of DCAE-1D and the diagnosis accuracy is considered as the test result of the method combination. The test is carried for several times using test sets with different SNR ranging from −2 dB to 12 dB and the SNR in the same test is kept constant. The hardware configuration of training and testing is Intel i7-5820k + NVidia 1080ti while the software environment is Windows10 + Python + TensorFlow.
5. Conclusions
This paper proposes a combined method of 1-D denoising convolutional autoencoder named DCAE-1D and 1-D convolutional neural network named AICNN-1D, which aims at addressing the fault diagnosis problem under noisy environment. Compared with the existing method that only improves the anti-noise ability [
21,
22,
30], the extra noise reduction by DACE-1D is introduced in the combined method. With the denoising of raw signals, AICNN-1D with anti-noise improvements is then used for diagnosis. The method combination is validated by the bearing and gearbox datasets mixed with Gaussian noise. Through the analysis of the experimental results in
Section 4, conclusions are drawn as follows:
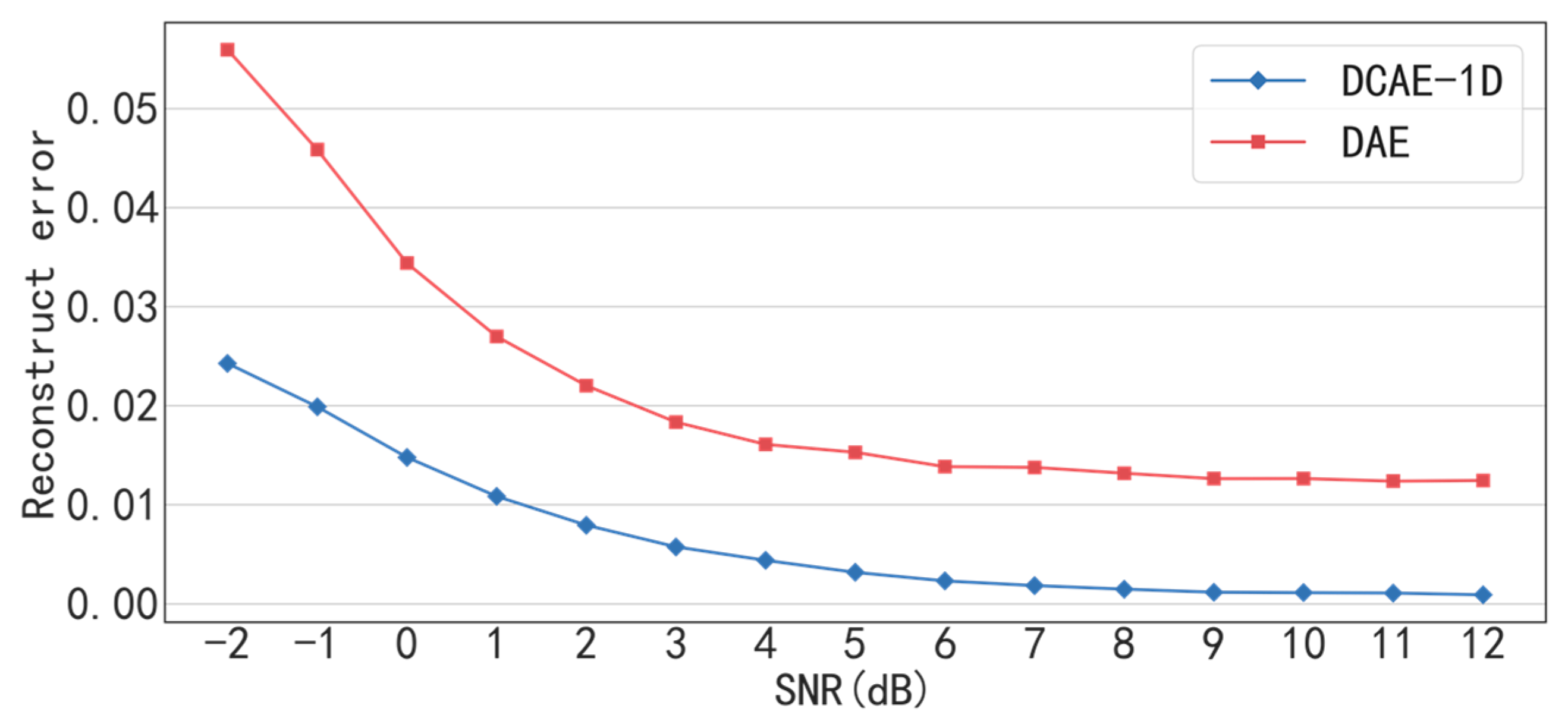
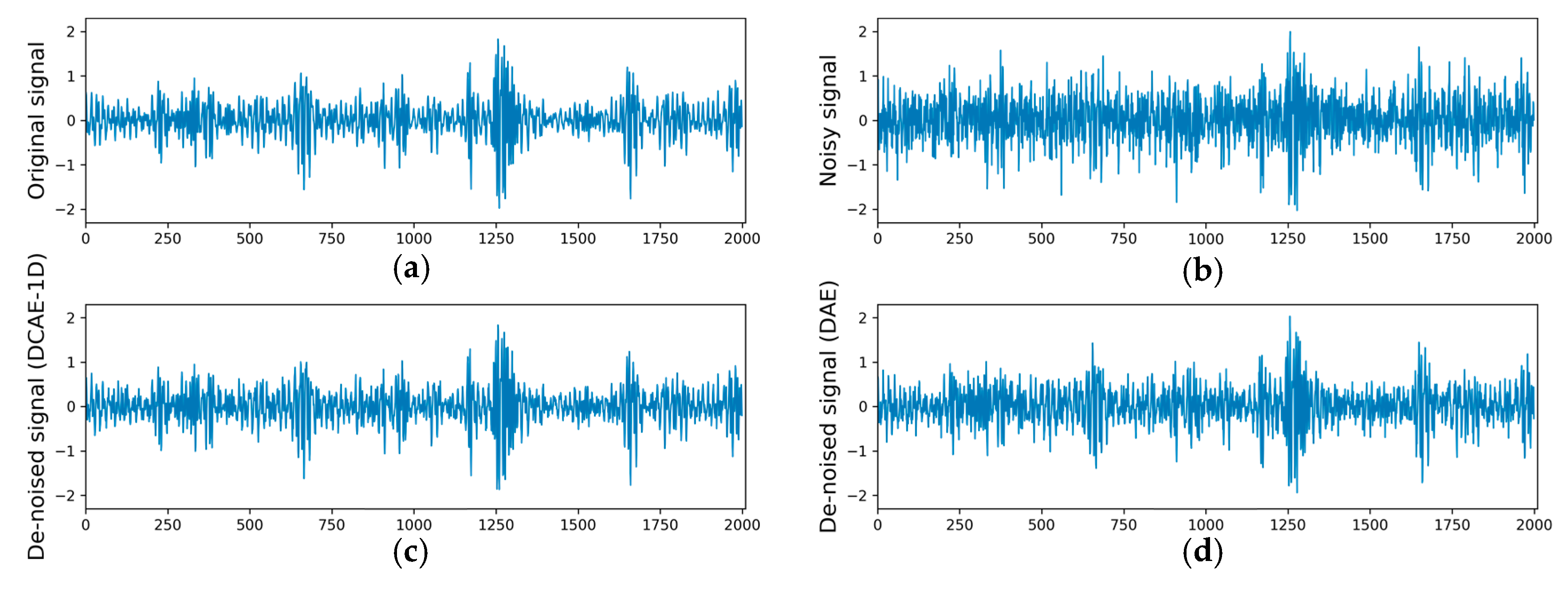
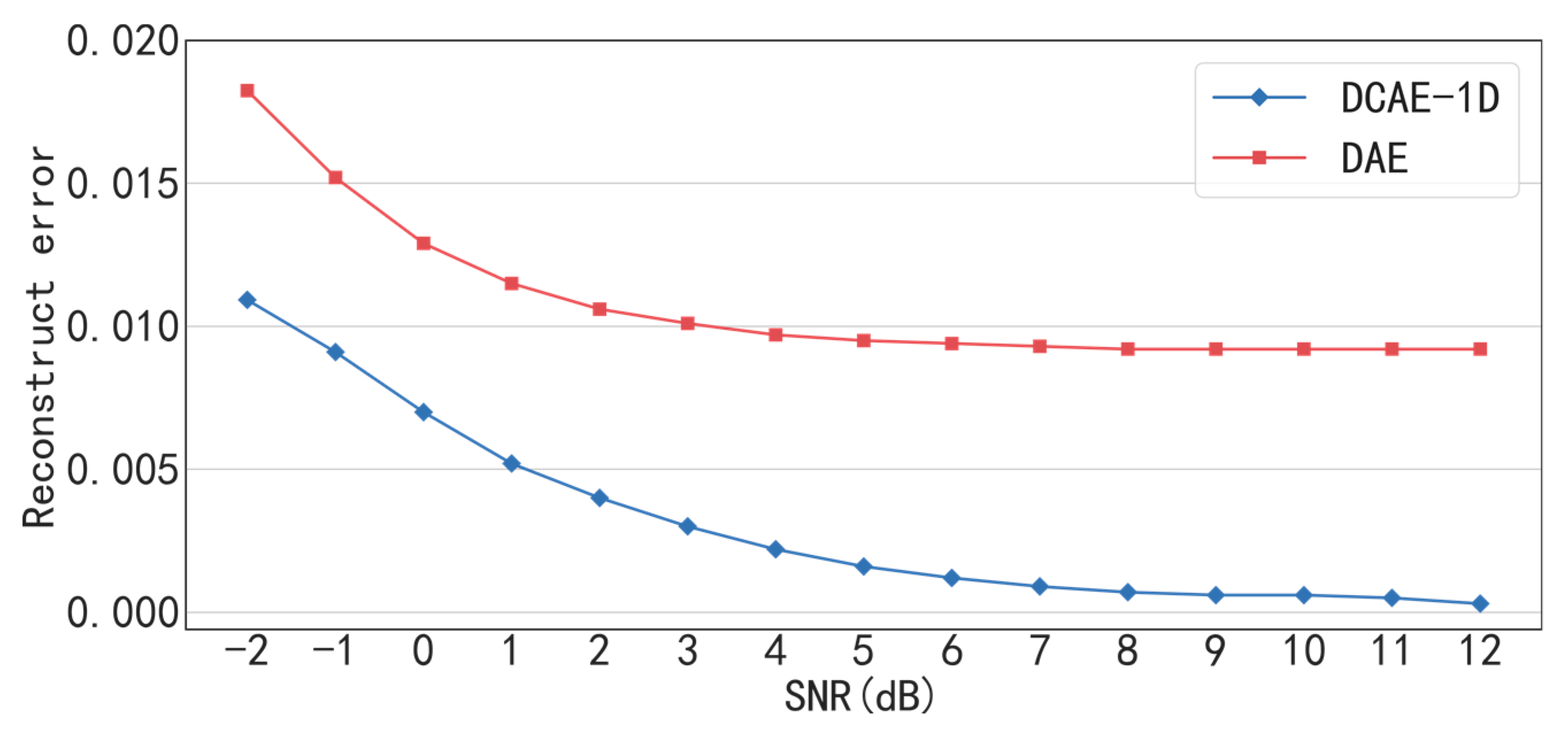
The proposed DCAE-1D with deep structure of three convolutional and three transposed convolutional layers is much more effective in denoising than the traditional DAE. The reconstruct errors of DCAE-1D in bearing and gearbox datasets are only 0.24 and 0.0109 even when the SNR= −2 dB, while that of DAE are 0.0559 and 0.01824 respectively. Besides, under the high SNR (> 4dB) conditions, the reconstruct errors are close to 0, which indicates that DACE-1D almost causes no loss of input information.
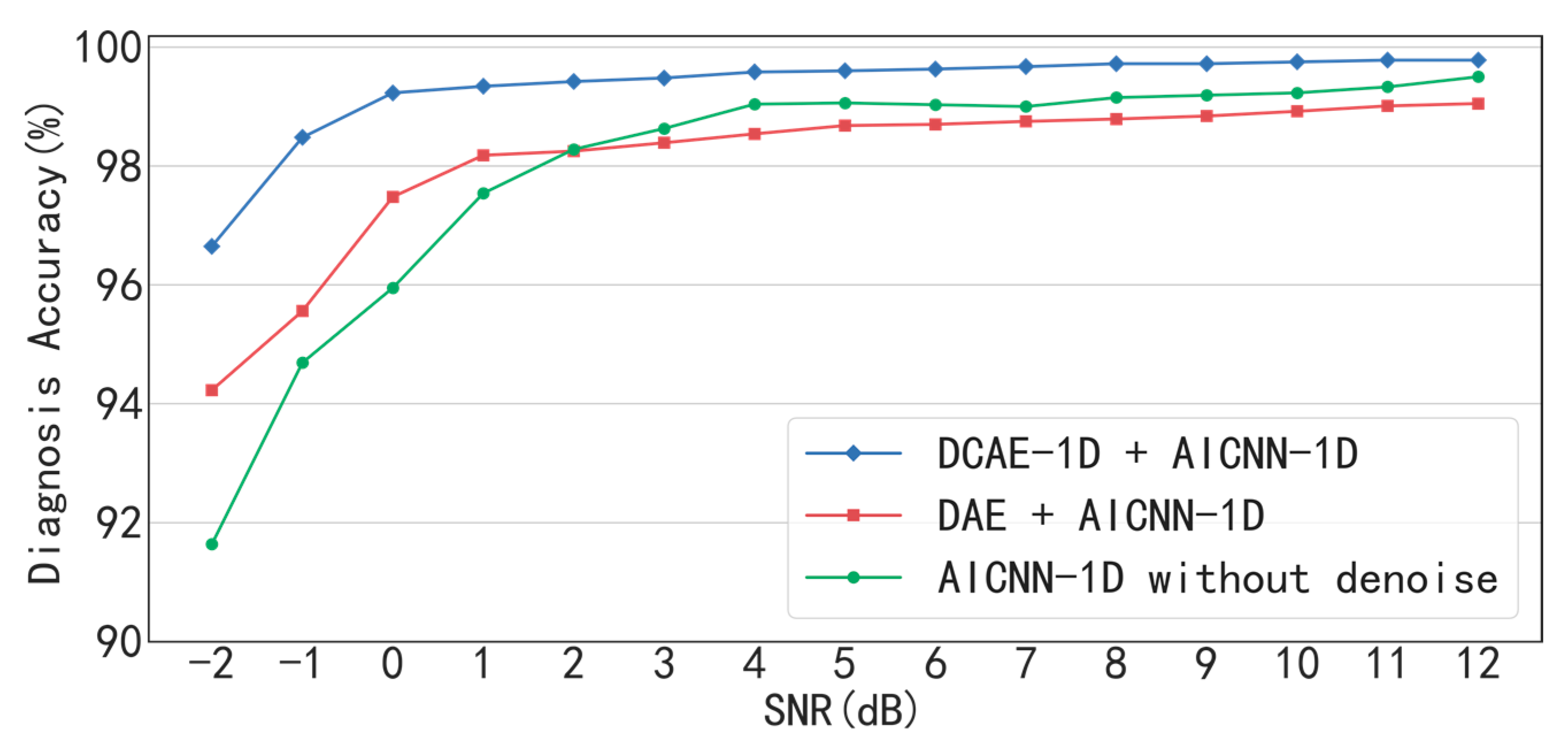
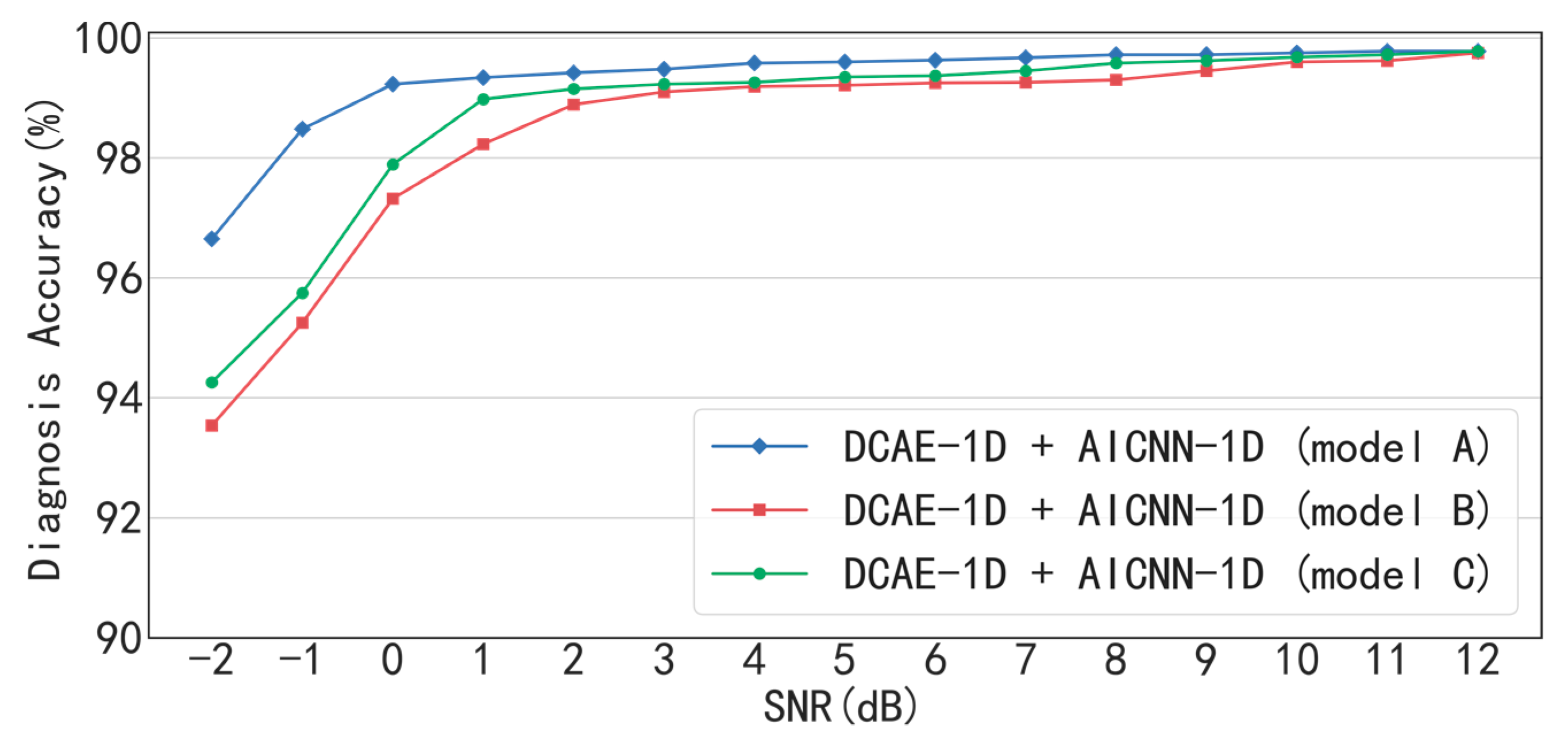
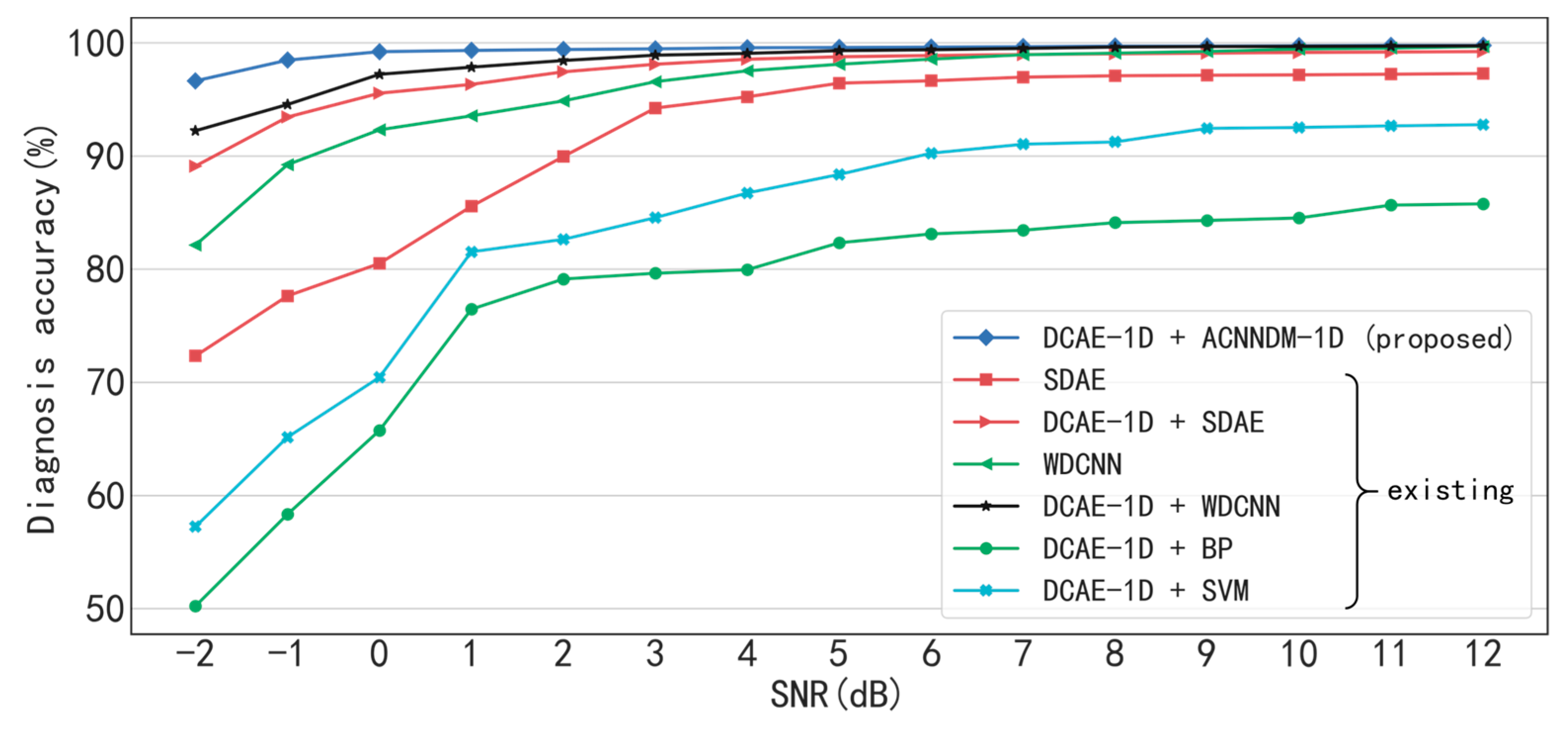
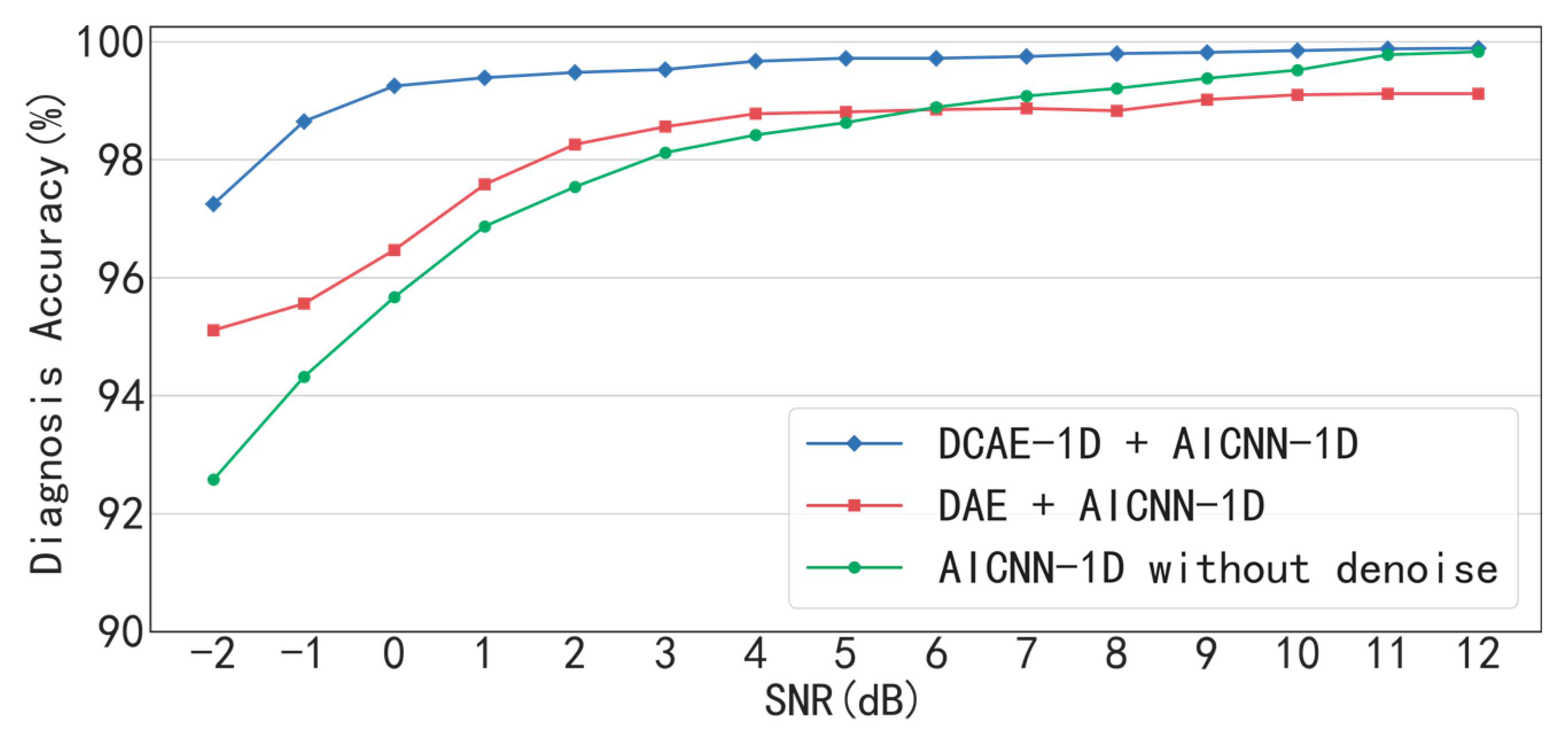
With the denoising of DCAE-1D, the diagnosis accuracies of AICNN-1D are 96.65% and 97.25% respectively in bearing and gearbox experiments even when SNR = −2 dB. When SNR> −1 dB, the diagnosis accuracies are greater than 99% in the two experiments. The result indicates that the proposed method combination realizes high diagnosis accuracy under low SNR conditions. In the bearing experiment, the AICNN-1D with “clean-input training + global average pooling” and “input-corrupt + fully-connected layers” drops to 93.54% and 94.26% in accuracy when SNR = −2 dB, compared with the proposed AICNN-1D. The results demonstrate that the using of input-corrupt training and global average pooling is effective in improving the anti-noise ability. Compared with the existing methods of the SDAE-based model and WDCNN presented in 2017, the proposed method shows its superiority under low SNR conditions. For instance, the diagnosis accuracies of the SDAE-based model and WDCNN are 72.34% and 82.13% when SNR = −2 dB in the bearing experiment. With the denoising by DCAE-1D, the diagnosis accuracies of the two models rise to 89.12% and 92.24% respectively, proving that both the denoisng of input signals and the anti-noise ability of the model are indispensable in accurate diagnosis under low SNR conditions.
In this paper, the load and rotating speed are kept constant during experiment, which is a simplification of the actual conditions in industrial applications. It will be more valuable to extend the proposed method to the cases with more complex conditions (e.g., variable speed and load) in the future. Besides, this paper focus on the diagnosis problem of industrial applications and validate the method with massive experimental data. However, the faulty sets in industrial systems are generally not readily to acquire. As the possible solutions, two kinds of methods are worth noticing: data augmentation and data fusion. The former focus on generating more samples on the basis of existing samples, such as data overlapping [
21] and Generative Adversarial Network (GAN) methods [
33]. The latter studies fusing the data of multiple kinds of sensors, which can be grouped into three main approaches: data-level fusion [
34], feature-level fusion [
35] and decision-level fusion [
36].


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}