Characterizing Word Embeddings for Zero-Shot Sensor-Based Human Activity Recognition


Abstract
:1. Introduction
- Word embedding vector has meaning ambiguity and representation complexity and,
- Word embedding vector is unstable depending on corpus and learning task used.
- In the embedded word vector space, are the issues of meaning ambiguity and representation complexity solved by expanding the region?
- Do these issues affect negatively the performance of sensor-based zero-shot activity recognition?
- Is the performance of embedded word vector increased when it closely represents the attributes defined by human?
- For the first time in the field of sensor-based activity recognition, we study zero-shot learning using word embedding as semantic space. In particular, we expose the difficulties of handling word embedding for human activity recognition, and study a solution via region expansion.
- We compare word embedding to the hand-crafted attribute vector in terms of accuracy of recognition of unknown classes and similarity of the spaces. We demonstrate that the automatically generated word embedding representation can perform as good as expert-designed attribute vectors.
- We examine the impact of region expansion on the performance of zero-shot recognition, as well as on the correctness of the meaning of the semantic vector. We demonstrate that there is no correlation between correct meaning and recognition accuracy. Instead, the performance depends on the correlation of the semantic space to characteristics measured by sensor data.
2. Related Work
2.1. Sensor-Based Activity Recognition
2.2. Zero-Shot Learning
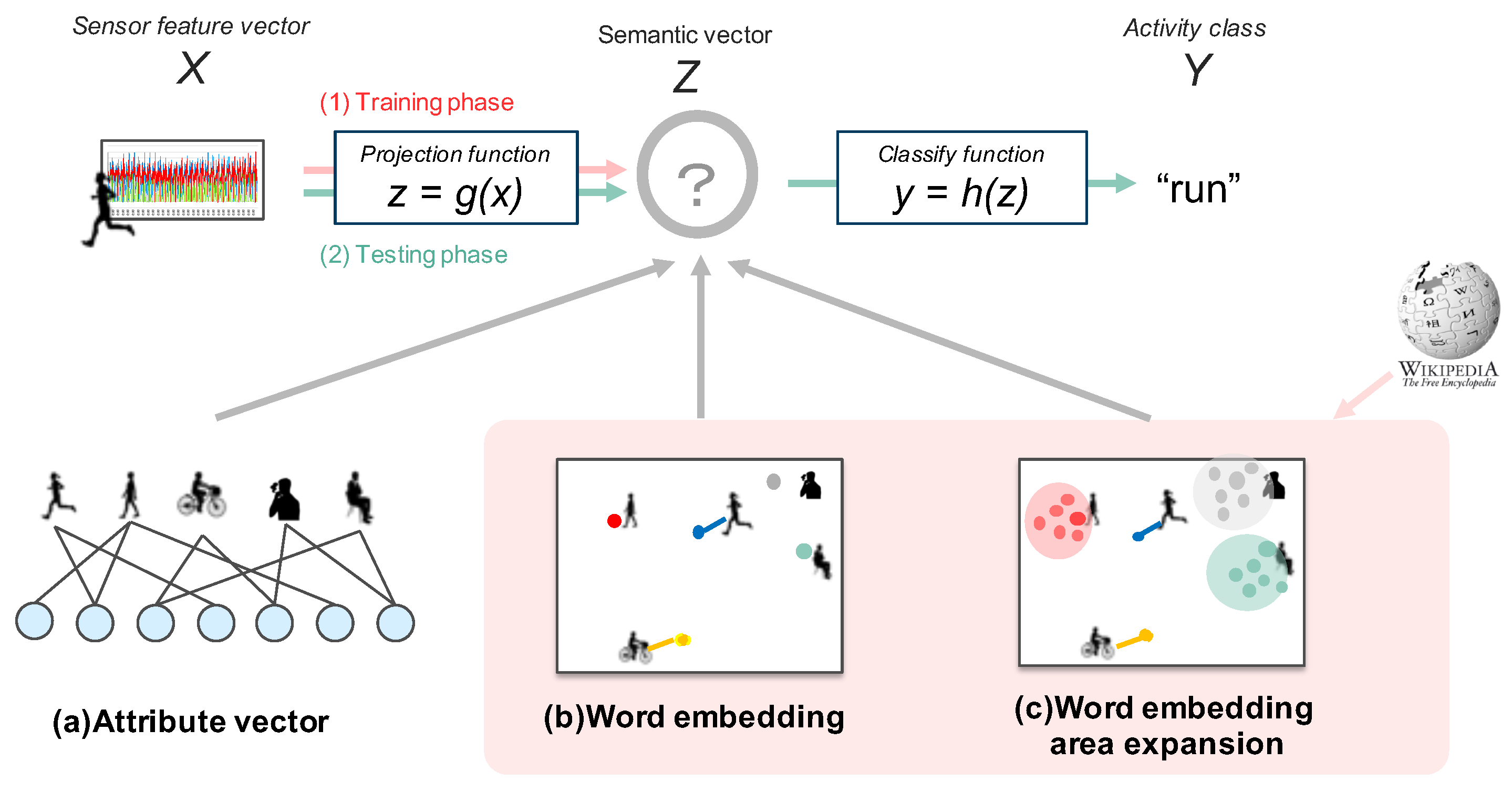
3. Zero-Shot Learning with Word Embedding
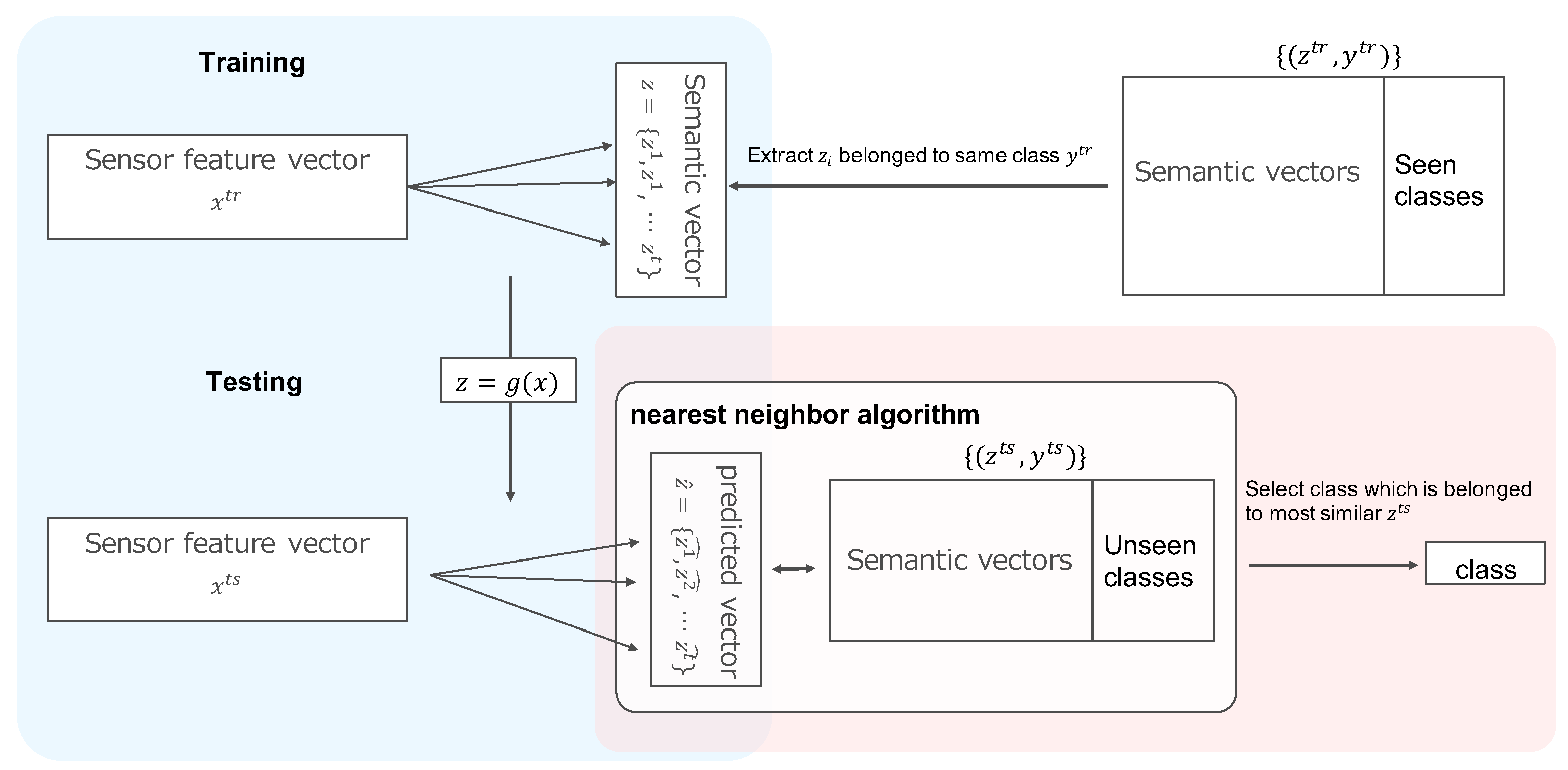
3.1. Zero-Shot Learning Setting
- (1)
- Training phase (red dotted lines in Figure 2)
- (2)
- Test phase (green dotted line in Figure 2)
3.2. Projection Model
3.3. Class-Output Function
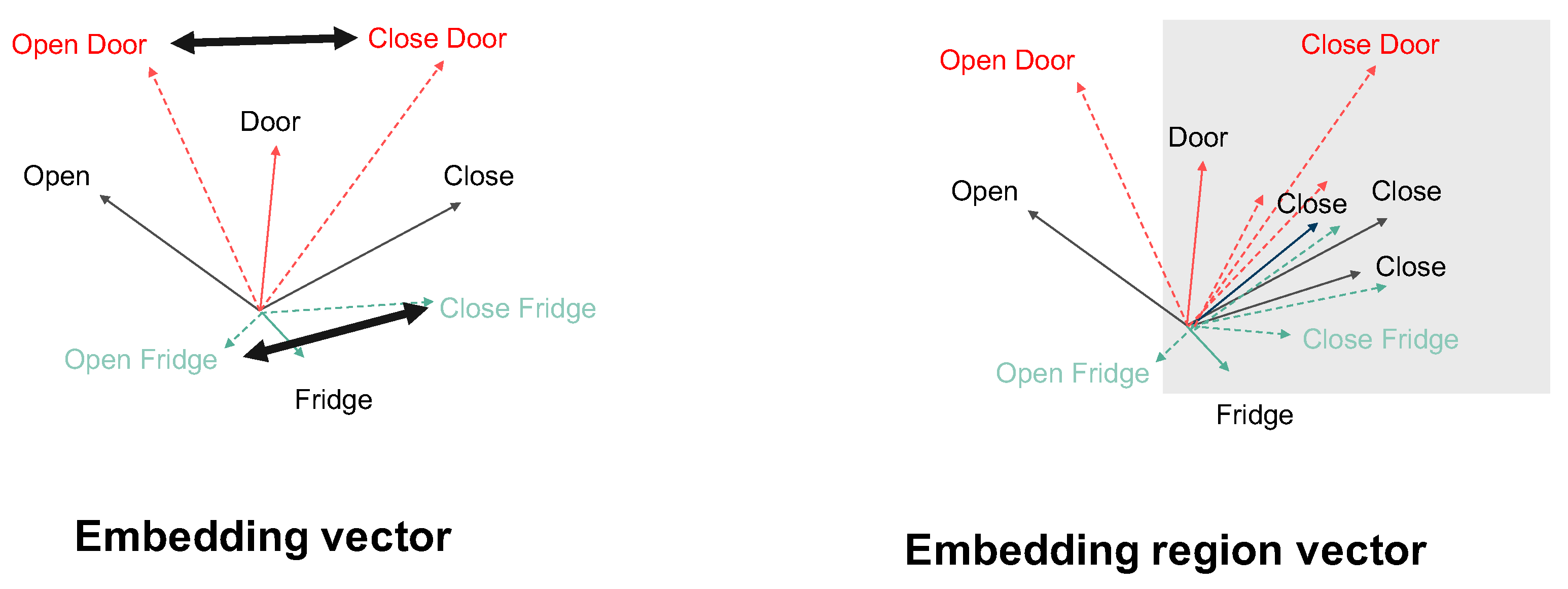
3.4. Word Embedding and Word Embedding Area Expansion
3.4.1. Word Embedding
- Generate a word vector by using word2vec for all Wikipedia words.
- Suppose that the required activity class is which is including seen and unseen.
- The set corresponding to is extracted from .
3.4.2. Expanded Word Embedding
4. Evaluation
- The recognition accuracy for unknown classes using word embedding and expanded word embedding as compared to the attribute vector, and
- The similarity between the word embedding semantic space/expanded word embedding semantic space and the attribute vector semantic space.
4.1. Datasets
4.1.1. Sensor Dataset and Pre-Processing
4.1.2. Semantic Spaces
4.2. Method of Analysis and Evaluation Experiment
4.2.1. Evaluation of Unknown Class Estimation
4.2.2. Analysis of the Similarity of Semantic Spaces
5. Analysis and Experimental Results
5.1. Analysis of Projection Methods
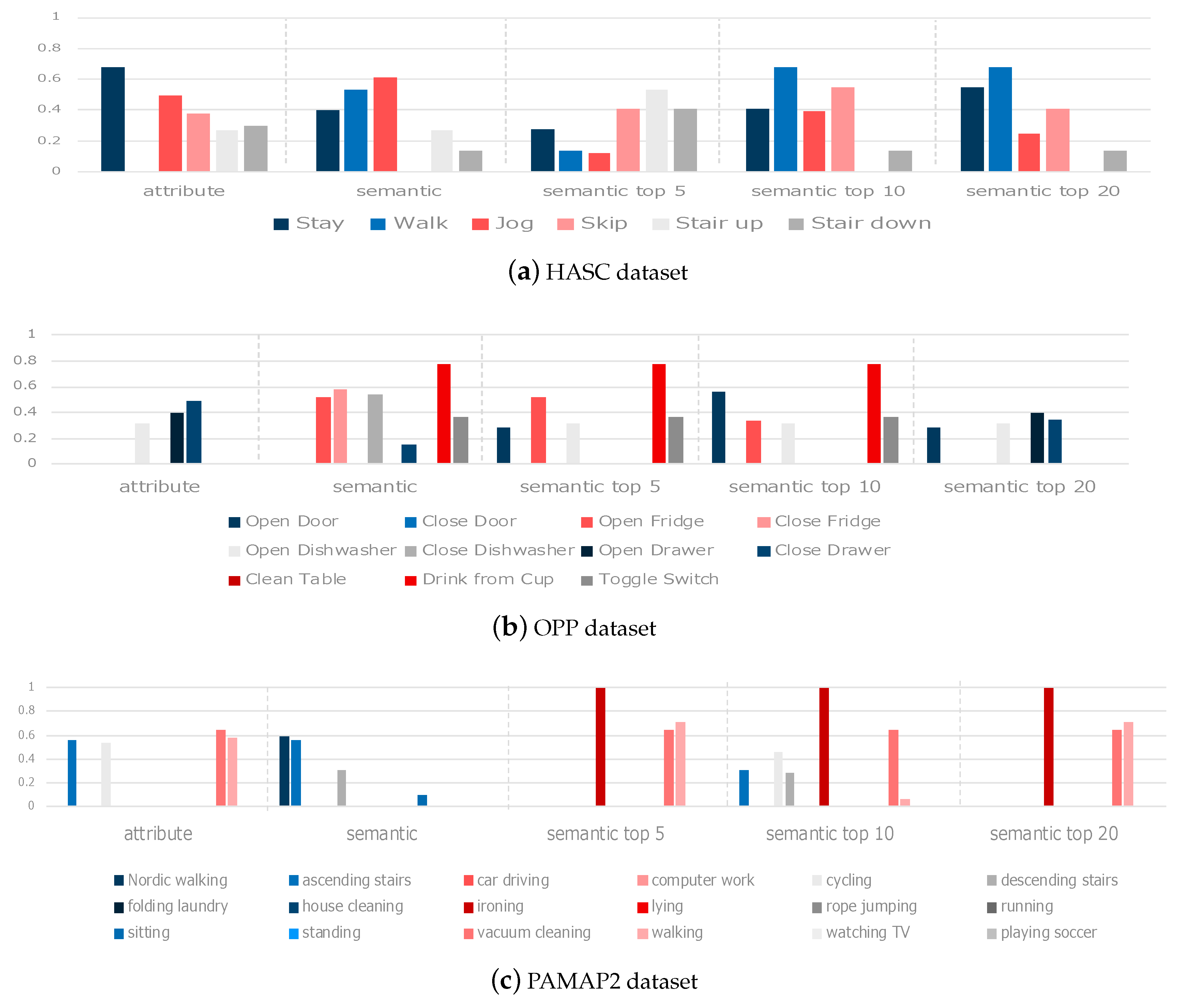
5.2. Results of Unknown Class Estimation
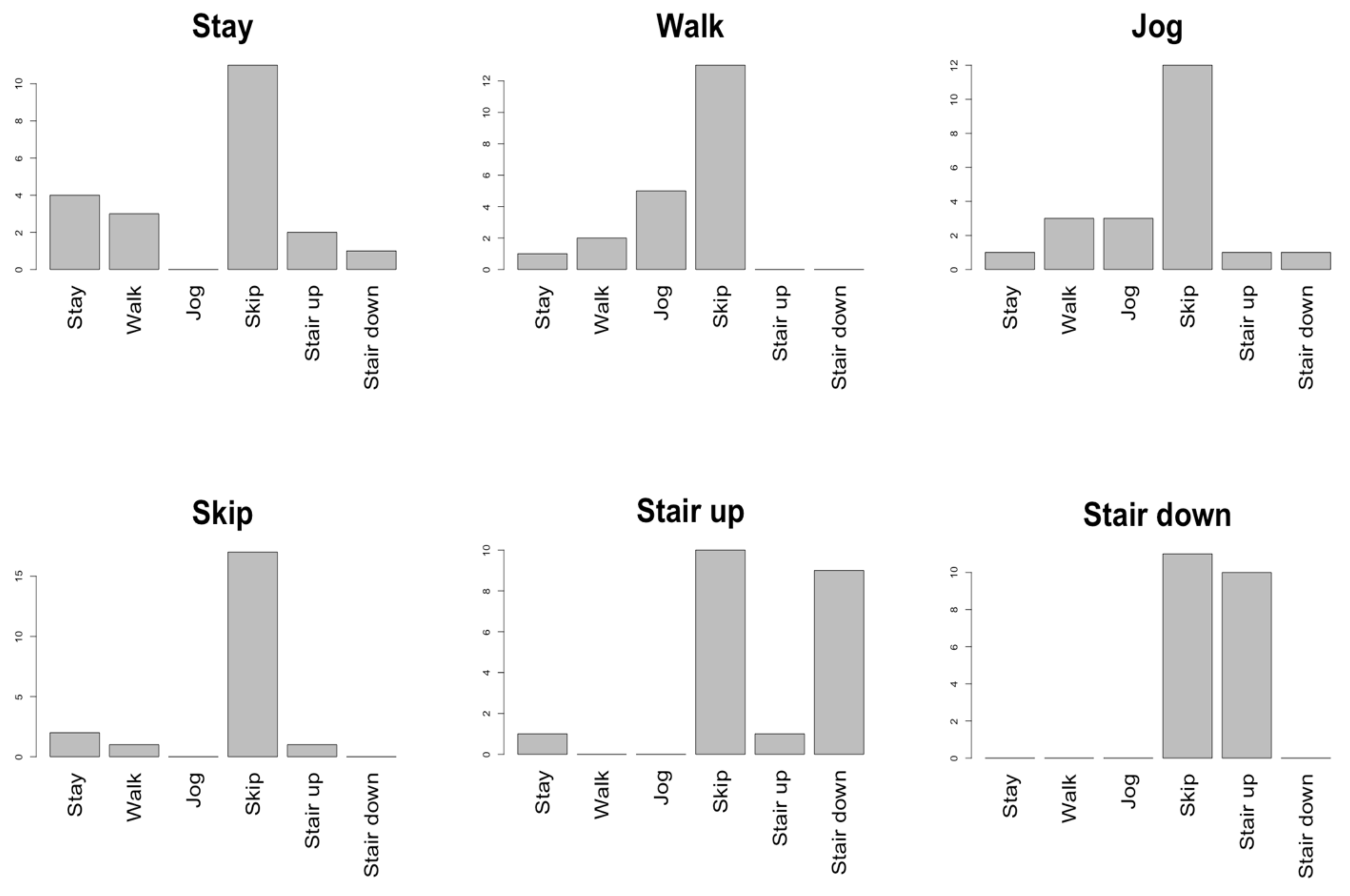
5.3. Correlation Analysis of Spatial Similarity
5.4. Summary of Results
6. Discussion
6.1. Word Meaning in Word Embedding Vector
6.2. Effect of the Choice of Semantic Space on the Performance
6.3. Compound Words
6.4. Future Work
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Attribute Vectors

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Act | Motion | Static | Cyclic Motion | Intense Motion | Translation Motion | Body Up | Body Down | Body in Place | Arms Motion | Arms Static | Arms Bent | Arms Straight | Arm Bent Straight Transform | Legs Motion | Legs Static | Legs Bent | Legs Straight | Legs Bent Straight Transform | Legs Alternate Move Forward | Legs Move Up and/or Down | Stairs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Stay | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | Walk | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 3 | Jog | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 4 | Skip | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 |
| 5 | Stair up | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
| 6 | Stair down | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
| Act | Motion | Static | Cyclic Motion | Intense Motion | Translation Motion | Free Motion | Body Vertical | Body Incline | Body Horizontal | Body Forward | Body Backward | Body Up | Body Down | Body in Place | Torso Transform | Arms Motion | Arms Static | Arms Bent | Arms Stranght | Arms Bent Straight Ransform | Hands Hold Something | Legs Motion | Legs Static | Legs Bent | Legs Straight | Legs Bent Straight Transform | Legs Alternate Move Forward | Legs Move Up and/or Down | Seat | Bike | Poles | Television | Computer | Car | Stairs | Vacuum | Iron | Clothes | Soccer | Rope | Indoor | Outdoor | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | lying | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 2 | sitting | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 3 | standing | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 4 | walking | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 5 | running | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 6 | cycling | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 7 | Nordic walking | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 8 | watching TV | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 9 | computer work | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 10 | car driving | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 11 | ascending stairs | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 12 | descending stairs | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 13 | vacuum cleaning | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 14 | ironing | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
| 15 | folding laundry | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 16 | house cleaning | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 17 | playing soccer | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 18 | rope jumping | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| Act | Open | Close | Clean | Drink | Toggle | Door | Fridge | Dishwasher | Drawer | Table | Cup | Switch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Open Door | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | Close Door | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | Open Fridge | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | Close Fridge | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 5 | Open Dishwasher | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6 | Close Dishwasher | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 7 | Open Drawer | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 8 | Close Drawer | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 9 | Clean Table | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 10 | Drink from Cup | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 11 | Toggle Switch | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Appendix A.2. Similarity Words for Each Activity Classes
| Activity Class | Top 5 | Top 10 | Top 20 |
|---|---|---|---|
| down | back, down”, down), down;, off | away, cut, down?, shut, upside | backwards, dragged, falling, finally, off;, out, slid, slowly, up, up” |
| jog | jogged, jogging, jogs, stroll, walk | bends, detour, half-mile, north-northwesterly, walking | driveway, eastbound, intersecting, intersects, lope, nap, ramp, straightens, swerves, veers |
| skip | go, miss, skipped, skipping, skips | Brier, curling, get, ignore, repeat | **the_Brier, Parsoid, Scribunto, append, editpreview, manually, redo, start, try, unwatch |
| stay | go, leave, remain, staying, stays | continue, settle, spend, wait, stayed | agrees, come, decide, decides, get, kept, marry, move, sit, vacation |
| up | back, up”, up:, up;, up? | down, forth, off, start, up) | 0:), aside, carrots→, finally, just, out, quickly, start, them, up! |
| walk | path, stroll, walked, walking, walks | **20_kilometres_walk, go, jump, trek, wander | barefoot, climb, distance, kilometres, pull, relax, sit, strolling, swim, throw |
| Activity Class | Top 5 | Top 10 | Top 20 |
|---|---|---|---|
| clean | cleaning, cleans, messes, tidy, wash | fixing, remove, rinse, scrubbing, washing | bring, clean-up, cleanup, fix, lighten, mess, recycle, soak, tidying, trash |
| close | closer, closest, closure, proximity, strong | busy, closes, contact, relative, ties | another, clear, closing, connection, friend, friends, keep, move, nearer, reopen |
| toggle | buttons, on/off, switch, toggled, toggles | disable, double-click, knob, right-click, show/hide | “Cite”, Rightclick, button, button;, doubleclicking, joystick, right-clicking, scrollbars, tabs, touchpad |
| drink | beer, beverage, beverages, drinks, nonalcoholic | carbonated, drank, soda, sodas, vodka | **soft_drink, **soft_drinks, caffeinated, coffee, cola, fizzy, juice, juices, lemonade, non-carbonated |
| open | **open_source, access, enclosed, space, spaces | “open, allow, doors, **open_plan, **open_source_software | Access, **Open-source_software, **open_content, accessible, create, door, extension, internal, opening, repository |
| Activity Class | Top 5 | Top 10 | Top 20 |
|---|---|---|---|
| ascending | ascend, ascends, descending, dhaivatam, panchamam | madhyamam, parallage, pentatonic, phthongos, scale) | (ascending, **chromatic_scale, **swara, arching, kaisiki, nishadham, rishabham, sadharana, shuddha, tetrachord |
| cleaning | clean, cleaners, cleans, laundry, washing | drying, polishing, repairing, scrubbing, vacuuming | Cleaning, cleanup, cleaner, dishwashers, ironing, plumbing, rinse, tidy, tidying, wash |
| cycling | Cycling, **2013_in_women’s_road_cycling, **2014_in_women’s_road_cycling, **Road_bicycle_racing, **track_cycling | **2013_UCI_Road_World_ Championships_Women’s_road_race, **List_of_women’s_road_bicycle_ races, **road_cycling , UCI, bicycle | BMX, **BMX_racing, **Mountain_bike_racing, **Track_cycling, **cyclocross, **race_stage, **road_bicycle_racing,**stage_race, cyclocross, cyclocross |
| descending | ascend, ascending, ascends, descend, downwards | climbs, descends, parallage, phthongos, scale) | (ascending, climb, descents, dhaivatam, downward, panchamam, steep, steeper, tetrachord, upward |
| driving | car, car’s, driver, drove, speeding | cars, drive, driver’s, drivers, stickshift | braking, burnouts, cornering, driver’s, drives, driving), motor, parked, vehicle, vehicle’s |
| folding | Folding, fold, folded, removable, sliding | adjustable, backrest, foldable, hinged, onepiece | Dbox, **protein_folding, armrests, chamferboards, folds, footrests, helical, laminated, nonslip, rearwards, |
| ironing | laundry, pillows, sewing, towels, washing | cleaning, dryer, mattresses, utensils, wash | **clothes_dryer, bathroom, clothes, cloths, dishwashers, dryers, napkins, towel, vacuuming, washable |
| jumping | **show_jumping, Jumping, dressage, ski, skiing | **eventing, **ski_jumping, Ski, downhill, eventing | **Show_jumping, **Ski_jumping, **dressage, **ski_cross, **ski_jumping_hill, jumper, leaping, paraNordic, snowboard, snowboarding |
| lying | bed, crying, dragged, lie, sleeping | beside, bluff, hiding, lied, scared | asleep, cheating, dragging, dumped, hugging, knees, pillow, screaming, slept, telling |
| playing | Playing, performing, play, played, plays | **full_back_(association_football), footballing, player, semiprofessional, singing | **Full_back_(association_football), **forward_(football), **midfield, career, club, midfield, playes, professionally, semiprofessionally, touring |
| running | cross, extending, ran, run, runs | Running, line, operating, stretch, walking | **road_running, **track_running, connecting, parallel, pulling, stretched, stretching, switching, walk, winding |
| sitting | **168th*, **169th*, **171st*, **172nd*, **176th* | **166th*, **167th*, **170th*, **173rd*, **174th* | 165th, 167th, 178th, **164th*, **165th*, **175th*, **177th*, **178th*, **179th*, **180th* |
| standing | holding, kneeling, seated, stands, stood | crouching, dressed, modified, sitting, stand | facing, hands, hangs, hung, ovation, resting, sits, smiling, unless, wearing |
| walking | jogging, trail, trails, walk, walks | accessible, bicycling, biking, hiking, strolling | **walking, barefoot, bike, distance, horseback, picnicking, rollerblading, sidewalk, stroll, walked |
| watching | enjoy, enjoying, laughing, watch, watched | chatting, crazy, listening, seeing, viewing | crying, enjoys, fun, kid, kids, loved, noticing, scared, screaming, staring |
| work | work:, work;, working, works, work | endeavors, job, necessary, studies, work) | Work, creations, efforts, endeavor, endeavours, experience, expertise, focus, oeuvre, research |
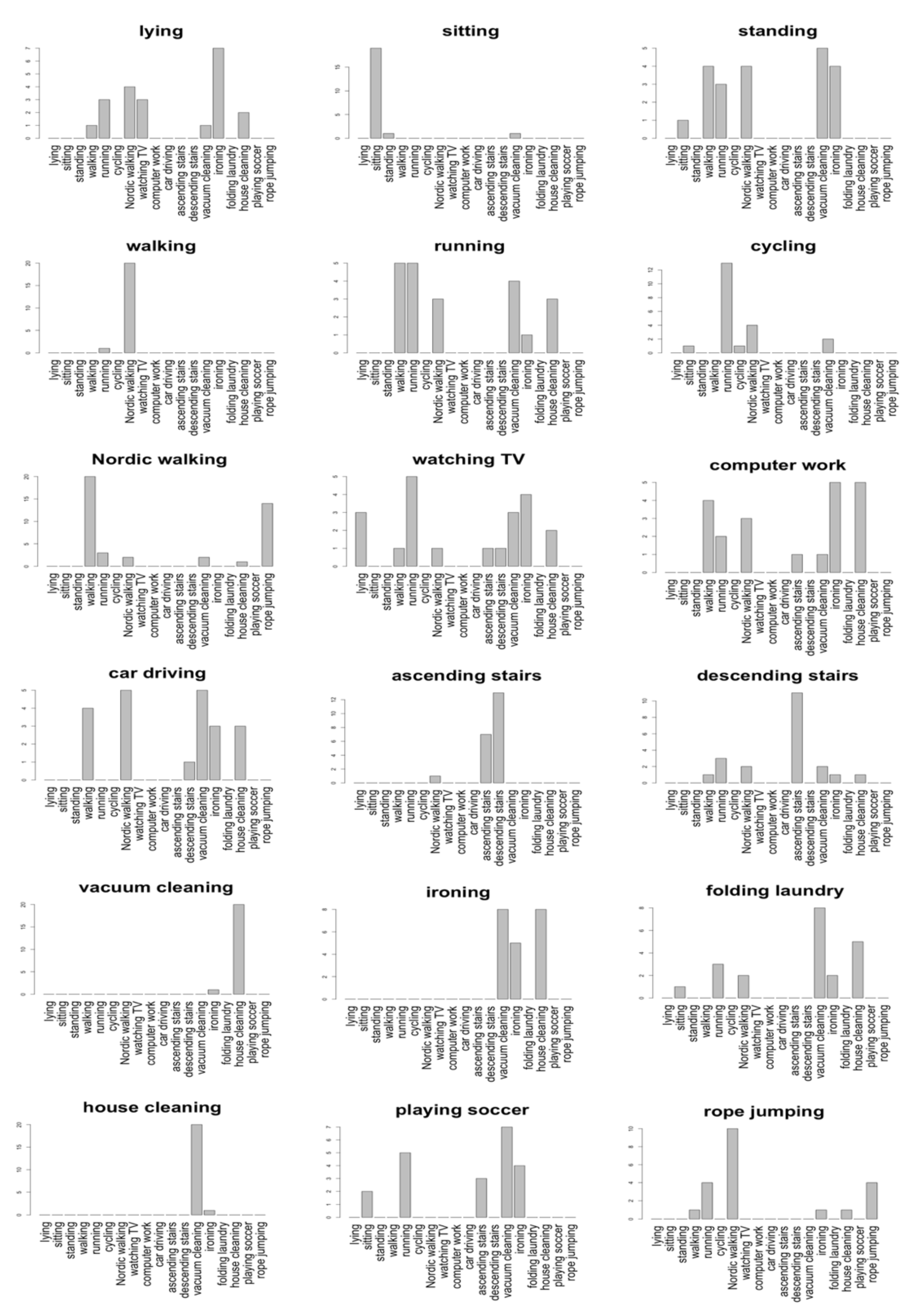
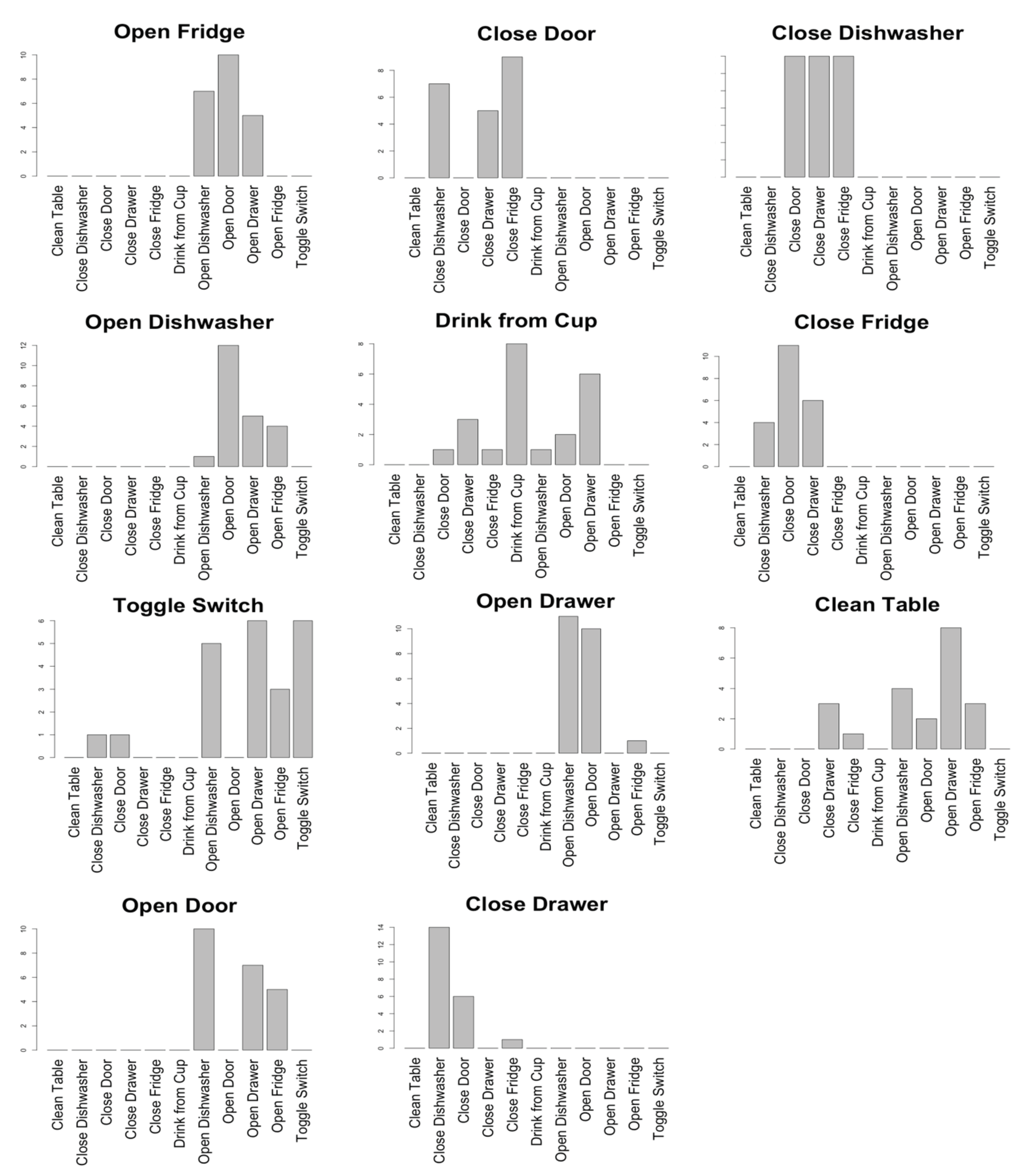
Appendix A.3. Spatial Similarity
| 1st | 2nd | 3rd | 1st | 2nd | 3rd | ||
|---|---|---|---|---|---|---|---|
| 1 | lying | standing | sitting | watching TV | descending stairs | car driving | ascending stairs |
| 2 | sitting | standing | computer work | watching TV | descending stairs | ascending stairs | standing |
| 3 | standing | sitting | lying | watching TV | descending stairs | ascending stairs | sitting |
| 4 | walking | Nordic walking | running | descending stairs | descending stairs | watching TV | playing soccer |
| 5 | running | walking | Nordic walking | cycling | standing | descending stairs | sitting |
| 6 | cycling | running | Nordic walking | walking | running | standing | vacuum cleaning |
| 7 | Nordic walking | walking | running | descending stairs | watching TV | descending stairs | walking |
| 8 | watching TV | computer work | sitting | lying | car driving | sitting | computer work |
| 9 | computer work | watching TV | sitting | standing | playing soccer | descending stairs | car driving |
| 10 | car driving | sitting | computer work | standing | descending stairs | ascending stairs | lying |
| 11 | ascending stairs | descending stairs | walking | Nordic walking | descending stairs | folding laundry | sitting |
| 12 | descending stairs | ascending stairs | walking | Nordic walking | ascending stairs | car driving | sitting |
| 13 | vacuum cleaning | house cleaning | folding laundry | ironing | house cleaning | folding laundry | sitting |
| 14 | ironing | folding laundry | vacuum cleaning | house cleaning | folding laundry | ascending stairs | standing |
| 15 | folding laundry | ironing | vacuum cleaning | house cleaning | ascending stairs | ironing | descending stairs |
| 16 | house cleaning | vacuum cleaning | folding laundry | ironing | vacuum cleaning | sitting | folding laundry |
| 17 | playing soccer | rope jumping | vacuum cleaning | house cleaning | descending stairs | computer work | ascending stairs |
| 18 | rope jumping | playing soccer | house cleaning | ascending stairs | standing | sitting | descending stairs |
| 1st | 2nd | 3rd | 1st | 2nd | 3rd | ||
|---|---|---|---|---|---|---|---|
| 1 | Open Door | Open Drawer | Open Dishwasher | Open Fridge | Close Drawer | Close Door | Open Fridge |
| 2 | Close Door | Close Drawer | Close Dishwasher | Close Fridge | Open Door | Clean Table | Drink from Cup |
| 3 | Open Fridge | Open Drawer | Open Dishwasher | Open Door | Close Fridge | Open Door | Open Drawer |
| 4 | Close Fridge | Close Drawer | Close Dishwasher | Close Door | Open Fridge | Close Drawer | Open Door |
| 5 | Open Dishwasher | Open Drawer | Open Fridge | Open Door | Close Dishwasher | Open Drawer | Toggle Switch |
| 6 | Close Dishwasher | Close Drawer | Close Fridge | Close Door | Open Dishwasher | Close Drawer | Close Fridge |
| 7 | Open Drawer | Open Dishwasher | Open Fridge | Open Door | Close Drawer | Open Dishwasher | Open Fridge |
| 8 | Close Drawer | Close Dishwasher | Close Fridge | Close Door | Open Drawer | Open Door | Close Dishwasher |
| 9 | Clean Table | Toggle Switch | Drink from Cup | Close Drawer | Close Door | Drink from Cup | Open Fridge |
| 10 | Drink from Cup | Toggle Switch | Clean Table | Close Drawer | Close Door | Open Fridge | Open Door |
| 11 | Toggle Switch | Drink from Cup | Clean Table | Close Drawer | Open Dishwasher | Close Dishwasher | Drink from Cup |


References
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Ransing, R.S.; Rajput, M. Smart home for elderly care, based on Wireless Sensor Network. In Proceedings of the 2015 International Conference on Nascent Technologies in the Engineering Field (ICNTE), Navi Mumbai, India, 9–10 January 2015; pp. 1–5. [Google Scholar]
- Aehnelt, M.; Wegner, K. Learn but work!: Towards self-directed learning at mobile assembly workplaces. In Proceedings of the 15th International Conference on Knowledge Technologies and Data-driven Business, Graz, Austria, 21–22 October 2015; p. 17. [Google Scholar]
- Perez, A.J.; Labrador, M.A.; Barbeau, S.J. G-sense: A scalable architecture for global sensing and monitoring. IEEE Netw. 2010, 24, 57–64. [Google Scholar] [CrossRef]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A. Zero-shot learning through cross-modal transfer. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 935–943. [Google Scholar]
- Zhang, Z.; Saligrama, V. Zero-shot recognition via structured prediction. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 533–548. [Google Scholar]
- Fu, Y.; Yang, Y.; Hospedales, T.; Xiang, T.; Gong, S. Transductive multi-label zero-shot learning. arXiv 2015, arXiv:1503.07790. [Google Scholar]
- Norouzi, M.; Mikolov, T.; Bengio, S.; Singer, Y.; Shlens, J.; Frome, A.; Corrado, G.S.; Dean, J. Zero-shot learning by convex combination of semantic embeddings. arXiv 2013, arXiv:1312.5650. [Google Scholar]
- Akata, Z.; Reed, S.; Walter, D.; Lee, H.; Schiele, B. Evaluation of output embeddings for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2927–2936. [Google Scholar]
- Bucher, M.; Herbin, S.; Jurie, F. Improving semantic embedding consistency by metric learning for zero-shot classiffication. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 730–746. [Google Scholar]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Learning to detect unseen object classes by between-class attribute transfer. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 951–958. [Google Scholar]
- Guadarrama, S.; Krishnamoorthy, N.; Malkarnenkar, G.; Venugopalan, S.; Mooney, R.; Darrell, T.; Saenko, K. Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2712–2719. [Google Scholar]
- Alexiou, I.; Xiang, T.; Gong, S. Exploring synonyms as context in zero-shot action recognition. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4190–4194. [Google Scholar]
- Xu, X.; Hospedales, T.; Gong, S. Semantic embedding space for zero-shot action recognition. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 63–67. [Google Scholar]
- Xian, Y.; Akata, Z.; Sharma, G.; Nguyen, Q.; Hein, M.; Schiele, B. Latent embeddings for zero-shot classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 69–77. [Google Scholar]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of posture and motion by accelerometry: A validation study in ambulatory monitoring. Comput. Hum. Behav. 1999, 15, 571–583. [Google Scholar] [CrossRef]
- Vishwakarma, S.; Anupam, A. A survey on activity recognition and behavior understanding in video surveillance. Vis. Comput. 2013, 29, 983–1009. [Google Scholar] [CrossRef]
- Tapia, E.M.; Intille, S.S.; Haskell, W.; Larson, K.; Wright, J.; King, A.; Friedman, R. Real-time recognition of physical activities and their intensities using wireless accelerometers and a heart rate monitor. In Proceedings of the 2007 11th IEEE International Symposium on Wearable Computers, Boston, MA, USA, 11–13 October 2007; pp. 37–40. [Google Scholar]
- He, Z.; Jin, L. Activity recognition from acceleration data based on discrete consine transform and svm. In Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 5041–5044. [Google Scholar]
- Parkka, J.; Ermes, M.; Korpipaa, P.; Mantyjarvi, J.; Peltola, J.; Korhonen, I. Activity classification using realistic data from wearable sensors. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 119–128. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.; Chen, L.; Ye, Z.; Zhang, Y. Aroma: A deep multi-task learning based simple and complex human activity recognition method using wearable sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 74. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer learning for activity recognition: A survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [PubMed]
- Inoue, S.; Pan, X. Supervised and unsupervised transfer learning for activity recognition from simple in-home sensors. In Proceedings of the 13th International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, Hiroshima, Japan, 28 November–1 December 2016; pp. 20–27. [Google Scholar]
- Wang, W.; Zheng, V.W.; Yu, H.; Miao, C. A survey of zero-shot learning: Settings, methods, and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 13:1–13:37. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Cheng, H.T.; Sun, F.T.; Griss, M.; Davis, P.; Li, J.; You, D. Nuactiv: Recognizing unseen new activities using semantic attribute-based learning. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 361–374. [Google Scholar]
- Cheng, H.T.; Griss, M.; Davis, P.; Li, J.; You, D. Towards zero-shot learning for human activity recognition using semantic attribute sequence model. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 355–358. [Google Scholar]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar]
- Kawaguchi, N.; Ogawa, N.; Iwasaki, Y.; Kaji, K.; Terada, T.; Murao, K.; Inoue, S.; Kawahara, Y.; Sumi, Y.; Nishio, N. HASC Challenge: gathering large scale human activity corpus for the real-world activity understandings. In Proceedings of the 2nd Augmented Human International Conference, Tokyo, Japan, 13 March 2011; p. 27. [Google Scholar]





| Dataset | Activity Class Type | Sensor Type |
|---|---|---|
| HASC | Basic (Walk, Run, Jog, Skip, Stair up and Stair down) | Accelerometer worn on arm (including acceleration sensor) on arm |
| OPP | Middle (open door, close door, open fridge, close fridge, open dishwasher, close dishwasher, open drawer, close drawer, clean table, drink from cup and toggle switch) | Ambient sensors and wearable sensors (including IMUs and acceleration sensor) on 7 points |
| PAMAP2 | Living (watching TV, house cleaning, lying, sitting, standing, walking, running, cycling, Nordic walking, computer work, car driving, ascending stairs, descending stairs, vacuum cleaning, ironing, folding laundry, playing soccer and rope jumping) | Wearable sensors (including IMUs and heart rate monitor sensor) on 3 points |
| Fold | Unknown Classes |
|---|---|
| fold 1 | Close Drawer, Clean Table, Toggle Switch |
| fold 2 | Open Fridge, Open Door, Close Drawer |
| fold 3 | Drink from Cup, Open Drawer, Close Dishwasher |
| fold 4 | Close Drawer, Close Door, Open Door |
| fold 5 | Close Fridge, Open Dishwasher, Close Door |
| Fold | Unknown Classes |
|---|---|
| fold 1 | watching TV, house cleaning, standing, ascending stairs |
| fold 2 | walking, rope jumping, sitting, descending stairs |
| fold 3 | playing soccer, lying, vacuum cleaning, computer work |
| fold 4 | cycling, running, Nordic walking |
| fold 5 | ironing, car driving, folding laundry |
| Fold | Unknown Classes | Fold | Unknown Classes |
|---|---|---|---|
| fold 1 | Stay (2013), Walk (2014) | fold 9 | Jog, Stair up |
| fold 2 | Stay, Jog (1608) | fold 10 | Skip, Stair up |
| fold 3 | Walk, Jog | fold 11 | Stay, Stair down (2012) |
| fold 4 | Stay, Skip (2010) | fold 12 | Walk, Stair down |
| fold 5 | Walk, Skip | fold 13 | Jog, Stair down |
| fold 6 | Jog, Skip | fold 14 | Skip, Stair down |
| fold 7 | Stay, Stair up (2015) | fold 14 | Skip, Stair down |
| fold 8 | Walk, Stair up | fold 15 | Stair up, Stair down |
| Fold | Number of Instances | Number of Classes | ||||||
|---|---|---|---|---|---|---|---|---|
| OPP | PAMAP2 | OPP | PAMAP2 | |||||
| Classes | Seen | Unseen | Seen | Unseen | Seen | Unseen | Seen | Unseen |
| fold 1 | 5868 | 1338 | 16377 | 3073 | 8 | 3 | 14 | 4 |
| fold 2 | 4986 | 2220 | 13661 | 5789 | 8 | 3 | 14 | 4 |
| fold 3 | 4647 | 2559 | 15770 | 3680 | 8 | 3 | 14 | 4 |
| fold 4 | 5087 | 2119 | 14927 | 4523 | 8 | 3 | 15 | 3 |
| fold 5 | 5525 | 1681 | 17065 | 2385 | 8 | 3 | 15 | 3 |
| HASC | OPP | PAMAP2 | |
|---|---|---|---|
| supervised_SVM | 0.84 | 0.85 | 0.92 |
| ZSL_attribute | 0.91 | 0.78 | 0.91 |
| ZSL_embedding | 0.92 | 0.92 | 0.91 |
| HASC | OPP | PAMAP2 | |
|---|---|---|---|
| attribute | 0.35 | 0.11 | 0.13 |
| semantic | 0.32 | 0.27 | 0.09 |
| semantic_top5 | 0.31 | 0.21 | 0.13 |
| semantic_top10 | 0.36 | 0.21 | 0.15 |
| semantic_top20 | 0.33 | 0.12 | 0.13 |
| 1st | 2nd | 3rd | 1st | 2nd | 3rd | ||
|---|---|---|---|---|---|---|---|
| 1 | Stay | Walk | Jog | Stair down | Walk | Jog | Stair up |
| 2 | Walk | Jog | Stair down | Stair up | Jog | Stay | Stair down |
| 3 | Jog | Skip | Walk | Stair down | Walk | Stay | Stair up |
| 4 | Skip | Jog | Stair up | Stair down | Walk | Jog | Stay |
| 5 | Stair up | Stair down | Skip | Jog | Stair down | Jog | Stay |
| 6 | Stair down | Stair up | Skip | Jog | Stair up | Jog | Walk |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matsuki, M.; Lago, P.; Inoue, S. Characterizing Word Embeddings for Zero-Shot Sensor-Based Human Activity Recognition. Sensors 2019, 19, 5043. https://doi.org/10.3390/s19225043
Matsuki M, Lago P, Inoue S. Characterizing Word Embeddings for Zero-Shot Sensor-Based Human Activity Recognition. Sensors. 2019; 19(22):5043. https://doi.org/10.3390/s19225043
Chicago/Turabian StyleMatsuki, Moe, Paula Lago, and Sozo Inoue. 2019. "Characterizing Word Embeddings for Zero-Shot Sensor-Based Human Activity Recognition" Sensors 19, no. 22: 5043. https://doi.org/10.3390/s19225043