1. Introduction
Air pollution is a serious problem [
1]. Many people die every year due to problems related to air pollution. Therefore, in order to reduce this type of pollution in an efficient way, it is important to create citizen awareness about it and take care of green areas and trees, build more urban parks, avoid the use of aerosols, and improve the transportation system, among other things.
Living in the city implies that citizens have to face the problem of air pollution very often. Therefore, it is important to design measurement and control systems that can eliminate or mitigate the problems that air pollution is causing to humans and nature. The smart city concept takes this idea into account, and one of the most harmful pollutants for humans is PM
2.5 (fine particulate matter with diameter smaller than 2.5 µm [
2].
In [
3], a method to perform the forecasting of PM
2.5 concentrations in Taiwan was proposed. This method used the moving average technique to perform the forecast, and the authors considered that there was no seasonality or trend when analyzing short-term PM
2.5 concentrations. The data used in [
3] were obtained from PM
2.5 sensing devices that were deployed all over Taiwan, and the forecast model shown in [
3] used exponential smoothing with a drift to perform the prediction of PM
2.5.
A low-cost air quality station designed to monitor environmental parameters and atmospheric pollutants was presented in [
4]. Furthermore, in [
4], the following variables were measured: air temperature, relative humidity, CO (carbon monoxide), CO
2 (carbon dioxide), NO
2 (nitrogen dioxide), O
3 (ozone), VOC (volatile organic compound), PM
2.5, and PM
10 (particulate matter with diameter smaller than 10 µm); and the PM
2.5 and PM
10 sensors were calibrated. For the calibration process, linear regression, robust linear regression, and non-linear regression were used. In addition, the
M-estimation method was used to reduce the influence of outliers on least squares fitting for robust linear regression.
Key components of a portable air pollution monitoring system based on low-cost sensors were introduced in [
5]. In addition, in [
5], the on-field testing of the sensing unit was described and roadside measurements from a mobile laboratory equipped with a calibrated instrument were used. Furthermore, in [
5], a case study was presented in order to demonstrate the application by mounting the low-cost air pollution monitoring system on an electric bike. The experiment was carried out in the city of Mons, Belgium, and the results of the PM
2.5 concentrations measurements were compared with measurements available from the local monitoring station. According to the authors of [
5], that research paper was aimed at presenting a low-cost mobile system to map particulate matter concentration levels generated by the daily activity of the human being in the area under study.
A study aimed at evaluating the precision, accuracy, practicality, and potential uses of a PM
2.5 miniaturized monitor was performed in [
6]. Miniaturized monitors (AirBeam, HabitatMap) were compared with real-time particulate matter monitors of PM
2.5 and a gravimetric reference method for PM
2.5. The PM
2.5 concentration measurements were carried out in Como, Italy. In [
6], it was made clear that in the scientific literature, there are few articles aimed at performing the evaluation or comparison of miniaturized monitors. In addition, in [
6], Shinyei PPD60PV sensors (AB) were chosen among others because of their practicability. Furthermore, several results of ABs evaluations that are reported in some scientific articles are also shown [
6].
In order to carry out the statistical analysis and data treatment shown in [
6], all data (except meteorological data averaged for a one-hour period) below the first percentile and above the 99th percentile were truncated. Also, a significance level of
was chosen for all tests. In addition, descriptive statistics were estimated for PM
2.5 concentration measurements, and the following tests were used: (1) precision evaluation (in accordance with [
7], the evaluation of the uncertainty between co-located miniaturized monitors by means of uncertainty analysis and linear regression was carried out); (2) comparison of the AB with the reference gravimetric method (in [
6], the Mann–Whitney test and the Spearman’s correlation were used, also, a regression analysis was performed in accordance with [
7]); (3) the evaluation of possible error trends by using Bland–Altman plots [
8,
9]; and (4) the impact of meteorological variables on measurement methods (a multiple linear regression analysis was carried out between AB absolute errors and meteorological parameters that were measured at the sampling point). The uncertainty between a couple of ABs was calculated in accordance with [
10].
In [
11], robust statistics were applied to assess temporal trends in PM
2.5, PM
10, and PM
2.5/PM
10 ratios. In accordance with [
11], robust statistics are those that are not-sensitive to non-normal distributions and to extreme values in both tails of the distributions. In [
11], the ratios of PM
2.5/PM
10 were characterized to better understand the behavior and potential future impacts of PM
2.5 in the United Kingdom. The robust statistics that were used for data analysis in [
11] were the following: median, various percentiles (fifth, 25th, 75th, and 95th), and Theil–Sen trend analysis [
12,
13].
According to [
14], the National Capital Territory (NCT) of Delhi, India, is one of the most polluted regions in the world. In Delhi NCT, the annual PM
2.5 concentration levels exceed the annual National Ambient Air Quality Standard of India, which is equal to
, by more than
[
14,
15,
16,
17,
18,
19,
20]. In addition, in [
21], a land-use regression model was used to estimate the mean annual PM
2.5 concentrations over Delhi.
The research work presented in [
14] was focused on tracking pollution build-up during the dry season (typically from the end of September to the end of June of the subsequent year, in the Delhi National Capital Region (NCR)). Furthermore, in [
14], an aerosol optical depth (AOD) dataset was used. This AOD dataset was generated at a resolution of
. In order to do this, the multiangle implementation of atmospheric correction (MAIAC) algorithm [
22,
23] applied to moderate resolution imaging spectroradiometer (MODIS) data was used. In addition, PM
2.5 was estimated from MAIAC-AOD by multiplying spatially and temporally varying conversion factors at a spatial resolution of
. Moreover, all 1 km
2 PM
2.5 concentrations that were bias-corrected within Delhi NCR were averaged for each day. Finally, in order to ensure enough samples for robust statistics, the analysis was presented at weekly scale by averaging over
days.
In [
24], PM
2.5 pollution process was analyzed using long-term PM
2.5 observations in three Chinese cities. In addition, the trend of the monthly mean of PM
2.5 concentrations rising rates and PM
2.5 concentrations using a robust Theil–Sen estimator was calculated.
In order to study the source and origin of ambient PM
2.5 concentrations at a traffic site in Delhi, persistence analysis and nonparametric wind regression (NWR) were used in [
25]. The persistence analysis was used to detect significant correlation between adjacent points and to infer the nature of sources that contribute to air pollution by PM
2.5 concentrations in an area. Moreover, NWR analysis was performed to infer the nature of the sources of PM
2.5 concentrations.
Nonparametric methods were also used in [
26] to assess the influence on air quality of four industrial facilities that burn hazardous waste in southeast Kansas, Unites States of America. In [
26], factors that affect spatial and temporal distribution of PM
10 and PM
2.5 concentrations in the region were investigated. Moreover, the effect of wind direction on the above-mentioned distribution was investigated as well. In [
26], the Kruskal–Wallis test was used for the following purposes: (i) to determine whether the sampling site and the sampling date were statistically significant factors for PM
10 and PM
2,5 concentrations; (ii) to check whether there were significant differences between the cities under analysis; and (iii) to check whether the effect that wind direction had over PM
10 and PM
2.5 concentrations was statistically significant. In addition, the effect of the targeted sources on PM
10 and PM
2.5 concentrations was analyzed by using the Wilcoxon-signed rank test.
The Kruskal–Wallis test was also used in [
27] to test whether there were significant differences between some stations of the Athens Subway System, Greece. In short, the research work presented in [
27] was aimed at studying the indoor environmental quality inside the natural ventilated and air-conditioned train cabins and platforms of four main stations of the Athens Metro.
Moreover, another example in which an application of the Kruskal–Wallis test can be found is [
28]. In [
28], this test was used to assess differences in PM
2.5 concentration levels in Beijing, China. In short, the study presented in [
28] was aimed at detecting spatiotemporal change patterns of PM
2.5 concentrations and evaluating the relation between PM
2.5 concentration and meteorological factors.
In [
29], a time-series study was carried out to evaluate the association between daily PM
2.5 concentrations and respiratory deaths in eight municipal districts in Beijing, using a generalized additive mixed model. In addition, as there was very little information about the time trend in mortality, a Bayesian model averaging method was used to develop a robust predictive performance.
In order to know the factors that affect citizens because of their exposure to NO
2 and NOx (nitrogen oxides) produced by traffic, [
30] was aimed at estimating the way in which the gradient near the road varies owing to changes in meteorological and ambient variables, and also due to traffic conditions. The study presented in [
30] was performed in Las Vegas, USA. In [
30], the authors employed generalized additive models to model the slopes of functions that were used to characterize the zones in which concentrations of NO
2 and NOx were assessed. Furthermore, the estimation of the concentration of NO
2 and NOx on the road was performed by using the ordinary least-squares regression method. The studies conducted in [
30] could be used to better understand the effects that roads that are heavily traveled and that are adjacent to sidewalks and houses have on people. All this helps to achieve a better urban design and to better predict the level of exposure that people have to certain variables that are harmful to human beings.
In addition, in order to study fine-scale variations of PM
2.5 concentrations and black carbon, in [
31], “a three-point synchronous observation experiment” was carried out. Such an experiment was performed in Shanghai, China. Moreover, a characterization of concentrations of PM
2.5 and black carbon was performed in [
31], and a generalized additive model was used to show the relationship that PM
2.5 concentrations and black carbon have with multiple factors. The results of [
31] could contribute to the development of air pollution control strategies at roadsides.
In [
32], in order to carry out indoor air quality predictions, a methodology based on modeling was presented. The predictions were made using artificial neural networks and the Personal-Exposure Activity Location Model [
33,
34]. The approach presented in [
32] can be employed to determine exposures that urban workers have to air pollutants. The study presented in [
32] was performed in Dublin, Ireland. In addition, in [
35], a research work on particulate matter produced by “vehicle emissions at traffic intersections of street canyons in Hong Kong” was presented. In [
35], detrended fluctuation analysis and autocorrelation analysis were used to study the distinguishing features of the concentration of particulate matter.
Furthermore, in [
36], a model consisting of a wavelet neural network and a genetic algorithm was used to predict CO and PM
2.5 concentrations. The above-mentioned model was developed to perform the estimation of concentrations of air pollutants in Shanghai. In addition, in [
37], both parts of the urban park La Carolina (Quito, Ecuador) and some of the surrounding streets were modeled as random variables, which represented routes made in some areas to measure the concentration of PM
2.5 in them. Then, nonparametric statistical inference techniques were used to classify the level of air pollution that the areas under study had, based on air quality indexes defined by the city of Quito [
38]. In [
37], a Kruskal–Wallis test was applied to test whether the above-mentioned random variables came from the same statistical population, and the Wilcoxon signed-rank test was used to perform the classification process in accordance with Quito air quality indexes [
38]. The results of [
37] showed that the air pollution level because of PM
2.5 concentrations in that urban park was not in alert level. However, there are important decisions that have to be taken by the city authorities in order to improve the air quality in the area under study.
For each statistical model, regardless of whether this is a location model, a scale model, a linear regression model, or a model of any other type, there are different robust statistical tools that increase the reliability and accuracy of modeling and/or data analysis [
39,
40].
The main objective of this article is to perform the robust statistical analysis of PM
2.5 concentration measurements in La Carolina Park, which is one of the most important urban parks of Quito. In this article, in order to robustly estimate the location and scale parameters of the data, the following estimators were used: (i) for robust location estimation:
-trimmed mean, trimean, and median estimators; and (ii) for robust scale estimation: median absolute deviation, semi interquartile range, biweight midvariance, and estimators based on a subrange [
39,
40,
41,
42].
The use of several of the above-mentioned estimators within the context of the analysis of PM2.5 concentrations in urban parks is novel and has its importance in the fact that with few data and without the need for them to fit a normal distribution, or some kind of parametric distribution, the central tendency and dispersion of the data can be estimated in a robust way. Thus, small variations in the data have no effect on their estimation.
In this article, in order to be able to understand characteristics of the type of data that were analyzed, the first thing that was done was to establish the selection criteria of the study area (i.e., La Carolina Park, Quito). Second, a statistical summary of the data was performed, and moments of first, second, third and fourth order were found. Moreover, the median and range of the data were found. Also, in order to reduce the effect that each data point could have, graphs of the data were shown, and attempts were made to soften the data under analysis. In addition, empirical confidence intervals for the median of the data were obtained with a 95% confidence level, and nonparametric confidence intervals for the median of the data were also obtained with a 95% confidence level.
Here, the air pollution levels of each variable under study were classified in accordance with the categories established by the city of Quito [
38]. After that, the robust statistical analysis of location parameters and scale parameters of the data was performed. The results of this article are compatible with [
37].
This article is structured as follows: The criteria that were taken into account to select the study area are explained in
Section 2. The description of the PM
2.5 measurement instrument that was used in this article and data collection process are given in
Section 3.
Section 4 is devoted to carry out the robust statistical analysis of the data. Finally, the conclusions are given in
Section 5.
3. PM2.5 Measurement Instrument and Data Collection Description
In this article, a portable CEL-712 Microdust Pro monitor pair with a GPS (Global Positioning System) device was used to perform the PM
2.5 concentration measurements. This measurement instrument was calibrated by CASELLA [
43]. The calibration results were the following:
Instrument type: Microdust Pro (Standard Range: ).
Serial Number: 4111986.
Calibration Principle: Calibration was performed using an ISO 12103 Pt1 A2 Fine test dust (Natural ground mineral dust, predominantly silica, Arizona Road Dust equivalent, Particle size range to ). A Wright Dust feeder system was used to inject and disperse calibration dust within a wind tunnel system. Particulate mass concentration was established using isokinetic sampling and gravimetric methods.
Calibration Results Summary:
- ○
Applied concentration: .
- ○
Indication: .
- ○
Error: .
- ○
Target Error .
In this article, the sampling time of the CEL-712 Microdust Pro monitor was 1 s, and the measurements were averaged to show the results each 10 s. Moreover, the GPS saved the coordinates of the route each 1 min.
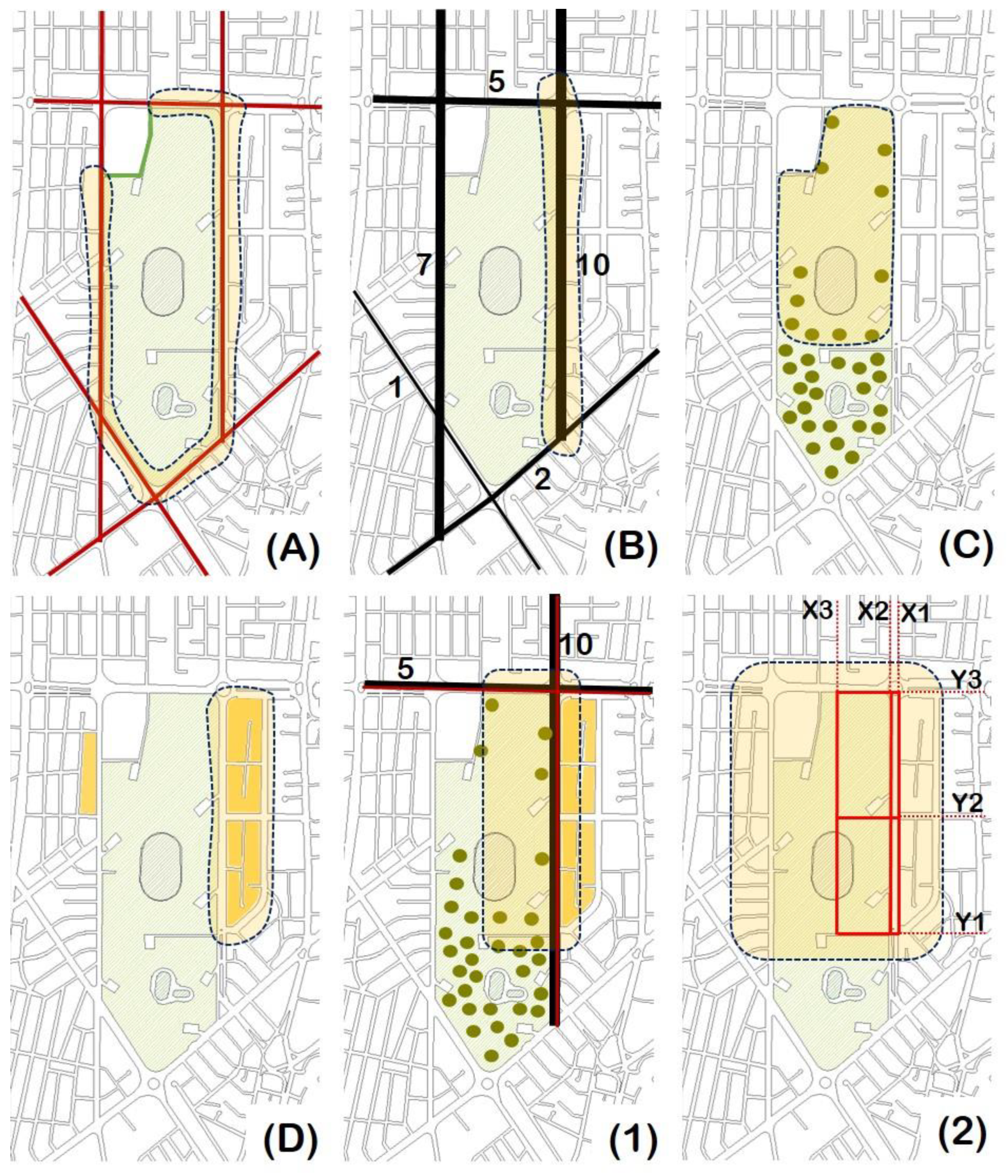
The above-mentioned equipment were used to carry out their measurements at a height of , placing the particle inlet forward. Here, the walking speed was approximately equal to . Then, in order to build a pollution map in QGIS software, both collected and GPS data were used. In this research work, PM2.5 concentration measurements were performed in October 2018 and January 2019. Moreover, all measurements were performed during the morning rush hours (8:00–10:00), as it is a time of the day with the worst air quality conditions, due to the low planetary boundary height and reduced atmospheric mixing.
According to [
44], the CEL-712 Microdust Pro has the highest measurement range of any occupational dust measurement instrument available on the market. In addition, due to the large data storage capacity of this equipment, up to 500 measurement results can be taken and stored. Moreover, the user can generate reports in an easy way using the intuitive report wizard. The key features of this instrument and applications can be found in [
44]. A characteristic of the CEL-712 Microdust Pro that was important in order to carry out the research work presented in this article is that this instrument can be used for spot checks and walk-through surveys. In addition, this instrument has the advantage that the user can instantly see when and where excessive dust levels are occurring [
44].
In accordance with [
44], another characteristic that this instrument has, which makes it unique because no other device has it, is that the CEL-712 Microdust Pro uses an on-site calibration filter to provide a spot check of the linearity of the instrument.
Furthermore, the CEL-712 Microdust Pro was validated by collocation following the instructions of the U.S. Environmental Protection Agency (U.S. EPA) to evaluate low-cost sensors [
45]. For the case under study, the U.S. EPA also recommends [
46,
47]. For the case under analysis, the CEL-712 Microdust Pro was validated by collocation with the Thermo Fisher Scientific BAM equipment of the Air Quality Network station of Quito, run by the Environmental Protection Agency (in Spanish, it is called “Secretaria de Ambiente” (SA)) of Quito, for six hours. The experiment time had to be limited to six hours, due to the battery lifetime, and the fact that the battery could not be replaced because the monitoring station was located in a school.
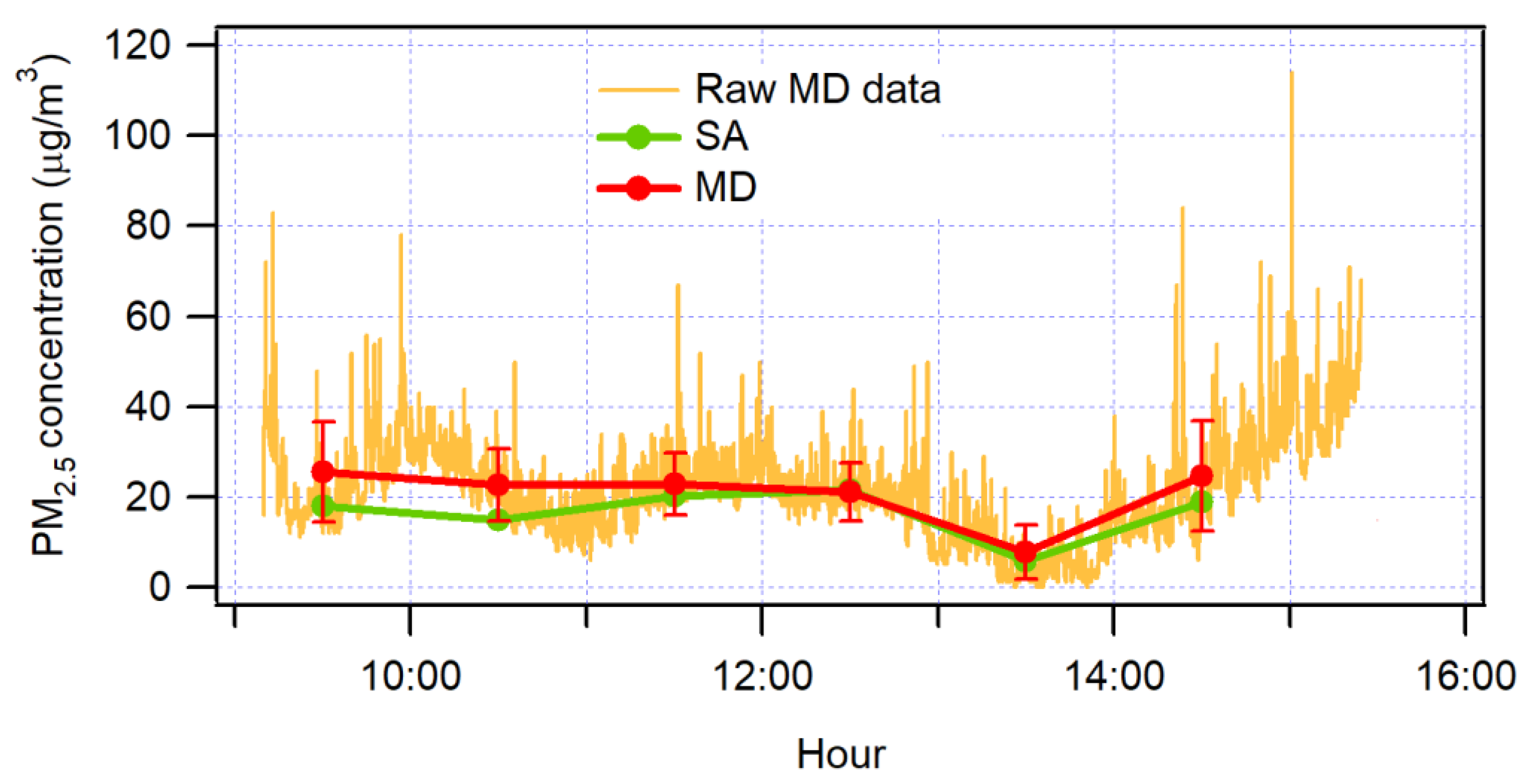
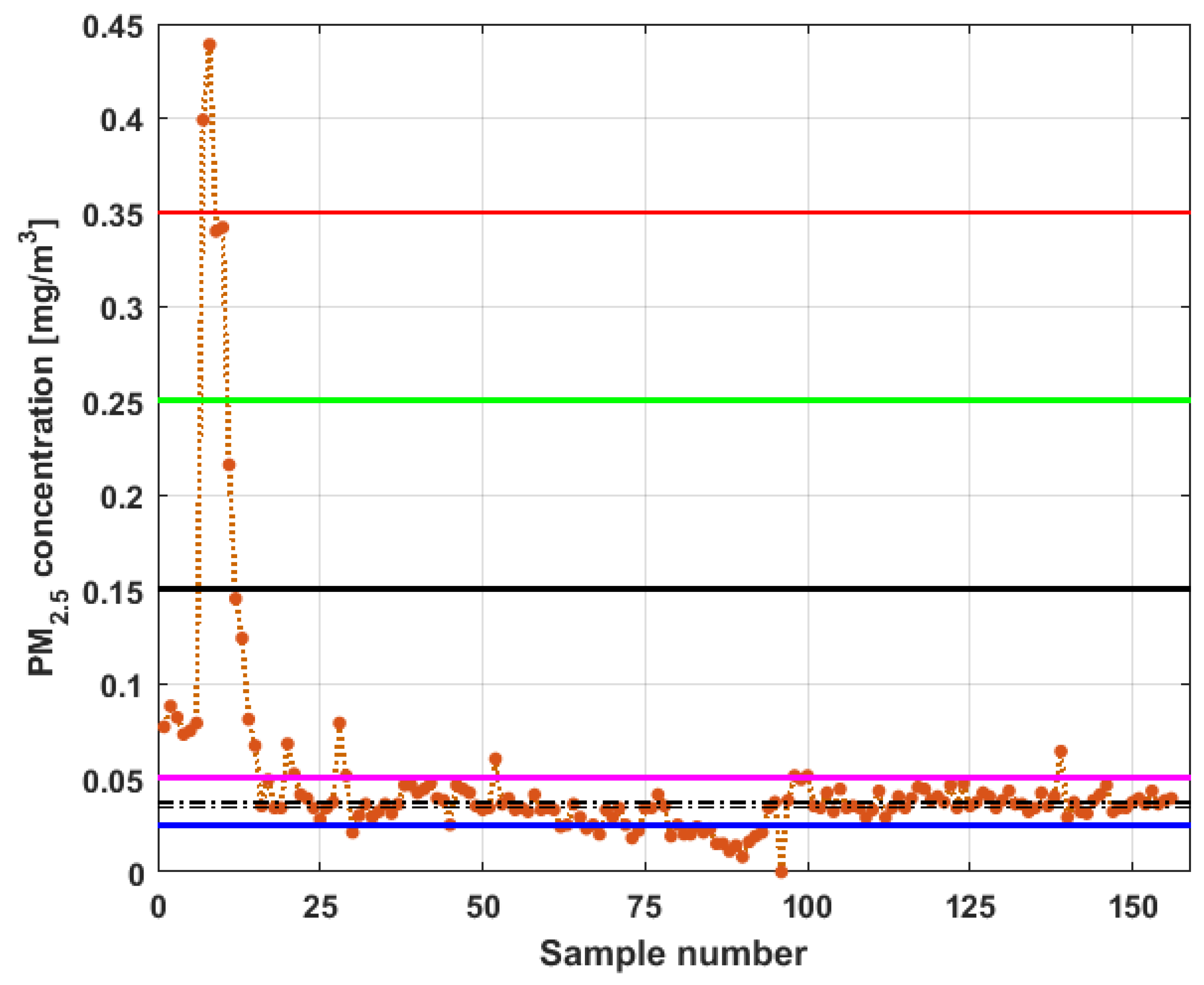
Figure 3 shows the raw Microdust Pro data and hourly averages of Microdust Pro and the BAM method. It can be seen that while there is a variation in the Microdust Pro data, BAM data fits in the one standard deviation of the Microdust Pro data. In accordance with [
48], the validation was performed at times were the relative humidity is low [
49].
Before finishing this section, it is important to mention that studies aimed at conducting the evaluation and comparison of several PM
2.5 monitors can be found in [
6]. In addition, research articles focused on the calibration and validation of low-cost particulate matter sensors can be found in [
4,
48].
4. Robust Data Analysis
This section is divided into three parts. First, a statistical summary of the data is presented. Second, a nonparametric inferential analysis is performed. Finally, the section ends using robust estimators to analyze measures of centralization and dispersion of the data of the variables under study. The latter is justified by the fact that robust estimators are relatively insensitive to small changes in the data.
4.1. Statistical Summary of the Dataset
In accordance with [
50], in this research work, there is a set of data that is going to be analyzed in order to properly interpret the relationships between them. Furthermore, in this subsection, different types of graphs will be used with the intention of showing a simple transmission of the analysis and conclusions. Here, it has been considered that these graphs will allow a simple comparison between the data and, on the other hand, highlight differences between the variables under study. According to [
51], these graphs make a clear and precise representation of the consequences.
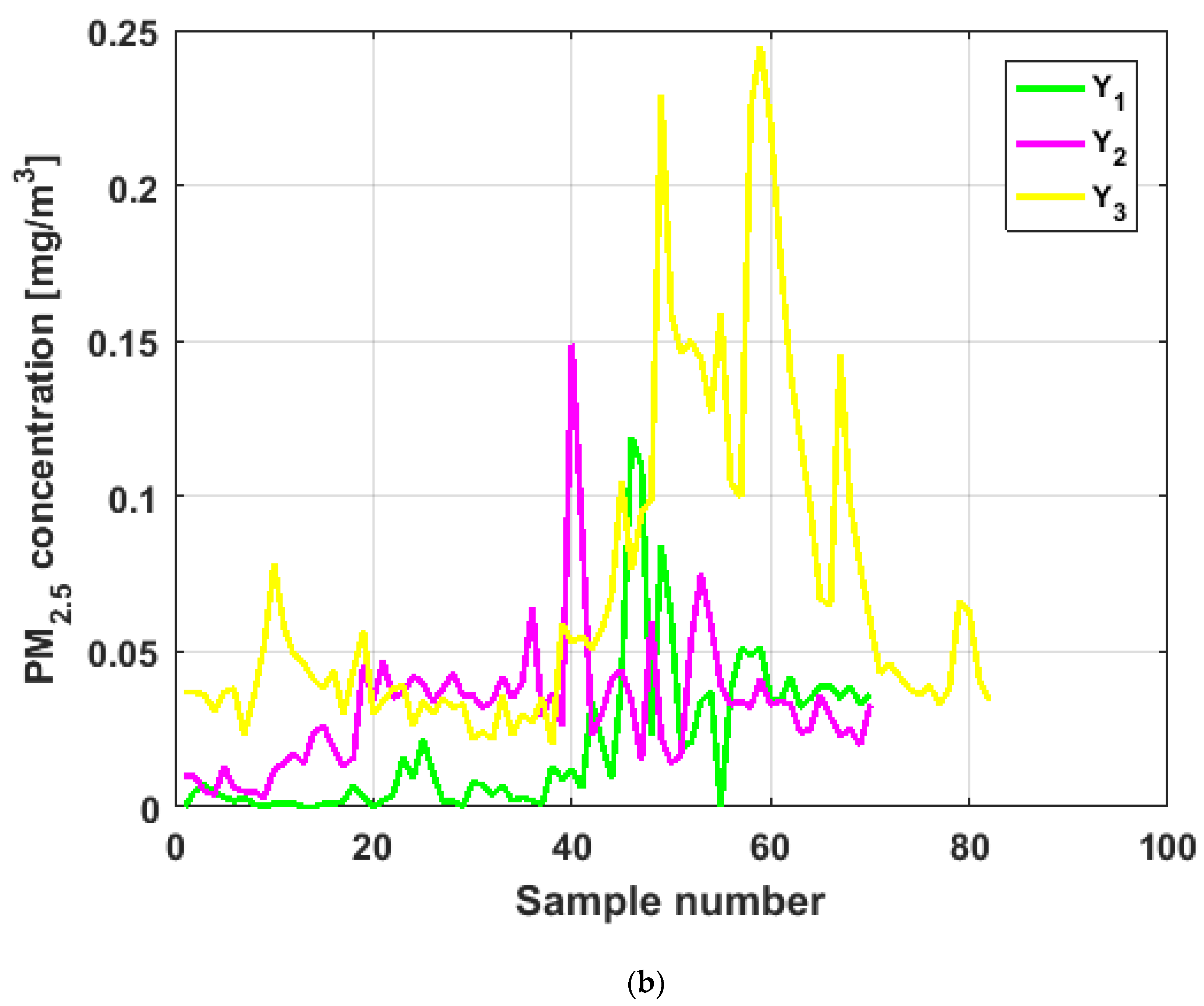
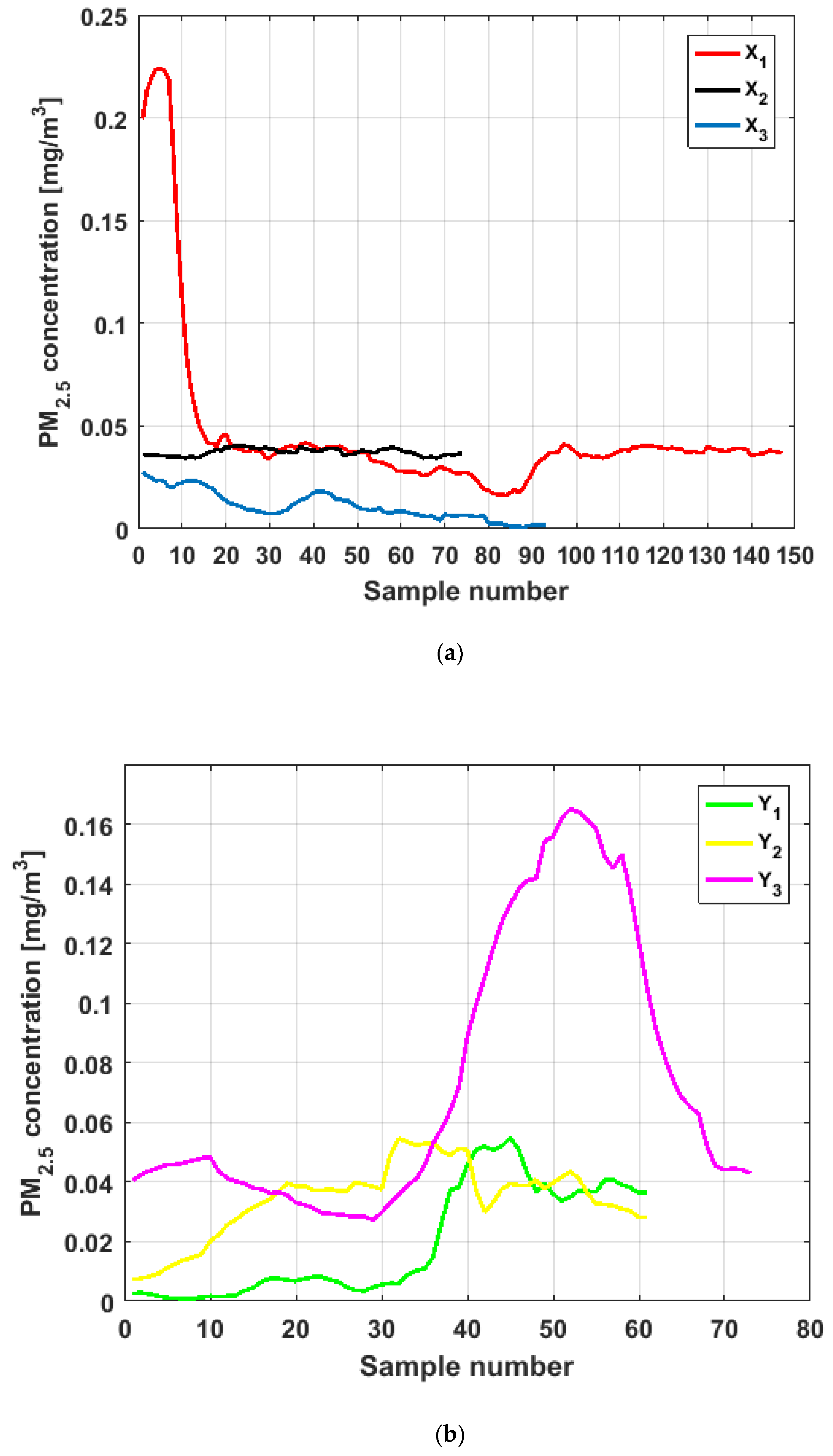
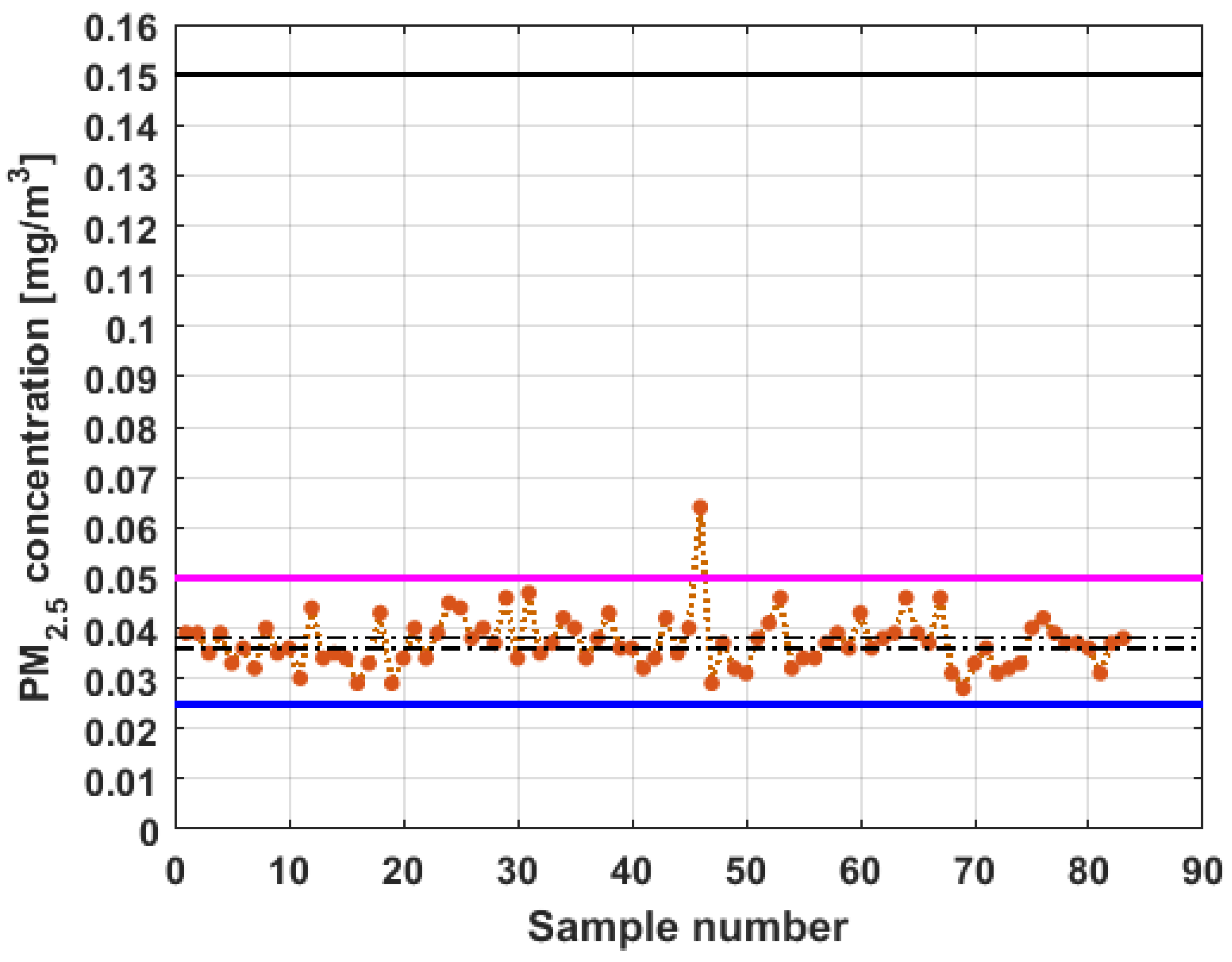
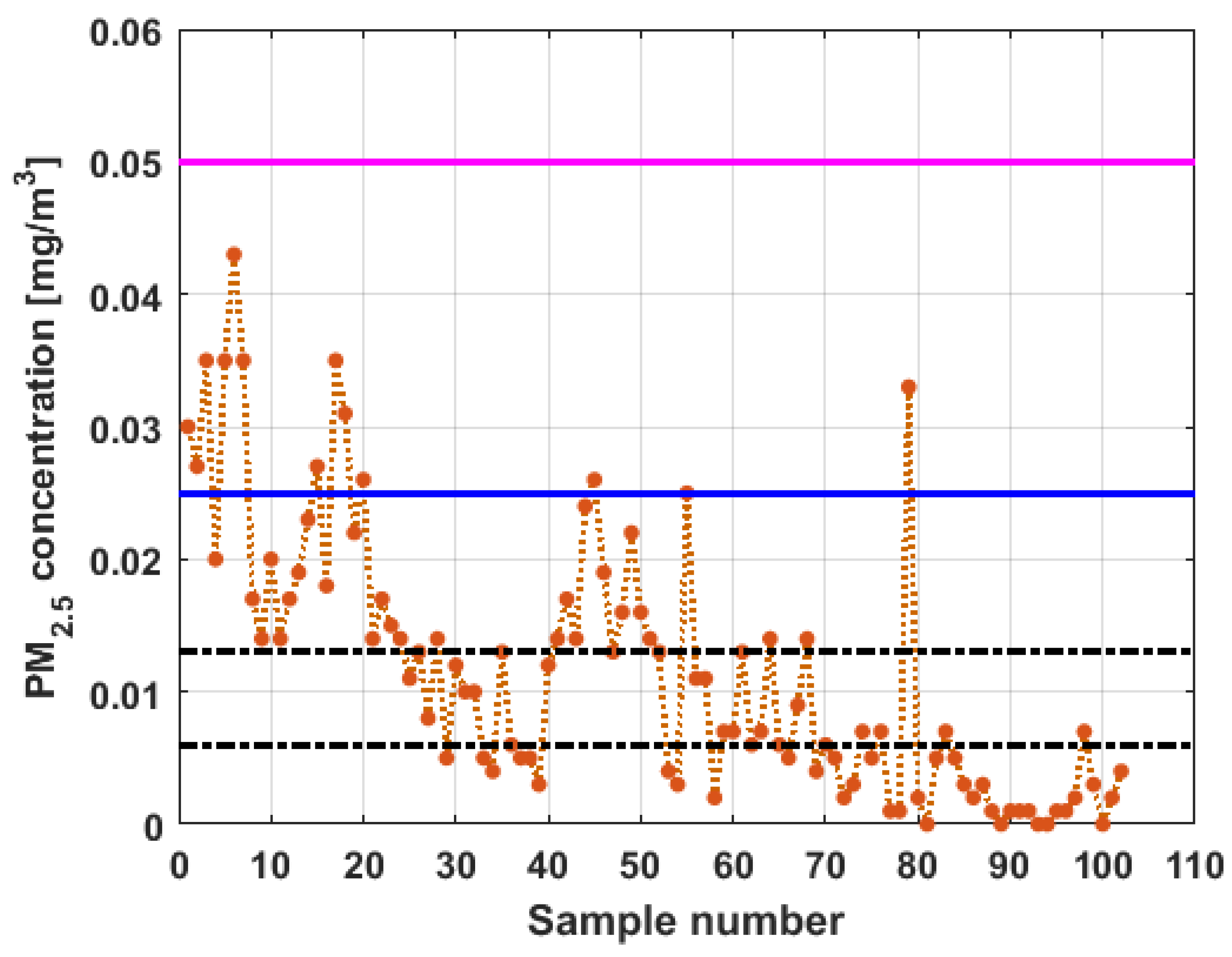
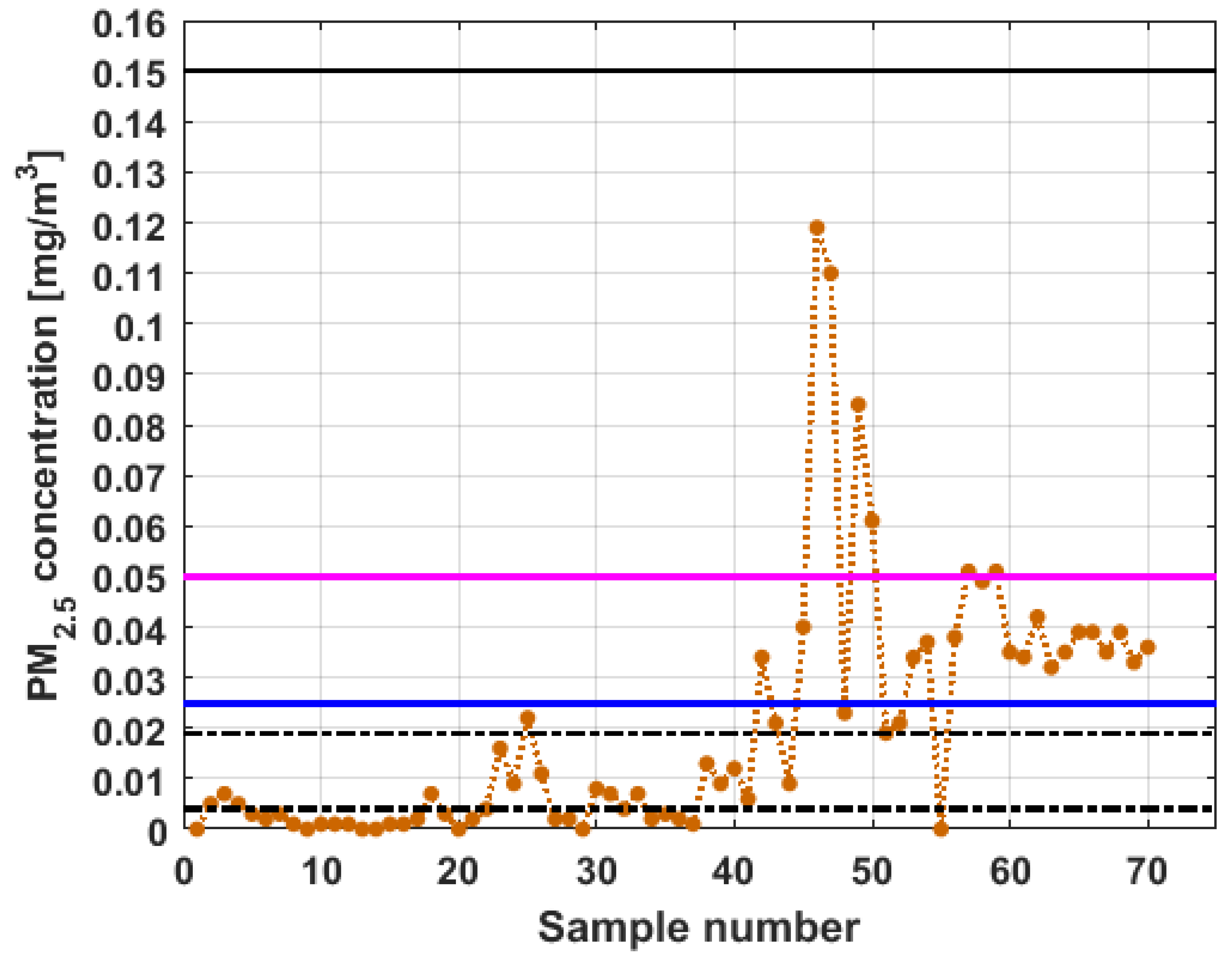
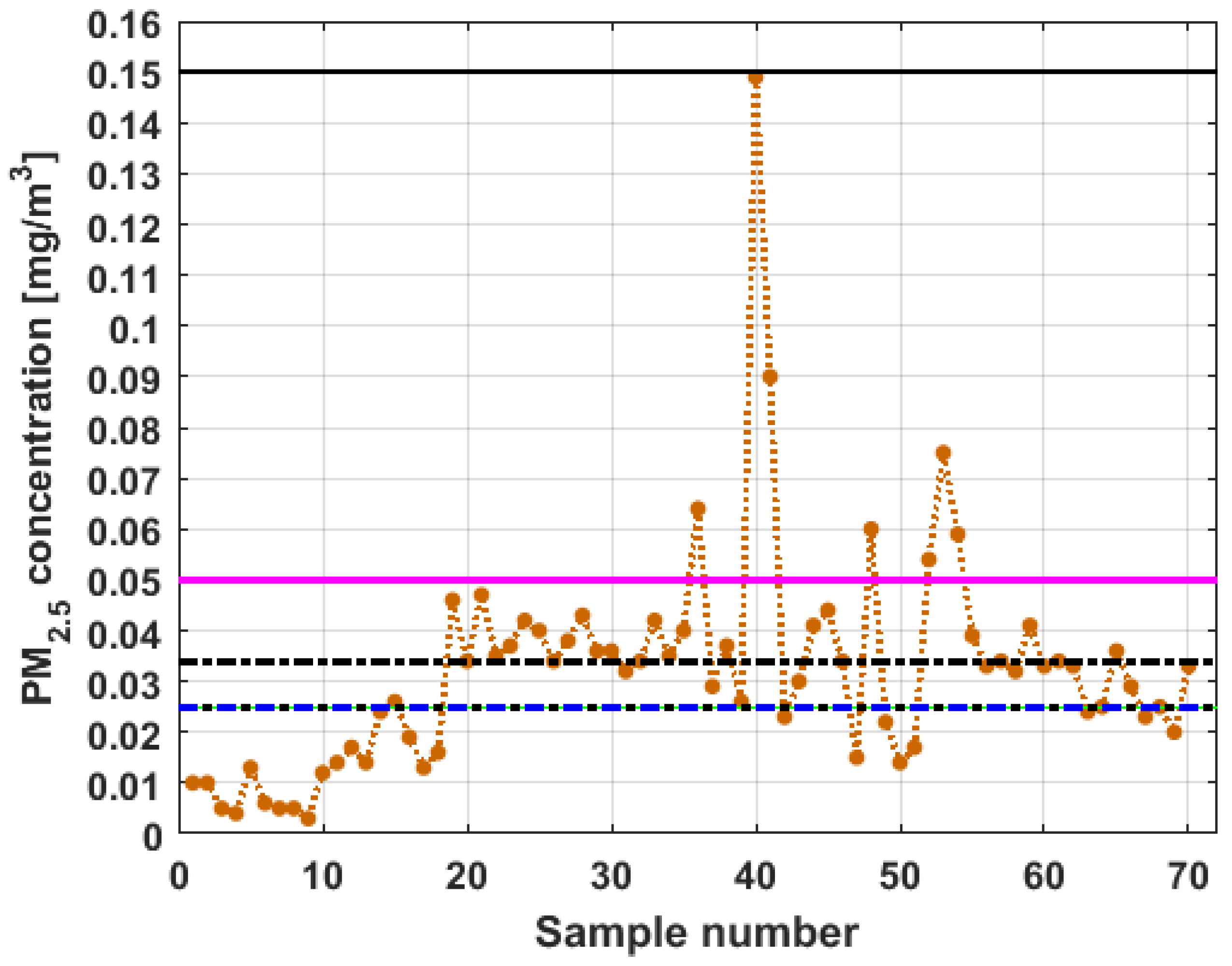
To perform the analysis, a graph of each of the datasets was first considered, where these were treated as if they were a time series (see
Figure 4). The order in which the data was collected is represented on the abscissa axis, while the value of the data is represented on the axis of the ordinates.
Figure 4 shows the collected data separated by the lines that are parallel to the park, which are represented by the letter
, and the lines that are perpendicular to the park, which are represented by the letter
(see
Figure 1 and
Figure 2). The results of the PM
2.5 measurements that are represented in this figure are the observations of the variables represented in
Figure 1, which have been explained in
Section 2.
From
Figure 4, it can be seen that the variable
, which is the one with the most data, and the variable
are the ones with the greatest fluctuations, while the variables
and
behave in a more linear way and with less variations, although the values of
are lower than those of
. The other two variables,
and
, apparently behave analogously to each other and different from the rest. Below, a statistical summary of the data is shown in
Table 1. This table includes measures of central tendency, variability, and shape.
When comparing the summary statistics presented in
Table 1 with those presented in [
6], it can be said that the difference between both studies is that in [
6], the skewness and kurtosis were not studied. However, in this article, it is important to study these third and fourth moments, because it is important to analyze whether the data comes from heavy-tailed distributions. According to [
40], heavy-tailed distributions are those probability distributions whose density tails are not bounded by the normal density tails.
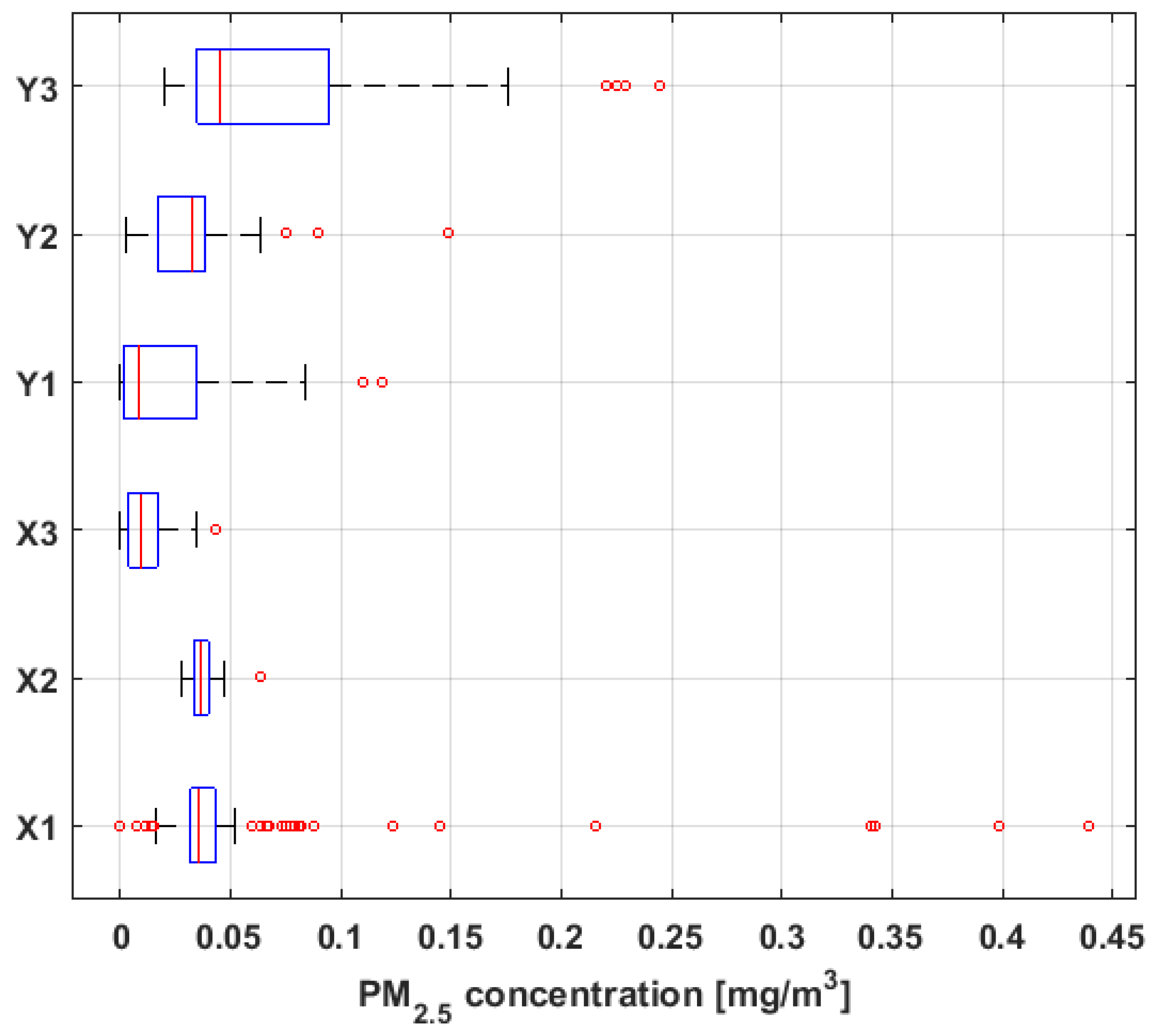
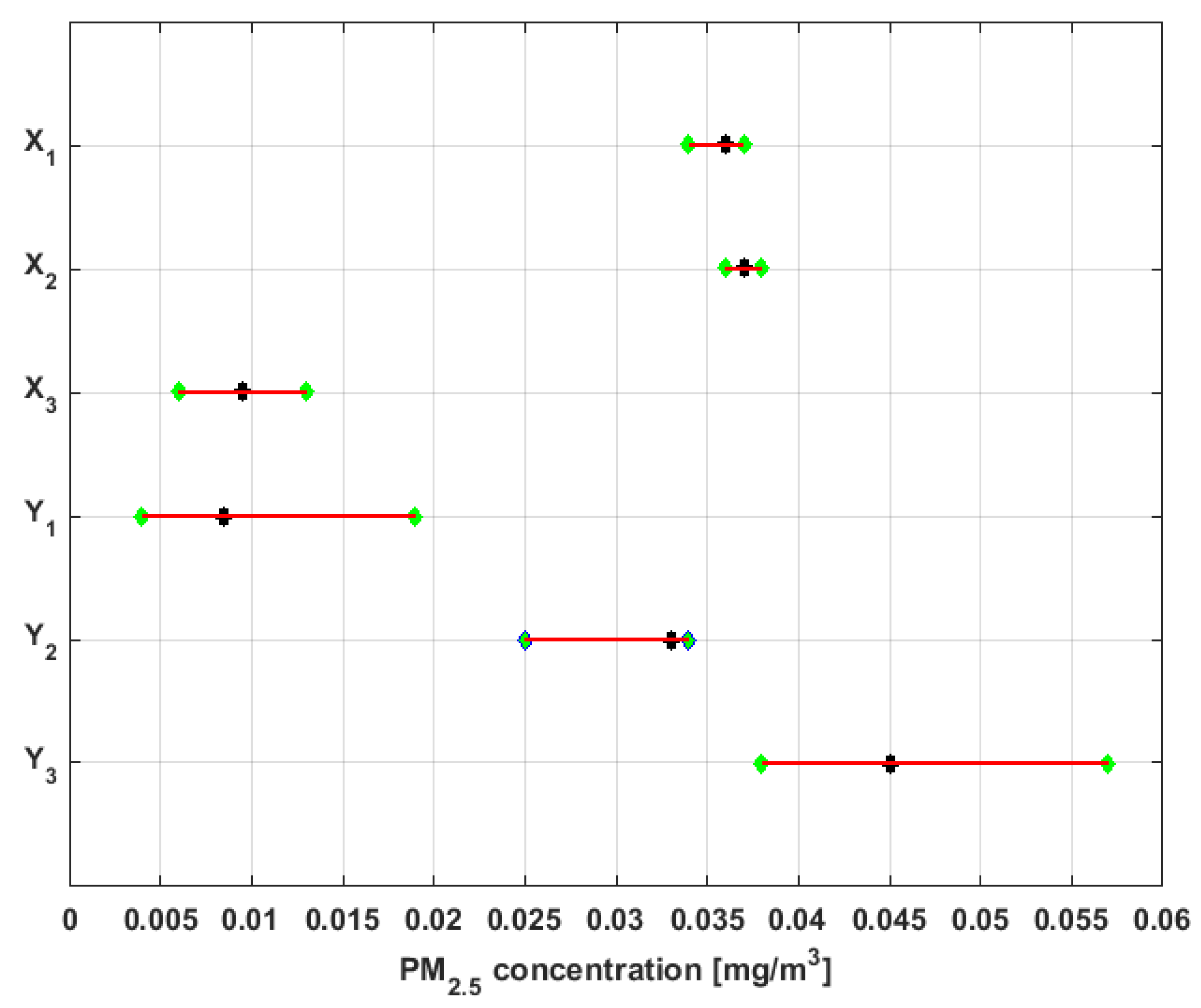
Figure 5 shows the multiple box-plot of data from each variable, and
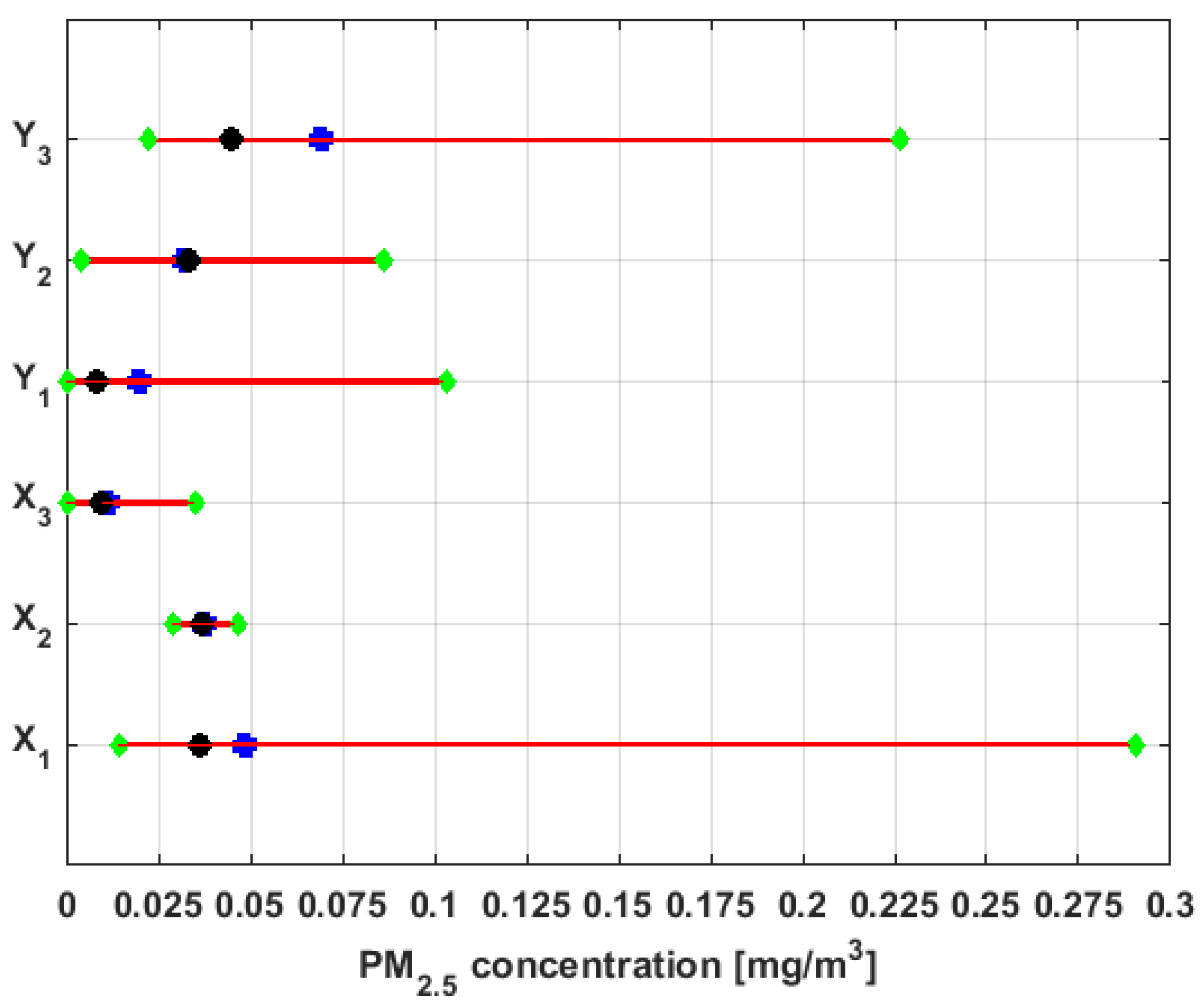
Figure 6 shows the empirical
confidence intervals for the median [
52], including both the mean and the median of the data.
Based on the previous figures, at first sight it is observed that the sizes of the six variables under study are different, with
having almost double the observations compared to each of the rest of the variables. In addition, it is observed that the means are higher than the medians in all cases, except for
. The aforementioned indicates the existence of extreme values on the right, which is corroborated by the multiple box-plot shown in
Figure 5.
In addition, the values of the standard deviation shown in
Table 1 confirm that the variability of
is similar to the variability of
, that the dispersion of the values of
and
is small, and that there is some similarity between the fluctuations of
and the fluctuations of
.
Moreover, it can be seen that all the variables present a great lack of normality due to the high skewness values. All the skewness values shown in
Table 1 are positive, so the distributions are lengthened to the right. The lack of normality is reaffirmed for most of the variables, since almost all the kurtosis values are much greater than 3, in particular the kurtosis values of
and
.
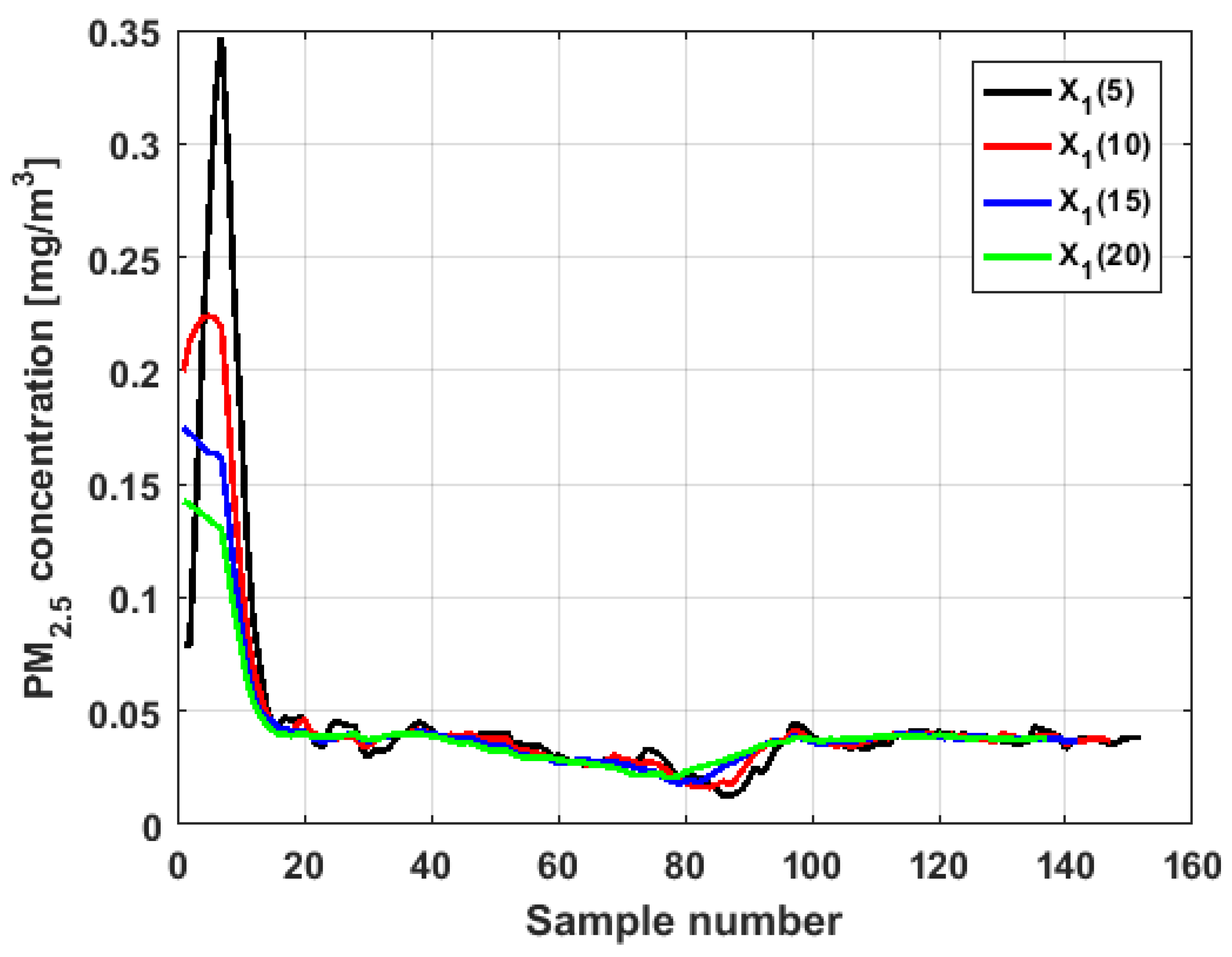
Next, in order to see the trends of the variables under study, the technique of moving average (MA) was used [
53]. The MA technique was used to soften the data of the time series, in order to reduce the influence that each individual data had.
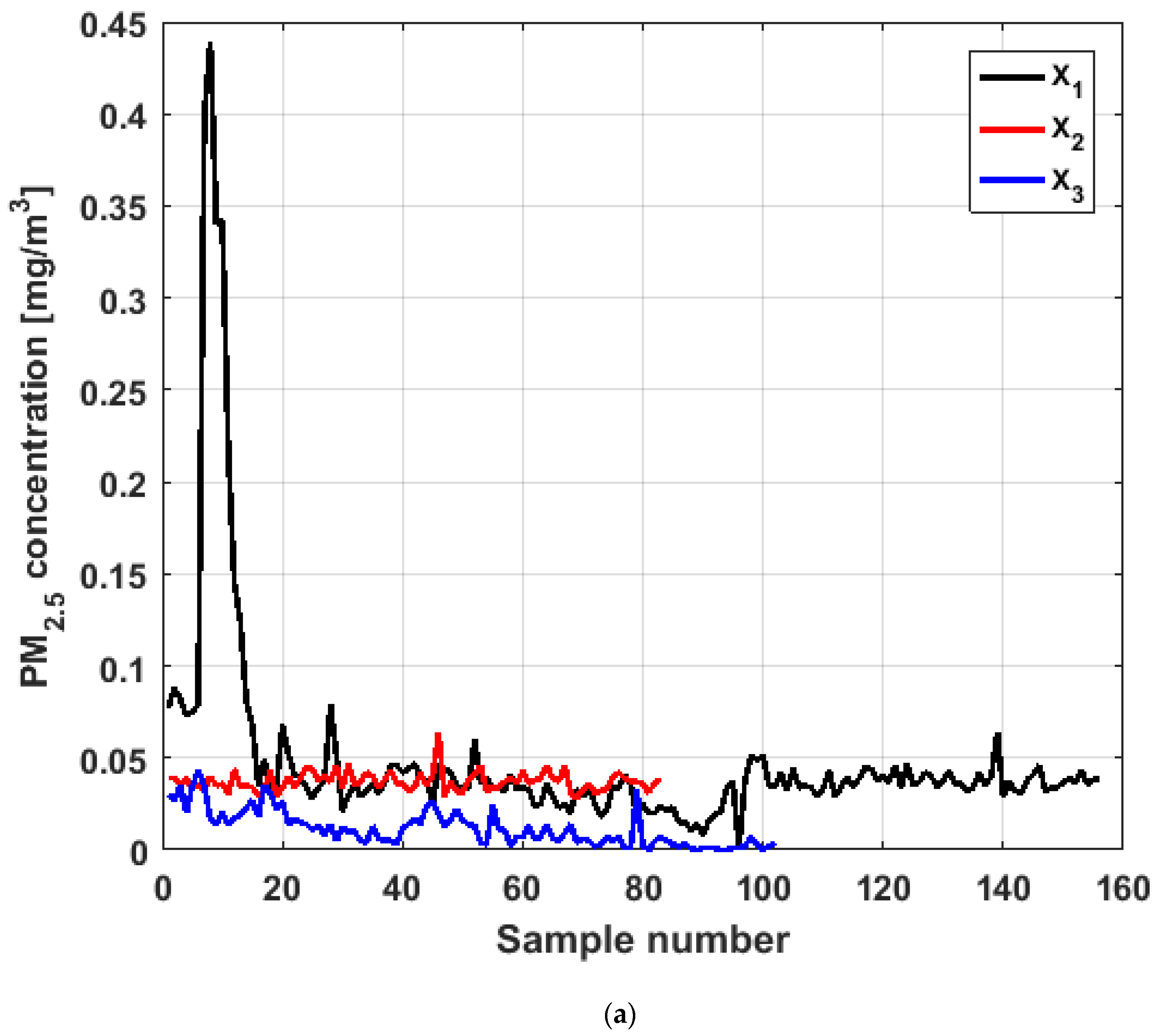
In this article, MA of size 5, 10, 15, and 20 were considered. However, after verifying that for each variable the MA technique behaved in the same way for each of the above-mentioned sizes, because the ends were maintained and the curves softened very little when the data were stable, it was decided to select the MA of size 10 to find representations analogous to those in
Figure 4.
Figure 7 shows the application of the MA of different sizes to the variable
, and the graphs of the application of the MA of size 10 to the six variables are shown in
Figure 8.
When analyzing
Figure 7 and
Figure 8, it can be said that the conclusions are the same as for
Figure 4. Specifically, the major fluctuations occur in the variables
and
, although these fluctuations occur by changing the trend. Moreover, the trend changes do not occur in specific moments, but rather in time intervals. The similarity between the variables
and
is repeated, where
has lower values. In addition, the similarity between
and
and its difference with the remaining variables are also repeated.
4.2. Nonparametric Inferential Statistical Analysis
In this part of the article, the first objective is to know if all the variables can be considered as samples that come from six continuous random variables with distribution functions , , , , , and , respectively. The location model for these samples can be established as that the six distribution functions are identical to the random variable , whose distribution function is , and that the six distribution functions are , , , , , and , respectively, in which (for ) is a location parameter, and will be assumed to be an order statistic.
If the six samples come from populations that have a common median, a statistical hypothesis test will be established and confidence intervals will be obtained, both bilateral, to compare whether the six variables have sufficiently different medians. In addition, it will be analyzed whether the cause of these differences between the medians can be attributed to chance, or to another cause [
54,
55,
56].
In this article, observations were carried out on different groups of variables, which will be considered to be independent of each other, because they are values that come from different places [
54].
Here, in accordance with [
54,
55,
56], it was considered the test where the null hypothesis was:
against the alternative hypothesis:
Taking into account that the variable is continuous, assuming that the null hypothesis is true and that the sample data are consistent with the median value, half of the observations will be less than , and the other half will be greater.
The test statistic will be , which represents the number of sample observations greater than the value, and although the order statistics with index , of a sample do not have the same distribution as the original variable and are not independent of each other, it does happen that the order statistics follow binomial distributions.
For the case under study, will be a binomial random variable of parameter , which is the number of observations, and have a probability of success equal to , . Therefore, the null hypothesis, , will be rejected if the test statistic, , takes values greater than a certain constant, , or takes values less than another constant, , where is the significance level.
If bilateral confidence intervals are chosen, these intervals will be of the form . By choosing those values so that the probability on the right is equal to the probability on the left, it can be shown that these values verify the following:
is the largest integer that verifies ,
is the smallest integer that verifies ,
The p-value of the statistical hypothesis test is equal to ,
where is the number of independent trials.
For the statistical hypothesis testing, where the null hypothesis was:
where
was the population median, and with a significance level
, the lower and upper rejection limits, and length of the confidence interval were found. In addition, the
p-value of the hypothesis test was found. In [
6], it was considered that a
p-value lower than
was statistically significant. In the present article, a
p-value lower than
was also considered statistically significant, due to the fact that the rejection limits were calculated at
. These results are shown in
Table 2. Also,
Figure 9 shows both the nonparametric confidence intervals for the medians of the variables, with a
confidence level [
54,
55,
56], and the medians of the variables.
In view of these results, it can be said that the median of is different from the median of any of the other variables, since the rejection limits include the rest of the medians. The same can be said of , because the rejection region of the hypothesis test for this variable includes the rest of the medians. In addition, the hypothesis that the medians of and can be the medians of the populations and is rejected, and the hypothesis that the medians of and are equal cannot be rejected. In addition, the hypothesis that the medians of the variables and are equal cannot be rejected.
The confidence intervals of smallest size are those corresponding to the variables and , which indicates that these two variables are the ones that have less variability. On the other hand, the confidence intervals of greatest size are those of the variables and . Therefore, it can be inferred that these variables have the greatest variability. Furthermore, the other two variables (i.e., and ) have intervals of an intermediate length with respect to the length of the other intervals. Therefore, the variability of these last two variables will also be intermediate with respect to the variability of the other variables.
In accordance with the above explanation and
Figure 9, the variables under study have been classified into four groups. One group consists of
, another group consists of
, a third group consists of
and
, and the last group consists of
and
.
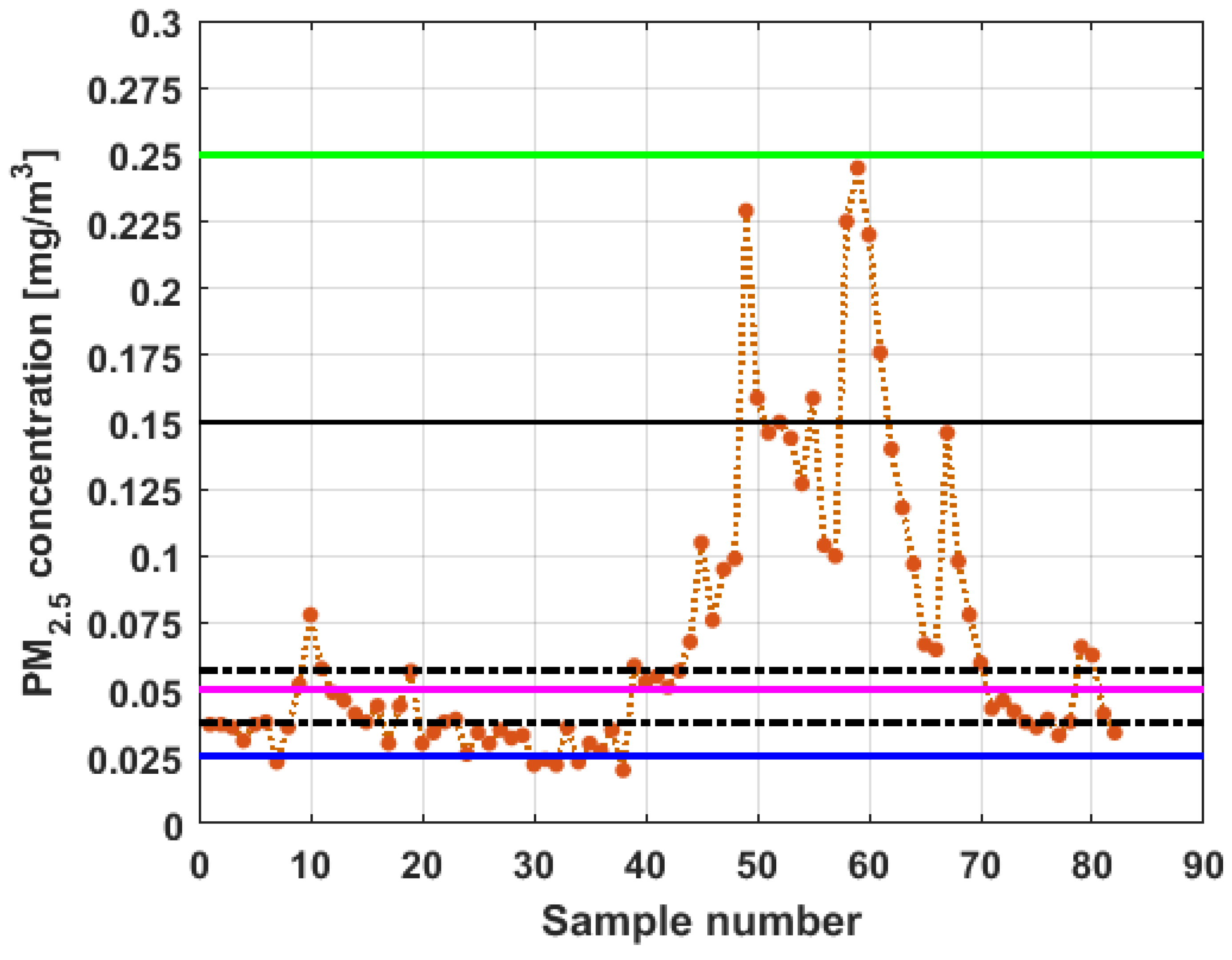
Next, the nonparametric hypothesis tests that were performed to test the category in which each of the six variables under study was located are going to be analyzed. In order to do this, the categories that are established by the Quito Air Quality Index (QAQI) for air pollution by PM
2.5 [
38] were taken into consideration.
In accordance with [
38], for an average concentration of PM
2.5 in 24 h, the air pollution categories are the following:
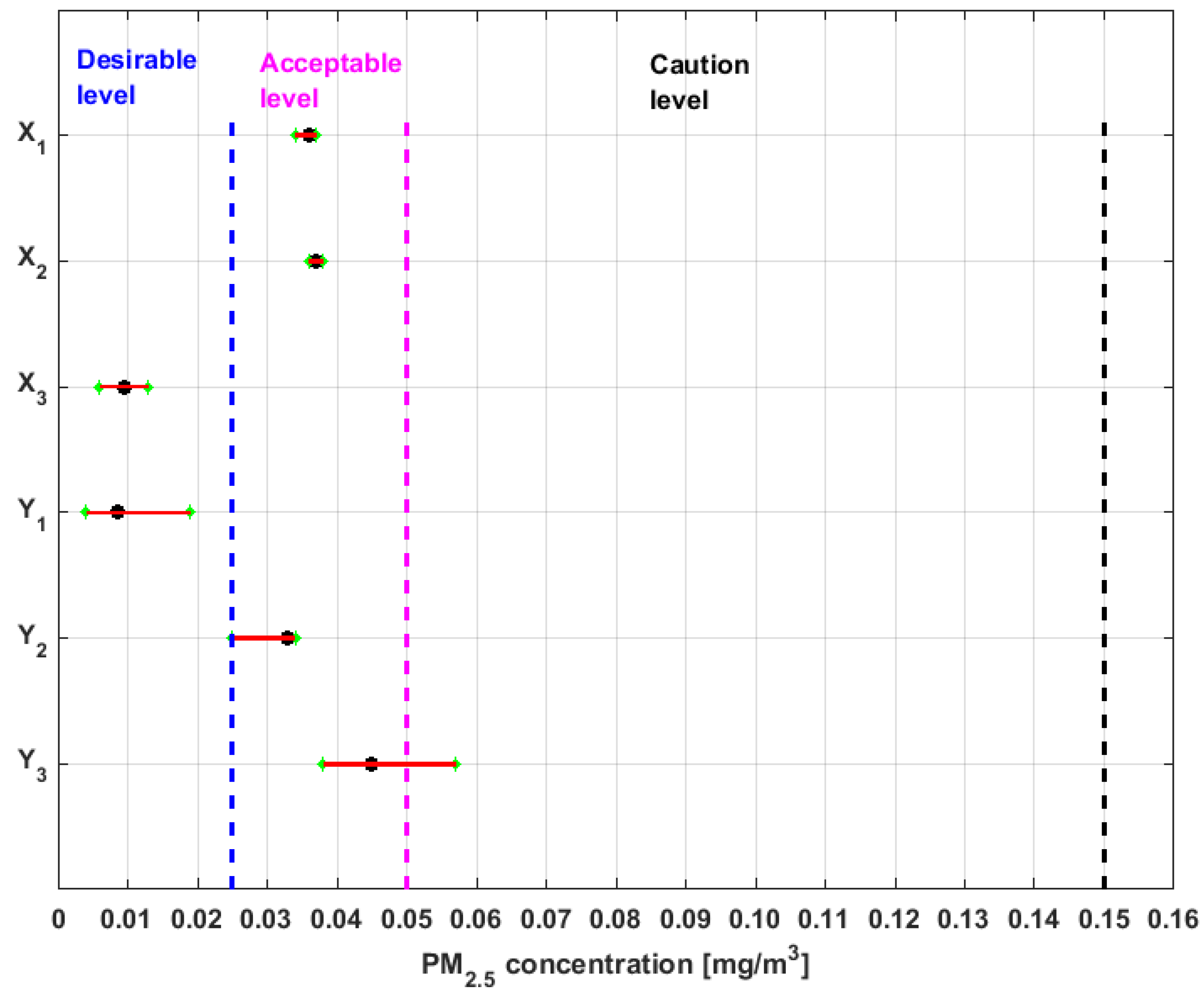
Interval for Desirable level of PM2.5 concentration: .
Interval for Acceptable level of PM2.5 concentration: .
Interval for Caution level of PM2.5 concentration: .
Interval for Alert level of PM2.5 concentration: .
Interval for Alarm level of PM2.5 concentration: .
Interval for Emergency level PM2.5 concentration: .
The medians,
confidence intervals for the medians, and bands that delimit the three lowest categories of air pollution by PM
2.5 concentration in which air quality in Quito is classified [
38] are shown in
Figure 10.
From
Figure 10, it can be seen that the nonparametric confidence intervals for the median of
and
are contained in the Desirable level. Therefore, the null hypothesis that the median of
and
are at the Desirable level cannot be rejected at a significance level of
. Moreover, it can be rejected the hypothesis that these medians belong to the other levels of air quality at the
confidence level.
Furthermore, the hypothesis that the medians of the variables , , and are at an Acceptable level cannot be rejected, and it is rejected the hypothesis that these medians can belong to the other levels.
In addition, the hypothesis that the median of variable can belong to the Acceptable level or Caution level cannot be rejected, but the hypothesis that this median belongs to the other four levels is rejected.
In addition, taking into account the moments of orders two, three, and four shown in
Table 1, although
has the same median as
, it does not come from the same distribution as
. Therefore, if
and
are considered to be elements of the same group, it can be said that the null hypothesis that the distributions of the five groups of variables are different from each other is rejected.
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16 show the observations of variables
,
,
,
,
, and
, respectively, together with the
nonparametric confidence interval for the median and the limits that define the categories of the above-mentioned levels of air pollution by PM
2.5 concentrations [
38].
From
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16, it can be said that the only variable that at any time exceeds all the air quality limits is
. In addition, this variable has many observations outside its nonparametric confidence band for the median, which is also a common characteristic that all the variables under study have. In addition, in terms of exceeding the air quality limits, there is the variable
, which almost reaches the Alarm level, and indicates a significant variability.
With respect to , it can be said that this variable practically does not exceed the Acceptable level. Furthermore, it can be said that sometimes exceeds the Desirable level; however, most observations of remain below the Desirable level.
Finally, it can be said that exceeds the Acceptable level with few observations, and many of its observations are at the Desirable level, while a large part of the observations of are above the Desirable level, and some exceed the Acceptable level, being below Caution level.
Before finishing this subsection, the six variables under study are going to be divided into two different groups, one consisting of the variables and the other consisting of the variables. In addition, it will be said that the variables are parallel to the park and some of them cross it in this way, while the variables are perpendicular to the park and some of them cross it in this way.
Therefore, it is going to be analyzed whether the air pollution by PM
2.5 is more harmful for citizens when the park is crossed longitudinally or when it is crossed transversely. To this end, the Wilcoxon rank-sum test adapted to compare the above-mentioned two groups against a one-sided alternative is going to be used [
54].
For this case, the null hypothesis is:
and the alternative hypothesis is:
Table 3 shows the count data—that is, the number of observations that respond in a certain manner to air pollution by PM
2.5 concentrations. This table shows the multivariate frequency distribution of the variables.
For the case under study, the Wilcoxon rank-sum test statistic [
54] for the
sample is
, the expected value is
, and the variance is
. Therefore, the approximate
p-value, using the normal approximation to the distribution of
with continuity correction [
54], is 0.4066. As a result, the null hypothesis that air pollution due to group
is equal to air pollution due to group
cannot be rejected at a significance level of
. Statistically speaking, the air pollution due to group
is equal to the air pollution due to group
.
The difference between the nonparametric statistical tools used in [
26,
27,
28] and the analysis performed in this subsection, is that in [
26,
27,
28], the study focused on obtaining only estimates of the median of the analyzed data. To carry out the study that was presented in [
26,
27,
28], the Kruskal–Wallis test and the Wilcoxon-signed rank test were used. However, in this subsection, a nonparametric statistical analysis procedure that was focused on obtaining measures to estimate the central tendency of the data and their dispersion was developed. The nonparametric statistical analysis procedure developed in this article not only estimates the median of the data, but also analyzes the variability of the data, and uses all this information to classify the variables under study according to established categories of air pollution levels [
38].
4.3. Robust Analysis of Location Parameters
A parameter, , is called the location parameter for the random variable if the density function can be written as a function of . Therefore, the random variable does not depend on . The location parameters usually indicate a value around which the bulk of the observations are grouped.
In this subsection,
was a sample and, in order to establish the estimators that were used, the sample order statistics [
56] were considered:
. In addition, in order to find estimates where the distribution symmetry center can be found, some
L-location estimators that are linear combinations of order statistics were considered. In short, the
-trimmed family [
39,
40] with
given by Equation (1) was used. Moreover, other location estimators that will be considered are the mean and the median:
where
denotes the integer part. In addition, the trimean [
39,
41] was used, which is given by Equation (2):
where
is the
i-th quartile.
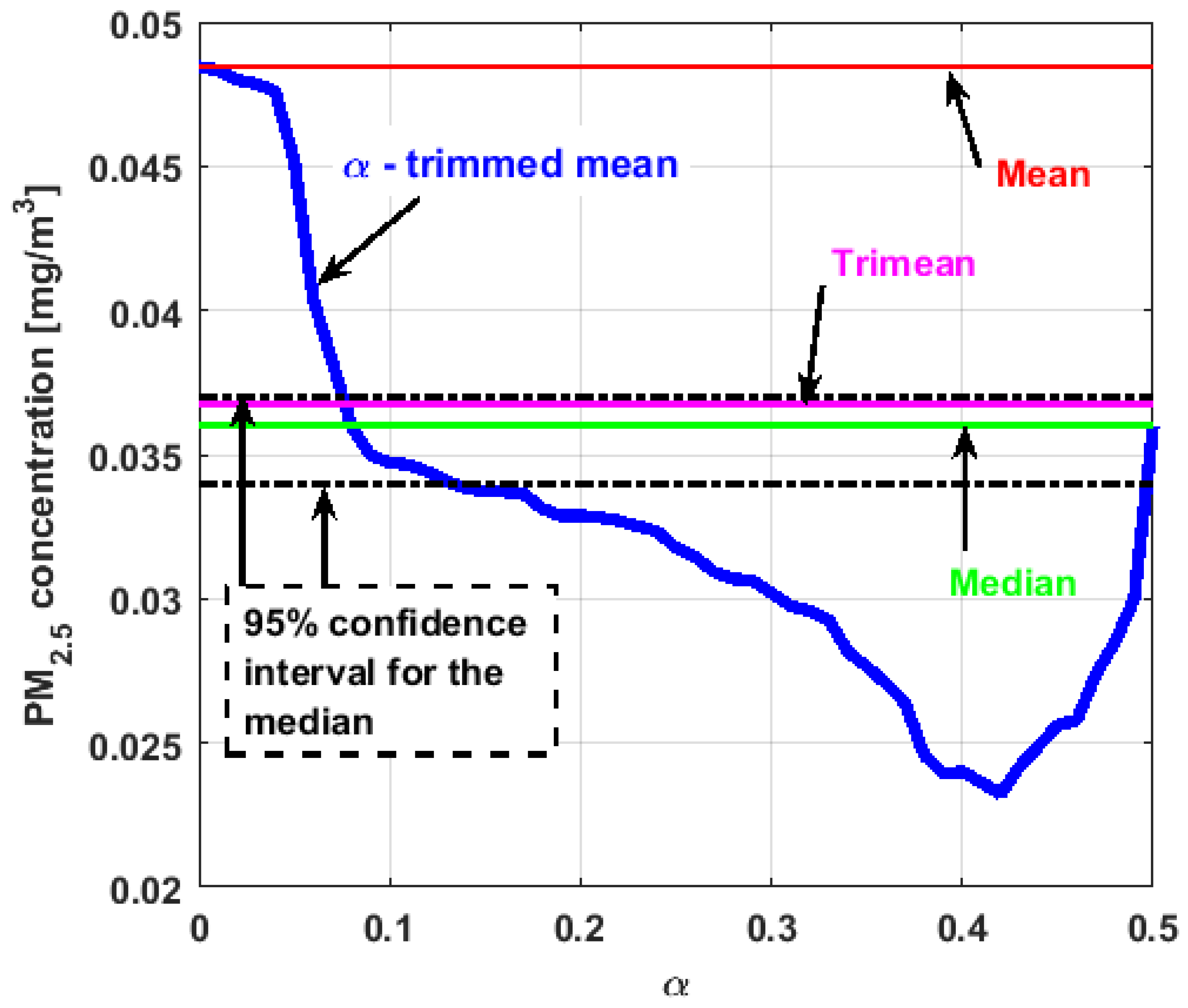
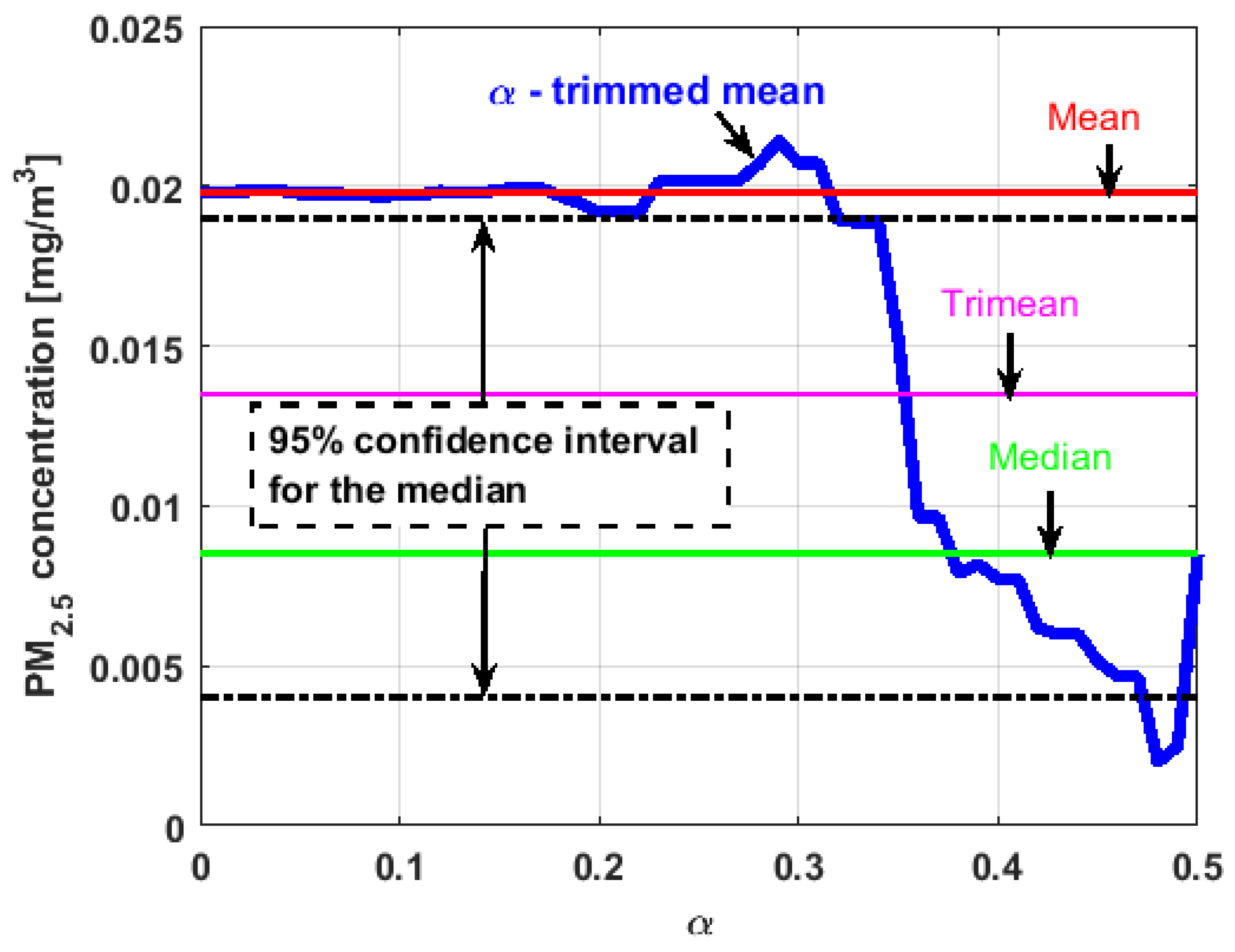
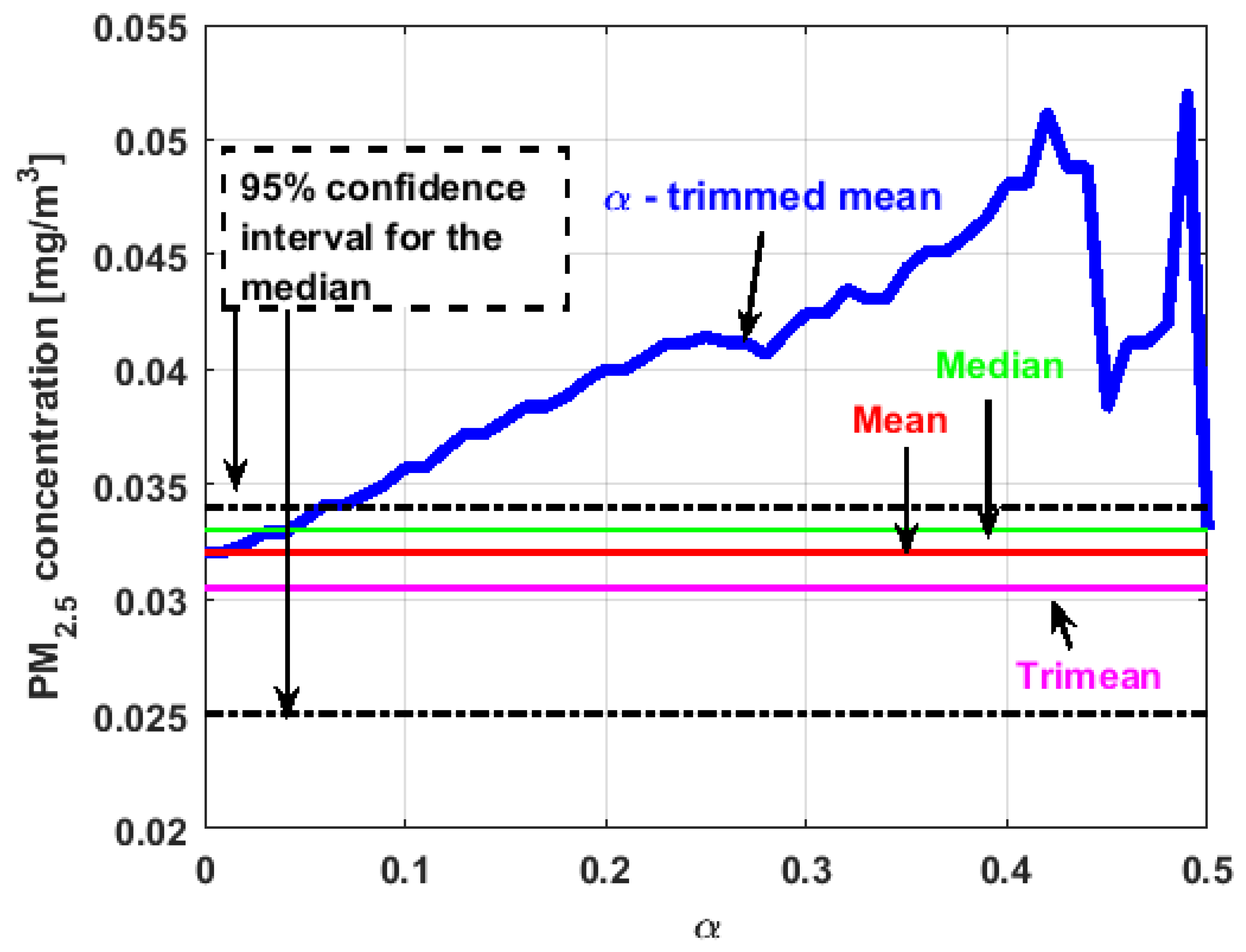
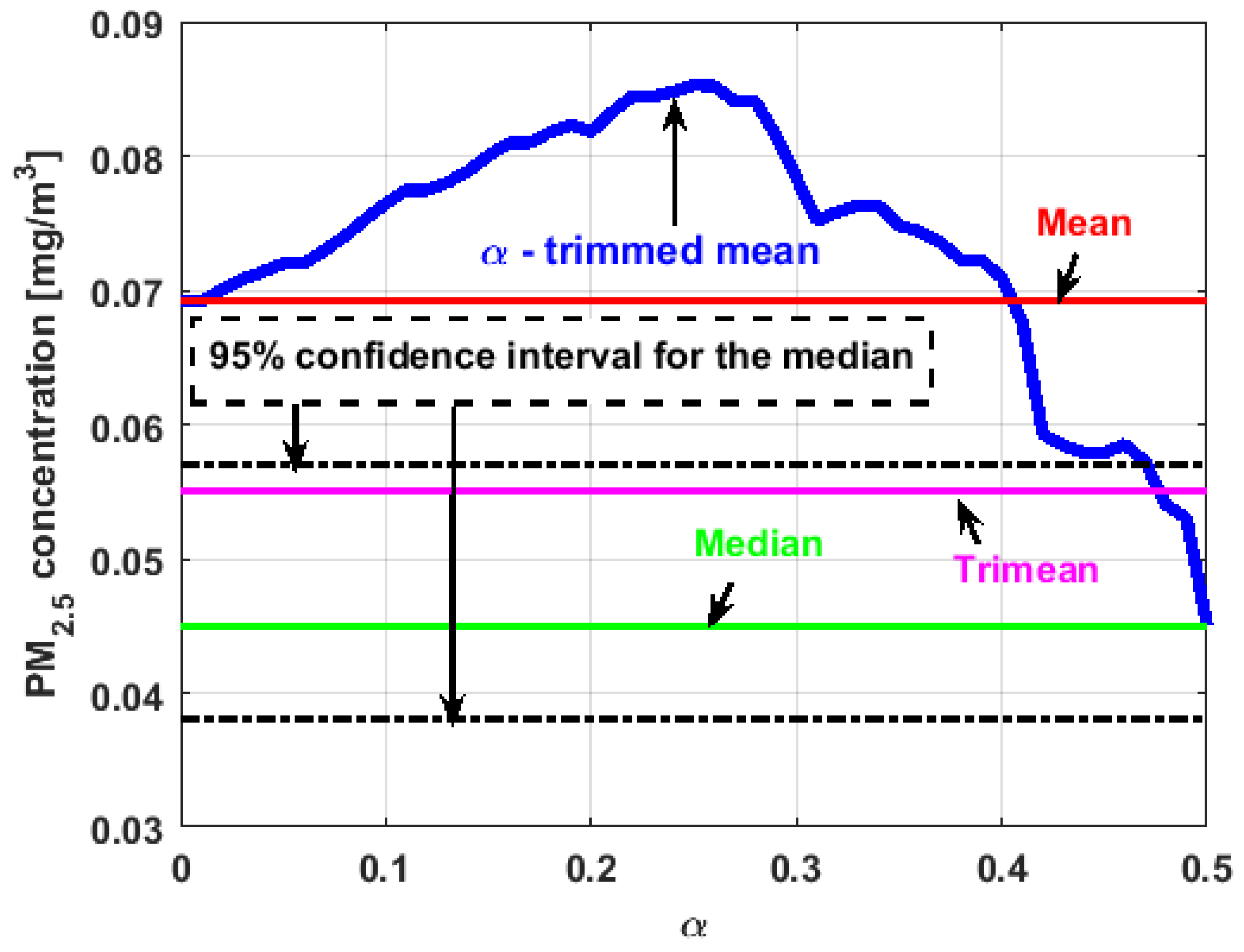
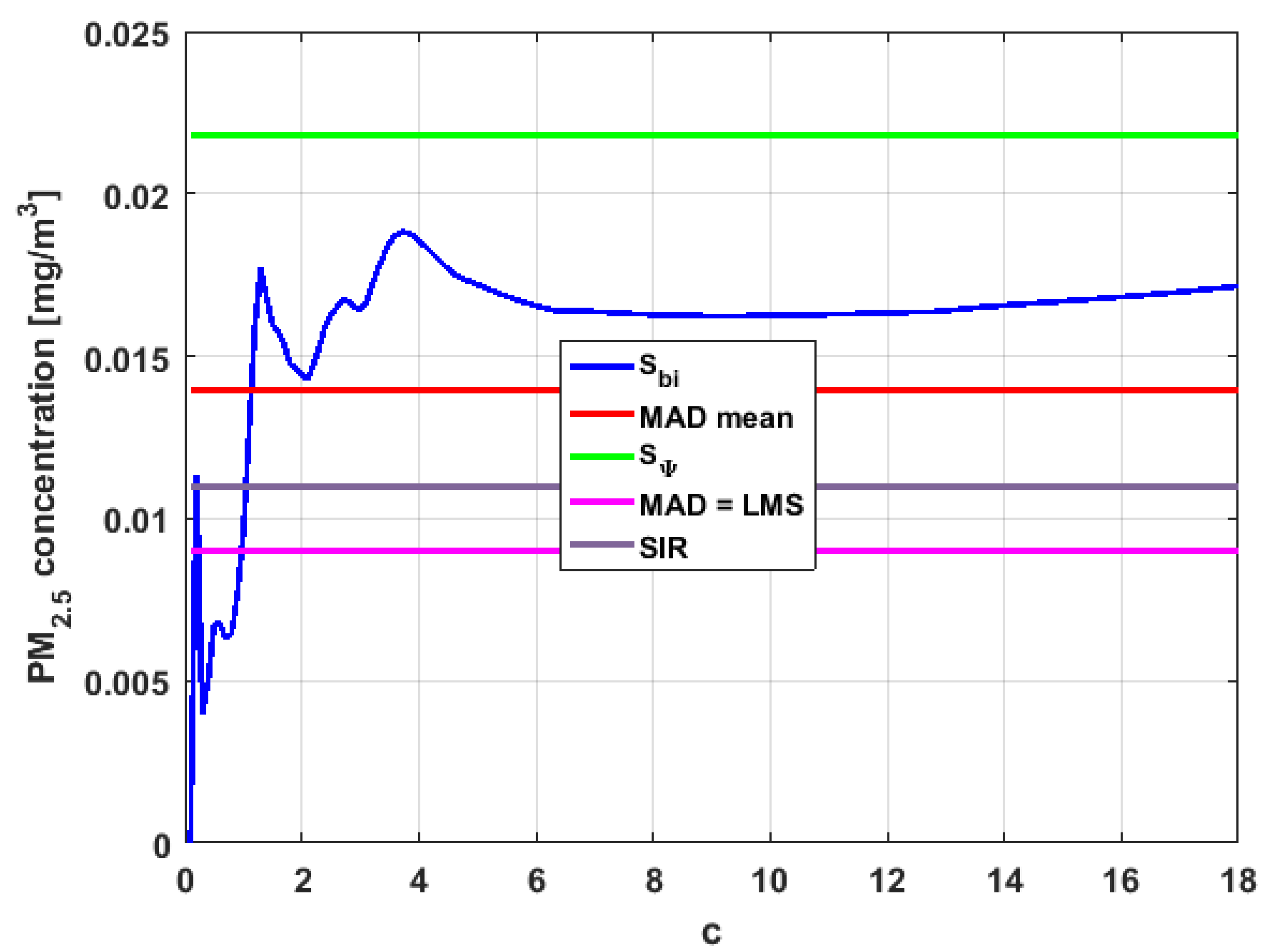
In the graphs shown in
Figure 17,
Figure 18,
Figure 19,
Figure 20,
Figure 21 and
Figure 22, the values of the
-trimmed mean function with low abscissa correspond to the extreme data of the distribution of values of the variable under study, and the values of the
-trimmed mean function with high abscissa correspond to the data close to the center of the distribution.
From
Figure 17,
Figure 18,
Figure 19,
Figure 20,
Figure 21 and
Figure 22, it can be concluded that all the medians and trimeans are within the confidence band. Furthermore, the means of
,
, and
are within the confidence band. All this indicates stability of these variables. In contrast, the means of
and
are well above the upper limit of the confidence band, which suggests the greater variability of these variables.
In addition, the most influential observations for the value of the mean of are those with the highest pollution values, since the -trimmed mean function in abscissa low values is decreasing, and by the center of the distribution, the values fall outside the confidence band. This shows again the great variability of , which has already been observed through other previous arguments.
In addition, is the variable that has the most regular behavior of the location measurements. The observations that most influence the value of the median are the lowest, as the function for low abscissa values is increasing. Values near the center have many fluctuations, but are much smaller than those observed in .
Moreover,
has many observations with very low values, which leads to the fact that the values of the
-trimmed mean function are far from the lower limit of the confidence band. Similar to
, the function values close to the center of the distribution data suffer from fluctuations, and these fluctuations are similar to those of
and lower than the fluctuations of the rest of the variables. The difference between
and
is that the air pollution values of
, for the most part, are higher than those of
. This fact and the high variability of
were already anticipated in
Figure 4a.
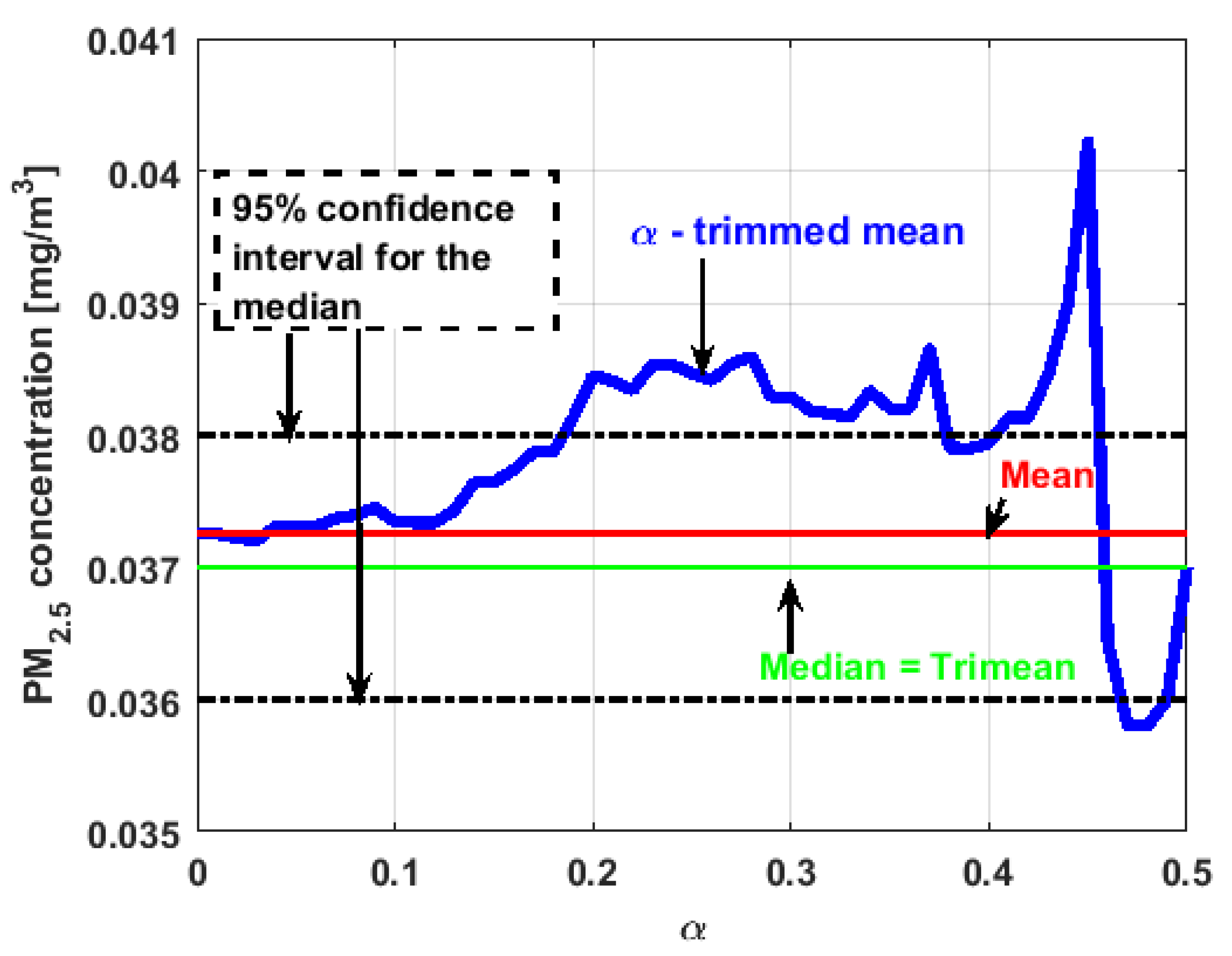
When evaluating the -trimmed mean function in , it is observed that in the central values of the function, it occurs the same as in the variables already analyzed. Specifically, it seems that the most decisive observations for the value of the median are grouped near it. At the extremes, it behaves symmetrically, but through the center of the data, there is a lower level of pollution. All this again suggests high variability.
In addition, has many observations with low values. Thus, the values of the -trimmed mean function are far from the lower limit of the confidence band. When suppressing extreme values, the function evaluated in low abscissa is increasing, remarking the presence of many observations of values well below the median. It is the only variable in which the median is greater than the mean.
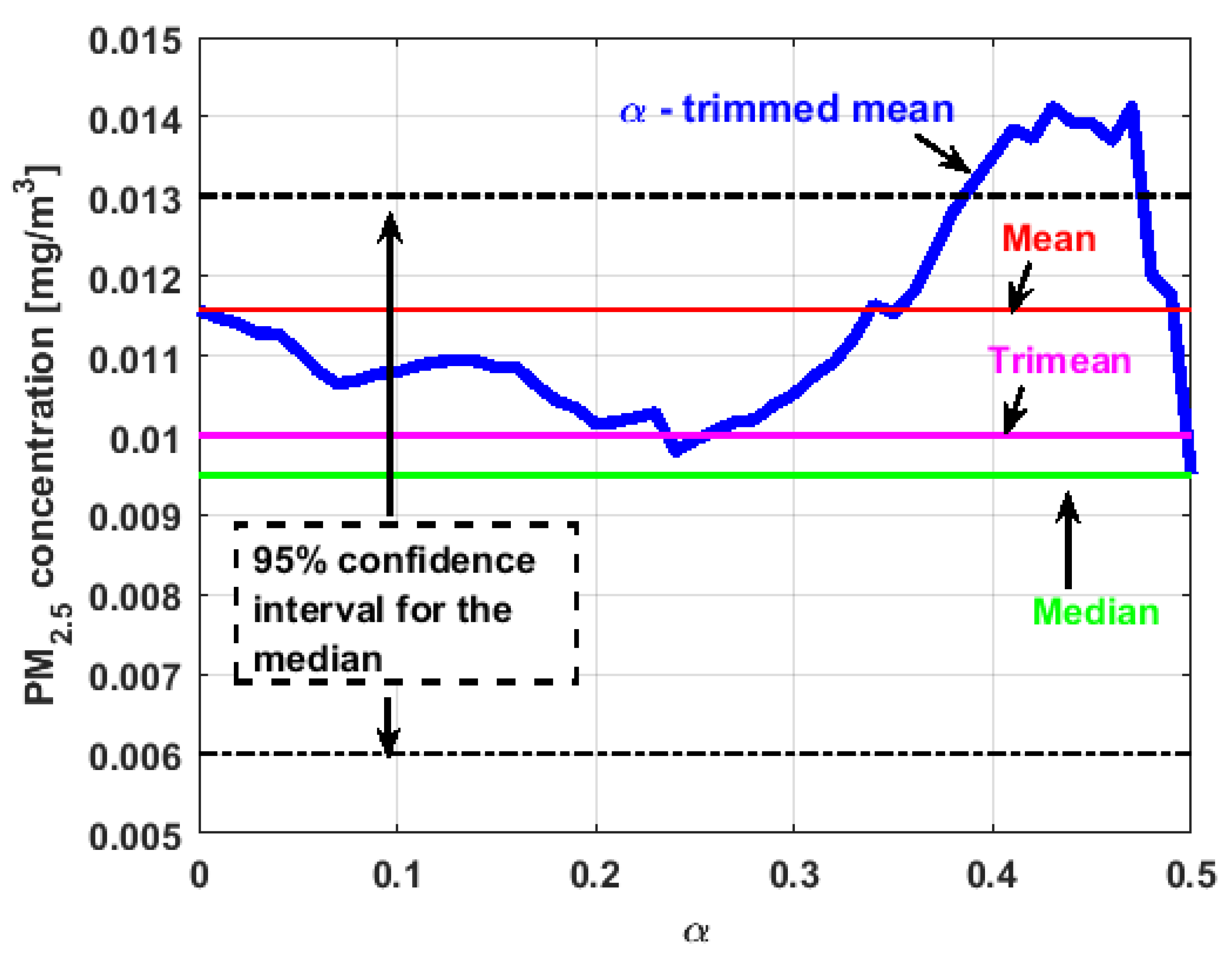
Furthermore,
is the variable for which the
-trimmed mean function has the highest range. The initial growth indicates a suppression of low values, which is corroborated by the fact that the function moves away from the lower limit of the confidence band. When for obtaining the
-trimmed mean function, it started to delete values greater than
of the extreme data, and this function decreased. This suggests that the central values of the distribution are greater than the median. What has been said here can also be seen in
Figure 4b.
In [
4], in order to achieve robust linear regression, the
M-estimation method was used to reduce the influence of outliers in least squares fitting. According to [
4], the
M-estimation method was given in the form of a weight function of residuals, and its performance was satisfactory provided that the distribution of the response was normal and had no outliers. For the case under study in [
4], the best model was the robust linear regression using the Talwar
M-estimator.
However, in this research article,
L-location estimators were used to estimate the central tendency of the data in a robust manner. Here, it was not assumed that the data fits a normal distribution. In fact, the skewness and kurtosis values shown in
Table 1 show that the data do not fit a normal distribution. In addition, the box plots shown in
Figure 5 show that some variables have many outliers. What have been explained above is a characteristic of heavy-tail distributions [
40]. This situation justified the need to use robust estimators in this article.
Despite the fact that the research objectives in [
4] and in this article were different, the use of
M-estimators and
L-location estimators gave satisfactory results. In addition, these results demonstrate that these estimators can be applied in cases where it is required to robustly estimate the concentration of PM
2.5 and the sample size is small, as is the case study in this article.
4.4. Robust Analysis of Scale Parameters
Taking into account the obtained results, it was necessary to find an estimate of the dispersion of the variables under study. Although and could be left out of this analysis, because they do not have enough extreme observations, the estimation of the dispersion of all the variables was carried out.
The measure that is commonly used to describe the variability of a sample of size
of a random variable,
, is the sample standard deviation, given by Equation (3):
satisfies both the
shift invariance condition,
, and the
scale equivariance condition,
. According to [
40], any statistic satisfying these two conditions is a
dispersion estimate. The scale estimators used in this subsection were the following [
39]:
The family of scale estimators
is based on an
M-estimator and, according to [
42], the scale measurement performed with this estimator has greater efficiency than conventional scale measurements in a wide type of distributions.
Taking into account that approximately the expected value of the MAD statistic is , where is the standard deviation of the population, if in Equation (8) it is chosen that , then in order to find the desired estimate, the observations that are at a distance of MAD in more than will not be considered. So, if , then only those observations whose distance from MAD is less than times the standard deviation will be considered. As increases, the values of decrease in absolute value, and the value of the denominator of increases. Therefore, this function decreases.
- 6.
Estimators based on a subrange [
57]:
where
,
is the length of the dataset that we want to estimate its spread,
are order statistics [
56],
denotes the integer part, and
is the inverse of standard normal cumulative distribution function, evaluated at the probability values in
.
As grows, the subtractions between the order statistics shown in Equation (9) are carried out between order statistics that are increasingly separated from each other. Therefore, the observations that are more toward the center of the dataset will be located close to the minimum of the subtractions between the order statistics mentioned above, and also the value of the denominator of Equation (9) will increase. Due to this, the function has less influence from extreme observations as grows.
In accordance with [
57], for
the least median squares (LMS) estimator is obtained. In this paper, the LMS estimator given by Equation (10) was used:
This estimator has an expression that is analogous to
, except only for the quotient [
57].
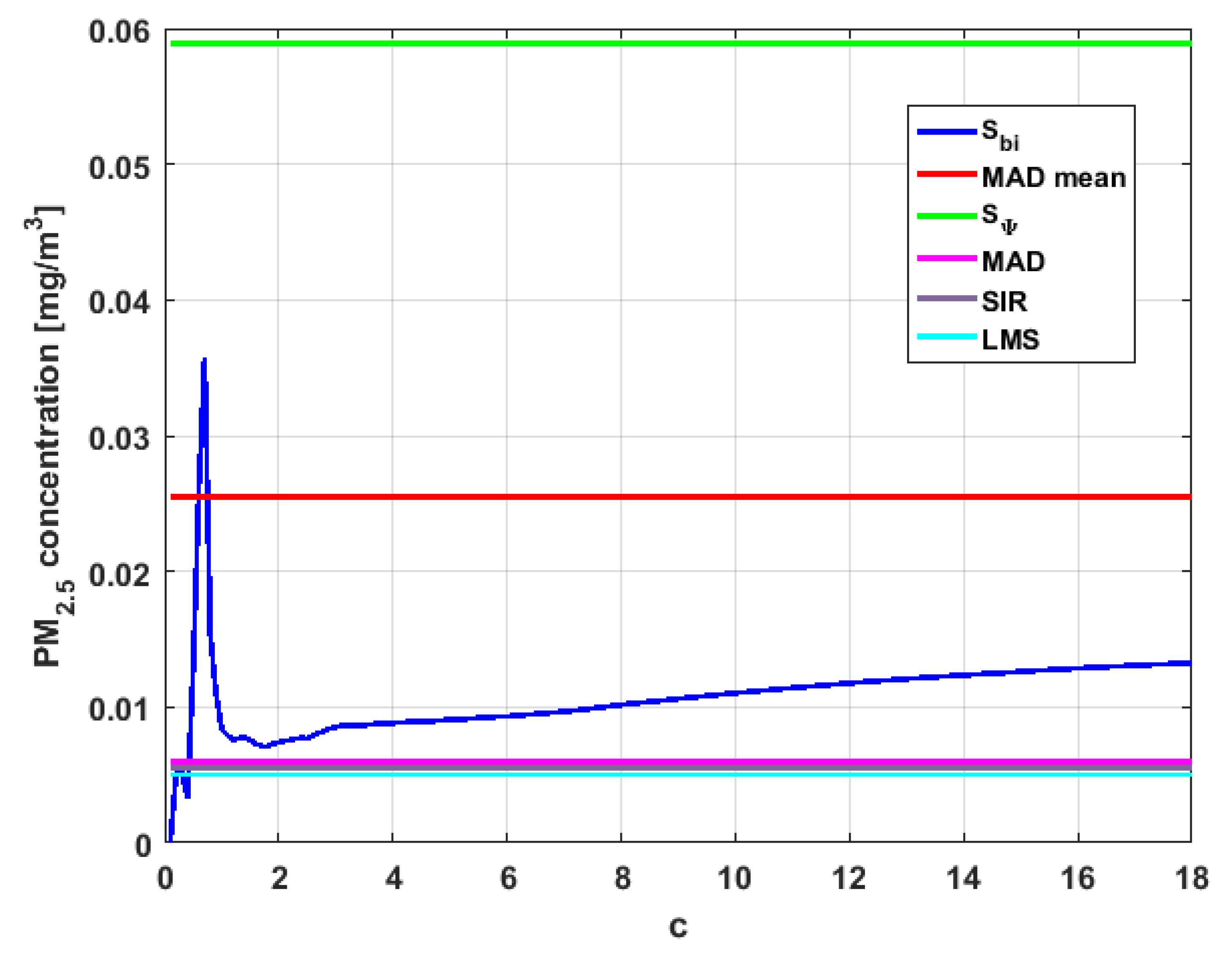
Table 4 shows the value of the statistics obtained for each variable.
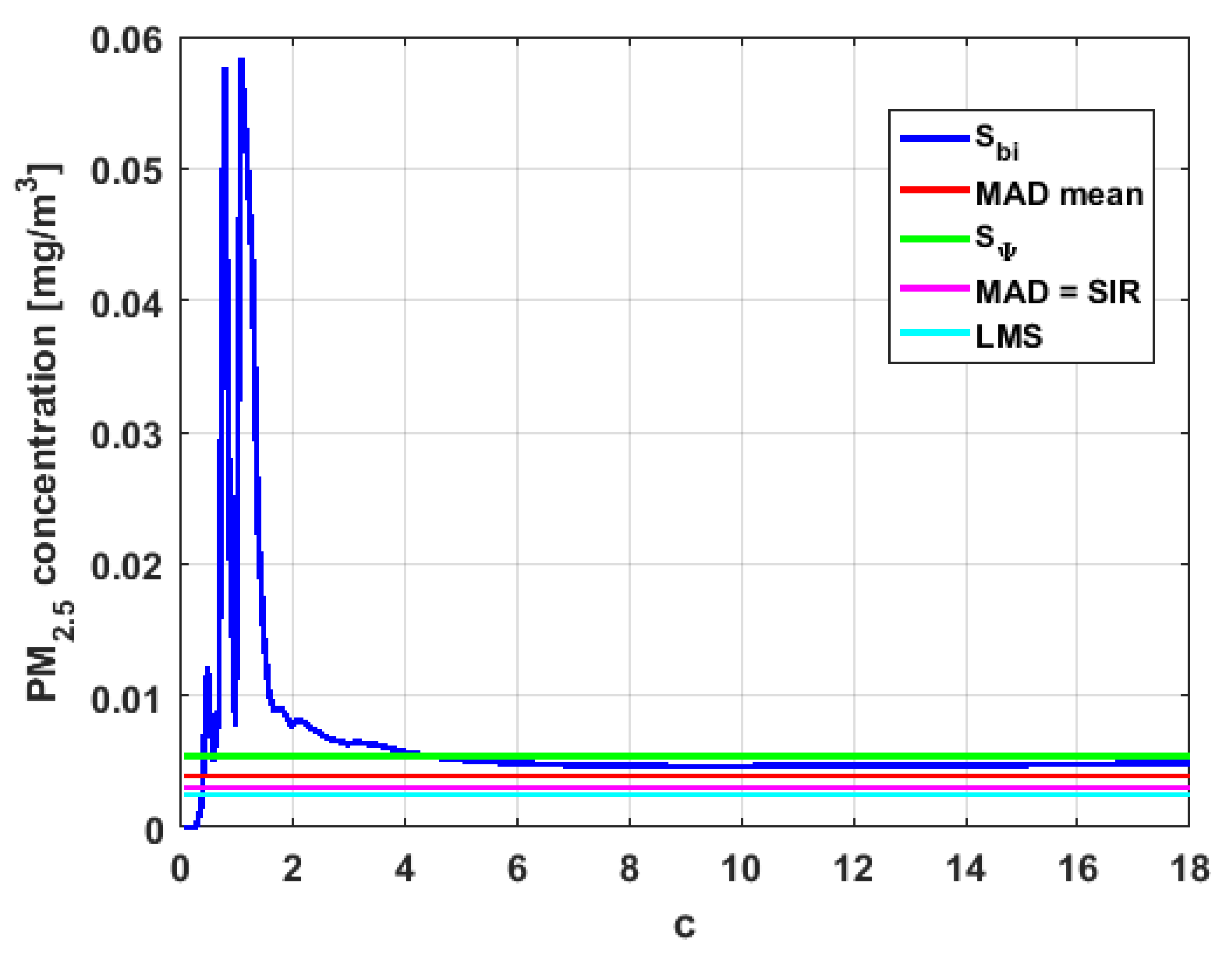
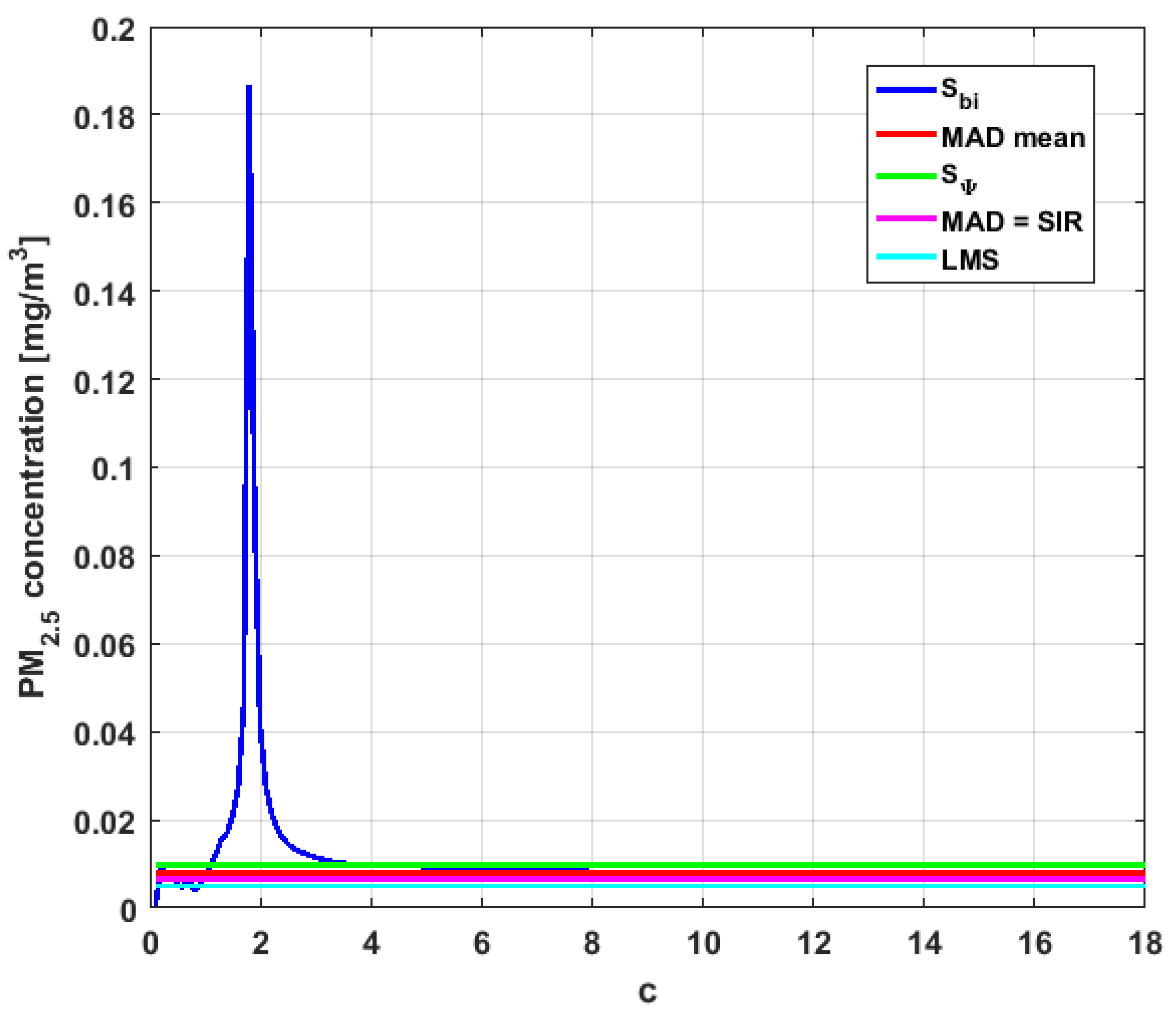
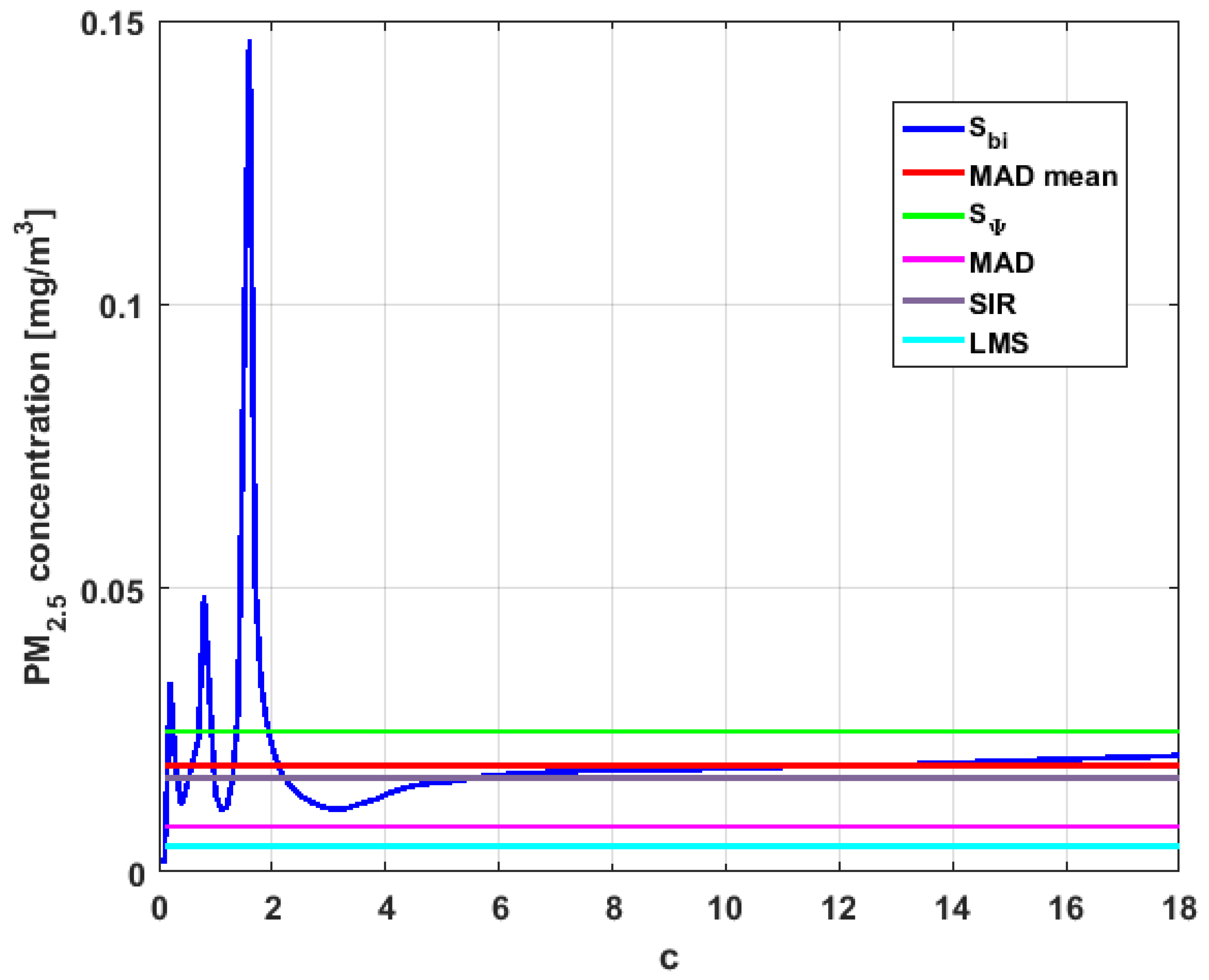
Figure 23,
Figure 24,
Figure 25,
Figure 26,
Figure 27 and
Figure 28 show estimates of the estimator
for all variables,
.
Figure 29,
Figure 30,
Figure 31,
Figure 32,
Figure 33 and
Figure 34 show estimates of the estimator
for all variables,
.
Taking into consideration what is shown in the graphs of
Figure 23,
Figure 24,
Figure 25,
Figure 26,
Figure 27,
Figure 28,
Figure 29,
Figure 30,
Figure 31,
Figure 32,
Figure 33 and
Figure 34 and in
Table 4, it can be said that for each variable, the estimate
is greater than the estimate
, and in turn,
is greater than the other three estimates, noting that the estimates
,
, and
are more robust than the first two.
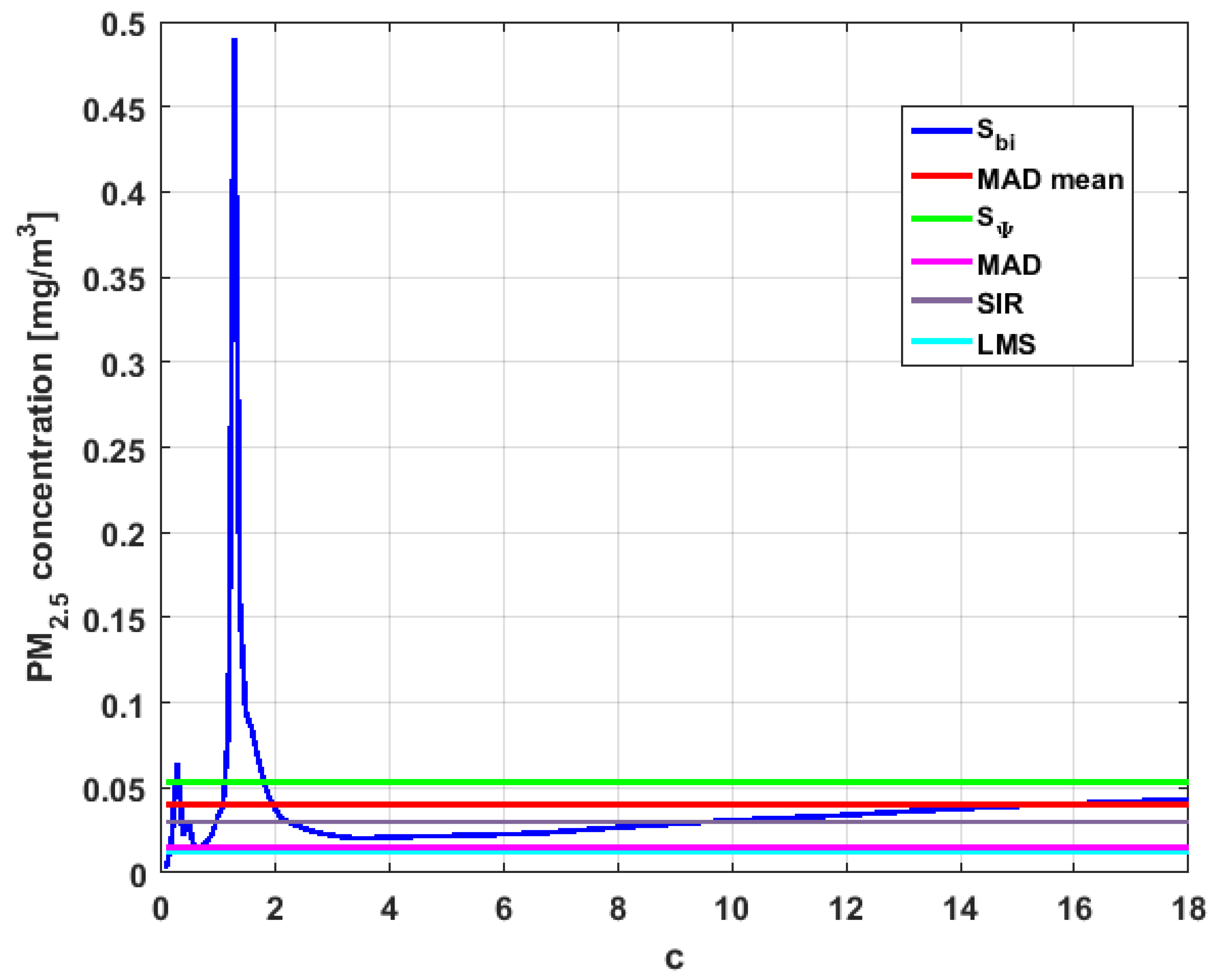
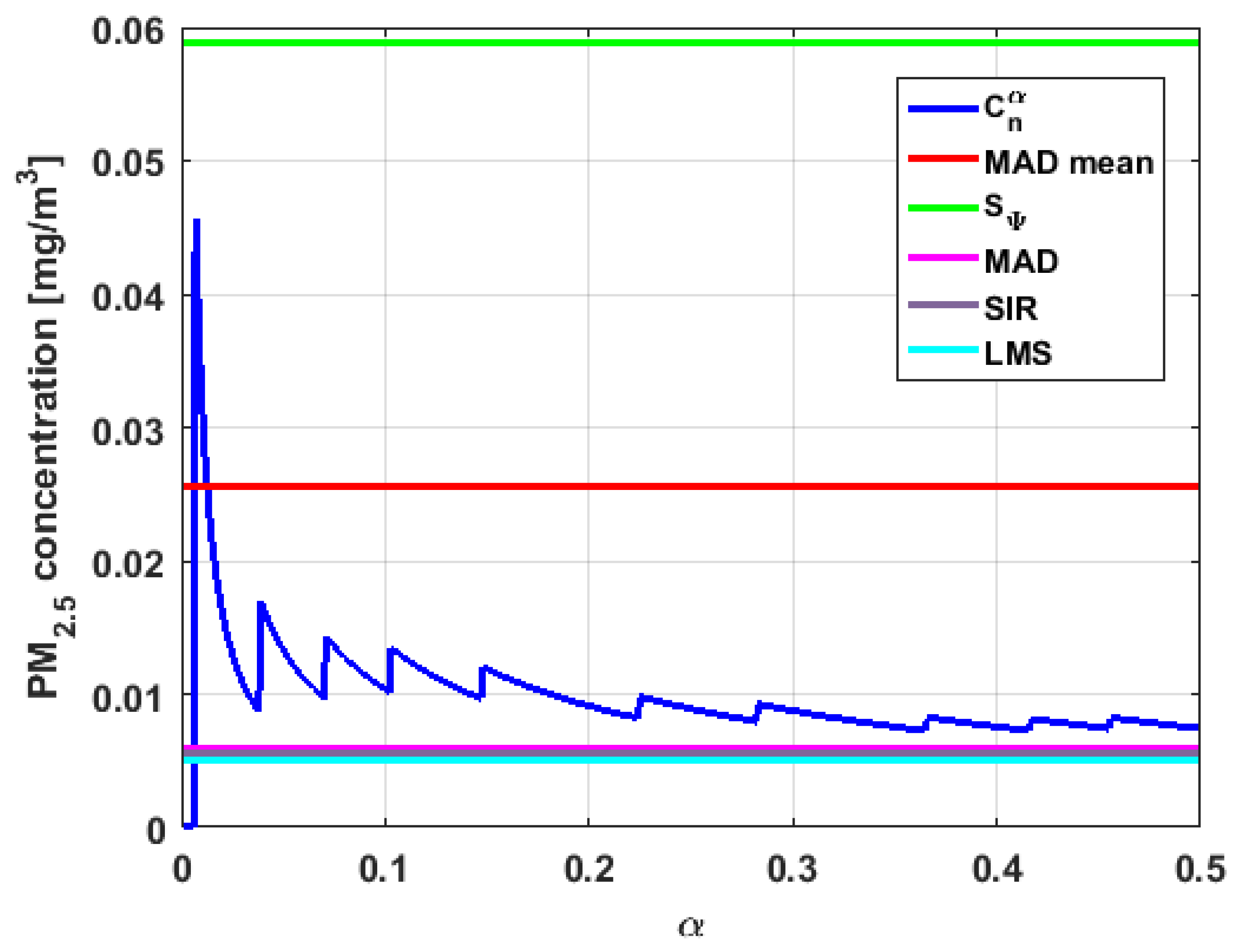
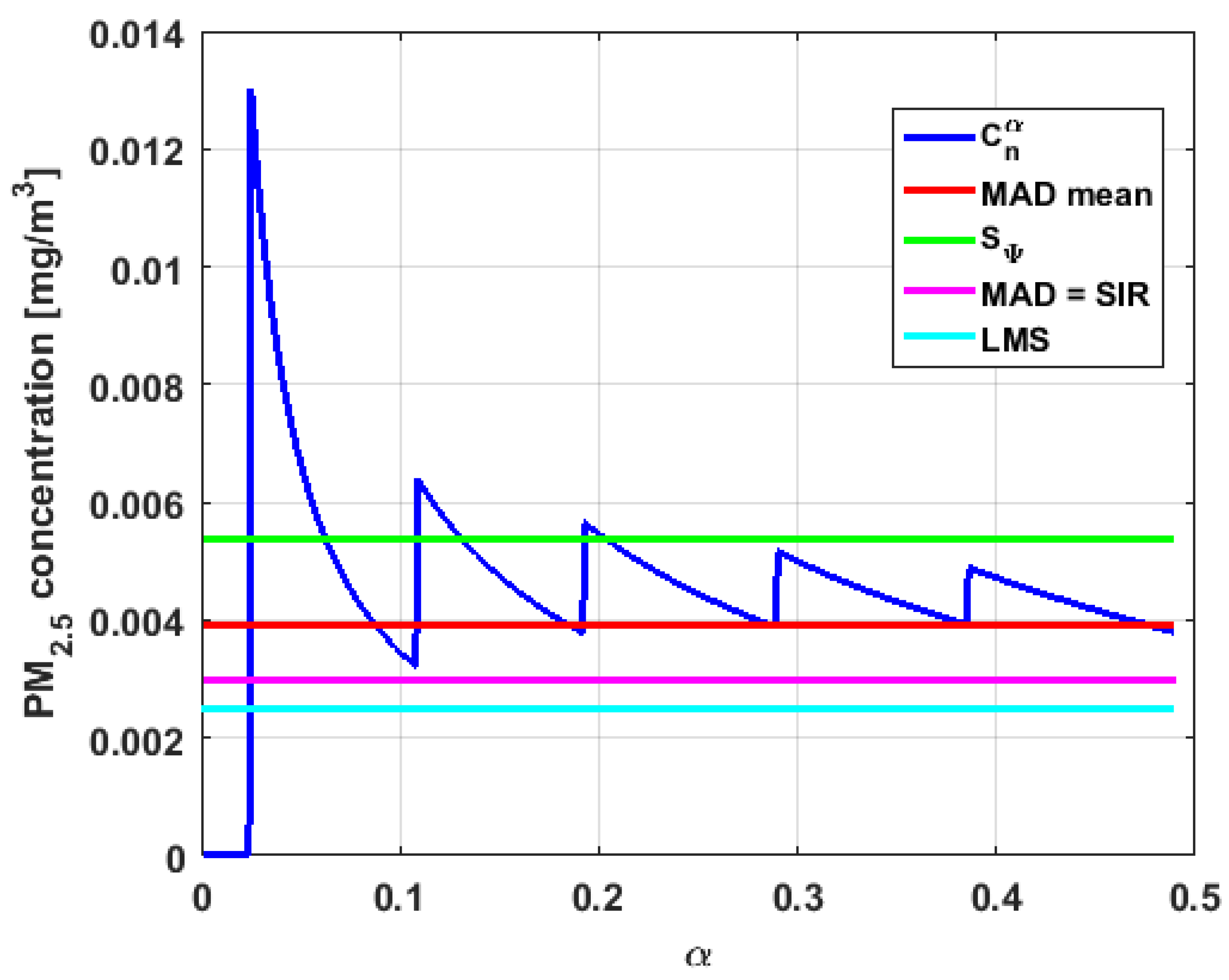
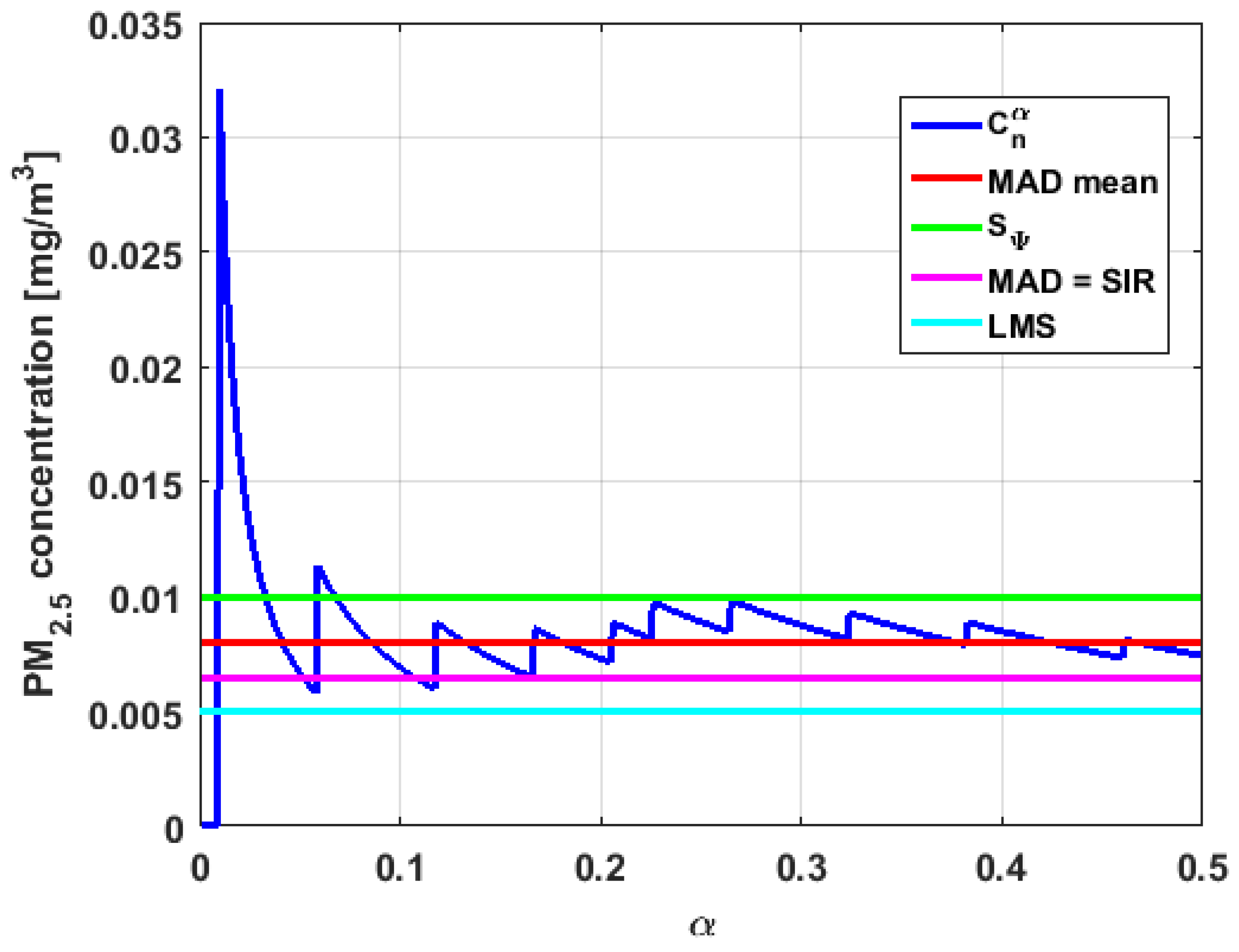
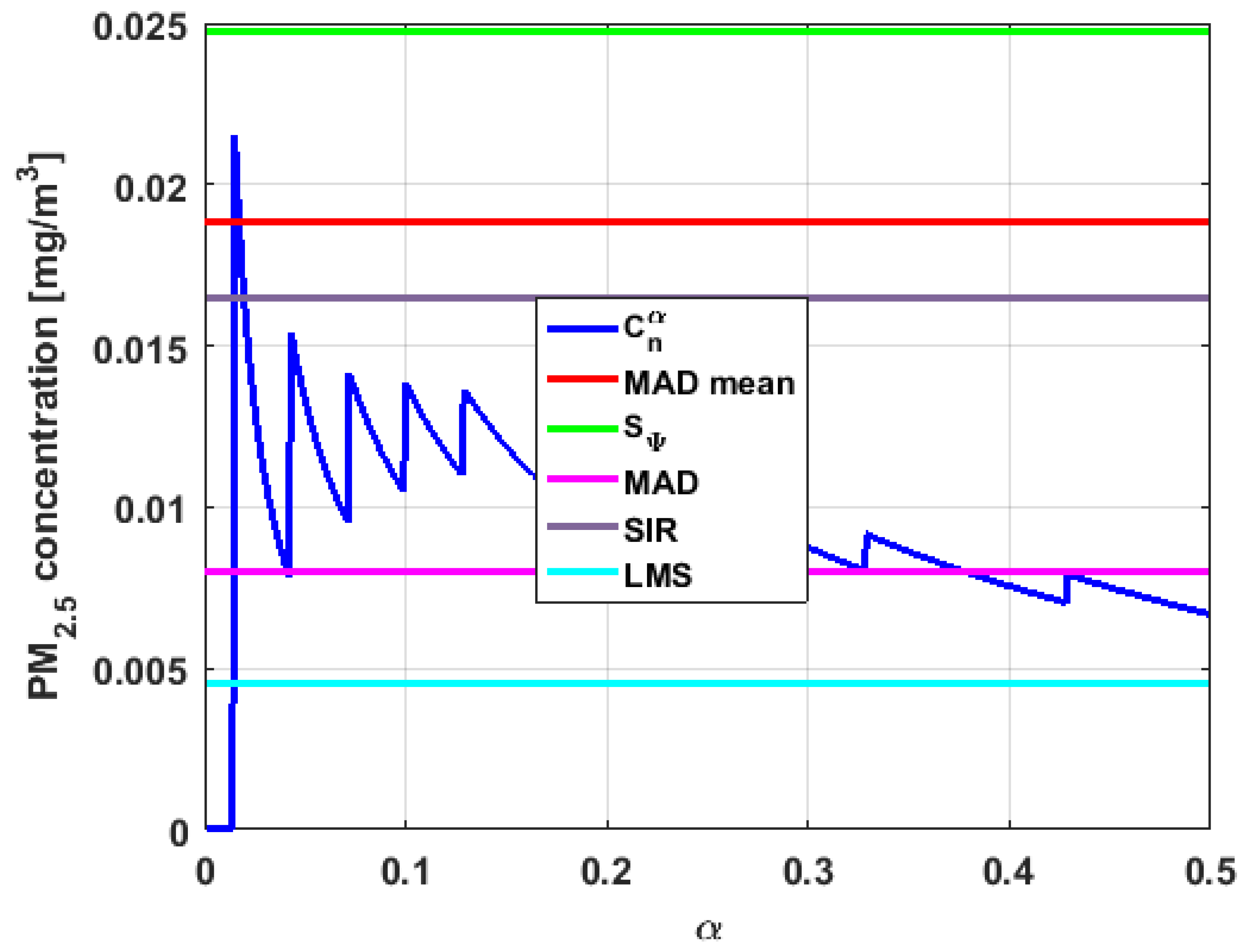
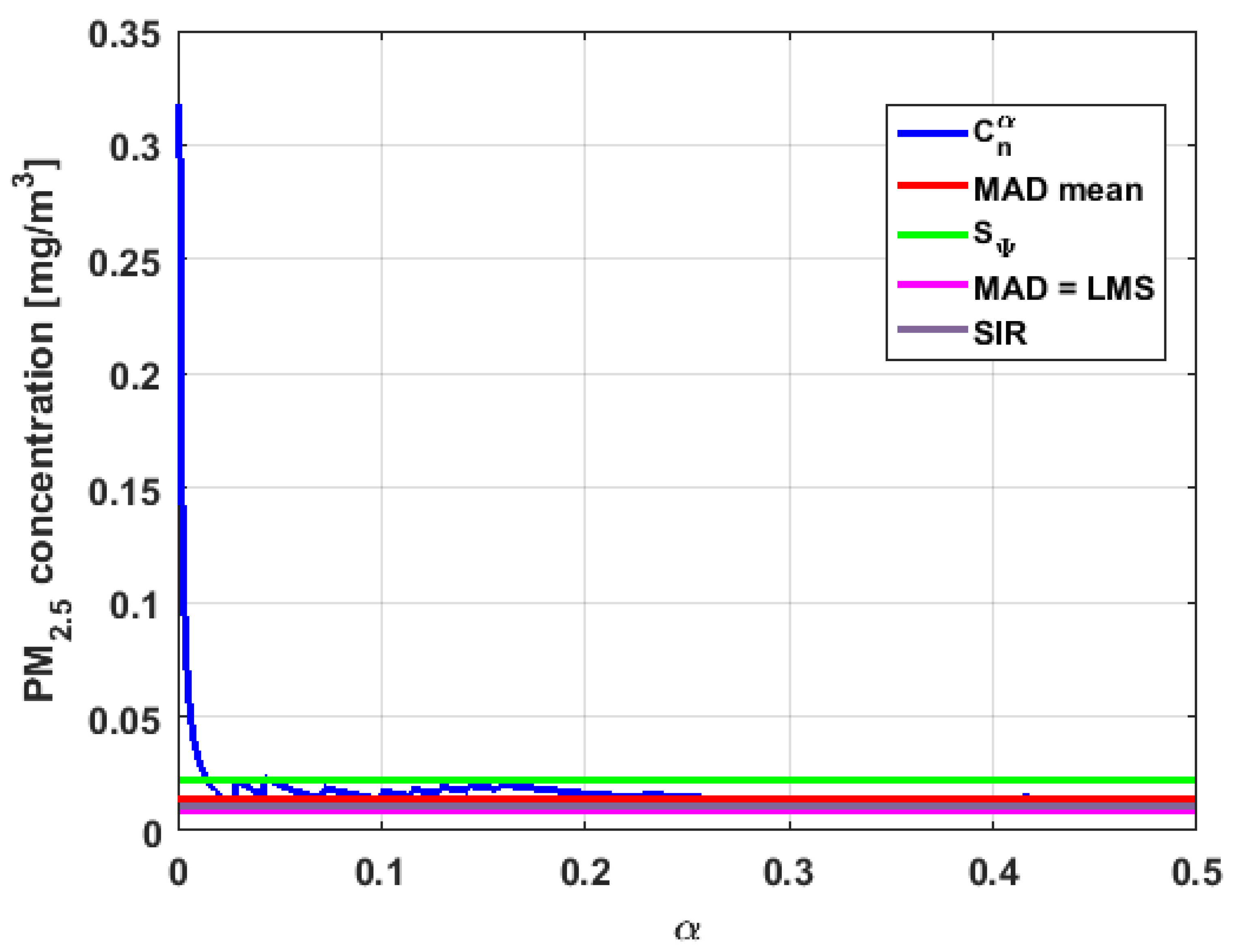
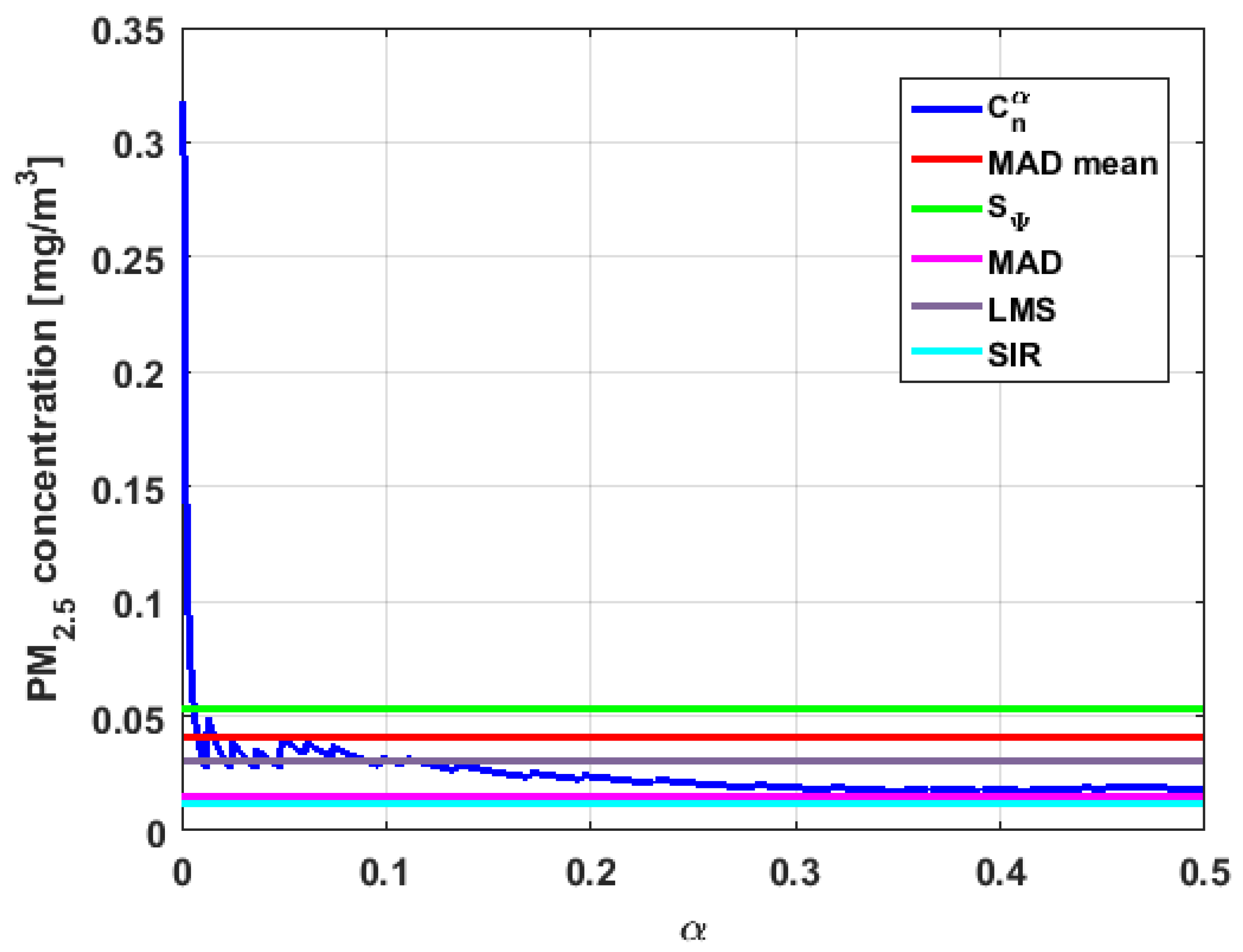
In addition, has a great value of , which is much greater than the estimate, and the latter is, in turn, approximately four times greater than the other three estimates: , , and . Taking into account that these last three estimators are the most robust among all those considered, it can be said that the extreme observations that have, in general, very high values and others very close to zero are very influential in the estimates that include them. The graphs that represent the functions and are very similar, when they are compared to each other for low abscissa values. Therefore, estimates consider most of the observations. In addition, both functions show fluctuations, but then the two families of estimates stabilize around values between and .
With respect to , the first thing that can be said is that the point estimates of scale , , , and are very similar to each other. The graph of the function has two very pronounced maximums for low values of , while the graph of function also has a maximum for low values of that is much lower than the two above-mentioned maximums. Moreover, it can be seen how both functions immediately stabilize around the point estimates. The foregoing indicates that there are not many extreme values that influence scale estimates, and that all the scale estimates found are acceptable. Furthermore, the scale estimates of that are more robust (i.e., , , and ) are slightly greater than the respective scale estimates of the variable .
With respect to , it can be said that the value of the robust estimates (i.e., , , and ) of this variable are greater than more of the half of the value of the non-robust estimates (i.e., and ). The graphs of and have characteristics analogous to the respective graphs of . It can be seen that has a very pronounced maximum for low values of , and that and also has a low pronounced maximum for low values of . In addition, both functions immediately begin to fluctuate around the found point estimates. Therefore, it can be said that there are few extreme values, with high values, that influence the estimates remarkably. However, unlike what happens in the case of , the estimates obtained with the families of estimators are below , for the case of , and below , for the case of . Therefore, the estimators and are not so similar. Moreover, the most robust scale estimates are similar to each other in the case of and , but these robust estimates have somewhat greater values than those corresponding to the case of .
In addition, the point estimates of scale of show appreciable differences. It can be seen that is appreciably higher than the rest of the estimators. In addition, the and estimates are similar, the value is half the value of the previous ones, and the value is half the value. All this indicates that there are influential observations in the scale estimates. The graphs of and are similar to the respective graphs of , even in the difference with . Therefore, there are a few extreme high observations that produce estimates above the possible real value. The family oscillates around and the family oscillates around .
Moreover, has quite different point estimates of scale, although the most robust estimators (i.e., , , and ) are very similar to each other, and slightly greater than the point estimators of scale of the variables that have been previously analyzed. The graphs of the functions and are different from the other graphs of the rest of the variables. It can be seen that is the graph that is most influenced by extreme values and the high values of the variable. By suppressing the extreme observations, the estimates are around . The point scale estimates seem somewhat greater than those of the variables previously analyzed, but lower than those of the variable .
Furthermore, by removing the scale estimate of variable , the point scale estimates of are greater than all the remaining ones. In addition, if only the most robust estimates (i.e., , , and ) are considered, then it can be seen that the differences with the estimates of the rest of the variables are 50% higher than the value of the estimates that so far were the highest; that is, those of the variable . In addition, it can be said that has similar characteristics to other variables. For example, there were observations with extremely high values that greatly influenced the estimates that took them into account. In addition, the family tends to be bounded by point estimates of scale and to oscillate around . Moreover, the family tends to have oscillations, and it tends to .
Before moving on to the next section, it is important to highlight that, taking into account the previous comments, the variables under study can be classified according to their scale of variation. In this sense,
is classified as the smallest. Second, the variables that have the least variation, but with greater variation than
, are
and
.
and
can be placed in third and fourth place, respectively. Finally, the variable with the greatest variation is
, which has both the greatest variation and most of the points of influence. The results of this paper are compatible with those of [
37].
5. Conclusions
In this article, data from PM2.5 concentration measurements performed in La Carolina Park, Quito, Ecuador, were analyzed using robust statistics techniques. First, a statistical summary of the data was shown. In addition, it was found that the distributions of the data were not normal and that they could be heavy-tailed distributions.
In a preliminary analysis of the data, it was seen that all the extreme observations of the variables under study corresponded to high values of air pollution by PM2.5 concentrations. In addition, it was seen that was the only variable that had extreme values for low air pollution levels. Furthermore, the lack of normality was a characteristic that was common of all the variables.
From hypothesis tests and the establishment of nonparametric confidence intervals, it was concluded that the median of was the greatest. It was also concluded that the median of was different from the other medians, and that the medians of and are equal to each other but different from all other medians. In addition, it was shown that the medians of and are equal to each other and smaller than the other medians.
From the analysis carried out in this article, it was observed that the numerical values of were the only ones that sometimes exceeded all air quality limits established by the Quito Air Quality Index (QAQI). All the numerical values of except one of them were below the Acceptable level, and the numerical values of rarely exceeded the Desirable level. Few numerical values of exceeded the Acceptable level, and many of its observations were at the Desirable level. Most of the observations of were below the Caution level, and the vast majority were below the Acceptable level. The variable with the highest observations after was , although its observations did not exceed the Alarm level. Furthermore, a Wilcoxon rank-sum test showed that air pollution due to , and was equal to air pollution due to , and , at the significance level.
In this paper, it was shown that neither the streets that border the park nor the park itself (i.e., , , , and ) were on Alert level. According to categories established by QAQI, the most critical case was ( refers to a route along which measurements were performed in the street Avenida Naciones Unidas), which was at the Caution level. Therefore, measures that help to improve air quality in the region where La Carolina Park is located must be taken.
Once this first analysis was completed, it was decided to provide some robustness with respect to the estimates of both the central tendency of the data and its dispersion, because it is very important to give estimates that are practically immune at least to small variations in the data. Thus, unless a natural disaster occurs, such as an earthquake or a volcanic eruption, among others, regardless of the possible distribution of the data, estimates of the central tendency of the data and its dispersion will be limited by intervals that guarantee, with great certainty, that the true values of the magnitudes of the quantities under study are not very far from their estimates.
For centralization measures, the family of -trimmed means and point estimates of the mean, median, and trimean were considered. For scale estimations, five point estimators were considered, which are not all robust. These estimators were the following: standard deviation, mean absolute deviation, median absolute deviation, semi interquartile range, and least median squares. Moreover, two families of robust estimators were considered: biweight midvariance estimators and estimators based on a subrange.
The results of this research showed that robust estimates of location of were very dependent on the number of observations that were not considered, although all these estimates were between the Desirable level and Acceptable level. On the other hand, robust estimates of the scale of were around units. These data indicated the possibility that the distribution of is a distribution of heavy tails. This argument was corroborated by the high values of its skewness and kurtosis.
With respect to , most of the location estimates were in the nonparametric confidence band established for that variable. Since had barely extreme observations, the values of the robust location and scale estimators of this variable were all similar. In this case, all the robust location estimations were at the Acceptable level, and the robust scale estimations were close to . and would have their location measurements at the Acceptable level; the scale of is half that of the scale for , and their medians cannot be medians of the other variables that have been analyzed.
The above agrees with the fact that the difference between and is the street Avenida de los Shyris, where refers to a route that is right next to La Carolina Park and refers to a route where there is a highly commercial area. Therefore, the measurement results of are greater than the measurements results of , causing the displacement of the frequency distribution of to a higher value zone, and that the observations of with low numerical values appear as lower extreme data. Moreover, the above entails the appearance of a greater variability in the data compared to the data. This explanation demonstrates that the park is working as an air pollution filter.
Most of the robust location estimates of and were in the confidence band established by nonparametric statistics, and all estimates were at the Desirable level. Therefore, the medians of the other variables cannot be medians of these two variables. In , there seemed to be a breaking point from which robust location estimates were near the mean on the left, and near the median on the right. In addition, the scale estimates of were somewhat higher than the scale estimates of . This happened because the range of observations of for high pollution values was longer on the right than the range of . These two variables also showed a similarity regarding the geographical area, because the observations of both variables were taken on wooded areas of the park.
With respect to robust scale estimates of , it can be said that these were similar to the robust scale estimates of . In addition, robust scale estimates of were significantly greater than robust scale estimates of . and were the variables with the best air quality levels.
Furthermore, the robust location estimates of that came from the -trimmed means were above the nonparametric confidence interval, indicating that there were few high observations and many low observations. However, almost all the estimates were below the Acceptable level. showed analogies with in terms of the distribution of the data, but with a shift of them toward higher values. In spite of the fact that the measurements of were performed in the middle of the park, in the area where these measurements were performed, there was not any wooded region. Once again, it is observed that where there are more trees and vegetation in an area, the lower the air pollution level in that area.
The robust scale estimates of were similar to each other and larger than those of the other variables, except for .
In addition, showed robust location estimates from the -trimmed means that were above the nonparametric confidence interval. Moreover, is the variable that produced location estimates significantly greater than those of the other variables, being able to fall between the Acceptable level and the Caution level. This variable was the one with the greatest values of scale estimates.
The above is in accordance with the geographical situation in which the street Avenida Naciones Unidas is located and the route to which refers. The street Avenida Naciones Unidas goes from east to west in the city, and it is well known that in Quito, the circulation speed of cars, buses, and trucks in that direction is slower than in any other direction. Therefore, there are more traffic jams when driving in that direction and, as a result, citizens on that street are much more exposed to air pollution.
At this point, it is important to say that in this article, robust confidence intervals were not included. Therefore, this is a task that remains pending for future research works. However, these confidence intervals are based on robust location and scale estimators, and these robust estimators in turn depend on the order statistics that were used to find the nonparametric confidence intervals. Therefore, it seems that there must be a close relationship between both kinds of confidence intervals.
The results of this study confirm that the efficiency of all urban dynamics (that is, mobility, recreation, cultural activities, and work activity, among others) must be subject to appropriate environmental quality standards. In the case of La Carolina Park, the quality and diversity of the activities that can be carried out in the park, together with the urban offer of the sector in which this part is located (which offers great competitiveness in terms of the following activities: commercial, labor, hotel, banking, governmental, and educational, among others), make this urban park one of the most visited spaces in Quito. Nevertheless, two critical areas were identified in the study:
First critical area: For the case of La Carolina Park, the area near the intersection between Avenida Naciones Unidas and Avenida de los Shyris. Various sports are practiced in this area, which represents activities that demand more oxygen. This part of the park contains less woodland that mitigates the pollution that is generated in these two avenues.
Second critical area: The paths of the roads that surround the park (most of them very wide), where from Monday to Friday they are very busy by people who work and/or live in the area. In these paths, the access to the premises located on the ground floor and the bus stops (specifically in Avenida Naciones Unidas, in Avenida de los Shyris, and in the northern part of the Avenida Rio Amazonas) are very exposed to the air pollution that is generated in these paths.
Therefore, as a result of the study carried out, it is recommended that these two areas have a new design and environmental management to reduce pollution emitting agents, and to mitigate and/or reduce the exposure of people to polluted air. As the reduction of pollution sources is subject to the urban structure of the city of Quito (which is a long, narrow city), and as there is also a need for more efficient and less polluting public transport, it is suggested that the urban decision makers, owners, and citizens in general take control (C) and mitigation (M) measures, such as:
(C1) Urban decision makers: Control the entry of polluted air to the food preparation and sale premises that are located on the ground floor by regulating the design of the accesses, especially when the access is direct from a route large vehicular flow.
(C2) Owners (especially of food premises on ground floors): Control food processing processes so that they are located in areas less exposed to polluted air.
(C3) Owners (of premises and/or homes): Consider natural ventilation habits (preferably cross-ventilation) of the buildings, taking into account the hours when pollution levels are lower (from 5:00 to 6:00 and from 20:00 to 21:00).
(M1) Urban decision makers: Mitigate exposure to pollution in the northeast part of the park, redesigning the placement of trees with more foliage at the edge of the park and promoting that sports activities be protected from pollution by a green filter. To achieve this goal, it is important that urban design can redirect activities that take the edge of the park as a unit of measurement, such as: walking, running and/or walking domestic animals.
(M2) Urban decision makers: Mitigate exposure to pollution through elements that protect people from polluted air, especially in the busiest sidewalks, which are on the urban edge of the roads surrounding the park.
(M3) Urban decision makers: Mitigate exposure to pollution by informing the population about the levels of pollution in each area of the park. In addition, do this taking into account the precautions that must be taken into account to develop urban dynamics in the best possible environmental conditions.








































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}