Estimation of Arsenic Content in Soil Based on Laboratory and Field Reflectance Spectroscopy

Abstract
:1. Introduction
2. Materials and Methods
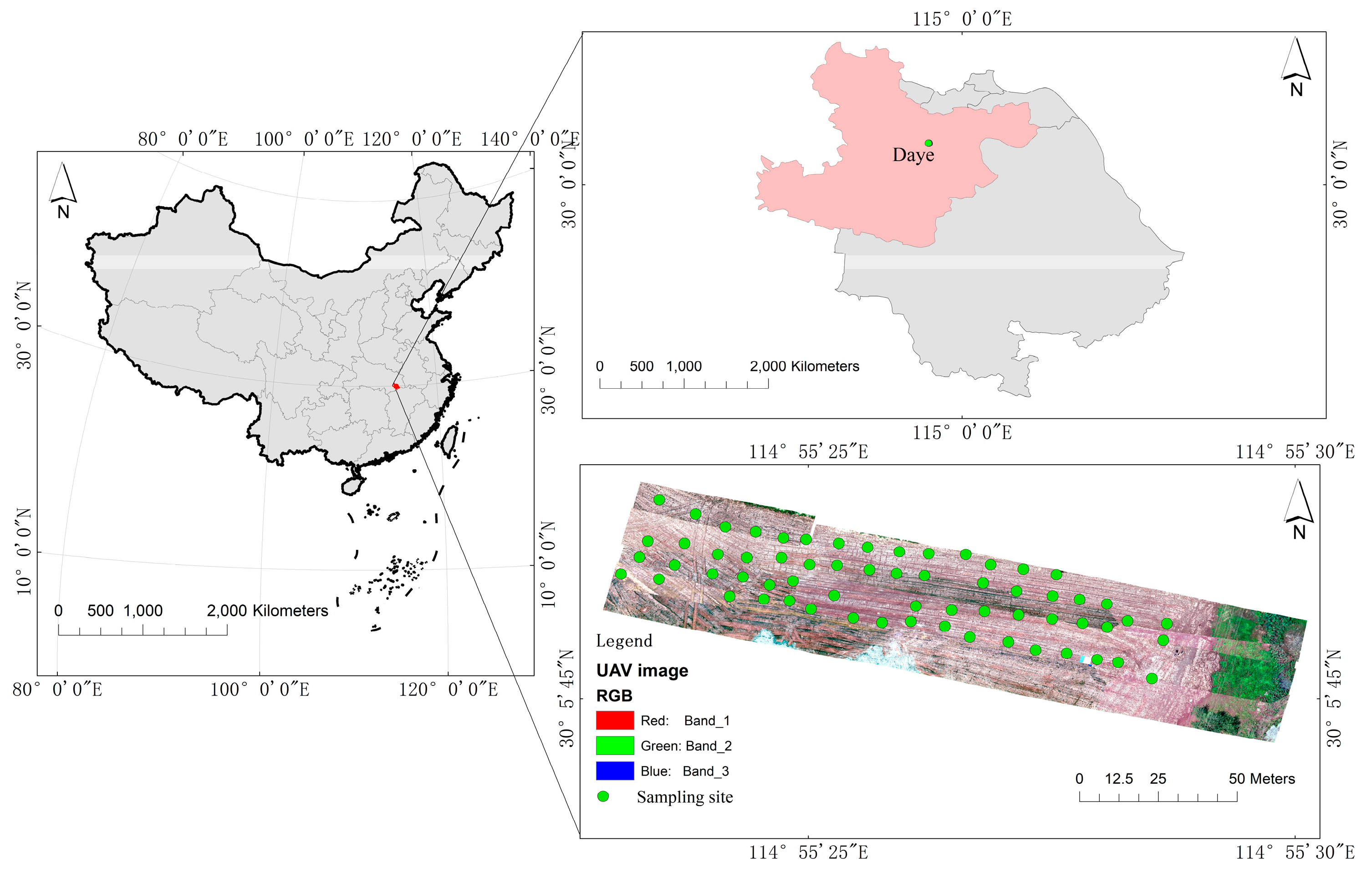
2.1. Study Area
2.2. Research Methods
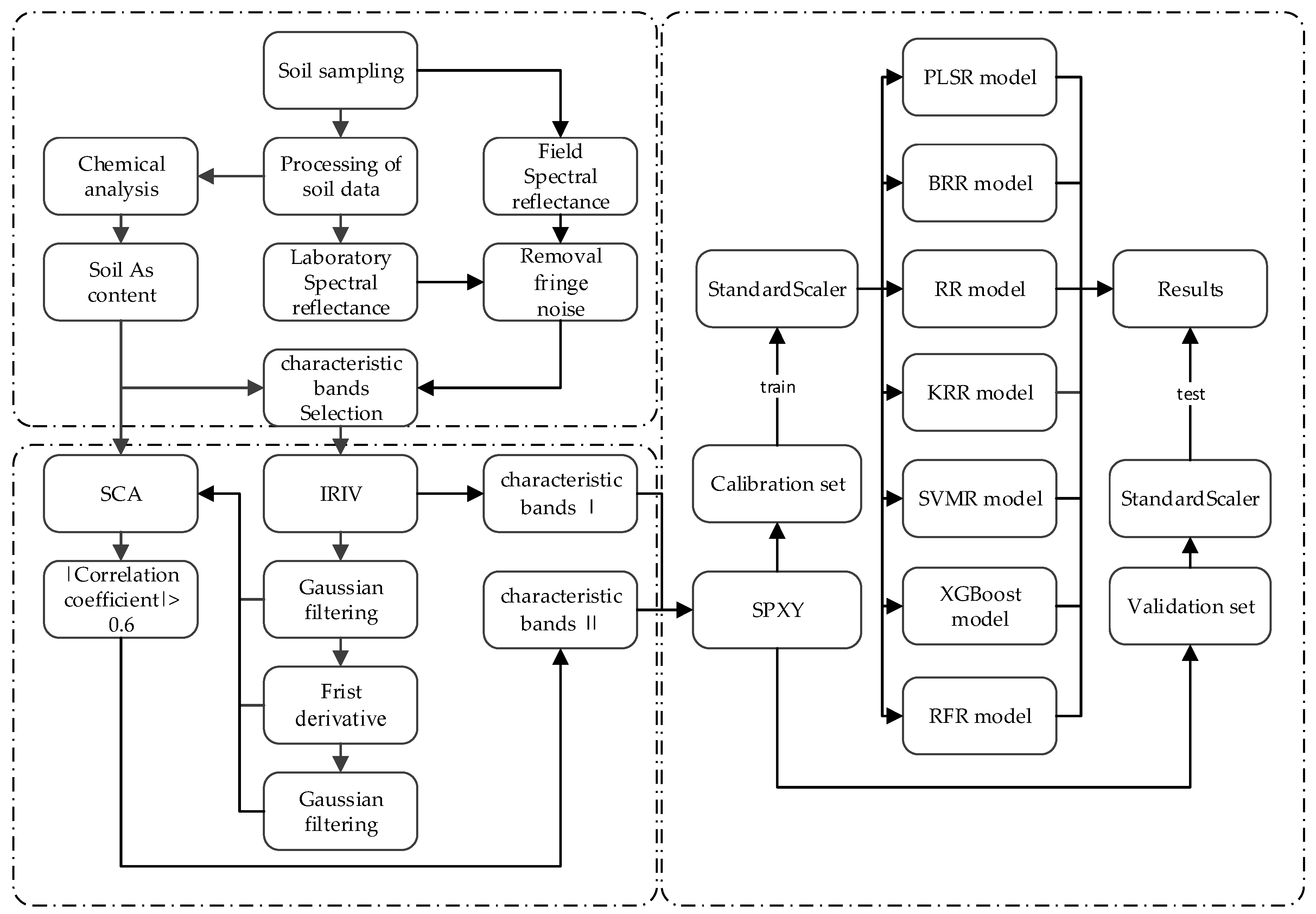
2.2.1. IRIV-SCA Characteristic Band Selection Algorithm
- Step 1: The raw data of samples of variables are formed into a matrix containing only the numbers 0 and 1, where the number 1 represents a variable used for modeling, and the number 0 means that the variable was not used for the modeling. The RMSECV value obtained by five-fold cross-validation was used as the evaluation standard, and the vector of size was recorded as . Substitute 1 in the ith column (i = 1, 2, …, p) of matrix for 0, and 0 for 1 to obtain matrix . The partial least squares (PLS) model is also established in each row of matrix , and the vector of size is recorded as .
- Step 2: Define and to evaluate the importance of each variable as follows:where represents the kth line in the vector, and the and represent the values of the kth row in the vectors and , respectively. The mean values of and are denoted as and , respectively, and the two mean values are subtracted to obtain . If , it is a strongly informative variable or a weakly informative variable; if , it is an uninformative variable or an interfering variable.P = 0.05 was defined as the threshold for the Mann–Whitney U test [19,21], where the value, denoted as pi, is computed by the Mann–Whitney U test with the distribution of and . The smaller the value, the more significant the difference between the two distributions. Finally, the variables were divided into the four categories (strongly informative variables, weakly informative variables, uninformative variables, and interfering variables).
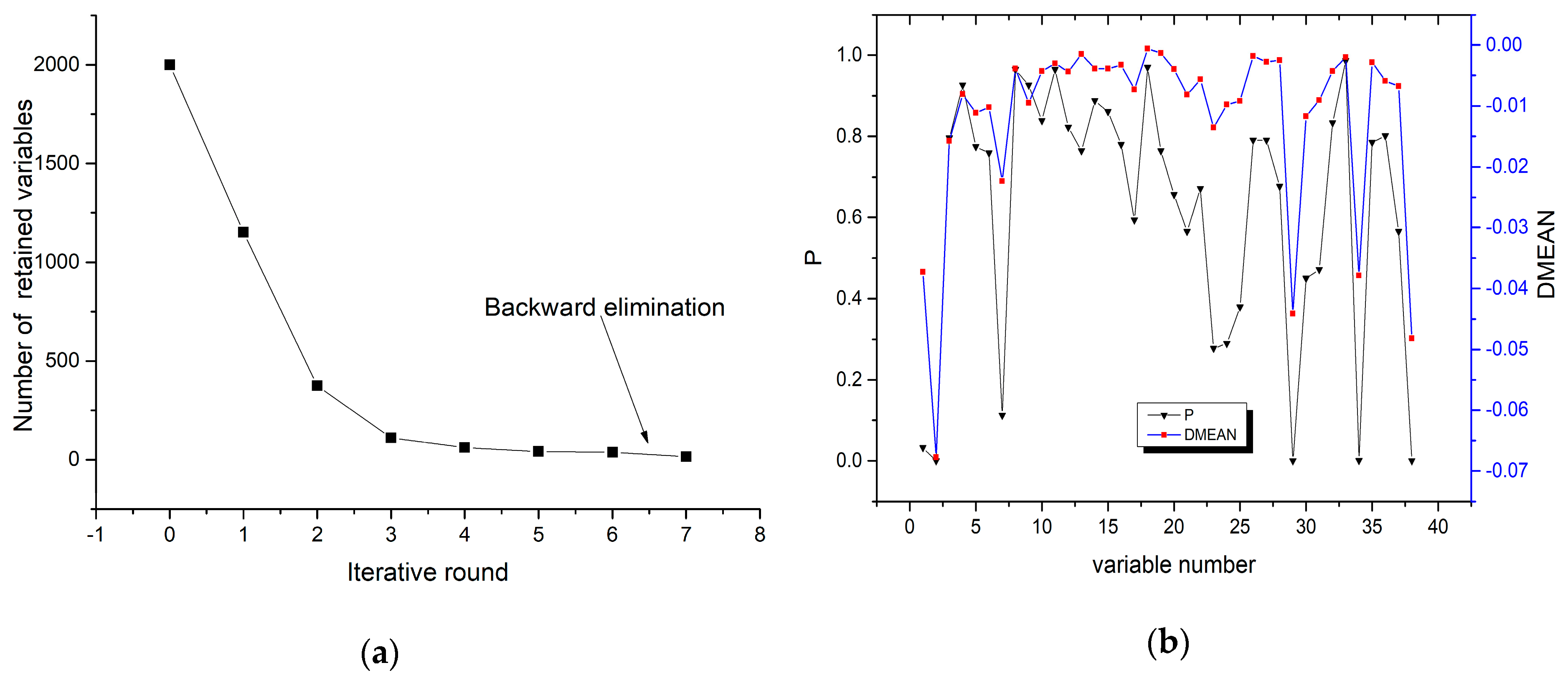
- Step 3: Strongly informative variables and weakly informative variables are retained for each iteration, and uninformative variables and interfering variables are eliminated, so that a new subset of variables is generated. Return to step 1 for the next iteration until there are only strong and weak informative variables left. The defined variable types are listed in Table 1.
- Step 4: The backward elimination of the reserved variables is undertaken as follows:
- (a)
- Denote as the number of reserved variables.
- (b)
- For all the reserved variables, obtain the RMSECV value with five-fold cross-validation using PLS, which is denoted as .
- (c)
- Leave out the ith variable and apply five-fold cross-validation to the remaining variables to obtain the RMSECV valu . Conduct this for all variables .
- (d)
- If , step (g) is performed.
- (e)
- When excluding the ith variable with the minimum RMSECV value, remove the ith variable and change to be .
- (f)
- Repeat steps (a) to (e).
- (g)
- The remaining variables are the final informative variables.
- Step 5: The final informative variables are selected to form the matrix set . are subject to Gaussian filtering (GF), first derivative (FD) filtering, and Gaussian filtering again (GFA), and the processed data and the soil samples are respectively subject to SCA. All the results are combined, and the top k numbers with the highest absolute values () of correlation coefficients are selected. The corresponding data of GF, FD, and GFA are combined to obtain the k result sets with the best correlation as the characteristic bands.
- (a)
- The Gaussian filter (GF) [22] is a kind of linear smoothing filter which chooses weights according to the shape of a Gaussian function. It is very effective for suppressing noise obeying a normal distribution. The GF is expressed as shown in Equation (3):where χ is the distance of the weight function from the maximum point, and the scale parameter σ represents the width of the Gaussian function, which determines the smoothness of the filtering.
- (b)
- First derivative (FD) filtering can eliminate some baseline and other background noise, while improving the spectral resolution and sensitivity. It is widely used in spectral analysis [23].where represents the reflectance value of the ith band, represents the reflectance value of the next band, and is the wavelength interval.
- (c)
- Spearman’s rank correlation analysis (SCA) is used to describe the relationship between the soil spectral characteristics and the soil As content [24]. It evaluates the correlation of two statistical variables using a monotonic equation. SCA is expressed as shown in Equation (5):where is the reflectance of the ith band, is the ith soil As content, is the average of the band reflectance, and is the average As content of the soil.
- Step 6: StandardScaler [25] is used to calculate the mean and standard deviation of the training set so that the test data set can use the same transformation. The features are standardized by removing the mean and scaling to unit variance. Centering and scaling happen independently on each feature by computing the relevant statistics on the samples in the training set. The mean and standard deviation are then stored to be used on the test data using the transform method.where is the spectral matrix, is the standard deviation of the spectral matrix data, and is the mean of the spectral matrix data.
2.2.2. Partial Least Squares Regression (PLSR)
2.2.3. Bayesian Ridge Regression (BRR)
2.2.4. Ridge Regression (RR)
2.2.5. Kernel Ridge Regression (KRR)
2.2.6. Support Vector Machine Regression (SVMR)
2.2.7. EXtreme Gradient Boosting Regression (XGBoost)
2.2.8. Random Forest Regression (RFR)
2.2.9. Technical Process
2.3. Accuracy Evaluation
2.4. Software
3. Experiments and Analysis
3.1. Experimental Procedure
3.1.1. Soil Spectral Reflectance Measurement
3.1.2. Soil Collection and Preparation
3.1.3. Chemical Analysis
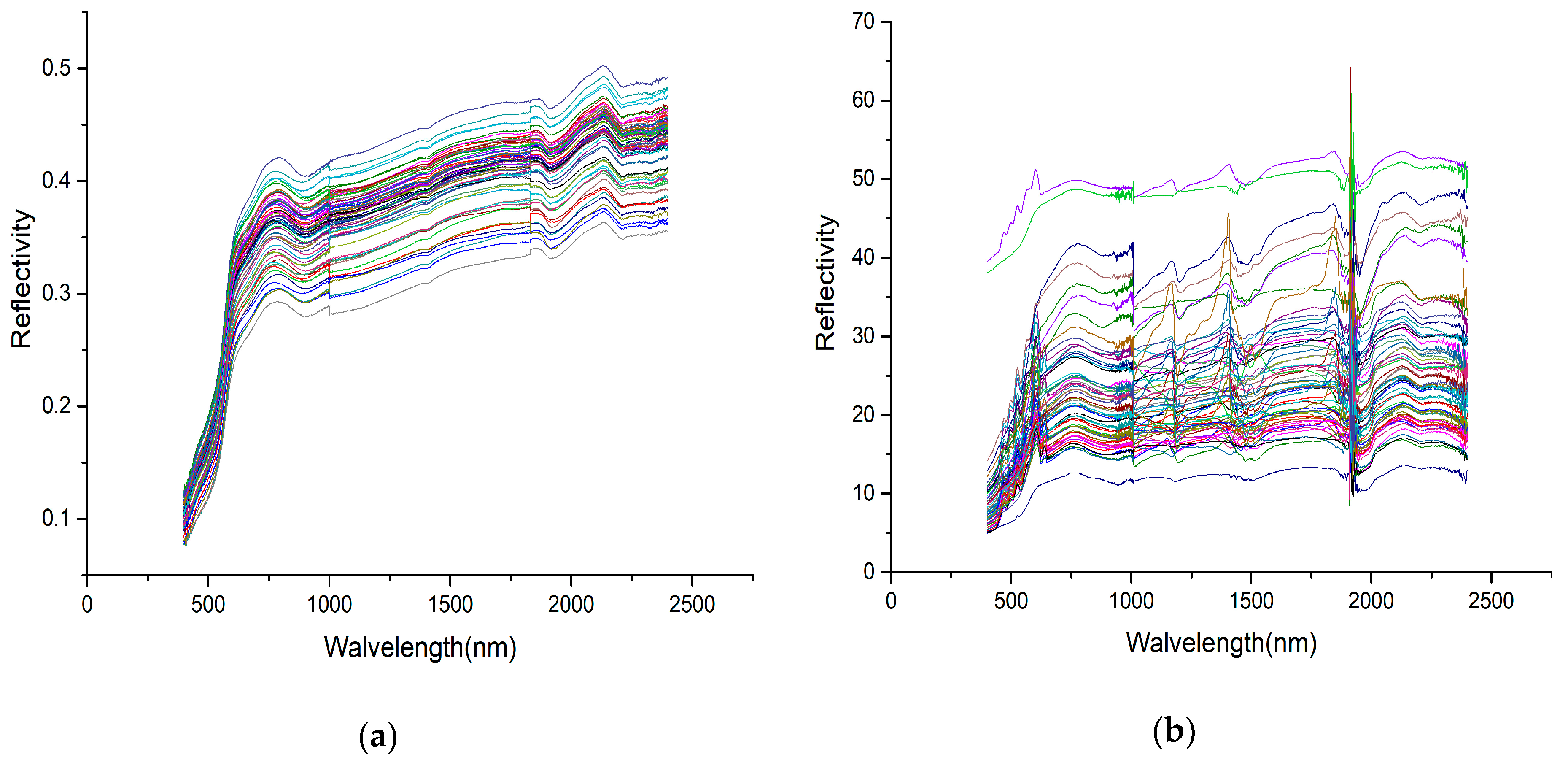
3.2. Preprocessing of the Spectral Data
3.3. Calibration Set and Validation Set
4. Results
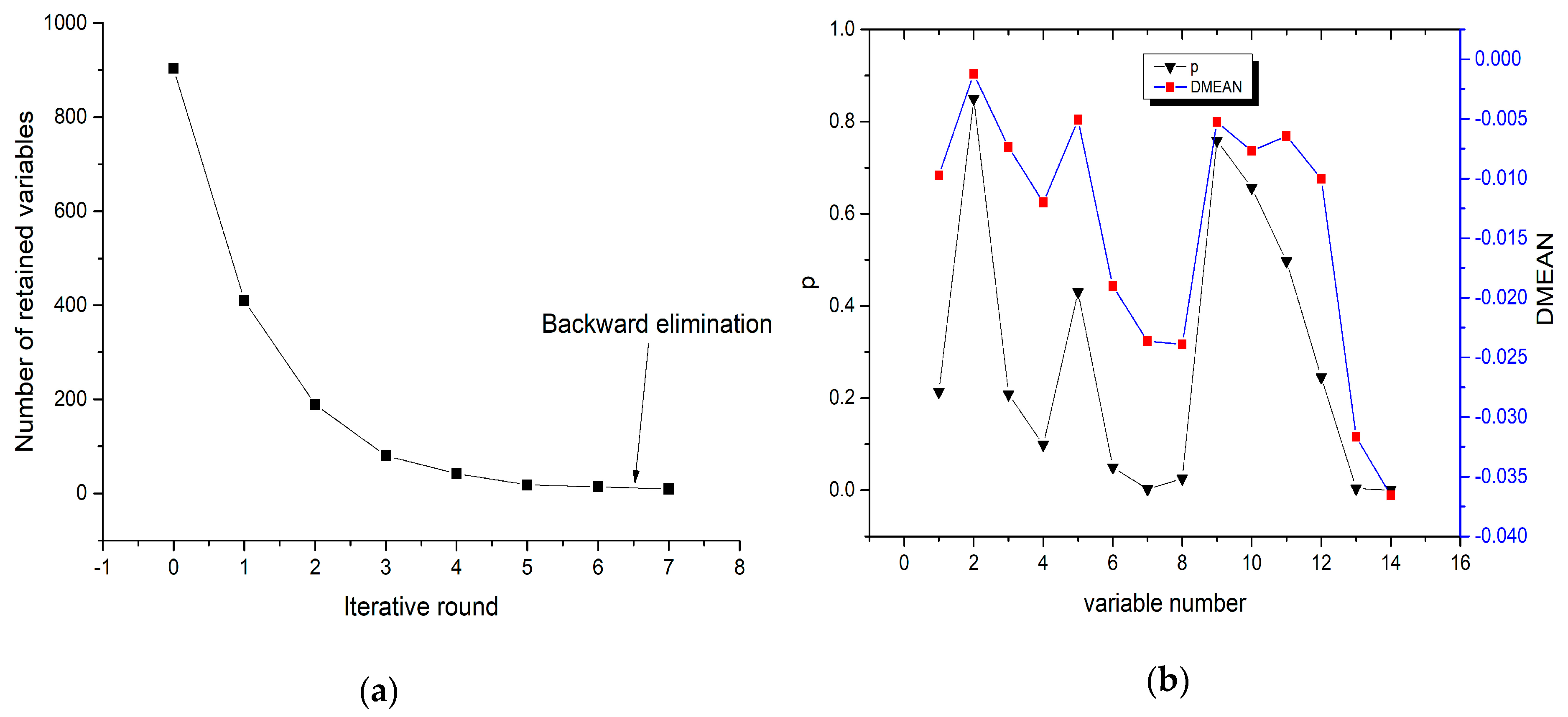
4.1. IRIV Characteristic Band Selection Algorithm
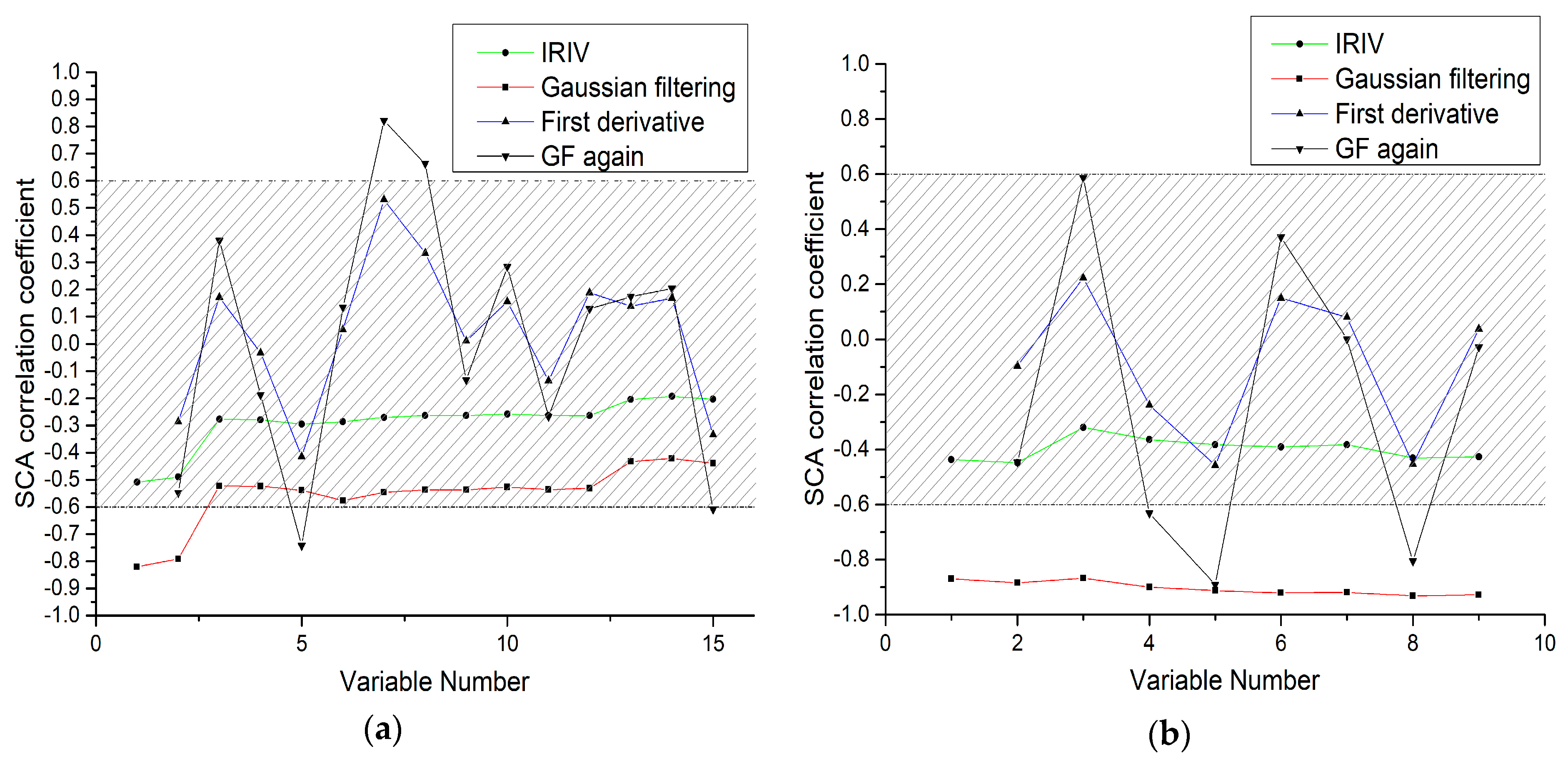
4.2. IRIV-SCA Characteristic Band Selection Algorithm
4.3. Analysis of the Results of the IRIV Feature Selection Algorithm
4.4. Analysis of the Results of the IRIV-SCA Feature Selection Algorithm
4.5. Model Performance
- (1)
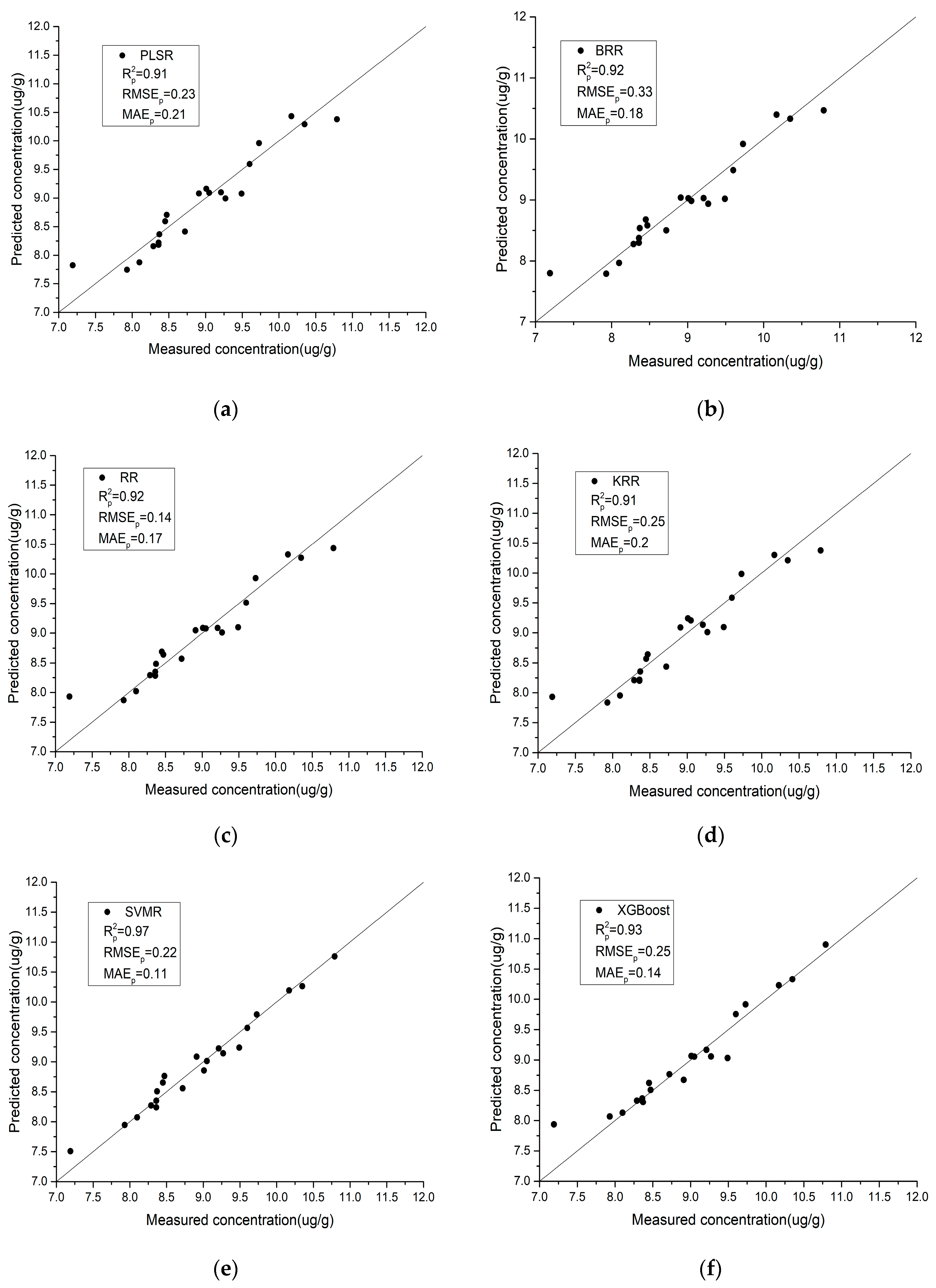
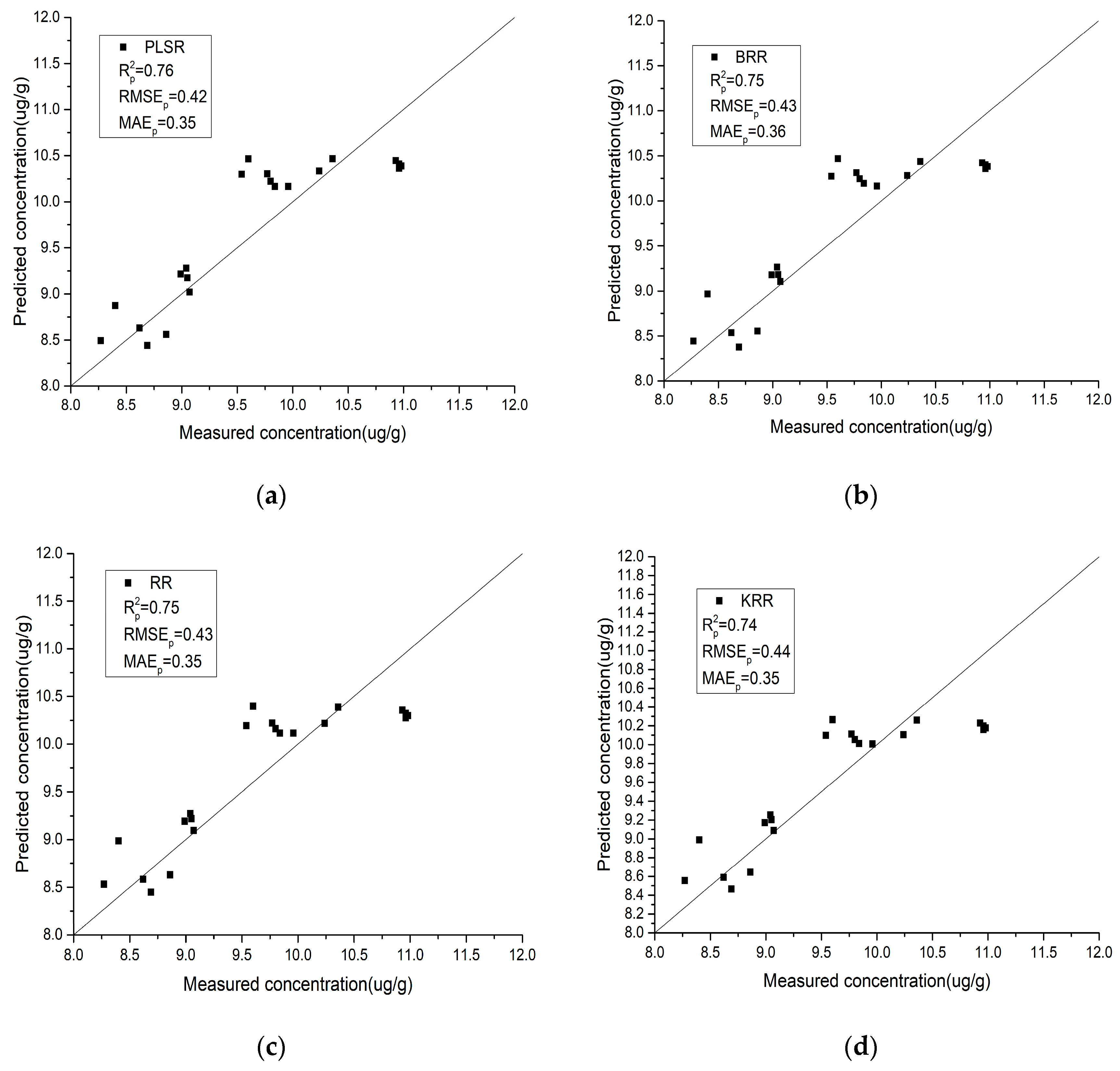
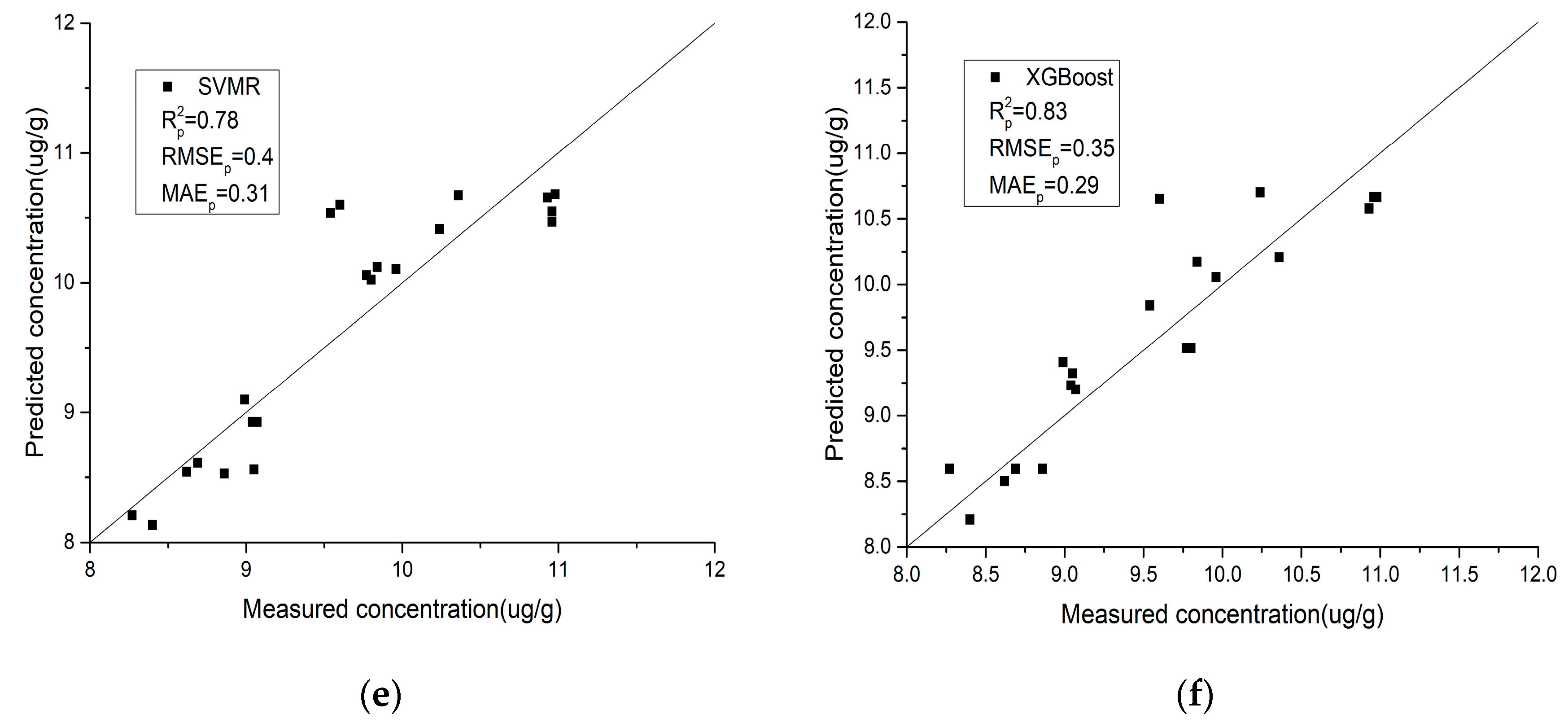
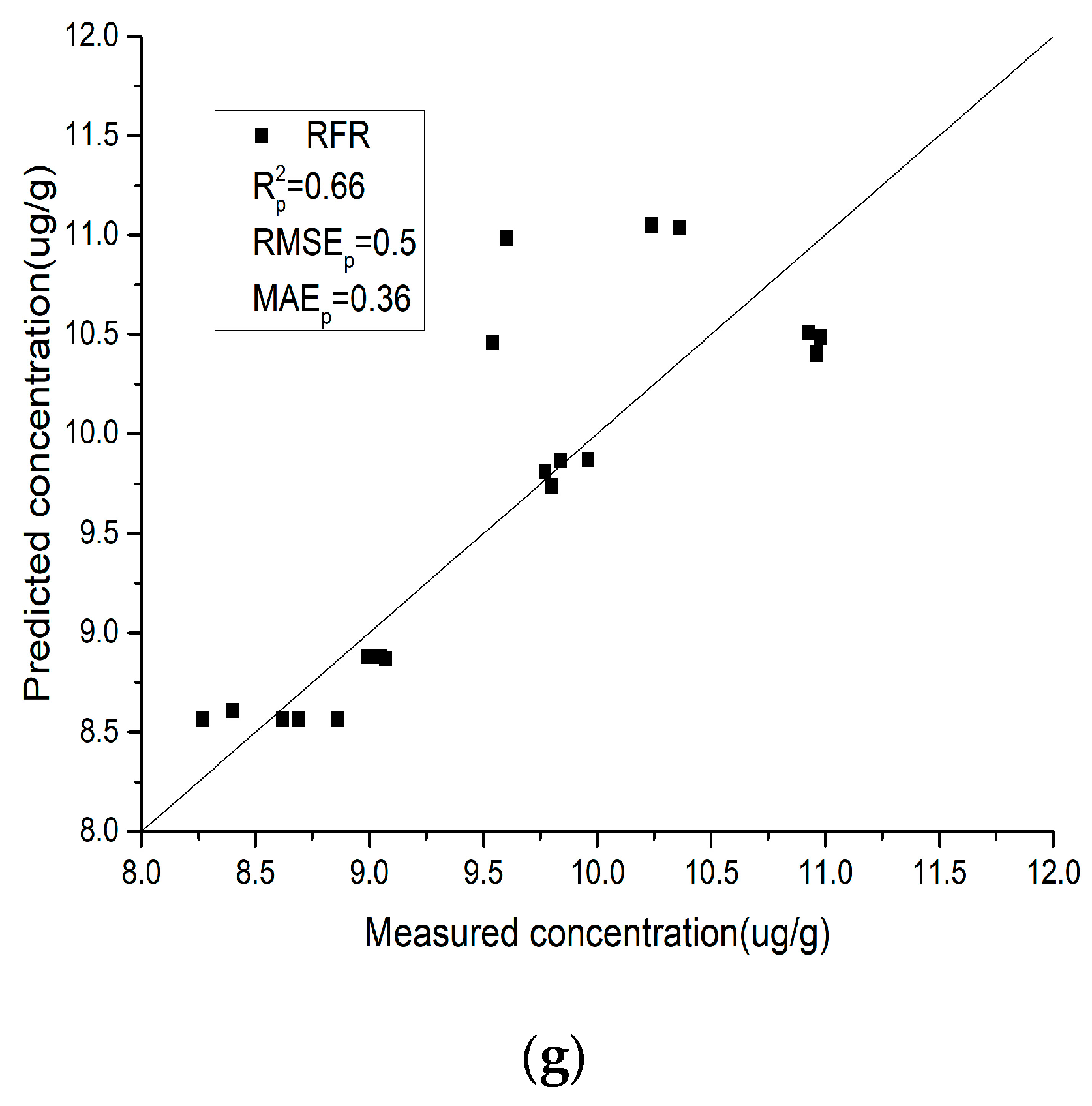
- Compared with the field spectra, the laboratory spectra are generally closer to the y = x line, which indicates that the laboratory spectra have better stability and predictive ability for the As content in soil. IRIV-SCA was used to intelligently select the characteristic bands, and the modeling accuracy and prediction accuracy of the model are both relatively high.
- (2)
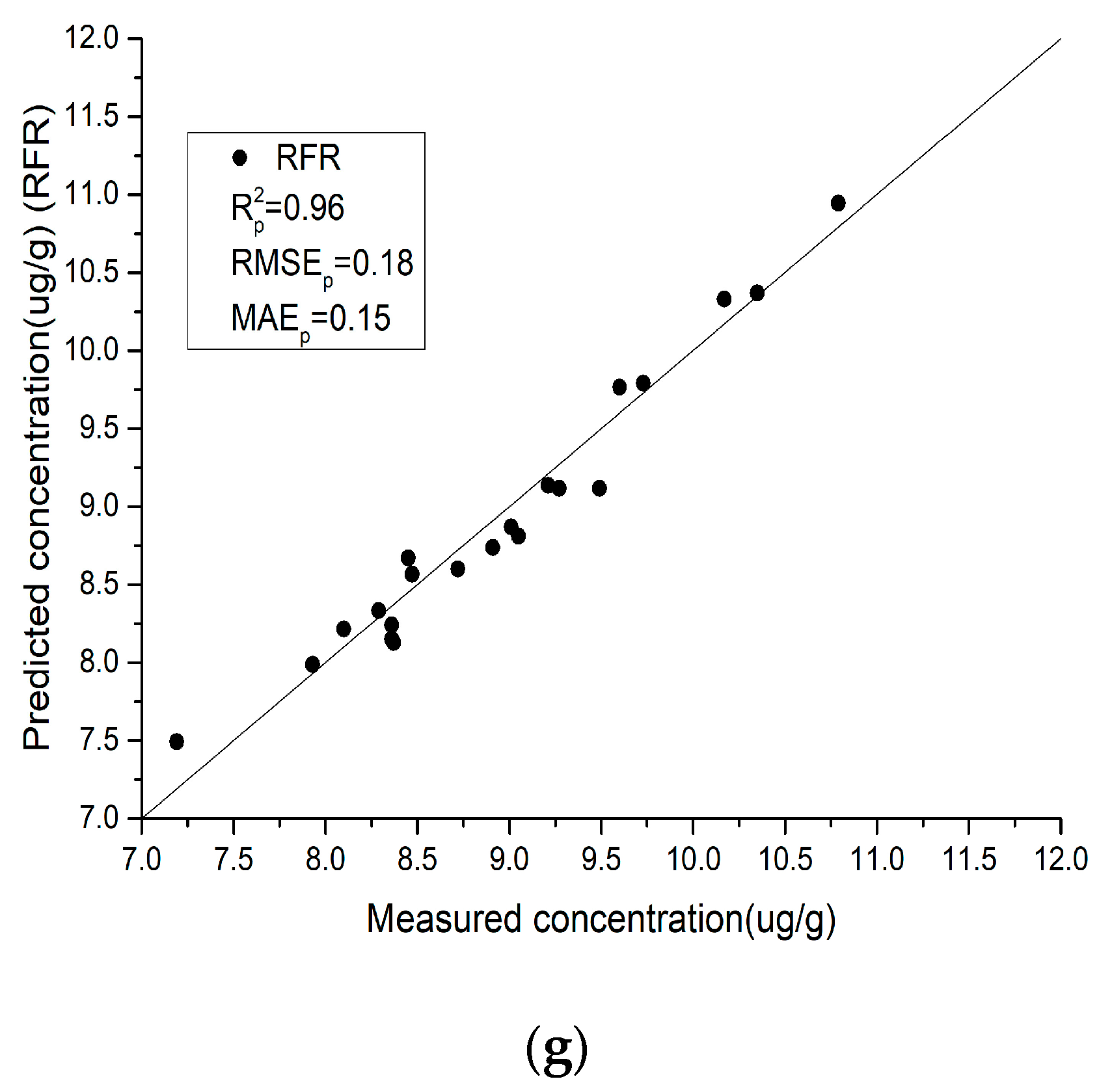
- For the laboratory spectra, SVMR obtains the highest R2 and the lowest RMSE and MAE values. This is shown in Figure 7e, where the black scatter points are located closest to the y = x line, and the trend is the most consistent with the y = x line. PLSR obtains the lowest R2 and the highest RMSE and MAE values. This is shown in Figure 7a, where the black scatter points are located close to the y = x line, but a few points exhibit slight deviations. For the field spectra, XGBoost obtains the highest R2 and the lowest RMSE and MAE values. This is shown in Figure 8f, where the black scatter points are located close to the y = x line and the trend is more consistent with the y = x line. RFR obtains the lowest R2 and the highest RMSE and MAE values. This is shown in Figure 8g, where the black scatter points exhibit large differences.
5. Discussion
6. Summary and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Leung, H.M.; Duzgoren-Aydin, N.S.; Au, C.K.; Krupanidhi, S.; Fung, K.Y.; Cheung, K.C.; Wong, Y.K.; Peng, X.L.; Ye, Z.H.; Yung, K.K.L.; et al. Monitoring and assessment of heavy metal contamination in a constructed wetland in Shaoguan (Guangdong Province, China): Bioaccumulation of Pb, Zn, Cu and Cd in aquatic and terrestrial components. Environ. Sci. Pollut. Res. 2017, 24, 9079–9088. [Google Scholar] [CrossRef]
- de Jesus, A.; Zmozinski, A.V.; Damin, I.C.F.; Silva, M.M.; Vale, M.G.R. Determination of arsenic and cadmium in crude oil by direct sampling graphite furnace atomic absorption spectrometry. Spectrochim. Acta Part B Spectrosc. 2012, 71, 86–91. [Google Scholar] [CrossRef]
- Chen, Y.; Zeng, Y.; Wu, H.J.; Wang, Q.E. Determination of cadmium by HG-aFS in soil of virescent zone in Chengdu city. Guang Pu Xue Yu Guang Pu Fen Xi = Guang Pu 2008, 28, 2979. [Google Scholar] [PubMed]
- Ciftci, H.; Temuz, M.M.; Ciftci, E. Simultaneous Preconcentration and Determination of Ni and Pb in Water Samples by Solid-Phase Extraction and Flame Atomic Absorption Spectrometry. J. AOAC Int. 2013, 96, 875–879. [Google Scholar] [CrossRef] [PubMed]
- Gholizadeh, A.; Saberioon, M.; Ben-Dor, E.; Borůvka, L. Monitoring of selected soil contaminants using proximal and remote sensing techniques: Background, state-of-the-art and future perspectives. Crit. Rev. Environ. Sci. Technol. 2018, 48, 243–278. [Google Scholar] [CrossRef]
- Hahn, D.W.; Omenetto, N. Laser-Induced Breakdown Spectroscopy (LIBS), Part II: Review of Instrumental and Methodological Approaches to Material Analysis and Applications to Different Fields. Appl. Spectrosc. 2012, 66, 347–419. [Google Scholar] [CrossRef]
- Kim, G.; Kwak, J.; Kim, K.R.; Lee, H.; Kim, K.W.; Yang, H.; Park, K. Rapid detection of soils contaminated with heavy metals and oils by laser induced breakdown spectroscopy (LIBS). J. Hazard. Mater. 2013, 263, 754–760. [Google Scholar] [CrossRef] [PubMed]
- Shoshany, M.; Goldshleger, N.; Chudnovsky, A. Monitoring of agricultural soil degradation by remote-sensing methods: A review. Int. J. Remote Sens. 2013, 34, 6152–6181. [Google Scholar] [CrossRef]
- Pascucci, S.; Belviso, C.; Cavalli, R.M.; Palombo, A.; Pignatti, S.; Santini, F. Using imaging spectroscopy to map red mud dust waste: The Podgorica Aluminum Complex case study. Remote Sens. Environ. 2012, 123, 139–154. [Google Scholar] [CrossRef]
- Gholizadeh, A.; Borůvka, L.; Vašát, R.; Saberioon, M.; Klement, A.; Kratina, J.; Tejnecký, V.; Drábek, O. Estimation of Potentially Toxic Elements Contamination in Anthropogenic Soils on a Brown Coal Mining Dumpsite by Reflectance Spectroscopy: A Case Study. PLoS ONE 2015, 10, e117457. [Google Scholar] [CrossRef]
- Javier, M.; Silvia, F.O.D.V.; Ainara, G.; Alberto, D.D.; Juan Manuel, M.; Salvador, G.; Miguel, D.L.G. Use of reflectance infrared spectroscopy for monitoring the metal content of the estuarine sediments of the Nerbioi-Ibaizabal River (Metropolitan Bilbao, Bay of Biscay, Basque Country). Environ. Sci. Technol. 2009, 43, 9314–9320. [Google Scholar]
- Zhang, Y.L.; Feng, Y.; Niu, T.; Yin, J.Q.; Bao, A.M. Establishment and Evaluation of Prediction Model for Heavy Metal Content Based on Hyperspectral Data. Environ. Prot. Xinjiang 2016, 38, 15–21. [Google Scholar]
- Zheng, G.H.; Zhou, S.L. Prediction of As in Soil with Reflectance Spectroscopy. Spectrosc. Spect. Anal. 2011, 31, 173. [Google Scholar]
- Wang, W.; Shen, R.P.; Cao-Xiang, J.I. Study on Heavy Metal Cu based on Hyperspectral Remote Sensing. Remote Sens. Technol. Appl. 2011, 26, 348–354. [Google Scholar]
- Sun, W.; Xia, Z. Estimating soil zinc concentrations using reflectance spectroscopy. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 126–133. [Google Scholar] [CrossRef]
- Jin, Z.; Zhao, H.L.; Jin, C.; Min, W.; Ran, T.; Dan, L. Assessment of heavy metal contamination status in sediments and identification of pollution source in Daye Lake, Central China. Environ. Earth Sci. 2014, 72, 1279–1288. [Google Scholar]
- Ramirez-Lopez, L.; Schmidt, K.; Behrens, T.; van Wesemael, B.; Dematte, J.A.M.; Scholten, T. Sampling optimal calibration sets in soil infrared spectroscopy. Geoderma 2014, 226, 140–150. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Liu, C.; Jiang, H. Influence of surfactant CTAB on the electrochemical performance of manganese dioxide used as supercapacitor electrode material. J. Alloy. Compd. 2012, 517, 1–8. [Google Scholar] [CrossRef]
- Yun, Y.H.; Wang, W.T.; Tan, M.L.; Liang, Y.Z.; Li, H.D.; Cao, D.S.; Lu, H.M.; Xu, Q.S. A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration. Anal. Chim. Acta 2014, 807, 36–43. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, H.; Dai, Z.; Chen, M.S.; Yuan, Z. Improving accuracy for cancer classification with a new algorithm for genes selection. BMC Bioinform. 2012, 13, 298. [Google Scholar] [CrossRef]
- Mann, H.B.; Whitney, D.R. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Khan, T.M.; Bailey, D.G.; Khan, M.A.; Kong, Y. Efficient Hardware Implementation for Fingerprint Image Enhancement Using Anisotropic Gaussian Filter. IEEE Trans. Image Process. 2017, 26, 2116–2126. [Google Scholar] [CrossRef] [PubMed]
- Fernández, D.C.D.R.; Boom, P.D.; Zingg, D.W. Corner-corrected diagonal-norm summation-by-parts operators for the first derivative with increased order of accuracy. J. Comput. Phys. 2017, 330, 902–923. [Google Scholar] [CrossRef]
- Fawzy, M.S.; Toraih, E.A.; Aly, N.M.; Fakhr-Eldeen, A.; Badran, D.I.; Hussein, M.H. Atherosclerotic and thrombotic genetic and environmental determinants in Egyptian coronary artery disease patients: A pilot study. BMC Cardiovasc. Disor. 2017, 17, 26. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2013, 12, 2825–2830. [Google Scholar]
- Ramoelo, A.; Skidmore, A.K.; Cho, M.A.; Mathieu, R.; Heitk Nig, I.M.A.; Dudeni-Tlhone, N.; Schlerf, M.; Prins, H.H.T. Non-linear partial least square regression increases the estimation accuracy of grass nitrogen and phosphorus using in situ hyperspectral and environmental data. ISPRS J. Photogramm. Remote Sens. 2013, 82, 27–40. [Google Scholar] [CrossRef]
- Clavaud, M.; Roggo, Y.; Dégardin, K.; Sacré, P.Y.; Hubert, P.; Ziemons, E. Global regression model for moisture content determination using near-infrared spectroscopy. Eur. J. Pharm. Biopharm. 2017, 119, 343–352. [Google Scholar] [CrossRef] [PubMed]
- Mackay, D.J.C. Bayesian Interpolation. Neural. Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Walker, S.G.; Page, C.J. Generalized ridge regression and a generalization of the CP statistic. Cardiovasc. Res. 2017, 28, 911–922. [Google Scholar]
- Avron, H.; Clarkson, K.L.; Woodruff, D.P. Faster Kernel Ridge Regression Using Sketching and Preconditioning. Siam J. Matrix Anal. Appl. 2017, 38, 1116–1138. [Google Scholar] [CrossRef] [Green Version]
- Avron, H.; Kapralov, M.; Musco, C.; Musco, C.; Velingker, A.; Zandieh, A. Random Fourier Features for Kernel Ridge Regression: Approximation Bounds and Statistical Guarantees. In Proceedings of the 34th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Tong, H.; Chen, D.R.; Yang, F. Support vector machines regression with unbounded sampling. Appl. Anal. 2019, 98, 1626–1635. [Google Scholar] [CrossRef]
- Tan, K.; Wang, H.; Zhang, Q.; Jia, X. An improved estimation model for soil heavy metal(loid) concentration retrieval in mining areas using reflectance spectroscopy. J. Soils Sediments 2018, 18, 2008–2022. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd SIGKDD Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Ishwaran, H.; Lu, M. Standard errors and confidence intervals for variable importance in random forest regression, classification, and survival. Stat. Med. 2018, 38, 558–582. [Google Scholar] [CrossRef] [PubMed]
- Singh, B.; Sihag, P.; Singh, K. Modelling of impact of water quality on infiltration rate of soil by random forest regression. Model. Earth Syst. Environ. 2017, 3, 999–1004. [Google Scholar] [CrossRef]
- Saeys, W.; Mouazen, A.M.; Ramon, H. Potential for Onsite and Online Analysis of Pig Manure using Visible and Near Infrared Reflectance Spectroscopy. Biosyst. Eng. 2005, 91, 393–402. [Google Scholar] [CrossRef]
- Vohland, M.; Besold, J.; Hill, J.; Fründ, H.C. Comparing different multivariate calibration methods for the determination of soil organic carbon pools with visible to near infrared spectroscopy. Geoderma 2011, 166, 198–205. [Google Scholar] [CrossRef]
- Xia, Z.; Weichao, S.; Yi, C.; Lifu, Z.; Nan, W. Predicting cadmium concentration in soils using laboratory and field reflectance spectroscopy. Sci. Total Environ. 2019, 650, 321–334. [Google Scholar]
- Chen, T.; Chang, Q.; Clevers, J.G.P.W.; Kooistra, L. Rapid identification of soil cadmium pollution risk at regional scale based on visible and near-infrared spectroscopy. Environ. Pollut. 2015, 206, 217–226. [Google Scholar] [CrossRef]
- Yanfang, L.; Yannian, L.U.; Long, G.; Fengtao, X.; Yiyun, C. Construction of Calibration Set Based on the Land Use Types in Visible and Near-InfRared (VIS-NIR) Model for Soil Organic Matter Estimation. Acta Pedol. Sin. 2016, 53, 332–341. [Google Scholar]
- Tian, S.; Wang, S.; Bai, X.; Zhou, D.; Luo, G.; Wang, J.; Wang, M.; Lu, Q.; Yang, Y.; Hu, Z.; et al. Hyperspectral Prediction Model of Metal Content in Soil Based on the Genetic Ant Colony Algorithm. Sustainability 2019, 11, 3197. [Google Scholar] [CrossRef]
- Galvao, R.K.H.; Araujo, M.C.U.; Jose, G.E.; Pontes, M.J.C.; Silva, E.C.; Saldanha, T.C.B. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Xia, Z.; Sun, X.; Sun, Y.; Yi, C. Predicting nickel concentration in soil using reflectance spectroscopy associated with organic matter and clay minerals. Geoderma 2018, 327, 25–35. [Google Scholar] [CrossRef]
- Wang, J.; Cui, L.; Gao, W.; Shi, T.; Chen, Y.; Gao, Y. Prediction of low heavy metal concentrations in agricultural soils using visible and near-infrared reflectance spectroscopy. Geoderma 2014, 216, 1–9. [Google Scholar] [CrossRef]
- Ji, W.; Rossel, R.V.; Shi, Z. Improved estimates of organic carbon using proximally sensed vis–NIR spectra corrected by piecewise direct standardization. Eur. J. Soil. Sci. 2015, 66, 670–678. [Google Scholar] [CrossRef]
- Lamine, S.; Petropoulos, G.P.; Brewer, P.A.; Bachari, N.-E.-I.; Srivastava, P.K.; Manevski, K.; Kalaitzidis, C.; Macklin, M.G. Heavy Metal Soil Contamination Detection Using Combined Geochemistry and Field Spectroradiometry in the United Kingdom. Sensors 2019, 19, 762. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Chen, Y.; Wang, M.; Zhao, Y.; Li, J. SPA-Based Methods for the Quantitative Estimation of the Soil Salt Content in Saline-Alkali Land from Field Spectroscopy Data: A Case Study from the Yellow River Irrigation Regions. Remote Sens. 2019, 11, 967. [Google Scholar] [CrossRef]
- Tan, K.; Ye, Y.; Du, P. Estimation of heavy-metals concentration in reclaimed mining soils using reflectance spectroscopy. Spectrosc. Spectr. Anal. 2014, 34, 3317–3322. [Google Scholar]
- Tan, K.; Ye, Y.; Cao, Q.; Du, P.; Dong, J. Estimation of Arsenic Contamination in Reclaimed Agricultural Soils Using Reflectance Spectroscopy and ANFIS Model. IEEE J.-STARS 2014, 7, 2540–2546. [Google Scholar] [CrossRef]
- Wei, L.; Yuan, Z.; Zhong, Y.; Yang, L.; Hu, X.; Zhang, Y. An Improved Gradient Boosting Regression Tree Estimation Model for Soil Heavy Metal (Arsenic) Pollution Monitoring Using Hyperspectral Remote Sensing. Appl. Sci. 2019, 9, 1943. [Google Scholar] [CrossRef]
- Angelopoulou, T.; Tziolas, N.; Balafoutis, A.; Zalidis, G.; Bochtis, D. Remote Sensing Techniques for Soil Organic Carbon Estimation: A Review. Remote Sens. 2019, 11, 676. [Google Scholar] [CrossRef]
- Zhao, L.; Hu, Y.; Zhou, W.; Liu, Z.; Pan, Y.; Shi, Z.; Wang, L.; Wang, G. Estimation Methods for Soil Mercury Content Using Hyperspectral Remote Sensing. Sustainability 2018, 10, 2474. [Google Scholar] [CrossRef]
- Wang, H.; Liu, F.; Yunger, J.A.; Cui, J.; Ma, L. Fitting Model of Soil Total Nitrogen Content in Different Soil Particle Sizes Using Hyperspectral Analysis. Trans. Chin. Soc. Agric. Mach. 2019, 50, 195–204. [Google Scholar]
- Liu, J.; Dong, Z.; Sun, Z.; Ma, H.; Shi, L. Study on Hyperspectral Characteristics and Estimation Model of Soil Mercury Content. IOP Conf. Ser. Mater. Sci. Eng. 2017, 274, 12030. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wavelength Variable Type | Classification Rules |
|---|---|
| Strongly informative | , |
| Weakly informative | , |
| Uninformative | , |
| Interfering | , |
| Study Area | Dataset | Sample Size | Minimum (ug/g) | Maximum (ug/g) | Mean (ug/g) | SD | CV (%) | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|---|
| Daye | Entire | 63 | 7.04 | 12.84 | 9.28 | 1.11 | 11.97% | 0.58 | 0.41 |
| Algorithm | Spectral Type | Spectral Set (nm) | Correlation Coefficients |
|---|---|---|---|
| IRIV | Laboratory spectra | 486, 527, 740, 769,849, 1033, 1147, 1184, 1185, 1241, 1359, 1365, 2233, 2336, 2382 | −0.509, −0.490, −0.278, −0.279, −0.296, −0.287, −0.271, −0.264, −0.264, −0.259, −0.264, −0.264, −0.205, −0.194, −0.204 |
| Field spectra | 619.6, 621, 1186.8, 1422.1, 1871.7, 1896.8, 1907.5, 2348.2, 2383.4 | −0.437, −0.448, −0.320, −0.364 −0.383, −0.391, −0.383, −0.431, −0.427 | |
| IRIV-SCA | Laboratory spectra | GF486, GF527, GFA849–769, GFA1147–1033, GFA1184–1147, GFA2382–2336 | −0.821, −0.792, −0.743, 0.822, 0.663, −0.609 |
| Field spectra | GF619.6, GF621, GF1186.8, GF1422.1, GF1871.7, GF1896.8, GF1907.5, GF2348.2, GF2383.4, GFA1871.7–1422.1, GFA1896.8–1871.7, GFA2348.2–1907.5 | −0.870, −0.885, −0.868, −0.901, −0.913, −0.921, −0.919, −0.931, −0.929, −0.632, −0.892, −0.806 |
| Algorithm | Spectral Type | Models | Calibration Set | Validation Set | ||||
|---|---|---|---|---|---|---|---|---|
| IRIV | Laboratory spectra | PLSR | 0.29 | 0.94 | 0.73 | 0.52 | 0.67 | 0.49 |
| BRR | 0.91 | 0.34 | 0.26 | 0.79 | 0.44 | 0.36 | ||
| RR | 0.49 | 0.80 | 0.62 | 0.49 | 0.69 | 0.56 | ||
| KRR | 0.55 | 0.76 | 0.59 | 0.48 | 0.70 | 0.56 | ||
| SVMR | 0.99 | 0.11 | 0.10 | 0.59 | 0.62 | 0.49 | ||
| XGBoost | 0.87 | 0.40 | 0.31 | 0.57 | 0.63 | 0.49 | ||
| RFR | 0.78 | 0.53 | 0.39 | 0.27 | 0.82 | 0.69 | ||
| Field spectra | PLSR | 0.27 | 1.00 | 0.75 | 0.37 | 0.74 | 0.62 | |
| BRR | 0.16 | 1.07 | 0.85 | 0.20 | 0.84 | 0.73 | ||
| RR | 0.28 | 1.00 | 0.75 | 0.37 | 0.75 | 0.63 | ||
| KRR | 0.29 | 0.99 | 0.75 | 0.42 | 0.72 | 0.60 | ||
| SVMR | 0.75 | 0.59 | 0.32 | 0.23 | 0.83 | 0.64 | ||
| XGBoost | 0.99 | 0.14 | 0.10 | 0.29 | 0.79 | 0.69 | ||
| RFR | 0.83 | 0.49 | 0.34 | 0.49 | 0.67 | 0.56 | ||
| Algorithm | Spectral Type | Models | Calibration Set | Validation Set | ||||
|---|---|---|---|---|---|---|---|---|
| IRIV-SCA | Laboratory spectra | PLSR | 0.93 | 0.31 | 0.22 | 0.91 | 0.23 | 0.21 |
| BRR | 0.94 | 0.30 | 0.19 | 0.92 | 0.33 | 0.18 | ||
| RR | 0.93 | 0.31 | 0.19 | 0.92 | 0.14 | 0.17 | ||
| KRR | 0.92 | 0.33 | 0.20 | 0.91 | 0.25 | 0.20 | ||
| SVMR | 0.98 | 0.15 | 0.11 | 0.97 | 0.22 | 0.11 | ||
| XGBoost | 0.98 | 0.13 | 0.01 | 0.93 | 0.25 | 0.14 | ||
| RFR | 0.97 | 0.30 | 0.12 | 0.96 | 0.18 | 0.15 | ||
| Field spectra | PLSR | 0.77 | 0.56 | 0.40 | 0.76 | 0.42 | 0.35 | |
| BRR | 0.78 | 0.55 | 0.38 | 0.75 | 0.43 | 0.36 | ||
| RR | 0.77 | 0.56 | 0.37 | 0.75 | 0.43 | 0.35 | ||
| KRR | 0.75 | 0.58 | 0.38 | 0.74 | 0.44 | 0.35 | ||
| SVMR | 0.87 | 0.42 | 0.24 | 0.78 | 0.40 | 0.31 | ||
| XGBoost | 0.99 | 0.12 | 0.10 | 0.83 | 0.35 | 0.29 | ||
| RFR | 0.88 | 0.41 | 0.30 | 0.66 | 0.50 | 0.36 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Yuan, Z.; Yu, M.; Huang, C.; Cao, L. Estimation of Arsenic Content in Soil Based on Laboratory and Field Reflectance Spectroscopy. Sensors 2019, 19, 3904. https://doi.org/10.3390/s19183904
Wei L, Yuan Z, Yu M, Huang C, Cao L. Estimation of Arsenic Content in Soil Based on Laboratory and Field Reflectance Spectroscopy. Sensors. 2019; 19(18):3904. https://doi.org/10.3390/s19183904
Chicago/Turabian StyleWei, Lifei, Ziran Yuan, Ming Yu, Can Huang, and Liqin Cao. 2019. "Estimation of Arsenic Content in Soil Based on Laboratory and Field Reflectance Spectroscopy" Sensors 19, no. 18: 3904. https://doi.org/10.3390/s19183904